Example 2.44
Sums of Independent Binomial Random Variables
If  and
and  are independent binomial random variables with parameters
are independent binomial random variables with parameters  and
and  , respectively, then what is the distribution of
, respectively, then what is the distribution of  ?
?
Solution: The moment generating function of  is given by
is given by

But  is just the moment generating function of a binomial random variable having parameters
is just the moment generating function of a binomial random variable having parameters  and
and 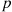 . Thus, this must be the distribution of
. Thus, this must be the distribution of  . ■
. ■
Example 2.45
Sums of Independent Poisson Random Variables
Calculate the distribution of  when
when 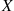 and
and  are independent Poisson random variables with means
are independent Poisson random variables with means  and
and  , respectively.
, respectively.

Hence,  is Poisson distributed with mean
is Poisson distributed with mean 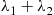 , verifying the result given in Example 2.37. ■
, verifying the result given in Example 2.37. ■
Example 2.46
Sums of Independent Normal Random Variables
Show that if 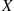 and
and  are independent normal random variables with parameters
are independent normal random variables with parameters  and
and 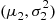 , respectively, then
, respectively, then  is normal with mean
is normal with mean  and variance
and variance  .
.
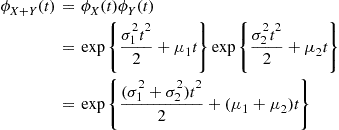
which is the moment generating function of a normal random variable with mean 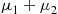 and variance
and variance  . Hence, the result follows since the moment generating function uniquely determines the distribution. ■
. Hence, the result follows since the moment generating function uniquely determines the distribution. ■
Example 2.47
The Poisson Paradigm
We showed in Section 2.2.4 that the number of successes that occur in  independent trials, each of which results in a success with probability
independent trials, each of which results in a success with probability 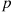 is, when
is, when 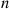 is large and
is large and 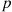 small, approximately a Poisson random variable with parameter
small, approximately a Poisson random variable with parameter 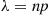 . This result, however, can be substantially strengthened. First it is not necessary that the trials have the same success probability, only that all the success probabilities are small. To see that this is the case, suppose that the trials are independent, with trial
. This result, however, can be substantially strengthened. First it is not necessary that the trials have the same success probability, only that all the success probabilities are small. To see that this is the case, suppose that the trials are independent, with trial 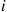 resulting in a success with probability
resulting in a success with probability 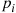 , where all the
, where all the 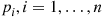 are small. Letting
are small. Letting 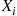 equal 1 if trial
equal 1 if trial 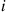 is a success, and 0 otherwise, it follows that the number of successes, call it
is a success, and 0 otherwise, it follows that the number of successes, call it  , can be expressed as
, can be expressed as

Using that 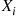 is a Bernoulli (or binary) random variable, its moment generating function is
is a Bernoulli (or binary) random variable, its moment generating function is
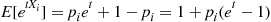
Now, using the result that, for  small,
small,
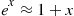
it follows, because  is small when
is small when  is small, that
is small, that
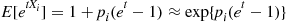
Because the moment generating function of a sum of independent random variables is the product of their moment generating functions, the preceding implies that

