Major Players and Their Characteristics—or, Who’s at the Party?
Exemplar Massive Digital Libraries
Despite the long gestation period in the development of digital systems from the 1960s to their uniform application across all libraries by the late 1990s and early 2000s, the creation and development of massive digital libraries (MDLs) almost seems to have occurred overnight in the mid-2000s. Google’s announcement in 2004 that it would join the fray by digitizing all the world’s books seems to have galvanized a number of already-existing projects and to have spawned a few more. Several MDL projects developed simultaneously over the past decade and have become the leading exemplars of the movement toward larger aggregated collections of digitized print material.
Interestingly, many of these MDLs comprise partners that overlap with other MDLs. As a result, many of the projects can provide similar accessibility to online content. Books digitized by the Google Books Library Project, for example, appear in HathiTrust, Internet Archive, and the Open Content Alliance. An exact number is not forthcoming, however.
The following looks at these major players among MDLs and briefly examines their characteristics. The list is by no means exhaustive, but it should allow readers to get a better sense of how the major MDLs stack up against one another. Criteria described for each MDL include their dates of inception, modi operandi, the estimated size of the collections, the subjects collected, the number of partner institutions, the languages covered in the collections, and so on. The Alexa ranking included in the list of descriptors provides a general metric allowing evaluators to assess the amount of users and site traffic.
This chapter examines the following MDLs: Google Books, HathiTrust, Internet Archive, the Open Content Alliance’s Open Library, the Library of Congress’s American Memory, the Networked Digital Library of Theses and Dissertations, the Virtual Library of Historical Newspapers, the European Commission’s digital libraries initiative, and France’s Gallica. The MDLs are discussed in general order of collection size and split between US-based MDLs, European-based MDLs, and MDLs of special note.
Current US-Based MDLs
Google Books
Fact Sheet
• Starting date: 2004
• Modus operandi: “To create a comprehensive, searchable, virtual card catalog”
• Size: 30 million volumes
• Subjects or scope: All
• Partner institutions: 20–25 estimated
• Languages: English primarily, but many other languages as well; breakdowns are undetermined (request from Google for breakdowns was not honored)
• URL: http://books.google.com/
• Accessibility: Snippet, partial view and full view
• Digital collection development policy: “Digitize the whole of the world’s 129,864,880 books”
• Alexa ranking: No. 1 in the world (April 2014)
The Google Books (see figure 3.1) project started in 2004. It currently holds about fifteen million volumes in its collections. Sergei Brin, a founder of Google and co-inventor of its revolutionary search engine, envisioned Google Books as a replacement for the library card catalog. This effectively threw down the gauntlet against a number of institutions, including national cultural institutions, public and academic libraries, and the publishing industry. The number 129,864,880 listed in the Google Books fact sheet is significant in that a software engineer working on the Google Books project estimated this figure.1

Figure 3.1
Snippet view of Google Books’ display of Baseball History, by Peter Levine. Metadata provided next to the thumbnail image of the book’s cover and at the bottom of the page (not shown).
Google Books is characterized in part by its extremely robust and flexible search engine. When searching in this MDL, a large amount of set results often appear. Mistakes in the search are often autocorrected. Google’s stated goal is the digitization of all the books in the world, a number that reaches about 120 million. The project works with about twenty public and academic institutions in several countries, including Japan, Germany, England, and Spain. Overall collection diversity is present, with a large number of languages represented and accessible, although most materials in the corpus are in the English language.
The Google Books corpus is open to anyone able to use a computer that is connected to the Internet. However, because of copyright restrictions and the threat of litigation, any materials not within the public domain have been closed to full-text viewing. Google allows users three levels of accessibility to the texts beyond the metadata record: “snippet view,” which is a few sentences of the book; “partial view,” which is often several to dozens of pages; and ”full view,” which is the complete text.
One issue that arises with the functionality of Google Books, however, is the inability of the search engine to accurately retrieve and coherently display single works of multiple volumes. A search, for example, of the Harvard Classics—a fifty-one-volume series—results in a very jumbled retrieval. Unless a user knew beforehand that the Harvard Classics series contained fifty-one volumes, he or she might never get an accurate accounting from Google’s set result.
