17.3 Datenquellen
Project Server 2016 speichert alle für das Berichtswesen relevanten Informationen in einer Datenbank, die vom SQL Server verwaltet wird. Egal, ob Sie beispielsweise aus dem Client Project Professional heraus Projektpläne speichern und veröffentlichen oder in der Project Web App Änderungen vornehmen, die Transaktionen werden im Hintergrund in der Datenbank protokolliert und abgelegt. In einer reinen Cloud-Architektur beim Betrieb von Project Online befindet sich die Datenbank in einem sogenannten Datacenter von Microsoft.
![]() In der Vorversion gab es für den Project Server noch eine eigene dedizierte Datenbank, welche nun in die Inhaltsdatenbank von SharePoint Server integriert wurde. Dies bietet vor allem Vorteile für den Datenbankadministrator bei der Verwaltung des Systems. Änderungen am Datenmodell wurden jedoch nicht vorgenommen, die alte Struktur wird durch ein entsprechendes Schema mit einem Präfix gekennzeichnet.
In der Vorversion gab es für den Project Server noch eine eigene dedizierte Datenbank, welche nun in die Inhaltsdatenbank von SharePoint Server integriert wurde. Dies bietet vor allem Vorteile für den Datenbankadministrator bei der Verwaltung des Systems. Änderungen am Datenmodell wurden jedoch nicht vorgenommen, die alte Struktur wird durch ein entsprechendes Schema mit einem Präfix gekennzeichnet.
Tabelle 17.4 gibt Ihnen einen Überblick über jedes Schema und dessen Zweck für ein Microsoft-Project-Server-System der Version 2016, sofern direkter Zugriff auf die Datenbank möglich ist.
Tabelle 17.4 Überblick Project-Server-Datenbankschemas
Die Objekte des Archive-Schemas speichern ältere Versionen von Entitäten in Project Server. Dieser Datenspeicher wird dann genutzt, wenn Objekte in der Project Web App gesichert und archiviert werden. Beispielsweise können Sie folgende Objekte über die Datenbank administrativ sichern:
- Projekte
- Ressourcen
- Zuordnungen
- Vorgänge
- benutzerdefinierte Felder
Weitere Informationen dazu finden Sie auch in Abschnitt 20.3.6, »Administrative Sicherung (nur in SharePoint-Zentraladministration)«.
Innerhalb des Draft-Schemas werden unveröffentlichte Daten aus den Projektplänen abgelegt. Diese Objekte werden also angesprochen, wenn Sie lediglich Ihre Änderungen auf dem Project Server speichern, ohne das Projekt zu veröffentlichen.
Die Tabellen des Published-Schemas hingegen enthalten Daten aller veröffentlichten Projekte und Ressourcen sowie alle Arten von Vorlagen. Veröffentlichte Daten sind vor allem dadurch gekennzeichnet, dass sie in der PWA sichtbar sind. Weiterhin enthält dieser Datenspeicher auch spezifische Project-Server-Tabellen wie Arbeitszeittabellen, Ressourceninformationen und Ansichten.
Mit dem Reporting-Schema wird Ihnen ein Datencontainer zur Verfügung gestellt, um Berichte sowie OLAP-Datenbanken und -Würfel (OLAP-Cubes) zu erstellen. Diese Tabellen werden nahezu in Echtzeit aktualisiert und sind für den Lesezugriff optimiert. Weiterhin finden Sie dort auch ausgewählte Daten der Projektwebsites, welche aus den Tabellen des SharePoint Servers synchronisiert werden.
Direkter Zugriff nicht unterstützt
![]() Der direkte Zugriff auf Tabellen und Sichten der Schemas Archive (pjver), Draft (pjdraft) und Published (pjpub) wird von Microsoft nicht unterstützt. Dies kann z.B. zu einem korrupten Project-Professional-Cache oder einer fehlerhaften Datenbank führen. Daher dürfen Reports nur die Objekte des Schemas Reporting (pjrep) verwenden. Zwar gibt es keinen Mechanismus, der den programmatischen Zugriff verhindert, jedoch sollten Sie sich darüber im Klaren sein, dass Sie in diesem Fall Ihren Anspruch auf Produkt-Support verlieren und nur im Ausnahmefall auf offizielle Empfehlung von Microsoft solche Operationen ausführen sollten.
Der direkte Zugriff auf Tabellen und Sichten der Schemas Archive (pjver), Draft (pjdraft) und Published (pjpub) wird von Microsoft nicht unterstützt. Dies kann z.B. zu einem korrupten Project-Professional-Cache oder einer fehlerhaften Datenbank führen. Daher dürfen Reports nur die Objekte des Schemas Reporting (pjrep) verwenden. Zwar gibt es keinen Mechanismus, der den programmatischen Zugriff verhindert, jedoch sollten Sie sich darüber im Klaren sein, dass Sie in diesem Fall Ihren Anspruch auf Produkt-Support verlieren und nur im Ausnahmefall auf offizielle Empfehlung von Microsoft solche Operationen ausführen sollten.
17.3.1 SharePoint-Server-Datenbank
Sind Sie durch Ihr Nutzungsmodell (on premises oder hybrid) also in der Lage, direkt auf den SQL Server zuzugreifen, können Sie die SharePoint-Server-Datenbank als mögliche Datenquelle für das Reporting in Betracht ziehen. Dort werden in den Objekten des Schemas Reporting (Präfix pjrep) des Project Servers 2016 berichtsrelevante Daten gespeichert. Die Tabellen halten stets aktuelle bzw. veröffentlichte Informationen bereit, beispielsweise zu Projekten, Vorgängen, Ressourcen oder Zuordnungen.
