CHAPTER 9
Different Delivery Models
Gentlemen, we are going to relentlessly chase perfection, knowing full well we will not catch it, because nothing is perfect. But we are going to relentlessly chase it, because in the process, we will catch excellence.
—Vince Lombardi, as quoted in Game of My Life by Chuck Carlson
In this chapter, I will describe the three different IT delivery models that are currently being leveraged for successful IT delivery. I will also describe the different capabilities required to make them work. But as I have mentioned a few times already, the challenge goes beyond just the technical uplift to master those capabilities; it depends on the organization to make the appropriate changes across the organization to support the delivery model.
Overview of Delivery Models
I have seen three models that are actively being used or targeted within large organizations to deal with legacy technologies and modern digital technologies at the same time:
There is a fourth delivery model evolving at the moment, based on serverless technologies like Amazon Lambda. At the time I am writing this book, I have not worked with clients to define delivery models for serverless technologies and have not seen a formulated delivery model for them. Perhaps in the next version of this book, I can extend the chapter to include this fourth delivery model.
Within your organization, you will likely have multispeed delivery concerns, which means you will use a mix of these delivery models. When I speak about the transition impacts toward each of these models, remember that this will not be an everyone-at-once approach but will be rather gradual as you move applications and technologies to these delivery models.
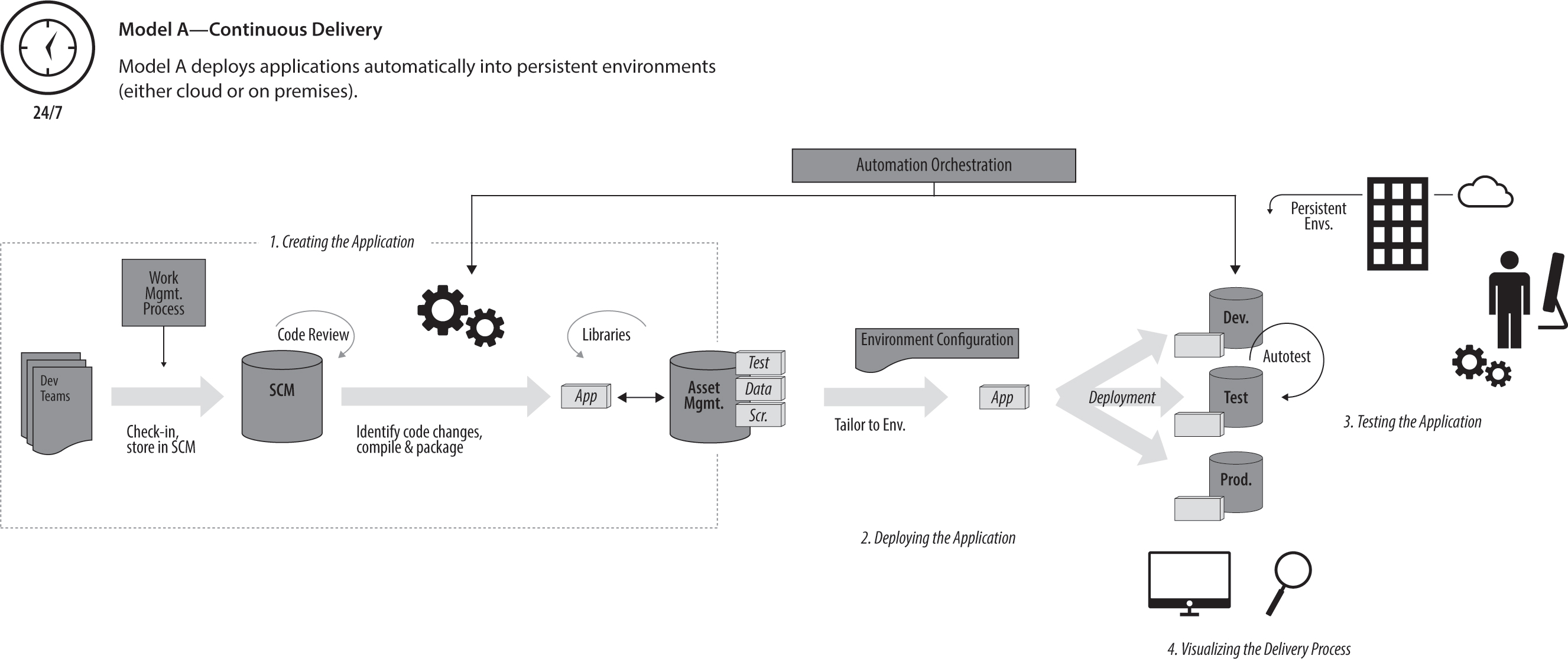
Delivery Model A: Continuous Delivery
This model is probably the most well known and has been around for a while, though many companies still struggle to implement it effectively. Continuous delivery means that you can potentially deploy into production with every build, as all the required steps are automated. The word “potentially” is to be read the same way it is used in the Agile community, which means the importance is on the ability to do so, not on actually doing it. You might still choose not to deploy automatically into production—for example, to allow for manual testing or hardening later on. You can leverage this delivery model for both cloud or on-premises environments.
