
Getting tests in place to make changes can be a bit of a problem. If you can instantiate your class separately in a test harness, consider yourself lucky. Many people can’t. If you’re having trouble, take a look at Chapter 9, I Can’t Get This Class into a Test Harness.
Instantiating a class is often only the first part of the battle. The second part is writing tests for the methods we need to change. Sometimes we can do this without instantiating the class at all. If the method doesn’t use much instance data, we can use Expose Static Method (345) to get access to the code. If the method is pretty long and difficult to deal with, we can use Break Out Method Object (330) to move the code to a class that we can instantiate more easily.
Fortunately, in most cases, the amount of work that we have to do to write tests for methods isn’t as drastic. Here are some of the problems that we can run into.
• The method might not be accessible to the test. It could be private or have some other accessibility problem.
• It might be hard to call the method because it is hard to construct the parameters we need to call it.
• The method might have bad side effects (modifying a database, launching a cruise missile, and so on), so it is impossible to run in a test harness.
• We might need to sense through some object that the method uses.
The rest of this chapter contains a set of scenarios that show different ways of getting past them and some of the trade-offs involved.
We need to make a change to a method in a class, but it’s a private method. What should we do?
The first question to ask is whether we can test through a public method. If we can, it is a worthwhile thing to do. It saves us the trouble of trying to find a way of accessing the private method, and it has another benefit. If we test through public methods, we are guaranteed to be testing the method as it is used in the code. This can help us constrain our work a bit. In legacy code, there are often methods of very dubious quality lying around in classes. The amount of refactoring we’d have to do to make a private method useful for all callers might be rather large. Although it’s nice to have very general methods that are useful to many callers, the fact is that each method has to be just functional enough to support the callers that use it and clear enough to understand and change easily. If we test a private method through the public methods that use it, there isn’t much danger of making it too general. If the method needs to become public someday, the first user outside of the class should write test cases that explain exactly what the method does and how a caller can use it correctly.
All that is fine, but in some cases, we just want to write a test case for a private method, a method whose call is buried deep in a class. We want concrete feedback and tests that explain how it is used—or, who knows, maybe it is just a pain to test it through the public methods on the class.
So, how do we write a test for a private method? This has to be one of the most common testing-related questions. Fortunately, there is a very direct answer for this question: If we need to test a private method, we should make it public. If making it public bothers us, in most cases, it means that our class is doing too much and we ought to fix it. Let’s look at the cases. Why would making a private method public bother us? Here are some reasons:
1. The method is just a utility; it isn’t something clients would care about.
2. If clients use the method, they could adversely affect results from other methods on the class.
The first reason isn’t very severe. An extra public method in a class’s interface is forgivable, although we should try to figure out whether it would be better to put the method on another class. The second reason is a bit more serious, but fortunately there is a remedy: The private methods can be moved to a new class. They can be public on that class and our class can create an internal instance of it. That makes the methods testable and the design better.
Yes, I know this advice sounds strident, but it has some very positive effects. The fact remains: Good design is testable, and design that isn’t testable is bad. The answer in cases like this is to start using the techniques in Chapter 20, This Class Is Too Big and I Don’t Want It to Get Any Bigger. However, when there aren’t many tests in place, we might have to move carefully and do some other work until we can break things down.
Let’s see how to get past this problem in a realistic case. Here is part of a class declaration in C++:
class CCAImage
{
private:
void setSnapRegion(int x, int y, int dx, int dy);
...
public:
void snap();
...
};
The CCAImage class is used to take pictures in a security system. You might wonder why an image class is snapping pictures, but this is legacy code, remember? The class has a snap() method that uses a low-level C API to control a camera and “take” the picture, but this is a very special kind of image. A single call to snap() can result in a couple of different camera actions, each of which takes a picture and places it on a different part of an image buffer held in the class. The logic used to decide where to place each picture is dynamic. It depends on the motion of the subject, the thing we are taking a picture of. Depending upon how the subject moves, the snap() method can make several repeated calls to setSnapRegion to determine where the current picture will be placed on the buffer. Unfortunately, the API for the camera has changed, so we need to make a change to setSnapRegion. What should we do?
