Impact on Librarianship—or, How Do I Deal with This?*
Now that the characteristics of massive digital libraries have been clearly delineated in Chapter 2 and their main exemplars outlined in Chapter 3, we arrive at some important questions. First, how will libraries come to deal with MDLs? How will MDLs affect librarians and librarianship? How will they be examined and analyzed from an information science perspective?
When Jeanneney (2007) staked his position against Google, he was pointing out what he saw as proprietary interests overtaking the traditional cornerstones of both culture and academia. In many ways, Jeanneney’s suspicions were not entirely unwarranted. As we will see in Chapter 5, the dispute with Google regarding the need to gain copyright permission to digitally index the entire corpus of the extant books still remains controversial. Jeanneney also predicted some dire consequences that have yet to come to pass. In time, though, the initially jarring presence of MDLs has given way to more reasoned acceptance. Some parties may now even see the benefit of these tools.
At the same time, MDLs are not limited merely to Google Books. Other massive digital libraries have been established that provide very different organizational philosophies and policies. HathiTrust, Internet Archive, Open Content Alliance, Europeana, and Gallica provide some of the same content, though on slightly smaller scales, but without the influence of shareholders and profiteering.
As for future impact, the answer is difficult to come by. First, it is difficult to pin down which problems will arise in the future and which current ones will either be resolved or worsen. The train may be coming, but it’s difficult to always know if and when it will cross our path. Many predictions have failed to occur, making prognosticators look foolish at best.
However, certain broad trends are obvious. The major impacts of the past twenty years are here to stay for the immediate and midrange future, including the rise of ubiquitous high-speed Internet, the development of mobile technology, and the development of open access web publishing as an alternative to traditional publishers. MDLs are no different in their potential for long-term impact on libraries.
The traditional library has always offered an array of typical services, including access to print books, for those just-in-case uses; access to online digital works behind paywalls; access to old and rare materials; provision of study spaces, and increasingly quiet and collaborative (though some would say loud) study areas; provision of interlibrary loan (ILL) materials; preservation of print and digital assets; and collection shaping to meet the needs of perceived immediate user groups, cohorts, and stakeholders.
This chapter looks at some of these traditional roles of libraries and offers some ideas on how, philosophically and practically, MDLs might influence them in positive and negative ways.
Access to Print Books
First and foremost, patrons primarily associate the library with access to print media, especially books, magazines, newspapers, and maps. In this regard MDLs may appear to have the greatest impact. MDLs have taken as their philosophies the digitization and provision of access to print books as they have traditionally been defined over the centuries: a bound collection of a single work or series of works in multiple volumes. Yet currently the models for MDLs have mostly been indiscriminate about their collection development, focusing purely on the traditional book model but in a digitally replicated form. Essentially, monographs, fiction, nonfiction, and the like, exist as facsimile copies with the added value of full-text searchability.
Yet other print materials associated with libraries are not well represented or approached by MDLs uniformly. Maps, atlases, newspapers, and magazines have all been underrepresented or ignored among the major MDLs. With the primacy of the monograph book in MDLs, much content remains outside their spheres of influence. A notable exception appears to be Google Books’ inclusion of Life magazine in its corpus. If a large amount of magazines were represented in the corpus, this might have an impact on libraries. Yet again, the number of possible magazines and the amount published over the past hundred years may prevent this.

Figure 4.1
Screenshot of a map in the Atlas of World History, by Patrick Karl O’Brien, as it appears in the Google Books viewer, showing insufficient image resolution for detailed examination.
Although some MDL projects, like the Spanish-language Virtual Library of Historical Newspapers, include newsprint, the sheer volume of these works may prevent MDLs from developing viable collections around them. As for atlases, image resolution and visibility currently impede the readability of oversize maps or atlases with maps printed across two pages. As book pages are rendered in the Google Books viewer as they are in print, some issues of pixelation can appear in maps. While text may be visible, the details in the image are not.
Figure 4.2
Detail of Atlas of World History, by Patrick Karl O’Brien, as it appears in the Google Books viewer, showing insufficient image resolution at high magnification.
In figures 4.1 and 4.2, taken from Google Books, for example, a map in the seventh edition of Essential World Atlas, pixelates under magnification and displays on its side. The page cannot be rotated and as a result is almost useless to a typical user. This shows the difficulty that mass digitization may have in presenting non-text-focused books. Additionally, the large sizes of atlases and their often irregular shapes—some can be square, for example—may slow down mass digitization projects.
