Załóżmy, że Czytelnik korzysta z internetu od kilku lat i bardzo skrupulatnie zapisuje całą elektroniczną korespondencję, na wypadek gdyby jej kiedyś potrzebował (on sam, jego adwokat lub oskarżyciel). W rezultacie na archiwum musiał przeznaczyć całą jedną partycję dysku o pojemności 5 GB. Dodatkowo załóżmy, że Czytelnik pamięta, iż gdzieś tam znajduje się list od osoby o imieniu Angie lub Anjie. A może to była Angy? Nie pamięta jednak, jak ten list był zatytułowany ani gdzie został zapisany. A zatem trzeba go poszukać.
Choć niektórzy próbowaliby otworzyć w edytorze i sprawdzić wszystkie 15 milionów zapisanych listów, ja odnajdę poszukiwany dokument przy użyciu jednego prostego polecenia. Każdy system operacyjny zawierający mechanizmy obsługi wyrażeń regularnych udostępnia kilka sposobów poszukiwania wzorca. Poniżej został przedstawiony najprostszy z nich:
Angie|Anjie|Angy
Jak łatwo można odgadnąć, oznacza on, że wystarczy odnaleźć dowolną wersję imienia. A oto nieco bardziej zwarta forma wyrażenia (przy której „będzie można mniej napisać, ale więcej pomyśleć”):
An[^ dn]
Ten zapis stanie się jasny podczas dalszej lektury rozdziału. Najprościej rzecz ujmując: „A” i „n” są odnajdywane w formie, w jakiej zostały podane, co oznacza, że poszukiwany wyraz musi się zaczynać od ciągu znaków „An”. Z kolei tajemnicze wyrażenie [^ dn] narzuca warunek, że po ciągu „An” nie może (w tym kontekście znak ^ oznacza „nie”) się pojawić znak odstępu (co eliminuje możliwość dopasowania wzorca do bardzo popularnego w języku angielskim słowa „An” umieszczonego na początku zdania) ani litera „d” (zabezpieczając nas przed dopasowaniem wzorca do słowa „and”), ani, w końcu, litera „n” (uniemożliwiając dopasowanie wzorca do imienia Anne oraz kilku innych słów języka angielskiego). Czy używany przez Czytelnika edytor tekstu w ogóle zdążył się już uruchomić? Cóż, nie ma to większego znaczenia, gdyż mnie udało się już odnaleźć poszukiwany plik. Aby uzyskać odpowiedź, wystarczyło wpisać poniższe polecenie:
grep 'An[^ dn]' *
Wyrażenia regularne (określane także skrótowo jako RE) udostępniają zwięzłą i precyzyjną specyfikację wzorców, jakie należy odszukać w tekście.
W ramach kolejnego przykładu pokazującego ogromne możliwości wyrażeń regularnych można rozważyć problem grupowej aktualizacji setek plików. Kiedy zaczynałem pracę z językiem Java, tablice były deklarowane przy użyciu następującej składni: typBazowy zmiennaTablicowa[]. Na przykład metoda, której argumentem ma być tablica, jak choćby main() we wszystkich programach pisanych w Javie, była deklarowana w następujący sposób:
public static void main(String args[]) {Jednak z upływem czasu stało się jasne, że znacznie lepszym sposobem zapisu byłoby typBazowy[] zmiennaTablicowa. Na przykład:
public static void main(String[] args) {Przewaga tego sposobu zapisu polega na tym, że kojarzy on „tablicowy” charakter typu z samym typem, a nie z nazwą argumentu lokalnego. Obecnie kompilator Javy akceptuje oba te sposoby zapisu. Chciałem zatem zmienić wszystkie wystąpienia metody main zapisane w stary sposób na nowy. Zastosowałem więc wzorzec main(String [a-z] wraz z przedstawionym już wcześniej programem grep, by odnaleźć nazwy wszystkich plików zawierających deklaracje zapisane w stary sposób (czyli łańcuch main(String zakończony znakiem odstępu i znakiem innym niż otwierający nawias kwadratowy). Następnie użyłem kolejnego narzędzia systemu Unix wykorzystującego wyrażenia regularne, edytora sed, i napisałem krótki skrypt wsadowy zamieniający wszystkie wystąpienia łańcucha main(String *([a-z][a-z]*)[] na main(String[] $1 (zastosowana tu składnia została dokładniej opisana w dalszej części rozdziału). Także w tym przypadku rozwiązanie korzystające z wyrażeń regularnych było o rząd wielkości szybsze niż ręczne wykonanie analogicznych modyfikacji, i to nawet w przypadku zastosowania całkiem potężnego edytora, takiego jako vi lub emacs, nie wspominając już w ogóle o graficznym edytorze tekstów.
Składnia wyrażeń regularnych zmieniała się kilkakrotnie — wraz z dodawaniem do kolejnych narzędzi i języków programowania możliwości ich wykorzystania, dlatego też składnia wyrażeń przedstawionych w powyższych ćwiczeniach nie jest dokładnie taka sama, jakiej należałoby użyć w kodzie pisanym w Javie. Niemniej w pełni pokazuje precyzję i ogromne możliwości, jakie zapewnia mechanizm obsługi wyrażeń regularnych[23].
W ramach trzeciego przykładu można się zastanowić nad analizą plików dziennika zapisywanych przez serwer WWW Apache, w których niektóre pola są zapisywane w cudzysłowach, inne w nawiasach kwadratowych, a jeszcze inne są od siebie oddzielane znakami odstępu. Napisanie doraźnego programu analizującego takie pliki byłoby kłopotliwe w dowolnym języku programowania, jednak inteligentnie skonstruowane wyrażenie regularne pozwala podzielić cały wiersz tekstu na pola w jednej operacji (implementacja tego przykładu została przedstawiona w „4.10. Program — analiza dziennika serwera Apache”).
Dzięki temu programiści korzystający z wyrażeń regularnych w języku Java mogą zaoszczędzić sporo czasu. Obsługa wyrażeń regularnych w standardowej wersji tego języka była dostępna od wieków i jest z nim doskonale zintegrowana (oznacza to, że metody korzystające z wyrażeń regularnych są dostępne zarówno w klasie java.lang.String, jak i w pakiecie udostępniającym „nowe metody obsługi operacji wejścia-wyjścia”). Dostępnych jest także kilka innych pakietów obsługujących wyrażenia regularne i od czasu do czasu można znaleźć kod, który z nich korzysta, niemniej z dużą dozą pewności można przyjąć, że każdy kod napisany w tym wieku korzysta już ze standardowych, wbudowanych mechanizmów obsługi wyrażeń regularnych. Sama składnia wyrażeń regularnych stosowanych w języku Java została opisana w „4.1. Składnia wyrażeń regularnych”, a składnia API pozwalającego na korzystanie z tych wyrażeń — w „4.2. Wykorzystanie wyrażeń regularnych w języku Java — sprawdzanie występowania wzorca”. Pozostałe receptury przedstawiają niektóre z zastosowań wyrażeń regularnych w języku Java.
Najlepszą książką o wyrażeniach regularnych, zawierającą wszelkie szczegółowe informacje na ich temat, jest książka Wyrażenia regularne autorstwa Jeffreya E.F. Friedla, wydana przez wydawnictwo Helion. Większość książek poświęconych systemom Unix także zawiera jakieś informacje ich dotyczące; na przykład zagadnieniom tym jest poświęcony jeden rozdział książki UNIX Power Tools wydanej przez wydawnictwo O’Reilly.
Lista znaków o specjalnym znaczeniu wykorzystywanych w wyrażeniach regularnych została przedstawiona w Tabela 4-1.
Znaki te pozwalają na tworzenie wyrażeń o sporych możliwościach. Tworząc wyrażenia regularne, można stosować dowolne kombinacje normalnych łańcuchów znaków oraz znaków specjalnych, nazywanych także metaznakami, przedstawionych w Tabela 4-1. Symboli tych i znaków można używać w dowolnych sensownych kombinacjach. Na przykład wzorzec a+ odpowiada pojedynczej literze a lub ciągowi liter a o dowolnej długości. Wzorzec Mrs?\. odpowiada ciągom znaków Mrs. lub Mr.. Natomiast wzorzec .* reprezentuje „dowolny znak powtórzony dowolną ilość razy”, a zatem jego znaczenie odpowiada symbolowi * wykorzystywanemu przez większość interpreterów poleceń. Wzorzec \d+ oznacza ciąg cyfr o dowolnej długości; zaś \d{2,3} reprezentuje liczbę składającą się z dwóch lub trzech cyfr.
