W tym rozdziale zostaną omówione wybrane zagadnienia wstępne, które koniecznie należy poznać przed lekturą dalszej części niniejszej książki — jak to się mówi: trzeba raczkować, zanim zacznie się chodzić, i chodzić, zanim zacznie się jeździć na rowerze. Aby przetestować jakikolwiek przykład podany w tej książce, trzeba będzie umieć go skompilować i uruchomić Javę, dlatego też rozpocznę od przedstawienia kilku sposobów wykonania tych czynności — z wykorzystaniem JDK, zintegrowanych środowisk programistycznych, tak zwanych IDE (ang. Integrated Development Environment), oraz narzędzi do budowania kodu (Ant, Maven itd.). Często pojawiają się także problemy z prawidłowym określeniem wartości zmiennej środowiskowej CLASSPATH — opiszę więc także to zagadnienie. Kolejną sprawą, którą się zajmę, będzie unikanie komunikatów o odrzuconych metodach, które często się pojawiają w przypadku korzystania ze „starego” kodu. Na samym końcu rozdziału podam informacje o kompilacji warunkowej, testach jednostkowych, stosowaniu asercji oraz testowaniu aplikacji.
Jeśli Czytelnik jeszcze nie zainstalował Javy na swoim komputerze, to będzie musiał ją pobrać. Trzeba przy tym pamiętać, że istnieje kilka różnych plików związanych z językiem Java, które można pobrać z jego witryny. JRE (ang. Java Runtime Environment — środowisko wykonawcze Javy) to mniejszy plik przeznaczony dla użytkowników końcowych. Pełne środowisko programistyczne, określane jako JDK lub Java SDK, jest dostarczane w formie większego pliku, który będzie nam potrzebny, jeśli chcemy pisać programy w Javie.
Standardowe wersje Javy można obecnie pobrać z witryny firmy Oracle: http://www.oracle.com/technetwork/java/javase/downloads/index.html.
Czasami w witrynie http://java.net/ można także znaleźć wstępne wersje kolejnych głównych wersji języka Java. Niemal cały JDK jest udostępniany w formie projektu o otwartym kodzie źródłowym — i to właśnie kody OpenJDK są używane (wraz z pewnymi dodatkami i modyfikacjami) podczas tworzenia komercyjnych wersji JDK udostępnianych przez firmę Oracle.
Jeśli Czytelnik już korzysta z jakiegoś zintegrowanego środowiska programistycznego i umie się nim posługiwać, to prawdopodobnie zdecyduje się pominąć całość lub niektóre fragmenty informacji zamieszczonych w tym rozdziale. Zostały one podane, aby przed przejściem do kolejnych zagadnień każdy był w stanie kompilować i testować programy pisane w języku Java.
Jest to jedno z niewielu zagadnień, w których znaczenia nabiera używany system operacyjny, co koliduje nieco z ideą przenośności oprogramowania pisanego w języku Java. Postarajmy się zatem rozwiązać ten problem.
Użycie Java Development Kit (w skrócie JDK) — zestawu narzędzi programistycznych obsługiwanych z poziomu wiersza poleceń systemu — może być jednym z najlepszych sposobów pozwalających na wykorzystanie najnowszych usprawnień wprowadzanych w języku Java. Bez wątpienia JDK nie zawiera najszybszego z dostępnych kompilatorów; kompilator ten jest bowiem napisany w Javie i interpretowany w momencie uruchamiania, jest to zatem dobre początkowe rozwiązanie, choć niezbyt optymalne pod względem szybkości tworzenia oprogramowania. Niemniej w przypadku korzystania z JDK firmy Sun (czyli Java SDK) polecenie javac służy do kompilowania programów, a polecenie java do ich uruchamiania. Poniżej zostały przedstawione stosowne przykłady:
C:\javasrc>javac HelloWorld.java C:\javasrc>java HelloWorld Witaj, świecie C:\javasrc>
Jak się można domyślić na podstawie informacji wyświetlanych przez kompilator (a raczej ich braku), działa on zgodnie z zasadą: „brak wiadomości jest dobrą wiadomością”, znaną z systemu Unix. Jeśli program był w stanie wykonać to, o co został poproszony, nie powinien zaprzątać uwagi użytkownika wyświetlaniem komunikatów informujących, że wykonał zadane czynności. Wiele osób korzysta z tego kompilatora lub programów wzorowanych na nim.
Dostępna jest także dodatkowa, opcjonalna zmienna środowiskowa o nazwie CLASSPATH, która dokładniej zostanie opisana w „1.4. Efektywne wykorzystanie zmiennej środowiskowej CLASSPATH”. Zmienna ta określa miejsca, w których Java szuka klas. Programy javac oraz java korzystają z wartości tej zmiennej, o ile została ona określona. We wcześniejszych wersjach Javy konieczne było dodanie do zmiennej CLASSPATH łańcucha ".", nawet jeśli uruchamiało się prosty program przechowywany w bieżącym katalogu. W nowszych implementacjach języka Java nie jest to już konieczne.
Kompilator javac — opracowany niegdyś przez firmę Sun, a obecnie rozwijany przez Oracle — jest oficjalną implementacją wzorcową kompilatora Javy. Dostępnych jest kilka alternatywnych „otwartych” kompilatorów, takich jak Jikes lub Kaffe, jednak znaczna część z nich nie jest już aktywnie rozwijana.
Dostępne są także rozwiązania wzorowane na środowisku wykonawczym Javy, takie jak Apache Harmony, Japhar lub środowisko Jikes opracowane przez firmę IBM (i dostępne w witrynie o tej samej nazwie), a nawet JNode — kompletny system operacyjny napisany w całości w Javie; jednak od czasu kiedy JVM firmy Sun/Oracle zostało udostępnione na zasadach oprogramowania otwartego (GPL), większość z tych projektów przestała być rozwijana. Projekt Harmony został zawieszony przez Fundację Apache w październiku 2011 roku, choć niektóre jego elementy wciąż są używane (na przykład elementy biblioteki uruchomieniowej Java SE projektu Harmony są używane w popularnym systemie operacyjnym dla urządzeń mobilnych — Android).
Narzędzia dostępne w JDK są obsługiwane wyłącznie z poziomu wiersza poleceń systemu. Na drugim krańcu spektrum „wiersz poleceń a narzędzia wizualne” znajdują się komputery Apple Macintosh. O tym, jak wspaniałe są komputery Macintosh, napisano wiele książek i nie mam zamiaru uczestniczyć w tej debacie. System Mac OS X (wersja 10.x systemu Mac OS) został stworzony na bazie systemu BSD Unix (oraz jądra Mach). Oznacza to, że dysponuje on zwyczajnym wierszem poleceń (aplikacja Terminal jest dostępna w menu /Aplikacje/Narzędzia), jak również tradycyjnymi narzędziami dostępnymi w systemie Mac OS. Java SE 6 została udostępniona przez firmę Apple i można ją pobrać przy użyciu mechanizmu aktualizacji. Wraz z pojawieniem się wersji Java 7 firma Apple przekazała rozwój oprogramowania języka Java na swoich komputerach firmie Oracle; zatem to z jej witryny można obecnie pobierać wszelkie pliki związane z językiem Java (Czytelnicy tej książki nie powinni jednak pobierać wersji JRE). Więcej informacji na temat wersji Javy przygotowywanych przez Oracle dla systemu Max OS X można znaleźć na stronie http://www.java.com/en/download/faq/java_mac.xml.
Użytkownicy systemu Mac OS X mogą korzystać zarówno z narzędzi JDK obsługiwanych z poziomu wiersza poleceń, jak i z programów takich jak Ant (patrz „1.6. Automatyzacja kompilacji przy użyciu programu Ant”). Skompilowane pliki klasowe można następnie spakować w formie „klikalnych aplikacji”, używając w tym celu programu Jar Bundler przedstawionego w „21.5. Uruchamianie programu zapisanego w pliku JAR”. Ewentualnie można także skorzystać z jednego z wielu dostępnych zintegrowanych środowisk programistycznych opisanych w „1.3. Kompilacja, uruchamianie i testowanie programów przy użyciu IDE”.
Jesteśmy znużeni korzystaniem z narzędzi obsługiwanych z poziomu wiersza poleceń, jednak jeszcze nie jesteśmy gotowi, by skorzystać ze zintegrowanego środowiska programistycznego.
To znacznie mniej niż zintegrowane środowisko programistyczne (przedstawione w następnej recepturze), a jednocześnie znacznie więcej niż narzędzia obsługiwane z poziomu wiersza poleceń. A zatem czym jest taki program? Jest to edytor wyposażony w narzędzia ułatwiające tworzenie programów w Javie. Do programów tego typu zaliczyć można: TextPad (http://www.textpad.com/), Visual SlickEdit oraz wiele innych niedrogich edytorów (w większości przypadków przeznaczonych do użycia w systemach Windows) wyposażonych w narzędzia ułatwiające pisanie programów w języku Java i umożliwiające ich kompilację bezpośrednio z edytora. Program TextPad rozpoznaje całkiem sporo plików, w tym pliki wsadowe, skrypty powłoki, C, C++, Java, JSP, JavaScript oraz wiele innych. Dla każdego z tych typów program używa opcji kolorowania syntaktycznego, pokazującej, które fragmenty edytowanego pliku są słowami kluczowymi, komentarzami, łańcuchami znaków zapisanymi w cudzysłowach itd. Kolorowanie syntaktyczne jest niezwykle przydatne przy sprawdzaniu, czy jakiś fragment kodu nie został uznany za komentarz (poprzez pominięcie odpowiedniego symbolu kończącego) lub łańcuch znaków.
Bez wątpienia możliwości oferowane przez programy tego typu nie dorównują narzędziom, w jakie są wyposażone zintegrowane środowiska programistyczne (IDE), jednak praktyka pokazuje, że i tak są w stanie ogromnie poprawić efektywność pracy programistów. Program TextPad dysponuje także poleceniami umożliwiającymi skompilowanie kodu Javy oraz uruchomienie zewnętrznego programu. Są one w stanie przechwytywać wszelkie komunikaty generowane w oknie wiersza poleceń i wyświetlać je bezpośrednio w programie, co w niektórych systemach operacyjnych może znacznie ułatwiać pracę w porównaniu z wykorzystywaniem standardowego okna wiersza poleceń. Jednak z drugiej strony takie rozwiązanie sprawia, że nie można obserwować wyników wyświetlanych w oknie wiersza poleceń aż do momentu zakończenia wykonywania programu. Przysparza to problemów, na przykład gdy aplikacja wykorzystująca graficzny interfejs użytkownika zgłosi jakiś wyjątek jeszcze przed zamknięciem swojego okna głównego. Oprócz tych niewielkich niedogodności TextPad jest bardzo przydatnym narzędziem. Inne edytory dysponujące opcją kolorowania syntaktycznego to: vim (rozbudowana wersja edytora vi dostępnego w systemach Unix — program vim jest dostępny zarówno w wersji przeznaczonej dla systemów Unix, jak i Windows; można go znaleźć pod adresem http://www.vim.org/), bardzo popularny edytor Emacs i wiele, wiele innych.
A skoro już jesteśmy przy edytorze Emacs, to wziąwszy pod uwagę ogromne możliwości rozszerzania, jakie on zapewnia, nie jest żadnym zaskoczeniem, że wyposażono go w rozbudowane możliwości pisania w języku Java. Jednym z przykładów takich narzędzi jest Java Development Environment for Emacs (JDEE, http://jdee.sourceforge.net/) oraz tryb pracy „major mode” (jde-mode, bazujący na c-mode) udostępniający dodatkowe opcje menu, takie jak Generate Getters/Setters. Można uznać, że JDEE to coś pośredniego pomiędzy edytorem wyposażonym w mechanizmy kolorowania składni oraz zintegrowanym środowiskiem programistycznym.
Nawet bez JDEE edytor Emacs dysponuje narzędziem dabbrev-expand, które zapewnia możliwość uzupełniania nazw metod i klas. Bazuje ono jednak tylko na zawartości aktualnego bufora edytora, nie pozwala zatem na uzupełnianie nazw klas i metod dostępnych w standardowym API lub w zewnętrznych plikach JAR. Aby uzyskać takie możliwości funkcjonalne, trzeba skorzystać ze zintegrowanego środowiska programistycznego (IDE), jednego z tych, które przedstawiłem w „1.3. Kompilacja, uruchamianie i testowanie programów przy użyciu IDE”.
Wykonywanie różnych czynności programistycznych przy użyciu kilku odrębnych narzędzi jest bardzo niewygodne.
Należy użyć zintegrowanego środowiska programistycznego (IDE), które zapewnia możliwość edycji kodu, jego testowania, kompilacji, wykonywania, debugowania i zarządzania pakietami.
Wielu programistów uważa, że korzystanie z kilku niezależnych narzędzi — edytora, kompilatora, programu służącego do wykonywania skompilowanych programów Javy, nie wspominając już w ogóle o programie uruchomieniowym (patrz „1.12. Wykorzystanie programu uruchomieniowego”) — to zbyt wiele. Zintegrowane środowisko programistyczne (ang. Integrated Development Environment, IDE) łączy wszystkie te narzędzia w jeden zestaw o spójnym graficznym interfejsie użytkownika. Dostępnych jest bardzo wiele zintegrowanych środowisk programistycznych, poczynając od edytorów pozwalających na kompilację i uruchamianie programów napisanych w Javie, a kończąc na w pełni zintegrowanych narzędziach wyposażonych we własne kompilatory i wirtualne maszyny Javy. Przeglądarki klas oraz inne cechy zintegrowanych środowisk programistycznych dodatkowo ułatwiają korzystanie z tych narzędzi. Przeprowadzono już wiele dyskusji na temat tego, czy zintegrowane środowiska programistyczne faktycznie poprawiają efektywność pracy, czy tylko sprawiają, że programiści lepiej się bawią, wykonując te same czynności. Jednak obecnie — ze względu na poprawę wydajności pracy — przeważająca większość programistów korzysta z IDE. Nawet ja, choć zaczynałem jako zagorzały zwolennik narzędzi wykonywanych z poziomu wiersza poleceń, przychylam się do opinii, że ze względu na poniższe zalety zintegrowane środowiska programistyczne faktycznie poprawiają wydajność pracy:
- Uzupełnianie kodu
W myśl mojej zasady, jeśli IDE zna jakąś nazwę, to aby ją umieścić w kodzie, nigdy nie trzeba wpisać więcej niż trzy znaki. Niech resztą wpisywania zajmie się komputer!
- Możliwość „kompilacji przyrostowej”
Pozwala ona na wykrywanie i wyświetlanie błędów kompilacji już w trakcie wpisywania kodu, dzięki czemu aby je poprawić, nie trzeba czekać do momentu kompilacji.
- Refaktoryzacja
To możliwość wprowadzania poważnych zmian w strukturze kodu bez modyfikowania jego działania, i to bez konieczności samodzielnej edycji dziesiątków różnych plików z kodem źródłowym.
