Chapter 9. Information Extraction
When working with text, we generally want to extract some meaning. Many tasks involve extracting events or entities from the text. We may also want to find all the places in a document that reference a particular person. We may want to find what happened in a particular place. These tasks are called information extraction.
Information extraction tasks are focused on entities (nouns and noun phrases) and events (verb phrases including their subjects and objects). This is different than part-of-speech tasks in which, instead of needing to tag everything, we need to identify only the “important” pieces of the text. However, the techniques used to extract this information are generally the same as those used in sequence modeling.
By far, the most common type of information extraction is named-entity recognition. This is the task of finding references to specific entities.
Named-Entity Recognition
Named-entity recognition (NER) is the task of finding specific things (nouns) in text. Often, the desired named entities are proper nouns, but there are other things we may wish to extract as well. Let’s look at some of the common types of nouns that are extracted.
To fully understand the linguistics behind named-entity recognition, we need to define some terms:
- Referring expression or R-expression
- A word or phrase that refers to an actual or conceptual thing. This is broken into different types based on how specific the R-expression is and how it is specified.
- Referent
- The actual or conceptual thing that an R-expression refers to.
- Definiteness and Indefiniteness
- This refers to how specific the referent is. If an R-expression is definite, there is a particular referent. There are different kinds of indefiniteness, but languages differ on what kinds are distinguished.
- Deixis
- An R-expression whose referent can be resolved only with contextual information.
Let’s look at some examples.
- “Cows” in “Cows eat grass” is an example of an indefinite noun. In English, there is no required indefinite article, though “some” can be used.
- “France” in “France is in Europe” is an example of a proper noun. A proper noun is, by its nature, definite. In English, most proper nouns don’t use a definite article. There are some exceptions—mostly geographical regions and bodies of water, like “The Arctic” and “The Gobi.” There are some other exceptions, mainly non–proper-noun phrases that are proper in context—for example, sports teams like “the Cowboys.”
- “The Sun” in “The Sun is shining” is an example of a definite noun. In English, definite nouns that are not proper nouns require the definite article “the.”
- The “that” in “Are you going to eat that” is an example of deixis. In context, the referent is a specific food item, but without the context it’s impossible to resolve the reference.
- “I” and “here” in “I am here” are also examples of deixis. This sentence can be interpreted as a tautology, but it is still common. This is due to the deictic center being different for “I” and “here.” “I” has the speaker or writer as the deictic center, while “here” has some location introduced earlier as the deictic center.
- The “tomorrow” in “The next episode airs tomorrow” is an example of deixis used as an adverb.
As you can see, this is a complicated aspect of language. Fortunately, when doing NER, we restrict what entities we are looking for. Commonly, NER models identify people, places, organizations, and times. These models are generally looking for proper nouns. We will refer to this as generic NER. Another common NER task is finding particular concepts—for example, clinical procedures. This task is made easier by being focused on a particular set of vocabulary. A fluent speaker of a language can generally identify whether a noun is proper, but identifying domain-specific categories requires a domain expert. We will refer to this as domain-specific NER.
We can approach either general or domain-specific NER with the sequence-modeling techniques we discussed in Chapter 8. Let’s look at how to construct our data. The general notion is that we want to turn this into a classification task in which the classes are “inside a named entity” or “outside a named entity.” The basic classes are O, which is the class for tokens outside of a named entity. B-PER, I-PER, B-LOC, and I-LOC are the classes for tokens in a named entity phrase whose referent is a person (B-PER, I-PER) or location (B-LOC, I-LOC). Sometimes, there are more classes. It’s common to also have B-* classes for beginning named-entity phrases. Let’s look at some examples, with results in Tables 9-1 and 9-2.
“King Arthur went to Camelot.”
| token | class |
|---|---|
| King | B-PER |
| Arthur | I-PER |
| went | O |
| to | O |
| Camelot | B-LOC |
| . | O |
In clinical text, instead of looking for persons or locations, we are more interested in procedures (B-PROC, I-PROC).
“The patient received a bone scan”
| token | class |
|---|---|
| The | O |
| patient | O |
| received | O |
| a | O |
| bone | B-PROC |
| scan | I-PROC |
With these labels, you can approach modeling similarly to how you performed part-of-speech tagging.
