Figure 27.1 Input and Output Key–Value Pairs for Three Documents
The skillful soldier does not raise a second levy, nor are his supply wagons loaded more than once.
—Sun Tzu
Hyper-growth, or even slow steady growth over time, presents unique scalability problems for our storage systems. The amount of data that we keep, and the duration for which we keep it, have significant cost implications for our business and can negatively affect our ability to scale cost-effectively
Time affects the value of our data in most systems. Although not universally true, in many systems, the value of data decreases over time. Old customer contact information, although potentially valuable, probably isn’t as valuable as the most recent contact information. Old photos and videos aren’t likely to be accessed as often and old log files probably aren’t as relevant to us today. So as our costs increase with all of the additional data being stored, the value on a per-data-unit-stored basis decreases, presenting unique challenges for most businesses.
This chapter addresses data storage. Specifically, how do we store large volumes of data and process them, while keeping our business from being overly burdened? Which data do we get rid of, and how do we store data in a tiered fashion that allows all data to be accretive to shareholder value?
Data is costly. Your first response to this statement might be that the costs of mass storage devices have decreased steadily over time and with the introduction of cloud storage services, storage has become “nearly free.” But “free” and “nearly free” obviously aren’t the same things. A whole lot of something that is nearly free actually turns out to be quite expensive. As the price of storage decreases over time, we tend to care less about how much we use; in turn, our usage typically increases significantly. Prices might drop by 50%, but rather than passing that 50% reduction in price off to our shareholders as a reduction in our cost of operations, we may allow the size of our storage to double because it is “cheap.”
Of course, the initial cost of this storage is not the only cost you incur with every piece of data you store on it. The more storage you have, the more storage management is needed. This might increase the overhead of systems administrators to handle the data, capacity planners to plan for the growth, or maybe even software licenses that allow you to “virtualize” your storage environment and manage it more easily. As your storage grows, so does the complexity and cost of managing that resource.
Furthermore, as your storage increases, the costs of handling that storage increase as well (“costs” here may be power costs or the cost of space to handle the storage). You might argue here that the advent of Infrastructure as a Service (IaaS) or cloud storage services eliminates many of these costs. We applaud you if you have put your infrequently accessed data on such a storage infrastructure. However, even when working with these solutions, a single massive array will still cost you less than 10 massive arrays, and less storage in the cloud will still cost you less than more storage in the cloud. If you are using cloud services, you still need the staff and processes to understand where that storage is located and to ensure it can be properly accessed.
And that’s still not all the costs! If this data resides in a database upon which you are performing transactions for end users, each query of that data increases with the size of the data being queried. We’re not talking about the cost of the physical storage at this point, but rather the time to complete the query. If you are querying upon a properly balanced index, it’s true that the time to query that data is not linear (it is more likely log2N, where N is the number of elements). Nevertheless, this time increases with an increase in the size of the data. Sixteen elements in binary tree will not cost twice as much to traverse and find an element as eight elements—but the larger number of elements still costs more. This increase in steps to traverse data elements takes more processor time per user query, which in turn means that fewer things can be processed within any given amount of time.
To see how this works, suppose we have 8 elements and it takes us on average 1.5 steps to find our item with a query. Now suppose that with 16 elements, it takes us on average 2 steps to find our item. This is a 33% increase in processing time to handle 16 elements versus 8 elements. Although this seems like a good leverage scaling method, it’s still taking more time. This increased response time doesn’t just impact the database: Even if performed asynchronously, it likely increases the time an app server is waiting for the query to finish, the time the Web server is waiting for the app server to return data, and the time your customer is waiting for a page to load.
Consider the normal peak utilization time in the afternoon, which takes place between 1 and 2 p.m. If each query takes us 33% more time on average to complete and we want to run at 100% utilization during our peak traffic period, we might need as many as 33% more systems to handle the additional data (16 elements versus the original 8) without impacting user response times. In other words, we either let each of the queries take 33% more time to complete and affect the user experience as new queries get backed up waiting for longer-running queries to complete given the constrained capacity, or we add capacity to limit the impact on users. At some point—without disaggregation of the data similar to the trick we performed with search in Chapter 24, Splitting Databases for Scale—user experience will inevitably begin to suffer. Although you may argue that faster processors, better caching, and faster storage will support a better user experience, none of these factors addresses the fact that having more data costs you more in processing time.
The costs of increased data aren’t limited to storage overhead, increased processing time, and increased user response times. Undoubtedly, you’ll also need to back up your storage from time to time. As your data grows, the work necessary to perform a “full backup” grows as well—and, of course, this work will be repeated with each full backup. While most of your data may not be changing, you are nevertheless rewriting it every time a full backup is conducted. Although incremental backups (backing up only the changed data) help alleviate this concern, you will more than likely perform a periodic full backup to forego the cost of needing to apply a multitude of incremental backups to a single full backup that might be years old. If you did only a single full backup and then relied on incremental backups alone to recover some section of your storage infrastructure, your recovery time objective (the amount of time to recover from a storage failure) would be long indeed!