Oprócz tych kilku uwag nie mam zamiaru prowadzić dalszej debaty ani porównywać IDE z wykorzystaniem narzędzi uruchamianych z poziomu wiersza poleceń — używam obu tych sposobów pracy, zależnie od bieżących potrzeb i projektu, nad którym pracuję. W dalszej części receptury mam zamiar przedstawić kilka przykładów wykorzystania różnych zintegrowanych środowisk programowania służących do tworzenia oprogramowania w Javie.
Trzema najbardziej popularnymi zintegrowanymi środowiskami programistycznymi do pisania programów w Javie, które działają na wszystkich głównych platformach systemowych oraz kilku rzadziej używanych, są: Eclipse, NetBeans oraz IntelliJ IDEA. Spośród nich najczęściej używany jest program Eclipse, jednak pozostałe dwa także mają liczne grupy oddanych użytkowników. Jeśli Czytelnik pisze aplikacje na platformę Android, to pakiet ADT tradycyjnie już był tworzony właśnie z myślą o Eclipse, choć obecnie jest też dostępna wstępna wersja środowiska Android Studio bazującego na IDE IntelliJ IDEA.
W pierwszej kolejności przyjrzymy się IDE NetBeans. Początkowo zostało ono stworzone przez firmę NetBeans.com i nosiło nazwę Forte. Okazało się tak dobrym produktem, że firma Sun wykupiła NetBeans, a Oracle obecnie udostępnia to środowisko jako otwarte, bezpłatne narzędzie dla programistów używających Javy. Jest to środowisko rozszerzalne i istnieje całkiem sporo wtyczek pozwalających na rozbudowę jego możliwości. Można je pobrać ze strony https://netbeans.org/. Gdyby ktoś potrzebował wsparcia, to oferowany przez firmę Oracle program „Java Development Tools Support” obejmuje wsparcie dla NetBeans, Oracle JDeveloper oraz Oracle Enterprise Pack for Eclipse; więcej informacji na jego temat można znaleźć w sekcji „Professional Support” na stronie https://netbeans.org/kb/support.html. Osoby, które dopiero zaczynają przygodę z Javą, mogą sobie nieco ułatwić życie i jednocześnie pobrać JDK oraz środowisko NetBeans; odpowiednio przygotowane pliki są dostępne w witrynie firmy Oracle — http://www.oracle.com/technetwork/java/javase/downloads/index.html.
NetBeans zawiera wiele różnego rodzaju szablonów. Rysunek 1-1 przedstawia okno dialogowe z wybraną opcją pozwalającą na utworzenie zwyczajnej aplikacji Javy.
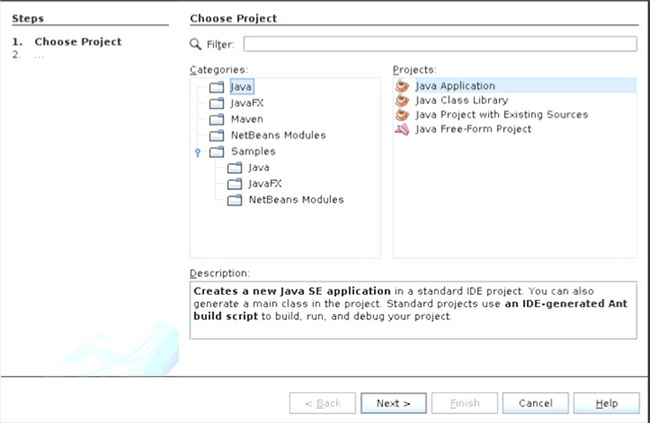
Rysunek 1-2 przedstawia kolejne okno dialogowe, w którym NetBeans pozwala określić nazwy projektu oraz pakietu, do którego będzie należał tworzony program, a także (opcjonalnie) pełną nazwę nowej klasy.
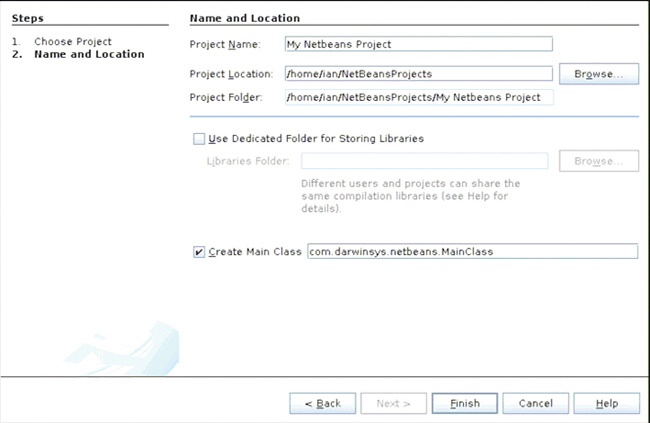
Kolejny rysunek, 1.3, pokazuje IDE z widocznym oknem edycji, w którym można wpisać kod głównej klasy programu.
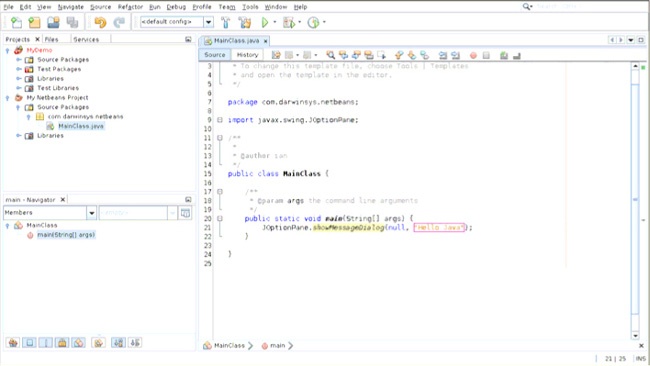
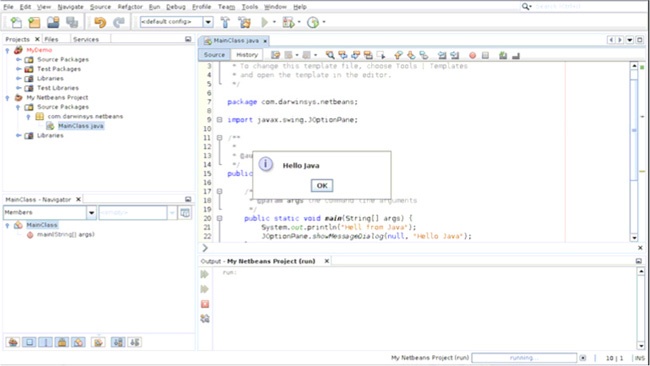
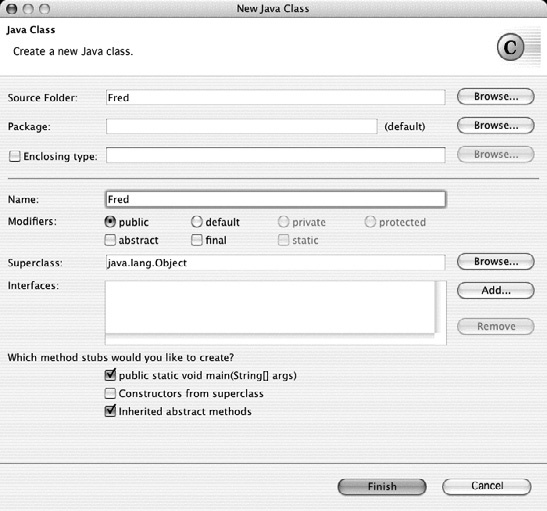
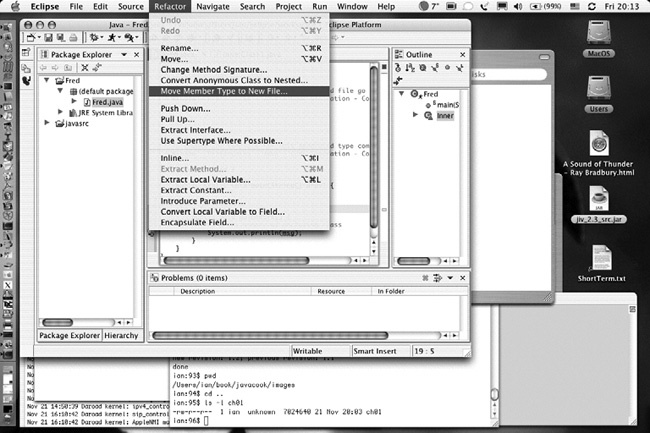
Prawdopodobnie najbardziej popularnym zintegrowanym środowiskiem programistycznym działającym na wielu różnych platformach jest Eclipse. Zostało ono stworzone przez firmę IBM, lecz obecnie jego rozwojem zajmuje się Fundacja Eclipse (http://eclipse.org/), która oprócz tego prowadzi wiele innych projektów programistycznych. Eclipse jest podstawą platformy Rational Application Developer (RAD) firmy IBM, podobnie jak NetBeans stał się podstawą dla środowiska programistycznego Sun Studio. Podczas rozpoczynania tworzenia aplikacji wszystkie zintegrowane środowiska programistyczne dają mniej więcej podobne możliwości; przykładem może być przedstawione na Rysunek 1-5 okno dialogowe New Java Class Eclipse. Środowisko to udostępnia także grupę narzędzi służących do refaktoryzacji, przedstawionych na Rysunek 1-6.
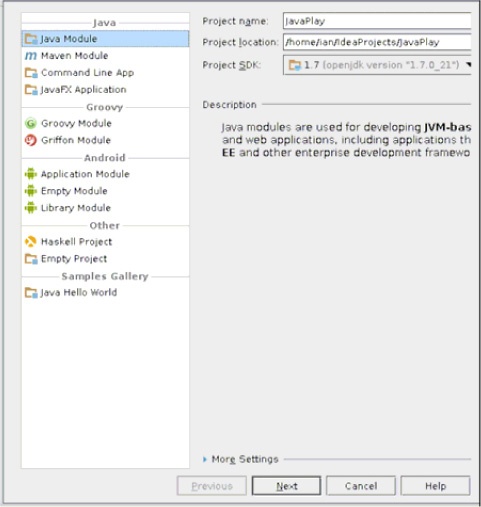
Trzecim z najpopularniejszych zintegrowanych środowisk programistycznych jest IntelliJ IDEA. Także ono jest udostępniane zarówno w wersji bezpłatnej (jako oprogramowanie otwarte), jak i komercyjnej. Środowisko to dzięki możliwości stosowania wtyczek obsługuje wiele różnych języków programowania (w środowisku, którego użyłem do zrobienia zamieszczonych tu rysunków, zainstalowałem wtyczki do pisania programów przeznaczonych dla systemu Android oraz pisania programów w języku Haskell). Pracę w tym środowisku zaczynamy od zdefiniowania nowego projektu, co pokazałem na Rysunek 1-7.
Aby utworzyć nową klasę, należy kliknąć folder zawierający kody źródłowe projektu prawym przyciskiem myszy i wybrać opcję New/Java Class. Na ekranie zostanie wyświetlone okno dialogowe przedstawione na Rysunek 1-8 — należy w nim podać nazwę klasy i określić pakiet, do którego będzie ona należeć.
Początkowo zostanie utworzona pusta klasa. Wystarczy umieścić w niej odpowiedni kod, na przykład nieśmiertelną aplikację typu „Witaj, świecie”, taką jak ta przedstawiona na Rysunek 1-9.

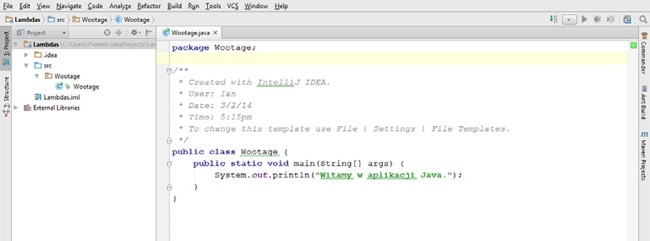
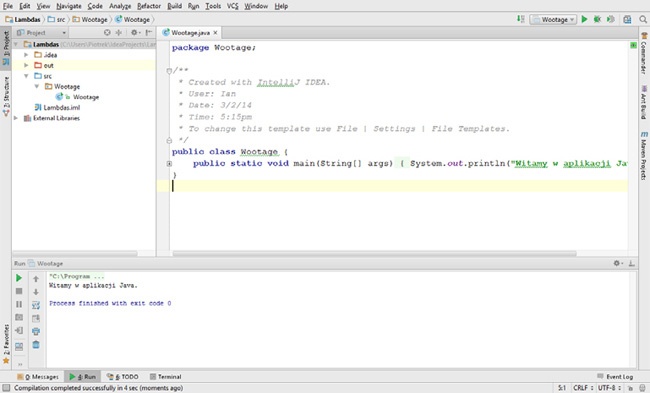
Potem można uruchomić aplikację, klikając zielony przycisk Run lub klikając kod źródłowy klasy i wybierając z menu kontekstowego opcję Run. Jak widać na Rysunek 1-10, także w IntelliJ, podobnie jak w innych zintegrowanych środowiskach programistycznych, wyniki wykonania aplikacji zostaną wyświetlone w oknie konsoli.
W systemie Mac OS X dostępny jest pakiet narzędziowy Developer Tools firmy Apple. Jego głównym elementem jest zintegrowane środowisko programistyczne Xcode. Niestety, jego najnowsza wersja w zasadzie nie pozwala na pisanie programów w języku Java, dlatego też w naszym przypadku polecanie go mija się z celem — środowisko to służy głównie do pisania aplikacji przeznaczonych wyłącznie dla systemów iOS oraz Mac OS X, tworzonych przy użyciu języka Objective-C. Dlatego też, nawet jeśli Czytelnik korzysta z systemu Mac OS X, to w celu pisania aplikacji w Javie będzie musiał użyć jednego z trzech przedstawionych wcześniej IDE.
W jaki sposób wybrać IDE dla siebie? Wziąwszy pod uwagę, że każde z opisanych środowisk programistycznych (Eclipse, NetBeans oraz IntelliJ) można pobrać i używać za darmo, może warto wypróbować je wszystkie i przekonać się, które nam najbardziej odpowiada? Niezależnie od używanej platformy systemowej, jeśli chcemy pisać programy w Javie, będziemy mieli naprawdę szeroki wybór dostępnych narzędzi programistycznych.
W witrynach poświęconych poszczególnym zintegrowanym środowiskom programistycznym można znaleźć aktualną listę dodatkowych zasobów i źródeł informacji, w tym także książek.
Wszystkie najpopularniejsze IDE pozwalają na rozszerzanie swoich możliwości i udostępniają bogatą listę wszelkiego rodzaju wtyczek. Większość z nich pozwala na odnajdywanie i instalowanie wtyczek bezpośrednio z poziomu IDE, choć różnią się pod względem prostoty tego procesu. W ostateczności można samemu napisać wtyczki rozszerzające możliwości tych programów — także to można zrobić w Javie.
Musimy przechowywać nasze pliki klasowe w jednym, wspólnym katalogu bądź też bez większych efektów staramy się użyć zmiennej środowiskowej CLASSPATH.
W zmiennej środowiskowej CLASSPATH należy podać listę katalogów i (lub) plików JAR zawierających wszystkie potrzebne klasy.
