EMBRACING HTTP AS AN APPLICATION PROTOCOL puts the Web at the heart of distributed systems development. But that’s just a start. In this chapter, we will go further, building RESTful services that use hypermedia to model state transitions and describe business protocols.
When browsing the Web, we’re used to navigating between pages by clicking links or completing and submitting forms. Although we may not realize it, these interlinked pages describe a protocol—a series of steps we take to achieve a goal, whether that’s buying books, searching for information, creating a blog post, or even ordering a coffee. This is the very essence of hypermedia: by transiting links between resources, we change the state of an application.
Hypermedia is an everyday part of our online activities, but despite this familiarity, it’s rarely used in computer-to-computer interactions. Although Fielding’s thesis on REST highlighted its role in networked systems, hypermedia has yet to figure significantly in contemporary enterprise solutions.
The phrase hypermedia as the engine of application state, sometimes abbreviated to HATEOAS, was coined to describe a core tenet of the REST architectural style. In this book, we tend to refer to the hypermedia tenet or just hypermedia. Put simply, the tenet says that hypermedia systems transform application state.
Note
What is application state? If we think of an application as being computerized behavior that achieves a goal, we can describe an application protocol as the set of legal interactions necessary to realize that behavior. Application state is a snapshot of an execution of such an application protocol. The protocol lays out the interaction rules; application state is a snapshot of the entire system at a particular instant.
A hypermedia system is characterized by the transfer of links in the resource representations exchanged by the participants in an application protocol. Such links advertise other resources participating in the application protocol. The links are often enhanced with semantic markup to give domain meanings to the resources they identify.
For example, in a consumer-service interaction, the consumer submits an initial request to the entry point of the service. The service handles the request and responds with a resource representation populated with links. The consumer chooses one of these links to transition to the next step in the interaction. Over the course of several such interactions, the consumer progresses toward its goal. In other words, the distributed application’s state changes. Transformation of application state is the result of the systemic behavior of the whole: the service, the consumer, the exchange of hypermedia-enabled resource representations, and the advertisement and selection of links.
On each interaction, the service and consumer exchange representations of resource state, not application state. A transferred representation includes links that reflect the state of the application. These links advertise legitimate application state transitions. But the application state isn’t recorded explicitly in the representation received by the consumer; it’s inferred by the consumer based on the state of all the resources—potentially distributed across many services—with which the consumer is currently interacting.
The current state of a resource is a combination of:
The values of information items belonging to that resource
Links to related resources
Links that represent a transition to a possible future state of the current resource
The results of evaluating any business rules that relate the resource to other local resources
This last point emphasizes the fact that the state of a resource is partly dependent on the state of other local resources. The state of a sales order, for example, is partly a function of the state of a local copy of an associated purchase order; changes to the purchase order will affect the state of the sales order the next time the business rules governing the state of the sales order are evaluated (i.e., the next time a representation of the sales order is generated).
Importantly, the rules that control the state of a resource are internal to the service that governs the resource: they’re not made available to consumers. In other words, resource state is a function of a private ruleset that only the resource owner knows about: those rules don’t leak into the external representation.
Business rules that relate a resource to other resources should refer only to locally owned resources, however. This allows us to identify and prevent circular dependencies, whereby the state of resource A is partly a function of the state of resource B, which in turn is partly a function of the state of resource A, and so on. We can always arrange locally owned resources so as to prevent circular dependencies; we can’t do the same if the associated resources are governed by another service. If you need to relate the state of a resource to a third-party resource, we recommend making a local copy of the third-party resource using the Atom-based state alignment mechanisms described in Chapter 7.
A service enforces a protocol—a domain application protocol, or DAP—by advertising legitimate interactions with relevant resources. When a consumer follows links embedded in resource representations and subsequently interacts with the linked resources, the application’s overall state changes, as illustrated in Figure 5-1.
Note
Domain application protocols (DAPs) specify the legal interactions between a consumer and a set of resources involved in a business process. DAPs sit atop HTTP and narrow HTTP’s broad application protocol to support specific business goals. As we shall see, services implement DAPs by adding hypermedia links to resource representations. These links highlight other resources with which a consumer can interact to make progress through a business transaction.
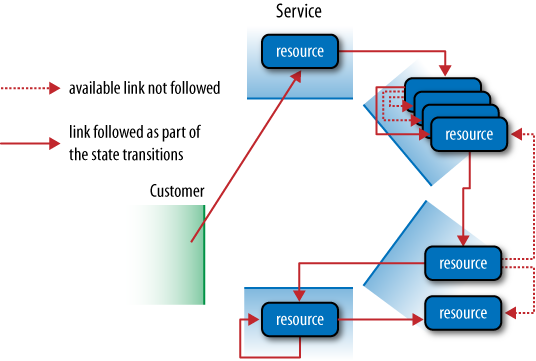
Consumers in a hypermedia system cause state transitions by visiting and manipulating resource state. Interestingly, the application state changes that result from a consumer driving a hypermedia system resemble the execution of a business process. This suggests that our services can advertise workflows using hypermedia. Hypermedia makes it easy to implement business protocols in ways that reduce coupling between services and consumers. Rather than understand a specific URI structure, a consumer need only understand the semantic or business context in which a link appears. This reduces an application’s dependency on static metadata such as URI templates or Web Application Description Language (WADL). As a consequence, services gain a great deal of freedom to evolve without having to worry whether existing consumers will break.
Note
Services should ensure that any changes they introduce do not violate contracts with existing consumers. While it’s fine for a service to make structural changes to the relationships between its resources, semantic changes to the DAP or to the media types and link relations used may change the contract and break existing consumers.
When developing a service we abstract away implementation details from consumers, thereby decreasing coupling. But no matter the degree of loose coupling, consumers must have enough information available in order to interact with our service. We need to provide some way for them to bind to our service and drive the supported application protocol. The beauty of hypermedia is that it allows us to convey protocol information in a declarative and just-in-time fashion as part of an application’s resource representations.[43]
Note
Web contracts are expressed in media types and link relations. Accepting a media type means you understand how to process that format when interacting with a service. Using the media types and link relations supported by the service, we can extend a contract over the Web at runtime by advertising new valid links and state transitions.
For computer-to-computer interactions, we advertise protocol information by embedding links in representations, much as we do with the human Web. To describe a link’s purpose, we annotate it. Annotations indicate what the linked resource means to the current resource: “status of your coffee order,” “payment,” and so on. For annotations we can use microformats or Semantic Web technologies, or we can design our own application-specific formats. We call such annotated links hypermedia controls, reflecting their enhanced capabilities over raw URIs.
Note
Forms are hypermedia controls too. Though we use links
exclusively throughout the remainder of this chapter, forms can also
be used to guide a consumer’s interaction with linked resources. At
the HTTP level, POSTing a
representation to a URI in a link is equivalent to submitting a
form.
To illustrate the key aspects of hypermedia-driven services, we’ll build the ordering and payment parts of Restbucks’ service using a custom hypermedia format.
Hypermedia-driven distributed systems put similar demands on their consumers as the Web does on humans: consumers need to discover and interact with resources so that they can realize an application’s goal. To illustrate how representation formats allow consumers to discover and interact with resources, let’s consider XHTML, one of the most popular representation formats on the World Wide Web. XHTML is used to represent information on a page (its business payload) and to link to other pages or content (its protocol description). The inclusion of links to other resources makes XHTML a hypermedia format. As humans, we take this property for granted. We use web browsers to move from one page to another without thinking of the underlying mechanics (which is a good thing, of course). Browsers apply the hypermedia tenet and interpret links to show possible transitions from one resource (page) to another.
The Web is agnostic to the representation formats exchanged by consumers and services, which is one of the primary reasons for its success in diverse domains. But when it comes to hypermedia, not all formats are equal.
Despite the success of hypermedia formats on the Web, today’s
distributed applications typically use nonhypermedia formats such as
plain XML to integrate systems. Although XML is easy to use as
a data interchange format, and despite its near ubiquity, it is
utterly oblivious to the Web. This is neatly demonstrated by our
humble order XML representation
from Chapter 4, which we show again in
Example 5-1.
Example 5-1. XML lacks hypermedia controls
<order xmlns="http://schemas.restbucks.com">
<location>takeAway</location>
<item>
<name>latte</name>
<quantity>1</quantity>
<milk>whole</milk>
<size>small</size>
</item>
<status>pending</status>
</order>There’s nothing intrinsically wrong with this order representation when considered in isolation. After all, it conveys the current state of the order well enough. But it fails to provide any context; that is, it doesn’t indicate the current state of the business process, or how to advance it. Informally, we know we need to pay for a drink once ordered, but the representation of Example 5-1 doesn’t indicate how to make that payment.
The use of plain XML leaves the consumer without a guide—a protocol—for successfully completing the business transaction it has initiated. Because there are no hypermedia controls in the order representation, the consumer must rely on out-of-band information to determine what to do next. From a loose coupling point of view, that’s a poor design decision. Aspects of the service’s implementation leak through mechanisms such as URI templates into the consumer’s implementation, making change difficult and risky.
We can, of course, communicate protocol information to the developers of a consumer application using written documentation, or static contracts such as Web Services Description Language (WSDL), WADL, or URI templates. But, as we’ll see, the Web and hypermedia enable us to do better.
Let’s consider first how Restbucks might communicate protocol
information if it chose the static, upfront approach. As we wrote in
Chapter 3, Restbucks could share URI
templates with its consumers. For example, it could document and share
the template http://restbucks.com/payment/{order_id}. The
documentation would describe how consumers are expected to PUT a payment representation to a URI
generated by replacing the order_id
part of the template with the ID of the original order. It’s hardly
rocket science, and with a little URI manipulation it can quickly be
made to work. Unfortunately, it can be made to fail just as
rapidly.
If Restbucks chose to publish URI templates to consumers, it
would then be bound to honor those templates for the long term, or
risk breaking existing consumer applications. Publishing URI template
details outside a service’s boundary exposes too much information
about the service’s implementation. If the implementation of the
ordering and payment services were to change, perhaps as a result of
outsourcing the payment capability to a third party, there’d be an
increased risk that consumers built to the (now defunct) http://restbucks.com/payment/{order_id}
template would break. Since that kind of business change happens
frequently, Restbucks ought to encapsulate its implementation details
as far as possible.
Generally, it’s better to expose only stable URIs. These stable URIs act as entry points to services, after which hypermedia takes over. For example, the entry point to the Restbucks ordering service is http://restbucks.com/order. Interacting with the resource at that URI generates further resource representations, each of which contains hypermedia links to yet more resources involved in the ordering business process.
This doesn’t mean URI templates are a bad idea. In fact, they are an excellent metadata format. But as with all good things, we must learn how to use them in moderation. We believe URI templates are an excellent means for documenting service design. Restbucks’ implementations all embrace URI templates for internal documentation and implementation purposes. However, those same implementations only ever share completed (opaque) URIs with consumers. The templates remain a private design and development detail.
Formats provide the means for interacting with a service, and as such they’re part of that service’s contract. Because a format is part of the service contract, it’s important to choose an appropriate hypermedia format at design time.
REST’s hypermedia tenet doesn’t prescribe a specific representation format, but it does require a format capable of conveying necessary hypermedia information. Different hypermedia formats suit different services. The choice depends on a trade-off between reach and utility—between the ability to leverage existing widely deployed software agents and the degree to which a format matches our domain’s needs.
Several of the hypermedia formats already in use on the Web today are capable of supporting some of our requirements. Formats such as Atom[44] (and RSS) and XHTML are widely used and understood. Correspondingly, many software tools and libraries are available to produce, consume, and manage resource representations in these formats. Web browsers, for example, know how to render XHTML representations as pages, and Atom representations as lists of entries.
Note
Underlying the Web is a principle of generality, which prefers a few commonly agreed-upon, general-purpose formats to many specialized formats. The principle of generality allows huge numbers of different programs and systems to interoperate using a few core technologies.
However, widespread tool support alone doesn’t make a format
suitable for every domain. For example, XHTML supports hypermedia
(and is therefore capable of describing business protocols) because
it implements hypermedia controls such as <a href>. Still, as Example 5-2 shows, it’s a verbose format
for representing a Restbucks order in a computer-to-computer
interaction.
Example 5-2. Encoding an order in XHTML
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN"
"http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd">
<html xmlns="http://www.w3.org/1999/xhtml">
<body>
<div class="order">
<p class="location">takeAway</p>
<ul>
<li class="item">
<p class="name">latte</p>
<p class="quantity">1</p>
<p class="milk">whole</p>
<p class="size">small</p>
</li>
</ul>
<a href="http://restbucks.com/payment/1234"
rel="http://relations.restbucks.com/payment">payment</a>
</div>
</body>
</html>By encoding our order as XHTML, we are able to render it in a
web browser, which is helpful for debugging. We leverage XHTML
controls, such as the class
attribute, to convey semantics about the contents of an element. The
approach of mixing business data with web page presentation
primitives has been popularized through microformats, which we’ll
discuss in Chapter 10. Example 5-2 illustrates, however, how
the fusion of business data and presentation primitives comes at the
expense of some noisy XHTML markup. In choosing XHTML, we make the
conscious decision to trade expressiveness for reach by shoehorning
a specific application format into a more general format.