With this discussion, we hope we’ve disabused you of the notion that storage is free. Storage prices may be falling, but they represent only one portion of your true cost to store information, data, and knowledge.
All data is not created equally in terms of its value to our business. In many businesses, time negatively impacts the value that we can get from any specific data element. For instance, old data in most data warehouses is less likely to be useful in modeling business transactions. Old data regarding a given customer’s interactions with your ecommerce platform might be useful to you, but it’s not likely to be as useful as the most current data that you have. Detailed call records for the phone company from years ago aren’t as valuable to the users as new call records, and old banking transactions from three years ago probably aren’t as useful as the ones that occurred in the last few weeks. Old photos and videos might be referenced from time to time, but they aren’t likely to be accessed as often as the most recent uploads. Although we won’t argue that older data is always less valuable than new data, it holds true often enough to call it generally true and directionally correct.
If the value of data decreases over time, why do we keep so darn much of it? We call this question the cost-value data dilemma. In our experience, most companies simply do not pay attention to the deteriorating value of data and the increasing cost of maintaining increasing amounts of data over time. Often, new or faster technologies allow us to store the same data for a lower initial cost or store more data for the same cost. As unit cost of storage drops, our willingness to keep more of it increases.
Moreover, many companies point to the option value of data. How can you possibly know for what you might use that data in the future? Almost all of us can remember a point in our careers when we have said, “If only we had kept that data.” The lack of a critical element of data one time often becomes a reason to keep all data for all time.
Another reason commonly cited for excessive data retention is strategic competitive advantage. Often, this reason is couched as, “We keep this data because our competition doesn’t keep it.” It is entirely possible that your data is a source of competitive advantage, though our experience suggests that the value of keeping data infinitely is not as much of an advantage as simply keeping it longer than your competition (but not infinitely).
Ignoring the cost-value data dilemma, citing the option value of data, and claiming competitive advantage through infinite data retention—all have potentially dilutive effects on shareholder value. If the real upside of the decisions (or lack of decisions, in the case of ignoring the dilemma) does not create more value than the cost, the decision is dilutive to shareholders. In the cases where legislation or a regulation requires you to retain data, such as emails or financial transactions, you have little choice but to comply with the letter of the law. In all other cases, however, it is possible to assign some real or perceived value to the data and compare it to the costs. Consider the fact that the value is likely to decrease over time and that the costs of data retention, although declining on a per-unit basis, will likely increase in aggregate value in hyper-growth companies.
As a real-world analog, your company may be mature enough to associate a certain value and cost to a class of user. Business schools often spend a great deal of time discussing the concept of unprofitable customers. An unprofitable customer is one that costs you more to keep than it represents in revenue, inclusive of all referral business the customer generates. Ideally, you do not want to service or keep your unprofitable customers. The science and art of determining and pruning unprofitable customers is more difficult in some businesses than others.
The same concept of profitable and unprofitable customers nevertheless applies to your data. In nearly any environment, with enough investigation, you will likely find data that adds shareholder value and data that is dilutive to shareholder value. Just as some customers may be unprofitable to us as a business (customers that cost us more than we make from them in revenue), so some data may cost us more than it represents in value.
The business and technology approach to deciding which data to keep and how to keep it is relatively straightforward: Architect storage solutions that allow you to keep all data that is profitable for your business, or is likely to be accretive to shareholder value, and simply remove the rest. Let’s look at the most common factors driving data bloat and then examine ways to match our data storage costs to the value of the data.
All options have some value to us. The precise value may be determined by what we believe the probability is that we will ultimately execute the option to our personal benefit. This may be a probabilistic equation that calculates both the possibility that the option will be executed and the likely benefit of the value of executing the option. Clearly, we cannot claim that the value of any option is infinite. Such a claim would suggest infinite shareholder wealth creation, which simply isn’t possible.
The option value of our data, then, is some bounded (i.e., non-infinite) number. To suggest a bound on this number, we should start asking ourselves pertinent questions: “How often have we used data in the past to make a valuable decision?” “What was the age of the data used in that decision?” “What was the value that we ultimately created versus the cost of maintaining that data?” “Was the net result profitable?”
These questions aren’t meant to advocate the removal of all data from your systems. Your platform probably wouldn’t work if it didn’t have some meaningful data in it. Rather, we are simply indicating that you should evaluate and question your data retention policy to ensure that all of the data you are keeping is, in fact, valuable. If you haven’t used the data in the past to make better decisions, there is a good chance that you won’t start using all of it tomorrow. Even when you do start using your data, you aren’t likely to use all of it. As such, you should decide which data has real value, which data has value but should be stored in a lower-cost storage solution, and which data can be removed.
