3
Reading at a Glance
In Chapter 1 we explored why sound is vital to reading; the alphabetic code is one of sound, and indeed, it must be sound‐based—recreating grammar in a written system is too hard, and it's much easier to simply recode what we say. In Chapter 2 we examined evidence that reading is a matter of learning and then using this sound‐based code. But at the end of the chapter we saw that it is difficult to read a paragraph which ought to be perfectly readable based on the sound of the words (“Wunce uhpawn uh thyme”). One way to interpret this difficulty is that the typical spellings of the words help you to access the meaning. They don't seem to be essential—you can still work out the meaning of the paragraph—but they sure seem to help. How can this demonstration be squared with the idea that reading is sound‐based?
Spelling Representations in the Mind
The visual appearance of words, not just the sound they signify, does matter. (From here on I'll use the word “spelling,” rather than the clunky phrase “visual appearance of words.”) Understanding the role of spelling will be clearer if we situate it in the context of what we've already talked about. Chapters 1 and 2 conceptualized reading as a way to get from vision (seeing letters) to semantics (mental representation of meaning) via phonology (mental representations of sound) (Figure 3.1.)
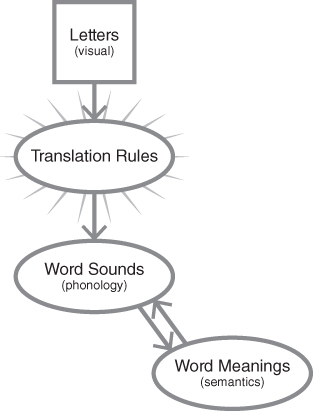
Figure 3.1. Letters, sounds, and meaning.
© Daniel Willingham
This spelling‐sound translation process is laborious; it consumes a lot of your attention, especially when you're first learning it. I've depicted that fact with the little lines radiating out from the oval representing the process. If you've seen a beginning reader you don't need much convincing that sounding words out takes a lot of attention. We'll return to this point, but right now let's get to spelling.
The “Wunce uhpawn uh thyme” paragraph indicates that what words look like (and not just what they sound like) matters in reading. We might also note that English has homophones: words that sound alike but are spelled differently and have different meanings like “knight” and “night” or “wholly” and “holy.” We need some way to account for our success in reading such words, so maybe we do pay attention to spelling. That means we need another oval in our figure, to signify a mental representation of how words are spelled, what they look like on the page. (Researchers call these orthographic representations.) (Figure 3.2.)
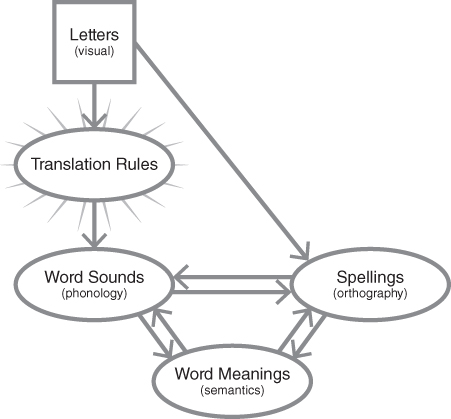
Figure 3.2. Letters, sounds, meaning, and spelling. Experienced readers can access word meaning not only through sound, but via another route that directly matches letters to knowledge of how words are spelled.
© Daniel Willingham
This new set of mental representations allows a reader to go directly from printed letters to meaning, bypassing sound altogether. Just as we proposed for meaning and sound, we're proposing that spelling representations are separate, but linked.1 That separation matches our intuition: you might know two features of a word (how to pronounce it and what it means) but not the third (how to spell it). These orthographic representations develop through reading practice, but before we consider their development, let's examine how researchers know that these spelling representations exist in the first place.
Perhaps the most persuasive evidence for readers using two routes to meaning (sound translation and the spelling route) comes from patients with brain damage. You're probably used to thinking of dyslexia as a problem in learning how to read, but there's another type of dyslexia. Some adults who were typical readers suffer some damage to the brain—usually because of a stroke—that affects their reading. For a very small number of people, the stroke is highly selective, and it happens to knock out just one of the two reading mechanisms. Thus, some people can use the letter‐sound translation rules, but they cannot get to orthography directly from visual input. So when they see a word like “cake” they can read it aloud, no problem, because the translation rules work. But when presented with an irregular word like “yacht” they are stumped. They apply the translation rules and say to themselves “Yatch‐ette. Hmm. I don't know that word.”
