T
esting is a dynamic analysis verification and validation (V&V) method. ISO/IEC/IEEE Systems and Software Engineering—Vocabulary
(ISO/IEC/IEEE 2010) defines testing
as “the process of operating a system or component under specified conditions, observing or recording the results, and making an evaluation of some aspect of the system or component.”
One of the objectives of testing is to find yet undiscovered, relevant defects in the software. Relevant defects
are defects that will negatively impact the stakeholders. Both software developers and software testers are responsible for the quality of the delivered software. It has to be a team effort. The job of a software developer is to prevent defects in the product and to build quality into the software products. Software developers are also responsible for V&V activities early in the life cycle, including static analysis techniques discussed in Chapter 20
. As the software moves into testing, however, a mental shift must occur. While software developers make the software work, testers do everything they can, to find all the ways possible, to “break” the software. Even if the developers are also doing testing, they are switching to the tester role and must make this shift to the tester mentality. Testers are successful every time they uncover a yet undiscovered,
relevant defect, because that means one less defect will make its way to the users of the software and impact the stakeholders’ satisfaction with that product (assuming that any uncovered defects are corrected before release).
Given that testing, like all other development activities, has a limited amount of resources (time, money, people, other resources), the goal of the tester is to select a set of test cases that are most likely to uncover as many different relevant defects as possible within those constraints. Therefore, the tester is part detective, hunting for clues as to how the software might fail. The tester is part amateur psychologist, trying to look into the mind of the programmer to figure out what kinds of mistakes they might have made when developing the software. The tester is also part psychic, trying to predict how the users might use the software inappropriately or in ways not accounted for by the software being tested. Testers must understand how interfacing entities (hardware, other software applications, and databases) might fail, have their communications corrupted or interrupted, or interface differently than defined in the software requirements.
The actual act of testing, a dynamic analysis technique, requires the execution of a software system or one of its components. Therefore, test execution can not be performed until executable software exists. With the exception of prototypes and simulations, this means that, in Waterfall life cycle models, most test execution starts during or after the coding phase of the software development life cycle. However, while test execution can not start until these later phases, test planning and design can and should be done as
early as possible in the life cycle, as illustrated in Figure 21.1
. In fact, test planning and design can start as soon as the software requirements are identified. Simply designing test cases (even without actually executing them) can help identify defects in the software work products, and the earlier those defects are discovered, the less expensive they will be to correct. The V-model, discussed in Chapter 9
and illustrated in Figure 9.2
, highlights the relationship between the testing phases and the products produced in the early life cycle phases:
-
When stakeholder requirements are available, acceptance test planning and design can begin
-
When product requirements are available, system test planning and design can begin
-
When software architecture and component designs are available, one or more levels of integration test planning and design can begin
-
When component designs and source code modules are available, unit test planning and design can begin
Testers are also excellent candidates for participating in peer reviews. This can be especially true if the work product being reviewed will provide the basis for the test design. For example, a tester who will write test cases to validate the requirements should participate in the peer review of the requirements specification, and the integration tester should participate in the peer review of the architectural design. The testing effort must be ongoing and managed throughout the software life cycle.
In agile, similar test activities occur, but they are conducted iteratively throughout software development. In fact, in test-driven development, the test cases are created from the stakeholder level requirements and take the place of product-level software requirements. Testers also participate in peer reviews, as appropriate. As source code is written, it is continuously integrated into the software executable and tested.
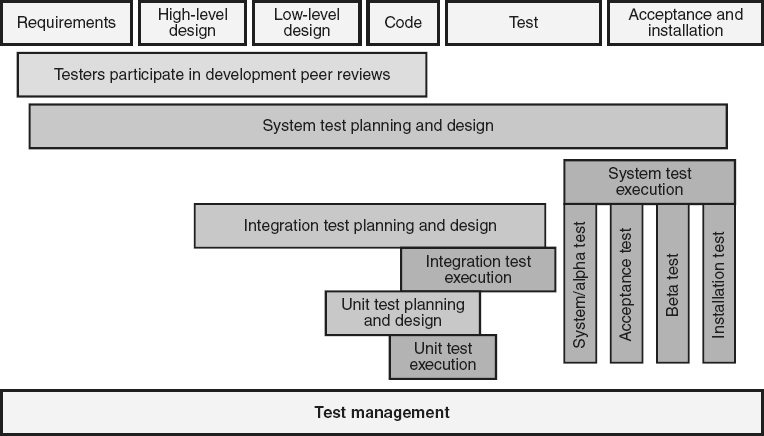
Figure 21.1
Test activities throughout Waterfall life cycles.
Select and analyze test strategies (e.g., test-driven design, good-enough, risk-based, time-box, top-down, bottom-up, black-box, white-box, simulation, automation, etc.) for various situations. (Analyze)
BODY OF KNOWLEDGE VI.B.1
There are many different strategies that can be used when testing software. Each of these strategies has its own strengths and weaknesses, so a combination of different strategies is typically the best approach for uncovering a variety of defect types.
White-Box Testing
White-box testing
, also known as
structural, structure-based, clear-box
, or glass-box testing
, is testing that is based on the internal structure of the software and looks for issues in the framework, construction, or logic of the software. White-box testing is typically executed early in the testing cycle, starting at the module-level, and may also be performed as source code modules are combined into components. White-box testing explores the internals of each source code module/component, looking at the control flow and/or data flow through the individual lines of source code.
White-box testing can find certain types of control or logic-flow defects that are all but invisible using a black-box testing strategy. It is also much easier to thoroughly investigate a suspicious source code module/component when the tester can clearly see into its internal structure. Early structural testing allows the tester to more easily trace defects back to their origin by isolating them to individual source code modules or paths through that code. Other strengths of white-box testing include the ability to look at:
-
Coverage : When the testers can see into the source code module/component’s internal structure, they can devise tests that will cover areas of the code that may not be touched using black-box testing.
-
Flow : When the testers can see into the source code module/component’s internal structure, they can determine what the software is supposed to do next, as a function of its current state. The testers can use debuggers or other tools to run the software, in order to track the sequence in which lines of code are executed and determine the values of key variables at specific points during the execution.
-
Data integrity : When the testers know which part(s) of the software should modify a given data item, they can then determine the value a selected data item should have at a given point in the software, compare that expected value with the value the variable actually has, and report deviations. The white-box testers can also detect data manipulation by inappropriate source code modules/components.
-
Boundaries: Using structural techniques, the tester can see internal boundaries in the code that are completely invisible to the black-box tester.
-
Algorithms: Using structural techniques, the testers can check for common mistakes in calculation (for example, division by zero, or the use of incorrect operators or operands). Testers can also verify intermediate data values (including appropriate rounding), at each step in the algorithm or calculation.
Gray-Box Testing
When larger numbers of source code modules/components are integrated together, it usually becomes unwieldy to perform pure white-box testing. In any complex system, there are just too many possible paths through the software. As illustrated in Figure 21.2
, at some point testing typically progresses into various levels (shades) of gray-box testing, which is a blending of the white-box and black-box testing strategies. During development, source code modules/components are integrated into programs, programs into subsystems, and subsystems into the software system (note that the number of levels of integration can vary based on the needs of the project). At the lowest level of gray-box testing, the individual source code modules/components are treated as gray boxes, where the tester peeks into the internals of each source code module/component just enough to determine how they interact and interface with each other, ignoring the rest of the internal
details. At each subsequent level of integration, the individual programs/subsystems are treated as gray boxes, where the tester peeks into their internals just enough to determine how those programs/subsystems interact and interface.
There are two basic strategies for conducting gray-box testing. The first strategy, called top-down
, is illustrated in Figure 21.3
at the source code module to component integration level. The top-down strategy tests one or more of the highest-level software items (source code modules, components, programs, subsystems) in the tree, using stubs for lower-level called software items that have not yet been integrated (or developed). These stubs simulate the required actions of those lower-level software items. The lower-level software items and their stubs are then integrated, one or more at a time, replacing these stubs. Gray-box testing focuses on the interfaces of the newly integrated software items as they are added, and their interactions with the rest of the already integrated software. The top-down strategy is typically chosen when:
-
Control flow structures are critical or suspected of being defect-prone
-
Critical or high-risk software items (or associated high-risk hardware items control by the software) are near the top of the structure, since items that are integrated earlier will be tested more extensively during grey-box testing
-
Top-level software items contain menus or other important external interface elements that make testing easier
-
There is more fan-out than there is fan-in in the software structure being integrated
-
A skeletal version would be beneficial for demonstration
-
It will take less effort to create stubs than drivers
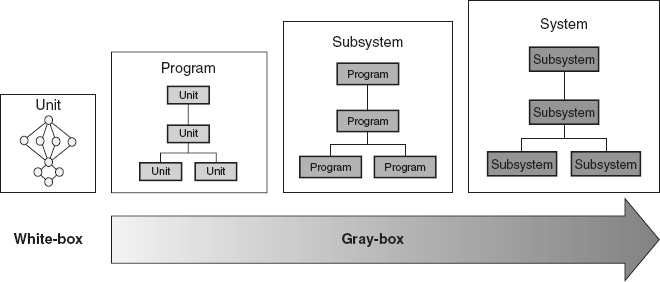
Figure 21.2
White-box testing and the transition to gray-box testing.
The second gray-box testing strategy is called bottom-up
, as illustrated in Figure 21.4
. This strategy tests one or more of the lowest-level software items in the tree using drivers for higher-level calling software items that have not yet been integrated (or developed).
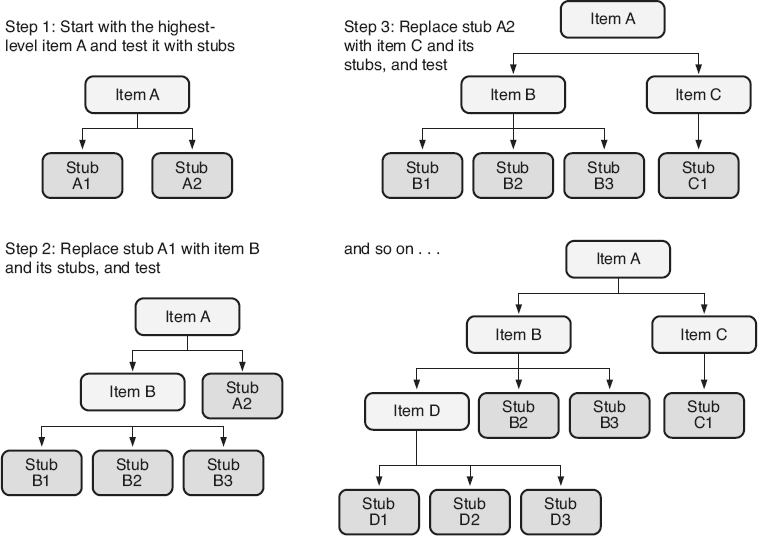
Figure 21.3
Top-down testing strategy.
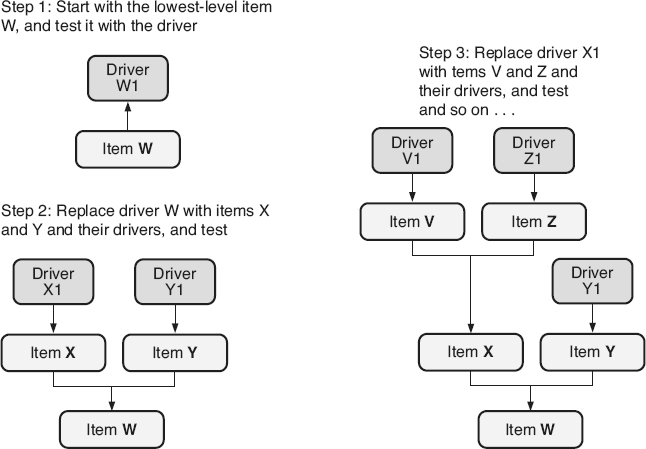
Figure 21.4
Bottom-up testing strategy.
These drivers simulate the required actions of those higher-level software items. The higher-level software items and their drivers are then integrated one or more at a time, replacing the drivers. Testing again focuses on the interfaces to the newly integrated software items as they are added, and their interactions with already integrated software. The bottom-up strategy is typically chosen when:
-
Critical or high-risk software items (or associated high-risk hardware items control by the software) are near the bottom of the structure
-
Bottom-level software items contain menus or other important external interface elements that make testing easier
-
There is more fan-in than there is fan-out in the software structure being integrated
-
It will take less effort to create drivers than stubs
Selection of an integration testing strategy depends on software characteristics, and sometimes project schedule. Different approaches can also be used for different parts of the software. For example, some parts of the software can be integrated using a bottom-up strategy, and other parts using a top-down strategy. The resulting software items could then be integrated using a top-down strategy.