Tabela 4-1. Składnia wyrażeń regularnych
Podwyrażenie | odpowiada | Uwagi |
|---|---|---|
Informacje ogólne | ||
| początkowi wiersza lub łańcucha znaków | |
| końcowi wiersza lub łańcucha znaków | |
| granicy słowa | |
| dowolnemu znakowi, który nie stanowi granicy słowa | |
| początkowi całego łańcucha znaków | |
| końcowi całego łańcucha znaków | |
| końcowi całego łańcucha znaków (za wyjątkiem dozwolonego zakończenia ostatniego wiersza) | |
| dowolnemu pojedynczemu znakowi | |
| „klasie znaków”, czyli dowolnemu ze znaków podanych w nawiasach | |
| dowolnemu znakowi, który nie został podany w nawiasach | patrz „4.2. Wykorzystanie wyrażeń regularnych w języku Java — sprawdzanie występowania wzorca” |
Alternatywa i grupowanie | ||
| grupowanie | |
| alternatywa | |
| nawiasy nieprzechwytujące | |
| koniec wcześniejszego dopasowania | |
| odwołanie wstecz do grupy przechwytującej o numerze | |
Normalne („zachłanne”)[a] metaznaki powielające („dołączanie zachłanne”) | ||
| powiela wyrażenie od | |
| powiela wyrażenie m lub więcej razy | |
| powiela wyrażenie dokładnie | |
| powiela wyrażenie od 0 do | |
| powiela wyrażenie 0 lub więcej razy | skrót zapisu |
| powiela wyrażenie 1 raz lub więcej razy | skrót zapisu |
| powiela wyrażenie 0 razy lub 1 raz | skrót zapisu |
Metaznaki powielające „niezachłanne” („dołączanie niezachłanne”) | ||
| powiela niezachłannie wyrażenie od | |
| powiela niezachłannie wyrażenie | |
| powiela niezachłannie wyrażenie od 0 do | |
| powiela niezachłannie 0 lub więcej razy | |
| powiela niezachłannie 1 raz lub więcej razy | |
| powiela niezachłannie 0 razy lub 1 raz | |
Metaznaki powielające „bardzo zachłanne” („dołączanie bardzo zachłanne”) | ||
| powiela zachłannie wyrażenie od | |
| powiela zachłannie wyrażenie | |
| powiela zachłannie wyrażenie od 0 do | |
| powiela zachłannie 0 lub więcej razy | |
| powiela zachłannie 1 raz lub więcej razy | |
| powiela zachłannie 0 razy lub 1 raz | |
Sekwencje sterujące i skróty | ||
| znak sterujący (unikowy) — wyłącza przetwarzanie metaznaków i zamienia kolejną literę ( | |
| wyłącza przetwarzanie znaków sterujących aż do sekwencji | |
| koniec cytowania rozpoczętego sekwencją | |
| znak tabulacji | |
| znak powrotu karetki | |
| znak nowego wiersza | |
| znak przesunięcia kartki | |
| znaki tworzące słowa (duże i małe litery oraz znak podkreślenia) | wzorzec |
| dowolny znak, który nie jest znakiem tworzącym słowa | |
| cyfry | wzorzec |
| dowolny znak niebędący cyfrą | |
| odstęp | znak odstępu, tabulacji oraz wszelkie inne znaki określane przez metodę |
| dowolny znak, który nie jest cyfrą | |
Bloki Unicode (wybrane przykłady) | ||
| znak należący do bloku greckiego | (blok prosty) |
| znak, który nie należy do bloku greckiego | |
| wielka litera | (prosta kategoria) |
| symbol waluty | |
Klasy znaków wzorowane na standardzie POSIX (zdefiniowane wyłącznie dla kodu US-ASCII) | ||
| znak alfanumeryczny |
|
| znak alfabetu |
|
| znak kodu ASCII |
|
| znaki odstępu lub tabulacji | |
| znaki odstępu |
|
Klasy znaków wzorowane na standardzie POSIX (zdefiniowane wyłącznie dla kodu US-ASCII) | ||
| znaki sterujące |
|
| znaki reprezentujące cyfry |
|
| znaki, które można wydrukować, lub widoczne (czyli inne niż znaki odstępu oraz znaki sterujące) | |
| znaki, które można wydrukować | |
| znaki przestankowe | jeden ze znaków
|
| małe litery |
|
| wielkie litery |
|
| cyfry szesnastkowe |
|
[a] W kontekście wyrażeń regularnych słowo „zachłanne” oznacza, że mechanizm obsługi wyrażeń będzie się starał dopasować do danego wzorca lub jego fragmentu możliwie największy fragment łańcucha znaków. | ||
Wyrażenia regularne są dopasowywane w dowolnym miejscu łańcucha. Wzorce zakończone zachłannymi metaznakami powielającymi (a jest to jedyny rodzaj metaznaków powielających, które były dostępne w tradycyjnych wyrażeniach regularnych systemu Unix) obejmują tak wiele znaków (czyli są dopasowywane do nich), jak to tylko możliwe bez narażania na szwank dopasowania podwyrażeń umieszczonych za nimi. Wzorce zakończone bardzo zachłannymi metaznakami powielającymi obejmują tak wiele znaków, jak to tylko możliwe, i to bez zwracania uwagi na podwyrażenia umieszczone za nimi. Z kolei wzorce zakończone niezachłannymi metaznakami powielającymi obejmują tylko tyle znaków, ile trzeba do zapewnienia dopasowania.
Co więcej, w odróżnieniu od pakietów obsługi wyrażeń regularnych w innych językach programowania, te zaimplementowane w Javie od samego początku obsługują znaki Unicode. A standardowa sekwencja specjalna Javy \unnnn jest używana także do umieszczania znaków Unicode we wzorcach wyrażeń regularnych. Do określania właściwości znaków Unicode, takich jak to, czy dany znak jest odstępem, używane są metody klasy java.lang.Character. Trzeba przy tym pamiętać, że w przypadku podawania znaku Unicode wewnątrz łańcucha znaków Javy konieczne jest powielenie znaku odwrotnego ukośnika, gdyż w przeciwnym przypadku kompilator potraktuje go jako zwyczajny znak odwrotnego ukośnika i kilka cyfr.
Aby pomóc Czytelnikowi w poznaniu sposobu działania wyrażeń regularnych, w niniejszej książce przedstawiony został niewielki program o nazwie REDemo[24]. Jego kod jest zbyt długi, by publikować go w tej książce; można go jednak znaleźć w dołączonych do niej kodach (w katalogu /redemo w pliku REDemo.java). Można z niego skorzystać, by przekonać się, jak działają wyrażenia regularne.
W górnym polu tekstowym (patrz Rysunek 4-1) należy wpisać wzorzec wyrażenia regularnego. Trzeba przy tym zauważyć, że podczas wpisywania kolejnych znaków sprawdzana jest poprawność składni wyrażenia. Jeśli wyrażenie jest prawidłowe, to pole wyboru widoczne z prawej strony wyrażenia będzie zaznaczone. Następnie u dołu okna można wybrać jeden z przycisków opcji: Dopasuj, Znajdź lub Znajdź wszystkie. Pierwszy z nich, Dopasuj, oznacza, że cały łańcuch znaków musi pasować do podanego wyrażenia. Wybranie przycisku Znajdź prowadzi do odnalezienia wyrażenia w dowolnym miejscu łańcucha. (Zaznaczenie ostatniego przycisku opcji, Znajdź wszystkie, pozwala policzyć liczbę odszukanych wystąpień wzorca w podanym łańcuchu znaków). W drugim polu tekstowym wpisywany jest łańcuch znaków, w którym będzie wyszukiwany wzorzec. Zachęcam do zabawy z tym programem. Kiedy wyrażenie zostanie już zapisane w odpowiedniej postaci, można je skopiować i wkleić do kodu pisanego programu. Wszelkie znaki, które zarówno kompilator Javy, jak i pakiet obsługi wyrażeń regularnych traktują w specjalny sposób, takie jak znaki cudzysłowu, należy przy tym poprzedzić znakami odwrotnego ukośnika (patrz poniższa notatka).
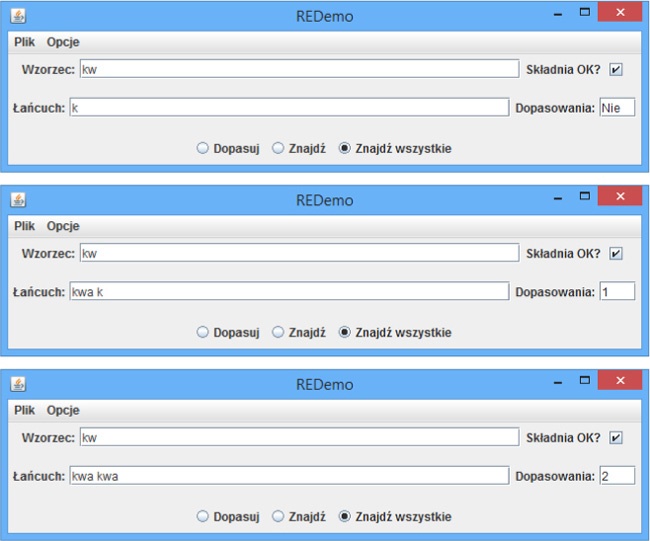
W przykładzie przedstawionym na Rysunek 4-1 w programie REDemo w polu Wzorzec wpisałem kw i, jak widać, jest to prawidłowe wyrażenie regularne: zwyczajne litery reprezentują w wyrażeniach regularnych same siebie, a zatem to wyrażenie poszukuje litery k, po której jest umieszczona litera w. W pierwszym przypadku, widocznym na samej górze, w polu dopasowywanego łańcucha znaków celowo wpisałem tylko literę k, przez co wyrażenia nie uda się dopasować. W drugim przypadku wpisałem kwa i pierwszą literę k z drugiego słowa kwa. Ponieważ wybrałem opcję Znajdź wszystkie, program pokazał, że udało mu się znaleźć tylko jeden fragment pasujący do podanego wzorca. Zaraz gdy tylko wpisałem drugą literę — w, liczba odnalezionych pasujących fragmentów została powiększona do 2, co widać na trzecim z przedstawionych okien dialogowych.
Jednak wyrażenia regularne potrafią znacznie więcej, niż tylko dopasowywać pojedyncze litery. Na przykład wyrażenie regularne w postaci ^T odpowiada początkowi wiersza (^), po którym bezpośrednio występuje duża litera T, czyli dowolnemu wierszowi rozpoczynającemu się wielką literą T. To, czy wiersz rozpoczyna się od słowa Towarzysz, Tornado, czy też Tytoń, nie ma najmniejszego znaczenia, o ile na początku wiersza występuje litera T.
Jednak ten przykład nie posunął nas zbytnio do przodu. Czy naprawdę te wszystkie wysiłki zostały zainwestowane w technologię wyrażeń regularnych tylko po to, aby można było sprawdzić coś, co równie łatwo dałoby się zrobić przy wykorzystaniu metody startsWith() klasy java.lang.String? Hm, widzę, że niektórzy z Czytelników już powoli tracą cierpliwość. Proszę poczekać! A co by było, gdybyśmy chcieli odszukać nie tylko literę T umieszczoną na samym początku wiersza, lecz także jakąś samogłoskę występującą bezpośrednio za nią (na przykład a, e, i, o lub u) i dowolną liczbę znaków tworzących wyrazy, umieszczonych za samogłoską, a wszystko to zakończone znakiem wykrzyknika? Czy takie zadanie można wykonać, korzystając ze standardowych możliwości języka Java poprzez utworzenie warunków startsWith("T") oraz charAt(1) == 'a' || charAt[1] == 'e' i tak dalej? Owszem, ale powstały w ten sposób kod byłby wysoko wyspecjalizowany i nie można by go wykorzystać w żadnej innej aplikacji. W przypadku wyrażeń regularnych wystarczy posłużyć się następującym wzorcem: ^T[aeiou]\w*!. Składa się on ze znaków ^ oraz T, znanych już z poprzedniego przykładu, klasy znaków składającej się z pięciu samogłosek, dowolnej liczby znaków tworzących wyraz (\w*) oraz znaku wykrzyknika.
