Chapter 14
Monetizing Data and Data Science Expertise
IN THIS CHAPTER
 Selling data services
Selling data services
Monetizing your data science products
Making money from data itself
Doubling down on data privacy
“Data is the new oil.” Clive Humby, a British mathematician and data science entrepreneur, said that all the way back in 2006! What did he know that most didn’t? Well, he clearly must have seen the explosive potential for revenue generation that is available via the right combination of data resources, data expertise, and business-building know-how. I discuss Clive later in this chapter, but first I want to acquaint you with the various alternatives when it comes to monetizing data services, data products, and data partnerships. At the end of this chapter, I want to have a serious talk with you about AI ethics and their paramount importance in the survival of the planet, our businesses and societies, and the future of humanity. Make sure not to skip that part!
Setting the Tone for Data Monetization
Data monetization — the direct or indirect sale of data resources, technologies, or skill sets — isn’t new per se, but what has changed is the variety of formats in which data is being monetized. In 2015, MIT Technology Review published a listing of the 50 Smartest Companies in the World. Over a quarter of those companies were AI companies — companies heavily dependent on AI to deliver their businesses’ products and services. It isn’t unreasonable to estimate that, these days, all of the world’s smartest companies are in some way dependent on AI to help them in operating, growing, and scaling their business, products, and services.
Over the past several years, online listings and awards of the top AI start-ups have proliferated across the Internet. After spending only a few minutes browsing these listings, you or any other business-savvy data professional can see the obvious bias. Most of these listings only include AI SaaS products, and completely omit any mention of companies that in fact offer AI support but choose not to sell a particular AI SaaS solution — including service-based companies that build custom AI solutions for their clients or other forms of products that support companies in building out their AI products and services. Making matters worse, some of the companies listed as the top AI start-ups aren’t even AI companies.
What has happened is that, since about 2017, the term AI became the holy grail buzzword that every technology company wanted to claim it offered its customers. And though most of these companies are surely data companies — companies that monetize some combination of data resources, technologies, or skill sets — they’re not actually AI companies. For a SaaS solution to truly qualify as artificial intelligence, it needs to deploy machine learning within a software application, where the software application is the actor and the machine learning engine acts as the internal decision-maker. (For more on the difference between machine learning and AI, see Chapter 3.) Some of the SaaS companies in these listings of the top AI start-ups don’t actually deliver any predictive or prescriptive analytics whatsoever — only descriptive analytics, which report what happened in the past. They might be more accurately described as top BI companies, but that label isn’t nearly as sexy. (If all this talk of descriptive analytics and BI has you scratching your head, check out Chapter 12, where I discuss these topics in greater detail.)
Why then are non-AI data companies being highlighted and promoted as top AI companies? Well, I hate to say it, but that situation comes down to these three main factors:
- A widespread deficiency in data literacy
- Potentially questionable marketing alliances
- Investment money (the elephant in the room)
Most technology investors want to see that a company is AI-enabled. And many of these lists of top AI companies showcase data companies according to how much outside investment funding they’ve raised. It’s only my opinion, but I believe that the top label should be assigned to companies that have generated the most positive impact on the world around them, not the companies who’ve managed to convince investors to give them the most amount of money. That said, despite COVID’s disastrous impact on global economies in 2020, AI start-ups managed to raise record-breaking funding that totaled $33 billion dollars in 2020 alone. Needless to say, there is money to be had in the credibility conferred on you when you manage to get your company listed as a top AI start-up. That’s marketing.
 For a full listing of the research sources I’ve used in writing this book — including the resources I've used to investigate this whole idea of top AI start-ups — head over to
For a full listing of the research sources I’ve used in writing this book — including the resources I've used to investigate this whole idea of top AI start-ups — head over to https://businessgrowth.ai/.