Black-Box Testing
Black-box testing
, also known as specification-based, data-driven, input/output-driven
, or functional testing
, ignores the internal structure of the software and tests the behavior of the software from the perspective of the users. Black-box testing is focused on inputting values into the software, under known conditions and/or states, and evaluating the resulting software outputs against expected values, while treating the software itself as a black-box. When the software is treated as a black-box, its internal structure is not considered when designing and executing the tests. This helps maintain an external focus on the software requirements and stakeholder needs.
Since black-box testing does not require an intimate knowledge of the software’s internal structure, individuals other than those with knowledge of the source code can perform black-box testing. That allows testing to be performed by people who are independent of the developers and know nothing about how the software was designed. Black-box testers may not even know how to read/interpret the coding language used to write source code. Developers have a natural bias and will test the software based on the same set of assumptions they used to create that software.
Independent testing allows for more objectivity and a different perspective that can result in more defects being identified. Developers are also focused on making the software work. It is easier for an independent tester to focus on how to “break” the software.
The entire assembled software system is often too large and complex to test using pure white-box testing strategies. Black-box testing can be used to test the entire system, as well as its smaller individual source code modules and components, as illustrated in Figure 21.5
. Black-box testing is also capable of finding defects that are very difficult or impossible to identify using a white-box strategy. For example:
-
Timing-related issues and race conditions. A race condition is where the software output is dependent on the sequencing of timing of uncontrolled events. A race condition becomes a defect when events do not happen in the order the programmer expects or intended. For example, when writing the source code, the programmer may have assumed that event A would always occur before event B, but somehow event B occurs first, creating an incorrect output. Another defect might occur if the programmer was unaware of the race condition and did not take it into account when programming the source code.
-
Unanticipated error conditions and interoperability issues that may be initiated by another interfacing software application or hardware component.
-
Inconsistencies in how the users interface with the system.
-
Inconsistencies between different displays and reports.
-
Issues related to how the software tolerates real-time functioning and multitasking, including high levels or volumes of environmental load or stress.
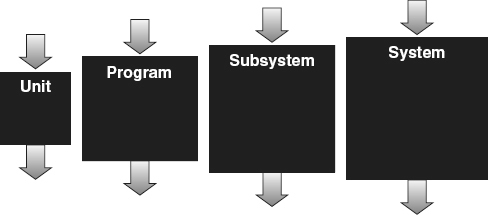
Figure 21.5
Black-box testing.
In fact, many of the strengths of black-box testing are weaknesses of white-box testing, and many of the strengths of white-box testing are weaknesses of black-box testing. Therefore, the best strategy is usually a balancing of both approaches.
Test-Driven Design
Test-driven design
(TDD), also called test-driven development
, is an agile iterative software development methodology. As discussed in Chapter 9
, TDD implements software functionality based on writing the test cases that the code must pass. Those test cases become the product-level requirements used as the basis for implementing the code. Those test cases are then run often to verify that additional changes have not broken any existing capability (regression testing). While TDD obviously has a testing component, it is in no way limited to being a testing strategy. TDD addresses the entire software development process.
TDD requires the maintenance of a set of automated test cases,
written to exhaustively test the existing code before it goes to the independent testers for their testing (and potentially into operations). As illustrated in Figure 21.6
, the software is considered in the “green” state when it passes all of these automated test cases. When new functionality is identified, the first step in TDD is to write test cases for that new functionality. Since code does not yet exist to implement these test cases, they fail, and the software goes into the “red” state. The developer then writes just enough code to pass these new test cases and move the software back to the “green” state. According to Astels (2003), “that means you do the simplest thing that could possibly work.” Refactoring is then done on the changed code, as necessary, to improve the quality of that new code. If changes made during the refactoring cause any of the automated test cases to fail, the code is corrected until the software returns to the “green” state (all test cases pass).
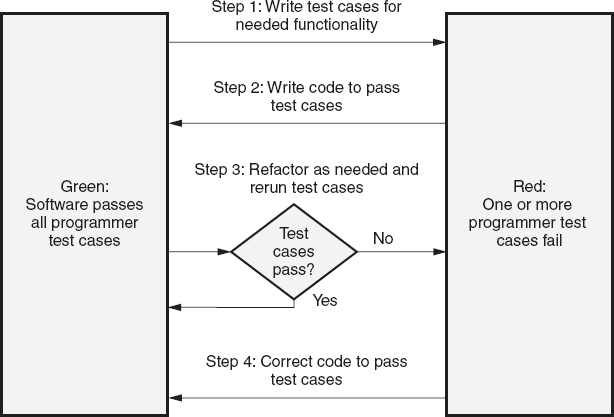
Figure 21.6
Test-driven design model—example.
Risk-Based Testing, Good-Enough Software and Time-Box Testing
According to Myers (2004), “it is impractical, often impossible, to find all the errors in a program.” One reason for this is that exhaustive testing is impossible. For example, consider the black-box testing of a function that accepts a positive integer as one of its inputs. How many possible test cases are there? To exhaustively test this single input there are literally an infinite number of possible test cases. First, there are an infinite number of positive integers to test. There is always the possibility that inputting the number 3,256,319 will cause some strange anomaly to happen. Then there are also an infinite number of invalid inputs that could be tested, including negative numbers and non-numbers (character strings including one or more alpha or other
nonnumeric characters). Since exhaustive testing is impossible, then all testing in the real world is based on sampling. Answering the question “How much sampling is needed?” leads to the concepts of risk-based testing, good-enough software and time-box testing.
Risk-based testing
focuses on identifying software items (for example, work products, product components, features, functions) with the highest risk (see the discussion of risk-based V&V in Chapter 20
) or that require the highest integrity levels. Limited testing resources are then proportionally distributed to spend more resources testing higher-risk/integrity items and fewer resources testing lower-risk/integrity items. Risk-based testing also embraces the “law of diminishing returns.” At the start of testing a large number of problems and anomalies are discovered with little effort. As testing proceeds, discovering additional problems and anomalies requires more and more effort. At some point, the return on investment in discovering those last few defects, if they even exist, is outweighed by the cost of additional testing.
The concept of good-enough software
recognizes the fact that not all software applications are created equal and not all software applications, or even all components within a single software application, have an equal amount of risk. For example, word processing software does not require the same level of integrity as banking software, and banking software does not require the same level of integrity as biomedical software that impacts a person’s health or even their life. Doing good-enough software analysis has to do with making conscious, logical decisions about the trade-offs between the level of
quality and integrity that the stakeholders need in the software, and the basic economic fact that increasing software quality and integrity will cost more and take longer. This is not meant to discount the impacts of long-term continual improvement initiatives—but right now, on today’s project, with
current skills and capabilities, this is reality. Hard business decisions need to be made about how much testing (and other V&V activities) a project can afford, what the stakeholders are willing to pay for it and what the acceptable level of risk is that the developers, acquirers and other stakeholders are willing to accept.
In project management, a time-box is a fixed amount of calendar time allocated to complete a given task, like testing. In time-box testing,
the calendar time for testing is fixed, and the scope of the testing effort must be adjusted to fit inside that time-box. This can be accomplished by prioritizing test activities and tests based on risk and benefit, and then executing the activities and/or tests in priority order. If time runs out before all of the activities and tests are accomplished, at least the lowest-priority ones are the ones left unfinished.
Simulation
The test environment often can not duplicate the real-world environment where the software will actually be executed. For example, in the test bed, the testers performing capacity testing for a telecommunications switch do not have access to 10,000 people all calling in to the switch at once. One way of solving this gap is to create a simulator that imitates the real world by mimicking those 10,000 people. Another example of when simulators might be needed is when other interfacing software applications or hardware are being developed in parallel with the software being tested and are not ready for use, or are unavailable for use, during testing.
Since a simulator only mimics the other software and hardware in the real-world environment, strategic decisions need to be made about when it is appropriate to spend testing resources creating simulators and utilizing simulation. These are again risk-based decisions because:
-
Resources are limited: Resources spent creating and testing the simulators are not spent testing other parts of the software
-
Simulators are not the real environment: If incorrect choices are made in creating the simulators, defects may still escape testing, or issues that would never have become actual defects may be reported, and unnecessary or incorrect changes could be made
Test Automation
Test automation is the use of software to automate the activities of test design, test execution, and the capturing and analysis of test results. Strategic decisions here involve:
-
How much of the testing to automate
-
Which tests or test activities to automate
-
Which automation tools to purchase
-
How to apply limited resources to the automation effort
Automated tests can typically be run much more quickly and therefore more often, than manual tests, providing increased visibility into the quality of the software at any given time. This can be particularly beneficial during regression testing, especially with iterative or agile development life cycles. Automation can also eliminate human error when comparing large amounts of output data with expected results.
As a trade-off, however, test automation requires an initial investment in tools and resources to create the automation, and a long-term investment to maintain the automated test suites as the software being developed changes over time. For software items that are expected to change frequently, more time may be spent maintaining the test automation than manual testing would require. Test automation also requires a different skill set than
testing itself. Therefore, additional staff or additional training for existing staff may be necessary to implement test automation.
Finally, test automation has limitations, in that it can only compare test results with a finite set of expected results. Since automated tests only look for what they are programmed to check, they can not identify other anomalous or unexpected behaviors that may result from software defects. For example, if the input to the test case is a number and the expected output is the square root of that number, then an automated test case would check that the square root value is correct for the selected input value. However, the automated test case would not identify that the background screen erroneously changed colors before it displayed the square root value. A human tester, conducting manual testing, would probably catch this type of anomaly easily.
As with other testing strategies, a mix of manual and automated testing strategies may provide the most effective approach to testing.
Develop and evaluate test plans and procedures, including system, acceptance, validation, etc., to determine whether project objectives are being met and risks are appropriately mitigated. (Create)
BODY OF KNOWLEDGE VI.B.2
V&V Plan
Test planning starts with the overall V&V plans as discussed in Chapter 20
, where decisions are made about the levels of testing that will be done, the testing objectives, strategies, and approaches
that will be used at each level, and the allocation of testing staff and other resources. V&V planning determines what V&V activities, including testing, will be used to evaluate the implementation of each requirement. The V&V plan is one of several test planning documents, as illustrated in Figure 21.7
.
Test Plans
For each of the major testing levels (for example, integration testing, system testing, acceptance testing, beta testing), additional test plans may be created to refine the approach and define additional details for that level. Each test plan defines the specific strategies and tactics that will be used to make certain that project/program objectives associated with that level of testing are being met, and that the requirements that are to be verified and/or validated at that level (as allocated by the V&V plan) are adequately tested. Each test plan may be a separate document, or the test plans can be incorporated as part of:
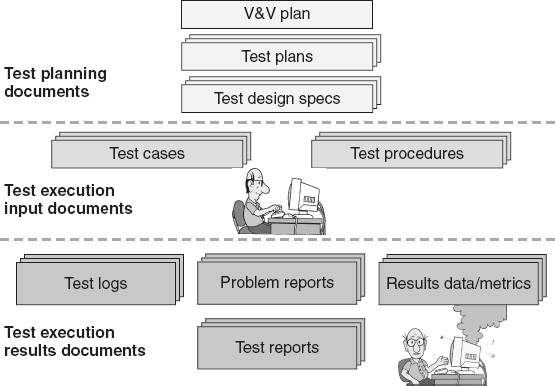
Figure 21.7
Types of testing documentation.
-
A single overall test plan for the project/program
-
As one or more sections in the V&V plan or Software Quality Assurance (SQA) plan
-
As one or more sections in the overall project/program plan
-
As data entries in an automated test planning and management tool
The test planning process includes developing the test plans, and reviewing and approving that plan. These test plans may be separate stand-alone documents or be included in the V&V plan or other planning document as appropriate to the needs of the project. According to IEEE Standard for Software Test Documentation
(IEEE 2008a) and ISO/IEC/IEEE Software and
Systems Engineering—Software Testing—Part 3: Test Documentation
(ISO/IEC/IEEE 2013), test plans should include:
-
Introduction or overview : A description of the context and structure of the plan, the plan’s scope, a summary of the unique nature of this particular level of testing, and the plan’s history. Other information that may be included in this section, as appropriate, includes:
-
The plan’s unique identifier
-
The issuing and approving organizations
-
Assumptions and constraints
-
References
-
Glossary and acronyms
-
-
Project/program : The project and/or program associated with the test plan.
-
Level of testing : The level(s) of testing, or the testing sub-processes, for which this plan is being written.
-
Items to be tested : A list of the software configuration items that will be tested under the plan including their versions and/or revisions, and a list of any known defects reports associated with the items to be tested.