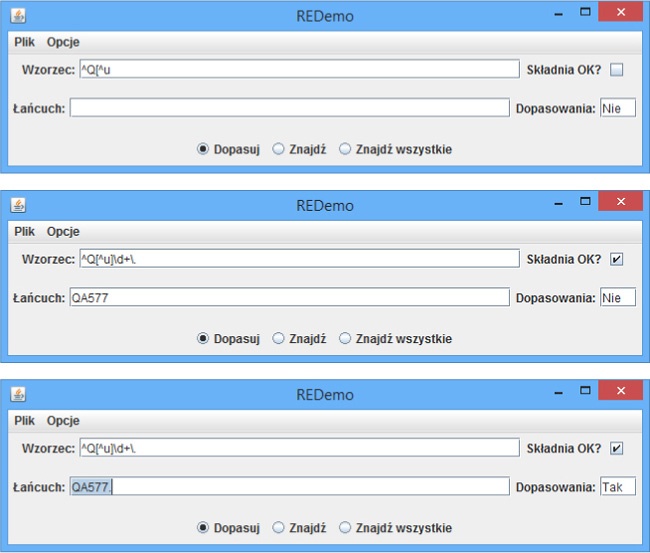
„Ale poczekaj, to nie wszystko!” — jak zwykł mawiać mój wielki szef Yuri Rubinsky. A co w przypadku, gdybyśmy chcieli mieć możliwość modyfikacji poszukiwanego wzorca w czasie działania programu? Pamiętasz ten cały kod napisany w Javie, który sprawdza, czy na początku łańcucha znajduje się litera T, za nią jedna z pięciu samogłosek, następnie dowolnej długości ciąg znaków tworzących wyrazy, a na samym końcu wykrzyknik? Cóż, nadszedł czas, aby wyrzucić ten kod i zapomnieć o nim, a to dlatego, że dziś musimy szukać litery Q, po której może wystąpić dowolna litera za wyjątkiem u, dowolna liczba cyfr i kropka. Choć niektórzy z Czytelników już pewnie zaczynają pisać nową funkcję, która testowałaby ten warunek, pozostali wybiorą się na przechadzkę do RegExp Grill-bar, zamówią ^Q[^u]\d+\. u barmana, po czym będą dalej kontynuować spacer.
W porządku, [^u] oznacza „dopasuj dowolny znak za wyjątkiem litery u”. Symbol \d+ reprezentuje jedną lub więcej cyfr. Plus (+) jest metaznakiem powielającym, oznaczającym jedno lub większą liczbę wystąpień elementu wyrażenia podanego wcześniej, a \d wskazuje na dowolną cyfrę. Pamiętamy również, że wzorzec \d+ oznacza jedną, dwie lub większą liczbę cyfr. No dobrze, a końcowa część wyrażenia — \.? Cóż, sama kropka (.) jest metaznakiem. Specjalne działanie pojedynczego metaznaku można „wyłączyć”, poprzedzając go tak zwanym „znakiem unikowym”. Oczywiście nie chodzi tu o klawisz Esc na klawiaturze. W przypadku wyrażeń regularnych tym znakiem unikowym jest lewy ukośnik. Poprzedzenie metaznaku takiego jak kropka znakiem unikowym sprawi, że metaznak straci swoje specjalne znaczenie, a zatem wzorzec \. oznacza, że poszukujemy znaku kropki, a nie „dowolnego znaku”. Poprzedzenie kilku wybranych zwyczajnych znaków (n, r, t, s oraz w) lewym ukośnikiem sprawia, że stają się one metaznakami. Rysunek 4-2 przedstawia testy działania wyrażenia regularnego ^Q[^u]\d+\.. W pierwszym przedstawionym okienku został wpisany jedynie jego początkowy fragment — ^Q[^u, a ponieważ brakuje w nim zamykającego nawiasu kwadratowego, pole wyboru Składnia OK? nie jest zaznaczone. Program zaznaczy je, kiedy wyrażenie zostanie dokończone. W drugim z przedstawionych okienek wyrażenie zostało już podane w całości, a w polu poniżej został wpisany łańcuch QA577 (który powinien pasować do wzorca ^Q[^u]\d+, lecz nie do kropki, której w tym łańcuchu brakuje). Wreszcie, trzecie okienko przedstawia sytuację po dopisaniu kropki do sprawdzanego łańcucha — jak widać, pole Dopasowania zostało zaznaczone.
Dobrym rozwiązaniem jest wyobrażenie sobie, że wyrażenia regularne są „niewielkim językiem” służącym do dopasowywania wzorców znaków występujących w tekście. Czytelnik może sobie przyznać dodatkowe punkty, jeśli zauważył, że jest to wzorzec projektowy o nazwie Interpreter. API wyrażeń regularnych jest interpreterem służącym do dopasowywania wyrażeń regularnych.
A zatem Czytelnik powinien już obecnie dysponować podstawową wiedzą o praktycznym działaniu wyrażeń regularnych. W dalszej części tego rozdziału zostały zamieszczone kolejne przykłady oraz wyjaśnienia związane z bardziej zaawansowanymi zagadnieniami, takimi jak grupy przechwytujące. Osoby zainteresowane teoretycznymi podstawami działania wyrażeń regularnych — a istnieje wiele teoretycznych szczegółów i różnic pomiędzy różnymi wersjami wyrażeń regularnych — mogą skorzystać z książki Wyrażenia regularne. W międzyczasie jednak zajmijmy się nauką pisania programów korzystających z wyrażeń regularnych w języku Java.
Jesteśmy gotowi do wykorzystania wyrażeń regularnych w programach pisanych w Javie, a konkretnie do sprawdzania, czy podany wzorzec występuje w danym łańcuchu znaków.
Należy skorzystać ze standardowego pakietu do obsługi wyrażeń regularnych dostępnego w Javie — java.util.regex.
Wszystkich zapewne ucieszy wiadomość, że interfejs programistyczny do obsługi wyrażeń regularnych w języku Java jest łatwy do wykorzystania. Jeśli chodzi wyłącznie o sprawdzenie, czy dane wyrażenie można dopasować do konkretnego łańcucha znaków, wystarczy w tym celu skorzystać z wygodnej metody boolean matches() klasy String, w której wywołaniu podawane jest wyrażenie regularne zapisane w formie łańcucha znaków:
if (inputString.matches(stringRegexPattern)) {
// Jeśli pasuje... to robimy coś z łańcuchem.
}Jednak jest to jedynie metoda pomocnicza, a wygoda zawsze ma swoją cenę. Jeśli wyrażenie regularne będzie używane w programie więcej niż raz lub dwa razy, to bardziej wydajnym rozwiązaniem będzie utworzenie obiektów Pattern oraz Matcher. Poniżej został przedstawiony kompletny program, który tworzy obiekt Pattern, a następnie korzysta z jego metody matcher(), by dopasować wyrażenie regularne do podanego tekstu.
/regex/RESimple.java
public class RESimple {
public static void main(String[] argv) {
String pattern = "^K[^w]\\d+\\.";
String[] input = {
"KA777. Jesteście o czasie. Możecie lądować.",
"Kwa, kwa, kwa!"
};
Pattern p = Pattern.compile(pattern);
for (String in : input) {
boolean found = p.matcher(in).lookingAt();
System.out.println("'" + pattern + "'" +
(found ? " pasuje " : " nie pasuje ") + input);
}
}
}Pakiet java.util.regex zawiera dwie klasy: Pattern oraz Matcher, których publiczny interfejs programistyczny został przedstawiony na Przykład 4-1.
Przykład 4-1. Publiczny interfejs programistyczny pakietu java.util.regex
/** Główne, publiczne API klasy java.util.regex. * Przygotowane w formie czytelnej przez javap i Iana Darwina. */ package java.util.regex; public final class Pattern { // Wartości flag (można je łączyć operatorem 'or'). public static final int UNIX_LINES, CASE_INSENSITIVE, COMMENTS, MULTILINE, DOTALL, UNICODE_CASE, CANON_EQ; // Brak publicznych konstruktorów; należy korzystać // z metod wytwórczych. public static Pattern compile(String patt); public static Pattern compile(String patt, int flags); // Metoda pobierająca obiekt Matcher dla danego obiektu Pattern public Matcher matcher(CharSequence input); // Metody informacyjne. public String pattern(); public int flags(); // Metody pomocnicze. public static boolean matches(String pattern, CharSequence input); public String[] split(CharSequence input); public String[] split(CharSequence input, int max); } public final class Matcher { // Operacje: metody odnajdujące lub dopasowujące. public boolean matches(); public boolean find(); public boolean find(int start); public boolean lookingAt(); // Metody zwracające "informacje o poprzednim dopasowaniu". public int start(); public int start(int whichGroup); public int end(); public int end(int whichGroup); public int groupCount(); public String group(); public String group(int whichGroup); // Metody przywracające stan początkowy. public Matcher reset(); public Matcher reset(CharSequence newInput); // Metody zastępujące. public Matcher appendReplacement(StringBuffer where, String newText); public StringBuffer appendTail(StringBuffer where); public String replaceAll(String newText); public String replaceFirst(String newText); // Metody informacyjne. public Pattern pattern(); } /* Klasa String, metody związane z wyrażeniami regularnymi */ public final class String { public boolean matches(String regex); public String replaceFirst(String regex, String newStr); public String replaceAll(String regex, String newStr); public String[] split(String regex); public String[] split(String regex, int max); }
Ten interfejs programistyczny jest na tyle duży, że wymaga pewnych wyjaśnień. Standardowa procedura wykonywana w programach produkcyjnych w celu dopasowania wyrażeń regularnych składa się z następujących operacji:
Utworzenie obiektu
Patternpoprzez wywołanie metodyPattern.compile().Pobranie obiektu
Matcherz obiektuPatternpoprzez wywołanie metodypattern.matcher(CharSequence)dla każdego łańcucha znaków (lub obiektuCharSequence), który należy sprawdzić.Wywołanie (raz lub więcej razy) jednej z metod odnajdujących obiektu
Matcherpobranego w poprzednim kroku.
Interfejs java.lang.CharSequence zapewnia bardzo proste możliwości odczytu z obiektów zawierających kolekcję znaków. Standardowymi implementacjami tego interfejsu są klasy String, StringBuffer oraz StringBuilder (opisane w Rozdział 3.), jak również „nowa klasa wejścia-wyjścia” — java.nio.CharBuffer.
