With a syllabus outlining the content of your course, where effective learning objectives have been clearly stated, you have the basic building blocks of a quiz or test. In this chapter, we introduce a framework for building a test blueprint, which serves as an item-writing guide allowing you to write items that produce a test with the right balance of content and intended cognitive tasks. Test blueprints lay out the basic structure of the test, including the types of test items or tasks, the number of items, and the ways students can respond. In this chapter, we also introduce the basic forms of selected-response and constructed-response item formats, with a focus on multiple-choice formats.
Chapter Learning Objectives
- Describe the purpose and key features of a test blueprint.
- Summarize the advantages and disadvantages of selected-response items.
- Recognize learning objectives that are more or less easily measured with selected-response items.
- Identify and describe the differences between commonly used item formats.
- Explain how multiple-choice items can be used to assess higher levels of cognitive tasks.
A Blueprint Framework
The framework presented in this chapter can be used by instructors that are writing isolated items to be administered during the course of instruction, particularly through the use of a classroom response system. The framework also applies to short quizzes that might only contain four or five items. In any case, items should result from and be linked to learning objectives. When administered in the midst of a lecture or class activity, MC items can be designed to support understanding that facilitates instruction—instructional decisions can be made in terms of whether to proceed in a lesson, stop and review an important concept, or return to earlier concepts to build the additional scaffolding needed to support the learning of new material.
As an example of the context in this case, when the distractors (incorrect options) of the MC item are carefully constructed to contain common errors or misconceptions, knowing how many students retain those misconceptions can be powerful in informing instructional decisions. But this requires that the options be written to contain relevant misconceptions (one of the MC item-writing guidelines described in Chapter 4). In the case of using a classroom response system, you can quickly and meaningfully check student understanding and the presence of persistent misconceptions or problem-solving errors. But of course, this doesn’t require a specific classroom response system.
Why Is Validity So Important?
The purpose for testing drives our design decisions. First, we clearly state the purpose. For example: To assess student knowledge of the first major unit. Second, every unit has a set of learning objectives. For example: The students will be able to identify effectively constructed learning objectives. Third, that claim (as a result of the purpose) requires evidence (validation). To support that claim, we build the test in a way that supports the intended interpretation and use by design. An important source of evidence is the Test Blueprint. From the evidence, we can make inferences about our intended claims and meet the purpose of the test. Figure 3.1 illustrates these three components.
Other evidence that supports score interpretation and use has to do with test score quality, which is a function of item quality (i.e., following item-writing guidelines). We review these issues in Chapter 7. But first, we introduce the big ideas of test blueprints, with some guidance for constructing effective tests.
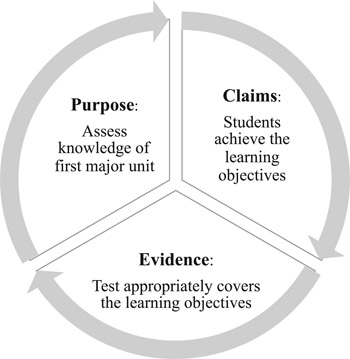
Figure 3.1 The Connections Between Test Purpose, Claims, and Evidence
What Is a Test Blueprint?
In testing at all levels, the Test Blueprint provides the Keys to the Kingdom—in other words, it provides essential validity evidence for test score interpretation and use. The test blueprint provides the design specifications (and is sometimes called test specifications). Just as in an architectural project, the blueprint lays out the design requirements—to achieve the desired result.
Consider the following straightforward argument:
- I have learning objectives for Unit 1.
- I need to test student achievement of the Unit 1 learning objectives.
- I can write test items to test achievement of those learning objectives.
- I adequately represent achievement in Unit 1 by balancing the number of items appropriately across those learning objectives.
That’s all there is to it. We need to make sure that the unit is appropriately covered on the test so that the total score represents the unit in a way that supports our score interpretation. We’ve all taken tests that are unbalanced—tests in which half of the items are on a topic that was only briefly introduced or discussed or that was insignificant compared to other topics. Bottom line: The tests in a course should align with the course syllabus—the test should reflect what we, the instructors, say the course is about.
A great volume of research indicates that students learn while preparing for the test, while taking the test, and while reviewing the test (see the reviews by Black and Wiliam, 1998 and Phelps, 2012). Learning at all three stages is maximized when the test actually covers the core and important learning objectives—so the target of testing is clear and consistent with what actually happens in the course, which is hopefully consistent with the syllabus.
