WHEN BUILDING DISTRIBUTED APPLICATIONS ON THE WEB, you’ll see one thing is clear: document formats matter. The meaning, or semantics, behind the data and information in a document must be understood by both parties in an interaction in order to successfully achieve a business goal.
This chapter explores some of the possibilities raised by the advent of semantic technologies. It focuses on data, information, and the technologies that have emerged to help in integration scenarios. Semantics and Semantic Web are popular terms; here we show how they apply both to the example of Restbucks and more generally to building distributed systems on the Web. We’ll also briefly explore some popular technologies from the Semantic Web, including RDF and SPARQL.
Most distributed computing models enforce the structural or
syntactic correctness of a system’s APIs and
messages using interface or contract definition languages and message schemas. The
semantics of these structural elements, however, is usually communicated
through some other mechanism—typically a natural language specification.
From a syntactic point of view, a <cost>2.0</cost> element is as
good as an <a11119eb>2.0</a11119eb> element,
just so long as both conform to the schema defined by the service
provider. The difference is that the former is immediately meaningful to
a human developer of an application, whereas the latter requires some
interpretation—most likely involving reading a specification
document.
Note
Of course, the implied semantics of a human-readable document
element, operation, or operation name can sometimes be misleading—as
many of us know all too well. How many times have you come across a
method whose implementation is entirely at odds with its name? What
would you make of a document element that is entirely in conformance
with a message schema, but which reads <cost>In store</cost>?
Throughout this book, we’ve suggested that applications need to agree on the way information is encoded, structured, and represented. With distributed systems, however, individual services need to have a common understanding of how to interpret the (structurally correct) information they exchange so as to ensure meaningful interactions. Our use of link relations to provide semantic context for a hypermedia control takes us a small way toward creating this common understanding. The introduction of contracts in Chapter 5 further addressed this requirement, but unsatisfactorily required some level of human involvement.
We believe there is little chance of real machine automation unless we can somehow enrich these contracts for machines. Today, there is a great deal of interest in how information can be represented and explicitly exposed in a way that allows (some parts of) its semantics to be understood and processed by machines. But before we can approach building systems with Semantic Web technology, we need to understand a little theory.
Throughout this chapter, we distinguish between the structure and representation of information. While the former is about the relationship between the different information pieces that make up the details of a document, concept, or business entity, the latter is about choices in representing that information. The choice of representation might have a significant impact on our ability to share the information in an interoperable manner.
The terms data, information, and knowledge are often encountered in discussions related to semantics. Here we’ll explain what we mean by these terms. Though you may find them used differently elsewhere, we’ve tried to align ourselves with more popular definitions.[120]
We use the term data to refer to the raw,
uninterpreted bits that make up a business entity (e.g., an invoice, a
receipt, the customer details).[121] We call information the
interpretation of data within the context of a particular application
domain (e.g., the contents of the <milk> element in a Restbucks order
when interpreted as a customer’s choice of milk). Finally,
knowledge represents our understanding of a
domain after we collect, analyze, and reason over the available data
and information.
The result of this reasoning is a set of information facts—knowledge—that we can use to make business decisions. Knowledge can be explicitly recorded, or it can be inferred, or probabilistically assumed, based on analysis such as “Paul is a valued Restbucks customer because he buys coffee every day.”
Data can contain different layers of information. For example, a PNG image on the Web is represented as a series of bits in a file. A software agent can interpret the raw data and produce (and manipulate) a visual representation of that image only if it understands the PNG specification. We can interpret the visual depiction of the image as the “information” hidden inside the raw “data” (e.g., a photograph of a car). However, in the context of a different application or user, the same PNG image may convey different information because of some additional context. For example, the statement “this is a photograph of my Ferrari” may be inferred from the same photograph because the person recognizes the car as being a Ferrari, and that it belongs to the person (probably due to a unique characteristic or because of the origin of the photograph).
The cognitive transition from “data” to “information” is dependent on an application’s requirements and on the context in which the data is interpreted. That context may be implicit (e.g., a common understanding and experience, such as our familiarity with a sports car’s appearance) or explicitly recorded (e.g., the specification of the Restbucks domain application protocol, or DAP). In many cases, the interpretation of data and information may even be subjective.
Turning aside from philosophical discussion about data and information, let’s see how semantics might relate to our efforts to build the Restbucks coffee service.[122] Example 10-1 shows a possible representation of a coffee order.
Without some additional context or explanation, it’s practically impossible for anyone to interpret the data in Example 10-1 as a customer’s order (even though we made things easier using ASCII characters instead of binary). At first glance, it looks like a series of meaningless characters. If, however, we were to record the thought process that accompanied the creation of the data, or the algorithmic process that one needs to follow in order to decode the information behind the data, the string of Example 10-1 no longer appears to be a random collection of characters; it becomes instead an order for a take-away coffee and two cookies.
As it happens, the string in Example 10-1 represents a Restbucks order:
The order is to be taken away (
ta).The first item ordered is a
lattewith the following details:Quantity: 1 (
q1)Milk: whole (
m1)Size: 12oz (
s12)
The second item is a cookie with the following details:
Quantity: 2 (
q2)Kind: chocolate chip (
k1)
It’s clear that there is a lot of context not explicitly recorded in the order’s representation. The set of rules needed to extract information from the string is encoded externally by that representation’s specification. If a Restbucks consumer is to meaningfully interact with a Restbucks barista software agent, a common understanding of those rules needs to be in place. Otherwise, any attempt to engage in a meaningful exchange would be unsuccessful.