Vielleicht fragen Sie sich an dieser Stelle, genau wie der IT-Verantwortliche der AIRBI GmbH, warum im Prinzip eine doppelte Datenhaltung betrieben wird. Denn, wie im vorigen Abschnitt beschrieben, sind die eigentlichen Daten ja in den Tabellen mit dem Schema Published (Präfix pjpub) gespeichert. Trotzdem bietet das Auslagern auf eine eigene Datenstruktur mehrere Vorteile. Einerseits sind die Tabellen des Schemas Reporting denormalisiert und ermöglichen Ihnen auch als Anwender mit wenig Erfahrung einfachen und schnellen Zugriff auf berichtsrelevante Informationen. Andererseits werden die Tabellen des Schemas Published als Transaktionsspeicher mit vielen Schreib- und Lesezugriffen entlastet. Zudem lassen sich durch verschiedene Schemas leichter Berechtigungen an Berichtsautoren vergeben, ohne die Stabilität des Systems durch möglicherweise unerfahrene Nutzer zu gefährden. Ein spezielles Datenbankdesign sorgt außerdem dafür, dass der Server mit besonders guter Performance auf Lesezugriffe reagiert, wenn Sie als Anwender oder die BI-Anwendung Abfragen an die Reporting-Tabellen oder -Ansichten absetzen.
Schema der Reporting-Objekte herunterladen
![]() Leider ist das aktualisierte Schema für die Version Project Server 2016 zum Zeitpunkt des Redaktionsschlusses dieses Buches noch nicht verfügbar. Die derzeit aktuellste Version für Project Server 2013 finden Sie unter:
Leider ist das aktualisierte Schema für die Version Project Server 2016 zum Zeitpunkt des Redaktionsschlusses dieses Buches noch nicht verfügbar. Die derzeit aktuellste Version für Project Server 2013 finden Sie unter:
https://msdn.microsoft.com/de-de/library/office/ms512767.aspx
Die Dokumentation ist ein Bestandteil des Software Development Kit (SDK) für Microsoft Project Server. Dort finden Sie nähere Erläuterungen zu den einzelnen Tabellen, Ansichten und Feldern sowie zu deren Beziehungen untereinander. Außerdem enthält das SDK neben weiteren Dokumentationen u.a. auch Codebeispiele, Anleitungen und weitere Programmierreferenzen.
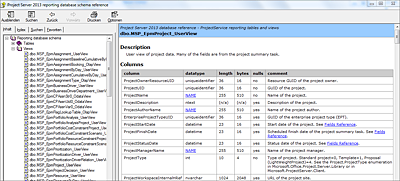
Abbildung 17.5 Dokumentiertes Schema der Reporting-Objekte
In Tabelle 17.5 finden Sie eine Auflistung der wichtigsten Datenbanktabellen und ‐ansichten für bestimmte Informationstypen innerhalb des Reporting-Schemas.
| Informationstyp | Tabelle | Ansicht |
|---|---|---|
| Stammdaten zu Projekten | pjrep.MSP_EpmProject | pjrep.MSP_EpmProject_UserView |
| Stammdaten zu Vorgängen | pjrep.MSP_EpmTask | pjrep.MSP_EpmTask_UserView |
| Stammdaten zu Ressourcen | pjrep.MSP_EpmResource | pjrep.MSP_EpmResource_UserView |
| Stammdaten zu Zuordnungen | pjrep.MSP_EpmAssignment | pjrep.MSP_EpmAssignment_UserView |
| zeitliche Verteilung der Zuordnungsarbeit und Kosten (berechnet/aktuell) | pjrep.MSP_EpmAssignmentByDay | pjrep.MSP_EpmAssignmentByDay_UserView |
| Brutto- und Nettokapazität der Ressourcen | pjrep.MSP_EpmResourceByDay | pjrep.MSP_EpmResourceByDay_UserView |
| Statusinformationen zu Workflows | pjrep.MSP_EpmWorkflowStatusInformation | – |
| Stammdaten zu Arbeitszeittabellen | pjrep.MSP_Timesheet | – |
| aktuelle Arbeit in Arbeitszeittabellen | pjrep.MSP_TimesheetActual | – |
| Stammdaten zu Risiken | pjrep.MSP_WssRisk | – |
| Stammdaten zu Problemen | pjrep.MSP_WssIssue | – |
Tabelle 17.5 Wichtige Tabellen und Ansichten des Reporting-Schemas
Tabellen und Sichten werden untereinander durch eindeutige Schlüssel vom Datentyp UNIQUEIDENTIFIER verknüpft. Die Spalten tragen dementsprechend auch eindeutige Namen wie ProjectUID, TaskUID oder ResourceUID. Sollte sich Ihnen eine Beziehung zwischen Tabellen oder Ansichten nicht eindeutig erschließen, können Sie in der Dokumentation die Abhängigkeiten nachschlagen.
