A core element in securing business information systems is appreciating how the users of those systems interact with them. Consequently, in this chapter we are going to discuss how to understand cybersecurity behaviour and try to gain insight into what is happening with this on a psychological level.
It is important that we spend time trying to understand the nuances of our colleagues’ mental, emotional and social processes if we are to encourage them to be more security conscious. As such, this chapter will lay the foundations for changing cybersecurity behaviours, which we will cover in Chapter 5.
This chapter first looks at some examples of how cybersecurity behaviour is defined. The idea here is to tease these definitions apart in order to get a better sense of how tricky it can be to accurately describe what we are interested in, and also to try to relate them to cybersecurity in practice. Ultimately what we are trying to do is to get a clear picture of what we mean by ‘cybersecurity behaviour’ – what is relevant, and what can be ruled out.
Second, we will examine some theories of human psychology; here we will try to get to grips with how psychological science operates and to see how its theories can be applied to a cybersecurity context. This will involve studying the theories most commonly used to explain cybersecurity behaviour in academic research. Additionally, we will show how these theories can be applied in practice by illustrating them through some potential workplace scenarios.
Third, we will investigate the basics of studying cybersecurity behaviour. This will involve examining social science research methods and seeing how they can be applied to a cybersecurity context. As such, this means discussing things like hypothesis development and research design. There are lots of different methods that can be used here, depending on which behaviours we are interested in. So, in this section we will discuss the relative advantages and disadvantages of deploying tools like surveys, focus groups and interviews when trying to understand cybersecurity behaviour.
Throughout this chapter and the next we will discuss a survey carried out by the authors at the (ISC)2 Secure Summits in 2017. During workshops at conferences in Amsterdam, Stockholm, Zurich and London, over a hundred senior information security professionals gave us some fascinating insight into working with end user cybersecurity behaviour.
Finally, this chapter will conclude with a list of concrete next steps for you to follow as you try to better understand your own professional context. These actions are designed to ease you into getting to grips with behaviour without changing too much too soon.
DEFINING SECURITY BEHAVIOUR
When we say, ‘cybersecurity behaviour’, or ‘information security behaviour’ what exactly do we mean? In the modern office environment, almost every behaviour has a digital element and is therefore vulnerable to error or compromise. In that light, nearly everything that today’s employee does could conceivably fall under that heading. Yet at the same time, security professionals instinctively know what they are concerned about. You know risky behaviour when you see it, don’t you? But how do we take that implicit knowledge, and formulate it into something that can be used, and indeed reproduced?
First, let’s take a look at this useful definition published in the journal Computers & Security by a professor of computing at the University of South Africa:
Compliant information security behavior refers to the set of core information security activities that have to be adhered to by end-users to maintain information security as defined by information security policies.
(Padayachee, 2012)
Note how this definition does not actually mention any specific behaviours, it merely mentions ‘security activities’ – the implication being that we should already know what those are. It further says that these activities not only should be adhered to by end users, but that they are ‘defined by information security policies’. This should be our first important lesson in understanding cybersecurity behaviour.
Security professionals may be interested in a given end user behaviour. Or perhaps more accurately, ordered to put a stop to a given behaviour.
However, rather than trying to understand what’s going on in your colleagues’ minds when they are carrying out this behaviour, it is wise to first look at existing information security policies. Is this problematic behaviour explicitly forbidden?
In other words, you can’t blame people for doing something wrong, if it has not already been clearly specified as wrong. Of course, there may be gaps here, but at the very least, this should be your first port of call when trying to understand user behaviour.
Let’s take a look at another academic definition of cybersecurity behaviour. This one comes from a team of Australian researchers:
Human behaviours that may put an organisation at risk include inadvertently or deliberately divulging passwords to others, falling victim to phishing emails by clicking on embedded web site links, or inserting non-familiar media into work or home computers.
