Chapter 10
Improving Operations
IN THIS CHAPTER
 Plugging into operational improvement use cases
Plugging into operational improvement use cases
Manufacturing with autonomous robotics
Building up business process efficiency
Logging some serious logistics wins
Creating content with the click of a button
What company doesn’t want to operate more efficiently? What company doesn’t want to spend (or waste) fewer resources on the internal processes it needs in order to produce its assets or services and sell them in exchange for money? None. All businesses want to improve and refine their operations so that they can make better profits with the same levels of input resources. That’s business, and it’s why data science is used extensively in making improvements to business operations. In fact, operational improvement is one of the most important types of use cases for data science and AI. In this chapter, you’ll do a shallow dive into how data science is being used to optimize operations with respect to manufacturing, business processes, logistics, and media. Within each of these cases, you'll also take a deeper dive into operational improvements, use cases, technology specifications, and how data science is supercharging operational efficiency across multiple industries.
Establishing Essential Context for Operational Improvements Use Cases
Every time you begin making plans to take on a new data science project, you’ll want to refresh your awareness of what’s happening across the data science industry. This is especially true if your company is looking to you to help make operational improvements. That’s because, operational improvements often come in the form of AI-infused automation, and this is a rapidly evolving area within data science.
Before diving into the nuts-and-bolts of data-science-driven operational improvements, let’s talk about you and how this chapter applies to where you are in your data career. If you’ve read about the data superhero type earlier, in Chapter 1, you probably have already self-identified as either a data implementer, a data leader, or a data entrepreneur. Now, implementing an operational improvement use case at this time may — or may not — be the most appropriate choice, depending on where you work and the current priorities of that business. In either case, the knowledge shared in this chapter is valuable to you, personally, as an up-and-coming data expert. Here’s how:
- Data implementers: It’s worth the time and effort to tap into the technology and machine learning aspects introduced within this chapter as a jumping-off point for explorations into demand across the data sector. If a particular aspect of this chapter looks especially interesting to you, I recommend that you do some market research to establish how much demand exists for these sorts of implementation skills. Just because an operational use case may not make sense for your company at this time doesn’t mean that you can’t incorporate the use cases’ underlying technologies and methodologies to make improvements or create more efficiencies within the day-to-day work you’re doing as a data science implementation worker.
- Data leaders: The thing to understand about operational improvement use cases is that, although they may be proven by case studies in industries different from your own, it’s possible that these use cases can be applied to drive improvements in your industry as well. While reading up on operational improvements use cases, be sure to continually “check in,” by asking yourself, “Where might this fit into our company as it is today? Can this use case possibly be retrofitted to create value for the company as well? If so, how?”
- Data entrepreneurs: It doesn’t matter what sort of business you run, or plan to run; you’ll continually look for ways to make operational improvements on your business. If you have a business-to-business (B2B) company — a company that works with and supports other companies, usually larger corporations — chances are good that you’re selling products or services geared to make some sort of operational improvement for your client’s company. If you see promising information in this chapter, I recommend looking deeper into its associated costs as well as time-to-market — the time required to set up a product or service and get it operationalized and out into the market.
Now that I’ve established the ground rules for how to use this chapter, let’s get into all the glorious details about how data science is successfully being used to improve business operations!
Exploring Ways That Data Science Is Used to Improve Operations
When I talk about business operations with respect to data science, what I’m talking about are the operational processes within a business that are required to
- Create and increase recurring revenues.
- Increase the monetary value of existing assets.
- Preserve the existing revenues and overall valuation of the business.
Beyond that, operational improvements come in many flavors. From quality assurance to improved forecasting, the improvements a company makes on an operational level subsequently feed into every single line of business that the company maintains. What’s more, operational improvements are available to help businesses across every industry under the sun.
Table 10-1 provides you with more concrete examples of real-life operational improvement use cases for data science across a wide variety of industries.
Now let’s take a closer look at ways in which data science is being used to improve operational efficiency in manufacturing.