If you are doing domain-specific NER, you can use a curated set of terminology to find the occurrences in the document without a model. Let’s look at some ways we can implement this. Let’s look at the Brown corpus again. We will look for occurrences of stop words in text.
from collections import defaultdict, Counter from random import sample, seed from time import time from nltk.corpus import brown from nltk.corpus import stopwords
en_stopwords = set(stopwords.words('english'))
Let’s define some functions that will help us.
brown_fileids = brown.fileids()
def detokenize(sentence):
"""
This will let us look at the raw text,
not split into sentences or tokens.
"""
text = ''
for token in sentence:
if text and any(c.isalnum() for c in token):
text += ' '
text += token
return text
def get_sample_files(k):
"""
This will give us a sample of the documents
"""
sample_files = []
for fid in sample(brown_fileids, k):
tokens = []
for sent in brown.sents(fid):
tokens.extend(sent)
sample_files.append((fid, detokenize(tokens)))
return sample_files
def get_match_counts(texts, search_fn, *args):
"""
This will run the given search function, search_fn
on the texts. Additional arguments are passed as
*args
"""
references = defaultdict(Counter)
for fid, text in texts:
for term, begin, end in search_fn(text, *args):
references[term][fid] += 1
return references
Let’s create some samples of documents so we can see how long it takes to find matches.
seed(123) raw_10 = [(fid, tokens) for fid, tokens in get_sample_files(10)] raw_50 = [(fid, tokens) for fid, tokens in get_sample_files(50)] raw_100 = [(fid, tokens) for fid, tokens in get_sample_files(100)] raw_500 = [(fid, tokens) for fid, tokens in get_sample_files(500)]
Let’s try the simple naïve approach. For each position in the text, we will try and match each term in our vocabulary to one of our search terms.
def simple_match(text, vocabulary):
text = text.lower()
for term in vocabulary:
for i in range(len(text) - len(term) + 1):
j = i+len(term)
end_of_word = j == len(text) or not text[j].isalpha()
begin_of_word = i == 0 or not text[i-1].isalpha()
if begin_of_word and \
end_of_word and \
term == text[i:i+len(term)]:
yield (term, i, j)
timing = []
for texts in [raw_10, raw_50, raw_100]:
start = time() # milliseconds
references = get_match_counts(texts, simple_match, en_stopwords)
timing.append((len(texts), int(time() - start) * 1000))
print('the', sum(references['the'].values()))
print('about', sum(references['about'].values()))
print('wouldn\'t', sum(references['wouldn\'t'].values()))
print('{} documents in {} ms'.format(*timing[-1]))
Let’s see how long it takes to process documents using the naïve approach.
the 1404 about 34 wouldn't 2 10 documents in 6000 ms the 6876 about 177 wouldn't 15 50 documents in 30000 ms the 13962 about 380 wouldn't 40 100 documents in 60000 ms
That is quite slow. Let’s look at the time complexity of the naïve approach.
If the size of a document is N characters, and M is the sum of the lengths of the vocabulary, this approach has O(MN) complexity. Your timing may be worse, but this is because we are also building the dictionary of references.
There are many wasted checks in this approach. If we are at an ’s', we don’t need to check for “about.” It would be better if we could limit the number of vocabulary items that we need to consider. We can do this with a trie.
A trie is a data structure that lets us store many sequences in a tree. A trie stores each sequence as a path in the tree. Let’s look at an example.
def build_trie(sequences, empty=lambda: ''):
"""
This will build our trie. We include the path in
each node to make explaining the trie easier, even
though this increases our memory footprint.
"""
trie = {'<path>': empty()}
for seq in sequences:
curr = trie
path = empty()
for elem in seq:
path += elem
curr = curr.setdefault(elem, {'<path>': path})
curr['<END>'] = True
return trie
def traverse(trie, empty=lambda: ''):
"""
This is breadth-first traversal. This will traverse
the trie one layer at a time.
"""
queue = [trie]
while len(queue) > 0:
head = queue[0]
path = head['<path>']
queue = queue[1:] + list(
node
for key, node in head.items()
if not key[0] == '<'
)
yield (path, head)
def traverse_depth_first(trie, empty=lambda: ''):
"""
This is depth-first traversal. This will traverse
the trie one path at a time.
