Przy użyciu języka Java można tworzyć różne rodzaje programów korzystających z sieci. W tradycyjnych programach posługujących się gniazdami programista odpowiada za cały proces interakcji pomiędzy klientem i serwerem; „gniazda” TCP zapewniają tylko tyle, że dane, które zostały zapisane na wejściu, będzie można odczytać na wyjściu. W programach działających na wyższym poziomie abstrakcji, wykorzystujących takie technologie jak RMI, CORBA lub EJB, używane rozwiązania programistyczne mają znacznie większe znaczenie i kontrolę nad działaniem programu. Gniazda są często wykorzystywane w przypadkach komunikowania się ze „starymi” serwerami; jeśli od podstaw tworzymy zupełnie nową aplikację, to lepiej wykorzystać rozwiązania działające na wyższym poziomie.
Przydatne może być porównanie gniazd z systemem telefonicznym. Telefony służyły początkowo do przekazywania sygnałów analogowych, które nie mają żadnej określonej struktury. Następnie sieci telefoniczne zaczęto wykorzystywać w aplikacjach „warstwowych”; pierwszą z nich było wysyłanie faksów. Czym byłyby faksy bez ogólnej dostępności zwyczajnej telefonii głosowej? Drugą bardzo popularną aplikacją warstwową są komutowane połączenia TCP/IP. W połączeniu z World Wide Web stały się one popularną usługą o ogromnym zasięgu. Jednak czym byłyby komutowane sieci IP bez rozbudowanej sieci zwyczajnych łączy telefonicznych? A czym byłby dzisiejszy internet bez dostępu komutowanego?
Gniazda dobrze odpowiadają temu porównaniu. WWW, RMI, JDBC, CORBA oraz EJB to wszystko przykłady technologii wykorzystujących gniazda, lecz operujących na „wyższym poziomie abstrakcji”. Obecnie najczęściej używanym protokołem jest TCP/IP — i to zazwyczaj on powinien być używany, kiedy chcemy przekazać dane z punktu A do punktu B.
Od momentu pojawienia się pierwszej wersji języka Java w maju 1995 roku (język ten stanowił wtedy dodatek do przeglądarki HotJava) był on popularnym narzędziem tworzenia aplikacji sieciowych. Bardzo łatwo można się przekonać, dlaczego tak się stało, zwłaszcza jeśli wcześniej mieliśmy okazję pisać programy sieciowe w języku C. Przede wszystkim programiści używający języka C muszą zwracać uwagę na wykorzystywany system operacyjny. W systemie Unix używane są gniazda synchroniczne, które pod względem operacji zapisu i odczytu przypominają obsługę zwyczajnych plików dyskowych. Z kolei w systemach operacyjnych firmy Microsoft wykorzystywane są gniazda asynchroniczne, w których informacje o zakończeniu operacji odczytu lub zapisu są przekazywane za pomocą funkcji zwrotnych. W Javie różnice te nie istnieją. Poza tym niezbędna ilość kodu, jaki trzeba napisać w języku C, aby utworzyć gniazdo, jest deprymująca. Na Przykład 13-1 przedstawiłem „typowy” kod napisany w języku C służący do utworzenia gniazda w programie klienckim. Należy przy tym pamiętać, że jest to kod nadający się do użycia jedynie w systemach Unix. A co więcej, służy on wyłącznie do nawiązania połączenia. Aby można go było użyć w systemie MS Windows, trzeba by wykorzystać dodatkowy kod warunkowy (dołączany przy użyciu mechanizmu #ifdef języka C). Mechanizmy dołączania plików (#include) stosowane w języku C wymagają, aby były dołączane tylko odpowiednie pliki, i to w ściśle określonej kolejności (w porównaniu z nimi mechanizm importowania klas dostępny w języku Java jest znacznie bardziej elastyczny).
Przykład 13-1. Tworzenie gniazda w kliencie napisanym w języku C
#include <sys/types.h>
#include <sys/socket.h>
#include <netinet/in.h>
#include <netdb.h>
#include <stdio.h>
#include <string.h>
#include <fcntl.h>
int
main(int argc, char *argv[])
{
char* server_name = "localhost";
struct hostent *host_info;
int sock;
struct sockaddr_in server;
/* Sprawdzamy adres IP zdalnego komputera */
host_info = gethostbyname(server_name);
if (host_info == NULL) {
fprintf(stderr, "%s: nieznany host: %s\n", argv[0], server_name);
exit(1);
}
/* Tworzymy gniazdo */
if ((sock = socket(AF_INET, SOCK_STREAM, 0)) < 0) {
perror("tworzenie gniazda klienta");
exit(2);
}
/* Konfiguracja adresu gniazda na serwerze */
server.sin_family = AF_INET;
memcpy((char *)&server.sin_addr, host_info->h_addr,
host_info->h_length);
server.sin_port = htons(80);
/* Nawiązanie połączenia z serwerem */
if (connect(sock,(struct sockaddr *)&server,sizeof server) < 0) {
perror("nawiązujemy połączenie z serwerem");
exit(4);
}
/* Teraz, w końcu, można odczytywać i zapisywać dane, używając gniazda */
/* ... */
(void) close(sock);
}W pierwszej recepturze zamieszczonej w niniejszym rozdziale pokażę, w jaki sposób w języku Java można nawiązać połączenie sieciowe z serwerem za pomocą jednego wiersza kodu (i kilku dodatkowych wierszy związanych z obsługą wyjątków). W dalszej kolejności zajmiemy się obsługą błędów oraz przekazywaniem danych za pośrednictwem gniazd. Następnie przyjrzymy się datagramom i protokołowi UDP — w tym celu stworzyłem klienta implementującego znaczną część protokołu TFTP (ang. trivial file transfer protocol — bardzo prosty protokół przesyłu plików), używanego przez blisko dwie dekady przez stacje robocze, które nie były wyposażone w dyski twarde. Na samym końcu rozdziału przedstawię program, który nawiązuje interaktywne połączenie z serwerem tekstowym, takim jak serwer Telnet lub serwer poczty elektronicznej.
Wszystkie programy przedstawione w tym rozdziale łączy jedna cecha — wykorzystanie istniejących serwerów, dzięki czemu nie musimy jednocześnie tworzyć zarówno klienta, jak i serwera. Z jednym wyjątkiem są to usługi dostępne w każdym standardowym systemie Unix. Jeśli nie jesteś w stanie znaleźć żadnego uniksowego serwera, z którego mógłbyś skorzystać, to radzę Ci poszukać dowolnego starego komputera PC (być może zbyt „słabego”, aby można w nim uruchomić system Windows) i zainstalować w nim dowolny bezpłatny system operacyjny Unix. Moim ulubionym jest system OpenBSD, natomiast na rynku dominują różne wersje systemu Linux. Wszystkie te systemy są dostępne na CD-ROM-ach lub można je bezpłatnie zainstalować poprzez internet. Udostępniają one także wszystkie standardowe usługi używane w przykładach przedstawionych w tym rozdziale, w tym także serwer czasu oraz serwer TFTP. Dostępne są również wersje języka Java przeznaczone do użycia w systemach Unix i Linux.
W niniejszej książce zamieściłem również podstawowe informacje na temat usług internetowych (ang. web services). Termin „usługa internetowa” oznacza zazwyczaj „komunikację pomiędzy programami prowadzoną przy użyciu protokołu HTTP”. Usługi te można podzielić na dwie podstawowe kategorie: usługi SOAP oraz usługi REST. Usługi REST są bardzo proste — aby z nich skorzystać, należy przesłać żądanie HTTP, a usługa zwraca odpowiedź w formie zwykłego tekstu, danych w formacie JSON (patrz Rozdział 19.) lub danych w formacie XML (patrz Rozdział 20). Usługi SOAP wymagają szczegółowej specyfikacji zapisanej w postaci kodu XML i szczegółowo opisującej wszystkie aspekty komunikacji; oprócz tego zmuszają one do prowadzenia całej interakcji z wykorzystaniem stosunkowo rozbudowanego kodu XML. Udostępniają one pewne możliwości, które są wspólne dla SOAP i REST, są to jednak rozwiązania zaawansowane, którymi nie będziemy się zajmować w tej książce. Więcej informacji na temat tworzenia oprogramowania sieciowego można znaleźć w książce Java Network Programming (wydanej przez wydawnictwo O’Reilly). W niniejszej książce nie przedstawię także interfejsów programistycznych służących do tworzenia aplikacji serwerowych — JAX-RS oraz JAX-WS — gdyż są one szczegółowo opisywane w kilku innych książkach wydawnictwa O’Reilly.