Zmienna środowiskowa CLASSPATH to jeden z „ciekawszych” aspektów korzystania z języka Java. Nasze pliki klasowe mogą być przechowywane w dowolnych katalogach, plikach JAR lub ZIP. Analogicznie do zmiennej PATH używanej przez system operacyjny do odnajdywania plików, środowisko wykonawcze Javy używa zmiennej środowiskowej CLASSPATH do odnajdywania klas. Nawet jeśli użyjemy najprostszego polecenia, takiego jak java HelloWorld, interpreter Javy będzie kolejno przeglądał wszystkie katalogi podane w zmiennej CLASSPATH, aż odnajdzie poszukiwaną klasę. Przeanalizujmy to na przykładzie.
W systemach, które na to pozwalają (takich jak Microsoft Windows, Unix oraz Max OS X), wartość tej zmiennej można określić w systemie operacyjnym. Robi się to dokładnie w taki sam sposób, w jaki określa się wartości wszystkich innych zmiennych środowiskowych, np. zmiennej PATH. Oprócz tego wartość zmiennej środowiskowej CLASSPATH można także podać w wierszu wywołania; oto przykład:
C:\> java -classpath c:\ian\classes MyProgZałóżmy, że nasza zmienna CLASSPATH ma wartość C:\classes (w systemie Windows) lub ~/classes:. (w systemie Unix; w przypadku systemu Mac OS X wartość tej zmiennej środowiskowej można określić przy użyciu programu JBindery). Załóżmy, że właśnie skompilowaliśmy plik o nazwie HelloWorld.java, dzięki czemu uzyskaliśmy plik HelloWorld.class, i teraz chcemy go wykonać. Jeśli w systemie Unix użyjemy narzędzi śledzących (takich jak trace, strace, truss lub ktrace), to zapewne zauważymy, że program java spróbuje otworzyć (lub sprawdzić) następujące pliki:
jakieś pliki w katalogu JDK;
następnie plik ~/classes/HelloWorld.class, którego zapewne nie znajdzie;
i w końcu plik ./HelloWorld.class, który znajdzie, otworzy i wczyta do pamięci.
Znaczenie niejasnego określenia „jakieś pliki w katalogu JDK” zależy od używanej wersji języka Java. Z plikami wchodzącymi w skład JDK raczej nie należy eksperymentować, lecz jeśli ktoś będzie bardzo ciekawy, to może je znaleźć w katalogu określonym we właściwościach systemowych, a konkretnie we właściwości sun.boot.class.path (informacje na temat właściwości systemowych można znaleźć w „2.2. Pobieranie informacji z właściwości systemowych”).
Załóżmy również, że zainstalowaliśmy archiwum JAR z dodatkowymi klasami używanymi przez nasz program, na przykład darwinsys-api.jar (w nazwie faktycznego pliku może się także pojawić określenie numeru wersji). W takim przypadku zmienna środowiskowa CLASSPATH może przyjąć wartość C:\classes;C:\classes\darwinsys-api.jar;. (w systemie Windows) lub ~/classes:~classes/darwinsys-api.jar;. (w systemie Unix). Należy zwrócić uwagę, że określając wartość tej zmiennej, nazwy plików JAR trzeba podawać jawnie. W odróżnieniu od pojedynczych plików klasowych, umieszczenie archiwum JAR w jednym z katalogów wymienionych w zmiennej środowiskowej CLASSPATH nie sprawi, że zgromadzone w nim klasy staną się dostępne.
Warto także zwrócić uwagę, że niektóre wyspecjalizowane programy (takie jak serwery WWW, na których działają kontenery serwletów) mogą nie używać wspomnianych wcześniej ścieżek — ani ścieżki dostępu do klas środowiska uruchomieniowego Javy, ani ścieżek określonych w zmiennej środowiskowej CLASSPATH. Te serwery aplikacji korzystają zazwyczaj z własnych mechanizmów wczytywania klas (więcej informacji na ten temat można znaleźć w „23.5. Tworzenie nowej klasy od podstaw przy użyciu obiektu ClassLoader”). Na przykład kontenery sieciowe Java EE dodają do ścieżki klas aplikacji katalog WEB-INF/classes oraz wszystkie archiwa JAR umieszczone w katalogu WEB-INF/lib.
A czy istnieje jakiś prosty sposób pozwalający na umieszczanie kompilowanych plików klasowych w katalogu określonym w zmiennej CLASSPATH? Otóż kompilator javac udostępnia opcję -d, która pozwala określić, gdzie mają być zapisywane generowane przez niego pliki. Aby na przykład skorzystać z tej opcji i umieścić plik klasowy HelloWorld w katalogu $HOME/classes, wystarczy użyć następującego polecenia (proszę zwrócić uwagę, że od tej chwili oprócz nazwy klasy będę także grzecznie podawał nazwę pakietu):
javac -d $HOME/classes HelloWorld.java java -cp $HOME/classes starting.HelloWorld Witaj, świecie!
Jeśli tylko ten katalog docelowy będzie podany w zmiennej środowiskowej CLASSPATH, to będzie można uzyskać dostęp do klas niezależnie od bieżącego katalogu. Właśnie to stanowi jedną z największych zalet korzystania z tej zmiennej.
Określanie wartości zmiennej CLASSPATH może być trudne, zwłaszcza gdy (tak jak ja) używamy kilku różnych wersji JVM bądź też jeśli katalogów, w których należy poszukiwać plików JAR, jest kilka. Niektóre dystrybucje systemu Linux udostępniają mechanizm pozwalający na stosowanie różnych „alternatywnych” ustawień. W innych przypadkach można sobie radzić, korzystając z plików wsadowych lub skryptów powłoki. Poniżej przedstawiłem fragment skryptu, którego sam używałem — jest on przeznaczony dla standardowej powłoki systemu Unix (powinien działać w powłokach Bash, Ksh itd.), jednak analogiczne skrypty można napisać dla innych powłok, jak również w formie pliku wsadowego dla systemu DOS:
# Ten plik musi się znaleźć w mojej zmiennej CLASSPATH...
export CLASSPATH=/home/ian/classes/darwinsys-api.jar:
# A to jest pętla for, poszukująca plików .jar, .zip lub
# katalogów podanych w opcji [ -d ... ].
OPT_JARS="$HOME/classes $HOME/classes/*.jar
${JAVAHOME}/jre/lib/ext/*.jar
/usr/local/jars/antlr-3.2.0"
for thing in $OPT_JARS
do
if [ -f $thing ]; then // to musi być plik...
CLASSPATH="$CLASSPATH:$thing"
else if [ -d $thing ]; then // lub katalog.
CLASSPATH="$CLASSPATH:$thing"
fi
done
CLASSPATH="$CLASSPATH:."Powyższy skrypt konstruuje ścieżkę dostępu do plików klasowych, która w najprostszym przypadku będzie określać położenie archiwum darwinsys-api.jar. Oprócz tego skrypt sprawdza listę podanych plików i katalogów, aby upewnić się, że są one dostępne w systemie (używam tego skryptu na kilku komputerach podłączonych do sieci), a na samym końcu zmiennej środowiskowej CLASSPATH umieszcza znak kropki (.).
Ostrzeżenie
Należy pamiętać, że w systemie Unix skrypt powłoki może zmieniać wartość zmiennej środowiskowej, takiej jak CLASSPATH, tylko na własne potrzeby; „powłoka nadrzędna” (czyli używana przez nasz terminal lub okno) nie jest w żaden sposób modyfikowana. Zmiany, które mają mieć charakter trwały, muszą zostać wprowadzone w plikach startowych (takich jak .profile, .bashrs lub inne).
Chcielibyśmy wypróbować przykłady zamieszczone w tej książce lub wykorzystać jedną z klas pomocniczych.
Należy skopiować plik archiwalny zawierający przykłady dołączone do tej książki, rozpakować go i wykonać program Maven (patrz „1.7. Automatyzacja zależności, kompilacji, testowania i wdrażania przy użyciu programu Apache Maven”), aby je skompilować.
Kody źródłowe przykładów zamieszczonych w tej książce pochodzą z kilku repozytoriów, które są bezustannie rozwijane od 1995 roku. Przedstawiłem je w Tabela 1-1.
Tabela 1-1. Główne repozytoria kodu tej książki
Nazwa repozytorium | Adres w serwisie GitHub.com | Opis pakietu | Przybliżona wielkość |
|---|---|---|---|
javasrc | Klasy ze wszystkich API | 1200 klas | |
darwinsys-api | Opublikowane API | 250 klas |
Pewna niewielka liczba przykładów pochodzi z wcześniejszego repozytorium o nazwie javasrcee (Java EE), które wydzieliłem z javasrc ze względu na jego wielkość; także to dodatkowe repozytorium jest dostępne w serwisie GitHub.
Zawartość każdego z tych repozytoriów można pobrać, posługując się adresami URL podanymi w Tabela 1-1. Serwis GitHub pozwala pobierać repozytoria przy użyciu polecenia git clone lub w formie archiwum ZIP, pozwala także przeglądać repozytorium i wyświetlać treść plików na stronach WWW. Preferowanym sposobem pobierania repozytoriów jest skorzystanie z polecenia git clone, gdyż pozwala ono na bardzo łatwe aktualizowanie kodów przy użyciu polecenia git pull. A przy ilości zmian, jakie zostały wprowadzone w związku z udostępnieniem wersji Java 8, można mieć pewność, że jakieś modyfikacje kodów pojawią się także po wydaniu książki.
Czytelnicy, którzy nie znają programu Git, mogą się dowiedzieć czegoś więcej na jego temat w ramce CSV, Subversion, Git, o rany!.
To największe repozytorium, zawierające przede wszystkim kod napisany w celu przedstawienia konkretnej możliwości języka lub interfejsu programistycznego. Pliki tworzące to repozytorium są zgrupowane tematycznie i umieszczone w odrębnych katalogach, których znaczna część odpowiada rozdziałom niniejszej książki; przykładami mogą być katalogi: strings — zawierający przykłady związane z łańcuchami znaków (patrz Rozdział 3.), regexp — zawierający przykłady wykorzystania wyrażeń regularnych (patrz Rozdział 4.), numbers — zawierający przykłady związane z liczbami (patrz Rozdział 5.), i tak dalej.
Repozytorium javasrc składa się z ponad 80 podkatalogów (w katalogu /src/main/java), a to znacznie za dużo, bym mógł je wszystkie przedstawić w treści tej książki. Ich pełną listę można znaleźć w pliku /src/main/java/index-of-directories.txt.
To repozytorium stanowi kolekcję użytecznych narzędzi, które stworzyłem, przenosząc z repozytorium javasrc klasy nadające się do wielokrotnego wykorzystania i przekształcając je we własne API, którego używam w swoich projektach. W niniejszej książce przedstawiam fragmenty kodów z tego repozytorium, a w wielu przykładach importuję pochodzące z niego klasy. Dlatego jeśli ktoś będzie chciał pobierać i kompilować tylko wybrane przykłady z tej książki, powinien w pierwszej kolejności pobrać plik darwinsys-api-1.x.java (z najwyższą dostępną wartością x) i dodać go do zmiennej środowiskowej CLASSPATH. Warto zauważyć, że w przypadku budowania całego repozytorium javasrc przy użyciu IDE Eclipse lub programu Maven można pominąć pobieranie tego archiwum, gdyż główny skrypt Maven zrobi to automatycznie.
To jedyne z moich repozytoriów, które jest dostępne w serwisie Maven Central (http://search.maven.org/); można je znaleźć pod nazwą darwinsys. Jego bieżący artefakt Maven ma postać:
<dependency> <groupId>com.darwinsys</groupId> <artifactId>darwinsys-api</artifactId> <version>1.0.3</version> </dependency>
Ten interfejs programistyczny składa się z ponad 25 pakietów com.darwinsys przedstawionych w Tabela 1-2. Można zauważyć, że ich struktura jest dosyć zbliżona do struktury standardowego API języka Java; ta zbieżność jest zamierzona. Pakiety te zawierają obecnie ponad 200 klas i interfejsów, a większość z nich posiada dokumentację, którą można przeglądać po pobraniu.
Tabela 1-2. Pakiety com.darwinsys
Nazwa pakietu | Opis |
|---|---|
| Przykładowa akcja programu Ant |
| Klasy do obsługi plików zawierających wartości oddzielone przecinkami |
| Klasy służące do wykonywania operacji na bazach danych |
| Klasy ułatwiające porównywanie |
| Ogólne narzędzia związane z obsługą graficznego interfejsu użytkownika |
| Klasy związane z kodami krajów, stanów, prowincji i tak dalej |
| Klasy związane z grafiką |
| Klasy (na razie tylko jedna) do obsługi kodu HTML |
| Klasy do obsługi operacji wejścia-wyjścia, korzystające ze standardowych klas Javy |
| Znaczniki JSP |
| Klasy związane z wykorzystaniem standardowych możliwości języka Java |
| Narzędzia do blokowania pesymistycznego |
| Klasy związane z operowaniem na wiadomościach e-mail, głównie ułatwiające ich wysyłanie |
| Klasy związane z modelowaniem |
| Klasy związane z operacjami sieciowymi |
| Klasy związane z prezentacjami |
| Klasy związane z introspekcją |
| Narzędzia do korzystania z wyrażeń regularnych; program REDemo, moja wersja programu Grep itd. |
| Klasy związane z zabezpieczeniami |
| Klasy pomocnicze do tworzenia serwletów |
| Klasy do korzystania z baz danych SQL |
| Klasy ułatwiające tworzenie aplikacji z użyciem pakietu Swing |
| Kilka interesujących implementacji menedżerów układu |
| Generatory danych testowych |
| Narzędzia do testowania |
| Klasy pomocnicze dla aplikacji przeznaczonych dla systemów Unix |
| Kilka różnych klas pomocniczych |
| Narzędzia do obsługi kodu XML |
Wiele spośród klas należących do tego repozytorium zostało użytych jako przykład przedstawiony w treści tej książki; wystarczy poszukać kodów zaczynających się od instrukcji:
import com.darwinsys;
Łatwo także zauważyć, że wiele innych przykładów będzie korzystało z klas importowanych z pakietów com.darwinsys.
Jeśli Czytelnikowi zależy na czasie, to ogromna większość przykładów przedstawionych w tej książce wchodzi w skład repozytorium javasrc, zatem pobranie go przy użyciu instrukcji git clone lub w formie archiwum ZIP zapewni dostęp do większości kodów używanych w książce. Co więcej, umieszczony w przykładach skrypt Maven odwołuje się do repozytorium darwinsys-api umieszczonego w serwisie Maven Central, a więc około 90 procent kodów można zdobyć, pobierając repozytorium javasrc przy użyciu polecenia git clone. A zatem zdecydowanie najlepszym rozwiązaniem będzie pobranie kodów właśnie w ten sposób, a następnie aktualizowanie ich co kilka miesięcy z wykorzystaniem polecenia git pull.
