The beginning of coding is a good time to start writing detailed tests. The high-level tests written before the iteration, or in the first couple days of it, provide enough information for the programmers to start their own test-driven development. So now we have a bit of breathing room, but if we don’t move quickly, coding could get way ahead of testing and go off in the wrong direction.
Now’s the time to start writing executable tests that illustrate the details about a story in order to keep development moving forward smoothly and help testing keep pace with coding. Like the high-level tests, we base detailed tests on examples provided by the customers.
At this point, we’re mainly writing tests that will be automated, but we’re also thinking ahead to the important exploratory testing we need to do as coding is completed.
As testers, we’re easily distracted by interesting code smells and edge cases. However, if we’re using tests to guide coding, we have to start with the basics. Write the simplest happy path test you can in order to show that the core functionality works.
Why executable tests? We’re working on an extremely tight schedule, and neither the programmers nor the testers have time to stop and run manual tests over and over. They do have time to click a button and run an automated test. That test needs to fail in a way that makes the cause as obvious as possible. Ideally, we would give these tests to the programmers so that they could execute them as they code. That is one reason why picking the right automation framework is so important.
Chapter 14, “An Agile Automation Strategy,” gives pointers for selecting the right tools.
For some stories, automating the tests might take a long time. By keeping the first test simple, you keep the focus on designing the automation solution. When the simple test works, it’s worth putting time into more complex test cases.
We stress the importance of automation, but Janet has worked with teams that have successfully used manual tests in the form of checklists or spreadsheets to give the programmers the information they need to start. However, to be successful in the long run, these tests do need to be automated.
As soon as the happy path test works, start adding more test cases. Add boundary and edge conditions. The tests may show that the programmers misunderstood a requirement, or they may show that a tester did, or maybe the requirement’s true meaning eluded everyone. The important thing is that everyone talks about it and gets on track.
As testers think of new scenarios to validate with executable tests, they also think about potential scenarios for manual exploratory testing. Make a note of these for later pursuit.
Remember the purpose of these tests. They should provide examples that tell the programmers what code to write. As the code evolves, your tests can challenge it more, but resist the temptation to immediately follow smells into edge cases. Get the basics working first. If you think of more cases based on some risk analysis, you can always add extra tests later.
Testers have used risk analysis to help prioritize testing for a long time, and consideration for risk is already built into agile development. High-risk stories may get higher size estimates, and teams consider risk as they prioritize stories during release and iteration planning.
Some quick risk analysis can help you decide what testing to do first and where to focus your efforts. We never have time to test everything, and we can use risk analysis to figure out how much testing is just enough.
If you have a really complex story, you may want to start by listing all of the potential risks related to the story. These aren’t limited to functionality. Consider security, performance, usability, and other “ilities.” Next, for each item, rate the impact on the business if it were to occur, using a scale of 1 to 5 (or whatever scale works for you): 1 being a low impact, 5 being a critical negative impact.
Now, consider the likelihood of each item occurring, using the same scale: 1 for not at all likely to happen, and 5 for items that probably will come up. Multiply the two ratings together to get the total risk rating for each item. This makes it easy to pick out the areas where your team should focus its testing efforts first. Low-risk items can be left for last, or, because their impact is low or they’re highly unlikely to occur, may not be addressed at all.
Your domain makes a huge difference here. If you’re testing software that runs in heart pacemakers, you probably need to cover all risks with your testing no matter how low or unlikely they are. If you’re testing an internal company web application to be used by a few trained subject matter experts, you may be able to skip over scenarios that are unlikely or have an obvious workaround.
Consider the story in Figure 18-1.
Figure 18-2 shows a possible risk assessment for this shipping cost story.
Table 18-2 Sample risk assessment
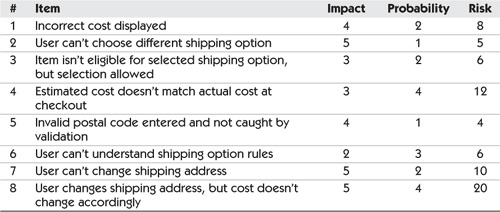
Item 8 is the highest-risk item, so we’d want to be sure to test changing shipping addresses and verify the updated costs. We might want to automate an end-to-end test with this scenario. We’re not too worried about item 5; maybe we have already tested our postal code validation and feel good about it, so we don’t need to test it more. You may even have a very low-risk item that you chose not to test.
History is usually a good teacher. Take note of past issues and make sure they don’t happen again.
Coding and Testing Progress Together
At this point in the iteration, coding and testing continue hand in hand. Testers, programmers, database experts, and other team members collaborate to develop the stories, following the guidelines provided by examples and tests. Different team members may contribute their particular expertise, but all of them feel responsible for making sure each story is finished. All of them learn about the story and learn from each other as work progresses.