Wystarczy utworzyć obiekt klasy java.net.Socket, przekazując w jego konstruktorze nazwę komputera oraz numer portu.
W zasadzie na temat nawiązywania połączeń sieciowych w języku Java nie można powiedzieć zbyt dużo. Tworząc gniazdo, należy przekazać nazwę komputera oraz numer portu. Konstruktor klasy java.net.Socket wywołuje funkcje systemowe gethostbyname() oraz socket(), zapisuje niezbędne dane w strukturze sockaddr_in serwera, po czym wywołuje systemową funkcję connect(). Jedyne, co nam pozostaje do zrobienia, to przechwytywanie wyjątków będących obiektami klas potomnych klasy IOException. Program przedstawiony na Przykład 13-2 nawiązuje klienckie połączenie sieciowe, choć nie używa go do przeprowadzenia jakichś faktycznych operacji wejścia-wyjścia. Wykorzystuje on technikę umieszczania operacji na zasobach wewnątrz instrukcji try (więcej informacji na ten temat można znaleźć w punkcie „Instrukcja try zarządzająca zasobami” w podrozdziale „Nowości wprowadzone w wersji Java 7” Dodatek B), aby wymusić prawidłowe i automatyczne zamknięcie gniazda, kiedy już nie będzie ono potrzebne.
Przykład 13-2. /network/ConnectSimple.java (nawiązywanie klienckiego połączenia sieciowego)
import java.net.Socket; /* Prosty klient sieciowy bez żadnego kodu obsługi błędów. */ public class ConnectSimple { public static void main(String[] argv) throws Exception { try (Socket sock = new Socket("localhost", 8080)) { /* Skoro dotarliśmy tutaj, to oznacza, że możemy odczytywać * i zapisywać dane przy użyciu "gniazda". */ System.out.println(" *** Nawiązano połączenie. ***"); /* Wykonujemy operacje wejścia-wyjścia... */ } } }
Ta wersja programu nie zawiera żadnego kodu, który pozwalałby na raportowanie problemów; taki kod można natomiast znaleźć w programie ConnectedFriendly.java, który został przedstawiony w „13.3. Obsługa błędów sieciowych”.
W języku Java dostępne są także inne sposoby wykorzystywania aplikacji sieciowych. Można również otworzyć połączenie z zasobem o określonym adresie URL i odczytać jego zawartość (patrz „13.9. URI, URL czy może URN?”). Można też napisać kod, który w razie otworzenia w przeglądarce będzie pobierany z miejsca określonego adresem URL, a w innych przypadkach zostanie uruchomiony jako aplikacja.
Chcemy sprawdzić nazwę lub numer adresu komputera bądź określić adres komputera, z którym zostało nawiązane połączenie sieciowe.
Obiekt klasy InetAddress reprezentuje internetowy adres danego komputera lub komputera głównego. Klasa ta nie ma żadnego publicznego konstruktora — obiekt InetAddress można utworzyć, wywołując statyczną metodę getByName(), do której przekazywana jest bądź to nazwa komputera (na przykład: www.darwinsys.com), bądź też adres sieciowy zapisany w formie łańcucha znaków (na przykład: "1.23.45.67"). Wszystkie „informacyjne” metody klasy InetAddress mogą zgłaszać sprawdzany wyjątek UnknownHostException, który należy przechwycić lub zadeklarować w nagłówku metody. Żadna z tych metod nie wymienia informacji ze zdalnym komputerem, a zatem nie są zgłaszane żadne inne wyjątki związane z obsługą połączeń sieciowych.
Metoda getHostAddress() zwraca adres IP komputera (zapisany w formie łańcucha znaków) odpowiadający danemu obiektowi InetAddress. W odwrotny sposób działa metoda getHostName(), która zwraca nazwę odpowiadającą obiektowi InetAddress. Korzystając z tych metod, można zatem wyświetlić nazwę komputera, jeśli dysponuje się jego adresem IP (lub na odwrót):
/network/InetAddrDemo.java
public class InetAddrDemo {
public static void main(String[] args) throws IOException {
String hostName = "www.darwinsys.com";
String ipNumber = "8.8.8.8"; // powszechnie znany serwer DNS
// Odnajdujemy komputer na podstawie nazwy.
System.out.println("Komputer " + hostName + " ma adres " +
InetAddress.getByName(hostName).getHostAddress());
// Odnajdujemy komputer na podstawie adresu.
System.out.println("Komputer o adresie " + ipNumber +
" nosi nazwę " + InetAddress.getByName(ipNumber).getHostName());
// Odnajdujemy adres skojarzony z nazwą localhost.
final InetAddress localHost = InetAddress.getLocalHost();
System.out.println("Adres localhost to: " + localHost);
// Sposób uzyskiwania obiektu InetAddress przy użyciu
// otworzonego gniazda (Socket).
String someServerName = "www.google.com";
// Zakładamy, że na komputerze o podanej nazwie działa
// serwer WWW:
Socket theSocket = new Socket(someServerName, 80);
InetAddress remote = theSocket.getInetAddress();
System.out.printf("Adres InetAddress komputera %s to %s%n",
someServerName, remote);
}
}Obiekt InetAddress można także uzyskać, wywołując metodę getInetAddress() obiektu klasy Socket. Z kolei obiekt Socket można utworzyć, używając obiektu InetAddress zamiast nazwy komputera. A zatem poniższy fragment kodu pozwala nawiązać połączenie z portem o numerze myPortNumber w komputerze, z którym jest już nawiązane połączenie sieciowe reprezentowane przez obiekt Socket:
InetAddress remote = theSocket.getInetAddress(); Socket anotherSocket = new Socket(remote, myPortNumber);
Wreszcie, można także określić wszystkie adresy skojarzone z pewnym komputerem — ostatecznie serwer może działać w kilku sieciach. Służy do tego statyczna metoda getAllByName(host) zwracająca tablicę obiektów InetAddress, z których każdy reprezentuje jeden adres IP skojarzony z komputerem o podanej nazwie.
Dostępna jest również statyczna metoda getLocalHost() zwracająca obiekt InetAddress odpowiadający komputerowi o nazwie localhost lub o adresie 127.0.0.1. Obiekt InetAddress zwrócony przez tę metodę można wykorzystać do nawiązania połączenia z serwerem działającym w tym samym komputerze co klient.
W razie korzystania z protokołu IPv6 zamiast klasy InetAddress można używać klasy Inet6Address.
Warto się także przyjrzeć interfejsowi NetworkInterface zamieszczonemu w „16.11. Znajdowanie interfejsów sieciowych”, który pozwala na uzyskiwanie wielu informacji na temat możliwości sieciowych komputera, na którym została uruchomiona aplikacja.
Na razie nie ma jeszcze sposobu na odnajdywanie usług. Na przykład nie można stwierdzić, że serwer HTTP działa na porcie 80. Pełne implementacje protokołu TCP/IP zawsze zawierały dodatkowe funkcje informacyjne; w języku C wywołanie funkcji getservbyname("http", "tcp"); spowodowałoby odnalezienie podanej usługi[46] i zwróciło strukturę servent (strukturę z informacjami o usłudze), której pole s_port miałoby wartość 80. Numery konkretnych usług nie zmieniają się — jeśli jednak trzeba zdobyć informacje o nowych usługach lub usługach zainstalowanych w niestandardowy sposób, to możliwość zmiany numeru usługi we wszystkich programach na danym komputerze lub w danej sieci (niezależnie od języka, w jakim programy te zostały napisane) poprzez zmianę definicji tej usługi jest bardzo przydatna i wygodna. Kolejne wersje języka Java także powinny dawać tę możliwość.
W przypadku wystąpienia błędów potrzebujemy bardziej szczegółowych informacji niż te, których dostarcza wyjątek IOException.
