In diesem Kapitel schließen wir an die Verarbeitung von Bilddaten aus dem vorherigen Kapitel an. Während wir dort passende Paare von Ein- und Ausgaben hatten und so der Lernprozess eine Imitation der menschlichen Eingabe darstellte, arbeiten wir in diesem Kapitel mit Bilddaten ohne passende Labels.
Einen solchen Trainingsansatz, der lediglich einen Satz von ungelabelten Daten benötigt, nennt man Unsupervised Learning bzw. unüberwachtes Lernen. Im Vergleich zum Supervised Learning ist genau das der Vorteil: Es sind keine Labels notwendig, und der aufwendige Prozess des manuellen Labellings kann entfallen. Auch wenn Labels vorhanden sind, kann dieser Ansatz interessant sein, weil sich ganz neue Möglichkeiten ergeben. In diesem Kapitel geht es um Autoencoder und damit um einen Ansatz mit neuronalen Netzen, bei denen Eingabe und Ausgabe im Training identisch sind. Warum das eine gute Idee sein kann, erklärt dieses Kapitel.
Der komplette und ausführbare Code für dieses Kapitel ist unter der URL https://github.com/DJCordhose/buch-machine-learning-notebooks (https://bit.ly/ml-kug) als Notebook kap8.ipynb zu finden.
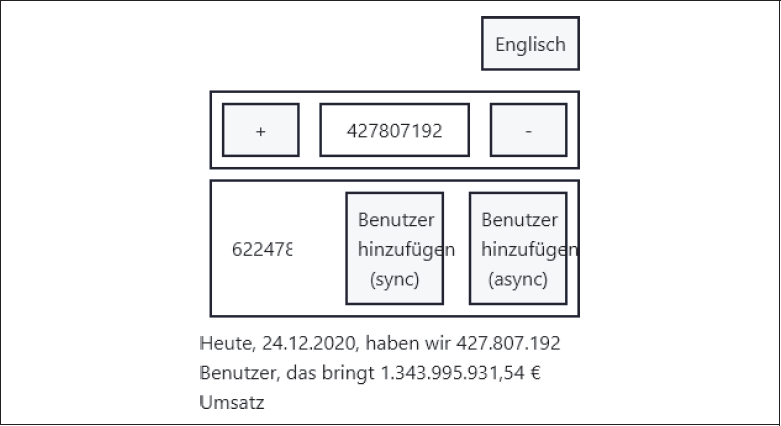
Unser Beispiel basiert auf einer einfachen Anwendung, mit der ein Umsatz anhand der Anzahl der Benutzer vorhergesagt werden soll. Sie wird in Abbildung 8-1 dargestellt. Darauf möchten wir Regressionstests ausführen. Wikipedia definiert diese folgendermaßen:
»Unter einem Regressionstest (von lateinisch regredior, regressus sum ›zurückschreiten‹) versteht man in der Softwaretechnik die Wiederholung von Testfällen, um sicherzustellen, dass Modifikationen in bereits getesteten Teilen der Software keine neuen Fehler (›Regressionen‹) verursachen. Solche Modifikationen entstehen regelmäßig z.B. aufgrund der Pflege, Änderung und Korrektur von Software. Der Regressionstest gehört zu den dynamischen Testtechniken.«
Unsere Regressionstests haben somit nichts mit den in Kapitel 4 besprochenen Regressionen als Form des Machine Learning zu tun. Es ist wichtig, das nicht durcheinanderzubringen.
Abbildung 8-1: Unser einfacher Umsatzkalkulator
Ziel ist es, visuelle Regressionen, also Fehler in der Darstellung, die sich eingeschlichen haben, zu erkennen. Dabei ist es im Vorfeld nicht möglich, vorherzusagen, was für Fehler das sein könnten. Das macht es schwierig für das Supervised Learning. Denn dort müssten wir Kategorien für fehlerhafte und fehlerfreie Seiten haben, die allgemein genug wären, um auf ganz neue Arten von Fehlern reagieren zu können. Dies ist typischerweise nicht mit Supervised Learning zu erreichen.
Vielmehr ist unsere Frage: Wenn die im Wesentlichen fehlerfreie Anwendung so aussieht, sieht denn die neue Version an manchen Stellen gänzlich anders aus? Falls ja, muss das nicht zwingend bedeuten, dass sich ein Fehler eingeschlichen hat. Die Änderung kann ja auch ein Feature und damit so gewollt sein. Allerdings kann uns das Machine-Learning-Modell darauf hinweisen, und wir als Menschen müssen nicht mehr die komplette Anwendung durchtesten, sondern nur noch die Teile, die unserem Modell sonderbar vorkommen. Dies setzt voraus, dass wir diesem Modell vertrauen – dass es also gute Ergebnisse liefern muss.