(Parsons et al., 2014)
This probably looks a lot more familiar to the average security professional: there are lots of things that we don’t want users to do. Don’t use a weak password, don’t leave your workstation unlocked – lots of don’ts. But while this is probably more recognisable, it should not really sit comfortably with us. The question remains, what is good cybersecurity behaviour? You can tell the end users what not to do, but can you tell them what to do?
When we are trying to understand cybersecurity behaviour, we should try to bear in mind a number of lessons from this exercise in trying to define it. First, while we may be professionally interested or concerned about a particular behaviour that is occurring in our workplace, we should first ask whether or not it is actually contrary to our organisation’s information security policy. If not, why not? What is the process involved in changing that, and informing end users of that change? How do we create good ‘rule books’ that end users can understand and have input to, and that can adapt to rapidly evolving technological environments?
Second, security professionals are often mostly interested in preventing users from doing harmful or risky things – ‘don’t do this’, ‘don’t do that’. Do you think that this kind of negative awareness-raising can be successful in the long term? As described in the last chapter, we have to be careful when we use fear in the context of cybersecurity.
Third, we need to reflect on what we are most concerned with here. Note the line of commonality between the two definitions: involving the end user in reducing the risk to the organisation. How do we do that? Recall also the advice in the previous chapter about knowing your audience and making your content relevant to them.
In sum, remember to specify as clearly as possible what behaviours you want users to do, and not to do, and to make sure these are included in organisational policy documentation. In Chapter 5 we will go into more detail regarding the types of specific behaviours you may be interested in – such as choosing strong passwords and not being fooled by phishing emails – but for now we will continue to focus on trying to better understand behaviour generally.
THEORIES OF SECURITY BEHAVIOUR
Because research into the human aspects of cybersecurity behaviour is still largely in its infancy, theories specifically written to understand this context are few and far between. Instead, what is more common is that theories from wider social science are interpreted in a cybersecurity context. For the most part, cybersecurity behaviour research has been carried out with regard to two particular theories. Each of these has its own particular strengths and weaknesses in helping us to understand end user behaviour so we will go through them one by one. In comparing and contrasting them, we will get closer to understanding the psychology of the end user and better at involving them in protecting their organisation. Furthermore, both these theories will be explained with illustration to common cybersecurity behaviours, in order to show you how you can better understand your end users’ difficulties.
Theory of planned behaviour
The theory of planned behaviour (Ajzen, 1991) originates in studies of interpersonal persuasion but is now used widely across the social sciences, including studies of cybersecurity. The basic idea with this theory is that when trying to understand why a person carries out any behaviour, we must think about their intentions around that behaviour. Moreover, their intention to act or not to act is composed of attitudes pertaining to that behaviour.
First, a person’s behaviour is influenced by their attitude to the behaviour – how they feel about it, whether or not they think it is a good thing to do and so on. Second, it is influenced by what are known as subjective norms, or whether or not the behaviour is common, or something that everyone else is doing. And finally, it is influenced by perceived behavioural control – or how easy the individual thinks the behaviour is to carry out. Furthermore, these factors interact with each other in a number of interesting ways.
So, for example, let’s take a given behaviour in a cybersecurity context – such as locking the screen of your computer when leaving your desk. We all know we should do this, but often we don’t. According to the theory of planned behaviour, this could be because of a number of reasons. In the case of behavioural attitude, it might simply be that we don’t like locking our computer or feel that it is unimportant. In the case of subjective norms, it could be that none of our co-workers bothers locking their computers, so we don’t feel like we need to either. And in the case of perceived behavioural control, it might simply be that we feel that locking our workstation is a pain – perhaps our password is too long and complicated, and we don’t like having to type it in so often.
More to the point, in any given context, while a person’s attitude and subjective norms are important, their perceived behavioural control is the critical one. For example, say we dislike locking our workstation every time we step away from our desk, and also believe that it is pointless (low attitude to the behaviour), and maybe we can see that none of our colleagues locks theirs (low subjective norms). However, if at the same time we think that we are capable of doing it easily and effectively (high perceived behavioural control), then it is possible that we will still actually lock our workstation regularly.