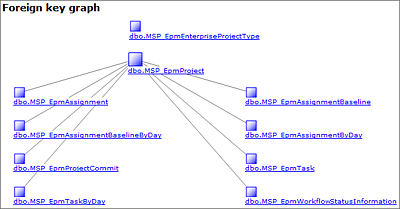
Abbildung 17.6 Beispiel für Fremdschlüssel der Tabelle »pjrep.MSP_EpmProject«
Ansichten enthalten die benutzerdefinierten Felder
Benutzen Sie als Einsteiger so weit wie möglich die Ansichten, auch wenn diese eine weniger gute Performance gerade bei größeren Datenmengen oder einer großen Anzahl benutzerdefinierter Felder bieten. Der entscheidende Vorteil dabei ist, dass im Standard vorhandene Ansichten die benutzerdefinierten Felder der jeweiligen Entität als Spalten enthalten, aber die korrespondierende Tabelle allein nicht. Sobald Sie ein neues benutzerdefiniertes Feld anlegen oder löschen, werden die Ansichten angepasst. Weiterhin enthalten Ansichten eine Reihe weiterer Zusatzinformationen, wie z.B. den Klarnamen des Projektbesitzers oder Arbeits- und Kostendaten aus den Basisplänen.
Eine Ausnahme für unsere Empfehlung zur Nutzung von Ansichten stellen die zeitphasenbasierten Daten dar. Diese sind gekennzeichnet dadurch, dass im Namen der Ansicht das Schlüsselwort »ByDay« enthalten ist. In der Konsequenz bedeutet das eine Zeile pro Entität und Tag, also z.B. bei einer einzigen Zuordnung einer Ressource auf einen Vorgang über ein Jahr, dass etwa 365 Datensätze dafür gespeichert werden. Weichen Sie in diesen Fällen unbedingt auf die entsprechenden Tabellen aus und erstellen die notwendigen Verknüpfungen (Joins), es sei denn, die Geschwindigkeit der Abfrage spielt für Ihre Anwendung keine Rolle. Bei der Entwicklung von Joins hilft Ihnen auch hier wieder die Dokumentation bei der Findung der Abhängigkeiten, wie in Abbildung 17.7 beispielhaft für Projekte dargestellt wird.
Wundern Sie sich bitte nicht, wenn die Ansichten nach der Installation und dem Anlegen der Datenbank noch nicht vorhanden sind. Im Gegensatz zu allen Vorversionen des Project Servers bis einschließlich 2013 werden die Views jetzt erst dann angelegt, wenn auch tatsächlich das erste benutzerdefinierte Feld für die jeweilige Entität über die Konfiguration erstellt wird.
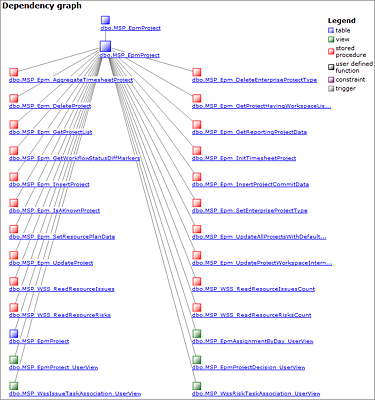
Abbildung 17.7 Beispiel für Abhängigkeiten einer Tabelle
![]() Die Abfragen selbst werden in der proprietären Erweiterung des SQL-Standards von Microsoft Transact-SQL (T-SQL) formuliert. Um Ihnen den Einstieg zu erleichtern, haben wir Ihnen in Tabelle 17.6 ein paar einfache gebräuchliche Abfragen an die Project-Server-Tabellen und -Ansichten zur Verfügung gestellt. Diese Abfragen können Sie z.B. im Management Studio des SQL Servers an jede Instanz von Microsoft Project Server 2016 absetzen.
Die Abfragen selbst werden in der proprietären Erweiterung des SQL-Standards von Microsoft Transact-SQL (T-SQL) formuliert. Um Ihnen den Einstieg zu erleichtern, haben wir Ihnen in Tabelle 17.6 ein paar einfache gebräuchliche Abfragen an die Project-Server-Tabellen und -Ansichten zur Verfügung gestellt. Diese Abfragen können Sie z.B. im Management Studio des SQL Servers an jede Instanz von Microsoft Project Server 2016 absetzen.