Let’s look at how a team might work on the shipping cost story in Figure 18-1. Patty Programmer picks up a task card to code the estimated shipping cost calculations. She already understands the story pretty well from earlier discussions, but she may look at the wiki pages or back of the story card where the testers wrote down some narrative describing the purpose of the story, some examples of how it should work, and some high-level tests to make sure she has a good idea of where to start. Tammy Tester sees that coding work has begun and starts to write behind-the-GUI test cases for the cost calculations.
The team had agreed during planning to start by calculating the 5-day shipping cost based on the shipping address and item weight. Items can only be shipped within continental North America, but that validation will be done in the presentation layer, so the cost calculation tests can assume only valid destinations are considered for input. They’re using a cost calculation API provided by the shipping partner, and Tammy asks Patty where to find the algorithms so she can figure the cost herself in order to write the tests. Tammy writes the simplest test case she can think of in their behind-the-GUI test tool. We show it as a simple table in Figure 18-3.
Table 18-3 Simple happy path test

Patty hasn’t finished the code that would make this test pass yet, so Tammy starts working on another testing task for the story, setting up the test environment to work with the shipping partner’s test system.
Because this story and the test are so straightforward, Patty and Tammy don’t discuss the test design and tweak it as they might on more complex stories. They also haven’t needed to ask the product owner more questions yet. Patty calls Tammy over to show her that the simple test is now working. Tammy writes up more test cases, trying different weights and destinations within the United States. Those all work fine. She tries a Canadian postal code, and the test gets an exception. She shows this to Patty, who realizes that the API defaults to U.S. postal codes, and requires a country code for codes in Canada and Mexico. She hadn’t written any unit tests yet for other countries. They revise the test inputs, and Patty pairs with Paul Programmer to change the code that calls the API. Now the test looks something like Figure 18-4.
Table 18-4 Revised happy path test

This simple example illustrates the iterative back-and-forth between coding and testing. Different teams take different approaches. Patty and Tammy might pair on both the coding and testing. Tammy might pair with Paul to write the fixture to automate the test. Tammy might be in a remote office, using an online collaboration tool to work with Patty. Patty might write the executable story tests herself and then write the code to make them work, practicing true story test-driven development. The point is that testing and coding are part of one development process in which all team members participate.
Tammy can continue to identify new test cases, including edge cases and boundary conditions, until she feels all risk areas have been covered by the minimum amount and variety of test cases. She might test with the heaviest item available on the website sent to the most expensive destination. She might test having a large quantity of the same item. Some edge cases may be so unlikely that she doesn’t bother with them, or she decides to run a test but after it passes doesn’t include it in the regression suite. Some tests might be better done manually after a UI is available.
Patty has written unit tests with Hawaii as the shipping destination, but Tammy believes that only continental destinations are acceptable. Neither of them is sure whether military post office box destinations are acceptable. They go see Polly Product-Owner to ask what she thinks. They’re using the Power of Three. When disagreements or questions arise, having three different viewpoints is an effective way to make sure you get a good solution and you won’t have to rehash the issue later. If one of the participants in the discussion isn’t familiar with the topic, the others will have to organize their thoughts to explain it clearly, which is always helpful. Involving people in different roles helps make sure that changes to requirements don’t fly under the radar and surprise team members later.
When unexpected problems arise, as they always do, the Power of Three rule is a great place to start. You may need to pull in more people, or even the whole team, depending on the severity or complexity of the issue. What if the shipping partner’s API proves to be so slow that the response time on the website will be unacceptable? Both the development team and the customer team need to quickly explore alternative solutions.
Paul looks for a programming task to work on. Although the UI tasks for the estimated shipping cost story are still in the “to do” column on the task board, he’s more interested in the story to delete items out of the shopping cart, so he picks up one of those cards. Nobody has time to start writing the executable tests for that story, so he plunges ahead on his own.
Now the team has two stories going. They don’t really know how much time it will take to finish either story. A much better approach would be for Paul to start working on a UI task for the first story so that story can be finished sooner. When a story’s done (meaning all of the code is written and tested), you know exactly how much work is left to do on it: zero. If disaster struck and no other stories got finished this iteration, there is at least one completed story to release.
Completing the whole story isn’t a testing concept, but it’s one that testers should promote and follow. If a programmer has started coding on a story, make sure someone has also started working on testing tasks for that story. This is a balancing act. What if nobody has written even high-level tests for the delete items story? Maybe that’s the highest testing priority? Usually, finishing a story should be the goal before the team can move on to the next story.
Unless the team is very small, there is always more than one story in progress at any given time. It might be more difficult, but try to focus on finishing one story at a time. Patty is about to wrap up the shipping cost story, and Paul has moved on to the delete items story. Patty runs into a snag, and she isn’t sure how to solve it. Paul helps her to finish the code so that Tammy can finish her exploratory testing and they can mark the story “done.” Now they have a better idea of how much they have left to finish this iteration (or at least, how much they don’t still have to work on).
