Fire suppression
Fire suppressionImplementing Disaster Recovery and Incident Response Procedures
Life is filled with risks. There is always the chance that a fire can break out, someone may try and gain unauthorized information or access, or (depending on your location) an earthquake, tornado, or blizzard could happen. The potential threats can be diverse. However, just as you have insurance on your car and smoke detectors in your house, security-minded organizations make efforts to protect their assets, including equipment, facilities, and the people who work for them from coming to harm.
When you think of securing systems from harm, you might initially think of hackers and viruses. However, the environment where your equipment resides can cause equal or greater damage. Servers, switches, and other devices in server rooms and other locations can have poor heating, air conditioning, or other factors that damage equipment. As we’ll discuss in this chapter, protecting equipment from environmental factors is of vital importance to keeping things up-and-running.
When a disaster does occur, it’s important that Information Technology (IT) staff and other members of an organization know what to do. As we discussed in Chapter 13, alternate sites and other measures may be implemented beforehand in preparation of a disaster. As we’ll see in this chapter, the ability to respond to incidents and recover from a disaster relies on preparation and having the proper procedures in place.
Even with educated users and all critical systems locked behind closed doors, equipment and data are still at risk if the environment beyond those locked doors is insecure. Environment refers to the surroundings in which the computers and other equipment reside. If an environment is insecure, data and equipment can be damaged. To prevent the environment from affecting a system’s safety and capability to function, the following elements should be considered:
Fire suppression
Temperature
Humidity
Airflow
Electrical and other types of interference
Electrostatic discharge (ESD)
In the sections that follow, we’ll discuss how equipment and data can be damaged by these various elements and discuss various measures that you can implement to safeguard them.
Fire is a major risk in any environment that contains a lot of electrical equipment, so fire suppression systems must be put in place to protect servers and other equipment. Because problems with moisture and flooding can damage or destroy equipment, water sprinklers are not an option in server rooms or other areas storing devices. Other problems may occur if the fire suppression system releases foam that damages equipment, creates significant smoke when putting out a fire, or causes other potential problems that can result in collateral damage. When choosing a fire suppression system, it is important to choose one that will put out a fire but not destroy the equipment in the process. These are often referred to as clean agent fire extinguishing systems.
Halon is a fire suppressant often found in older facilities. When a fire occurred, this chemical would be dumped into the room at high pressure, removing necessary elements needed to work with the oxygen and fuel the fire. Halon 1301, made by DuPont, worked by having bromine combine with the hydrogen released by the fire, effectively removing it from the air. Because the oxygen and hydrogen were no longer able to work together, the fire would be extinguished. Although it worked, it was found to be damaging to the ozone and was banned from new installations of fire suppression systems. This means that once an older system dumps its existing load of halon to put out a fire (or some unfortunate soul accidentally sets off the system), the company must now pay to install a completely different fire system that doesn’t have adverse effects.
There are many different alternatives to halon, which can be used safely without negative impacts on the environment. These include the following:
Inergen (IG-541) A combination of three different gases: nitrogen, argon, and carbon dioxide. When released, it lowers the oxygen content in a room to the point that the fire cannot be sustained.
Heptafluoropropane (HFC-227ea) A chemical agent that is also known as FM-200. This agent is released as a gas suppressing the fire but has been found not to be harmful to persons in the room.
Trifluromethane (FE-13) A chemical originally developed by DuPont as a refrigerant but commonly used in new fire suppression systems. FE-13 molecules absorb heat, making it impossible for the air in the room to support combustion. It is considered to be one of the safest clean agents.
Carbon Dioxide Systems A popular method of fire suppression, as carbon dioxide reduces the oxygen content to the point where the atmosphere can no longer support combustion.
When deciding on a fire suppression system, it is important to examine whether it will damage equipment or is toxic to people when the fire suppression system is deployed.
EXAM WARNING Remember that halon isn’t manufactured anymore, so fire suppressants used in new systems use other chemicals to put out a fire without damaging equipment.
Before a fire suppressant becomes activated, the signs of a fire must be detected. There are several types of devices that will detect the signs of fire, which in turn should then activate the fire suppressant system in a server room or other location where equipment resides. These are as follows:
Smoke detection is the most common method of detecting a fire. One that you may have in your home uses an optical (photoelectric) detector, which uses a light sensor. As smoke passes in front of the beam of light, it disrupts the beam and sets off the alarm. There are also other types of smoke alarms that sample the air to check for smoke particles, and others that are designed to check for high levels of carbon monoxide and carbon dioxide.
Heat detection is used to monitor the temperature levels of a room. When the temperature increases at a rapid rate or reaches a set temperature threshold, the alarm is triggered.
Flame detection is used to detect the movement of flames or certain types of energy (that is, ultraviolet and infrared) that indicates a fire has occurred.
EXAM WARNING The three indicators of fire used by detection systems are smoke, heat, and flame. Once these systems detect a fire, the fire suppression system is activated.
HVAC is an acronym for heating, ventilation, and air conditioning. It is the control system used to control humidity, temperature, and air flow. The environment in server rooms and other areas where sensitive equipment resides needs to have controlled conditions to operate properly. If temperatures or humidity are too high or too low, it can damage the equipment and result in the loss of data.
If a computer overheats, components inside it can be permanently damaged. Although the temperature of the server room may feel comfortable to you, the inside of a computer can be as much as 40° F warmer than the air outside the case. The hardware inside the case generates heat, raising the interior temperature. Computers are equipped with fans to cool the power supply, processor, and other hardware so that temperatures do not rise above 110° F. If these fans fail, the heat can rise to a level that destroys the hardware.
Computers are also designed to allow air to flow through the machine, keeping the temperature low. If the airflow is disrupted, temperatures can rise. For example, say you removed an old adapter card that was no longer needed by a computer. Because you did not have a spare cover, there is now an opening where the card used to be. Because air can now pass through this hole, you might expect that this would help to cool the hardware inside, but airflow is actually lost through this opening. Openings in the computer case prevent the air from circulating inside the machine as it was designed to, causing temperatures to rise.
TEST DAY TIP Remember that HVAC stands for heating, ventilation, and air conditioning, which is the climate control system that’s necessary for server rooms and other areas where equipment is used or stored. Because computers and other sensitive equipment can be damaged by changes in temperature, humidity, and other environmental factors, it is important that an HVAC system is always operating properly.
A common problem with computers is when fans fail, causing increases in temperature within the case. These fans may be used to cool the processor, power supply, or other components. As with other causes of temperature increases, the machine may not fail immediately. The computer may experience reboots, “blue screens of death,” memory dumps, and other problems that occur randomly. To determine whether increases in temperature are the cause of these problems, you can install hardware or software that will monitor the temperature and inform you of increases. When the temperature increases above a normal level, you should examine the fans to determine if this is the cause. Variations in temperature can also cause problems. If a machine experiences sudden changes in temperature, it can cause hardware problems inside the machine. Heat makes objects expand, whereas cold makes these same objects contract. When this expansion and contraction occurs in motherboards and other circuit boards, chip creep (also known as socket creep) can occur. As the circuit boards expand and contract, it causes the computer chips on these boards to move until they begin to lose contact with the sockets in which they are inserted. When the chips lose contact, they are unable to send and receive signals, resulting in hardware failure.
To prevent problems with heat and cold, it is important to store servers and other equipment in a temperature-controlled environment. Keeping machines in a room that has air conditioning and heat can keep the temperature at a cool level that does not fluctuate. To assist in monitoring temperature, alarms can be set up in the room to alert you when the temperature exceeds 80° F. Other alarms can be used that attach to the servers, automatically shutting them down if they get too hot.
ESD is another threat to equipment, as static electricity can damage hardware components, so they cease to function. If unfamiliar with ESD, think of the times when you have walked over a dry carpet and received a shock when you touched someone. The static electricity builds up, and electrons are discharged between the two objects until both have an equal charge. When you receive a shock from touching someone, the discharge is around 3000 volts. To damage a computer chip, you only need a discharge of 20 or 30 volts. Humidity levels can increase ESD. If the humidity in a room is below 50 percent, the dry conditions create an atmosphere that allows static electricity to build up. This creates the same situation as mentioned above. A humidity level that is too high can also cause ESD, as water particles that conduct electricity can condense and stick to hardware components. Not only can this create ESD problems, but if the humidity is very high, the metal components may rust over time. To avoid humidity problems, keep the levels between 70 and 90 percent. Installing humidifiers and dehumidifiers to, respectively, raise and lower the level of humidity can be used to keep it at an acceptable point.
Poor air quality is another issue that can cause problems related to ESD and temperature. As mentioned earlier, fans in a machine circulate air to cool the components inside. If the air is of poor quality, dust, smoke, and other particles in the air will also be swept inside the machine. Because dust and dirt particles have the capability to hold a charge, static electricity can build up, be released, and build up again. The components to which the dust and dirt stick are shocked over and over again, damaging them over time. If the room is particularly unclean, dust and dirt can also build up on the air intakes. Because very little air can enter the case through the intake, temperatures rise, causing the components inside the machine to overheat. Vacuuming air intakes and installing an air filtration system in rooms with critical equipment can improve the quality of air and avoid these problems.
