CHAPTER 5
Integration with Other Systems
Hadoop is introduced into an organization's IT environment when the organization needs to more effectively manage big data. Of course databases, enterprise data warehouses, and other IT systems already exist in your organization's IT environment. And, it is likely that new systems, especially emerging technologies, will be added into the data center in the near future.
Before Hadoop, your organization ran analytical workloads in the data warehouse provided by vendors such as Teradata, Netezza or Vertica. After adding Hadoop into the data center, it is common practice to migrate the heavy Extract, Transform and Load (ETL) process to Hadoop. First, you extract data from the source systems, such as the Relational Database Management System (RDBMS) into HDFS (introduced in Chapter 2). You can leverage Hadoop's parallel processing to transform the data into target data models. Then the transformed data is loaded from Hadoop into the data warehouse. Apache Sqoop, from the Hadoop ecosystem, is the tool that can be used for this kind of integration. In this chapter we will first introduce Sqoop, to learn how it can efficiently transfer bulk data between Hadoop and structured data stores such as relational databases.
In addition to database systems, application servers have data your organization wants to capture. One example is web server logs that can be collected for website user click stream analysis, network security, and system operation monitoring. Hadoop is designed to be useful for this kind of processing, so this chapter will also introduce Apache Flume, which is a tool originally designed to stream server logs into Hadoop.
Hadoop MapReduce (introduced in Chapter 3) is designed as a batch-oriented data paradigm, taking in massive bounded data sets and processing them in a batch. It does not support streaming processing, because even the data is streamed into its storage. The batch processing naturally introduces high latency from the time when business events occur, to the time businesses can use the analysis results to make decisions. Business moves faster in the Internet era, so near-real time or real time data analysis is required. New technologies are coming out from the Hadoop ecosystem to advance the processing capability of Hadoop. For instance, Apache Spark makes it possible to process data faster in Hadoop. Apache Ignite boosts the performance of both the computation and storage layer. In this chapter, we will also introduce the other two cousins from the Apache family: Kafka and Storm, which together enable moving data faster to process data in real time. In this chapter we will take a detailed look at all of these technologies that are part of the Hadoop ecosystem.
APACHE SQOOP
Apache Sqoop is a command line tool built for efficiently transferring bulk data between Hadoop and structured data stores such as RDBMS, enterprise data warehouses, NoSQL and mainframe systems. It became a top-level Apache project in March of 2012.
Sqoop was initially developed as a tool to transfer data from RDBMS to Hadoop (its name Sqoop actually means “SQL-to-Hadoop”). It later became a standalone open source project on Github submitted by Cloudera. It can import existing tables or databases from RDBMS into HDFS, and can even populate tables in Hive and HBase (see Figure 5.1). This is really helpful for organizations that have recently set up a new cluster. Conversely, Sqoop can also be used to export data from Hadoop into external structured data stores.

At the time of writing, the latest stable version of Sqoop is 1.4.6. You may also be aware that the next generation of Sqoop (a.k.a. Sqoop2) is also under active development. In this book we focus on version 1 and do not cover any new features from Sqoop2.
How It Works
With Sqoop, you can import data from a database or a mainframe system into HDFS. For this input, you can use either database table(s) or mainframe dataset(s). For databases, Sqoop will read the table row-by-row into HDFS. For mainframe data sets, Sqoop will read records from each mainframe dataset into HDFS. The output of this process yields a set of files containing a copy of the imported table or data set. The import process is performed in parallel, and for this reason, the output will be in multiple files. The files' format may be text delimited (CSV or TSV for example), a SequenceFile, or Avro, etc.
After processing data in Hadoop (for example, with Hive or Pig) you may have a result data set that you can then export to the relational database for consumption by external applications or users. Sqoop's export process will read a set of delimited text files from HDFS in parallel, parse them into records, and insert them as new rows in a target database table, or update existing rows if you specify the column name as an update-key.
The import process from a database to Hadoop is done in two steps as depicted in Figure 5.2. First, Sqoop introspects the database to gather the necessary table metadata for the data being imported. Second, there is a map-only MapReduce job that Sqoop submits to Hadoop. This job uses DBInputFormat, which is backed with JDBC to interact with the database. With the proper JDBC driver installed, Sqoop can interact with any database system implemented by JDBC. DBInputFormat is a subclass of InputFormat, which can split up the input (here in a database table) into logical InputSplits; each of the splits will be assigned to an individual Mapper. When the Sqoop import command is invoked, it retrieves the table's metadata, and generates a class definition that can be used to de-serialize the data emitted from DBInputFromat, and then submit the job to start importing data. The job spawn mapper transfers data into HDFS in parallel. Sqoop also outputs to Mapper according to the specified arguments in the command line.