“Strategic competitive differentiation” is one of our favorite reasons to keep data. It’s the easiest to claim and the hardest to disprove. The general thought is that keeping massive amounts of data (more than your competitors) can competitively differentiate a company. Ostensibly, the company can then make better decisions, and customers will have access to more and better data.
In most cases, however, the value of data degrades over time and infinite data does not equate to infinite value. These two ideas converge to highlight a decay curve in data, where the value of older data starts to decay significantly. As such, to address competitive differentiation, we need to understand the value of data at year Y versus the values at year Y – 2, Y – 5, and so on. We need to identify the point at which data is no longer profitable as well as the point at which additional data adds near-zero value to customer retention, better decision making, and so on. These two points may be the same, but most likely they are not.
After we recognize that some data has immense value, some data has lower value, some data “might have value,” and some data has no value at all, we can determine a tiered cost storage solution for data with value and remove the data with very low or no value. We can also transform and compact the data to make sure that we retain most of the value at significantly lower costs.
Let’s assume that a company determines that some of its data has real value, but the cost of storing it makes the data unprofitable. This is the time to consider a tiered storage solution. Many companies settle on a certain type of storage based on the primary needs of their transaction processing systems. The result of this decision is that almost everything else relies upon this (typically) premium storage solution—even though not absolutely everything needs the redundancy, high availability, and response of your primary applications. For your lower-value (but nevertheless valuable) services and needs, consider moving the data to tiered storage solutions.
For instance, infrequently accessed data that does not require immediate response times might be provisioned on a slower, less costly, and less power-consuming storage solution. Another option is to split up your architecture to serve some of these data needs from a y-axis split that addresses the function of “serve archived data.” To conserve processing power, perhaps the requests to “serve archived data” might be made in an asynchronous fashion and emailed after the results are compiled.
A number of other options for reducing costs through tiered solutions are also available. Infrequently accessed customer data can be put on cloud storage systems. Data that is old and does not change (such as order history data) can be removed from databases and stored statically. The older such data gets, the less frequently it is accessed; thus, over time, it can be moved to lower and lower tiers of storage.
The solution here is to match the cost (or cost-justify) the solution with the value that it creates. Not every system or piece of data offers the same value to the business. We typically pay our employees based on their merit or value to the business, so why shouldn’t we approach systems design in the same fashion? If there is some, but not much, value in some group of data, simply build the system to support the value. This approach does have some drawbacks, such as the requirement that the product staff support and maintain multiple storage tiers, but as long as those additional costs are evaluated properly, the tiered storage solution works well for many companies.
Often, the data we keep for transactional purposes simply isn’t in a form that is consumable or meaningful for our other needs. As a result, we end up processing the data in near real time to make it meaningful to corporate decision making or to make it useful to our product and platform for a better customer experience.
As an example of our former case, where we are emphasizing making good business decisions, consider the needs of a marketing organization concerned about individual consumer behavior. Our marketing organization might be interested in demographic analysis of purchases over time of a number of our products. Keeping the exact records of every purchase might be the most flexible approach to fulfill those needs, but the marketing organization is probably comfortable with being able to match buyer purchases of products by month. All of a sudden, our data requirements have shrunk: Because many of our customers are repeat purchasers, we can collapse individual transaction records into records indicating the buyer, the items purchased, and the month in which those items were purchased. Now, we might keep online transaction details for four months to facilitate the most recent quarterly reporting needs, and then roll up those transactions into summary transactions by individual for marketing purposes and by internal department for finance reasons. Our data storage requirements might decrease by as much as 50% with this scheme. Furthermore, as we would otherwise perform this summarization during the time of the marketing request, we have reduced the response time of the application generating this data (it is now prepopulated), thereby increasing the efficiency of our marketing organization.
As an example of data processing intended to provide a better customer experience, we might want to make product recommendations to our customers while they are interacting with our platform. These product recommendations might give insight as to what other customers bought who have viewed or purchased similar items. It goes without saying that scanning all purchases to develop such a customer affinity-to-product map would likely be too complex to calculate and present while someone is attempting to shop. For this reason alone, we would want to precalculate the product and customer relationships. However, such calculation also reduces our need to store the details of all transactions over time. As a result in developing our precalculated affinity map, we have not only reduced response times for our customers, but also reduced some of our long-term data retention needs.
The principles on which data transformations are based are couched within a process that data warehousing experts refer to as “extract, transform, and load” (ETL). It is beyond the scope of this book to even attempt to scratch the surface of data warehousing, but the concepts inherent to ETL can help obviate the need for storing larger amounts of data within your transactional systems. Ideally, these ETL processes, besides removing the data from your primary transaction systems, will reduce your overall storage needs as compared to keeping the raw data over similar time periods. Condensing expensive detailed records into summary tables and fact tables focused on answering specific questions helps save both space and processing time.