Alternatywnym rozwiązaniem może być pobranie pojedynczego archiwum składającego się z wybranych elementów wszystkich trzech wymienionych wcześniej repozytoriów i obejmującego wyłącznie pliki prezentowane w tej książce. Można je znaleźć na stronie poświęconej książce w witrynie wydawnictwa O’Reilly — http://shop.oreilly.com/product/0636920026518.do. To archiwum zawiera pliki źródłowe, które są używane do wstawiania kodu do treści książki podczas jej formatowania, dlatego umieszczone w nim kody powinny bezpośrednio odpowiadać kodom prezentowanych w niej przykładów. Niemniej jednak nie będzie ono zawierało tak wielu plików jak wszystkie trzy podane wcześniej repozytoria.
Przykłady do książki można także pobrać z serwera FTP wydawnictwa Helion — ftp://ftp.helion.pl/przyklady/jarec3.zip. Jest to zbiór wszystkich przykładowych kodów prezentowanych w treści książki, jak również wszystkich dodatkowych plików niezbędnych do prawidłowej kompilacji przykładów.
Odnośniki do każdego z tych źródeł można znaleźć na stronie poświęconej książce (http://javacook.darwinsys.com/) — wystarczy kliknąć odnośnik Downloads.
Każde z tych trzech repozytoriów stanowi odrębny projekt, który można zbudować zarówno w środowisku Eclipse (patrz „1.3. Kompilacja, uruchamianie i testowanie programów przy użyciu IDE”), jak i przy użyciu programu Maven (patrz „1.7. Automatyzacja zależności, kompilacji, testowania i wdrażania przy użyciu programu Apache Maven”). Warto zwrócić uwagę, że program Maven — uruchomiony po raz pierwszy w celu przygotowania konkretnego repozytorium — automatycznie pobierze obszerny zestaw wszystkich niezbędnych bibliotek dodatkowych. Dlatego trzeba pamiętać, by wykonując tę operację, dysponować szybkim połączeniem z internetem. A zatem Maven zagwarantuje, że przed zbudowaniem kodów w danym repozytorium zostaną spełnione wszystkie wymagania wstępne. Jeśli ktoś zdecyduje się na pobieranie pojedynczych przykładów, to powinien zajrzeć do pliku pom.xml, w którym znajdzie listę wszystkich niezbędnych bibliotek dodatkowych. Niestety, jeśli Czytelnik nie używa ani Eclipse, ani programu Maven, to najprawdopodobniej nie będę mu w stanie pomóc w przygotowaniu plików kontrolnych zarządzających wszystkimi zależnościami.
Jeśli Czytelnik używa wersji Java 7 języka, a nie najnowszej wersji Java 8, to niektórych z przykładów nie uda się skompilować. Takie przykłady można jawnie „wyłączyć” w skrypcie Maven.
Wszystkie kody wchodzące w skład moich repozytoriów są udostępniane na zasadach najmniej restrykcyjnej z dostępnych licencji, licencji BSD, która składa się z dwóch punktów i wymaga jedynie wskazania źródła podchodzenia pliku. Jeśli ktoś uzna, że moje kody mogą mu się do czegoś przydać, to może ich bez przeszkód używać w swoich projektach. Nie ma potrzeby proszenia mnie o jakiekolwiek pisemne pozwolenie — można z nich korzystać i jedynie podać źródło, z którego pochodzą.
Podpowiedź
Większość przykładów komend wydawanych w wierszu poleceń odwołuje się do plików źródłowych i zakłada, że bieżącym katalogiem jest /src/main/java. Polecenie odwołujące się do skompilowanych plików klasowych zakłada, że bieżący katalog jest tym, w którym są umieszczane pliki klasowe (lub że został on dodany do zmiennej środowiskowej CLASSPATH; w przypadku programu Maven jest to katalog target/classes, a w przypadku Eclipse — katalog build). Nie będę już o tym wspominał przy okazji prezentowania poszczególnych przykładów, gdyż byłoby to niepotrzebnym marnowaniem papieru.
Przedstawione wcześniej repozytoria są rozwijane od 1995 roku. Oznacza to, że można w nich znaleźć kod, który nie jest aktualny i nie odpowiada najnowszym wytycznym dotyczącym najlepszych sposobów programowania. Nie ma w tym nic dziwnego: każdy fragment kodu będzie się starzeć, jeśli nie jest aktywnie utrzymywany. (W tym momencie chciałbym przypomnieć pewne zdanie z piosenki zespołu Culture Club „Do You Really Want to Hurt Me?”, a konkretnie: „Give me time to realize my crimes”[7]). Warto o tym pamiętać, kiedy okaże się, że jakieś rady podane w tekście tej książki nie odpowiadają kodom umieszczonym w repozytorium. Jedną z praktyk metodologii Extreme Programming jest bezustanna refaktoryzacja — możliwość poprawienia dowolnego kodu w dowolnym momencie. Nie należy się także dziwić, jeśli kody umieszczone w internetowym repozytorium nie będą idealnie odpowiadać tym przedstawionym w książce; bardzo rzadko zdarza się, bym w ciągu tygodnia nie wprowadził w repozytorium jakichś zmian, a ich efekty są publikowane w repozytoriach dosyć często. A zatem jeśli okaże się, że kod w książce różni się od tego w repozytorium w serwisie GitHub, nie powinieneś być z tego powodu smutny, lecz raczej zadowolony, gdyż będzie to oznaczać, że możesz skorzystać z efektów nieco spóźnionych przemyśleń. Co więcej, serwis GitHub pozwala wszystkim na współuczestniczenie w poprawianiu plików, a to dzięki możliwości przesłania prośby o uwzględnienie zmian (przy użyciu opcji „pull request”); co sprawia, że sytuacja staje się jeszcze bardziej interesująca. Jeśli komuś udało się znaleźć błąd lub sposób na usprawnienie przykładów, warto skorzystać z tej opcji!
Archiwum dostępne w witrynie wydawnictwa O’Reilly (http://oreilly.com/) nie będzie aktualizowane równie często.
Ant jest napisanym w Javie programem do automatyzacji procesu budowania oprogramowania. Jest to program dostępny bezpłatnie, który można pobrać z witryny WWW projektu Jakarta fundacji Apache (http://jakarta.apache.org/ant/) zarówno w formie kodów źródłowych, jak i programu gotowego do użycia. Podobnie jak make, program Ant korzysta z pliku lub plików, przy czym w jego przypadku są to pliki zapisane w języku XML, które zawierają informacje, co należy zrobić, a w razie konieczności także jak wykonać niezbędne czynności. Reguły zostały stworzone w taki sposób, aby można z nich było korzystać niezależnie od używanej platformy systemowej, choć jeśli to będzie konieczne, można także tworzyć procedury przeznaczone do wykonania wyłącznie w określonym systemie operacyjnym.
Aby użyć programu Ant, należy stworzyć plik definiujący przeróżne opcje. Plik ten powinien nosić nazwę build.xml; jeśli zostanie użyta inna nazwa, to w wywołaniu programu Ant konieczne będzie podanie odpowiedniego parametru. Przykład 1-1 przedstawia skrypt używany do skompilowania plików znajdujących się w katalogu o nazwie starting. Więcej informacji na temat składni XML można znaleźć w Rozdział 20. Jak na razie wystarczy wiedzieć, że w języku XML znacznik <!-- rozpoczyna komentarz, który kończy się znacznikiem -->.
Przykład 1-1. Przykładowy plik budowy programu Ant (build.xml)
<project name="Java Cookbook Examples" default="compile" basedir=".">
<!-- Określamy główne właściwości procesu budowy. -->
<property name="src" value="."/>
<property name="build" value="build"/>
<!-- Określamy kompilator, jakiego należy użyć. -->
<property name="build.compiler" value="modern"/>
<target name="init">
<!-- Tworzymy znacznik czasu. -->
<tstamp/>
<!-- Tworzymy strukturę katalogów używanych przez kompilator. -->
<mkdir dir="${build}"/>
</target>
<!-- Określamy, co należy kompilować.
W naszym przypadku kompilujemy wszystko. -->
<target name="compile" depends="init">
<!-- Kompilujemy kod Javy z ${src} na ${build}. -->
<javac srcdir="${src}" destdir="${build}"
classpath="../darwinsys-api.jar"/>
</target>
</project>Podczas działania program Ant, podobnie zresztą jak program make, generuje całkiem sporo komunikatów:
$ ant compile Buildfile: build.xml Project base dir set to: /home/ian/javasrc/starting Executing Target: init Executing Target: compile Compiling 19 source files to /home/ian/javasrc/starting/build Performing a Modern Compile Copying 22 support files to /home/ian/javasrc/starting/build Completed in 8 seconds $
Warto się również zapoznać z zamieszczoną poniżej notatką Make a Ant oraz wydaną przez wydawnictwo O’Reilly książką Ant: The Definitive Guide, której autorem jest Steve Holzner (http://shop.oreilly.com/product/9780596006099.do).
Wypróbowaliśmy program Ant i dosyć nam się spodobał, ale chcielibyśmy narzędzia, które działa bardziej automatycznie.
Porównując działanie programów Maven i Ant, należałoby powiedzieć, że ten pierwszy działa na nieco wyższym poziomie. Choć Ant doskonale nadaje się do obsługi kompilacji, to Maven dysponuje wyszukanym, rozproszonym systemem zarządzania zależnościami, pozwalającym także na tworzenie pakietów aplikacji, takich jak archiwa JAR, WAR i EAR oraz na zdalne ich wdrażanie. O ile pliki budowy programu Ant koncentrują się na tym, jak należy to zrobić, pliki programu Maven koncentrują się na tym, co robić, poprzez określanie, co ma być zrobione.
Działanie programu Maven jest kontrolowane przez plik o nazwie pom.xml (co stanowi skrót od słów Project Object Model — model obiektów projektu). Poniżej przedstawiłem prosty przykład takiego pliku:
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0
http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.example</groupId>
<artifactId>my-se-project</artifactId>
<version>1.0-SNAPSHOT</version>
<packaging>jar</packaging>
<name>my-se-project</name>
<url>http://com.example/</url>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
</properties>
<dependencies>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.8.1</version>
<scope>test</scope>
</dependency>
</dependencies>
</project>Ten plik informuje, że projekt o nawie „my-se-project” (mój projekt pisany w standardowej wersji Javy) zostanie umieszczony w archiwum JAR; projekt zależy od szkieletu JUnit 4.x służącego do przeprowadzania testów jednostkowych (patrz „1.13. Testowanie jednostkowe — jak uniknąć konieczności stosowania programów uruchomieniowych?”), jednak jest on potrzebny wyłącznie do skompilowania i wykonania testów. Jeśli po przejściu do katalogu zawierającego taki plik wydam polecenie mvn install, program Maven upewni się, że jest dostępna odpowiednia wersja szkieletu JUnit (jak również wszystkie inne biblioteki niezbędne do jego działania), następnie skompiluje wszystkie kody (nadając odpowiednią wartość zmiennej środowiskowej CLASSPATH i używając odpowiednich opcji kompilatora), wykona wszystkie dostępne testy jednostkowe, a jeśli nie wystąpią żadne błędy, wygeneruje plik JAR programu; dodatkowo zainstaluje go w moim prywatnym repozytorium Maven (w katalogu ~/.m2/repository), tak by inne projekty przygotowywane przy użyciu programu Maven mogły z niego korzystać. Warto zwrócić uwagę, że nie musiałem informować programu Maven, gdzie się znajdują pliki źródłowe — zadbają o to sensowne ustawienia domyślne, bazujące na dobrze zdefiniowanej strukturze projektu. Maven oczekuje, że kody źródłowe programu będą umieszczone w katalogu src/main/java, a testy — w katalogu src/test/java; w przypadku aplikacji internetowych Maven oczekuje, że głównym katalogiem z jej kodami będzie src/main/webapp. Oczywiście wszystkie te ustawienia można zmienić.
Warto zwrócić uwagę, że powyższy plik Maven nie musi być, i nie został, napisany ręcznie. Reguły generowania programu Maven pozwalają mu przygotować początkową wersję takiego pliku dla każdego z kilkuset typów projektów. A oto w jaki sposób wygenerowałem powyższy plik:
$ mvn archetype:generate \
-DarchetypeGroupId=org.apache.maven.archetypes \
-DarchetypeArtifactId=maven-archetype-quickstart \
-DgroupId=com.example -DartifactId=my-se-project
\[INFO] Scanning for projects...
Downloading: http://repo1.maven.org/maven2/org/apache/maven/plugins/
maven-deploy-plugin/2.5/maven-deploy-plugin-2.5.pom
\[several dozen or hundred lines of downloading POM files and Jar files...]
\[INFO] Generating project in Interactive mode
\[INFO] Archetype [org.apache.maven.archetypes:maven-archetype-quickstart:1.1]
found in catalog remote
\[INFO] Using property: groupId = com.example
\[INFO] Using property: artifactId = my-se-project
Define value for property 'version': 1.0-SNAPSHOT: :
\[INFO] Using property: package = com.example
Confirm properties configuration:
groupId: com.example
artifactId: my-se-project
version: 1.0-SNAPSHOT
package: com.example
Y: : y
\[INFO] ------------------------------------------------------------------------
\[INFO] Using following parameters for creating project from Old (1.x) Archetype:
maven-archetype-quickstart:1.1
\[INFO] ------------------------------------------------------------------------
\[INFO] Parameter: groupId, Value: com.example
\[INFO] Parameter: packageName, Value: com.example
\[INFO] Parameter: package, Value: com.example
\[INFO] Parameter: artifactId, Value: my-se-project
\[INFO] Parameter: basedir, Value: /private/tmp
\[INFO] Parameter: version, Value: 1.0-SNAPSHOT
\[INFO] project created from Old (1.x) Archetype in dir: /private/tmp/
my-se-project
\[INFO] ------------------------------------------------------------------------
\[INFO] BUILD SUCCESS
\[INFO] ------------------------------------------------------------------------
\[INFO] Total time: 6:38.051s
\[INFO] Finished at: Sun Jan 06 19:19:18 EST 2013
\[INFO] Final Memory: 7M/81M
\[INFO] ------------------------------------------------------------------------Zintegrowane środowiska programistyczne (przedstawione w „1.3. Kompilacja, uruchamianie i testowanie programów przy użyciu IDE”) dysponują narzędziami pozwalającymi na korzystanie z programu Maven. Na przykład z myślą o środowisku Eclipse została przygotowana wtyczka M2Eclipse, pozwalająca na zbudowanie projektu Eclipse wraz ze wszystkimi jego zależnościami na podstawie pliku POM. Wtyczka ta jest dostępna w bieżącej wersji Eclipse (Luna), jak również w poprzedniej (Kepler), została przetestowana w jeszcze starszej wersji środowiska (Juno), a jest dostępna także dla kilku innych jeszcze starszych wersji. Wszelkie informacje na jej temat można znaleźć na stronie http://eclipse.org/m2e/.
Plik POM może zmienić definicję każdego ze standardowych „celów”. Poniżej przedstawiłem kilka powszechnie stosowanych celów Maven (posiadających predefiniowane znaczenie, które pozwala im zrobić coś sensownego):
- clean
Usuwa wszystkie wygenerowane artefakty.
- compile
Kompiluje wszystkie kody źródłowe.
- test
Kompiluje kody i wykonuje wszystkie testy jednostkowe.
- package
Buduje pakiet.