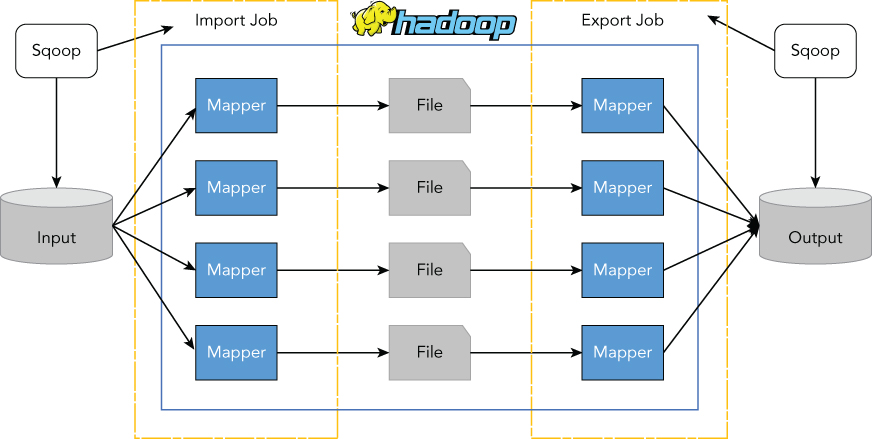
The export process from Hadoop to a database is done in two steps, but in a reversed way as depicted in Figure 5.2. The first step is to introspect the database for metadata of the target table, followed by the second step of transferring the data with a map-only job. Sqoop divides the input dataset into splits with the help of the concrete FileInputFormat, and then uses individual map tasks to write the splits into the target table with the configured ExportOutputFormat. Note that DBOutputFormat is not involved in actual write operations, but it's only used for configuration by Sqoop's default export job.
Let's use MySQL as an example to see how to import data into HDFS:
$ $SQOOP_HOME/bin/sqoop import --connect jdbc:mysql://mysqlhost/db --table ↲
employees --target-dir /sqoop/mysqlimport/employees
16/01/29 22:32:00 INFO sqoop.Sqoop: Running Sqoop version: 1.4.6
16/01/29 22:32:00 INFO manager.MySQLManager: Preparing to use a MySQL streaming ↲
resultset.
16/01/29 22:32:00 INFO tool.CodeGenTool: Beginning code generation
16/01/29 22:32:00 ERROR sqoop.Sqoop: Got exception running Sqoop: java.lang.Runtime↲
Exception:
Could not load db driver class: com.mysql.jdbc.Driver
java.lang.RuntimeException: Could not load db driver class: com.mysql.jdbc.DriverFrom the error message in the terminal, you can see Sqoop requires a JDBC driver to work with the source database. Install the driver JAR under the $SQOOP_HOME/lib folder and rerun the import command:
$ ls -l $SQOOP_HOME/lib/mysql*
-rw-r--r-- 1 sqoop hadoop 855946 Jan 29 22:34 mysql-connector-java-5.1.13.jar
$ $SQOOP_HOME/bin/sqoop import --connect jdbc:mysql://mysqlhost/db --table ↲
employees --target-dir /sqoop/mysqlimport/employees
16/02/09 23:12:06 INFO sqoop.Sqoop: Running Sqoop version: 1.4.6
16/02/09 23:12:06 INFO manager.MySQLManager: Preparing to use a MySQL streaming ↲
resultset.
16/02/09 23:12:06 INFO tool.CodeGenTool: Beginning code generation
16/02/09 23:12:07 WARN manager.MySQLManager: It looks like you are importing from ↲
mysql.
16/02/09 23:12:07 WARN manager.MySQLManager: This transfer can be faster! Use the ↲
--direct
16/02/09 23:12:07 WARN manager.MySQLManager: option to exercise a MySQL-specific ↲
fast path.Sqoop recognizes that the import source is MySQL, and suggests that the transfer can be faster if you use an additional option: --direct. Transferring large volumes of data through JDBC is often inefficient, since database vendors usually provide native utility tools that imports/exports data in a more high-performance manner. With the option --direct, mysqldump can be used by Sqoop to import data from MySQL to Hadoop, and mysqlimport can be used for the export process. Sqoop provides a pluggable mechanism for optimal connectivity to external systems. It provides a convenient framework for building new connectors, which can be dropped into Sqoop installations to provide connectivity to various systems. Sqoop itself comes bundled with various connectors that can be used for popular database and data warehousing systems. Apart from the built-in connectors, many companies have developed their own connectors that can be plugged into Sqoop. These range from specialized connectors for enterprise data warehouse systems to NoSQL datastores. To leverage those native utility tools and optimal connectors in Sqoop jobs, you need to make sure they are installed properly along with Sqoop on Hadoop worker nodes (where the mapper tasks run).
APACHE FLUME
Apache Flume is a distributed, reliable, and available service for efficiently collecting, aggregating, and moving large amounts of log data. It has a simple and flexible architecture based on streaming data flows. It is robust and fault tolerant with tunable reliability mechanisms and many failover and recovery mechanisms. It uses a simple extensible data model that allows for online analytic application. It became a top-level Apache project in June of 2012.
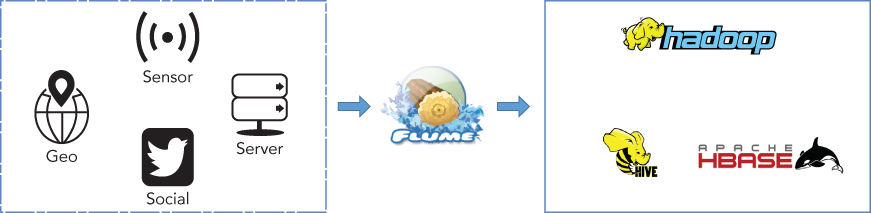
Sqoop lets users ingest structure data into Hadoop, while Flume enables users to ingest high-volume streaming data into HDFS, Hive and HBase (See Figure 5.3). Flume was initially created by Cloudera to enable reliable and simplified collection of log information from many distributed sources, for example, web servers of large internet companies. It's also designed to be extensible for other typical streaming sources like sensor and machine data, geo-location data, and social media posts. Hadoop is an ideal system to store and process a large volume and variety of those types of data, but it's not able to handle a large number of low-bandwidth connections and small files being continuously generated. Flume is designed to address all of these challenges.