But the right side of the preceding is the moment generating function of a Poisson random variable with mean 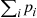 , thus arguing that this is approximately the distribution of
, thus arguing that this is approximately the distribution of 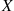 .
.
Not only is it not necessary for the trials to have the same success probability for the number of successes to approximately have a Poisson distribution, they need not even be independent, provided that their dependence is weak. For instance, recall the matching problem (Example 2.31) where 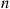 people randomly select hats from a set consisting of one hat from each person. By regarding the random selections of hats as constituting
people randomly select hats from a set consisting of one hat from each person. By regarding the random selections of hats as constituting  trials, where we say that trial
trials, where we say that trial  is a success if person
is a success if person  chooses his or her own hat, it follows that, with
chooses his or her own hat, it follows that, with  being the event that trial
being the event that trial 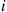 is a success,
is a success,
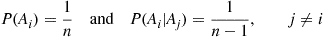
Hence, whereas the trials are not independent, their dependence appears, for large  , to be weak. Because of this weak dependence, and the small trial success probabilities, it would seem that the number of matches should approximately have a Poisson distribution with mean 1 when
, to be weak. Because of this weak dependence, and the small trial success probabilities, it would seem that the number of matches should approximately have a Poisson distribution with mean 1 when  is large, and this is shown to be the case in Example 3.23.
is large, and this is shown to be the case in Example 3.23.
The statement that “the number of successes in  trials that are either independent or at most weakly dependent is, when the trial success probabilities are all small, approximately a Poisson random variable” is known as the Poisson paradigm. ■
trials that are either independent or at most weakly dependent is, when the trial success probabilities are all small, approximately a Poisson random variable” is known as the Poisson paradigm. ■
Remark
For a nonnegative random variable  , it is often convenient to define its Laplace transform
, it is often convenient to define its Laplace transform 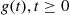 , by
, by
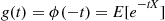
That is, the Laplace transform evaluated at 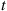 is just the moment generating function evaluated at
is just the moment generating function evaluated at  . The advantage of dealing with the Laplace transform, rather than the moment generating function, when the random variable is nonnegative is that if
. The advantage of dealing with the Laplace transform, rather than the moment generating function, when the random variable is nonnegative is that if  and
and 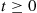 , then
, then
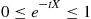
That is, the Laplace transform is always between 0 and 1. As in the case of moment generating functions, it remains true that nonnegative random variables that have the same Laplace transform must also have the same distribution. ■
It is also possible to define the joint moment generating function of two or more random variables. This is done as follows. For any  random variables
random variables  , the joint moment generating function,
, the joint moment generating function,  , is defined for all real values of
, is defined for all real values of  by
by

It can be shown that  uniquely determines the joint distribution of
uniquely determines the joint distribution of  .
.
Example 2.48
The Multivariate Normal Distribution
Let  be a set of
be a set of  independent standard normal random variables. If, for some constants
independent standard normal random variables. If, for some constants  ,
,  , and
, and  ,
,
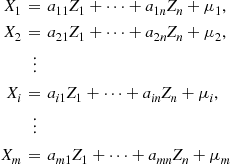
then the random variables  are said to have a multivariate normal distribution.
are said to have a multivariate normal distribution.
It follows from the fact that the sum of independent normal random variables is itself a normal random variable that each 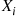 is a normal random variable with mean and variance given by
is a normal random variable with mean and variance given by
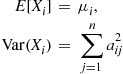
Let us now determine

the joint moment generating function of  . The first thing to note is that since
. The first thing to note is that since  is itself a linear combination of the independent normal random variables
is itself a linear combination of the independent normal random variables  , it is also normally distributed. Its mean and variance are respectively
, it is also normally distributed. Its mean and variance are respectively
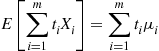
and

Now, if 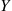 is a normal random variable with mean
is a normal random variable with mean  and variance
and variance 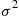 , then
, then

Thus, we see that

which shows that the joint distribution of  is completely determined from a knowledge of the values of
is completely determined from a knowledge of the values of 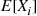 and Cov(
and Cov( ),
),  . ■
. ■
2.6.1 The Joint Distribution of the Sample Mean and Sample Variance from a Normal Population
Let  be independent and identically distributed random variables, each with mean
be independent and identically distributed random variables, each with mean  and variance
and variance 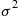 . The random variable
. The random variable 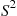 defined by
defined by
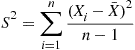
is called the sample variance of these data. To compute 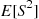 we use the identity
we use the identity
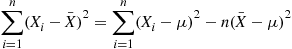 (2.21)
(2.21)which is proven as follows:

and Identity (2.21) follows.
Using Identity (2.21) gives

Thus, we obtain from the preceding that
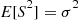
We will now determine the joint distribution of the sample mean  and the sample variance
and the sample variance 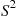 when the
when the 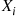 have a normal distribution. To begin we need the concept of a chi-squared random variable.
have a normal distribution. To begin we need the concept of a chi-squared random variable.
Definition 2.2
If  are independent standard normal random variables, then the random variable
are independent standard normal random variables, then the random variable 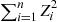 is said to be a chi-squared random variable with
is said to be a chi-squared random variable with 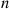 degrees of freedom.
degrees of freedom.
We shall now compute the moment generating function of 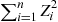 . To begin, note that
. To begin, note that