| Fragestellung | T-SQL-Abfrage |
|---|---|
| Liste veröffentlichter Projekte, Start- und Enddatum sowie Projektbesitzer | SELECT ProjectName, ProjectStartDate, ProjectFinishDate, ProjectOwnerName FROM pjrep.MSP_EpmProject_UserView |
| Name und Benutzerkonto aller aktiven Ressourcen vom Typ Arbeit | SELECT ResourceName, ResourceNTAccount FROM pjrep.MSP_EpmResource_UserView WHERE (ResourceType = 2) AND (ResourceIsActive = 1) |
| Meilensteine des aktuellen Monats mit Datum und zugehörigem Projekt | SELECT P.ProjectName, T.TaskName, T.TaskFinishDate FROM pjrep.MSP_EpmTask_UserView AS T INNER JOIN pjrep.MSP_EpmProject_UserView AS P ON T.ProjectUID = P.ProjectUID WHERE (T.TaskIsMilestone = 1) AND (MONTH(T.TaskFinishDate) = MONTH(GETDATE())) AND (YEAR(T.TaskFinishDate) = YEAR(GETDATE())) |
| Nettokapazität aller Ressourcen pro Monat im Jahr 2016 | SELECT R.ResourceUID, R.ResourceName, MONTH(RBD.TimeByDay) AS Month, SUM(RBD.Capacity) AS Capacity FROM pjrep.MSP_EpmResourceByDay AS RBD INNER JOIN pjrep.MSP_EpmResource AS R ON RBD.ResourceUID = R.ResourceUID WHERE (YEAR(RBD.TimeByDay) = 2016) GROUP BY R.ResourceUID, R.ResourceName, MONTH(RBD.TimeByDay) |
| Arbeit und aktuelle Arbeit pro Ressource und Monat im Jahr 2016 | SELECT R.ResourceUID, R.ResourceName, MONTH(ABD.TimeByDay) AS Month, SUM(ABD.AssignmentWork) AS [Work], SUM(ABD.AssignmentActualWork) AS ActualWork FROM pjrep.MSP_EpmAssignment AS A INNER JOIN pjrep.MSP_EpmAssignmentByDay AS ABD ON A.ProjectUID = ABD.ProjectUID AND A.AssignmentUID = ABD.AssignmentUID INNER JOIN pjrep.MSP_EpmResource AS R ON A.ResourceUID = R.ResourceUID WHERE (YEAR(ABD.TimeByDay) = 2016) GROUP BY R.ResourceUID, R.ResourceName, MONTH(ABD.TimeByDay) |
Tabelle 17.6 Einstiegsabfragen an den Project-Server-Datenbestand
Noch eine gute Nachricht, falls Sie bereits Berichte unter Einbeziehung des Reporting-Schemas von Project Server 2010 oder 2013 entwickelt haben. Diese werden bei einer Migration auf 2016 grundsätzlich weiterhin funktionieren, da das Datenbankschema lediglich gewechselt, jedoch nicht grundlegend geändert wurde.
Migration bestehender Abfragen und Reports durchführen
![]() Mit der Integration der Daten des Project Servers 2016 in die Inhaltsdatenbank des SharePoint Servers wurde auch das Datenbankschema für das Reporting geändert. Deshalb müssen leider alle T-SQL-Abfragen angepasst werden, die bisher in Vorversionen für Reports und Anwendungen in produktivem Einsatz sind. Ersetzen Sie daher in allen Objektnamen das Präfix dbo durch pjrep. Haben Sie kein Präfix verwendet, besteht zwar theoretisch die Möglichkeit, dem Datenbankbenutzer das Standardschema pjrep zuzuweisen, wir empfehlen aber, grundsätzlich immer ein Präfix zu verwenden. So muss beispielsweise die Abfrage SELECT ProjectName FROM dbo.MSP_EpmProject oder SELECT ProjectName FROM MSP_EpmProject geändert werden in SELECT ProjectName FROM pjrep.MSP_EpmProject.
Mit der Integration der Daten des Project Servers 2016 in die Inhaltsdatenbank des SharePoint Servers wurde auch das Datenbankschema für das Reporting geändert. Deshalb müssen leider alle T-SQL-Abfragen angepasst werden, die bisher in Vorversionen für Reports und Anwendungen in produktivem Einsatz sind. Ersetzen Sie daher in allen Objektnamen das Präfix dbo durch pjrep. Haben Sie kein Präfix verwendet, besteht zwar theoretisch die Möglichkeit, dem Datenbankbenutzer das Standardschema pjrep zuzuweisen, wir empfehlen aber, grundsätzlich immer ein Präfix zu verwenden. So muss beispielsweise die Abfrage SELECT ProjectName FROM dbo.MSP_EpmProject oder SELECT ProjectName FROM MSP_EpmProject geändert werden in SELECT ProjectName FROM pjrep.MSP_EpmProject.
Verwenden Sie die SharePoint-Server-Datenbank für das Berichtswesen vor allem dann, wenn Sie auf aktuelle Daten angewiesen sind und Änderungen, welche gerade durchgeführt wurden, sofort im Bericht erscheinen sollen. Dazu gehört vor allem das Statusberichtswesen, wo Änderungen der Projektleiter in einheitlichen Statusberichten sofort in alle Reports übernommen werden sollten, da diese aus der Erfahrung häufig erst kurz vor dem Statusmeeting aktualisiert bzw. angefertigt werden.
Solange die Abfragen also erträgliche Antwortzeiten haben und direkter Zugriff überhaupt möglich ist, besteht auch kein Grund, sich gegen die SharePoint-Server-Datenbank als Datenquelle zu entscheiden. Aber gerade bei großen Datenmengen mit möglicherweise vielen zeitphasenbasierten Daten kann die Performance ganz schnell in den Keller gehen. Hier wäre unsere Empfehlung, wenn möglich auf die Datenanalyse mit OLAP-Cubes auszuweichen, deren Geschwindigkeitsvorteile Sie sich allerdings auf Kosten der Aktualität der Daten erkaufen müssen. Wie genau das funktioniert, erfahren Sie im folgenden Abschnitt.