"""
stack = [trie]
while len(stack) > 0:
head = stack[0]
path = head['<path>']
stack = list(
node
for key, node in head.items()
if not key[0] == '<'
) + stack[1:]
yield (path, head)
Let’s look at the trie with a simple vocabulary.
trie = build_trie(['cat', 'catharsis', 'dog', 'destiny'])
print('Breadth-first traversal')
for path, _ in traverse(trie):
print(path)
print()
print('Depth-first traversal')
for path, _ in traverse_depth_first(trie):
print(path)
Breadth-first traversal c d ca do de cat dog des cath ... destiny catharsi catharsis Depth-first traversal c ca cat cath ... catharsis d do dog de ... destiny
Now that we have this data structure, we can use it to search the text. The gist of the algorithm is to iterate over the text and use the characters from the text to traverse the trie. Let’s look at the code.
def trie_match(text, trie):
text = text.lower()
curr = trie
# for each character in text
for i in range(len(text)):
j = i # begin traversing the trie from text[i]
begin_of_word = i == 0 or not text[i-1].isalpha()
if not begin_of_word:
continue
while j < len(text) and text[j] in curr:
# move down the trie
curr = curr[text[j]]
# check if we are not in the middle of a word
end_of_word = j == len(text) - 1 or not text[j+1].isalpha()
# if we are at the end of a word and we are currently at
# an entry, emit a match
if end_of_word and '<END>' in curr:
term = curr['<path>']
yield (term, j-len(term)+1, j+1)
j += 1
# when we run out of matching characters or reach the
# end of the trie, reset and move on to the next character
curr = trie
Let’s time the trie-based approach.
en_stopwords_trie = build_trie(en_stopwords)
timing = []
for texts in [raw_10, raw_50, raw_100, raw_500]:
start = time() # milliseconds
references = get_match_counts(texts, trie_match, en_stopwords_trie)
timing.append((len(texts), int((time() - start) * 1000)))
print('the', sum(references['the'].values()))
print('about', sum(references['about'].values()))
print('wouldn\'t', sum(references['wouldn\'t'].values()))
print('{} documents in {} ms'.format(*timing[-1]))
the 1404 about 34 wouldn't 2 10 documents in 38 ms the 6876 about 177 wouldn't 15 50 documents in 186 ms the 13962 about 380 wouldn't 40 100 documents in 371 ms the 70003 about 1817 wouldn't 129 500 documents in 1815 ms
This is much faster. This is a classic trade-off in NLP. To improve speed we increase our memory footprint, in addition to the time necessary to precompute our trie. There are more complex algorithms, like the Aho-Corasick, which uses extra links in the trie to reduce the time spent backtracking.
If you have a constrained vocabulary, a dictionary search—like our previous trie-matching algorithms—can get a lot of information from the document. It is limited by not being able to recognize anything that is not in the curated vocabulary. To decide what approach is best for your project, consider the following:
- Do you have a domain-specific NER requirement? Or is it general NER?
- If you need general NER, you need to build a model.
- Do you have a curated vocabulary? Do you have labeled text?
- If you have both, you probably want to create a model to potentially recognize new terms. If you have neither, consider which one would be easier to create.
Once we have our entities, we may want to connect them to external data. For example, let’s say that we are looking for mentions of pharmaceuticals in clinical notes. We may want to associate the named entities (drugs) with information from a drug database. How we do this matching will depend on how we are doing the NER. Because this is a domain-specific NER task, we can use either a dictionary-search approach or a model approach. If we have such a database, it can actually be used to create our curated vocabulary. This makes it straightforward to associate recognized drug names with their metadata in our database. If we are using a model approach, things can be a little murkier, since models can recognize names that may not exactly occur in our database. One way we can approach this task is to search for the drug name in our database that is closest to the found drug name.
In Spark NLP, there are two ways to do NER. One strategy uses CRFs, and the other is deep learning based. Both approaches take word embeddings as inputs, so we will see examples in Chapter 11 when we discuss word embeddings.