-
Test traceability matrix : Include or point to the traceability matrix that provides linkages between the requirements and the test cases/procedures that will be executed as part of this testing.
-
The functions that will and will not be tested : For example, if the project is adding additional functions to an existing product, risk-based analysis is used to determine which existing functions are not impacted by the changes and therefore do not need to be retested. Based on risk, this section may also include the depth and level of rigor required for testing each function and establish priorities for testing.
-
The test approaches and methods that will be used for the testing level : This includes the identification of policies, test strategies, approaches (positive and negative testing, domain testing, boundary testing, exploratory testing, error guessing), and manual and automated testing methods that will be used for:
-
Functional, user scenario, and/or operational profile testing
-
Testing quality and product attribute requirements (for example, usability, performance, environmental load/volume/stress, safety, security, interoperability, conversion, installability, internationalization)
-
External interface and environmental configuration testing
-
Data and database testing
-
Testing user documentation (for example, user manuals, operator manuals, marketing materials, installation instructions)
-
Regression testing
This may include additional details in the system test matrix to define the exact approaches and methods to use for each requirement being tested, at the stated level of testing. In addition, this section defines approaches and methods for:-
Problem reporting and resolution
-
Issues reporting and resolution
-
Configuration management of test deliverables and testing tools
-
Test status reporting and other stakeholder communications, including reviews and metrics
-
-
Item pass/fail criteria : Specific, measurable criteria for determining if the item under test has successfully passed the cycle of tests typically used as exit criteria for the testing cycle. Examples might include:
-
Allowable minimum level of test coverage of the requirements
-
Allowable number of non-closed problem reports by severity, and requirements for work-arounds
-
Allowable arrival rates of new problems
-
Allowable number of unexecuted or unpassed test cases
-
Allowable variance between planned and actual testing effort
-
-
Suspension criteria : Specific, measurable criteria that when met indicate that the testing activities should be stopped until the resumption criteria are met. For example, if a certain number of critical defects are discovered or if a certain percentage of test cases are blocked, it may no longer be considered cost-effective to continue the testing effort until development corrects the software.
-
Resumption criteria: Specific, measurable criteria that when met indicate that the testing activities can be restarted after suspension. For example, a new build is received from development with corrections to most of the critical defects or defects that are blocking test case execution.
-
Test deliverables: Outputs from this cycle of testing, examples include:
-
Test plans
-
Test design specification
-
Test designs, including test cases, procedures, and scripts
-
Problem reports
-
Status reports and metrics
-
Test logs
-
Interim and final test completion reports
-
-
Testing tasks with assigned responsibilities (roles), resources, and schedules : This includes the work breakdown structure, schedule, and the staffing and other resources allocated for this level of testing. This information may be kept as part of the project information in a project management tool and pointed to by the test plan.
-
Environmental needs : This section defines:
-
Test bed requirements, including the physical setup, technologies, and tools
-
Mechanisms for validating the test bed setup
-
Methods for requesting updates or changes to the test bed configuration during testing
-
Allocation and schedules of test bed resources
-
-
Staffing plans and training needs for test personnel : Testing personnel may include test managers, test designers, test automation specialists, testers (people to perform manual and exploratory testing), test bed coordinators, and support staff. Skill gap analysis should be performed to make sure that the testing personnel have the requisite knowledge and skills, and the training plans need to define how identified gaps will be filled.
-
Risk management plans for risks associated with this level of testing, including :
-
Product and project risks associated with this plan and any associated risk handling
-
Risks that are being mitigated with this testing
-
Test Design Specification
A test design specification
is a further refinement of a test plan and is only needed if the complexity of the system is high or there is a need for additional levels of information. According to IEEE (IEEE 2008a), a test design specification is an optional document that defines the features to be tested, the approach refinements, test identification, and feature pass/fail criteria.
Select and evaluate various test designs, including fault insertion, fault-error handling, equivalence class partitioning, boundary value. (Evaluate)
BODY OF KNOWLEDGE VI.B.3
Test planning activities include performing requirements analysis to determine the approach needed to evaluate the implementation of each requirement. Test planning also includes performing risk, criticality, and hazard analysis to determine how extensively to test each requirement. Based on this analysis, test design is performed to then design, document, and verify test cases and procedures for each requirement. Test design also includes performing traceability analysis to confirm the completeness of the set of tests. Finally, test design activities may include the automation of tests that will be repetitively executed.
There are techniques the tester can use during test design to systematically minimize the number of tests while maximizing the probability of finding undiscovered relevant defects.
Equivalence Class Partitioning
Equivalence class partitioning
is a testing technique that takes a set of inputs and/or outputs and divides them into valid and invalid sets of data that are expected to be treated in the same way by the software. This allows the tester to systematically sample from each equivalence class, also called a partition, during testing, using a minimum set of tests while still achieving coverage. The assumption is that if one sampled value from an equivalence class uncovers a defect, then any other sample from the same equivalence class would probably catch the same defect. If the sampled value does not catch a defect, other samples probably would not catch it either. Rules of thumb when selecting equivalence classes include:
-
If the input/output is a continuous range (for example, from 1 to 100), there is one valid input class (number from 1 to 100) and two invalid classes (number less than 1 and numbers greater than 100)
-
If the input/output condition is a “must be” (for example, the first character must be a numeric character), there is one valid input class (inputs where the first character is a numeric) and one invalid class (inputs where the first character is not a numeric)
-
If the input/output condition specifies a set of valid input values (for example, the jobs of programmer, analyst, tester, QA, and manager), then each valid input is its own equivalence class (in this example there are five valid classes) and there is one invalid class (everything that is not in the list of valid inputs)
-
If the input/output condition is a specific number of values (for example one to six inspectors can be listed for a formal inspection), there is one valid equivalence class (having one to six inspectors) and two invalid classes (zero and more than six inspectors)
Test cases and procedures should be written generically for each equivalency class (input a number from 1 to 100, or input a number less than 1) so that the tester selects the sample at the time of test execution. Testers then strive to select a different sample from the equivalence class with every execution of the test case. If test execution is automated, this may require the use of a random number generator or some other mechanism for varying the input with each execution.
Boundary Value
Boundary value
analysis explores the values on or around the boundaries of the equivalence classes or for each input or output. This technique will help identify an error where the programmer uses < instead of ≤, uses > instead of ≥, or forgets or mishandles the boundary in some other way. In boundary value testing, tests are created to test values at the boundaries, the minimum boundary value, and the maximum boundary value, and values just below the minimum and just above the maximum. For example, for the inputs in the range of 1 to 100, boundary value tests would include the inputs of 0, 1, 100, and 101.
Another example of boundaries would be to consider an input dialog box, as illustrated in Figure 21.8
. Assuming that the box displays up to 25 characters and that it is a scrolling box that actually allows an input string of up to 255 characters, boundary value testing would test the null input, a single character, 25 characters, 26 characters, 255 characters, and 256 characters. There may also be invisible boundaries for this input, for example,
the input buffer size used by the operating system that the tester might want to explore.
Other boundaries to consider when writing tests include:
-
Zero : The boundary between positive and negative numbers (boundary value tests should include the inputs of −1, 0, +1 for testing around the zero boundary for numeric inputs and outputs)
-
Null : The boundary between having an input and not having an input (boundary value tests should include the inputs of the null sting and a single character string for testing around the null boundary for character string inputs and outputs)
-
Hard copy output sizes : Characters per line or lines per page on outputs to a printer (remember, paper sizes can vary in different countries)
-
Screen output sizes : Screen width, length, and pixels
-
Hardware device outputs : Communication packet sizes or block sizes used in storing data on media
-
Lists : First item and last item in each list
-
Date and time : The boundaries between specific times or dates, where special actions or conditions may occur that need to be tested to confirm that the software handles the boundary correctly (time zones, international date line, daylight savings time transitions, end of day, end of month, end of quarter, end of year, end of century, leap year)
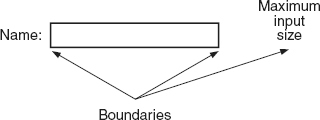
Figure 21.8
Input field boundary—example.
Fault Insertion
Fault insertion,
also called fault seeding
or defect salting,
is a mechanism for estimating the number of undetected defects that escaped from a testing process. Fault insertion literally intentionally inserts known defects into the software (typically done by people independent of either the developers or testers). The software is then tested and the defects that are found are analyzed to determine if they are part of the intentionally inserted, known defects or if they are new, unknown defects. The number of unfound, unknown defects is then estimated through the use of the simple ratio:

For example, assume 100 known defects were inserted into the software prior to system test. The software is tested and 72 of the inserted defects were found and 165 other defects were found. That means that 28 (100 minus 72) of the inserted (known) defects were not found during system test. The number of unfound, unknown defects (UUD) can be estimated:
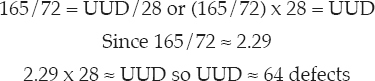
This technique assumes that the known defects are being found at the same rate as the unknown defects. Care must be taken to “seed” the software with a representative set of defects for this assumption to hold true. For example, if only logic errors are inserted into the code, then only logic type errors can be reasonably analyzed and predicted.
Good configuration management is required to make certain that the software, prior to fault insertion, can be retrieved for use moving forward. If not, care must be taken when removing all of the known defects so that all known defects are removed and so that new defects are not introduced by mistake. To verify this, regression testing must be performed after the completion of the removal activities.
Fault-Error Handling
Testing techniques that examine exception handling
, also called fault-error handling
or negative testing
, look at how well the software handles errors, invalid conditions, invalid or out-of-sequence inputs, and invalid data.
Testing should check to confirm that exception handling is triggered whenever an exception occurs. Exception handlers should allow graceful software recovery or shutdown if necessary. They should prevent abandonment of control to the operating system (obscure crashes). Testing should also check that any reserved system resources (for example buffers, allocated memory, network channels) are appropriately released by creating tests that produce multiple exceptions to see how the software
handles these repeated exception conditions.
One technique for selecting fault-error handling tests is called error guessing.
The main idea behind error guessing is to “attack” the software with inputs that expose potential programmer mistakes or represent the kinds of invalid inputs that the software would receive if user or hardware mistakes occurred. It is hard to specifically describe this technique since it is largely intuitive and experience-based. One technique for error guessing is to brainstorm probable types of faults or errors that might occur, given the specific software. Another technique, is to create and use checklists of common errors in past software products. For example:
-
What mistakes do programmers make:
-
< versus ≤ or > versus ≥ (boundary value testing)
-
Not appropriately handling zero, negative numbers, or null inputs
-
Failure to initialize data or variables
-
Declaring variables as one type or size, and then using them as a different type or size
-
Not performing adequate error checking on inputs
-
Allowing buffer or variable overflows
-
Not appropriately handling zero times through a loop or only once through a loop
-
Incorrect logic or control flow
-
Not releasing resources or not reinitializing variables
-
-
What mistakes do users make:
-
Creative invalids (alpha versus numeric, decimals versus integers, alt key versus control key versus function key versus shift key, left versus right mouse clicks)
-
Too many or too few inputs (not completing required fields)
-
Invalid user entries resulting from inadequate instructions (should spaces, parentheses, dashes be included in number sequences like phone numbers, credit card numbers and social security numbers)
-
Too little or too much input (not putting in an input or overflowing input fields)
-
Invalid combinations (State = Texas, but entered with a New York zip code)
-
Invalid processes (attempting to delete a customer record from the database before it is added)
-
Recursive processes (a spreadsheet cell that adds that cell to itself)
-
Doing things out of sequence (trying to pump gas before selecting gas type)
-
Incorrect usage (hint: look at problem reports from the field that were operator errors)
-
-
What errors do machines make:
-
Defective boards (hint: collect them as they are returned from the field)
-
Bad or corrupted data
-
Failure to communicate (not responding when expected or responding after software times out)
-
Interrupted or incomplete communications
-
Power failures
-
Limited, full, unavailable, or busy resources
-
Write protected, unavailable or damaged/corrupted media (no media in drive, or corrupted block or sector on media)
-
Race conditions and other timing issues
-
Cause-Effect Graphing
Cause-effect graphing (CEG)
is a model used to help design productive test cases by using a simplified digital-logic circuit (combinatorial logic network) graph. Its origin is in hardware engineering but it has been adapted for use in software. The CEG technique takes into consideration the combinations of causes that result in effecting the system’s behavior. The commonly used process for CEG can be described in six steps.
Step 1
: In the first step, the functional requirements are decomposed and analyzed. To do this, the functional requirements are partitioned into logical groupings, for example, commands, actions, and menu options. Each logical grouping is then further analyzed and decomposed into a list of detailed functions, sub-functions, and so forth.