Należy przechwytywać więcej różnych wyjątków. Dostępnych jest kilka klas potomnych klasy SocketException, z których najbardziej godne uwagi są klasy ConnectException oraz NoRouteToHostException. Nazwy tych klas są na tyle opisowe, iż nie trzeba ich dodatkowo komentować — pierwsza z nich oznacza, że połączenie zostało odrzucone przez zdalny komputer, a druga, że nie można było określić trasy do komputera docelowego. Przykład 13-3 przedstawia zmodyfikowany fragment programu Connect wzbogacony o możliwości obsługi wymienionych wcześniej wyjątków.
Przykład 13-3. /network/ConnectFriendly.java
public class ConnectFriendly {
public static void main(String[] argv) {
String server_name = argv.length == 1 ? argv[0] : "localhost";
int tcp_port = 80;
try (Socket sock = new Socket(server_name, tcp_port)) {
/* Teraz można odczytywać i zapisywać dane za pośrednictwem
gniazda. */
System.out.println(" *** Nawiązano połączenie z " + server_name
+ " ***");
/* Jakieś operacje wejścia-wyjścia... */
} catch (UnknownHostException e) {
System.err.println("Komputer " + server_name + " nie jest znany");
return;
} catch (NoRouteToHostException e) {
System.err.println("Komputer " + server_name +
" jest niedostępny" );
return;
} catch (ConnectException e) {
System.err.println("Komputer " + server_name +
" odrzucił połączenie");
return;
} catch (java.io.IOException e) {
System.err.println(server_name + ' ' + e.getMessage());
return;
}
}
}Należy stworzyć obiekt BufferedReader lub PrintWriter, posługując się odpowiednio metodami getInputStream() lub getOutputStream() obiektu Socket.
Klasa Socket dysponuje metodami, które pozwalają na pobranie obiektów InputStream lub OutputStream. Za ich pomocą można odpowiednio odczytywać i zapisywać dane w gnieździe. Nie ma żadnych metod pozwalających na uzyskanie obiektów Reader lub Writer; po części wynika to z faktu, że niektóre usługi sieciowe operują wyłącznie na znakach ASCII, niemniej jednak głównym powodem jest to, iż klasa Socket została zaprojektowana przed stworzeniem klas Reader i Writer. Zawsze można stworzyć obiekt Reader, jeśli dysponuje się obiektem InputStream, lub obiekt Writer, gdy ma się obiekt OutputStream — wystarczy się posłużyć odpowiednimi klasami konwertującymi. Poniżej przedstawiłem najczęściej spotykane rozwiązanie:
BufferedReader is = new BufferedReader(
new InputStreamReader(sock.getInputStream()));
PrintWriter os = new PrintWriter(sock.getOutputStream(), true);Poniżej, na Przykład 13-4, przedstawiłem kod programu odczytującego wiersze tekstu wysyłane przez usługę „daytime” dostępną w rozbudowanych pakietach obsługi protokołu TCP/IP (takich jak te używane w większości systemów Unix). Do serwera usługi Daytime nie trzeba wysyłać żadnych danych, wystarczy nawiązać z nim połączenie i odczytać jeden wiersz tekstu. Serwer generuje pojedynczy wiersz tekstu zawierający aktualną datę i czas, a następnie zamyka połączenie.
Poniżej pokazałem sposób wykorzystania omawianego programu. W pierwszej kolejności wyświetliłem datę i czas na lokalnym komputerze, a następnie uruchomiłem program DaytimeText, aby przekonać się, jaka jest aktualna data i godzina na serwerze (moim lokalnym serwerem jest komputer o nazwie „darian”):
C:\javasrc\network>date The current date is: 2002-10-12 Enter the new date: (yy-mm-dd) C:\javasrc\network>time The current time is: 21:36:59,31 Enter the new time: C:\javasrc\network>java network.DaytimeText darian Czas na komputerze darian to Sat Oct 12 13:34:11 2002
Kod źródłowy klasy DaytimeText został przedstawiony na Przykład 13-4.
Przykład 13-4. /network/DaytimeText.java
public class DaytimeText {
public static final short TIME_PORT = 13;
public static void main(String[] argv) {
String hostName;
if (argv.length == 0)
hostName = "localhost";
else
hostName = argv[0];
try {
Socket sock = new Socket(hostName, TIME_PORT);
BufferedReader is = new BufferedReader(new
InputStreamReader(sock.getInputStream()));
String remoteTime = is.readLine();
System.out.println("Czas na komputerze " + hostName +
" to " + remoteTime);
} catch (IOException e) {
System.err.println(e);
}
}
}Kolejny program, przedstawiony na Przykład 13-5, pokazuje, w jaki sposób można odczytywać i zapisywać dane w tym samym gnieździe. Serwer Echo działa w bardzo prosty sposób — przesyła z powrotem nadesłane do niego wiersze tekstu. Choć nie jest to wyjątkowo „inteligentny” serwer, to jest całkiem przydatny — pomaga bowiem podczas testowania sieci oraz klientów, takich jak te przedstawiane w niniejszym rozdziale!
Metoda converse() przeprowadza krótką wymianę informacji z serwerem Echo działającym na komputerze o podanej nazwie; jeśli nazwa komputera nie została podana, to program próbuje nawiązać połączenie z komputerem localhost. „Localhost” to uniwersalna nazwa zastępcza[47] „komputera, na którym został uruchomiony dany program”.
Przykład 13-5. /network/EchoClientOneLine.java
public class EchoClientOneLine {
/** Wysyłany tekst. */
String mesg = "Witamy inny komputer w sieci";
public static void main(String[] argv) {
if (argv.length == 0)
new EchoClientOneLine().converse("localhost");
else
new EchoClientOneLine().converse(argv[0]);
}
/** Wymiana informacji za pośrednictwem sieci. */
protected void converse(String hostName) {
try {
Socket sock = new Socket(hostName, 7); // Serwer Echo.
BufferedReader is = new BufferedReader(new
InputStreamReader(sock.getInputStream()));
PrintWriter os = new PrintWriter(sock.getOutputStream(), true);
// Sami obsługujemy CRLF, gdyż metoda println dodaje \r tylko
// w systemach, gdzie to zakończenie wierszy jest stosowane.
os.print(mesg + "\r\n"); os.flush();
String reply = is.readLine();
System.out.println("Wysłano \"" + mesg + "\"");
System.out.println("Odebrano \"" + reply + "\"");
} catch (IOException e) {
System.err.println(e);
}
}
}Ciekawym ćwiczeniem mogłoby być wydzielenie z metody converse() kodu wysyłającego i odbierającego dane i zaimplementowanie go w formie klasy NetWriter dodającej obsługę znaków \r\n oraz opróżnianie bufora. Prawdopodobnie powinna to być klasa potomna klasy PrintWriter.
Należy utworzyć obiekty klas DataInputStream oraz DataOutputStream, używając w tym celu metod getInputStream() oraz getOutputStream() obiektu Socket.
Poniżej przedstawiłem najprostszy sposób utworzenia potrzebnych obiektów:
DataInputStream is = new DataInputStream(sock.getInputStream()); DataOutputStream os = new DataOutputStream(sock.getOutputStream());
Jeśli ilość przekazywanych danych może być duża, to warto wykorzystać strumienie buforowane. W tym przypadku obiekty DataOutputStream oraz DataInputStream mają następującą postać:
DataInputStream is = new DataInputStream(
new BufferedInputStream(sock.getInputStream()));
DataOutputStream os = new DataOutputStream(
new BufferedOutputStream(sock.getOutputStream()));Program przedstawiony poniżej, na Przykład 13-6, korzysta z kolejnej usługi zwracającej czas, jednak w tym przypadku czas zwracany jest w postaci binarnej — jako liczba całkowita wyrażająca ilość sekund, jakie upłynęły od początku 1900 roku. Ponieważ w języku Java punktem odniesienia wykorzystywanym przy wyznaczaniu dat jest rok 1970, od odczytanej liczby odejmujemy ilość sekund odpowiadających różnicy pomiędzy latami 1900 i 1970. Gdy przedstawiłem ten przykład na prowadzonym przeze mnie kursie, większość słuchaczy chciała dodawać tę różnicę, rozumując, że rok 1970 jest późniejszy. Jeśli jednak dokładnie to przemyśleć, to okazuje się, że ilość sekund pomiędzy latami 1999 i 1970 jest mniejsza od ilości sekund pomiędzy latami 1999 i 1900, a zatem poprawny wynik uzyskujemy, odejmując obliczoną ilość sekund. Ponieważ konstruktor klasy Date wymaga podania czasu wyrażonego jako ilość milisekund, obliczoną wcześniej liczbę sekund mnożymy razy 1000.