In summary, better access to print works in MDLs is likely to remain limited to monographs for some time. The specialty print items like atlases that resist large-scale efficient digitization projects may require more care in digitization efforts. Ultimately, should there be an interest or need for it, libraries might consider working to digitize these works locally over time until the time is right for the federation of such large collections.
Access to Old and Rare Materials
Access to old and rare materials is likely the greatest positive benefit that MDLs might confer upon libraries and their users. People would surely be able to access materials that were hidden or protected from the general public. A great example of this is the Vatican Library’s attempt to digitize forty million pages of the nearly eighty-two thousand ancient manuscripts held in its collection. Although slightly smaller in scope than the largest MDLs, the project provides a glimpse into the future as a hybrid approach to creating a high-quality mass-digitized corpus that also treats the source material with great care.1
Other MDLs provide such an important service as well. In the end, the greatest benefits will likely come to those interested in public domain works, including pre-1923 materials in the United States. In particular, nineteenth-century works are likely to see a large increase in access for several reasons, including the large amount of material that was published as well as the relative dearth of its accessibility until now. While current subjects and contemporary historical events and knowledge are well represented in the digital era, subjects from the early nineteenth and twentieth centuries may have been ignored.
Furthermore, libraries are likely to see changes in the way patrons access special collections. There should be a drop in the amount of people coming to visit archives without a specific need in mind. Instead of patrons coming just to find information on a hunch, they will be able to have greater knowledge of a collection’s contents and will come seeking “other things” about the originals.
Patrons’ information needs will be related less to what is found printed on the pages and more on those things that are not captured by the digital image or that are not knowable without the viewing the physical structure of the original. This might include things such as the condition of the cover; the materials from which the original was made; and the notes or marginalia that might not appear on digital scans because of light, deterioration, mold, or tight bindings.
A great example of attempting to capture the extra material often lost in other digital collections is Melville’s Marginalia, a project developed at Boise State University.2 Most digital print collections focus on allowing access to the print, and for those merely interested in the print content, the digital version would provide much-needed access. However, by creating a collection with so-called marginalia, as seen in figure 4.3, the editors of this collection provide historical information that cannot easily be replicated digitally and needs to be examined up close. In this way, one can perhaps see the future of MDLs. If they provide multiple versions of a text online with the various notes of readers, the result might be like a “reconstructed” commentary, similar to what one finds on SoundCloud, where users provide comments and reactions to streamed audio recordings. It may be of use to historians if all such texts containing variant readings as well as marginalia and/or personal commentary were aggregated.
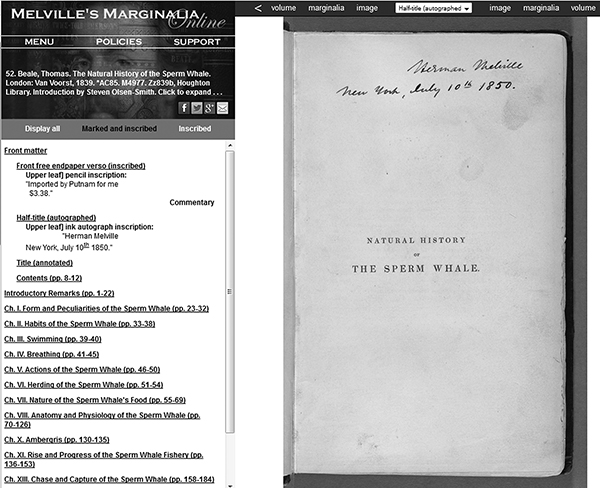
Figure 4.3
Image of Herman Melville’s copy of Natural History of the Sperm Whale from the website Melville’s Marginalia.
Study Spaces
MDLs would probably have only a minor effect on student study spaces. The digital world still does not have a direct impact on the design of physical library spaces at this time. The best way that libraries can anticipate the move toward all-digital collections is through the development of smart study rooms. Current library practice appears to be moving toward such collaborative study spaces. As a result there will be a need for such spaces.
Though this is not entirely the impact of MDLs, the major shift to near-universal online content will increase pressure for spaces that meet needs while also reducing space overall in the library. The first things to go will be the stacks, especially any remaining print journals and public domain books. Next, the wide-open and undeveloped study spaces will be claimed. Eventually, all real estate within the library will need to be justified, as nearly everything besides local print and historical special collections will be transferred to digital media.