The most common environment pattern into which to deploy is that of persistent environments (e.g., environments that have more than one software drop being deployed). This is often a necessity when working with legacy applications that require a very specific environment setup, so this model is very well suited. The benefits of moving to this model from a more manual, traditional delivery model are a significant improvement of delivery speed, a removal of risk out of your delivery by removing manual steps and increasing the frequency of inspection and feedback, and a reduction of unhelpful noise from the delivery process by increasing transparency across the delivery life cycle.
Figure 9.1: Model A—Continuous delivery: Continuous delivery automates delivery to persistent environments
Description of Capabilities
Continuous delivery is supported by four different capabilities that you need to master. I will only provide a short overview to describe the basics, as there is a lot of material already available to go deeper if you need to.
Transition Concerns and Organizational Impact
As you transition to continuous delivery, there are a few things you want to consider. First of all, configuration management is crucial; without that, you really can’t do anything else. Configuration management allows you to operate at speed. All code (including the tests and the automation code) needs to be in a configuration management system so that it can be accessed and used reliably. The transition to this model requires that your operations and infrastructure teams work closely with the platform team to implement abstract environment configuration (a practice that places variables instead of concrete values in configuration files that are replaced at deployment time, when the true values are known). And you will need to have the right environment access for your automation. This will feel like a loss of control to those operations teams, but if you manage this process carefully by involving all groups in the necessary change management, the transition will go much more smoothly.
Change management is also crucial for the transition to this delivery model and all the others. I have been part of several projects to implement new delivery models, and initially, I underestimated the change management efforts (training people, motivating the change in the organization, communicating about the changes and benefits, updating process and role descriptions). After all, if we build a great solution, everyone will jump on the bandwagon, right? Not at all, it turns out. After I noticed this challenge in my first couple of projects, I started to factor this in and staff a dedicated change-management person for my subsequent projects. It turns out that change management is absolutely required and helps everyone on the team. Developers are not that interested in creating training material or process documentation, and the change-management people know how to generate support material that people actually want to use. I think you can come up with a cost-and-effort estimate for this and then double that estimate; and you will probably still look back at the end and think you should have done more.
The organizational changes for the quality organization mentioned in chapter 7 will have to be in place for this model, as you will otherwise have too much friction between the delivery teams who are highly optimized for speed and the separate testing organization.
One last thing to consider is the infrastructure for the tooling platform. Very often, this does not get treated like a production system. But think about it: when your production is down with a defect and your SCM and automation tooling is also down, you are in serious trouble. You should have a production environment of your tooling that you use for your deployments to all environments (from development environment through to production environments), and you will need a development environment of your tooling so that you can continue to test, experiment, and evolve your tooling. You don’t want to do this in an environment that you will use for your next production deployment.
Delivery Model B: Cloud-Enabled Delivery
The cloud-based delivery model leverages a couple of practices that became popular after the continuous-delivery concept was already established. The cloud capabilities became more mature; and environment configuration management tools like Chef, Puppet, and Ansible changed the way we think about creating and managing environments. Together, they also account for the main difference from the previous model: we treat environments and infrastructure like code and hence can build additional environments quickly and reliably. Infrastructure as code means that all infrastructure is defined through configuration, which can be stored in a file and, in turn, can be treated as you would treat the source code of a program.
