Compression is the process of reducing data in a digital signal by eliminating redundant information. This process reduces the amount of bandwidth required to transmit the data and the amount of storage space required to store it. Any type of digital data can be compressed. Reducing the required bandwidth permits more data to be transmitted at one time.
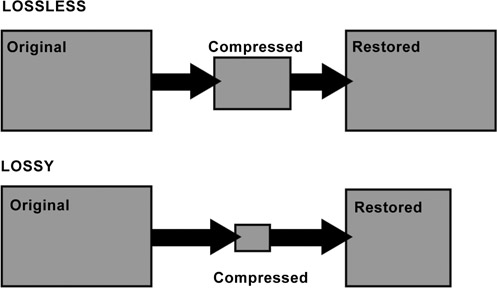
Compression can be divided into two categories: lossless and lossy. In lossless compression, the restored image is an exact duplicate of the original with no loss of data. In lossy compression, the restored image is an approximation, not an exact duplicate, of the original (Figure 14.1).
Lossless Compression
In lossless compression, the original data can be perfectly reconstructed from the compressed data that was contained in the original image. Compressing a document is a form of lossless compression in that the restored document must be exactly the same as the original. It cannot be an approximation. In the visual world,
lossless compression lends itself to images that contain large quantities of repeated information, such as an image that contains a large area of one color, perhaps a blue sky. Computer-generated images or flat colored areas that do not contain much detail—e.g., cartoons, graphics, and 3D animation—also lend themselves to lossless compression.
One type of lossless compression commonly used in graphics and computer-generated images (CGI) is run-length encoding. These images tend to have large portions using the same colors or repeated patterns. Every pixel in a digital image is composed of the three component colors—red, green, and blue—and every pixel has a specific value for each color. Therefore, it takes three bytes of information, one byte for each color, to represent a pixel.
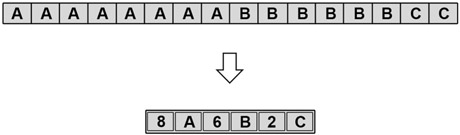
Run-length encoding, rather than store the RGB value for each individual pixel, groups each scan line into sections, or run-lengths, of identical pixel values (Figure 14.2). For example, one section of a line of video might consist of a row of 25 black pixels. This section
would be run-length encoded as 25, 0, 0, 0. This translates as 25 pixels, each composed of R = 0, G = 0, and B = 0, or black. The original image would have required 75 bytes (25 pixels × 3 bytes) to hold this data. When compressed using run-length encoding, the same data can be contained in four bytes.
Lossy Compression
Video images generated by a camera are generally not suited for lossless compression techniques. Rarely are there long enough run lengths of the same pixel value in an image to maximize the efficiency of these techniques. Compression used for active video is usually in the lossy category. With lossy compression, the restored image will be an approximation of the original. When a lossy image is reproduced or uncompressed, not all the data left out during compression will be restored exactly as it was.
To minimize the visible loss of data, lossy compression techniques generally compress the data that comprise those parts of the image the human eye is less sensitive to, or that contain less critical image data. The human eye is more sensitive to changes in light levels or luminance than it is to changes in color, both hue and saturation. Within the color gamut, the human eye is more sensitive to the yellow-green-blue range. The human eye is also more sensitive to objects in motion than to still objects.
In lossy compression, the data compressed is the data that does not fall within the human sensitivity range or data that contains a great deal of motion. Two commonly used lossy compression techniques are JPEG and MPEG. These techniques, and variations of them, are described in this and the next chapter.
Data Reduction
Video files generally contain redundancy that can be used to reduce the amount of data to be stored. This can be done by registering the differences within a frame (intraframe) and between frames (interframe) rather than storing all the information from each frame.
Intraframe Compression
Intraframe compression utilizes spatial redundancy, or the repetition of data within the space of the frame, to define the data that can be discarded. This compression is achieved through a technique called sub-sampling. In sub-sampling, the number of bits needed to describe an image is reduced by storing only some of the pixels that make up the image. For instance, every second pixel in a row and the entirety of every second row could be ignored. Those pixels that are retained would then be increased in size to compensate for the data that has been left out (Figure 14.3).
Another sub-sampling strategy uses the average values for a group of pixels. This average is substituted for the original values for those pixels. Sub-sampling effectively reduces the number of pixels in an image. Alternatively, rather than reduce the number of pixels in an image, the amount of information about each pixel can be reduced. This, however, also reduces the number of gradations of color and grays in the image.
Quantization is another method for reducing the amount of data. Quantizing sets a limit on the quantity for the range of values to be stored and the increments between values for the data to be coded, thereby compressing the amount of data needed to be stored.
Transform coding uses a complex conversion process to turn coded blocks of the image into a compressed image or video file for storage or transmission.
Interframe Compression
Interframe compression compares the unchanging portions of successive frames from one frame to the other. Simple movements of objects between one frame and another or changes in light, for example, can be stored as similar commands between frames (Figure 14.4). The commands take up less storage than the actual data required to store the complete frame. Interframe compression utilizes a version of sub-sampling in which not all frames are transmitted. Instead, the commands are stored to recreate the data. Other strategies used in Interframe compression are difference coding, block-based difference coding, and block-based motion compensation.
