HTML REMAINS THE MOST POPULAR HYPERMEDIA FORMAT IN USE TODAY, but as the Web extends its reach beyond the browser, we’re seeing other useful formats emerge. Of these newer hypermedia types, one in particular deserves our attention: the Atom Syndication Format, or Atom for short.[73] Atom is an XML-based hypermedia format for representing timestamped lists of web content and metadata such as blog postings and news articles.
Note
In Chapter 5, we used a custom hypermedia format to expose data and protocols to consumers. By contrast, Atom is a general-purpose hypermedia format.
Atom interests us because it provides a flexible and extensible interoperability format for transferring data between applications. Its success has led to wide cross-platform support, and you can now find Atom libraries in all popular languages, including Java and C#.
Atom represents data as lists, called feeds. Feeds are made up of one or more timestamped entries, which associate document metadata with web content.
The structure of an Atom document is defined in the Atom specification (RFC 4287), but the content of a feed will vary depending on our domain’s requirements. On the human Web, it might be blog posts or news items, whereas for computer-to-computer interactions, it might be stock trades, system health notifications, payroll instructions, or representations of coffee orders.
To illustrate the Atom format, let’s share a list of coffee orders between a cashier, who takes orders, and a barista, who prepares them. Example 7-1 shows an Atom feed produced by the Restbucks ordering service. The feed is consumed by the order management system (we’ll see more of the order management system in the next chapter).
Example 7-1. An Atom feed containing two entries
<?xml version="1.0"?>
<feed xmlns="http://www.w3.org/2005/Atom">
<id>urn:uuid:d0b4f914-30e9-418c-8628-7d9b7815060f</id>
<title type="text">Recent Orders</title>
<updated>2009-07-01T12:05:00Z</updated>
<generator uri="http://restbucks.com/order">Order Service</generator>
<link rel="self" href="http://restbucks.com/order/recent"/>
<entry>
<id>urn:uuid:aa990d44-fce0-4823-a971-d23facc8d7c6</id>
<title type="text">order</title>
<updated>2009-07-01T11:58:00Z</updated>
<author>
<name>Jenny</name>
</author>
<link rel="self" href="http://restbucks.com/order/1"/>
<content type="application/vnd.restbucks+xml">
<order xmlns="http://schemas.restbucks.com/order">
<item>
<milk>whole</milk>
<size>small</size>
<drink>latte</drink>
</item>
<item>
<milk>whole</milk>
<size>small</size>
<drink>cappuccino</drink>
</item>
<location>takeAway</location>
</order>
</content>
</entry>
<entry>
<id>urn:uuid:6fa8eca3-48ee-44a9-a899-37d047a3c5f2</id>
<title type="text">order</title>
<updated>2009-07-01T11:25:00Z</updated>
<author>
<name>Patrick</name>
</author>
<link rel="self" href="http://restbucks.com/order/2"/>
<content type="application/vnd.restbucks+xml">
<order xmlns="http://schemas.restbucks.com/order">
<item>
<milk>semi</milk>
<size>large</size>
<drink>cappuccino</drink>
</item>
<location>takeAway</location>
</order>
</content>
</entry>
</feed>Here, Atom entries represent coffee orders, with the Atom metadata capturing useful business information, such as who took the order and when.
Note
While entries are typically contained inside feeds, they can also be treated as standalone, individually addressable resources. Individually addressable entries present numerous opportunities for caching. Caching, as we discussed in Chapter 6, helps tremendously when building scalable systems.
Feeds, like entries, have metadata associated with them. Feed metadata allows us to provide friendly descriptions of content, links to other services or resources, and, most importantly, a means of navigating to other feeds—all in a standard manner.
Atom doesn’t attach any significance to the order of entries in a
feed. A feed will often be sorted by the <atom:updated> or <atom:published> value of its
constituent entries, but it can as easily be sorted by other elements—by
category, or author, or title, for instance. In our example, we’ve
organized the feed based on when coffee orders were placed, with the
most recent order appearing at the top of the feed.
Our orders feed is typical of how Atom is used in a computer-to-computer scenario. The feed’s metadata sets the context for the enclosed coffee orders, allowing consumers to reason about the list’s origin, its purpose, and its timeliness. This feed metadata includes the following elements:
<atom:id>is a permanent, universally unique identifier for the feed.<atom:title>provides a human-readable name for the feed.<atom:updated>indicates when the feed last changed.<atom:generated>identifies the software agent that created the feed, which in this case is the ordering service.<atom:link>contains the canonical URI for retrieving the feed.
The ordering service feed in Example 7-1 contains two <atom:entry> elements, each representing
an order (of course, there could have been more). Each entry is a
mixture of Atom metadata markup and application-specific XML content.
The following elements are included in the <atom:entry> metadata:
<atom:id>is a unique identifier for the entry.<atom:title>provides a human-readable title for the entry.<atom:updated>is a timestamp indicating when the entry last changed, which in this instance is the time the order was accepted by the system.<atom:author>identifies who created the entry, which in our example is the cashier who took the order.<atom:link>contains the URI for addressing this entry as a standalone document.
Each entry also contains an <atom:content> element. <atom:content> elements can contain
arbitrary foreign elements, including elements that share the default
namespace. Here, the content includes a piece of Restbucks XML
representing an order’s details. The <atom:content> element’s type attribute contains a media type value
(application/vnd.restbucks+xml) so
that the consumers of an entry know how to process the
payload.
In Restbucks, we use Atom feeds to move business information between providers and consumers of coffee operations, exactly as we would using other enterprise integration techniques. This is just one use of Atom in the enterprise; other uses include:
- Syndicating content
Atom is an ideal representation format when the creation and consumption of resources closely mirrors a syndication model, with a producer or publisher distributing content to many consumers.
- Representing documents and document-like structures
Many domain resources are structured like documents; if this is the case, we might consider mapping the resource’s attributes to Atom’s metadata elements.
- Creating metadata-rich lists of resources
We can use Atom feeds to represent ordered lists, such as search results or events, especially if the Atom metadata is useful in the context of our service. In this scenario, Atom establishes a domain processing context for some other domain content. The event example later in this chapter shows how we can use Atom metadata to represent event metadata, thereby establishing an event-oriented processing context for each Atom entry’s payload.
- Adding metadata to existing resource representations
We can use feeds and entries to add metadata to existing resource representations. In particular, we can use Atom metadata elements to surface information related to a resource’s publishing life cycle: its author, the date it was created, when it was last updated, and so on. Just as importantly, we can attach hypermedia links to existing resource representations by embedding the representation inside an Atom entry and adding one or more
<atom:link>elements to the entry.- Creating directories of nonhypermedia content
We can use Atom to create entries that link to resources that cannot otherwise be represented in a hypermedia format, such as binary objects. Use the
<atom:content>element’ssrcattribute to link to the resource, and specify a media type using the element’stypeattribute.
Now that we’ve looked at the anatomy of an Atom feed, we’re ready to see how such feeds can be used for simple computer-to-computer interactions. As an example, let’s see how Atom can be used to implement a staple of enterprise computing: events. Normally with event-driven systems, events are propagated through listeners. Here, however, we plan to publish an ordered list of events that readers can poll to consume events.
Note
We believe Atom is an ideal format for highly scalable event-driven architectures. But as with any web-based system, Atom-based solutions trade scalability for latency, making Atom often inappropriate for very low-latency notifications.[74] However, if we’re building solutions where seconds, or better still, minutes or hours, can pass between events being produced and consumed, publishing Atom feeds works very well.
Restbucks’ headquarters chooses which coffees and snacks will be served in its stores. HQ is also responsible for organizing promotions across the regions. It maintains product and promotion information in a centralized product catalog, but a number of other business functions within Restbucks depend on this information, including distribution, local inventory management, point of sale, and order management.
This situation is typical of the integration challenges facing many organizations today: systems that support key business processes need access to data located elsewhere. Such shared data may be required to enable end-to-end processing, or it may be needed in order to provide the organization with a single, consistent view of a business resource.
The benefits of data integration include increased consistency and availability of core data. But to get to this state we often have to overcome the challenges of data redundancy, poor data quality, lack of consistency among multiple sources, and poor availability.
As it has grown, Restbucks has evolved its data and application integration strategy to mirror its business capabilities and processes. This strategy has led to independent services, each of which authoritatively manages the business processes and data belonging to a business unit.
Effectively, Restbucks has decomposed its information technology ecosystem into islands of expertise. The product catalog service, for example, acts as an authoritative source of data and behavior for Restbucks’ product management capabilities.
Data such as product and promotions data is often called reference data. Reference data is the kind of data other applications and services refer to in the course of completing their own tasks.
Sourcing and using reference data are two quite separate concerns. Typically, an application will source a piece of reference data at the point in time it needs to use it. To preserve service autonomy and maintain high availability in a distributed system, however, it is best to maintain separation of concerns by decoupling the activities that own and provide access to reference data from those that consume it. If order management has to query the product catalog for a price for every line item, we’d say the two services were tightly coupled in time. This coupling occurs because the availability of order management is dependent on the availability of the product catalog. By breaking this dependency—separating the sourcing of data from its use—we reduce coupling and increase the availability of the order management service.
Warning
Temporal coupling weakens a solution because it requires numerous independent systems to be running correctly at a specific instant in time. When multiple servers, networks, and software all need to be functioning to support a single business behavior, the chances for failure increase.
To reduce coupling between producers and consumers of reference data, we generally recommend that reference data owners publish copies of their data, which consumers can then cache. Consumers work with their local copy of reference data until it becomes stale. By distributing information this way, services can continue to function even if the network partitions or services become temporarily unavailable. This is exactly how the Web scales.
To solve the coupling problem between the product catalog and its several consumers, Restbucks replicates its product catalog data. Each consumer maintains a local cache of the reference data, which it then updates in response to notifications from the provider. Each consumer can continue to function, albeit with possibly stale data, even if the product catalog becomes unavailable.
To ensure that updates to the product catalog are propagated in a timely manner, Restbucks uses Atom feeds.
To communicate data changes from the product catalog service to the distribution, inventory, and order management systems, Restbucks has chosen to implement an event-driven architecture. Whenever a new product is introduced, an existing product is changed, or a promotion is created or canceled, the product catalog publishes an event. The systems responsible for distribution, inventory, and order management consume these events and apply the relevant changes to their reference data caches.
Figure 7-1 shows how Restbucks’ product catalog exposes an Atom feed of events. Stores poll this feed at regular intervals to receive updates. When processing a feed, a store first finds the last entry it successfully processed the last time it polled the feed, and then works forward from there.
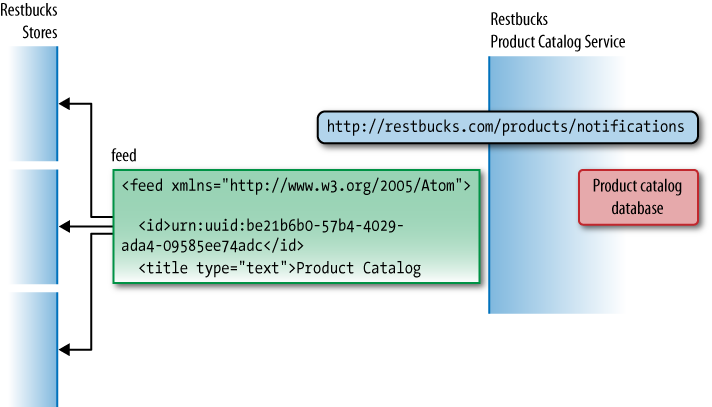
Restbucks’ underlying business process in this instance isn’t latency-sensitive. Products and promotions don’t change very often, and when an event occurs, it’s OK for stores to find out several minutes later. But while low latency isn’t an issue, guaranteed delivery is: price optimization and campaign management depend on HQ’s product catalog changes definitely being propagated to stores. It’s important, therefore, that we can guarantee that changes reach the stores, and that they are applied by the start of the next business day.