On the other hand, take password behaviour. Imagine a person who knows that password security is important and is a good thing (high attitude to the behaviour). And they know that there is a lot of pressure to maintain good password security within their organisation (high social norms). But imagine also that this person does not think that they are capable of remembering their new password (low perceived behavioural control). In this case, despite the former two factors, I suspect we are likely to see passwords written on sticky notes. As such, the crucial point to take from the theory of planned behaviour is that not only do we have to work on positive attitudes to cybersecurity behaviours, and improving social norms around them too, but, fundamentally, we have to convince end users that they are actually capable of executing these behaviours too.
Protection motivation theory
In contrast, the protection motivation theory (Rogers, 1975) originated in the health sector, and has been more used around issues like exercise, lifestyle and also cancer prevention and alcohol consumption. What it is essentially concerned with is how people respond to warnings telling them not to do certain things – such as eat unhealthy food or smoke cigarettes. As such, you can see how it can fit in with the kind of fear-based messaging that is common in the information security profession. So how does it explain how end users should react to this kind of messaging?
The protection motivation theory posits that an individual’s behaviour when encountering fear-based warnings is influenced by, on the one hand, their threat appraisal, and on the other hand, their coping appraisal. These two elements both comprise three further factors each. So, a person’s threat appraisals comprise the following assessments: how severe the threat is, how vulnerable they personally are to it, and how valuable the rewards are that they will lose if they follow the warning. In contrast, a person’s coping appraisal comprises another batch of assessments: how effective their response to the threat is likely to be, how much they can actually cope with the threat, and how much their response will cost them.
For example, let’s imagine that you are messaging users that they must install security updates. You warn them that they risk compromising their device by not doing so. However, the protection motivation theory might posit an individual’s thought response as follows. In terms of threat appraisal, they might agree that the threat is severe, and that they themselves are vulnerable to it. However, they may decide that if they do not install the updates, they could be working instead and deem this to be too valuable an activity to lose. And in terms of coping appraisal, this individual may think that their response to the threat would be ineffective and that they would be unable to cope with it if it happened, but that the act of installing the updates will cost them too much effort.
Now in this theory, there is no superior factor, unlike with perceived behavioural intention in the theory of planned behaviour above. But it does make you think about what might be happening psychologically in your work environment. Let’s break down your colleagues’ reaction to your fear-based messaging:
- I agree that the threats are severe.
- I agree my device(s) may be vulnerable.
- But anything I do will be ineffective because the threats are so severe.
- If something does go wrong, I have no idea what to do; I won’t be able to cope.
- I will have to spend time on trying to do something that won’t really help me (see three and four above).
So, how will they react? In all probability, they’ll make the decision that what you’re asking them to do will take too much time, require too much effort and won’t change a thing. Thus, they won’t run the update. As a result, you’ve been wasting your time too.
To be clear, you don’t need to start testing these theories in your workplace, and it isn’t necessarily important either to pick one or the other. The point is to try to get to grips with the psychological processes that may underlie your end users’ behaviours. Think about what could possibly motivate them. What are their intentions? What are they afraid of? What do they think is normal? What do they think they are capable of? Asking yourself questions like these is an important step to understanding cybersecurity behaviour.
MEASURING BEHAVIOUR
These days in professional working environments, measurement is key. ‘If you can’t measure it, you can’t manage it’ seems to be the modern management mantra. Consequently, security professionals dealing with improving end user cybersecurity behaviour will usually be tasked with somehow first benchmarking and then improving these numbers. That’s the idea: measure the behaviour, intervene somehow and then measure the behaviour again, with hopefully improved numbers. But, as social scientists have been realising for many years, measuring human activity is a tricky business.