- install
Instaluje plik pom.xml oraz pakiet w lokalnym repozytorium Maven, tak by mogły z niego korzystać inne projekty.
- deploy
Próbuje zainstalować pakiet (na przykład na serwerze aplikacji).
Większość z tych celów w niejawny sposób wykonuje poprzednie; na przykład cel package skompiluje kody, generując wszystkie brakujące pliki klasowe (.class), i wykona testy, które nie zostały przeprowadzone po tej kompilacji.
Zazwyczaj dostępne są cele przygotowane z myślą o konkretnych serwerach aplikacji; jako jeden z wielu przykładów może posłużyć serwer aplikacji JBoss „WildFly” (określany wcześniej jako JBoss AS) — przygotowując na niego aplikację, zgodnie z dokumentacją należałoby zainstalować kilka dodatkowych wtyczek, a następnie wdrożyć aplikację na serwerze za pomocą polecenia:
mvn jboss-as:deploy
co pozwoliłoby uniknąć konieczności wdrażania w standardowy sposób.
Maven potrafi obsługiwać duże projekty i zapewnia ogromne możliwości konfiguracji. Używałem go do przygotowywania repozytoriów darwinsys-api oraz javasrc i doskonale radził sobie z odnajdywaniem zależności i zmniejszaniem pobieranych kodów źródłowych projektów (przenosił bowiem związane z tym narzuty na same serwery projektów). Jedyną wadą programu Maven jest to, że przygotowanie go do wykorzystania zabiera sporo czasu, a jeśli coś nie działa, to zdiagnozowanie przyczyn problemów może być dość trudne. W takich przypadkach naszym najlepszym przyjacielem będzie dobra wyszukiwarka.
Jedyną rzeczą, której się nieco obawiam, jest sytuacja, w której na witrynę projektu włamie się jakiś hacker i zmieni plik POM lub umieści w niej nową wersję tego pliku. Maven automatycznie pobierze taki zmieniony plik POM. Choć dokładnie to samo może się zdarzyć także w przypadku ręcznego zarządzania zależnościami, to jednak prawdopodobieństwo, że problem zostanie wykryty przed pobraniem zainfekowanej wersji pliku, będzie wówczas większe. Nie wiem, czy taka sytuacja już się kiedyś zdarzyła, niemniej jednak możliwość jej wystąpienia mnie martwi.
Zacznij od wejścia na stronę http://maven.apache.org/.
Chcemy używać programu do budowania kodu, który nie zmuszałby nas do tworzenia plików konfiguracyjnych w języku XML.
Można użyć programu Gradle, którego pliki konfiguracyjne korzystają z „potężnych, a jednocześnie elastycznych konwencji”.
Maven Central — odwzorowywanie świata oprogramowania pisanego w Javie
Użytkownicy programu Maven mają dostęp do przeogromnej kolekcji bezpłatnego oprogramowania, z którego mogą korzystać poprzez proste dodanie do pliku pom.xml elementu <dependency> lub „artefaktu Maven”. To repozytorium kodu można przeglądać, korzystając ze stron WWW: http://search.maven.org/ oraz https://repository.sonatype.org/index.html.
Rysunek 1-11 przedstawia próbę odszukania projektu darwinsys-api oraz zwracane informacje na jego temat. Warto zauważyć, że element <dependency> wyświetlony w sekcji Dependency Information to wszystko, co jest potrzebne, by dodać tę bibliotekę do swojego projektu. Wystarczy go skopiować i wkleić do sekcji <dependencies> w pliku POM projektu — i to wszystko! Ponieważ serwis Maven Central stał się najlepszym z istniejących miejsc do poszukiwania kodów, dlatego też korzysta z niego bardzo wiele narzędzi służących do budowania oprogramowania pisanego w Javie. Aby ułatwić życie wszystkim tym użytkownikom, Maven Central udostępnia informacje o zależnościach zapisane w formatach, które można bezpośrednio skopiować, by użyć ich w kilku innych programach do budowania.
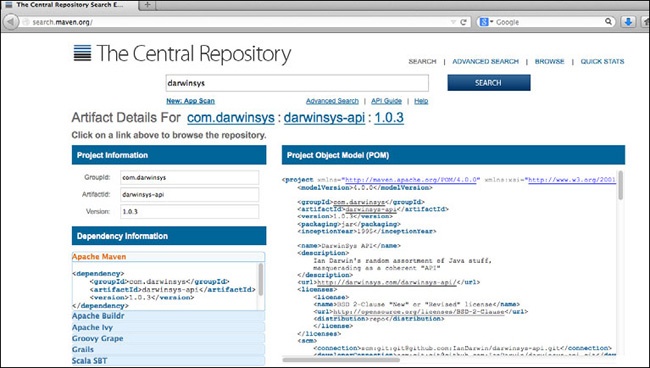
Kiedy będziemy już dysponować użytecznym projektem o otwartym kodzie źródłowym, z którego inni programiści mogliby chcieć skorzystać, to możemy uznać, że warto go opublikować w serwisie Maven Central. Ten proces jest nieco dłuższy od samodzielnego budowania projektu, lecz nie uciążliwy. Informacje na jego temat można znaleźć w poradniku http://maven.apache.org/guides/mini/guide-central-repository-upload.html oraz na stronie http://central.sonatype.org/pages/ossrh-guide.html.
Gradle jest najnowszym z grupy narzędzi (make, Ant oraz Maven) służących do budowania kodu pisanego w Javie. Jest on określany jako „program automatyzujący do zastosowań korporacyjnych” i dysponuje możliwością integracji z innymi programami do budowy kodu oraz zintegrowanymi środowiskami programistycznymi.
W odróżnieniu od innych narzędzi do budowania przeznaczonych do obsługi kodu pisanego w Javie, Gradle nie używa języka XML do tworzenia plików konfiguracyjnych, służy do tego język DSL (ang. domain-specific language), bazujący na języku skryptowym Groovy (http://groovy.codehaus.org/), który z kolei jest stworzony w oparciu o Javę i wykonywany przez JVM.
Program Gradle można pobrać z jego witryny WWW (http://gradle.org/) w formie archiwum ZIP. Następnie wystarczy je rozpakować i dodać katalog bin do zmiennej systemowej PATH.
Po wykonaniu tych czynności można już rozpocząć korzystanie z programu. Jeśli założymy, że korzystamy ze „standardowych” katalogów źródłowych (src/main/java, src/main/test), które obsługuje zarówno program Maven, jak i Gradle (oraz kilka innych), to przykładowy plik build.gradle przedstawiony na Przykład 1-2 zbuduje naszą aplikację i wykona wszystkie testy jednostkowe:
Przykład 1-2. Przykładowy plik build.gradle
# Prosty plik budowy Gradle, przygotowany dla projektu DataVis.
apply plugin: 'java'
# Przygotowanie powiązań z projektem Eclipse IDE.
apply plugin: 'eclipse'
# Używana wersja Javy.
sourceCompatibility = 1.7
# Wersja projektu.
version = '1.0.3'
# Skonfigurowanie umieszczania kodu w archiwum JAR.
jar {
manifest {
attributes 'Main-class': 'com.somedomainnamehere.data.DataVis',
'Implementation-Version': version
}
}
# Możliwość opcjonalna: np. -Dtesting=true, można ją jednak stosować tylko
# w przypadku uruchamiania testów ("test task").
test {
systemProperties 'testing': 'true'
}Dodatkowo można wykorzystać już istniejącą, bardzo rozbudowaną infrastrukturę programu Maven, dodając do pliku build.gradle poniższe wiersze:
# Każemy szukać w serwisie Maven Central
repositories {
mavenCentral()
}
# Potrzebujemy biblioteki darwinsys-api do skompilowania kodów oraz
# JUnit do wykonania testów.
dependencies {
compile group: 'com.darwinsys', name: 'darwinsys-api', version: '1.0.3+'
testCompile group: 'junit', name: 'junit', version: '4.+'
}Program Gradle zapewnia znacznie większe możliwości; poznawanie ich warto rozpocząć od wyświetlenia strony programu (http://www.gradle.org/) i przejrzenia jego dokumentacji (http://www.gradle.org/documentation).
Kod, który niegdyś kompilował się bez najmniejszych problemów, teraz powoduje zgłaszanie komunikatów o odrzuconych metodach.
Na pewno Czytelnik nieraz już przecierał oczy ze zdziwienia w takiej sytuacji. Istnieją dwie metody rozwiązania problemu: można zignorować komunikaty (co jest niebezpieczne) lub zmodyfikować kod tak, aby komunikaty się nie pojawiały.
Każda nowa wersja Javy zawiera wiele nowych potężnych możliwości funkcjonalnych. Niestety, ma to swoją cenę — podczas wprowadzania tych nowych możliwości programiści tworzący język Java od czasu do czasu znajdują kod, który nie został napisany poprawnie i którego nie należy już używać, gdyż nie można go poprawić. Na przykład podczas tworzenia wersji 1.1 języka Java okazało się, że klasa java.util.Date posiada poważne ograniczenia związane z tworzeniem programów wielojęzycznych. Właśnie z tego względu wiele metod i konstruktorów tej klasy zostało oznaczonych jako „odrzucone” (ang. deprecated). Według Słownika języka polskiego „odrzucać” oznacza między innymi „nie przyjąć, nie zgadzać się na coś” lub „pozbyć się czegoś”. A zatem używając tego określenia, twórcy języka Java sugerują, aby nie stosować już wcześniejszych sposobów wykonywania pewnych operacji. Spróbujmy skompilować poniższy fragment kodu:
/starting/Deprec.java
import java.util.Date;
/** Demonstracja komunikatów o odrzuconych metodach. */
public class Deprec {
public static void main(String[] av) {
// Tworzymy obiekt Date odpowiadający dacie 5 maja 1986 r.
// Należy się spodziewać komunikatów o odrzuconych metodach.
Date d = new Date(86, 04, 05); // TA INSTRUKCJA SPOWODUJE
// WYŚWIETLENIE KOMUNIKATU!
System.out.println("Data: " + d);
}
}Co się stało? Gdy skompilowałem powyższy fragment kodu, pojawiło się następujące ostrzeżenie:
C:\javasrc>javac Deprec.java
Note: Deprec.java uses or overrides a deprecated API. Recompile with "-
deprecation" for details.
1 warning
C:\javasrc>Należy zatem postąpić zgodnie z zaleceniami — ponownie skompilować plik, wykorzystując przy tym opcję -deprecation (w przypadku korzystania z programu Ant należy użyć znacznika <javac deprecation=true...>):
C:\javasrc>javac -deprecation Deprec.java
Deprec.java:8: warning: constructor Date(int,int,int) in java.util.Date has
been deprecated
Date d = new Date(86, 05, 05); // TA INSTRUKCJA SPOWODUJE
^
1 warning
C:\javasrc>Ostrzeżenie jest całkiem jasne: konstruktor Date pobierający trzy argumenty będące liczbami całkowitymi został odrzucony. Jak można rozwiązać ten problem? Otóż zarówno w tym, jak i we wszystkich innych przypadkach związanych z wykorzystaniem języka najlepiej zajrzeć do dokumentacji klasy, z którą mamy problemy. Poniżej został przedstawiony początkowy fragment strony poświęconej klasie Date, wchodzącej w skład dokumentacji języka.
Klasa
Datereprezentuje konkretny moment, określony z dokładnością do milisekundy.Przed wprowadzeniem JDK 1.1 klasa
Datemiała dwie dodatkowe funkcje. Pozwalała na interpretację dat podanych przy użyciu wartości wyrażających rok, miesiąc, dzień, godziny, minuty oraz sekundy. Klasa ta umożliwiała także formatowanie oraz przetwarzanie dat zapisanych w formie łańcuchów znaków. Niestety, rozwiązań programowych wykorzystywanych przez te funkcje nie dało się przystosować do mechanizmów Javy służących do tworzenia programów o wielu wersjach językowych. Z tego względu w JDK 1.1 do konwertowania dat i czasu należy wykorzystywać klasęCalendar, natomiast do formatowania dat i analizy dat zapisanych w formie łańcuchów znaków należy używać klasyDateFormat. Metody klasyDate, które wcześniej zapewniały wymienione możliwości funkcjonalne, zostały odrzucone.
Z kolei poniższy fragment został zaczerpnięty z opisu konstruktora klasy Date wymagającego podania trzech liczb całkowitych:
Date(int year, int month, int date) Odrzucony. W JDK 1.1 konstruktor ten został zastąpiony przez Calendar.set year+1900, month, date) lub GregorianCalendar(1900 + year, month, date)
Ogólnie rzecz biorąc, należy się kierować zasadą, w myśl której jeśli jakaś metoda została odrzucona, to podczas konserwacji programu należy się postarać tak go zmodyfikować, aby komunikaty ostrzegawcze przestały się pojawiać.
W standardowym API komunikaty o odrzuconych metodach najczęściej pojawiają się w przypadku korzystania z klasy Date (o czym już wspominałem; w wersji 8 języka Java wprowadzone zostało zupełnie nowe API do obsługi dat i godzin, opisane w Rozdział 6.), starych mechanizmów obsługi zdarzeń oraz niektórych metod klasy Thread (z których kilka jest ważnych).
Istnieje także możliwość oznaczenia własnego kodu jako odrzuconego, jeśli uda się nam znaleźć lepszy sposób wykonywania tych samych czynności. W tym celu bezpośrednio przed klasą, którą chcemy odrzucić, należy umieścić adnotację @deprecated oraz ewentualnie poprzedzić ją komentarzem dokumentacyjnym ze znacznikiem @deprecated (patrz „21.2. Tworzenie dokumentacji klas przy użyciu programu Javadoc”). Dzięki dodaniu komentarza będziemy mogli wyjaśnić przyczyny odrzucenia danej klasy lub metody, natomiast niektórym narzędziom programistycznym łatwiej rozpoznawać adnotacje, gdyż są one dostępne w czasie kompilacji kodu (co pozwala na wykorzystanie mechanizmów introspekcji, opisanych w Rozdział 23.).
Także wiele innych narzędzi analizuje kod źródłowy pisany w Javie. Informacje na ten temat można znaleźć w napisanej przeze mnie książce Checking Java Programs (http://shop.oreilly.com/product/9780596510237.do) wydanej przez wydawnictwo O’Reilly.
Chcemy przeprowadzić kompilację warunkową, lecz najwidoczniej Java nie daje takiej możliwości.
W zależności od zamierzonych efektów należy użyć zmiennych ustalonych, argumentów podawanych w wierszu wywołania programu lub asercji (przedstawionych w „1.11. Zapewnianie poprawności programu za pomocą asercji”).
Niektóre ze starszych języków programowania, takie jak C, PL/I oraz C++, udostępniały możliwość określaną jako kompilacja warunkowa. Kompilacja warunkowa oznacza, że wybrane fragmenty kodu mogą być dołączane lub usuwane z programu podczas jego kompilacji, w zależności od określonego warunku. Mechanizm ten jest bardzo często wykorzystywany w celu dołączania lub usuwania z kodu instrukcji wyświetlających komunikaty używane podczas testowania programu. Gdy wydaje się, że program już działa poprawnie, programista jest tak dumny, że usuwa wszystkie fragmenty kodu związane z kontrolą błędów. Znacznie częstszą przyczyną usuwania komunikatów o błędach jest chęć skrócenia programu wynikowego (to zaprawdę szczytny cel) lub poprawienie jego efektywności poprzez eliminację instrukcji warunkowych.