Event-driven systems in general exhibit a high degree of loose coupling. Loose coupling provides failure isolation and allows services and consumers to evolve independently of each other. Restbucks uses polling and caching to loosely couple providers and consumers. This polling solution respects the specific technical and quality-of-service requirements belonging to the challenge at hand (many consumers, guaranteed delivery, but latency-tolerant).
Polling propagates product catalog events in a timely fashion, limited only by the speed with which a store can sustainably poll a service’s feeds. But polling can introduce its own challenges: as stores multiply and polling becomes more frequent, there’s a danger that the product catalog service becomes a bottleneck. To mitigate this, we can introduce caching. As we saw in Chapter 6, local or intermediary caches help by reducing the workload on the server and masking intermittent failures.
An event represents a significant change in the state of a
resource at a particular point in time (in the case of the product
catalog, the resource is a product or a promotion). An event carries
important metadata, including the event type, the date and time it
occurred, and the name of the person or system that triggered it. Many
events also include a payload, which can contain a snapshot of the
state of the associated resource at the time the event was generated,
or simply a link to some state located elsewhere, thereby encouraging
consumers to GET the latest
representation of that resource.
Note
Interestingly, the polling approach inverts the roles and responsibilities normally associated with guaranteed message delivery in a distributed system. Instead of the service or middleware being responsible for guaranteeing delivery of messages, each consumer now becomes responsible for ensuring that it retrieves all relevant information. Since messages are collocated in time-ordered feeds, there’s no chance of a message arriving out of order.
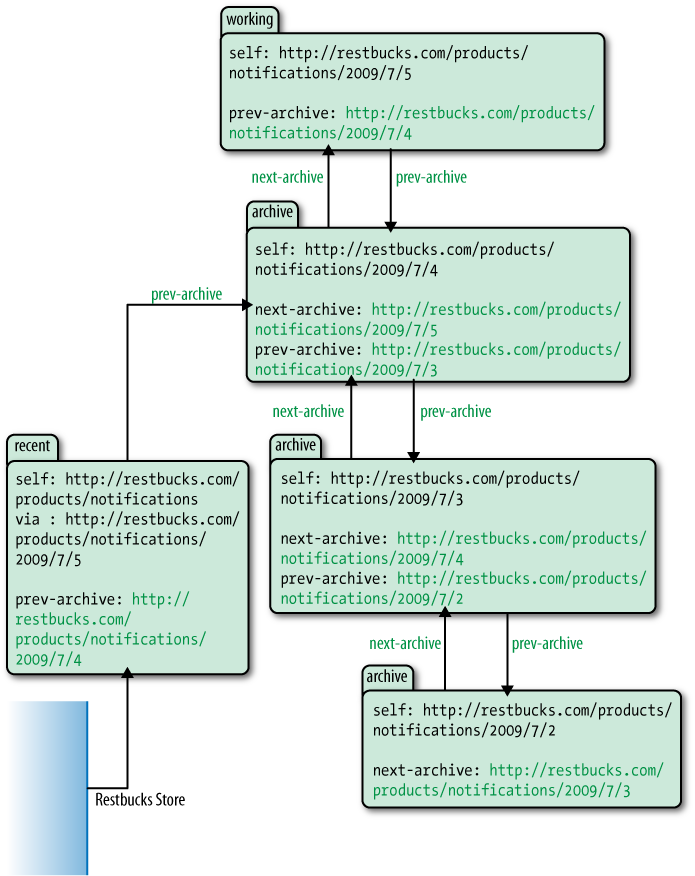
Restbucks’ product catalog feed is treated as a continuous logical feed. In practice, however, this logical feed consists of a number of physical feeds chained together, much like a linked list. The chain begins with a “working” feed, followed by a series of “archive” feeds. The working feed contains all the events that have occurred between the present moment and a cutoff point in the past. This historical cutoff point is determined by the notification source (the product catalog service in our case). The archives contain all the events that occurred before that cutoff point. The contents of the working feed continue to change until the feed is archived, whereupon the feed becomes immutable and is associated with a single permanent URI.
The product catalog service is responsible for creating this series of feed resources. The contents of each feed represent all the changes that occurred during a particular interval. At any given point in time, only one of these feeds is the working feed. The service creates an entry to represent each event and assigns it to the working feed. When the service determines that the working feed is “complete,” either because a certain period has elapsed since the feed was started or because the number of entries in the feed has reached a predetermined threshold, the service archives the working feed and begins another.
Each feed relates to a specific historical period. This includes the working feed, which always relates to a specific period. The only thing that differentiates the working feed from an archive feed is the open-ended (the “as yet” not determined) nature of the working feed’s period.
In addition to these historical feeds there is one more resource, which we call “the feed of recent events.” Unlike the other feeds, the feed of recent events is not a historical feed; it’s always current. At any given moment, the feed of recent events and the working feed contain the same information, but when the service archives the current working feed and starts a new one, the feed of recent events changes to contain the same data as the new working feed.
As we’ll see, consumers need never know about working or archive feeds. Working and archive feeds are implementation details; as far as consumers are concerned, the notifications feed is the feed of recent events (the current feed). As service designers, however, we’ve found it useful to distinguish between these three types of feeds because of some subtle differences among them, particularly in terms of caching and links.
Using a linked list of feeds, we can maintain a history of everything that has taken place in the product catalog. This allows Restbucks’ stores to navigate the entire history of changes to the catalog if they so wish. Figure 7-2 shows how all these feeds link together, including the feed of recent events, the working feed, and the archive feeds.
At the Atom level, each feed and entry has its own unique
atom:id. A feed’s atom:id remains the same for the lifetime of
that feed, irrespective of whether it’s the working feed or it has
become an archive feed. This guarantees that stores can identify feeds
even if the addressing (URI) scheme radically changes, further
ensuring that the solution is loosely coupled and capable of being
evolved.
Note
In Chapter 1, we described
how a URI both identifies and addresses a resource. But putting
identification and addressability together in this way is not always
possible in practice. The authors of the Atom format recognized that while feeds and entries require
stable identities, the URIs through which they can be addressed
often change (due to changes in website property ownership or
infrastructure, for example). To put it bluntly, cool URIs never
change; URIs change—get over it. Hence the division of
responsibilities between atom:id,
which provides identification (and in combination with atom:updated identifies the
latest version of a document), and a feed or
entry’s self link, which provides
addressability.
The lessons learned by the Atom authors apply more generally, meaning that you should consider providing identities for your domain resources as well as addressable URIs. In the Restbucks example, however, for the sake of brevity we continue to identify products and promotions using only their addressable URIs.
Because we’ve split the notifications feed into a series of
linked feeds, we need to help stores navigate them. In other words, we
need to both link feeds together and describe how they relate to each
other. We do this using Atom’s <atom:link> element.
The <link> element is
Atom’s primary hypermedia control. As we discussed in Chapter 5, connecting resources is an important
part of building web-friendly systems. Hypermedia controls allow
services to connect and clients to access and manipulate resources by
sending and receiving resource representations using a uniform set of
operations.
To use a hypermedia control successfully, a client must first
understand the control’s semantic context. The client must then be
able to identify and address the resource with which the control is
associated. Finally, it must know which media type to send or what
representation formats it can expect to receive when it makes use of
the control. These requirements are satisfied by the <atom:link> element’s rel, href, and type attributes, respectively:
A
relattribute’s value describes the link relation or semantic context for the link.The
hrefattribute value is the URI of the linked resource.The
typeattribute describes a linked resource’s likely media type.
Note
The <link> element
captures most of the connectedness characteristics we want to
include in our resource representations. This fact, coupled with the
growing popularity of Atom as a syndication format and the
corresponding rise in Atom clients, leads us to suggest making
atom:link a common building block
of web-friendly distributed systems.
We say that the type
attribute value represents the likely media type because this value
can always be overridden by the owner of the resource at the end of
the link. The Content-Type header
in a response is always authoritative, irrespective of any prior
indication of the linked resource’s media type. The type attribute remains useful, however,
insofar as it allows clients to distinguish between different media
type representations of the same resource. Consider a situation in
which an entry is linked to JSON and XML representations of a
resource. A client interested in only JSON representation would look for links with a type
attribute value of application/json.
The Atom specification describes five link relations. Using two of these core link relations, we can now describe the relationships between some of the product catalog feeds, as shown in Table 7-1.
Table 7-1. The core Atom link relations
Link relation | Meaning |
|---|---|
| Advertises a link whose |
| Identifies the source for the information in the current feed or entry. Restbucks uses this link to indicate the current source for the feed of recent events. |
Table 7-2 describes the remaining three Atom link relations.
Table 7-2. The remaining core Atom link relations
Link relation | Meaning |
|---|---|
| Indicates that the link connects to an alternative representation of the current feed or entry. |
| Indicates that the referenced resource is potentially large in size. |
| Indicates that the resource at the |
IANA’s Registry of Link Relations contains a larger list
of recognized link relation values.[75] This list has nearly quadrupled since 2008, and now
includes values such as payment
(for describing links to resources that accept payments), first, last, previous, next,
previous-archive, and next-archive (for navigating paged and
archived feeds). For the Restbucks product catalog service, we will
use several of these values to help navigate between the feeds that
compose the overall set of product notifications.
Note
Though the link relation values in the Registry are primarily for use in Atom documents, their semantics are in many cases more generally applicable to a wide variety of application protocols. The Registry is a good place to find commonly used shared semantics that we can reuse to build hypermedia consumers and providers.
Recall that the feed of recent events is the entry point
for all consumers of the list of product notifications.
The feed is located at the well-known URI http://restbucks.com/products/notifications. The
entries in this feed represent the most “recent” events (relative to
the point in time when the feed is accessed). But these entries also
belong to a specific historical period, which began when the previous
working feed was archived. The feed of recent events therefore
includes a link (a via link) to the
source of the entries for this specific historical period.
Example 7-2 shows a store polling the feed of recent events.