Różnica pomiędzy czasami odniesienia jest obliczana poprzez pomnożenie liczby lat przez 365. Następnie dodawana jest do niej liczba dni przestępnych pomiędzy obiema datami (czyli dodatkowych dni w latach przestępnych, np. 1904, 1908..., 1998) — a zatem w sumie 19 dni.
Liczba całkowita odczytywana z serwera jest typu unsigned int i została zapisana w sposób charakterystyczny dla języka C. Jednak Java nie udostępnia typu liczbowego bez znaku (unsigned); zazwyczaj, aby używać liczb bez znaku, wykorzystywany jest kolejny, „większy” typ liczbowy, czyli w naszym przypadku byłby to typ long. Niemniej jednak Java 2 nie udostępnia także żadnego sposobu odczytywania liczb całkowitych bez znaku ze strumienia danych binarnych. Metoda readInt() klasy DataInputStream odczytuje liczby całkowite ze znakiem stosowane w języku Java. Dostępne są także metody readUnsignedByte() oraz readUnsignedShort(), nie ma jednak metody readUnsignedInt(). W związku z tym symulujemy możliwość odczytania liczby całkowitej bez znaku (zapisywanej w liczbie typu long, gdyż w innym przypadku zostałby utracony bit znaku), odczytując kolejne bajty i łącząc je przy użyciu operatorów przesunięć bitowych.
Na samym końcu kodu tworzę obiekt LocalDateTime i używam go do wyświetlenia daty i godziny na lokalnym (klienckim) komputerze; korzystam przy tym z nowego API do obsługi dat i godzin (opisanego w Rozdział 6.).
$ java network.DaytimeBinary darian
Czas na komputerze zdalnym: 3600895637
BASE_DIFF = 2208988800
Różnica czasów == 1391906837
Czas na komputerze darian to Sat Feb 08 19:47:17 EST 2014
Lokalna data/godzina = 2014-02-08T19:47:17.703
$Patrząc na przedstawione powyżej wyniki działania programu, można zauważyć, że różnica czasów pomiędzy komputerem lokalnym i serwerem wynosi kilkanaście sekund; można zatem przypuszczać, że sposób obliczania daty zastosowany na Przykład 13-6 jest poprawny.
Przykład 13-6. /network/RDateClient.java
public class RDateClient {
/** Port TCP używany przez usługę zwracającą czas w postaci binarnej. */
public static final short TIME_PORT = 37;
/** Liczba sekund pomiędzy 1970, punktem odniesienia przy wyznaczaniu
* dat Date(long) oraz czasu Time w języku Java.
* Uwzględnia lata przestępne (aż do 2100).
* Odejmuje 1 dzień z roku 1900, dodaje pół dnia dla lat 1969 - 1970.
*/
protected static final long BASE_DAYS =
(long)((1970-1900)*365 + (1970-1900-1)/4);
/* Liczba sekund od początku roku 1970. */
public static final long BASE_DIFF = (BASE_DAYS * 24 * 60 * 60);
/** Stała używana przy konwersji sekund na milisekundy. */
public static final int MSEC = 1000;
public static void main(String[] argv) {
String hostName;
if (argv.length == 0)
hostName = "localhost";
else
hostName = argv[0];
try {
Socket sock = new Socket(hostName, TIME_PORT);
DataInputStream is = new DataInputStream(new
BufferedInputStream(sock.getInputStream()));
// Musimy odczytać 4 bajty z sieci jako liczby bez znaku.
// Musimy wykonać to sami, gdyż nie ma metody readUnsignedInt().
// Typ long w Javie ma wielkość 8 bajtów, jednak
// my używamy istniejącego protokołu daytime korzystającego
// z liczb całkowitych o długości 4 bajtów.
long remoteTime = (
((long)(is.readUnsignedByte()) << 24) |
((long)(is.readUnsignedByte()) << 16) |
((long)(is.readUnsignedByte()) << 8) |
((long)(is.readUnsignedByte()) << 0));
System.out.println("Czas na komputerze zdalnym: " + remoteTime);
System.out.println("BASE_DIFF = " + BASE_DIFF);
System.out.println("Różnica czasów == " +
(remoteTime - BASE_DIFF));
Date d = new Date((remoteTime - BASE_DIFF) * MSEC);
System.out.println("Czas na komputerze " + hostName + " to " +
d.toString());
System.out.println("Lokalna data/godzina = " +
LocalDateTime.now());
} catch (IOException e) {
System.err.println(e);
}
}
}Należy utworzyć obiekty ObjectInputStream oraz ObjectOutputStream, posługując się metodami getInputStream() oraz getOutputStream() obiektu Socket.
Serializacja obiektów to możliwość przekonwertowania obiektów przechowywanych w pamięci komputera na zewnętrzną postać, którą można wysłać w sposób szeregowy (czyli bajt po bajcie). Zagadnienia związane z transmisją szeregową zostały omówione w „10.20. Zapisywanie i odczytywanie obiektów”.
Przedstawiony tu program (oraz współpracujący z nim serwer) stanowią jedyną prezentowaną w tym rozdziale usługę, która nie jest dostępna w pakietach implementujących protokół TCP/IP, usługa ta jest bowiem charakterystyczna dla języka Java. Sam kod przypomina program DaytimeBinary przedstawiony w poprzedniej recepturze, jednak w tym przypadku serwer przesyła utworzony już obiekt Date. Kod klienta został przedstawiony poniżej, na Przykład 13-7, natomiast kod serwera — w „16.2. Zwracanie odpowiedzi (łańcucha znaków bądź danych binarnych)”.
Przykład 13-7. /network/DaytimeObject.java
public class DaytimeObject {
/** Port TCP, na którym działa usługa. */
public static final short TIME_PORT = 1951;
public static void main(String[] argv) {
String hostName;
if (argv.length == 0)
hostName = "localhost";
else
hostName = argv[0];
try {
Socket sock = new Socket(hostName, TIME_PORT);
ObjectInputStream is = new ObjectInputStream(new
BufferedInputStream(sock.getInputStream()));
// Odczytujemy i sprawdzamy poprawność danej klasy Object.
Object o = is.readObject();
if (o == null) {
System.err.println("Serwer przesłał wartość null!");
} else if ((o instanceof Date)) {
// Poprawna, rzutujemy do typu Date i wyświetlamy.
Date d = (Date) o;
System.out.println(
"Komputer, na którym działa serwer, to: " + hostName);
System.out.println("Czas na serwerze: " + d.toString());
} else {
throw new IllegalArgumentException(
"Oczekiwano typu Date, otrzymano " + o);
}
} catch (ClassNotFoundException e) {
System.err.println("Oczekiwano daty, odebrano obiekt " +
" NIEWŁAŚCIWEJ KLASY (" + e + ")");
} catch (IOException e) {
System.err.println(e);
}
}
}Najpierw wyświetliłem datę i czas na lokalnym komputerze, a następnie uruchomiłem program podający informacje o dacie i czasie na zdalnym komputerze:
C:\javasrc\network>date /t 2000-01-23 C:\javasrc\network>time /t 2:52:34.43p C:\javasrc\network>java network.DaytimeObject aragorn Komputer, na którym działa serwer, to: aragorn Czas na serwerze: Sun Jan 23 14:52:25 GMT 2000 C:\javasrc\network>
Musimy wykorzystać połączenie rozsyłające datagramy (UDP), a nie połączenie korzystające ze strumieni (TCP).
Transmisja datagramów lepiej odpowiada możliwościom niższych warstw sieciowych — Ethernet oraz IP (ang. Internet Protocol). W odróżnieniu od połączeń wykorzystujących strumienie, takich jak TCP, protokoły transmisji datagramów, na przykład UDP, wysyłają poszczególne „pakiety” (lub fragmenty danych) jako niezależne jednostki[48]. Bardzo często protokół TCP porównuje się z rozmowami telefonicznymi, natomiast protokół UDP — z wysyłaniem kartek pocztowych lub faksów.