Having discussed the need to match storage costs with data value and to eliminate data of very low value, let’s now turn our attention to a more exciting problem: What do we do when our data is valuable but there is just far too much of it to process efficiently? The answer is the same as it is in complex mathematical equations: Simplify and reduce the equation.
If the data is easily segmented into resources or can be easily associated with services, we need simply apply the concepts we learned in Chapters 22 through 24. The AKF Scale Cube will solve your problems in these situations. But what about the case when an entire data set needs to be traversed to produce a single answer, such as the count of all words in all of the works contained within the Library of Congress, or potentially an inventory count within a very large and complex inventory system? If we want to complete this work quickly, we need to find a way to distribute the work efficiently. This distribution of work might take the form of a multiple-pass system where the first pass analyzes (maps) the work and the second pass calculates (reduces) the work. Google introduced a software framework to support distributed processing of just such large data sets, called MapReduce.1 The following is a description of that model and an example of how it can be applied to large problems.
1. Jeffrey Dean and Sanjay Ghemawat. “MapReduce: Simplified Data Processing on Large Clusters.” http://static.googleusercontent.com/media/research.google.com/en/us/archive/mapreduce-osdi04.pdf.
At a high level, MapReduce has a Map function and a Reduce function. The Map function takes as its input a key–value pair and produces an intermediate key–value pair. This might not immediately seem useful to the layperson, but the intent is that the distributed process creates useful intermediate information for another distributed process to compile. The input key might be the name of a document or pointer to a subsection of a document. The value could be content consisting of all the words within the document or subsection itself. In our distributed inventory system, the key might be the inventory location and the value all of the names of inventory within that location with one name for each piece and quantity of inventory. For instance, if we had five screws and two nails, the value would be screw, screw, screw, screw, screw, and nail, nail.
The canonical form of Map looks like this in pseudocode:2
2. Jeffrey Dean and Sanjay Ghemawat. “MapReduce: Simplified Data Processing on Large Clusters.” http://research.google.com/archive/mapreduce-osdi04-slides/.
map(String input_key, String input_value):
// input_key: document name or inventory location name
//input_value: document contents or inventory contents
For each word w (or part p) in input_value:
EmitIntermediate(w, "1") (or EmitIntermediate(p,"1"));
We’ve identified parenthetically that this pseudocode could work for both the word count example (also given by Google) and the distributed parts inventory example. Only one or the other would exist in reality for your application and you would eliminate the parenthesis.
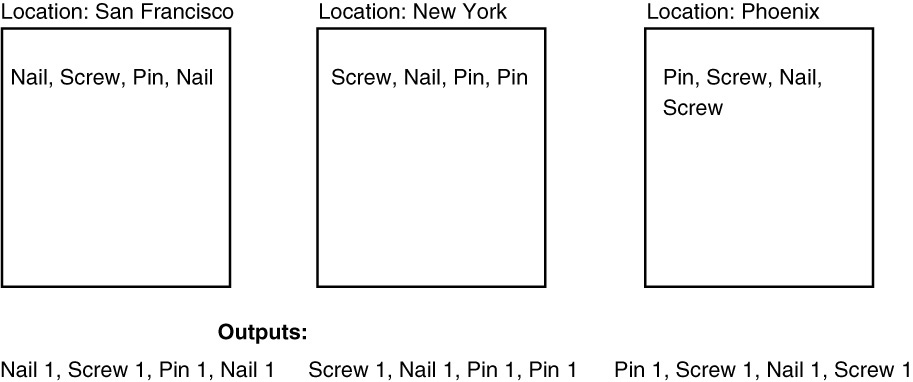
Some input_key and input_values and output keys and values are presented in Figure 27.1. The first example is a set of phrases including the word “red” of which we are fond, and a small set of inventories for different locations.
Note here how Map takes each of the documents and simply emits each word with a count of 1 as we move through the document. For the sake of speed, we had a separate Map process working on each of the documents. Figure 27.2 shows the output of this process.
Again, we have taken each of our initial key–value pairs, where the key is the location of the inventory and the value is the individual components listed with one listing for each occurrence of that component per location. The output is the name of the component and a value of 1 per each component listing. To create this output, we used separate Map processes.