Besides requiring a common, out-of-band understanding of the rules needed to extract information, a significant problem with data formats such as that of Example 10-1 is that they are very difficult to modify, extend, and evolve without breaking existing applications. Although it is often criticized as being a verbose encoding mechanism, XML explicitly expresses hierarchical structure; furthermore, because of its textual nature, it can often be self-describing. Consider, for example, the same order from Example 10-1, but represented using XML (see Example 10-2).
Example 10-2. A Restbucks order in XML
<order xmlns="http://restbucks.com">
<consume-at>takeAway</consume-at>
<item>
<name>latte</name>
<quantity>1</quantity>
<milk>whole</milk>
<size>12</size>
</item>
<item>
<name>cookie</name>
<kind>chocolate-chip</kind>
<quantity>2</quantity>
</item>
</order>The XML document of Example 10-2 encodes exactly the same data as the string of Example 10-1, but using more characters (because XML is verbose). However, the move to XML brings a shared understanding about how the data is structured. Since we know this is an XML document, we can infer information by simply examining it within that context:
The
<item>tags are contained by (children of) the<order>tag.The
<quantity>, <size>, and<milk>tags are also children of the<item>tag.And so on.…
The XML specification does not dictate how an application should take advantage of structure; nor does it determine how to interpret the data. However, because there is a shared understanding of how XML documents look, we can leverage commodity tools to process the order. We can copy, query, or transform the XML document without having to interpret or reason over the information it conveys. XML allows us to maintain a separation between the structured data and the represented information.
Note
In building distributed systems on the Web, we often use XML processing libraries without really having to interpret the contents of the XML documents in the infrastructure layers of our applications (e.g., digital signatures, structure validation, query frameworks, etc.). The interpretation and processing of the data are left to the business layer of our application.
Humans can understand the tag elements in the XML document of Example 10-2, making it possible to infer (some of) the intended use of the captured data. As a result, a technically literate English speaker can assume by inspection that the document describes an order.
However, a software agent usually needs more than just assumptions. We need to be careful how information is inferred. For example, what volume measurement does Restbucks use to express the size of the latte in Example 10-2? Such issues arise in application integration scenarios all the time, as the JPL and the Lockheed Martin engineers will testify.[123]
As developers, we need to encode the information used by our application’s business logic in the document formats we use. We also need to capture and externalize the context so as to allow correct interpretation of that information. Services can only interact correctly if this information is shared. Sharing context and interpretation semantics, however, is easier said than done, partly because interactions between distributed services tend to become more intricate as coupling becomes looser. Automation can help us when we need to share interpretation context for both the exchanged information and the semantics of the interactions between the participations in a distributed system.
When we deal with the exchange of data in an integration scenario, it’s critical that all parties interpret the conveyed information in the same way. Otherwise, a Restbucks customer could order “a latte with whole milk” only for the barista to interpret it as “tea with sugar.”
We’ve already shown how the protocols and formats in use on the Web address the problem of how to exchange data between components. Format it using XML or JSON and coordinate its exchange with HTTP, and suddenly data has been transferred. Data exchange isn’t the problem; the key challenge is to actually make sure all parties in an interaction interpret the information consistently.
It’s part of every developer’s life to read specifications and convert them to working software. In Chapter 5, we suggested that hypermedia application contracts require written specifications. The process of converting a specification written in a natural language to a computer program is difficult and error-prone. Nevertheless, that’s the predominant mechanism for implementing a shared understanding of exchanged information.
The web community is trying to address this problem through techniques that automate how applications represent and describe data and information. The goal is for machines rather than developers to reason over the semantics of any information in transferred representations.
The term semantics is overloaded and
overhyped, in part thanks to the Semantic Web.
Since this book is about building distributed systems, we concentrate
on the semantics of distributed system components. We use the term
semantics to refer to the shared understanding
defined by a contract, the meaning of a sequence of
request-response exchanges, or the manner in which a resource
representation should be interpreted. For example, the semantics of
the Restbucks ordering protocol defines why we PUT a payment resource representation to a
particular URI before allowing the associated order to be given to the
barista. Similarly, the semantics attached to the Restbucks media type
allows the barista to interpret the <milk> element under <item> as the type of milk to be
used.
Representing and sharing semantics makes it possible for humans
and computers to meaningfully exchange information. For computer systems, we want to automate
the mechanics of sharing this understanding as much as possible. The
Semantic Web, microformats, and even the humble rel attribute are all techniques that allow
us to capture and convey semantics.
Human knowledge is captured on the Web in various digital forms: web pages, news articles, blog posts, digitized books, scanned paintings, videos, podcasts, lyrics, speech transcripts, and so on. Over the years, services have emerged to aggregate, index, and enable rapid searching of this digital data. However, the full meaning of that data is only interpretable by humans. Machines are typically incapable of understanding or reasoning about this vast source of information.
The Semantic Web promises to enable machines to meaningfully process, combine, and infer information from the world’s data. With the W3C’s support, a community was formed to deliver a set of technologies, such as RDF(S) and OWL.
Machines become capable of analyzing all the data on the Web—the content, links, and transactions between people and computers. A “Semantic Web,” which should make this possible, has yet to emerge, but when it does, the day-to-day mechanisms of trade, bureaucracy, and our daily lives will be handled by machines talking to machines, leaving humans to provide the inspiration and intuition. The intelligent “agents” people have touted for ages will finally materialize. This machine-understandable Web will come about through the implementation of a series of technical advancements and social agreements that are now beginning.[124]
Semantic Web technologies attempt to standardize the mechanics of information sharing so that it can be more easily supported in software. It should come as no surprise that resources and URIs are the building blocks on top of which the Semantic Web is built.