Other people—again, it's rare, but it does happen—have a stroke affecting the translation process, but the spelling route works fine. So they can read “yacht” and they can read “cake” because there is a spelling representation for each, and that representation is linked to the sound of the word (Figure 3.2). They are stumped, however, by simple nonwords like “rilf.” They can't use sound translation rules—those have been lost because of the stroke—and there's no spelling representation of “rilf” that would be linked to the sound representation.2,3 So they cannot read “rilf” aloud.
These results indicate that both routes—the sound‐based and the spelling—live side‐by‐side in experienced readers. The patients described can only use the single remaining route. But what about those who have not suffered a stroke? You might suppose that readers use one path or the other under different circumstances. Maybe they use the spelling path when spelling is important, like when they must differentiate “knight” and “night” and they use sound translation when sound is important, like when figuring out whether “sow” means a female pig or the act of planting. Cool idea, but that's not what happens. Both pathways operate all the time.4
Lots of technical experiments show that even for proficient readers, the sound‐translation pathway continues to influence reading, even after the spelling path develops. (We'll get to that development shortly.) Here are three easy‐to‐appreciate examples. First, even skilled readers are a little slower to read words with irregular pronunciation (e.g., “foot”) than words that follow translation rules (e.g., “week”). Second, people are slower to (silently) read tongue‐twisters than other sentences that are just as nonsensical in meaning, but don't twist the tongue in pronunciation.5 Third, if you ask people to proofread text, they are less likely to flag errors that have the right sound, e.g., “He said he was pleased to meat me” than errors that don't, e.g., “He said he was pleased to melt me.”6,7 So sound matters, even for experienced readers, reading silently.
This two‐path model represents researchers' best guess as to how experienced readers read individual words.* In Chapter 5 we'll deal with more complex meanings like those found in sentences and paragraphs. Let's get more specific about what we mean by orthographic knowledge, your knowledge of how words are spelled.
What Does Spelling Knowledge Look Like?
I've been making it sound as though orthographic knowledge is rather like a list of words that we know how to spell. That's partly true but there's more to it than that. To get started, let's look at a couple of odd abilities of experienced readers.
Seeing What's Not There
Which of these looks more like a word to you: “ppes” or “sepp”? How about “nuck” or “ckun”? Now compare “fage” and “fajy.” Experienced readers find this task relatively easy, but it's actually peculiar that you can do it—after all, none of these are words. What makes some more “wordy” than others?
It seems that we have some knowledge of which letters tend to go together—e.g., “fajy” looks wrong because “j” is seldom followed by “y”—and some knowledge of where in a word certain letter combinations tend to occur—e.g., double letters like “pp” tend not to occur at the beginning of words. Is this task merely a curiosity, or does it have anything to do with reading? Well, performance on tasks like this are associated with reading ability.10–15 And evidence from other, more fine‐grained laboratory tasks support the idea that we're tapping something important.
Let me describe a simple experiment, one that will help us get to the bottom of these spelling representations (and that offers another example of the peculiar abilities of readers). You sit in front of a computer monitor. There's an asterisk on the screen and you're told that a letter will replace the asterisk, but it will appear only very briefly before it disappears and the asterisk returns. Your job is to identify the letter. Sometimes other letters appear nearby, but you can ignore them. The interesting finding is that people are more likely to correctly identify the letter if there are other letters nearby—but only if they form a word with the target. Random letters don't help.16 (This finding is called the word superiority effect, by the way.)
If it's not obvious why the word superiority effect is strange, consider this. You're better at identifying the target letter if it forms a word with the neighboring letters. But how can you know that the letters form a word unless you know what the letters are? And if you've identified the letters, well, you know the letters; so identifying the letter where the asterisk was shouldn't be helped or hurt by whether or not it forms a word with the others.
This result is confusing because we assume that reading works by first identifying letters, and then putting them together to figure out what word they spell (Figure 3.3).