What is the value of such a construct? We can now feed these key–value pairs into a distributed process that will combine them and create an ordered result of key–value pairs, where the value is the number of items that we have of each type (either a word or a part). The trick in our distributed system is to ensure that each key is routed to one and only one collector or reducer. We need this affinity to a reducer (or tier of reducers, as we will discuss in a minute) to ensure an accurate account. If the part “screw” will go to reducer 1, all instances of “screw” must go to reducer 1. Let’s see how the Google reduce function works in pseudocode:3
3. Jeffrey Dean and Sanjay Ghemawat. “MapReduce: Simplified Data Processing on Large Clusters.” Slide 4. http://labs.google.com/papers/mapreduce-osdi04-slides/.
reduce(String input_key, Iterator intermediate_values):
// output_key: a word or a part name
//output_values: count
For each v in intermediate_values:
Result += ParseInt(v);
Emit(AsString(result));
For our reduce function to work, we need to add a program to group the words or parts and append the values for each in a list. This is a rather trivial program that will sort and group the functions by key. It, too, could be distributed, assuming that the key–value pairs emitted from the map function are sent to the same function intended to sort and group and then submit to the reduce function. Passing over the trivial function of sorting and grouping, which is the subject of many computer science undergraduate textbooks, we can display our reduce function as in Figure 27.3 for our inventory system (we will leave the word count output as an exercise for our readers).
Multiple layers of sorting, grouping, and reducing can be employed to help speed up this process. For instance, if we had 50-map systems, they could send their results to 50 sorters, which could in turn send their results to 25 sorters and groupers, and so on, until we had a single sorted and grouped list of parts and value lists to send to our multiple reducer functions. Such a system is highly scalable in terms of the amount of processors and processing power you can throw at it. We highly recommend that you read the Google Labs MapReduce documentation.
There is no doubt in our minds that the decreasing unit cost of storage and the increase in processing power and speed of compute devices have given rise to the era of “Big Data.” As with the term “cloud,” “Big Data” means so many things to so many people that it is tough to really understand what anyone means when they use this term. For our purposes, we will stick to the Wikipedia definition: “Big Data is an all-encompassing term for any collection of data sets so large and complex that it becomes difficult to process using traditional data processing applications.”4
4. “Big Data.” Wikipedia. http://en.wikipedia.org/wiki/Big_data; accessed September 17, 2014.
While the vast majority of this book has been focused on transaction-processing products that face clients, the concepts we’ve presented here are nevertheless equally applicable to Big Data. In fact, the MapReduce functionality described previously was implemented in some of the earliest “Big Data” products to hit the Internet. Is there a larger “Big Data” problem than trying to gather a response set for a search query that spans the entire Internet? In fact, MapReduce serves as part of the backbone for some of the most successful NoSQL implementations (e.g., Hadoop, Mongo) to date. Moreover, few things have helped create value within the Big Data movement like the NoSQL movement.
Many books, both technical and business, have been written on the topic of Big Data. Rather than try (and fail) to create a meaningful contribution to the extant literature, we will instead focus on two themes and how they can help in your Big Data endeavors. These themes are partitioning of data along the y- and z-axes of our cube of scale.
The y-axis partitioning approach is useful when we want to investigate deep and meaningful relationships between small “vertical” groups of data. Such segmentation can help identify “why” a relationship exists. One such grouping might be “customers and products,” which contains all of our customer data and all of our product data and which we use to explain why a product sells better in the Northeast than the Southwest. By looking at customer and product attributes, we can try to identify the independent variables (should they exist) that are most closely correlated with the phenomenon. Because we have excluded all other data, response times will be faster than if we used a monolithic online analytical processing (OLAP) solution.
By comparison, z-axis segmentation is useful when we want to do broad analysis across horizontal slices of data to try to identify where relationships exist. These types of analysis tend to be exploratory in nature, attempting to identify which relationships exist rather than why those relationships exist. The data is segmented to include all attributes, but for only a subset of the total population of data, which allows us to perform broad queries at a reduced response time relative to a monolithic system.
The astute reader may point out that many NoSQL options will do some of this work, especially the z-axis splits. While many do offer this functionality, they can perform such analysis on extremely large data sets only if they are provisioned properly. In other words, you must either rent a lot of capacity in the cloud or spend a lot of capital to answer all of your questions with fast response times across all of your data. If you subject a single environment to all of the questions that you want answered from your data, you will either go bankrupt feeding your cash to that environment or wait forever for responses.