Sometimes, several different stories can be done at the same time if a programmer and tester pair up to complete each story together. This works if the stories are small and independent. What you don’t want to see is programmers starting coding without testing tasks being completed at the same time.
Tests that Critique the Product
As soon as testable chunks of code are available, and the automated tests that guided their coding pass, take time to explore the functionality more deeply. Try different scenarios and learn more about the code’s behavior. You should have task cards for tests that critique the product, both business- and technology-facing. The story’s not “done” until all of these types of tests are complete.
This becomes more important when all tasks except testing are complete for a story. Now you should be able to test from one end of the story’s thread to the other end, with all of the variations in between. Don’t put this testing off. You may find requirements that were in the story but were missed with the tests that drove development and are thus missing in the code. Now’s the time to write those missing tests and code. Fill in all of the gaps and add more value while the team is still focused on the story. Doing this later will cost much more.
Be aware that some of what you learn in testing the final story may be considered “nice to have,” perhaps making the functionality easier to use or faster, items that weren’t part of the original story. Consult with your customer. If there’s time to add it in the iteration, and the business can use the extra value, go ahead. These additions are much cheaper to add now. But don’t jeopardize other stories by spending too much time adding “bling” that doesn’t have a big ROI.
If your exploratory testing leads the team and the customers to realize that significant functionality wasn’t covered by the stories, write new stories for future iterations. Keep a tight rein on “scope creep” or your team won’t have time to deliver the value you planned originally.
Technology-facing tests to critique the product are often best done during coding. This is the time to know if the design doesn’t scale, or if there are security holes.
Collaborate with Programmers
Our vignette describing a team writing and using detailed tests to drive coding shows how closely testers and programmers collaborate. This continues as coding and testing proceed. Working together enhances the team’s ability to deliver the right product and provides many opportunities to transfer skills. Programmers learn new ways of testing, and they’ll be better at testing their own code as they write it. Testers learn more about the process of coding and how the right tests might make it easier.
Paul Programmer has completed the user interface for the estimated shipping options story, but he hasn’t checked it in yet. He asks Tammy to come sit with him and demonstrates how the end user would enter the shipping address during the checkout process. The estimated shipping cost displays right away. Tammy changes the shipping address and sees the new cost appear. She enters a postal code that doesn’t match the rest of the address and sees the appropriate error message appear. The UI looks good to both of them, so Paul checks in the code, and Tammy continues with her exploratory manual testing of it.
Janet likes to have the programmer “drive” during these pair testing sessions while she watches what happens. She finds that it is far more effective than taking control of the keyboard and mouse while the programmer watches.
Tammy is especially concerned with changing the shipping address and having the estimated cost recalculate, because they identified that as a risky area. She finds that if she displays the estimated cost, goes ahead to the billing address page, and then comes back to change the shipping address, the estimated costs don’t change properly. She gets Paul to come observe this behavior. He realizes there is a problem with session caching and goes back to fix it.
Showing someone a problem and working through it together is much more effective than filing a bug in a defect tracking system and waiting for someone to have time to look at it. It’s harder to do if the team isn’t co-located. If team members are working in vastly different time zones, it’s even harder. Stick to the most direct communication available to you. One of Lisa’s teammates is in a time zone 12½ hours ahead. He works late into his nighttime, and when needed, he calls Lisa and they work through test results and examples together.
The simple act of showing the GUI to another person may help Paul realize he’s implemented some erroneous behavior. Similarly, if Tammy is having trouble getting her GUI test script to work, explaining the problem might be enough for her to realize what’s causing it. If there is nobody available to look at what you’ve just coded or help you debug a problem, it sometimes helps to explain it out loud to yourself. “Rubber Ducking” and “Thinking Out Loud” are surprisingly effective ways to solve your own problems. Janet likes to have her own little rubber duck sitting on her desk to remind herself to think before she asks.
The bibliography contains references for further reading on this subject.
It’s shockingly easy for development team members to get their heads down cranking out stories and forget to keep customers in the loop. In addition to consulting business experts when we have questions, we need to show them what we’ve delivered so far.
Hopefully, you were able to review test cases with customers, or with someone who could represent the customer, before coding began. If not, it’s never too late. For situations where customers need to be more involved with the details of the executable tests, be sure to find test tools that work for them as well as for technical team members.
As we described in the last two chapters, you may have already gone over mock-ups or paper prototypes with your customers. If tasks to mock up a report or interface remain in the iteration plan, remember to keep the process simple. For example, don’t code an HTML prototype when drawing on a whiteboard will do just as well. We want to keep the process as simple as possible; simplicity is a core value.
As soon as a coded user interface or report is ready, even if it’s still rudimentary, lacking all features or displaying hard-coded data, show it to the appropriate customers. Nobody can explain exactly what they want ahead of time. They need to see, feel, and use the application to know if it’s right. You may not be able to implement big changes mid-iteration, but if you start early, there may be time for minor tweaks, and your customers will know what to expect.