Różnice pomiędzy tymi dwoma rodzajami transmisji sieciowych uwidaczniają się głównie w obsłudze błędów. Pakiety, podobnie jak kartki pocztowe, mogą się gubić. Kiedy ostatni raz zdarzyło się, że listonosz przyszedł i poinformował, że urząd pocztowy zgubił jedną z kilku kartek? Coś takiego nigdy się nie zdarzyło ani się nie zdarzy, a to dlatego, że urząd pocztowy nie rejestruje przesyłanych kartek. Z drugiej strony, jeśli podczas rozmowy telefonicznej pojawią się jakieś zakłócenia — takie jak szumy lub nawet problemy z połączeniem — to zawsze można poprosić rozmówcę o powtórzenie tego, co przed chwilą powiedział.
W przypadku połączeń strumieniowych, jak poprzez gniazda TCP, to sieciowa warstwa transportowa odpowiada za obsługę błędów — prosi o powtórzenie transmisji. W przypadku protokołów rozsyłających datagramy, takich jak UDP, za obsługę transmisji odpowiada programista. To coś w stylu numerowania wysyłanych kartek pocztowych, aby mieć możliwość ponownego wysłania tych, które nie doszły; może to dobra wymówka, aby wrócić do miejsca, w którym się spędziło wakacje.
Kolejna różnica polega na tym, iż w przypadku rozsyłania datagramów zachowywane są granice poszczególnych wiadomości. W przypadku wykorzystania protokołu TCP, jeśli serwer prześle 20 bajtów, a następnie kolejne 10 bajtów, to program odczytujący te dane nie będzie wiedzieć, czy została wysłana jedna wiadomość składająca się z 30 bajtów, dwie składające się z 15 bajtów, czy też 30 niezależnych znaków. W przypadku wykorzystania połączeń operujących na datagramach (DatagramSocket) dla każdej „porcji” (bufora) danych tworzony jest obiekt DatagramPacket, który jest następnie przesyłany jako pojedyncza, niezależna jednostka; jego zawartość nie zostanie połączona z zawartością jakiejkolwiek innej „porcji” danych. Obiekt DatagramPacket udostępnia między innymi takie metody jak getLength() oraz setPort().
A zatem dlaczego mielibyśmy w ogóle używać protokołu UDP? Otóż protokół ten ma znacznie mniej narzutów niż TCP, co może być szczególnie przydatne w przypadkach przesyłania bardzo dużych ilości danych przez niezawodną sieć lokalną bądź przez internet pomiędzy komputerami oddalonymi od siebie o niewielką liczbę segmentów sieci. Jednak w przypadku przesyłania na duże odległości preferowany będzie protokół TCP, gdyż obsługuje on ponowne przesyłanie utraconych pakietów. Poza tym jeśli zachowywanie granic rekordów może nam ułatwić życie, to może to stanowić ważny argument za wykorzystaniem protokołu UDP.
Przykład 13-8 przedstawia krótki program, który nawiązuje połączenie UDP z serwerem daty i czasu wykorzystanym wcześniej w „13.4. Odczyt i zapis danych tekstowych”. Ponieważ w protokole UDP nie występuje pojęcie „połączenia”, klient zazwyczaj inicjuje „konwersację” (czasami oznacza to przesłanie pustego pakietu), a serwer UDP używa umieszczonych w niej informacji o adresie, by odesłać odpowiedź.
Przykład 13-8. /network/DaytimeUDP.java
public class DaytimeUDP {
/** Numer portu UDP. */
public final static int DAYTIME_PORT = 13;
/** Bufor wystarczająco duży, aby pomieścić w nim łańcuch znaków. */
protected final static int PACKET_SIZE = 100;
/** Program główny obsługujący klienta sieciowego.
* @param argv[0] hostname, running daytime/udp server
*/
public static void main(String[] argv) throws IOException {
if (argv.length < 1) {
System.err.println("Sposób użycia: java DayTimeUDP komputer");
System.exit(1);
}
String host = argv[0];
InetAddress servAddr = InetAddress.getByName(host);
DatagramSocket sock = new DatagramSocket();
//sock.connect(servAddr, DAYTIME_PORT);
byte[] buffer = new byte[PACKET_SIZE];
// Pakiet UDP, który wyślemy i odbierzemy.
DatagramPacket packet = new DatagramPacket(
buffer, PACKET_SIZE, servAddr, DAYTIME_PORT);
/* Wysyłamy do serwera pusty pakiet o długości max-length
* (-1 na bajt null). */
packet.setLength(PACKET_SIZE-1);
sock.send(packet);
System.out.println("Wysłano żądanie.");
// Odbieramy pakiet i wyświetlamy dane.
sock.receive(packet);
System.out.println("Odebrano pakiet o długości " +
packet.getLength());
System.out.print("Data na komputerze " + host + " to " +
new String(buffer, 0, packet.getLength()));
sock.close();
}
}Uruchomiłem ten program, korzystając z mojego serwera, aby mieć pewność, że działa poprawnie:
$ java network.DaytimeUDP dalai
Wysłano żądanie.
Odebrano pakiet o długości 26
Data na komputerze dalai to Sat Feb 8 20:22:12 2014
$Program przedstawiony w tej recepturze jest klientem protokołu TFTP — doskonale znanej usługi wykorzystywanej w systemach Unix do uruchamiania stacji roboczych za pośrednictwem sieci, która pojawiła się na długo przed systemem Windows 3.1. Wybrałem ten protokół, gdyż jest on dobrze obsługiwany po stronie serwera, a zatem bez problemu można znaleźć serwer do testowania naszego przykładowego programu.
Protokół TFTP jest trochę dziwny. Klient nawiązuje połączenie z serwerem, korzystając z dobrze znanego portu UDP o numerze 69, przy czym sam używa portu o wygenerowanym numerze[49], a serwer odpowiada podobnie (korzystając z portu o wygenerowanym numerze).
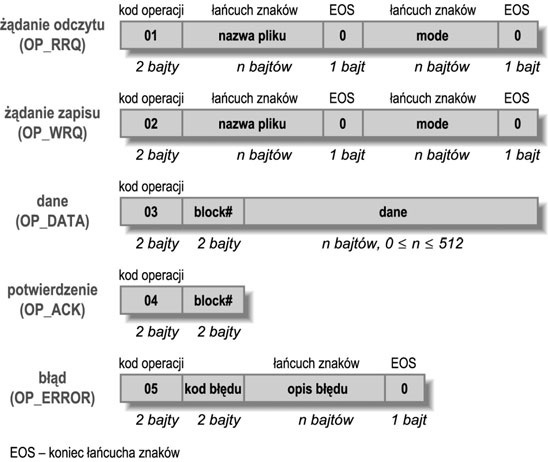
Zajmijmy się teraz szczegółami. Jak widać na Rysunek 13-1, klient rozpoczyna od wysłania żądania odczytu, w którym podawana jest nazwa pliku, a następnie odczytuje pierwszą porcję danych. Żądanie odczytu składa się z dwóch bajtów zawierających kod żądania (jest to krótka liczba całkowita o wartości 1 zdefiniowana jako OP_RRQ), dwóch bajtów zawierających numer żądania w sekwencji, nazwy pliku zawierającej znaki ASCII i zakończonej znakiem o kodzie 0 oraz kolejnym łańcuchem znaków zakończonych znakiem o kodzie 0. Serwer odczytuje żądanie przesłane przez klienta, sprawdza, czy może otworzyć wskazany plik, a jeśli może, to wysyła pierwszy pakiet danych (OP_DATA) i odczytuje kolejny pakiet. Teraz klient odczytuje nadesłaną odpowiedź i jeśli jest prawidłowa, przekształca pakiet w pakiet potwierdzenia i wysyła go. Taka wymiana danych z potwierdzaniem jest kontynuowana aż do momentu odczytania całego pliku. Należy zauważyć, że każdy pakiet, za wyjątkiem ostatniego, ma długość 516 bajtów (512 bajtów danych, 2 bajty określające typ pakietu oraz 2 bajty wskazujące numer kolejnego pakietu). Ostatni pakiet może mieć dowolną długość z zakresu od 4 (taki pakiet nie zawiera żadnych danych) do 515 (511 bajtów danych). Jeśli podczas przesyłania pakietu pojawią się jakieś problemy, to zostanie on ponownie przesłany. Jeśli jakiś pakiet zostanie zgubiony, to zarówno klient, jak i serwer mają odczekać odpowiedni czas. Klient przedstawiony w tej recepturze nie zachowuje się w ten sposób, jednak serwer, z którego korzysta, działa zgodnie z nim. Takie opóźnienia można dodać bądź to przy użyciu wątków (patrz „22.4. Spotkania i ograniczenia czasowe”), bądź też poprzez wywołanie na rzecz gniazda metody setSoTimeout(); w takim przypadku, jeśli pakiet faktycznie został zgubiony, należy przechwycić wyjątek SocketTimeoutException i ponownie przesłać potwierdzenie (lub żądanie odczytu); czynności te być może trzeba będzie powtórzyć, przy czym liczba tych powtórzeń jest ograniczona. Implementację tego rozwiązania pozostawiam jako ćwiczenie dla Czytelnika. Aktualna wersja kodu klienta została przedstawiona na Przykład 13-9.