Example 7-2. A store polls the feed of recent events
Request:GET /product-catalog/notifications HTTP/1.1 Host: restbucks.comResponse:HTTP/1.1 200 OK Date: ... Cache-Control: max-age=3600 Content-Length: ... Content-Type: application/atom+xml;charset="utf-8" ETag: "6a0806ca" <feed xmlns="http://www.w3.org/2005/Atom"> <id>urn:uuid:be21b6b0-57b4-4029-ada4-09585ee74adc</id> <title type="text">Product Catalog Notifications</title> <updated>2009-07-05T10:25:00Z</updated> <author> <name>Product Catalog</name> </author> <generator uri="http://restbucks.com/products">Product Catalog</generator> <link rel="self" href="http://restbucks.com/products/notifications"/> <link rel="via" type="application/atom+xml" href="http://restbucks.com/products/notifications/2009/7/5"/> <link rel="prev-archive" href="http://restbucks.com/products/notifications/2009/7/4"/> <entry> <id>urn:uuid:95506d98-aae9-4d34-a8f4-1ff30bece80c</id> <title type="text">product created</title> <updated>2009-07-05T10:25:00Z</updated> <link rel="self" href="http://restbucks.com/products/notifications/95506d98-aae9-4d34-a8f4- 1ff30bece80c"/> <link rel="related" href="http://restbucks.com/products/527"/> <category scheme="http://restbucks.com/products/categories/type" term="product"/> <category scheme="http://restbucks.com/products/categories/status" term="new"/> <content type="application/vnd.restbucks+xml"> <product xmlns="http://schemas.restbucks.com/product" href="http://restbucks.com/products/527"> <name>Fairtrade Roma Coffee Beans</name> <size>1kg</size> <price>10</price> </product> </content> </entry> <entry> <id>urn:uuid:4c6b6b57-81af-4501-8bbc-12fee2e3cd50</id> <title type="text">promotion cancelled</title> <updated>2009-07-05T10:15:00Z</updated> <link rel="self" href="http://restbucks.com/products/notifications/4c6b6b57-81af-4501-8bbc- 12fee2e3cd50"/> <link rel="related" href="http://restbucks.com/promotions/391"/> <category scheme="http://restbucks.com/products/categories/type" term="promotion"/> <category scheme="http://restbucks.com/products/categories/status" term="deleted"/> <content type="application/vnd.restbucks+xml"> <promotion xmlns="http://schemas.restbucks.com/promotion" href="http://restbucks.com/promotions/391"> <effective>2009-08-01T00:00:00Z</effective> <product type="application/vnd.restbucks+xml" href="http://restbucks.com/products/156" /> <region type="application/vnd.restbucks+xml" href="http://restbucks.com/regions/23" /> </promotion> </content> </entry> </feed>
The response here contains two useful HTTP headers:
ETag and Cache-Control. The ETag header allows Restbucks’ stores to
perform a conditional GET the next
time they request the list of recent events from the product catalog
service, thereby potentially conserving network bandwidth (as
described in Chapter 6). The Cache-Control header declares that the
response can be cached for up to 3,600 seconds, or one hour.
The decision as to whether to allow the feed of recent events to be cached depends on the behavior of the underlying business resources and the quality-of-service expectations of consumers. In this particular instance, two facts helped Restbucks determine an appropriate caching strategy: products and promotions change infrequently, and consumers can tolerate some delay in finding out about a change. Based on these factors, Restbucks decided the feed of recent events can be cached for at least an hour (and probably longer).
The feed itself contains three <atom:link> elements. The self link contains the URI of the feed
requested by the store, which in this case is the feed of recent
events. The via link points to the
source of entries for the feed of recent events; that is, to the
working feed. (Remember, the working feed is a
feed associated with a particular historical period. It differs from
an archive feed in that it is still changing, and is
therefore cacheable for only a short period of time. It differs from
the feed of recent events in that at some point it will no longer be
current.) The last link, prev-archive, refers to the immediately
preceding archive document.[76] This archive document contains all the events that
occurred in the period immediately prior to this one.
Note
In our example, the Restbucks product catalog service ticks
over every day, archiving the current working feed at midnight.
Because we use “friendly” URIs for feed links, it looks as if stores
can infer the address of an archive feed from the URI structure, but
we must emphasize that’s not really the case. Stores should not
infer resource semantics based on a URI’s structure. Instead, they
should treat each URI as just another opaque address. Stores
navigate the archive not by constructing URIs, but by following
links based on rel attribute
values.
Moving now to the content of the feed, we see that each entry
has a self link, indicating that
it’s an addressable resource in its own right. Besides being
addressable, in our solution every entry is cacheable. This is not
always the case with Atom entries, since many Atom feeds contain
entries that change over time. But in this particular solution, each
entry represents an event that occurs once and never changes. If an
underlying product changes twice in quick succession, the product
catalog service will create two separate events, which in turn will
cause two separate entries to be published into the feed. The service
never modifies an existing entry.
Note
The working feed is mutable, limiting its cache friendliness. Every entry, however, is immutable, and therefore cacheable from the moment it is created.
Below the self link are two
<atom:category> elements.
Atom categories provide a simple means of tagging feeds and entries.
Consumers can easily search categorized feeds for entries matching one or more categories. (And by
adding feed filters on the server side, we can produce
category-specific feeds based on consumer-supplied filter
criteria.)
An <atom:category>
element must include a term
attribute. The value of this term
attribute represents the category. Categories can also include two
optional attributes: label, which
provides a human-readable representation of the category value, and
scheme, which identifies the scheme
to which a category belongs. Schemes group categories and disambiguate
them, much as XML and package namespaces disambiguate elements and
classes. This allows entries to be tagged with two categories that
have the same terms, but belong to two different schemes.
In Restbucks, we use categories to identify the event type
(product or promotion), and its status (new, updated, or cancelled). The last entry in the feed in
Example 7-2, for example, indicates that the promotion for the
product http://restbucks.com/products/156 has been
canceled. Using these categories, Restbucks’ stores can filter
specific kinds of events from a feed.
Navigating an individual feed is straightforward. Feeds are
ordered by each entry’s <atom:updated> timestamp element, with
the most recent entry first.[77] To process a feed, a Restbucks store steps through the
entries looking for the combination of atom:id and atom:updated that belongs to the last entry
it successfully processed. Once it has found that entry, it works
forward through the feed, applying each entry’s payload to its own
local copy of the product catalog data.
Atom doesn’t prescribe how a consumer should process the entries
in a feed. In our example, Atom entries represent event metadata. This
metadata provides a processing context for the event’s business
payload. When an Atom processor encounters an <atom:content> element, it delegates
control to a media type processor capable of handling the contained
product or promotion representation. The client invokes the
specialized handler for the content in the knowledge that it is
dealing with a representation of state at a particular point in time.
We call this ability to hand off from one media type processor to
another media type composition.
If the consumer can’t find in the current feed the last entry it
successfully processed, it navigates the prev-archive link and looks in the previous
archive. It continues to trawl through the archives until either it
finds the entry it’s looking for or comes to the end of the oldest archive feed (the
oldest archive has no prev-archive
link). Example 7-3
shows a consumer retrieving a previous archive.
Example 7-3. The consumer retrieves the previous archive
Request:GET /product-catalog/notifications/2009/7/4 HTTP/1.1 Host: restbucks.comResponse:HTTP/1.1 200 OK Cache-Control: max-age=2592000 Date: ... Content-Length: ... Content-Type: application/atom+xml;charset="utf-8" ETag: "a32d0b30" <feed xmlns="http://www.w3.org/2005/Atom" xmlns:fh="http://purl.org/syndication/history/1.0"> <id>urn:uuid:be21b6b0-57b4-4029-ada4-09585ee74adc</id> <title type="text">Product Catalog Notifications</title> <updated>2009-07-04T23:52:00Z</updated> <author> <name>Product Catalog</name> </author> <generator uri="http://restbucks.com/products">Product Catalog</generator> <fh:archive/> <link rel="self" href="http://restbucks.com/products/notifications/2009/7/4"/> <link rel="prev-archive" href="http://restbucks.com/products/notifications/2009/7/3"/> <link rel="next-archive" href="http://restbucks.com/products/notifications/2009/7/5"/> <!-- Entries omitted for brevity --> </feed>
The first thing to note about this archive feed is that it
contains an <fh:archive>
element, which is a simple extension element defined in the Feed
Paging and Archiving specification.[78] The presence of <fh:archive> is a further indication
that this archive feed will never change and is therefore safe to cache.
Following the <fh:archive> element are three
<atom:link> elements. As with
the feed of recent events, this archive feed contains self and prev-archive links, but it also includes a
next-archive link, which links to
the feed of events that have occurred in the period immediately
following this one—that is, to a feed of more recent events. A store
can follow next-archive links all
the way up to the current working feed.
Again, just like the feed of recent events, the response
contains a Cache-Control header.
Whereas the recent feed can only be cached for up to an hour, archive
feeds are immutable, meaning they can be cached for up to 2,592,000
seconds, or 30 days.
Feeds can be cached locally by each store, as well as by gateway
and reverse proxy servers along the response path. Processing an
archive is a “there and back again” operation: a consumer follows
prev-archive links until it finds
an archive containing the last entry it successfully processed, and
then works its way back to the head feed—this time following next-archive links. Whenever a consumer
dereferences a prev-archive link,
its local cache stores a copy of the response. When the consumer next
accesses this same resource, most likely as a result of following a
next-archive link on the return
journey, the cache uses its stored response. Navigating the full
extent of an archive is a potentially expensive operation from a
network point of view: caching locally helps save valuable network resources
when returning to the head feed.
Note
This ability to create or reconstruct a local copy of the product catalog based on the entire archive is a great pattern for bringing a new system online or for supporting crash recovery, and is one of the ways the Restbucks infrastructure scales to thousands or even millions of stores if necessary.
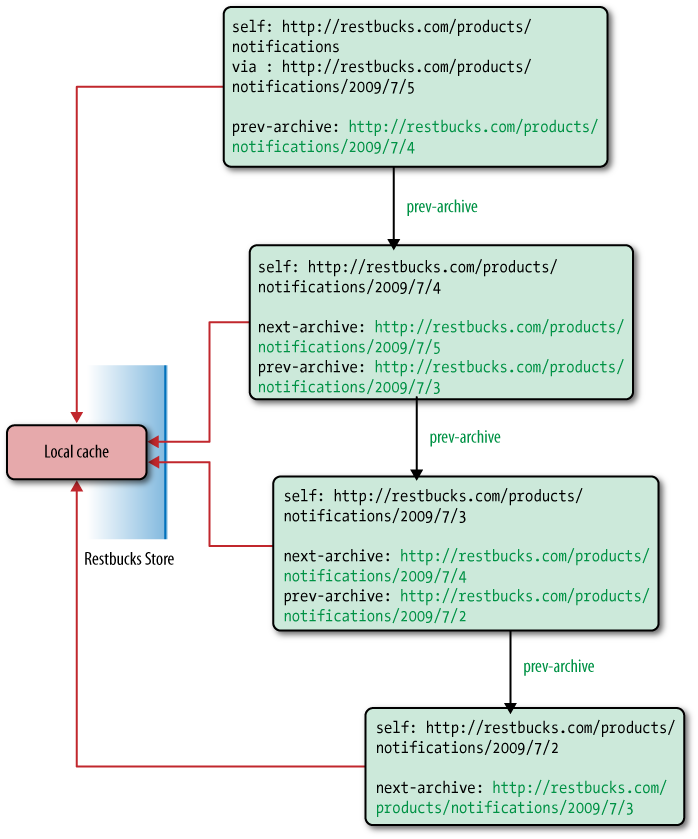
To explore the implications of this strategy in more detail,
let’s assume a store goes offline for a period of time—perhaps because
of a problem with its local infrastructure. When the store eventually
comes back up, it begins to update its local copy of the product
catalog by polling the feed of recent events, and then working its way
through prev-archive links looking
for an archive feed containing the last entry it processed. Figure 7-3 shows the store
following prev-archive links and
working its way back in time through the archives. At each step, it
caches the response locally in accordance with the metadata it
receives in the HTTP cache control headers.
At some point, the store finds the last entry it successfully
processed. The store can now start working forward in time, applying
the contents of each feed entry to its local copy of the product
catalog, and following next-archive
links whenever it gets to the top of a feed. This forward traversal is
shown in Figure 7-4.