17.3.2 Analysis Services Cubes (OLAP)
Wie bereits in Abschnitt 17.2.2 erwähnt, können Sie OLAP abhängig vom Nutzungsmodell ebenfalls nur im reinen on-premises-Betrieb oder in hybriden Szenarien verwenden. Aus den Datensätzen der SharePoint-Server-Datenbank werden dann bei Bedarf OLAP-Datenbanken gemäß Ihrer Konfiguration erstellt bzw. aktualisiert. Voraussetzung zur Erstellung einer OLAP-Datenbank und deren enthaltener Datenwürfel sind die SQL Server Analysis Services (SSAS), die eine optionale Komponente des Microsoft SQL Servers sind und bei Bedarf installiert werden können. Jede erstellte Analysis-Services-Datenbank besteht aus den 14 Cubes, welche wir in Tabelle 17.7 aufgelistet haben. Die durch OLAP-Würfel bzw. -Cubes zur Verfügung gestellten Daten können mit nahezu allen Autorenwerkzeugen für Reports als Datenquelle genutzt werden. Dadurch lassen sich in den verschiedensten Arten von Berichten die Daten bequem auswerten und einer Ad-hoc-Analyse unterziehen.
| Name des Würfels | Art |
|---|---|
| Assignment Non Timephased | Enterprise |
| Assignment Timephased | Enterprise |
| Deliverables | SharePoint |
| EPM Timesheet | Enterprise |
| Issues | SharePoint |
| MSP_Portfolio_Analyzer | virtuell (Assignment Timephased, Resource Timephased) |
| MSP_Project_SharePoint | virtuell (Deliverables, Issues, Project Non Timephased, Risks) |
| MSP_Project_Timesheet | virtuell (Assignment Timephased, EPM Timesheet, Resource Timephased) |
| Project Non Timephased | Enterprise |
| Resource Non Timephased | Enterprise |
| Resource Timephased | Enterprise |
| Risks | SharePoint |
| Tasks Non Timephased | Enterprise |
| Timesheet | Enterprise |
Tabelle 17.7 Die 14 Cubes einer Standard-OLAP-Datenbank
Die Namen der Cubes sprechen eigentlich selbst für deren Inhalt und die zur Verfügung gestellten Daten. Sie können sich auch an den Namen der SQL Server-Tabellen des Reporting-Schemas in der SharePoint-Server-Datenbank orientieren. Sollte das für Sie nicht ausreichen, ist auch das Schema der OLAP-Cubes dokumentiert. In einer Excel-Arbeitsmappe finden Sie für jeden Würfel ein Arbeitsblatt mit den entsprechenden Informationen. Den Link zum Download finden Sie im vorigen Abschnitt 17.3.1.
Bereits seit der Version 2007 des Project Servers ist die Anzahl der Datenwürfel auf 14 aufgestockt worden, allerdings wurden diese in nur einer einzigen OLAP-Datenbank verwaltet, welche alle Daten enthielt. Schon damals hatte Microsoft dort Handlungsbedarf erkannt, da Dienstleister und Lieferanten mit der Datenbank für die Analyse arbeiteten, welche beispielsweise alle sensiblen Kostendaten enthielt. Gerade in großen Unternehmen mit vielen Abteilungen war dies ein großes Problem, und zudem dauerte die Erstellung der Cubes mit dem kompletten Datenbestand unverhältnismäßig lange.
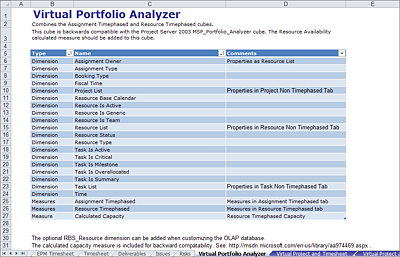
Abbildung 17.8 Dokumentation des Cube-Schemas
Mit Project Server 2016 haben Sie die Möglichkeit, beliebig viele Analysis-Services-Datenbanken zu erstellen, um Daten gemäß der Struktur Ihres Unternehmens zu segmentieren. Somit können Sie gezielt kleinere Datenbanken für einen bestimmten Nutzerkreis zur Verfügung stellen, die auch viel schneller erstellt werden und damit auch die Möglichkeit einer höheren Frequenz der Aktualisierung bieten. Diese Aufgabe können Sie entweder durch Datenfilterung erledigen, oder Sie geben in den Einstellungen an, welche Datenelemente in einer bestehenden Datenbank enthalten sein sollen. In Project Server 2016 können Sie den Inhalt einer OLAP-Datenbank aus einer Kombination der folgenden Kriterien filtern:
- Projektabteilungen
- Ressourcenabteilungen
- Zeitraum
Zur Erstellung einer OLAP-Datenbank gehen Sie wie folgt vor:
-
Rufen Sie im Browser die Webseite der SharePoint-2016-Zentraladministration z.B. über eine Remote-Verbindung zum Anwendungsserver auf. Klicken Sie auf Anwendungsverwaltung • Dienstanwendungen verwalten. Dort klicken Sie zunächst auf Project Server Dienstanwendung und wählen im Kontextmenü der bereitgestellten Instanz den Punkt Verwalten aus. Klicken Sie dann unter der Überschrift Warteschlangen- und Datenbankverwaltung auf den Link OLAP-Datenbankverwaltung.

Abbildung 17.9 OLAP-Datenbankverwaltung in der Zentraladministration
 Alternativ können Sie in der Zentraladministration auch direkt den Punkt Allgemeine Anwendungseinstellungen auswählen und dann unter PWA-Einstellungen auf Verwalten klicken. Sollten Sie bereits mehrere PWA-Instanzen bereitgestellt haben, wechseln Sie gegebenenfalls im Kontextmenü rechts oben zur entsprechenden Instanz.