Przykład 13-9. /network/RemCat.java
public class RemCat {
/** Numer portu UDP. */
public final static int TFTP_PORT = 69;
/** Używany tryb pracy - zawsze "octet". */
protected final String MODE = "octet";
/** Przesunięcie kodu/odpowiedzi w bajtach */
protected final int OFFSET_REQUEST = 1;
/** Przesunięcie numeru pakietu w bajtach */
protected final int OFFSET_PACKETNUM = 3;
/** Flaga testowania */
protected static boolean debug = false;
/** Kody operacji protokołu TFTP dla żądania odczytu. */
public final int OP_RRQ = 1;
/** Kody operacji protokołu TFTP dla żądania odczytu. */
public final int OP_WRQ = 2;
/** Kody operacji protokołu TFTP dla żądania odczytu. */
public final int OP_DATA = 3;
/** Kody operacji protokołu TFTP dla żądania odczytu. */
public final int OP_ACK = 4;
/** Kody operacji protokołu TFTP dla żądania odczytu. */
public final int OP_ERROR = 5;
protected final static int PACKET_SIZE = 516; // == 2 + 2 + 512
protected String host;
protected InetAddress servAddr;
protected DatagramSocket sock;
protected byte buffer[];
protected DatagramPacket inp, outp;
/** Program główny obsługujący klienta sieciowego.
* @param argv[0] nazwa komputera, na którym działa serwer TFTP
* @param argv[1..n] nazwy plików (musi być przynajmniej jedna)
*/
public static void main(String[] argv) throws IOException {
if (argv.length < 2) {
System.err.println("Sposób użycia: rcat komputer nazwaPliku[...]");
System.exit(1);
}
if (debug)
System.err.println("Uruchamiamy program RemCat.");
RemCat rc = new RemCat(argv[0]);
for (int i = 1; i<argv.length; i++) {
if (debug)
System.err.println("-- Rozpoczynamy pobieranie pliku " +
argv[0] + ":" + argv[i] + "---");
rc.readFile(argv[i]);
}
}
RemCat(String host) throws IOException {
super();
this.host = host;
servAddr = InetAddress.getByName(host);
sock = new DatagramSocket();
buffer = new byte[PACKET_SIZE];
outp = new DatagramPacket(buffer, PACKET_SIZE, servAddr, TFTP_PORT);
inp = new DatagramPacket(buffer, PACKET_SIZE);
}
/* Tworzymy pakiet żądania odczytu protokołu TFTP. To nieco
* złożone, gdyż długości pól są zmienne. Poszczególne bajty
* liczb muszą być zapisywane w kolejności "sieciowej";
* na szczęście Java wydaje się dość "inteligentna",
* gdyż sama używa właśnie tej kolejności zapisu.
*/
void readFile(String path) throws IOException {
buffer[0] = 0;
buffer[OFFSET_REQUEST] = OP_RRQ; // Żądanie odczytu
int p = 2; // Liczba znaków w buforze
// Konwersja łańcucha znaków zawierającego nazwę pliku na
// bajty (zapisane w buforze). Zmienna "p" służy jako
// wskaźnik przesunięcia precyzyjnie umieszczający wszystkie
// bajty żądania w odpowiednim położeniu.
byte[] bTemp = path.getBytes(); // Na przykład ASCII
System.arraycopy(bTemp, 0, buffer, p, path.length());
p += path.length();
buffer[p++] = 0; // Bajt o wartości 0 kończy łańcuch znaków
// Podobnie konwertujemy tryb (MODE - "octet"), zapisując go
// w buforze w postaci bajtów.
bTemp = MODE.getBytes(); // Na przykład ASCII
System.arraycopy(bTemp, 0, buffer, p, MODE.length());
p += MODE.length();
buffer[p++] = 0; // Bajt o kodzie 0 kończy łańcuch
/* Wysyłamy żądanie odczytu do serwera tftp */
outp.setLength(p);
sock.send(outp);
/* Pętla odczytująca pakiety danych z serwera aż do
* momentu odnalezienia pakietu krótszego niż standardowy;
* taki pakiet oznacza koniec pliku.
*/
int len = 0;
do {
sock.receive(inp);
if (debug)
System.err.println(
"Pakiet # " + Byte.toString(buffer[OFFSET_PACKETNUM])+
"KOD ODPOWIEDZI " +
Byte.toString(buffer[OFFSET_REQUEST]));
if (buffer[OFFSET_REQUEST] == OP_ERROR) {
System.err.println("BŁĄD: " +
new String(buffer, 4, inp.getLength()-4));
return;
}
if (debug)
System.err.println("Odebrano pakiet wielkości " +
inp.getLength());
/* Wyświetlenie danych odczytanych z pakietu */
System.out.write(buffer, 4, inp.getLength()-4);
/* Potwierdzenie odbioru pakietu.
* Numer pakietu, który chcemy potwierdzić, jest już
* w buforze, a zatem wystarczy zmienić kod.
* Potwierdzenie jest wysyłane na port, z którego
* serwer wysłał dane, a nie na port TFTP_PORT.
*/
buffer[OFFSET_REQUEST] = OP_ACK;
outp.setLength(4);
outp.setPort(inp.getPort());
sock.send(outp);
} while (inp.getLength() == PACKET_SIZE);
if (debug)
System.err.println(
"** GOTOWE ** Koniec pętli, wielkość ostatniego pakietu " +
inp.getLength());
}
}Do przetestowania tego programu konieczny będzie serwer protokołu TFTP. Jeśli korzystasz z komputera z systemem Unix, którym sam administrujesz, to uruchomienie serwera TFTP będzie wymagało jedynie modyfikacji pliku /etc/inetd.conf i ponownego uruchomienia serwera inetd (lub jego przeładowania przy użyciu polecenia kill -HUP). inetd to program, który oczekuje na różnego typu połączenia, a jeśli jakieś połączenie od klienta zostanie odebrane, to uruchamia odpowiedni serwer (jest to pewien rodzaj „przetwarzania leniwego”[50]). Ja stworzyłem tradycyjny katalog /tftpboot, dodałem następujący wiersz tekstu do pliku inetd.conf i ponownie uruchomiłem serwer inetd:
tftp dgram udp wait root /usr/libexec/tftpd -s /tftpboot
Następnie w katalogu /tftpboot umieściłem kilka plików, w tym jeden o nazwie foo. Wykonanie polecenia:
$ java network.RemCat localhost foopowoduje utworzenie czegoś, co wygląda jak plik. Aby jednak mieć pewność, wyniki działania programu RemCat porównałem z oryginalnym plikiem, używając w tym celu polecenia diff. Brak wiadomości jest dobrą wiadomością:
$ java network.RemCat localhost foo | diff - /tftpboot/fooJak na razie wszystko jest w porządku. Nie umieszczajmy jednak tego programu w sieci bez wcześniejszego, choćby pobieżnego, przetestowania obsługi błędów:
$ java network.RemCat localhost takiegoPlikuNieMa
BŁĄD: File not found
$Należy kontynuować lekturę tego rozdziału lub zajrzeć do dokumentacji klasy java.net.URI.