The iteration review meeting is a great opportunity to show what the team delivered and get feedback for the next iteration, but don’t wait until then to get input from customers. Keep them involved throughout the iteration.
Although we get caught up in the fast pace of iterations, we also need to stop and take time to understand the business better. Spend some time talking to business people about their jobs and what aspects might be enhanced with new software features. The better you understand your customer’s business, the better you can be at providing a good product.
Some teams actually sit with the business people permanently so that they are involved with the actual business on a daily basis.
Agile testers are proactive. We don’t sit and wait for work to come to us. Testers who are accustomed to a waterfall process may feel there’s nothing to do until a story is 100% complete. That’s rarely true during an agile iteration. Work with programmers so that they produce some testable piece of code early on. The shipping cost algorithm presented earlier is a good example. It can be tested completely in isolation, without needing to access the database or the user interface. Alternatively, the user interface could be stubbed out with hard-coded data before the services accessing the real data are complete, and the behavior of the presentation layer can be tested by itself.
We’ve known many teams that struggle with the question of how to track bugs, or whether to track them at all. As Tom and Mary Poppendieck write in their book Implementing Lean Software Development: From Concept to Cash [2006], defect queues are queues of rework and thus collection points for waste. Some teams simply fix bugs as soon as they’re discovered. They write a unit test to reproduce the bug, fix the code so the test passes, check in the test and the bug fix, and go on. If someone breaks that piece of code later, the test will catch the regression.
Other teams find value in documenting problems and fixes in a defect tracking system (DTS), especially problems that weren’t caught until after code was released. They may even look for patterns in the bugs that got to production and do root cause analysis to learn how to prevent similar issues from recurring. Still, defect systems don’t provide a good forum for face-to-face communication about how to produce higher-quality code.
Lisa and her fellow testers prefer to talk to a programmer as soon as a problem is found. If the programmer can fix it immediately, there’s no need to log the bug anywhere. If no programmer is available immediately to work on the problem, and there’s a possibility the bug might be forgotten, they write a card for it or enter it into their DTS.
We’ve added this section to this chapter because this is when you run into the problem. You have been writing tests first, but are finding problems as you work with the programmer. Do you log a bug? If so, how? You’ve been doing your exploratory testing and found a bug from a story that was marked done. Do you log a bug for that? Let’s discuss more about defects and consider options that are open to you and your team.
Is It a Defect or Is It a Feature?
First, let’s talk about defects versus features. The age-old question in software development is, “What is a bug”? Some answers we’ve heard are: It’s a deviation from the requirements or it’s behavior that is not what was expected. Of course, there are some really obvious defects such as incorrect output or incorrect error messages. But what really matters is the user’s perception of the quality of the product. If the customer says it is a defect, then it is a defect.
In agile, we have the opportunity to work with customers to get things fixed to their satisfaction. Customers don’t have to try to think of every possible feature and detail up front. It is okay for them to change their minds when they see something.
In the end, does it really matter if it is a bug or a feature if it needs to be fixed? The customer chooses priorities and the value proposition. If software quality is a higher priority for the customer than getting all of the new features, then we should try to fix all defects as we find them.
Customers on the team use their knowledge to give the best advice they can to the team on day-to-day development. However, when a product goes to UAT and is exposed to a larger customer base, there will always be requests in the form of bugs or new enhancements.
One way of thinking about defects is as technical debt. The longer a defect stays in the system and goes undetected, the greater the impact. It also is true that leaving bugs festering in a code base has a negative effect on code quality, system intuitiveness, system flexibility, team morale, and velocity. Fixing one defect in buggy code may reveal more, so maintenance tasks take longer.
Janet encourages teams that she works with to strive for “zero tolerance” toward bug counts. New agile teams usually have a hard time believing it can be done. In one organization Janet was working with, she challenged each of the five project teams to see how close they could come to zero bugs outstanding at the end of each iteration, and zero at release time.
As part of any development, you will always need to make trade-offs. Your team may decide to release with some outstanding bugs because it is deemed more important to get new functionality out the door than to fix low-level bugs.
Teams have solved the problem of how to handle defects in many different ways. Some teams put all of their bugs on task cards. Other teams have chosen to write a card, estimate it, and schedule it as a story. Still others suggest adding a test for every bug—that way you don’t have to record the defect, just the test.
Is there one right way? Of course not! But, how do you know what is right for your team? We have some suggestions to help you choose and decide what is right for you. Think about your team and your product and what might work in your situation. First, we’ll talk about what defects we should log, then we’ll talk a bit about when you should fix them, and finally we’ll look at what media to choose. The right combination will depend on how far along your team is in its agile journey and how mature your product is.
Not all bugs need to be logged, but teams often struggle with which ones should be recorded and which ones don’t need to be. We recommend that you avoid creating a defect report if possible. Have a conversation with a real person first, and only produce a defect report if it is truly a real problem that demands a change to the product or the programmers just can’t get to it right away.