All these approaches to NER miss a class of reference. These approaches identify only direct references. None of them can identify what pronouns to refer to. For example:
The coelacanth is a living fossil. The ancient fish was discovered off the coast of South Africa.
The “ancient fish” won’t be identified as the same thing as “coelacanth.”
Coreference Resolution
We previously discussed R-expressions and referents. A coreference is when two R-expressions share a referent. This can be valuable in text if we are trying to understand what is being said about our named entities. Unfortunately, this is a difficult problem.
Humans understand coreference through a number of syntactic and lexical rules. Let’s look at some examples.
He knows him.
He knows himself.
In the first sentence, we know that there are two people involved, whereas in the second there is only one. The reason for this is in a subfield of syntax called government and binding. A reflexive pronoun, like “himself,” must refer back to something in its clause. For example, look the following nongrammatical sentence.
They were at the mall. *We saw themselves.
Although we can guess that “themselves” refers to the same group to which “they” refers, it seems odd. This is because the reflexive nature tried to bind itself to the other entity in the sentence, “We.” Nonreflexives must not be bound in their clause.
Pronominal references aren’t the only type of coreference. There are often many ways to refer to an entity. Let’s look at an example.
Odysseus, known to the Romans as Ulysses, is an important character in the works of Homer. He is most well known for the adventures he had on his way home from the Trojan War.
In this sentence, Odysseus is referred to five times. In linguistics, it is common to give a subscript to indicate coreference. Let’s look at the same sentence marked for coreference.
Odysseusi, known to the Romans as Ulyssesi, is an important character in the works of Homer. Hei is most well known for the adventures hei had on hisi way home from the Trojan War.
Now that we understand coreference, how do we extract it from text? It is a difficult problem. Adoption of deep learning techniques have been slower for this task than the others because it is not often attempted. It is possible to approach this with a rule-based approach. If you parse the sentence into a syntax tree, you can use syntactic rules to identify which R-expressions share a referent. There is a big problem with this, however. It will work only on text with regular syntax. So this approach will work well on newspapers but very poorly on Twitter and clinical notes. An additional downside to this is that the rules require someone who has a strong knowledge of the syntax of the language for which we are building our rules.
The machine learning approach can be treated as a sequence-modeling problem. We must try and identify, for a given R-expression, whether it is the same as a previous R-expression or if it has a new referent. There are a number of data sets available out there that we can practice on.
Now that we have talked about how to get the R-expressions and how to identify coreferents, we can talk about what to do next.
Assertion Status Detection
Imagine we are looking for patients who exhibited a particular symptom when taking a drug—for example, dizziness. If we look for just any clinical report mentioning dizziness, we will find many mentions like the following.
No dizziness.
I have prescribed a drug that may cause dizziness. Patient denies dizziness.
Surely, these are not the patients we are looking for. Understanding how the speaker or author is using the information is as important as understanding what is being referred to in the information. This is called the assertion status task in the clinical setting. There are uses for it in other styles of communication, like legal documents and technical specifications.
Let’s look at it from the linguistic point of view. When we see “false positives” like in the previous “dizziness” example, it is because the statement is in the wrong mood or in the wrong polarity.
Polarity is whether a statement is affirmative or negative. Mood is a feature of a statement that indicates how the speaker or author feels about the statement. All languages have ways of indicating these things, but they differ greatly from language to language. In English, we use adverbs to express doubt, but in some other languages it is expressed in the morphology. Let’s see some examples of polarity and mood.
- The patient did not have difficulty standing.
- The movie may come out in April.
- I would have liked the soup if it were warmer.
The first example is an example of negation (negative polarity), the second is an example of the speculative mood, and the third is an example of the conditional. Negation is a feature of all languages, but how it is expressed varies considerably—even between dialects of the same language. You have likely heard of the rule about double negation in English; that is, that a double negative makes a positive.
I don’t have nothing ~ I have something
This is not always the case, however. Consider the following example:
You’re not unfriendly.
Here, the verb is negated by “not,” and the predicate is negated by the “un-” prefix. The meaning of this sentence is certainly not “You are friendly,” though. Natural language is much more ambiguous than formal logic. In certain dialects of English, double negation can serve to intensify the statement, or it can even be required. In these dialects, “I don’t have nothing” means the same as “I have nothing.”