But sometimes, trading expressiveness for reach isn’t the right thing to do. Do our consumers really need to understand XHTML and all its verbiage? Given that Restbucks isn’t concerned with user-facing software (browsers), XHTML appears more an overhead than a benefit. In this case, it’s probably better to devise our own hypermedia format.
Because the Web is agnostic to representation formats, we’re free to create custom formats tailored to our own problem domains. Whether we use a widely understood format or create our own, hypermedia formats are more web-friendly than nonhypermedia formats. A good hypermedia format conveys both domain-specific and protocol information. Domain-specific information includes the values of information elements belonging to a business resource, such as the drinks in an order. Protocol information declares how to make forward progress in a business process—how to move from ordering to payment, for example.
In a hypermedia format, hypermedia controls represent protocol information. A hypermedia control includes the address of a linked resource, together with some semantic markup. In the context of the current resource representation, the semantic markup indicates the meaning of the linked resource.
Creating a domain-specific hypermedia format isn’t as difficult as it might seem. In Restbucks’ case, we can build on the XML schemas we’ve already created. All we have to do is to introduce additional elements into the representations. We can add hypermedia controls to these schemas by defining both a link and the necessary semantic markup. Example 5-3 shows a first attempt at adding an application-specific hypermedia control to an order.
Example 5-3. A coffee order with a custom hypermedia link
<order xmlns="http://schemas.restbucks.com">
<location>takeAway</location>
<item>
<name>latte</name>
<quantity>1</quantity>
<milk>whole</milk>
<size>small</size>
</item>
<cost>2.0</cost>
<status>payment-expected</status>
<payment>https://restbucks.com/payment/1234</payment>
</order>In this format, the order representation contains a
proprietary <payment>
element. <payment> is a
hypermedia control.
If we wanted to represent hypermedia controls in this manner, we would specify
in our format description that a <payment> element indicates “a
linked resource responsible for payments relating to the current
order.” A consumer wanting to make a payment now knows which
resource it needs to interact with next.
But that’s not the only way to add hypermedia controls to our
representation format. In fact, we believe it’s a suboptimal method
because it results in multiple elements with almost identical link
semantics, but different protocol semantics. <payment> bears the joint
responsibility of being both a link and a semantic annotation. If we
added a <cancel> element to
our scheme, this new element would have exactly the same link
semantic as <payment>, but
a wholly different protocol semantic.
Our preferred approach is to separate concerns by
distinguishing between the act of linking and the act of adding
meaning to links. Linking is a repeatable process. The meanings we
attach to links, however, change from context to context. To achieve
this separation of concerns, we define a <link> element to convey the
domain-agnostic link function, and a rel attribute to represent the application
semantics associated with a particular link. Composing this <link> element into Restbucks’
representation format is easy, as shown in Example 5-4.
Example 5-4. A coffee order with hypermedia
<order xmlns="http://schemas.restbucks.com">
<location>takeAway</location>
<item>
<name>latte</name>
<quantity>1</quantity>
<milk>whole</milk>
<size>small</size>
</item>
<cost>2.0</cost>
<status>payment-expected</status>
<link rel="http://relations.restbucks.com/payment"
href="https://restbucks.com/payment/1234" />
</order>The Restbucks hypermedia format specification would have to
document the meaning of the rel
attribute’s payment value so that
consumers understand the role of the linked resource in relation to
the current resource.
Note
By incorporating reusable hypermedia controls in our format, we can minimize how much of our representation we need to document and explain to consumers. If we can construct our business documents solely from widely understood and reusable building blocks, so much the better. Indeed, we’ll have a closer look at a collection of such building blocks when we discuss the Atom format in Chapter 7 and semantics in Chapter 10.
By adding a <link>
element to our order schema, we’ve successfully defined our own
custom hypermedia format. Designing our own format allows us to
express our specific application needs, yet retain the benefits of
hypermedia. Of course, as with any design trade-off, there are
downsides. For example, the representations in Examples Example 5-3 and Example 5-4 don’t have the same
reach—the ability to be processed by widely deployed generic
clients—as more established hypermedia formats such as XHTML. In essence, we’re
creating a closed hypermedia ecosystem—one that’s specific to
Restbucks. This ecosystem is for consumers who are prepared to
process our domain-specific payloads. Though this limits an
application’s reach, for Restbucks and enterprise systems in
general, it might be just what we need.
Introducing a custom hypermedia format feels like a step in the right direction. Now consumers of Restbucks services can receive both business data and the information necessary to drive the ordering and payment protocol, all in a concise and expressive format specific to the business domain.
Still, we need to convey to consumers how to process and reason
about these representations. Fortunately, HTTP provides a way of
identifying particular media type representations
using the Content-Type header
(e.g., Content-Type:
application/xml, which we have used in previous
chapters).
Grafting hypermedia controls onto XML documents is easy, but it’s only half the story. What we really need to do is to create a media type. A media type specifies an interpretative scheme for resource representations. This scheme is described in terms of encodings, schemas, and processing models, and is a key step in creating a contract for a service.
A media type name (such as application/xml) is a key into a media
type’s interpretative scheme. Media types are declared in Content-Type HTTP headers. Because they’re
situated outside the payload body to which they’re related,
consumers can use them to determine how to process a representation
without first having to crack open the payload and deeply inspect
its content—something that might require relatively heavy
processing, such as a decrypt operation, for example.
Note
Media type names may also appear in some inline links and forms, where they indicate the likely representation format of the linked resource.
A media type value indicates the service’s preferred scheme for interpreting a representation: consumers are free to ignore this recommendation and process a representation as they see fit.
For example, we know that XHTML is valid XML and can be consumed by any software that understands XML. However, XHTML carries richer semantics (it supports hypermedia) than plain XML, and so processing it as XML rather than XHTML is lossy—we lose information about linked resources.
If a consumer interprets a received representation ignoring
the rules set out by the media type in the accompanying Content-Type header, all bets are
off.
Warning
Willfully ignoring a media type declaration in a Content-Type header is not to be taken
lightly, and is a rare occurrence.
Media types are one of three key components of DAPs. The other two components are link relation values, which describe the roles of linked resources, and HTTP idioms, which manipulate resources participating in the protocol. Link relation values help consumers understand why they might want to activate a hypermedia control. They do so by indicating the role of the linked resource in the context of the current representation.
A media type value helps a consumer understand
what is at the end of a link. The
how of interacting with a resource is realized
by HTTP constructs such as GET,
PUT, and POST (and
their conditional counterparts) and the control alternatives
suggested by the HTTP status codes.
Note
Media types and DAPs are not the same. A media type specification describes schemas, processing models, and link relation values for a representation format. A DAP specification lays out the rules for achieving an application goal based on interactions with resource representations belonging to one or more media types. DAPs augment media type specifications with application-specific link relation values where necessary.
The media type declaration used in the Content-Type header for interactions with
Restbucks is application/vnd.restbucks+xml. Breaking it
down, the media type name tells us that the payload of the HTTP
request or response is to be treated as part of an application-specific interaction. The
vnd.restbucks part of the media
type name declares that the media type is vendor-specific (vnd), and that the owner is restbucks. The +xml part declares XML is used for the
document formatting.
More specifically, the vnd.restbucks part of the media type name
marks the payload as being part of Restbucks’ DAP. Consumers who
know how to interact with a Restbucks service can identify the media
type and interpret the payloads accordingly.[45]
As we described earlier, we chose to stick with XML for the
Restbucks representation formats. This decision allows us to reuse
existing schemas/formats in our media type description.[46] However, this doesn’t mean we should use text/xml or application/xml as the value of the
Content-Type header, and for good
reason. The Content-Type header
sets the context for how the payloads should be processed.
Suggesting that the payload is just XML gives the wrong indication
to software agents about the content and processing model for a
representation. Treating Restbucks content and its hypermedia
control format as plain XML simply leads to a hypermedia dead
end.
For example, in Example 5-5 we see a
Restbucks order, which contains
two <link> elements
advertising other resources of interest to the customer. Using this
simple protocol representation format, the service shows consumers
how they can make forward progress through the business process by
interacting with the payment and special offer resources.
Example 5-5. Content-Type dictates how entity bodies are processed
HTTP/1.1 200 OK Content-Length: 342 Content-Type: application/xml Date: Sun, 21 Mar 2010 17:04:10 GMT <order xmlns="http://schemas.restbucks.com"> <location>takeAway</location> <item> <name>latte</name> <quantity>1</quantity> <milk>whole</milk> <size>small</size> </item> <cost>2.0</cost> <status>payment-expected</status> <link rel="http://relations.restbucks.com/payment" href="https://restbucks.com/payment/1234"/> <link rel="http://relations.restbucks.com/special-offer" href="http://restbucks.com/offers/cookie/1234"/> </entry>
But all is not well with Example 5-5. While the
root XML namespace of the payload clearly indicates that this is a
Restbucks order (and is therefore
hypermedia-friendly, as defined by the Restbucks specification), the
Content-Type header declares it
should be processed as plain XML, not as the hypermedia-friendly
application/vnd.restbucks+xml.
When we encounter an HTTP payload on the Web whose Content-Type header is set to application/xml, we’re meant to process
that payload in accordance with its media type specification, as set
out in RFC 3023.
By treating XML hypermedia formats as plain XML, we skip many of their
benefits. The interpretative scheme for each format includes
hypermedia control definitions that enable programs to identify and
process hypermedia controls embedded within a document of that
type. These processing imperatives do not exist in the application/xml media type specification,
which means that the payload of Example 5-5 should be
treated simply as structured data. The protocol information (the
<link> elements) will
appear as odd-looking business information.
Warning
HTTP is not a transport protocol, it is an application protocol. An HTTP message’s body cannot be divorced from its headers, because those headers set the processing context for the entity body payload.
XML thinking encourages us to separate protocol and data—usually to our detriment. Too often, we end up designing containers for data, with no inline provision for protocol information. This leads us to advertise the protocol using an out-of-band mechanism such as URI templates. The burden then falls to consumer applications to keep current with changes in the service implementation (particularly around URIs)—changes that ordinarily the service would not be obliged to share.
Adding hypermedia controls to an XML representation doesn’t
help much if we then go on to recommend the representation be
treated as plain XML. The controls can play their part in a
hypermedia system only if the Content-Type header suggests using a
hypermedia-aware interpretative scheme. This is the case even if the
document’s root XML namespace alludes to a useful processing model. Content-Type headers, not XML namespaces,
declare how a representation is to be processed: that’s the
convention on the Web.
Note
Services and consumers are bound by the application protocol semantics of HTTP. When a service declares that a payload is in a particular format, consumers should honor that directive rather than second-guess the processing model by deeply examining the payload contents.
A diligent consumer might later examine the XML namespace or associated schema and discover a more specialized type. Activities such as this take place outside the well-understood, predictable mechanisms defined by HTTP. Wrongly inferring the processing model may even harm the application if the originating service explicitly meant for the payload to be interpreted in a specific way—not all representations with angle brackets are well-formed XML, after all.
For example, as part of its monitoring processes, Restbucks
may produce a feed of malformed orders: corrupted documents
submitted by inept or malicious customers. In the Content-Type header, the service indicates
that the representation should be treated as text/plain. Consumers that decide to treat
these representations as XML, because they contain angle brackets,
had better guard against exceptions arising from malformed XML since
the service has made no stronger commitment than to provide plain
text.
Balancing the number of media types we use against the number of representation formats that our DAP uses can be a tricky affair. On the one hand, it’s possible to create a new media type for each representation format hosted by a service. On the other hand, we might choose to create one media type for the entire application domain.
Creating a one-to-one mapping between media types and
representation formats, with specialized media type values such as
application/vnd.restbucks.order+xml and
application/vnd.restbucks.payment.creditCard+xml,
can lead to extremely tight coupling between a service’s domain
layer and its consumers. The interactions in the application
protocol might have to be fine-grained since the composition of
representation formats will not be possible, given that there can be
only one media type per HTTP request or response. At the other
extreme, a single monolithic media type can add unnecessary overhead
when we want to share a subset of schemas between application domain
contexts.
In our case, we’ve chosen to make application/vnd.restbucks+xml generally
applicable to the entire domain of orders and payments in Restbucks.
As a result, our media type defines the order, payment, and receipt
schemas, and our chosen hypermedia control format and processing model (the <link> element). It also defines a
number of link relation values, which our DAP uses to identify the
relationship between resources.
Note
Although Restbucks defined the core functionality for its media type, there’s nothing to stop other DAPs from composing our media type with other media types, or adding to our set of link relation values. By composing other media types or layering on other link relations, the Restbucks media type can be easily extended and put to other uses, just like any other good media type.