Wir werden es mit zwei Arten von Fehlern zu tun haben:
Abbildung 8-2: Die neue Übersetzung sprengt Kästen.
Abbildung 8-3: Die Ausgabe wächst und schiebt nach und nach den rechten Knopf ins Unsichtbare.
Autoencoder sind im Prinzip genauso wie die neuronalen Netze aus Kapitel 7 aufgebaut. Wie das zweite Netz zur Bildverarbeitung aus Kapitel 7 nehmen wir auch hier Convolutional Layer zur Verarbeitung der Bilder. Dabei codieren wir das Bild erst durch eine Reihe von Convolutional Layern (Encoder) und decodieren es danach wieder in umgekehrter Reihenfolge von denselben Layern (Decoder). In der Mitte gibt es eine niedrigdimensionale Repräsentation in Form eines Dense-Layers, des sogenannten h- oder z-Layers. Dieser Layer wird in der Literatur auch »Latent Representation«, »Compressed Representation«, »Hidden Representation« oder »Bottleneck« (Flaschenhals) genannt. Wir werden im Folgenden die Bezeichnung Flaschenhals verwenden.
Diese Repräsentation hat zwei Funktionen. Als Erstes sorgt sie für eine Abstraktion, da in diesem Flaschenhals die entscheidenden Informationen abgelegt werden müssen. Das führt zu einer Kompression, die nur für Bilder sehr ähnlicher Natur einigermaßen gut funktioniert. Ein Autoencoder, dessen Dimension des Flaschenhalses kleiner ist als die Dimension der Eingabe, heißt »undercomplete«. Wenn die Dimension größer ist, heißt er »overcomplete«. In beiden Fällen ist eine Abstraktion möglich. Als Zweites kann die Repräsentation extrahiert und in nachfolgenden Schritten zur Visualisierung und zum Clustering bzw. zur Outlier Detection genutzt werden.
Das Training erfolgt ebenso über das bekannte Verfahren der Minimierung des Loss zwischen erwarteter und tatsächlicher Ausgabe. Dabei ist als Besonderheit die Ausgabe dieselbe wie die Eingabe. Das heißt, der Autoencoder lernt, Eingaben so gut wie möglich wiederherzustellen. Wie bereits erklärt, erschweren wir dies künstlich durch die schmale Repräsentation in der Mitte.
Ein Autoencoder mit linearem Encoder und Decoder sowie Mean Squared Error als Loss hat als optimale Lösung etwas der PCA Äquivalentes. Die Ausgaben des Flaschenhalses entsprechen dabei den Principal Components der PCA. Tatsächlich gibt es Implementierungen der PCA, die statt einer geschlossenen Form genau so funktionieren. Wenn man jedoch die Encoder und Decoder – wie bei uns – komplex aufbaut, erhalten wir beliebige Nichtlinearitäten. Das heißt, wir können viel effizientere Abstraktionen erzielen.