Step 2
: In the second step, the causes and effects
are identified. The first part of step 2 is to identify the causes and assign each cause a unique identifier. A cause can also be referred to as an input, as a distinct input condition, or as an equivalence class of input conditions. Examining the specification, or other similar artifact, word-by-word and underlining words or phrases that describe inputs helps to identify the causes. Causes (input conditions)
are events that are generated outside an application that the application must react to in some fashion. Examples of causes include hardware events (for example, keystrokes, pushed buttons, mouse clicks, and sensor activations), API calls, and return codes.
The second part of step 2 is to identify the effects, and assign each effect a unique identifier. An effect can also be referred to as an output action, as a distinct output condition, as an equivalence class of output conditions, or as an output such as a confirmation message or error message. Examples of outputs include a message
printed on the screen, a string sent to a database, a command sent to the hardware, and a request to the operating system. System transformations, such as file or database record updates are considered effects as well. As with causes, examining the specification, or other similar artifact, word-by-word and underlining words or phrases that describe outputs or system transformations helps to identify the effects.
For example, Table 21.1
lists the causes and effects for the following example set of requirements for calculating car insurance premiums:
-
R101 For females less than 65 years of age, the premium is $500
-
R102 For males less than 25 years of age, the premium is $3000
-
R103 For males between 25 and 64 years of age, the premium is $1000
-
R104 For anyone 65 years of age or more, the premium is $1500
Table 21.1
Causes-and-effects—example.
|
Causes (input conditions)
|
Effects (output conditions or system transformations)
|
|
|
Listing the causes and effect can help identify the completeness of the requirements and identify possible problem areas. For example, these requirements do not list a minimum or maximum age, or what should happen if an entry other then “male” or “female” is entered into the sex field. The tester can use these potential problem areas to design test cases to make certain that the software either does not allow the entry of invalid values or responds appropriately with invalid input error messages. Of course, the tester should also ask the requirements analyst about these issues when they are identified so that potential problems can be corrected as soon as possible in the product life cycle.
Step 3
: In the third step, cause–effect graphs are created. The semantic content of the specification is analyzed and transformed into Boolean graphs linking the causes and effects. These are the cause–effect graphs. It is easier to derive the Boolean function for each effect from their separate CEGs. Table 21.2
illustrates the individual cause- effect graphs from the example list of requirements.
Step 4
: In the fourth step the graphs are annotated with constraints describing combinations of causes and/or effects that are impossible because of syntactic or environmental constraints or considerations. For example, for the purpose of calculating the insurance premium in the above example, a person can not be both a “male” and a “female” simultaneously, as illustrated in Figure 21.9
. To show this, the CEG is annotated, as appropriate, with the constraint symbols shown in Table 21.3
.
Table 21.2
Cause-and-effect graphs—example.
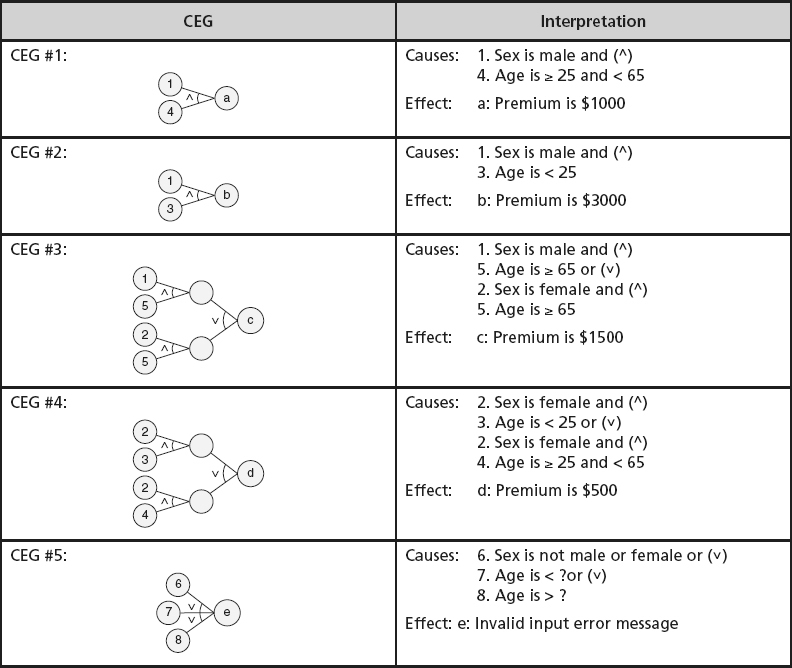
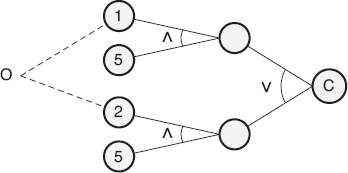
Figure 21.9
Cause-and-effect graph with constraints—example.
Table 21.3
Cause effect graph constraint symbols—example (based on Myers [2004]).

Step 5
: In the fifth step, state conditions in the graphs are methodically traced and converted into a limited-entry decision table. The ones (1) in the limited-entry decision table column indicate that the cause (or effect) is true in the CEG and zeros (0) indicate that it is false. Table 21.4
illustrates the limited-entry decision table created by converting the CEG from the “calculating car insurance premiums” example. For example, the CEG #1 from step 3 converts into test case column 1 in Table 21.4
. From CEG #1,
causes 1 and 3 being true result in effect b being true.
Some CEGs may result in more than one test case being created. For example, because of the one and only one constraint in the annotated CEG #3 from step 4, this CEG results in test cases 3 and 4 in Table 21.4
.
Step 6
: In the sixth step the columns in the decision table are converted into test cases, as illustrated in Table 21.5
. It should be noted that the example used above to illustrate the basic steps of CEG was kept very simple. An astute software developer could probably jump right to this set of test cases from the requirements without using the CEG method. However, for large, complex systems with multiple causes (inputs) and effects (outputs or transformations) this method is a systematic way to analyze them to create test cases. If CEG is performed early in the project, it can help in developing and verifying the completeness of the specification.
Table 21.4
Limited-entry decision table—example.

Table 21.5
Test cases from cause-effect graphing—example.

Identify and use various tests, including unit, functional, performance, integration, regression, usability, acceptance, certification, environmental load, stress, worst-case, perfective, exploratory, system. (Apply)
BODY OF KNOWLEDGE VI.B.4
Levels of Testing
There are various levels of software testing that can be done, as illustrated in Figure 21.10
. These different levels of testing are known by different names in different organizations. Even the number of levels of testing may vary from organization to organization. The discussion below should be considered as an example of the different levels of testing and include some of the more common names for these levels.
At the lowest level, during unit testing
, also called
module testing
or component testing
, the individual source code modules that make up the software product are tested separately. A source code module is the smallest software element that can be separately compiled. The author of a source code module usually performs this unit testing. One of the advantages of unit testing is fault isolation. Any problems that are found during unit test execution are isolated to the individual source code module being tested. Unit testing is typically the earliest level of test execution and therefore identifies defects earlier, when they are less expensive to fix, than if they were found during later levels of test execution. At the unit test level it is also easier to confirm that every line of code or every branch through the source code module is tested during test execution. An analogy for unit testing is to make sure that the individual bricks are good before the workers start building the wall out of them.
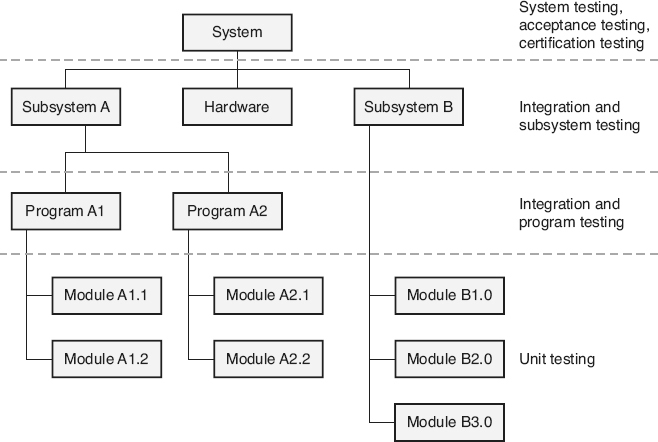
Figure 21.10
Levels of testing.
During software integration
, aggregating two or more source code modules or other components (constituent configuration items) are used to create an integrated software component (composite configuration item). With large software development projects, integration testing
often includes software from many developers. Integration testing may be accomplished in several levels, for example:
-
Integrating source code modules into software program components and testing the interfaces and interactions between those source code modules
-
Integrating software program components into software subsystem components and testing the interfaces and interactions between those software programs
-
Integrating software subsystem components into the software system and testing the interfaces and interactions between those software subsystems
Depending on the organization and the size of the project, integration testing may be performed by the developers or by a separate independent test team. The focus of integration testing is on the interfaces and interactions between the integrated components or source code modules. Since the individual source code modules are already tested at the module-level, integration testing can maintain this focus without the distraction of an excessive amount of module-level defects. To continue the analogy used above, integration testing focuses on making sure the mortar between the bricks is good and that the wall is solid as it is being built.
Software system testing
, also called software qualification testing
, is testing conducted on a complete, integrated software
application or product to evaluate the software’s compliance with its specified requirements.
During system integration
, if the software is part of a larger system, there may be other levels of integration testing where the software, hardware, and other system components are integrated into the system and testing focuses on the interfaces and interactions between those system components.
System testing
, also called system qualification testing
, is “testing conducted on a complete, integrated system to evaluate the system’s compliance with its specified requirements” (ISO/IEC/IEEE 2010). The system may be an aggregation of software, hardware, or both that is treated as a single entity for the purpose of system testing, as well as operational use after release. To finish the analogy, system testing focuses on the functionality and quality of the entire house.
If the system is part of a system of systems, yet another level of integration and testing may occur followed by system of system testing and so on as needed.
Acceptance testing
, also called user acceptance test (UAT)
, is a special type of testing performed by or for the acquirer of the software/system to demonstrate that the as-built product performs in accordance with its acceptance criteria. Typically, the acceptance test criteria are defined in a set of acceptance tests and agreed to as part of the contract, or other early agreement between the development organization and the acquirers. Acceptance tests are designed to provide a mechanism for formal acceptance of the software as it transitions into operations.
Certification testing
is also a special type of testing that is typically done by a third party (an organization other than the supplier or acquirer of the software/system). Certification test criteria and any standards that the software/system must meet, should be defined and agreed to in advance. Contractual agreements between the supplier and acquirer may call for
certification testing in place of, or in addition to, acceptance testing. A software development organization may also voluntarily seek some form of certification for their products for marketing or other purposes. Commercial-off-the-shelf (COTS) may also be
put through certification testing as needed. For example, if the COTS software is used in or to build for safety-critical or security-critical systems, certification testing may be considered as a cost-effective, efficient way of performing V&V.
Functional Testing
Functional testing
focuses on testing the functional requirements of the software—“what the software is supposed to do.” Functional testing strategies include:
-
Testing each individual function
-
Testing usage scenarios
-
Testing to the operational profile
To test each individual function, the tester decomposes and analyzes functional requirements and partitions the functionality into logical components (commands, actions, menu options). For each component, a list is made of detailed functions and sub-functions that need to be tested, as illustrated in the example in Figure 21.11
.
According to Whittaker (2003), “functional software testing is about intelligence.” First, the testers must become familiar with the environment in which each function/sub-function operates. This involves identifying “users” of that function or sub-function from outside of the software being tested. As illustrated in Figure 21.12
, there are four classes of environmental users that need to be considered.
-
Humans and hardware : Human users can not interface directly with the software. Instead they must communicate using hardware devices (for example, keyboard, mouse, or button) whose inputs are processed by device drivers. Software may also interface directly with hardware without human interaction.
-
Operating system : The operating system user provides memory and file pointers. Operating systems provide a set of functions needed and used by most applications (for example, time and date functions), and provide the necessary linkages to control a computer’s hardware.