Alternativ können Sie in der Zentraladministration auch direkt den Punkt Allgemeine Anwendungseinstellungen auswählen und dann unter PWA-Einstellungen auf Verwalten klicken. Sollten Sie bereits mehrere PWA-Instanzen bereitgestellt haben, wechseln Sie gegebenenfalls im Kontextmenü rechts oben zur entsprechenden Instanz.
-
Klicken Sie auf die Schaltfläche Neu. Tragen Sie dann in den vorgesehenen Feldern die Werte ein. In Abbildung 17.10 sehen Sie Beispieleinstellungen für eine Datenbank, die nur OLAP-Daten des Jahres 2016 enthält. Lassen Sie die Felder für Projekt- und Ressourcenabteilung einfach leer, und begrenzen Sie den Zeitraum auf das aktuelle Jahr. Wählen Sie alternativ für den Zeitraum die Einstellung Den frühesten Anfangstermin und den spätesten Endtermin des Projekts verwenden, wenn Sie eine Datenbank mit allen Daten erzeugen wollen.
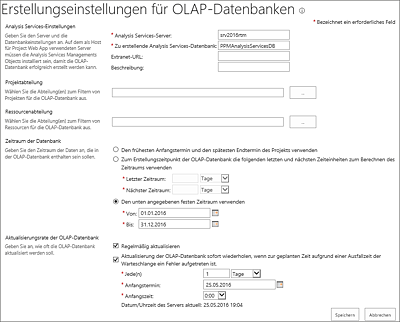
Abbildung 17.10 Einstellungen für neue OLAP-Datenbank
- Klicken Sie dann auf Speichern.
In diesem Dialog legen Sie auch fest, welche Benutzer aus welcher Abteilung welche Daten sehen dürfen, die Möglichkeit dazu hatten wir bereits am Anfang dieses Abschnitts erwähnt.
Vielleicht stellen Sie sich jetzt gerade die Frage, welche Cubes durch welche Einstellungskombinationen von der Filterung betroffen sind. In Abbildung 17.11 haben wir diese Informationen in Form einer Matrix für Sie zusammengefasst.
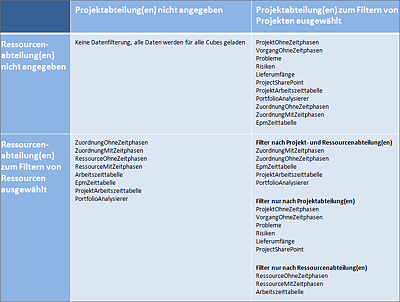
Abbildung 17.11 Durch Projekt- und Ressourcenabteilung(en) gefilterte Daten
In einer bestehenden Analysis-Services-Datenbank können Sie auch steuern, welche Elemente vorhanden sein sollen. Wählen Sie beispielsweise benutzerdefinierte Felder aus, die als Dimensionen oder Measures hinzugefügt werden. Sollten Sie nicht alle Basispläne benutzen oder die Kosten in anderen Systemen pflegen, entfernen Sie einfach die entsprechenden Haken aus den integrierten Measures. Weiterhin ist es möglich, den Vorgangstyp Inaktive Vorgänge explizit in die Auswertung mit einzubeziehen und berechnete Ausdrücke mit der OLAP-Datenbanksprache von Microsoft Multidimensional Expressions (MDX) zu integrieren. Markieren Sie dazu die Zeile der entsprechenden Datenbank, und klicken Sie auf Konfiguration.
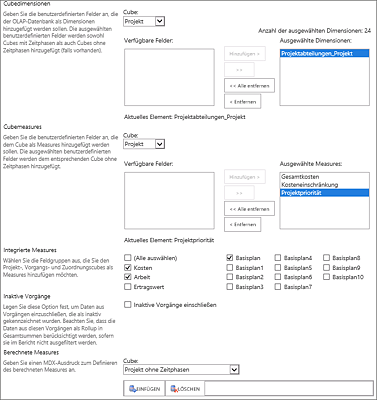
Abbildung 17.12 Kontrolle der Datenelemente einer OLAP-Datenbank über Konfiguration der Cubes
Speichern Sie Ihre Konfigurationseinstellungen, und markieren Sie dann wieder die Zeile der entsprechenden Datenbank. Klicken Sie auf die Schaltfläche Jetzt erstellen, um den Erstellungsprozess anzustoßen.
Durch die Filterung und Auswahl der Elemente können Sie die in den Cubes enthaltenen Werte stark einschränken. Ein positiver Nebeneffekt ist dabei natürlich auch, dass sich die Erstellungszeiten dadurch erheblich verkürzen lassen. Dadurch wiederum können Sie spezialisierte Würfel mehrmals täglich erstellen lassen, die für Berichte als Datenquelle dienen, welche auf aktuellere Daten angewiesen sind.
17.3.3 SharePoint-Inhalte
Neben den eigentlichen Plandaten des Project Servers im Kontext des Projektmanagements, welche durch tatsächliche Planungsaktivitäten und Fortschrittskontrolle erstellt und gesammelt werden, wie z.B. Termine von Arbeitspaketen, Kosten für Material, diverse Projektkennzahlen oder Ressourcenauslastungen, gibt es noch eine Vielzahl von Informationen, welche nicht über den Projektplan oder über die unter der Kontrolle des Projektleiters liegenden Projektdetailseiten gepflegt werden.