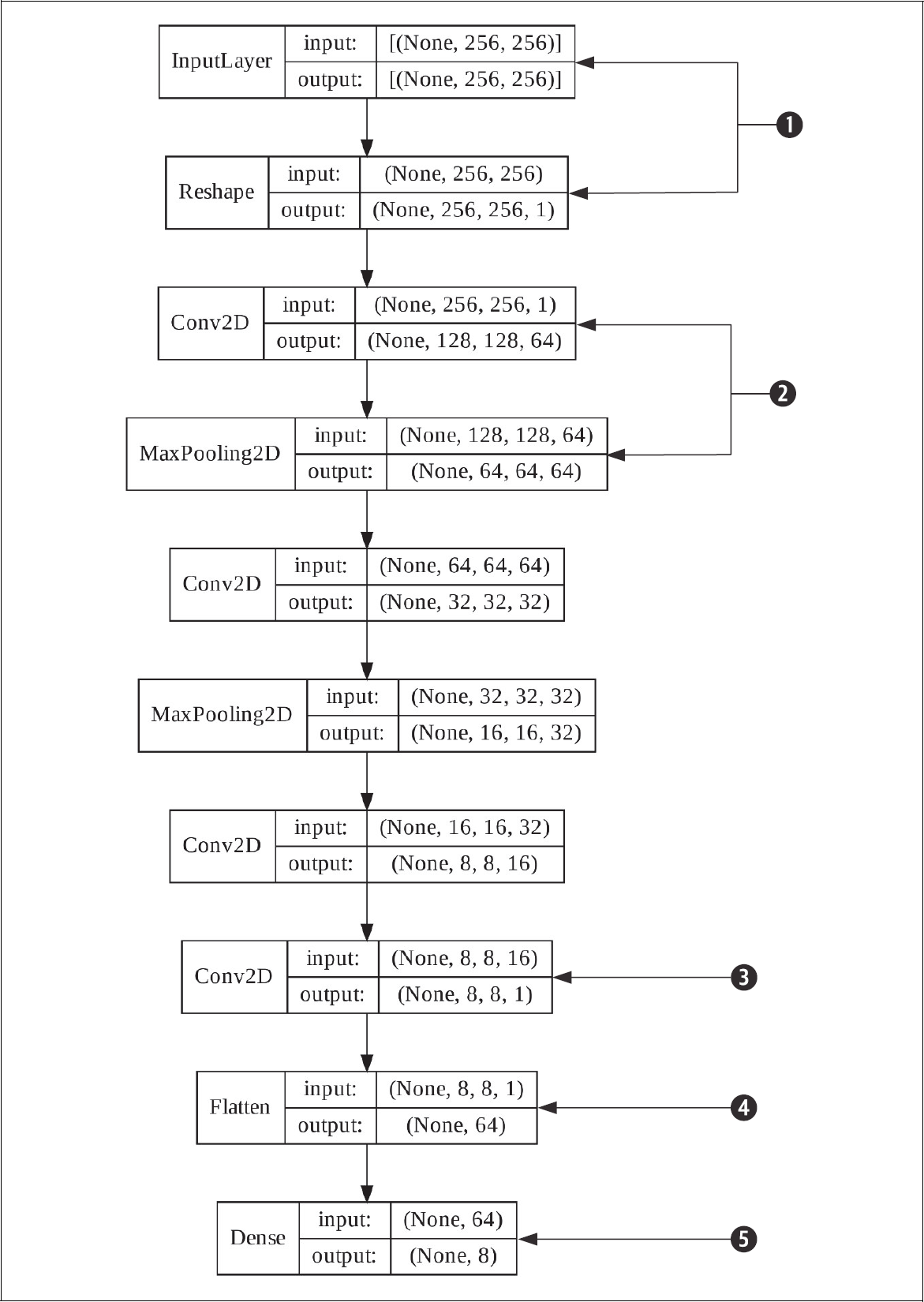
Unser Autoencoder ist in zwei Netze aufgeteilt, das Encoder- und das Decoder-Netz. Der Encoder nimmt die Bilder entgegen und wandelt sie schrittweise in die interne Repräsentation um. Diese dient im nächsten Schritt dem Decoder als Eingabe. Den Encoder zeigt Abbildung 8-4.
 Die Bilder haben eine Auflösung von 256 × 256 und einen einzigen Farbkanal. Dieser drückt eine Graustufe als Wert zwischen 0 und 1 aus. Damit Convolutional Layer damit klarkommen, muss dieser Farbkanal durch ein Reshape in eine weitere Dimension verpackt werden. Theoretisch hätten wir damit 65.536 mögliche Werte. Da aber die überwiegende Mehrheit der Pixel schlicht weiß ist, sollten wir uns beim Informationsgehalt eher an der Größe der passenden PNGs orientieren, die zwischen 5k und 7k liegt. Das bedeutet, dass ein Flaschenhals über dieser Größe liegen müsste, um alle möglichen Bilder unserer Anwendung perfekt zu reproduzieren. Ist er kleiner, dann ist der Autoencoder »undercomplete«.
Die Bilder haben eine Auflösung von 256 × 256 und einen einzigen Farbkanal. Dieser drückt eine Graustufe als Wert zwischen 0 und 1 aus. Damit Convolutional Layer damit klarkommen, muss dieser Farbkanal durch ein Reshape in eine weitere Dimension verpackt werden. Theoretisch hätten wir damit 65.536 mögliche Werte. Da aber die überwiegende Mehrheit der Pixel schlicht weiß ist, sollten wir uns beim Informationsgehalt eher an der Größe der passenden PNGs orientieren, die zwischen 5k und 7k liegt. Das bedeutet, dass ein Flaschenhals über dieser Größe liegen müsste, um alle möglichen Bilder unserer Anwendung perfekt zu reproduzieren. Ist er kleiner, dann ist der Autoencoder »undercomplete«. Erster von n Blöcken, die die Anzahl der Filter immer weiter reduzieren. Alle Convolutional Layer haben die Schrittweite des Filters auf 2 gesetzt. Damit wird die Auflösung des Bilds mit jeder Convolution halbiert. Ein Max-Pooling-Layer reduziert nach jeder Convolution nochmals die Auflösung, sodass wir uns schrittweise der Dimension des Flaschenhalses annähern.