Similarly, the speculative case is also ambiguous. How you treat such statements will depend on the application you are building. If you are building something that extracts movie release dates, you may very well want to include a speculative statement. On the other hand, considering the medical example with “may cause dizziness,” we likely would not want to include the phrase describing this patient in the set of patients who suffer from dizziness. An additional factor to consider is hedged speech. If someone wishes to soften a statement, they can use the speculative mood or other similar moods. This is a pragmatic effect that can appear to change the semantics.
You may want to close the window ~ [pragmatically] Close the window
You might feel a pinch ~ [pragmatically] You will feel a pinch
You could get your own fries ~ [pragmatically] You should get your own fries
Finally, let’s consider the third example, “I would have liked the soup if it were warmer.” This sentence has at least two interpretations. One interpretation is, “I would have also liked the soup if it were warmer.” The other, and perhaps the more likely, interpretation is, “I did not like the soup because it was not warm enough.” This is an example of implied negation. Another common source of implied negation is phrases like “too X to Y,” which implies a negation on “Y.”
The patient is in too much pain to do their physical therapy.
This communicates that “the patient did not do their physical therapy” and also gives the reason. Clinical terminology contains many special ways to refer to negation. This is why Wendy Chapman et al. developed the negex algorithm. It is a rule-based algorithm that identifies what sections of a sentence are negated depending on the type of cues.
The different cues or triggers signify beginnings and ends of negated scopes, and they prevent negex from incorrectly identifying nonnegated words as negated. Let’s look at some examples. We will first show the original sentence, and then the sentence with the cues italicized and the negated words struck through.
- The patient denies dizziness but appears unstable when standing.
- The patient denies
dizzinessbut appears unstable when standing.
- The patient denies
- The test was negative for fungal infection.
- The test was negative for
fungal infection.
- The test was negative for
- The XYZ test ruled the patient out for SYMPTOM.
- The XYZ test ruled the patient out for
SYMPTOM.
- The XYZ test ruled the patient out for
- Performed XYZ test to rule the patient out for SYMPTOM.
- Performed XYZ test to rule the patient out for SYMPTOM.
In examples 1 and 2, we see that the negation was not signaled by a normal grammatical negative like “not.” Instead, there are clinical-specific cues, “denies” and “negative for.” Also, note that the negation was terminated by “but” in the first example. In examples 3 and 4, cues are made to rule out false positives. In example 4, the results of the test are not actually discussed.
We’ve seen how the polarity and mood of verbs can affect entities in the sentence, but is there a way to get out more information? In the next section we will briefly discuss the idea of extracting relationships and facts from text.
Relationship Extraction
Relationship extraction is perhaps the most difficult task in information extraction. This is because we could spend a lot of research and computation time trying to extract more and more fine-grained information. So we should always understand exactly what kind of relationships we want to extract before trying something so challenging.
Let’s consider the scenario in which we are trying to extract statements from clinical documents. The nature of these documents limits the kinds of entities that may appear.
- The patient
- Conditions (diseases, injuries, tumors, etc.)
- Body parts
- Procedures
- Drugs
- Tests and results
- Family and friends of the patient (in family history and social history sections)
There can be other entities, but these are common. Let’s say our application is supposed to extract all the entities and make statements. Let’s look at an example.
CHIEF COMPLAINT Ankle pain HISTORY OF PRESENT ILLNESS: The patient is 28 y/o man who tripped when hiking. He struggled back to his car, and immediately came in. Due to his severe ankle pain, he thought the right ankle may be broken. EXAMINATION: An x-ray of right ankle ruled out fracture. IMPRESSION: The right ankle is sprained. RECOMMENDATION: - Take ibuprofen as needed - Try to stay off right ankle for one week
The patient ... is 28 y/o man has severe ankle pain tripped when hiking struggled back to his car immediately came in The right ankle ... may be broken is sprained The x-ray of right ankle ... rules out fracture Ibuprofen ... is recommended take as needed Try to stay off right ankle ... is recommended is for one week
To perform relationship extraction using this data, there are a number of steps we need to take. We will need all the basic text processing, section segmenting, NER, and coreference resolution. This is just for processing the document. Creating the output would also require some text generation logic. However, we may be able to combine a syntactic parser and some rules to get some of this done. As described in the previous chapter, a syntactic parser will transform sentences into a hierarchical structure. Let’s look at some of the sentences.
