V
The Rate for a Continuous Source
27. Fidelity Evaluation Functions
In the case of a discrete source of information we were able to determine a definite rate of generating information, namely the entropy of the underlying stochastic process. With a continuous source the situation is considerably more involved. In the first place a continuously variable quantity can assume an infinite number of values and requires, therefore, an infinite number of binary digits for exact specification. This means that to transmit the output of a continuous source with exact recovery at the receiving point requires, in general, a channel of infinite capacity (in bits per second). Since, ordinarily, channels have a certain amount of noise, and therefore a finite capacity, exact transmission is impossible.
This, however, evades the real issue. Practically, we are not interested in exact transmission when we have a continuous source, but only in transmission to within a certain tolerance. The question is, can we assign a definite rate to a continuous source when we require only a certain fidelity of recovery, measured in a suitable way. Of course, as the fidelity requirements are increased the rate will increase. It will be shown that we can, in very general cases, define such a rate, having the property that it is possible, by properly encoding the information, to transmit it over a channel whose capacity is equal to the rate in question, and satisfy the fidelity requirements. A channel of smaller capacity is insufficient.
It is first necessary to give a general mathematical formulation of the idea of fidelity of transmission. Consider the set of messages of a long duration, say T seconds. The source is described by giving the probability density, P(x), in the associated space, that the source will select the message in question. A given communication system is described (from the external point of view) by giving the conditional probability Px(y) that if message x is produced by the source the recovered message at the receiving point will be y. The system as a whole (including source and transmission system) is described by the probability function P(x, y) of having message x and final output y. If this function is known, the complete characteristics of the system from the point of view of fidelity are known. Any evaluation of fidelity must correspond mathematically to an operation applied to P(x, y). This operation must at least have the properties of a simple ordering of systems; i.e., it must be possible to say of two systems represented by P1(x, y) and P2(x, y) that, according to our fidelity criterion, either (1) the first has higher fidelity, (2) the second has higher fidelity, or (3) they have equal fidelity. This means that a criterion of fidelity can be represented by a numerically valued evaluation function:
v(P(x, y))
whose argument ranges over possible probability functions P(x, y). The function v(P(x, y)) orders communication systems according to fidelity, and for convenience we take lower values of v to correspond to “higher fidelity.”
We will now show that under very general and reasonable assumptions the function v(P(x, y)) can be written in a seemingly much more specialized form, namely as an average of a function ρ(x, y) over the set of possible values of x and y:
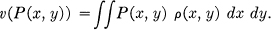
To obtain this we need only assume (1) that the source and system are ergodic so that a very long sample will be, with probability nearly 1, typical of the ensemble, and (2) that the evaluation is “reasonable” in the sense that it is possible, by observing a typical input and output x1 and y1, to form a tentative evaluation on the basis of these samples; and if these samples are increased in duration the tentative evaluation will, with probability 1, approach the exact evaluation based on a full knowledge of P(x, y). Let the tentative evaluation be ρ(x, y). Then the function ρ(x, y) approaches (as T → ∞) a constant for almost all (x, y) which are in the high probability region corresponding to the system:
ρ(x, y) → v(P (x, y))
and we may also write
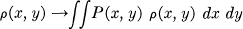
since
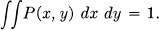
This establishes the desired result.
The function ρ(x, y) has the general nature of a “distance” between x and y.9 It measures how undesirable it is (according to our fidelity criterion) to receive y when x is transmitted. The general result given above can be restated as follows: Any reasonable evaluation can be represented as an average of a distance function over the set of messages and recovered messages x and y weighted according to the probability P(x, y) of getting the pair in question, provided the duration T of the messages be taken sufficiently large.
The following are simple examples of evaluation functions:
- R.M.S. criterion.
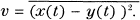
In this very commonly used measure of fidelity the distance function ρ(x, y) is (apart from a constant factor) the square of the ordinary Euclidean distance between the points x and y in the associated function space.