Note
We make a distinction between the general approach of computing based on semantic technologies (machine learning, ontologies, inference, etc.), and the Semantic Web, which is the term used to refer to a specific ecosystem of technologies such as RDF and OWL.[125][126] The Semantic Web has gained a lot of attention; however, we consider the Semantic Web technologies to be just some of the many tools at our disposal when we build semantically aware solutions.
The Semantic Web community has produced many technologies (and an equal number of acronyms) over the past decade—acronyms such as RDF, RDFS, RDFa, OWL, SPARQL, and GRDDL.[127] While we won’t cover all of these technologies in depth, we will look at how Restbucks can utilize RDF and OWL (and, in subsequent sections, SPARQL and RDFa) to offer some additional functionality.
The Resource Description Framework (RDF) provides a model for describing data as a directed, labeled graph.[128] RDF’s simple structure and resource orientation make it easy for us to evolve data representations, merge different graphs, and reason over the results. For example, part of the Restbucks order can be represented as the graph of Figure 10-1.
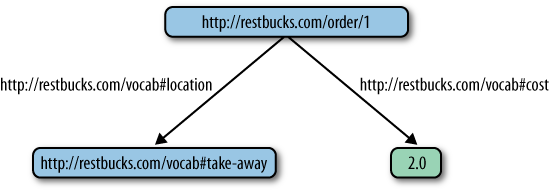
Note the use of URIs in Figure 10-1. RDF supports statements of the form [subject, predicate, object], also known as
triples. The subject
and the predicate here are always
URIs, whereas the object can be
either a URI or a literal (e.g., a string or a number). In the case of
an order, we could use a literal object value to define whether the order is
“take-away” or “to be consumed in house.” A URI, however, allows us to
represent the possible locations for consuming a beverage as resources
with which we can explicitly associate additional information and
processing semantics. For example, we could create a list of textual
representations in different languages for “take-away,” which can then
be automatically used by consuming systems in other countries.
By combining URIs and literals in a structured way, RDF allows us to make statements about resources such as those in Example 10-3. This is because URIs have meaning attached to them, either because there is another RDF graph that describes them (e.g., an OWL description, as we will see shortly), or because they are “well-known” URIs, with well-understood semantics defined by either a natural language specification or a folksonomy.[129]
Example 10-3. Statements based on the graph of Figure 10-1
Order 1 is to be taken away Order 1 costs 2.0
As we add more information from a typical Restbucks order to our graph, the graph begins to take on a familiar shape, coming to look like the kind of hierarchical structure we find in XML documents (see Figure 10-2). RDF, however, is not restricted to representing tree structures; it can also represent arbitrary relationships between nodes in a graph.
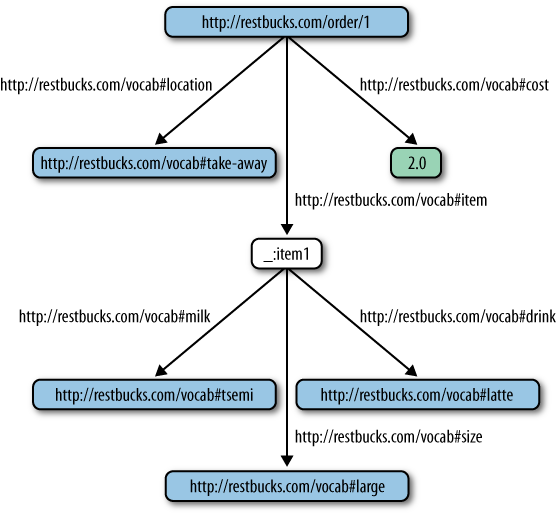
Please note the “anonymous” node in the graph of Figure 10-2—that is, the one that is not
given its own URI. When we don’t want all the information in a graph
to be identifiable through a URI, we introduce anonymous nodes. For
example, we obviously want the Restbucks order to be identifiable as a
resource. We also want the predicates and many of the objects in each
[subject, predicate, object]
relationship to be identifiable—this allows them to be reused across
graphs, and their semantics described using machine-readable
representations. There are occasions, however, where it is not an
application requirement to refer to a node in a graph outside an
RDF document. This is the case for all the _:itemN nodes in an RDF
Restbucks order, where N is a sequence number.
Restbucks doesn’t expect individual item entries in an order to be
referenced outside the context of an order. Anonymous RDF nodes allow
us to build graphs without having to make all its subjects and objects
explicitly identifiable outside its context.
There are multiple representation formats for RDF graphs, including Notation 3[130] and RDF/XML.[131] We’ve chosen to use RDF/XML for Restbucks. Example 10-4 shows the graph from Figure 10-2 represented using RDF/XML.
Example 10-4. A Restbucks order in RDF/XML
<?xml version="1.0"?>
<!DOCTYPE rdf:RDF [<!ENTITY xsd "http://www.w3.org/2001/XMLSchema#">]>
<rdf:RDF xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
xmlns:restbucks="http://restbucks.com/vocab#">
<rdf:Comment>This graph represents a simple Restbucks order</rdf:Comment>
<rdf:Description rdf:about="http://restbucks.com/order/1">
<restbucks:location rdf:resource="http://restbucks.com/vocab#take-away"/>
<restbucks:cost rdf:datatype="&xsd;decimal">2.0</restbucks:cost>
<restbucks:item rdf:resource="_:item1" />
</rdf:Description>
<rdf:Description rdf:about="_:item1">
<restbucks:milk rdf:resource="http://restbucks.com/vocab#semi" />
<restbucks:size rdf:resource="http://restbucks.com/vocab#large />
<restbucks:drink rdf:resource="http://restbucks.com/vocab#latte />
</rdf:Description>
</rdf:RDF>Example 10-4 doesn’t contain
any more domain information about a Restbucks order than a typical XML
representation, with the exception of the @datatype attribute, which conveys the type
of the literal. What, then, is the value of moving to RDF? The
strength of RDF lies in its processing model and use of URIs to build
statements.[132] This means all aspects of a Restbucks order can be
further described using additional RDF statements. These additional
statements can be either embedded directly in our order representation
or delivered to consumers through other means. For example, the
current representation contains the price of the order, together with
the type of the literal (a decimal), but it doesn’t specify which
currency is being used. Using RDF, however, we can easily add that
information to the representation, as shown in Example 10-5.