Damage and Defense
Protecting Equipment from ESD
When working on equipment, you should take precautions to prevent ESD. ESD wristbands and mats can ground you, so you do not give the components a shock. An ESD wristband is a strap that wraps around your wrist with a metal disc on it. A wire is attached to this metal disc, whereas the other end has an alligator clip that can be attached to an electrical ground. An ESD mat is similar but has two wires with alligator clips attached to them. One wire is attached to an electrical ground, whereas the other is attached to the computer you are working on. When you place the computer on the mat, the computer becomes grounded and any static charge is bled away.
Shielding refers to materials that are used to prevent data signals from being affected by external sources. This not only applies to wireless data escaping outside of an office but also pertains to external signals or interference affecting data being carried along cables.
Data transmitted on wireless technologies is inherently insecure and requires additional measures to secure that data. If equipment used to transmit and receive data from these devices is placed too close to exterior walls, wireless transmissions can leak outside of an office area. This may enable others outside of the office to connect to the network or intercept data, using a packet sniffer and other equipment that can be purchased from any store selling computer products. This is why encrypting all data on a wireless network is so important. The encryption prevents unauthorized individuals who access the signal from deciphering any of the data. Aside from moving antennas away from exterior walls, shielding can also be used to prevent wireless transmissions from escaping a building or office area. Shielding blocks signals from escaping but may also have the unwanted effect of blocking cellular communications.
Not only can communications signals leak out of a prescribed area but unwanted signals can also leak in and interfere with communications. Thus, shielding is also necessary to prevent data from being damaged in transmission from radio frequency interference (RFI) and electromagnetic interference (EMI). RFI is caused by radio frequencies emanating from microwaves, furnaces, appliances, radio transmissions, and radio frequency-operated touch lamps and dimmers. Network cabling can pick up these frequencies much as an antenna would, corrupting data traveling along the cabling. EMI is caused by electromagnetism generated by heavy machinery such as elevators, industrial equipment, and lights. The signals from these sources can overlap those traveling along network cabling, corrupting the data signals so that they need to be retransmitted by servers and other network devices. When EMI and RFI cause interference, it is called noise.
To prevent data corruption from EMI and RFI, computers and other equipment should be kept away from electrical equipment, magnets, and other sources. This will minimize the effects of EMI and RFI because the interference will dissipate, as it travels over distance.
When cabling travels past sources of EMI and RFI, a higher grade of cabling should be used, which has better shielding and can protect the wiring inside from interference. Shielded twisted-pair (STP) is a type of cabling that uses a series of individually wrapped copper wires encased in a plastic sheath. Twisted-pair can be unshielded or shielded. When the cabling is STP, the wires are protected with foil wrap for extra shielding.
Coaxial cable is commonly used in cable TV installations but can also be found on networks. This type of cabling has a solid or stranded copper wire surrounded by insulation. A wire mesh tube and a plastic sheath surround the wire and insulation to protect it. Because the wire is so shielded from interference, it is more resistant to EMI and RFI than twisted-pair cabling.
Although each of the cabling we’ve discussed so far involves data being transmitted across copper wires, this is not the case for fiber-optic cable. Data is transmitted as light along the glass or plastic in the cabling, so it is not affected by electromagnetic or RFI. This makes fiber optics an ideal alternative for areas where interference may impede or corrupt the transmission of data.
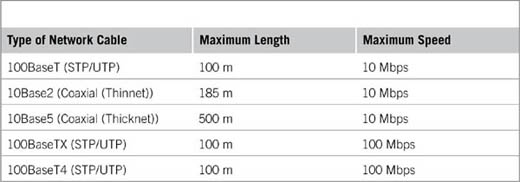
Network performance should always be considered when deciding what type of cable to use. Different types of cable allow data to travel at different speeds and to maximum lengths before devices must be used to lengthen transmission distances. The varying specifications for different types of coaxial, unshielded twisted-pair (UTP), and STP cable are shown in Table 14.1.
In looking at this table, you will notice that each of the different types of cabling has a maximum length. This is because as the data travels over the line, it will slowly degrade. Attenuation is the decrease of a signal’s strength over the length of a cable. Because the signal’s power weakens over distance, devices must be used to boost the signal strength or different cable that is more resistant to attenuation and supports greater lengths should be used.
Another issue with cabling is crosstalk, which is a term used to describe when a signal from one channel or circuit interferes with another. In cabling where there are multiple wires close together, there is a chance that the signals from one wire can cause interference with another wire. Because the signal from one wire is essentially jumping over to the other wire, creating distortion can corrupt data.
When installing cabling, it is important that the cable is not easily accessible to unauthorized people. If an intruder or malicious user accesses the cable used on a network, they can tap the wire to access data traveling along it, or the cabling can be physically damaged or destroyed. Cable should not be run along the outside of walls or open areas where people may come into contact with it. If this cannot be avoided, then the cable should be contained within tubing or some other protective covering that will prevent accidental or malicious actions from occurring.
Table 14.1 Specifications for Networks UsingDifferent Cablng
Head of the Class
Fiber-Optics Are Immune to EMI and RFI
An alternative to copper cabling and wireless technologies is using fiber-optic cabling, in which data is transmitted by light. Fiber-optic cable has a core made of light-conducting glass or plastic, surrounded by a reflective material called cladding. A plastic sheath surrounds all this for added protection. Because the signal is transmitted via light, data that travels along fiber-optic cable is not affected by interference from electromagnetism or radio frequencies. This makes it an excellent choice for use in areas where there are sources of EMI or RFI.
One way or another, fiber-optic cabling has become a common element in many networks. If it is a small company, then most of the internal network will probably be made up of cabling that uses some form of copper wiring (that is, UTP, STP, or coaxial). However, even in this situation, Internet access is probably provided to users on the network, meaning they will connect out to a backbone that uses fiber optics. In larger companies, it has been increasingly common to connect different locations together using fiber-optic cabling. If buildings are connected together with fiber optics, it doesn’t mean that copper cabling isn’t present on the network. UTP (or some other cabling) will generally be used within buildings to connect computers to the network or connect networks on different floors together. Because of this, EMI and RFI will still be an issue.
After the events of September 11, 2001, the widespread effects of a disaster became evident. Equipment, data, and personnel were destroyed, staggering amounts of money were lost by individual businesses, and the economic ripples were felt internationally. Although some companies experienced varying levels of downtime, some never recovered and were put out of business. Although this was an extreme situation, a disaster recovery plan is used to identify such potential threats of terrorism, fire, flooding, and other incidents and provide guidance on how to deal with such events when they occur.
In the same way that natural disasters can negatively affect a company, the actions of people can cause incidents that could damage data and equipment. These incidents can occur as a result of employees accidentally or maliciously deleting data, intrusions of the system by hackers, viruses and malicious programs that damage data, and other events that cause downtime or damage.
To deal with the various incidents and disasters that can affect an organization, procedures need to be in place so that professionals within the company can deal with them. These procedures can reduce confusion in a disaster, protect resources, and/or be used to follow best practices that allow a suspect behind an incident to be prosecuted at a later time.
Preparation for disaster recovery begins long before a disaster actually occurs. Backups of data need to be performed daily to ensure data can be recovered, plans need to be created that outline what tasks need to be performed by whom, and other issues need to be addressed as well. Although it is hoped that such preparation is never needed, it is vital that a strategy is in place to deal with incidents.
The disaster recovery plan should identify as many potential threats as possible and include easy-to-follow procedures. When discussing disaster recovery plans in greater detail, a plan should provide countermeasures that address each threat effectively.
Disaster recovery plans are documents that are used to identify potential threats and outline the procedures necessary to deal with different types of threats. When creating a disaster recovery plan, administrators should try to identify all the different types of threats that may affect their company. For example, a company in California would not need to worry about blizzards, but it would need to be concerned about earthquakes, fire, flooding, power failures, and other kinds of disasters. Once the administrators have determined what disasters their company could face, they can then create procedures to minimize the risk of such disasters.
Disasters are not limited to acts of nature but can be caused through electronic methods. For example, denial-of-service (DoS) attacks occur when large numbers of requests are sent to a server, which overloads the system and causes legitimate requests for service to be denied. When an e-commerce site experiences such an attack, the losses can be as significant as any natural disaster.
Risk analysis should be performed to determine what is at risk when a disaster occurs. This should include such elements of a system as follows:
Loss of data
Loss of software and hardware
Loss of personnel
Software can be backed up, but the cost of applications and operating systems (OSes) can make up a considerable part of a company’s operating budget. Thus, copies of software and licenses should be kept off-site so that they can be used when systems need to be restored. Configuration information should also be documented and kept off-site so that it can be used to return the system to its previous state.
Additional hardware should also be available. Because hardware may not be easily installed and configured, administrators may need to have outside parties involved. They should check their vendor agreements to determine whether they provide on-site service within hours or days, as waiting for outsourced workers can present a significant bottleneck in restoring a system.