TABLE 10-1 Operational Improvement Use Cases for Data Science, by Industry
|
Industry |
Operational Improvement |
Company |
|---|---|---|
|
Transportation |
Hundreds of millions of US dollars saved per year |
United Postal Service (UPS) |
|
Government, healthcare |
A 120x reduction in report generation time |
US Centers of Disease Control (CDC) |
|
Media, news, and entertainment |
Fifteen-fold increase in news stories generated |
Associated Press (AP) |
|
Food and beverage |
Fifteen % reduction in restocking trips |
Coca-Cola |
|
Business services |
Thirty % to 70% increase in business processes automation |
Deutsche Bank |
|
Finance and credit |
Detection acuity increased by 250% for criminal transactions |
NASDAQ |
|
Computer software |
Saved 75% of overall GPU cost for visual search |
Bing |
|
Lawyers, law firms |
Automated Round 1 of document review |
BA-HR |
|
Transportation |
Substantial fuel costs saved and data wrangling reduced by 60% |
Southwest Airlines |
|
Oil and gas |
Substantial improvement in company's overall performance |
Shell Oil |
Source: Data Use Case Collection Workbox, Data-Mania.com
Making major improvements to traditional manufacturing operations
Over the past decade, advancements in Internet connectivity, AI, and robotics automation have turned traditional manufacturing on its head, catapulting the world into what’s come to be known as the fourth industrial revolution — a period in which AI technology is producing a profound and rapid overhaul of the traditional manufacturing industry, seeking to replace traditionally manual labor with automated control and execution of production via robots. It’s good for business but bad for factory workers — in fact, you’ve probably seen a lot about factory layoffs on the news, and this AI-enabled robotics automation is to blame. This was as true pre-COVID as it is today.
Manufacturing started off as the customized production of goods and then moved into an era of mass production; this fourth industrial revolution, however, marks an era in which manufacturing companies are developing the full flexibility they need to actually carry out mass customization production — customized production on a massive scale. With mass production, long lines of mass-producing robots were fixed in an operational series, and that was adequate to meet production requirements, but things have changed. To meet the demands of mass customization production, manufacturing robots must collaborate and be designed with the flexibility they need in order to integrate, change, and adjust production requirements autonomously and on demand.
When it comes to mass customization production, robot work can be performed within what’s called a robot workcell — an autonomously operating work environment where robots can produce at their fullest speed and capacity without adherence to safety protocols that would generally be required in the presence of humans, as shown in Figure 10-1.

FIGURE 10-1: AI-enabled robotics automation.
Within a robot workcell, predictive machine learning models can be run inside the programmable logic controller (PLC) — also known as the robot task controller. With machine learning making decisions in the PLC and the robots executing on those decisions in the physical world, you pass from industrial machine learning into full-fledged, honest-to-life artificial intelligence.
As machine learning advances, PLC units are able to offer increasingly more sophisticated robot task control. The following list describes just a few of the ways that industrial machine learning is making manufacturing operations dramatically more efficient:
- Defect analysis: With the help of K-means clustering, you can categorize data on manufacturing parts to classify quality and reliability. For more on K-means clustering, refer to Chapter 5.
- Production forecasting: One strategy is to use regression analysis on historical production data in order to predict production levels from a system, or even any given process within that system. Regression analysis is covered in Chapter 4.
- Self-tuning vision systems: Neural networks are useful for computer vision technology — processes that use the automated extraction of information from images in order to support manufacturing units as they autoregulate and adapt based on data captured via live camera footage recorded during production work. Deep learning and neural networks are covered in Chapter 3.
Optimizing business operations with data science
Traditionally, it’s been business process automation (BPA) solutions that are known for producing radical efficiencies within business processes. In case it’s new to you, business process automation is the streamlining of day-to-day business operations by automating repetitive tasks that would otherwise be carried out manually. Though BPA is still a relevant and powerful force in the operational improvements space, data science has also stepped up as an outstanding companion to any business that seeks to optimize and improve its operations. The following are a few ways data science is being used to optimize business operations:
- Automated document analysis: Deep learning and neural networks are commonly implemented to produce computer vision applications that are capable of taking written reports, breaking them down to their most fundamental data points and then evaluating those data points in order to produce actionable insights from a written document without the need for human intervention.
- Automated report writing: It’s now completely possible for businesses to take data from financial reports and apply natural language processing to automatically convert the raw financial data into fully customized written reports.
- Automated customer service support: Companies are now using machine learning to improve, personalize, and automate their client interaction processes. More details on this use case are discussed in the case study highlighted in the next section.