The patient is 28 y/o man who tripped when hiking.
(ROOT
(S
(NP (DT The) (NN patient))
(VP (VBZ is)
(NP
(NP (ADJP (CD 28) (JJ y/o)) (NN man))
(SBAR
(WHNP (WP who))
(S
(VP (VBN tripped)
(SBAR
(WHADVP (WRB when))
(S
(VP (VBZ hiking)))))))))
(. .)))
This looks complicated, but it is relatively straightforward. Most sentences can be described in a simple tree structure.
(ROOT
(S
(NP (NNS SUBJECT))
(VP (VBP VERB)
(NP (NN OBJECT)))
(. .)))
Embedded wh-clauses can inherit their subjects. For example, let’s take the following sentence:
The man who wears a hat.
In the wh-clause “who wears a hat,” “who” is coreferent with “The man.” In the following sentence we see a clause with no explicit subject:
The man went to the store while wearing a hat.
The subject “wearing” is “The man.” The actual syntax behind identifying the subject of an embedded clause can get complicated. Fortunately, such complicated sentences are less common in the terse English found in clinical notes. This means that we can group sentences by the entity that is their subject.
PATIENT
The patient is 28 y/o man who tripped when hiking.
who tripped when hiking
He struggled back to his car, and immediately came in.
he thought the right ankle may be broken.
RIGHT ANKLE
the right ankle may be broken
The right ankle is sprained.
X-RAY
An x-ray of right ankle ruled out fracture.
IBUPROFEN
Take ibuprofen as needed
This gets us most of the sentences we are interested in. In fact, if we make embedded sentences their own sentences and split conjoined verbs, we get all but one of the statements about the patient. The remaining statement, “has severe ankle pain,” will be more difficult. We would need to turn something of the form (NP (PRP$ his) (JJ severe) (NN ankle) (NN pain))) into (ROOT (S (NP (PRP He)) (VP (VBZ has) (NP (JJ severe) (JJ ankle) (NN pain))) (. .))) Converting noun phrases with possessives into “have” statements is a simple rule. We have glossed over the coreference resolution here. We can simply say that any third-person singular pronoun outside of family history or social history is the patient. We can also create special rules for different sections—for example, anything mentioned in a recommendation section gets a statement “is recommended.” These simplifying approaches can get us most of the statements. We still need something to recognize “Try to stay off right ankle” as a treatment.
Let’s use NLTK and CoreNLP to look at what is actually parsed.
text_cc = ['Ankle pain']
text_hpi = [
'The patient is 28 y/o man who tripped when hiking.',
'He struggled back to his car, and immediately came in.',
'Due to his severe ankle pain, he thought the right ankle may be broken.']
text_ex = ['An x-ray of right ankle ruled out fracture.']
text_imp = ['The right ankle is sprained.']
text_rec = [
'Take ibuprofen as needed',
'Try to stay off right ankle for one week']
First, let’s start our CoreNLPServer and create our parser.
from nltk.parse.corenlp import CoreNLPServer from nltk.parse.corenlp import CoreNLPParser server = CoreNLPServer( 'stanford-corenlp-3.9.2.jar', 'stanford-corenlp-3.9.2-models.jar', ) server.start() parser = CoreNLPParser()
parse_cc = list(map(lambda t: next(parser.raw_parse(t)), text_cc)) parse_hpi = list(map(lambda t: next(parser.raw_parse(t)), text_hpi)) parse_ex = list(map(lambda t: next(parser.raw_parse(t)), text_ex)) parse_imp = list(map(lambda t: next(parser.raw_parse(t)), text_imp)) parse_rec = list(map(lambda t: next(parser.raw_parse(t)), text_rec))
Each parsed sentence is represented as a tree. Let’s take a look at the first sentence in the “History of Present Illness” section (as shown in Figure 9-1).