Personnel working for a company may have distinct skill sets that can cause a major loss if that person is unavailable. If a person is injured, dies, or leaves a company, his or her knowledge and skills are also gone. Imagine a network administrator getting injured in a fire, with no one else fully understanding how to perform that job. This would cause a major impact to any recovery plans. Thus, it is important to have a secondary person with comparable skills who can replace important personnel, documentation on systems architecture and other elements related to recovery, and clear procedures to follow when performing important tasks.
When considering the issue of personnel, administrators should designate members who will be part of an Incident Response Team and who will deal with disasters when they arise. Although we’ll discuss incident response in greater detail later in this chapter, members should have a firm understanding of their roles in the disaster recovery plan and the tasks they will need to perform to restore systems. A team leader should also be identified, so a specific person is responsible for coordinating efforts.
Recovery methods discussed in the plan should focus on restoring the most business-critical requirements first. For example, if a company depends on sales from an e-commerce site, restoring this server would be the primary focus. This would allow customers to continue viewing and purchasing products while other systems are being restored.
Another important factor in creating a disaster recover plan is cost. As discussed in Chapter 13, hot, warm, and cold sites require additional cost such as rent, purchasing hardware that may not be used until a disaster occurs (if one ever does), stock office supplies and other elements that allow a business to run properly. This can present a dilemma; you do not want to spend more money on preparation than it would cost to recover from a disaster, but you also do not want to be overly frugal and not be able to restore systems in a timely manner. Finding a balance between these two extremes is the key to creating a disaster recovery plan that is affordable and effective.
Backing up data is a fundamental part of any disaster recovery plan. When data is backed up, it is copied to a type of media that can be stored in a separate location. The type of media will vary depending on the amount of data being copied but can include digital audio tape (DAT), digital linear tape (DLT), compact disks (CDR/ CD-RW) and DVDs, or a folder location on a separate server. If data is destroyed unintentionally, it can be restored as if nothing had happened.
When making backups, the administrator needs to decide what data will be copied to alternative media. Critical data, such as trade secrets that a business relies on to function, and other important data crucial to a business’ needs must be backed up. Other data, such as temporary files, applications, and other data, may not be backed up as they can easily be reinstalled or missed in a backup. Such decisions, however, will vary from company to company.
Once the administrator has decided on what information needs to be backed up, they can determine the type of backup that will be performed. Common backup types include the following:
Full backup backs up all data in a single backup job. Generally, this includes all data, system files, and software on a system. When each file is backed up, the archive bit is changed to indicate that the file was backed up.
Incremental backup backs up all data that was changed since the last backup. Because only files that have changed are backed up, this type of backup takes the least amount of time to perform. When each file is backed up, the archive bit is changed.
Differential backup backs up all data that has changed since the last full backup. When this type of backup is performed, the archive bit is not changed, so data on one differential backup will contain the same information as the previous differential backup plus any additional files that have changed.
Copy backup makes a full backup but does not change the archive bit. Because the archive bit is not marked, it will not affect any incremental or differential backups that are performed.
Because different types of backups will copy data in different ways, the methods used to back up data vary between businesses. One company may do daily full backups, whereas another may use a combination of full and incremental backups (or full and differential backups). As will be seen in later sections, this affects how data is recovered and what tapes need to be stored in alternative locations. Regardless of the type used, however, it is important that data are backed up on a daily basis so that large amounts of data will not be lost in the event of a disaster.
TEST DAY TIP Make sure you know the difference between the different types of backups you can perform. The backup types are full, incremental, differential, and copy. Each of these may be used for different purposes and can affect whether the archive bit is reset on a file.
It is important to keep at least one set of backup tapes off-site so that all the tapes are not kept in a single location. If backup tapes were kept in the same location as the servers that were backed up, all the data (on the server and the backup tapes) could be destroyed in a disaster. By rotating backups between a different set of tapes, data is not always being backed up to the same tapes, and a previous set is always available in another location.
A popular rotation scheme is the Grandfather-Father-Son (GFS) rotation, which organizes rotation into a daily, weekly, and monthly set of tapes. With a GFS backup schedule, at least one full backup is performed per week, with differential or incremental backups performed on other days of the week. At the end of the week, the daily and weekly backups are stored off-site, and another set is used through the next week. To understand this better, assume a company is open Monday through Friday. As shown in Table 14.2, a full backup of the server’s volume is performed every Monday, with differential backups performed Tuesday through Friday. On Friday, the tapes are moved to another location, and another set of tapes is used for the following week.
Table 14.2 Sample Backup Schedule Used in a Week

Because it is too expensive to continually use new tapes, old tapes are reused for backups. A tape set for each week in a month is rotated back into service and reused. For example, at the beginning of each month, the tape set for the first week of the previous month would be rotated back into service and used for that week’s backup jobs. Because one set of tapes is used for each week of the month, this means that most sets of tapes are kept off-site. Even if one set were corrupted, the setup tapes for the previous week could still be used to restore data.
In the GFS rotation scheme, the full backup is considered the “Father” and the daily backup is considered the “Son.” The “Grandfather” segment of the GFS rotation is an additional full backup that is performed monthly and stored off-site. The Grandfather tape is not reused but is permanently stored off-site. Each of the Grandfather tapes can be kept for a specific amount of time (such as a year) so that data can be restored from previous backups, even after the Father and Son tapes have been rotated back into service. If someone needs data restored from several months ago, the Grandfather tape enables a network administrator to retrieve the required files.
A backup is only as good as its capability to be restored. Too often, backup jobs are routinely performed, but the network administrator never knows whether the backup was performed properly until the data needs to be restored. To ensure that data is being backed up properly and can be restored correctly, administrators should perform test restores of data to the server. This can be as simple as attempting to restore a directory or small group of files from the backup tape to another location on the server.
Once backups have been performed, administrators should not keep all the backup tapes in the same location as the machines they have backed up. After all, a major reason for performing backups is to have the backed-up data available in case of a disaster. If a fire or flood occurred and destroyed the server room, any backup tapes in that room would also be destroyed. This would make it pointless to have gone through the work of backing up data. To protect data, the administrator should store the backups in a different location so that they will be safe until they are needed.
Off-site storage can be achieved in a number of ways. If a company has multiple buildings, such as in different cities, the backups from other sites can be stored in one of those buildings and the backups for servers in that building can be stored in another building. If this is not possible, there are firms that provide off-site storage facilities. The key is to keep the backups away from the physical location of the original data.
When deciding on an off-site storage facility, administrators should ensure that it is secure and has the environmental conditions necessary to keep the backups safe. They should also ensure that the site has air conditioning and heating, as temperature changes may affect the integrity of data. The facility should also be protected from moisture and flooding and have fire protection. The backups need to be locked up, and policies in place of who can pick up the data when needed.
EXAM WARNING Backups are an important part of disaster recovery, so it is possible there will be a question or two dealing with this topic. Remember that copies of backups must be stored in off-site locations. If the backups are not kept in off-site storage, they can be destroyed with the original data in a disaster. Off-site storage ensures backups are safe until the time they are needed.
Data are only as good as its capability to be restored. If it cannot be restored, the work performed to maintain backups was pointless. The time to ensure that backups can be restored is not during a disaster. Test restores should be performed to determine the integrity of data and to ensure that the restore process actually works.
Recovering from a disaster can be a time-consuming process with many unknown variables. If a virus, intruder, or other incident has adversely affected a small amount of data, it can be relatively simple to restore data from a backup and replace the damaged information. However, when disasters occur, hardware may be destroyed also, making it more difficult to restore the system to its previous condition.
Dealing with damaged hardware will vary in complexity, depending on the availability of replacement equipment and the steps required when restoring data to the network. Some companies may have additional servers with identical configurations to damaged ones, for use as replacements when incidents occur. Other companies may not be able to afford such measures or do not have enough additional servers to replace damaged ones. In such cases, the administrator may have to put data on other servers and then configure applications and drive mappings so the data can be accessed from the new location. Whatever the situation, administrators should try to anticipate such instances in their disaster recovery plan and devise contingency plans to deal with such problems when they arise.
Administrators also need to determine how data will be restored from backups. There are different types of backups that can be performed. Each of these take differing lengths of time to restore and may require additional work. When full backups are performed, all the files are backed up.
As a backup job can fit on a single tape (or set of tapes), administrators only need to restore the last backup tape or set that was used. Full backups will back up everything, so additional tapes are not needed.
Incremental backups take the longest to restore. Incremental backups contain all data that was backed up since the last backup, thus many tapes may be used since the last full backup was performed. When this type of backup is used, administrators need to restore the last full backup and each incremental backup that was made since.
Differential backups take less time and fewer tapes to restore than incremental backups. Because differential backups back up all data that are changed since the last full backup, only two tapes are needed to restore a system. The administrator needs to restore the tape containing the last full backup, and the last tape containing a differential backup.
Because different types of backups have their own advantages and disadvantages, the administrators will need to consider what type of backup is suitable to their needs. Some types of backups take longer than others to backup or restore, so they need to decide whether they want data backed up quickly or restored quickly when needed. Table 14.3 provides information on different aspects of backup types.
