Appendix A to Chapter 12: More on Accuracy (optional)
Background
As explained in
the main chapter, point values of statistics have the disadvantage
that on their own they cannot be used to assess how accurate they
are. To assess accuracy, you need more. For example, perhaps you need
confidence intervals that give a range for the statistic at a certain
level of confidence.
To properly explain
how we form p-values and confidence intervals, I will start with the
best-case scenario for assessing accuracy — which we cannot
usually achieve — and then show how we compromise by forming
p-values and confidence intervals.
(Unrealistic) Best Case for Assessing Statistical Accuracy
Usually when
you do a statistical analysis you draw a sample to make inferences
about the broader population[3]. Your
interest is usually in making statistical estimates of interest on
the sample data, so that you can generalize these to the broader population.
For instance, you may make simple estimates on single variables (e.g.
means), or relational estimates between variables or groups (e.g.
correlation, regression, ANOVA, time series).
When doing sample-based
statistics, the best-case scenario is for you to draw not
one sample but multiple samples of similar size and characteristics.
This is usually unrealistic for cost, time and other reasons, but
theoretically possible and the benchmark for accuracy. You might even
draw hundreds, or thousands, of samples. If you could achieve this
theoretical best-case scenario then you would estimate
your statistic of interest (e.g. a correlation) not on just one sample
but on each of the multiple samples. For example,
perhaps you could draw hundreds of different and large samples of
business customers where each sample is similar in size and characteristic
(i.e. essentially the same number and type of customer firms in each
sample). If you were interested in average monthly spend, you would
measure this average on each of the samples.
Having done this, the
statistic of interest would differ between each sample.
Perhaps in the first sample you would discover that average spending
is $1,500, but in the second sample it is $1,710 and in the third
sample it is $1,382. You can already see that the average is varying
between samples, and that there would be some inaccuracy if you settled
on $1,500 as the representative average. You would collect and arrange
each of these different estimates of the sample statistic, with enough
samples you would be getting a representative range of possibilities.
For example, if you had ten samples you might get the following range
of average spending:

Having multiple different
estimates of the statistic of interest, you can now compare
the different estimates of the statistic and see how close together
they lie. If there is a narrow range of estimates
of the statistic, then you would have confidence in the accuracy of
the statistic. If the range is very broad, then you would have less
confidence in the overall accuracy. We would not usually take the
whole range because outliers can happen; we might instead take the
middle 95% or 99% of the values generated in the multiple samples.
This, incidentally, would give us 95% and 99% confidence intervals.
This would give us the best way of assessing the realistic range of
values and therefore the relative accuracy.
Obviously very few studies
have the ability to draw multiple different samples like this; most
of the time you only have one sample. Even if you can draw multiple
samples you usually will not have many and the few you have may not
be comparable. (In the best-case scenario, it is important that the
multiple samples all represent the underlying population and therefore
be comparable; otherwise you cannot compare the statistical estimates.)
You have to compromise
away from the best-case scenario. How do we compromise? Two major
approaches are the traditional parametric approach, which I explain
next, and the bootstrapping approach, which I explain afterwards.
The Traditional Parametric Approach
Introduction to the Parametric Approach
With
only a single sample instead of the best-case scenario, how do we
usually assess accuracy? I say usually because the bootstrapping approach
in the next section does it using a far better method. The following
is the traditional method, also called the parametric method for reasons
I will explain.
The traditional method
subsists on certain assumptions that link it, in theory, to the best-case
scenario, namely:
-
Assumption #2: Second, we make the assumption that if we were able to measure our statistic of interest among all those other samples out there, together all our estimates of the statistic would be normally distributed. For example, we assume that of all the samples of shoppers that could have been collected in theory, the average spends on beauty products would be normally distributed.
In assuming these three
things, we are approximating the best-case scenario with one very
important difference: instead of actually estimating our statistic
from multiple different samples, we have only one sample and one point
estimate and we are assuming that if we did take further samples they
would be normally distributed around our single point estimate. Figure 12.20 Representation of parametric assumption for accuracy measures shows a pictorial
representation of this for our average spending example.