In the Restbucks application domain, we assume that consumers
who understand the application/vnd.restbucks+xml media type
are capable of dealing with everything defined by it. However, it
occasionally happens that some consumers want to handle only a
subset of the representation formats defined in a media type. While
there is no standard solution to this issue on the Web, there is a
popular convention defined by the Atom community. The application/atom+xml media type defines
both the feed and the
entry resource representation formats.[47] While the vast majority of consumers can handle both,
there is a small subset wishing only to deal with standalone
entries. In recognition of this need, Atom Publishing Protocol
(AtomPub) added a type parameter
to the media type value (resulting in Content-Type headers such as application/atom+xml;type=entry). With
such a value for the ContentType
header, it is now possible to include “entry” resource
representations as payloads in HTTP requests or responses without
requiring that the processing software agents have a complete
understanding of all the Atom-defined formats.
Note
Though the Restbucks media type contains multiple schemas,
we’ve chosen not to implement a type parameter. Instead, we distinguish
individual representations based on their XML namespaces. It’s
worth keeping this convention in mind, however, for situations
where we only want to provide support for a subset of a media
type’s representation formats.
In many of the examples in the remainder of this chapter,
we’ll omit the HTTP headers and focus on the hypermedia payloads. These examples assume the
Content-Type header is set to
application/vnd.restbucks+xml.
Contracts are a critical part of any distributed system since they prescribe how disparate parts of an application should interact. Contracts typically encompass data encodings, interface definitions, policy assertions, and coordination protocols. Data encoding requirements and interface definitions establish agreed-upon mechanisms for composing and interpreting message contents to elicit specific behaviors. Policies describe interoperability preferences, capabilities, and requirements—often around security and other quality-of-service attributes. Coordination protocols describe how message exchanges can be composed into meaningful conversations between the disparate parts of an application in order to achieve a specific application goal.[48]
The Web breaks away from the traditional way of thinking about upfront agreement on all aspects of interaction for a distributed application. Instead, the Web is a platform of well-defined building blocks from which distributed applications can be composed. Hypermedia can act as instant and strong composition glue.
Contracts for the Web are quite unlike static contracts for other distributed systems. As Figure 5-2 shows, contracts are a composition of a number of aspects, with media types at their core. Protocols extend the capabilities of a media type into a specific domain. Currently, there is no declarative notation to capture all aspects of a contract on the Web. While technologies such as XML Schema allow us to describe the structure of documents, there is no vocabulary that can describe everything. As developers, we have to read protocol and media type specifications in order to implement applications based on contracts.
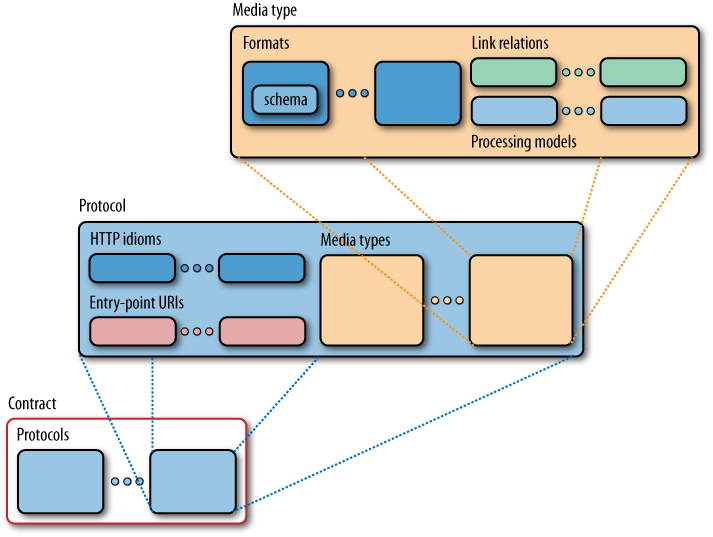
The core of any contract on the Web is the set of media types a service supports. A media type specification sets out the formats (and any schemas), processing model, and hypermedia controls that services will embed in representations.
There are numerous existing media type specifications that we can use to meet the demands of our service. Occasionally, we may create new media types to fit a particular domain. The challenge for service designers is to select the most appropriate media type(s) to form the core service contract.
On entering into the contract, consumers of a service need simply to agree to the format, processing model, and link relations found in the media types the service uses. If common media types are used (e.g., XHTML or Atom), widespread interoperability is easily achievable since many systems and libraries support these types.
We believe an increase in the availability of media type processors will better enable us to rapidly construct distributed applications on the Web. Instead of coding to static contracts, we will be able to download (or build) standard processors for a given media type and then compose them together.[49]
Often, that’s as far as we need to go in designing a contract. By selecting and optionally composing media types, we’ve got enough collateral to expose a contract to other systems. However, we need not stop there, and can refine the contract by adding protocols.
On the Web, protocols extend the base functionality of a media type by adding new link relations and processing models.
Note
A classic example of protocols building on established media types is Atom Publishing Protocol. AtomPub describes a number of new link relations, which augment those declared in the Atom Syndication Format. It builds on these link relations to create a new processing model that supports the specific application goal of publishing and editing web content.
While media types help us interpret and process a format, link relations help us understand why we might want to follow a link. A protocol can add new link relations to the set provided by existing media types. It can also augment the set of HTTP idioms used to manipulate resources in the context of specific link relations. Service designers can also use independently defined link relations, such as those in the IANA Link Relations registry, mixing them in with the link relations provided by media types and protocols to advertise specific interactions.[50]
Underpinning all media types and protocols is the HTTP uniform interface, which provides the plumbing through which contracts are enacted at runtime. Even with media types and protocols to describe a contract, consumers still need to know how individual resources should be manipulated at runtime. In other words, contracts define which HTTP idioms—methods, headers, and status codes—consumers should use to interact with a linked resource in a specific context.
Such information can come from several sources. Many hypermedia controls have attributes that describe
transfer options. XHTML’s <form> element, for example, includes
a method attribute that specifies
the HTTP method to use to send form data. Occasionally, the current
application context can be used to determine which idiom to use next.
If the consumer receives a representation accompanied by an ETag header, it’s reasonable to assume that
subsequent requests for the same resource can be made using a
precondition: If-Match or If-None-Match, as appropriate. Similarly, a
303 See Other status code and
accompanying Location header
instruct the recipient to perform a GET on the Location header’s URI. When neither the
current payload nor the processing context indicates which idioms to
use, OPTIONS can be used on the
linked resource’s URI.
Note
We should always remember that the OPTIONS method allows us to query for
information regarding the communication options currently supported
by a resource. However, if we find the need to use many OPTIONS requests or probe linked resources
with best-guess requests, we should be concerned about the
predictability and robustness of our distributed application.
At runtime, a contract is enacted over the Web as shown in Figure 5-3. The final contract element put into place is a well-known entry point URI (or URIs), which is advertised to consumers so that they can bind to the service.
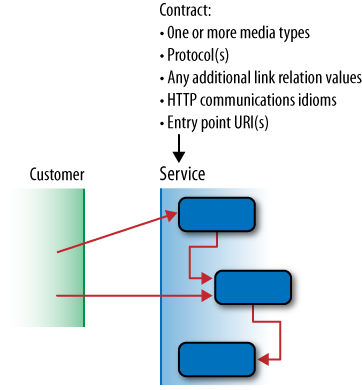
Although media types, protocols, and link relations are defined orthogonally to any given service, they still constitute a strong contract. A consumer that understands a set of media types, protocols, and link relations can interact with any service that supports them (in any combination).
Since consumers know the service contract, its protocol can be driven entirely by exchanging and processing representations whose content and hypermedia controls are consistent with that contract. This scheme provides loose coupling, and it also allows services to lead their consumers through business protocols.
REST introduces a set of tenets that, when applied to distributed systems design, yield the desirable characteristics of scalability, uniformity, performance, and encapsulation. Using HTTP, URIs, and hypermedia, we can build systems that exhibit exactly the same characteristics. These three building blocks also allow us to implement application protocols tailored to the business needs of our solutions.
As a web-based system, Restbucks supports a DAP for ordering and payment. Figure 5-4 summarizes the HTTP requests that the ordering service supports and the associated workflow logic each request will trigger.
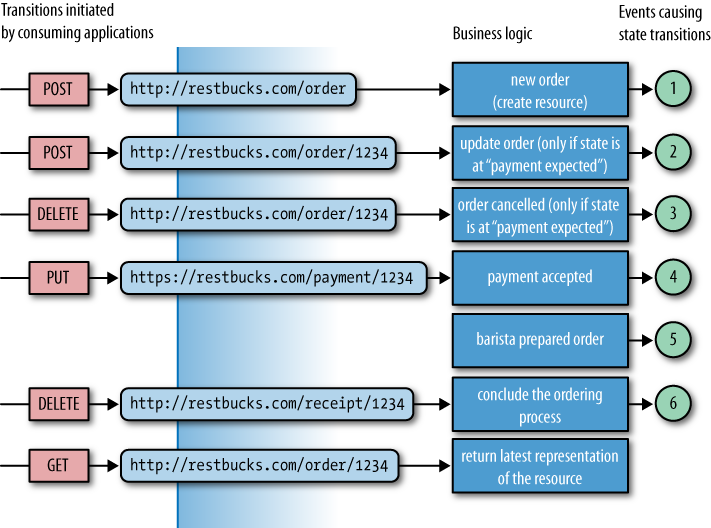
The permitted interactions shown in Figure 5-4 constitute a complete business protocol for lodging, managing, and paying for an order. Each interaction invokes a workflow activity that changes the underlying state of one or more resources managed by the service.[51] Modeling Restbucks’ business processes as a DAP and then representing that protocol as a state machine in this manner is a useful way of capturing a business process at design time.
Moving from design to implementation, we need to think about the protocol in a slightly different way. In a resource-oriented distributed application, an application protocol can be thought of as a function of one or more resource life cycles and the business rules that connect these resources. Because of its resource-centric nature, the Restbucks service does not host an application protocol state machine. In other words, there’s no workflow or business logic for the application protocol as such. Rather, the service governs the life cycles of the orders and payments participating in the application protocol. Any workflows in the service implementation relate to resource life cycles, not the application protocol life cycle. While we’ve been explicit in modeling the business process as an application protocol state machine, we’ve been diligent in implementing it wholly in terms of resource state machines.
Figure 5-5 shows the resource state machine for an order as implemented in the service. From this diagram and Figure 5-4, we can derive the DAP:
POSTcreates an order.Any number of
POSTs updates the order.A single
DELETEcancels the order, or a singlePUTto a payment resource pays for the order.And finally, a single
DELETEconfirms that the order has been received.
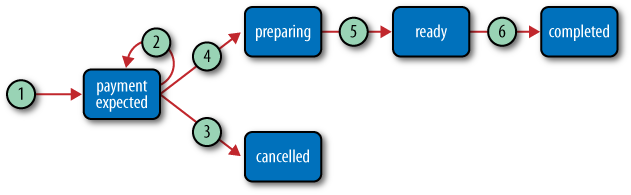
The state machine diagram in Figure 5-5 is a useful design artifact, but it isn’t a good representation format for sharing protocols over the Web. For that, we use hypermedia, which starts with a single, well-known entry point URI.
For our hypermedia service implementation, we’ll create an entry
point to the ordering service at http://restbucks.com/order. To initiate the ordering
protocol, a consumer POSTs a
request with an order representation to http://restbucks.com/order, which results in a new
order being created. The payload of the POST request must be a Restbucks order XML
representation, and the Content-Type header must contain the value
application/vnd.restbucks+xml.
Changing the media type to application/vnd.restbucks+xml from application/xml might seem a modest step,
but in doing so we’ve realized some fundamental goals: the
entry point to the Restbucks service gives
consumers a way of triggering an instance of our DAP. From this point
onward, hypermedia takes over, with link relations from the Restbucks
media type leading consumers from one step in the business protocol to
the next. If all goes well, by the end of the process we will have the
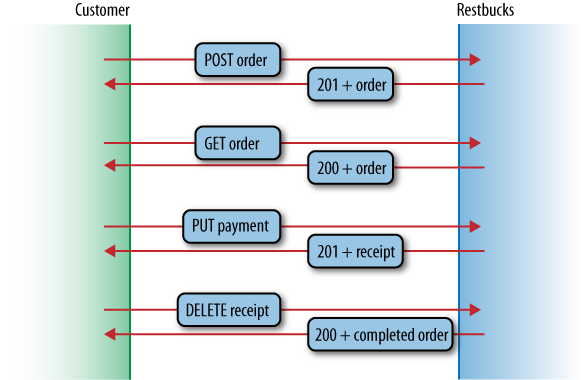
set of interactions shown in Figure 5-6.
Figure 5-6 shows the trace of HTTP interactions that occur during a normal, successful interaction with Restbucks. Each interaction is guided by hypermedia links, so it’s easy to piece this puzzle together, starting from the beginning.
If Restbucks accepts the POSTed order, the ordering service generates
a 201 Created response, which
contains a representation of the service’s version of the order. So
far, this matches the CRUD approach we saw in the preceding chapter.
The marked differences are in the use of the Content-Type header, and in the contents of
the returned resource representation, which now uses links to
advertise the next set of accessible resources.