As everyone working in this sector will appreciate, getting reliable and valid measures of security compliance is difficult, but there are a number of tools that can be used in this regard. For example, in our Secure Summits survey of 2017, we used a variety of methods to understand participants’ understanding and experience of the information security industry. Before each workshop, participants were contacted and asked if they had any specific questions or challenges. This kind of ‘fishing exercise’ allowed us to get a sense of what was important to the security professionals we were going to be working with and prepare accordingly. It might not have given us a completely accurate reflection of what every participant was interested in, but that’s not the point – it gave us a rough indication of what to expect: what people felt strongly enough about to type out before coming to the workshop itself. In other words, sometimes you don’t need to measure user behaviour per se, sometimes you just need to get a sense of what they are experiencing and feeling. Those early responses then fed into the drafting of the questions we asked them in the survey.
The survey was carried out at each of the four (ISC)2 Secure Summits in 2017, with 118 responses in total: 33 in Amsterdam, 17 in Stockholm, 18 in Zurich and 50 in London. As you can see from Figure 4.1, most of these participants were highly experienced information security professionals.
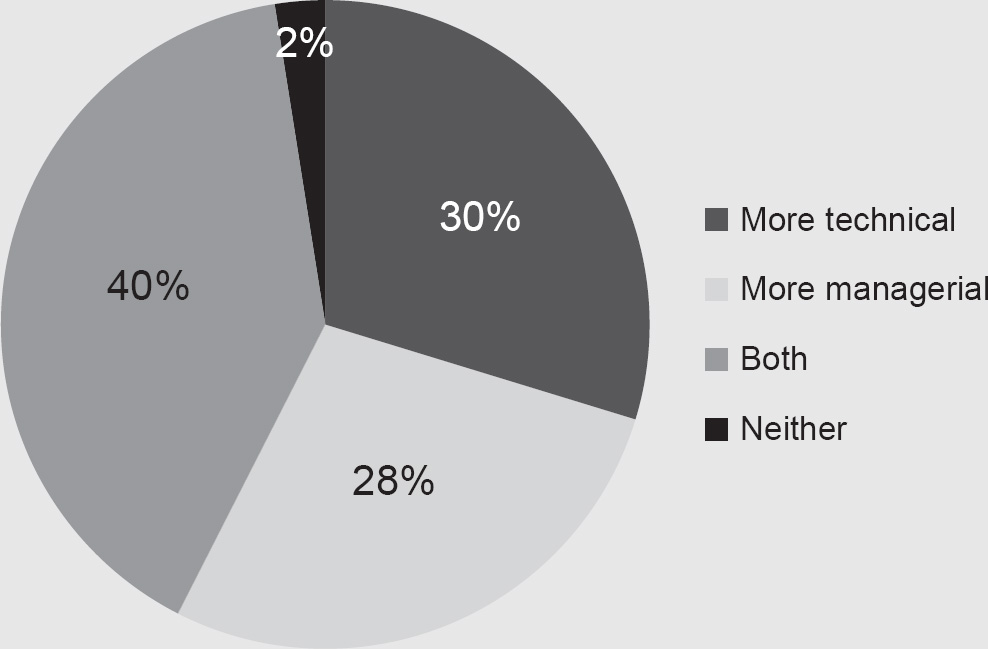
Additionally, you can see from Figure 4.2 that our respondents comprised a good mix of technical versus managerial roles, with many holding dual positions. Consequently, we are confident that the responses to the survey represent a good indication of the current state of the art in how security professionals deal with human factors in their roles.