One thing that we could do is just make it public. Unfortunately, that could have some very negative consequences. The CCAImage class holds on to some variables that determine the current location of the snap region. If someone starts to call setSnapRegion in production code outside of the snap() method, it could cause serious trouble with the camera’s tracking system.
Well, that is the problem. Before we look into some solutions, let’s talk about how we got into this mess. The real reason we can’t test the image class well is that it has too many responsibilities. Ideally, it would be great to break it down into smaller classes using the techniques described in Chapter 20, but we have to carefully consider whether we want to do that much refactoring right now. It would be great to do it, but whether we can depends on where we are in our release cycle, how much time we have, and all the associated risks.
If we can’t afford to separate the responsibilities right now, can we still write tests for the method that we are changing? Fortunately, yes. Here’s how we can do it.
The first step is to change setSnapRegion from private to protected.
class CCAImage
{
protected:
void setSnapRegion(int x, int y, int dx, int dy);
...
public:
void snap();
...
};
Next, we can subclass CCAImage to get access to that method:
class TestingCCAImage : public CCAImage
{
public:
void setSnapRegion(int x, int y, int dx, int dy)
{
// call the setSnapRegion of the superclass
CCAImage::setSnapRegion(x, y, dx, dy);
}
};
After we’ve done this, we can call setSnapRegion on CCAImage in a test, albeit indirectly. But is this a good idea? Earlier, we didn’t want to make the method public, but we are doing something similar. We’re making it protected and making the method more accessible.
Frankly, I don’t mind doing this. For me, getting the tests in place is a fair trade. Yes, this change does let us violate encapsulation. When we are reasoning about how the code works, we do have to consider that setSnapRegion can be called in subclasses now, but that is relatively minor. Maybe that little piece will be enough to trigger us to do the full refactoring the next time we touch the class. We can separate the responsibilities in CCAImage into different classes and make them testable.
Language designers often try to make our lives easier, but they have a tough job. They have to balance ease of programming against security concerns and safety. Some features initially look like a clear “win” balancing all of these concerns well, but when we attempt to test code that uses them, we discover the cruel reality.
Here is a piece of C# code that accepts a collection of uploaded files from a web client. The code iterates through each of them and returns a list of streams associated with files that have particular characteristics.
public void IList getKSRStreams(HttpFileCollection files) {
ArrayList list = new ArrayList();
foreach(string name in files) {
HttpPostedFile file = files[name];
if (file.FileName.EndsWith(".ksr") ||
(file.FileName.EndsWith(".txt")
&& file.ContentLength > MIN_LEN)) {
...
list.Add(file.InputStream);
}
}
return list;
}
We’d like to make some changes to this piece of code and maybe refactor it a little, but writing tests is going to be difficult. We’d like to create an HttpFileCollection object and populate it with HttpPostedFile objects, but that is impossible. First of all, the HttpPostedFile class doesn’t have a public constructor. Second, the class is sealed. In C#, this means that we can’t create an instance of an HttpPostedFile, and we can’t subclass it. HttpPostedFile is part of the .NET library. At runtime, some other class creates instances of this class, but we don’t have access to it. A quick look at the HttpFileCollection class shows us that it has the same problems: no public constructors and no way to created derived classes.
Why did Bill Gates do this to us? After all, we’ve kept our licenses up-to-date and everything. I don’t think he hates us. But if he does, well, maybe Scott McNealy does, too, because it’s not just an issue with Microsoft’s languages. Sun has a parallel syntax for preventing subclassing. They use the keyword final in Java to mark classes that are particularly sensitive when it comes to security. If just anyone could create a subclass of HttpPostedFile or even a class such as String, they could write some malicious code and pass it around in code that uses those classes. It’s a very real danger, but sealed and final are pretty drastic tools; they leave us in a bind here.