An AI case study: Automated, personalized, and effective debt collection processes
LendUp is a company specializing in financial technology, credit card, financial education, credit reporting, and loan services to lending clients. LendUp has developed a machine learning platform that prompts debtors to schedule and send debt payments through the use of personalized offers, repayment plans, and reminders. LendUp’s mission is to promote AI technological approaches to real-world problems, and to deliver value-adding applications of AI technology. LendUp’s main functions revolve around finding and implementing automated, technological solutions in the areas of account management and customer management.
As a financial tech company, LendUp wants to use a machine learning system to improve its credit card and loan services as well as its customer management mechanisms. To this end, LendUp sought out TrueAccord to utilize its machine learning platform. TrueAccord’s system is capable of influencing customer behavior by publishing personalized reminders to make repayments of debts. This machine learning platform can also create and deliver customized debt repayment plans and personalized offers for LendUp’s customers.
The solution
LendUp opted to work with TrueAccord because of the many benefits that its machine learning platform offers. TrueAccord’s data-driven platform can increase LendUp’s recovery rates, lower compliance-related risks, and optimize LendUp’s customer experiences.
TrueAccord offers code-based and code-driven credit and other debt collection compliance measures, thus reducing LendUp’s compliance risk and exposure levels. The platform also permits LendUp to fully monitor consumer behaviors. Additionally, it allows for quick and simple notifications to be sent and updates to be made as relevant requirements and regulations shift over time. Content that is prewritten and preapproved can be sent via TrueAccord’s omnichannel approach (discussed further in Chapter 11), which can vastly reduce issues such as consumer complaints and the debt collection outreach frequency that’s required to collect on loans due. During all of this, TrueAccord’s system can log a complete record of the consumer interaction process that can be easily retrieved and reviewed by LendUp’s teams.
With TrueAccord, LendUp can reach higher customer engagement levels and give consumers the tools that they need to clear up their debts by using on-demand and self-service features. TrueAccord’s approach is consumer-centric, offering consumers personalized payment plans and offers that allow them to repay their debts more efficiently than would be the case if these machine learning systems weren’t in place. LendUp is thus able to provide tailored, personal plans for its customers to guide them through the collections process and create successful debt payment arrangements, thus improving its recovery rates.
By working with TrueAccord, LendUp readily acknowledges that modern technology is now the norm in terms of consumer demands. Through a data-driven, digital-first collections approach, TrueAccord can further empower and engage LendUp’s consumers by creating a tailored contact strategy — an automated procedure for directing consumers to self-service payment models and giving nurturing messages until their debts have been completely paid in full. In this way, LendUp’s consumers can sustain high motivation levels with respect to paying off their loans or credit card debts and eventually reaching excellent financial health. The result is that LendUp gains valuable consumer loyalty while lowering its risks for losses in the present and future.
TrueAccord’s decision engine, Heartbeat (patent pending), creates digital-first, personalized consumer experiences that are driven by machine learning. It chooses from internally generated and legally preapproved messages to keep track of real-time events related to each consumer, such as links clicked and emails opened. Its platform uses a state machine — a behavioral model that represents interactions as transitions and machine modes as states with the goal to reach a predetermined final state and produce a desired output. This state machine is used to craft a virtual interaction model with LendUp’s consumers, and it uses a clustering engine to compare a given consumer to the over 1.5 million consumers who have interacted with the system in the past. Using data points that range in the hundreds of millions, TrueAccord’s machine learning platform can offer actionable predictions when it comes to consumer reactions to elements such as content, communication timing, frequency, and channel. Through TrueAccord, LendUp has served over 2.5 million consumers and processed tens of millions of collections-related interactions.
The result
LendUp doesn’t show it’s cards by outright stating exactly how much money they are making from savings and increased revenue generation due to TrueAccord’s Heartbeat solution, but let’s review all of the ROI-generating outcomes their enjoying:
- Dramatic decrease in expenditures on payroll for customer service representatives: TrueAccord automates customer service at mass-scale. What’s more, Heartbeat uses machine learning to improve upon the results that human customer services agents would have produced. All of this means significantly less money spent on payroll as well as improved results.