The current stable version of Flume is 1.6.0. You may find that some old books, documents or web blogs mention “Flume NG.” It is actually the current version of Apache Flume (1.x). Back in 2011 it was the next generation of Flume, compared to the original implementation (pre 1.0) open sourced by Cloudera in 2009. In this book, we only talk about the current version.
How It works
Flume is designed to be a flexible distributed system to provide reliable and scalable ways of efficiently collecting, aggregating and transporting large amounts of data from many different sources to a centralized datastore. Below is the list of its key concepts. By understanding these concepts, you can better understand the architecture of Flume and how it works:
- Event: The unit of data transported by Flume from its origination to its destination. Event has a byte array payload accompanied by an optional header, which is a collection of string key-value pairs.
- Client: The entity that generates events and sends them to one or multiple agents. An example of a client is Flume log4j Appender. A client is not needed if your application embedded a Flume agent.
- Agent: The unit of Flume deployment that is a container (single JVM process) of hosting sources, channels, sinks, and other components that enable the transportation of events from one place to another.
- Source: The active component that receives events from a specialized place and is put into one or multiple channels.
- Channel: The passive component that buffers incoming events from a source until they are drained by sinks.
- Sink: The active component that pulls events out of a channel and transmits them to a final destination or the next agent in the flow.
- Interceptor: An optional component that can transform events before they are put into a channel.
- Flow: The pipeline starts from the origination where the event is coming from to its final destination. The simplest flow has one agent.
Table 5.1 is a summary of commonly used components in the Flume agent. For a more comprehensive list of components that Flume supports, you can refer to Flume's user guide. Like Sqoop, Flume is also designed to be extensible. The plugin-based architecture enables users to build custom components. The flexible architecture and those reusable components allow you to design a large range of possible deployment scenarios.
Table 5.1 Common Flume Agent Components
| Type Alias | Description | Implementation Class |
| Source | ||
| -avro | Receives Avro events from upstream | org.apache.flume.source.AvroSource |
| Source | ||
| -http | Starts http server and turns POST request into events | org.apache.flume.source.http.HTTPSource |
| Source | ||
| -jms | Converts JMS message into events | org.apache.flume.source.jms.JMSSource |
| Source | ||
| -spooldir | Monitors a directory and create events from the data file under the directory | org.apache.flume.source.SpoolDirectorySource |
| Channel | ||
| -memory | Holds events in memory | org.apache.flume.channel.MemoryChannel |
| Channel | ||
| -file | Persists events to local disk to avoid data loss in memory | org.apache.flume.channel.file.FileChannel |
| Channel | ||
| -kafka | Buffering events with Kafka | org.apache.flume.channel.kafka.KafkaChannel |
| Sink | ||
| -avro | Sends Avro events downstream | org.apache.flume.sink.AvroSink |
| Sink | ||
| -hbase | Writes events into HBase | org.apache.flume.sink.hbase.HBaseSink |
| Sink | ||
| -hdfs | Writes events into HDFS | org.apache.flume.sink.hdfs.HDFSEventSink |
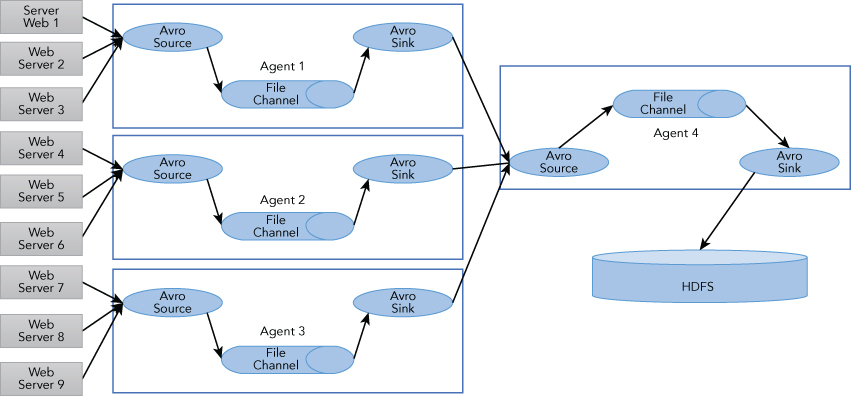
In Figure 5.4, you can see a common scenario with Flume being used in a log collection. A large number of web servers (log producing clients) are sending data to a few tier 1 Agents, while connecting to a tier 2 Agent, which consolidates the data that is then written to HDFS.
Each agent should be started using a Flume shell script called flume-ng. You need to specify the agent name, the config directory, and the config file on the command line:
$ $FLUME_HOME/bin/flume-ng agent -c <config-dir> -f <config-file> -n <agent-name>The configuration file follows the Java properties file format, and describes the data flow within the agent. Here is a template for the configuration file.