It may sound harsh, but if it’s not profitable, it’s a hobby, not a business. And, though I can’t speak to AI companies like Uber, which has maybe had a positive impact from a carbon-footprint perspective yet has never managed to turn an actual profit after seven years in operation, I can say that moving from big data hype (the negative consequences of which are discussed in Chapter 2) to AI hype is like switching rooms in the Titanic: Either room you’re in, hype-based investment is a recipe for disaster.
Throughout the remainder of this chapter, you get a chance to move beyond the AI hype and learn about data monetization and the wide variety of alternatives out there to monetize data resources, data skills, and data technologies. Although AI SaaS is incredible — and I myself would love to own one — throughout this chapter, my goal is to educate you on the wide variety of ways to monetize data — including AI SaaS products as well as strategies with or without investors. Figure 14-1 shows the data monetization approaches I cover throughout the remainder of this chapter.
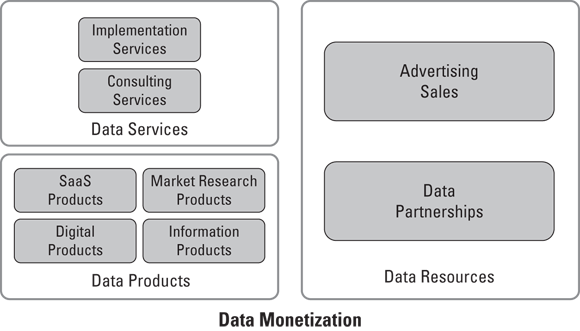
FIGURE 14-1: The three main ways to monetize data.
Before tackling data monetization in earnest, let's turn back to Clive Humby for a moment and talk about where he fits within the data monetization picture. How did he know more about data’s monetization potential back in 2006 than most people know even today? It’s simple, actually. He emerged from university in 1972, with his degrees in applied mathematics and computer science in hand — but with a heart for business and leadership. What does any good entrepreneurial STEM graduate do? They naturally look for ways to turn their Science, Technology, Engineering, and Mathematics expertise into a business, of course! People who are of a mind to be a data leader or a data entrepreneur waste their talents when they spend their careers implementing data science solutions. Some people love to do data science implementation, and they’re great at it. Other data science professionals love to solve big picture business problems, and often wind up being extremely successful leaders and entrepreneurs in the data space. As for Clive Humby, he’s spent almost 50 years using his data science expertise to lead businesses or run his own. And for someone like that, “Data is the new oil” would be the most natural of conclusions — he just got a darned good head-start on the rest of us.
Monetizing Data Science Skills as a Service
If you’ve always worked as an employee in someone else’s business, it can be difficult to see how your data science skills can translate to monetary value on the open market — that unlimited market that provides open access to buyers and sellers of all backgrounds, ethnicities, genders, and socioeconomic brackets. About ten years ago, there was no such a thing as “data science,” and buying and selling data science services on the open market was a rare practice until about 2017. What has always been around, however, are vendors who sold services as add-ons to their product subscription packages. Most of these packages, though, were prohibitively expensive for small- and medium-size businesses.
The number of workers with data science expertise has grown incredibly fast since 2017. The good news about this expansion is that it has helped open up a space for businesses of all sizes to purchase and access data science support. Let's be real: Most businesses can afford to pay a data science consultant $20,000 to come in and build a few models for them. Heck, for that budget, you could be well on your way to building a data science product that you could monetize directly within your existing customer base. What most small- and medium-sized businesses cannot afford, however, is to pay $250,000 — maybe even multiple millions of dollars — per year for bloated data products and cookie-cutter services that miss the mark in terms of generating any measurable ROI.
And so you see, you have a wide gap in the market for data services, freelance data professionals, data services companies (agencies that sell data services), and data consulting companies (companies that sell data strategy consulting services). Throughout the rest of this section, you get a bird’s-eye view of the data science services landscape — a landscape ripe for the picking for the entrepreneurs and businesses out there that have the expertise needed to fill that gap.
 Data science is a popular and important part of the data services sector, but you can offer data services many other ways that don’t necessarily equate to “proper” data science. For brevity's sake, I’ve excluded these types of services from this discussion.