HathiTrust
Fact Sheet
• Starting date: 2008
• Modus operandi: “Contribute to the common good by collecting, organizing, preserving, communicating, and sharing the record of human knowledge”
• Size: 11 million volumes (approximately 3 million in public domain)
• Subjects or scope: University academic library subject matter
• Partner institutions: approximately 72 research libraries
• Languages: 429 languages—48% English, 9% German, 7% French, 4.5% Spanish, 4% Chinese, 3.7% Russian, 3% Japanese
• URL: www.hathitrust.org
• Accessibility: Limited view with full-text search results only and full view
• Digital collection development policy: “Build a comprehensive archive of published literature from around the world and develop shared strategies for managing and developing their digital and print holdings in a collaborative way”
• Alexa ranking: No. 53,758 (April 2014)
HathiTrust (see figure 3.2) started in 2008. It currently holds about eleven million volumes in its collections. HathiTrust’s essential mission is to meet the needs of the members of its partnering institutions. Collection development is focused on gathering digitized books and journals from partner institutions and in-house digital initiatives and those books digitized in part by Google Books and the Internet Archive. The partners include nearly seventy-two world-class academic research and national libraries. Notable partners include the Library of Congress and the California Digital Library.
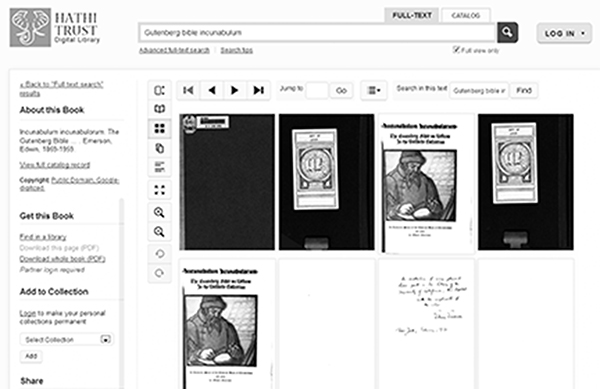
Figure 3.2
Full view of thumbnails in the HathiTrust of Miguel Cervantes’ Don Quixote de la Mancha, London, J. J. Dubochet, 1837–39. Translated from the Spanish, v. 1. Cervantes Saavedra, Miguel de, 1547–1616. (public domain book).
As one might expect, English is the main language of the archive. Nearly three million books, representing 48 percent of holdings, are in English. The second-largest represented group is German, followed by French, Spanish, Chinese, Russian, and Japanese. Given the large Spanish-speaking population in the United States, the small amount of Spanish-language materials is surprising. However, given that the audience is college students and faculty, German and French have long represented the frontiers of scholarship in more disciplines than Spanish has.
HathiTrust is characterized by a robust search engine and extremely well-organized metadata and records management. Where Google Books has issues with the retrieval of specific dates and other types of metadata, HathiTrust performs information retrieval and document display with superior results. The system allows, however, only two types of views to users who are not members: a limited view, which allows only search results to retrieve word counts for queries (i.e., full-text search), and full view, which is reserved for materials in the public domain.
Access is open to anyone able to use a computer connected to the Internet, but partnering institutions and their members can benefit from extra services, such as content storage, data preservation, and copyright clearance and usage consultation. Although the current size of the collection is smaller than that of Google Books, the ability to find information more easily should make the HathiTrust the go-to MDL for libraries.
Another positive aspect is the manner in which HathiTrust handles multivolume works. Compared to the mish-mash one gets from a Google Books search result for multiple-volume works—the Harvard Classics, for example—HathiTrust generally keeps these volumes bundled together in a record. The user can then easily find and access all volumes together.
Open Content Alliance
Fact Sheet
• Starting date: 2005
• Modus operandi: “A collaborative effort of a group of cultural, technology, nonprofit, and governmental organizations from around the world that helps build a permanent archive of multilingual digitized text and multimedia material”
• Size: 2,654,228 works; 23 million book records in Open Library beta
• Subjects or scope: Public library, government, and individual international authors
• Partner institutions: Initially: Yahoo!, Internet Archive, Microsoft, University of California, and University of Toronto—currently approximately 2,300 individual organizations (in several consortia)
• Languages: Primarily English, with a large amount of Spanish, Japanese, and other languages. Full breakdowns unknown.
• URL: www.opencontentalliance.org
• Accessibility: Full view or a record; log-in for members to check out books; DAISY-standard compliant digital files for visually impaired users, including the blind and dyslexic (DAISY Consortium)
• Digital collection development policy: “One web page for every book,” and to provide books for people with visual impairments and/or disabilities
• Alexa ranking: No. 1,542,664 (April 2014)

Figure 3.3
OCA metadata for Don Quijote translated into German.