# list the sources, sinks and channels for the agent
<agent-name>.sources = <Source>
<agent-name>.sinks = <Sink>
<agent-name>.channels = <Channel1> <Channel2>
# set channel for source
<agent-name>.sources.<Source>.channels = <Channel1> <Channel2> …
# set channel for sink
<agent-name>.sinks.<Sink>.channel = <Channel1>
# properties for sources
<agent-name>.sources.<Source>.<someProperty> = <someValue>
# properties for channels
<agent-name>.channels.<Channel>.<someProperty> = <someValue>
# properties for sinks
<agent-name>.sources.<Sink>.<someProperty> = <someValue>Based on the template, the Agent 4 in Figure 5.4 can be defined as:
agent4.sources = source-4-avro
agent4.sinks = sink-4-hdfs
agent4.channels = channel-4-file
agent4.sources.source-4-avro.channels = channel-4-file
agent4.sinks.sink-4-hdfs.channel = channel-4-file
agent4.sources.source-4-avro.type = avro
agent4.sources.source-4-avro.bind = localhost
agent4.sources.source-4-avro.port = 10000
agent4.channels.channel-4-file.type = memory
agent4.channels.channel-4-file.capacity = 1000000
agent4.channels.channel-4-file.transactionCapacity = 10000
agent4.channels.channel-4-file.checkpointDir = /mnt/flume/checkpoint
agent4.channels.channel-4-file.dataDirs = /mnt/flume/data
agent4.sinks.sink-4-hdfs.type = hdfs
agent4.sinks.sink-4-hdfs.hdfs.path = hdfs://namenode/flume/weblogsFlume provides channel-based transactions to guarantee reliable event delivery. When an event moves from one agent to another, two transactions are started, one on the agent that delivers the event and the other on the agent that receives the event. The first transaction is initiated by sending agent's sink, while the second one is initiated by receiver's source. The commit of first transaction depends on the second transaction. The receiving agent returns a success indication if its transaction committed properly (the event successfully put into the channel), then the sending agent commits its transaction. This ensures guaranteed delivery semantics with the host that the flow makes. This mechanism also forms the basis for failure handling in Flume. Failure can be propagated from downstream to upstream through the flow. When the upstream agent is not able to pass the event downstream (due to network connection error, for example), it starts buffering the events in its channel. Once the connection has recovered, the buffered event will be drained out toward the final destination. The memory channel simply holds the events in memory, which is fast, but it's not recoverable if any crash happens. As a result, use the file channel, which is backed by the local filesystem and is recommended if you need durability and recoverability. Using a Kafka channel is even better, because Kafka is a high-throughput distributed messaging system that keeps strong durability and fault-tolerance guarantees. We will continue to discuss Kafka in the next section.
APACHE KAFKA
Apache Kafka is a high performance system for moving data in real time. From a high level, Kafka looks like a messaging system—clients publish messages to Kafka and messages are delivered in milliseconds. But Kafka works more like a distributed database: When you write a message to Kafka, it is replicated to multiple servers and committed to disk. Kafka is designed as a modern distributed system. The cluster is elastically scalable and fault tolerant, and applications can transparently scale out to produce or consume massive distributed streams. Kafka has become a key enabler for real time data processing.
Kafka was originally developed by LinkedIn, and subsequently became an open source project in 2011. In October 2012, it graduated from the Apache Incubator and started flourishing in the open source community. Initially, Kafka was designed as an efficient and scalable event queueing solution for user activity tracking on LinkedIn's website. Later it was extended to feed all activity events to the data warehouse and Hadoop for offline batch analysis. Because of its high throughput, reliable event delivery, and horizontal scalability, Kafka is being widely used as a general-purpose messaging system to support various use cases, which include:
- Website activity tracking
- Metrics collection and monitoring
- Log aggregation
- Stream processing and real time analytics
- Internet of Things
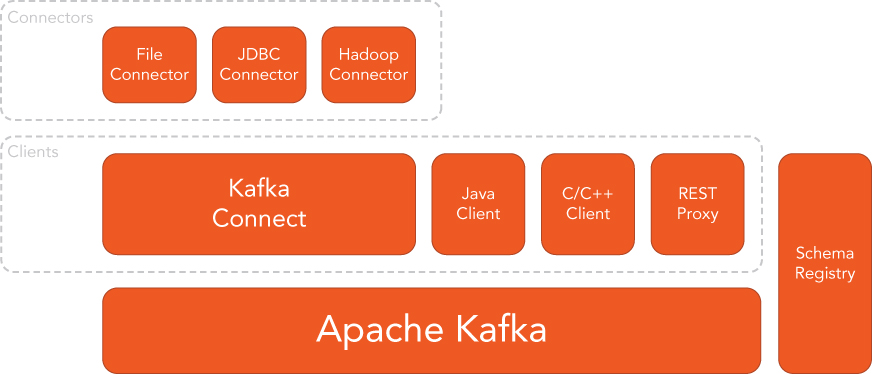
The original engineers of Kafka departed LinkedIn and started a company named Confluent to focus on building out the Kafka ecosystem to broaden its community. The major product of the company is the Confluent Platform (see Figure 5.5), which includes Kafka as the core and several components around Kafka to make it enterprise ready. The Confluent Platform is open source, free to use, and was released with an Apache license. The company provides commercial support for the platform, so it runs the same business model as Hortonworks for Hadoop.
The latest version of Kafka is 0.9.0, whereas the latest stable version is 0.8.2.2. We are going to use the version 0.9.0 for discussion in this section, because in this release, several new features have been introduced, which make Kafka enterprise ready. Those features include security, user defined quota, and Kafka Connect.
How It Works
Kafka basically provides a distributed, partitioned, and replicated commit log service to its users. It has a simple high level design that can be depicted, as shown in Figure 5.6.