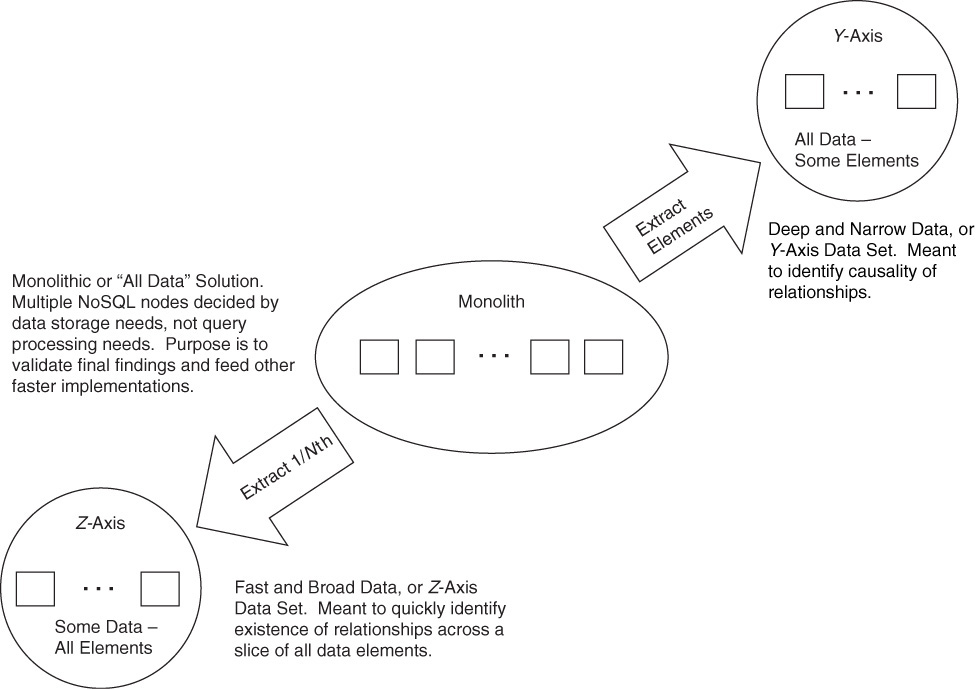
Our preferred approach is to think in terms of three environments: a monolith that has all data, but is not meant to process a lot of queries; a z-axis split of 1/Nth of all of the data that is meant for rapid query responses; and a configurable y-axis environment that we can load with various deep data sets or slices for confirmation of the z-axis findings. We can then follow a progression of identifying relationships (induction) in the z-axis solution, validating existence across the entire customer base in the y-axis solution, and finalizing the findings in the monolithic solution. Note that each of these steps can be either a relational or NoSQL solution. That said, nonrelational systems seem intuitively best suited to answer questions about the relationships between objects, as they have fewer relational boundaries. Figure 27.4 depicts the three-environment solution discussed here.
By splitting our data into three data sets, we can allow the monolithic data set to be driven primarily by data storage needs. This reduces its overall cost relative to a solution that must also handle all of our queries. We use this data set to feed the “fast and broad” (z-axis) and “deep and narrow” (y-axis) data sets. This scheme also serves to perform final validation of anything that we find.
The z-axis split allows us to quickly find relationships on an indiscriminate cross section of our data. This keeps both query processing node needs and data node needs in check, as data sets are smaller. With this solution, we can rapidly iterate through ideas, peruse data to find potential meaning (induction), and queue these potential relationships up for proof in the y-axis. Operationally, should we need to use this data in real time in our products, the z-axis split (by customer) can also exist in each swim lane. The fast and broad data set is populated by an extract, transform, and load (ETL) program. This program can operate either in batch mode or using a real-time but asynchronous “trickle load” from either the monolith or the product.
The y-axis split allows us to find causation for relationships and perform a primary validation of those relationships. It scales by both processing needs and data needs, but because it is constrained it should not be as costly as attempting to scale the monolith. It, too, is fed by an ETL program.
Using this approach, or a variant, helps us not only meet our real-time needs in getting answers to our questions, but also keep overall costs down. Because the systems scale independently and are based on individual variables, the costs tend to be lower and overall response times faster than with a single monolith.
No book on scalability would be complete without at least a nod to NoSQL. As with Big Data, many books have been written on the various flavors of NoSQL and a great deal of information is available from sources like Gartner and its kin. Rather than attempt to do a poor job at re-creating all of this work, we offer some thoughts on how the various families of NoSQL solutions compare and when you might use them. Our intent here is to provide structure to the NoSQL universe to assist you in applying this technology.
The NoSQL revolution was, at least in part, born of the insights derived from Brewer’s theorem (see Chapter 24, Splitting Databases for Scale). They tend to eschew—completely or at least in part—many of the aspects of Structured Query Language (SQL) and relax the consistency constraint within the ACID properties of databases (see Chapters 24 and 25 for definitions and discussions of these). These changes allow for lower costs of scale and better “worst case” response times for queries that are unstructured in nature. In many cases, NoSQL solutions also offer better “best case” and “average case” response times for precomputed cache implementations (refer to the discussion of object caches in Chapter 25, Caching for Performance and Scale). In addition, the relaxation of consistency allows for easier distribution of data to support disaster recovery, high availability, and proximity to customers through native replication capabilities. The general principles we apply in deciding which tool to use (SQL/relational or NoSQL/nonrelational systems) focus on the structure of the data and the purpose of retrieval.