Choć w języku Java nie ma jawnej kompilacji warunkowej, to jednak jest w nim dostępny mechanizm, który można uznać za niejawną kompilację warunkową. Otóż wszystkie kompilatory języka Java muszą przeprowadzać analizę przepływu, aby upewnić się, że wszystkie ścieżki programu wykorzystujące pewną zmienną przechodzą przez instrukcję, która określa wartość tej zmiennej, że wszystkie instrukcje kończące wykonywanie funkcji zwracają wartość i tak dalej. Zastanówmy się, co zrobi kompilator, jeśli napotka instrukcję warunkową, o której już w czasie kompilacji programu wiadomo, że nigdy nie zostanie wykonana. Po co kompilator miałby w ogóle generować kod takiej instrukcji? Można się z tym zgodzić, lecz jednocześnie rodzi się pytanie, w jaki sposób już w czasie kompilacji programu można mieć pewność, że warunek instrukcji if przyjmie wartość false. To całkiem proste — wystarczy użyć zmiennych typu boolean oznaczonych jako final. Jeśli wiadomo, że wartość warunku instrukcji if zawsze będzie przyjmować wartość false, to kod znajdujący się wewnątrz tej instrukcji nigdy nie powinien się znaleźć w programie wygenerowanym przez kompilator. W opisany powyżej prosty sposób można uzyskać efekt kompilacji warunkowej!
/starting/IfDef.java
final boolean DEBUG = false;
System.out.println("Witaj, świecie");
if (DEBUG) {
System.out.println("Życie jest podróżą, nie celem.");
}Po skompilowaniu programu zawierającego powyższy fragment kodu analiza uzyskanego pliku klasowego pozwala się przekonać, że instrukcja wyświetlająca łańcuch znaków "Witaj, świecie" została wygenerowana, w odróżnieniu od wywołania metody println() umieszczonej wewnątrz instrukcji warunkowej if. A zatem język Java posiada swój własny mechanizm kompilacji warunkowej.
darian$ jr IfDef jikes +E IfDef.java java IfDef Witaj, świecie darian$ strings IfDef.class | grep celem # Nie znaleziono łańcucha. darian$ javac IfDef.java # Wypróbujmy inny kompilator. darian$ strings IfDef.class | grep celem # Wciąż nie można znaleźć. darian$
A co zrobić, aby wykorzystać kod testujący podobny do tego przedstawionego we wcześniejszym przykładzie, przy czym wartość warunku ma być określana w trakcie wykonywania programu? W takim przypadku zamiast tego mechanizmu kompilacji warunkowej można się zdecydować na pozostawienie instrukcji wyświetlających informacje testujące w kodzie, lecz uaktywniać je tylko w przypadku wystąpienia problemów. To bardzo dobre rozwiązanie, które można stosować niemal zawsze — jedynym wyjątkiem mogą być aplikacje obciążające system w naprawdę dużym stopniu. Wynika to z faktu, że obciążenia generowane przez proste instrukcje warunkowe nie są zbyt duże. Spróbujmy zatem połączyć elastyczność testów wykonywanych w trakcie działania programu z prostą instrukcją if w celu przetestowania hipotetycznej metody fetch() (zdefiniowanej w pliku /starting/Fetch.java):
String name = "wiersz", value;
if (System.getProperty("debug.fetch") != null) {
System.err.println("Pobieramy " + name);
}
value = f.fetch(name);Taki program możemy skompilować i wykonać w standardowy sposób, w takim przypadku komunikat testujący zostanie pominięty. Jeśli jednak w wierszu wywołania programu podamy argument -D, by włączyć właściwość debug.fetch, to komunikat zostanie wyświetlony:
> java starting.Fetch # Widzisz? Komunikat nie został wyświetlony. > java -Ddebug.fetch starting.Fetch Pobieramy wiersz >
Oczywiście stosowanie większej liczby takich instrukcji warunkowych może być męczące. Początkowo zawarłem analogiczne możliwości funkcjonalne w klasie Debug, która wciąż jest dostępna w pakiecie com.darwinsys.util. Jednak obecnie zalecam raczej wykorzystanie rozbudowanych pakietów do rejestracji komunikatów, takich jak java.util.logging (przedstawionego w „16.10. Rejestracja przez sieć przy użyciu pakietu java.util.logging”), Log4J (przedstawionego w „16.9. Rejestracja przez sieć przy użyciu log4j”) lub innego.
W tym miejscu można także wspomnieć o jeszcze jednej możliwości — zastępowaniu wywołań metod ich kodem. W językach C i C++ istnieje słowo kluczowe inline, które służy kompilatorowi jako sygnał, że dana funkcja (metoda) nie jest używana nigdzie poza bieżącym plikiem źródłowym. Dzięki temu, kiedy kompilator generuje kod maszynowy programu, wywołanie funkcji oznaczonej jako inline może zostać zastąpione jej kodem, co eliminuje narzut czasowy związany z umieszczaniem argumentów na stosie, przekazywaniem sterowania do funkcji, pobieraniem parametrów oraz zwracaniem wartości wynikowej. W przypadku języka Java zastosowanie modyfikatora final informuje kompilator, że wywołanie funkcji można zastąpić jej kodem. Jest to optymalizacja opcjonalna, której kompilator nie musi wykonywać, choć może, by zapewnić większą wydajność działania.
Warto zajrzeć do „1.11. Zapewnianie poprawności programu za pomocą asercji”.
Niektóre języki programowania używają „kompilacji warunkowej”, aby włączać lub wyłączać wyświetlanie bądź „rejestrowanie” dużej liczby komunikatów testujących. W języku Java odpowiednikiem takich rozwiązań jest zastosowanie odpowiedniego pakietu do „rejestracji komunikatów”. Niektóre z takich rozwiązań — w tym także takie, które pozwalają na rejestrowanie komunikatów na zdalnych komputerach — opisałem w „16.7. Rejestracja operacji sieciowych”, „16.9. Rejestracja przez sieć przy użyciu log4j” oraz „16.10. Rejestracja przez sieć przy użyciu pakietu java.util.logging”.
Chcemy pozostawić testy w kodzie, a jednocześnie nie narażać się na związane z tym narzuty czasowe, dopóki tego nie zażądamy.
Język Java udostępnia słowo kluczowe assert, które wymaga podania dwóch argumentów oddzielonych dwukropkiem (co ma stanowić analogię dla operatora warunkowego). Pierwszym z tych argumentów jest wyrażenie, które jest sprawdzane i ma przyjąć wartość true, a drugim łańcuch znaków, który zostanie wyświetlony, jeśli wyrażenie przyjmie wartość false. Standardowo asercje mają być umieszczane w kodzie na stałe (co odróżnia je od tymczasowych sposobów testowania poprzez wyświetlanie komentarzy przy użyciu metody print(), które są umieszczane w kodzie podczas testów, a potem z niego usuwane). Aby wyeliminować narzuty związane z testowaniem wyrażeń, asercje są domyślnie wyłączane; aby z nich skorzystać, należy je jawnie włączyć, umieszczając w wierszu wywołania programu flagę -enableassertions (lub -ea). Poniżej przedstawiłem prosty program demonstrujący wykorzystanie mechanizmu asercji:
/testing/AssertDemo.java
public class AssertDemo {
public static void main(String[] args) {
int i = 4;
if (args.length == 1) {
i = Integer.parseInt(args[0]);
}
assert i > 0 : "i nie jest liczbą dodatnią";
System.out.println("Witamy po asercji.");
}
}
$ javac -d . testing/AssertDemo.java
$ java testing.AssertDemo -1
Witamy po asercji.
$ java -ea testing.AssertDemo -1
Exception in thread "main" java.lang.AssertionError: i nie jest liczbą dodatnią
at AssertDemo.main(AssertDemo.java:15)
$Należy skorzystać z programu uruchomieniowego, najlepiej takiego, który jest wbudowany w używane zintegrowane środowisko programistyczne.
JDK zawiera program uruchomieniowy jdb obsługiwany z poziomu wiersza poleceń; wszystkie najpopularniejsze zintegrowane środowiska programistyczne także zawierają swoje własne narzędzia uruchomieniowe. W przypadku stosowania konkretnego środowiska programistycznego warto nauczyć się korzystać z dostępnego w nim programu uruchomieniowego. Jeśli jednak Czytelnicy są zwolennikami narzędzi obsługiwanych z poziomu wiersza poleceń, prawdopodobnie będą woleli poznać choćby podstawowe sposoby obsługi programu jdb.
Poniżej przedstawiłem przykład programu zawierającego błędy. Błędy te zostały wprowadzone celowo, aby można było zobaczyć, jak są one obsługiwane w programie uruchomieniowym.
/** W tym programie celowo wprowadzono kilka błędów, dzięki czemu
* można go sprawdzić przy użyciu programu uruchomieniowego. */
public class Buggy {
static String name;
public static void main(String[] args) {
int n = name.length(); // błąd # 1
System.out.println(n);
name += "; Koniec."; // błąd #2
System.out.println(name); // #3
}
}Poniżej przedstawiłem sesję testowania programu Buggy przy użyciu jdb:
$ java starting.Buggy Exception in thread "main" java.lang.NullPointerException at Buggy.main(Compiled Code) $ jdb starting.Buggy Initializing jdb... 0xb2:calss(Buggy) > run run Buggy running ... main[1] Uncaught exception: java.lang.NullPointerException at Buggy.main(Buggy.java:6) at sun.tools.agent.MainThread.runMain(Native Method) at sun.tools.agent.MainThread.run(MainThread.java:49) main[1] list 6 public class Buggy { 7 static String name; 8 9 public static void main(String[] args) { 10 => int n = name.length(); // błąd # 1 11 System.out.println(n); 12 13 name += "; Koniec."; // błąd #2 14 System.out.println(name); // #3 main[1] print Buggy.name Buggy.name = null main[1] help ** command list ** threads [threadgroup] -- list threads thread <thread id> -- set default thread suspend [thread id(s)] -- suspend threads (default: all) resume [thread id(s)] -- resume threads (default: all) where [thread id] | all -- dump a thread's stack wherei [thread id] | all -- dump a thread's stack, with pc info threadgroups -- list threadgroups threadgroup <name> -- set current threadgroup print <id> [id(s)] -- print value of expression dump <id> [id(s)] -- print all object information locals -- print all local variables in current stack frame classes -- list currently known classes methods <class id> -- list a class's methods stop in <class id>.<method>[(argument_type,...)] -- set a breakpoint in a method stop at <class id>:<line> -- set a breakpoint at a line up [n frames] -- move up a thread's stack donw [n frames] -- move down a thread's stack clear <class id>.<method>[(argument_type,...)] -- clear a breakpoint in a method clear <class id>:<line> -- clear a breakpoint at a line step -- execute current line step up -- execute until the current method returns to its caller stepi -- execute current instruction next -- step one line (step OVER calls) cont -- continue execution from breakpoint catch <class id> -- break for the specified exception ignore <class id> -- ignore when the specified exception list [line number|method] -- print source code use [source file path] -- display or change the source path memory -- report memory usage gc -- free unused objects load classname -- load Java class to be debugged run <class> [args] -- start exection of a loaded Java class !! -- repeat last command help (or ?) -- list commands exit (or quit) -- exit debugger main[1] exit ian>
Dostępnych jest także wiele innych programów uruchomieniowych; informacje o nich można znaleźć w czasopismach poświęconych językowi Java. Wiele z nich można obsługiwać z innych komputerów, gdyż uruchomieniowy interfejs programistyczny (API) języka Java napisano w sposób umożliwiający pracę sieciową.
Należy wykorzystać technikę testowania jednostkowego w celu sprawdzania poprawności działania każdej z klas już w czasie jej tworzenia.
Wykorzystanie programu uruchomieniowego zabiera wiele czasu. Znacznie lepszym rozwiązaniem jest testowanie tworzonego kodu już wcześniej. Technika określana mianem testowania jednostkowego była znana już od dłuższego czasu i jest wypróbowaną, doskonałą metodą testowania kolejno małych fragmentów kodu. W przypadku języków obiektowych metoda ta polega na testowaniu pojedynczych klas, co odróżnia tę metodę od testowania metodą „czarnej skrzynki”, która polega na sprawdzaniu poprawności działania całej aplikacji.
Osobiście już od dawna byłem zwolennikiem tej niezwykle prostej metody testowania oprogramowania. Prawdę powiedziawszy, twórcy metodologii o nazwie Extreme Programming (w skrócie XP; patrz http://www.extremeprogramming.org/) zalecają stosowanie metody określanej mianem „programowania w oparciu o testy” (ang. Test Driven Development, TDD), polegającej na tworzeniu testów jednostkowych, jeszcze zanim przystąpimy do pisania kodu, i zachęcają do wykonywania tych testów niemal po każdej kompilacji. Zadają przy tym jedno, ale bardzo celne pytanie: „Jeśli nie będziemy dysponowali testem, to skąd będziemy wiedzieć, czy nasz kod (wciąż) działa?”. Na czele tej grupy stoją bardzo znane osoby, takie jak Erich Gamma (jeden ze współautorów niezwykle znanej książki Wzorce projektowe) oraz Kent Beck, autor równie znanej książki Wydajne programowanie. Całkowicie podzielam ich opinie na temat testów jednostkowych.
Prawdę powiedziawszy, wiele moich klas zawiera „wbudowane” mechanizmy testujące. Klasy, które nie są programami głównymi, często zawierają metodę main, umożliwiającą przetestowanie możliwości funkcjonalnych danej klasy. Zaskoczyło mnie, że nim poznałem metodologię XP, myślałem, że takie testy wykonuję często, lecz po dokładniejszym przejrzeniu projektów okazało się, że tylko jedna trzecia moich klas dysponowała odpowiednimi testami — bądź to wewnętrznymi, bądź zewnętrznymi. Oczywiste jest zatem, że należy wykorzystać jednolitą metodologię. Metodologią taką jest JUnit.
JUnit jest metodologią związaną przede wszystkim z językiem Java i służącą do tworzenia testów. Niezbędne oprogramowanie można bezpłatnie skopiować z witryny http://www.junit.org/. JUnit jest bardzo prostym, lecz jednocześnie przydatnym narzędziem testowym. Korzystanie z niego jest bardzo łatwe — wystarczy napisać klasę testową zawierającą grupę metod i dodać do nich adnotację @Test (w wersji JUnit 3.8 oraz starszych nazwy metod testowych muszą się zaczynać od słowa „test”). Narzędzie to, wykorzystując technologię introspekcji (przedstawioną dokładniej w Rozdział 23.), odnajduje wszystkie te metody i wywołuje je. Dostępne są także rozbudowane wersje tego narzędzia o bardzo różnym przeznaczeniu — zaczynając od testowania obciążenia, a kończąc na testowaniu komponentów EJB (ang. Enterprise JavaBeans). Odnośniki do tych narzędzi można znaleźć w witrynie JUnit. Wszystkie nowoczesne zintegrowane środowiska programistyczne dysponują narzędziami do generowania oraz wykonywania testów jednostkowych.