Another way to think about this is in the context of opportunity to learn (OTL) and instructional sensitivity. Tests provide the means to evaluate OTL and assume that students had the opportunity to learn the material. It is difficult to differentiate two competing interpretations of a test if we don’t have evidence of OTL:
- Scores reflect the extent to which students achieved the learning objectives.
- Scores reflect the ability of the instructor to help students achieve the learning objectives.
This is why we need to clearly communicate the learning objectives, use them to organize our instructional activities and learning opportunities, and represent them appropriately on the test. We also need the test results to inform us about how students are doing on each learning objective in a way that can tell us what we need to reteach, provide additional opportunities for learning, or not to worry about and move on. Test scores can only do this if they represent the contents of instruction (are instructionally sensitive) and those things that students have had adequate opportunity to learn. We want to be able to say that because of our instruction, students are achieving the learning objectives—students who have had instruction do well on the items, whereas students who have not been instructed do poorly on the items.
In creating a test blueprint, we can specify a number of conditions to help us design an effective test:
- How many items can be administered in the available time?—or—How many items do we need to administer to meet the purpose of the test?
- What types of items can be used to test the relevant learning objectives?
- What are the specific content areas given in the learning objectives? How should these be weighted to match the importance of the learning objectives?
- What are the cognitive levels, tasks, or processes described in the learning objectives? How should these be weighted?
The answers to these questions have implications for validity—as they determine (or limit) the kinds of interpretations we can make of resulting scores.
A test blueprint provides for greater equity in how we evaluate students, particularly across sections and years of a course.
When the test blueprint matches the learning objectives, instruction, and opportunities to learn, the resulting test is more likely to be a true reflection of the course and an appropriate tool to evaluate student performance. An equality approach would be to administer the exact same exam year after year—regardless of how topics roll out each year or how much time and emphasis we put on various topics each year or the extent to which new topics are introduced by us or our students. Using the same test may seem like the right way to evaluate students—equally—but fails to recognize that each year, there are likely to be different needs in terms of teaching and learning. Equity requires us to meet those unique needs and provides for fairer student evaluation.
Creating a Test Blueprint
Each unit in a course has learning objectives (if not, return to Chapter 2). The learning objectives from each unit represented on the test need to be weighted in the test blueprint. But how do we determine the weights? Consider the following questions:
- How much time was spent on each topic?
- How important are the topics in the field?
- What topics are worth learning and studying for?
- What topics and skills are assessed in other ways (not via tests)?
Answers to these questions can help determine the proportion of the test devoted to each topic area—which then tells us how many items to write.
Consider a unit test that includes four content topic areas (A, B, C, and D) and three cognitive tasks (Remember, Understand, and Apply). We spent most of the unit time on the two most important topics (40% on A and 40% on B), with the remaining time and emphasis on two less important topics (10% on C and 10% on D). We also focused most attention to principles of application, so that we assign 20% to Remember, 30% to Understand, and 50% to Apply. This is represented in the illustration of the test blueprint that follows (Figure 3.2).
To end this example in a simple way, let’s say we want to write a test with 100 items. We can now distribute the number of items to topics and cognitive tasks in a way that reflects our weights so that the content and skills tested provide us with the relevant evidence given the learning objectives of the unit. For example, if 40% of the items should cover topic A, then 40 items will be written to tap this topic. Among those 40 items, 50% should be application items, so we write 20 application items tapping topic A, and so on. However, not every content area may be associated with the same balance of cognitive tasks.
Consider the test blueprint for a course on educational measurement, covering the first third of the course. We’ve determined that 40 items can be administered in one course period (75 minutes—which approximates one item per two minutes). Six topic areas were covered in this part of the course (relatively evenly, ranging from 10% to 25% emphasis) with two cognitive tasks, including Remember (35%) and Understand/Apply (65%). The following blueprint distributes the 40 items according to the proportions across topics and cognitive tasks (Figure 3.3).
Notice that the number of items doesn’t match exactly the percentages intended in each cell. For instance, the Reliability items are split equally (3 and 3) across the two cognitive tasks whereas there are more Validity items written for Understand/Apply (8 items or 80% of 10) than for Remember (2 items, or 20% of 10). This is because for Reliability, the course content emphasized
knowledge (learning terms and definitions) just as much as understanding and application (determining what kind of reliability applies to different test purposes, etc.). And for validity, the course emphasized understanding and application at a much higher level than simple knowledge (identifying the kinds of validity evidence relevant to different test score interpretations and uses, how to conduct validity studies, how contexts impact validity).