Oczywiście, dopasowywanie wyrażeń regularnych można wykonywać także na inne sposoby, na przykład korzystając z metod pomocniczych udostępnianych przez klasy Pattern lub java.lang.String. Oto przykład takiego rozwiązania:
/regex/StringConvenience.java
public class StringConvenience {
public static void main(String[] argv) {
String pattern = ".*Q[^u]\\d+\\..*";
String line = "Zamów QT300. Już dziś!";
if (line.matches(pattern)) {
System.out.println(line + " pasuje do \"" + pattern + "\"");
} else {
System.out.println("Nie pasuje!!");
}
}
}Jednak trzy opisane powyżej czynności stanowią „standardowy” sposób dopasowywania wyrażeń regularnych. W programach, w których wyrażenie jest dopasowywane tylko jeden raz, zazwyczaj będzie używana metoda pomocnicza klasy String; jeśli jednak wyrażenie będzie dopasowywane kilka razy, to warto poświęcić nieco czasu na jego „skompilowanie”, gdyż tak przygotowane wyrażenia działają szybciej.
Co więcej, obiekty Matcher udostępniają kilka metod wyszukujących, które zapewniają znacznie większą elastyczność niż metoda matches() klasy String. Należy do nich zaliczyć następujące metody:
matches()Metoda ta jest stosowana do dopasowywania do wyrażenia regularnego całego łańcucha znaków. Odpowiada ona metodzie o tej samej nazwie, zdefiniowanej w klasie
java.lang.String. Ponieważ metoda ta dopasowuje do wyrażenia cały łańcuch znaków, na początku i końcu wzorca trzeba dodać.*.lookingAt()Ta metoda służy do dopasowywania wyrażenia regularnego wyłącznie na początku łańcucha.
find()Ta metoda służy do dopasowywania wyrażenia regularnego w łańcuchu (niekoniecznie od jego pierwszego znaku), zaczynając od jego początku, lub, jeśli metoda ta została wywołana już wcześniej i udało się jej odnaleźć fragment pasujący do wzorca, to zaczynając od pierwszego znaku łańcucha, który wcześniej nie został dopasowany.
Każda z tych metod zwraca wartość logiczną, przy czym true oznacza dopasowanie, a false — jego brak. Aby sprawdzić, czy konkretny łańcuch znaków pasuje do wyrażenia regularnego, wystarczy użyć poniższego fragmentu kodu:
Matcher m = Pattern.compile(patt).matcher(line);
if (m.find()) {
System.out.println("Wiersz: " + line + "pasuje do wzorca " + patt);
}Może się jednak zdarzyć, że konieczne będzie pobranie dopasowanego fragmentu łańcucha znaków. Rozwiązanie tego problemu zostało przedstawione w następnej recepturze.
Kolejne receptury przedstawiają przykłady zastosowania opisanego tu interfejsu programistycznego służącego do obsługi wyrażeń regularnych. Początkowo danymi wejściowymi są zwyczajne łańcuchy znaków — obiekty String; zastosowanie obiektów typu CharSequence zostało przedstawione w „4.5. Wyświetlanie wszystkich wystąpień wzorca”
Czasami sama informacja, czy łańcuch znaków pasuje do zadanego wyrażenia regularnego, nie wystarcza. W edytorach oraz wielu innych narzędziach konieczne będzie uzyskanie informacji, jakie litery będą pasowały do danego wyrażenia. Należy pamiętać, że w przypadku wykorzystania metaznaków powielających, takich jak *, długość łańcucha pasującego do zadanego wzorca nie musi pozostawać w żadnej relacji z długością tego wzorca. W żadnym przypadku nie należy lekceważyć wyrażenia .*, które — jeśli tylko będzie miało okazję — może pasować do łańcucha o długości wielu milionów znaków. Jak pokazała poprzednia receptura, występowanie dopasowania można sprawdzić na podstawie wyniku zwracanego przez metody find() lub matches(). Jednak w tym przykładzie chodzi o pobranie znaków pasujących do podanego wyrażenia regularnego.
Po udanym wywołaniu jednej z powyższych metod można wywołać jedną z metod „informacyjnych”, by uzyskać więcej informacji dotyczących dopasowania:
start(),end()Zwracają odpowiednio położenie początkowego oraz końcowego znaku fragmentu łańcucha, który udało się dopasować do wyrażenia regularnego.
groupCount()Zwraca liczbę grup przechwytujących (zapisanych w nawiasach), jeśli takie istnieją, lub
0w przeciwnym przypadku.group(int i)Ta metoda zwraca znaki wchodzące w skład i-tej grupy przechwytującej dla danego dopasowania, przy czym i jest liczbą większą lub równą 0 i mniejszą lub równą wartości zwróconej przez metodę
groupCount(). Grupa zerowa reprezentuje dopasowanie całego wyrażenia, a zatemgroup(0)(lub po prostugroup()) zwraca cały fragment wejściowego łańcucha znaków, dopasowany do podanego wyrażenia regularnego.
Zapis wykorzystujący nawiasy (nazywane także „grupami przechwytującymi”) ma kluczowe znaczenie dla przetwarzania wyrażeń regularnych. Można je bowiem zagnieżdżać, tworząc wyrażenia o dowolnie wysokim poziomie złożoności. Wywołanie group(int) pozwala pobrać znaki dopasowane do konkretnej grupy przechwytującej. Jeśli w wyrażeniu nie zostały jawnie zastosowane nawiasy, to całe wyrażenie można potraktować jako „grupę zerową”. Przykład 4-2 przedstawia fragment programu REmatch.java.
Przykład 4-2. /regex/REmatch.java
public class REmatch {
public static void main(String[] argv) {
String patt = "Q[^u]\\d+\\.";
Pattern r = Pattern.compile(patt);
String line = "Zamów QT300. Już dziś!";
Matcher m = r.matcher(line);
if (m.find()) {
System.out.println(patt + " pasuje do \"" +
m.group(0) +
"\" w \"" + line + "\"");
} else {
System.out.println("Nie pasuje!!");
}
}
}Po uruchomieniu program wyświetla następujący komunikat:
Q[^u]\d+\. pasuje do "QT300." w "Zamów QT300. Już dziś!"
Rozszerzona wersja programu REDemo przedstawionego w „4.2. Wykorzystanie wyrażeń regularnych w języku Java — sprawdzanie występowania wzorca”, REDemo2, wyświetla zawartość wszystkich grup przechwytujących danego wyrażenia regularnego; przykład wyników działania tego programu został przedstawiony na Rysunek 4-3.
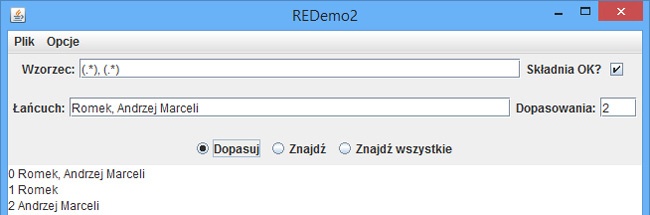
Można także pobrać indeks początku i końca łańcucha odpowiadającego wyrażeniu w danej parze nawiasów oraz długość tego łańcucha (należy bowiem pamiętać, że wzorzec taki jak \d+ może odpowiadać dowolnej liczbie cyfr). Informacje te można wykorzystać wraz z metodą String.substring(), jak pokazałem w poniższym przykładzie:
/regex/REsubstr.java
String patt = "Q[^u]\\d+\\.";
Pattern r = Pattern.compile(patt);
String line = "Zamów QT300. Już dziś!";
Matcher m = r.matcher(line);
if (m.find()) {
System.out.println(patt + " pasuje do \"" +
line.substring(m.start(0), m.end(0)) +
"\" w \"" + line + "\"");
} else {
System.out.println("Nie pasuje!!");
}Przypuśćmy, że musimy pobrać kilka informacji z łańcucha znaków. Dane wejściowe mają następującą postać:
Kowalski, Jędrzej Adamski, Andrzej Alojzy
natomiast my chcemy uzyskać wyniki w następującej postaci:
Jędrzej Kowalski Andrzej Alojzy Adamski
W tym celu możemy wykorzystać poniższy kod:
/regex/REmatchTwoFields.java
public class REmatchTwoFields {
public static void main(String[] args) {
String inputLine = "Adamski, Andrzej Alojzy";
// Tworzymy wyrażenie regularne z dwoma parami nawiasów, które
// "pobierze" obie części łańcucha - field1 i field2.
Pattern r = Pattern.compile("(.*), (.*)");
Matcher m = r.matcher(inputLine);
if (!m.matches())
throw new IllegalArgumentException("Nieprawidłowe dane wejściowe.");
System.out.println(m.group(2) + ' ' + m.group(1));
}
}Jak można się było przekonać na przykładzie przedstawionym w poprzedniej recepturze, jeśli wzorzec wyrażenia regularnego zawiera metaznaki powielające, to niewielka liczba metaznaków może odpowiadać dowolnej ilości znaków łańcucha porównywanego z wyrażeniem. Przydałaby się nam możliwość zastępowania fragmentu łańcucha pasującego do wyrażenia regularnego bez jednoczesnego modyfikowania pozostałych części tego łańcucha. Operację taką można wykonać manualnie, posługując się metodą substring() klasy String. Niemniej operacje tego typu są na tyle popularne, że narzędzia programistyczne służące do obsługi wyrażeń regularnych udostępniają metody, które realizują to zadanie. Argumentami wywołania wszystkich tych metod są łańcuch znaków, którego fragment należy zastąpić, oraz zamiennik — tak zwana „prawa strona operacji zamiany”. To historyczny termin, gdyż w poleceniu zamiany stosowanym w edytorach tekstowych po lewej stronie podawany był wzorzec, a po prawej — nowy tekst, który miał zastąpić fragment pasujący do wzorca. Poniżej przedstawione zostały wszystkie metody pozwalające na zastępowanie fragmentów łańcuchów znaków:
replaceAll(newString)Zastępuje wszystkie pasujące fragmenty nowym łańcuchem znaków.
appendReplacement(StringBuffer, newString)Kopiuje znaki poprzedzające pierwsze dopasowanie i dołącza do nich podany łańcuch —
newString.appendTail(StringBuffer)Dołącza tekst, umieszczając go za ostatnim dopasowaniem (zazwyczaj metoda ta jest wywoływana po metodzie
appendReplacement).
Przykład zastosowania tych trzech metod został przedstawiony na Przykład 4-3.