Od czego zacząć korzystanie z narzędzia JUnit? Wszystko sprowadza się do napisania testu. W poniższym przykładzie fragment kodu klasy Person umieściłem w klasie PersonTest (warto zwrócić uwagę na przejrzysty schemat nazewnictwa obu klas).
/testing/PersonTest.java
public class PersonTest {
@Test
public void testNameConcat() {
Person p = new Person("Ian", "Darwin");
String f = p.getFullName();
assertEquals("Konkatenacja imienia i nazwiska", "Ian Darwin", f);
}
}Aby uruchomić powyższym program ręcznie, wystarczy go skompilować i wywołać mechanizm testowy junit o nazwie TestRunner:
$ javac PersonTest.java $ java -classpath junit4.x.x.jar junit.textui.TestRunner testing.PersonTest . Time: 0.188 OK (1 tests) $
Ciągłe podawanie pełnej nazwy klasy jest dosyć uciążliwe, dlatego do używanych plików program Ant dodaje zazwyczaj cel o nazwie regress. To zadanie junit dostępne w pakiecie „zadań opcjonalnych” programu Ant[8].
<target name="regress" depends="build">
<junit>
<test name="PersonTest" />
</junit>
</target>Jednak nawet to rozwiązanie jest męczące, dlatego obecnie umieszczam testy w „standardowej strukturze katalogów” (czyli src/test/java/) w tym samym pakiecie, w którym znajduje się testowany kod, i uruchamiam program Maven (patrz „1.7. Automatyzacja zależności, kompilacji, testowania i wdrażania przy użyciu programu Apache Maven”), który automatycznie kompiluje testy jednostkowe, wykonuje je i przerywa proces budowania w przypadku wystąpienia jakichś błędów.
Pakiet Hamcrest Matchers pozwala na pisanie bardziej ekspresyjnych testów, choć aby z niego skorzystać, trzeba go będzie osobno pobrać ze strony http://hamcrest.org bądź przy użyciu programu Maven. JUnit 4 dysponuje wbudowanym wsparciem dla tego pakietu — jego testy są obsługiwane przez statyczną metodę assertThat.
Poniżej przedstawiłem przykład wykorzystania pakietu Hamcrest Matchers:
/testing/HamcrestDemo.java
public class HamcrestDemo {
@Test
public void testNameConcat() {
Person p = new Person("Ian", "Darwin");
String f = p.getFullName();
assertThat(f, containsString("Ian"));
assertThat(f, equalTo("Ian Darwin"));
assertThat(f, not(containsString("/"))); // Sztuczny przykład,
// mający jedynie pokazać składnię testów.
}
}Jeśli preferowany jest graficzny sposób prezentacji wyników, to można skorzystać z kilku wariantów JUnit (stworzonych z wykorzystaniem bibliotek Swing oraz AWT; patrz Rozdział 14.), które wykonują testy i prezentują ich wyniki za pomocą graficznego interfejsu użytkownika. Trzeba także pamiętać, że wszystkie nowoczesne zintegrowane środowiska programistyczne dysponują wbudowanymi mechanizmami wykonywania testów. W Eclipse można kliknąć prawym przyciskiem myszy nazwę projektu w oknie Package Explorer, a następnie wybrać z menu kontekstowego opcję Run As/Unit Test; w efekcie Eclipse odszuka i wykona wszystkie testy jednostkowe dostępne w projekcie.
JUnit udostępnia rozbudowaną dokumentację; można ją pobrać z witryny http://www.junit.org/.
Do ręcznego testowania komponentów graficznych stworzyłem specjalny, prosty komponent testowy, opisany w „12.2. Testowanie komponentów graficznych”.
Istnieje także alternatywny szkielet do tworzenia testów jednostkowych, o nazwie TestNG. Początkowo cieszył się on pewnym zainteresowaniem, gdyż wcześniej niż JUnit zaczął stosować adnotacje, ponieważ jednak JUnit także zaczął ich używać, to on pozostaje zdecydowanie najpopularniejszym narzędziem do tworzenia testów jednostkowych.
Proszę pamiętać, aby testować tworzony kod jak najwcześniej i jak najczęściej!
Chcemy mieć pewność, że cały kod projektu kompiluje się poprawnie i przechodzi testy jednostkowe, wykonując te operacje cyklicznie co pewien czas.
Jeśli Czytelnik nie korzystał wcześniej z ciągłej integracji, zastanawia się pewnie, co to jest i jak z niej skorzystać. Ciągła integracja polega na tym, że wszyscy programiści pracujący nad projektem cyklicznie, co pewien czas, integrują swoje zmiany z główną kopią „źródeł” projektu. Czynności te mogą być wykonywane kilka razy dziennie lub nawet co kilka dni, choć lepiej to robić częściej, gdyż w przeciwnym razie mogą wystąpić większe problemy z integracją plików, które zostały zmodyfikowane przez kilku programistów.
Jednak nie tylko duże projekty mogą czerpać korzyści z wykorzystania ciągłej integracji. Także w przypadku małych projektów, które są tworzone przez jedną osobę, dobrze mieć do dyspozycji jeden przycisk, którego kliknięcie sprawdzi najnowszą wersję kodów, skompiluje je, spakuje, wykona zautomatyzowane testy jednostkowe, a na koniec wyświetli czerwony lub zielony znacznik informujący, że pojawiły się problemy lub że wszystko jest w porządku.
Co więcej, nie tylko projekty programistyczne mogą korzystać z ciągłej integracji. Jeśli dysponujemy grupą niewielkich witryn WWW, to objęcie ich kontrolą ciągłej integracji jest jednym z kilku ważnych kroków w celu wypracowania zautomatyzowanych sposobów tworzenia i eksploatacji.
Jeśli Czytelnik po raz pierwszy spotkał się z ideą ciągłej integracji, to najlepszą rzeczą, jaką może zrobić, jest przeczytanie (jak zwykle) odkrywczej publikacji Martina Fowlera na jej temat, którą można znaleźć na stronie http://martinfowler.com/articles/continuousIntegration.html. Jednym z kluczowych zagadnień jest automatyzacja nie tylko zarządzania kodem, lecz także wszelkimi innymi zasobami niezbędnymi do utworzenia projektu, oraz automatyzacja samego procesu jego budowania, i to w optymalnym przypadku z wykorzystaniem jednego z narzędzi opisanych w tym rozdziale[9].
Istnieje wiele serwerów ciągłej integracji — zarówno bezpłatnych, jak i komercyjnych. Jeśli chodzi o rozwiązania bezpłatne, to warto wspomnieć o serwerach CruiseControl oraz Jenkins/Hudson. Jenkins/Hudson (odpowiednio http://jenkins-ci.org/ oraz http://hudson-ci.org/) początkowo nosił nazwę Hudson i w znacznej części został napisany przez Kohsuke Kawaguchiego, w czasie gdy był on pracownikiem firmy Sun Microsystems. Nie powinno zatem być wielkim zaskoczeniem, że serwer ten został napisany w Javie. Równie małym zaskoczeniem powinien być fakt, że po przejęciu firmy Sun przez Oracle projekt ten, podobnie jak wiele innych[10] udostępnianych na zasadach oprogramowania otwartego, przeżył pewne kulturowe perturbacje, takie jak ta, że kluczowe osoby zaangażowane w jego rozwój (w tym Kohsuke) spakowały walizki, wyprowadziły się i stworzyły nową wersję projektu. Kohsuke pracuje nad częścią projektu, która obecnie jest określana jako Jenkins (przez bardzo długi czas oba projekty traktowały siebie jako „ten prawdziwy projekt”, a ten drugi jako kopię). W dalszej części tekstu będę korzystał z nazwy Jenkins, gdyż to właśnie tej wersji serwera używam, a poza tym ciągłe pisanie „Jenkins/Hudson” zajmuje zbyt dużo czasu. Jednak niemal wszystkie zamieszczone tu informacje dotyczą także serwera Hudson.
Jenkins jest aplikacją internetową; kiedy już zostanie uruchomiony, jego interfejsem użytkownika może być dowolna przeglądarka WWW. Instalacja i uruchomienie tego serwera sprowadzają się do rozpakowania archiwum i wykonania polecenia:
java -jar jenkins.war
Jeśli to zrobimy, a nasz komputer jest podłączony do internetu, to koniecznie musimy pamiętać o włączeniu odpowiednich zabezpieczeń. Powyższe polecenie spowoduje, że Jenkins uruchomi własny, niewielki serwer WWW. Wiele osób uważa, że bezpieczniejsze jest uruchamianie Jenkinsa jako aplikacji na pełnym serwerze Java EE lub serwerze WWW napisanym w Javie; można to zrobić przy użyciu dowolnego oprogramowania tego typu, zaczynając do serwerów Tomcat i JBoss, a kończąc na WebSphere lub WebLogic; a rozwiązanie to ma tę zaletę, że pozwoli korzystać z dodatkowych zabezpieczeń.
Kiedy Jenkins zostanie już uruchomiony, zabezpieczenia włączone, a my zalogujemy się na koncie z odpowiednimi uprawnieniami, to będziemy mogli tworzyć „zadania”. Jedno zadanie zazwyczaj odpowiada jednemu projektowi — i to zarówno pod względem miejsca pochodzenia (jednokrotnego pobrania kodów z systemu kontroli wersji), jak i pod kątem wyników (jednego pliku WAR, programu wykonywalnego, biblioteki lub innego efektu zbudowania projektu). Skonfigurowanie projektu jest bardzo proste i sprowadza się do kliknięcia przycisku New Item[11] umieszczonego na samej górze lewej kolumny strony głównej, określanej jako Dashboard (patrz Rysunek 1-12).
Teraz można już wpisać kilka pierwszych informacji: nazwę projektu i jego krótki opis. Warto zwrócić uwagę, że przy każdym polu tekstowym jest umieszczona ikona „?” — można z niej skorzystać, by uzyskać dodatkowe informacje na temat konkretnego pola. Nie ma się czego obawiać i w razie potrzeby warto skorzystać z tych podpowiedzi! Rysunek 1-13 przedstawia kilka pierwszych kroków związanych z tworzeniem nowego zadania.
W kilku kolejnych sekcjach formularza Jenkins korzysta z dynamicznych możliwości języka HTML, by wyświetlać pola zależnie od opcji wybranych wcześniej. Mój przykładowy projekt MałyIBezproblemowy początkowo nie ma żadnego repozytorium kodu źródłowego, jednak prawdziwy projekt korzystałby z repozytorium Git, Subversion lub może nawet CVS czy jeszcze innego. Nie ma się co przejmować, jeśli używanego przez nas repozytorium nie ma początkowo na liście — jest mnóstwo wtyczek obsługujących niemal wszystkie istniejące typy repozytoriów. Po wybraniu typu repozytorium należy podać jego parametry — adres URL w przypadku systemu Git, CVSROOT w przypadku systemu CVS i tak dalej — wszystkie informacje, dzięki którym Jenkins będzie w stanie pobrać kod źródłowy projektu z repozytorium.
Oprócz tego będziemy musieli poinformować serwer, kiedy oraz jak ma budować (ewentualnie także pakować, testować i wdrażać) projekt. Jeśli chodzi o określenie czasu, to dostępnych jest kilka możliwości, zaczynając od budowania projektu po zbudowaniu innego, poprzez cykliczne budowanie co podany okres czasu (w sposób przypominający format stosowany przez program cron), a kończąc na cyklicznym sprawdzaniu repozytorium i budowaniu projektu, jeśli kody zostały zmienione. Jeśli nasz projekt jest umieszczony w serwisie GitHub (a nie na lokalnym serwerze Git) lub w jakimś innym repozytorium, to możemy zażądać, by projekt był budowany za każdym razem, gdy ktoś wprowadzi w tym repozytorium jakieś zmiany. Wszystko sprowadza się do znalezienia odpowiednich wtyczek i postępowania zgodnie z ich dokumentacją.
Kolejna grupa informacji, które należy podać, dotyczy tego, jak ma być przeprowadzony proces budowania. Także w tym przypadku kilka sposobów postępowania zostało dołączonych do serwera Jenkins, a znacznie więcej dalszych jest dostępnych w formie wtyczek. Ja korzystałem z plików budowy programów Ant, Maven, Gradle, tradycyjnych plików make, a nawet ze zwyczajnych skryptów powłoki oraz poleceń. Podobnie jak wcześniej, także w tym przypadku zostaną wyświetlone pola dostosowane do wybranego narzędzia. Do budowy mojego przykładowego projektu MałyIBezproblemowy używam polecania /bin/false (które powinno być dostępne we wszystkich systemach Unix i Linux), by zapewnić, że projektu nie uda się zbudować, i przekonać się, jakie to da efekty.
Proces budowy może się składać z jednego lub większej liczby etapów; wystarczy klikać przycisk Add build step, by dodawać kolejne, jak pokazałem na Rysunek 1-14.
Rysunek 1-14. Jenkins — dynamiczna strona WWW służąca do dodawania repozytoriów kodu źródłowego oraz etapów budowania
Kiedy już uznamy, że wprowadziliśmy wszystkie niezbędne informacje, można kliknąć przycisk Zapisz umieszczony na samym dole strony, co spowoduje przejście do strony głównej projektu. Na niej można kliknąć mały, śmieszny odnośnik Build Now umieszczony w lewej kolumnie strony, aby zainicjować proces budowy projektu. Jeśli wcześniej zdefiniowaliśmy jakieś zdarzenia wyzwalające ten proces, to możemy poczekać, aż one wystąpią; ale czy nie lepiej będzie od razu przekonać się, czy projekt uda się zbudować pomyślnie? Rysunek 1-15 przedstawia stronę główną serwera po dodaniu kolejnego zadania.
Jeśli zadania nie uda się prawidłowo wykonać, to zamiast ikony zielonej kulki zostanie wyświetlona czerwona. Okazuje się, że w przypadku powodzenia domyślnie wyświetlana jest ikona niebieskiej kulki; jednak ponieważ większość osób kojarzy sukces z kolorem zielonym, zazwyczaj pierwszą wtyczką dodawaną do nowej instalacji serwera jest „Green Balls”, która sprawia, że ikona reprezentująca pomyślne wykonanie zadania będzie mieć postać zielonej kulki.
Oprócz ikony czerwonej lub zielonej kulki wyświetlana jest także informacja o ostatnich wykonaniach zadania, określana jako „raport pogody” i przyjmująca postać ikony słońca (wszystkie ostatnie próby budowania zakończyły się pomyślnie), słońca za chmurami, chmur z deszczem oraz burzy (jeśli żadna z ostatnich prób budowania nie zakończyła się pomyślnie).
Teraz można kliknąć odnośnik z numerem wykonanego zadania, którego nie udało się zbudować, a na następnej stronie kliknąć odnośnik Console Output — w ten sposób będzie można określić, co poszło nie tak. Standardowym sposobem postępowania w takim przypadku jest wprowadzenie stosownych zmian w projekcie, zatwierdzenie ich, przesłanie do repozytorium kodów i ponowne wykonanie zadania zdefiniowanego w serwerze Jenkins.