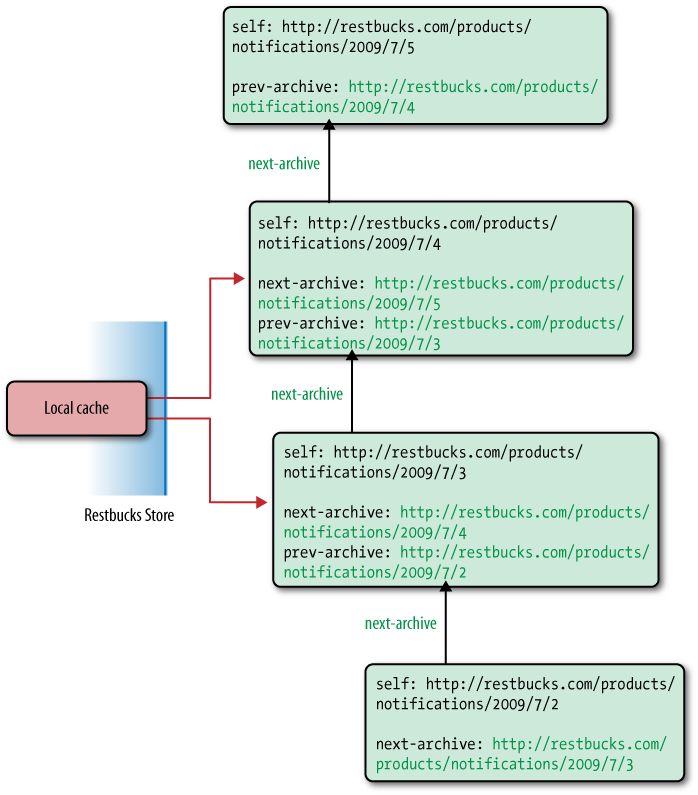
Every time the store traverses a next-archive link, the response is fetched
from the local cache (or an intermediary cache somewhere on the
Restbucks network). This happens with every next-archive link—except the last one, when
the request once again goes across the network. This last network
request happens because the head of the feed is cached (if it is
cached at all) against the well-known entry point URI, http://restbucks.com/products/notifications, rather
than the working feed URI, which is http://restbucks.com/products/notifications/2009/7/5.
Because the store hadn’t accessed the working feed while working back
through the archives (it went from the feed of recent events to the
first archive feed), it now has to fetch the working feed from the
origin server.
This linking and caching strategy trades efficiency for generalization.
Generalization comes from our being able to build hypermedia clients
that can navigate feeds using standardized prev-archive and next-archive link relations. In other words,
there’s no need to build any special logic to prevent unnecessary
end-to-end requests: it’s the local caching infrastructure’s job to store and return archive
feeds at appropriate points in the feed traversal process. To a
consumer, a request that returns a cached response looks the same as a
request that goes all the way to the product catalog service.
The overall efficiency of this solution, however, breaks down
with the final GET, when the
consumer has to make one last network request. Assuming we started
with empty caches all the way along the response path, navigating
forward and backward through N
feeds will cause the product catalog service to handle
N+1 requests.
In designing this solution, we’ve assumed Restbucks’ stores won’t navigate the archive quite as often as they access the head feed by itself. If in practice the stores navigated the archives almost every time they polled the feed, we’d change the solution so that every request for the feed of recent events is redirected immediately to the current working feed, as shown in Example 7-4. Such a change would ensure that the head feed is cached against the current working feed’s URI, rather than the entry point URI. An immediate redirect doesn’t cut down on the overall number of wire requests, since the redirect response itself counts as an over-the-wire interaction, but it does reduce the overall volume of data sent in comparison to the first solution.
Example 7-4. Redirecting requests for the feed of recent events to the current working feed
Request:GET /product-catalog/notifications HTTP/1.1 Host: restbucks.comResponse:HTTP/1.1 303 See Other Location: http://restbucks.com/products/notifications/2009/7/5Request:GET /product-catalog/notifications/2009/7/5 HTTP/1.1 Host: restbucks.comResponse:HTTP/1.1 200 OK Date: ... Cache-Control: max-age=3600 Content-Length: ... Content-Type: application/atom+xml;charset="utf-8" ETag: "6a0806ca" <feed xmlns="http://www.w3.org/2005/Atom"> ... </feed>
Recall that at some point the current working feed will be
archived. When this happens, an <fh:archive> element and an <atom:link> element with a rel attribute value of next-archive will be inserted into the feed.
The link points to the new current working feed. Responses containing
the newly archived feed will include a Cache-Control header whose value allows the
now immutable feed to be cached for up to 30 days.
What distinguishes the working feed from an archive feed? As developers, we must distinguish between these feeds because the combination of caching strategy and available links differs. The working feed is cacheable only for short periods of time, whereas archive feeds are cacheable for long periods of time.
Using prev-archive and
next-archive links saves us from
having to add to each store some specialized knowledge of the product
catalog’s URI structure and the periodization rules used to generate
archives. Because they depend instead on hypermedia, stores need never
go off the rails; they just follow opaque links based on the semantics
encoded in link relations. This allows the catalog to vary its URI
structure without forcing changes in the consumers. More importantly,
it allows the server to vary its feed creation rules based on the flow
of events.
During particularly busy periods, for example, the product
catalog service may want to archive feeds far more frequently than it
does during quiet periods. Instead of archiving at predefined
intervals, the service could archive after a certain number of events
have occurred. This strategy allows the service to get feeds into a
cacheable state very quickly. As far as Restbucks’ stores are
concerned, however, nothing changes. Each store still accesses the
system through the feed of most recent events, and navigates the
archives using prev-archive and
next-archive links.
Note
In low-throughput situations, it’s often acceptable to generate feeds on demand, as and when consumers ask for them. But as usage grows, this approach puts increasing strain on both the application and data access layers of the feed service. In high-throughput scenarios, where lots of consumers make frequent requests for current and archive feeds, we might consider separating the production of feeds from their consumption by clients. Such an approach can use a background process to generate feeds and store them on the filesystem (or in memory), ready to be served rapidly with minimal compute cost when requested by a consumer.
At a feed level, links with link relation values of self, alternate, next-archive, and prev-archive encapsulate the product catalog
service’s implementation details—in particular, the service’s
archiving strategy and the location of its current and archive feeds.
This interlinking helps us both size feeds and tune performance. It
also establishes a protocol that allows consumers to navigate the set
of feeds and consume the event data held within.
The Restbucks product catalog uses many other Atom elements besides links to create an entire processing context for a list of domain-specific representations. In other words, Restbucks uses Atom to implement hypermedia-driven event handlers. To build this processing context, stores use:
<atom:id>and<atom:updated>to identify the oldest entry requiring processingCategories to further refine a list of entries to be processed
relatedlinks to correlate entries with domain-specific resourcesAn entry’s
<atom:content>element’stypeattribute value to determine the processing model to be applied to the enclosed domain-specific representation
Atom helps us separate protocol and processing context from business payload using media type composition. Because the processing context for an event is conveyed solely at the Atom document level, the event-handling protocol itself can be implemented by domain-agnostic client code—that is, by generic Atom clients. The split between event context and business resource state snapshot allows stores to use Atom processors to determine which events to process, and allows domain- or application-specific media type processors to act on an entry’s business payload.
For Java solutions, on the server side our basic tools are a web server, an HTTP library, and a feed generator. On the client side, we need only an HTTP library and a feed parser. For our Java implementation, we’ve chosen Jersey[79] (a JAX-RS[80] implementation) to provide the HTTP plumbing for the service and its consumers, and ROME[81] for generating and consuming Atom feeds. For development purposes, we’ve chosen to use the Grizzly web server because it works nicely with Jersey.
The server-side architecture follows a classic layered pattern, as shown in Figure 7-5. At the lowest layer is a repository, which holds a history of changes to products and promotions, much like a source repository holds the records of changes to code. The domain objects in the middle layer encapsulate the information in the repository and make it available to the upper layers.
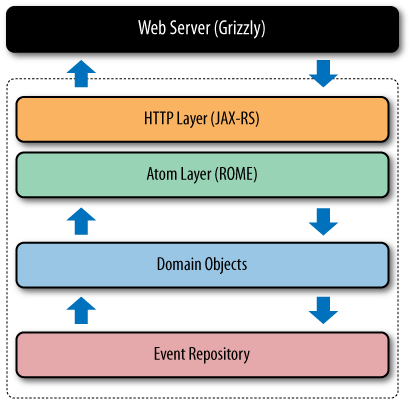
The uppermost layers compose the interface to the network. Here we must address two separate concerns: creating Atom feeds and providing access to feeds via HTTP. Generating feeds is a matter of querying and pushing appropriate events from the domain model into feed objects through the ROME library. Exposing feeds to the Web is done through the JAX-RS layer, which provides connectivity to the underlying web server.
Recall that our strategy for managing the many events the service produces is to partition events across separate feeds, and then to link feeds so that clients can navigate between them. For the Java implementation, rather than archiving on an hourly or daily basis, we split the feeds based on a maximum number of entries per feed. By optimizing the size of feeds, we trade granularity for the number of network interactions needed to read the feed history.
The strategy we use for archiving feeds is application-specific, and has no bearing on the way in which consumers access and navigate the feed.
Service consumers navigate feeds by following next-archive and prev-archive links. While our service has a
predictable algorithm for creating these links, to consumers the links
are just opaque URIs. Example 7-5
shows a couple of links.
Internally, the Java service generates links according to a
simple URI template: http://restbucks.com/product-catalog/notifications/{start},{end}.
Using this template, the service extracts from the request URI a pair
of numerical identifiers, which it then uses to retrieve the
appropriate events from the underlying event repository.
Warning
The Java service uses a URI template internally for design and documentation purposes, but it doesn’t share this template with consumers. Doing so would tightly couple the service and its consumers; a change to the service’s URI structure would break clients.
Consumers who choose to infer URIs based on this structure are treading a dangerous path, because the service isn’t obliged to honor them.
The URIs we’re using in Example 7-5 look different from the others we’ve seen so far. This is a result of the different (but equivalent) feed generation strategy we’ve used for our Java implementation. The changes serve to emphasize that URIs are opaque to consumers, and that it is the link relations that drive the protocol.
On the Java platform, we have a ready set of components to build out each layer of our service. Some of these (such as Jersey, our JAX-RS implementation) we’ve seen in prior chapters; others (such as ROME, our Atom library) are new.
JAX-RS provides a comfortable abstraction over HTTP, especially when compared to lower-level APIs such as the Servlet interface.[82] Using Jersey as our friendly interface to the HTTP stack allows us to delegate the plumbing details to the framework, and to concentrate instead on the overall design of the service.
Our first task is to expose the feed of recent events at a
well-known URI, thereby providing an entry point into the service
for consumers. The implementation for this is shown in Example 7-6. To expose the
feed, we simply declare the verb (GET), the path where the feed will be
hosted (/recent), and the
representation format for the resource, which of course is Atom
(application/atom+xml).
Once we’ve got the framework code out of the way, all that’s
left for us to do is to generate a feed. We do this using our own EventFeedGenerator, which wraps an
underlying Feed object from the
ROME framework. We then turn the generated feed into a string
representation. Finally, using a JAX-RS builder, we build and return
a 200 OK response, adding the appropriate
caching directive (Cache-Control:
max-age=3600, to cache the feed
for one hour) and the Atom media type. Any exceptions are handled by Jersey,
which generates an HTTP 500
Internal Server Error response.
Example 7-6. Exposing feeds for recent events and the working feed through JAX-RS
@GET @Path("/recent") @Produces("application/atom+xml") public Response getRecentFeed() { EventFeedGenerator generator = new EventFeedGenerator(uriInfo.getRequestUri(), ENTRIES_PER_FEED); Feed feed = generator.getRecentFeed(); return Response.ok().entity(stringify(feed)) .header(CACHE_CONTROL_HEADER, cacheDirective(CachePolicy.getRecentFeedLifetime())) .type(ATOM_MEDIA_TYPE).build(); }
We follow a similar pattern for archive feeds, though the
framework code here is a little more intricate than the code for the
feed of recent events. The framework declarations in Example 7-7 include an @Path annotation, which defines the URI
template the service implementation uses to extract parameters
(“/{startPos},{endPos}”), and
which Jersey uses to dispatch requests to the method. Only request
URIs matching the template will be routed to this method.