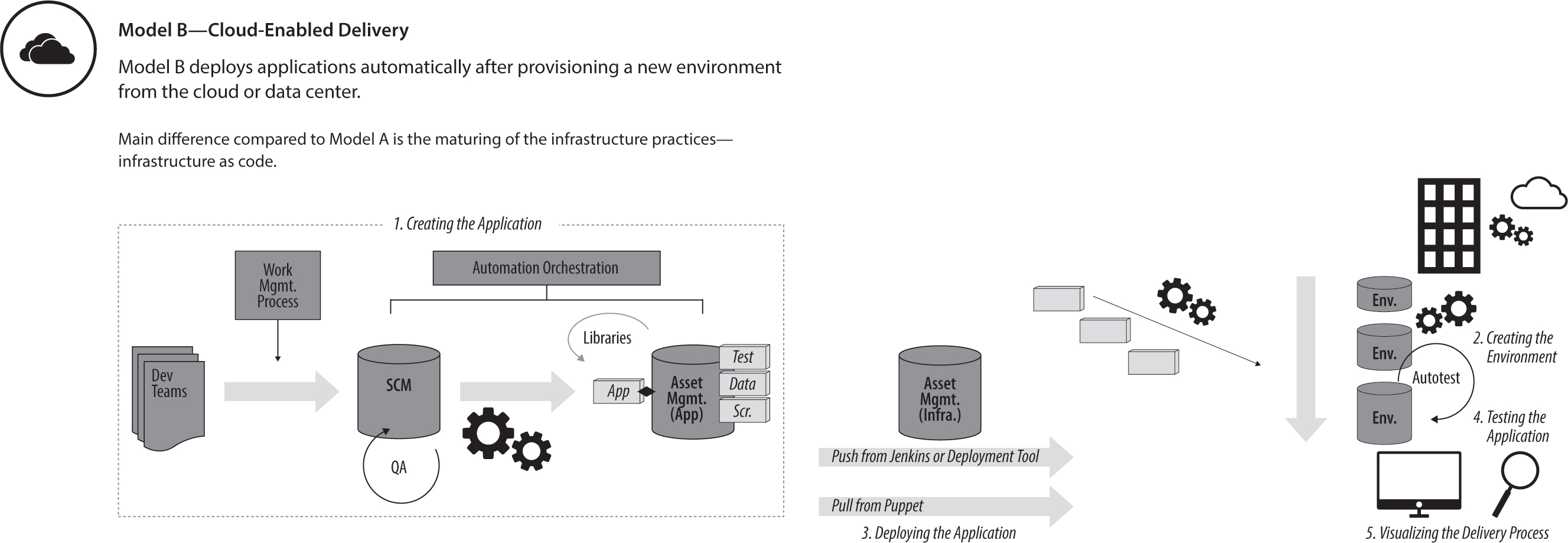
Figure 9.2: Model B—Cloud-enabled delivery: Cloud-enabled delivery creates a new environment with each deployment
In this model, we create a completely new production environment from scratch, including the applications in their latest version. We can then use this environment to test it with a subset of the production traffic to see whether the changes were successful. If we are happy with the result, we can increasingly move more production traffic to the new environment until no traffic goes to the original environment. At this point, we can destroy the old production environment. This is a really low-risk delivery model, as you can manage the risk by the level of testing of the new environment and by the speed of cutover.
Description of Capabilities
Many of the capabilities are very similar but are just being used in the different context of working with brand-new environments each time. This, for example, eliminates the incremental deployment concern mentioned before, as there is nothing to deploy incrementally to. This means you have to find other ways to deal with persistence between environments (e.g., how do you transition all the transactional data or keep it in a different permanent part of the environment?). This gives an indication of the limitation and complexities with this delivery model and why you might not use it for your whole portfolio of applications.
Transition Concerns and Organizational Impact
Because the infrastructure is not a separate concern from the overall platform anymore, for this delivery model you should merge your infrastructure team with your platform team. It has become more important for that team to understand automation techniques than to be knowledgeable with Windows or UNIX. You still need those skills, but rather than logging into machines, this team focuses on infrastructure as code.
Mastering the capabilities of the continuous-delivery model is really a prerequisite for this model, as any manual steps in this process diminish the benefits you can get out of this. Additionally, the cloud-based model becomes a lot more beneficial if you change the application architecture to leverage the cloud for elasticity and flexibility. I will discuss this further in chapter 12.