What can we do to write tests for the getKSRStreams method? We can’t use Extract Interface (362) or Extract Implementer (356); the HttpPostedFile and HttpFileCollection classes aren’t under our control, they are library classes and we can’t change them. The only technique that we can use here is Adapt Parameter (326).
We’re lucky, in this case, because the only thing that we do to the collection is iterate over it. Fortunately, the sealed HttpFileCollection class that our code uses has an unsealed superclass named NameObjectCollectionBase. We can subclass it and pass an object of that subclass to the getKSRStreams method. The change is safe and easy if we Lean on the Compiler (315).
public void LList getKSRStreams(OurHttpFileCollection files) {
ArrayList list = new ArrayList();
foreach(string name in files) {
HttpPostedFile file = files[name];
if (file.FileName.EndsWith(".ksr") ||
(file.FileName.EndsWith(".txt")
&& file.ContentLength > MAX_LEN)) {
...
list.Add(file.InputStream);
}
}
return list;
}
OurHttpFileCollection is a subclass of NameObjectCollectionBase and NameObjectCollectionBase is an abstract class that associates strings with objects.
That gets us past one problem. The next problem is tougher. We need HttpPostedFiles to run getKSRStreams in a test, but we can’t create them. What do we need from them? It looks like we need a class that provides a couple of properties: FileName and ContentLength. We can use Skin and Wrap the API (205) to get some separation between us and HttpPostedFile class. To do that, we extract an interface (IHttpPostedFile) and write a wrapper (HttpPostedFileWrapper):
public class HttpPostedFileWrapper : IHttpPostedFile
{
public HttpPostedFileWrapper(HttpPostedFile file) {
this.file = file;
}
public int ContentLength {
get { return file.ContentLength; }
}
...
}
Because we have an interface, we can also create a class for testing:
public class FakeHttpPostedFile : IHttpPostedFile
{
public FakeHttpPostedFile(int length, Stream stream, ...) { ... }
public int ContentLength {
get { return length; }
}
}
Now, if we Lean on the Compiler (315) and change our production code, we can use HttpPostedFileWrapper objects or FakeHttpPostedFile objects through the IHttpPostedFile interface without knowing which is being used.
public IList getKSRStreams(OurHttpFileCollection) {
ArrayList list = new ArrayList();
foreach(string name in files) {
IHttpPostedFile file = files[name];
if (file.FileName.EndsWith(".ksr") ||
(file.FileName.EndsWith(".txt"))
&& file.ContentLength > MAX_LEN)) {
...
list.Add(file.InputStream);
}
}
return list;
}
The only annoyance is that we have to iterate the original HttpFileCollection in the production code, wrap each HttpPostedFile that it contains, and then add it to a new collection that we pass to the getKSRStreams method. That’s the price of security.
Seriously, it is easy to believe that sealed and final are a wrong-headed mistake, that they should never have been added to programming languages. But the real fault lies with us. When we depend directly on libraries that are out of our control, we are just asking for trouble.
Some day, mainstream programming languages might provide special access permissions for tests, but in the meantime, it is good to use mechanisms such as sealed and final sparingly. And when we need to use library classes that use them, it’s a good idea to isolate them behind some wrapper so that we have some wiggle room when we make our changes. See Chapter 14, Dependencies on Libraries Are Killing Me, and Chapter 15, My Application Is All API Calls, for more discussion and techniques that address this problem.
In theory, writing a test for a piece of functionality shouldn’t be too bad. We instantiate a class, call its methods, and check their results. What could go wrong? Well, it can be that easy if the object we create doesn’t communicate with any other objects. If other objects use it and it doesn’t use anything else, our tests can use it also and act just like the rest of our program would. But objects that don’t use other objects are rare.
Programs build on themselves. Often we have objects with methods that don’t return values. We call their methods, and they do some work, but we (the calling code) never get to know about it. The object calls methods on other objects, and we never have a clue how things turned out.