Figure 4.1 Respondents’ years of experience in the information security sector
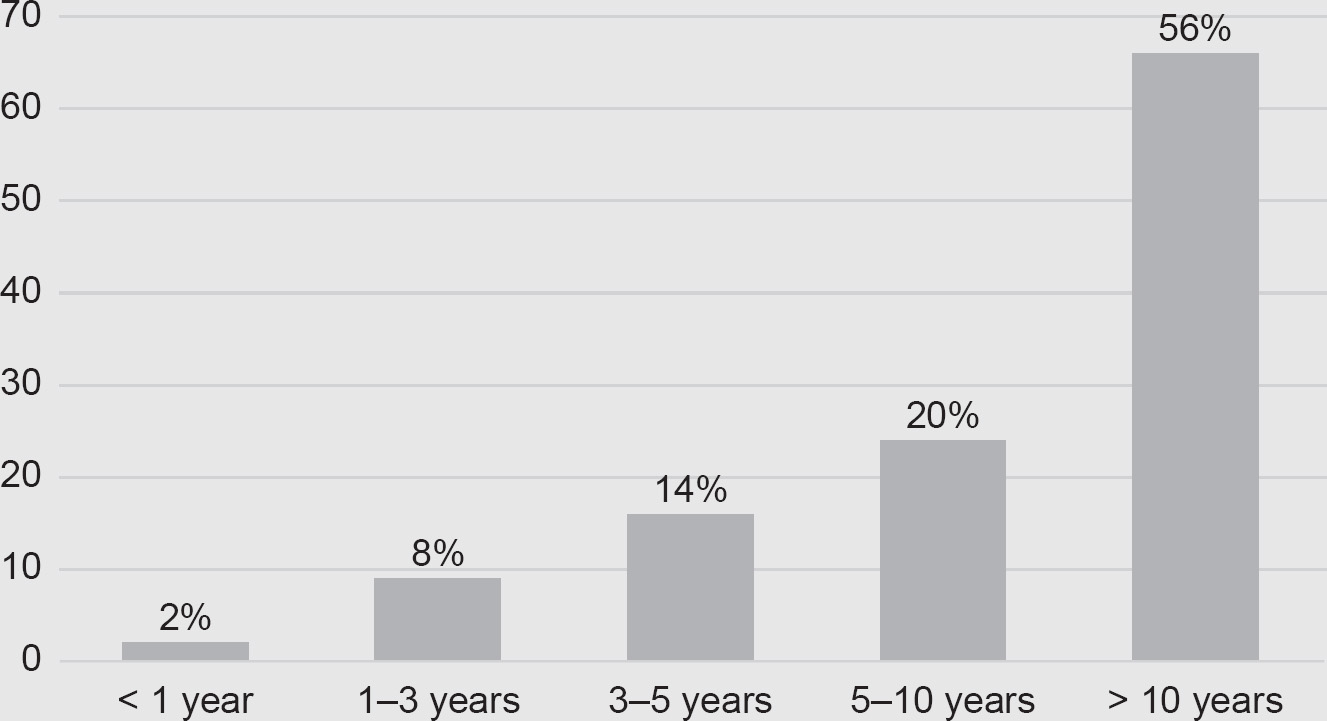
Figure 4.2 Respondents’ description of their professional roles
A key point in social science methodologies, such as surveys, is to only ask questions that you need to know the answer to. For example, in the ‘About You’ section we did not ask participants about their age or gender. This is because knowing the answer to those questions does not really shed any light on the rest of the data. This isn’t to say that age or gender are not important issues within the information security sector, but rather that they were not what we were primarily interested in with this survey.
Good research ethics like this has the double bonus of not wasting participants’ time, and also reducing the amount of personally identifiable information you gather, and hence minimising data protection risk. Hence, we didn’t ask participants for their email address either. As a result, it would be next to impossible to reidentify participants from the data set. You can save your participants’ time and save yourself a General Data Protection Regulation (GDPR) headache at the same time.
In a practical sense, we found that Google Forms worked very well for our survey. Alternatively, you may have an internal product of choice, or there are other services like SurveyMonkey and so on you could utilise. It is a good idea to play around with these tools before beginning any research project as you may find that they can or cannot do certain tasks that you might require. For example, with regard to multiple choice questions, there are several different ways of presenting these and it can take some time to get this right. It is good practice to ensure a certain level of consistency across how questions are presented, and this can also be time-consuming to achieve.