Przykład 4-3. /regex/ReplaceDemo.java
/** * Krótka prezentacja zastępowania z wykorzystaniem wyrażeń * regularnych. Zastępujemy słowo "prac" słowem "samokształcenia". * @author Ian F. Darwin, http://www.darwinsys.com/ */ public class ReplaceDemo { public static void main(String[] argv) { // Dopasowywane będą całe słowa (\b - to granica słowa) String patt = "\\bprac\\b"; // Testowe dane wejściowe. String input = "Plan prac zmusza pracowników do dużego wysiłku."; System.out.println("Dane wejściowe: " + input); // Uruchamiamy wyrażenie i sprawdzamy, czy działa. Pattern r = Pattern.compile(patt); Matcher m = r.matcher(input); System.out.println("Zastąpienie wszystkich: " + m.replaceAll("samokształcenia")); // Prezentacja działania metody appendReplacement. m.reset(); StringBuffer sb = new StringBuffer(); System.out.print("Metody dołączające: "); while (m.find()) { // Skopiowanie przed pierwszym wystąpieniem // Dodanie słowa "prac" m.appendReplacement(sb, "samokształcenia"); } m.appendTail(sb); // Skopiowanie pozostałej części System.out.println(sb.toString()); } }
Oczywiście po uruchomieniu program działa zgodnie z naszymi oczekiwaniami:
Dane wejściowe: Plan prac zmusza pracowników do dużego wysiłku. Zastąpienie wszystkich: Plan samokształcenia zmusza pracowników do dużego wysiłku. Metody dołączające: Plan samokształcenia zmusza pracowników do dużego wysiłku.
Musimy wyświetlić wszystkie łańcuchy znaków pochodzące z jednego lub kilku plików bądź innych źródeł, pasujące do podanego wyrażenia regularnego.
Przedstawiony poniżej przykład odczytuje zawartość pliku wiersz po wierszu. Gdy zostanie odnaleziony fragment pasujący do podanego wyrażenia regularnego, program pobiera go z wykorzystaniem metod klasy CharacterIterator i wyświetla na ekranie.
Program ten wykorzystuje metodę group() przedstawioną w „4.3. Odnajdywanie tekstu pasującego do wzorca”, metodę substring() interfejsu CharacterIterator oraz metodę find() klasy Matcher. Został on napisany w taki sposób, aby wyświetlał wszystkie „nazwy” w podanym pliku; przeanalizowanie pliku ReaderIter.java za jego pomocą spowoduje wyświetlenie takich słów jak: import, java, util, regex i tak dalej.
C:\\> javac -d . ReaderIter.java C:\\> java regex.ReaderIter ReaderIter.java import java util regex import java io Print all the strings that match given pattern from file public ... C:\\>
Wyniki nie zostały przedstawione w całości, aby zaoszczędzić trochę papieru. Program ten można zapisać na dwa sposoby: tradycyjny, analizujący zawartość pliku wiersz po wierszu (to rozwiązanie zostało przedstawione na Przykład 4-4), a także w nieco bardziej zwarty sposób przy użyciu „nowych operacji wejścia-wyjścia” (to rozwiązanie zostało przedstawione na Przykład 4-5; natomiast pakiet implementujący „nowe operacje wejścia-wyjścia” został zaprezentowany w Rozdział 10.).
Przykład 4-4. /regex/ReaderIter.java
public class ReaderIter {
public static void main(String[] args) throws IOException {
// Wzorzec
Pattern patt = Pattern.compile("[A-Za-z][a-z]+");
// FileReader (patrz rozdział o operacjach wejścia-wyjścia - I/O)
BufferedReader r = new BufferedReader(new FileReader(args[0]));
// Dla każdego odnalezionego fragmentu pasującego do wzorca
// pobieramy go i wyświetlamy
String line;
while ((line = r.readLine()) != null) {
// Dla każdego dopasowanego wiersza pobieramy go
// i wyświetlamy.
Matcher m = patt.matcher(line);
while (m.find()) {
// Najprostszy sposób:
// System.out.println(m.group(0));
// Pobieramy indeks początku tekstu.
int start = m.start(0);
// Pobieramy indeks końca tekstu.
int end = m.end(0);
// Wyświetlamy dopasowany fragment tekstu,
// używając metody CharacterIterator.substring(offset, end);
System.out.println(line.substring(start, end));
}
}
}
}Przykład 4-5. /regexp/GrepNIO.java
public class GrepNIO {
public static void main(String[] args) throws IOException {
if (args.length < 2) {
System.err.println("Sposób użycia: GrepNIO wzorzec plik [...]");
System.exit(1);
}
Pattern p=Pattern.compile(args[0]);
for (int i=1; i<args.length; i++)
process(p, args[i]);
}
static void process(Pattern pattern, String fileName) throws IOException {
// Tworzymy obiekt FileChannel dla danego pliku.
FileChannel fc = new FileInputStream(fileName).getChannel();
// Odwzorowujemy zawartość pliku.
ByteBuffer buf = fc.map(FileChannel.MapMode.READ_ONLY, 0, fc.size());
// Dekodujemy ByteBuffer do postaci CharBuffer
CharBuffer cbuf =
Charset.forName("ISO-8859-1").newDecoder().decode(buf);
Matcher m = pattern.matcher(cbuf);
while (m.find()) {
System.out.println(m.group(0));
}
}
}Druga wersja programu przedstawiona na Przykład 4-5 korzysta z faktu, że obiekt Buffer pakietu „nowych operacji wejścia-wyjścia” może być traktowany jako obiekt typu CharSequence. Jest on nieco bardziej ogólny, gdyż wzorzec wyrażenia regularnego jest przekazywany jako argument podawany w wierszu poleceń. Jeśli w wierszu wywołania programu zostanie przekazany wzorzec z poprzedniego listingu, to program ten wyświetli identyczne rezultaty jak te przedstawione na początku rozdziału:
java regex.GrepNIO "[A-Za-z][a-z]+" ReaderIter.javaMożna się zastanawiać nad użyciem wzorca \w+. Jedyna różnica pomiędzy nimi polega na tym, że wyrażenie regularne zastosowane w przykładzie poszukuje słów prawidłowo zaczynających się wielką literą, natomiast \w+ będzie akceptować wszelkie osobliwości występujące w kodzie Javy, takie jak nazwy zmiennych podobne do theVariableName, zawierające wielkie litery nie tylko na początku, lecz także wewnątrz łańcucha.
Warto także zwrócić uwagę, że druga wersja programu może być nieco bardziej wydajna, gdyż nie będzie przywracać obiektu Matcher do stanu początkowego dla każdego wiersza kodu, jak dzieje się w przypadku programu ReaderIter.
W jednym lub kilku plikach musimy odszukać wiersze zawierające fragment pasujący do danego wyrażenia regularnego.
Jak już wspominałem, dysponując pakietem obsługującym wyrażenia regularne, można napisać program działający podobnie do programu grep używanego w systemach operacyjnych Unix. Przykład takiego programu podawałem już wcześniej. W wywołaniu tego programu można podać kilka argumentów opcjonalnych, jedno niezbędne wyrażenie regularne oraz dowolną liczbę nazw plików. Program wyświetla wszystkie wiersze zawierające fragment pasujący do podanego wyrażenia, co odróżnia go od programu przedstawionego w „4.5. Wyświetlanie wszystkich wystąpień wzorca”, który wyświetlał jedynie pasujący fragment tekstu. Na przykład polecenie:
grep "[dD]arwin" *.txtposzukuje dowolnych wierszy tekstu zawierających słowa darwin lub Darwin we wszystkich plikach z rozszerzeniem .txt[25]. Przykład 4-6 przedstawia kod źródłowy pierwszej wersji programu, który realizuje to zadanie. Program ten nosi nazwę Grep0. Ta wersja programu odczytuje dane ze standardowego strumienia wejściowego i nie jest w stanie pobierać żadnych argumentów opcjonalnych, lecz pozwala na stosowanie dowolnych wyrażeń regularnych, które można zaimplementować z wykorzystaniem klasy Pattern (i dlatego nie jest dokładnym odpowiednikiem programów dostępnych w systemie Unix). Jak na razie nie omawiałem jeszcze pakietu java.io obsługującego operacje wejścia-wyjścia (pakiet ten został przedstawiony w Rozdział 10.), niemniej jednak wykonywane tu czynności są na tyle proste, że można je zrozumieć intuicyjnie. W internetowym repozytorium kodów można znaleźć program o nazwie Grep1, który robi dokładnie to samo, lecz którego kod ma nieco lepszą strukturę (i dlatego jest także nieco dłuższy). W dalszej części tego rozdziału, w „4.12. Program — pełna wersja programu grep”, przedstawiłem program JGrep, który wykorzystuje klasę GetOpt (patrz „2.6. Analiza argumentów podanych w wierszu wywołania programu”) do analizy argumentów przekazywanych w wierszu poleceń.
Przykład 4-6. /regex/Grep0.java
public class Grep0 {
public static void main(String[] args) throws IOException {
BufferedReader is =
new BufferedReader(new InputStreamReader(System.in));
if (args.length != 1) {
System.err.println("Sposób użycia: MatchLines wzorzec");
System.exit(1);
}
Pattern patt = Pattern.compile(args[0]);
Matcher matcher = patt.matcher("");
String line = null;
while ((line = is.readLine()) != null) {
matcher.reset(line);
if (matcher.find()) {
System.out.println("DOPASOWANO: " + line);
}
}
}
}Aby podczas sprawdzania, czy łańcuch pasuje do wyrażenia regularnego, nie była uwzględniana wielkość znaków, należy skompilować obiekt Pattern z użyciem zmiennej statycznej Pattern.CASE_INSENSITIVE. Jeśli program będzie mógł być używany na komputerach z innymi ustawieniami lokalnymi (patrz Rozdział 15.), to należałoby skorzystać w nim ze zmiennej statycznej Pattern.UNICODE_CASE. Bez podawania tych zmiennych (nazywanych także flagami) stosowany będzie domyślny sposób dopasowywania wyrażeń regularnych, uwzględniający wielkość liter. Powyższe (jak również wszelkie inne) flagi są przekazywane w wywołaniu metody Pattern.compile() w sposób przedstawiony w poniższym przykładzie:
/regex/CaseMatch.java
Pattern reCaseInsens = new Pattern.compile(pattern, Pattern.CASE_INSENSITIVE | Pattern.UNICODE_CASE);
reCaseInsens.matches(input); // Dopasowanie bez uwzględniania wielkości liter.Flagi należy przekazywać podczas tworzenia obiektu Pattern, gdyż obiekty tej klasy są niezmienne — po utworzeniu nie można ich już modyfikować.
Pełny kod tego przykładu można znaleźć w plikach dołączonych do książki, w pliku /regex/CaseMatch.java.
Obiekt Pattern należy skompilować z użyciem flagi Pattern.CANON_EQ (oznaczającej „równość kanoniczną”).