The Open Content Alliance’s (OCA) Open Library (see figure 3.3) started as a counterpoint to Google Books, with Yahoo!, Internet Archive, and University of California joining to create the initiative. Microsoft joined the mass-digitization movement with its own digitization project, Live Book Search, in 2005 but dropped out by 2008 after having scanned roughly 750,000 books. One of the priorities of Open Library is accessibility for people who are blind and/or have disabilities, such as dyslexia, with its reliance on the Digital Accessible Information System (DAISY) technology.
Open Library has also positioned itself as an alternative to WorldCat, by championing its service as a “web page for every book.” The site provides information about most books and provides readable book image files for users. Members can also borrow the physical books and access other books that at-large public users may not.
Internet Archive
Fact Sheet
• Starting date: 1996
• Modus operandi: “Universal access to all knowledge”
• Size: 10 million web pages: 1.6 million volumes and 23 million book records (as a result of partnering and/or sponsoring the Open Library project with OCA)
• Subjects or scope: Combination of media (audio and video), books, and web pages—archives using Wayback Machine
• Partner institutions: OCA, Smithsonian, Library of Congress, and more; includes access to the online initiatives of Universal Library, Project Gutenberg, Children’s Library, Biodiversity Heritage Library, and more
• Languages: English primarily, Spanish, and more; full breakdowns unknown
• URL: http://archive.org
• Accessibility: All items included are open access and public domain, so no restrictions in access
• Digital collection development policy: “Change the content of the Internet from ephemera to enduring artifacts of our political and cultural lives”
• Alexa ranking: No. 159 (April 2014)
The Internet Archive (see figure 3.4) is a unique addition to the MDL category. On the one hand, its main focus appears to be archiving the Internet via its Wayback Machine. One of its stated goals, in fact, is to create archival artifacts of the web itself. This is important, as the Internet may replace many print media sources that are available, including books. On the other hand, its primary concern has been less on the number of titles acquired than do Google Books, HathiTrust, and even the OCA, which focus heavily on collection sizes. Instead, the Internet Archive gathers and approves only those materials in the public domain or that have author permissions. As a result, its print-derived digital collections are smaller but completely accessible.
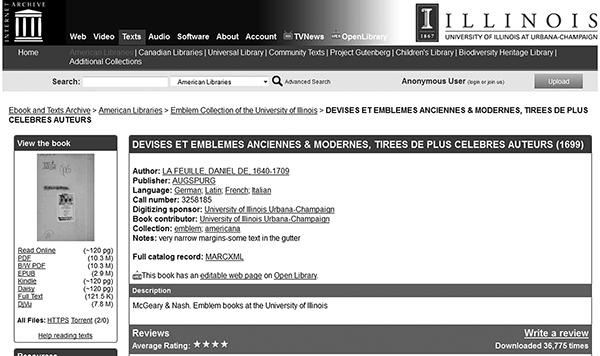
Figure 3.4
View of screenshot showing Internet Archive’s display of Devises et emblemes anciennes and modernes, 1699.
An advantage of the Internet Archive is also that it provides links to several mass-digitization projects and allows the projects to exist under their own names, as well as within the Internet Archive web pages. Projects such as the Biodiversity Heritage Library, Project Gutenberg, the Universal Library, and Children’s Library are worthy open access book digitization initiatives aimed at providing people with free access to resources, which falls under the Internet Archive umbrella.
A difference of Internet Archive is one of scope, with its emphasis on video and audio, especially in relation to its well-known Grateful Dead Collection of the band’s legendary live recordings. Additionally, Internet Archive also provides access to about 9,500 audio recordings of books, including literature and poetry.