Data science is a popular and important part of the data services sector, but you can offer data services many other ways that don’t necessarily equate to “proper” data science. For brevity's sake, I’ve excluded these types of services from this discussion.
Data preparation services
I bet you didn’t know that companies are outsourcing their data clean-up services, did you? They are. I’m not talking about the traditional type of email-list data validation and clean-up service, either — I’m talking about bona fide data-preparation-as-a-service businesses. Though still few and far between, these companies offer services like these:
- Data cleaning: Removing strays, duplicates, and out-of-range records as well as standardizing casing
- Data transformation: Treating missing values, dealing with outliers, and scaling variables
-
Data normalization: Preprocessing in order to transform data from its raw and imperfect format into a canonical standardized format
The transformation can involve correcting spelling and grammar errors, converting abbreviations to their long-form equivalents, reformatting casing, transforming emojis into their emotional equivalents, and more.
- Data processing: Data parsing, recoding of variables, concatenation, and other methods of reformatting your dataset to prepare it for analysis
- Data taxonomy services: Manually assigning category labels to data points in a data set in order to create multiple, hierarchical relationships between data points in the data set
For perspective, let me point out that I took these offers from one service provider’s website and elaborated on them. As you can see, service providers that offer similar services on a piecemeal basis have really just broken out the various steps involved in preparing data for data science and are then selling them as separate offers. You could structure these types of services in more profitable ways, but in the end, implementation-based services tend to be less scalable and have lower profit margins in the long run. This underscores the importance of diversity in revenue models in a data business.
I’ve created some mini trainings on optimal business models and revenue models for data businesses. If you’d like to see those, head over to the https://businessgrowth.ai/ website.
Model building services
Some companies offer the whole data science kit-and-caboodle. On top of preparing your data for analysis and machine learning, they also model it for you and present their findings. Machine learning model-building services can include these elements:
- Data mining: In data mining, you work to narrow down data sets by using pattern recognition techniques to identify and select only the most relevant data sources for the problem at hand. After you’ve identified these data sets, you have to extract enough of these select data resources in order to build a reliable model.
- Data preparation: I describe the steps for this process in the earlier section “Data preparation services.”
- Data ingestion: This involves loading data into a system, platform, or environment. (For more on data ingestion, see Chapter 13.)
- Machine learning model selection: After testing out various machine learning algorithms, you then need to select the model that performs the best. This is what’s known as model selection.
- Machine learning model-tuning: Model-tuning is where you adjust model parameters in order to achieve peak predictive performance from the model in terms of accuracy and reliability, without causing the model to be overfit or overgeneralized.
- Ranking and scoring data: The idea here is to figure out which data can provide the most benefit for you. I discuss in Chapter 4 the various statistical methods for ranking and scoring data.
- Training and retraining machine learning models: This is basically the whole kitchen sink, where the service provider starts by splitting your data into training and test sets, fits and tunes the model, and then selects for you the model that performs the best. In other words, it's a combination of all services in this list.
Again, these offers are based directly on what I saw on one company's website when I researched various online data science service providers. Similar to the data preparation services I discuss in the previous section, businesses that offer data science services in a piecemeal manner like this could restructure their service packages for better profitability. That said, in the model-building services I just described, the provider has made a move toward optimizing its offers.
 Way too many services in the model building area are the same, which confuses any service provider's would-be clients and can significantly decrease sales. I like the idea of a package for training and retraining machine learning models, because it represents a level up from all the other data services offered by combining them all into a single package. Hopefully, any provider offering it is selling it for a higher price but at a bit of a discounted rate than if the services were purchased separately. That strategy helps increase sales of the higher-priced package. Needless to say, most data entrepreneurs have much to learn when they first make the move from data science employee to data science entrepreneur. Everyone has to start somewhere, and often that means starting from the beginning.