- Increased conversion rates for new offers: TrueAccord deploys machine learning to improve offer personalization. This results in more revenue, due to an increase in new loan contracts, as well as lower costs associated with customer acquisition.
- Improved customer satisfaction: Customized debt repayment plans (delivered in a way that’s not annoying to customers), self-service payment models, and nurturing messages that keep customers engaged and motivated … all of these result in lower customer churn, greater lifetime value per customer, and a net increase in loan repayment success.
But what does all this mean for you and your company? Well, your company might not be in the finance industry, but it probably does need to interact with its client regularly. In this case, it’s possible that implementing a similar approach could streamline customer service operations and save the company lots of time and costs! It’s definitely worth taking a deeper look into the types of tools, technologies, and techniques that are running under the hood. That’s where the use case comes in, so let’s take a quick look at it.
 Anytime you see an especially promising case study, do some Internet research and try to map out a theoretical use case for it so that you can see how a particular data science win might be made reproducible in your own business. I did that in Table 10-2 for the LendUp case study I just introduced.
Anytime you see an especially promising case study, do some Internet research and try to map out a theoretical use case for it so that you can see how a particular data science win might be made reproducible in your own business. I did that in Table 10-2 for the LendUp case study I just introduced.
It’s equally valuable to do some Internet research and dig into the types of tools, technologies, and data science methodologies that are required to build out this type of use case. Table 10-3 documents the theoretical technology stack that would support this type of debt-recovery use case.
If you're a data implementer and you like this use case, dig deeper into the technology specifications that are described in Table 10-3 above. If you’re a data leader, you now have a blueprint for the people, processes, tools, and data resources you’d need to spearhead a project similar to this one for your company. Lastly, if you’re a data entrepreneur, you could either explore ways to adopt processes from Table 10-2 to streamline your own customer service operations or you could decide to look into how feasible it is for your company to build and sell a similar but sufficiently unique product in a different vertical. That was easy! Now let’s look at a few examples of how data science is being used to make operational improvements in industries outside financial services.
TABLE 10-2 Theoretical Business Use Case for Automating Client Interactions
|
A — BUSINESS USE CASE |
|---|
|
Recover debt |
|
B1: DESCRIPTION |
|
This use case describes how a LendUp debt collector creates personalized reminders, repayment plans, and offers for consumers, using TrueAccord’s Heartbeat algorithm. It begins when the debt collector inputs consumer information and ends when Heartbeat recommends a repayment plan and an offer to the consumer. |
|
B2: ACTORS |
|
Primary actor: Debt collector |
|
Supporting actors: Heartbeat, content writer, legal reviewer |
|
Offstage actor: Consumer |
|
B3: PRECONDITIONS + POST-CONDITIONS |
|
Preconditions |
|
|
|
Post-conditions |
|
|
C: MAIN SUCCESS SCENARIO |
|
Actor intention |
|
|
|
|
|
|
|
|
Success scenario |
|
A personalized repayment plan, reminders, and an offer are created for the consumer. |
|
D: INDUSTRIES AND FUNCTIONS |
|
Industries: Fintech, banking |
|
Functions: Debt recovery, relationship management, account management |
|
E: BUSINESS USE CASE DIAGRAM |
|
See Figure 10-2. |
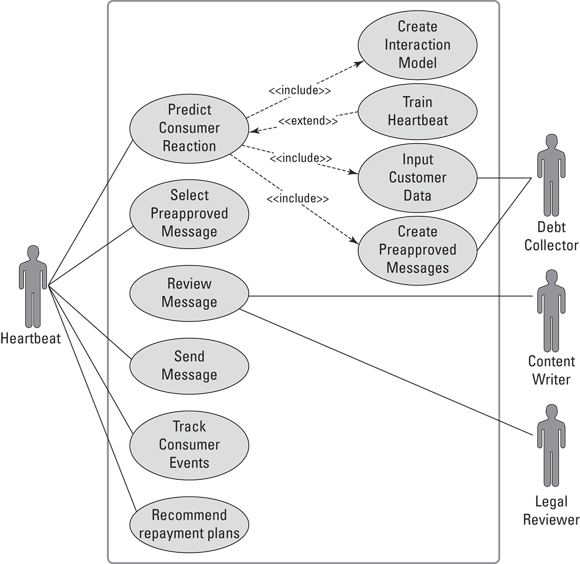
FIGURE 10-2: Diagram of a debt-recovery business use case.