Hence,

Now, let  be independent normal random variables, each with mean
be independent normal random variables, each with mean  and variance
and variance 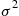 , and let
, and let  and
and  denote their sample mean and sample variance. Since the sum of independent normal random variables is also a normal random variable, it follows that
denote their sample mean and sample variance. Since the sum of independent normal random variables is also a normal random variable, it follows that 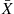 is a normal random variable with expected value
is a normal random variable with expected value  and variance
and variance  . In addition, from Proposition 2.4,
. In addition, from Proposition 2.4,
 (2.22)
(2.22)Also, since 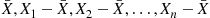 are all linear combinations of the independent standard normal random variables
are all linear combinations of the independent standard normal random variables 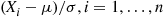 , it follows that the random variables
, it follows that the random variables  have a joint distribution that is multivariate normal. However, if we let
have a joint distribution that is multivariate normal. However, if we let  be a normal random variable with mean
be a normal random variable with mean 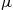 and variance
and variance  that is independent of
that is independent of  , then the random variables
, then the random variables 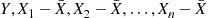 also have a multivariate normal distribution, and by Equation (2.22), they have the same expected values and covariances as the random variables
also have a multivariate normal distribution, and by Equation (2.22), they have the same expected values and covariances as the random variables 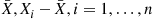 . Thus, since a multivariate normal distribution is completely determined by its expected values and covariances, we can conclude that the random vectors
. Thus, since a multivariate normal distribution is completely determined by its expected values and covariances, we can conclude that the random vectors 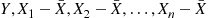 and
and  have the same joint distribution; thus showing that
have the same joint distribution; thus showing that 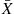 is independent of the sequence of deviations
is independent of the sequence of deviations  ,
, 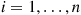 .
.
Since 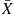 is independent of the sequence of deviations
is independent of the sequence of deviations 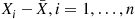 , it follows that it is also independent of the sample variance
, it follows that it is also independent of the sample variance
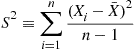
To determine the distribution of 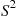 , use Identity (2.21) to obtain
, use Identity (2.21) to obtain

Dividing both sides of this equation by  yields
yields
 (2.23)
(2.23)Now,  is the sum of the squares of
is the sum of the squares of 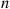 independent standard normal random variables, and so is a chi-squared random variable with
independent standard normal random variables, and so is a chi-squared random variable with 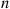 degrees of freedom; it thus has moment generating function
degrees of freedom; it thus has moment generating function  . Also
. Also  is the square of a standard normal random variable and so is a chi-squared random variable with one degree of freedom; it thus has moment generating function
is the square of a standard normal random variable and so is a chi-squared random variable with one degree of freedom; it thus has moment generating function  . In addition, we have previously seen that the two random variables on the left side of Equation (2.23) are independent. Therefore, because the moment generating function of the sum of independent random variables is equal to the product of their individual moment generating functions, we obtain that
. In addition, we have previously seen that the two random variables on the left side of Equation (2.23) are independent. Therefore, because the moment generating function of the sum of independent random variables is equal to the product of their individual moment generating functions, we obtain that

or
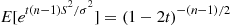
But because 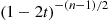 is the moment generating function of a chi-squared random variable with
is the moment generating function of a chi-squared random variable with  degrees of freedom, we can conclude, since the moment generating function uniquely determines the distribution of the random variable, that this is the distribution of
degrees of freedom, we can conclude, since the moment generating function uniquely determines the distribution of the random variable, that this is the distribution of 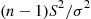 .
.
Summing up, we have shown the following.
Proposition 2.5
If  are independent and identically distributed normal random variables with mean
are independent and identically distributed normal random variables with mean  and variance
and variance  , then the sample mean
, then the sample mean 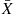 and the sample variance
and the sample variance  are independent.
are independent. 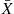 is a normal random variable with mean
is a normal random variable with mean 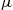 and variance
and variance  is a chi-squared random variable with
is a chi-squared random variable with 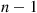 degrees of freedom.
degrees of freedom.
2.7 The Distribution of the Number of Events that Occur
Consider arbitrary events  , and let
, and let  denote the number of these events that occur. We will determine the probability mass function of
denote the number of these events that occur. We will determine the probability mass function of  . To begin, for
. To begin, for 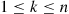 , let
, let
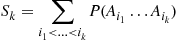
equal the sum of the probabilities of all the  intersections of
intersections of 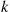 distinct events, and note that the inclusion-exclusion identity states that
distinct events, and note that the inclusion-exclusion identity states that
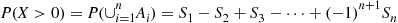
Now, fix  of the
of the 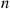 events — say
events — say  — and let
— and let

be the event that all  of these events occur. Also, let
of these events occur. Also, let

be the event that none of the other  events occur. Consequently,
events occur. Consequently, 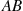 is the event that
is the event that  are the only events to occur. Because
are the only events to occur. Because

we have

or, equivalently,
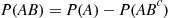
Because  occurs if at least one of the events
occurs if at least one of the events 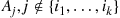 , occur, we see that
, occur, we see that
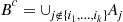
Thus,
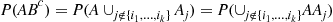
Applying the inclusion-exclusion identity gives