In difference coding, each frame is compared to the preceding one and only those pixels that are changed are stored.
Block-based difference coding works in the same fashion but at a block level rather than a pixel level. The frames are divided into blocks of pixels, and it is these blocks that are compared between frames.
Block-based motion compensation is a further refinement of difference coding. The frame is divided into blocks as before. These blocks are then compared to blocks in the preceding frame to find blocks that are similar. If the similar blocks are in different locations, it is this difference of position that is stored rather than the actual information in the block.
A further refinement is bidirectional motion compensation, in which the current frame is compared to both the preceding and following frame and the differences stored rather than the content of the frame (intraframe and interframe compression are discussed in more detail in the following chapter).
Data Transmission Limitations
The requirements of the programming source, as well as the transmission and storage devices being used, may limit your choice of compression types. The limitations for transmission are controlled by the quantity of data the transmission and receiving systems can handle in a given time period. The limitations for storage are obviously limited by the space available. Therefore, another factor to be considered in data compression is the bit rate needed to store, transmit, and reproduce the data accurately.
Bit Rates
The complexity of an image is a result of the combination of the amount of movement or change from frame to frame and the quantity of detail contained in the image. To maintain proper image motion in time, the zeros and ones, or digital bits, that comprise the data must be transmitted and received quickly enough to reproduce the image in the proper time frame. Depending on the complexity of the image and the required level of quality, different data rates, or bit rates—that is, the speed at which the data is processed—are used.
If the images are less complex in nature, or if the required level of quality is not high, a fixed or constant data rate or bit rate may be used. Where the images are either more complex or the required level of quality is high, variable bit rates may be used in order to maintain a reduced data rate while not compromising the quality. Because of these differences, constant bit rates can be used to compress images in real time, whereas variable bit rates cannot.
Constant Bit Rates
Fixed or constant bit rates (CBR) result in varying levels of picture quality because there is no allowance for image complexity. Broadcast media—such as cable, satellite, and terrestrial broadcasting—require constant bit rates for their transmission equipment. Live broadcasts, satellite linkups, and playback of uncompressed video all require immediate real-time compression while being transmitted.
Variable Bit Rates
Although video runs at a fixed frame rate, the amount of data required to encode each frame can be variable, depending on scene complexity. Variable bit rates (VBR) allow for consistent picture quality when the complexity of the image varies. Each part of the image is analyzed and compressed at its optimal compression rate. Less complex portions of the image are compressed at higher rates while more complex portions of the image are compressed at lower rates. In order to achieve variable bit rates, there must be greater analysis of the image content to achieve the best quality with the least amount of data; most encoding software and equipment does two-pass variable bit rate encoding, with the first pass over the video devoted to simply analyzing the video. With variable bit rates, the encoding process is more complex and cannot be done in real time. VBR encoding is used for storage in media such as DVDs.
JPEG Compression
JPEG defines the standards for compressing still images, such as graphics and photographs. Similar to video standards groups discussed in previous chapters, JPEG compression was developed by the Joint Photographic Experts Group, a joint working group of the International Standardization Organization (ISO) and the International Electrotechnical Commission (IEC).
In JPEG compression, the image data is converted from RGB into luminance (the Y component) and chrominance information (the color difference signals, the Cb and Cr components). JPEG takes advantage of the human eye’s greater sensitivity to changes in luminance than changes in color by sampling the chroma or color information in the image less often than the luminance. This process is known as downsampling or chroma subsampling.
Downsampling can result in data reduction by a factor of 2 in the horizontal direction only or by a factor of 2 in both the horizontal and vertical directions if both are used. The components are then grouped in blocks of 8 × 8 pixels and converted using a type of transform coding called Discrete Cosine Transform, or DCT. Data can be reduced further by encoding redundant luminance information in the image using intraframe coding methods.
JPEG compression of 10 to 1 results in images that appear to be unchanged from the original. More aggressive compressions of 100 to 1 are possible, but visual degradation is apparent. The levels of compression used are dependent on the end use of the image file.
JPEG 2000
JPEG 2000 was designed to handle higher compression ratios than can JPEG, but without introducing the artifacts that are a by-product of higher compression under the DCT-based JPEG standards. Instead of the Discrete Cosine Transform method of coding, JPEG 2000 uses Discrete Wavelet Transform, or DWT. The DWT approach does not divide the image into blocks but analyzes the whole image and organizes the image data to a more easily compressed form. This reduces the blocking artifacts introduced by DCT.
NOTE JPEG 2000 can handle both lossless and lossy compression. Apart from being designed to deliver higher compression ratios, JPEG 2000 has been designed to detect and conceal errors introduced into the file by transmission, such as over wireless channels.
As with JPEG, the images are transformed from RGB to the luminance and chrominance (Y, Cb, and Cr) information. The image is then tiled into areas that are encoded separately. The results are called sub-bands, which are then quantized and further processed into what are called precincts, which are approximately related blocks in the image. The precincts are divided into code blocks that are of equal sizes, and the encoder codes these blocks (Figure 14.5).