Erster von n Blöcken, die die Anzahl der Filter immer weiter reduzieren. Alle Convolutional Layer haben die Schrittweite des Filters auf 2 gesetzt. Damit wird die Auflösung des Bilds mit jeder Convolution halbiert. Ein Max-Pooling-Layer reduziert nach jeder Convolution nochmals die Auflösung, sodass wir uns schrittweise der Dimension des Flaschenhalses annähern. Der letzte Convolutional Layer hat eine besondere Funktion. Er fasst die 16 Filtereingaben des vorherigen Layers in einer einzigen Ausgabe zusammen. Dies ist nicht zwingend notwendig, erlaubt aber einen weiteren Messpunkt für eine menschlich verständliche Ausgabe, die wir später nutzen werden. Ein Bild ist leichter verständlich als 16. Der vorherige Convolutional Layer hat kein Max Pooling mehr, um die Information nicht noch weiter zu reduzieren. Experimentell wurde herausgefunden, dass ein weiterer Pooling-Layer kein erfolgreiches Training mehr zulässt. Ebenfalls experimentell hat sich bestätigt, dass dieser Layer einen stabilisierenden Einfluss auf das Trainingsergebnis hat.
Der letzte Convolutional Layer hat eine besondere Funktion. Er fasst die 16 Filtereingaben des vorherigen Layers in einer einzigen Ausgabe zusammen. Dies ist nicht zwingend notwendig, erlaubt aber einen weiteren Messpunkt für eine menschlich verständliche Ausgabe, die wir später nutzen werden. Ein Bild ist leichter verständlich als 16. Der vorherige Convolutional Layer hat kein Max Pooling mehr, um die Information nicht noch weiter zu reduzieren. Experimentell wurde herausgefunden, dass ein weiterer Pooling-Layer kein erfolgreiches Training mehr zulässt. Ebenfalls experimentell hat sich bestätigt, dass dieser Layer einen stabilisierenden Einfluss auf das Trainingsergebnis hat. Die Eingabe kann man sich vorstellen wie 8 × 8 Bilder in Graustufen. Diese werden flach geklopft in 64 einzelne Werte, damit diese als Eingabe für den Flaschenhals dienen können. Die Bilder dazu werden wir später zur Veranschaulichung visualisieren.
Die Eingabe kann man sich vorstellen wie 8 × 8 Bilder in Graustufen. Diese werden flach geklopft in 64 einzelne Werte, damit diese als Eingabe für den Flaschenhals dienen können. Die Bilder dazu werden wir später zur Veranschaulichung visualisieren. Die Dimensionierung des Flaschenhalses unterliegt unserer Willkür. Experimentell hat sich herausgestellt, dass ein Wert unter 8 nicht mehr zum Training genügt. An dieser Stelle können auch L1- und L2-Regularisierung auf die Ausgabe des Layers angewandt werden. L1-Regularisierung führt zu vielen 0-Werten, und L2 schränkt die Größe der Werte ein. Bei einem »overcomplete« Autoencoder ist dies eine gängige Methode der Regularisierung, die auch zu einer besseren Visualisierung und Clusterbarkeit des Flaschenhalses führt. In unserem »undercomplete« Fall ist das nicht zwingend notwendig. Im Gegenteil, zusätzliche unbrauchbare 0-Ausgaben würden die niedrige Dimension unserer Repräsentation zusätzlich schwächen.
Die Dimensionierung des Flaschenhalses unterliegt unserer Willkür. Experimentell hat sich herausgestellt, dass ein Wert unter 8 nicht mehr zum Training genügt. An dieser Stelle können auch L1- und L2-Regularisierung auf die Ausgabe des Layers angewandt werden. L1-Regularisierung führt zu vielen 0-Werten, und L2 schränkt die Größe der Werte ein. Bei einem »overcomplete« Autoencoder ist dies eine gängige Methode der Regularisierung, die auch zu einer besseren Visualisierung und Clusterbarkeit des Flaschenhalses führt. In unserem »undercomplete« Fall ist das nicht zwingend notwendig. Im Gegenteil, zusätzliche unbrauchbare 0-Ausgaben würden die niedrige Dimension unserer Repräsentation zusätzlich schwächen.Abbildung 8-4: Der verwendete Encoder
Durch die explizite Zweiteilung des Autoencoders halten wir diesen übersichtlicher, und gleichzeitig ist es trivial, die Bilder nur durch den Encoder zu schicken und dann die Ausgabe abzugreifen. Diese ist pro Bild ein Array mit acht Werten, die der Ausgabe des Flaschenhalses entsprechen. Durch eine Dimensionsreduktion mit klassischen Mitteln könnten diese einfach auf zwei Dimensionen gebracht und zur direkten Ausgabe und auch zum weiteren Clustering genutzt werden.