Even if data has been backed up, it doesn’t mean that it can be restored. You don’t want to be caught in a situation where you find that the data stored on backup tapes or other media can’t be recovered. It is possible that even though the backup program you’re using appears to be backing up data correctly, data is not being stored properly (if at all). To ensure backed up data can be recovered, test restores should occasionally be performed. By restoring a series of files to a server, you can ensure that the data can be restored when it’s actually needed. Once these files are restored, you should open them to determine whether the restored data is corrupted.
No matter how secure you think your network is, there may come a time when a security breach or disaster occurs. When such problems do occur, an incident response policy provides a clear understanding of what decisive actions will be taken and who will be responsible for investigating and dealing with problems. Without one, significant time may be lost trying to decide what to do and how to do it.
Incidents can be any number of adverse events affecting a network or computer system or violations of existing policy. They can include but are not limited to unauthorized access, denial or disruptions of service, viruses, unauthorized changes to systems or data, critical system failures, or attempts to breach the policies and/or security of an organization. Because few companies have the exact same services, hardware, software, and security needs, the types of incidents an organization may face will often vary from business to business.
A good incident response policy outlines who is responsible for specific tasks when a crisis occurs. It will include such information as follows:
Who will investigate or analyze incidents to determine how they occurred and what problems are faced because of it?
Which individuals or departments are to fix particular problems and restore the system to a secure state?
How certain incidents are to be handled and references to other documentation.
Including such information in the incident response policy ensures that the right person is assigned to a particular task. For example, if the Webmaster was responsible for firewall issues and the network administrator performed backups of data, you would assign each of them tasks relating to their responsibilities in the incident response policy. Determining who should respond and deal with specific incidents allows you to restore the system to a secure state more quickly and effectively.
Incident response policies should also provide information on how to deal with problems when they occur or provide references to procedures. As mentioned earlier, procedures should be clearly defined so that there is no confusion as to how to deal with an incident. Once an incident has been dealt with, the Incident Response Team should determine ways to ensure the same incident will not happen again. Simply resolving the crisis but not changing security methods increases the likelihood that the same incident may occur again in the exact same manner. Taking a proactive approach to future incidents decreases the chance of recurring problems.
Incident Response Teams are IT professionals used to handle incidents that occur in a company and may be formed in a number of ways. Some organizations use the people who have on-call duties and are used to respond to any problems that users may encounter or with the network after hours. Because these people are training and have the experience to troubleshoot and handle situations after hours, and generally are selected from a group of IT staff with diverse duties, many companies select them as the obvious choice for responding to incidents as a group. Other companies may form a formal team of selected individuals, whereas others create them as needed based on the type of incident being encountered.
In responding to an incident, the team should be trained in best practices and proper procedures. In an incident, they will go through a process of the following steps:
Identification
Investigation
Repair
Documentation
The identification phase is where the Incident Response Team identifies the type of incident occurring. They may have been alerted by an intrusion detection system (IDS) on the network, which monitors for signs of intrusion attempts. The team will determine what is affected, the scope of the incident, and whether an attack is coming from internal or external sources.
Once the incident has been verified and identified, investigation is the next step in the team’s process. It is at this point that logs, information from programs that monitor the network and computer affected by the incident, and other sources of information are reviewed. From this, it can be determined whether an incident is actually occurring (that is, a false positive from an IDS), whether it is a random incident (such as someone scanning a port), or whether it is part of a widespread attack. The team analyzes what has occurred and is impacted by an intrusion or other incident, so they can then move to the next step of controlling the situation and repairing the damage.
Once a system has been compromised, it must be repaired. If an intrusion has occurred, the way that the unauthorized person got into the system needs to be secured to prevent further damage. In cases of a virus or worm, antivirus software may be used to remove it. In some cases, such as a DoS attack, they may simply need to reboot the server. The level of work at this stage is determined by what kind of incident they are dealing with, and what must be done to regain control. Once control has been reestablished and the system is secure again, they will need to determine whether any files need to be restored from backups, whether damaged applications need to be reinstalled, and whether software needs to be upgraded or settings need to change to prevent similar attacks.
Documentation is the final step in the process of incident response. It is here that all the information that was gathered in the previous steps is written as a permanent record of the incident. This can be used as reference if similar attacks occur, can be used to evaluate the team’s performance, and may also be used if criminal charges or civil suits are filed against the person(s) responsible for the attack.
Computer forensics is the application of computer skills and investigation techniques for the purpose of acquiring evidence. It involves collecting, examining, preserving, and presenting evidence that is stored or transmitted in an electronic format. Because the purpose of computer forensics is its possible use in court, strict procedures must be followed for evidence to be admissible.
Even when an incident isn’t criminal in nature, forensic procedures are important to follow. You may encounter incidents where employees have violated policies. These actions can result in disciplinary actions (up to and including termination of employment). Actions against the disciplined employee must be based on sound evidence to protect the company from a lawsuit for wrongful termination, discrimination, or other charges. If such a suit is filed, your documentation will become evidence in the civil trial.
For example, an employee may have violated a company’s acceptable use policy and spent considerable time viewing pornography during work hours. By using forensic procedures to investigate the incident, you will create a tighter case against the employee. Because every action you took followed established guidelines and acquired evidence properly, the employee will have a more difficult time arguing the facts. Also, if during your investigation you find illegal activities (such as possession of child pornography), then the internal investigation becomes a criminal one. Any actions you took in your investigation would be scrutinized, and anything you found could be evidence in a criminal trial.
As we’ll see in the sections that follow, there are a number of standards that must be met to ensure that evidence isn’t compromised and that information has been obtained correctly. If you don’t follow forensic procedures, judges may deem evidence inadmissible, defense lawyers may argue its validity, and the case may be damaged significantly.Legal differences exist between In many cases, the only evidence available is that which exists in a digital format. This could mean that the ability to punish an offender rests with your abilities to collect, examine, preserve, and present evidence.
NOTE Legal differences exist between how a private citizen and law enforcement will gather evidence. There are stricter guidelines and legislation controlling how agents of the government may obtain evidence. Because of this, evidence that’s collected before involving law enforcement is less vulnerable to being excluded in court.
Constitutional protection against illegal search and seizure apply to government agents (such as police) but may not apply to private citizens. Before a government agent can search and seize computers and other evidence, a search warrant, consent, or statutory authority (along with probable cause) must be obtained. This doesn’t apply to private citizens, unless he or she is acting as an “agent of the government” and is working under the direction or advice of law enforcement or other government parties.
Although fewer restrictions apply to private citizens, forensic procedures should still be followed. By failing to follow forensic procedures, the evidence may be lost or unusable. The procedures outlined in this section will help to preserve the evidence and will help to ensure the evidence is considered admissible in court.
Awareness
As with any security issue, the first issue that needs to be dealt with is promoting awareness. Often, users of a system are the first to notice and report problems. If someone notices a door to a server room is unlocked, you want that person to notify someone so the door can be locked. The same applies to issues that are criminal or breach corporate policy or violate security in some other way. Until the proper parties are notified, computer forensic examinations cannot be performed because those in a position to perform them do not know a problem exists.
Management and employees need to be aware of the need to support computer forensic examinations. Funding needs to be available for tools and ongoing training in examination procedures or to hire outside parties to perform the investigation. If law enforcement is called in whenever there is an incident, then there are no direct costs, but there is still the need of cooperation with investigators.
Because digital evidence may be damaged or destroyed by improper handling or examination, management must also be aware that considerable time may be involved to effectively investigate an incident. Vital systems or facilities might be unavailable while evidence is being gathered, and it might be necessary for equipment to be removed from service to be examined and stored as evidence until a criminal case has reached its conclusion. Because personnel may need to be interviewed and employees may be unable to do their jobs for periods of time, managers may become impatient and hinder the investigation by attempting to rush it along and get people back to work. The goal of management should be to assist the investigation in any way possible, and an atmosphere of cooperation should be nurtured to make the investigation proceed quickly and effectively.
To address how a company should handle intrusions and other incidents, it is important that a contingency plan is created. The contingency plan will address how the company will continue to function during the investigation, such as when critical servers are taken offline during forensic examinations. Backup equipment may be used to replace these servers or other devices so that employees can still perform their jobs and (in such cases as e-commerce sites) customers can still make purchases. The goal of any investigation is to avoid negatively impacting the normal business practices as much as possible.
Conceptual Knowledge
Computer forensics is a relatively new field that emerged in law enforcement in the 1980s. Since then, it has become an important investigative practice for both police and corporations. It uses scientific methods to retrieve and document evidence located on computers and other electronic devices. By retrieving this information, it may result in the only evidence available to convict a culprit or enhance more traditional evidence obtained through other investigative techniques.
Computer forensics uses specialized tools and techniques that have been developed over the years and are accepted in court. Using these tools, digital evidence may be retrieved in a variety of ways. Electronic evidence may reside on hard disks and other devices, even if it has been deleted, so it’s no longer visible through normal functions of the computer or hidden in other ways. Forensic software can reveal this data that is invisible through normal channels and restore it to a previous state.
TEST DAY TIP Forensics has four basic components: evidence must be collected, examined, preserved, and presented. The tasks involved in forensics will either fall into one of these groups or be performed across most or all of them. A constant element is the need for documentation so that every action in the investigation is recorded. When taking the test, remember the four basic components and that everything must be documented.