This coding takes place in three stages and the resultant bit stream is then divided into packets for transmission. Those packets containing the least significant bits can be discarded. JPEG 2000 is designed for applications such as multimedia devices, video streaming and video servers, HD satellite imagery, and storage of video sequences.
Motion JPEG Compression
Motion JPEG, or M-JPEG, while not covered by the JPEG standard, was developed from JPEG as an early attempt to compress moving images by treating each image as a single still picture. M-JPEG compression uses intraframe coding and is used in nonlinear editing systems, some Internet browsers, game consoles, and compressed video disks.
MPEG Compression
MPEG compression was developed by the Motion Picture Experts Group and defines the standards for compressing moving images. MPEG techniques establish the protocols for compressing, encoding, and decoding data, but not the encoding methods themselves. In other words, the rules dictate the order of the data and what the data must contain but not the method by which the data
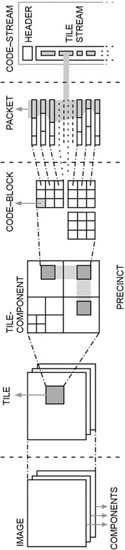
Figure 14.5
Discrete Wavelet Transform (DWT) Process Figure 14.5
is derived. This allows for continuous improvement in encoding techniques without having to constantly change existing equipment. The following chapter takes a more in-depth look at MPEG compression.
Other Compression Codecs
Many other compression systems are based on MPEG and JPEG. Some formats, such as HDV and XDCam, use the toolsets of MPEG, but are adapted to specific uses. Other formats, such as H.264 or AVC (Advanced Video Coding), are MPEG formats with names based on other standards groups categories or marketing by equipment manufacturers who developed improved compression formats within the MPEG protocols. The next generation of these codecs, H.265 or HEVC (High Efficiency Video Coding) is able to compress video into smaller files and has the ability to work with the larger frames of 4K and 8K images.
Problems Introduced During Compression
During compression and encoding of digital data, various errors and inaccuracies can be introduced into the image. Some of these problems include aliasing, quantization noise, overload, and degradation.
Aliasing occurs when frequencies being digitized are too high for the sampling frequency. Aliasing produces a distortion consisting of vertical lines through the image.
Quantization noise is caused by the quantization process, which forces the frequencies into a limited fixed number of levels or steps, producing coarseness in the final image.
Overload occurs if the amplitude of a signal is too great. All levels exceeding the maximum level that can be correctly digitized are converted to white and produce a bleached final image. In another type of overload caused by low amplitude signals, all levels below a minimum are converted to black causing a darkened final image.
Degradation can occur during the transmission of the compressed images. The nature of the compression process means that a single bit error can have an exaggerated effect on the final image.
Compression Artifacts
The compression and decompression process sometimes introduces small visible errors into the restored image. These errors are called artifacts. The type of artifact depends on the type of compression used and the signal content.
Chrominance smear—As a result of low luminance levels or high chroma levels, colors can bleed across sites on a chip. The result is called smearing. The appearance is that of colors blending between areas in the image.
Chrominance crawl—Very fine vertical stripes in a scene can produce high frequency luminance signals that start to be interpreted as chrominance information. This appears as a shimmer of rainbow colors over the striped surface.
Blocking—This is the appearance of small, regular squares that appear to tile an entire still image.
Mosquitoes—This refers to the fuzzy dots that can appear around sharp edges after video compression.
Codec Attributes
There are dozens of different codecs in use in image processing, each having strengths and weaknesses, which make them suitable for different tasks in the stages of video production.
For image capture, a codec that preserves as much image detail as possible is ideal. Compressing too much at this early stage will discard detail that can make post processing—such as color correction and image compositing—more difficult. Very high-end cameras record as much detail as possible by capturing uncompressed data from each of the RGB channels. This leads to the creation of tremendous volumes of data to store and move.
At the other end of the camera spectrum, phones and inexpensive consumer cameras heavily compress the signal using long GOP codecs like H.264. While this creates very manageable file sizes, post production image processing is limited by the lack of color depth and detail that is retained.
Post production editing is best done in an intraframe codec. Codecs that use interframe techniques, such as MPEG and H.264, require decoding the video to find the individual frames to make an edit, then re-encoding the frames on the fly. This process can tax even the most powerful computer edit systems, and make for a slow and frustrating editing experience. Codecs such as DN ´ HD and ProRes are designed by edit system manufacturers to address this issue.
Video destined for the web needs to be compressed in a codec that is designed for streaming the data over the Internet. The files can be more heavily compressed and long GOP codecs are ideal (GOP codecs are discussed in the following chapter). H.264 is frequently the best choice, but there is also much content on the web in Windows Media formats and other codecs as well.
From capture to delivery, an image may move from one codec to another, or be transcoded, several times. Keep in mind that as the images go from less compressed to more compressed, detail and color fidelity are reduced. Once parts of the image are discarded in favor of smaller file sizes, they cannot be recovered. Going from a heavily compressed image to a less compressed format does not improve the image.
NOTE You can read more about codecs in Chapter 19.