European-Based MDLs of Note
Europeana
Fact Sheet
• Starting date: 2008
• Modus operandi: Meta-aggregator and display space for European digitized works
• Size: 10 million objects, almost 4.3 million volumes of texts and books (more than 350,000 in English)
• Subjects or scope: European culture
• Partner institutions: Roughly 130 institutions, including universities, museums, and organizations across Europe
• Languages: Full range of European languages, including English, Slavic, and Basque
• URL: www.europeana.eu/portal/
• Accessibility: Items available as open access, restricted and behind pay-walls
• Digital collection development policy: Very strong application of public domain rights; “the Europeana Foundation believe in and wish to strengthen the concept of the Public Domain in the digitised world”
• Alexa ranking: No. 44,296 (April 2014)
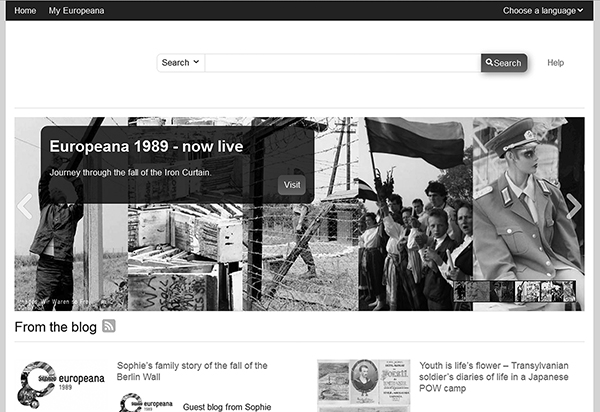
Figure 3.5
Screenshot showing the home page of the Europeana Digital Library.
The Europeana digital library (see figure 3.5) aggregates content from more than 130 institutions across Europe. As a result, it is a fully multilingual, multicultural endeavor. There appears not to be one dominant language in the project. With a huge collection of more than four million texts, the digital library should be considered a leading MDL in the field. Its emphasis on interoperability and a strong metadata schema allows users to refine searches and hone in on more relevant search results easily. The main focus for the library is to ensure that digital materials of numerous cultures remain freely accessible to all. The project advocates the strongest pro–public domain stance of nearly all the MDLs. It is a vital and important MDL as a result.
Gallica
Fact Sheet
• Starting date: 1997
• Modus operandi: “Collective digital library”
• Size: 2.5 million documents—460,000 books and 36,145 manuscripts
• Subjects or scope: —
• Partner institutions: Mainly French libraries, museums, and universities, but also the Library of Congress and the National Library of Brazil
• Languages: Primarily French, but other languages on a small scale, including English, Spanish, Portuguese, and German
• URL: http://gallica.bnf.fr; English-language URL: http://gallica.bnf.fr/?lang=EN
• Accessibility: Many resources are open access; provide permanent links to items
• Digital collection development policy: Unknown
• Alexa ranking: No. 13,641 (April 2014)
Gallica, supported by the Bibliothèque Nationale de France (see figure 3.6) despite its relatively smaller book collection size, is noteworthy for several reasons. First, it is an MDL primarily focused on France and Francophone works. Its partners include many universities and museums in France, but also the National Library of Brazil and the Library of Congress. There are some books offered in English, but these are few compared to other MDLs and are dwarfed, obviously, by the size of the French-language collection. Gallica is also, in many ways, an MDL counterpoint to Google Books, with a very different philosophy and approach to the digital library.

Figure 3.6
Screenshot showing the home page for Bibliothèque Nationale de France’s Gallica.
Virtual Library of Historical Newspapers
Fact Sheet
• Starting date: 2006
• Modus operandi: “To search for any word on any page of any digital newspaper”
• Size: 1,049,943 issues, from 2,037 serials
• Subjects or scope: Spanish-language newspapers and serials from the Iberian Peninsula
• Partner institutions: 18 autonomous regions of Spain, 57 provinces (subdivisions of the autonomous regions), and 180 towns
• Languages: Primarily Spanish
• URL: http://prensahistorica.mcu.es/en/consulta/busqueda.cmd
• Accessibility: Open access for 5 million pages of newspapers
• Digital collection development policy: To preserve bibliographic materials that are in danger of disappearing because of their physical characteristics and to disseminate more broadly information resources that are widely used by researchers and citizens in general
• Alexa ranking: No. 29,466 (April 2014)

Figure 3.7
Screenshot showing the home page for the Virtual Library of Historical Newspapers.
The Virtual Library of Historical Newspapers (VLHN) (see figure 3.7) focuses on Spanish-language newspapers and serials. Nearly five million pages are available through OCR full-text search. Many of the regions of Spain and its provinces and towns are represented by the library. Explanatory information is available in English, but the MDL is mainly Spanish in its focus. It is meant to provide access to fragile and rare serial materials, and it allows users to access the information without risking damage or loss to the original materials. In contrast to many other digital newspaper aggregators, the project is providing the papers in an openly accessible manner.