Don’t log unit test failures. If you are part of a team that is practicing TDD (test-driven development) and has good coverage with its unit tests, you know that failed tests during the build should not be logged. A failed test during the continuous integration build is a signal for the programmers to address the problem right away. Logging these bugs would be redundant and a waste of time.
Failures in Higher-Level Regression Tests
Many teams have builds that run regression tests above the unit level, such as tests behind the GUI and tests through the GUI. When one of these builds fails, should you log the bug in a DTS?
Failing tests in themselves are a type of recorded bug. But sometimes, as in Lisa’s case, more information needs to be added to allow for an effective and clean fix, so logging the defect is warranted.
Story Bugs within the Current Iteration
Don’t log bugs that can be fixed immediately, especially if you would otherwise record them in an electronic DTS. If your team is working closely with the programmers and is practicing pair testing as soon as a story is completed, we strongly recommend that you don’t log those bugs as long as the programmer addresses them right away. As you notice issues, talk them over with the programmer and decide whether they are real issues or not. Talk to the customer if you need to, but make a couple of notes so you remember what you saw so you can adjust your tests if needed.
If you are using index cards to log bugs, you may want to put an index card up on the task board (or a card on your electronic board) just as a reminder.
Post-Iteration Bugs (Or Those that Can’t Be Fixed Immediately)
Do log bugs that can’t be fixed right away. We stress testing early in order to catch as many bugs as possible while the programmers are still working on the story. We know it is cheaper to fix them when caught early; however, sometimes we just don’t catch them right away. The programmer has moved on to another story and can’t drop everything to fix it now. Those are the ones that are good candidates for logging. Sometimes a “bug” is really a missed requirement and needs to be handled as a story—estimated and prioritized for a future iteration.
Do log bugs that occur in the legacy system. If your product has been around a long time, it likely has a number of bugs that have been lurking in the background just waiting to be discovered. When you find them, you have a couple of choices. If your product owner thinks it is worthwhile to fix them, then log the bugs and they can be prioritized as part of the product backlog. However, if they have been around a long time and cause no issues, your product owner may decide it is not worth fixing them. In this case, don’t bother logging them. They will never get addressed anyhow, so don’t waste your time.
Do log all production bugs. When your application is in production, all bugs found by the customer should be logged. Depending on their severity, these bugs may be fixed immediately, at the time of the next release, or they’ll be estimated, prioritized, and put in your product backlog.
Choose When to Fix Your Bugs
There are three options. All bugs you find need to be triaged to determine if you fix them now, fix them later, or don’t fix them at all. This triage may be as simple as a discussion with the programmer to determine if they are really bugs in the story he is working on. The triage may be a discussion with the product owner to determine if there should be another story for the next iteration. The triage may also be a formal process with the customers to prioritize which bugs to fix.
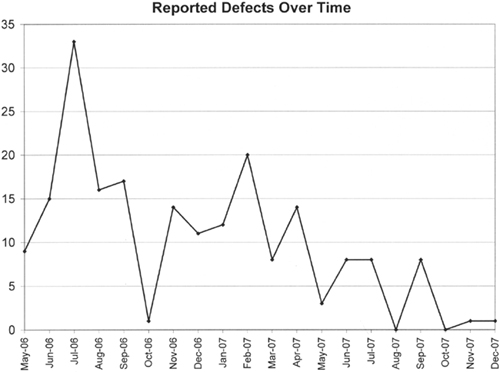
The more bugs you can fix immediately, the less technical debt your application generates and the less “defect” inventory you have. Defects are also cheaper to fix the sooner they are discovered. In an article in iSixSigma Magazine, Mukesh Soni [2008] quotes a report from IBM that the cost to fix an error found after product release was four to five times as much as one uncovered during design, and up to 100 times more than one identified in the maintenance phase (see Figure 18-5).
Figure 18-5 shows a statistic based on phased methodology, but the statistic still holds true for agile development. It is cheaper to fix bugs that are found during development than after.
If a defect is found while developing a new feature, or is a side effect from another bug fix, it should be automatically fixed. But, as usual, this is to be applied with prudence. For example, if a bug is found that the programmers say will be difficult to fix and may destabilize the product, it should be taken to the customers to prioritize.
If you fix the bugs during development, you lessen the presence of bugs later in the process. Your team velocity can include time to fix bugs. Over time, your team members will get a good idea of how long they spend on fixing bugs found by the testers for a story. Hopefully, there are few. If your team is a new agile team, there may be quite a few bugs that escape development, but as the team gets more comfortable with the tools and the processes, the number of bugs found will lessen. To start, try making the estimate for a story to include two hours or half a day for fixing associated bugs.
Different teams have different ways of handling defects. Some teams believe that all defects found should be prioritized by the customers before they get put on the list to fix. They believe it is completely up to the customer to determine whether they really are defects, and if so, whether they should be fixed.