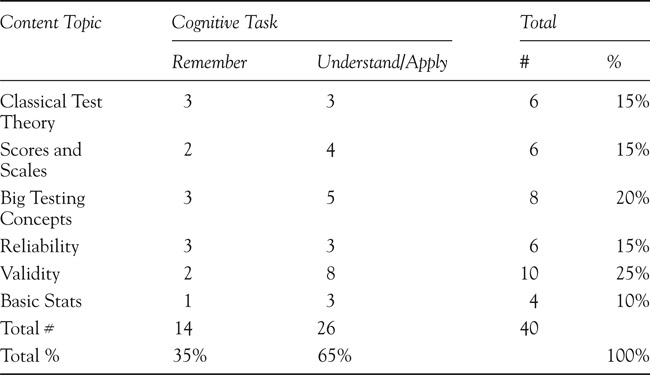
Figure 3.3 Educational Measurement Course Test Blueprint

Figure 3.4 Tests With Different Purposes Require Different Types of Blueprints

Figure 3.5 A Generic Test Blueprint Including Five Cognitive Tasks
Test blueprints provide a strong guide for item writing and test design, but as an instructor, you make the final determination of how to cover the content appropriately (see Figure 3.4). But remember the goals of grading described in Chapter 1. Tests designed for formative purposes (to check understanding or evaluate the adequacy of our instruction) should be weighted less—as we intend to use that information to improve teaching and learning. We want grades to reflect learning and achievement, and so we weight tests designed for summative purposes, those designed to contribute to grades, more heavily. Just as we want the interpretations about content mastery to be valid (through the appropriate design of test blueprints), we also want the interpretations about overall course achievement (through appropriately weighted grades) to be valid (see Figure 3.5).
What Are the Most Common Test Item Formats?
Having developed the test blueprint, the next step is identifying appropriate item format(s). The available item formats have in common three basic components:
- A question or task for the test taker,
- some conditions or rules regarding the required response, and
- scoring rules or procedures.
Furthermore, nearly all item formats can be classified in three groups based on the second and third components of response conditions and scoring procedures:
- Selected response (SR) that is objectively scored,
- constructed response that can be objectively scored (CROS), and
- constructed response that is subjectively scored (CRSS).
This chapter focuses on SR items. Because of their unique nature and purposes, CROS and CRSS items are not discussed further here. The Handbook of Test Development provides chapters that allow us to explore these more subjective assessment options (see Haladyna and Rodriguez, 2013; Lane and Iwatani, 2016; and Swygert and Williamson, 2016).
What Are the Advantages and Disadvantages of SR Items?
Table 3.1 Advantages and Disadvantages of SR Items
|
Advantages
|
Disadvantages
|
|
| • Allows for broad coverage of content. |
• Challenging to construct high-quality items. |
| • Can be used to measure many different objectives (described in what follows). |
• Time consuming to construct well. |
| • Can provide diagnostic information about errors in thinking, misconceptions, etc. |
• Not good for measuring innovative thinking, creating something. |
| • Easy to score; can be machine scored. |
• Students are familiar with the format. |
| • Efficient for large classes. |
• May be affected by student reading skills. |
| • Able to control difficulty to some degree. |
• May encourage overtesting recall. |
|
• Doesn’t reflect real-world problem solving. |
Table 3.2 Example Learning Objectives That Can Be Measured Well or Not So Well by SR Items
| Measured well
|
Not measured as well
|
|
| • Analyzing conditions and phenomena |
• Explaining reasoning or thinking |
| • Applying concepts and principles in new contexts |
• Providing information to support an argument |
| • Evaluating cause-and-effect associations |
• Organizing thoughts |
| • Evaluating the relevance of information or evidence |
• Performing tasks |
| • Solving problems |
• Producing innovative ideas |
| • Discriminating between facts and opinions |
• Providing examples |
| • Interpreting graphical displays |
|
| • Drawing inferences from data |
|
There are multiple reasons for utilizing SR item formats for tests in college courses. As mentioned in the introduction and Chapter 1, SR items are efficient tools for collecting information about a broad range of KSAs, covering
lots of content in a short period of time, and they are easy to administer and score (see Figure 3.1). Because we can construct items to provide information about common misconceptions, misinformation, and problem-solving errors (see the section on distractor development in the next chapter), they can also provide diagnostic information. Table 3.2 provides example learning objectives well suited for SR items.