Hier sind wir aber nur an der kompletten Transformation interessiert und schicken die Ausgabe direkt in den Decoder, der wieder ein Bild derselben Struktur aus dieser Repräsentation erzeugt.
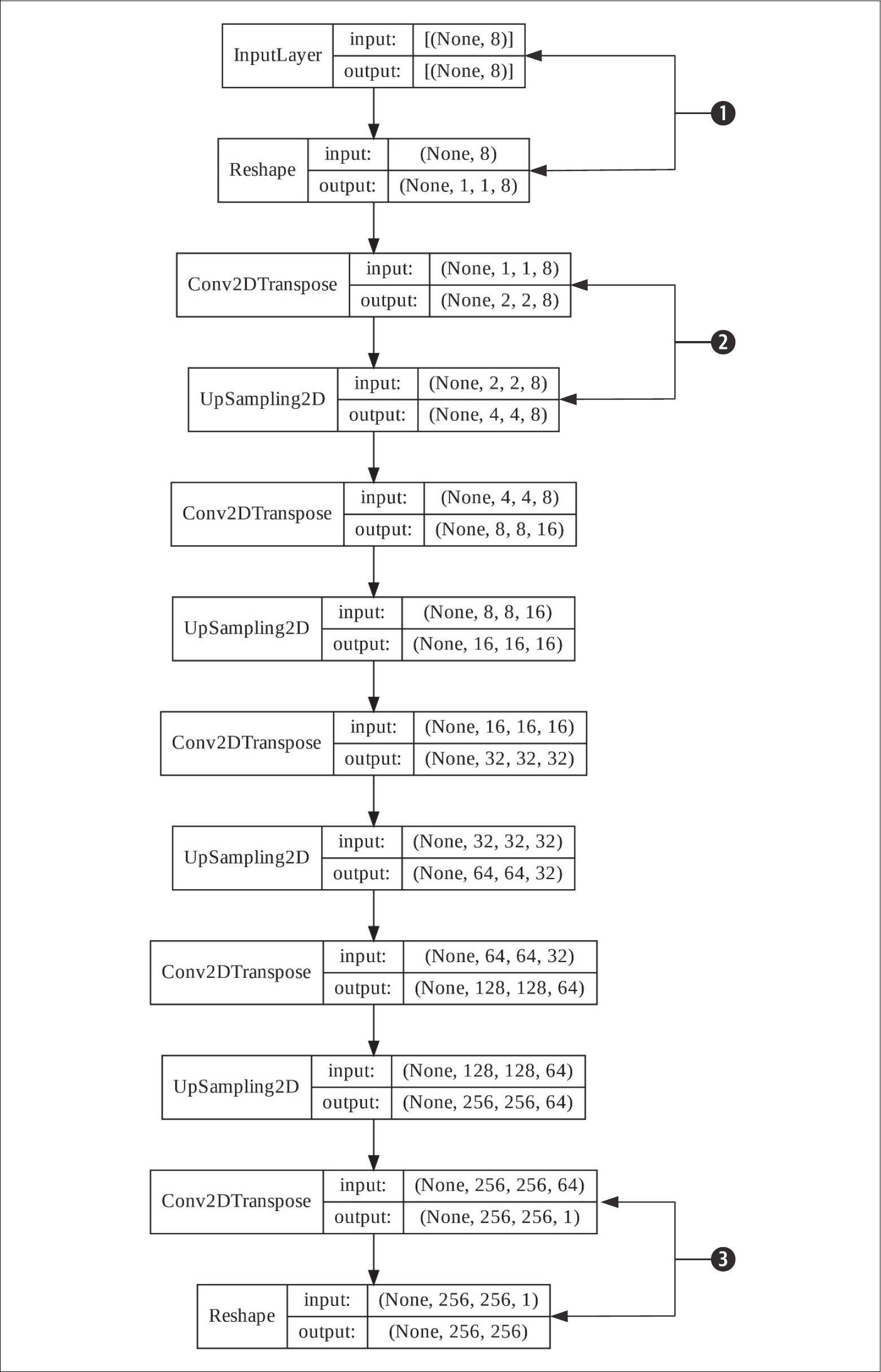
Der Decoder ist in Abbildung 8-5 dargestellt.