Example 10-5. Capturing the currency for the cost of the Restbucks order
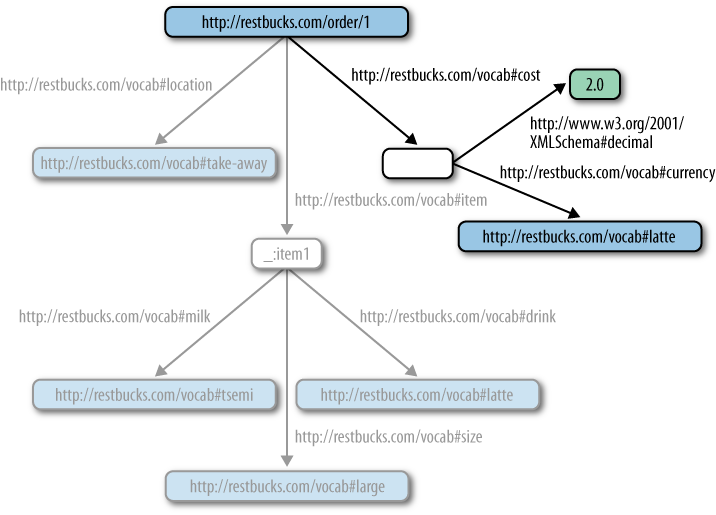
<rdf:Description rdf:about="http://restbucks.com/order/1"> <restbucks:location rdf:resource="http://restbucks.com/vocab#take-away"/><restbucks:cost rdf:parseType="Resource"><rdf:value rdf:datatype="&xsd;decimal">2.0</rdf:value><restbucks:currency rdf:resource="http://restbucks.com/vocab#uk-pounds" /></restbucks:cost><restbucks:item rdf:resource="_:item1" /> </rdf:Description>
Adding the rdf:parseType=“Resource” attribute to the
<restbucks:cost> property
element allows us to add blank nodes to the restbucks:cost subgraph. Blank nodes are
nodes that aren’t explicitly identified through a URI. In this case,
we want to describe the value of the cost predicate as being currency in UK
pounds. In Example 10-5, the rdf:value and restbucks:currency[133] blank nodes describe properties of the restbucks:cost node; the restbucks:cost node in turn describes a
property of http://restbucks.com/order/1.
Adjusting the graph in this way allows a software agent to
reason about the value 2.0 and
treat it as a currency, not just a decimal. If we were using plain
XML, we would have to associate this semantic information with the
price value using a natural language specification. Using RDF, the
semantic information can be consumed by an application directly. Figure 10-3 shows how the
added information changes the order’s graph.
Note
The RDF processing model includes more constructs than we can cover here. It provides ways to describe collections of items as bags, sequences, and sets of alternatives. It offers a mechanism, called reification, for making statements about statements, such as “Berlin has been the capital of Germany since 1991,” or “Jim likes his latte to be hot.” Finally, through the use of RDF Schema, it is possible to describe simple vocabularies, such as the one that we have been using for Restbucks orders.
RDF makes it simple to combine information from different
graphs, as long as matching URIs are used. This allows software
libraries to bring together the known statements about a resource. For
example, consider the RDF of Example 10-6, which states
that customer http://restbucks.com/customer/123 has placed
the order http://restbucks.com/order/1. The document
also states that the URI representing the choice “latte” is associated
with the “latte” label in English and the “une crème” label in French
(using the SKOS[134] vocabulary); that its origin is Italy (using GeoNames[135]); and that its milk is hot (using a proprietary coffee
vocabulary). Finally, given that Restbucks wishes to be transparent
about the ingredients it uses, it declares that its coffee beans come
from Brazil.
Example 10-6. Additional RDF graphs can be combined with a Restbucks order
<rdf:Description rdf:about="http://restbucks.com/customer/123"> <restbucks:order rdf:resource="http://restbucks.com/order/1" /> </rdf:Description <rdf:Description rdf:about="http://restbucks.com/vocab#latte"> <skos:prefLabel xml:lang="en">latte</skos:prefLabel> <skos:prefLabel xml:lang="fr">une crème</skos:prefLabel> <coffee-vocab:origin rdf:resource="http://www.geonames.org/countries/#IT" /> <coffee-vocab:milk rdf:resource="http://coffee.org/milk#hot" /> <coffee-vocab:beans-origin rdf:resource="http://www.geonames.org/countries/#BR"/> </rdf:Description>
RDF defines a set of basic rules and constructs that software agents can use as the building blocks for constructing the documents they exchange. However, these building blocks are not enough for all our scenarios. They can be used as the basis for developing vocabularies of concepts, such as “order,” “cost,” and “drink,” which we can then use in our application domains. Due to the absence of a widely used coffee industry vocabulary, Restbucks has defined its own. The Semantic Web community refers to such vocabularies as ontologies.
The Ontology Web Language (OWL) is a family of knowledge representation languages. These languages allow us to define, represent, and share the meaning of things, concepts, relationships, and abstractions.[136] OWL provides the building blocks for creating vocabularies specific to a particular domain of interest. Each term in the vocabulary can be associated with semantics in a machine-readable way. OWL’s formal underpinnings make it possible for applications to reason over the set of facts expressed using one or more defined vocabularies. Developers can use available software libraries, such as Jena,[137] to incorporate inferencing capabilities into their applications, allowing them to generate new information by processing facts captured in OWL and RDF documents.