Here is a class with this problem:
public class AccountDetailFrame extends Frame
implements ActionListener, WindowListener
{
private TextField display = new TextField(10);
...
public AccountDetailFrame(...) { ... }
public void actionPerformed(ActionEvent event) {
String source = (String)event.getActionCommand();
if (source.equals("project activity")) {
detailDisplay = new DetailFrame();
detailDisplay.setDescription(
getDetailText() + " " + getProjectionText());
detailDisplay.show();
String accountDescription
= detailDisplay.getAccountSymbol();
accountDescription += ": ";
...
display.setText(accountDescription);
...
}
}
...
}
This old class in Java does it all. It creates GUI components, it receives notifications from them using its actionPerformed handler, and it calculates what it needs to display and displays it. It does all of this in a particularly strange way: It builds up detailed text and then creates and displays another window. When the window is done with its work, it grabs information from it directly, processes it a bit, and then sets it onto one of its own text fields.
We could try running this method in a test harness, but it would be pointless. It would create a window, show it to us, prompt us for input, and then go on to display something in another window. There is no decent place to sense what this code does.
What can we do? First, we can start to separate work that is independent of the GUI from work that is really dependent on the GUI. Because we are working in Java, we can take advantage of one of the available refactoring tools. Our first step is to perform a set of Extract Method (415) refactorings to divide up the work in this method.
Where should we start?
The method itself is primarily a hook for notifications from the windowing framework. The first thing it does is get the name of a command from the action event that is passed to it. If we extract the whole body of the method, we can separate ourselves from any dependency on the ActionEvent class.
public class AccountDetailFrame extends Frame
implements ActionListener, WindowListener
{
private TextField display = new TextField(10);
...
public AccountDetailFrame(...) { ... }
public void actionPerformed(ActionEvent event) {
String source = (String)event.getActionCommand();
performCommand(source);
}
public void performCommand(String source) {
if (source.equals("project activity")) {
detailDisplay = new DetailFrame();
detailDisplay.setDescription(
getDetailText() + " " + getProjectionText());
detailDisplay.show();
String accountDescription
= detailDisplay.getAccountSymbol();
accountDescription += ": ";
...
display.setText(accountDescription);
...
}
}
...
}
But that isn’t enough to make the code testable. The next step is to extract methods for the code that accesses the other frame. It will help to make the detailDisplay frame an instance variable of the class.
public class AccountDetailFrame extends Frame
implements ActionListener, WindowListener
{
private TextField display = new TextField(10);
private DetailFrame detailDisplay;
...
public AccountDetailFrame(...) { .. }
public void actionPerformed(ActionEvent event) {
String source = (String)event.getActionCommand();
performCommand(source);
}
public void performCommand(String source) {
if (source.equals("project activity")) {
detailDisplay = new DetailFrame();
detailDisplay.setDescription(
getDetailText() + " " + getProjectionText());
detailDisplay.show();
String accountDescription
= detailDisplay.getAccountSymbol();
accountDescription += ": ";
...
display.setText(accountDescription);
...
}
}
...
}
Now we can extract the code that uses that frame into a set of methods. What should we name the methods? To get ideas for names, we should take a look at what each piece of code does from the perspective of this class, or what it calculates for this class. In addition, we should not use names that deal with the display components. We can use display components in the code that we extract, but the names should hide that fact. With these things in mind, we can create either a command method or a query method for each chunk of code.
Here’s what the performCommand method looks like after a series of extractions:
public class AccountDetailFrame extends Frame
implements ActionListener, WindowListener
{
public void performCommand(String source) {
if (source.equals("project activity")) {
setDescription(getDetailText() + " " + getProjectionText());
...
String accountDescription = getAccountSymbol();
accountDescription += ": ";
...
display.setText(accountDescription);
...
}
}
void setDescription(String description) {
detailDisplay = new DetailFrame();
detailDisplay.setDescription(description);
detailDisplay.show();
}
String getAccountSymbol() {
return detailDisplay.getAccountSymbol();
}
...