Figure 3.3. How one might assume words are identified. The word on the page goes into the eye, then your mind figures out the letters, and then your mind puts the letters together to figure out what word they spell.
© Daniel Willingham
If we modify this simple model in two ways, it can explain the word superiority effect. First, we allow that knowledge of words can influence letter identification. Second, we assume that the process of identifying words starts before each letter is completely identified (Figure 3.4).

Figure 3.4. How words are identified—a more complete model. The process that identifies the word can inform the process identifying letters; knowledge of what words are possible can constrain what letters might be on the page.
© Daniel Willingham
Cooperation in Identifying Letters and Words
Here's how that might work. Suppose there's a process in the mind that's figuring out which letter is in the first position of the word “ERROR.” There's another process figuring out the letter in the second position, another working on the third position, and so on. Now, that assertion might seem strange—wouldn't you figure out the first letter, then the second letter and so on? It turns out we don't read letter by letter, we read in letter clumps, figuring out a few letters at a time.
Here's another surprising aspect of word‐reading. It would seem logical that the visual system would identify letters, and then identify words (Figure 3.3). In other words, the visual system would be quite sure that the first letter is an “E” before passing that information to the process that figures out words. After all, if the letter‐identification process jumped the gun and sent along incomplete information, how is the word‐identification process supposed to do its job?
But the visual system doesn't wait. It forwards the information before identity is certain, saying (in essence): “First letter is probably an ‘E’ or ‘F’, or ‘H’. Outside chance it's an ‘A’ or ‘B’. Very unlikely it's any of the others.” Meanwhile, the second letter is being analyzed and an educated guess about its identity is also forwarded (“probably a ‘P’, ‘R’, or ‘B’ . . .”).
The process that identifies words can compare the guesses for different positions and thereby make the letter guesses better. The first letter might be “E”, “F”, or “H”; knowing that the second letter might be “P”, “R”, or “B” means that the first letter is probably not an “H” because there aren't any words that begin “HR” or “HP” or “HB.” So the process that identifies words communicates that information back to the process that's still figuring out the identity of the letter in the first position: “probably not ‘H’.” In short, guesses about the identity of letters inform guesses about the identity of words, and information about what words are possible inform guesses about individual letters.
Now we can see what's behind the word superiority effect. The person is told, “identify the letter at the center of the screen and ignore the others.” But the mind of a skilled reader can't ignore the others. Her mind will begin the process of identifying those neighboring letters whether she wants to or not, trying to put all the letters together as a word. And that process that's trying to figure out the word will help identify the target letter. But that process can only help if the letters actually form a word. If they are random, knowledge of what words are possible doesn't help.
This hypothesis of how orthographic knowledge influences letter identification can also explain how ambiguous letters are interpreted, the sort of letters we saw in the Introduction (Figure 3.5).
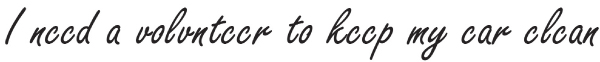
Figure 3.5. Ambiguous letters. The “v” and the “u” in “volunteer” are the same shape. So are the “c” and the “e” in “clean.”
© Daniel Willingham
The surrounding letters provide context that tell you that the ambiguous letter must be an “e” in “need” because “nccd” is not a word. The same shape is readily interpreted as a “c” at the start of “clean” because “elean” is not a word. It's not that you look at the ambiguous figure and consciously reason “I guess that's supposed to be a ‘c.’” In context, you just read it as a “c.”
But we haven't explained the phenomenon we started with. Why do we confidently say that “chim” looks more like a word than “chym”? We shouldn't have an orthographic representation of either, because neither is a word. The answer is that we have representations in memory not just of individual letters and full words, but of groups of letters. For example, we have a representation for the letter pair “im” but we don't have one for “ym” because we have seen “im” in many words, but have seldom seen “ym.” The idea is that any letter string that appears frequently enough merits its own representation, whether or not it's a complete word, and even if the string is kind of long (e.g., “ould”). Words that are rated as typical‐looking are those that have letter groups that appear frequently in the language, and people are able to read them a bit faster, compared to words with unusual letter groups.17
This notion that reading uses several levels of visual information—letters, letter groups, words—is important in demonstrations like this one, which made the rounds on Facebook a few years ago (Figure 3.6).