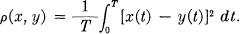
- Frequency weighted R.M.S. criterion. More generally one can apply different weights to the different frequency components before using an R.M.S. measure of fidelity. This is equivalent to passing the difference x(t) — y(t) through a shaping filter and then determining the average power in the output. Thus let
e(t) = x(t) — y(t)
and
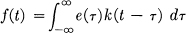
then
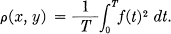
- Absolute error criterion.
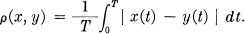
- The structure of the ear and brain determine implicitly a number of evaluations, appropriate in the case of speech or music transmission. There is, for example, an “intelligibility” criterion in which ρ(x, y) is equal to the relative frequency of incorrectly interpreted words when message x(t) is received as y(t). Although we cannot give an explicit representation of ρ(x, y) in these cases it could, in principle, be determined by sufficient experimentation. Some of its properties follow from well-known experimental results in hearing, e.g., the ear is relatively insensitive to phase and the sensitivity to amplitude and frequency is roughly logarithmic.
- The discrete case can be considered as a specialization in which we have tacitly assumed an evaluation based on the frequency of errors. The function ρ(x, y) is then defined as the number of symbols in the sequence y differing from the corresponding symbols in x divided by the total number of symbols in x.
28. The Rate for a Source Relative to a Fidelity Evaluation
We are now in a position to define a rate of generating information for a continuous source. We are given P(x) for the source and an evaluation v determined by a distance function ρ(x, y) which will be assumed continuous in both x and y. With a particular system P(x, y) the quality is measured by
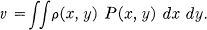
Furthermore the rate of flow of binary digits corresponding to P(x, y) is
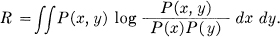
We define the rate R1 of generating information for a given quality v1 of reproduction to be the minimum of R when we keep v fixed at v1 and vary Px(y). That is:
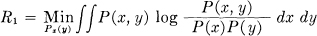
subject to the constraint:
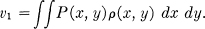
This means that we consider, in effect, all the communication systems that might be used and that transmit with the required fidelity. The rate of transmission in bits per second is calculated for each one and we choose that having the least rate. This latter rate is the rate we assign the source for the fidelity in question.
The justification of this definition lies in the following result:
Theorem 21: If a source has a rate R1 for a valuation v1 it is possible to encode the output of the source and transmit it over a channel of capacity C with fidelity as near v1 as desired provided R1 ≤ C. This is not possible if R1 > C.
The last statement in the theorem follows immediately from the definition of R1 and previous results. If it were not true we could transmit more than C bits per second over a channel of capacity C. The first part of the theorem is proved by a method analogous to that used for Theorem 11. We may, in the first place, divide the (x, y) space into a large number of small cells and represent the situation as a discrete case. This will not change the evaluation function by more than an arbitrarily small amount (when the cells are very small) because of the continuity assumed for ρ(x, y). Suppose that P1(x, y) is the particular system which minimizes the rate and gives R1. We choose from the high probability y's a set at random containing
2(R1 + ∊)T
members where ∊ → 0 as T → ∞. With large T each chosen point will be connected by high probability lines (as in Fig. 10) to a set of x's. A calculation similar to that used in proving Theorem 11 shows that with large T almost all x's are covered by the fans from the chosen y points for almost all choices of the y's. The communication system to be used operates as follows: The selected points are assigned binary numbers. When a message x is originated it will (with probability approaching 1 as T → ∞) lie within at least one of the fans. The corresponding binary number is transmitted (or one of them chosen arbitrarily if there are several) over the channel by suitable coding means to give a small probability of error. Since R1 ≤ C this is possible. At the receiving point the corresponding y is reconstructed and used as the recovered message.
The evaluation v′1 for this system can be made arbitrarily close to v1 by taking T sufficiently large. This is due to the fact that for each long sample of message x(t) and recovered message y(t) the evaluation approaches v1 (with probability 1).
It is interesting to note that, in this system, the noise in the recovered message is actually produced by a kind of general quantizing at the transmitter and is not produced by the noise in the channel. It is more or less analogous to the quantizing noise in PCM.