Another point worth noting here regarding data collection is what is known as HARKing (Hypothesizing After the Results are Known). You can see that in our 2017 data collection exercise we gathered data in four cities, so you might wonder if there were differences in participants’ responses between them. But that wasn’t an idea we had before we designed the study – because while cross-cultural cybersecurity might be interesting, it was not our aim here – so it doesn’t make sense to look at it now. In other words, don’t try to pull findings out of your data that you didn’t design your study to look for. Human behaviour is tricky enough to understand without building a house of mirrors around yourself in the process.
SOCIAL EXPERIMENTS
There are a few more concepts from social science that are useful to note before trying to measure any aspect of human behaviour. Some of these may seem obvious in retrospect, having carried out a project, but it is much better to think them through before you start putting a plan in action.
On the one hand, there is what is known as the Hawthorne effect. First noticed in an industrial context in the United States in the 1930s, this refers to the fact that when being observed while they’re working, people may be more productive than usual. Of course, this isn’t surprising, but it has tripped up many an organisational change project over the years.
For example, you may decide that you are interested in improving a particular type of cybersecurity behaviour. As you begin attempting to measure its current level, word gets around the office. Hence, thanks to people’s reactions, you record an abnormally high level of activity. Consequently, you may think that your colleagues are actually performing this behaviour at a decent level already, and not bother with your intervention to improve it. Worse still, you carry out the intervention anyway, but will be comparing it to an unrealistic baseline. Hence, you have to think of some way of recording this behaviour in as unobtrusive way as possible. Tricky, eh?
On the other hand, there is also what is known as the experimenter or observer effect. In this case, it’s not so much the people being tested who react, but the person doing the testing. What happens here is that you unconsciously try to find what you go looking for. This may cause you to miss some things and over-emphasise others. Imagine you are doing a Universal Serial Bus (USB) key drop across a building in a company that you know well. In this case you should really be dropping the keys throughout the campus at random. But the fact that you know the place already may impinge on your behaviour – you already have an opinion on which teams will be good, and which will be weak on this exercise, and that knowledge can easily affect the results you achieve. You might drop more keys in the departments that you had poor relationships with, or you may over-compensate and drop none. Complicated, huh?
This is why the ‘double-blind’ experiment is the gold standard of human subject research. Perhaps you are interested in how many of your co-workers leave their workstations unlocked at lunchtime. To counteract the Hawthorne effect, you won’t signal what is being tested – that is, you don’t mention the behaviour in a company-wide email. And to counteract the observer effect, you get someone else to do the measuring – and without telling them what they’re measuring. One possible method here would be to get a trainee or intern to help. You might tell them that you are interested in recording how many employees still use sticky notes. In order to do this, you need them to take photographs of everyone’s workstation at lunchtime. Hence, you will get an accurate record of every computer that is unlocked, and with neither the employees’ attention being sparked, nor your own observer effect biasing the results. Of course, using this method you may pick up some passwords written on the sticky notes too, but only record this behaviour if you said you were looking for this too – no HARKing, remember!
RELIABILITY AND VALIDITY
It’s important you keep in mind two important features of good behavioural measurement with any such exercise. In the first case, measures should be reliable. In this context, reliability refers to the degree to which a measure will produce the same result again and again. And in the second case, measures should also be valid. Here, validity refers to the degree to which a measure actually measures what it claims to measure.
Neither of these factors on its own is good enough. For example, say my weighing scales says that I haven’t put on any weight since before Christmas. Because it’s giving me the same result as the last time, I presume that it’s reliable. But that doesn’t mean that it’s valid – the scales might be jammed. Similarly, a breathalyser kit might be able to validly test the amount of alcohol in my bloodstream – but it’s not reliable, as it’s a single use test. However, in cybersecurity, we are not trying to measure physical or chemical quantities. We’re trying to measure people, who are a lot more complicated.
