This chapter describes pipes and FIFOs. Pipes are the oldest method of IPC on the UNIX system, having appeared in Third Edition UNIX in the early 1970s. Pipes provide an elegant solution to a frequent requirement: having created two processes to run different programs (commands), how can the shell allow the output produced by one process to be used as the input to the other process? Pipes can be used to pass data between related processes (the meaning of related will become clear later). FIFOs are a variation on the pipe concept. The important difference is that FIFOs can be used for communication between any processes.
Every user of the shell is familiar with the use of pipes in commands such as the following, which counts the number of files in a directory:
$ ls | wc -lIn order to execute the above command, the shell creates two processes, executing ls and wc, respectively. (This is done using fork() and exec(), which are described in Chapter 24 and Chapter 27.) Figure 44-1 shows how the two processes employ the pipe.
Among other things, Figure 44-1 is intended to illustrate how pipes got their name. We can think of a pipe as a piece of plumbing that allows data to flow from one process to another.
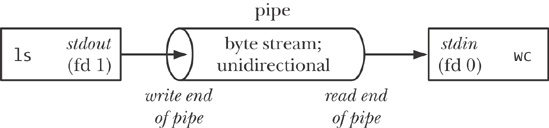
One point to note in Figure 44-1 is that the two processes are connected to the pipe so that the writing process (ls) has its standard output (file descriptor 1) joined to the write end of the pipe, while the reading process (wc) has its standard input (file descriptor 0) joined to the read end of the pipe. In effect, these two processes are unaware of the existence of the pipe; they just read from and write to the standard file descriptors. The shell must do some work in order to set things up in this way, and we see how this is done in Section 44.4.
In the following paragraphs, we cover a number of important characteristics of pipes.
When we say that a pipe is a byte stream, we mean that there is no concept of messages or message boundaries when using a pipe. The process reading from a pipe can read blocks of data of any size, regardless of the size of blocks written by the writing process. Furthermore, the data passes through the pipe sequentially—bytes are read from a pipe in exactly the order they were written. It is not possible to randomly access the data in a pipe using lseek().
If we want to implement the notion of discrete messages in a pipe, we must do this within our application. While this is feasible (refer to A Client-Server Application Using FIFOs), it may be preferable to use alternative IPC mechanisms, such as message queues and datagram sockets, which we discuss in later chapters.
Attempts to read from a pipe that is currently empty block until at least one byte has been written to the pipe. If the write end of a pipe is closed, then a process reading from the pipe will see end-of-file (i.e., read() returns 0) once it has read all remaining data in the pipe.
Data can travel only in one direction through a pipe. One end of the pipe is used for writing, and the other end is used for reading.
On some other UNIX implementations—notably those derived from System V Release 4—pipes are bidirectional (so-called stream pipes). Bidirectional pipes are not specified by any UNIX standards, so that, even on implementations where they are provided, it is best to avoid reliance on their semantics. As an alternative, we can use UNIX domain stream socket pairs (created using the socketpair() system call described in Creating a Connected Socket Pair: socketpair()), which provide a standardized bidirectional communication mechanism that is semantically equivalent to stream pipes.
If multiple processes are writing to a single pipe, then it is guaranteed that their data won’t be intermingled if they write no more than PIPE_BUF bytes at a time.
SUSv3 requires that PIPE_BUF be at least _POSIX_PIPE_BUF (512). An implementation should define PIPE_BUF (in <limits.h>) and/or allow the call fpathconf(fd, _PC_PIPE_BUF) to return the actual upper limit for atomic writes. PIPE_BUF varies across UNIX implementations; for example, it is 512 bytes on FreeBSD 6.0, 4096 bytes on Tru64 5.1, and 5120 bytes on Solaris 8. On Linux, PIPE_BUF has the value 4096.
When writing blocks of data larger than PIPE_BUF bytes to a pipe, the kernel may transfer the data in multiple smaller pieces, appending further data as the reader removes bytes from the pipe. (The write() call blocks until all of the data has been written to the pipe.) When there is only a single process writing to a pipe (the usual case), this doesn’t matter. However, if there are multiple writer processes, then writes of large blocks may be broken into segments of arbitrary size (which may be smaller than PIPE_BUF bytes) and interleaved with writes by other processes.
The PIPE_BUF limit affects exactly when data is transferred to the pipe. When writing up to PIPE_BUF bytes, write() will block if necessary until sufficient space is available in the pipe so that it can complete the operation atomically. When more than PIPE_BUF bytes are being written, write() transfers as much data as possible to fill the pipe, and then blocks until data has been removed from the pipe by some reading process. If such a blocked write() is interrupted by a signal handler, then the call unblocks and returns a count of the number of bytes successfully transferred, which will be less than was requested (a so-called partial write).
Note
On Linux 2.2, pipe writes of any size are atomic, unless interrupted by a signal handler. On Linux 2.4 and later, any write greater than PIPE_BUF bytes may be interleaved with writes by other processes. (The kernel code implementing pipes underwent substantial changes between kernel versions 2.2 and 2.4.)
A pipe is simply a buffer maintained in kernel memory. This buffer has a maximum capacity. Once a pipe is full, further writes to the pipe block until the reader removes some data from the pipe.
SUSv3 makes no requirement about the capacity of a pipe. In Linux kernels before 2.6.11, the pipe capacity is the same as the system page size (e.g., 4096 bytes on x86-32); since Linux 2.6.11, the pipe capacity is 65,536 bytes. Other UNIX implementations have different pipe capacities.
In general, an application never needs to know the exact capacity of a pipe. If we want to prevent the writer process(es) from blocking, the process(es) reading from the pipe should be designed to read data as soon as it is available.
Note
In theory, there is no reason why a pipe couldn’t operate with smaller capacities, even with a single-byte buffer. The reason for employing large buffer sizes is efficiency: each time a writer fills the pipe, the kernel must perform a context switch to allow the reader to be scheduled so that it can empty some data from the pipe. Employing a larger buffer size means that fewer context switches are required.
Starting with Linux 2.6.35, the capacity of a pipe can be modified. The Linux-specific call fcntl(fd, F_SETPIPE_SZ, size) changes the capacity of the pipe referred to by fd to be at least size bytes. An unprivileged process can change the pipe capacity to any value in the range from the system page size up to the value in /proc/sys/fs/pipe-max-size. The default value for pipe-max-size is 1,048,576 bytes. A privileged (CAP_SYS_RESOURCE) process can override this limit. When allocating space for the pipe, the kernel may round size up to some value convenient for the implementation. The fcntl(fd, F_GETPIPE_SZ) call returns the actual size allocated for the pipe.