Understanding
Because any evidence may be used in possible criminal proceedings, thorough documentation cannot be stressed enough. Documentation provides a clear understanding of what occurred to obtain the evidence, and what the evidence represents. No matter what role you play in an investigation, you must document any observations and actions that were made. Information should include the date, time, conversations pertinent to the investigation, tasks that were performed to obtain evidence, names of those present or who assisted, and anything else that was relevant to the forensic procedures that took place.
Documentation may also be useful as a personal reference, should the need arise to testify in court. Because of the technical nature involved, you may need to review details of the evidence before testifying at trial. Without it, your memory may fail you at a later time, especially if a case doesn’t go to court until months or years later. These notes may also be referred to on the stand, but doing so will have them entered into evidence as part of the court record. As the entire document is entered into evidence, you should remember not to have notes dealing with other cases or sensitive information about the company in the same document, as this will also become public record.
What Your Role Is
Although law enforcement agencies perform investigations and gather evidence with the understanding that the goal is to find, arrest, prosecute, and convict a suspect, the motivation isn’t always clear in businesses. A network administrator’s job is to ensure the network is back up and running, whereas a Webmaster works to have an e-commerce site resuming business. With this in mind, why would computer forensics be important to these jobs? The reason is that if a hacker takes down a Web site or network, he or she may continue to do so until caught. Identifying and dealing with threats is a cornerstone of security, whether those threats are electronic or physical in nature.
Even when police have been called in to investigate a crime, a number of people will be involved. Members of the IT staff assigned to an Incident Response Team will generally be the first people to respond to the incident and will then work with investigators to provide access to systems and expertise, if needed. Senior staff members should be notified to deal with the effects of the incident and any inability to conduct normal business. In some cases, the company’s Public Information Officer may be involved, if the incident becomes known to the media and is deemed newsworthy.
If police aren’t called in and the matter is to be handled internally, then the Incident Response Team will deal with a much broader range of roles. Not only will team members deal with the initial response to the incident but will conduct the investigation and provide evidence to an internal authority. This authority may be senior staff, or in the case of a law enforcement agency, an Internal Affairs department. Even though no police may be involved in the situation, the procedures used in the forensic examination should be the same.
When conducting the investigation, a person must be designated as being in charge of the scene. This person should be knowledgeable in forensics and directly involved in the investigation. In other words, just because the owner of the company is available, he or she should not be in charge if he or she’s computer illiterate and/ or unfamiliar with procedures. The person in charge should have authority to make final decisions on how the scene is secured and how evidence is searched, handled, and processed.
There are three major roles that people may perform when conducting an investigation. These roles are as follows:
First Responder
Investigator
Crime Scene Technician
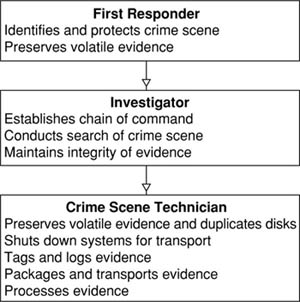
As we’ll see in the paragraphs that follow, and shown in Figure 14.1, each of these roles has specific duties associated with them that are vital to a successful investigation. In certain situations, such as those involving an internal investigation within a company, a person may perform more than one of these roles.
FIGURE 14.1
Roles in a Computer Forensic Investigation
The first responder is the first person to arrive at a crime scene. This doesn’t mean the janitor who notices a server is making funny noises and calls someone else to begin the investigation. Although someone like this is still important, as they become the complainant if they notify the appropriate parties, a first responder is someone who has the knowledge and skill to deal with the incident. The first responder may be an officer, security personnel, a member of the IT staff or Incident Response Team, or any number of other individuals. The first responder is responsible for identifying the scope of the crime scene, securing it, and preserving volatile evidence.
Securing a scene is important to both criminal investigations and internal incidents, which both use computer forensics to obtain evidence. The procedures for investigating internal policy violations and criminal law violations are basically the same, except that internal investigations may not require the involvement of law enforcement. However, for the remainder of this discussion, we’ll address the incident as a crime that’s been committed.
Identifying the scope of a crime scene refers to establishing its scale. What is affected and where could evidence exist? When arriving on the scene, it is the first responder’s role to identify which systems have been affected, as these will be used to collect evidence. If these systems were located in one room, then the scope of the crime scene would be the room itself. If it were a single server in a closet, then the closet would be the crime scene. If a system of networked computers were involved, then the crime scene could extend to several buildings.
Once the crime scene has been identified, the first responder must then establish a perimeter and protect it. Protecting the crime scene requires cordoning off the area where evidence resides. Until it is established what equipment may be excluded, everything in an area should be considered a possible source of evidence. This includes functioning and nonfunctioning workstations, laptops, servers, handheld personal digital assistants (PDAs), manuals, and anything else in the area of the crime. Until the scene has been processed, no one should be allowed to enter the area, and people who were in the area at the time of the crime should be documented.
The first responder shouldn’t touch anything that is within the crime scene. Depending on how the crime was committed, traditional forensics may also be used to determine the identity of the person behind the crime. In the course of the investigation, police may collect DNA, fingerprints, hair, fibers, or other physical evidence. In terms of digital evidence, it is important for the first responder not to touch anything or attempt to do anything on the computer(s), as it may alter, damage, or destroy data or other identifying factors.
Preserving volatile evidence is another important duty of the first responder. If a source of evidence is on the monitor screen, they should take steps to preserve and document it, so it isn’t lost. For example, a computer that may contain evidence may be left on and have programs opened on the screen. If a power outage occurred, the computer would shut down and any unsaved information that was in memory would be lost. Photographing the screen or documenting what appeared on it would provide a record of what was displayed and could be used later as evidence.
When investigators arrive on the scene, it is important that the first responder provide as much information to them as possible. If the first responder touched anything, it is important that the investigator be notified so that it can be added to a report. Any observations should be mentioned, as this may provide insight into resolving the incident.
The investigator may be a member of law enforcement or the Incident Response Team. If a member of the Incident Response Team arrives first and collects some evidence and the police arrive or are called later, then it is important that the person in charge of the team hand over all evidence and information dealing with the incident. If more than one member of the team was involved in the collection of evidence, then documentation will need to be provided to the investigator dealing with what each person saw and did.
A chain of command should be established when the person investigating the incident arrives at the scene. The investigator should make it clear that he or she is in charge so that important decisions are made or presented to him or her. As we’ll discuss in the next section, a chain of custody should also be established, documenting who handled or possessed evidence during the course of the investigation and every time that evidence is transferred to someone else’s possession. Once the investigation begins, anyone handling the evidence is required to sign it in and out so that there is a clear understanding of who possessed the evidence at any given time.
Even if the first responder has conducted an initial search for evidence, the investigator will need to establish what constitutes evidence and where it resides. If additional evidence is discovered, the perimeter securing the crime scene may be changed. Either the investigator will have crime scene technicians begin to process the scene once its boundaries are established or the investigator will perform the duties of a technician. The investigator or a designated person in charge remains at the scene until all evidence has been properly collected and transported.
Crime scene technicians are individuals who have been trained in computer foren-sics and have the knowledge, skills, and tools necessary to process a crime scene. The technician is responsible for preserving evidence and will make great efforts to do so. The technician may acquire data from a system’s memory, make images of hard disks before shutting them down, and ensure that systems are properly shut down before transport. Before transporting, all physical evidence will be sealed in a bag and/or tagged to identify it as a particular piece of evidence. The information identifying the evidence is added to a log so that a proper inventory of each piece exists. Evidence is further packaged to reduce the risk of damage, such as from ESD or jostling during transport. Once transported, the evidence is then stored under lock and key to prevent tampering, until such time that it can be properly examined and analyzed.
As you can see, the roles involved in an investigation have varying responsibilities, and the people in each role require special knowledge to perform it properly. Although the paragraphs above provide an overview of what’s involved, we still need to look at the specific tasks to understand how certain duties are carried out. Understanding these aspects of forensic procedure is not only vital to an investigation but also for success in the Security+ exam.
Because of the importance of evidence, it is essential that its continuity is maintained and documented. A “chain of custody” must be established to show how evidence made it from the crime scene to the courtroom. It proves where a piece of evidence was at any given time and who was responsible for it. By documenting this, you can establish that the integrity of evidence wasn’t compromised.
If the chain of custody is broken, it could be argued that the evidence fell into the wrong hands and may have been tampered with or that other evidence was substituted. This brings the value of evidence into question and could make it inadmissible in court. To prevent this from happening, policies and procedures dealing with the management of evidence must be adhered to. Evidence management begins at the crime scene, where it is bagged and/or tagged. When the crime scene is being processed, each piece of evidence should be sealed inside of an evidence bag. An evidence bag is a sturdy bag that has two-sided tape that allows it to be sealed shut. Once sealed, the only way to open it is to damage the bag, such as by ripping or cutting it open. The bag should then be marked or a tag should be affixed to it, showing the person who initially took it into custody. The tag would provide such information as a number to identify the evidence, a case number (which shows what case the evidence is associated with), the date and time, and the name or badge number of the person taking it into custody. A tag may also be affixed to the object, providing the same or similar information to what’s detailed on the bag. However, this should only be done if it won’t compromise the evidence in any manner.