Note
OWL has evolved a great deal with the move from v1.1 to v2.0. The latter is more expressive and offers different levels of semantics in representing knowledge, depending on our application’s requirements.
OWL provides the mechanics for defining classes, relationships, properties/predicates, instances, constraints, and axioms. While there are several ways it can be used on the Web, in this chapter we focus on its potential uses in building distributed systems.
So far, we haven’t defined the vocabulary we’ve been using to describe Restbucks orders. OWL uses RDF Schema (RDFS) to describe basic class hierarchies, class properties, and type constraints for property values.[138] OWL’s own vocabulary includes axioms for defining more sophisticated interclass relationships and the constraints on these relationships, such as cardinalities, existential relationships (e.g., there exists some value), universal relationships (e.g., all values must hold true), and so on. In addition to the description of concepts, OWL’s vocabulary can also be used to describe instances of those concepts, known as individuals.
Figure 10-4 shows a visual representation of a simple Restbucks ontology. The graph includes concepts such as coffee and ingredient, and their specializations. It also includes the concepts of an order and an item.
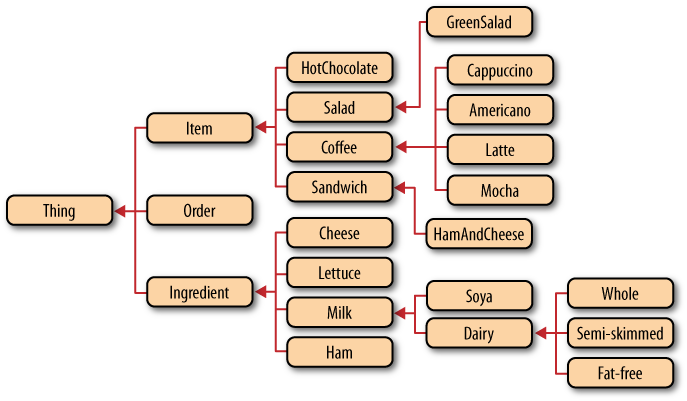
Example 10-7[139] shows part of the OWL document for the Restbucks ontology. There are multiple renderings of an OWL document: OWL/XML, RDF/XML, Manchester, Turtle, and Functional.[140] We decided to avoid the XML-based ones given their verbose nature. Instead, we use the Manchester Syntax.[141]
Example 10-7. The Restbucks order and item declarations
Ontology: <http://restbucks.com/vocab#>
Class: <Order>
Class: <Item>
ObjectProperty: <containsItem>
Domain: <Order>
Range: <Item>
DataProperty: <quantity>
Domain: <Item>
Range: xsd:positiveInteger
DataProperty: <size>
Domain: <Item>
Range: {"12oz" , "6oz"}Example 10-7
first declares the classes Order
and Item. Next, the object
property containsItem is declared
with Order as its
domain (source of a relationship) and Item as its range
(target of a relationship). Finally, the quantity and size data properties for the Item class are declared to be an integer
and one of “6oz” or “12oz” strings, respectively. Effectively, the
OWL of Example 10-7 allows us to
make statements of the form “an Order may contain an Item” and “an
Item may have the quantity and size data properties.”
The links between nodes in graphs are always one-way. Without OWL, we would have to explicitly record a statement such as “an Item may be contained by an Order,” which is the inverse of the one we saw earlier. If we were describing individuals, rather than concepts, we would have to record both statements for every pair of individuals.
With OWL, however, we can declare two object properties as
being the inverse of each other. As a result, when reasoning over a
set of statements, we can assume the existence of one relationship
when we encounter its inverse, even if that relationship is not
explicitly declared. Example 10-8 shows the
declaration of the itemContainedBy property and how it is
declared as the inverse of containsItem.
Example 10-8. The properties containsItem and itemContainedBy are declared to be the inverse of each other
ObjectProperty: <containsItem> Domain: <Order> Range: <Item> InverseOf: <itemContainedBy> ObjectProperty: <itemContainedBy> Domain: <Item> Range: <Order> InverseOf: <containsItem>
Now, let’s have a look at one of the Restbucks menu
entries—the ones that have been declared as specializations of the
Item class (see Example 10-9).
Example 10-9. The Coffee Restbucks menu item and its hasMilk object property
Class: <Coffee> SubClassOf: <Item> EquivalentTo: <hasMilk> max 1 <Milk> ObjectProperty: <hasMilk> Domain: <Coffee> Range: <Milk> Class: <Latte> SubClassOf: <Coffee> Class: <Mocha> SubClasSOf: <Coffee>
Example 10-9
shows the declaration of the Coffee class and two of its
specializations, Latte and
Mocha. Note that the Coffee class is declared to be equivalent
to a class that includes at maximum one instance of the hasMilk object property, whose range is
the Milk class. Example 10-9 allows us to
make a statement such as “A coffee may have one, but no more, milk
individuals.” Example 10-10 shows
the declaration of some of the Ingredient concepts.
Example 10-10. The Milk and Dairy concepts
Class: <Ingredient> Class: <Milk> SubClassOf: <Ingredient> Class: <Dairy> SubClassOf: <Milk> DisjointWith: <Soya> Class: <Whole> SubClassOf: <Dairy> Class: <Soya> SubClassOf: <Milk> DisjointWith: <Dairy> Class: <Cheese> SubClassOf: <Ingredient> EquivalentTo: <containsIngredient> some <Dairy>
Example 10-10 also shows how
the Dairy and Soya concepts are declared to be
disjoint. In other words, a class or an
individual cannot be Dairy and
Soya at the same time. Such a
declaration allows us to capture the fact that soya milk is not
considered dairy and that dairy milk cannot be made out of soya.