29. The Calculation of Rates
The definition of the rate is similar in many respects to the definition of channel capacity. In the former
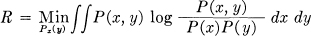
with Px(y) fixed and possibly one or more other constraints (e.g., an average power limitation) of the form K = ∫∫ P(x, y) λ(x, y) dx dy.
A partial solution of the general maximizing problem for determining the rate of a source can be given. Using Lagrange's method we consider
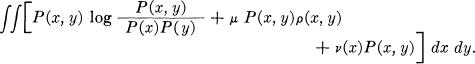
The variational equation (when we take the first variation on P(x, y)) leads to
Py(x) = B(x) e–λρ(x, y)
where λ is determined to give the required fidelity and B(x) is chosen to satisfy
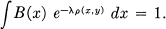
This shows that, with best encoding, the conditional probability of a certain cause for various received y, Py(x) will decline exponentially with the distance function ρ(x, y) between the x and y in question.
In the special case where the distance function ρ(x, y) depends only on the (vector) difference between x and y,
ρ(x, y) = ρ(x — y)
we have
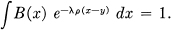
Hence B(x) is constant, say α, and
Py(x) = αe–λρ(x–y).
Unfortunately these formal solutions are difficult to evaluate in particular cases and seem to be of little value. In fact, the actual calculation of rates has been carried out in only a few very simple cases.
If the distance function ρ(x, y) is the mean square discrepancy between x and y and the message ensemble is white noise, the rate can be determined. In that case we have
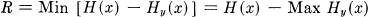
with 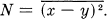 But the Max Hy(x) occurs when y − x is a white noise, and is equal to W1 log 2πeN where W1 is the bandwidth of the message ensemble. Therefore
But the Max Hy(x) occurs when y − x is a white noise, and is equal to W1 log 2πeN where W1 is the bandwidth of the message ensemble. Therefore
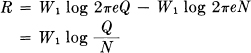
where Q is the average message power. This proves the following:
Theorem 22: The rate for a white noise source of power Q and band W1 relative to an R.M.S. measure of fidelity is
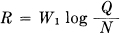
where N is the allowed mean square error between original and recovered messages.
More generally with any message source we can obtain inequalities bounding the rate relative to a mean square error criterion.
Theorem 23: The rate for any source of band W1 is bounded by
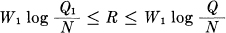
where Q is the average power of the source, Q1 its entropy power and N the allowed mean square error.
The lower bound follows from the fact that the Max Hy(x) for a given 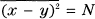 occurs in the white noise case. The upper bound results if we place the points (used in the proof of Theorem 21) not in the best way but at random in a sphere of radius
occurs in the white noise case. The upper bound results if we place the points (used in the proof of Theorem 21) not in the best way but at random in a sphere of radius 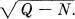 .
.
Acknowledgments
The writer is indebted to his colleagues at the Laboratories, particularly to Dr. H. W. Bode, Dr. J. R. Pierce, Dr. B. McMillan, and Dr. B. M. Oliver for many helpful suggestions and criticisms during the course of this work. Credit should also be given to Professor N. Wiener, whose elegant solution of the problems of filtering and prediction of stationary ensembles has considerably influenced the writer's thinking in this field.
Appendix 1. The Growth of the Number of Blocks of Symbols with a Finite State Condition
Let Ni (L) be the number of blocks of symbols of length L ending in state i. Then we have
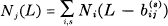
where  are the length of the symbols which may be chosen in state i and lead to state j. These are linear difference equations and the behavior as L → ∞ must be of the type
are the length of the symbols which may be chosen in state i and lead to state j. These are linear difference equations and the behavior as L → ∞ must be of the type
Nj = AjWL.
Substituting in the difference equation
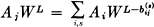
or
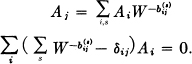
For this to be possible the determinant
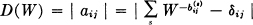
must vanish and this determines W, which is, of course, the largest real root of D = 0.
The quantity C is then given by
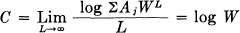
and we also note that the same growth properties result if we require that all blocks start in the same (arbitrarily chosen) state.