Interlibrary Loan, Course Reserves, and Student Textbooks
Inter-library loan departments in libraries will be affected in positive ways by the development of MDLs. If more works are available online and in digital, full-text readable format, the need for sending books through the mail and for physical delivery systems will reduce workloads for such departments.
Course reserves would also benefit from the open content of MDLs. Faculty would be able to place works on course reserve by providing links to works in Google Books or HathiTrust, and so on. In similar ways, if full access to works were granted to member institutions of an MDL consortium, then more students would benefit from lower costs for certain works.
The new model of access derived from MDLs does not exclude publishers, who might still offer new versions of texts, either as born-digital creations or as new print materials. New editions of material will still be offered, and even as professors move to e-texts, publication opportunities still exist.
Collection Development: Shaping and Weeding
Although Chapters 6 and 7 focus more directly on collection development, it should be mentioned that MDLs could have an effect on libraries in terms of how they shape collections. MDLs’ provision of open access versions of a book will help libraries make better decisions about which books to keep or to throw away. In coordination with a consortium, libraries would be able to open up even more space for other types of uses within their traditional bricks-and-mortar structures. Remodeling the library to meet new needs and trends, such as learning commons and collaborative study rooms would be included.
Additionally, if works of major importance were somehow not part of the larger MDLs, the decision could be made by individual libraries at the local level to digitize and add the works to local institutional repositories, as well as to the major MDLs, such as Internet Archive, HathiTrust, and Google Books, as a contributor or even partner. Therefore, MDLs still have an important role to play in this aspect of librarianship. At the same time, local needs will remain of primary concern, and the decision to contribute works to MDLs will need to be weighed with local users in mind.
Consortium Opportunities and “Strength in Numbers”
Following the example of HathiTrust, it may be in many academic libraries’ best interest to band together to create their own mass-digitization projects. If several large institutions with specialized collections of materials—for example, the University of Hawaii’s Hawaiian and Pacific Collection—were to combine their holdings with those of other major institutions, a greater digital presence for these works would come to fruition. Although in this case the Pacific Rim Digital Library Alliance (http://prdla.org) currently fills this need somewhat, the scale is not nearly the same as it could be with an MDL. The benefits of such endeavors would be immense. Libraries would be able to function as indexers and holders of information that previous had been the realm of publishers. The benefit of a strengthened public domain and increased profiles for some more obscure or underrepresented subjects would accrue to users interested in these areas. Ultimately, the public good will only strengthen with increased availability of previously unknown or underutilized works.
Preservation and Quality of Digital and Print Assets
Preservation—More Than Meets the Eye
Thus far, MDLs have taken a fairly conservative approach to the acquisition of books. They ingest collections of existing libraries that are already carefully curated, aggregate them into one massive collection, and arrange that into a singular online package. However, libraries not only acquire and house items; they also preserve them for the long term. If MDLs are to have an impact beyond access, they will have to work to ensure digital preservation as a major policy, and libraries will need to be vigilant with preservation regardless of whether they are active partners with MDLs.
It is easy for those unfamiliar with digital preservation to assume that once something is scanned into a digital format and saved on a disk or hard drive that it is therefore in a state of preservation. However, this is far from the truth. Preservation, as most libraries with digitization initiatives can attest, involves a large and varied cycle of procedures and overarching, forward-looking policies that ensure long-term sustainability. Such procedures include the following:
• Bitstream copying, which is mainly data backup
• Refreshing (i.e. copying from one medium to another), using durable or persistent media (e.g., gold CDs)
• Implementing technology preservation, which involves saving the whole technological ecosystem (e.g., CD player, Beta-Max video)
• Utilizing digital archaeology, which involves emergency saving of formats by recovering bitstreams from unreadable files
• Creating analog backups (e.g., using silver halide microfilm)
• Performing migration
• Performing replication (e.g., making multiple copies, like LOCKSS)
• Relying on standards (e.g., standard digital file formats such as JPEG, TIFF, MOV, MPEG)
• Performing normalization, which is essentially following formalized implementations procedures for various standards
• Performing canonicalization, which determines whether the essential characteristics of a document have remained intact through conversion (an issue that arises in MDLs and the conversion of print books to e-books)
• Performing emulation, which reproduces essential aspects of another computer’s performance
• Performing encapsulation, the grouping of digital objects (e.g., files) with the metadata necessary for description and access3
Libraries currently considering the mass digitization of their collections, or joining any MDL projects such as HathiTrust or Google Books, would be wise to help create a digital preservation consortium based on the digitized works in their own right. Various options exist, including LOCKSS, MetaArchive, Glacier, and other cloud storage and digital preservation systems. LOCKSS focuses on preserving journals, but a similar approach might be used to tackle the long-term digital preservation of monographs.