What Are the Most Common SR Formats?
We review common SR item formats here. For a complete review of the many SR formats and additional examples, see Haladyna and Rodriguez (2013). The formats reviewed here include:
- multiple choice
- multiple response
- complex type-K
- context-based item sets
- true-false, multiple true-false
- matching
Each format is described and presented with an example.
Multiple Choice (MC)
As the most common item format in achievement tests, this format is the focus of the book, and Chapter 4 is devoted to item-writing guidelines and other considerations for MC items. An MC item includes a question with options or a statement where the options complete the sentence.
If a distribution of test scores is negatively skewed, standardizing the scores into z-scores will result in what type of distribution?
- A. Positively skewed
- B. Normal
- C. Negatively skewed
Multiple-Response MC
The multiple-response MC item is an MC item with the potential of multiple correct options, typically where all correct options must be selected to get credit for the item. This format is gaining use in some standardized testing programs (e.g., GRE). There is little research in the literature on its quality. For classroom tests, it is very important for students to know that it may be possible to select multiple correct answers, but realize that an instruction to select “the best answer” will not work with this format. Some recommend partial-credit scoring if one or some of the correct options are selected but not all of them. For these reasons, we recommend against using multiple-response MC items and recommend considering multiple true-false items instead (described below).
Which interpretations are criterion referenced?
- A. Eighty percent of the class scored above a T-score of 55.
- B. Hattie scored above the 95th percentile requirement to win the scholarship.
- C. Jean Luc answered 80 percent of the items correctly.
- D. Mariana scored in the Exceeds Standards range on the reading test.
- E. Santiago’s score is three standard deviations above the state mean.
Complex Type-K MC
The complex MC format is often called the type-K item. It includes a standard MC item, where there are multiple correct responses and the options selected by students include different combinations of the responses. This item format is common in the health sciences. Many times, there are multiple conditions, symptoms, clinical tests, or possible treatments that are appropriate. For these reasons, it is important for students to distinguish among sets of options that provide the best answer.
Research has shown that complex MC items are more difficult and require more reading time. It may be possible to answer these questions correctly with partial knowledge, when one option is known as absolutely correct or incorrect, allowing the student to eliminate certain option combinations. Research has also found that this format tends to reduce item discrimination, the ability of the item to distinguish between higher-ability and lower-ability students—which is an important indicator of item quality. This also leads to lower test score reliability.
Which scores are developmental norm-referenced scores?
- Normal curve equivalents
- Grade equivalent
- Mental age
- Percentiles
- A. 1 and 2
- B. 1 and 4
- C. 2 and 3
- D. 2 and 4
Context-Based Item Sets
Context-based item sets can be composed of items in any format, but what makes this format different is that the item set is associated with context material. Providing context materials, such as a reading passage, graphic, picture, data table, or any course-related material, is a great way to create more authentic assessment and test higher-order thinking skills. A test can provide authentic scenarios through which we can test students’ KSAs. This also helps test higher-order thinking skills, as it is easier to test application, analysis, and evaluation skills by presenting a real-life context or a scenario on which to base the test items.
Consider the following example, where a test blueprint can provide the context for several questions:
Blueprint for Midterm Statistics Exam
|
Content Areas
|
Cognitive Task
|
Total
|
|
|
Remembering
|
Understanding
|
Applying
|
|
|
| Frequency |
# |
# |
# |
20% |
| Distributions |
|
|
|
|
| Transformations |
# |
# |
# |
10% |
| Central |
# |
# |
# |
30% |
| Tendency |
|
|
|
|
| Variability |
# |
# |
# |
40% |
| Total |
20% |
30% |
50% |
100% |
From the test blueprint, what appears to be the most important topic covered?
- A. Frequency Distributions
- B. Transformations
- C. Central Tendency
- D. Variability
If the statistics exam will have 50 items, how many Frequency Distributions items should be written that require the cognitive task of Applying?
True-False, Multiple True-False
You can ask many more true-false (TF) items than MC items in the same time period, covering a lot of content in a short time period. TF items are also very easy to score (objectively). However, there are numerous reasons to avoid using them. It is very hard to write TF items that are unambiguously true or false. TF items tend to measure low levels of cognitive processes, typically remembering, with a 50% chance of guessing correctly.