When products rely on highly structured data with a limited and predefined set of operations on those data, relational databases are appropriate. SKU-based product catalog systems are a great example of such a solution. In this approach, the business imposes relationships upon objects, such as a hierarchical structure that adds meaning to items (soap and hair products may be under a personal hygiene hierarchy). Locations within warehouses may also be important as a structural component of such a system. Operations such as purchase, stock, and pick for shipping are all fairly well defined. Indexes can be efficiently created to minimize operations on the data such as retrieval, updates, insertions, and deletion.
When solutions or products rely on lightly structured and nonhierarchical models, or when the operations and relationships between data elements are not well known, NoSQL solutions excel. An example is fast retrieval object caches, where we need only match data elements to users or operations. Another great example is Big Data or deep analytic systems, where we ask questions about relationships between objects that are not well known. Perhaps we are trying to answer the question of whether user location (geographic), seasonal temperature averages, and shipping costs all have an effect on varietal and quantity of wine purchase by season. Relational systems may superimpose relationships upon these entities that confound this analysis, or at the very least make it laborious and slow in response time. The appropriate NoSQL solution would not have these relationships, so it may be both easier to query and faster to respond.
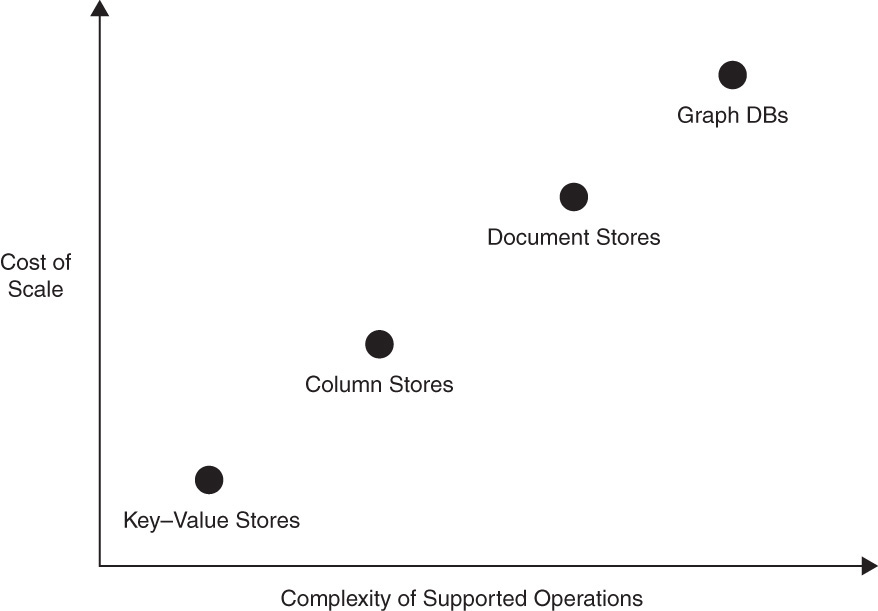
We like to think of NoSQL solutions as being classified into four broad categories: key–value stores (such as Memcached from Chapter 25), column stores, document stores, and graph databases. Technically speaking, graph databases aren’t a NoSQL solution, but they often get thrown into conversations regarding relational database alternatives so we’ve included them here. These four families of NoSQL solutions scale differently in terms of cost and, accordingly, offer varying degrees of flexibility in the query operations that they support. Figure 27.5 graphs these families against cost of scale and query flexibility.
Key–value stores allow for incredible low-cost growth (low cost of scale) given the simplicity of the data that they keep. These solutions typically map a single key to a single value. The operations set deployed against this data tends to be simple, consisting of adding data (set), updating data (replace), and retrieving data (get). The low cost of scale, limitations on query complexity, and resulting speed of use make key–value stores ideal choices for queues, caches, and distributed object stores for fast lookups. They are not meant for most Big Data or analytics purposes.
Column stores are an evolution of the key–value system. These systems tend to have multiple attributes assigned to any key, similar to what you would find in a relational database table. While the name implies a columnar-only format, some implementations use rows rather than columns. Typically a key–value pair is used to map to a column within the solution. This column holds the remaining attributes of the item being mapped. The structure allows for a greater amount of data to be kept while still minimizing the cost of scale. Query flexibility is increased, as more items are available and associated to keys. Column stores, therefore, are great solutions for keeping massive amounts of comparatively nonvolatile information. Examples might be tracking multiple aspects of users for the purposes of retargeting, important customer messages, and semi-static associations within social networks. These solutions may be appropriate as fast-read z-axis implementations (as described in the Big Data discussion), but are limited in the depth of data they can provide and the complexity of the query formations they can support—properties that are important for many deep analytics implementations.