Way too many services in the model building area are the same, which confuses any service provider's would-be clients and can significantly decrease sales. I like the idea of a package for training and retraining machine learning models, because it represents a level up from all the other data services offered by combining them all into a single package. Hopefully, any provider offering it is selling it for a higher price but at a bit of a discounted rate than if the services were purchased separately. That strategy helps increase sales of the higher-priced package. Needless to say, most data entrepreneurs have much to learn when they first make the move from data science employee to data science entrepreneur. Everyone has to start somewhere, and often that means starting from the beginning.
I’ve created some mini trainings on how to best price and package data science services. If you want to see those, head over to https://businessgrowth.ai.
I could go on and on about monetizing data by selling data services. You could skin the data-science-as-a-service cat in about a million different ways. Though some companies out there are providing data science services on the open market, there’s plenty of room (and plenty of need) for more providers. On top of that, most of what I’ve seen in terms of online data science service providers is way too generic. These small companies have, and sell, data science services, but they sell them to everyone. Don’t do that.
Attempting to sell to everyone is a bad business idea, and it flies in the face of the presumption that a data scientist has specific business expertise within an industry.
I’ve created a directory of online data service providers, and I always update it when I find exciting new examples of ways to sell data services on the open market. This includes data visualization services, data storytelling services, data strategy services, data management, data engineering, and so much more that I can’t cover here. Feel free to peruse that directory over on the companion website to this book: https://businessgrowth.ai.
Summing things up, it’s difficult to explain in words how much opportunity there is for data science service providers who specialize in their specific industry and who use that true expertise to deliver services that move the needle for their customers’ businesses.
Selling Data Products
Most AI start-ups fall within the data monetization ecosystem. These companies utilize their sophisticated data skills, expertise, and technologies to build unique SaaS products for businesses that operate in a wide variety of industries, from government to retail, from healthcare to manufacturing, and everything in between. Most of these SaaS products offer some form of predictive analytics and would therefore be considered proper AI SaaS products. Other solutions, however, offer more simple reporting or data visualization capabilities. Although valuable in their own right, they cannot be considered true AI SaaS products.
One interesting difference between data businesses that sell SaaS products and those that offer only data services is that the SaaS product businesses tend to be a lot more specialized and thus more focused on helping customers in a specific industry. That probably has a lot to do with the incredible amount of time and expense that goes into developing a SaaS product. The significant financial risk would drive most product owners to do their homework first.
Other data businesses, like SafeGraph (which I tell you more about later in this chapter), take raw data resources and then apply data skills and technologies to produce market research products — reports and dashboards that support businesses in making data-backed decisions on how to invest and develop, given current market conditions. Some of these products are developed from data that the company owns and uses for its own in-house purposes. Other market research products are derived solely from data that’s sourced through one or more data partnerships. (This is the case with the SafeGraph example I’m about to describe.)
Another format in which data products are sold is the digital product, which can be any sort of data analysis, evaluation, visualization, or summary tool that’s useful in creating value from data. A simple example is a plug-and-play dashboard that a customer can buy and install within their own environment to gain the insights they need without building the dashboard themselves.
Lastly, certain information products focus on data-intensive topics. These vehicles enable the transfer of data knowledge between one professional and another, which can include anything from books to self-service online courses, as well as done-for-you guides, action plans, or project management templates. (This book itself is an example of an information product.)
Direct Monetization of Data Resources
Companies directly monetize their data in two main ways: advertising and data partnerships. I cover both of these data monetization practices in this section, and I present you with a compelling case for why you should be interested in the collection, sale, and resale of your personal data — information that relates to you as “an identifiable, live individual” according to the European Commission.
Coupling data resources with a service and selling it
The most common way that data resources are directly monetized is via advertising, where advertising platforms bundle the right to access their audience with the right to access personal data on audience members in order to sell targeted advertising services to businesses. Without the data resources that describe a platform’s user base, access to advertise to its users is almost worthless — you’d never be able to sort through and find the right users for whom your ad is relevant. That’s why I categorize advertising as a form of direct data monetization rather than as a data service: The value is in the data, not the audience, as you can see in Figure 14-2.