Your team has recognized a defect, but know it won’t get fixed. Perhaps that section of code needs a complete rewrite later because the functionality will change, or perhaps it is just such a low-priority issue or so obscure that your customers may never find it. There are a multitude of reasons why it won’t get fixed. If your triage determines this is the case, we suggest you just close the bug. Don’t keep it open pretending that you will fix it someday.
Choose the Media You Should Use to Log a Bug
When we talk about media, we mean the variety of ways you can log a bug. It could be a defect tracking system or index cards, or maybe you choose to have no physical record at all.
Index cards (whether real or virtual cards in an online planning and tracking system) don’t leave a lot of room for a lot of clerical details, but they do give great visibility to outstanding issues when they are pinned on the story board, especially if they are in another color. Some teams use screen prints and staple them to the back of the card or write the details in a text file, or even record steps in audio form on a hand-held voice recorder.
There are lots of options, but we would suggest that you pick one that contains enough information to guide someone to reproduce a problem or to focus a discussion when the programmer is ready to fix it. The card is tangible. Five hundred bugs in a DTS are just a number. A stack of 500 cards is impressive.
Use cards in the following circumstances:
 You are a disciplined agile team and are fixing all bugs within an iteration.
You are a disciplined agile team and are fixing all bugs within an iteration.
You want to make bugs visible to the team.
There is nothing stopping you from having both index cards and a DTS.
Use a DTS in the following circumstances:
Your team is distributed.
You need to track bugs for audit purposes or to capture them in release notes.
You have bugs that escape an iteration and you need to remember to fix them later.
You have a legacy system with a large number of defects.
One way or the other, you will likely want to have some kind of DTS to log some of the bugs. This does not mean you need to log them all. Be smart about which ones you do log.
Why wouldn’t you log a bug? Most teams that we have worked with have set rules for themselves that no bug is fixed without a unit test. If you also have a functional automation suite, then you can catch the larger bugs with those. The argument is that if there is a test that will catch the bug, you have no need to log the bug. Anything learned from fixing the bug was captured in the test and the code. However, you need to recognize that not all tests are easy to automate.
Use tests to capture bugs in the following circumstance:
Your team is disciplined and writes tests for every bug found.
Alternatives and Suggestions for Dealing with Bugs
As teams mature, they find procedures that work for them. They eliminate redundant tasks. They become more practiced at using story cards, story boards, and project backlogs. They use tests effectively, and learn which bugs to log and what metrics make sense to their team. In this section, we’ll share some ideas that other teams have found work for them.
Set rules like, “The number of pink cards (bugs) should never get higher than ten at any one time.” Revisit these each time you have a team retrospective. If your defect rate is going down, no worries. If the trend is the opposite, spend time analyzing the root cause of bugs and create new rules to mitigate those.
Don’t forget to fix low-priority bugs found during the iteration as well, because they have an effect on future development. In our experience, there seems to be a strong correlation between “low priority” and “quick to fix,” although we don’t have hard facts to support that. We suggest stopping small, isolated bugs before they become large, tangled bugs.
If you find a lot of bugs in one area, think about combining them into an enhancement or story.
If a “bug” is really missed functionality, choose to write a card for the bug and schedule it as a story. These stories are estimated and prioritized just like any other story. Be aware that bug stories may not receive as much attention as the new user stories in the product backlog. It also takes time to create the story, prioritize, and schedule it.
If bugs are simply logged in a DTS, important information might be effectively lost from the project. When we write acceptance tests to drive development, we tend to focus on desired behavior. Learning about undesired behavior from a defect, and turning that into stories is a vital addition to producing the right functionality.
Blue, Green, and Red Stickers
Each team needs to determine the process that works for it, and how to make that process easily visible. The following story is about one process that worked for Janet.
This approach worked for this team because there was a lot of discipline in the team, and most new bugs were fixed in the iteration if they were part of the new or changed functionality. The only bugs that went into the backlog were legacy bugs that were deemed low risk.
We suggest using as simple a system as possible and applying complexity as required. Code produced test-first is, in our experience, fairly free of bugs by the time it’s checked in. If you’re finding a lot of bugs in new code, your team needs to figure out why, and take action. Try to shorten the cycle of coding, integrating and testing so that programmers get immediate feedback about code quality. Perhaps some buggy section of legacy code needs to be redesigned before it mires your team in technical debt. Maybe you need to work more closely with the business experts to understand the desired functionality.
Another idea might be to create an ongoing “start, stop, continue” list so that you can remember some of the issues during the iteration retrospective.
The daily stand-up helps teams maintain the close communication they need. Everyone on the team learns the current status of tasks and stories, and can help each other with obstacles. Often, hearing programmers describe tasks they’re working on provides a clue that they may have misunderstood the customer’s requirements. That signals the need for a group discussion after the stand-up. If a tester needs help with a testing issue that’s come up, she might ask the team to stay after the stand-up to talk about it. Missed tasks are often identified during stand-ups, and new cards can be written on the spot.