At this point, the ordering protocol allows the consumer to check the status of the order, cancel it, update it, or pay for it (see Figure 5-7). For example, if the consumer checks the status of the order prior to paying, the service returns a representation with a business payload part depicting the status of the order, and a protocol part indicating payment is still required, as shown shortly in Example 5-6.
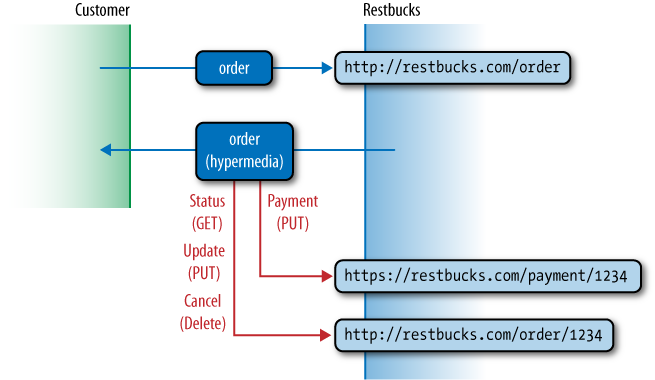
Note
The protocol parts of the payload direct customers through the ordering process, but the service can’t assume that every customer will follow these directions. Because we can’t control the development of consumer applications, we need to make sure the service can process any incoming request—even an out-of-order or invalid request—and return the appropriate response codes.
The semantics of the links in the order representation must be communicated
to, and understood by, Restbucks’ customers. This is the purpose of
the Restbucks media type.[53] By accepting HTTP responses with the Content-Type header set to application/vnd.restbucks+xml, consumers
enter into a contract that requires them to understand Restbucks’
representation format and link relation values if they wish to make
forward progress. As per the media type description, Restbucks
leverages a reusable <link>
element to convey business protocol information. We separate the
<link> element and its
attributes from the rest of the Restbucks representation format
elements and we define it in its own http://schemas.restbucks.com/dap
namespace:
<link>elements have auriattribute whose value indicates a resource with which the consumer can interact to progress the application protocol.<link>elements have arelattribute containing semantic markup. The definitions of the markup values imply which HTTP verb to use when following the link, as well as required HTTP headers, and the structure of the payload.If a request requires an entity body, the
<link>element will contain amediaTypeattribute that declares the format of the request payload. If a request does not require an entity body, themediaTypeattribute will be absent.
With the <dap:link>
hypermedia control at our disposal, let’s see an
example order representation. Example 5-6 shows a response
representation generated immediately after an order has been
accepted.
Example 5-6. Hypermedia order representation
<order xmlns="http://schemas.restbucks.com"
xmlns:dap="http://schemas.restbucks.com/dap">
<dap:link mediaType="application/vnd.restbucks+xml"
uri="http://restbucks.com/order/1234"
rel="http://relations.restbucks.com/cancel"/>
<dap:link mediaType="application/vnd.restbucks+xml"
uri="http://restbucks.com/payment/1234"
rel="http://relations.restbucks.com/payment"/>
<dap:link mediaType="application/vnd.restbucks+xml"
uri="http://restbucks.com/order/1234"
rel="http://relations.restbucks.com/update"/>
<dap:link mediaType="application/vnd.restbucks+xml"
uri="http://restbucks.com/order/1234" rel="self"/>
<item>
<milk>semi</milk>
<size>large</size>
<drink>cappuccino</drink>
</item>
<location>takeAway</location>
<cost>2.0</cost>
<status>unpaid</status>
</order>This order representation shows the different URIs and
associated rel values consumers can
use to advance the DAP. The semantic markup definitions are shared
widely with consumers as part of the media type specification, and are
as follows:
paymentThe linked resource allows the consumer to begin paying for the order. Initiating payment involves
PUTting an appropriate resource representation to the specified URI, as defined in the Restbucks media type.selfThe
urivalue can be used toGETthe latest resource representation of the order.updateConsumers can change the order using a
POSTto transfer a representation to the linked resource.cancelThis is the
urito be used toDELETEthe order resource should the consumer wish to cancel the order.
At this point in the workflow, if the customer GETs the status of the order via http://restbucks.com/order/1234, the customer will be
presented with the resource representation shown in Example 5-6. Once payment has been
PUT to the payment URI, however,
subsequent requests for the order will return a representation with
different links, reflecting a change in application state and the
opening up of a new set of steps in the DAP.
At any point in the execution of the ordering process, the
service can inject hypermedia controls into response bodies. For example,
if the customer submits a payment via POST, as shown in Example 5-7, the service updates
the state of the order to reflect the fact that payment is no longer
required.
Example 5-7. A payment resource representation
<payment xmlns="http://schemas.restbucks.com"> <amount>2.0</amount> <cardholderName>Michael Faraday</cardholderName> <cardNumber>11223344</cardNumber> <expiryMonth>12</expiryMonth> <expiryYear>12</expiryYear> </payment>
The service then injects links to both the order and receipt resources into the response, as shown in Example 5-8.
Example 5-8. Payment response contains links to order and receipt resources
<ns2:payment xmlns:dap="http://schemas.restbucks.com/dap" xmlns="http://schemas.restbucks.com"><dap:link mediaType="application/vnd.restbucks+xml"uri="http://restbucks.com/order/1234"rel="http://relations.restbucks.com/order"/><dap:link mediaType="application/vnd.restbucks+xml"uri="http://restbucks.com/receipt/1234"rel="http://relations.restbucks.com/receipt"/><amount>2.0</amount> <cardholderName>Michael Faraday</cardholderName> <cardNumber>11223344</cardNumber> <expiryMonth>12</expiryMonth> <expiryYear>12</expiryYear> </payment>
In the newly minted representation in Example 5-8, we have two
<link> elements to consider.
The order link takes the customer
directly to the order resource (where the customer can complete the
ordering protocol) while the receipt link leads to a receipt resource
(should the customer need a receipt).
If the customer requires a receipt, a GET on the receipt link returns the representation in
Example 5-9. If the
customer doesn’t want a receipt, it can follow the order link in Example 5-8 directly back to
the order. Whichever route is chosen, the customer ends up at a point
in the workflow where the order is paid for and we have a
representation similar to the one in Example 5-10.
Example 5-9. Receipt representation with a link to the order resource
<receipt xmlns:dap="http://schemas.restbucks.com/dap" xmlns="http://schemas.restbucks.com"><dap:link mediaType="application/vnd.restbucks+xml"uri="http://restbucks.com/order/1234"rel="http://relations.restbucks.com/order"/><amount>2.0</amount> <paid>2010-03-03T21:58:03.834+01:00</paid> </receipt>
Example 5-9
contains two elements that allow us to infer the state of the
distributed application. The <paid> element, which contains a
timestamp, provides business-level confirmation that the order has
been paid for. This sense of application state is reinforced at the
protocol level by the presence of a single <link> element, which directs the
consumer toward the order resource and the end of the business
process. And because the payment
link is now absent, the consumer has no way of activating that part of
the protocol.
Note
While all this is going on in full view of the consumer, behind the scenes an internal process is initiated to add the order to a barista’s queue. Restbucks’ customers aren’t exposed to any of this detail. All they need to know is the next protocol step after payment.
We know that having paid for the order, the customer might
GET a receipt—and following that,
the latest order representation—or the customer might simply go
straight to the latest representation of the order. Either way, the
customer eventually ends up with the order information shown in Example 5-10.
There are two things to note here. First, the value of the
<status> element has changed
to preparing. Second, there is only
one possible transition the customer can initiate, which is to request
the status of the order through the self link.
Example 5-10. The updated order resource representation after payment has been accepted
<order xmlns="http://schemas.restbucks.com" xmlns:dap="http://schemas.restbucks.com/dap"><dap:link mediaType="application/vnd.restbucks+xml"uri="http://restbucks.com/order/1234" rel="self"/><item> <milk>semi</milk> <size>large</size> <drink>cappuccino</drink> </item> <location>takeAway</location> <cost>2.0</cost><status>preparing</status></order>
While the order is in this state, every inquiry regarding the
status of the order will receive the same response. This is the
equivalent of the service saying, “Your order is being prepared; thank
you for waiting.” Every time the customer GETs the order representation, it will see
the same preparing value, until the
barista delivers the coffee.
Warning
Once a service has exposed information to the outside world, it no longer controls how or when that information might be used. For example, when Restbucks exposes a URI for canceling an order, it can’t know when—or if—a customer will use it.
Similarly, customers can’t be sure an order (including its hypermedia links) won’t change as a result of an internal business process. Even if they try immediately to initiate a transition based on a link in a representation they’ve just received, they may find the resource no longer supports the transition—the barista may have been even faster!
As with any consumer or service application on the Web, our
service implementation must be prepared to deal with any
out-of-order request, even if it is just to return an error
condition, or to flag conflicting state with a 409 Conflict response.
Once the order is complete, the barista changes the status of the underlying resource to
ready. This is an example of how an
internal, backend business process can change the state of a resource
without consumer intervention. The next time the customer GETs the order resource representation, the
response will include the final possible transition in the ordering
process, as shown in Example 5-11.
Example 5-11. Order resource representation after the barista has prepared it
<order xmlns="http://schemas.restbucks.com" xmlns:dap="http://schemas.restbucks.com/dap"><dap:link mediaType="application/vnd.restbucks+xml"uri="http://restbucks.com/receipt/1234"rel="http://relations.restbucks.com/receipt"/><item> <milk>semi</ milk> <size>large</size> <drink>cappuccino</drink> </item> <location>takeAway</location> <cost>2.0</cost><status>ready</status></order>
Note
As it stands, there’s no way for Restbucks to notify a
customer that its order is ready. Instead, the solution uses
GET-based polling. We could ask that as part of order
submission, customers register a callback URI to which a
notification could be POSTed, but
this presumes the customer has the means to deploy a service
somewhere and accept HTTP requests.
The lack of notification capabilities isn’t a big problem. The Web is designed to deal with “impatient” customers who repeatedly try to update their orders. Paradoxical as it might seem, polling and caching enable the Web to scale. Because representations can be cached close to consumers, no additional load needs to be generated on the service. Caching and its implications for service design are discussed in Chapter 6.
The representation in Example 5-11 includes a single, final state transition in the ordering process:
This DELETE request takes the
receipt from Restbucks, at least as far as the consumer is concerned.
It’s the logical equivalent of physically taking a receipt from the
cashier’s hand, and in doing so completing the order process.
Inside the service, we probably wouldn’t remove the resource, but instead maintain it as part of Restbucks’ audit trail. This final resource state transition has the effect of completing the order, and transitions our DAP to its final state.
The response to DELETE
transfers a final copy of the order. The representation, as shown in
Example 5-12, has no
hypermedia constructs, indicating that the resource is not part of an
active business process.
Example 5-12. Representations of completed orders have no links
<order xmlns="http://schemas.restbucks.com"
xmlns:dap="http://schemas.restbucks.com/dap">
<item>
<milk>semi</milk>
<size>large</size>
<drink>cappuccino</drink>
</item>
<location>takeAway</location>
<cost>2.0</cost>
<status>taken</status>
</order>And with that, our protocol instance is complete. But our exploration into hypermedia isn’t—at least not yet.
One advantage of using hypermedia to advertise protocols is that
we can introduce new features without necessarily breaking existing
consumers. The media type application/vnd.restbucks+xml contains
numerous schemas and link relation values, not all of which are
required for the basic ordering workflow; some of them are for
optional interactions, such as special offers, which Restbucks
occasionally runs.
Warning
Remember that media types and link relations act as contracts between a service and its consumers. Any additional link relation values that a service adds to its protocols over time must either be supported by existing media types or made optional.
For example, Restbucks might run a loyalty program based on coffee cards: after a customer places nine coffee orders, the tenth drink is free. To allow consumers to create or update a coffee card, Restbucks adds a link to the receipt representation returned after payment has been taken and the drinks dispensed, as shown in Example 5-13.
Example 5-13. Advertising a coffee card loyalty program
<order xmlns="http://schemas.restbucks.com" xmlns:dap="http://schemas.restbucks.com/dap"> <item> <milk>semi</milk> <size>large</size> <drink>cappuccino</drink> </item> <location>takeAway</location> <cost>2.0</cost> <status>taken</status><dap:link rel="http://relations.restbucks.com/coffee-card"uri="http://restbucks.com/order/1234/coffeecard"mediaType="application/vnd.restbucks+xml"/></order>
Customers that don’t understand the semantics of the coffee-card link are free to ignore it—they
just won’t get any free drinks. Customers who do understand the
semantics of the http://relations.restbucks.com/coffee-card
relation but who don’t already have a coffee card can issue a simple
GET request to the URI identified
by the coffee-card link. The
response contains the representation of a new coffee card with the
coffee that was just purchased already recorded, as shown in Example 5-14.