Dazu wieder die Erläuterungen im Detail:
Die Ausgabe des Encoders ist ein flacher Vektor mit acht Werten. Das müssen wir auch so als Input deklarieren. Zur Weiterverarbeitung mit Convolutional Layern könnten wir daraus ein Bild mit 2 × 4 oder 4 × 2 machen oder acht Bilder mit einem Pixel als Auflösung. Wir entscheiden uns für die zweite Option, da die acht Werte nicht sinnvoll räumlich zueinander angeordnet werden können und wir so auch unabhängig von der Dimension des Flaschenhalses arbeiten können. Letztlich gibt uns das Experiment recht, da die Trainingsergebnisse mit dieser Codierung weit besser sind.Conv2DTranspose und UpSampling2D sind zwei neue Arten von Layern, die aber nur alte Bekannte in neuer Kleidung sind. Transposed Convolution oder Deconvolution ist die Umkehrung der Convolution. Ohne auf die Details eingehen zu wollen: Wo die Convolution das Bild kleiner macht, macht die Deconvolution das Bild größer, und das brauchen wir. Das Upsampling ist der Gegenspieler des Downsamplings und macht das Bild durch einfache Duplizierung von Pixeln größer. Von dieser Kombination schalten wir so viele Blöcke hintereinander, wie wir brauchen, um die ursprüngliche Auflösung des Bilds wiederzuerlangen. Gegenläufig zum Encoder steigt dabei die Anzahl der Filter.Abbildung 8-5: Der passende Decoder
Die letzte Deconvolution fasst als Vorbereitung auf die Ausgabe alle 64 vorherigen Kanäle zu einem einzigen Kanal zusammen und komprimiert den Wertraum mit einem Sigmoid auf den Bereich zwischen 0 und 1. Dies wird dann mit einem zum Encoder gegenläufigen Reshape wieder als Grauwert ausgegeben, damit die Ausgabe des Netzes zu den Trainingsdaten passt. Es soll ja wieder dasselbe herauskommen, was wir hineingesteckt haben.Bei jedem Training müssen wir uns als Erstes überlegen: Was wollen wir eigentlich erreichen, und wie messen wir den Grad des Erreichens? Zunächst wollen wir erreichen, dass der Autoencoder die Bilder des Trainingssatzes so gut wie möglich reproduziert. Da die gleiche Auflösung der Bilder von vornherein durch die bereits beschriebene Architektur des Netzes erzwungen wird, ist ein perfektes Ergebnis gleichbedeutend mit: Jedes Pixel hätte in der Eingabe denselben Wert wie in der Ausgabe.
Dies würde auf Mean Squared Error als Loss hindeuten. Ein Training mit diesem Loss führt jedoch zu einer rein weißen Ausgabe für jede Eingabe. Eine triviale, aber naheliegende Lösung, da ja die meisten Pixel tatsächlich perfekt weiß sind. Dadurch sind im Durchschnitt etwa 94% der Pixel richtig reproduzierbar. Ein solcher Versuch einer perfekten Reproduktion scheint also unsere auf Abstraktion ausgelegte »undercomplete« Architektur zu überfordern.
Wir wählen daher einen Ansatz, den Aurélien Géron in Kapitel 17 seines Buchs Praxiseinstieg Machine Learning mit Scikit-Learn, Keras und TensorFlow, 2. Auflage (O’Reilly), beschreibt. Wir vereinfachen das Problem, indem wir es von Graustufen auf Schwarz-Weiß reduzieren. 0 sei Schwarz und 1 Weiß, alle Werte dazwischen entsprechen einer Unsicherheit zwischen den beiden Werten. Dazu übernehmen wir als Metrik eine gerundete Accuracy von Aurélien, die alle Werte auf 0 oder 1 reduziert:
def rounded_accuracy(y_true, y_pred):
return keras.metrics.binary_accuracy(
tf.round(y_true),
tf.round(y_pred))
Dazu passt ein Loss, der für jedes Pixel eine binäre Vorhersage annimmt und diese für das gesamte Bild kombiniert. Ein solcher Loss ist die Binary Crossentropy. Tatsächlich funktioniert das Training mit diesem Loss, und das trainierte Modell liefert erstaunlich akkurate Ergebnisse. In Abbildung 8-7 wird der Fehler bei der Reproduktion in Pink dargestellt.