parse_hpi[0]
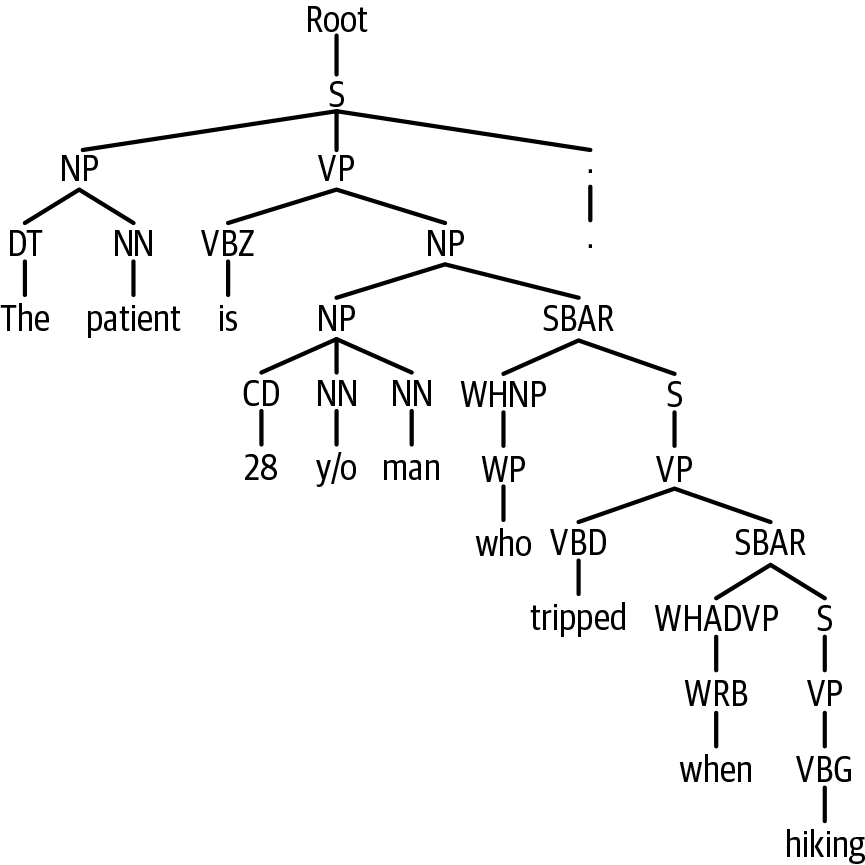
Figure 9-1. Parse of “The patient is 28 y/o. . .”
We can traverse the tree via the indices. For example, we can get the subject-noun phrase by taking the first child of the sentence (as shown in Figure 9-2).
parse_hpi[0][0][0]
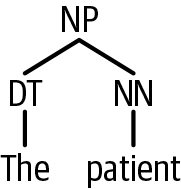
Figure 9-2. Subject of first HPI sentence
The leaves of the tree are the tokens:
parse_hpi[0][0][0][0][0]
'The'
Summary
Now we see how far we can get when we have documents with a narrow set of language. These assumptions would not work if we tried to apply them to tweets, patents, or movie scripts. When we build applications like this, we must iterate on problems by reviewing the data, training our models, and looking at the product.
These topics have been heavy in linguistics. This is natural, since we are trying to extract information encoded in language. Linguistics is the study of language, so we can get a lot of advantage by using its knowledge. But what if we don’t want to extract the information for human consumption, but for use in modeling? We’ll need something better than TF.IDF. The next two chapters talk about distributional semantics. Chapter 10 is about topic modeling, in which we treat documents as a combination of different topics. Chapter 11 is about word embeddings, in which we try to represent words as vectors.
Exercises
In this exercise, you will be traversing the parse trees looking for SVO triplets.
from nltk.tree import Tree
def get_svo(sentence):
parse = next(parser.raw_parse(sentence))
svos = []
# svos.append((subject, verb, object))
return svos
Here are some test cases to use.
# [("The cows", "eat", "grass")]
get_svo('The cows eat grass.')
# [("the cows", "ate", "grass")]
get_svo('Yesterday, the cows ate the grass.')
# [("The cows", "ate", "grass")]
get_svo('The cows quickly ate the grass.')
# [("the cows", "eat", "grass")]
get_svo('When did, the cows eat the grass.')
# [("The cows", "eat", "grass"), ("The cows", "came", "home")]
get_svo('The cows that ate the grass came home.')