URL jest tradycyjną nazwą adresów sieciowych zawierających schemat (na przykład http), adres (czyli nazwę witryny) oraz określenie zasobu lub ścieżkę dostępu. Jednak w sumie istnieją trzy odrębne terminy:
URI (ang. Uniform Resource Identifier),
URL (ang. Uniform Resource Locator),
URN (ang. Uniform Resource Name).
Informacje umieszczone pod koniec dokumentacji nowej klasy wyjaśniają, jakie są relacje pomiędzy URI, URL oraz URN. URI reprezentują grupę wszystkich identyfikatorów, natomiast adresy URL i nazwy URN stanowią jej podgrupy.
Identyfikatory URI są najbardziej ogólne; analizuje się je zgodnie z prostą składnią bez zwracania uwagi na schemat (jeśli taki w ogóle został określony) i nie muszą się one odwoływać do żadnego konkretnego serwera. Adresy URL zawierają nazwę komputera, schemat oraz inne komponenty; są one analizowane zgodnie z regułami określanymi przez podany w adresie schemat. W przypadku tworzenia adresu URL automatycznie tworzony jest także obiekt InputStream. Z kolei URN określają nazwy zasobów, natomiast nie informują, jak należy je odnajdywać; typowymi przykładami nazw URL są mailto: oraz news:.
Podstawowe operacje udostępniane przez klasę URI obejmują normalizację (czyli usunięcie nadmiarowych segmentów ścieżki, w tym podwójnych znaków kropki ..) oraz relatywizację (choć właściwie operację tę należałoby określać jako „przekształcenie do postaci względnej”, jednak ktoś chciał mieć jedno słowo, by móc wygodnie nazwać metodę). Obiekt URI nie dysponuje żadnymi metodami służącymi do otwierania zasobów określanych przez dany identyfikator; do tego celu są zazwyczaj używane obiekty URL tworzone za pomocą łańcuchowej reprezentacji URI w sposób przedstawiony poniżej:
URL x = new URL(theURI.toString());
Program zaprezentowany na Przykład 13-10 pokazuje przykłady normalizacji, określania ścieżek względnych oraz tworzenia adresów URL na podstawie identyfikatorów URI.
Przykład 13-10. /netweb/URIDemo.java
public class URIDemo {
public static void main(String[] args)
throws URISyntaxException, MalformedURLException {
URI u = new URI(
"http://www.darwinsys.com/java/../openbsd/../index.jsp");
System.out.println("Forma początkowa: " + u);
URI normalized = u.normalize();
System.out.println("Po normalizacji: " + normalized);
final URI BASE = new URI("http://www.darwinsys.com");
System.out.println("Po relatywizacji względem adresu " + BASE +
": " + BASE.relativize(u));
// Obiekt URL jest rodzajem URI
URL url = new URL(normalized.toString());
System.out.println("URL: " + url);
// Nic ważnego.
URI uri = new URI("bean:WonderBean");
System.out.println(uri);
}
}Musimy odczytać zawartość zasobu określonego adresem URL (na przykład nawiązać połączenie z usługą internetową REST).
Należy użyć standardowej klasy URLConnection lub biblioteki HttpClient rozwijanej przez Fundację Apache.
Choć biblioteka HttpClient stanowiąca jeden z projektów rozwijanych przez Fundację Apache zapewnia bardzo dużą elastyczność, to jednak w sytuacjach gdy chcemy jedynie korzystać z prostych usług internetowych REST, stosowanie jej jest sporą przesadą. W takich przypadkach zależy nam zazwyczaj jedynie na możliwości otworzenia adresu URL oraz odczytania zawartości zasobu określanego przez ten adres. W naszym prostym przykładzie wykorzystamy bezpłatną usługę freegeoip.net. Geolokalizacja adresu IP polega na określeniu położenia geograficznego odbieranego połączenia IP, przy czym zazwyczaj jest to adres klienta lub serwera (bądź jego serwera proxy, jeśli taki jest używany).
Usługa FreeGeoIP udostępnia trzy formaty, w których mogą być zwracane dane wynikowe: CVS (patrz „3.13. Przetwarzanie danych rozdzielonych przecinkami”), JSON (patrz Rozdział 19.) oraz XML (patrz Rozdział 20.). Ponieważ jest ona typową usługą REST udostępniającą wiele formatów wynikowych, interesujący nas format wybiera się poprzez podanie go jako jednego z elementów adresu URL. Dokumentacja usługi określa, że stosowany adres URL ma następującą postać:
http://freegeoip.net/{format}/{komputer}Z usługi można korzystać zarówno przy użyciu protokołu HTTP, jak i HTTPS, a dostępnymi formatami są: csv, json lub xml (wszystkie zapisywane małymi literami). Segment „komputer” jest opcjonalny: jeśli nie zostanie podany, to usługa określi położenie adresu IP komputera, który nawiązał połączenie; w przeciwnym razie można podać adres IP komputera lub jego nazwę.
A oto kod tej usługi:
/weserviceclient/RestClientFreeGeoIp.java
public class RestClientFreeGeoIp {
public static void main(String[] args) throws Exception {
URLConnection conn = new URL(
"http://freegeoip.net/json/www.oreilly.com")
.openConnection();
try (BufferedReader is =
new BufferedReader(new InputStreamReader(conn.getInputStream()))){
String line;
while ((line = is.readLine()) != null) {
System.out.println(line);
}
}
}
}Wyniki są zwracane w wybranym formacie. W razie wskazania formatu JSON wyniki są zwracane w postaci jednego, długiego wiersza tekstu, zawierającego wszystkie informacje na temat podanego komputera (poniższy przykład pokazuje informacje o serwerze O’Reilly Media). Zamieszczone poniżej przykładowe dane zostały podzielone w miejscach występowania przecinków, dzięki czemu mogłem dostosować je do szerokości strony:
{"ip":"207.152.124.48","country_code":"US","country_name":"United States",
"region_code":"CO","region_name":"Colorado","city":"Englewood",
"zipcode":"80111","latitude":39.6237,"longitude":-104.8738,
"metro_code":"751","areacode":"303"}Jak wszystkie duże, komercyjne organizacje, także O’Reilly używa rozproszonej sieci rozpowszechniania treści (CDN), dlatego uzyskiwane wyniki mogą się zmieniać; poniżej przedstawiłem zupełnie inne wyniki uzyskane po wykonaniu tego samego programu kilka minut później:
{"ip":"69.31.106.26","country_code":"US","country_name":"United States",
"region_code":"MA","region_name":"Massachusetts","city":"Cambridge",
"zipcode":"02142","latitude":42.3626,"longitude":-71.0843,
"metro_code":"506","areacode":"617"}Więcej informacji na temat usług internetowych REST (w tym także sposoby implementacji komponentów serwerowych tych usług) można znaleźć w książce RESTful Java with JAX-RS 2.0, 2nd Edition (http://shop.oreilly.com/product/0636920028925.do) napisanej przez Billa Burke’a i wydanej przez wydawnictwo O’Reilly.
Musimy komunikować się z klientem SOAP, a słyszeliśmy, że jest to bardziej złożone niż komunikowanie się z usługami REST.
Owszem, jest to bardziej złożone. Jednak poradzimy sobie z tym zadaniem, korzystając z pomocy JAX-WS. Należy pobrać plik WSDL, przetworzyć go przy użyciu programu wsimport, po czym wywołać utworzoną przez niego klasę wytwórczą (nazywaną także czasami fabryką) w celu utworzenia namiastki usługi, a następnie wywołać jej odpowiednią metodę, by nawiązać połączenie z usługą.
SOAP jest protokołem komunikacyjnym używanym przez usługi internetowe przesyłające dane w formacie XML. SOAP nie jest akronimem, początkowo był to skrót pochodzący od słów „Simple Object Access Protocol” (prosty protokół dostępu do obiektów); jednak w momencie kiedy zaczął nad nim pracować międzynarodowy komitet standaryzacyjny, nie można było już o nim powiedzieć, że jest prosty, a jeśli chodzi o obiekty, to tak naprawdę nigdy nie był on z nimi związany. Dlatego też zdecydowano się porzucić rozwinięcie skrótu, lecz zostawić samą nazwę. A... i jeszcze jedno: właściwie nie jest to także „protokół” — SOAP korzysta bowiem z protokołów HTTP i HTTPS. A zatem SOAP to obecnie jedynie SOAP, choć użycie w jednym zdaniu słów „simple” (prosty) oraz „SOAP” wywołuje jedynie śmiech u zwolenników usług REST.