}
Now that we’ve extracted all of the code that deals with the detailDisplay frame, we can go through and extract the code that accesses components on the AccountDetailFrame.
public class AccountDetailFrame extends Frame
implements ActionListener, WindowListener {
public void performCommand(String source) {
if (source.equals("project activity")) {
setDescription(getDetailText() + " " + getProjectionText());
...
String accountDescription
= detailDisplay.getAccountSymbol();
accountDescription += ": ";
...
setDisplayText(accountDescription);
...
}
}
void setDescription(String description) {
detailDisplay = new DetailFrame();
detailDisplay.setDescription(description);
detailDisplay.show();
}
String getAccountSymbol() {
return detailDisplay.getAccountSymbol();
}
void setDisplayText(String description) {
display.setText(description);
}
...
}
After those extractions, we can Subclass and Override Method (401) and test whatever code is left in the performCommand method. For example, if we subclass AccountDetailFrame like this, we can verify that given the "project activity" command, the display gets the proper text:
public class TestingAccountDetailFrame extends AccountDetailFrame
{
String displayText = "";
String accountSymbol = "";
void setDescription(String description) {
}
String getAccountSymbol() {
return accountSymbol;
}
void setDisplayText(String text) {
displayText = text;
}
}
Here is a test that exercises the performCommand method:
public void testPerformCommand() {
TestingAccountDetailFrame frame = new TestingAccountDetailFrame();
frame.accountSymbol = "SYM";
frame.performCommand("project activity");
assertEquals("SYM: basic account", frame.displayText);
}
When we separate out dependencies this way, very conservatively, by doing automated extracting method refactorings, we might end up with code that makes us flinch a bit. For instance, a setDescription method that creates a frame and shows it is downright nasty. What happens if we call it twice? We have to deal with that issue, but doing these coarse extractions is a decent first step. Afterward, we can see if we can relocate the frame creation to a better place.
Where are we now? We started with a class that had one class with one important method on it: performAction. We ended up with what is shown in Figure 10.1.
Figure 10.1 AccountDetailFrame.
We can’t really see this in a UML diagram, but getAccountSymbol and setDescription use the detailDisplay field and nothing else. The setDisplayText method uses only the TextField named display. We could recognize these as separate responsibilities. If we do, we can eventually move to something like what is shown in Figure 10.2.
Figure 10.2 AccountDetailFrame crudely refactored.
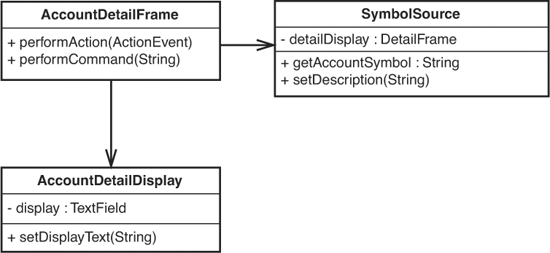
This is an extremely crude refactoring of the original code, but at least it separates responsibilities somewhat. The AccountDetailFrame is tied to the GUI (it is a subclass of Frame) and it still contains business logic. With further refactoring, we can move beyond that, but at the very least, now we can run the method that contained business logic in a test case. It is a positive step forward.
The SymbolSource class is a concrete class that represents the decision to create another Frame and get information from it. However, we named it SymbolSource here because, from the point of view of the AccountDetailFrame, its job is to get symbol information any way it needs to. I wouldn’t be surprised to see SymbolSource become an interface, if that decision ever changes.
The steps we took in this example are very common. When we have a refactoring tool, we can easily extract methods on a class and then start to identify groups of methods that can be moved to new classes. A good refactoring tool will only allow you to do an automated extract method refactoring when it is safe. However, that just makes the editing that we do between uses of the tool the most hazardous part of the work. Remember that it is okay to extract methods with poor names or poor structure to get tests in place. Safety first. After the tests are in place, you can make the code much cleaner.