A critical point here is that people can react to being tested. Always bear in mind the concept of reflexivity – people can learn or improve from how they are being tested, perhaps even try to outwit the tester.
One particularly troublesome example of this is known as the Dunning–Kruger effect. In this classic study (Kruger and Dunning, 1999), a sample drawn from the general population were given tests of basic arithmetic and general knowledge, but also asked where they expected to score compared to everyone else. Extraordinarily, those who ended up scoring lowest had expected to score in the upper end. Moreover, those who thought they would be in the midrange actually scored close to the top. In other words, the smart people were underconfident, and the overconfident were pretty dumb. As it was put more poetically by W. B. Yeats ‘The best lack all conviction, while the worst / Are full of passionate intensity’ (‘The Second Coming’, 1920).
Perhaps you’ve come across this in infosec? The person who loudly proclaims that they ‘know all of this stuff’ and therefore doesn’t need to attend your cybersecurity awareness workshop? And later it transpires that in reality they have the riskiest behaviours of all? In fact, in the next chapter we will discuss a number of scientific research papers that suggest something like this at work in certain cybersecurity contexts and consider how to deal with it. As such, the Dunning–Kruger effect is something that I suspect many of you reading this book will recognise. Don’t be misled!
RESEARCH METHODS
When we start putting a plan in place to try to understand the security behaviour of our end users, we have to be careful and also a little cunning. First, we have to formulate the problem as precisely as possible: what exactly is the behaviour we are interested in? What exactly is the problem? This can only come from carefully observing the context you are interested in – don’t simply start off trying to change things without understanding and describing what is happening. In particular, at this point you should try to define what you are interested in, and what you are not interested in.
So, for example, you may decide that you are only concerned with behaviour that occurs within your organisation’s premises, on its workstations and during office hours. That doesn’t mean that what employees do on their smartphones on their commute home isn’t important, it just means that for the purpose of this current exercise, you have put it to one side for the time being. Mission creep is a problem all over industry, but when you are attempting to scientifically understand human behaviour, not only can it mean you will likely end up gathering more personal information than you need, but it will be much more difficult to interpret what is actually happening in the data you acquire.
Second, after formulating the problem and limiting your areas of interest, we need to generate a hypothesis. A hypothesis is the scientist’s version of a bet. Because X is happening, if we do Y, Z will occur. The critical aspect of a hypothesis is not that it ‘comes true’, but that there is a distinct possibility that it may not come true. In other words, when your hypothesis is written down, it can be clearly seen that it can be falsified. It’s not ‘this person will never do that’, it’s more like ‘this person will not do that within the next month’.
Hence a hypothesis is similar to an acronym you might have come across before: SMART. This usually stands for something like specific, measurable, achievable, relevant and time-bound. We might say something like: ‘employees who take this training session will, on average, click on 50 per cent fewer phishing links over the following week’. By spelling it out precisely like this, you have clear pass or fail states (which is clearly of benefit to management). Notably, to accurately test this hypothesis you need to be able to compare this group to something else. That could be themselves the previous month (bearing in mind the Hawthorne and observer effects mentioned above), or you could use a control group: another bunch of people who are, to all intents and purposes, the same as the group that you give the training to. The latter option would be preferred scientifically, but managers tend not to like spending money on half their workforce not getting trained. Again, there are practical limitations to what you can achieve in even the most well-resourced organisations.
Moreover, you can now see why scientists also use what is known as the null hypothesis: clearly describing the default position, where nothing of significance has happened. In this case, we can say that the null hypothesis would be something like: having taken this training session employees will, on average click on less than 50 per cent fewer phishing links over the following week. Note the null hypothesis does not say the training session will have no effect. Rather, it gives a specific and measurable method for ascertaining what will be deemed to be a significant effect. In social science there are statistical methods for this but in your case you will likely have to make a business decision as to what is a meaningful result. Hence, we distinguish a ‘test hypothesis’ from the ‘null hypothesis’ in order to be able to clearly state when interventions, such as a training session, have not been effective.