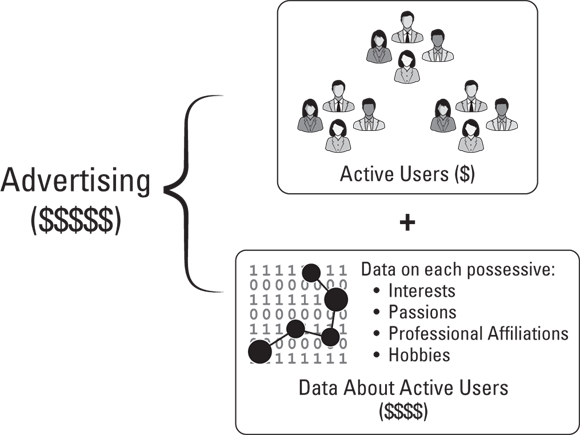
FIGURE 14-2: The value proposition of personal data in advertising.
Some popular data companies that monetize in this way are Facebook, Google, Snapchat, TikTok, and almost every other free communications application that people enjoy today. You pay nothing to use these marvels of technology, because advertisers are paying for you. Pretty cool, right? Well, after the Cambridge Analytica scandal — a topic I cover in Chapter 11 — people have become increasingly wary when it comes to their data privacy and to how data about them is being used behind the scenes. (I discuss this important issue in greater detail later in this chapter.)
Making money with data partnerships
In a business context, a data partnership is an agreement between companies wherein they sell their data to other companies. The data that’s sold by way of these partnerships almost always includes customer data — more specifically, their customer’s personal data. With respect to data privacy and the potential misuse of personal data, there’s a lot not to love about data partnerships. I’ll let you decide for yourself after reading about the data business SafeGraph in the nearby sidebar, “Monetizing a product that’s built solely from partners’ data resources.”
Not surprisingly, most people feel violated when they learn that their location data has been collected, sold, and resold as an asset by various businesses. If you’re considering developing this type of revenue model for your business, you’re putting your company’s reputation at risk in the long term. Application development companies do not now have a means by which to collect informed express consent from their users. They get by with it because people haven’t been aware of what was happening. As you can see in the section on data privacy that follows, the freewheeling and highly profitable era of data collection and resale seems to me to be coming to a screeching halt.
Pricing Out Data Privacy
The cookieless world is coming. You’re seeing birthing pains now, with events such as Apple’s iOS 14 software update, a data privacy change-maker where Apple put a full stop to user tracking for anyone using iOS 14 or higher software versions on their Apple products. With this move, Apple software no longer reports the user ID of its customers or any of their activities.
Consumers who opt not to share their data can heave a sigh of relief with the open assurance that their activities are no longer being recorded, tracked, or shared on the open market. Forced data privacy is coming!! Hooray, right? Unfortunately, within a data-intensive ecosystem like the Internet, things are never as they seem. You need to dig deeper into what’s happening with personal data, technology businesses, and data businesses. My goal in this section is to help spread awareness about what’s happening under the hood with respect to late-breaking data privacy developments.
The first thing you need to understand is the difference in business models for relevant actors in the data privacy war that rages in 2021. Though these businesses are all technology businesses, their business models are completely different. The most important of these now are described in this list:
- Hardware (that comes with software) product companies: I'm talking here about Apple, Samsung, and the like. These hardware companies aren’t now focusing on monetizing the personal data that they have on their users, but that’s not to say they won’t in the future. Rather than advertise to their customers on other platforms, they’ve built their own ecosystem in which they do indeed use personal data to advertise their products to their users.
- Data companies: I'm talking here about companies like Facebook, Google, TikTok, Snapchat, and the like. These companies sell access to your personal data, including data that’s collected via software on Apple and Samsung phones. For reasons shown earlier, in Figure 14-2, the only way companies like these can stay in business is because of the value of the data they collect from their users. Unlike hardware companies like Apple, they don’t have much of a need to advertise their own products, because they already have the users — so they monetize by offering the chance for other businesses to advertise within their ecosystem.