Indicate whether each statement is True (T) or False (F) by circling T or F.
| The vectors a′ = (10, 12, 9) and are equal |
T / F |
| a + (b + c) = a + b + c |
T / F |
| a′ b = ab′ |
T / F |
There is limited diagnostic information available in responses to TF items, limiting their use for formative purposes. However, in multiple TF items, diagnostic information can be obtained, similarly to MC items.
These statements accurately reflect ideas about reliability.
|
|
True
|
False
|
|
| a. Some kinds of test errors are more important than others. |
☒ |
☐ |
| b. Some of the variance of test scores may be attributed to characteristics of the test takers. |
☒ |
☐ |
| c. Test reliability is consistent, every time a test is used. |
☐ |
☒ |
| d. The true score plus the error score equals the observed test score. |
☒ |
☐ |
TF items can also be written as either/or items, where the response options are one thing or the other. Consider the following example. It could have been written to suggest each statistic is an index of item difficulty, true or false, but since the statistics are of one type or the other, this format is more direct and better.
Do these statistics provide information about item difficulty or item discrimination?
|
|
Difficulty
|
Discrimination
|
|
| a. proportion correct |
☒ |
☐ |
| b. a-parameter |
☐ |
☒ |
| c. b-parameter |
☒ |
☐ |
| d. p-value |
☒ |
☐ |
| e. point-biserial |
☐ |
☒ |
Guidelines for writing true-false items:
- Statements should be based on important content, not trivial content.
- Statements should clearly express a single idea in a declarative sentence.
- Statements should be unequivocally true or false, with no exceptions.
- Do not use statements taken directly from textbooks or course materials.
- Do not write negative statements.
- Write both versions of each statement, a true and a false version. Of course, select only one version for the test.
- Avoid specific determiners such as always, never, all, none, and the like.
In addition, most of the guidelines for MC item writing also apply to writing TF items. MC item-writing guidelines are described in Chapter 4.
Matching
Matching items do not require a high reading ability and can cover a lot of content in a short period of time, providing many of the benefits of TF items. However, it is challenging to create matching items that require more than simple recall or remembering. It is possible to create a set of conditions with plausible outcomes or implications, requiring the application of criteria or analysis of causes and effects or other higher-level thinking skills.
Directions: On the line next to each study method, place the letter of the type of validity evidence that is most likely obtained from the method. Choices of validity evidence may be used once, more than once, or not at all.
|
Validity Study Methods
|
Validity Evidence
|
|
| B Correlations with future performance |
A. Concurrent criterion related |
| A Correlations with current grades |
B. Predictive criterion related |
| E Correlations among subscores |
C. Content related |
| E Confirmatory factor analysis |
D. Response processes |
| D Think-alouds |
E. Internal structure |
| C Alignment to professional standards |
|
Guidelines for writing matching items:
- Each stimulus and response option should be homogenous (of the same content and type).
- Instructions should clearly state the basis for matching and that responses can be used more than once or not at all.
- Write no more than 10 stimuli, keeping each brief with short phrases or single words.
- Include more responses or stimuli to prevent identifying the correct response through elimination.
Because we focus on MC items in the remaining chapters, here is an example of a poorly constructed matching item set. Can you identify the item-writing flaws?
Directions: The descriptions on the left can be attributed to one of the important individuals or key terms on the right. Match the descriptions with one individual or key term. Each individual or key term may be used once, more than once, or not at all.
| Description |
Individuals & Key Terms |
| f Explored applications of latent trait theory to testing |
a. H. Mann |
| e The summarized the principles of true score theory |
b. C. C. Brigham and R.M.Yerkes |
| c Offered the first course in educational measurement |
c. E. L. Thorndike |
| a He advocated for written examinations in education |
d. Multiple-Choice Items |
| d Referred to as the “new-type” tests in the 1920s |
e. H. Gulliksen |
| j Introduced the term “mental tests” |
f. F.M. Lord |
| h He tested people to promote segregation |
g. L. L. Thurstone |
| g The author of The Reliability and Validity of Tests |
h.H.H.Goddard |
| i Studied the existence of general intelligence |
i. C. Spearman |
| b He promoted the development of eugenics |
j.J.M. Cattell |
| k An attribute that is not directly observable |
k. Latent Trait |
| l A quantitative method |
1. Measurement |
There are a number of item-writing flaws:
- There should be a different number of Descriptions and Individuals/Key Terms. A student could identify the final response through elimination.