As can be seen in Figure 12.20 Representation of parametric assumption for accuracy measures, we have only
a single average spending value of $1,500. We assume that the same
averages calculated from other similar samples would be normally distributed
around our point estimate. This is why it is called the parametric
approach: parametric statistics assume that certain underlying distributions
exist.
Now, having made these
assumptions, we can use this assumed distribution to estimate accuracy.
How? Well, because of the properties of a normal distribution, we
can find estimates of variation. How this is done is described next.
The Parametric Standard Error, Test Statistic and P-Value
Believing that our statistic of interest is distributed
normally allows us to generate a sense of its variation, or inaccuracy.
As discussed earlier,
the standard error is often
the measure of inaccuracy of a statistic. Assume you have the point
value of a statistic (say the average of a variable) and you then
get a standard error which is a hard-to-interpret measure of inaccuracy
of that statistic. We need to bring together these two concepts. The
following set of points gives the usual approach, as well as an example
using the average.
-
Generate your point estimate. In this case it is the average of a variable, say our average for spending of $1,500.
-
Generate the single estimate of inaccuracy: In this case the correct estimate of inaccuracy for the average is the standard error. Other statistics have different measures of inaccuracy. The standard error in this case is a function of two things:
-
The standard deviation: The standard error is related directly to how much we think the distribution of the average varies in the population. Figure 12.20 Representation of parametric assumption for accuracy measures shows that we assume that the distribution of averages is normal, so the standard deviation would be the correct estimate of variability as discussed in Chapter 7. We don’t know the standard deviation of the averages (remember we are only assuming that there is a normal distribution), so we base the estimate of variability on the standard deviation of the actual variable itself. Figure 12.22 Statistical output for mean including standard error and p-value below shows the standard deviation of the variable (it is the second figure in the table, and is 286.79). Why is the standard error based on the standard deviation? Because the more variance in the data, the less confident we can be that a single statistical estimate represents every piece of data.
-
The sample size: The standard error gets smaller, the bigger the sample size. Why? Simply because the bigger the sample the more likely that the statistic represents the entire population accurately.
-
To be precise, the standard
error is measured as follows:
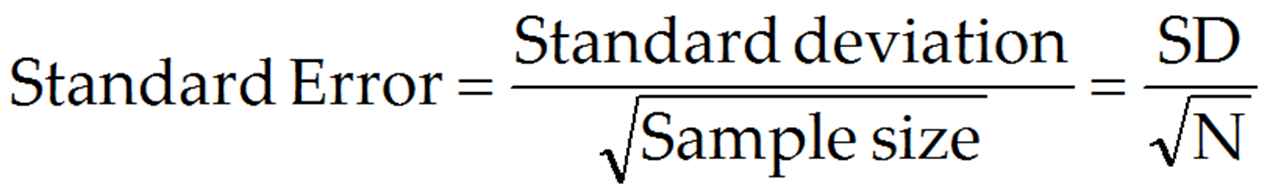
I will not explain exactly
why we use the square root of N; standard statistics texts can tell
you.
In our example, the
standard deviation is 286.79, and sample size is 2000. The standard
error is therefore 286.79/(square root of 2000) = 6.41. This is our
estimate of inaccuracy.

-
Combine the point estimate and measure of inaccuracy into a test statistic: The bigger the estimate of inaccuracy, the less accurate the point estimate (obviously). Therefore, we usually divide the point estimate by the estimate of inaccuracy to get a certain combined value (the test statistic) that simultaneously measures both the size of the point estimate and its inaccuracy. Therefore, the test statistic is usually:

In our example, we found
an average of 1500.01 and a standard error (SE) of 6.41. The test
statistic is 1500.01/6.41 = 233.91.
-
Assess the value of the test statistic on its distribution: Generally, prior statistical work would have established that the test statistic is distributed according to a given distribution. In the case of standard error estimations, the test statistic is usually distributed on what is known as a T-distribution. Therefore, our test statistic is identified in Figure 12.22 Statistical output for mean including standard error and p-value as the “t value” in the second last column. The value of the test statistic on the T-distribution tells us the probability that the slope that we found is significantly higher or lower than zero (the p-value, as seen in the last column). For example, if the test statistic is bigger than 1.96 or less than -1.96 then it lies in the far 2.5% tails of the T-statistic such that we can be 95% confident that the slope is not close to zero.
-
Use the standard error to construct confidence intervals: Similarly, with confidence intervals, the 95% interval is = (estimate)±(1.96*SE). In our example, our average is 1500.01 and the standard error is SE = 6.41. So, the 95% confidence interval is 1500.01±1.96*6.41 = 1487.43-1512.59 as indicated in Figure 12.22 Statistical output for mean including standard error and p-value. Since the whole of this confidence interval lies above zero, we can be 95% confident that the feasible range of the slope does not include zero.
In statistics we are
more often than not interested in whether the p-value is less than
.05 or .01 (indicating that the statistic is significantly different
from zero) or that the entire range of the confidence interval is
greater or less than zero, expressing the same idea. In such cases,
we conclude that the average is statistically different from zero,
therefore possibly worth taking seriously.
Bootstrapping: A Good Alternative
Introduction to Bootstrapping
The parametric method of generating accuracy measures
is a poor one, because of the assumption that the statistic would
be normally distributed around your observed statistic if other samples
were measured. This is simply often not the case in reality, and as
a result it leads to poor confidence intervals or standard errors
for two reasons:
Bootstrapping comes
in a few forms, but the most common type (non-parametric bootstrapping)
tries to replicate the best-case scenario of multiple samples and
estimates of the same statistic, with one important difference. You
still have only a single sample and a single true, observed number
for your statistic. Bootstrapping simply seeks to simulate multiple
samples by creating those many different samples using
the data from your one sample.
How does this work?
It is actually a very simple process, called resampling with replacement.
Broadly, the non-parametric bootstrapping process is as follows:
-
Draw your single, original sample. Say hypothetically that you have a single variable (say years of service of 10 employees), and this sample contains the numbers 1,3,4,5,6,8,9,9,10,10.
-
Do whatever statistical estimation you require on the original sample. For example we may wish to estimate the mean, and get an accuracy measure. The mean of the original dataset 1,3,4,5,6,8,9,9,10,10 is 6.5.
-
Resample from the original sample, creating B new and different samples of same size as the original sample (e.g. we might create B = 2000 new samples using the data from our one sample). The computer program will generally do all this for you, but the following points explain how one achieves this. You create a new sample by resampling with replacement as follows:
-
Randomly take one of the values from your original sample and place into the new sample.
-
Do so again, using the entire original sample (i.e. when you picked the first value, it does not disappear from the sample when choosing the second value to go into the new dataset; it can be chosen again)
-
Keep on doing this until your new bootstrap sample is the same size as your original sample;
-
Keep on forming new bootstrap samples in this way, until you have B new resamples. Figure 12.24 Pictorial example of creating bootstrap resamples shows a pictorial example of creating resamples. Note that this procedure means that the same value can appear several times in any one of the bootstrap samples, and that any value can be absent from a given bootstrap sample.
-

Note that there are
other methods for creating bootstrap resamples, this is the most common.
-
Do the same statistical estimation on each sample. In this case for each of the B new samples we would recalculate the average spending. Figure 12.25 Example of bootstrap re-samples and estimation of statistics shows the case for 10 new re-samples from the small dataset discussed above, where for each one the mean is calculated.
-
Combine the estimates into a summary bootstrap estimate, which is usually nearly the same as the original estimate but not always. In this case we would take each of the 2000 averages and in turn average them into a single bootstrap average.
-
Because your B estimates of the statistic differ from each other, they form a real distribution from low to high. This is an empirical distribution, not assumed like in the parametric case. In the same way as before you can use this distribution to create confidence intervals or standard errors. For example, simply taking the middle 95% of the B estimates gives a very simple 95% confidence interval (“percentile intervals”) for the statistic. Your computer will calculate the bootstrap intervals for you.
-
Use the new, bootstrapped confidence intervals to make accuracy assessments as before. I recommend sticking with the bootstrap confidence limits and ignoring standard error judgments.

More on BCA Bootstrapping
The computer program will normally do all the bootstrapping
steps for you, but you may be called on to make some choices.
There are different
refinements of bootstrapping techniques that can improve the confidence
intervals even more. Two such refinements are adjustments for bias and acceleration.
I will not explain these here, but will note that adjusting for these
is often valuable. Confidence intervals adjusted for bias are generally
referred to as bias-corrected (BC) confidence intervals. Those adjusted
for both bias and acceleration are Bias Corrected and Accelerated
(BCA) confidence intervals, which are offered in SAS using the jackboot
macro – you would have to learn how to use this. Generally,
bias and accelerated corrected confidence intervals are more accurate
than those without. Note however that to get BCA and possibly even
BC intervals, you need something like 10,000 resamples of your original
sample, and if your sample is very large this can then be computationally
intensive and slow for your computer to achieve. You may wish to wait
till you are ready to finalize and report an analysis before running
a full BCA bootstrap, and then be prepared to leave your computer
for many hours or even a day or more (depending on sample size, type
of analysis and number of variables) to get your analysis.