Information on the tag is also written in an evidence log, which is a document that inventories all evidence collected in a case. In addition to the data available on the tag, the evidence log will include a description of each piece of evidence, serial numbers, identifying marks or numbers, and other information that’s required by policy or local law.
The evidence log will also provide a log that details the chain of custody. This document will be used to describe who had possession of the evidence after it was initially tagged, transported, and locked in storage. To obtain possession of the evidence, a person will need to sign in and sign out evidence. Information is added to a chain of custody log to show who had possession of the evidence, when, and for how long. The chain of custody log will specify the person’s name, department, date, time, and other pertinent information.
In many cases, the investigator will follow the evidence from crime scene to court, documenting who else had possession along the way. Each time possession is transferred to another person, it is written in the log. For example, the log would show the investigator had initial custody, while the next line in the log shows a computer forensic examiner took possession on a particular date and time. Once the examination is complete, the next line in the log would show the investigator again took custody. Even though custody is transferred back to the investigator, this is indicated in the log, so there is no confusion over who was responsible on any date or time.
NOTE To reduce the length of the chain of custody and limit the number of people who will need to testify having possession of the evidence, you should try to limit the number of people collecting evidence. It is a best practice (whenever possible) to have only one person collecting all the electronic evidence. This may not always be practical in larger investigations, where numerous machines will need to be examined for possible evidence. However, even in these situations, you shouldn’t have more people than absolutely necessary having access to the scene and evidence contained within it.
Damage and loss control is the process of attempting to reduce or minimize the impact of an incident. When an incident occurs, it is vital for members of the Incident Response Team to know what they should and shouldn’t do to prevent a problem from spreading (as in the case of a virus) or stop an attacker from causing further damage. Because systems can be complex, these procedures need to be documented before a problem occurs.
Incident response policies should include information on what servers or systems should not be shut down or even touched. For example, if a hacker had gained access to the network, a person might disconnect the Internet connection, but this would also prevent anyone in the organization from accessing the Internet. If the company had an e-commerce site, such an action would bring business to a grinding halt. Similarly, if the organization used the Internet connection for virtual private networks (VPNs) to other networks or branch offices, it would prevent anyone connecting to files, databases, or other resources through the VPN. Providing information on what not to do is just as important as knowing what to do during an incident.
Similarly, startup and shutdown procedures need to be available so that servers will start up and provide the same resources they did before being shut down. An example would be a server that was used for allowing Blackberry devices access to internal e-mail. If the e-mail server was shut down by a person, and he or she didn’t know that certain services needed to be manually restarted, it would prevent anyone using a Blackberry to have access to internal communications. By the time someone realized that the services hadn’t been restarted, critical information may not have reached a user who needed it.
Procedures on disclosing and reporting information about an incident should also be outlined in an incident response policy. When an incident occurs, it may be up to a public relations person within the company to decide whether a media release is issued about the incident or if it will be kept quiet. Beyond disclosing an incident to the public, there are also other organizations that may be contacted including the following:
Operating system, application, or equipment manufacturer: if you believe the incident occurred due to vulnerabilities in a particular system, notifying the manufacturer of that software or hardware could help in having a security patch created to prevent the incident occurring again (to your company and others who use it).
Computer Emergency Response Team (CERT) is located at Carnegie Mellon University and coordinates communication during computer security emergencies. By notifying CERT (www.cert.org), others can be made aware of the attack so that it doesn’t become widespread.
Legal authorities: contacting local police about an attack can begin the process of having an attacker arrested when he or she is found.
Hacking may be done through expert computer skills, programs that acquire information, or an understanding of human behavior. This last method is called social engineering. When social engineering is used, hackers misrepresent themselves or trick a person into revealing information. Using this method, a hacker may ask a user for his or her password or force the user to reveal other sensitive information.
Hackers using social engineering to acquire information will often misrepresent themselves as authority figures or someone in a position to help their victim. For example, a hacker may phone a network user and say that there is a problem with the person’s account. To remedy the problem, all the caller needs is the person’s password. Without this information, the person may experience problems with his or her account or will be unable to access certain information. Because the person will benefit from revealing the information, the victim often tells the hacker the password. By simply asking, the hacker now has the password and the ability to break through security and access data.
Social engineering often involves more subtle methods of acquiring information than simply asking for a password. In many cases, the hacker will get into a conversation with the user and slowly get the person to reveal tidbits of information. For example, the hacker could start a conversation about the Web site, ask what the victim likes about it, and determine what the person can access on the site. The hacker might then initiate a conversation about families and pets and ask the names of the victim’s family members and pets. To follow up, the hacker might ask about the person’s hobbies. Because many users make the mistake of using names of loved ones or hobbies as a password, the hacker may now have access. Although the questions seem innocuous, when all the pieces of information are put together, it can give the hacker a great deal of insight into getting into the system.
In other cases, the hacker may not even need to get into the system because the victim reveals all the desired information. People enjoy when others take an interest in them and will often answer questions for this reason or out of politeness. Social engineering is not confined to computer hacking. A person may start a conversation with a high-ranking person in a company and get insider information about the stock market or manipulate a customer service representative at a video store into revealing credit card numbers. If a person has access to the information the hacker needs, then hacking the system is not necessary.
A variation of social engineering is phishing, otphising, in which a hacker uses e-mail to acquire information from the recipient. Because the hacker is fishing for information using the e-mail as bait, and hackers replaced “f” with “ph,” the term phishing was born. A hacker will send e-mail to groups of people, posing as some authoritative source, and request the recipient to provide specific information. Although this may be a single department or an entire company (as we’ll see in the next section), most often it is sent as spam across the Internet. For example, common e-mails on the Internet pose as banks or companies like eBay and request that people fill out a Hypertext Markup Language (HTML) form or visit a Web site to confirm their account information. The form asks for personal and credit card information, which can then be used to steal the person’s identity. The same technique can be used to pose as network administrators, human resources, or other departments of a company and request the recipient to confirm information stored in various systems. For example, it could ask them to provide their employment information (that is, name, position, department, Social Security number, and so forth), business information (that is, business accounts, credit card numbers, and so forth), or network information such as usernames and passwords. Although many people are educated in this technique, it succeeds, because out of the sheer number of people who are contacted, someone will eventually fall for the trick.
Phishing is particularly effective in business environments because unlike banks or companies who don’t use e-mail to collect information over the Internet, businesses may actually contact departments through internal e-mail to acquire information. For example, finance departments have requested other departments provide information about their purchase accounts, credit cards, and other information, whereas human resource departments have requested updated information on employees. Because it takes knowledge to read the Multipurpose Internet Mail Extension (MIME) information and identify whether e-mail was sent internally or externally, a member of a department may be easily duped by phishing. To prevent such problems, it is important to educate users and implement policies to specify how such information is to be collected. This may include stages, such as sending out internal e-mails stating that on a specific date, a request for such information will be sent out. It is equally important that measures be taken to inform users what information is never requested, such as passwords.
Spear phishing is a variation of phishing that involves targeting groups of people. Although normal phishing expeditions involve sending out thousands or even millions of e-mails in the hope a few people may respond and provide the requested information, spear phishing focuses on selected victims. These victims may work in the same organization, the same department of the company, or another group that they are all a part of.
Spear phishing initially involves some research into the victims. The person behind the scam will attempt to acquire information about a targeted group. For example, by calling a company or looking at its Web site, you could find information on partners of the organization, vendors they deal with, and so forth. By looking on social networking sites like Facebook, you could find groups that provide information on people working at the same business. Such research not only allows you to determine whom you will target but whom you will pose as to get information.
Once a target has been identified, an e-mail can be sent to the group that appears to come from a legitimate source. For example, if your target was everyone on a board of directors, you might send an e-mail that appears to come from a department within the organization. The e-mail may ask to click on a link, which takes them to a Web site where they are asked to enter personal information, provide trade secrets, enter corporate bank account numbers, or other sensitive data. Spear phishing is especially convincing because of the shared experience of the victims. If the victims talk to each other, they will all confirm that they received the same message, and some may even encourage others to do as the e-mail asks.
Although phishing attempts to trick users into clicking a link to go to a bogus Web site, pharming is another type of scam that involves using various methods to redirect users to a bogus site. Even if a user types the correct URL into the address bar of his or her Web browser, the browser is automatically redirected to a different site that is designed to acquire personal or other sensitive information from the user.
There are several different methods of redirecting users to a different Web site. The hosts file is a text file on computers that is used to resolve a host’s name to a specific Internet Protocol (IP) address. On machines running Windows NT and later, it is found in %systemroot%/system32/drivers/etc. As we can see in the lines that follow, the hosts file contains the IP address of the node and its friendly name:
#Host file
127.0.0.1 L0CALH0ST
#Bogus Site
207.46.197.32 novell.com
In this example, the domain novell.com has the IP address for Microsoft’s Web site. If people using a computer with this hosts file were to enter the domain name into their Web browser, the name would be resolved to the IP address in the hosts file and the user would be sent to Microsoft’s site.