Along with this procedural side, digital preservation also has a policy side. To ensure that the methods of digital preservation are followed correctly, policies need to be developed that address the needs of libraries and MDLs together. This will be important. Without them, even if the flesh is willing, so to speak, the spirit will be weak. Incentives and specific polices such as undergoing periodic audits in the vein of trusted digital repositories, or following such models as the Open Archival Information System (OAIS) will help ensure that things do not fall by the wayside or, as is often the case in for-profit endeavors, that corners are not cut for the sake of profitability.
Ultimately, for libraries and MDLs to fully work together, they will have to address funding sources and promises of long-term funding as well. Microsoft’s own short-lived mass-digitization project is a sobering example of how lack of true long-term commitment and policy making can destroy the work.
Quality: Sisyphus or Hercules? Tragic or Heroic?
Quality may seem like a tangential topic, but in reality it is central to the issue of preservation in ways that may not be immediately obvious. Quality has been to date the easiest entry into the study of MDLs, especially the Google Books project. Scholars have fretted over poorly scanned pages; erroneous metadata records; and poor OCR application of texts, especially for languages that do not use the Roman alphabet.
The issue raised, therefore, becomes one of futility or utility. Is it ultimately a tragic, Sisyphean task to digitize the entire corpus of print books, or is it a Herculean, heroic task to ensure the quality of items stored within MDLs? The answer to this essential question boils down to whether it is worthwhile to spend resources to preserve poor-quality scans of books for long periods of time.
At its most basic level, we can examine how well MDLs have converted text on the pages of codicils in new digital versions. As errors occur in everything human, some texts show evidence of poor scanning, unreadable pages, or files that have become corrupted. The issue of quality in MDLs encompasses the adequacy of the scanned book to accurately reflect the information on the printed page, as well as what represents the best version of the book.
One of the workarounds for this error rate is to digitize the same book multiple times. If the same edition of King Lear, for example, has been scanned by ten different libraries, the odds of its accuracy and long-term quality and viability are greatly improved. Given a random distribution of errors, among ten copies it would seem likely that a complete, readable authoritative version could be created, and that authoritative version would have a greater chance of being preserved. The problem, though, that arises with attempting to ensure quality through the multiple-text digitization approach is the cost and burden of creating redundancies, as well as the costs of formulating an authoritative version.
However, there is also the issue of “low-hanging fruit.” The best version of a book can change over time, but it is costly to scan multiple editions or multiple versions of the same book. In some cases, it is hard to see why Google or HathiTrust would necessarily scan another version of a book when the payoff may simply be better to scan a different title. Given the choice, it seems logical that an MDL would simply ingest an already-digitized book rather than spend the money to scan a different version of the same book.
Taking this idea to another level of abstraction, how does one rate the quality or value of items that fall outside the dominant culture? In an ideal world in which unlimited resources exist for all cultures, everything from high to low, old to new, canonized to apocryphal, would be preserved and not ranked against one another. But as the situation stands, resources remain limited, and it is not possible to preserve our cultures for the long run. Furthermore, quality becomes a cultural value, but quality as value doesn’t necessarily adhere to the needs of all cultures. The dominant cultures may not see quality in certain items, and as a result, those items are inevitably passed over in favor of other things.
In this light, the prospect of safeguarding the quality of digital output can be either a tragic endeavor in which the worst of both worlds destroys the best qualities of both the print and the digital, or it can be a heroic endeavor in which the best aspects remain at the forefront and preserved for the foreseeable future.
Metadata: The Needle in the Information Haystack
MDLs have grown out of the smaller digital collections and libraries that started in the 1990s. Yet the best of them, such as the HathiTrust and Europeana, still have to resolve issues related to the representation of monographs through simplified metadata schema. For decades the library staked its information technology reputation on the MARC record, which is perhaps one of the most detailed metadata schemes in existence, and controlled vocabularies (e.g., LCSH, MESH, AAT, TGN). The combination of these two things provided users with a high level of information accuracy but a low level of usability for patrons.
Yet the MDLs are now dealing with digital collections instead of print. In the case of the HathiTrust, this seems to be of little problem, as the project is based on the best practices of librarianship. HathiTrust’s handling of multivolume works is exemplary; it bundles multiple digital files in an easy-to-find manner. However, Google Books underperforms with multivolume works. It is often too difficult, for example, to find all volumes of a multivolume work or to retrieve them in a coherent manner. This comes down to metadata. If Google did not rely entirely on the full-text search and provided better methods for describing the data itself, it might not have this problem.