Example 5-14. Coffee card GET response
HTTP/1.1 200 OK
Content-Length: 242
Content-Type: application/vnd.restbucks+xml
Date: Sun, 21 Mar 2010 19:04:49 GMT
<coffeeCard xmlns="http://schemas.restbucks.com">
<link rel="self"
href="http://restbucks.com/coffeecard/4456afd23" />
<tamperProof>37d8c227a9e6e255327bb583dd149274</tamperProof>
<numberOfCoffees>1</numberOfCoffees>
</coffeeCard>The coffee card’s resource representation in Example 5-14 contains a self link, which identifies the card; a
<numberOfCoffees> element,
which records how many coffees have been purchased using the card; and
a tamper-proofing mechanism, which allows Restbucks to determine
whether malicious customers have adjusted the card’s data.[54]
Note
It’s safe for us to add links to representations for optional parts of a business process. Nonparticipating consumers will just ignore the optional hypermedia controls and proceed as normal. What’s noticeable is how easy it is to add and publish new functionality.
If a customer has a coffee card from a previous purchase, the
customer can update it by POSTing
it to the identified URI. Doing so updates both the number of coffees
purchased and the tamper proofing. In accordance with the business
rules around the promotion, if the presented card already carries
enough endorsements to obtain a free coffee, a new card will be
generated; this new card will then be returned in the response.
Note
There is no correlation between the coffee card and a specific order, despite the format of the URI in Example 5-13. Remember, URIs are opaque to consumers. In this case, the link contains information that the Restbucks ordering service uses when updating the count of endorsements in the coffee card.
Upon successfully accepting and updating the customer’s coffee
card, the service returns the latest representation of the coffee card
resource using a 200 OK response,
as per Example 5-15.
Example 5-15. Coffee card POST response
HTTP/1.1 200 OK
Content-Length: 242
Content-Type: application/vnd.restbucks+xml
Date: Sun, 21 Mar 2010 19:07:33 GMT
<coffeeCard xmlns="http://schemas.restbucks.com">
<link rel=http://relations.restbucks.com/self
href="http://restbucks.com/coffeecard/4456afd23">
<tamperProof>fff405268fea556a351459e7368bc1d3</tamperProof>
<numberOfCoffees>2</numberOfCoffees>
</coffeeCard>Spending fully endorsed coffee cards is simple: at the payment step, customers present their card toward full or partial fulfillment of the bill. While Restbucks is running the promotion, the order’s set of hypermedia controls is extended to encompass this activity, as shown in Example 5-16.
Example 5-16. Payment by coffee card is available during the promotion
<order xmlns="http://schemas.restbucks.com" xmlns:dap="http://schemas.restbucks.com/dap"> <dap:link mediaType="application/vnd.restbucks+xml" uri="http://restbucks.com/order/1234" rel="http://relations.restbucks.com/cancel"/> <dap:link mediaType="application/vnd.restbucks+xml" uri="http://restbucks.com/payment/1234" rel="http://relations.restbucks.com/payment"/><dap:link mediaType="application/vnd.restbucks+xml"uri="http://restbucks.com/payment/coffee-card/1234"rel="http://relations.restbucks.com/coffee-card-payment"/><dap:link mediaType="application/vnd.restbucks+xml" uri="http://restbucks.com/order/1234" rel="http://relations.restbucks.com/update"/> <dap:link mediaType="application/vnd.restbucks+xml" uri="http://restbucks.com/order/1234" rel="self"/> <item> <milk>semi</milk> <size>large</size> <drink>cappuccino</drink> </item> <location>takeAway</location> <cost>2.0</cost> <status>unpaid</status> </order>
Customers that don’t want (or are unable) to participate in a
promotion simply ignore the coffee-card-payment hypermedia control.
Customers that do want to participate simply POST their endorsed card to the coffee-card-payment URI (see Example 5-17).
Example 5-17. Coffee card POST response
POST /order HTTP/1.1
Host: restbucks.com
Content-Length: 270
Content-Type: application/vnd.restbucks+xml
Date: Sun, 21 Mar 2010 19:08:22 GMT
<coffeeCard xmlns="http://schemas.restbucks.com">
<link rel=http://relations.restbucks.com/self
href="http://restbucks.com/coffeecard/4456afd23">
<tamperProof>19590f1ed86f3b2ecaf911267067e8a8</tamperProof>
<numberOfCoffees>9</numberOfCoffees>
</coffeeCard>If the coffee card payment covers the bill, the customer
receives a payment confirmation as per Example 5-8. If not, the
customer receives another order representation with the <cost> element adjusted to reflect the
value of the submitted coffee card.
Note
The benefit of using a closed set of
hypermedia control definitions with an open set
of link relation values is that consumers can recognize the presence
of a hypermedia control even if they don’t understand what it means.
Consumers that can’t understand the coffee-card link relation value will
nonetheless be able to report the presence of a link. This can
encourage the consumer development team to discover the significance
of the additional functionality associated with the link.
We recommend that proprietary link relation values take the
form of fully qualified URIs, which, if dereferenced, return a
human-readable description of the link semantic. That way,
processors that report the presence of an unknown link relation
value can include the link relation description in any log output,
thereby documenting the evolution of the application. <link> elements and rel attributes thus provide a high degree
of discoverability.
Our discussion to this point has concentrated on using hypermedia to model and implement business protocols. But hypermedia has other uses, including the provision of network-friendly data models.
Note
Although we think hypermedia will be used primarily in distributed systems to drive business protocols, we recognize that some systems will need to exchange data in a way that respects and leverages the underlying network. Accessing linked information items over the Web is just as RESTful as interacting with services through DAPs.
On the Web, pages and other media are composed together using links. A web browser fetches a web page and then fetches other resources, such as images and JavaScript. The browser renders the page and exposes links to the user to support page transitions.
This model respects the underlying network. Information is loaded as lazily as possible (but no lazier), and the user is encouraged to browse pages—traverse a hypermedia structure—to access information. Breaking information into hypermedia-linked structures reduces the load on a service by reducing the amount of data that has to be served. Instead of downloading the entire information model, the application transfers only the parts pertinent to the user.
Not only does this laziness reduce the load on web servers, but the partitioning of data across pages on the Web allows the network infrastructure itself to cache information. An individual page, once accessed, may be cached for up to a year (the maximum allowed by HTTP) depending on how the service developer configures the service. As a result, subsequent requests for the same page along the same network path will be satisfied using a cached representation, which in turn further reduces load on the origin server.
Importantly, the same is true of computer-to-computer systems: hypermedia allows sharing of information in a lazy and cacheable manner. For example, if Restbucks wanted to share its complete menu with other systems, it could use hypermedia to split the menu details across separate resources. This would allow different resource representations to be cached for different lengths of time, depending on the business use. Coffee descriptions, for example, might be long-lived, while pricing might change daily. Examples Example 5-18 and Example 5-19 show some of these hypermedia-linked representations.
Example 5-18. Sharing Restbucks’ menu in a network-friendly manner
<menu xmlns="http://schemas.restbucks.com" xmlns:dap="http://schemas.restbucks.com/dap"> <drink name="latte"><dap:link rel="http://relations.restbucks.com/description"uri="http://restbucks.com/description/latte"/><dap:link rel="http://relations.restbucks.com/pricing" uri="http://restbucks.com/pricing/latte"/> <dap:link rel="http://relations.restbucks.com/image" uri="http://restbucks.com/images/latte.png"/> </drink> <!-- More coffees, removed for brevity --> </menu>
Example 5-19. A resource linked from the Restbucks menu
<drink xmlns="http://schemas.restbucks.com"
xmlns:dap="http://schemas.restbucks.com/dap" name="latte">
<description>
Classic Italian-style coffee with 1/3 espresso, 1/3 steamed milk,
and 1/3 foamed milk
</description>
<dap:link rel="http://relations.restbucks.com/image"
uri="http://restbucks.com/images/latte.png"/>
</drink>As Examples Example 5-18 and Example 5-19 show, a large information model such as the Restbucks menu can easily be partitioned for network access using hyperlinks.
Note
Structural hypermedia is best suited for read-mostly systems, where the dual benefits of lazy loading of information and caching are available.
It’s quite valid to mix structural and protocol hypermedia in a representation. But there are other
options: some systems may choose to split hypermedia controls from
business payload in their representations. In Restbucks, for example,
we could choose to separate the representation of an order from its
DAP links. We’d then put the DAP links into a separate
resource, as shown in Example 5-20. rel=“http://relations.restbucks.com/dap”
indicates that the consumer can dereference the link to establish the
next legal steps in the DAP.
Example 5-20. The DAP links for the order are a separate resource
<order xmlns="http://schemas.restbucks.com"
xmlns:dap="http://schemas.restbucks.com/dap">
<location>takeAway</location>
<item>
<name>latte</name>
<quantity>1</quantity>
<milk>whole</milk>
<size>small</size>
<dap:link rel="coffee-beans"
uri="http://restbucks-coffee-beans-supplier.com/beans-no10"
mediaType="application/xml"/>
<dap:link rel="coffee-image"
uri="http://restbucks.com/latte.jpg"
mediaType="image/jpeg"/>
</item>
<cost>2.0</cost>
<status>preparing</status>
<dap:link rel="http://relations.restbucks.com/dap"
uri="http://restbucks.com/order/1234/dap"
mediaType="application/vnd.restbucks.dap+xml"/>
</order>The decision on what should be decomposed into separate, or even overlapping, resources is part of the design process for a service. In making these decisions, we need to consider numerous design factors:
- Size of the representation
How large is the payload going to be? Is it worth decomposing into multiple resources to optimize network access and caching?
- Atomicity
Is there a chance that the application might enter an inconsistent state because a resource is in a composite relationship with other resources? Does the entire representation of a resource need to be packaged together in the same payload?
- Importance of the information
Do we really need to send all the information as an atomic block? Can we allow consumers to decide which of the linked resources they need to request?
- Performance/scalability
Is the resource going to be accessed frequently? Is it computationally or transactionally expensive to generate its representation?
- Cacheability
Can resource representations be cached and replicated? Do different information items associated with the resource change at different rates? Which information items are dependent on the request context, and which are agnostic to that context? Answering these questions helps partition the resource by freshness criteria, allowing some of its representations to be cached for long periods of time, others to be regenerated with every request.
Implementing a hypermedia service might seem at first to be an intimidating prospect, but in practice, the overhead of building a hypermedia system is modest compared to the effort of building a CRUD system. Moreover, the effort generally has a positive return on investment in the longer term as a service grows and evolves. Although the implementation details will differ from project to project, there are three activities that every service delivery team will undertake throughout the lifetime of a service: designing protocols, choosing formats, and writing software.
We’ve been describing Restbucks’ DAP and formats throughout this chapter, so we’re already one step toward a working implementation.
To build the ordering service in Java, we need only two framework components: a web server and an HTTP library. On the client side, we need only an HTTP library. For these tasks, we’ve chosen Jersey[55] (a JAX-RS[56] implementation), which provides the HTTP plumbing for both the service and its consumers, and the Grizzly web server, because it works well with Jersey. Apart from framework support, all we need is a handful of patterns for services and consumers, beginning with the server-side architecture.
The Java server-side architecture is split across several layers, as shown in Figure 5-8.
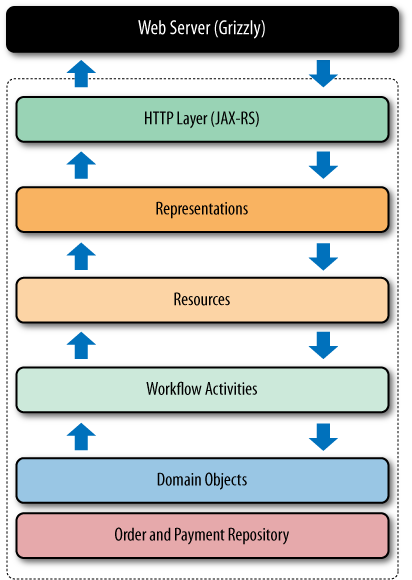
Although crucial to the deployment of a working service, the web server implementation is less important architecturally. Fortunately, it is abstracted from the service developer through the JAX-RS layer. The JAX-RS layer—although its name implies much more—simply provides a friendly programmatic binding to the underlying web server.
Using JAX-RS, we declare a set of methods, to which the framework routes HTTP interactions. Inside the service, resources act as controllers for workflow activities, passing through business information extracted from the representations and marshalling results and exceptions into HTTP responses.
Workflow activities implement the individual stages of the Restbucks workflow in terms of resource life cycles: creating orders, updating orders, canceling orders, creating payments, and delivering completed orders to customers. They’re also responsible for changing the state of the underlying domain objects, which in turn are persisted in repositories.
Though their value in partitioning work into smaller, more manageable units is obvious, workflow activities provide more than just a unit of work abstraction; they also provide choreography between tasks.
Each activity knows which downstream activities are valid. For example, if payment succeeds, the valid next steps are to ask for a receipt or to check the order status. No other activities are valid, and any attempt to do anything else will result in an error being propagated to the consumer via an HTTP status code. Knowing which activities are valid given the current state of current resources, the service can advertise the next steps in the protocol by embedding hypermedia controls in the representations sent to the consumer.
The hypermedia controls that the service makes available to the consumer describe the parts of the DAP the consumer can use to drive the service through the next stages of its business workflow, as we see in Figure 5-9.