Delivery Model C: Container-Enabled Delivery
The fast rise in popularity of Docker (which has made working with Linux containers a lot easier and brought working with containers into the mainstream) has created this new delivery model that many organizations want to leverage. It works extremely well with a microservice architecture due to the low footprint and flexibility of containers. The speed of this delivery model is impressive, as a new container can be created and deployed in seconds. While the previous delivery models required several minutes to several hours, this is, by far, the fastest model. However, this is only true if you have an architecture with relatively small containers. (If you try to run Siebel or SAP in a container, I suspect the experience will be different.) The immutable nature of containers (at least they should be) will force a lot of good behavior in the organization, as it is not possible to patch the containers manually once they have been created.
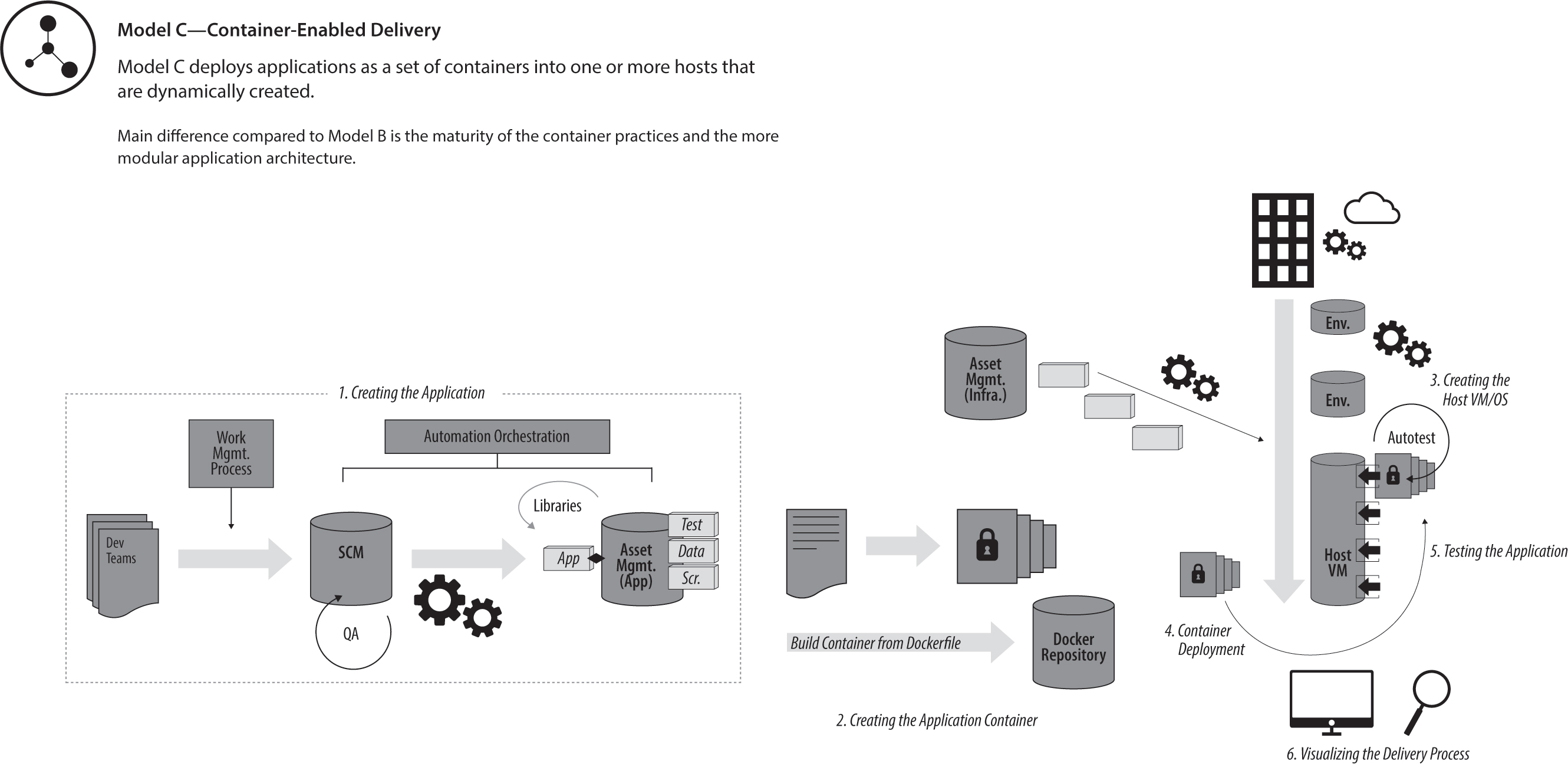
Figure 9.3: Container-enabled delivery manages an application in containers
Description of Capabilities
As with the previous model, the capabilities continue to build on top of each other; and all the capabilities built for the previous model can be reused and are, to some degree, prerequisites. The new capabilities have to do with creating and deploying containers.