The stand-up is a good time to look at progress. Use big, visible charts such as story boards, burndown charts, and other visual cues to help keep focus and know your status. If the end of the iteration is drawing near, and coding on a story seems “stuck,” raise a red flag and ask the team what can be done about it. Perhaps some pairing or extra help will get things going. Lisa has often noted when there’s a lot of testing left to do and time is running out. She asks for help to pick up the slack. The whole team focuses on what needs to be done to complete each story and talks about the best approach.
When teams use an electronic medium for keeping track of stories, there is a tendency to forget the story board. Janet finds that having both may seem like a duplication of effort, but the visibility of progress to the team far outweighs the extra overhead of writing up the task cards and moving them as they are completed. Having the story board gives your team focus during the stand-ups or when you are talking to someone outside the team about your progress.
Testers Facilitate Communication
Testers can help keep the iteration progressing smoothly by helping make sure everyone is communicating enough. Talk to programmers when they start working on a story, and make sure they understand it. Lisa finds that she can write all of the tests and examples she wants on the team wiki, but if nobody bothers to read them, they don’t help. When in doubt, she goes over requirements and tests with the programmer who picks up the task cards.
Programmers will always have questions as they develop a story, even if they understand the business and the story well. It’s best if a customer is available to answer questions, because that is the most direct communication. Testers shouldn’t get in the way of that; however, we’ve observed that business experts sometimes have trouble explaining a requirement, or a programmer simply gets the wrong idea and can’t get on the same page with the customer. The Power of Three applies here. Testers can help customers and programmers find a common language.
Facilitating communication usually involves drawing on a whiteboard, mocking up interfaces, listing other areas that might be affected, or working through real examples. Whenever communication appears to reach a dead end, or confusion is rampant, ask for a new example and focus on that.
Work through as many examples as you need until the team understands enough different aspects of the system. Try a different format if it’s not working. For example, if pictures drawn on the whiteboard aren’t sufficient to understand the story, try spreadsheets or some other format that’s familiar to the business experts.
As we’ve noted in other chapters, having team members in different locations and different time zones means you have to work harder at communication. Phones, email, and instant messaging form the basics of communication, but better collaboration tools are developed all the time.
You will need to experiment to see what works for your distributed team. Use retrospectives to evaluate whether collaboration and communication need improving, and brainstorm ways to improve. You, as a tester, may have a lot of experience in helping with process improvement projects. Just think about improving communication as one of those continual improvement needs.
We all need to be able to communicate well with each other for our projects to succeed. When teams are in diverse geographic locations, they might have to work twice as hard to stay in constant touch.
Unless you’re on a team that’s just starting its automation efforts, you have automated regression tests covering stories from previous iterations. Hopefully, these are running as part of a continual build process, or at least part of a daily build process. If they aren’t, ask your team to make implementing this critical infrastructure a priority, and brainstorm with them how this might be done. Plan time in the next iteration to start a build process.
Programmers should run all automated unit tests before checking in new code. However, unit tests may fail in the continual build, either because someone forgot to run them before check-in, or because of a difference in runtime environment or IDE. We have unit tests for a reason, so whenever one fails, the team’s highest priority (apart from a showstopper production issue) should be to fix it and get the build working again.
Teams take different approaches to make sure their build stays “green.” Lisa’s team has a build process that emails results after every build. If the build fails, the person who checked in the failure usually fixes it right away. If it’s not clear why the build failed, team members will get together to investigate. Their ScrumMaster has a stuffed toy that she puts on the desk of the person who “broke the build,” as a visual reminder that it has to be fixed right away.
Some teams use a traffic light, ambient orb, GUI build monitoring tool, or other electronic visual way to show the build status. When the lights turn red, it’s time to stop new development and fix the build. Another technique is to have a screen pop up in everyone’s IDE showing that the build has failed, and the popup won’t go away until you click “Ok, I’ll fix the build.” Have some fun with it, but keeping the build running is serious business.
In extreme cases, you may have to temporarily comment out a failing test until it can be diagnosed, but this is a dangerous practice, especially for a novice team. Everyone on the team should stop what they’re doing if necessary until the build works again.
The build needs to provide immediate feedback, so keep it short. If the build takes longer than the average frequency of code check-ins, builds start to stack up, and testers can’t get the code they need to test. The XP guideline for build time is ten minutes [Fowler, 2006]. Lisa’s team tries to keep the build less than eight minutes, because they check in so often.
Tests that take too long, such as tests that update the database, functional tests above the unit level, or GUI test scripts, should run in a separate build process. If the team is limited in hardware, they might have to run the “full” build with the full suite of tests at night and the “ongoing” build that has only unit tests continually during working hours. Having a separate, continual “full” build with all of the regression test suites is worth the investment. Lisa’s team gets feedback every 90 minutes from their “full” build, and this has proven invaluable in heading off regression issues. This secondary suite of tests does not stop a programmer from checking in their code.