It is also important to note that not all MDLs operate under standardized definitions for all the metadata they employ, and some even generate more problems in aggregate than the source collections do. For example, Google Books routinely conflates the role of author, editor, and translation in the “author” metadata fields in its online records. This is serious malpractice from a librarian’s perspective, but it likely arrives from problems of crosswalking metadata sets and standards to Google’s in-house standards.
For the time being, then, robust human-created and human-readable metadata remains one of the great intangible “added values” of libraries that MDLs may have a hard time replacing without more rigorous standardization. It is hard at this point to imagine that the superior metadata of libraries could be replaced by inaccurate, dumbed-down systems, yet superior technologies have sometimes been replaced by inferior ones for the sake of expediency or profit.
Exploratory Methods, Exploratory Searching, and User Experience
This section discusses some of the basic tools librarians might use to explore and evaluate MDLs, including exploratory methods, searching, and applying both to an examination of user experience.
Exploratory Methods
Exploratory methods are used to develop a general impression of the massive digital library through more informal examinations of information. Specifically, content, scope, depth of subject matter, metadata quality, scan quality, OCR accuracy, and user experience can be explored to arrive at a more general understanding of MDLs. At this point, once the area of exploration is chosen, librarians can raise multiple questions, including the following:
• What am I looking at?
• What content is available?
• What are the functions of the software interface?
• How are the files organized?
• Are there subject headings and call numbers?
• What other metadata is available, and how accurate is it?
• Was the digital scan of the text also converted using OCR into another file format?
• Is the content accessible to patrons with disabilities?
• Is the available content relevant and useful to our patrons?
Exploratory methods can address these and many more questions. The goal is not necessarily to find a definitive quantitative answer in hard data, but to arrive at new knowledge that can be used in practical ways.
The primary benefit of exploratory methods is that they are relatively quick to implement. Examples include forecasting tools such as trend, impact and cross-impact analyses, and conventional Delphi methods. Such methods might be useful in comparing and contrasting the different MDLs. They usually do not require any expenditures. The information gained can be used to alter library policies and practices and to educate staff. The complexity of exploratory methods is generally low, and they require little preparation time or planning. For all of these reasons librarians can use exploratory methods, or these research tasks can be assigned to student assistants or paraprofessional staff.
It is, however, part of librarians’ so-called tradecraft to know where the system functions well at delivering information and where its shortcomings exist. The basic point, then, of exploratory methods is to reach a basic understanding of what MDL collections have to offer and how libraries might best use them to meet a given patron’s specific information needs.
Exploratory methods, however, do have a few limitations. For one, they cannot be used to answer research questions; they cannot reject, or fail to reject, null hypotheses (which is important, as science is about failure and rejection, not acceptance); they also cannot provide the data necessary for a detailed analysis of a research question. Whereas exploratory methods generate information, sometimes data is needed instead. This is where systematic methods become more important for gathering and analyzing data. However, this is outside the scope of this book.
Exploratory Searching
Unlike a traditional bricks-and-mortar library, it is not possible to wander the stacks of an MDL to gather a general sense of its collections. As a result, users and researchers must resort to other methods, such as exploratory searching. This term encompasses a wide range of activities, including keyword searching, metadata searching, subject-heading browsing, known-item searching, and general browsing.
Keyword Searching
Keyword searching (via taxonomies) can be done from a list of relevant words or from a random list of words. Creating a list of relevant words involves developing a basic taxonomy. Synonyms play a particularly important role in the process. For example, bunny, rabbit, and Lepidorae all refer to the same animal, but certain patron groups would prefer one term over another. A children’s book is unlikely to contain the term Lepidorae just as a scientific monograph is unlikely to contain the term bunny. The development of a taxonomic list would improve the exploratory search.
The constructed list of words can also be employed as a proxy, or estimate, for the types of terms typical patrons might use. A knowledge, then, of subject-specific terms, synonyms, and patron-preferred terms would be useful to help examine the effectiveness of the MDL. Noting the terms that proved irrelevant or that yielded poor search results can help librarians understand the problems that patrons in specific user groups will have with MDLs.
As an aside, random keyword searching can also be employed in MDL analysis, but it is more useful as a systematic method. Simple approaches include random-word generation, such as by flipping through the dictionary at random points and choosing the first word that appears.