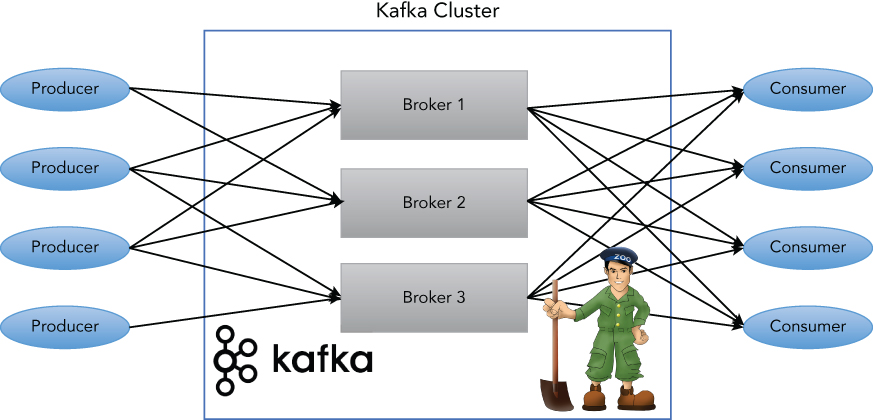
From the architecture perspective, Kafka provides the functionality for message producing and consuming. Topic is the category or feed name to which messages are published. Producer is the client process that publishes messages to a Kafka topic. Messages are simply byte arrays and can hold any object in any format, such as: String, JSON, and Avro. Consumer is the client process that subscribes to topics. Kafka itself runs as a cluster with one or more servers, each process of which is called a Broker. Kafka maintains feeds of messages in categories called topics. As for coordination and facilitation of distributed systems, ZooKeeper is used, for the same reason the Kafka cluster is using it. ZooKeeper is used for managing and coordinating Kafka brokers. Starting from 0.9, ZooKeeper's dependency from the clients (both Producer and Consumer) can be completely removed, but it is required internally by Kafka cluster.
The topic can be partitioned, and each partition is an ordered, immutable sequence of messages that is continually appended to—a commit log. The messages in the partitions are each assigned a sequential id number called the offset that uniquely identifies each message within the partition. The partition allows the log to scale beyond a size that will fit on a single server. Each partition must fit on the servers that host it, but a topic may have many partitions so it can handle an arbitrary amount of data. The partitions of the log are distributed over the brokers in the cluster, with each server handling data and requests for a share of the partitions. More partitions allow greater parallelism. A partition can be replicated across a configurable number of servers for fault tolerance. Each partition has one broker that acts as the leader, and zero or more brokers that act as followers. The leader handles all read and write requests for the partition, while the followers passively replicate the leader. If the leader fails, one of the followers will automatically become the new leader (coordinated by Zookeeper). Each broker acts as a leader for some of its partitions, and a follower for others, so the load is well balanced within the cluster. To illustrate, let's create a topic with a Kafka command line tool; “mytopic” is created with two partitions and two replicas across two brokers:
$ $KAFKA_HOME/bin/kafka-topics.sh --create --zookeeper localhost:2181
--replication-factor 2 --partitions 2 --topic mytopic
$ $KAFKA_HOME/bin/kafka-topics.sh --describe --zookeeper localhost:2181 --topic ↲
mytopic
Topic:mytopic PartitionCount:2 ReplicationFactor:2 Configs:
Topic: mytopic Partition: 0 Leader: 0 Replicas: 0,1 Isr: 0,1
Topic: mytopic Partition: 1 Leader: 1 Replicas: 1,0 Isr: 1,0Here is an explanation of output. The first line gives a summary of all of the partitions, and each additional line gives information about one partition.
Leaderis the broker node responsible for all reads and writes for the given partition. Each node will be the leader for a randomly selected portion of the partitions.Replicasis the list of nodes that replicate the log for this partition, regardless of whether they are the leader or even if they are currently alive.Isris the set of in-sync replicas. This is the subset of the replicas list that is currently alive and has caught-up to the leader.
The producer is responsible for choosing which message to assign to which partition within the topic. This can be done in a round-robin fashion, simply to balance the load, or it can be done according to some semantic partition function (based on some key in the message). The cluster retains all messages—whether or not they have been consumed—for a configurable period of time or size of data. Once the configured retention time or size is reached, old messages will be discarded to free up space.
The only metadata retained on a per-consumer basis is the offset. The consumer tracks the maximum offset it has consumed in each partition, and periodically commits its offset vector, so that it can resume from those offsets in the event of a restart. Consumer can also reset the offset for consumption if it needs to consume old messages. Since version 0.9.0, the Consumer offset can be managed through a special compacted Kafka topic, without Zookeeper, which was seen as the potential bottleneck in previous versions of Kafka.
As a distributed messaging system, Kafka is able to provide different levels of message delivery guarantees. Kafka guarantees at-least-once delivery (messages are never lost but may be redelivered) by default, and allows you to implement at-most-once delivery (messages may be lost, but are never redelivered) by disabling retries on the producer, and committing its offset prior to processing a batch of messages. Exactly-once delivery (strongest guarantee, since each message is delivered once and only once) requires cooperation with the destination system, but Kafka provides the offset that makes implementing this straight forward.
Kafka Connect
Kafka's flexible and scalable design allows Consumers to periodically consume batch data loads that periodically bulk-load data into an offline system such as Hadoop.
Before Kafka 0.9, there were two ways to load Kafka messages into Hadoop: Use a customized MapReduce job or use Kafka as source in Flume. Camus is the most famous solution of the first approach, which is also initiated in LinkedIn. From the previous section in this chapter, you have learned how Flume works. Now, you can see how there is significant overlap in the functions of Flume and Kafka. Flume has many built-in sources and sinks, and Kafka source and sink is among them. Flume can also use Kafka as a reliable channel. If you have already set up Flume to work with your Hadoop cluster, then Kafka can be easily integrated with the cluster through Flume (see Figure 5.7).