Example 7-7. Exposing older feeds through JAX-RS
@GET
@Path("/{startPos},{endPos}")
@Produces("application/atom+xml")
public Response getSpecificFeed(@PathParam("startPos") int startPos,
@PathParam("endPos") int endPos) {
if (validStartAndEndEntries(startPos, endPos)) {
// Bad URI - the paramters don't align with our feeds
return Response.status(Status.NOT_FOUND).build();
}
if(workingFeedRequested(startPos)) {
return getWorkingFeed();
}
EventFeedGenerator generator = new
EventFeedGenerator(uriInfo.getRequestUri(), ENTRIES_PER_FEED);
Feed feed = generator.feedFor(startPos);
return Response.ok().entity(stringify(feed)).header(CACHE_CONTROL_HEADER,
cacheDirective(CachePolicy.getArchiveFeedLifetime()))
.type(ATOM_MEDIA_TYPE).build();
}
private Response getWorkingFeed() {
EventFeedGenerator generator = new
EventFeedGenerator(uriInfo.getRequestUri(),
ENTRIES_PER_FEED);
Feed feed = generator.getWorkingFeed();
return Response.ok().entity(stringify(feed))
.header(CACHE_CONTROL_HEADER,
cacheDirective(CachePolicy.getWorkingFeedLifetime()))
.type(ATOM_MEDIA_TYPE).build();
}Jersey extracts the URI parameters from the URI at runtime and
passes them into the method via the two @PathParam annotations in the method
signature. From there, we validate whether the parameters fit with
our feed-splitting scheme by testing whether the values are
divisible by our feed size. If the values from the URI template
don’t fit our feed scheme, the service returns a 404 Not
Found response.
If the URI parameters are valid, we check whether the
requested feed refers to the current working feed. If it does, we
generate a representation of the working feed and send that back to
the consumer. Otherwise, we call into the archive feed generation
logic to create a feed using generator.feedFor(startPos). Once the feed
has been created, we turn it into a string representation and build
a 200 OK response containing the feed plus the
Content-Type header, as shown in
the final line of the method.
The HTTP-centric code is only half the implementation of the service. Under the covers is a great deal of code that generates Atom feeds on demand.
Warning
ROME can be an awkward library to work with. Many of the API
calls in the 1.0 release are weakly typed using String and nongeneric collections. It’s
helpful to have the Javadoc comments on hand when working with
it.[83]
Example 7-8 shows the
EventFeedGenerator.feedFor(…)
method, which creates a feed by orchestrating several calls into the
underlying ROME library.
Example 7-8. Generating an Atom feed with ROME
public Feed feedFor(int startEntry) {
Feed feed = new Feed();
feed.setFeedType("atom_1.0");
feed.setId("urn:uuid:" + UUID.randomUUID().toString()); // We don't need stable
// ID because we're not
// aggregating feeds
feed.setTitle(FEED_TITLE);
final Generator generator = new Generator();
generator.setUrl(getServiceUri());
generator.setValue(PRODUCING_SERVICE);
feed.setGenerator(generator);
feed.setAuthors(generateAuthorsList());
feed.setAlternateLinks(generateAlternateLinks(startEntry));
feed.setOtherLinks(generatePagingLinks(startEntry));
feed.setEntries(createEntries(EventStore.current()
.getEvents(startEntry, entriesPerFeed)));
feed.setUpdated(newestEventDate(events));
return feed;
}The first few lines in Example 7-8 set the feed
metadata: feed type, title, creation date, generator, and authors.
These elements are created by the setters setFeedType(…) through to setAuthors(…).
Note
We’re using a randomly generated feed identifier here. This means that consumers receive a different identifier each time they request the feed. If we had multiple feed providers (as Atom supports), the identifier would need to be stable over time, and crash-recoverable, so that consumers could safely merge separate physical feeds into a single logical feed.
The setter methods in Example 7-8 give us the beginnings of the Atom feed shown in Example 7-9. This feed contains all the necessary feed metadata.
Example 7-9. Generated feed metadata
HTTP/1.1 200 OK
server: grizzly/1.8.1
Cache-Control: max-age=3600
Content-Type: application/atom+xml
<feed xmlns="http://www.w3.org/2005/Atom">
<title>Restbucks products and promotions</title>
<author>
<name>A Product Manager</name>
</author>
<id>urn:uuid:4679956d-b084-48f7-a20f-6e7b3891d951</id>
<generator uri="http://restbucks.com/product-catalog/notifications">
Product Catalog
</generator>
<updated>2009-08-13T16:42:04Z</updated>
<!-- Remainder of feed omitted for brevity -->
</feed>Things get more interesting when we have to generate some of
the dynamic feed content, particularly links. For the feed, this
means identifying the URI through which the feed was accessed
(rel=“self”) and the source of
entries for that feed (rel=“via”). Both of these are serialized
as <atom:link> elements as
the feed is constructed. The code in Example 7-10 shows how the dynamic
content for the /recent feed is
created.
Example 7-10. Generating self and via links
public Feed getRecentFeed() {
int startEntry = findStartingEntryForHeadFeeds();
Feed recent = feedFor(startEntry);
Link self = new Link();
self.setHref(requestUri.toString());
self.setRel("self");
self.setType(ATOM_MEDIA_TYPE);
recent.getAlternateLinks().add(self);
recent.getAlternateLinks().addAll(generatePagingLinks(startEntry));
Link via = new Link();
via.setHref(this.generateCanonicalUri(startEntry));
via.setRel("via");
via.setType(ATOM_MEDIA_TYPE);
recent.getAlternateLinks().add(via);
return recent;
}To generate the self link
we take the (previously validated) request URI and add it to the
list of Link objects with a
rel value of self. If the requested feed is the feed of
recent events, as accessed via the well-known URI /recent, we also
need to generate the source URI so that a consumer can still access
the entries associated with this particular time period when the
current feed is archived. That’s easily done by adding another
Link object with a rel value of via to the list of links for the
feed.
With the links added to the feed, we now get the XML shown in Example 7-11 for the feed of recent events, and that in Example 7-12 for an archive feed.
Example 7-11. Generated self and via links in the feed of recent events
<link rel="self" type="application/atom+xml" href="http://restbucks.com/product-catalog/notifications/recent" /> <link rel="via" type="application/atom+xml" href="http://restbucks.com/product-catalog/notifications/160,179" />
Example 7-12. Generated self link in archive feed
<link rel="self" type="application/atom+xml" href="http://restbucks.com/product-catalog/notifications/80,99" />
The final feed metadata comprises the links we need to
navigate back (prev-archive) and
forth (next-archive) through
older feeds. In Example 7-13, we generate
these links by determining whether there are newer and older feeds
relative to the current feed; if there are, we calculate the link
values using our algorithm for splitting feeds. Once calculated, we
add the paging links to the list of links returned to the feed
generator.
Example 7-13. Generating navigation links between feeds
private List<Link> generatePagingLinks(int currentFeedStart) {
ArrayList<Link> links = new ArrayList<Link>();
if(hasNewerFeed(currentFeedStart)) {
Link next = new Link();
next.setRel("next-archive");
next.setType(ATOM_MEDIA_TYPE);
next.setHref(generatePageUri(getServiceUri(),
currentFeedStart + entriesPerFeed));
links.add(next);
}
if(hasOlderFeed(currentFeedStart)) {
Link prev = new Link();
prev.setRel("prev-archive");
prev.setType(ATOM_MEDIA_TYPE);
prev.setHref(generatePageUri(getServiceUri(),
currentFeedStart - entriesPerFeed));
links.add(prev);
}
return links;
}The code in Example 7-13 gives us the feed-level links shown in Example 7-14.
Example 7-14. Navigation links in an Atom feed
<link rel="prev-archive" type="application/atom+xml" href="http://restbucks.com/product-catalog/notifications/140,159" /> <link rel="next-archive" type="application/atom+xml" href="http://restbucks.com/product-catalog/notifications/180,199" />
Once the feed-level metadata has been created, it’s time to
populate the feed with entries. Each entry in a feed represents a
business event pertaining to a product or promotion. The createEntries(…) method shown in Example 7-15 is responsible
for creating the entries for a given set of events.
Example 7-15. Populating a feed with entries containing events
private List<Entry> createEntries(List<Event> events) {
ArrayList<Entry> entries = new ArrayList<Entry>();
for(Event e : events) {
final Entry entry = new Entry();
entry.setId(e.getTagUri());
entry.setTitle(e.getEventType());
entry.setUpdated(e.getTimestamp());
entry.setAlternateLinks(generateLinks(e));
entry.setCategories(generateCategories(e));
entry.setContents(generateContents(e));
entries.add(entry);
}
return entries;
}The events provided to the createEntries(…) method are supplied from
the underlying event store. For each event, the following metadata
is extracted and pushed directly into the entry:
An identifier from the event’s stable, long-lived tag URI[84]
The event type, being a product or promotion event
The timestamp for when the event was generated
Following on from the metadata, we add two links, self and related, to the entry. The self link contains the entry’s URI; the
related link correlates the entry
with the underlying product or promotion’s URI in the product
catalog service.
Finally, we serialize the event payload into XML, and
add it to the entry’s <content> element. We then add the
new entry to the feed. The snapshot of the state of a product or
promotion appears as a child of an <atom:content> element, as shown in
Example 7-16.
Example 7-16. Event payloads exposed as entry content in an Atom feed
HTTP/1.1 200 OK server: grizzly/1.8.1 Cache-Control: max-age=2592000 Content-Type: application/atom+xml ... <entry> <title>product</title> <link rel="self" href="http://restbucks.com/product-catalog/notifications/notifications/120" /> <link rel="related" href="http://restbucks.com/products/2012703733" /> <category term="product" scheme="http://restbucks.com/product-catalog/notifications/categories/type" /> <category term="new" scheme="http://restbucks.com/product-catalog/notifications/categories/status" /> <id>tag:restbucks.com,2009-08-15:120</id> <updated>2008-04-04T16:24:02Z</updated> <content type="application/vnd.restbucks+xml"><product xmlns="http://schemas.restbucks.com/product"href="http://restbucks.com/products/2012703733"><name>product name 543809053</name><price>2.34</price></product></content> </entry> <entry> <title>promotion</title> <link rel="self" href="http://restbucks.com/product-catalog/notifications/notifications/148" /> <link rel="related" href="http://restbucks.com/promotions/1669488880" /> <category term="promotion" scheme="http://restbucks.com/product-catalog/notifications/categories/type" /> <category term="new" scheme="http://restbucks.com/product-catalog/notifications/categories/status" /> <id>tag:restbucks.com,2009-08-15:148</id> <updated>2008-04-04T16:24:02Z</updated> <content type="application/vnd.restbucks+xml"><promotion xmlns="http://schemas.restbucks.com/promotion"xmlns:ns2="http://www.w3.org/2005/Atom"href="http://restbucks.com/promotions/1669488880"><effective>2009-08-15</effective><ns2:product type="application/vnd.restbucks+xml"href="http://restbucks.com/products/1995649500" /><ns2:region type="application/vnd.restbucks+xml"href="http://restbucks.com/regions/2140798621" /></promotion></content> </entry> ...