Furthermore, the example shows how the Cheese class is defined to be equivalent
to any class that is declared to contain some dairy as an
ingredient.
We now have all the concepts and object properties that we need in order to describe an actual order (see Example 10-11).
Example 10-11. A Restbucks order using OWL
Individual: <WholeMilk>
Types: <Whole>
Individual: <WholeMilk>
Types: <SoyaMilk>
Individual: <MyDairyOrder>
Types: <Order>
Facts: <containsItem> <LatteOrderItem>,
<containsItem> <MochaOrderItem>
Individual: <LatteOrderItem>
Types: <Latte>
Facts: <hasMilk> <WholeMilk>,
<quantity> "2"^^xsd:positiveInteger,
<size> "6oz"
Individual: <MochaOrderItem>
Types: <Mocha>
Facts: <hasMilk> <SoyaMilk>,
<quantity> "1"^^xsd:positiveInteger,
<size> "12oz"The OWL in Example 10-11
describes an individual order whose identity is http://restbucks.com/vocab#MyDairyOrder,
and which contains the individuals …#LatteOrderItem and …#MochaOrderItem. The former is a Latte, has WholeMilk, has a quantity of 2, and is “6oz” in size. The latter has SoyaMilk, has a quantity of 1, and is “12oz” in size.
What if a consuming application wanted to determine whether this order contains any dairy?
A reasoner can use the set of classes and individuals that we have declared in order to determine the answer to our question. Of course, we need to express our question in OWL first (see Example 10-12).
Example 10-12. The ContainingDairy class
Class: <ContainingDairy>
EquivalentTo:
<Order>
and (<containsItem> some (
(<containsIngredient> some <Dairy>) or (<hasMilk> some <Dairy>)))Example 10-12 shows the
declaration of the ContainingDairy class, which can be read
as “ContainingDairy is a class that is an Order and contains an item
with some dairy as an ingredient or some dairy milk.” In addition to
checking whether a coffee contains dairy milk, the declaration also
checks to see if an ingredient used is dairy or not. Indeed, using
the Hermit OWL reasoner[142] (used as a plug-in to Protégé[143]), we can determine that MyDairyOrder is indeed of type ContainingDairy. An order that included
only the MochaLatteOrder of Example 10-11 wouldn’t be categorized as
ContainingDairy (see Example 10-13).
Example 10-13. A Restbucks order that doesn’t contain dairy
Individual: <MyNonDairyOrder> Types: <Order> Facts: <containsItem> <MochaOrderItem>
The declaration of the ContainingDairy class makes use of the
containsIngredient object
property, which we haven’t defined yet (see Example 10-14).
Note the use of the Transitive axiom in Example 10-14. A reasoner
must now consider the transitive closure of all the classes or
individuals that make use of the containsIngredient object property. In
other words, if an order item A contains ingredient B, and B
contains ingredient C, a reasoner can assume that order item A
contains ingredient C. We can now declare order items such as ham
and cheese and describe their ingredients in detail.
In addition to characterizing object properties (the predicates in relationships) as transitive, OWL allows us to use other mathematical axioms as well. Object properties can be declared to be symmetric, reflective, or functional.
Now that we have an OWL description of the Restbucks vocabulary, we can make it part of our DAP’s contract, and so share it with our customers and partners. We can extend the vocabulary to capture the semantics of all the formats and protocols in the DAP so that machines can understand them.
Of course, we’ve barely scratched the surface of what OWL can do in terms of capturing information and knowledge in a machine-processable manner.
Remember that the RDF and OWL documents can be combined into a single information graph of subject-predicate-object triples. Designed to support the RDF data model, SPARQL is the query language for such graphs. Those familiar with SQL will recognize large parts of its syntax.
Using SPARQL, we can match patterns within a graph or subgraphs. The result may consist of a set of resources and their interrelationships that satisfy the given conditions; answers to true/false questions, given the encoded knowledge; or new graphs that were generated by inferring new triples over the existing set of statements.
As an example, let’s assume that Restbucks offers a registry for loyal customers. The registry uses the Friend of a Friend (FOAF) vocabulary.[144] A service allows customers to register their details; Restbucks then stores all customer information in a large graph at http://internal.restbucks.com/customers.rdf, and makes it available to internal services. Example 10-15 shows what a simple query such as “List the Restbucks customers who are over 40” would look like in SPARQL.
Example 10-15. A simple SPARQL query
PREFIX foaf: <http://xmlns.com/foaf/0.1/>
PREFIX rest: <http://restbucks.com/vocab#>
PREFIX xsd: <http://www.w3.org/2001/XMLSchema#>
SELECT ?name
FROM <http://internal.restbucks.com/customers.rdf>
WHERE { ?x foaf:name ?name;
foaf:age ?age.
FILTER (xsd:positiveInteger(?age) > 40) }One of the advantages of Semantic Web technologies is that we can build graphs of information facts without having to fix on a predefined and fixed schema. Sometimes we might not even have a schema for our information model at all. Unlike relational database technologies, RDF allows us to combine information in arbitrary ways, without having to adhere to a data layout defined and fixed in advance of an application’s deployment. We saw an example of this earlier in the chapter when we augmented an order’s graph with information about how the cost should be interpreted. SPARQL can query these dynamic graphs, thereby supporting an evolutionary approach to data and application design.
RDF and OWL are built around the concepts of resources and URIs. Despite the use of web technologies, however, the promise of linked data has been difficult to achieve. Today, the machine-driven semantic processing of information is nowhere near as pervasive as the human-driven navigation of linked documents.