Jak już wspominałem, dostępnych jest kilkaset różnych wtyczek rozszerzających możliwości serwera. Dla wygody użytkownika większość z nich można zainstalować, klikając odnośnik Manage Jenkins, a następnie Manage Plug-ins (Zarządzaj dodatkami). Wszystkie wtyczki dostępne w witrynie Jenkins.org zostaną wyświetlone na zakładce Available (Dostępne), wystarczy zaznaczyć pole wyboru obok tych, które chcemy zainstalować, i kliknąć przycisk Apply (Zainstaluj bez ponownego uruchamiania lub Pobierz teraz, zainstaluj po ponownym uruchomieniu)[12]. Pełną listę wtyczek można także obejrzeć na stronie https://wiki.jenkins-ci.org/display/JENKINS/Plugins.
Wspominałem już wcześniej, że Jenkins początkowo nosił nazwę Hudson. Projekt Hudson wciąż istnieje i jest dostępny w witrynie Eclipse. Kiedy ostatnio sprawdzałem, oba projekty zachowały zgodność, jeśli chodzi o możliwości stosowania wtyczek, zatem wiele — o ile nie większość — wtyczek z jednego serwera będzie można używać w drugim. W rzeczywistości najbardziej popularne wtyczki pojawiają się na zakładce Available (Dostępne) w obu serwerach. Podobnie, większość informacji, które podałem w tej recepturze, będzie się także odnosić do serwera Hudson. Jeśli Czytelnik używa innego systemu ciągłej integracji, to będzie musiał się zapoznać z jego dokumentacją, niemniej idea jego działania oraz korzyści, jakie zapewnia, będą takie same.
Podczas wykonywania programu wyświetlany jest zrzut stosu wyjątku, jednak w jego najważniejszych miejscach nie ma informacji o numerach wierszy.
Należy się upewnić, że kod zostały skompilowany z włączoną opcją zapisywania informacji dla programu uruchomieniowego. W starszych wersjach Javy należy wyłączyć translację JIT i ponownie ją uruchomić. Można także skorzystać ze środowiska wykonawczego HotSpot.
Gdy w programie napisanym w języku Java jest zgłaszany wyjątek, propaguje on ku górze stosu wywołań metod aż do momentu, gdy zostanie odnaleziona klauzula catch odpowiadająca danemu wyjątkowi. Gdy klauzula taka zostanie odnaleziona, interpreter Javy przechwytuje wyjątek i wyświetla informacje o bieżącym stanie stosu, pokazujące wszystkie wywołania metod, począwszy od głównego poziomu programu, a skończywszy na miejscu, w którym został zgłoszony wyjątek. Informacje te można wyświetlić w każdej klauzuli catch — służy do tego metoda printStackTrace() dostępna w klasie Throwable.
Informacje o stanie stosu obejmują numery wierszy kodu wyłącznie wtedy, gdy zostały one zapisane podczas kompilacji. W przypadku stosowania kompilatora javac są one dołączane domyślnie. Jednak zadanie javac programu Ant domyślnie nie zapisuje tych informacji; a zatem jeśli chcemy mieć dostęp do tych informacji, będziemy musieli umieścić w pliku build.xml element <javac debug="true"...>.
Tworzymy dużą aplikację i chcielibyśmy zminimalizować ilość pisanego kodu, unikając przy tym syndromu „Kod pochodzi z...”.
Użyj źródeł, Luke. Istnieją setki aplikacji Javy, szkieletów oraz bibliotek udostępnianych na zasadzie oprogramowania o otwartym kodzie źródłowym.
Przykładowe programy napisane w Javie wraz z ich kodami źródłowymi są dostępne wszędzie. Zgodnie z informacjami podanymi we wstępie kody źródłowe przykładów zamieszczonych w niniejszej książce są dostępne pod adresem ftp://ftp.helion.pl/przyklady/jarec3.zip.
Kolejnym cennym źródłem przykładów jest kod źródłowy Java API. Nie każdy o tym wie, lecz do każdego Java Development Kit dołączane są kody źródłowe publicznie dostępnych części Java API. Może Czytelnik chce poznać zasady działania klasy java.util.ArrayList? Przecież dostępny jest jej plik źródłowy. Pojawiły się problemy ze zmuszeniem klasy JTable do odpowiedniego działania? JDK firmy Sun zawiera kody źródłowe wszystkich publicznych klas! Wystarczy poszukać pliku src.zip lub src.jar; w niektórych wersjach JDK zawartość tych plików jest rozpakowywana, a w niektórych nie.
Jeśli i to okaże się niewystarczające, to można za darmo pobrać przez internet źródła całego JDK. W tym celu wystarczy zaakceptować warunki licencji Sun Java Community Source License i skopiować duży plik. Zawiera on kody źródłowe wszystkich części API — zarówno tych publicznych, jak i pozostałych, kompilator (napisany w języku Java) oraz obszerne fragmenty kodu „rodzimego” (C/C++) — sam system uruchomieniowy oraz interfejsy bibliotek rodzimych. Na przykład klasa java.io.Reader posiada metodę o nazwie read(), która odczytuje bajty danych z pliku lub połączenia sieciowego. Metoda ta została napisana w języku C, gdyż wywołuje funkcję read() danego systemu operacyjnego — Uniksa, Windowsa, MacOS-a, Palma, BeOS-a i wszelkich pozostałych. Pakiet źródłowy JDK zawiera kody wszystkich tych klas i metod.
Poza tym już od najwcześniejszego okresu wykorzystania języka Java dostępne są także witryny WWW służące rozpowszechnianiu oprogramowania napisanego w języku Java — zarówno tego bezpłatnego, jak i oprogramowania o ogólnie dostępnym kodzie. Podobne witryny są także dostępne dla innych „nawróconych” języków programowania, takich jak Perl, Python, Tk/Tcl itd. W rzeczywistości, jeśli Czytelnik będzie potrzebować kodu rodzimego w celu zaimplementowania w przenośny sposób jakichś dziwnych mechanizmów systemu operacyjnego, to kod źródłowy wymienionych wcześniej systemów wykonawczych jest doskonałym miejscem poszukiwań (wraz z materiałem podanym w Rozdział 11. niniejszej książki).
Choć ogromna większość tej książki jest poświęcona pisaniu programów w języku Java, to jednak ta receptura nie dotyczy pisania kodu, a raczej korzystania z kodu napisanego przez innych. Istnieją setki doskonałych bibliotek, które można dodawać do tworzonych przez nas aplikacji pisanych w Javie. Po co więc mamy wymyślać dziurawą oponę, skoro możemy kupić zupełnie nową i doskonałą? Wiele spośród tych bibliotek i szkieletów istnieje od lat i dzięki informacjom nadsyłanym od użytkowników zostało poprawionych i usprawnionych.
Ale jaka jest w zasadzie różnica pomiędzy biblioteką a szkieletem? Czasami jest ona dosyć ulotna, jednak ogólnie rzecz ujmując: „szkielet jest programem zawierającym elementy, które sami musimy uzupełnić”, natomiast biblioteka to jedynie „zbiór kodu, który możemy wywoływać”. W zasadzie sprowadza się to do różnicy pomiędzy zbudowaniem samochodu, który kupiliśmy prawie gotowy, lecz bez silnika, a zbudowaniem samochodu kupionego w częściach, które sami musieliśmy zmontować w jedną całość.
Rozważając zastosowanie gotowego szkieletu, konieczne jest dokonanie wielu wyborów oraz rozważenie wielu zagadnień. Jednym z nich jest koszt — sprowadza się on do wyboru rozwiązania „otwartego” bądź komercyjnego. Większość narzędzi udostępnianych jako oprogramowanie o otwartym kodzie źródłowym można pobrać i używać bezpłatnie, przy czym czasami, lecz nie zawsze, wiąże się to z koniecznością spełnienia jakichś warunków. Niniejsza książka nie jest miejscem na rozważanie kwestii licencji na oprogramowanie, dlatego zainteresowanych Czytelników odsyłam do książki Andrew M. St. Laurenta Understanding Open Source and Free Software Licensing wydanej przez wydawnictwo O’Reilly (http://shop.oreilly.com/product/9780596005818.do).
Kilka powszechnie znanych kolekcji oprogramowania o otwartym kodzie źródłowym przedstawiłem w Tabela 1-3. Większość z nich to projekty „sprawdzone”, czyli zweryfikowane w ramach jakiegoś procesu społecznościowego, który pozytywnie ocenił ich przydatność.
Tabela 1-3. Powszechnie cenione kolekcje oprogramowania otwartego napisanego w Javie
Organizacja | Adres URL | Uwagi |
|---|---|---|
Apache Software Foundation | To nie tylko serwer WWW! | |
Spring Framework | ||
Społeczność JBoss | To nie tylko serwer aplikacji Java EE! |
Istnieje także sporo ogólnie dostępnych repozytoriów kodu źródłowego, które nie są w żaden sposób „sprawdzane” — każdy, kto się w nich zarejestruje, może utworzyć projekt, niezależnie od wielkości społeczności programistów, którzy będą z niego korzystać (jeśli w ogóle taka społeczność będzie istnieć). Witryny tego typu, którym udało się odnieść sukces, gromadzą więcej projektów, niż można wyświetlić na jednej stronie — ich zawartość trzeba przeszukiwać. Kilka takich repozytoriów gromadzących projekty udostępniane na zasadach oprogramowania o otwartym kodzie źródłowym przedstawiłem w Tabela 1-4.
Tabela 1-4. Repozytoria udostępniające projekty o otwartym kodzie źródłowym
Nazwa | Adres URL | Uwagi |
|---|---|---|
Sourceforge.net | Jeden z najstarszych serwisów tego typu | |
GitHub | „Kodowanie społecznościowe” | |
Google code | ||
java.net | Zawiera tylko oprogramowanie pisane w Javie; serwis sponsorowany przez firmę Sun, a obecnie Oracle |
W żadnym razie nie sugeruję, że można dyskredytować wartość tych serwisów — kolekcja kodów źródłowych do tej książki także jest umieszczona w serwisie GitHub — chciałem tylko zaznaczyć, że trzeba wiedzieć, czego się szuka, i uważnie wybrać szkielet lub bibliotekę, z której chce się skorzystać. Czy dysponuje ona jakąś społecznością osób, które jej używają, czy też jest „martwa”?
Na końcu chciałbym zauważyć, że także ja prowadzę niewielką witrynę poświęconą językowi Java, która może się komuś przydać. Zamieściłem w niej listę zasobów związanych z Javą, jak również materiały do tej książki.
Jeśli zaś chodzi o korporacyjne lub internetowe zastosowania Javy, dostępne są dwa główne szkielety dysponujące mechanizmami „wstrzykiwania zależności”, są nimi: JavaServer Faces (JSF) i CDI oraz pakiet Spring Framework „Spring MVC”. JSF oraz wbudowany mechanizm CDI (ang. Context and Dependency Injection) udostępniają możliwości wstrzykiwania zależności oraz kilka dodatkowych kontekstów, takich jak bardzo użyteczny kontekst konwersacji, pozwalający na przechowywanie obiektów podczas długotrwałej interakcji z grupą stron WWW. Spring Framework udostępnia mechanizm wstrzykiwania zależności, a Spring MVC — klasy pomocnicze warstwy aplikacji internetowej. Wybrane zasoby warstwy aplikacji internetowej przedstawiłem w Tabela 1-5.
Tabela 1-5. Wybrane zasoby związane z aplikacjami internetowymi
Nazwa | Adres URL | Uwagi |
|---|---|---|
Lista 100 najpopularniejszych szkieletów aplikacji | ||
JSF | http://www.oracle.com/technetwork/java/javaee/overview/index.html | Nowa standardowa technologia Java EE do tworzenia aplikacji internetowych |
JSF jest szkieletem bazującym na wykorzystaniu komponentów, nic zatem dziwnego, że istnieje wiele dodatkowych komponentów, które — w porównaniu ze standardowymi komponentami JSF — znacząco rozszerzają możliwości (oraz wygląd) aplikacji. Kilka godnych uwagi bibliotek JSF przedstawiłem w Tabela 1-6.
Tabela 1-6. JSF i biblioteki dodatkowe
Nazwa | Adres URL | Uwagi |
|---|---|---|
PrimeFaces | Bogata biblioteka komponentów | |
RichFaces | Bogata biblioteka komponentów | |
OpenFaces | Bogata biblioteka komponentów | |
ICEfaces | Bogata biblioteka komponentów | |
Apache DeltaSpike | Różnego rodzaju dodatkowe kody do JSF | |
JSFUnit | Szkielet testów jednostkowych dla aplikacji JSF |
Obecnie dostępne są szkielety i biblioteki realizujące niemal wszystkie możliwe operacje. Jeśli zamieszczone tu informacje i źródła nie pozwoliły Czytelnikowi znaleźć oprogramowania, które jest mu potrzebne, to zapewne będzie musiał poszukać go w internecie. Jednak przede wszystkim starajmy się nie wymyślać koła na nowo!
Jak zawsze w przypadku korzystania z bezpłatnego oprogramowania, należy się upewnić, że dokładnie rozumiemy ograniczenia różnych systemów licencjonowania. Jeśli na przykład w tworzonym programie zostanie wykorzystany jakikolwiek fragment kodu rozpowszechnianego na warunkach licencji GPL, to także tworzony program będzie musiał być rozpowszechniany na warunkach tej licencji. Warto się skontaktować z prawnikiem. Koszty także mogą być różne. Niezależnie od tych prawnych ograniczeń kod źródłowy jest nieocenionym źródłem informacji dla osób pragnących lepiej poznać język Java.
[7] „Daj mi czas, bym uświadomił sobie swoje przestępstwa” — przyp. tłum.
[8] W niektórych wersjach programu Ant, aby to zadanie działało, konieczne będzie pobranie dodatkowych plików.
[9] Jeśli proces tworzenia lub budowania projektu obejmuje czynność „kazać Iksińskiemu zmodyfikować plik X na jego komputerze”, to nie możemy mówić o automatyzacji.
[10] Chodzi tu o takie projekty jak OpenOffice/LibreOffice oraz MySQL/mariadb, które także miały problemy z firmą Oracle.
[11] Jenkins jest aplikacją wielojęzyczną, która dostosowuje się do ustawień lokalnych komputera, na którym jest uruchamiana. Niemniej nie wszystkie teksty zostały w niej spolonizowane, dlatego niektóre opcje i komunikaty mogą być wyświetlane w języku angielskim. W dalszej części tekstu będę podawał oryginalne nazwy opcji oraz w nawiasach ich polskie odpowiedniki (jeśli takie istnieją). Warto także pamiętać, że Jenkins jest programem, który cały czas się rozwija, więc w jego nowszych wersjach mogą się pojawić kolejne tłumaczenia nazw opcji — przyp. tłum.
[12] Choć autor wspomina tylko o jednym przycisku, to w nowszej wersji serwera dostępne są dwie opcje instalacji wtyczek — przyp. tłum.