TABLE 10-3 Theoretical Technology Stack for Automating Client Interactions
|
Technology stack |
Data management On-premise/clou/hybrid data management Big data
Traditional data
Analytics and visualization tools
Machine learning technologies
Software engineering technologies
|
|
Data science methodologies |
|
Gaining logistical efficiencies with better use of real-time data
Given what you already know about data science, I’m sure you can already imagine some of the spectacular impacts AI has had on logistical operations. From Uber to UPS, the pace and scale of 21st century logistics is breathtaking. If successful today, these logistical operations are more than just cars, trains, freights, and delivery dates — they’re also data-intensive. That means they run on parallel computing systems that are designed expressly to meet the processing and evaluation needs required to convert big data into big dollars. In this section, you get the chance to take a closer look at how UPS serves parcels on its data platter, but let’s go broad first, by looking at various ways in which data science is used in supporting logistical operations. The most common logistical operations use cases for data science include these:
- Real-time optimized logistics routing: Real-time routing is useful in all areas of transportation but has proven especially valuable when it comes to logistics operations involved in air freight, sea freight, and even ground parcel transportation. I help you take a deeper dive into a real-time optimized routing use case next. For now, just be aware that the use of AI is as beneficial to the environment as it is to a company’s bottom line.
- Predictive maintenance: Especially relevant in today’s railway industry, transportation providers are now equipping freight locomotives with the cameras and predictive applications they need to identify physical objects and avoid potential collisions or derailments. To do this, they use neural networks to build a computer vision system that’s capable of real-time object detection. This use of AI not only saves lives but also decreases the cost associated with unplanned and avoidable breakdowns.
- Optical character recognition to optimize delivery address sorting: Optical character recognition is a form of computer vision that uses deep learning to detect handwritten and typed characters. Ground transport providers use this type of AI to “read” a parcel’s address label and then automatically categorize and sort each parcel into groups based on similarities in geographic location (based on identifiers like zip code and city name). This use of AI decreases the person-hours spent in manual sorting and increases the speed and accuracy of the mail delivery service.
Another AI case study: Real-time optimized logistics routing
The United Parcel Service (UPS) is a multinational supply chain management company best known for its package delivery services. Beyond package delivery, it offers services in retail-centric shipping and packaging services (The UPS Store), freight-focused trucking operation (UPS Freight), and cargo airlines (UPS Airlines).
Each winter, UPS faces a daunting problem: how to handle the logistical complications of bad weather hitting major cities — such as nasty storms. Bad weather can disrupt many thousands of packages that are usually transported through a major city on their way to their ultimate destinations. If UPS had a way to know in advance that the bad weather would significantly impact its delivery-related operations, what would be the most efficient means of moving these packages, gifts, and online orders around the bad weather?
To do so, UPS has to take on the difficult task of selecting the facility that is best suited for handling an unexpected, large shipment and is capable of shipping these packages toward their destination. Several variables complicate this sort of decision: The packages’ respective destinations, the types of packages, and their respective delivery deadlines. All these factors can slow down the logistical decisions of UPS engineers and can make it even harder to efficiently shift resources.
To manage the whole package-flow process, UPS employed several kinds of transportation planners and industrial engineers, including employees who set work hours and training for pilots and employees as well as employees who ran the coordination process for loading and unloading trucks. Teams used consumer software such as Microsoft Excel and Access, emailing lists to each other when the need arose. All this changed in September 2018, with the implementation of the initial version of UPS’ Network Planning Tools, or NPT.
The solution
The NPT is an internal, cloud-based machine learning platform with multiple modules that provides a host of benefits to its networks and its customers — particularly, hub and route optimization benefits. One main benefit is that it allows UPS to create more efficient package routing and rerouting paths through its advanced algorithms. This allows UPS to reroute packages already in transit to a near- or at-capacity hub to a different hub that can handle the package. The system allows UPS’s engineers to get a bird’s-eye view of package distribution and volume across the entire network. It also allows UPS to make decisions based on real-time data year-round and through any number of volume fluctuations.