Using that 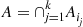 , the preceding shows that the probability that the
, the preceding shows that the probability that the  events
events  are the only events to occur is
are the only events to occur is
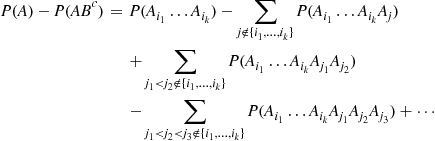
Summing the preceding over all sets of 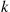 distinct indices yields
distinct indices yields
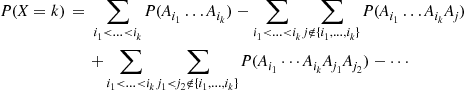 (2.24)
(2.24)First, note that

Now, consider

The probability of every intersection of  distinct events
distinct events 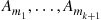 will appear
will appear 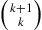 times in this multiple summation. This is so because each choice of
times in this multiple summation. This is so because each choice of 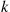 of its indices to play the role of
of its indices to play the role of  and the other to play the role of
and the other to play the role of 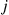 results in the addition of the term
results in the addition of the term  . Hence,
. Hence,

Similarly, because the probability of every intersection of  distinct events
distinct events  will appear
will appear  times in
times in 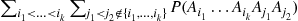 , it follows that
, it follows that

Repeating this argument for the rest of the multiple summations in (2.24) yields the result
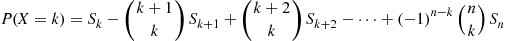
The preceding can be written as

Using this we will now prove that

The proof uses a backwards mathematical induction that starts with  . Now, when
. Now, when 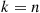 the preceding identity states that
the preceding identity states that

which is true. So assume that
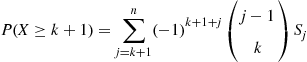
But then

which completes the proof.
2.8 Limit Theorems
We start this section by proving a result known as Markov’s inequality.
Proposition 2.6
Markov’s Inequality
If  is a random variable that takes only nonnegative values, then for any value
is a random variable that takes only nonnegative values, then for any value 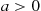

Proof
We give a proof for the case where 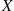 is continuous with density
is continuous with density  .
.

and the result is proven.
As a corollary, we obtain the following.
Proposition 2.7
Chebyshev’s Inequality
If  is a random variable with mean
is a random variable with mean  and variance
and variance  , then, for any value
, then, for any value  ,
,

Proof
Since 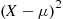 is a nonnegative random variable, we can apply Markov’s inequality (with
is a nonnegative random variable, we can apply Markov’s inequality (with  ) to obtain
) to obtain

But since  if and only if
if and only if 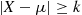 , the preceding is equivalent to
, the preceding is equivalent to

and the proof is complete.
The importance of Markov’s and Chebyshev’s inequalities is that they enable us to derive bounds on probabilities when only the mean, or both the mean and the variance, of the probability distribution are known. Of course, if the actual distribution were known, then the desired probabilities could be exactly computed, and we would not need to resort to bounds.
Solution: Let  be the number of items that will be produced in a week.
be the number of items that will be produced in a week.
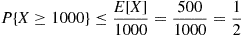
(b) By Chebyshev’s inequality,

Hence,
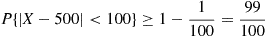
and so the probability that this week’s production will be between 400 and 600 is at least 0.99. ■
The following theorem, known as the strong law of large numbers, is probably the most well-known result in probability theory. It states that the average of a sequence of independent random variables having the same distribution will, with probability 1, converge to the mean of that distribution.
Theorem 2.1
Strong Law of Large Numbers
Let 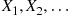 be a sequence of independent random variables having a common distribution, and let
be a sequence of independent random variables having a common distribution, and let  . Then, with probability 1,
. Then, with probability 1,