Znaki złożone mogą być wpisywane w wielu formach. W ramach przykładu przyjrzyjmy się literze „e" z ostrym akcentem. W tekstach Unicode taki znak może być zapisywany w różny sposób: jako pojedynczy znak é (znak Unicode \u00e9) bądź też jako sekwencja składająca się z dwóch znaków e´ (litery „e" oraz umieszczonego bezpośrednio za nią akcentu ostrego, \u0301). Aby umożliwić dopasowanie takiego znaku niezależnie od zastosowanej formy jego zapisu, pakiet wyrażeń regularnych zapewnia możliwość sprawdzania „równości kanonicznej”, która wszystkie formy zapisu traktuje jako swoje odpowiedniki. Opcję tę można włączyć, przekazując jako drugi argument wywołania metody Pattern.compile() flagę CANON_EQ (może ona być także jedną z kilku przekazywanych flag). Poniższy program przedstawia przykład zastosowania tej flagi w celu dopasowania kilku różnych form zapisu znaku:
/regex/CanonEqDemo.java
public class CanonEqDemo {
public static void main(String[] args) {
String pattStr = "\u00e9gal"; // egal
String[] input = {
"\u00e9gal", // egal - najlepsze dopasowanie :-)
"e\u0301gal", // e + "dołączany ostry akcent"
"e\u02cagal", // e + "znak modyfikatora ostrego akcentu"
"e'gal", // e + apostrof
"e\u00b4gal", // e + "ostry akcent" kodu Latin-1
};
Pattern pattern = Pattern.compile(pattStr, Pattern.CANON_EQ);
for (int i = 0; i < input.length; i++) {
if (pattern.matcher(input[i]).matches()) {
System.out.println(
pattStr + " dopasowano do " + input[i]);
} else {
System.out.println(
pattStr + " nie dopasowano do " + input[i]);
}
}
}
}Powyższy program prawidłowo dopasuje drugi z testowanych łańcuchów znaków (zawierający „dołączany ostry akcent”), lecz odrzuci pozostałe łańcuchy, choć niektóre z nich niestety na wydruku wyglądają na znaki z akcentem, mimo że nie są za takie uważane. Oto wyniki wykonania tego programu:
égal dopasowano do égal égal dopasowano do égal égal nie dopasowano do eˊgal égal nie dopasowano do e'gal égal nie dopasowano do e´gal
Więcej informacji na ten temat można znaleźć w tabelach znaków.
Należy użyć metaznaków \n oraz \r.
Dodatkowo można wykorzystać flagę Pattern.MULTILINE, która powoduje, że znaki nowego wiersza będą odpowiadały metaznakom reprezentującym początek (^) oraz koniec ($) wiersza.
Choć dostępne w systemie Unix narzędzia obsługiwane z poziomu wiersza poleceń, takie jak programy sed bądź grep, kolejno analizują wiersze tekstu, starając się dopasować je do wyrażenia regularnego, to jednak warto pamiętać, że nie wszystkie narzędzia działają w taki sposób. Edytor tekstów sam stworzony w Bell Laboratories był pierwszym znanym mi narzędziem, które umożliwiało stosowanie wyrażeń regularnych operujących na wielu wierszach; niedługo potem podobne możliwości zostały zaimplementowane w języku skryptowym Perl. W wykorzystywanym przez nas API znaki nowego wiersza nie mają żadnego szczególnego znaczenia. Metoda readLine() klasy BufferedReader zazwyczaj usuwa wszelkie odczytane znaki nowego wiersza. Jeśli jednak fragmenty tekstu są odczytywane przy użyciu innych metod niż readLine(), to w uzyskiwanych łańcuchach mogą się pojawić sekwencje znaków \n, \r lub \r\n[26]. Zazwyczaj są one traktowane jako odpowiedniki znaku \n. Jeśli jednak końce wierszy mają być dopasowywane wyłącznie do znaku \n, to w wywołaniu metody Pattern.compile() trzeba przekazać flagę UNIX_LINES.
W systemach Unix znaki ^ oraz $ są powszechnie używane do dopasowywania wyrażeń regularnych odpowiednio do początku oraz końca wiersza. W interfejsie programowania zaimplementowanym w języku Java metaznaki \^ oraz $ ignorują końcówki wierszy i są dopasowywane wyłącznie do początku i końca całego łańcucha znaków. Jeśli jednak w wywołaniu metody Pattern.compile() zostanie przekazana flaga MULTILINE, to metaznaki będą dopasowywane do znaków znajdujących się bezpośrednio za oraz bezpośrednio przed znakami końca wiersza; oprócz tego metaznak $ będzie także odpowiadał końcowi całego łańcucha znaków. Ponieważ końce wierszy są normalnymi znakami, będą pasować do wzorca . lub jemu podobnych; poza tym jeśli konieczne będzie precyzyjne określenie ich położenia, to można we wzorcu umieścić metaznaki \n oraz \r. Innymi słowy, dla używanego przez nas API są to normalne znaki, które nie mają żadnego szczególnego znaczenia. Warto zajrzeć także do ramki Flagi metody Pattern.compile(), zamieszczonej w „4.7. Kontrola wielkości znaków w metodach match() i subst()”. Przykład dopasowywania znaków końca wierszy został przedstawiony na Przykład 4-7.
Przykład 4-7. /regex/NLMatch.java
public class NLMatch {
public static void main(String[] argv) {
String input =
"Marzę o nowych silnikach\nwięcej silników dla każdego";
System.out.println("DANE WEJŚCIOWE: " + input);
System.out.println();
String[] patt = {
"silnikach\nwięcej silników",
"silnikach$"
};
for (int i = 0; i < patt.length; i++) {
System.out.println("WZORZEC " + patt[i]);
boolean found;
Pattern p1l = Pattern.compile(patt[i]);
found = p1l.matcher(input).find();
System.out.println("Flaga DEFAULT - dopasowano: " + found);
Pattern pml = Pattern.compile(patt[i],
Pattern.DOTALL|Pattern.MULTILINE);
found = pml.matcher(input).find();
System.out.println(
"Flaga MULTILINE - dopasowano: " + found);
System.out.println();
}
}
}Użyty w programie łańcuch znaków zawsze pasuje do pierwszego zdefiniowanego wyrażenia regularnego (zawierającego znak \n), natomiast w przypadku drugiego wyrażenia (zawierającego metaznak $) łańcuch pasuje do niego wyłącznie w sytuacji, gdy została ustawiona flaga Pattern.MULTILINE.
> java regex.NLMatch
DANE WEJŚCIOWE: Marzę o nowych silnikach
więcej silników dla każdego
WZORZEC silnikach
więcej silników
Flaga DEFAULT - dopasowano: true
Flaga MULTILINE - dopasowano: true
WZORZEC silnikach$
Flaga DEFAULT - dopasowano: false
Flaga MULTILINE - dopasowano: trueApache jest najpopularniejszym serwerem WWW i był stosowany niemal od samego początku istnienia WWW. Jest on jednym z najlepiej znanych na świecie projektów oprogramowania otwartego i pierwszym, który prowadziła Fundacja Apache. Niektórzy twierdzą, że nazwa ta jest grą słów nawiązującą do samych początków serwera; jego twórcy zaczynali pracę od darmowego serwera NCSA, a następnie modyfikowali go (w slangu programistów działania takie określane są angielskim słowem „patching”) tak długo, aż zaczął działać zgodnie z ich oczekiwaniami. Kiedy już nowy serwer w odpowiednio dużym stopniu różnił się od pierwowzoru, konieczne było wymyślenie dla niego nowej nazwy. A ponieważ był to „pozmieniany serwer” (ang. a patchy server), wybrano nazwę Apache. Oficjele zaprzeczają takim twierdzeniom, niemniej jednak historia jest ciekawa. Jednym z miejsc, w których modyfikacje serwera wychodzą na jaw, jest format pliku dziennika. Przeanalizujmy przykład przedstawiony na Przykład 4-8.
Przykład 4-8. Fragment pliku dziennika serwera Apache
123.45.67.89 - - [27/Oct/2000:09:27:09 -0400] "GET /java/javaResources.html HTTP/1.0" 200 10450 "-" "Mozilla/4.6 [en] (X11; U; OpenBSD 2.8 i386; Nav)"
Oczywiście format tego pliku został zaprojektowany z myślą o przeglądaniu go przez ludzi, a nie zapewnianiu prostoty analizy. Problem polega na zastosowaniu różnych znaków oddzielających poszczególne informacje: daty są zapisane w nawiasach kwadratowych, żądania w cudzysłowach, a wszędzie widocznych jest wiele odstępów. Wystarczy się zastanowić nad próbami analizy takiego pliku przy użyciu klasy StringTokenizer; choć na pewno dałoby się to zrobić, to jednak kosztowałoby to nas bardzo dużo czasu i zachodu. Niemniej to nieco zagmatwane wyrażenie regularne[27] pozwala na bardzo łatwe analizowanie zawartości plików dziennika:
\^([\d.]+) (\S+) (\S+) \[([\w:/]+\s[+\-]\d{4})\] "(.+?)" (\d{3}) (\d+) "([\^"]+)" "([\^"]+)"Być może warto ponownie zajrzeć do Tabela 4-1 i przypomnieć sobie składnię zastosowaną w tym wyrażeniu. W szczególności należy zwrócić uwagę na zastosowanie niezachłannych metaznaków powielających +? w podwyrażeniach \"(.+?)\" dopasowywanych do łańcuchów znaków zapisanych w cudzysłowach. W ich przypadku nie można użyć metaznaku powielającego .+, gdyż można by go dopasować do zbyt dużego fragmentu wiersza (a konkretnie objąłby on cały fragment wiersza, zaczynając od pierwszego cudzysłowu, a kończąc na tym umieszczonym na samym końcu wiersza). Kod pobierający m.in. wszystkie pola dziennika, adres IP, żądanie i adres URL strony, która wygenerowała żądanie, został przedstawiony na Przykład 4-9.