Metadata Searching
Metadata searching is the process of limiting a search to one or more metadata fields, such as title, author, publisher, publication date, and so on. There is a wide variance in the numbers and types of metadata fields used by MDLs. A specific MDL might also collect certain metadata fields for some materials but not for others. Even within a specific MDL there is variation. Some books scanned by Google Books use BISAC subject headings, Dewey decimal classification subject headings, Library of Congress subject headings, or a combination of all three.
Searching can be done by known-item searching or by selecting relevant terms. Known-item searching allows one to check holdings with a list of predetermined items. The list could be generated by a librarian’s knowledge of a subject, or from bibliographies or literary canons. Searching for specific titles might help determine the appropriateness of a particular MDL for certain patron groups. It might also give insight into the coverage of rare but important materials.
Examining User Experience
Exploratory methods are well suited for helping approximate the challenges and obstacles users might confront when using an MDL. One of the best ways to explore the user interface is to conduct simple test searches. Some questions that arise at this stage include the following:
• How is the results list organized? Does it make sense?
• Is the MDL consistent in providing the same metadata fields for each book?
• Is it clear in the set results who the author is? The publisher? The publication date?
• Is it clear that the edition is the same as the one I’m looking for?
• Where do I click to access the book?
• Why can or can’t I access the book?
Such questions are important to ask in order to get at patrons’ specific needs when they are conducting a search. Users are often confused about the steps to take to access the information they want. The challenge for librarians and information science practitioners is to find out what users want to know and then see what problems untrained users face.
An additional issue to consider is how to serve patrons with disabilities. Certain software and hardware can be challenging for people with disabilities. Librarians are in unique positions to advocate for universal access to information. Seemingly small and insignificant features of a software program’s interface can be insurmountable barriers to some. As a result, testing the interfaces for compliance with the guidelines in section 508 of the Americans with Disabilities Act (ADA) is an important aspect of examining all software, but especially MDLs, which purport to be universal tools. Librarians interested in ADA compliance might consider running the pages of MDLs and their displayed content through various web accessibility tools, including the WAVE web accessibility tool, Fangs screen reader emulator, and University of Illinois at Urbana-Champaign’s Functional Accessibility Evaluator (http://fae.cita.uiuc.edu). Each of these tools provides analyses of the ADA compliance of web resources.4 Even if this seems difficult or time consuming, librarians do have a duty to point out to those managing MDLs that a universal library also needs to be universally accessible.
Conclusion
It is clear that all librarians will have a stake in MDLs at some point. However, just because large consortia and private enterprises are running the best-known MDLs, individual librarians still have a role in vetting them for not only their bricks-and-mortar libraries and digital collections but also for their very real, flesh-and-blood patrons. Libraries will benefit from the collection development and space creating impacts of online digital books. The opportunities for creating larger alliances will surely strengthen the overall viability and accessibility of their collections.
However, the world of information science research must begin to develop strategies for examining how well they actually serve patrons. To move wholesale to the digital world will be a disservice for some patrons, even as it serves a greater number of patrons. It will be essential to develop sound methods and policies for long-term digital preservation. It will also be important for librarians to perform various exploratory methods to look at how and when the MDLs can serve users and to develop criteria for when the traditional role of the library might actually remain—as in the case of metadata—far superior to its purported replacement.
Reference
Jeanneney, Jean-Noël. 2007. Google and the Myth of Universal Knowledge: A View from Europe. Chicago: University of Chicago Press. First published in French in 2005.
Notes
* Ryan James contributed to this chapter.
1. Lesley Taylor, “Digitizing History: 82,000-Manuscript Collection Vatican Library Goes Online,” Toronto Star, May 2, 2013, www.thestar.com/news/world/2013/05/02/digitizing_history_82000manuscript_collection_vatican_library_goes_online.html.
2. See the website Melville’s Marginalia, at http://melvillesmarginalia.org; and “History of the Sperm Whale,” http://melvillesmarginalia.org/tool.php?id=7&pageid=22.
3. “Digital Preservation Management,” Cornell University Library, 2007, www.dpworkshop.org/dpm-eng/terminology/strategies.html.
4. See the Fangs Screen Reader Emulator (http://sourceforge.net/projects/fangs/); WebAim’s Wave Web Accessibility Tool (http://wave.webaim.org/toolbar/); and University of Illinois at Urbana-Champaign’s Functional Accessibility Evaluator (http://fae.cita.uiuc.edu).