Figure 3.6. Digits can substitute for letters.
© Daniel Willingham
Being able to read this text is not a sign of a “strong mind,” but it is a sign of well‐developed orthographic representations. In fact, this type of writing was commonly used by teens in the 1990s when texting. Texting was available before cell phones with full keyboards were common. It was sometimes simpler to substitute digits for letters when typing on a phone. A “7” or “1” in isolation is a digit, but in the context of other letters like “7H1NK1NG” they can be evaluated as “T” and “I.”
The way we've described orthographic representations also explains another Internet meme:
This text retains the first and last letter of each word and jumbles any other interior letters. Experienced readers can manage to read it, although a good bit more slowly than they would read an un‐jumbled version.18 But the fact that they can read it at all would seem to conflict with the idea that we read by letter‐sound translation or by spelling, both of which are disrupted.
But note that other texts using the same rules are tougher to read:
If you found this sentence harder, you know that “you only need the first and last letter in place” can't be right. The “Cmabrigde” text is simpler because it uses a lot of short words, so the jumbled letters are more likely to be adjacent to one another. I won't go into more detail here, but that turns out to be important—we can overcome minor errors in position,19 especially if we can understand enough of the other words so that the possible meaning of a difficult word is constrained. (By the way, the scrambled words in the text box form the first sentence of another book I wrote: “Arguably the greatest mysteries in the universe lie in the three pound mass of cells, approximately the consistency of oatmeal, that resides in the skull of each of us”).20
Developing orthographic knowledge—mental representations that allow you to identify letters, groups of letters, and words, by their appearance—is essential to being a good reader.9, 21, 22 But why?
Why Orthographic Representations Matter
I said before that we need orthographic representations to read homophones correctly—“night” vs. “knight,” for example. That's not their most important function, however. Orthographic representations make for better reading, in two ways.
Saving Working Memory
As shown in Figure 3.2, reading words via orthographic representations bypasses the letter‐sound translation rules. Using those rules demands attention. (You'll no doubt recall my so‐ingenious representation of this cost—little lines radiating from the oval representing the process.) Bypassing the translation rules makes reading faster and easier. It's so easy that it's automatic, a term used by psychologists to denote a process that requires very little of your working memory. Working memory is the “workspace” in which thought happens, and it is, alas, limited. You can only think of so many things at the same time. That's why driving a car is all‐consuming for the beginner, who must consciously think about how far to turn the steering wheel to change lanes, how closely to follow the car ahead, and so on. Once those processes become automatic, space in working memory is freed and becomes available for other cognitive work; the driver can carry on a conversation with a passenger, for example.
Likewise, when a beginning reader uses the letter‐sound translation process (i.e., sounds a word out), her working memory is occupied mostly by translation rules—“let's see, ‘o’ usually sounds like aw, but when there are two of them, ‘oo,’ they make a different sound. . . . what was it again?” That leaves little working memory space for the task of comprehension, for actually understanding the meaning of what she's reading. With practice, the demand on working memory imposed by translation rules is reduced. Reduced, but never completely eliminated. You very likely felt the speed impediment when you read the “Wunc uhpawn uh thyme” paragraph.
The real gain comes when orthographic representations develop. They don't require much in the way of working memory capacity at all, and they provide a second, supporting source of information to help you home in on the right word. I mentioned before that the spelling route and the sound route operate simultaneously in experienced readers. That sometimes slows you down a bit—for example, you're a little slower to read irregularly pronounced words like “foot” because the sound route guides you towards the wrong interpretation. But most of the time the two routes complement and support one another, making reading easier.
The savings to working memory afforded by the addition of orthographic representations is important because reading is so demanding. Reading requires figuring out the parts of speech that words will play in a sentence. It requires keeping in mind previous sentences so you can relate the current sentence to what you've read. It requires drawing information from your long‐term memory that will allow you to make inferences. It's little wonder that working memory capacity is associated with reading comprehension.23 If you'd like a concrete example of how important working memory is to reading comprehension, have someone read a random sentence from this book to you, at a pace of one word per second. That will remind you what it was like to decode words slowly.