Immer wieder werden wir auch nach der Auswertung von Daten der Projektwebsite gefragt, welche durch die rege Zusammenarbeit des Projektteams meist eine Fülle an berichtsrelevanten Informationen beinhaltet. Diese Daten werden z.B. in SharePoint-Listen gespeichert, welche zum Teil bereits eine Verbindung zum Projektplan haben und über gängige Projekt-Berichtsmethoden zur Verfügung stehen.
Im Standard sind das zunächst nur die folgenden Listen:
- Risiken
- Probleme
- Lieferumfang
- Dokumente
Daten aus Einträgen in diesen genannten Listen werden durch einen programmierten Mechanismus in die Tabellen des Reporting-Schemas (pjrep) synchronisiert und stehen auch über andere Zugriffsmethoden zur Verfügung.
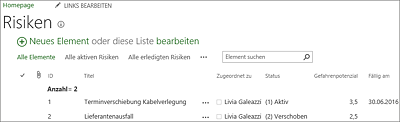
Abbildung 17.13 Risikoliste eines Projekts auf der Projektwebsite
Neben den in Standardlisten gespeicherten Informationen kann es aber noch weitere Bibliotheken und Listen auf der Projektwebsite mit Projektbezug oder an irgendeiner anderen Stelle des SharePoint Servers geben, die Sie aufgrund ihrer unternehmensweiten Gültigkeit mit in das Berichtswesen einbeziehen möchten. So werden z.B. Standort- oder Produktinformationen in zentralen Listen vorgehalten, welche dann im Berichtswesen verwendet werden sollen, oder die Vorlage der Projektwebsite wurde von Ihnen mit benutzerdefinierten Inhaltstypen erweitert.
Der Zugriff auf diese Informationen ist je nach gewähltem Werkzeug in der Regel nicht ganz trivial. Einfach und unkompliziert ist es meist dann, wenn nur eine zentrale Liste mit in die Auswertung einbezogen wird. Eine Herausforderung ist aber die Zusammenfassung von Daten aus allen Projektwebsites, die nicht im Standard vorhanden sind. In diesem Fall empfehlen wir, auf Partnerlösungen von Drittanbietern zurückzugreifen. Die Integration von Projektdokumenten aller Art in Formaten wie Word, Excel oder PowerPoint sollte in den Reports über Hyperlinks auf die eigentliche Projektwebsite erfolgen.
Listen und Bibliotheken
![]() An dieser Stelle ein Hinweis zu Listen und Bibliotheken: Technisch betrachtet, sind im SharePoint Server Bibliotheken und Listen das Gleiche. An der Benutzeroberfläche aber verhalten und präsentieren sich Listen und Bibliotheken unterschiedlich. An ein Listenelement können zusätzlich mehrere Dateien angehängt, in einer Bibliothek hingegen können zu einem Dokument mehrere Informationen (Metadaten) gespeichert werden.
An dieser Stelle ein Hinweis zu Listen und Bibliotheken: Technisch betrachtet, sind im SharePoint Server Bibliotheken und Listen das Gleiche. An der Benutzeroberfläche aber verhalten und präsentieren sich Listen und Bibliotheken unterschiedlich. An ein Listenelement können zusätzlich mehrere Dateien angehängt, in einer Bibliothek hingegen können zu einem Dokument mehrere Informationen (Metadaten) gespeichert werden.
17.3.4 Zugriff über OData
Bisher sind wir in Bezug auf das Nutzungsmodell davon ausgegangen, dass die AIRBI GmbH die Project-Server-Umgebung entweder rein oder teilweise on premises betreibt. Die direkten Zugriffsmechanismen auf den Datenbestand des SQL Servers im eigenen Netz sind seit Langem bekannt und etabliert, die Zugriffszeiten sind kurz, und auch große Datenmengen können relativ schnell mit hoher Bandbreite übertragen werden.
Was bedeutet es allerdings für den Datenzugriff und das Berichtswesen, wenn der Vorstand die Entscheidung treffen sollte, alle Dienste mit dem Modell Project Online in die Cloud auszulagern? Dann stehen IT und Berichtsautoren vor ganz neuen Herausforderungen, denn nun sind die bekannten Zugriffsmechanismen nicht mehr verwendbar, da diese alle ein Konzept gemeinsam haben, welches darauf basiert, dass die Datenquelle und Datensenke im selben virtuellen Netz beheimatet sind. So funktioniert bei einer on-premises-Farm der Zugriff auf die Daten mehr oder weniger direkt über das Dateisystem, Named Pipes oder über andere Wege. Diese betrifft nicht nur die Installation im firmeneigenen Intranet, auch eine Webapplikation kommuniziert mit ihrem Back-End über den direkten Weg.
![]() Hier kommt jetzt das Zugriffsverfahren OData ins Spiel, um auch den Datenaustausch in einer Cloud-Architektur zu ermöglichen. OData ist ein offenes Zugriffsprotokoll, das genau diesen Zugang auf entfernte Daten realisieren kann.
Hier kommt jetzt das Zugriffsverfahren OData ins Spiel, um auch den Datenaustausch in einer Cloud-Architektur zu ermöglichen. OData ist ein offenes Zugriffsprotokoll, das genau diesen Zugang auf entfernte Daten realisieren kann.