Appendix 2. Derivation of H = — ∑ pi log pi
Let 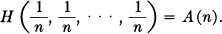 From condition (3) we can decompose a choice from sm equally likely possibilities into a series of m choices each from s equally likely possibilities and obtain
From condition (3) we can decompose a choice from sm equally likely possibilities into a series of m choices each from s equally likely possibilities and obtain
A(sm) = m A(s).
Similarly
A (tn) = n A(t).
We can choose n arbitrarily large and find an m to satisfy
sm ≤ tn < s(m+1).
Thus, taking logarithms and dividing by n log s,
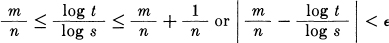
where ∊ is arbitrarily small. Now from the monotonic property of A(n),
A(sm) ≤ A(tn) ≤ A (sm+1)
m A(s) ≤ nA(t) ≤ (m + 1) A (s).
Hence, dividing by nA (s),
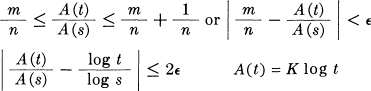
where K must be positive to satisfy (2).
Now suppose we have a choice from n possibilities with commeasurable probabilities 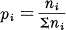 where the ni are integers. We can break down a choice from ∑ni possibilities into a choice from n possibilities with probabilities p1,…, pn and then, if the ith was chosen, a choice from ni with equal probabilities. Using condition (3) again, we equate the total choice from ∑ni as computed by two methods
where the ni are integers. We can break down a choice from ∑ni possibilities into a choice from n possibilities with probabilities p1,…, pn and then, if the ith was chosen, a choice from ni with equal probabilities. Using condition (3) again, we equate the total choice from ∑ni as computed by two methods
K log Σni = H(p1,…, pn) + KΣ pi log ni.
Hence
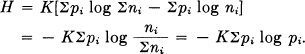
If the pi are incommeasurable, they may be approximated by rationals and the same expression must hold by our continuity assumption. Thus the expression holds in general. The choice of coefficient K is a matter of convenience and amounts to the choice of a unit of measure.
Appendix 3. Theorems on Ergodic Sources
We assume the source to be ergodic so that the strong law of large numbers can be applied. Thus the number of times a given path pij in the network is traversed in a long sequence of length N is about proportional to the probability of being at i, say Pi, and then choosing this path, PipijN. If N is large enough the probability of percentage error ± δ in this is less than ∊ so that for all but a set of small probability the actual numbers lie within the limits
(Pipij ± δ)N.
Hence nearly all sequences have a probability p given by
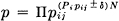
and 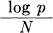 is limited by
is limited by
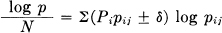
or
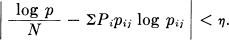
This proves Theorem 3.
Theorem 4 follows immediately from this on calculating upper and lower bounds for n(q) based on the possible range of values of p in Theorem 3.
In the mixed (not ergodic) case if
L = Σ piLi
and the entropies of the components are H1 ≥ H2 ≥…≥ Hn
we have the
Theorem: 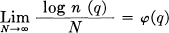 is a decreasing step function,
is a decreasing step function,
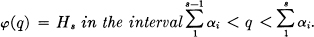
To prove Theorems 5 and 6 first note that FN is monotonic decreasing because increasing N adds a subscript to a conditional entropy. A simple substitution for pBi(Sj) in the definition of FN shows that
FN = N GN — (N — 1) GN-1
and summing this for all N gives  Hence GN ≥ FN and GN monotonic decreasing. Also they must approach the same limit. By using Theorem 3 we see that
Hence GN ≥ FN and GN monotonic decreasing. Also they must approach the same limit. By using Theorem 3 we see that 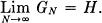 .
.