The process of building orthographic representations happens over months and years. As he gains reading experience, the child develops a larger and larger repertoire of words he can recognize at a glance, rather than sounding out. And the representations of individual words (and letter groups) get stronger, and more reliable. As this happens, the child's reading becomes faster, smoother, and more accurate. That's called fluency.
It's easy to see that fluency would aid comprehension; as we've said, sound translation demands a lot of working memory space, and reducing that demand leaves more working memory space to accomplish other tasks of reading. There's just a small spelling difference between “petty” and “pretty” or between “absent” and “assent.” Readers with finely tuned orthographic representations make those distinctions more quickly and reliably than readers with low‐quality orthographic representations, and that makes them better readers.24 There's also a second, somewhat more subtle way that fluency helps comprehension. Fluency actually ends up helping comprehension through sound.
Better Reading Through Sound
First, note that we can take the same set of words and change the meaning by saying them in different ways. Imagine saying “what a great party” with enthusiasm. Now imagine saying those same four words in a sarcastic voice. You can't see the difference on the page—the sound of the sentences would differ: the words that you stress, the speed of the utterance, when and where the pitch changes. These cues, collectively called prosody, are often referred to as the melody of speech. And this melody carries information. It helps you differentiate sarcasm from enthusiasm, but it also helps with the essential but less glamorous donkey work of comprehension; prosody helps you work out the grammatical roles that various words play.25
Even when you read silently, you can add prosodic information to help you comprehend. Poet Billy Collins put it more eloquently: “I think when you're reading in silence you actually hear the poem in your head because the skull is like a little auditorium.”26 Remember the passage from Billy Bathgate I quoted in the Introduction? “Abbadabba” Berman is said to “die of the effort” of relaying the safe combination. Most readers will put that effort and exhaustion into Berman's voice when he says, “Right. Three three. Left twice. Two seven. Right twice. Three three.” And hearing a voice in our head when we read is almost irresistible if we know the person who is speaking (Figure 3.7).

Figure 3.7. Silent reading. The sense that we hear a voice in our head when we read can be very strong.
Modified by the author, original © Everett Collection / Shutterstock.com
Psychologists Stephen Kosslyn and Ann Matt gathered experimental evidence for this mental voice.27 They had participants listen to recordings of individuals speaking either quickly or slowly. Then participants read prose allegedly written by these individuals. The researchers found that reading times were faster or slower, depending on the speaking speed of the purported author, consistent with the idea that, at least in some cases, people simulate speech as they read.
Orthographic representations make access to individual words more nearly automatic, and that means you have more working memory space to devote to working out the prosody. Indeed, some data show that it's the development of prosody, and not reading rate per se, that leads to the boosts in reading comprehension associated with fluency,28 but this conclusion is controversial.29
Fluency allows for better comprehension of what you read. And fluency depends on orthographic representations. So where do orthographic representations come from?
How Orthographic Representations Develop
I want to start by clarifying what might have sounded like a contradiction. In Chapter 1, I said, “a writing system wouldn't work if people had to memorize what words look like.” Now I'm concluding that “people have mental representations of what words look like.” But these claims don't really contradict one another. A system that requires memorizing what words look like is impractical for learning to read. But once you know the sound‐based way to decode, your mind learns what words look like, even if you're not especially trying to do so. If the child can sound words out, then the visual experience—what the word looks like—is consistently paired with the identity of the word (determined by the sounding‐out process).
This is called the self‐teaching hypothesis.30 Most children are taught how to sound words out, but they teach themselves (without knowing they are doing so) what letter pairs and whole words look like, based on practice distributed over months and years.31 These visual representations build slowly, but there is a lot of practice available; even reluctant readers read 50,000 words each year (although avid readers encounter many more words—as many as 4,000,000).26 The more frequently you encounter a word (or clump of letters), the richer the visual representation.32, 33
In this chapter, we've established that readers care about how words sound and how they look. But what about meaning? Obviously vocabulary is important to reading, and we'll examine the process of learning new word meanings in the next chapter.