-
File systems : File system users read, write, and store data in binary or text format. Files are used to store persistent data, as opposed to internally stored global or local data structures (for example, integers, characters, arrays, strings, stacks, queues, pointers) that only exist while the program that defined them is executing. Because file contents are easily corrupted and are also easy to change from outside the confines of the applications that create and process them, the tester must be concerned with testing issues such as how the software handles:
-
Corrupt data (for example, wrong type, incorrectly formatted, field delimiters misplaced, fields in the wrong order, file too large for the system under test to handle)
-
A privileged user changing the permissions of a file while another user is editing the file contents
-
-
Software applications : Other software programs (for example, databases, runtime libraries, applications) that supply inputs and receive outputs. Testers should consider:
-
Data that is passed to the application, return values and error codes, and failure scenarios of external resources
-
Databases, math libraries, and any other external resource the application may link to or communicate with, for potential failure
-
Environment issues (for example, congested networks, busy or slow responses)
-
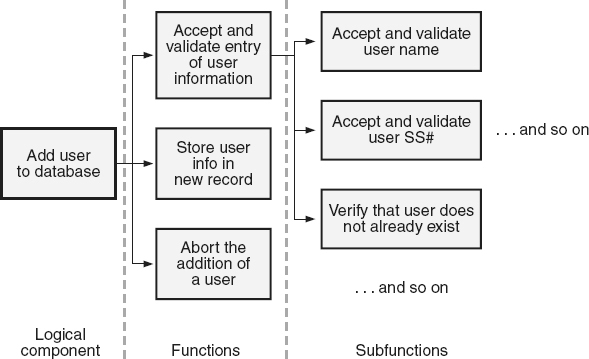
Figure 21.11
Function and sub-function list—example.

Figure 21.12
Environment in which the function operates.
Once the environmental users for the function/sub-function are identified, the tester must explore the capabilities of each function/sub-function as it relates to each of those users. For example:
-
What inputs, both valid and invalid, can each user provide the function/sub-function : The tester first tests to make certain that valid input values are handled appropriately. The tester then tests to confirm that the software prevents invalid input from being accepted or that the software handles it correctly.
-
What outputs do the functions/sub-functions send to each user : The tester must test to make sure that the function responds to specific conditions, inputs, and events with output of the right form, fit, and function. For example, if the user hits the print command from a word processor, the appropriate document is sent to the printer (function), it is formatted correctly (form), and the right number of pages printed (fit). The tester must also test to make certain that the function does not respond with outputs unless the proper conditions, inputs, or events occur. For example, the word processor does not send the document to the printer when the “open” function is activated or when no function at all has been selected.
-
What data are stored or retrieved because of interactions with each user : The tester must test to confirm that data are stored and retrieved in the proper formats and structures. Data structures should be tested to make certain that data can be appropriately added, stored, read, and deleted from them. Testers should test to make sure that overflowing of the data structures could not occur. Testers should also consider other data system-related issues including data integrity and data control (for example, security, refresh, backup, and recovery).
-
What computation(s) are done because of interactions with each user : Testers should think about what computations occur and how they might overflow (or underflow), or how they might interact or share data poorly with other computations or features.
To test usage scenarios, the tester chains together individual tests, from testing of the functions/sub-functions, into test scenarios that test start-to-finish user interactions with the system. Each feature may work independently, but they may not “play well together” to get real work accomplished for the users.
Testers perform operational profile testing
in order to
thoroughly evaluate the areas where defects are most likely to impact the reliability of the software. To perform operational profile testing, the tester must identify the different threads through the software. A thread
is a sequential set of usage steps through the software that a user takes to accomplish a start to finish task. For example, as illustrated in the decision tree in Figure 21.13
, one thread would be to enter the credit card correctly the first time, enter the PIN correctly the first time, and then select and pump regular gas. A different thread would repeat these steps except for selecting and pumping premium gas. A third thread would be to enter the card correctly but take two tries before entering the PIN correctly and selecting and pumping regular gas. Once the threads have been identified, probabilities must be assigned to the paths out of any given state. The sum of all of the probabilities (percentages) for paths out of any given state must be 1 (100%). For example, in the decision tree in Figure 21.13
:
-
For the card entry state: Putting the card in correctly is assigned a 95% (0.95) probability and putting the card in incorrectly is assigned a 5% (0.05) probability
-
For the await grade selection state: Selecting regular gas is assigned a 65% (0.65) probability, selecting super gas is assigned a 25% (0.25) probability, and selecting premium gas is assigned a 10% (0.10) probability
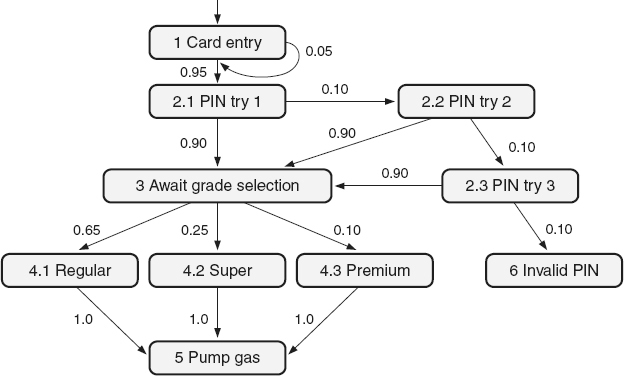
Figure 21.13
Decision tree—example.
The probability of a given thread is calculated by multiplying the assigned probabilities on that thread together. Those threads with the highest probability are the most frequently traversed threads. For example, again using the example in Figure 21.13
:
-
Thread #1 through states 1, 2.1, 3, 4.1, and 5 = .95 × .90 × .65 × 1 ≈ 55.58%
-
Thread #2 through states 1, 2.1, 3, 4.2, and 5 = .95 × .90 × .25 × 1 ≈ 21.38%
-
Thread #3 through states 1, 2.1, 3, 4.3, and 5 = .95 × .90 × .10 × 1 ≈ 8.56%
-
Thread #4 through states 1, 2.1, 2.2, 3, 4.3, and 5 = .95 × .10 × .90 × .10 × 1 ≈ 0.85%
-
Thread #5 through states 1, 2.1, 2.2, 2.3, 3, 4.1, and 5 = .95 × .10 × 10 × .90 × .65 × 1 ≈ 0.56 %
-
And so on
Using this example, if 1000 tests are going to be executed, operational profile testing would sample 556 (1000 × 55.58%) of those tests as variations on thread #1, for example, using different types of cards, different valid PINs and pumping different amounts of gas. A sample of 214 tests would be executed as variations on thread #2, 86 tests would be executed as variations on thread #3, and so on through each possible thread.
Performance, Environmental Load, Volume, and Stress Testing
The objective of performance testing
is to determine if the system has any problems meeting its performance requirements including throughput (number of transactions per time unit), response time, or capacities (for example, the number of simultaneous users, terminals, or transactions). Performance testing is usually done at the system level under full environmental load. Typically, software can perform to specification when not much is going on. However, the performance of some software applications may degrade at full volume, with multiple users interacting with the software, and other applications running in the background taking up system resources. Performance tests should be performed after other testing is complete and the software is relatively problem free.
Environmental load testing
evaluates the software’s performance capabilities (throughputs, response times, and capacities) under normal load conditions, as illustrated in Figure 21.14
.
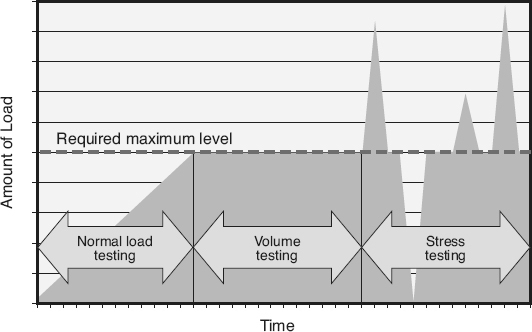
Figure 21.14
Load, stress, and volume testing.
Volume testing
, also called endurance testing
or soak testing
, is a special type of environmental load testing that subjects the software to heavy loads over long periods of time and evaluates the software’s capability. For example, does the software have any problems handling the maximum required volumes of data, transactions, users, and peripherals over several days or weeks?
Stress testing
is another special type of environmental load testing that subjects the software to surges or spikes in load over short periods of time, and evaluates the software’s performance. For example, is the software able to appropriately deal with jumping from no load to a spike of maximum data, transactions, or users? Stress testing can also involve testing for excess load. For example, if the requirement states that the maximum capacity that a telecommunication switch can handle is 10,000, does the software appropriately handle a spike to 11,000 calls by reporting
the appropriate messages (“all lines are currently busy, please call back later”) or does it result in an inappropriate failure condition?
Worst-Case Testing
One type of worst-case testing
is an extension of boundary testing. Boundary testing investigates the boundaries of each input variable separately by exploring the minimum value, one below the minimum, the maximum value, and one above the maximum. During routine boundary testing, if multiple variables are needed as inputs to the software, each variable is boundary tested individually, while all of the other variables are input at their normal values. For example, if a software function has two inputs x with boundaries at 0 and 5 and y with boundaries at 20 and 50, boundary testing would first boundary-test variable x with y set to its typical value. Then variable x would be set to its typical value and variable y would be boundary-tested. This example would require eight tests.
Worst-case testing explores the boundaries of multiple input variables in combination at their boundary values. To continue the example above with the two inputs x and y, worst-case testing would require 16 test cases:
-
x = −1 and y = 19
-
x = −1 and y = 20
-
x = −1 and y = 50
-
x = −1 and y = 51
-
x = 0 and y = 19
-
x = 0 and y = 20
-
x = 0 and y = 50
-
x = 0 and y = 51
-
x = 5 and y = 19
-
x = 5 and y = 20
-
x = 5 and y = 50
-
x = 5 and y = 51
-
x = 6 and y = 19
-
x = 6 and y = 20
-
x = 6 and y = 50
-
x = 6 and y = 51
Another type of worst-case testing is to execute testing under worst-case resource conditions, for example, with the minimum allowable amount of memory, bandwidth, processing speed or network speed, or with the maximum volume of users, peripherals, or other applications running in the background. Testing performance requirements is a particular concern when testing under worst-case conditions.
Resource Utilization Testing
The objective of resource utilization testing
is to determine if the system uses resources (for example, memory or disk space) at levels that exceed requirements, or if the software has any problems when needed resource levels fluctuate or when resources are busy or unavailable. To perform resource utilization testing, the testers must evaluate objectives or requirements for resource availability. By testing the software with inadequate resources or by saturating resources with artificially induced overloads, the tester can force resource-related exception conditions. Other resource-related testing considerations include whether the software can appropriately handle hardware or resource failures like:
-
Full disk, directory, memory area, print queue, message queue, stack
-
Disk not in drive, out of service, missing
-
Printer off-line, out of paper, out of ink, jammed, or missing
-
Extended memory not present or not responding
Usability Testing
The objective of usability testing
is to make certain that the software matches the user’s actual work style and determines whether the software has any areas that will be difficult or inconvenient for the users. The characteristics of usability include:
-
Accessibility : Can users enter, navigate, and exit with relative ease
-
Responsiveness : Can users do what they want, when they want
-
Efficiency : Can users do what they want in a minimum amount of time or steps
-
Comprehensibility : Do users understand the product structure, its help system, and its documentation
-
Aesthetics : Are the screens, reports, and other user interfaces pleasing to the user’s senses
-
Ease of use : How intuitive is the software use
-
Ease of learning : How intuitive is it to learn how to use the software
When designing tests for usability, the tester has to consider the different potential users of the system, including:
-
Novice users
-
Occasional users
-
Different types of typical users (for example gas station managers, attendants, family car drivers, eighteen-wheeler drivers)
-
Power users
-
Enterprise users (for example, drivers from a taxi fleet or a trucking company that have special requirements for pay-at-the pump software)
-
Database administrators (DBAs)
-
Operators or maintenance personnel
-
People with disabilities (focus on accessibility)
These different types of users may interpret usability very differently. Features that make the system user-friendly to novice or occasional users may drive power users crazy.
One method that is often employed in usability testing is to have different types of actual users work with the software, and observe their interactions. Usability tests can include having these users perform freeform, unplanned tasks as part of the testing process. This includes allowing users to work in a manner that reflects how they actually expect to work with the system. Alternately, the user may be asked to perform predefined, written scripts containing step-by-step instructions for the user to follow. This method facilitates better coverage but may not effectively reflect the user’s actual work patterns. Using a preliminary prototype or mock-up rather than the final product allows usability testing to be performed earlier in the life cycle. Conducting and observing beta testing or field trials on the software at the actual user’s site, or in the actual environment where the software will be used, can also be used to perform usability testing.
Exploratory Testing
In exploratory testing
, the testers design the test cases and procedures at the same time they are testing the software. Unlike preplanned test design, where test cases and procedures are written well in advance based on the software specifications, in exploratory testing the testers use the information they learn
about the product as they are testing it to create additional tests. Unlike ad hoc testing, exploratory testing is not just randomly wandering around the software. It is a systematic exploration of part of the software. The testers consciously think about what they do not know but want to find out. Also unlike ad hoc testing, the exploratory tester should “always write down what you do and what happens when you run exploratory tests” (Kaner 1999).