- The set of statements should be homogenous, so only include descriptions of individuals or descriptions of key terms. These should be in two different matching sets.
- The Individuals for option b include two people, but the Description starts with “He promoted….” This suggests one person, but the answer is two people.
- The last two Descriptions are based on the two Key Terms on the right, and they are in the same order in both lists.
- There are 12 descriptive statements; too many.
- Descriptive statement e is also grammatically incorrect; it should begin “He proposed …”
- Some Description statements are phrases, whereas others are complete sentences. They should be homogenous in structure.
How Do We Write MC Items to Tap Higher-Order Thinking?
MC items have a bad reputation for only measuring recall—remembering. But we can write items that tap higher-order cognitive skills, including understanding, applying, analyzing, and evaluating. It seems like a real stretch to measure creating skills with MC items, but we wouldn’t say it’s impossible. To increase the cognitive skills assessed in your MC items, consider the following recommendations. Many of these come from Tom Haladyna (1997), who has dedicated much of his career to improving the skills of item writers.
- Use novel situations, contexts, conditions, scenarios, graphical displays, and other materials. But make sure students have had experience with the kinds of materials used in the test.
- Real-world contexts provide practical and engaging problems and allow us to test students’ abilities to generalize KSAs.
- Build in a requirement for reasoning in the item. Often this can be done by extending instructional content so that students must transfer their knowledge and understanding in broader ways.
- Require students to correctly interpret the problem.
- Ask students to hypothesize or predict outcomes, given sets of conditions.
- Require students to determine the principles or components that are relevant.
- Ask students to select reasons or justifications for a result presented in the item, scenario, or data display.
- Ask students to select a course of action, given the problem or conditions.
- Present a scenario with specific circumstances so that students can select the most likely outcome or result.
- Create a scenario that is not complete, where students identify the missing pieces.
- Given relevant criteria, ask students to select solutions to various problems.
MC Items With Justification
Arthur Odom (1995) created a measure to diagnose student misconceptions in biology regarding diffusion and osmosis. He argued that such measures allow instructors to develop lessons that change conceptual understanding. He began by defining misconceptions as student ideas that are “different from those generally accepted by scientists” (p. 409). He created a list of 22 propositional knowledge statements required for understanding diffusion and osmosis. Two example items include (p. 414):
- 1a. Suppose there is a large beaker full of clear water and a drop of blue dye is added to the beaker of water. Eventually the water will turn a light blue color. The process responsible for blue dye becoming evenly distributed through the water is:
- a. Osmosis
- b. Diffusion
- c. A reaction between water and dye
- 1b. The reason for my answer is:
- a. The lack of a membrane means that osmosis and diffusion cannot occur.
- b. There is movement of particles between regions of different concentrations.
- c. The dye separates into small particles and mixes with water.
- d. The water moves from one region to another.
Any other combination of responses other than b (for 1a.) an b (for 1b.) comprise different forms of misconceptions. A more recent version of the Diffusion and Osmosis Diagnostic Test has been developed and studied (Fisher, Williams, and Lineback, 2011).
Item Starters
While Ron Berk (1996) was a professor at the Johns Hopkins University School of Nursing, he created a guide to MC item formats that measure complex cognitive outcomes. In this, he provided an excellent set of item “starters” that can be used as models to write test items. Here are the generic stems that Berk recommended:
Prediction
- If …, then what happens?
- What will probably happen?
- What would happen if …?
- What is the cause of …?
Evaluation and Decision Making
- Which is the most or least important, significant …?
- Which of… is the most or least effective …?
- Which action, decision, procedure… demonstrates/illustrates …?
- What is the most/least appropriate action/response …?
- What is the best/worst step/procedure …?
- What is the most useful/useless strategy/approach …?
- What is the best/worst action/decision/advice …?
Berk also offered a number of generic stems for measuring complex cognitive outcomes. These examples are slightly modified from his suggestions:
- What is the effect of …?
- What principle explains …?
- Which exemplifies the principle …?
- Which procedure should be used when …?
- Which generalization can be made from the data …?
- Which feature is a major strength/weakness of …?
- Which approach will result in …?
- This situation will create …?