Now that we have exposed interlinked feeds with entries representing business events, clients can traverse and consume those feeds, and use the information in the events to trigger local processing. This leads us to the consumer-side infrastructure.
Like the product catalog service, the consumer implementation has been developed using Jersey for HTTP plumbing code, and ROME for parsing Atom feeds. Unlike the service implementation, however, the consumer code—excluding any business logic and error handling—is quite small, with Jersey and ROME providing most of the necessary functionality.
The code to request an Atom feed is shown in Example 7-17.
Example 7-17. Consuming an event feed with Jersey and ROME
private Feed getFeed(URI uri) {
// Jersey
Client client = Client.create();
ClientResponse response = client.resource(uri)
.accept(ATOM_MEDIA_TYPE)
.get(ClientResponse.class);
String responseString = response.getEntity(String.class);
// Rome code
WireFeedInput wfi = new WireFeedInput();
WireFeed wireFeed;
try {
wireFeed = wfi.build(new StringReader(responseString));
} catch (Exception e) {
throw new RuntimeException(e);
}
return (Feed) wireFeed;
}The responsibilities in Example 7-17 are split
between Jersey and ROME. The Jersey code creates an HTTP client, and
then sends an HTTP GET request with
an Accept header of application/atom+xml to the product catalog
service.
The get(…) call populates the
HTTP response object with the
results of the interaction, including an Atom feed if the request was
successfully processed. This Atom feed is extracted as a String instance and passed into the ROME
library where it is converted to an object representation that can be
processed by the consumer’s business logic.
Of course, this isn’t the end of the story for our consumer. If
the consumer can’t find the entry it last successfully processed in
the current feed, it will have to look through the archives.
Fortunately, because feeds are navigable via their next-archive and prev-archive links, the consumer need only
follow these links to discover and consume the archive feeds.
Programmatically, this is straightforward, since we already have a
means to access feeds by URI (Example 7-17), and ROME
provides us the means to extract URIs from feeds, as we see in Example 7-18.
Example 7-18. Navigating feeds from a consumer perspective
private URI getUriFromNamedLink(String relValue, Feed feed)
throws URISyntaxException {
for (Object obj : feed.getOtherLinks()) {
Link l = (Link) obj;
if (l.getRel().equals(relValue)) {
return new URI(l.getHref());
}
}
return null;
}
private URI getPrevArchive(Feed feed) throws URISyntaxException {
return getUriFromNamedLink("prev-archive", feed);
}
private URI getNextArchive(Feed feed) throws URISyntaxException {
return getUriFromNamedLink("next-archive", feed);
}Example 7-18
shows how a consumer extracts links from a feed. Moving forward
through a set of feeds is a matter of looking for next-archive links, while moving backward is
a matter of acting on the corresponding prev-archive links in each feed. As each
feed is discovered, the consumer filters and applies the feed’s
entries to the objects in its local domain model.
Our .NET solution serves pregenerated Atom feeds from the filesystem rather than constructing them on the fly. This way, we separate the construction of feeds from the handling of requests. The benefit of this approach is that it conserves computing resources. The downside is that it introduces additional latency between an event occurring and its appearing in a feed. We can tolerate this trade-off because transferring products and offers to Restbucks stores isn’t very latency-sensitive, and so any additional delay doesn’t prevent the solution from working effectively.
Note
Using pregenerated static files for archive feeds is particularly effective at web scale. Most web servers are very good at serving static files; furthermore, public-facing services can use content delivery networks (CDNs) to store copies of archive feeds closer to their globally distributed consumers. Static files allow us to implement additional optimizations, such as storing and serving feeds in a gzipped state.
This separation of concerns between constructing feeds and
handling requests is reflected in two core components: ProductCatalog.Writer, which generates feeds,
and ProductCatalog.Notifications,
which handles requests.
Writing feeds to files is triggered by a timer, which fires periodically. When the timer fires, the feed writer reads new events from a buffer and writes them to the recent events feed file. If during this process the recent events feed becomes full, the service archives it and starts a new one.
Importantly, with this approach, once a file has been written to the filesystem, it’s never updated. This is to prevent contention between file readers and writers. Consider, for example, the situation where a client request is being served from a file at the same time as the recent events feed is being updated. If we were to allow file updates, we’d run the risk of blocking consumers while the service obtains a lock on the underlying file and modifies its contents, complicating the solution for little gain.
Making a file unchangeable once it has been published works fine in the case of archive feeds: archives by their very nature are immutable. But things are trickier with the feed of recent events, which continues to grow as more events occur.
One solution to this problem is to publish the feed of recent events as a series of temporary files. Each time the feed writing process is triggered, the service creates a copy of the recent events feed, and then it adds new events to this copy. The service maintains an in-memory mapping between the resource identifier for the recent events feed and the newest temporary file containing this feed. When the feed updating process completes, the service updates the mapping.
Updating the in-memory mapping is an atomic operation. Until the mapping is updated, requests continue to be served from the older temporary file. Once the mapping has been updated, however, new requests are satisfied from the new temporary file. A reaper process cleans up older temporary files after a short interval.
The feed writing process is controlled by an instance of the
FeedWriter class, which hosts a
timer. Timer events are handled by the FeedWriter.WriteFeed() method shown in Example 7-19. WriteFeed() stops the timer, loops through
and executes the tasks responsible for updating the recent events
feed, and then restarts the timer.
We’ve broken down the feed writing process down into a series of discrete tasks. Each task is responsible for a single activity. Once it has completed its activity, the currently executing task creates and returns the next task to be executed. By breaking the process of updating the recent events feed into a number of discrete tasks, we make the solution easier to develop and test.
Each task executed by WriteFeed() implements the ITask interface shown in Example 7-20.
Example 7-20. The ITask interface
public interface ITask
{
bool IsLastTask { get; }
ITask Execute(IFileSystem fileSystem,
IEventBuffer buffer,
FeedBuilder feedBuilder,
Action<FeedMappingsChangedEventArgs> notifyMappingsChanged);
}ITask’s Execute(…) method takes four
parameters:
fileSystemAn object that implements the
IFileSysteminterface, which provides access to the filesystem directories containing the recent events feed, archive feeds, and feed entries.bufferProvides access to new events waiting to be written to a feed. Example 7-21 shows the
IEventBufferinterface. In a production system, we might use a persistent queue or database table to back this buffer. In our sample application, the event buffer is implemented as an in-memory queue.feedBuilderFormats feeds and entries. We’ll look at the
FeedBuilderclass in more detail later.notifyMappingsChangedA delegate, which is used to raise an event indicating the feed mappings have changed. Tasks can invoke this delegate when the process of writing a feed has been completed. Doing so notifies other parts of the system that the recent events feed has changed.
Example 7-21. The IEventBuffer interface
public interface IEventBuffer
{
void Add(Event evnt);
IEnumerable<Event> Take(int batchSize);
}Figure 7-6 shows how the tasks responsible for updating the recent events feed are organized into a processing pipeline for events.
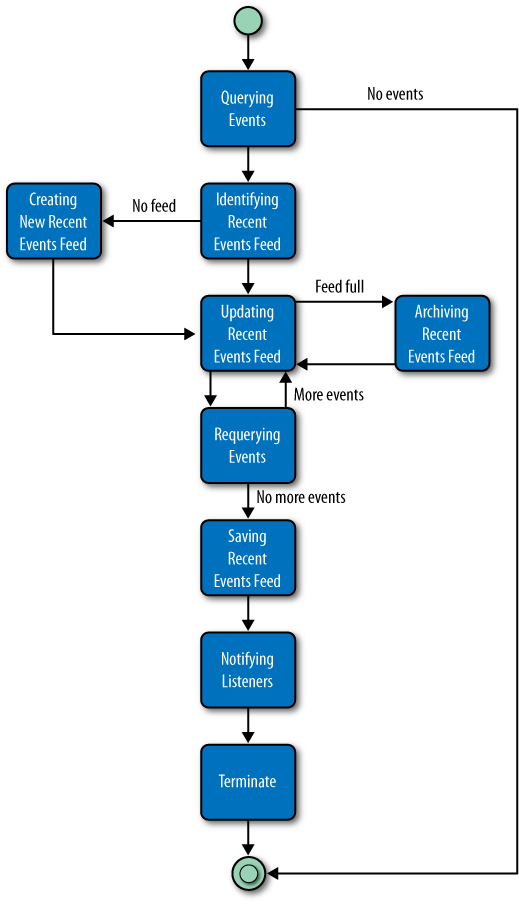
QueryingEventsTakes a batch of events from the buffer. If there are no new events in the buffer,
QueryingEventsreturns aTerminatetask; otherwise, it returns anIdentifyingRecentEventsFeedtask.IdentifyingRecentEventsFeedIdentifies the latest recent events feed file. If the file exists, this task uses the feed builder to load the feed into memory. It then returns an
UpdatingRecentEventsFeedtask, passing the in-memory feed and the new events waiting to be added to the feed to the new task’s constructor. IfIdentifyingRecentEventsFeedcan’t find a recent events feed file on the filesystem, it returns aCreatingNewRecentEventsFeedtask.UpdatingRecentEventsFeedIterates over new events retrieved from the buffer and updates the recent events feed. If during this process the feed’s entry quota is reached, the task returns an
ArchivingRecentEventsFeedtask. If, on the other hand, the task gets through all the new events without having to archive the recent events feed, it returns aRequeryingEventstask.RequeryingEventsGets another batch of new events from the buffer. If there are no new events, this task returns a
SavingRecentEventsFeedtask; otherwise, it returns a newUpdatingRecentEventsFeedtask.SavingRecentEventsFeedTells the in-memory recent events feed to save itself to the filesystem and then returns a
NotifyingListenerstask.NotifyingListenersInvokes the
notifyMappingsChangeddelegate with the latest recent events feed’s details and then returns aTerminatetask.CreatingNewRecentEventsFeedIs executed when the service can’t find a recent events file on the filesystem. This will be the case, for example, when the service starts for the very first time.
CreatingNewRecentEventsFeedcreates an empty recent events feed and returns a newUpdatingRecentEventsFeedtask, passing the newly created feed to this new task. (This new feed is not saved to the filesystem untilSavingRecentEventsFeedis executed.)ArchivingRecentEventsFeedUses the current feed to create a new recent events feed, which is empty. It then archives the old feed and creates and returns an
UpdatingRecentEventsFeedtask, passing the new recent events feed to the new task’s constructor.TerminateCompletes the process of updating the recent events feed.
Together, these tasks retrieve batches of new events from the event buffer and update the recent events feed. When the current feed’s entry quota has been reached, the service archives the feed and begins a new one. The service then repeats the process of retrieving events, adding them to the recent events feed and archiving where necessary, until there are no more new events in the buffer.
FeedBuilder creates in-memory
representations of feeds and entries. Feeds are of two types: RecentEventsFeed and ArchiveFeed. The feed builder is responsible
for creating new recent events feeds and restoring recent events feeds
from the filesystem. It can also create a subsequent feed and an
archive feed from the current feed.
A feed builder uses a helper class, Links, to generate links. When the service
starts, it configures a Links
object with some service-specific URI templates. The feed builder
parameterizes these templates at runtime with resource Ids to generate URIs for feeds and
entries.
RecentEventsFeed and ArchiveFeed objects are initialized with a
FeedMapping object. Feed mappings
encapsulate the mapping between a resource ID and its filename. An
Id is the service’s own internal
representation of the distinguishing part of a feed or entry’s
address. Links uses an Id object to generate a feed or entry URI by
filling in a URI template. Our sample service is configured at startup
with a base address of http://restbucks.com/product-catalog/notifications/,
and a URI template for feeds of /?page={id}. An Id object with an integer value of 4,
therefore, will result in the following feed URI: http://restbucks.com/product-catalog/notifications/?page=4.