The NPT can also efficiently divert packages heading into bad weather to several different hubs that are out of harm’s way, all while tracking the relative capacity levels of these hubs to not overwhelm any of these facilities. All this can be done in a way that still ensures that packages are delivered on time to their respective destinations. Essentially, the NPT serves as a comprehensive big data platform that includes a simulation function, informing employees of the impact of each work decision they make.
The result
The results of the NPT platform haven’t been fully released, but UPS expected this platform to save the company hundreds of millions of dollars each year. NPT was also successful enough for UPS to add another feature to it: the Peak Volume Alignment Tool (PVAT). This analytical tool better pairs incoming volume flows with the available capacity of networks, improving operating efficiency and capacity utilization.
Now that you’ve seen this use case from the outside looking in, let’s take a shot at creating a business use case that describes how this sort of thing would work in terms of business processes. Table 10-4 documents the theoretical technology stack that would support this type of route optimization use case.
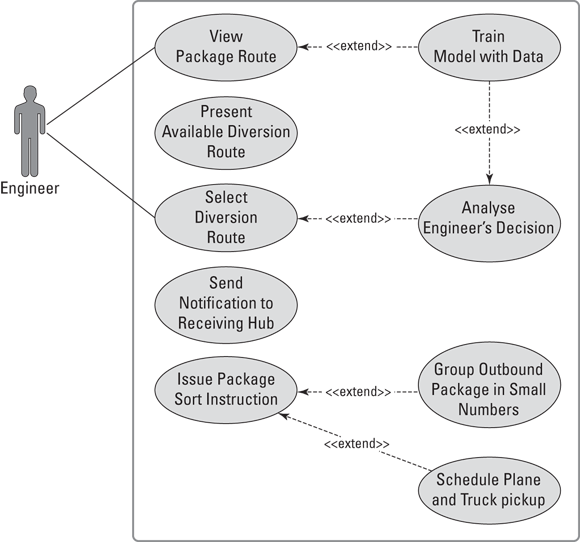
FIGURE 10-3: Diagram of a logistics-routing business use case.
TABLE 10-4: Theoretical Business Use Case for Real-Time Optimized Logistics Routing
|
A: BUSINESS USE CASE |
|---|
|
Real-time optimized logistics routing |
|
B1: DESCRIPTION |
|
This use case describes how a UPS engineer uses network planning tools to route shipments to the facilities with the highest capacities. |
|
B2: ACTORS |
|
Primary actor: Engineer Offstage actor: Customer |
|
B3: PRECONDITIONS + POST-CONDITIONS |
|
Preconditions
Post-Conditions
|
|
C: MAIN SUCCESS SCENARIO |
|
Actor intention
Success scenario
|
|
D: INDUSTRIES AND FUNCTIONS |
|
Industries: Logistics and freight Functions: Route planning |
|
E: BUSINESS USE CASE DIAGRAM |
|
See Figure 10-3. |
Business use cases are all well and good, but because you’re reading a book on data science, I’m sure you’re itching to see the potential tools, technologies, and data science methodologies that are useful in this type of use case. Table 10-5 documents the theoretical technology stack you could build in order to support a route optimization use case like this one.
 Google Search is your friend when you want to look into the sorts of technologies that go into building out a data science use case.
Google Search is your friend when you want to look into the sorts of technologies that go into building out a data science use case.
Clearly, if you’re a data implementation buff who is working in the logistics sector, you have a lot to play with here. Don’t worry, though: I’m sure no one is expecting you to singlehandedly build a system like the one UPS came up with — that’s not even possible! What you can do is start small — probably with a classification algorithm — and look to see how you can create some new efficiencies within your company’s current logistical operations. Once you’ve achieved some small measure of success, you’ll have some ground to stand on in terms of doing more.
TABLE 10-5 Theoretical Technology Stack for Real-Time Optimized Logistics Routing
|
Technology stack |
Data management Cloud data management
On-premise / cloud / hybrid data management Big data
Machine learning technologies
Software engineering technologies
|
|
Data science methodologies |
|
When it comes to implementing new data use cases, always start small. Once you’ve achieved reproducible success on the small scale, you’ll have a stronger sense of a solution's future feasibility when you start looking to implement your solution on a larger scale. (More on this topic in Chapter 17.)