- Which consequence will (likely) result from …?
- What is the most effective/efficient/complicated solution to …?
- This scenario is an example of the principle …?
- What is the first step following …?
- What is the next step after …?
- What is the (most) appropriate action to resolve …?
Recognize that we could change the key terms in each stem by relying on a thesaurus. For example, using the Microsoft Word thesaurus (while writing this sentence), there are several synonyms for the word “effect,” including “result,” “consequence,” “outcome,” “conclusion,” “influence.” This is a good way to find words so that we can ask several questions that vary on a common theme, and not be repetitive. Keeping students’ interest level high is a way to engage them in the test and encourage more accurate responses.
How Do We Put Items Together in a Test?
Hopefully, you didn’t just sit down one night and write all of your test questions. Also, hopefully you are not just using last year’s test without reviewing the content in light of the course experiences from the current year. It’s best to write items as the course progresses. Many items can be written throughout a unit or section of the course. Lectures and class discussions provide a great deal of fuel for test items. Keep notes with important topics, contexts, problems, questions, and issues raised by students from each session. Test items can be effective when they address the questions, challenges, and issues brought up through lectures and class discussions.
Here are just a few guidelines for putting everything together in a test form.
- Give clear and explicit directions (don’t assume anything).
- Make sure the items are consistent with the test blueprint.
- Arrange items based on test content (with similar content together).
- Leave enough room for complete answers to constructed-response items.
- Do not split questions across a page—or reading or graphic materials associated with an item, if possible.
Provide Clear Instruction
Instructions for the test should state how many items in each format are on the test and how many points each item format is worth. For each section of the test, you can state how much time students should spend on the section given the number of items and their format. Also, provide some instruction about the possibility of guessing—don’t encourage it, but students should answer all questions. All of this is to help students be more efficient in their effort. An example general instruction to a test is:
This exam consists of 25 multiple-choice items each worth one point, 5 constructed-response items each worth two points, and two context-dependent item sets, one with 5 questions worth 5 points and one with 5 questions worth 10 points; 50 points in total. Your score on this exam will be the number of MC items you have marked correctly and the number of points you obtain on the constructed-response items. Select the best answer to each item, but do not spend too much time on any one item. The exam is designed to be completed within 1 hour, but you have 75 minutes. If an item is unclear, feel free to write a comment directly on the test form for reference when we review the test. This exam is provided as a tool to measure achievement of the course objectives for the units covered to date.
Consider the Amount of Time Available for Taking the Test
It is difficult to estimate the amount of time it takes to respond to a single MC item. If the item requires remembering or understanding and the test takers are native speakers of the language of the test, 30 to 60 seconds per item should be sufficient. If the items require more thought or higher-order thinking, 1½ minutes per item should be sufficient. If the test takers are not native speakers of the language of the test and if the items require more consideration of graphic materials, reading passages, or computation (or estimation), it may take as much as 2 minutes per item. Some items will only take 15 to 30 seconds, whereas others will take 2 minutes of consideration and reconsideration. For typical college courses, 45 MC items can be administered in 60 minutes—and of course, for items requiring more extensive reading, graph analysis, computation, or estimation, more time will be needed.
Ask a Colleague to Review the Test
Tests used to contribute toward grades in a big way should be reviewed by a colleague. Colleagues are in a good position to notice problems with test items, including things such as having no correct answer or multiple correct answers, confusing terms, clues to the correct answer, and unnecessarily complex language and maybe even provide advice about content that is irrelevant or potentially misleading. Colleagues can also provide guidance as to whether the problem or issue presented in the test item is worth asking or if it is trivial and not important.
The department could develop a culture of assessment, supporting instructors’ abilities to develop meaningful, appropriate, and useful learning objectives and assessment practices that allow for meaningful, appropriate, and useful evaluation of those learning objectives. An important part of a culture of assessment is the shared responsibility and collegiality among instructors. This includes the practice of reviewing each other’s assessment activities and tests. Not only are we supporting each other in our important roles as instructors, but we are learning from each other as well.
In large-scale standardized testing, item writing is a collaborative effort. Subject-matter experts (like you) are trained to develop items tapping relevant content and cognitive tasks. The items are reviewed by lead item writers and sometimes returned to item writers for editing. Test items are also reviewed by sensitivity specialists or committees, where members look for potential bias due to content-irrelevant features, including gender, race/ethnicity, region, and language. Items are piloted or field tested in a way that allows us to gather student responses to the items without having the item count in the score. These data are used to evaluate the quality of the item and the extent to which each item contributes to the total score. They also provide for a means to do more technical analyses of possible item bias (differential item functioning examines the extent to which items function differently in various groups). The item might then undergo additional review for possible bias.