Kafka Connect is a new feature added in version 0.9. It is the standard framework for Kafka connectors, which standardizes integration of other data systems with Kafka, thus simplifying connector development, deployment, and management. You may realize that the primary goal of Kafka Connect, copying data between systems, has been tackled by a variety of frameworks and tools. So why do we need another framework? The detailed motivation and rationale can be found in the original proposal (KIP-26) for this feature. In short, most of the existing solutions do not integrate optimally with Kafka. Kafka Connect abstracts the common problems the third party connectors need to solve: fault tolerance, partitioning, offset management, and message delivery semantics. Since Kafka is becoming the de facto standard stream data store, Kafka Connect will be the solution to make Kafka the central hub for data exchange between different systems.
The Kakfa HDFS Connector is one of the connectors created for Kafka Connect, which moves data from Kafka into HDFS, integrating it with Hive. The connector periodically polls data from Kafka and writes it to HDFS. The data from each Kafka topic is partitioned by the provided partitioner and divided into chunks. Each chunk of data is represented as an HDFS file with the topic, the Kafka partition, and the start and end offsets of this data chunk in the filename. If no partitioner is specified in the configuration, the default partitioner preserves the Kafka partitioning that will be used. The size of each data chunk is determined by the number of records written to HDFS, and the time written to HDFS and schema compatibility. This connector can optionally integrate with Hive. When enabled, the connector automatically creates an external Hive partitioned table for each Kafka topic and updates the table according to the available data in HDFS.
The Kafka JDBC Connector is another connector shipped with Confluent Platform. It allows loading data from any JDBC-compatible database into Kafka. Data is loaded by periodically executing a SQL query, and creating an output record for each row in the result set. By default, all tables in a database are copied, each to its own output topic, making it easy to ingest entire databases into Kafka. The database is monitored for new or deleted tables, and adapts automatically. When copying data from a table, the connector can load only new or modified rows by specifying which columns should be used to detect changes. Using HDFS and JDBC Connector together, you can build a scalable data pipeline to export data from RDBMS and load it into Hadoop. Does it sound like a similar functionality as Sqoop? Yes, but it is implemented in a totally different way. But unlike Sqoop, the only destination of the database records is Hadoop. With Kafka Connect, however, the destination could be stream processing systems, illustrating its unique feature set.
Stream Processing
Stream processing in our context is the processing of data streams being produced as data arrives in the system. It enables continuous computation, real time data processing, and transformation. Kafka provides guaranteed message delivery with low end-to-end latency. A single Kafka broker can handle hundreds of megabytes of reads and writes per second from thousands of clients. It makes stream processing a common use case of Kafka, because it is the ideal system of both source and sink for stream processing.
Stream processing can be modeled as a transformation between streams, seen as a Directed Acyclic Graph (DAG, shown in Figure 5.8). A stream processing job continually reads from one or more data streams, and outputs one or more data streams of output. For example, data is consumed from topics of raw data and then aggregated, enriched, filtered, and transformed into new Kafka topics for further consumption. Publishing data back into Kafka like this provides a number of benefits. First, it decouples parts of the processing graph. One set of processing jobs may be written by one team and another by another. And they may be built using different technologies. Most importantly, we don't want a slow downstream processor to be able to cause back-pressure to seize up anything that feeds data to it. Kafka acts as this buffer between the processors that can let an organization happily share data.
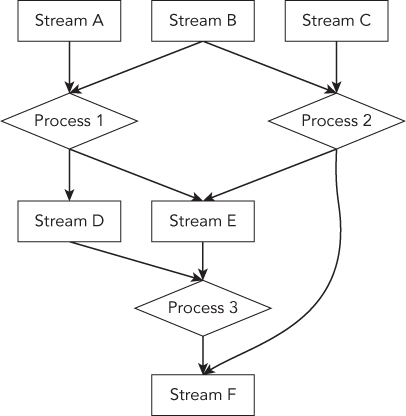
The most basic approach is writing an application, directly using the Kafka APIs, to create a custom Consumer to read input data stream, process that input, and produce output stream as a custom Producer. This can be done in a simple program in any programming language. However, this type of application can be made easier and more scalable with the help of a stream processing framework—such as Storm, Samza, Flink, or Spark's Streaming module—that provides richer stream processing primitives. All of them provide good integration with Kafka.
APACHE STORM
Apache Storm is a distributed real time computation system for processing large volumes of high-velocity data. Storm makes it easy to reliably process unbounded streams of data, doing for stream processing what MapReduce did for batch processing. Storm provides a simple API and enables developers to write Storm topologies using any programming language. It adds reliable real time processing capabilities to the Hadoop ecosystem. Using Storm, a Hadoop cluster can efficiently process a full range of workloads, from real time to interactive to batch.
In September 2013, Storm entered the Apache Software Foundation (ASF) as an incubator project. It became a top level Apache project in September of 2014. There are several major branches in Storm's codebase: 0.9.X, 0.9.6 (the latest stable release version), and 0.10.X. 0.10.0 is another release version that includes security, multi-tenant deployment support, and a couple of performance improvements: 1.x is targeting the next major release (V1) and also 2.x, and the community is actively working on merging JStorm's codebase into Storm. JStorm was originally a fork of Storm, where Clojure implemented the core module reimplemented in Java by Alibaba. After 4 years of active development and production deployment at Alibaba's scale, JStorm has been proven to be more stable, feature rich, and better than Storm. In October 2015, JStorm was officially donated to the Apache Foundation, and the community decided to merge it into Storm. In this book we are using version 0.9.6 of Storm.