By making the creation of temporary filenames private to a feed mapping, we ensure that we generate a different temporary filename every time we create a mapping, thereby guaranteeing that feed files will never be updated once they’ve been saved. A feed mapping can generate new feed mappings in three different ways. It can create a copy of itself with the same ID but a different temporary filename. It can generate a new feed mapping with an incremented ID (and different filename). Finally, it can create a copy with the same ID and a permanent, archive filename—as opposed to a temporary filename—based on that same ID.
A feed builder’s primary responsibility is to create a recent
events feed. Its CreateRecentEventsFeed(…) method is shown in
Example 7-22.
Example 7-22. Creating an in-memory representation of a new feed
public RecentEventsFeed CreateRecentEventsFeed(FeedMapping mapping,
IPrevArchiveLinkGenerator prevArchiveLinkGenerator)
{
SyndicationFeed feed = new SyndicationFeed
{
Id = new UniqueId(Guid.NewGuid()).ToString(),
Title = SyndicationContent.CreatePlaintextContent(Title),
Generator = ServiceName,
LastUpdatedTime = DateTime.Now,
Items = new List<SyndicationItem>()
};
feed.Authors.Add(new SyndicationPerson {Name = ServiceName});
feed.Links.Add(links.CreateRecentFeedSelfLink());
feed.Links.Add(links.CreateViaLink(mapping.Id));
prevArchiveLinkGenerator.AddTo(feed, links);
return new RecentEventsFeed(feed, mapping, this);
}CreateRecentEventsFeed(…)
accepts a feed mapping and an object that implements IPrevArchiveLinkGenerator. Depending on its
underlying implementation, this latter parameter will either add a
prev-archive link to the generated
feed or do nothing. The very first feed to be generated doesn’t
require a prev-archive link, but
all the others do.
CreateRecentEventsFeed(…)
uses the .NET Framework’s SyndicationFeed to build the feed. SyndicationFeed is one of many classes in
the System.ServiceModel.Syndication
that together make up a media type library for constructing and
parsing Atom feeds. CreateRecentEventsFeed(…) initializes a new
syndication feed with some feed-level metadata. It then adds a
self link and a via link, and uses the prevArchiveLinkGenerator parameter to add a
prev-archive link.
Feed builders are also responsible for creating individual Atom
entries. FeedBuilder.CreateEntry(…), which is shown
in Example 7-23, initializes
a SyndicationItem and sets its
Id, Title, and LastUpdatedTime properties. Note that the
entry’s ID value is computed using the same Tag
scheme we used in our Java solution. After creating and adding
self and related links (the self link is a standalone URI for the entry,
the related link the URI of the
domain entity to which the event refers), CreateEntry(…) serializes the supplied event
to the entry’s Content
property.
Example 7-23. FeedBuilder.CreateEntry(…) method
public Entry CreateEntry(Event evnt)
{
SyndicationItem item = new SyndicationItem
{
Id = string.Format("tag:restbucks.com,{0}:{1}",
evnt.Timestamp.ToString("yyyy-MM-dd"), evnt.Id),
Title = SyndicationContent.CreatePlaintextContent(evnt.Subject),
LastUpdatedTime = evnt.Timestamp
};
item.Links.Add(links.CreateEntrySelfLink(new Id(evnt.Id)));
item.Links.Add(links.CreateEntryRelatedLink(evnt.Body.Href));
item.Content = new XmlSyndicationContent(evnt.Body.ContentType,
evnt.Body.Payload, null as DataContractSerializer);
return new Entry(item, new Id(evnt.Id).CreateFileName());
}FeedBuilder exposes three
more public methods:
LoadRecentEventsFeed(…)CreateNextRecentEventsFeed(…)CreateArchiveFeed(…)
The first of these, LoadRecentEventsFeed(…), uses an IFileSystem implementation to load a feed
from the current directory, as shown in Example 7-24. With the file
contents loaded into a syndication feed, the method parses out the
resource ID from the feed’s via
link and uses this to create a new feed mapping. It then uses the new
mapping to initialize a new RecentEventsFeed. This ensures that the
returned feed retains the loaded feed’s resource ID, but is given a
new temporary filename.
Example 7-24. Loading a feed from the filesystem
public RecentEventsFeed LoadRecentEventsFeed(IFileSystem fileSystem,
FileName fileName)
{
using (XmlReader reader = fileSystem.CurrentDirectory.GetXmlReader(fileName))
{
SyndicationFeed feed = SyndicationFeed.Load(reader);
Id id = links.GetIdFromFeedUri(feed.GetViaLink().GetAbsoluteUri());
return new RecentEventsFeed(feed, new FeedMapping(id), this);
}
}CreateNextRecentEventsFeed(…), which is
shown in Example 7-25,
takes a feed mapping belonging to the current recent events feed and
uses it to initialize a PrevArchiveLinkGenerator. This generator can
then be used to generate prev-archive links that point to the feed
associated with the mapping. It can
also be used to generate a new mapping containing the
next resource ID. The new feed mapping and the
link generator instance are used to call CreateRecentEventsFeed(…), which creates a
new RecentEventsFeed.
Example 7-25. Creating the next recent events feed
public RecentEventsFeed CreateNextRecentEventsFeed(FeedMapping mapping)
{
return CreateRecentEventsFeed(
mapping.WithNextId(), new PrevArchiveLinkGenerator(mapping.Id));
}Example 7-26 shows the
implementation of CreateArchiveFeed(…). This method takes a
syndication feed and feed mapping belonging to the feed to be
archived, together with a mapping belonging to the next recent events
feed, and uses them to create an ArchiveFeed based on a clone of the supplied
feed.
Example 7-26. Creating an archive feed
public ArchiveFeed CreateArchiveFeed(SyndicationFeed feed,
FeedMapping currentMapping, FeedMapping nextMapping)
{
SyndicationFeed archive = feed.Clone(true);
archive.GetSelfLink().Uri = archive.GetViaLink().Uri;
archive.Links.Remove(archive.GetViaLink());
archive.Links.Add(links.CreateNextArchiveLink(nextMapping.Id));
archive.ElementExtensions.Add(new SyndicationElementExtension(
"archive", "http://purl.org/syndication/history/1.0", string.Empty));
return new ArchiveFeed(archive, currentMapping.WithArchiveFileName());
}To create an archive feed from a recent events feed, CreateArchiveFeed(…) first clones the
supplied syndication feed. It then copies the cloned feed’s via link value into a new self link and removes the via link from the feed. Next, it adds a
next-archive link that points to
the next recent events feed. Finally, it adds an <archive> extension element.
Requests are handled by a NotificationsService object, which is hosted
by an instance of ServiceHost. The
service host encapsulates all the HTTP plumbing. In our
implementation, this means using a System.Net.HttpListener object to listen for
requests and send responses.
Example 7-27
shows the service host’s HandleRequest(…) method. This method is
dispatched to a thread from the .NET thread pool with each
request.
Example 7-27. ServiceHost.HandleRequest(…) wraps requests and applies responses to the output
private void HandleRequest(HttpListenerContext context)
{
Log.DebugFormat("{0} {1}", context.Request.HttpMethod, context.Request.RawUrl);
IResponse response = service.GetResponse(
new HttpListenerRequestWrapper(context.Request));
using (IResponseWrapper wrapper =
new HttpListenerResponseWrapper(context.Response))
{
response.ApplyTo(wrapper);
}
}HandleRequest(…) translates
between the requests and responses used by the service logic and the
request and response objects belonging to the HTTP plumbing. The method wraps the
request and response objects provided by the HttpListenerContext with simple wrapper
objects so as to prevent HttpListener specifics from leaking into the
rest of the service code. Doing so supports rapid test-driven
development because it allows the service implementation to be tested
without depending on any HTTP plumbing or
connectivity.
The service host itself simply translates between the HTTP
infrastructure and the service implementation. The real request
handling logic is implemented in NotificationsService.GetResponse(…), as
shown in Example 7-28.
Example 7-28. The notifications service handles requests
public IResponse GetResponse(IRequestWrapper request)
{
Log.DebugFormat("Received request. Uri: [{0}].", request.Uri.AbsoluteUri);
try
{
IRepositoryCommand command = routes.CreateCommand(request.Uri);
IRepresentation representation = command.Invoke(repository);
return request.Condition.CreateResponse(representation);
}
catch (ServerException ex)
{
Log.ErrorFormat("Server exception. {0}", ex.Message);
return Response.InternalServerError();
}
catch (InvalidUriException ex)
{
Log.WarnFormat("Invalid request. {0}", ex.Message);
return Response.NotFound();
}
catch (NotFoundException ex)
{
Log.WarnFormat("Invalid request. {0}", ex.Message);
return Response.NotFound();
}
}GetResponse(…) implements the
conditional GET HTTP
idiom. To implement a conditional GET,
GetResponse(…) first fetches a representation from a
repository. It then supplies this representation to the condition
specified in the request. This condition creates and returns a
response, which is handed back to the host for applying to the
response stream. We’ll look at how this condition is generated, and
how it determines whether to return 200 OK or
304 Not Modified, in more detail shortly. Before we
do that, let’s look at how the repository command is created.
Every feed has a unique URI. The notifications service uses
this URI to create a command that can retrieve a feed representation
from a repository. The logic for creating a command from a URI is
encapsulated in a Routes object,
which matches the request URI with some service-specific URI
templates. Example 7-29
shows the implementation of Routes
in its entirety.
Example 7-29. Routes creates repository functions based on request URIs
public class Routes
{
private readonly Uri baseAddress;
private readonly UriTemplateTable uriTemplates;
private static readonly Func<NameValueCollection, IRepositoryCommand>
GetFeedOfRecentEvents =
parameters => GetFeedOfRecentEventsCommand.Instance;
private static readonly Func<NameValueCollection, IRepositoryCommand>
GetFeed =
parameters => new GetFeedCommand(
new ResourceId(parameters.GetValues("id")[0]));
public Routes(UriConfiguration uriConfiguration)
{
Check.IsNotNull(uriConfiguration, "uriConfiguration");
baseAddress = uriConfiguration.BaseAddress;
uriTemplates = new UriTemplateTable(baseAddress);
uriTemplates.KeyValuePairs.Add(new KeyValuePair<UriTemplate, object>(
uriConfiguration.RecentFeedTemplate, GetFeedOfRecentEvents));
uriTemplates.KeyValuePairs.Add(new KeyValuePair<UriTemplate, object>(
uriConfiguration.FeedTemplate, GetFeed));
}
public Uri BaseAddress
{
get { return baseAddress; }
}
public IRepositoryCommand CreateCommand(Uri uri)
{
UriTemplateMatch match = uriTemplates.MatchSingle(uri);
if (match == null)
{
throw new InvalidUriException(string.Format("Invalid uri: [{0}]",
uri.AbsoluteUri));
}
var commandFactoryMethod = (Func<NameValueCollection, IRepositoryCommand>)
match.Data;
return commandFactoryMethod.Invoke(match.BoundVariables);
}
}GetFeedOfRecentEvents and
GetFeed are static functions, both
of which accept a NameValueCollection parameter and return a
command. In the case of GetFeedCommand, this command is initialized
with a ResourceId based on an
id value in the parameters
collection.