Transition Concerns and Organizational Impact
Because you are now dealing with immutable containers, the governance of the containers becomes a new organizational responsibility. If new vulnerabilities become known, how do you check where you have used certain libraries so that you can update all container images? Because you build out containers in layers, you could leverage an old image somewhere in the chain or from a public registry that contains known vulnerabilities. You will have to manage templates that you maintain for the organization to manage the number of flavors. Of course, with containers, you can use lots of different technologies at the same time; but as an organization, you want to manage the number of allowed patterns, as you need to maintain your architecture, and individual teams’ preferences for technologies might cause you problems later. Finding the right balance will be something you keep adjusting as you learn more about the usage in your organization.
Similar to the cloud concerns, working with containers means you want to re-architect existing applications to leverage this new paradigm. Just putting your existing application into a large container will not allow you to fully reap the benefits of container-enabled delivery. With this re-architecture activity should also come a reorganizational activity, as it is very inefficient to have an application container owned by more than one team. The best organizational model has the application container fully owned by one team. If the applications are really small, then one team can own multiple applications. If the application container is too large for one team, then it is probably too large in general and should be broken down further. Make Conway’s law work for you this time by creating an organizational structure that you would like to have reflected in your architecture.
Evolving Delivery Model: Serverless Delivery
For those of you who have not heard about serverless architectures, this is a service model where you don’t run servers as such but rather write a function to perform some business logic for you. When the function is called, an instance is created just for the duration of the function call. Amazon Lambda is an example of this architecture. While some of the organizations I work with have experimented with this architecture model, I have not seen wide adoption yet. You might want to investigate the usage of this and find a use-case model to experiment with in your organization.
Capability Roadmap
While there is always a contextual difference between capability roadmaps, I see common patterns to uplift your technical capabilities. You will need to deal with software configuration management (SCM) and application build first in order to reduce the noise, then you will need to follow with application deployments. If you do this in the opposite order, you will see a lot of rework in your deployment automation, as the build artifacts will change once you automate them.
Ideally, you should complete software configuration management and application build and deployment automation together. Test automation requires a somewhat predictable environment to work with (e.g., not one with configuration problems or difference between deployments), so it will benefit from having application build and deployment automated beforehand. Environment provisioning automation tends to have a long lead time, so you can start this in parallel so that it is ready when you need it. And the other capabilities are sitting on top of these foundational capabilities. All of this needs to be supported by the incremental build-out of your DevOps platform to support the automation activities and operational activities, such as monitoring.
In Figure 9.4, I have outlined a common pattern of initial capability uplift. Note that some infrastructure setup and organizational design are required before you start jumping into the technical build-out. The build-out follows the software configuration management/build automation first, the deployment automation next, and then followed by the test-automation pattern, which, in my experience, has the highest chance of success.

Figure 9.4: Sample plan for initial build of capabilities: Container-enabled changes and infrastructure setup are common first steps
First Steps for Your Organization
Map Your Application Delivery Models
As I described above, it is not advisable to push all applications into a container-enabled delivery model, as it would not be economical or feasible. In organizations with a large amount of legacy, you will probably have the largest proportion, targeting continuous delivery and cloud-enabled delivery with some container-enabled delivery in your digital applications. And that is realistic. Remember that the goal is to get better; too often, we make perfect the enemy of better. With this in mind, run a workshop where you review your applications and define what your current and ideal delivery model is for each application. You will need to bring people from your infrastructure, your architecture, and your delivery organization into the same room for this. Then do a fit/gap analysis of the capabilities required for the delivery model you assign to each application. Brainstorm a set of initiatives to build the capabilities that are missing. Often, you can reuse capabilities for applications of the same technology stack (e.g., Java) once they are built for another application. Identify those opportunities for reuse. With all these in mind, define a six-month roadmap, and review the roadmap and progress on a monthly basis to reprioritize based on the lessons learned so far.