Przykład 4-9. /regex/LogRegExp.java
import java.util.regex.*;
public class LogRegExp {
public static void main(String argv[]) {
String logEntryPattern =
"^([\\d.]+) (\\S+) (\\S+) \\[([\\w:/]+\\s[+-]\\d{4})\\] " +
"\"(.+?)\" (\\d{3}) (\\d+) \"([^\"]+)\" \"([^\"]+)\"";
System.out.println("Wyrażenie regularne:");
System.out.println(logEntryPattern);
System.out.println("Wiersz wejściowy:");
String logEntryLine = LogExample.logEntryLine;
System.out.println(logEntryLine);
Pattern p = Pattern.compile(logEntryPattern);
Matcher matcher = p.matcher(logEntryLine);
if (!matcher.matches() ||
LogExample.NUM_FIELDS != matcher.groupCount()) {
System.err.println("Nieprawidłowy wpis w dzienniku "
+ "(lub problem z wyrażeniem regularnym):");
System.err.println(logEntryLine);
return;
}
System.out.println("Adres IP: " + matcher.group(1));
System.out.println("Użytkownik: " + matcher.group(3));
System.out.println("Data/godzina: " + matcher.group(4));
System.out.println("Żądanie: " + matcher.group(5));
System.out.println("Odpowiedź: " + matcher.group(6));
System.out.println("Liczba bajtów: " + matcher.group(7));
if (!matcher.group(8).equals("-"))
System.out.println("Adres strony: " + matcher.group(8));
System.out.println("Przeglądarka: " + matcher.group(9));
}
}Klauzula import ma jedynie zapewnić możliwość wykorzystania interfejsu definiującego postać wejściowego łańcucha znaków; został on użyty także w programie demonstracyjnym, dzięki któremu można porównać rozwiązanie wykorzystujące wyrażenia regularne oraz rozwiązanie bazujące na obiekcie StringTokenizer. Kody źródłowe obu tych programów można znaleźć w przykładach dołączonych do książki. Wykonanie powyższego programu z wykorzystaniem przykładowych danych wejściowych przedstawionych na Przykład 4-8 generuje następujące wyniki:
Wyrażenie regularne:
^([\d.]+) (\S+) (\S+) \[([\w:/]+\s[+-]\d{4})\] "(.+?)" (\d{3}) (\d+) "([^"]+)" "([^"]+)"
Wiersz wejściowy:
123.45.67.89 - - [27/Oct/2000:09:27:09 -0400] "GET /java/javaResources.html HTTP/1.0" 200 10450 "-"
 "Mozilla/4.6 [en] (X11; U; OpenBSD 2.8 i386; Nav)"
Adres IP: 123.45.67.89
Użytkownik: -
Data/godzina: 27/Oct/2000:09:27:09 -0400
Żądanie: GET /java/javaResources.html HTTP/1.0
Odpowiedź: 200
Liczba bajtów: 10450
Przeglądarka: Mozilla/4.6 [en] (X11; U; OpenBSD 2.8 i386; Nav)
"Mozilla/4.6 [en] (X11; U; OpenBSD 2.8 i386; Nav)"
Adres IP: 123.45.67.89
Użytkownik: -
Data/godzina: 27/Oct/2000:09:27:09 -0400
Żądanie: GET /java/javaResources.html HTTP/1.0
Odpowiedź: 200
Liczba bajtów: 10450
Przeglądarka: Mozilla/4.6 [en] (X11; U; OpenBSD 2.8 i386; Nav)Program prawidłowo przeanalizował wpis z pliku dziennika, wykonując w tym celu jedno wywołanie metody matcher.matches().
Załóżmy, że jako autor chciałbym śledzić, jaka jest sprzedaż moich książek w porównaniu z innymi. Te informacje można uzyskać za darmo, wyświetlając w witrynie jednej z głównych internetowych księgarni stronę poświęconą jakiejś mojej książce, odczytując dane i dopisując liczbę do pliku tekstowego. Jednak rozwiązanie tego typu jest dosyć męczące. Z dużą dozą pychy napisałem kiedyś: „Płacimy za komputery po to, aby pobierały przydatne informacje z plików, a zatem nie należy dopuszczać do sytuacji, aby to ludzie wykonywali tak prozaiczne czynności”. Program przedstawiony w tej recepturze wykorzystuje API obsługujące wyrażenia regularne, a w szczególności możliwość odnajdywania znaków nowego wiersza w celu pobrania danych ze strony HTML umieszczonej na hipotetycznym serwerze QuickBookShop.web. Program pobiera także stronę o podanym adresie URL (zagadnienia te zostaną opisane w dalszej części książki, w „13.10. Klient usługi internetowej REST”). Poszukiwany przeze mnie tekst ma następującą postać (należy pamiętać, że kod HTML strony może w każdej chwili ulec zmianie, a zatem wzorzec poszukiwanych informacji powinien być dosyć ogólny):
<b>QuickBookShop.web Sales Rank: </b> 26,252 </font><br>
Ponieważ powyższy wzorzec może się powtarzać w wielu wierszach, zamiast stosować tradycyjną metodę polegającą na odczytywaniu zawartości pliku po jednym wierszu, odczytuję całą zawartość strony WWW o podanym adresie. Do tego celu wykorzystałem stworzoną przeze mnie klasę FileIO.readerAsString() (przedstawioną w „10.10. Odczytywanie zawartości pliku i zapisywanie jej w obiekcie String”), która zwraca zawartość pliku w formie jednego długiego łańcucha znaków. Po odczytaniu i przetworzeniu zawartości strony rysuję wykres, używając w tym celu zewnętrznego programu (patrz „24.1. Uruchamianie zewnętrznego programu”); oczywiście to rozwiązanie można (i powinno się) zmienić, tak aby wykres był rysowany przez program napisany w Javie i wykorzystujący graficzny interfejs użytkownika (kilka sugestii z tym związanych można znaleźć w „12.14. Program Grapher”). Pełny kod źródłowy programu został przedstawiony na Przykład 4-10.
Przykład 4-10. BookRank.java
public class BookRank {
public final static String DATA_FILE = "book.sales";
public final static String GRAPH_FILE = "book.png";
public final static String PLOTTER_PROG = "/usr/local/bin/gnuplot";
final static String isbn = "0596007019";
final static String title = "Java Cookbook";
/** Pobranie informacji o sprzedaży ze strony i zapisanie w pliku */
public static void main(String[] args) throws Exception {
Properties p = new Properties();
p.load(new FileInputStream(
args.length == 0 ? "bookrank.properties" : args[1]));
String title = p.getProperty("title", "NO TITLE IN PROPERTIES");
// Adres URL musi zawierać na końcu "isbn=", w przeciwnym razie
// przygotuj się na to, że dane będą przycięte.
String url = p.getProperty("url", "http://test.ing/test.cgi?isbn=");
// Dziesięcioznakowy symbol ISBN książki.
String isbn = p.getProperty("isbn", "0000000000");
// Wzorzec wyrażenia regularnego (MUSI zawierać jedną grupę
// przechwytującą pobierającą symbol książki).
String pattern = p.getProperty("pattern", "Rank: (\\d+)");
int rank = getBookRank(isbn);
System.out.println("Ocena to: " + rank);
// Niezależnie od tego, czy odnaleźliśmy bieżące dane, czy też nie,
// używamy zewnętrznego programu do wyświetlenia wszystkich
// danych historycznych. Można wykorzystać program gnuplot, R
// lub dowolny inny program matematyczno-graficzny.
// Lepsze rozwiązanie polega na wykorzystaniu graficznego API
// języka Java.
PrintWriter pw = new PrintWriter(
new FileWriter(DATA_FILE, true));
String date = new SimpleDateFormat("MM dd hh mm ss yyyy ").
format(new Date());
pw.println(date + " " + rank);
pw.close();
String gnuplot_cmd =
"set term png\n" +
"set output \"" + GRAPH_FILE + "\"\n" +
"set xdata time\n" +
"set ylabel \"Book sales rank\"\n" +
"set bmargin 3\n" +
"set logscale y\n" +
"set yrange [1:60000] reverse\n" +
"set timefmt \"%m %d %H %M %S %Y\"\n" +
"plot \"" + DATA_FILE +
"\" using 1:7 title \"" + title + "\" with lines\n"
;
if (!new File(PLOTTER_PROG).exists()) {
System.out.println(
"Oprogramowanie do rysowania nie zostało zainstalowane");
return;
}
Process proc = Runtime.getRuntime().exec(PLOTTER_PROG);
PrintWriter gp = new PrintWriter(proc.getOutputStream());
gp.print(gnuplot_cmd);
gp.close();
}
/**
* Szukamy czegoś takiego jak poniższy kod HTML:
* <b>Sales Rank:</b>
* #26,252
* </font><br>
* @throws IOException
* @throws IOException
*/
public static int getBookRank(String isbn) throws IOException {
// Wyrażenie regularne - dozwolone są cyfry i przecinki.
final String pattern = "Rank:</b> #([\\d,]+)";
final Pattern r = Pattern.compile(pattern);
// Adres URL -- musi zawierać na końcu "isbn=", w przeciwnym razie
// taki fragment zostanie dodany.
final String url = "http://www.amazon.com/exec/obidos/ASIN/" + isbn;
// Odwołujemy się do adresu i tworzymy obiekt Reader.
final BufferedReader is = new BufferedReader(new InputStreamReader(
new URL(url).openStream()));
// Odczytujemy zawartość strony, poszukując informacji o ocenie
// zapisanych jako jeden długi łańcuch znaków. Zatem każde
// wyrażenie może obejmować wiele wierszy.
final String input = readerToString(is);
// Jeśli uda się znaleźć dopasowanie, dodajemy je do pliku wyników.
Matcher m = r.matcher(input);
if (m.find()) {
// Grupa 1 to dopasowane cyfry (ewentualnie z przecinkiem, który
// jest usuwany).
return Integer.parseInt(m.group(1).replace(",",""));
} else {
throw new RuntimeException(
"Nie udało się dopasować wzorca na stronie: `" + url + "'!");
}
}
private static String readerToString(BufferedReader is) throws IOException {
StringBuilder sb = new StringBuilder();
String line;
while ((line = is.readLine()) != null) {
sb.append(line);
}
return sb.toString();
}
}Teraz, kiedy zobaczyliśmy już, jak działa pakiet narzędzi obsługujących wyrażenia regularne, nadszedł czas, by stworzyć program JGrep — pełną wersję narzędzia odnajdującego wiersze pasujące do zadanego wyrażenia regularnego, wyposażoną w możliwości analizy opcji wywołania. Typowe opcje dostępne w implementacji programu grep używanej w systemach Unix zostały podane w Tabela 4-2.