The constructor for Routes
associates these functions with UriTemplates by adding them to a UriTemplateTable object. When it receives a
request, CreateCommand(…) matches
the request URI with a template in this table. If it finds a match, it
invokes the associated function, passing in any variables parsed out
of the request URI. The command returned from this invocation becomes
the return value for CreateCommand(…).
At startup, the notifications service is initialized with a
repository, which is then passed to this command. With each request,
the repository queries the underlying store and returns a
representation object, which the notifications service then hands to
the condition (If-None-Match)
supplied in the request. This condition is responsible for creating a
Response object.
In Example 7-27, we saw that
the response returned by NotificationsService.GetResponse(…) is
applied to a wrapped instance of the HttpListener’s outgoing response. This
Response wrapper object applies a
representation to a ResponseContext object and then flushes
this context to the response stream. Example 7-30 shows how this
is implemented.
Example 7-30. Response.ApplyTo(…) applies a response context to an outgoing response
public void ApplyTo(IResponseWrapper responseWrapper)
{
ResponseContext context = new ResponseContext();
context.AddHeader(statusCode);
representation.UpdateContext(context);
context.ApplyTo(responseWrapper);
}In our .NET service, representation data is built up using a
decorator pattern.[85] The representation returned from a repository
comprises one of three feed instances—WorkingFeed, FeedOfRecentEvents, or
ArchiveFeed—plus, in each case,
an inner FileBasedAtomDocument
instance.
As a result of using the decorator pattern, several representation objects contribute HTTP headers and entity body strategies to the response context:
WorkingFeedAdds a short caching policy to the context, plus a response body rewriting strategy that transforms a recent events feed into a working feed
FeedOfRecentEventsSimply adds a short caching policy to the response context
ArchiveFeedAdds a long caching policy
FileBasedAtomDocumentAdds
Content-Type, Last-Modified, andETagHTTP headers to the response context, and a strategy that opens the feed file for reading
Entity body strategies are simply functions that open files
and apply transformations to file contents. By implementing a strategy as a function, we allow its
execution to be deferred until the service is certain it is needed.
While a FileBasedAtomDocument
object may add a function that opens a feed file to the response
context, and a WorkingFeed a
function that transforms feed file contents into a working feed,
neither function will be invoked until the service determines it is
necessary to open a file and write the contents to the response
stream. If the service receives a conditional GET and
determines that the requested feed has not changed since it was last
requested, it skips these functions and writes only the necessary
headers to the output.
As we mentioned, our .NET service supports conditional GET operations as a performance and
scalability optimization. The FileBasedAtomDocument class generates
several representation values, including an entity tag value based on
a feed’s filename and write time, as illustrated in Example 7-31.
Example 7-31. Generating HTTP headers based on file properties
public FileBasedAtomDocument(string fileName,
IChunkingStrategy chunkingStrategy)
{
fileInfo = new FileInfo(fileName);
if (!fileInfo.Exists)
{
throw new NotFoundException(
string.Format("File does not exist. File: [{0}].", fileInfo.FullName));
}
eTag = new ETag(
string.Format(@"""{0}#{1}""", fileInfo.Name, fileInfo.LastWriteTimeUtc.Ticks));
chunking = chunkingStrategy.CreateHeader(fileInfo.Length);
lastModified = new LastModified(fileInfo.LastWriteTimeUtc);
}Because they’re based on file properties rather than the
contents of a file, these entity tag values are relatively cheap to
generate. The service can compare an entity tag value supplied in a
request’s If-None-Match header with
a feed’s current value, and return 304 Not
Modified if the feed hasn’t changed
since it was last requested—all without once having to open and read a
file.
To see how this is implemented, we’ll look at the IfNoneMatch class. As we saw when we looked
at ServiceHost.HandleRequest(…),
every request is wrapped with an object that implements IRequestWrapper. The IRequestWrapper interface exposes an
ICondition property. Example 7-32 shows HttpListenerRequestWrapper’s implementation
of this Condition
property.
Example 7-32. Retrieving an entity tag value from a request
public ICondition Condition
{
get
{
string eTag = request.Headers["If-None-Match"];
if (string.IsNullOrEmpty(eTag))
{
return NullCondition.Instance;
}
Log.DebugFormat("If-None-Match header present. ETag: [{0}].", eTag);
return new IfNoneMatch(new ETag(eTag));
}
}The request member variable
here is an instance of HttpListenerRequest, which is the request as
it comes off the wire. The Condition property parses out the If-None-Match header from this request. If
the header value exists, it returns a new IfNoneMatch object; otherwise, it returns a
NullCondition instance.
Condition objects are responsible for creating responses. As
Example 7-33 shows, an
IfNoneMatch condition object will
return 304 Not Modified if the supplied representation
contains an ETag header and
matching entity tag value, or 200
OK if it doesn’t.
Example 7-33. IfNoneMatch creates a response based on evaluating a condition
public IResponse CreateResponse(IRepresentation representation)
{
HeaderQuery query = new HeaderQuery(eTag);
if (query.Matches(representation))
{
Log.DebugFormat("If-None-Match precondition failed.");
return Response.NotModified();
}
Log.DebugFormat("If-None-Match precondition OK.");
return Response.OK(representation);
}The IfNoneMatch object uses a
HeaderQuery to determine whether
the representation the service is about to write contains a specific
header and header value. Its Matches(…) method is shown in Example 7-34.
Example 7-34. HeaderQuery uses a local response context to determine whether a representation includes a header
public bool Matches(IRepresentation representation)
{
IResponseContext context = new ResponseContext();
representation.UpdateContext(context);
return context.ContainsHeader(header);
}IfNoneMatch is an example of
using a response context for a purpose other than writing to the
output stream. The response context gathers all the headers from the
supplied representation parameter. Matches(…) then uses this context to
determine whether the header exists. Because it doesn’t involve
opening a file or transforming a file’s contents, the context is cheap
to initialize.
In our .NET implementation, the feed writer and the notifications service run on separate threads inside the same process. The only time they need to synchronize is when the feed writer has updated the recent events feed. When that happens, the notifications service needs to know the name of the new temporary file associated with the recent events feed.
To achieve this, the feed writer exposes a FeedMappingsChanged event. This event is
raised when the NotifyingListeners
task calls the notifyMappingsChanged parameter
delegate.
When the service starts, it initializes a repository instance and then subscribes
the repository’s OnFeedMappingsChanged(…) event handler to
the feed writer’s FeedMappingsChanged event. The repository’s
implementation of OnFeedMappingsChanged(…) is shown in Example 7-35.
Example 7-35. A repository’s OnFeedMappingsChanged(…) event handler
public void OnFeedMappingsChanged(object sender,
FeedMappingsChangedEventArgs args)
{
Log.DebugFormat(
"FeedMappingsChanged event. ResourceId: [{0}]. StoreId: [{1}].",
args.RecentEventsFeedResourceId, args.RecentEventsFeedStoreId);
Interlocked.Exchange(ref feedMappings, new FeedMappings(
converter, new ResourceId(args.RecentEventsFeedResourceId),
new StoreId<string>(args.RecentEventsFeedStoreId)));
}A FeedMappings object is
responsible for creating functions that can retrieve a specific feed
file from a backing store based on an understanding of the current
working feed’s ResourceId and the
name of the temporary file containing the recent events feed. The
feedMappings reference changes
atomically each time the repository handles a FeedMappingsChanged event.
Atom, as we’ve seen, can be a powerful tool in our developer toolbox, but it’s not an integration panacea. Originally designed for syndicating news articles and blog entries, Atom has since proven to be applicable in many other areas—integration included. Broadly speaking, it can be used to enrich resource representations with general-purpose metadata, allowing consumers to search, sort, and filter representations without needing to understand their details.
Note
This separation of concerns between Atom and the resources it encapsulates is helpful. It means we can use Atom-specific software for managing and consuming Atom-formatted lists of resources, and more specialized software for handling embedded content only where necessary. In turn, this allows us to implement protocols based entirely on Atom.
Most development platforms today include an Atom library for creating and parsing feeds and entries. But cross-platform support alone isn’t a sufficient reason to choose Atom as a representation format. While it’s tempting to use Atom everywhere, to make every list and collection a feed and every item an entry, there are many situations where Atom is not the most appropriate representation format. If all we need is a list, not the feed metadata, we shouldn’t burden our application with Atom’s information overhead. If we’ve no real need for an entry’s document metadata, we shouldn’t use Atom entries. If we find ourselves populating Atom’s metadata elements with data that’s of no use to clients, or with default or “stub” data, we should consider employing an alternative representation format.
Assuming Atom is appropriate for our integration needs, we may still find we need to extend the format to support some domain- or application-specific requirements. Atom’s metadata elements implement the majority of feed syndication and document description use cases, but it’s still quite common to discover a requirement to extend the format.
There are a couple of options to choose from when extending Atom.
All Atom elements can be extended with new attributes. Many can also be
extended with additional elements. Extending Atom with additional
elements and attributes is called metadata
extensibility. In contrast, content
extensibility involves putting proprietary information inside
an entry’s <atom:content>
element. Content extensibility supports media type composition,
which tends to enforce a stricter separation of concerns.
Our guidelines for choosing between these options are pretty straightforward: use metadata extensions for adding generally applicable, application-agnostic metadata to a feed, and use content extensibility for domain- or application-specific information. In the majority of cases, you’re better off going with content extensibility. The more the Atom format itself is customized for a specific domain, the less the resultant feed and entry documents can be consumed and usefully manipulated by a generic Atom client.
Proprietary extensions to the Atom format can severely limit an application’s reach and longevity. A test of a good extension is to ask whether a client must understand it before it can process a feed or entry successfully. The best extensions accelerate specialized clients, but do not hinder nonspecialized ones. Clients should be able to ignore proprietary elements when processing a feed or entry and still achieve meaningful and useful results.
Add proprietary metadata to the Atom format only when you’re certain it has broad reach and applicability. Evaluate candidate elements in terms of their application agnosticism and their conformance with any existing standards or community initiatives. There’s an obvious parallel here with microformats, which draw on prior art and adapt commonly accepted formats.
Note
The Feed Paging and Archiving specification is a proprietary metadata extension with precisely this mix of application agnosticism and broad reach and applicability. The specification is set out in RFC 5005.
Content extensibility, on the other hand, forces a cleaner separation of responsibilities: Atom clients handle feed and entry metadata, and specialized processors handle the application-specific content, with content dispatched to specialized processors based on its type.
In this chapter, we explored the Atom Syndication Format and used it to develop an event-driven system for propagating product information around Restbucks. In particular, we saw how Atom as a hypermedia format can be used to create a simple protocol that allows consumers to consume both current and historical notifications. We also saw how load can be federated across the network with caches to increase availability and decrease load and response times for the product catalog service and downstream systems.
Atom-based services score highly on Richardson’s service maturity model. Atom feeds and entries advertise service-generated URIs that link to other resources; this is a simple but powerful example of the hypermedia constraint, and is considered level three (the highest level) on the Richardson maturity model.
[74] For extremely low-latency notifications, we might consider proprietary middleware designed for that domain. The trade-off is scalability for latency, but with the added complication of lock-in.
[76] The prev-archive link
relation value is defined in the Feed Paging and Archiving
specification: http://tools.ietf.org/html/rfc5005.
[77] The value of the feed’s <atom:updated> element matches
that of the first entry.
[84] Tag URIs are a way of creating a nonaddressable identifier from an addressable URI scheme such as HTTP. We use them here because events only have to be identifiable, whereas entries have to be addressable. See http://diveintomark.org/archives/2004/05/28/howto-atom-id for more information.