Note
The term Linked Data refers to the set of technologies, patterns, and practices used to describe and annotate data on the Web in a semantically rich and machine-processable way. The application of the Semantic Web suite of technologies is the primary focus of the Linked Data effort.[145][146][147]
RDF in attributes (RDFa) fills this gap by bringing RDF to the human Web. While it’s targeted mainly at the human Web, we believe it’s also useful for building distributed web-based applications.
The premise of RDFa is that web documents such as XHTML can convey both
presentation and semantic information. Through the use of XML
attributes, presentation constructs are annotated with semantic
information. This allows software agents other than browsers to
process and reason over the embedded information. For example, Example 10-16 illustrates how
an XHTML Restbucks coupon can be presented in a way that allows both
John Smith and a software agent to
process it.
Example 10-16. A coupon for a free latte in XHTML with RDFa annotations
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML+RDFa 1.0//EN"
"http://www.w3.org/MarkUp/DTD/xhtml-rdfa-1.dtd">
<html xmlns="http://www.w3.org/1999/xhtml"
xmlns:restbucks="http://restbucks.com/vocab#"
xmlns:foaf="http://xmlns.com/foaf/0.1/"
version="XHTML+RDFa 1.0" xml:lang="en">
<head>
<title>Offer to a valued customer</title>
<!-- Digitally signed thumbprint of a coupon number -->
<meta property="restbucks:coupon" content="123456" />
</head>
<body>
<h1>Receipt for order 1234</h1>
<p about="restbucks:coupon-recipient">Dear
<span property="foaf:name" typeof="foaf:Person">John Smith</span>,</p>
<p about="restbucks:coupon-product">Thank you for being a Restbucks
valued customer. Since you have been a valued customer, we would
like to offer you a complimentary
<span property="restbucks:name">latte</span>.</p>
</body>
</html>The <meta> element in
Example 10-16 tells us
that “this document represents a coupon with ID 123456.” We can also
see that the coupon is sent to “John Smith” and is for a “latte.” A
browser can render this information for a human to read, while a
software agent participating in a machine-to-machine interaction can
extract the necessary information for making forward progress in a
business process involving an offer.
We can leverage RDFa statements in Restbucks’ XML documents in order to avoid the expensive transition to RDF and OWL for computer-to-computer interactions. For example, rather than representing a Restbucks order in RDF, as we did earlier in this chapter, we could reuse our familiar XML representation together with RDFa statements to create self-describing documents.
Assuming that recipients of a Restbucks XML+RDFa document understand the Restbucks OWL vocabulary we defined earlier, Example 10-17 shows how the cost of an order can easily be annotated with the currency and the type of the value.
Example 10-17. A Restbucks XML+RDFa order
<order xmlns="http://restbucks.com"
xmlns:rv="http://restbucks.com/vocab#"
xmlns:xsd="http://www.w3.org/2001/XMLSchema#">
<location>takeAway</location>
<cost property="rv:uk-pounds" typeof="xsd:decimal">12.0</cost>
<item>
<name>latte</name>
<quantity>1</quantity>
<milk>whole</milk>
<size>12</size>
</item>
<item>
<name>cookie</name>
<kind>chocolate-chip</kind>
<quantity>2</quantity>
</item>
</order>Imagine the possibilities. We could add provenance information for the coffee beans used for the coffee, pointers to the recipe used for the chocolate cookie, or a link to the farmers who supplied the milk. Example 10-18 shows how simple this is.
Example 10-18. A Restbucks XML+RDFa order with more statements
<order xmlns="http://restbucks.com"
xmlns:rv="http://restbucks.com/vocab#"
xmlns:xsd="http://www.w3.org/2001/XMLSchema#">
<location>takeAway</location>
<link about="rv:coffee-beans" rel="rv:origin" href="http://coffeebeans.com" />
<cost property="rv:uk-pounds" typeof="xsd:decimal">12.0</cost>
<item>
<name>latte</name>
<quantity>1</quantity>
<milk rel="rv:supplier" href="http://localfarmer.com/">whole</milk>
<size>12</size>
</item>
<item>
<name>cookie</name>
<kind rel="rv:recipe"
href="http://restbucks.com/recipes/choc-cookie">chocolate-chip</kind>
<quantity>2</quantity>
</item>
</order>A software agent that understands Restbucks’ vocabulary will translate the highlighted RDFa statements of Example 10-18 to the statements of Example 10-19.
Example 10-19. Machine interpretation of the RDFa statements in Example 10-18
The coffee beans originate from http://coffeebeans.com The whole milk's supplier is http://localfarmer.com The recipe for a chocolate cookie is http://restbucks.com/recipes/choc-cookie
Note the use of the <link> element and rel attribute in the order in Example 10-18. We use the
rel attribute in our hypermedia
examples when we want to convey additional information about the
referenced resource. RDFa reuses this hypermedia control but allows
terms from different vocabularies, rather than just strings, to be
used as values.
Microformats are a collection of community-driven specifications for conveying machine-processable information.[148] The goal of this grassroots effort is to design small document formats that can be reused by humans first and machines second. Take, for example, the chocolate cookie recipe referenced by one of the RDFa statements in Example 10-18. Using microformats, we could represent this recipe as an XHTML document containing both human- and machine-processable information, as shown in Example 10-20.
Example 10-20. A recipe in an XHTML document as a microformat
<div class="hrecipe">
<h1 class="fn">Restbucks Chocolate Cookies</h1>
<p class="summary">This is how you can make Restbucks chocolate cookies</p>
<h2>Ingredients</h2>
<ul>
<li class="ingredient">
<span class="value">2.25</span> <span class="type">cups</span> flour.