The past decade has seen a revolution in data processing. MapReduce, Hadoop, and Spark related technologies have made it possible to store and process data at previously unthinkable scales. Unfortunately, these data processing technologies are not real time systems, nor are they meant to be. There's no hack that will turn Hadoop into a real time system. Spark Streaming is still a batch system at heart. Real time data processing has a fundamentally different set of requirements than batch processing. However, real time data processing at a massive scale is becoming more and more of a requirement for businesses. The lack of a “Hadoop of real time” has become the biggest hole in the data processing ecosystem. Storm fills that hole. Storm is extremely fast, with the ability to process over a million records per second per node. It is scalable, fault-tolerant, guarantees the data will be processed, and is easy to set up and operate.
Storm has many use cases: real time analytics, online machine learning, continuous computation, distributed RPC, ETL, and more. Theoretically, Storm can integrate with any message queues and database systems.
How It Works
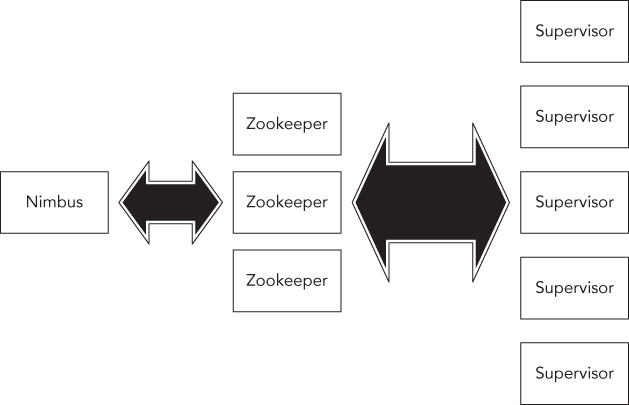
As a distributed computing system, Storm follows the classic master and slave style architecture. There is one master node that runs a daemon called Nimbus, which is responsible for distributing a job around the cluster, assigning tasks to machines, and monitoring for failures. There are multiple slave nodes, each of them running a daemon called the Supervisor. The supervisor listens for work assigned to its machine and starts and stops worker processes as necessary, based on what Nimbus has assigned to it. All coordination between Nimbus and the Supervisors is done through a Zookeeper cluster (see Figure 5.9). Additionally, the Nimbus and Supervisor daemons fail-fast and are stateless, given that all state is kept in Zookeeper or on a local disk. If the Nimbus dies, supervisors will continue to run.
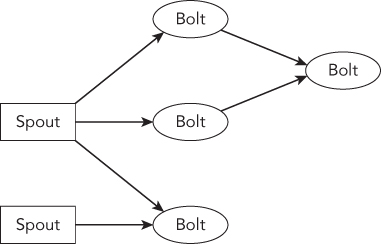
Storm uses two basic programming primitives to simplify distributed and parallel stream processing: Spout and Bolt. A Spout is a source of streams. For example, Kafka can be a type of Spout. A Bolt consumes any number of input streams, does some processing, by possibly emitting new streams or writing data into a data store. Complex stream transformations may require multiple steps and thus multiple Bolts (Figure 5.10). Networks of Spouts and Bolts are packaged into a Topology, which is the top-level abstraction that you submit to Storm clusters for execution. A topology can be represented as a graph of computation. Each node is a Spout or Bolt, and edges between nodes indicate how data should be passed around between them.
Storm uses Tuple as its key data structure to model the data being processed in a topology. A tuple is a named list of values, and a field in a tuple can be an object of any type. Out of the box, Storm supports all the primitive types, strings, and byte arrays as tuple field values. It also allows you to define your own type of tuple. A Spout can emit a stream of tuples from a data source. A Bolt can do anything from run functions, filter tuples, do streaming aggregations, do streaming joins, talk to databases, and so on.
Storm can spawn multiple worker processes across different Supervisors for a single topology. Each worker process is a physical JVM process that can spawn one or more executor threads. Each executor can run one or more actual data processing tasks for the same topology component (Spout or Bolt). Storm API allows you to configure the parallelism of a topology: number of worker processes, number of executors, and number of tasks.
Strom provides different kinds of stream grouping strategies to allow you to define how the stream should be partitioned across tasks and how tuples should be shuffled from Spout to Bolt, or from Bolt to Bolt. Here is a list of the grouping strategies:
- Shuffle grouping: Tuples are randomly distributed across the Bolt's tasks in a way such that each Bolt is guaranteed to get an equal number of tuples.
- Fields grouping: The stream is partitioned by the fields specified in the grouping. Tuples with the same value of the specified fields will always go to the same task.
- Partial Key grouping: The stream is partitioned by the fields specified in the grouping, like the Fields grouping, but are load balanced between two downstream Bolts, which provide better utilization of resources when the incoming data is skewed.
- All grouping: The stream is replicated across all of the Bolt's tasks.
- Global grouping: The entire stream goes to a single one of the Bolt's tasks.
- Direct grouping: This is a special kind of grouping. A stream grouped this way means that the producer of the tuple decides which task of the Consumer will receive this tuple. Direct groupings can only be declared on streams that have been declared as direct streams.
- Local or shuffle grouping: If the target Bolt has one or more tasks in the same worker process, tuples will be shuffled to only those in-process tasks. Otherwise, this acts like a normal shuffle grouping.
A topology runs forever, or until you kill it. Storm will automatically reassign any failed tasks. Additionally, Storm guarantees that there will be no data loss, even if machines go down and messages are dropped. Storm guarantees that every tuple emitted by Spout will be fully processed by the topology. It does this by tracking the tree of tuples triggered by every Spout tuple, thus determining when that tree of tuples has been successfully completed. Every topology has a “message timeout” associated with it. If Storm fails to detect that a Spout tuple has been completed within that timeout, then it fails the tuple and replays it later.