In its highly contentious, politicized play, Apple recently thrust itself into the limelight as a data privacy champion in the eyes of most. Yet Apple continues using its customers’ personal data to advertise to its own user base. Furthermore, by making this move, Apple has hurt its own customers and partners in at least two major ways:
- Hurting Apple application developers’ bottom line: Obviously, if you pay $1,000 or more for a cellular phone, you want it to come supplied with access to some awesome applications, right? As any iPhone user knows, Apple doesn’t “play friendly” with any non-Apple technology, so you can’t download apps from Google Play — Google’s application store for all Android users. Apple makes sure that you can get your applications only from its App Store. Well, the developers of those applications need customers in order to generate revenue and then reinvest a significant amount of that money into improving their applications. But where are most of these revenue-generating customers coming from? They come from ads that are run on data businesses like Facebook, Google, Snapchat, and others. Without these ads, how will application development companies stay in business?
- Decreasing Apple iOS app quality: To turn a profit, and subsequently reinvest in developing the best iOS applications possible, iOS app developers need customers. By cutting off user identification reporting, Apple’s own app developers can no longer gather the conversion tracking data they need in order to run ads to attract more customers. This strategy results in fewer customers for them, leading to decreasing revenues and subsequently lower quality standards for any applications they want to develop. Maintaining an excellent software product costs money. When you lose a leads source, you see decreased sales and have less money to use for product maintenance. This change can’t be good for Apple customers who are already trapped within the Apple ecosystem and unable to use any applications from elsewhere — the open-source Google Play Store, for example.
It almost seems as though Apple decided to cut off its own nose to spite its face, doesn’t it? Though Apple’s recent move means more privacy for its users, it also means less relevance with respect to advertisements those users see. It represents a complete loss of the ability to do any real-time advertising optimization. No one I know wants to see more ads for products they don’t care about. Who out there hasn’t discovered courses, products, or services that they absolutely adore but would never have known about if it weren’t for the precision at which Facebook was able to match their interest and passions with various marketplace offers?
I'm just here to remind you that the much-ballyhooed data privacy initiatives coming down the pike will come at a great cost to consumers, given that you can expect to pay by being forced to repeatedly consume the same annoying, spammy ads that you have absolutely no interest in seeing ever again. Relevant advertisers will no longer be able to find you, and the ads that do make it through won’t be optimized to conform with your desires, expectations, and preferences. Personally, it’s hard to imagine wanting to make this trade-off, but I remember how bad spammy online advertising was 20 or so years ago, before we developed the data expertise and systems required to serve high-quality targeted online advertisements. Newer generations may not realize how bad the bad old days were — and perhaps are not sufficiently fearful about the prospect of their return.
As rollouts like these affect more and more platforms, they and their advertisers will have less and less data to use in evaluating what’s working and what’s not. Current estimates are that 30 to 40 percent of the conversion tracking data will be lost by the platforms and all businesses, brands, and advertisers that use them. Imagine paying $1,000 to run an ad and in return not getting any information whatsoever about how that ad performed or whether it generated any leads or sales for your business. Who would do that? For professionals who make their living helping companies create value from data, the enormity of problems that this cookieless society movement, so to speak, will create should be beyond obvious.
For data professionals, these changes are like taking food right out of our mouths. Data resources, skill sets, and technologies were the main drivers behind a company's ability to find new customers and to reach their existing ones. That meant an abundance of funding and opportunity for data professionals. But as businesses lose the ability to use targeted advertising to draw customers, they’ll be forced to turn to more traditional marketing methods, which, coincidentally, don’t require sophisticated data skills to perform. That’s a net decrease in demand for data professionals in the online advertising industry.
The good news is that, although there will be less demand for data professionals in advertising, there will be more demand for data skills in marketing. (To learn more about organic data-intensive marketing methods that will increase in popularity with the loss of effectiveness in targeted advertising, check out Chapter 11.)