</li>
<li class="ingredient">
<span class="value">1</span> <span class="type">teaspoon</span> baking soda.
</li>
<li class="ingredient">
<span class="value">1</span> <span class="type">teaspoon</span> salt.
</li>
<!-- More ingredients -->
</ul>
<h2>Preparation instructions</h2>
<ul class="instructions">
<li>Preheat oven to 375° F.</li>
<li>Combine flour, baking soda, and salt in small bowl... </li>
<!-- More instructions -->
</ul>
</div>As you can see from Example 10-20, microformats use
existing HTML attributes—the class
attribute in particular—to transport machine-readable semantic
information. It’s this thrifty attitude toward reusing existing HTML
presentation attributes, rather than adding new elements and attributes
as RDFa does, together with a narrow focus on representing
everyday domain entities, such as contact details and calendar events,
that makes the microformat movement so appealing to those wanting to add
semantic annotations to their representations.
Microformats and RDFa are alike in that they separate
semantics from document structure. With plain XML,
semantics are bolted to a document’s structure: we understand that the
value of an <email> element
contained within a <user>
element signifies a user’s email address as a result of our correlating
an out-of-band description of the semantics with a part of the document
schema. Microformats and RDFa, on the other hand, can insert the
very same semantics into many different document structures. An hCard
parser, for example, is more interested in identifying any element with
a class attribute value of tel, indicating the presence of a telephone
number, than it is in navigating a specific XML or HTML
structure.
Despite being widely used on the Web today, microformats may soon lose out to RDFa, which will likely be included in future HTML standards. However, it is definitely worth keeping them in mind when designing distributed applications.
As previously mentioned, the Linked Data effort is all about exposing data and information so that computers, rather than humans, can consume and process it. Companies and organizations are encouraged to make their data available using Semantic Web technologies and link it with other data on the Web.
Structural hypermedia is at the core of this effort. It is used so that all data and information is interconnected in a semantically rich manner. HTTP and URIs, as used by RDF(S), RDFa, and OWL, allow us to create information and knowledge graphs that span organizational and geopolitical boundaries. Tim Berners-Lee has called it the “Giant Global Graph.”[149]
The UK government’s initiative to expose the public sector’s information using web APIs and Semantic Web technologies is a great example of the Linked Data effort.[150]
As developers of web services, we are all too aware of the importance of contracts and protocols for computer-to-computer interaction. It wouldn’t be possible to exchange information among computers if there wasn’t an agreement on how that information should be interpreted. Systems can’t work if the meaning represented by the exchanged data isn’t shared.
Note
It is important that a shared understanding of the exchanged information doesn’t get translated into a shared way of processing that information. Participants in loosely coupled distributed applications are free to deal with the documents they receive in any way they wish.
Natural language specifications—whether media type descriptions, protocols, or contracts—provide a mechanism for developers to agree on the meaning of the documents they exchange. However, as the complexity and scale of distributed applications grow, it is important to consider the representation of information using machine-processable formats.
Technologies are emerging, especially as part of the Semantic Web effort, to help with the definition of document formats, protocols, and contracts. Semantic technologies are a great asset in our development toolbox whenever we want to represent information that machines can “understand.” The intention of a service provider can be captured in semantically rich documents. These documents can be consumed directly by applications, removing the need for humans to read specifications and create programs from them. As a result, the correctness of our distributed system can be improved and the integration process accelerated.
[121] We are not just referring to the 0s and 1s of the binary system. A series of characters, or a collection of numbers without any way to interpret them within a particular context, is still “data.”
[122] See Sowa’s “Knowledge Representation: Logical, Philosophical, and Computational Foundations,” and Brachman’s and Levesque’s “Knowledge Representation and Reasoning” for more information on the subject—or many books on related areas of philosophy such as epistemology.
[123] The Mars Climate Orbiter was sent to its destruction because Lockheed Martin used pounds for measuring thrust while the JPL engineers interpreted the given number as newtons (http://en.wikipedia.org/wiki/Mars_Climate_Orbiter).
[124] Tim Berners-Lee, “Weaving the Web,” http://www.w3.org/People/Berners-Lee/Weaving/.
[125] Berners-Lee, T., J.A. Hendler, and O. Lasilla. The Semantic Web. Scientific American, May 2001.
[126] Shadbolt, N., T. Berners-Lee, and W. Hall.“The Semantic Web Revisited.” IEEE Intelligent Systems 21(3):2006, p. 96–101.
[129] A collection of terms defined by a community through collaborative tagging: http://en.wikipedia.org/wiki/Folksonomy.
[132] As per the RDF/XML specification, our examples make use of
Qualified Names (QNames), which are shorter versions
of URIs, for the RDF statements. For example, restbucks:milk is the QName for http://restbucks.com/vocab#milk.
[133] We could have reused an existing vocabulary to describe the currency node. For example, GoodRelations (http://www.heppnetz.de/ontologies/goodrelations/v1) includes terms to describe the cost of products and the requested currency. In general, the reuse of vocabularies is recommended.
[134] SKOS Simple Knowledge Organization System: http://www.w3.org/2004/02/skos/
[139] In all the OWL examples that follow, we are omitting the
declarations indicating that some of the concepts are subclasses
of owl:Thing, the top-level
concept declared by OWL. We have also omitted the http://restbucks.com/vocab# part of
the concepts’ and properties’ URIs in order to make the examples
more readable. <Order>
should be read as <http://restbucks.com/vocab#Order>.
[144] See http://www.foaf-project.org/. FOAF is an ontology used for representing information about people, such as their name, their email, their workplace, their friends, and much more.
[146] Tim Berners-Lee’s design note: http://www.w3.org/DesignIssues/LinkedData.html.