Another method of redirecting Web site traffic is Domain name system (DNS) cache poisoning. Browsers use the DNS to resolve friendly names like www.novell.com to IP addresses like 130.57.5.25. The entries for these domains and IP addresses are stored in databases. As we saw with hosts files, changing the IP address for a site will cause traffic to go somewhere else. By modifying the DNS table in a server, someone entering a domain name into an application like a browser will be redirected. Even though a user has entered a legitimate Web site address, they are taken to a different site.
Modifying DNS entries can be done on network servers or through Internet service providers (ISPs). Resourceful pharmers have also been known to trick ISPs into changing the DNS entries so that a domain name points to another location. Anyone using the ISP’s DNS servers is then redirected to the bogus site.
To fool users into believing they have gone to the correct site, pharmers will make the bogus site look as much like a legitimate Web site as possible. For example, if people entering a bank’s Web site address in a browser were redirected to a bogus site, that site would have the bank’s logo and appear as much like the real site as possible. This will trick people visiting the site into believing nothing is amiss, so they enter their usernames, passwords, bank account, and any other information desired by the pharmer.
E-mail hoaxes are those e-mails sent around the Internet about concerned parents desperately searching for their lost children, gift certificates being offered from retail stores for distributing e-mails for them, and dangerous viruses that have probably already infected the user’s computer.
There are a lot of different ways to separate hoaxes from real information. Most of the time, it comes down to common sense. If users receive e-mail that says it originated from Bill Gates who is promising to give $100 to everyone who forwards the e-mail, it is probably a hoax. The best rule of thumb is timeless—if something seems too good to be true, it probably is. If a user is still not sure of the validity of an e-mail message, there are plenty of sites on the Internet that specialize in hoaxes. One of the more popular sites is www.snopes.com. However, hoax e-mails have become such an issue that a number of organizations now provide a hoax or urban legend page on their sites, which offers explanations and warnings of inaccurate or outdated information being circulated about their company.
Virus hoaxes are a little different. As we discussed in Chapter 1, virus hoaxes are warnings about viruses that do not exist. In these cases, the hoax itself becomes the virus because well-meaning people forward it to everyone they know. Some virus hoaxes are dangerous, advising users to delete certain files from their computer to “remove the virus,” when those files are actually very important OS files. In other cases, users are told to e-mail information such as their password (or password file) to a specified address, so the sender can “clean” the system of the virus. Instead, the sender will use the information to hack into the user’s system and may “clean” it of its valuable data.
How do users know whether a virus warning is a hoax? Because users should never take a chance with viruses, the best place to go is to the experts—the antivirus companies. Most antivirus companies have information on their Web sites that list popular e-mail hoaxes. The most important thing to remember about e-mail hoaxes is to never follow any instructions within the e-mail that instructs users to delete a certain file or send information to an unknown party.
Shoulder surfing is a method of obtaining passwords by watching what the person types on a keyboard, personal identification number (PIN) pad, or other device that’s used to enter a password. In other words, they’re staring over the person’s shoulder and watching what’s being entered. Shoulder surfing can happen in such situations as when someone is typing in a password, entering information on an online form, or punching in a PIN on a numerical keypad.
Although the term often refers to someone physically being in the room and watching, some more high tech ways of obtaining this information can also be used. Security cameras, small cameras that can take digital video, or even binoculars can be used to watch what a person enters from a distance.
Users should be aware to protect what they are entering on a keypad. By shielding a keypad as a PIN is entered or waiting for others to look away when passwords are typed, a user can protect what’s being entered. Companies can also use recessed keypads or have plastic shields installed on keypads to prevent unauthorized individuals from obtaining the password or PIN and using it for malicious purposes.
Dumpster diving is the process of physically digging through a victim’s trash in an attempt to gain information. Often it is easy to find client or product information, internal memos, and even password information that have been placed in wastebaskets. In one famous example, a major clothing company had simply discarded photos and information about its upcoming clothing lineup. It didn’t take long for the carelessly discarded information to wind up in the hands of competitors, doing great damage to the victim company’s plans for a unique product launch. It is important to make sure that your organization has a method of securely disposing of the hard copies of confidential information.
The reason that this method of breaching security remains popular is because it is so effective. In addition to the rotting refuse of people’s lunches, one can find discarded printouts of data, papers with usernames and passwords, test printouts that have IP address information, and even old hard drives, CDs, DVDs, and other media containing the information you’d normally have to hack the network to obtain. Even the most innocuous waste may provide a wealth of information. For example, printouts of e-mail will contain a person’s name, e-mail address, contact information, and other data that could be used for social engineering purposes.
There are many solutions to resolving dumpster diving as a security issue. Dump-sters can be locked with a padlock to limit access, or they can be kept in locked garages or sheds until they’re ready for pickup. Companies can also implement a shredding policy so that any sensitive information is shredded and rendered unusable by anyone who finds it. This is especially important if the company has a recycling program, in which paper products are kept separate. If documents aren’t shredded, the recycling containers make it even easier to find information, as all the printouts, memos, and other documentation are isolated in a single container. Because discarded data are not always in paper form, companies also need to implement a strict hardware and storage media disposal policy so that hard disks are completely wiped and old CDs and DVDs containing information are destroyed. By obliterating the data before the media is disposed, and protecting the waste containers used afterwards, dumpster diving becomes difficult or impossible to perform.
TEST DAY TIP Remember that disposing of sensitive information requires that you destroy the electronic and printed data as well. Throwing a piece of paper or hard disk in the garbage means that it is out of sight and out of mind but does not mean it is gone forever. Anyone retrieving documents or media from the trash may be able to view it. Once you remember that disposal and destruction goes hand-in-hand, you will find it easier to identify proper disposal methods when they are presented in test questions.
The best way to protect an organization from social engineering is through education. People reveal information to social engineers because they are unaware they are doing anything wrong. Often they do not realize they have been victimized, even after the hacker uses the information for illicit purposes. There are many ways of disseminating educational material, including posting information on a corporate intranet site, e-mailing newsletters with tips on securing information, and having the information taught in formal training classes. By teaching users how social engineering works and stressing the importance of keeping information confidential, they will be less likely to fall victim to social engineering.
In this chapter, we discussed an array of different issues that can threaten an organization’s equipment, facilities, personnel, and other assets. Although many risks can negatively impact an organization’s security, there are also many methods of prevention. HVAC systems are used to control temperature, humidity, and airflow, thereby preventing sensitive equipment from being damaged. Fire detection and prevention systems can also be implemented to warn and extinguish fires without harming the equipment.
Planning is the key to taking a proactive approach to possible threats. Disaster recovery plans provide procedures for recovering after a disaster occurs and provide insight into methods for preparing for the recovery should the need arise. Incident response plans are similarly used to provide insight as to how Incident Response Teams should handle incidents. These incidents can occur in the form of an employee accidentally or maliciously deleting data, intrusions of the system by hackers, viruses and malicious programs that damage data, and other events that cause downtime or damage. Because preparation begins long before an incident or disaster actually occurs, these plans address such issues as proper methods and procedures, so everyone knows what to do in emergency situations.
Social engineering is another risk that organizations face. It relies on taking advantage of human behavior rather than technology. A user may be asked questions that reveal seemingly innocuous information that can be pieced together to obtain a person’s password, or using phishing to get the user to unwittingly reveal personal information and passwords. Such information can also be obtained through other methods, such as observing the user entering names and credit card numbers of passwords on the computer. Another low-tech method is to simply look in the company’s trash or recycling bins. This technique is called dumpster diving. The success of each of these methods relies on users being unaware that they’re doing anything wrong or how they can protect themselves. It’s because of this that user education and training is so important.
Environment refers to the surroundings in which the computers and other equipment reside.
Fire suppression systems are used to put out fires without damaging servers and other equipment.
Fire detection systems will detect a fire by monitoring for heat, smoke, or fire. Smoke detection will monitor an area for the presence of smoke, heat detectors will monitor temperature increases, whereas flame detectors will monitor for the movement of flames or energy like ultraviolet or infrared.
HVAC is an acronym for heating, ventilation, and air conditioning. It is the control system used to control humidity, temperature, and air flow.
Shielding is used to prevent wireless signals leaking out of a specific area, which would enable unauthorized persons from intercepting the transmissions. It is also used in cabling to prevent unwanted external signals from interfering with data transmitted along the media. Such signals can corrupt data traveling along cabling.
RFI is caused by radio frequencies. These frequencies emanate from a variety of sources, inclusive to microwaves, furnaces, appliances, radio transmissions, and radio frequency-operated touch lamps and dimmers.
EMI is caused by electromagnetism, which can corrupt data and otherwise impair the successful transmission of data. EMI is generated by heavy machinery such as elevators, industrial equipment, and lights.
Attenuation is the decrease of a signal’s strength over the length of a cable.
Crosstalk is a term used to describe when a signal from one channel or circuit interferes with another.
A disaster recovery plan identifies potential threats to an organization and provides procedures relating to how to recover from them.