MDLs of Special Note
Networked Digital Library of Theses and Dissertations
Fact Sheet
• Starting date: 1996
• Modus operandi: “Promotes the adoption, creation, use, dissemination and preservation of electronic theses and dissertations”
• Size: 2,400,000 (or more) records
• Subjects or scope: Electronic theses and dissertations from all academic subjects
• Partner institutions: 91 institutional members (mostly universities) and three well-known consortia: OhioLINK, Florida Consortium, and Triangle Research Libraries Network
• Languages: Primarily English; full breakdowns unknown
• URL: www.ndltd.org
• Accessibility: Varies—some ETDs are publicly available, but many are behind access walls or embargoed
• Digital collection development policy: limited only to ETDs; the MDL wants to partner with as many ETD-creating organizations as possible
• Alexa ranking: No. 1,014,425 (April 2014)
The Networked Digital Library of Theses and Dissertations (NDLTD) (see figure 3.8) began in the mid-1990s to promote the creation and accessibility of electronic theses and dissertations (ETDs). It is a robust system that allows users to search across numerous repositories and digital libraries to access ETDs. For the most part, the language most represented in the collection is English, especially as most member institutions are based in the United States.

Figure 3.8
Screenshot of NDLTD home page showing the first 10 of 3.112 million records.
Accessibility is a main issue for ETDs. They are somewhat of an outlier in terms of the publishing world—part publication, part archiving. Since a large majority of traditional publishers do not consider a thesis or dissertation placed online as a typical publication, accessibility should not be an issue. However, many students and scholars still fear not being able to publish their thesis if it appears already online. Embargoes therefore have become an issue with ETDs. Yet most publishers will also rarely publish a thesis or dissertation without major revisions and edits, essentially rendering moot the embargo protection. Though most of the organizations allied with the NDLTD advocate open access, the reality remains that many still limit access to content.
American Memory—Library of Congress
Fact Sheet
• Starting date: pilot 1990–94, launch 1996
• Modus operandi: “Be a gateway to the Library of Congress’s vast resources of digitized American historical materials. Comprising more than 9 million items that document U.S. history and culture”
• Size: 9 million items total, including films, maps, and images; number of books is unknown
• Subjects or scope: American history and American archival materials
• Partner institutions: None
• Languages: Primarily English
• URL: http://memory.loc.gov/ammem/index.html
• Accessibility: US government works are in the public domain
• Digital collection development policy: Only a small fraction of collection is digitized; the focus is on digitizing the library’s “unique holdings” and “exceptional primary sources”
• Alexa ranking: No. 4,366

Figure 3.9
Screenshot of the Library of Congress’s American Memory project.
The Library of Congress’s American Memory (see figure 3.9) project is probably one of the pioneering digital libraries not only in the United States but also in the world. Many of the works in the Library of Congress are of great historical interest. Digital versions of the Declaration of Independence, the Constitution, and other early documents are available through this site. Early texts are also available. The focus of this MDL, then, is more of historical and public domain materials related to the American experience. The size of the MDL’s books collection is undetermined at this time. Queries to the Library of Congress were successful, but specific numbers regarding the amount of books in the project were not provided in correspondence. The reference librarian for the Library of Congress wrote:
Items in American Memory have item records that correlate one-to-one and one-to-many with files. For example, some books have a single image file for each page and some have three (GIF, JPEG, TIFF) for each page. Some also have SGML and on-the-fly HTML text transcriptions, as well. Some have only transcriptions; some have transcriptions with images only for illustrated pages. (Personal communication, reference specialist, Digital Reference Section, Library of Congress, July 25, 2013)
As a result, it appears quite difficult to determine the exact number of books in the American Memory project.
Conclusion
The various MDLs covered in this chapter show striking individuality in their approaches to mass digitization and the mass distribution of digitized content. Their central missions, to share the content of print books that may be locked away on bookshelves, are admirable. Varying degrees of scope, subject matter, and audience shape the massive collections in individual ways, making each MDL unique. Overall, when looking at the main examples of MDLs currently in existence, one gets the sense that ambitions for a unified digital front for all types of materials is the impetus driving their development. Some of the implications for this have impacts, as readers will see in the next chapter, on bricks-and-mortar libraries, which may have to scramble to accommodate as well as take advantage of these new initiatives.
Note
1. Joab Jackson, “Google: 129 Million Different Books Have Been Published,” PC World, August 6, 2010, www.pcworld.com/article/202803/google_129_million_different_books_have_been_published.html.