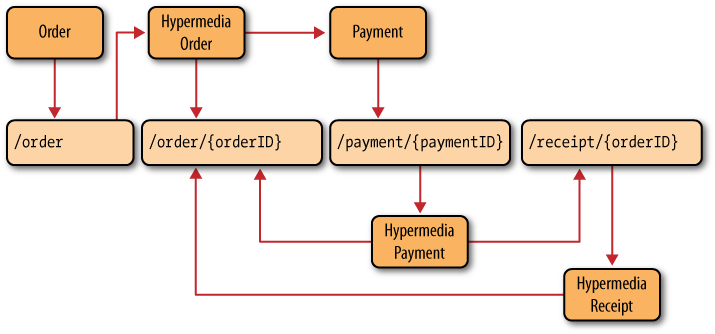
Each resource in Figure 5-9 is internally
identified by its URI or URI template. The well-known entry point URI
/order is the only URI consumers
are expected to know before interacting with the service. The URIs of
all other resources (whose templates are used for internal
documentation only) are discovered at runtime.
In accordance with Restbucks’ DAP, when the service receives a valid order at the entry point URI, it returns a confirmation. This response contains an order representation augmented with additional resource state, including cost and status. Importantly, it also contains links the consumer can use to progress the workflow. In Figure 5-9, the hypermedia-enhanced order representation returned to the consumer contains links to both the order resource and a payment resource.
The pattern repeats for the payment resource. When the service receives a valid payment representation, it generates an enhanced representation containing links to other resources with which the consumer can interact: the order resource (to check status) and a receipt resource (to request a receipt).
Underlying the DAP is code, of course. In the Java implementation, resource behavior is implemented by one or more activity classes, as shown in Figure 5-10.
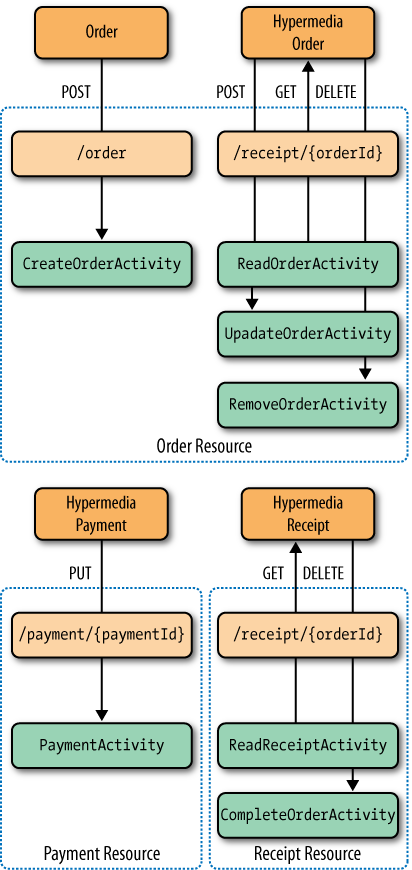
Each activity in Figure 5-10 is bound to a
particular URI and verb. For example, the UpdateOrderActivity is triggered by the
consumer POSTing a valid order
representation to URIs matching /order/{orderId}. Similarly, PaymentActivity is triggered by a PUT with a valid payment representation to
/payment/{paymentId} and the
protocol is completed with a DELETE
request to /receipt/{orderId}.
Here, we’re concerned simply that valid representations are transferred via the correct HTTP verb to a resource in the appropriate state. Consumers are corralled toward making the right request at the right time by the semantically annotated hypermedia controls in the representations they receive.
Jersey helps provide a programmatic abstraction over a web server, but it doesn’t help create hypermedia and DAPs. Because of this, most of the code in the service implementation is our own. In writing this code, we’ve devised some patterns to separate out the concerns of protocols from the concerns of the business activities they coordinate. With that in mind, let’s walk through the implementation.
The resource classes OrderResource,
PaymentResource, and ReceiptResource expose the service
implementation to the Web through Jersey. In our implementation, all
JAX-RS code is localized to the resource classes. Framework code is
not allowed to penetrate deeper into the service implementation—we
prefer most of our code to be (easily testable) Plain Old Java
Objects (POJOs).
The OrderResource class
shown in Example 5-21 is typical of the
resources in the ordering service implementation.
Example 5-21. OrderResource class
@Path("/order")
public class OrderResource {
private @Context UriInfo uriInfo;
@GET
@Path("/{orderId}")
@Produces("application/vnd.restbucks+xml")
public Response getOrder() {
try {
OrderRepresentation responseRepresentation = new ReadOrderActivity()
.retrieveByUri(new RestbucksUri(uriInfo.getRequestUri()));
return Response.ok().entity(responseRepresentation).build();
} catch(NoSuchOrderException nsoe) {
return Response.status(Status.NOT_FOUND).build();
} catch (Exception ex) {
return Response.serverError().build();
}
}
@POST
@Consumes("application/vnd.restbucks+xml")
@Produces("application/vnd.restbucks+xml")
public Response createOrder(String orderRepresentation) {
try {
OrderRepresentation responseRepresentation = new CreateOrderActivity()
.create(OrderRepresentation.fromXmlString(orderRepresentation).getOrder(),
new RestbucksUri(uriInfo.getRequestUri()));
return Response.created(
responseRepresentation.getUpdateLink().getUri())
.entity(responseRepresentation).build();
} catch (InvalidOrderException ioe) {
return Response.status(Status.BAD_REQUEST).build();
} catch (Exception ex) {
return Response.serverError().build();
}
}
@DELETE
@Path("/{orderId}")
@Produces("application/vnd.restbucks+xml")
public Response removeOrder() {
try {
OrderRepresentation removedOrder = new RemoveOrderActivity()
.delete(new RestbucksUri(uriInfo.getRequestUri()));
return Response.ok().entity(removedOrder).build();
} catch (NoSuchOrderException nsoe) {
return Response.status(Status.NOT_FOUND).build();
} catch(OrderDeletionException ode) {
return Response.status(405).header("Allow", "GET").build();
} catch (Exception ex) {
return Response.serverError().build();
}
}
@POST
@Path("/{orderId}")
@Consumes("application/vnd.restbucks+xml")
@Produces("application/vnd.restbucks+xml")
public Response updateOrder(String orderRepresentation) {
try {
OrderRepresentation responseRepresentation = new UpdateOrderActivity()
.update(
OrderRepresentation.fromXmlString(
orderRepresentation)
.getOrder(), new RestbucksUri(uriInfo.getRequestUri()));
return Response.ok().entity(responseRepresentation).build();
} catch (InvalidOrderException ioe) {
return Response.status(Status.BAD_REQUEST).build();
} catch (NoSuchOrderException nsoe) {
return Response.status(Status.NOT_FOUND).build();
} catch(UpdateException ue) {
return Response.status(Status.CONFLICT).build();
} catch (Exception ex) {
return Response.serverError().build();
}
}
}The JAX-RS annotations bridge the Web and the service implementation (activities in our case). Methods are invoked in response to a combination of a specific verb and URI or URI template, and each method consumes and produces a representation with a particular media type.
To illustrate, in Example 5-21 the
updateOrder method is invoked
whenever a representation with media type application/vnd.restbucks+xml is POSTed to the path[57] /order/{orderId}
concatenated with the service URI and web application context (e.g.,
http://restbucks.com/). The media
type, verb, and path elements are associated with the method using
the annotations @Consumes, @POST,
and @Path, respectively. If the
invocation is successful, the service produces a response with media
type application/vnd.restbucks+xml, as declared
by the @Produces
annotation.
All the public methods in the resource classes follow a similar pattern. For operations that require a received representation, the JAX-RS framework provides one. Domain objects are instantiated from such received representations and passed into a workflow activity for processing. We also pass the request URI into the workflow activity so that the activity can generate response links with the same base path. Once the workflow activity has completed, the representation it generates is packaged as an HTTP response with the appropriate status code and sent back to the consumer.
If an exception occurs during the execution of a workflow
activity, an HTTP response is generated to reflect the failure. For
instance, if the consumer sends an invalid order representation to
the /order or /order/{orderId} URI, an InvalidOrderException is raised in the
UpdateOrderActivity. This
exception is translated into an HTTP 400
Bad Request response by the OrderResource class. If there’s no
specific catch block for an exception, the service responds with an
HTTP 500 Internal Server
Error.
The representation classes in the service are much like
the underlying domain objects, except for two things: they’re marked
up with JAXB annotations to support XML serialization, and the serialized representations
contain links. In our implementation, each representation class
inherits from a common parent that stores named links and deals with
XML and HTTP metadata such as namespaces and media types. This base
Representation class is shown in
Example 5-22.
Example 5-22. Base Representation class
public abstract class Representation {
public static final String RELATIONS_URI = "http://relations.restbucks.com/";
public static final String RESTBUCKS_NAMESPACE =
"http://schemas.restbucks.com";
public static final String DAP_NAMESPACE = RESTBUCKS_NAMESPACE + "/dap";
public static final String RESTBUCKS_MEDIA_TYPE =
"application/vnd.restbucks+xml";
public static final String SELF_REL_VALUE = "self";
@XmlElement(name = "link", namespace = DAP_NAMESPACE)
protected List<Link> links;
protected Link getLinkByName(String uriName) {
if (links == null) {
return null;
}
for (Link l : links) {
if (l.getRelValue().toLowerCase().equals(uriName.toLowerCase())) {
return l;
}
}
return null;
}
}There’s only one JAXB annotation in the Representation class, and only one
@XmlElement annotation to help
serialize the links in the DAP namespace. The solution’s other
representation classes (OrderRepresentation,
PaymentRepresentation, and ReceiptRepresentation) extend the base
Representation class, adding in
links and business-specific information. The OrderRepresentation in Example 5-23 shows a typical
implementation.
Example 5-23. OrderRepresentation implementation
@XmlRootElement(name = "order", namespace = Representation.RESTBUCKS_NAMESPACE)public class OrderRepresentation extends Representation {@XmlElement(name = "item", namespace = Representation.RESTBUCKS_NAMESPACE)private List<Item> items;@XmlElement(name = "location", namespace = Representation.RESTBUCKS_NAMESPACE)private Location location;@XmlElement(name = "cost", namespace = Representation.RESTBUCKS_NAMESPACE)private double cost;@XmlElement(name = "status", namespace = Representation.RESTBUCKS_NAMESPACE)private OrderStatus status;public OrderRepresentation(Order order, Link... links) { try { this.location = order.getLocation(); this.items = order.getItems(); this.cost = order.calculateCost(); this.status = order.getStatus(); this.links = java.util.Arrays.asList(links); } catch (Exception ex) { throw new InvalidOrderException(ex); } } // Remainder of class ommitted for brevity }
Much of the code in Example 5-23 is simply JAXB annotations. We use @XmlRootElement and @XmlElement to declare how to serialize
fields into root and child nodes in XML. Aside from the framework
code, though, OrderRepresentation
instances are just value objects.
What’s more interesting about this code is the way it’s used
by the workflow activities. Recall that representations are created
by activities, and that activities know about subsequent valid
activities. Using the constructor OrderRepresentation(Order order,
Link…links), activities inject links into the
representation. Those links advertise subsequent valid activities to
consumers of the representation, informing them of the next steps to
take in the DAP.
The workflow activity classes are units of work that execute
some business interaction against the domain model on behalf of a
consumer. Each activity knows about the valid activities that follow
and is able to map those downstream activities to URIs, thereby
rendering hypermedia representations for consumers. To illustrate,
consider the create(…) method of
the CreateOrderActivity in Example 5-24.
Example 5-24. CreateOrderActivity implementation
public class CreateOrderActivity {
public OrderRepresentation create(Order order, RestbucksUri requestUri) {
order.setStatus(OrderStatus.UNPAID);
Identifier identifier = OrderRepository.current().store(order);
RestbucksUri orderUri = new RestbucksUri(requestUri.getBaseUri() + "/order/"
+ identifier.toString());
RestbucksUri paymentUri = new RestbucksUri(requestUri.getBaseUri() +
"/payment/" + identifier.toString());
return new OrderRepresentation(order,
new Link(Representation.RELATIONS_URI + "cancel", orderUri),
new Link(Representation.RELATIONS_URI + "payment", paymentUri),
new Link(Representation.RELATIONS_URI + "update", orderUri),
new Link(Representation.SELF_REL_VALUE, orderUri));
}
}The create(…) method in
Example 5-24 works as
follows. On receipt of an Order
instance for a given URI, we set the order status to UNPAID and attempt to store it in the
order repository. If the order is successfully stored, we take the
internal identifier generated by the repository and use it to
compute both a public URI for the order resource and a corresponding
URI for the payment resource.[58] We then create a new OrderRepresentation that contains the
updated order information and the valid DAP links. This
representation is then returned to the calling JAX-RS code and
dispatched to the consumer. For a newly created order, we return
four links marked up with appropriate rel and mediaType attributes in an OrderRepresentation instance:
rel=“http://relations.restbucks.com/cancel”The operation requires the order URI, but no media type declarations, because the cancel operation uses
DELETE.rel=“http://relations.restbucks.com/payment”The operation requires a Restbucks payment representation in the entity body to be transferred via
POSTto the payment URI.rel=“http://relations.restbucks.com/update”The operation needs a Restbucks order representation in the entity body to be transferred by
POSTto the order URI.rel=“self”The operation requires an order URI, with no entity body, and is invoked via
GET.