There is no way we can achieve the same level of item development in classroom testing as we see in standardized testing. But this does not mean the quality of our items is limited.
It is difficult to improve our item quality without some preparation or training in item writing. Oftentimes, we (the college instructors) are the only ones writing and reviewing items for our tests. If we follow the item-writing guidelines presented here (which include the recommendations of many other experts), we can reduce the potential errors or mistakes in item writing, especially the most common errors instructors make in developing test items. There are some things we can do to evaluate the quality of our test items, and these are discussed in Chapter 7. But let’s keep the focus on two very important points:
- High-quality test items provide important evidence of the quality of teaching and learning to support teaching and learning.
- Tests typically contribute to course grades, which are indicators of student achievement and their knowledge, skills, and abilities.
Grades are high stakes. We often talk about classroom assessment as low stakes (compared to high-stakes graduation tests, college admissions tests, or certification and licensure tests). But for many of our students, grades are high stakes, as they often provide information for decision making—Am I in the right major?— or provide access to future opportunities—Is this student able to succeed in a graduate degree program?
Applications
This chapter defines and presents examples of test blueprints and shows how a blueprint establishes content validity evidence for a test. Commonly used SR item formats are described with examples, and recommendations for writing, revising, and administering these item formats are provided, along with recommendations for writing SR items to assess higher levels of cognitive tasks. In the following applications, you will create your own test blueprint and evaluate the appropriateness of the item formats, content, and cognitive tasks outlined within your blueprint.
- Create a test blueprint showing the distribution of items over cognitive tasks and content areas within a course test. Your blueprint should represent important content, according to the learning objectives you developed in Chapter 2, and should utilize cognitive tasks that are appropriate to each content area.
- Write a matching item for chapter learning objective 4: Identify and describe the differences between commonly used item formats. The choices could involve matching the name of the item format with a certain feature, strength, or limitation of that format.
- Go through the items in a course test to determine whether each item format is justified and appropriately used. Convert multiple-response MC and complex MC items to other formats such as MC or multiple true-false items.
- Evaluate the cognitive tasks assessed within your own test items. Are these tasks appropriate for the content covered? How can the items be modified to improve the cognitive tasks assessed?
References
Berk, R. A. (1996). A consumer’s guide to multiple-choice item formats that measure complex cognitive outcomes. In National Evaluation Systems (Eds.), From policy to practice: Proceedings from the Teacher Certification Testing Conference (pp. 101–127). Amherst, MA: Author. Retrieved at www.pearsonassessments.com/teacherlicensure/conference-on-teaching/publications/from-policy-to-practice.html
Black, P., and Wiliam, D. (1998). Assessment and classroom learning. Assessment in Education, 5, 7–74.
Fisher, K. M., Williams, K. S., and Lineback, J. E. (2011). Osmosis and diffusion conceptual assessment. CBE Life Science Education, 10 (4), 418–429.
Haladyna, T. M. (1997). Writing test items to evaluate higher order thinking. Needham Heights, MA: Allyn & Bacon.
Haladyna, T. M., and Rodriguez, M. C. (2013). Developing and validating test items. New York, NY: Routledge.
Lane, S., and Iwatani, E. (2016). Design of performance assessments in education. In S. Lane, M. R. Raymond, and T. M. Haladyna (Eds.), Handbook of test development (2nd ed., pp. 274–293). New York, NY: Routledge.
Odom, A. L. (1995). Secondary & college biology students’ misconceptions about diffusion & osmosis. The American Biology Teacher, 57 (7), 409–415. Available in a pre-publication version (1993) at www.mlrg.org/proc3pdfs/Odom_DiffusionOsmosis.pdf
Phelps, R. P. (2012). The effect of testing on student achievement, 1910–2010. International Journal of Testing, 12, 21–43.
Swygert, K. A., and Williamson, D. M. (2016). Using performance tasks in credentialing tests. In S. Lane, M. R. Raymond, and T. M. Haladyna (Eds.), Handbook of test development (2nd ed., pp. 294–312). New York, NY: Routledge.