Exploratory testing is based on the tester’s intuition, experience, and observations. For example, a tester runs the preplanned set of test cases for a function and everything matches the expected results. Normally the tester would just move on to the next set of tests. However, if things just do not seem right, the tester uses exploratory testing to create additional test cases that further investigate the feature. Another example would be when the tester does find several problems in an area of the software, but believes there are still
more to find, even though all the preplanned test cases have been executed. Again, the tester creates additional test cases to explore the feature further, trying to confirm or refute their suspicions.
Exploratory testing can also leverage off of risk-based testing. For example, if a feature is expected to be low-risk, few planned test cases may be written for that feature. The exploratory testers can quickly investigate the low-risk feature to find out if they can find problems that might cause a reassessment of that feature’s risk. On the other hand, for features that are expected to be high-risk, time may be reserved in the schedule to plan for additional exploratory testing of those features.
Regression Testing
Regression testing
is concerned with how changes (fixes or updates) to software affect the unchanged portions of the software or hardware. Regression testing is “selective retesting of a software or software component to verify that modifications have not
caused unintended effects and that the system or component still complies with its specified requirements” (ISO/IEC/IEEE 2010).
Regression analysis
is the activity of examining a proposed software change to determine the depth and breadth of the effects the proposed change could have on the software. It is the determination of how extensively a change needs to be tested and how many already-executed test cases will need to be re-executed. Regression analysis must balance the risk of releasing the software with undiscovered defects, and the software’s quality and integrity requirements, against the cost of a more extensive testing effort.
Of course, the first testing step when software has been changed is to retest what changed. Both white-box and black-box testing strategies can be used to test the individual source code modules, components, and features that changed.
Regression analysis is then used to determine how extensively other parts of the software should be retested. When deciding what other white-box and gray-box regression tests to execute, consider source code modules/components that share the same local or global variables, or that directly call, or are called by, those source code modules/components that were changed. More rigorous regression testing might also consider going to a second level, as illustrated in Figure 21.15
. This more rigorous testing includes testing the source code modules/components that call, or are called by, the source code modules /component that directly call, or are called by, the source code modules /component that were changed. Regression analysis also includes deciding what other black-box regression tests to execute when changes are made to the software. Black-box regression analysis considers functions that:
-
Perform similar functions, or are closely associated with the changed functions
-
Interface with the same external device(s) or user(s)
-
Access the same external data or databases
The final step in regression testing is to execute the regression test suite
. The regression test suite includes white-box, gray-box, and black-box tests that are always repeated no matter what changes in the software. Candidate tests for the regression test suite are tests for the source code modules/components, and functions that:
-
Are mission-critical to the success of the software : For example, if everything else fails, the “save” command in a word processor, or the “self-destruct” in a missile system must work
-
Are defect-prone : Software that has been defect-prone in the past is more likely to be defect-prone in the future
-
Are the most used (operational profile) : Defects in areas of the software that are used most extensively will impact more users
-
Contain patches : Since patches are temporary fixes, it is very easy to make a mistake when adding existing patches into a new software build

Figure 21.15
Test what might be impacted by the changes.
Tests that are included in the regression test suite are prime candidates for automation because those tests will be rerun many times (every time the software is changed).
Determine appropriate levels of testing for integrating supplier, third-party, and subcontractor components and products. (Apply)
BODY OF KNOWLEDGE VI.B.5
When an external party-provided software component or product
is incorporated into a software system, it must be tested to the same level of rigor as other parts of that software system. That is, decisions about testing external software products should be based on risk analysis and the level of integrity required. If an externally- provided component or product is used to develop, build, or test the software system, it must also be tested to confirm that it does not cause problems in the software being developed. Externally-provided software components or products should be treated as an extended part of the primary development organization. The adequacy of the external supplier’s development and test processes should be prequalified and then monitored throughout the effort. Supplier processes do not necessarily have to mirror the acquirer’s process, but they need to achieve the same quality criteria for development and testing.
Throughout the software development process, the supplier of the external product should be performing V&V activities. The amount of visibility the acquirer needs into those V&V activities may vary, depending on the acquirer’s relationship to that supplier. For example, for commercial off-the-shelf (COTS) software or open source software, the acquirer may have no way of determining the extent to which the supplier tested their software. On the other hand, with custom-built software, the acquirer might be an active participant in some supplier testing activities, or at least have access to the test results and reports.
As part of product acceptance for custom-built software, the acquirer should conduct acceptance testing against negotiated acceptance criteria, which are included in the supplier contract or agreement to confirm that the delivered products meet all agreed-to requirements. The acquirer may also want to conduct alpha or beta testing. If the supplier’s software is being integrated into a larger product, it should be integration tested and system tested as part of that larger system. Black-box strategies are usually necessary for this testing since access to the acquired software
source code is typically not available.
As with other testing activities, risk should be considered when scoping any COTS testing effort. For example, for COTS software where the mainstream functionality is being utilized, less testing may be required because this functionality has already been validated extensively through operational use. However, if more fringe functionality is being used, or if this is a newly released COTS product, more extensive testing may be appropriate. If the COTS software is being integrated into the software system, it should be integration tested and system tested as part of that larger system. As with any supplier-supplied software, black-box strategies are usually necessary for this testing since access to the software source code is typically not available. If the COTS software is being used to develop or test the software being developed, risk-based validation and/or certification testing may be used to confirm that it performs as required. Any customization or wraparounds that are done for the COTS software should also be tested.
For open source software, risk should be considered when scoping any testing effort. If the open source software is being integrated into the software system, it should again be integration tested and system tested as part of that larger system. If the open source software is being used to develop or test the software being developed, risk-based validation and/or certification testing may be used to confirm that it performs as required like it was with COTS software. Any modifications, customization or wraparounds that are done for the open source software should also be tested. However, there may be legal issues associated with modifications to open source software that may need to be considered, so legal advice should be obtained before using open source software. Open source software can also be problematic when it comes to keeping up with changes and performing retesting and regression testing.
For some projects, the customers may also supply software that
will be integrated into the software system. If this is the case, this customer-supplied software must also be tested to the same level of rigor as other parts of the software system.
Evaluate the adequacy of test specifications such as functions, states, data and time domains, interfaces, security, and configurations that include internationalization and platform variances. (Evaluate)
BODY OF KNOWLEDGE VI.B.6
Test coverage
looks at the completeness of the testing. Test coverage maps the tests (test cases and test procedures) to some attribute of the source code modules, component, or software product being tested. These attributes can be attributes of the specification, as discussed in this section, or attributes of the code, as discussed in the next section.
Requirements Coverage
Requirements coverage
looks at the mapping of tests to each of the uniquely identified requirements in the specification. Traceability is one of the primary mechanisms used to make sure that all of the functional and other product requirements from the specification are covered. Every requirement should trace forward to one or more tests that will be used to evaluate the complete and correct implementation of that requirement. Requirements coverage metrics can be used to monitor progress toward complete coverage during the testing activities. The requirements coverage metric is the percentage of the requirements that trace forward to at least one test case. If the value of this metric is less than 100
percent then additional test cases need to be written to test the uncovered requirements. However, a value of 100 percent does not guarantee thorough testing, since more than one test case may be needed to comprehensively test each requirement.
A test matrix,
also called a system verification matrix
, is another tool for making certain that each requirement is appropriately tested. A test matrix traces each requirement to the method that will be used to test it. Initially, a test matrix is used to plan the level of testing and test strategy for each requirement, as shown in Table 21.6
. As test design progresses, additional detail can be added to the matrix to include more information about the specific approach to be taken. In this example, the test strategies include:
-
Inspection : Evaluation of the requirements is done through visual examination or static analysis of the software products (for example, source code or documentation) rather than through dynamic execution. Examples of the types of requirements that would be inspected are:
-
Product physical characteristics (for example, the screen will be blue)
-
Standards (for example, adherence to specified coding, commenting or modeling standards)
-
Specified languages or algorithms (for example, the software will be written in C++ or the data items will be sorted using a bubble sort)
-
-
Black-box demonstration : Evaluation of the requirements is done through the use of black-box strategies, where the evaluation can be accomplished through observation or visual confirmation. Examples of the types of requirements that would be demonstrated are:
-
Functional requirements
-
Performance-type requirements (for example, throughput, speed, response times, capacity)
-
Security- or safety-type requirements
-
Usability-type requirements
-
-
Black-box analysis and/or white-box analysis: Evaluation of the requirements that necessitate the use of independent calculations or other analytical techniques, used with either white-box or black-box testing strategies. Examples of the types of requirements that would be evaluated through analysis are:
-
Requirements that include calculations (for example, calculating payroll withholding, calculating monthly sales totals)
-
Requirements that include statistical techniques (for example, means, standard deviations, confidence intervals)
-
-
White-box execution: Evaluation of the requirements is done through the use of white-box techniques. Examples of the types of requirements that would be tested in this manner are most design constraint–type requirements, including:
-
Internal communication protocol requirements
-
Internal data storage requirements
-
Output format requirements like specifics for prompt/error message wording or report layouts
-
-
Not testable : Requirements that can not be evaluated because:
-
They are not really software requirements (for example, project constraints like delivery schedules)
-
It is not possible to test them with the current resources (for example, requirements that are not finite or not measurable)
-
Table 21.6
Test matrix—example.

An advantage of creating a test matrix early in the life cycle is the identification of non-testable requirements like R50 in Table 21.6
, before they propagate into other software work products. Non-testable requirements and other issues discovered during the creation of the test matrix should be reported to the requirements analyst for resolution. It should be remembered that any requirement that is not tested is a source of risk, because the implementation of that requirement may include undiscovered defects.
Functional Coverage
Of course, 100 percent requirements coverage automatically achieves 100 percent coverage of all of the functional requirements. Another way to measure functional coverage from a user perspective is to look at the percentage of threads through the program that map to test procedures.
State Coverage
State coverage
looks at the mapping of tests to the various states that the software can be in, and the various transitions between those states, to make certain that they are thoroughly tested. State testing is done to determine if the software:
-
Switches correctly from valid state to valid state, as specified
-
Performs any state transitions that are not valid (moving to a state that is not a valid transition from the previous state)
-
Loses track of its current state
-
Mishandles inputs or other data while it is switching states
Data Domain Coverage
Data domain coverage
looks at the mapping of tests to the various data domains in the software to confirm that they are thoroughly tested. Once the equivalency classes and boundaries for the inputs and outputs have been identified, as defined previously, data domain coverage evaluates the percentage of those classes and boundaries that have test cases associated with them.
Another data domain coverage technique creates a list of all of the data items in the software. This can be done through evaluating the data dictionary, or by looking at the specification to identify data items and structures. The CRUD acronym can then be used to investigate data domain coverage, by making certain that tests exist to evaluate any requirements or stakeholder needs for:
-
C: The creation and initializations of each data item or structure
-
R: The reading, querying, or displaying of each data item or structure
-
U: The updating or refreshing of each data item or structure
-
D: The deleting of each data item or structure
Some organizations use the alternative CRUDL acronym where the “L: is added for listing, or tracking of each data item or structure in reports.
Date and Time Domain Coverage
Date and time domain coverage
looks at the mapping of tests to the various date and/or time domains in the software to confirm that they are thoroughly tested. Date and time domain testing considers:
-
Different times of the day, days of the week, month, or year when the software is expected to perform differently. For example, performing background activities and/or maintenance, refreshing data, and/or creating reports.
-
Special dates and/or times when the software performs differently. For example, vacations when normal operations are shut-down.
-
Peak or minimum loads at certain times and/or dates.
Date and time domain testing also considers whether the software appropriately handles special dates and/or times. For example:
-
Shift changes, the end of the day, week, month, quarter or year, or even the end of the century
-
Holidays
-
Daylight savings time changes
-
Leap year
-
Time zone changes or international date line changes
Interface Coverage
An interface
is a shared boundary across which information is
passed. There are interfaces internal to the software between its source code modules/components. There are also interfaces between the software and external entities (user/hardware, operating systems, file systems, and other software applications), as illustrated in Figure 21.12
. Interface coverage looks at the mapping of tests to the various identified interfaces
to make certain that they are thoroughly tested. Integration testing typically focuses on confirming interface coverage.
Security Testing
The objective of security testing
is to determine if the security of the system can be attacked and breached, and to determine whether or not the software can handle the breaches, or recover from them if security is breached. Security coverage looks at the mapping of tests to the various identified security issues and then performs penetration testing to confirm that they are thoroughly tested. As our digital infrastructure gets increasingly complex and interconnected, the difficulty of achieving application security increases exponentially and so does the difficulty of the associated security test efforts. As with other types of testing, checklists are often used to make sure that key security areas are tested. Testers also use penetration testing techniques to attempt to break through access control and software security controls to identify weaknesses along specific paths of attack. (See Chapters 6
, 11
, 13
and 17
for additional discussions about software security.)