Appendix 4. Maximizing the Rate for a System of Constraints
Suppose we have a set of constraints on sequences of symbols that is of the finite state type and can be represented therefore by a linear graph, as in Fig. 2. Let lij(s) be the lengths of the various symbols that can occur in passing from state i to state j. What distribution of probabilities Pi for the different states and pij(s) for choosing symbol s in state i and going to state j maximizes the rate of generating information under these constraints? The constraints define a discrete channel and the maximum rate must be less than or equal to the capacity C of this channel, since if all blocks of large length were equally likely, this rate would result, and if possible this would be best. We will show that this rate can be achieved by proper choice of the Pi and pij(s). The rate in question is
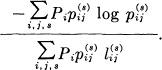
Let
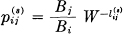
where the Bi satisfy the equations
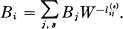
This homogeneous system has a non-vanishing solution since W is such that the determinant of the coefficients is zero:
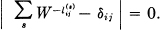
The pij(s) defined thus are satisfactory transition probabilities for in the first place,
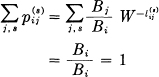
so that the sum of the probabilities from any particular junction point is unity. Furthermore they are non-negative as can be seen from a consideration of the quantities Ai given in Appendix 1. The Ai are necessarily non-negative and the Bi satisfy a similar system of equations but with i and j interchanged. This amounts to reversing the orientation on the lines of the graph.
Substituting the assumed values of pij(s) in the general equation for the rate we obtain
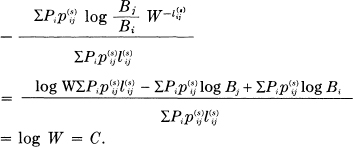
Hence the rate with this set of transition probabilities is C and since this rate could never be exceeded this is the maximum.
Appendix 5
Let S1 be any measurable subset of the g ensemble, and S2 the subset of the f ensemble which gives S1 under the operation T. Then
S1 = TS2.
Let Hλ be the operator which shifts all functions in a set by the time λ. Then
HλS1 = HλTS2 = THλS2
since T is invariant and therefore commutes with Hλ. Hence if m[S] is the probability measure of the set S
m[HλS1] = m[THλS2] = m[HλS2]
= m[S2] = m[S1]
where the second equality is by definition of measure in the g space, the third since the f ensemble is stationary, and the last by definition of g measure again. This shows that the g ensemble is stationary.
To prove that the ergodic property is preserved under invariant operations, let S1 be a subset of the g ensemble which is invariant under Hλ, and let S2 be the set of all functions f which transform into S1. Then
HλS1 = HλTS2 = THλS2 = S1
so that HλS2 is included in S2, for all λ. Now, since
m[HλS2] = m[S2] = m[S1]
this implies
HλS2 = S2
for all λ with m[S2] ≠ 0, 1. This contradiction shows that S1 does not exist.
Appendix 6
The upper bound,  3 ≤ N1 + N2, is due to the fact that the maximum possible entropy for a power N1 + N2 occurs when we have a white noise of this power. In this case the entropy power is N1 + N2.
3 ≤ N1 + N2, is due to the fact that the maximum possible entropy for a power N1 + N2 occurs when we have a white noise of this power. In this case the entropy power is N1 + N2.
To obtain the lower bound, suppose we have two distributions in n dimensions p(xi) and q(xi) with entropy powers 1 and 2. What form should p and q have to minimize the entropy power 3 of their convolution r(xi):
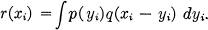
The entropy H3 of r is given by
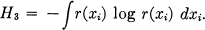
We wish to minimize this subject to the constraints
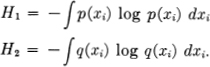
We consider then
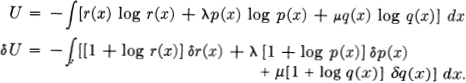
If p(x) is varied at a particular argument xi = si, the variation in r(x) is
δr(x) = q(xi — si)
and
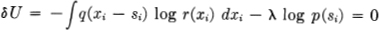
and similarly when q is varied. Hence the conditions for a minimum are
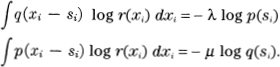
If we multiply the first by p(si) and the second by q(si) and integrate with respect to si we obtain
H3 = — λ H1
H3 = — μ H2
or solving for λ and μ and replacing in the equations
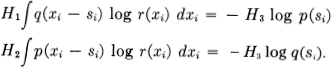
Now suppose p(xi) and q(xi) are normal
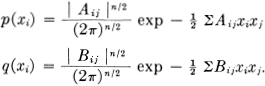
Then r(xi) will also be normal with quadratic form Cij. If the inverses of these forms are aij, bij, cij then
cij = aij + bij.