The Storm code base includes a sub-project storm-starter, and it's a good place for you to get started with Storm programming. The official documentation also provides a good summary of the common Topology patterns, With the concepts introduced previously, you can build some exciting streaming processing applications.
Trident
In addition to a normal API for building topologies, Storm also provides Trident API, which is a high-level abstraction for doing real time computing on top of Storm. The concepts of Trident will be very familiar to you, if you are familiar with high level batch processing frameworks like Pig or Cascading. Trident lets you elegantly express real time computation while still getting maximal performance. It allows you to build fault-tolerant real time computation in a natural way without touching low level APIs to control the stream groupings, and to acknowledge tuples. In addition to this, Trident adds primitives for doing stateful, incremental processing, on top of any database or persistence store. Most importantly, Trident has consistent and exactly-once semantics, which normal APIs don't have. If you need to build some applications that require the strongest consistency, you should use the Trident API.
The following code snippet illustrates the word counting program implemented with Trident.
TridentTopology topology = new TridentTopology();
TridentState wordCounts =
topology.newStream("spout1", spout)
.each(new Fields("sentence"), new Split(), new Fields("word"))
.groupBy(new Fields("word"))
.persistentAggregate(new MemoryMapState.Factory(), new Count(), new Fields
("count"))
.parallelismHint(6);Assume that the topology reads an infinite stream of sentences from Spout. With Trident's fluent API, split sentence and aggregation can be done in a single line of code. The aggregated counting result is then continuously persistent into a state. In this example, MemoryMapState.Factory, means store in memory, but it can be easily replaced by Memcached, Cassandra, or some other store. This is just a little taste of the Trident API, since you can refer to project storm-starter for more examples.
Kafka Integration
The Storm community provides a bunch of components to integrate with other systems. Some of them are shipped with Storm as built-in components. They are released as external modules in tandem with Storm in order to maintain version compatibility. Storm version 0.9.6 includes 3 external modules: storm-hbase, storm-hdfs, and storm-kafka. Version 0.10.0 includes even more: storm-hive, storm-jdbc, and storm-redis etc. And more will be added in future releases.
In terms of integrating with Kafka, from Figure 5.8, it's very clear that Kafka can act as a Spout or a Blot. The storm-kafka module provides both implementations. Let's take a look at the examples. It is necessary to add the below dependencies into your application's pom.xml file:
<dependency>
<groupId>org.apache.storm</groupId>
<artifactId>storm-core</artifactId>
<version>${storm.version}</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.storm</groupId>
<artifactId>storm-kafka</artifactId>
<version>${storm.version}</version>
</dependency>
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka_2.10</artifactId>
<version>0.8.2.2</version>
<scope>provided</scope>
<exclusions>
<exclusion>
<groupId>org.apache.zookeeper</groupId>
<artifactId>zookeeper</artifactId>
</exclusion>
<exclusion>
<groupId>log4j</groupId>
<artifactId>log4j</artifactId>
</exclusion>
</exclusions>
</dependency>Both normal and Trident Spouts are supported:
BrokerHosts hosts = new ZkHosts(zkConnString);//kafka zookeeper
//the Zkroot will be used as root path in zookeeper to store consumer offset
for this spout.
//The clientId should uniquely identify your spout.
SpoutConfig spoutConfig = new SpoutConfig(hosts, topicName, zkRoot, clientId);
//deserialize the message as string
spoutConf.scheme = new SchemeAsMultiScheme(new StringScheme());
//normal spout only accepts an instance of SpoutConfig
KafkaSpout kafkaSpout = new KafkaSpout(spoutConfig);
TridentKafkaConfig tridentSpoutConf = new TridentKafkaConfig(hosts, topicName);
tridentSpoutConf.scheme = new SchemeAsMultiScheme(new StringScheme());
//Trident spout takes TridentKafkaConfig
OpaqueTridentKafkaSpout spout = new OpaqueTridentKafkaSpout(tridentSpoutConf);To write tuples into Kafka you can use the bolt storm.kafka.bolt.KafkaBolt. If you use Trident you can use:
storm.kafka.trident.TridentState, storm.kafka.trident.TridentStateFactory
or: storm.kafka.trident.TridentKafkaUpdater
KafkaBolt bolt = new KafkaBolt()
.withTopicSelector(new DefaultTopicSelector("testTopic"))
.withTupleToKafkaMapper(new FieldNameBasedTupleToKafkaMapper());//from the
package storm.kafka.bolt.mapper
TridentKafkaStateFactory stateFactory = new TridentKafkaStateFactory()
.withKafkaTopicSelector(new DefaultTopicSelector("testTopic"))
.withTridentTupleToKafkaMapper(new FieldNameBasedTupleToKafkaMapper("word",
"count"));//from the package storm.kafka.trident.mapperSUMMARY
This chapter provides a broad overview of how to integrate Hadoop with other systems. We introduced four open source projects from the Apache family: Sqoop, Flume, Kafka, and Storm. Sqoop's main use case is to transfer bulk data between Hadoop and structured data stores, such as relational databases. Flume's main use case is to ingest data into Hadoop. Even Kafka and Storm can be used as the bridge to connect Hadoop with other systems. All of them are designed to be extensible to support a different data source, but they also have their own unique design and primary features. Kafka is the key enabler for stream processing, and can be used as a central message hub. Storm is designed to be a stream processing engine. Kafka, together with Storm, can move data faster and process data in real time. Now, you should have a better understanding of how to fit Hadoop into existing IT environments and extend its capability by integrating with these technologies.