In the other activities (ReadOrderActivity, UpdateOrderActivity,
RemoveOrderActivity, PaymentActivity, ReadReceiptActivity,
and CompleteOrderActivity), the
pattern is repeated: domain objects are created from any input
representations and the activity orchestrates an interaction with
the underlying domain model. On completion, activities generate a
response representation (if any is needed) and insert links
advertising next valid steps in the protocol, along with any media
type declarations needed to advance through those steps.
The consumer-side architecture for a hypermedia service is shown in Figure 5-11. In this stack, the Jersey client library provides HTTP connectivity and is responsible for mapping HTTP requests and responses into higher-level abstractions such as domain objects and exceptions, and dispatching them to workflow activities. The workflow activities process business payloads while actions handle hypermedia controls. Overall control of the consumer resides in the business logic, which uses the actions to orchestrate interactions with the service through the workflow activities.

Figure 5-12 shows how activities are again at the core of our architecture. Activities take business objects and use them to create representations to transfer to the service. For responses with representations, activities provide access to the business payload in the received data.
Importantly, activities also surface actions to the business logic—abstractions that correspond to future legal interactions with the service. Actions encapsulate the hypermedia controls and associated semantic context in the underlying representation, allowing the consumer business logic to select the next activity in the workflow.
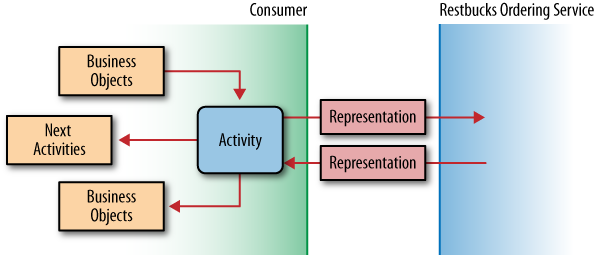
Activities also encapsulate error responses from the service,
providing a choice of actions to the consumer business logic. For
example, if the service responds with a 500
Internal Server Error message when trying to place an order,
the PlaceOrderActivity will yield a
retry action—the only valid thing to do at that point in the
protocol.
Implementing the consumer is nontrivial in the absence of frameworks that understand hypermedia. Nonetheless, with a few simple patterns, we can confidently build consumers for hypermedia services. To illustrate, we’ll walk through the code in Example 5-25.
Example 5-25. Actions and business objects in the consumer
public void orderAndPay(Order order, URI entryPointUri) {
PlaceOrderActivity placeOrderActivity = new PlaceOrderActivity();
placeOrderActivity.placeOrder(order, entryPointUri);
// Order processing omitted for brevity...
Actions actions = placeOrderActivity.getActions();
if(actions.has(PaymentActivity.class)) {
PaymentActivity paymentActivity = actions.get(PaymentActivity.class);
paymentActivity.payForOrder(
payment().withAmount(readOrderActivity.getOrder().getCost()).build());
actions = paymentActivity.getActions();
}
// Remainder of workflow omitted for brevity
}When building a consumer, we know the service’s contractual information is contained in the media types and link relations the service supports, as well as in any entry point URIs the service provider chooses to share with us. Because we already know the processing model for the Restbucks media type, building a consumer for services that support that media type is straightforward.
The orderAndPay(…) method in
Example 5-25 shows an
ordering and payment implementation that we used in the functional
testing of our Java service. The method takes the well-known Restbucks
ordering URI (http://restbucks.com/order) and
uses a PlaceOrderActivity to create
and send an order representation to the service via the underlying
Jersey client library.
Assuming the order is successfully lodged, the placeOrderActivity instance will contain a
local Order object for the consumer
to process and an Actions object
that encapsulates the legal next activities (if any). Under the
covers, the creation of an Actions
object is parameterized from the link relations that the consumer
plumbing finds in response representations.
Note
As consumers, we know the link relations that Restbucks uses and can code against that contract. Hence, in our implementation, specific consumer-side actions have been written to correspond to service-side activities advertised through link relations.
From the set of actions returned, the consumer-side business
logic can make choices about what to do next. For example, if the
consumer discovers an UpdateOrderActivity in the Actions instance (using the actions.has(UpdateOrderActivity.class)
call), it retrieves it by calling the actions.get(UpdateOrderActivity.class)
method and uses it to update the corresponding order resource on the
service.
From this point, the workflow proceeds through the remaining activities, updating (or canceling) the order, paying for the order, obtaining a receipt, and acknowledging receipt of the drinks. At each stage, the consumer follows the same pattern: look for the most desirable action to take at the current instant, execute it, and repeat.
Like Java, the .NET platform has frameworks, such as Windows Communication Foundation (WCF), that make working with HTTP more pleasant and productive. Again like Java, there’s no obvious framework for building hypermedia-aware services, so Restbucks developed one.
The Restbucks framework decouples hypermedia from business activities, and transparently maps between the service implementation and the DAP advertised to consumers. Figure 5-13 shows a logical view of how a service processes incoming and outgoing resource representations. A similar approach can be used to build consumers with the same framework.
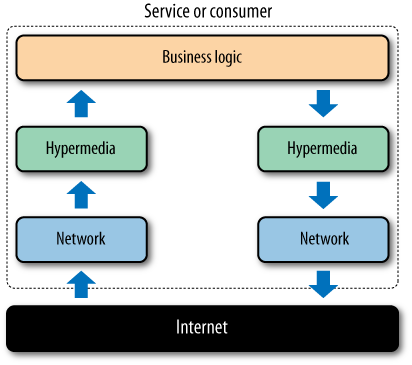
In our solution, the network layer deals with HTTP and is
provided by the .NET Framework. The hypermedia layer deals with
resource state transitions. For incoming representations, it
determines whether the request is valid given the current resource
state. For outgoing representations, the hypermedia layer injects
<dap:link> elements, which
advertise the next legal protocol steps, into the response. The
business layer, meanwhile, focuses exclusively on application logic
and its data.
The hypermedia framework manages resource state transitions by embedding appropriate hypermedia controls into a response based on both the state of the resource targeted by the request and the state of any associated resources. To express this protocol, we have devised a simple, declarative Domain-Specific Language (DSL). Scripts written with the Restbucks DSL choreograph numerous business actions and externalize application state to consumers.
The hypermedia framework and its scripts are hosted on a web
server implemented with the HttpListener class.[59] The server delegates incoming requests to the hypermedia
framework’s dispatcher. The dispatcher maintains a collection of the
currently active state machines, each of which runs an instance of our
DSL program.
Note
Remember that each workflow in the service implementation represents resource state machines, not a single, overarching application protocol state machine. By implementing the service solely in terms of resource states, we avoid having to save protocol instance state (application state) on the server, which allows us to scale the service horizontally.
Each state machine analyzes incoming HTTP requests and, depending on the state of the resource to which the request relates, dispatches the payload to an appropriate .NET method in the business logic layer. The method deals with XML documents as the input and output, and is unaware of the HTTP and hypermedia details of the interaction.
On the response path, the hypermedia framework receives XML documents from the business layer and augments them with any hypermedia constructs declared in the state machine DSL description. The resultant payload is then passed to the underlying HTTP infrastructure for delivery to the consumer, as we see in Figure 5-14.
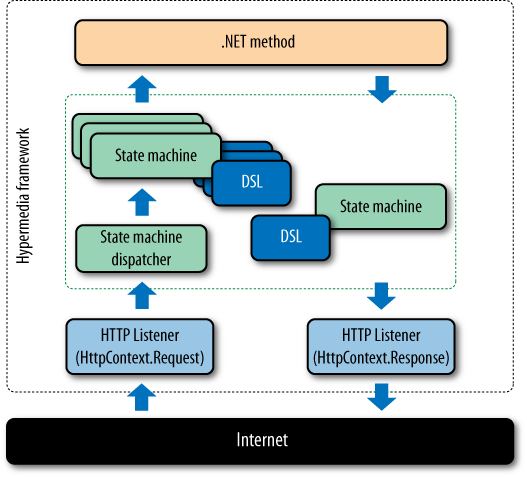
The DSL used for the Restbucks hypermedia framework is a state
machine description markup language. This language includes constructs
representing hypermedia controls, which are injected into
representations as XML <dap:link> elements.
The DSL in Example 5-26 declares the possible states of a Restbucks order resource and the supported transitions from each of those life-cycle states. It’s easy to see how tooling could be used to produce such DSL documents, but we think it’s easy enough to write by hand too. While the primary focus of the DSL is to describe a resource’s state transitions, it also includes those DAP-specific transitions that relate to the particular resource.
Example 5-26. Representing a resource state machine and the supported DAP transitions using the Restbucks hypermedia DSL
StateMachineUriTemplatehttp://restbucks.com/order/{id}NamespaceRestbucks.OrderingServiceMediaTypeapplication/vnd.restbucks+xmlRelationsInhttp://relations.restbucks.comStateOrderCreatedPOSTNewOrder 201=>UnpaidWhenNotValidOrder 400EndStateUnpaidGETGetOrderStatus 200WhenNoSuchOrder 404POSTUpdateOrder 200DELETECancelOrder 200=>CancelledLinkslatest # When the URI is missing, the active resource's one is assumed update payment http://restbucks.com/payment/{id} cancelEndStatePreparingGETGetOrderStatus 200LinkslatestEndStateReadyGETGetOrderStatus 200Linkslatest receipt http://restbucks.com/receipt/{id}EndFinal StateDeliveredEndFinal StateCancelledEnd
The state machine description in Example 5-26 consists of a declaration of a set of global properties and a series of states through which the order resource may transition. The first state lexically is considered to be the initial resource state.
The
UriTemplateproperty at the top of the DSL identifies the resource whose life cycle is managed by state machine instances based on this program. To keep things simple, we’ve assumed that theUriTemplatehas a specific structure, with the resource identifier at the end being the only variable part of the URI. The service implementation does not expose the URI template to consumers. Outside the boundaries of the ordering service, there is no way to determine which part of the URI is actually used as the internal order identifier.The
Namespaceproperty defines the .NET namespace in which any unqualified method and exception names will reside.The
MediaTypeproperty defines the media type that will be used in all HTTP requests and responses based on this DSL.The
RelationsInproperty defines the URI prefix for all the relations in theLinkssections of the DSL.
There are two different subconstructs in each state of Example 5-26:
The
HTTPVerbis used to identify valid incoming HTTP requests, given the current state of a resource and what action should be performed upon receipt of such requests. TheMethodNamespecifies the .NET method to dispatch followed by the HTTP status code of the response should that method complete normally. An optional=> StateNameidentifies the state to which the resource should automatically transition after successful processing of the incoming request. The optionalWhenconjunction allows us to deal with exceptions that the business logic from the invoked .NET method might generate, and the HTTP status code of the response in such a case.The
Linkssection declares the<dap:link>elements that should be included in the payload of the responses to consumers when the resource is at that particular state. The links can point to other resources hosted by Restbucks, or any other resources on the Web.
Using a declarative description of resource state transitions, such as the one shown in Example 5-26, we can modify and evolve a DAP without having to radically change our service’s implementation. Most importantly, however, we can rapidly develop and deploy new DAPs.
When the Restbucks service receives an HTTP request, it routes it to the hypermedia framework dispatcher, which in turn delivers it to the appropriate state machine instance. The dispatcher checks the request’s URI against each state machine’s URI template to determine which state machine should deal with the request.
The order resource state machine expects the first request to be a POST, as per the initial state of the
DSL script in Example 5-26. By activating
the initial state of a resource, the framework also creates an
instance of the state machine to track the resource’s life cycle and
its hypermedia interactions. The value of the UriTemplate property, up to but not
including the /{id} variable
part, is considered the URI for the initial request (http://restbucks.com/order). From that point on,
requests matching the resource’s URI template are checked against
the same state machine instance.
Note
Our sample implementation maintains resource state in memory. This solution is not easily scaled horizontally, nor is it resilient to machine failure. In a production environment, we would retrieve resource state on a per-request basis from a shared store or object cache.
If an incoming request doesn’t match any of the expected HTTP
verbs in the active state, the framework automatically responds
with a 405 Method Not
Allowed status code. Example 5-27 shows an initial POST request[60] to the .NET ordering service.