Tabela 4-2. Opcje wywołania programu grep
Opcja | Znaczenie |
|---|---|
| Tylko liczba wierszy — wyświetla jedynie liczbę wierszy pasujących do wyrażenia, a nie same wiersze. |
| Kontekst: wyświetla pewne wiersze tekstu powyżej i poniżej każdego dopasowanego wiersza (taka możliwość nie została zaimplementowana w tej wersji programu, a jej implementację Czytelnik może potraktować jako ćwiczenie do samodzielnego wykonania). |
| Wzorzec należy pobrać z pliku o podanej nazwie, a nie z wiersza poleceń. |
| Nazwy plików przed wierszami nie powinny być wyświetlane. |
| Należy nie uwzględniać wielkości znaków. |
| Tylko nazwy plików — wyświetlane są jedynie nazwy plików, w których odnaleziono wiersze pasujące do wyrażenia, same wiersze nie są wyświetlane. |
| Przed treścią odnalezionego wiersza należy wyświetlić jego numer. |
| Niektóre komunikaty o błędach nie będą wyświetlane. |
| Działanie przeciwne — wyświetlane są wiersze, które NIE pasują do podanego wyrażenia regularnego. |
Klasa GetOpt została już przedstawiona w „2.6. Analiza argumentów podanych w wierszu wywołania programu”. W tym programie służy ona do kontroli przeprowadzanych operacji. W odróżnieniu od kluczowych operacji wykonywanych przez program JGrep metoda main() działa w kontekście statycznym, co może zmusić nas do przekazywania wielu informacji w konstruktorze klasy JGrep. W celu zaoszczędzenia miejsca wszelkie ustawienia przekazywane z wiersza poleceń są zapisywane w zmiennych globalnych. W odróżnieniu od uniksowego programu grep ten program nie zapewnia możliwości łączenia opcji podawanych w wierszu poleceń, a zatem można użyć opcji w postaci -l -r -i, lecz nie w postaci -lri.
Program odczytuje wiersze tekstu, sprawdza, czy jakiś ich fragment pasuje do zadanego wyrażenia regularnego, a jeśli tak (lub w przypadku użycia opcji -v, jeśli pasujący fragment nie został odnaleziony), wyświetla dany wiersz (a opcjonalnie także inne informacje). A zatem gdy wiemy już to wszystko, możemy przejrzeć kod źródłowy programu przedstawiony na Przykład 4-11.
Przykład 4-11. /regex/JGrep.java
/** Program grep wykonywany z poziomu wiersza poleceń. * Program akceptuje kilka opcji i wymaga podania wzorca oraz * dowolnej liczby nazw plików tekstowych. * Uwaga. Aktualna implementacja klasy GetOpt nie pozwala łączyć krótkich * argumentów, zatem rozdzielenie ich odstępami, jak w przykładzie: * "JGrep -l -r -i wzorzec plik...", jest OK, jednak zapis * "JGrep -lri wzorzec plik..." doprowadzi do wystąpienia błędów. * Miejmy nadzieję, że klasa GetOpt zostanie niebawem poprawiona. */ public class JGrep { private static final String USAGE = "Sposób użycia: JGrep wzorzec [-chilrsnv][-f plikwzorca][nazwapliku...]"; /** Poszukiwany wzorzec. */ protected Pattern pattern; /** Obiekt Matcher dla danego wzorca. */ protected Matcher matcher; private boolean debug; /** Czy mamy tylko zliczać wiersze i nie wyświetlać ich? */ protected static boolean countOnly = false; /** Czy nie należy uwzględniać wielkości liter? */ protected static boolean ignoreCase = false; /** Czy nie należy wyświetlać nazw plików? */ protected static boolean dontPrintFileName = false; /** Czy mają być wyświetlane wyłącznie nazwy pasujących plików? */ protected static boolean listOnly = false; /** Czy mamy wyświetlać numery wierszy? */ protected static boolean numbered = false; /** Czy nie należy wyświetlać komunikatów o błędach? */ protected static boolean silent = false; /** Czy mamy wyświetlać wiersze, które NIE pasują do podanego wzorca? */ protected static boolean inVert = false; /** Czy jeśli argumenty są katalogami, to należy je * przeszukiwać rekurencyjnie? */ protected static boolean recursive = false; /** Tworzymy obiekt JGrep dla każdego wzorca i za jego pomocą * przetwarzamy wszystkie pliki, których nazwy zostały podane * w tablicy argv. * Należy pamiętać, że niektóre z opcji nie są obsługiwane przez * poniższą wersję programu. Implementacja obsługi tych opcji stanowi * ćwiczenie, które Czytelnik może wykonać samodzielnie. */ public static void main(String[] argv) { if (argv.length < 1) { System.err.println(USAGE); System.exit(1); } String patt = null; GetOpt go = new GetOpt("cf:hilnrRsv"); char c; while ((c = go.getopt(argv)) != 0) { switch(c) { case 'c': countOnly = true; break; case 'f': /* Wzorzec wyrażenia w pliku zewnętrznym. */ try (BufferedReader b = new BufferedReader(new FileReader(go.optarg()))) { patt = b.readLine(); } catch (IOException e) { System.err.println( "Nie można odczytać pliku wzorca " + go.optarg()); System.exit(1); } break; case 'h': dontPrintFileName = true; break; case 'i': ignoreCase = true; break; case 'l': listOnly = true; break; case 'n': numbered = true; break; case 'r': case 'R': recursive = true; break; case 's': silent = true; break; case 'v': inVert = true; break; case '?': System.err.println("Błąd klasy Getopts!"); System.err.println(USAGE); break; } } int ix = go.getOptInd(); if (patt == null) patt = argv[ix++]; JGrep prog = null; try { prog = new JGrep(patt); } catch (PatternSyntaxException ex) { System.err.println("Błąd składni wyrażenia w " + patt); return; } if (argv.length == ix) { dontPrintFileName = true; // Jeśli to standardowy strumień, // to nie wyświetlamy nazw plików. if (recursive) { System.err.println("Ostrzeżenie: rekurencyjne przeszukiwanie strumienia wejściowego!"); } prog.process(new InputStreamReader(System.in), null); } else { if (!dontPrintFileName) dontPrintFileName = ix == argv.length - 1; // Podobnie, jeśli // operujemy tylko na jednym pliku. if (recursive) dontPrintFileName = false; // Chyba że to katalog! for (int i=ix; i<argv.length; i++) { // Rejestrujemy indeks początkowy try { prog.process(new File(argv[i])); } catch(Exception e) { System.err.println(e); } } } } /** Konstruktor obiektu JGrep. * @param patt Poszukiwany wzorzec. * @param args Opcje wiersza poleceń. */ public JGrep(String patt) throws PatternSyntaxException { if (debug) { System.err.printf("JGrep.JGrep(%s)%n", patt); } // Kompilujemy wyrażenie regularne. int caseMode = ignoreCase ? Pattern.UNICODE_CASE | Pattern.CASE_INSENSITIVE : 0; pattern = Pattern.compile(patt, caseMode); matcher = pattern.matcher(""); } /** Metoda przetwarza jeden argument wiersza poleceń (plik lub katalog). * @throws FileNotFoundException */ public void process(File file) throws FileNotFoundException { if (!file.exists() || !file.canRead()) { System.err.println( "BŁĄD: nie można odczytać pliku " + file.getAbsolutePath()); return; } if (file.isFile()) { process(new BufferedReader(new FileReader(file)), file.getAbsolutePath()); return; } if (file.isDirectory()) { if (!recursive) { System.err.println( "BŁĄD: użyto opcji -r, lecz nie podano katalogu " + file.getAbsolutePath()); return; } for (File nf : file.listFiles()) { process(nf); // "Rekurencja, patrz rozdział o rekurencji." } return; } System.err.println( "DZIWNE: nie podano ani pliku, ani katalogu: " + file.getAbsolutePath()); } /** Analiza jednego pliku. * @param ifile Reader Otworzony obiekt Reader. * @param fileName String Nazwa pliku wejściowego. */ public void process(Reader ifile, String fileName) { String inputLine; int matches = 0; try (BufferedReader reader = new BufferedReader(ifile)) { while ((inputLine = reader.readLine()) != null) { matcher.reset(inputLine); if (matcher.find()) { if (listOnly) { // -l, Wyświetlamy nazwę pliku przy pierwszym // dopasowaniu i sprawa załatwiona. System.out.println(fileName); return; } if (countOnly) { matches++; } else { if (!dontPrintFileName) { System.out.print(fileName + ": "); } System.out.println(inputLine); } } else if (inVert) { System.out.println(inputLine); } } if (countOnly) System.out.println(matches + " dopasowań w pliku " + fileName); } catch (IOException e) { System.err.println(e); } } }
[23] Użytkownicy systemów Windows! Wy też macie powody do radości! Teraz, dzięki pakietowi o alternatywnej nazwie CygWin (akronim słów Cygnus Software) lub GnuWin32 (http://sources.redhat.com/cygwin/), te same operacje można także wykonać w 32-bitowych systemach operacyjnych Windows. Jeśli używany system operacyjny nie udostępnia polecenia grep, to możesz skorzystać z programu Grep napisanego przeze mnie i zamieszczonego w „4.8. Dopasowywanie znaków z akcentami lub znaków złożonych”. Polecenie grep pochodzi od polecenia g/RE/p, stosowanego w zamierzchłych czasach w wierszowym edytorze używanym w systemie Unix. Polecenie to służyło do globalnego odszukiwania podanego wyrażenia regularnego (RE) we wszystkich wierszach przechowywanych w buforze edycji i do wyświetlenia na ekranie wierszy zawierających ciąg pasujący do podanego wzorca. A zatem działanie tego polecenia dokładnie odpowiadało czynnościom realizowanym przez program grep operujący na zawartości plików.
[24] Jest on wzorowany na podobnym programie dostępnym w wycofanym już z użytku pakiecie do obsługi wyrażeń regularnych, wchodzącym w skład projektu Jakarta fundacji Apache (choć nie korzysta z jego kodów).
[25] W systemach Unix przed wykonaniem polecenia interpreter wiersza poleceń rozwija parametr *.txt do postaci nazw wszystkich pasujących plików; jednak w innych systemach operacyjnych, w których interpreter wiersza poleceń nie jest na tyle energiczny lub inteligentny, zrobi to za nas standardowy interpreter Javy.
[26] Bądź też kilka innych odpowiadających im znaków Unicode, takich jak znak następnego wiersza (\u0085), znak separatora wierszy (\u2028) czy też znak separatora akapitów (\u2029).
[27] Można by sądzić, że powinno ono zdobyć rekord świata pod względem stopnia złożoności, nie mam jednak wątpliwości, że napisano wiele znacznie bardziej złożonych wyrażeń.