Document stores are perhaps the most flexible solutions and, in turn, the most costly per unit of scale within the NoSQL family. Document stores tend to have the loosest relationships between data, making them very good choices for unstructured analytics and analysis of relationships between objects. Many are purpose built for specific types of objects, such as JavaScript Object Notation (JSON). Document stores tend to have the greatest flexibility (and associated complexity) in the types of queries they allow against document objects. For this reason, they are good choices for y-axis deep analytic data marts and monolithic feeder/validation solutions (like those described in the Big Data section). Given the affinity with JSON, this family is also JavaScript friendly and is often used in product solutions.
Graph databases are inherently more relational than true NoSQL solutions. As such, they tend to provide the greatest flexibility in query operations and, in turn, come with a higher cost of scale. They excel at quickly traversing relationships between entities, such as traversing nodes within a social network. These solutions excel at evaluating real-time models between entities, such as dynamic pricing calculators in real-time pricing systems (e.g., second price auctions).
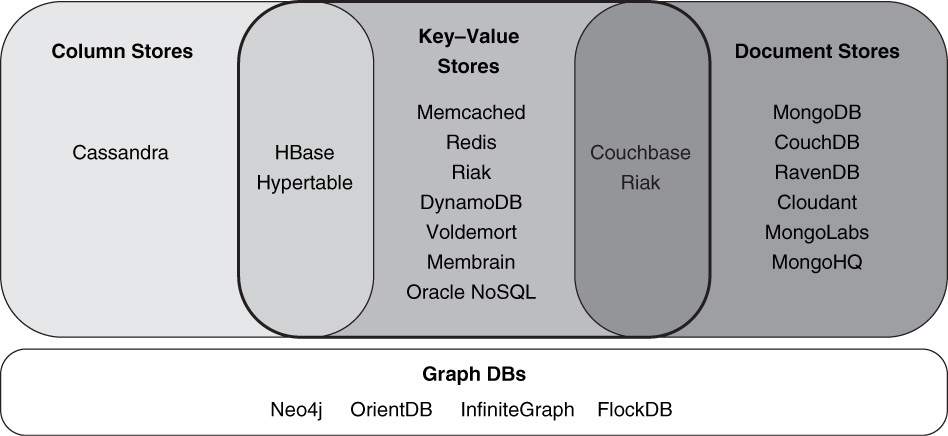
Figure 27.6 maps the various NoSQL implementations into their respective families. Note that because some implementations are difficult to classify, we’ve mapped them across familial boundaries.
This chapter discussed the storage and processing of large data sets. We examined the paradoxical relationship of cost and value for data. As data ages and data size grows, its cost to the organization increases. At the same time, as data ages in most companies, its value to the company and platform typically decreases. The reasons for clinging to data whose value has largely expired include ignorance, perceived option value, and perceived strategic competitive differentiation. Our remedies for perceived option value and perceived competitive differentiation are based in the notion of applying real dollar values to these perceived values to properly justify the existence (and the cost) of the data.
After identifying the value and costs of data, you should consider implementing tiered storage solutions that match the cost and access speed of data to the value that it creates for your shareholders. On one end of such a tiered strategy are high-end, very fast storage devices; on the opposite end is the deletion or purging of low-value data. Data transformation and summarization can help reduce the cost, and thereby increase the profitability, of data where the reduction in size does not significantly change the value of the data.
One approach to parallelize the processing of very large data sets is Google’s MapReduce approach. MapReduce has been widely adopted by many industries as a standard for processing large data sets quickly in a distributed fashion.
• Data is costly, and its cost includes more than just the cost of the storage itself. People, power, capital costs of the power infrastructure, processing power, and backup time and costs all influence the true cost of data.
• The value of data in most companies tends to decrease over time.
• Companies often keep too much data due to ignorance, perceived option value, and perceived competitive differentiation.
• Perceived option value and perceived competitive differentiation should include values and time limits on data to properly determine if the data is accretive or dilutive to shareholder value.
• You should eliminate data that is dilutive to shareholder value, or find alternative storage approaches to make this data accretive. Tiered storage strategies and data transformation are methods of cost-justifying data.
• Applying the concepts of distributed computing to large data sets helps us process those data sets quickly. Google’s MapReduce is a good example of a software framework for acting on large data sets.
• Leveraging the y- and z-axes of scalability can help to identify relationships faster (z-axis), determine causation of the relationships (y-axis), and validate results across the entire data set (monolith) at relatively low cost.
• NoSQL solutions relax the ACID component of consistency to speed up some queries and allow for easier distribution of data.
• The appropriate NoSQL solution can aid in analytics, as the lack of structure doesn’t confound or impede broad analytical queries across objects.
• Multiple families of NoSQL solutions exist, each with benefits and comparative drawbacks. Choose the right tool for your specific need.