Platform Configuration Coverage
The objective of platform configuration testing
is to determine if the software has any problems handling all the required possible hardware platforms and software configurations (for example, various servers, browsers, operating systems, and so on). Platform configuration coverage
looks at the mapping of tests to the
various possible platforms to confirm that the software is thoroughly tested on each platform. One method used for platform configuration coverage is to use a platform configuration test matrix. In a platform configuration test matrix
, all of the possible platforms are listed as column headers. The example in Table 21.7
includes various operating systems that the software needs to run on but other configurations can be included as needed. The left column lists the tests to be conducted. Each cell lists the status of those tests on that platform:
-
Blank : The test has yet to be executed on that configuration.
-
Passed : The test passed when it was executed on that configuration.
-
Failed : The test failed when it was executed on that configuration.
-
N/A : The test is not applicable or does not need to be executed on that configuration. For example. N/A might indicate that the test is not expected to react differently, or have different results, on that configuration than it will have on one or more other configurations in the matrix.
Table 21.7
Platform configuration test matrix—example.
This matrix only tests a single configuration entity variance per column. However, if combinations of configurations entities are expected to interact with the software in different ways, it may be necessary to test configuration combinations as well. For example, if there are multiple possible hardware platforms and multiple possible operating systems, configuration testing may require the testing of the software on each hardware platform/operating system pairing.
Internationalization Testing
The objective of internationalization testing
, also called localization testing,
is to determine if the software has any problems related to transitioning it to other geographic locations. This includes adaptation to different languages, cultures, customs, and standards. The tester must be fluent in each language used to test the system in order to confirm proper translation of screens, reports, error messages, help, and other items.
Internationalization configuration coverage
looks at the mapping of tests to the various possible geographic locations to confirm that the software is thoroughly tested on each location. Internationalization configuration coverage can also be tracked using a configuration test matrix, similar to the one illustrated in Table 21.7
. However, in the case of internationalization, all of the possible locations are listed as column headers instead of the platforms. Test considerations in internationalization testing include:
-
Character sets : Different character set are used in different countries. Verify that the software uses the proper set.
-
Keyboards : Keyboards should be tested with the software to make sure that they correctly interpret key codes according to the character set.
-
Text filters : The software may accept only certain characters in a field. Test that the software allows and displays every character in their appropriate places.
-
Loading, saving, importing, and exporting high and low ASCII : Save and read full character sets to every file format that the software supports. Display and print them to verify correctness.
-
Operating system language : Check variances in wild card symbols, file name delimiters, and common operating system commands.
-
Hot keys : Consider any underlined, bold, or otherwise highlighted character in a menu item (such as X in eXit). Do any hot keys from the original language have their original effect even though they do not appear in the localized menu?
-
Garbled in translation : If the software builds messages from fragments, how does that appear in the localized version? Are there file names and data values inserted into an error message to make it more descriptive?
-
Text displays : Different languages are oriented in different ways. For example, some languages are written right-to-left and others are written left-to-right.
-
Expanding text : Translated text expands and can overflow menus, dialog boxes, and internal storage, overwriting other code or data.
-
Spelling rules : Spelling rules vary across dialects of the same language. For example, in the United States the word “organization” is spelled with a “z” where in England it is spelled “organisation.” Does the spell-checker work correctly for the new location?
-
Hyphenation rules : Rules are not the same across languages.
-
Sorting rules: Character and word sorting rules vary from country to country (for example, sorting by last name, first name). The addition of special characters like letters with accents may not allow sorting using ASCII numeric order.
-
Case conversion : Only when the ASCII character set is uses can case conversion be done correctly by adding/subtracting 32 to/from a letter. Look for case conversion issues in any search dialog or other text pattern matching functions.
-
Underscoring rules : Underlining conventions differ between countries. It can be poor form to underscore punctuation, spaces, and other characters in some countries.
-
Printers : Though most European printers are essentially the same as those in the United States, printer differences can and do occur around the world.
-
Paper Size : Paper sizes can differ from country to country. Check that the default margins are correct for each size.
-
Data format and setup : Consider both the format and the numeric separators for time and date displays and money formats. For example, where the United States puts a comma, others put a decimal point or a space and some subroutines that the software links into may treat commas as separators between items in a list.
-
Rulers and measurements : Rulers, tab dialogs, grids, and every measure of length, height, volume, or weight that is displayed must be in the correct unit of measure.
-
Culture-bound graphics : Check clip art, tool icons, screens, manuals, and even packaging for culture-bound graphics.
-
Culture-bound outputs : Calendar formats vary, the appearance of a standard invoice varies, and address formats differ between countries. For example, in the United States, a date that reads 4/12/2016 is April12, 2016, while in other countries it is December 4, 2016.
Use and identify various tools and techniques to facilitate code coverage analysis techniques such as branch coverage, condition, domain, and boundary. (Apply)
BODY OF KNOWLEDGE VI.B.7
Unlike threads, which are usage/functionality focused, paths refer to control flow-sequences through the internal structure of the software source code. There are typically many possible paths between the entry and exit of a typical software application. A source code module containing nothing but straight line code has a single path. Every Boolean decision (IF, or IF THEN ELSE) doubles the number of potential paths, every case statement multiplies the number of potential paths by the number of cases, and every loop multiplies the number of potential paths by the number of different iteration values possible for the loop. For example, a source code module with a loop that can be iterated from one to 100 times has 100 possible paths. Add an if-than-else statement inside that loop and that increases the number of paths to 200. Add a case statement with four possible choices inside the loop as well, and there are 800 possible paths. Moving from the individual source code modules to the integration level, if this source code module
with 800 paths is integrated with a source code module that only has two sequential if-than-else statements (four paths), there are now 3200 paths through these two source code modules in combination.
Since there are rarely enough resources to test every path through a complex software application, or even a complex individual source code module, the tester uses white-box logic coverage techniques to systematically select the tests that are the most likely to help identify the yet undiscovered, relevant defects.
Statement, Decision, and Condition Coverage
To demonstrate the different statement, decision, and condition coverage techniques, the piece of nonsense code shown in Figure 21.16
will be used.
A statement
is an instruction or a series of instructions that a computer carries out. Statement coverage
is the extent that a given source code module/component statements are exercised by a set of tests. Statement coverage is the least rigorous type of code coverage technique. To have complete statement coverage, each statement must be executed at least once. Table 21.8
illustrates that it only takes one test case to have statement coverage of the code in Figure 21.16
. As long as input variables B and C are selected so that both decisions in this code are true, every statement is executed.

Figure 21.16
Code—example.
Table 21.8
Statement Coverage—example.

A decision
determines the branch path that the code takes. To have decision coverage
, also called branch coverage
, each decision takes all possible outcomes at least once. For example, if the decision is a Boolean expression, decision coverage requires test cases for both the true and false branches. If the decision is a case statement, decision coverage requires test cases that take each case branch. Table 21.9
illustrates the test cases needed to have decision coverage of the code in Figure 21.16
:
-
The first test case results in the first decision being true and the second decision being false
-
The second test case results in the first decision being false and the second decision being true
-
Thus, these two test cases in combination provide decision coverage because the true and false paths are taken out of each decision
A condition
is a state that a decision is based on. To have condition coverage
, each condition in a decision takes all possible outcomes at least once. For the code in Figure 21.16
there are three conditions that the input variable B can have:
-
B ≤ 40
-
40 < B < 60
-
B ≥ 60
There are also three conditions that input variable C can have:
-
C < 20
-
20 ≤ C < 100
-
C ≥ 100
Table 21.10
illustrates one choice of test cases that combines these into condition coverage of the code in Figure 21.16
. Note that condition coverage does not always imply decision coverage. For example, in the set of test cases in Table 21.10
:
-
Test case 1 results in the first decision being true and the second decision being false
-
Test cases 2 and 3 result in both decisions being false
-
Therefore, decision coverage has not been achieved because the true path has not been taken out of the second decision
Table 21.9
Decision coverage—example.

Table 21.10
Condition coverage—example.

Table 21.11
Decision/condition coverage—example.

Table 21.12
Multiple condition coverage—example.

The next level of rigor is to have condition and decision coverage
where each decision takes all possible outcomes at least once, and each condition in a decision takes all possible outcomes at least once. If decision/condition coverage exists, condition coverage, and decision coverage also all exist. Table 21.11
illustrates one choice of test cases that provides decision/condition coverage of the code in Figure 21.16
.
Modified condition/decision coverage (MC/DC)
expands on condition and decision coverage by adding the requirements that
each condition be shown to independently affect the outcome of the decision. The requirement for independence makes certain that the effect of each condition is tested relative to the other conditions (Hayhurst 2001).
To have multiple condition coverage
, each statement is executed at least once and all possible combinations of condition outcomes in each decision occur at least once. Multiple condition coverage always results in condition, decision, and statement coverage as well. Multiple condition coverage is the most rigorous type of structural coverage testing. Table 21.12
illustrates a choice of test cases that provides multiple condition coverage of the code in Figure 21.16
.
Domain and Boundary Testing
For structural testing, the conditions for the input variables define their domains
, or equivalence classes
. Once these domains are defined, sampling from these domains can be done when executing test cases.
Boundary value testing can also be done by sampling values on the boundaries of these domains. For example, for input variable B in the code in Figure 21.16
, the boundary values would be 39, 40, 60, and 61.
Boundary testing can also be performed on the loop counters when loops are included in the software source code. Boundary loop testing would have test cases for the minimum and maximum times through the loop (if there is a maximum), and one less than the minimum (which would skip the loop) and one more than the maximum. One more than the maximum is an error condition that the software should appropriately catch and handle, because the loop should never be able to be executed more than its maximum number of times. If the loop can be executed more than the maximum number of times, a problem should be reported.
Select and use simulations, test libraries, drivers, stubs, harnesses, etc., and identify parameters to establish a controlled test environment. (Analyze)
BODY OF KNOWLEDGE VI.B.8
Test Beds
A test bed
is an environment established and used for the execution of tests. The goal is to be able to create a test environment that matches the actual operating environment as closely as possible, while providing the testers with a known platform to test from, and visibility into test results. The test bed includes:
-
Hardware : At a minimum this includes the hardware required to execute the software, and it may also include additional hardware that inputs information into or accepts outputs from the software being tested.
-
Instrumentation : This may include oscilloscopes, or other hardware or software equipment needed to probe the software or its behaviors during test execution. For example, it may include instrumentation that monitors coverage, memory, disk space or band width utilization during test execution.
-
Simulators : As discussed earlier, simulators are used to substitute for (simulate) missing or unavailable system components (hardware, software, human) during test execution. Simulators mimic the behavior of these missing components in order to provide needed inputs to, and accept output from, the software being tested.
-
Software tools : This may include automation tools, stubs, and drivers. Other software tools used in testing include debuggers or other tools that allow step-by-step execution or breakpoints to be inserted to “watch” code execution and examine variable and memory values. This also includes the operating system and cohabitating software (including database software or other interfacing software applications) used to run and test the software.
-
Other support elements : For example, facilities, manuals, and other documentation.
Multiple test environments may be used throughout the testing processes. There may be different test environments for performing different levels of testing (unit, integration, system) or for performing different types of testing (performance, security, safety, usability). Requirements for the test environment may be documented in the V&V plans, test plans, test specifications, or even in the individual test cases.
Stubs
A stub
is a software source code module/component that can be used to minimally simulate the actions of a called (lower-level) source code module/component that has not yet been integrated, during top-down testing. Stubs can also be used in unit testing. Some required stubs need more than the minimal return response. For example, if the calling source code module/component under test expects a calculation from the invoked stub, that calculation capability may need to be programmed into the stub, or the stub can simply set the returned variable(s). Table 21.13
shows an example of a very simple stub and its associated calling routine.
A stub can also be used when the software needs to talk to an external device in order to replace that device. For example, a stub could intercept the data that would normally be sent to a
hardware device and automatically analyze that data against the expected values. This analysis can often be done more quickly and accurately by a stub than it can be manually, especially if the output is large or complex. For example, humans are not good at finding a single missing or incorrect data point in a long stream of data.
Drivers
A driver
is a source code module/component that can be used to minimally simulate the actions of a calling (higher-level) source code module/component that has not yet been integrated, during bottom-up testing. Drivers can also be used in unit testing. The driver typically establishes the values that will be passed to the source code module/component under test before calling it. Table 21.14
shows an example of a very simple driver and its associated called routine.