Modernizing media and the press with data science and AI
Deep learning AI is in the process of turning the content, media, and press industry on its head, and the changes that are underway are utterly irreversible. From tiny online mom-and-pop shops to the largest media companies in the world, late-breaking advances in AI aren't just making for a level playing field — they’re picking up the playing field and placing it into a whole new territory.
At the time of this book update, AI-assisted content creation tools are rapidly proliferating across the Internet. They’re now available for free on a trial basis or at a very low cost so that even the smallest of small-business owners can benefit from the efficiencies these tools create. I’m talking about AI tools for written content creation, visual content creation, and everything in between. Let’s start by looking at AI solutions that are available to small businesses, and then I’ll introduce you to a case study and use case for building an AI solution for a behemoth-size media company like the Associated Press.
Generating content with the click of a button
“GPT-3.” That has a ring to it, doesn’t it? But that echo might just be the ringing sound of the final round in a content boxing match between humans and the machine. And machines? They’re crushing it. If this sounds too apocalyptic to be true, let me explain.
GPT-3 is a language model that generates human-like language. Written in Python, it uses large amounts of text to generate new, similar text. It was developed by researchers from OpenAI — an AI research-and-deployment company determined to ensure that AI innovation benefits all of humanity, not just an unduly concentrated segment of rich-and-powerful business owners. On June 11, 2020, OpenAI announced user-friendly access to its API. Since then, many new data entrepreneurs have been busy building online businesses that sell automated AI content-generation services that run off the OpenAI API. These small data businesses are selling automated content services and making a good living helping content creators produce written content that can pass the Turing test — a standard set by famed mathematician and computer scientist Alan Turing in 1950. It says that machines will have achieved human-equivalent intelligence when they can produce outputs that are indistinguishable from similar outputs generated by humans.
OpenAI isn’t just creating language models, though. It’s also building models that can create visual images from text, called DALL·E, and Image GPT, a model that transforms partial images to full images by predicting and generating what would likely be contained in the missing portions of the images. What’s more, these aren’t the only types of AI-infused content generation tools, either. There are many others, like AI article spinners, AI content research tools, and AI grammar correction tools, just to name a few.
The $10 million dollar question here is, “Will AI put writers and content creators out of work permanently?” To that question, I reply with a resounding no. Though AI is now capable of creating human-esque, plagiarism-free content at the click of a button, it cannot generate the context that’s required for humans to transform information into meaning. To gather meaning from information, humans need knowledge. Without knowledge or context being provided within a written piece of work, readers can’t draw inferences or conclusions from the information the writing contains. In other words, will AI tools put non-experts and unskilled writers out of work? Probably. Will they be able to replace the human aspects required to generate an expert-level body of writing? It’s unlikely.
GPT-3 and friends may be all well and good for small mom-and-pop shops, but it's not designed to support the operational needs of large media companies. For large companies, you almost always need to build out a robust, custom solution. That’s exactly what the Associated Press did in order to generate a 15-fold increase in news stories it can generate per unit time. Let’s take a deeper look into this remarkable win, shall we?
Yet another case study: Increasing content generation rates
The Associated Press (AP) is an industry leader in terms of journalism and news media. This organization’s membership includes thousands of TV and radio broadcasters and roughly 1,400 daily newspapers around the US. Beyond the impressive amounts of news content that AP distributes, it’s also an organization well-known for its style. Professionals in the fields of journalism and in other industries regard “AP style” as the quintessential writing standard.
For many years, Associated Press reporters had to report on the corporate earnings of US public companies every quarter, a time-consuming and stressful process. AP sought out a data-oriented automation solution that would free up its reporters' time, giving the reporters a chance to focus more on reporting quality news content.
The problem
Reporting on these quarterly corporate earnings created a number of external and internal problems for AP and its many reporters.
Externally, AP's main issue was the sheer volume of US public corporations that report their earnings, numbering in the thousands. Internally, AP business reporters were faced with a daunting task each quarter, where they would have to grab data from corporate earnings press releases, copy them, place them within prewritten templates, add headlines, and then promptly publish them. These actions needed to be performed quickly and early in the morning so that stock traders would be adequately informed on whether they should buy or sell a given stock.
On top of this process being time-consuming and unpleasant, the AP reporters would manage to create only around 300 news stories of these corporate earnings each quarter. Thousands of US corporate earnings reports were left by the wayside, so many traders lacked the information they needed.