Third, we need to choose an experimental design. This choice will be influenced largely by how much we think we already understand the behaviour we are interested in. So, for example, if you think you know what particular type of training will reduce the amount of phishing links that your colleagues click on, a focus group won’t be much use to you. In this case, an experimental design like the one mentioned above would probably be best – that is, with a control group (who don’t do anything) and an experimental group (who are receiving the new training programme).
But on the other hand, it probably wouldn’t be a good idea to begin a project with an experiment. For example, if you are trying to establish what is involved when people share passwords, then a focus group first would probably be a better idea. Ultimately you have to cut your cloth to suit your measure.
The key idea I would stress here is a kind of elegance or parsimony – the best social scientists do not get lots of insight by carrying out large cumbersome projects with many concepts and lots of moving parts. Rather they use very simple, economical and well-thought-out research designs. You don’t have to reinvent the wheel; you just have to drill down carefully into what is most important to you, and what you can do with the tools at your disposal.
While information security professionals typically favour penetration testing methods such as USB key drops and phishing tools, there are many other, less dramatic, methods that can be used to get a very good sense of end user behaviour. These include straightforward online survey or questionnaire methods.
You may also find that it might be useful to go beyond simply measuring end user behaviour. Social science tries to overcome limitations in quantitative data by using qualitative research methods. These are methods where we are not merely trying to gather statistical evidence of the behaviour we’re interested in, but also to gather more context, language and description of the behaviour.
In other words, qualitative research involves interviews or focus groups – or even something very basic like putting an open text box at the end of a survey form for respondents to type in whatever they like. This tactic can be very good for picking up answers to questions that you might not have asked – things beyond the obvious. Take, for example, suggestion boxes. Of all the professions, surely those working in cybersecurity should appreciate the value of anonymous communication? Such tools can be very useful in revealing motivations and experiences that users might not talk about otherwise.
SUMMARY
In concluding this chapter let’s summarise what we have covered in trying to understand cybersecurity behaviour. We began by examining some definitions of cybersecurity behaviour and trying to decipher what these meant in terms of practical applications and policy enforcement. This moved the discussion to theories of human psychology and how they can be applied to the cybersecurity context – namely the theory of planned behaviour and the protection motivation theory. Following this we laid out the practicalities of measuring cybersecurity behaviour, and the complexities of carrying out research on human participants. We also discussed a variety of research methods and key concepts to bear in mind before setting out to analyse cybersecurity behaviour in a workplace.
NEXT STEPS
Let’s round up this chapter with key action points for you to put into practice in your own professional environment. You can start with some fairly simple steps towards better understanding your colleagues’ cybersecurity behaviour in your workplace without reinventing the wheel:
- Take a look at your organisation’s information security policy documents. What behaviours are explicitly mentioned or prohibited?
- Find out what internal research or studies have already been carried out in your workplace. What were the findings? What was the upshot of the project?
- Try drafting an internal survey of cybersecurity behaviour and compliance, based on previous research or audits carried out in your organisation.
- Take a given cybersecurity behaviour that currently occurs in your organisation. Can you formulate it clearly and precisely? Can you develop a test hypothesis, and a null hypothesis?
- More to the point, can you interpret what is happening here in relation to the theory of planned behaviour, and also in relation to the protection motivation theory? Do they make for different or similar predictions?
- Draw up a plan for how you would carry out a focus group with end users in your workplace. How would you structure it? Who would facilitate it? What would the topic be? How would you record participants’ input?
- How could you carry out an anonymous feedback submission system in your workplace? How would you ensure that your colleagues can trust that if they use it, their identities cannot be revealed to senior management?