We wish to show that these functions satisfy the minimizing conditions if and only if aij = Kbij and thus give the minimum H3 under the constraints. First we have
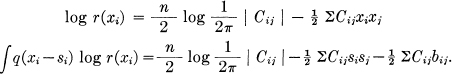
This should equal
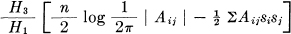
which requires 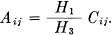 .
.
In this case 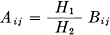 and both equations reduce to identities.
and both equations reduce to identities.
Appendix 7
The following will indicate a more general and more rigorous approach to the central definitions of communication theory. Consider a probability measure space whose elements are ordered pairs (x, y). The variables x, y are to be identified as the possible transmitted and received signals of some long duration T. Let us call the set of all points whose x belongs to a subset S1 of x points the strip over S1, and similarly the set whose y belong to S2 the strip over S2. We divide x and y into a collection of non-overlapping measurable subsets Xi and Yi approximate to the rate of transmission R by
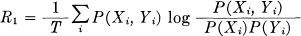
where
P(Xi) is the probability measure of the strip over Xi
P(Yi) is the probability measure of the strip over Yi
P(Xi, Yi) is the probability measure of the intersection of the strips.
A further subdivision can never decrease R1. For let X1 be divided into X1 = X′1 + X″1 and let
| P(Y1) = a P(X′1) = b P(X″1) = c |
P(X1) = b + c P(X′1, Y1) = d P(X″1, Y1) = e |
|
| P(X1, Y1) = d + e. | ||
Then in the sum we have replaced (for the Xl, Y1 intersection)
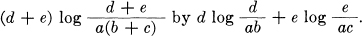
It is easily shown that with the limitation we have on b, c, d, e,
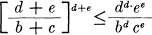
and consequently the sum is increased. Thus the various possible subdivisions form a directed set, with R monotonic increasing with refinement of the subdivision. We may define R unambiguously as the least upper bound for the R1 and write it
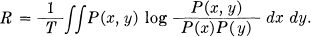
This integral, understood in the above sense, includes both the continuous and discrete cases and of course many others which cannot be represented in either form. It is trivial in this formulation that if x and u are in one-to-one correspondence, the rate from u to y is equal to that from x to y. If v is any function of y (not necessarily with an inverse) then the rate from x to y is greater than or equal to that from x to v since, in the calculation of the approximations, the subdivisions of y are essentially a finer subdivision of those for v. More generally if y and v are related not functionally but statistically, i.e., we have a probability measure space (y,v), then R(x,v) ≤ R(x,y). This means that any operation applied to the received signal, even though it involves statistical elements, does not increase R.
Another notion which should be defined precisely in an abstract formulation of the theory is that of “dimension rate,” that is the average number of dimensions required per second to specify a member of an ensemble. In the band limited case 2W numbers per second are sufficient. A general definition can be framed as follows. Let fα(t) be an ensemble of functions and let ρT[fα(t), fβ(t)] be a metric measuring the “distance” from fα to fβ over the time T (for example the R.M.S. discrepancy over this interval). Let N(∊, δ, T) be the least number of elements f which can be chosen such that all elements of the ensemble apart from a set of measure δ are within the distance ∊ of at least one of those chosen. Thus we are covering the space to within ∊ apart from a set of small measure δ. We define the dimension rate λ for the ensemble by the triple limit
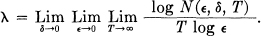
This is a generalization of the measure type definitions of dimension in topology, and agrees with the intuitive dimension rate for simple ensembles where the desired result is obvious.
9 It is not a “metric” in the strict sense, however, since in general it does not satisfy either ρ(x, y) = ρ(y, x) or ρ(x, y) + ρ(y, z) ≥ ρ(x, z).