Each quarter's news stories were crafted by interpreting financial information from the earnings reports of as many US corporations as the reporters could manage, but that still meant the stories for many companies went untold. Eventually, AP decided that it needed to find a better way — for the sake of its reporters, its customers, and the company at large.
The solution
One reason for AP's ability to last so long compared to other news organizations is its recognition of the need to take advantage of new technologies and strategies. AP thus turned to automation as an innovative potential solution to its reporting problems.
AP had a plan that would lead to its reporters spending much less time on gathering data and numbers and devoting more time to producing high-quality articles and stories for its customers and subscribers. It was able to put its plan into action with Automated Insights' Wordsmith platform. Wordsmith uses natural language generation (NLG) to convert collected data into a written-out, plain-language story. It’s capable of turning data from a corporate earnings report into an article worthy of being published at AP in only a fraction of a second. Wordsmith's products were able to meet AP's standards because the platform's team was able to customize the NLG engine in a way that matches AP style.
AP applied Wordsmith to different content areas at first. Over time, the Wordsmith platform was put through extensive and intensive testing, steadily reducing the error rates in the automated AP earnings reports. Eventually, testing was conducted on the automated earnings of corporations from Canada and from Europe.
The result
AP, working together with Automated Insights' Wordsmith platform, was able to achieve the following results:
- Produced 4,400 quarterly earnings stories
- Increased story generation rates by nearly 15-fold
- Freed up around 20 percent of the time that was spent by the reporting staff creating earnings reports each quarter
The Associated Press turned a problem into an opportunity to produce higher volumes of high-quality articles by way of automation. Through the automated NLG capabilities of Automated Insights' Wordsmith, AP converted raw corporate earnings data into thousands of AP news stories, creating many more stories about corporate quarterly earnings than previous efforts performed manually.
In terms of how the Associated Press was able to achieve this across the business unit, I’ve drawn up a theoretical business use case that could support the case study I just shared. Table 10-6 shows the fruit of my labors.
TABLE 10-6 Theoretical Business Use Case for Increasing Content-Generation Rates
|
A: BUSINESS USE CASE |
|---|
|
Increase content-generation rates |
|
B1: DESCRIPTION |
|
This use case describes how a news company content writer can create a narrative from quarterly earnings data using Automated Insights’ Wordsmith platform. It begins when the content writer uploads earnings data and ends when the content writer publishes a narrative created by Wordsmith. |
|
B2: ACTORS |
|
Primary actor: Content writer Supporting actors: Wordsmith, domain expert |
|
B3: PRECONDITIONS + POST-CONDITIONS |
|
Preconditions
Post-Conditions
|
|
C: MAIN SUCCESS SCENARIO |
|
Actor intention (basic flow)
Exception flow (if content writer is dissatisfied with narratives in Step 3)
Success scenario A textual summary of earnings is produced from data. |
|
D: INDUSTRIES AND FUNCTIONS |
|
Industries: Media and publishing Functions: General operations |
|
E: BUSINESS USE CASE DIAGRAM |
|
See Figure 10-4. |

FIGURE 10-4: Diagram of a content publishing business use case.
As helpful as this use case is to data leaders in the media industry, it probably doesn’t wet the whistle of any data implementers out there. Let’s look at Table 10-7 for some technology specifications for this use case, shall we?
That's the third and final technology specification for this chapter, and through them all, you’ve seen one overwhelmingly obvious trend: deep learning. In almost all the operations case studies I talk about, the company either utilizes, or wants to be utilizing, deep learning. Deep learning skills are clearly valuable and in demand, so if you’re a data implementation person, now is a good time to boost your skillset in that subniche and find yourself some golden opportunities.
If you’re a data professional in the news and media industry, it’s time to open your eyes to the incredible breakthroughs that AI is facilitating across your industry. Whether you give GPT-3 a go or build out a custom data science solution, you have some major opportunities to use AI to get ahead of your competition as a professional in the media industry.
TABLE 10-7 Theoretical Technology Stack for Increasing Content Generation Rates
|
Technology stack |
Data management Cloud data management
On-premise / cloud / hybrid data management Big data
Machine learning technologies
Software engineering technologies
|
|
Data science methodologies |
|