Weiterhin verfolgt OData auch das Ziel, den Zugriff auf Datenbestände für alle möglichen Anwendungen zu vereinheitlichen, denn wie Sie bereits gesehen haben, hat der Project Server allein schon eine Vielzahl von unterschiedlichen Datenquellen. Nun können Sie sich vorstellen, dass es außerdem auch eine mindestens genauso große Anzahl an infrage kommenden Clientanwendungen gibt, welche diese Datenquellen nutzen wollen. So müssen Daten in Desktop-Anwendungen genauso zur Verfügung stehen wie im Internetbrowser oder auf einem mobilen Endgerät. OData ist ein freier Standard und kann somit von jedem System implementiert und angeboten werden. So wird es Sie jetzt nicht verwundern, dass mithilfe des OData-Protokolls nicht nur Daten von Project Online in der Cloud, sondern auch von Project Server on premises abgerufen werden können.
Kernkonzept von OData ist das Entity Data Model (EDM). Dies transformiert ähnlich dem Entity Framework von Microsoft die physikalische Speicherstruktur der Daten in ein logisches Entitäten-Modell. Im Gegensatz zum Entity Framework wird das EDM von OData nicht automatisiert erstellt, sondern muss von den jeweiligen Systemen zur Verfügung gestellt werden. Genau deshalb werden Sie bei den folgenden Praxisbeispielen auch feststellen, dass die Datenbestände teilweise anders strukturiert sind, je nachdem, ob Sie direkt auf Tabellen oder Sichten zugreifen oder die Daten mit dem OData-Protokoll geladen werden.
Die Implementierung des OData-Protokolls in Project Server 2016 bzw. Project Online heißt ProjectData und ist ein WCF-Data Service. WCF steht hierbei für Windows Communication Foundation und ist eine Laufzeitumgebung, mit deren Hilfe auf .Net basierte Dienste bereitgestellt werden können. Für gemietete Project-Server-Instanzen ist ProjectData zurzeit der einzige Weg, die Daten des Project Servers an das jeweilige Berichtswerkzeug zu liefern. Laut Publikationen von Microsoft soll ProjectData den bisher üblichen direkten Datenzugriff mittels Datenbankverbindungen irgendwann ablösen bzw. überflüssig machen. Schauen Sie sich die Potenziale von ProjectData in den folgenden Beispielen an, und entscheiden Sie selbst, ob OData für Sie infrage kommt oder nicht.
Sie können den Zugriff mit OData sehr einfach über einen Browser ausprobieren, da dieser auch über URL-Request funktioniert. Gehen Sie dazu wie folgt vor:
- Öffnen Sie Ihren Webbrowser, z.B. Microsoft Internet Explorer.
-
Rufen Sie den ProjectData-Service über die folgende URL auf:
http://ServerName/PWAInstanz/_api/ProjectData
Nachdem Sie die URL eingegeben haben, erscheint eine Auflistung von allen verfügbaren Entitäten, welche Ihnen der Dienst zur Verfügung stellt. Dies wird auch als Data-Feed bezeichnet. Sie sehen jetzt allerdings noch keine Nutzdaten des Project Servers.
Dies ist eine gute Methode, um festzustellen, ob eine generelle Kommunikation mit dem ProjectData-Service möglich ist. Sollten Sie bereits eine Antwort des Service bekommen haben, so können Sie nun die zweite Hürde des Datenzugriffs überwinden: das Zugriffsrecht auf die Project-Server-Daten. Sollte die Project-Server-Instanz im SharePoint-Berechtigungsmodus laufen, so haben die Gruppen Portfolio Leser, Portfolio Manager und Administratoren Zugriff auf den ProjectData-Dienst. Läuft Ihre Project-Server-Instanz im Projektberechtigungsmodus, kann der Zugriff explizit auf einzelne Benutzer oder Gruppen beschränkt oder auch erweitert werden. Mehr über Project-Server-Berechtigungen lesen Sie in Abschnitt 20.1, »Sicherheit«.

Abbildung 17.14 Zugriff auf den ProjectData-Service im Browser
Sicherheit beachten
![]() Bitte bedenken Sie, dass innerhalb des ProjectData-Service keine Einschränkungen der Berechtigungen vorhanden sind. Dies bedeutet, dass ein Benutzer mit ProjectData-Zugriffsrechten alle Informationen des Project Servers auslesen kann. Dies umfasst alle Projekt-, Ressourcen- und Serverdaten. Anders verhält es sich bei SharePoint-Listen und -Bibliotheken. Dort können nur Zeilen abgefragt werden, auf die der Nutzer des ProjectData-Dienstes auch ein Zugriffsrecht hat.
Bitte bedenken Sie, dass innerhalb des ProjectData-Service keine Einschränkungen der Berechtigungen vorhanden sind. Dies bedeutet, dass ein Benutzer mit ProjectData-Zugriffsrechten alle Informationen des Project Servers auslesen kann. Dies umfasst alle Projekt-, Ressourcen- und Serverdaten. Anders verhält es sich bei SharePoint-Listen und -Bibliotheken. Dort können nur Zeilen abgefragt werden, auf die der Nutzer des ProjectData-Dienstes auch ein Zugriffsrecht hat.
Falls Sie Ihre Abfrage genauer spezifizieren und eine Ebene tiefer in den Feed einsteigen wollen, setzen Sie hierfür den Namen der Entität, geführt von einem weiteren »/« ans Ende der URL, z.B. http://ServerName/PWAInstanz/_api/ProjectData/Projekte.