Building a Regression Suite
During the iteration, you’re automating new tests. As soon as these pass, add them to the regression suite, as appropriate. You may not need every edge case or permutation included in the regression suite, and you want to keep the regression suites fast enough to provide timely feedback. As each story is completed, tests that confirm its functionality should be included in the regression suite and be part of the regular build cycle.
The regression tests themselves must be under some form of version control. It’s best to keep them in the same source code control system as the production code. That way, when you tag the code for production release, the tag also contains all of the versions of the tests that worked with the code. At minimum, keep a daily backup of the test code.
When tests have been added to the regression suite, their purpose changes. They no longer exist to help drive development, and they are not expected to find new bugs. There sole purpose in life is to detect unexpected changes or side effects in the system.
Checking the “Big Picture”
Hopefully, you wrote task cards to test the story in the context of the larger application and regression test other parts of the system to ensure the new story hasn’t had a negative effect. You may have automated some of those end-to-end tests like the example in Chapter 12, “Summary of Testing Quadrants.”
But sometimes, even if you have a large suite of regression tests, manual exploratory testing can be appropriate. The story isn’t “done” until you’ve completed these tasks as well.
In Chapter 5, “Transitioning Typical Processes,” we talked a bit about the purpose of metrics, but because metrics are critical to understanding how your coding and testing activities are progressing, we’ll delve into them more here. Know what problem you are trying to solve before you start measuring data points and going to all the work of analyzing the results. In this section, we’ll cover some of the typical measurements that teams gather through the iteration.
You need some way to know how much work your team has completed at any point in the iteration and an idea of how much work is left to do. You need to know when it becomes obvious that some stories can’t be completed and the team needs a Plan B. Iteration burndown charts and estimated versus actual time for tasks are examples used to measure team progress. They may or may not provide value for your particular team.
Story or task boards are a good visual way to know the iteration’s status, especially if color coding is used. If too many test task cards are still in the “to do” column or not enough coding task cards have been moved to “Done” or “Tested,” it’s time for the team to think of ways to make sure all of the testing is completed. Maybe some team members need to stop coding and start taking on testing tasks, or maybe one story or a less critical part of a story needs to be put off until the next iteration so that testing for all the other stories can be finished.
This can be accomplished with virtual story boards as well as physical ones. Get creative with your visual effects so that problems are instantly visible. Remember that no story is “done” until it’s tested at all appropriate levels. Teams may have other criteria for when a story is “done,” such as whether it has been peer reviewed or the automated regression tests are completed. On the story board shown in Figure 18-6, the “Done” column for each story row is the rightmost column. The column just to the left of it is the “Verify” column. The story isn’t considered “done” until all the cards, including testing task cards, are in that “Done” column. A glance at the board is enough to know which stories are finished.
Even teams that don’t track burndown at the task level can do so at the story level. Knowing how much work the team can do each iteration (its velocity) helps with the overall release plan, and the reprioritizing for each iteration. It simply may be enough to know the number of stories completed in an iteration if they tend to average out to the same size. Although plans are tentative at best, it’s helpful to get an idea of about how many stories can be completed by a hard release date or what stories might get done in the upcoming quarter.
We talked about defect metrics in Chapter 15, “Tester Activities in Release or Theme Planning” giving you some high level ideas about what to track. Gathering metrics on defects can be very time consuming so always consider the goal before you start to measure. What is the purpose of the metrics you would like to gather? How long will you need to follow the trend before you know if they are useful?
Defect containment is always a favorite metric to capture. When was the defect found? In traditional projects, it is much easier as you have “hard” requirements and coding phases. When the whole team is responsible for quality, and everyone is working together throughout, it is much harder to determine “when” the defect was injected into the system.
We would like to challenge the idea of this type of metric as not necessary in agile development. However, if you find a lot of bugs are slipping through, you may want to start tracking what type of bugs they are so you can address the root cause. For example, if the bugs could have been caught with unit tests, then maybe the programmers need more training on writing unit tests. If the bugs are missed or misunderstood requirements, then maybe not enough time is spent in iteration planning, or acceptance tests aren’t detailed enough.
If you are practicing zero tolerance for defects, then you probably have no need to be tracking defects during coding and testing. A simple card on the story board will give you all the information you need.
Whatever metrics you choose to measure, go for simplicity.
Don’t be afraid to stop using metrics when they are no longer useful. If the problem they were initially gathered for no longer exists, there is no reason to keep gathering them.
Your team may have to provide metrics to upper managers or a Project Management Office (PMO), especially if you work for a large organization. Patrick Fleisch, an Accenture Consultant who was working as a functional analyst at a software company during the time we wrote this book, gave us the following examples of metrics his team provides to their PMO.
Test execution numbers by story and functional area
Test automation status (number of tests automated vs. manual)
Line graph of the number of tests passing/failing over time
Summary and status of each story
Defect metrics
Gathering and reporting metrics such as these may result in significant overhead. Look for the simplest ways to satisfy the needs of your organization.