Allerdings war das gar nicht unser Ziel, sondern nur Mittel zum Zweck. Eigentlich wollten wir ja unterscheiden, ob ein Bild so aussieht wie in der als heil angenommenen Anwendung oder »irgendwie« anders. Dafür wählen wir die Screenshots der heilen Anwendung als Trainingsdaten und die der zu überprüfenden Version als Testdaten, die wir auch während des Trainings als Validierung mitlaufen lassen.
Damit die Unterscheidung möglich ist, sollte sich die Qualität der Reproduktion von Trainings- und Testdaten also deutlich unterscheiden. Ein erster Hinweis auf einen solchen Erfolg ist der Unterschied der Accuracy-Metrik für die beiden Sätze, wie in Abbildung 8-6 dargestellt (Training blau, Validation orange).
Abbildung 8-6: Die gerundete Accuracy im gelungenen Trainingsverlauf
Der nächste Test ist von anekdotischer Natur. Wir vergleichen anhand von Beispielen, wie gut das trainierte Modell ein Bild aus dem Trainingsdatensatz und eines aus dem Testdatensatz reproduzieren kann. Dies tun wir visuell in Abbildung 8-7 und Abbildung 8-8 mit http://rsmbl.github.io/Resemble.js/ und lassen uns gleichzeitig den Anteil fehlerhafter Pixel ausgeben. Das Bild aus dem Trainingssatz wird sehr gut wiedergegeben, lediglich die hoch variablen Teile sind verschwommen und verallgemeinert. Im offensichtlich fehlerhaften Bild aus dem Testdatensatz in Abbildung 8-8 sehen wir eine weit größere Abweichung, und der Fehler wird uns gleich in Pink angezeigt.
Abbildung 8-7: 0,44% der Pixel falsch beim Beispiel aus dem Trainingssatz
Abbildung 8-8: 2,94% der Pixel falsch beim Beispiel aus dem Testsatz
Zuletzt bestimmen wir für alle Bilder die Accuracy und geben sie wie in Abbildung 8-9 und Abbildung 8-10 als Histogramm aus. Hier erwarten wir für den Trainingssatz eine starke Häufung im obersten Prozentbereich und für den Testsatz etwas geringere Werte und eine deutliche Streuung, da manche Testbilder ja durchaus korrekt sind.
Abbildung 8-9: Histogramm der Accuracy der Trainingsdaten
Abbildung 8-10: Histogramm der Accuracy der Testdaten mit Schwellenwert
Die beiden Peaks in Abbildung 8-9 könnten wir noch genauer untersuchen. Sie können entweder durch die Zweisprachigkeit unserer Anwendung oder durch zwei unterschiedliche Arten von Bildern entstanden sein. Dies ist aber gut genug für uns und entspricht im Wesentlichen unseren Erwartungen.
Anhand der Darstellung in Abbildung 8-10 wählen wir einen Schwellenwert, unter dem wir ein Bild als verdächtig einstufen. Dieser unterliegt unserer Willkür und entspricht unserer Präferenz für »möglichst keinen kaputten Screen verpassen« oder »nur wirklich kaputte Screens zu sehen bekommen«. Diese Abwägung ist systematisch in Kapitel 6 im Abschnitt »Precision-Recall« auf Seite 124 abgehandelt.
Wir entscheiden uns für einen konservativen Schwellenwert, der eher einige korrekte Screenshots als verdächtig ausweist, und haben ihn in Abbildung 8-10 als zusätzliche Linie eingezeichnet. Mit diesem identifizieren wir nur ca. 10% aus dem Testsatz als korrekt. Das entspricht in etwa dem erwarteten Wert, da der Testsatz hauptsächlich fehlerhafte Darstellungen enthält.
Neuronale Netze und im Spezialfall unser Autoencoder sind größtenteils Blackboxes, die sich unserer Erkenntnis entziehen. Das wirkt sich emotional aus, aber auch auf unsere Fähigkeit, diese Netze sinnvoll aufzubauen und zu debuggen. Außer dem Zusammenhang zwischen Ein- und Ausgabe, Losses und Metriken steht uns kaum Introspektion zur Verfügung.
Unser Trick, um tiefere Einsichten zu erlangen, besteht darin, weitere Messpunkte im Modell anzuzapfen. Wie erwähnt, haben wir einen Layer eingefügt, der eine einfache grafische Repräsentation der Bilder direkt vor dem Flaschenhals erlaubt. Daneben können wir uns auch das Ergebnis des Flaschenhalses einfach ansehen.
In Abbildung 8-11 siehst du einige Beispiele für diese Repräsentation als Bild zusammen mit der Eingabe aus dem Testsatz. Die Bilder sind entsprechend der Konfiguration des Encoders als 8 × 8 in Graustufen codiert. Sie enthalten also 256 Mal weniger Daten als das Ursprungsbild.