Backing up data is a fundamental part of any disaster recovery plan and business continuity. When data is backed up, it is copied to a type of media that can be stored in a separate location.
Full backups will backup all data in a single backup job. When each file is backed up, the archive bit is changed to indicate that the file was backed up.
Incremental backups will back up all data that was changed since the last backup. When each file is backed up, the archive bit is changed.
Differential backups will back up all data that has changed since the last full backup. When this type of backup is performed, the archive bit is not changed, so data on one differential backup will contain the same information as the previous differential backup plus any additional files that have changed.
Copy backups will make a full backup but do not change the archive bit. Because the archive bit is not marked, it will not affect any incremental or differential backups that are performed.
GFS rotation organizes a rotation of backup tapes into a daily, weekly, and monthly set of tapes.
Incidents can be any number of adverse events affecting a network or computer system or violations of existing policy. They can include but are not limited to unauthorized access, denial or disruptions of service, viruses, unauthorized changes to systems or data, critical system failures, or attempts to breach the policies and/or security of an organization.
Incident Response Teams are IT professionals used to handle incidents that occur in a company.
IDSes are used on networks to monitor for signs of intrusion attempts.
Computer forensics is the application of computer skills and investigation techniques for the purpose of acquiring evidence. It involves collecting, examining, preserving, and presenting evidence that is stored or transmitted in an electronic format.
The first responder is the first person to arrive at a crime scene and is responsible for identifying the scope of the crime scene, securing it, and preserving volatile evidence.
In a computer forensic investigation, an investigator establishes a chain of command, conducts a search of the crime scene, and is responsible for maintaining the integrity of the evidence.
Crime scene technicians are individuals who have been trained in computer forensics and have the knowledge, skills, and tools necessary to process a crime scene. A crime scene technician is responsible for preserving volatile evidence, duplicating data on disks and other media, shutting down systems for transport, and tagging, logging, packaging, and processing evidence.
A chain of custody is used to monitor who has had possession of evidence at any point in time, from the crime scene to the courtroom.
Social engineering is a potentially devastating technique based on lying to trick employees into disclosing confidential information.
Phishing or phising is a variation of social engineering in which a hacker uses e-mail to acquire information from the recipient.
Spear phishing is a variation of phishing that involves targeting groups of people, such as individuals who work in the same department or company.
Pharming is a scam that involves redirecting traffic to a Web site to a different bogus site. By using DNS poisoning, changing host files, and other methods, a user who enters a legitimate Web site address is redirected to a different site that is designed to acquire personal or other sensitive information from the user.
Hoaxes are e-mail messages or other methods of circulating inaccurate information about companies, false virus warnings, or other stories that can negatively impact a business.
Shoulder surfing is a method of obtaining passwords by watching what the person types on a keyboard, PIN pad, or other device that’s used to enter a password.
Dumpster diving is the practice of going through commercial or residential trash in search of information that may be important from either a criminal perspective or an investigative perspective.
Q: I work for a small company that only has one facility, so storing backup tapes at another site is not an option. What can I do to keep the backup tapes safe in case of a disaster?
A: There are many options for storing backup tapes off-site. A safety deposit box could be rented at a bank to store the backup tapes, or a firm that provides storage facilities for backups could be hired. When deciding on a storage facility, ensure that it is secure and has protection against fires and other disasters. You do not want to store your backups in a location that has a higher likelihood of risk than your own facilities.
Q: What can be done to guard against the dangers of social engineering?
A: A policy forbidding the disclosure of information over the phone and e-mail is a good place to start. Warn employees that they need to be able to verify the identity of any person requesting information. Let them know that they will not be reprimanded for strictly enforcing this policy. Some employees worry that if a “boss” asks for information, they should give it immediately. Addition-ally, create an environment where information is obtained in appropriate ways rather than blindly over the telephone or via e-mail.
Q: Is there any way to protect against dumpster diving?
A: Having a policy in place that requires shredding of any discarded company documents will provide a decent amount of protection against dumpster diving. Remember, any document with employee names, phone numbers, or e-mail addresses could be potentially used against you by a social engineer.
1. Your organization is planning on installing a new fire suppression system in a server room. The system must be able to successfully extinguish the fire without causing damage to the servers and other equipment in the room. Which of the following will you use?
A. Water sprinkler system
B. A system that releases a fine mist of water to extinguish the fire
C. A system that uses halon to extinguish the fire
D. A system that uses Inergen to extinguish the fire
2. You are planning to install a new fire detection system in a server room, which will monitor the area for specific types of energy that would indicate the presence of a fire. Which of the following types of fire detection methods will be used?
A. Smoke
B. Heat
C. Flame
D. Halon
3. The air conditioning in your server room has broken down, and temperatures are rising dramatically. Which of the following can result if this problem isn’t fixed as soon as possible?
A. ESD
B. Chip creep
C. HVAC
D. Shielding
4. New cable has been installed in an elevator shaft, allowing network cabling to run from the basement to all the floors in the building. To save money, cabling with very little shielding is used. After the new cabling is installed, you find that the servers are repeatedly resending data to computers on other floors. This is causing a performance issue, and users begin complaining that the network is slower than before. Which of the following kinds of interference is resulting from the installation of the new cable?
A. EMI
B. RFI
C. Noise
D. UTP
5. You are planning to install new cable between the floors of a building where there are a high number of sources for interference from industrial equipment and devices that transmit radio frequencies. Which of the following cable is the most effective against interference under these circumstances?
A. UTP
B. STP
C. Fiberoptic
D. Coaxial
6. Data is degrading as it is transmitted down the length of cabling between two buildings. Which of the following is occurring?
A. Attenuation
B. Crosstalk
C. EMI
D. RFI
7. Data is being corrupted by a faulty cable, causing the signals from one wire to interfere with the signals on another wire. Which of the following is occurring?
A. Attenuation
B. Crosstalk
C. EMI
D. RFI
8. You receive a complaint from the network administrators of another company regarding an attempted hacking of their Web site. Their firewall logs show that the attempt came from an IP address from your company. Upon hearing the IP address, you find that this is the IP address of the proxy server belonging to your company. Further investigation on your part will be needed to identify who actually performed the attempted intrusion on the other company’s Web site. Who will you notify of this problem before starting the investigation?
A. Media outlets to publicize the incident
B. The Incident Response Team
C. Users of the network to ensure they are aware that private information dealing with employees may need to be shared with the other company
D. No one
9. You are designing a backup regime that will allow you to recover data to servers in the event of a disaster. Should a disaster occur, you want to use a backup routine that will take minimal time to restore. Which of the following types of backups will you perform?
A. Daily full backups
B. A full backup combined with daily incremental backups
C. A full backup combined with daily differential backups
D. A combination of incremental and differential backups
10. You are the administrator of a network that is spread across a main building and a remote site several miles away. You make regular backups of the data on your servers, which are centrally located in the main building. Where should you store the backup tapes so they are available when needed in the case of a disaster?
A. Keep the backup tapes in the server room within the main building, so they are readily at hand. If a disaster occurs, you will be able to obtain these tapes quickly and restore the data to servers.
B. Keep the backup tapes in another section of the main building.
C. Keep the backup tapes in the remote site.
D. Keep the backup tapes in the tape drives of the servers so that a rotation scheme can be maintained.
11. You have created a backup regime as part of a disaster recovery plan. Each day data on a server is backed up. After implementing it, you decide you want to make a separate backup of all data on the server but do not want it to interfere with the current backup jobs. Which of the following types of backups would you perform?
A. Full backup
B. Incremental backup
C. Differential backup
D. Copy backup
12. You are working in a server room and notice that someone has remotely accessed a server used for storing backups of data and is modifying files. You quickly realize that an unauthorized user has remote controlled the server and is hacking the system. To prevent any further damage to data, the file server is taken offline, and a member of the Incident Response Team who looks into these matters is called immediately. Which of the following roles have you fulfilled?
A. First responder
B. Investigator
C. Crime scene technician
D. Unauthorized user
13. A criminal is attempting to acquire information from people. In doing so, he sends out e-mails to a small group of individuals working in the finance department of your company. The e-mail appears to be from the bank your company uses. It has a link that takes the user to a Web site, where a form requests his or her name, department, bank account numbers, and other information. Which of the following social engineering methods is being used? Choose the best answer.
A. Phishing
B. Spear phishing
C. Pharming
D. Spaming
14. A member of the IT staff has just modified the hosts files on Windows XP computers on your network. After making this modification, you notice that a Web site commonly used by members of your organization’s staff looks somewhat different. You check the hosts file on a computer and realize that people are being redirected to a different site. Which of the following has occurred?
A. Phishing
B. Spear phishing
C. Pharming
D. Spaming
15. You are about to make configuration changes to a computer and log on to the workstation as the administrator. In doing so, you notice the user whose computer you’re working on is watching what you’re typing on the keyboard. Which of the following has occurred?
A. Phishing
C. Shoulder surfing
C. Dumpster diving
D. Hoaxes
1. D
2. C
3. B
4. A
5. C
6. A
7. A
8. B
9. A
10. C
11. D
12. A
13. B
14. B
15. B