Table 21.13
Stub—example.
|
Stub:
|
Calling (higher-level) source code module:
|
|
Procedure CALCULATE_TAX (taxes) Return taxes
|
Procedure SALE_PROCESS
|
|
begin;
|
begin;
|
|
return $1.32;
|
statement 1;
|
|
end CALCULATE_TAX;
|
statement 2;
|
|
TAX = CALCULATE_TAX (taxes);
|
|
|
statement 3;
|
|
|
end SALE_PROCESS
|
Table 21.14
Driver—example.
|
Driver:
|
Called (lower-level) source
code module:
|
|
Procedure EXEC_DRV
|
Function MEAN_VALUE
|
|
begin;
|
(X1, X2 : FLOAT) return FLOAT
|
|
NUM1= 15
|
begin
|
|
NUM2 = 25
|
return (X1 + X2) / 2.0;
|
|
MEAN_VALUE(NUM1, NUM2);
|
end MEAN_VALUE
|
|
end EXEC_DRV;
|
More-complex test drivers can be used to mimic large amounts of data being entered manually. For example, a driver could mimic data entry streams coming from multiple keyboards simply by reading a predefined set of inputs from a data file and using them to emulate the keyboard entries.
Harnesses
At its simplest, a test harness
is a set of test stubs and drivers used to automate unit testing. At its most sophisticated, a test harness, also called an automated test framework,
can be used as a scaffold for software, tests, and test data. This harness can be used to automate the testing of a source code module/component, by executing a set of test cases and/or scripts under a variety of conditions, and collecting, monitoring, and even evaluating the test results. The two primary parts of a test harness are the test execution engine and the repository of test scripts.
A test execution engine
, also called a test executive, test manager
, or test sequencer
, is a test automation tool that selects, loads, and executes a test specification from the repository of test scripts. The test execution engine then monitors the execution of that test specification, and reports and stores the results (pass/fail/abort status, time stamps, duration of the test, and other information) for every step in the test sequence. The test execution engine may also have an interface that allows the testers to interact with the automated tests.
A repository of test scripts
is a collection of test specifications, also called test sequences
, which constitute the specific test steps required to execute the tests and their associated test data.
Controlling Test Environments
Sometimes the time to set up the test environment is trivial. However, according to Black (2004), “A complex test environment can take a long time and involve a lot of effort to set up and configure.” Whatever the initial investment, it must be protected by managing and controlling the test environment as it is being utilized by the testers to execute their tests. The key here is to be able to restore the test environment to a known state with minimal effort because, as tests are being executed, unexpected events may occur that corrupt the data or the software being tested, or cause issues with some other part of the test bed. After the software is released into operations, the test bed may also need to be reproduced to test the software after maintenance changes are made.
Test environment control policies and processes should be established and followed to make sure that the test bed is not interjecting false positives (issues that look like software problems but are actually test bed problems) or false negatives (allowing software problems that should have been identified to be missed) into the test execution processes. The policies and procedures should include mechanisms for:
-
Controlling test bed security, including control of access to the test environment.
-
Controlling, backing up, and restoring test data and databases.
-
Controlling, restoring, “freezing,” or updating the software installed on the test bed so that the testers have a steady platform to test from.
-
Validating the test bed setup, the individual elements of the test bed, and their interoperability.
-
Requesting, approving, and implementing changes to the test bed’s hardware, software, instrumentation, tool set, or other elements. Change procedures should include performing impact analysis and notifying impacted stakeholders of implemented changes.
-
Training testers to use the test bed elements correctly and have access to user/operator manuals, help files, or other support documentation for test bed elements.
-
Providing support for the test bed’s hardware, software, instrumentation, tool set, or other elements including service level agreements and escalation processes.
-
Maintaining licenses for purchased test bed elements.
-
Identifying the current versions, revisions, and calibrations for the test bed elements, including the software being tested.
Identify and use test utilities, diagnostics, automation and test management tools. (Apply)
BODY OF KNOWLEDGE VI.B.9
There are many different tools that can be used to make software testing more efficient, consistent and repeatable. Testing tools also reduce the tedium of repetitive work, provide objective evaluation, and provide visibility into the testing processes, test results, and test sufficiency.
Like any other software product, testing tools should go through
verification and validation (V&V) prior to use. Requirements for the V&V of supplier-provided testing tools should be specified as part of acquisition plans for those tools. This may include requirements for supplier V&V activities, as well as plans for acquirer conducted V&V (joint reviews, alpha, beta, and acceptance testing). Both supplier-provided and in-house-developed software testing tools should go through an appropriate level of rigorous V&V for the required integrity level, and/or risk of the software they will be testing. This helps make sure that a tool does not indicate that the software passes tests that it actually failed. It also helps eliminate the waste caused when software developers spend time debugging reported software problems, which were actually defects in the testing tools and not in the software.
Test Planning and Management Tools
Test planning and management tools
can range from simple templates in a word processor to sophisticated test management tools. Test planning and management tools include:
-
Templates : Templates for various test documents, which allow the tester to focus on the content rather than the format of those documents.
-
Test management database tools : Tools that allow test cases and procedures to be entered into test databases and allow for automated test specification generation and automated tracking of test log information. These databases can automate the traceability links between the entered test cases and procedures and the associated requirements, design elements, source code modules, change requests, and problem reports.
-
Test planning tools : Planning tools can include project estimation and planning tools used for the testing part of the project. These tools can aid in test estimation, creating test related work breakdown structures, test scheduling and budgeting.
-
Test monitoring and reporting tools : Tools that keep track of the test status, control the testing effort, log of test results, and generate testing metrics and test status reporting information.
-
Test matrix tools : Used to link requirements to test strategies and methods for testing each requirement.
Test Design and Development Tools
Test design and development tools
analyze requirements and design models, software source code and graphical user interfaces, to help:
-
Design and develop test cases, for example:
-
Complexity analyzers : Identify paths through the source code and identify the necessary input into designing unit test cases to test each path.
-
Decision trees : Examine the probability that a thread is executed during normal operations. This information is used in designing operational profile tests.
-
Static code analyzers : Can be used to identify improper control flows, uninitialized variables, inconsistencies in data declarations or usage, redundant code, unreachable code, and overly complex code. This information can be used to eliminate defects before those defects need to be found using more expensive testing techniques.
-
Cross-referencing code analyzers : When a variable is modified in one section of code, these analyzers provide the programmers and testers with all the other the software uses that variable and therefore might be impacted by the change. This information can be extremely helpful when analyzing the amount of regression testing needed after a change.
-
-
Generate test input data or equivalence classes of test inputs
-
Generate expected results through automated oracles
-
Select combinations of possible factors to be used in testing (Copeland 2003)
Test data preparation tools
include features that provide support to: (Graham 2008)
-
Extract data fields or records from existing real-world files or databases, and modify that data to make it anonymous (not able to be identified with real people or other entities)
-
Create, generate, edit, and manipulate data for use during testing
-
Sort data or records into different sequences
-
Generate new records populated with pseudo-random data or data based on specific criteria (for example, the operational profile)
-
Construct large sets of data or databases populated with similar records based on a template (for example, for use in volume testing)
Test Execution Tools
There are many test execution tools
on the market. These include:
-
Capture-and-playback tools : That capture the keystrokes entered when performing manual testing and allow the playback of those keystrokes to re-execute that exact testing sequence
-
Programmable, integrated test tool suites : Including tools that use scripting languages to create, execute, and capture and/or analyze the results of automated testing
-
Test harnesses, stubs and drivers : As described previously
-
Simulators : For example, tools that induce various levels of environmental load into the software for load, volume and stress testing
-
Dynamic analysis tools :
-
Coverage analyzers are used to evaluate the percentage or amount of the software that is touched during the execution of a set of tests
-
Resource utilization analyzers used for monitoring disk space, memory, band width utilization, and other resource utilization during test execution
-
Timing tools for measuring response time and other timing parameters
-
Communication analyzers that allow the tester to view raw data moving across the network or other communication channels
-
Debuggers used to step through code or set breakpoints, and to examine memory values during structural testing
-
-
Hacking tools and penetration testing tool : Used for testing security
-
File comparison tools, screen capture and comparison tools, and other tools : Used to capture and analyze the actual results of test execution against expected results
-
Test logging tools : Used to log test activities and results
Test Support Tools
Support tools from other disciplines are also used in the testing effort, including:
-
Project management tools : Used for test planning and management
-
Requirements tools and other software development tools : These tools are discussed in Chapter 13
-
Software configuration management (SCM) tools : These tools are discussed in more detail in Chapter 24
-
SCM library tools : Used to create and manage test libraries for controlling and tracking changes to test plans, test cases, test procedures, test specifications, test scripts, and test data. These libraries act as test repositories that can also facilitate the reuse of test products across software products or product lines.
-
Problem reporting tools : Used to record and track problems and other anomalies identified during testing.
-
Configuration management status accounting tools : Used to identify what changed (and what did not change) between a new software build, and the build testers were previously testing.
-
Other Tools Used by Testers
There are also many simple tools used by testers to perform their work. These tools may or may not be part of the test bed discussed previously. These tools include:
-
Word processors : Used for test plans, test reports, and other test documentation
-
Spreadsheets : Used for test matrices, for test metrics, to perform analysis calculations, to track test status, to log test results, and for other testing tasks
-
Checklists : Lists of common defects and test heuristics so the testers remember to create tests for these items or features, or lists of attributes or other characteristics to map to tests to confirm coverage
-
Database software : Used to create test databases as inputs into testing, to query the databases of the software being tested to analyze test results, to record and track test data, and create test metrics (for example a test case database or a problem-reporting database)
-
Stopwatches, oscilloscopes, or other monitoring or probe devices : Used to analyze test results
-
Random number generators : Used to create random samples as test inputs
-
Video cameras or other recording devices : Used to record usability testing sessions
Ensure the integrity and security of test data through the use of configuration controls. (Apply)
BODY OF KNOWLEDGE VI.B.10
Test Data Requirements
Once test cases, test procedures and automated test scripts have been designed, the requirements for the specific test data items must be identified. Test data items
include specific input data for test cases and may also include “operations-like” databases, standing data tables and global data (Graham 2008).
Test data item requirements describe the data items and their characteristics, and properties needed to execute the tests, including:
-
The name of the test data item
-
The type of the data item, and if the data item is a structure (data array, data record, or database with multiple data records) the type of each data element in that structure
-
If the data item is a database, the number of records required in that database to perform the test (for example, to execute some performance or worst-case testing, that database may need to be very small, or for other tests it may need to be empty)
-
The person or persons responsible for extracting, creating, generating, editing, and manipulating the data item or its elements
-
Required values, or ranges of values, for each data item, or data element contained in a data item structure, including any default values
-
Units of measure for each data item, or for each data element contained in a data item structure, if necessary
-
Requirements to sanitize any data items or data elements to make the data anonymous (not able to be identified with real people or other entities), and thus maintain the confidentiality of any data copied from any database used in operations
Testing should never directly use data items in the operational environment. If operational data are needed as the basis for test data items that data should always be copied from the operational environment into the test environment in order to maintain the integrity and confidentiality of the operational data items.
Test Data Management
Test data management
involves the management and control of the test data after they are initially created. The most important methodology in test data management is the utilization of a central repository for test data items.
This allows test data items to be reusable, so that:
-
The same tests can be executed multiple times, using the same test data items with the same values each time
-
Tests at different levels (unit, integration, system, acceptance) can use the same test data items, so time and effort are not wasted duplicating the same/similar data items at each level
-
Test data items can be quickly refreshed if they become over-written, corrupted or otherwise damaged as tests are executed, rather than wasting the energy needed to recreate them
This can be accomplished through identifying test data items as configuration items, and placing them into a test library (central repository for test data items) in a SCM library tool, or by creating the central repository through other means, as appropriate to the project. As test data items are needed over time for new levels of testing, they can be reused if they are already in the central repository. If they are not in the repository, they can be created and added to the repository for future reuse. The central repository also acts as a single source of content for:
-
Multiple testers to find and use already existing test data items (rather than reinventing the wheel)
-
Access control and other security measures
-
Backing up and/or archiving of test data items
Test data management also includes mechanisms for:
-
Defining when, and for how long, each test data item is needed
-
Requesting changes to test data items over time, analyzing their impacts, reviewing and approving of those changes by the appropriate authority, and implementing and verifying approved changes
-
Identifying private, proprietary or otherwise sensitive test data items and implementing security mechanisms to protect that data from unauthorized access, unauthorized disclosure, corruption, destruction or other damage, and other breaches
-
Identifying test data items that have become defective or corrupted over time, and the implementation of corrective measures, including root cause analysis and correction/refreshing of those test data items
-
Determining when and/or under what conditions each test data item needs to be reinitialized, reset and/or returned to default values
-
Determining when and how test data will be archived, and/or disposed of when testing is completed