Abbildung 8-11: Die interne Repräsentation
Wahrscheinlich ergeben diese Bilder für dich ebenso wenig Sinn wie für uns, aber man bekommt einen Eindruck von der Leistung, aus so einer Repräsentation wieder ein ähnliches Bild zu erzeugen. Dies ist offensichtlich nur möglich, wenn der Decoder während des Trainings passende Ausgabefragmente mit vielen Details erlernt. Diese passen dann natürlich nur für Eingaben, wie sie im Training gezeigt wurden. Sehen sie wie bei den Testdaten anders aus, funktioniert die Reproduktion nicht mehr gut, der Fehler steigt, und wir können diese Auffälligkeit als möglicherweise kaputte Darstellung erkennen.
Passend zu den Beispielen in der bildlichen Darstellung hier zwei Beispiele für die Ausgabe des Flaschenhalses mit jeweils nur noch acht Werten. Hätten wir eine L1-Regularisierung benutzt, wären einige Nullen dabei. Bei L2 wären die Werte alle deutlich kleiner. Hier haben wir eine lineare Aktivierung, bei einer »ReLU«-Aktivierung hätten wir zudem nur positive Werte.
test_embedded_imgs = conv_encoder.predict(test)
test_embedded_imgs[7]
> array([ 38.59799 , -83.93206 , -25.386044, 56.212074, -58.50011 , 7.449939, 58.106182, -59.77407 ], dtype=float32)
test_embedded_imgs[43]
> array([ 53.575943 , -63.211693 , -13.942791 , 82.49099 , -48.120876 , -2.8139043, 43.14559 , -68.06632 ], dtype=float32)
Autoencoder sind neuronale Netze, die als Ein- und Ausgabe dieselben Daten nutzen. Die Natur der Daten ist dabei unerheblich, strukturierte Daten, Bilder und Zeitreihen sind möglich und sinnvoll. Damit ein solches Vorgehen Sinn ergibt, nutzt ein Autoencoder eine interne Repräsentation der Daten, die eine Abstraktion erzwingt. Diese Wirkung als Flaschenhals wird entweder durch eine kleine Dimensionierung oder eine erzwungene dünne Belegung durch L1-Regularisierung (Sparseness) erzwungen.
Ein solcher Autoencoder kann zur Reduktion von Fehlern oder zu deren Erkennen genutzt werden. Wenn man die interne Repräsentation abgreift, die eine Abstraktion der Eingabe darstellt, kann man diese zur Visualisierung nutzen oder auf dieser Basis klassische Verfahren des Unsupervised Learning nutzen, um Cluster oder Ausreißer zu erkennen.
Für unser Beispiel haben wir für eine bestehende und im Wesentlichen als korrekt angesehene Anwendung eine Reihe von Beispiel-Screenshots erzeugt. Mit diesen haben wir einen Autoencoder trainiert, sodass dieser die Screenshots in guter Qualität reproduzieren konnte. Die Dimension der internen Repräsentation haben wir mit nur acht Werten im Vergleich zu 65.536 als Eingabedimension sehr klein gewählt und so für eine extreme Abstraktion gesorgt.
Das Ziel unseres Beispiels ist, ein grundsätzlich anderes Aussehen der Anwendung nach einer Änderung zu erkennen. So sollen tückische visuelle Fehler, die nicht durch automatische Tests erkannt werden können, aufgespürt werden. Dazu lassen wir einen weiteren Satz von Screenshots, die auf der neuen Version der Anwendung erstellt wurden, durch den fertig trainierten Autoencoder laufen. Die Annahme ist, dass der Autoencoder nur Bilder gut reproduzieren kann, die so aussehen wie die Daten, mit denen er trainiert wurde. Wenn die Accuracy für ein reproduziertes Bild also unter einen festgelegten Schwellenwert fällt, gehen wir von einer fehlerhaften Darstellung aus. Dies erleichtert den manuellen Test, weil Bilder gezielter überprüft werden können.
Dieser Ansatz ist grundsätzlich mächtiger als ein klassisch eingesetzter visueller Regressionstest, bei dem Screenshots bestimmter Anwendungszustände paarweise miteinander verglichen werden. Unser Modell hat vielmehr allgemein gelernt, wie eine »heile« Anwendung aussieht, und kann nun auch auf bisher nicht gesehene Situationen generalisieren. Wir haben damit also einen weit allgemeineren und flexibleren Ansatz geschaffen.