Example 5-27. HTTP request for a new order
POST /order HTTP/1.1
Content-Type: application/vnd.restbucks+xml
Accept: application/vnd.restbucks+xml
Connection: keep-alive
Content-Length: 425
<?xml version="1.0" encoding="UTF-8" standalone="yes"?>
<order xmlns="http://schemas.restbucks.com">
<item>
<milk>skim</milk>
<size>medium</size>
<drink>cappuccino</drink>
</item>
<item>
<milk>semi</milk>
<size>small</size>
<drink>cappuccino</drink>
</item>
<item>
<milk>semi</milk>
<size>large</size>
<drink>cappuccino</drink>
</item>
<location>takeAway</location>
</order>The web server receives the request and hands it to the
dispatcher, which determines from the URI http://restbucks.com/order that the order state
machine should process the request. Since the URI template and the
verb match the conditions for the initial state and the media type
is as expected, the state machine extracts the payload from the
request and gives it to the NewOrder() method, as per the POST NewOrder definition.
Example 5-28 shows
the NewOrder() method. The
signatures for methods such as this, which handle requests for the
initial state of a state machine, differ from those of the methods
for the remaining states in that they return a string that acts as the identifier for the
state about to be instantiated. The same string will also be used as the value of
the {id} part in the state
machine’s URI template. The framework maintains an internal
dictionary of all the active states based on the unique key returned
by the NewOrder() method.
Example 5-28. Implementation of the NewOrder() method
namespace Restbucks
{
public class OrderingService
{
public static string NewOrder(XDocument request, XDocument response)
{
var order = Database.NewOrderFromXml(request.Root);
response.Add(order.ToXml());
return order.Id.ToString();
}
}
}As Example 5-28 shows, the hypermedia framework abstracts the HTTP details from the implementation. The application logic only needs to deal with XML payloads for the incoming requests and outgoing responses.
In our service, we create a new business object to represent
the order in the database, serialize it back to XML, add it to the
response, and return its identifier. The service will embed more
information about the order (e.g., its preparation status and cost)
in the payload. Remember that the hypermedia framework will add the
necessary <dap:link>
elements.
The response for this interaction has a 201 Created status code, as shown in Example 5-29, in accordance
with the state machine definition in Example 5-26. The payload
is the representation of the order resource. This representation
includes <status> and
<cost> elements, as well as
hypermedia links representing the possible transitions the
customer application can initiate. Notice the => Unpaid part following POST NewOrder 201 in Example 5-26; this tells
the hypermedia framework to transition the state machine instance
for the order to the Unpaid state
once the response has been sent.
Example 5-29. Response sent to the consumer after the successful creation of an order
HTTP/1.1 201 Created
Content-Type: application/vnd.restbucks+xml
Date: Sun, 21 Mar 2010 22:44:11 GMT
Content-Length: 1067
<?xml version="1.0" encoding="UTF-8" standalone="yes"?>
<order xmlns="http://schemas.restbucks.com">
<item>
<milk>skim</milk>
<size>medium</size>
<drink>cappuccino</drink>
</item>
<item>
<milk>semi</milk>
<size>small</size>
<drink>cappuccino</drink>
</item>
<item>
<milk>semi</milk>
<size>large</size>
<drink>cappuccino</drink>
</item>
<location>takeAway</location>
<cost>8.00</cost>
<status>payment-expected</status>
<dap:link rel="http://relations.restbucks.com/latest"
mediaType="application/vnd.restbucks+xml"
uri="http://restbucks.com/order/1" />
<dap:link rel="http://relations.restbucks.com/update"
mediaType="application/vnd.restbucks+xml"
uri="http://restbucks.com/order/1"/>
<dap:link rel="http://relations.restbucks.com/payment"
mediaType="application/vnd.restbucks+xml"
uri="http://restbucks.com/payment/1" />
<dap:link rel="http://relations.restbucks.com/cancel"
mediaType="application/vnd.restbucks+xml"
uri="http://restbucks.com/order/1" />
</order>Note
In Example 5-29, the link
for payment given to consumers is http://restbucks.com/payment/1. Remember: consumers
should treat this as an opaque URI since they have no way of
knowing that the URI path ending in /1 represents an internal identifier for
the resource.
In this initial state, the order representation contains links
that indicate that the customer can get the latest version of the
order resource, or update it, or cancel the order, or submit
payment. The verbs and the format of the payloads to be used are
captured by the rel and mediaType attributes of each <link> element, as per our
description of the Restbucks DAP.
Subsequent interactions continue in a similar manner. For
example, as long as the order is in the Unpaid state, a GET request sent to http://restbucks.com/order/1 will result in a call to
the GetOrderStatus() method, as
shown in Example 5-30.
Example 5-30. Ordering operations implemented in C#
namespace Restbucks{public class OrderingService{public static void GetOrderStatus(string id,XDocument request, XDocument response){var order = Database.GetOrder(id);response.Add(order.ToXml());}}// Other methods elided for brevity}
The GetOrderStatus() method
is given the order’s identifier and the request/response payloads
and interacts with an order repository on the caller’s behalf.
Correspondingly, the OrderingService class has methods (not
shown in Example 5-30)
to create, update, and delete an order, each of which follows the
same pattern.
Our next task is to add the payment logic. Without payment,
the order won’t transition to the Preparing state or be given to the
barista. From the moment an order is created, payment is expected.
We treat payment as a separate resource, with its own internal state
machine. The payment resource state machine is shown in Example 5-31.
Example 5-31. Payment state machine
StateMachineUriTemplatehttp://restbucks.com/payment/{id}NamespaceRestbucks.OrderingServiceMediaTypeapplication/vnd.restbucks+xmlRelationsInhttp://relations.restbucks.comStatePaymentCreated=>PaymentExpectedEndStatePaymentExpectedPUTPaymendReceived 201=>PaymentReceivedWhenNoValidPayment 400LinkspaymentEndFinal StatePaymentReceivedGETGetReceipt 200WhenNoSuchPayment 404Linksorder http://restbucks.com/order/{id} receiptEnd
Notice that there’s no service logic associated with the
initial state. The hypermedia framework will not call a method to
create a payment resource. Instead, it is expected that the resource
will be created out of band, in code. Therefore, once an instance of
the state machine is created, the framework will automatically
transition it to the PaymentExpected state.[61]
Because consumers have already been given a payment URI, we
have to follow a different pattern here. This requires a consumer to
submit a PUT request containing
the payment representation, which results in the PaymentReceived() method being called. The
implementation of PaymentReceived() is shown in Example 5-32.
Example 5-32. Payment implementation
namespace Restbucks
{
public static class OrderingService
{
public static void PaymentReceived(string id,
XDocument request,
XDocument response)
{
var payment = Payment.FromXml(request.Root);
payment.Paid = DateTime.Now;
var order = Database.GetOrder(id);
order.Status = "Preparing";
Database.UpdateOrder(order);
Database.PutPayment(id, payment);
response.Add(payment.ToXml());
OrderingService.PrepareOrder(id);
}
}
// Other methods elided for brevity
}When the service receives a payment request, it creates a
business object from the payload, and then retrieves the order from
the database and sets its Status
property to Preparing. The
service then adds the payment to the database and initiates the
preparation of the order. This last step starts an internal process
involving the barista. To do this, the service calls ThreadPool.QueueUserWorkItem() to add the
work to a queue. The barista receives the order information,
prepares it, and then notifies the rest of the ordering service that
the order is ready by calling OrderPrepared(), which moves the order
into the Ready state.
Notice that the OrderPrepared() method is able to interact
with the hypermedia framework without involving a consumer. This
allows Restbucks to transition the state machine to the Ready state by binding directly to the
state machine instance, rather than through the external HTTP
interface.
Recall that when the service receives a payment from a
consumer, it replies with a 201
Created response. The hypermedia framework adds an
order link to that response. In
this context, the link indicates to the client that it is expected
to GET the latest representation
of the order to find out whether it is ready for delivery.
When the barista calls the OrderPrepared() method, the order
transitions to the Ready state.
This change in resource state causes different links to be added
to the order’s representation the next time it is requested. This is
handled by the hypermedia DSL snippet shown in Example 5-33.
Example 5-33. The Ready state of the order resource
State Ready
GET GetOrderStatus 200
Links
latest
receipt http://restbucks.com/receipt/{id}
EndThe DSL here indicates that the receipt link will be included in the
payload of any response if the order is in the Ready state. To complete delivery of the
order, the consumer only needs to send a DELETE request, as defined by the
semantics of http://relations.restbucks.com/receipt of
the application/vnd.restbucks+xml
media type, to the receipt URI http://restbucks.com/receipt/1. The DSL for the
receipt resource is very simple and similar to that of the payment
resource, as shown in Example 5-34.
Example 5-34. Receipt state machine
StateMachineUriTemplatehttp://restbucks.com/receipt/{id}NamespaceRestbucks.OrderingServiceMediaTypeapplication/vnd.restbucks+xmlRelationsInhttp://relations.restbucks.comStateReceiptCreated=>ReceiptReadyEndStateReceiptReadyDELETEReceiveOrder 200WhenNoSuchReceipt 404LinksreceiptEnd
When the DELETE request is
received by the receipt resource, the ReceiveOrder() method is called, as shown
in Example 5-35.
Example 5-35. Completing an order
namespace Restbucks
{
public static class OrderingService
{
public static void ReceiveOrder(string id,
XDocument request,
XDocument response)
{
var order = Database.GetOrder(id);
order.Status = "received";
Database.UpdateOrder(order);
response.Add(order.ToXml());
}
}
}Like the other methods, the implementation here is very simple. We retrieve the order from the database, update its status, and add its representation to the response. Because the protocol has ended, the representation passes through the hypermedia framework untouched before being dispatched to the consumer.
With the addition of hypermedia, we’ve reached the pinnacle of Richardson’s service maturity model in Figure 5-15. While we still haven’t completed our journey—we have plenty more to learn about using the Web as a platform for building distributed systems—we now have all the elements at our disposal to build RESTful services.
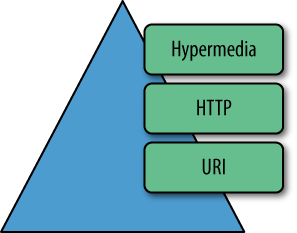
There’s more to the Web than REST, but this milestone is important because of the significant benefits, in terms of loose coupling, self-description, scalability, and maintainability, conferred by the tenets of the REST architectural style.
All of this comes at a rather modest cost when compared to what we did to build nonhypermedia services. This is encouraging, since it means the effort required to build and support a robust hypermedia service over its lifetime is comparable to that associated with building CRUD services. It’s certainly a better proposition than tunneling through the Web.
We’ve now seen how hypermedia services are straightforward to design, implement, and test using familiar tools and libraries. And by augmenting representations with hypermedia controls, we’re able to project DAPs over the Web to consumers. We’ve also seen that computer systems (not just browsers!) use hypermedia links to build DAPs that model (dynamically evolving) business workflows.
From here onward, we’ll assume that hypermedia and RESTful services are the norm. In the following chapters, we’ll see how scalability, security, and other higher-order protocols such as publish-subscribe can work harmoniously with the Web. Read on!
[43] Most middleware solutions, such as WS-*, emphasize the opposite: imperative contracts presented upfront.
[45] As more coffee shops bring their business to the Web, it’s
conceivable to create a common application protocol and a
vendor-agnostic media type (e.g., application/coffee+xml). Until such an
event, we will assume that Restbucks has the monopoly on coffee
on the Web.
[46] Media types can reference many schemas. When accepting the contract imposed by a media type, you’re indicating that you understand the associated schemas.
[47] We will discuss the Atom formats and Atom Publishing Protocol thoroughly in Chapters Chapter 7 and Chapter 8.
[48] In the WS-* stack, these contract elements are typically implemented using XML Schema, WSDL, WS-Policy, and BPEL or WS-Choreography, respectively.
[49] Examples of such processors already abound; these include Apache Abdera and .NET’s syndication types, both of which implement the Atom Syndication Format.
[50] IANA defines numerous top-level link relations that are broadly applicable across numerous domains. These relations aren’t bound to any particular media type or protocol, and can be freely reused in any service implementation with matching requirements.
[51] GET requests are also
associated with business logic, but don’t cause any state
transitions for which the consumer can be held accountable by
the service. This is consistent with the use of GET on the Web, and as we will see in
later chapters, it is one of the key enablers for massive
scalability.
[53] Since the media type maps entirely to the Restbucks business domain, all link relation values used in the application protocol are defined in its specification.
[54] This could be something as simple as a hash of the number of coffees and a secret key.
[56] Java API for RESTful Web Services; see http://jcp.org/en/jsr/detail?id=311.
[57] The path for the updateOrder(…) method is a combination
of the root path for the resource (/order) and the local path for the
method (/{orderId}).
[58] If Restbucks outsourced payment processing, instead of computing a URI for payment, we’d ask the payment provider for a URI.
[59] Internet Information Server (IIS) on Windows or any other web server that can host the .NET runtime and load SQL Server Modeling’s codename “M” language can be used.
[60] The XML payload was formatted for readability. The raw XML is unpleasant.
[61] It could be argued that PaymentExpected should be the initial
state and that the PUT
request would create the payment resource. However, the
semantics of the initial state in the DSL are such that we
expect an HTTP request to be sent to the URI template without
the {id} part. Since the
payment resource was already created through code, rather than
due to a request initiated by a consumer, we need to instruct
the hypermedia framework to perform this automatic transition
without expecting an initial request.