References
- 1. Nation, K. (2009). Form‐meaning links in the development of visual word recognition. Philosophical Transactions of the Royal Society of London. Series B, Biological Sciences, 364(1536), 3665–74. http://doi.org/10.1098/rstb.2009.0119.
- 2. Coltheart, M., Rastle, K., Perry, C., Langdon, R., & Ziegler, J. (2001). DRC: A dual route cascaded model of visual word recognition and reading aloud. Psychological Review, 108(1), 204–56. Retrieved from www.ncbi.nlm.nih.gov/pubmed/11212628/.
- 3. Price, C. J., & Mechelli, A. (2005). Reading and reading disturbance. Current Opinion in Neurobiology, 15(2), 231–238. http://doi.org/10.1016/j.conb.2005.03.003.
- 4. Leinenger, M., & Leinenger, M. (2014). Phonological Coding During Reading. Psychological Bulletin, 140(6), 1534–1555.
- 5. Haber, L. R., & Haber, R. N. (1982). Does silent reading involve articulation? Evidence from tongue twisters. The American Journal of Psychology, 95(3), 409–419. http://doi.org/10.2307/1422133.
- 6. Jared, D., Ashby, J., Agauas, S. J., & Levy, B. A. (2016). Phonological activation of word meanings in Grade 5 readers. Journal of Experimental Psychology: Learning, Memory, and Cognition, 42(4), 524–541.
- 7. Treiman, R., Freyd, J. J., & Baron, J. (1983). Phonological recording and use of spelling‐sound rules in reading of sentences. Journal of Verbal Learning and Verbal Behavior, 22(6), 682–700. http://doi.org/10.1016/S0022‐5371(83)90405‐X.
- 8. Levy, B. A., Gong, Z., Hessels, S., Evans, M. A., & Jared, D. (2006). Understanding print: Early reading development and the contributions of home literacy experiences. Journal of Experimental Child Psychology, 93(1), 63–93. http://doi.org/10.1016/j.jecp.2005.07.003.
- 9. Cunningham, A. E., Perry, K. E., & Stanovich, K. E. (2001). Converging evidence for the concept of orthographic processing. Reading and Writing, 14, 549–568.
- 10. Cassar, M., & Treiman, R. (1997). The beginnings of orthographic knowledge: Children's knowledge of double letters in words. Journal of Educational Psychology, 89(4), 631–644. http://doi.org/10.1037//0022‐0663.89.4.631.
- 11. Ise, E., Arnoldi, C. J., & Schulte‐Körne, G. (2012). Development of orthographic knowledge in German‐speaking children: A 2‐year longitudinal study. Journal of Research in Reading, 00(00). http://doi.org/10.1111/j.1467‐9817.2012.01535.x.
- 12. Juel, C. (2006). The impact of early school experiences on initial reading. In D. K. Dickinson & S. B. Neuman (Eds.), Handbook of early literacy research (pp. 410–426). New York: Guilford.
- 13. Stanovich, K. E., & West, R. F. (1989). Exposure to print and orthographic processing. Reading Research Quarterly, 24(4), 402–433.
- 14. Reicher, G. M. (1969). Perceptual recognition as a function of meaningfulness of stimulus material. Journal of Experimental Psychology, 81(2), 275–280.
- 15. Farmer, T. A., Christiansen, M. H., & Monaghan, P. (2006). Phonological typicality influences on‐line sentence comprehension. Proceedings of the National Academy of Sciences, USA, 103, 12203–12208. doi: 10.1073/pnas.0602173103.
- 16. Rayner, K., White, S. J., Johnson, R. L., & Liversedge, S. P. (2006). Raeding wrods with jubmled lettres: There is a cost. Psychological Science, 17(3), 192–193.
- 17. McCusker, L. X., Gough, P. B., & Bias, R. G. (1981). Word recognition inside out and outside in. Journal of Experimental Psychology: Human Perception and Performance, 7(3), 538–551.
- 18. Willingham, D. T. (2009). Why don't students like school? San Francisco: Jossey Bass.
- 19. Badian, N. A. (2001). Phonological and orthographic processing: Their roles in reading prediction. Annals of Dyslexia, 51(1), 177–202. http://doi.org/10.1007/s11881‐001‐0010‐5.
- 20. Freebody, P., & Byrne, B. (1988). Word‐reading strategies in elementary school children: Relations to comprehension, reading time, and phonemic awareness. Reading Research Quarterly, 23(4), 441–453.
- 21. Daneman, M., & Carpenter, P. A. (1980). Individual differences in working memory and reading. Journal of Verbal Learning and Verbal Behavior, 19(4), 450–466. http://doi.org/10.1016/S0022‐5371(80)90312‐6.
- 22. Perfetti, C. (2007). Reading ability: Lexical quality to comprehension. Scientific Studies of Reading, 11(4), 357–383.
- 23. Carlson, K. (2009). How prosody influences sentence comprehension. Language and Linguistics Compass, 3(5), 1188–1200. http://doi.org/10.1111/j.1749‐818X.2009.00150.x.
- 24. Rehm, D. (2013). Aimless love: New and selected poems. Retrieved from http://thedianerehmshow.org/shows/2013‐10‐22/billy‐collins‐aimless‐love‐new‐and‐selected‐poems/transcrip/.
- 25. Kosslyn, S. M., & Matt, A. M. (1977). If you speak slowly, do people read your prose slowly? Person‐particular speech recoding during reading. Bulletin of the Psychonomic Society, 9(4), 250–252.
- 26. Anderson, R. C., Wilson, P. T., Fielding, L. G., Anderson, R. C., & Fielding, L. G. (1988). Growth in reading and how children spend their time outside of school. Reading Research Quarterly, 23(3), 285–303.
- 27. Rayner, K., Pollatsek, A., Ashby, J., & Clifton, C. J. (2012). Psychology of Reading (2nd ed.). New York: Psychology Press.
- 28. Share, D. L. (1995). Phonological recoding and self‐teaching: Sine qua non of reading acquisition. Cognition, 55(2), 151–218.
- 29. Grainger, J., Lété, B., Bertand, D., Dufau, S., & Ziegler, J. C. (2012). Evidence for multiple routes in learning to read. Cognition, 123(2), 280–92. http://doi.org/10.1016/j.cognition.2012.01.003.
- 30. Arciuli, J., & Simpson, I. C. (2012). Statistical learning is related to reading ability in children and adults. Cognitive Science, 36(2), 286–304. http://doi.org/10.1111/j.1551‐6709.2011.01200.x.
- 31. Kessler, B. (2009). Statistical learning of conditional orthographic correspondences. Writing Systems Research, 1(1), 19–34. http://doi.org/10.1093/wsr/wsp004.
- 32. Shanahan, T., & Lomax, R. G. (1986). An analysis and comparison of theoretical models of the reading–writing relationship. Journal of Educational Psychology, 78(2), 116–123. Retrieved from http://psycnet.apa.orgjournals/edu/78/2/116.
- 33. Chard, D. J., Vaughn, S., & Tyler, B. J. (2002). A synthesis of research on effective interventions for building reading fluency with elementary students with learning disabilities. Journal of Learning Disabilities, 35(5), 386–406.
- 34. Kuhn, M. R., & Stahl, S. A. (2003). Fluency: A review of developmental and remedial practices. Journal of Educational Psychology, 95(1), 3–21.
- 35. Therrien, W. J. (2004). Fluency and comprehension gains as a result of repeated reading: A meta‐analysis. Remedial and Special Education, 25(4), 252–261.
- 36. Marchand‐Martella, N. E., Martella, R. C., Modderman, S. L., Petersen, H. M., & Pan, S. (2013). Key areas of effective adolescent literacy programs. Education and Treatment of Children, 36(1), 161–184.
- 37. Harm, M. W., & Seidenberg, M. S. (2004). Computing the meanings of words in reading: Cooperative division of labor between visual and phonological processes. Psychological Review, 111(3), 662–720. http://doi.org/10.1037/0033‐295X.111.3.662.
- 38. Seidenberg, M. S., & McClelland, J. L. (1989). A distributed, developmental model of word recognition and naming. Psychological Review, 96(4), 523–68. http://doi.org/10.1037/0033‐295X.96.4.523.