Pierwszą czynnością jest pobranie kopii dokumentu WSDL (ang. Web Service Description Language — język opisu usług internetowych). Dokument ten przetwarza się przy użyciu narzędzia wsimport (dostarczanego wraz z JDK). Program ten generuje klasę wytwórczą usługi, która z kolei pozwala na utworzenie obiektu namiastki tej usługi. Dopiero teraz można wywołać metodę namiastki, aby uzyskać dostęp do zdalnej usługi.
WSDL opisuje usługę ze wszelkimi szczegółami. Można go sobie wyobrażać jako interfejs Javy na sterydach. Interfejs przekazuje informacje o dostępnych metodach, ich argumentach, deklarowanych wyjątkach i tak dalej; nie daje jednak możliwości przekazywania informacji o tym, gdzie znaleźć daną usługę w internecie ani jak konwertować dane na format, który usługa będzie mogła zaakceptować. Z kolei WSDL zapewnia wszystkie te możliwości, a co więcej, sposoby korzystania z nich są standaryzowane (choć jednocześnie złożone).
Całe to rozwiązanie ma tę zaletę, że klient i serwer nie muszą być napisane w tym samym języku programowania ani działać w tym samym systemie operacyjnym lub na komputerach o tej samej architekturze procesorów. Usługa może działać na serwerze aplikacji Java EE, a korzystające z niej klienty — na urządzeniach mobilnych (z systemami Android, iOS, BlackBerry, Windows itd.); choć mogą także być napisane w językach Perl, Python lub Ruby i działać na komputerze z systemami Linux, Mac OS lub BSD. WSDL opisuje wszystkie zagadnienia związane z formatowaniem, dzięki czemu problemy z wielkością słów lub kolejnością zapisu bitów są rozwiązywane w sposób niewidoczny dla programisty. Nawet w świecie języka Java istnieje wiele pakietów narzędziowych służących do generowania klientów i usługi SOAP. W tym przykładzie skorzystamy z JAX-WS (ang. Java API for XML Web Services), gdyż jest on standardowym elementem platformy Javy (i to zarówno w wersji standardowej, Java SE, jak i korporacyjnej, Java EE).
Są osoby, które preferują ręczne generowanie plików WSDL. Nazywają to „programowaniem w oparciu o kontrakt”. Ja jednak do nich nie należę. Zacznę od istniejącego pliku WSDL bądź wygeneruję plik WSDL na podstawie istniejącego interfejsu Javy, a następnie ręcznie wprowadzę w nim niezbędne poprawki. Także interfejs języka Java jest określonym kontraktem, choć być może nie aż tak kompletnym (ani nie wypełnionym po brzegi legalnym bełkotem; co można by dodać, posuwając analogię jeszcze o krok dalej).
Na potrzeby usługi prezentowanej w tej recepturze przygotuję jeszcze inną wersję mojego prostego kalkulatora Calc. Warto zwrócić uwagę, że wszystkie kody prezentowane w tej recepturze pochodzą z repozytorium javasrcee (https://github.com/IanDarwin/javasrcee).
Aby przybliżyć nas do analizy kodu klienta, bardzo pobieżnie przedstawię, jak napisałem usługę, gdyż tworząc ją, można także utworzyć dokument WSDL. W realnych sytuacjach zazwyczaj będziemy chcieli komunikować się z już istniejącymi usługami, a więc można przyjąć, że już dysponujemy lub będziemy dysponować ich dokumentami WSDL. W takim przypadku można pominąć tę część rozdziału i kontynuować lekturę od kolejnego podpunktu, „Generowanie artefaktów klienta i pisanie jego kodu”.
Usługa Calc powstała jako implementacja klasy o tej samej nazwie i została umieszczona w pakiecie jaxwsservice:
import javax.jws.WebService;
@WebService(targetNamespace="http://toy.service/")
public class Calc {
public int add(int a, int b) {
System.out.println("CalcImpl.add()");
return a + b;
}
// Pozostałe trzy metody są bardzo podobne.Aby przekształcić tę klasę na usługę w celach testowych oraz aby wygenerować odpowiedni plik WSDL, JDK udostępnia zadziwiające narzędzie o nazwie javax.xml.ws.Endpoint, które pozwala wybrać dowolną klasę (o ile tylko zostanie do niej dodana adnotacja @WebService) i opublikować ją jako usługę internetową!
/jaxwsservice/ServiceMain.java
// Tworzymy "namiastkę usługi". Calc impl = new Calc(); // Uruchamiamy usługę. Endpoint ep = Endpoint.publish("http://localhost:9090/calc", impl); System.out.println("Usługa uruchomiona: " + ep);
Zakładając, że wcześniej na głównym poziomie kodów z repozytorium javasrcee wykonaliśmy polecenie mvn compile, to teraz powyższą usługę będziemy mogli wykonać, używając polecania:
$ java -cp target/classes javaxwsservice.ServiceMain Usługa uruchomiona: com.sun.xml.internal.ws.transport.http.server.EndpointImpl@f0f7074
A co jest takiego niesamowitego w tym wszystkim? Otóż jeśli ktoś nie zetknął się jeszcze ze złożonością wdrażania niektórych usług internetowych, to zapewne uzna, że nie ma tu nic ciekawego. Ale uwierzcie mi, to naprawdę jest ciekawe. Otóż nie tylko udało się nam uruchomić serwer i udostępnić implementację prostego, starego obiektu Javy (POJO) jako usługę internetową, lecz jednocześnie został wygenerowany plik WSDL, i to w całości bez naszego udziału! No dobrze, została przy tym wykorzystana adnotacja, którą wcześniej dodaliśmy do klasy Calc. Dzięki temu mogę teraz pokazać zawartość dokumentu WSDL. Kiedy serwis zostanie już uruchomiony, należy wpisać w przeglądarce adres URL usługi, dodając do niej parametr HTTP o nazwie wsdl (nie trzeba podawać jego wartości — wystarczy dodać do adresu ?wsdl). A zatem adres URL pozwalający na pobranie dokumentu WSDL będzie mieć postać: http://localhost:9090/calc?wsdl.
Choć w zasadzie kopiowanie dokumentu WSDL nie jest potrzebne do szczęścia, to jednak można go zapisać na dysku. Jeśli dysponujemy sensownym klientem FTP, takim jak program ftp w systemie BSD lub program wget, to możemy zapisać go bezpośrednio w pliku, używając następującego polecenia:
$ ftp -o calc.wsdl http://localhost:9090/calc?wsdl Requesting http://localhost:9090/calc?wsdl 100% |**************************************************| 3745 00:00 3745 bytes received in 0.00 seconds (9.18 MB/s) $ ls -l calc.wsdl -rw-r--r-- 1 ian wheel 3745 Jan 3 09:53 calc.wsdl $
Oczywiście warto zajrzeć do pobranego pliku WSDL — przede wszystkim po to, by przekonać się o tym, że faktycznie jest on tak złożony (a przynajmniej rozwlekły), jak twierdziłem. Jednym z argumentów wysuwanych przez zwolenników tworzenia dokumentów WSDL w pierwszej kolejności jest to, że dokumenty te pisane ręcznie przez programistów są zazwyczaj mniejsze i prostsze.
Teraz możemy już ponownie zająć się generowaniem kodu klienta. Program wsimport odczytuje dokument WSDL — bądź to podany w formie adresu URL, bądź też z pliku na dysku — i na jego podstawie generuje cały zestaw tak zwanych artefaktów:
$ mkdir jaxwsclient $ wsimport -d jaxwsclient -keep 'http://localhost:9090/calc?wsdl' parsing WSDL... Generating code... Compiling code... $ ls jaxwsclient/service/toy/*.java Add.java Divide.java ObjectFactory.java AddResponse.java DivideResponse.java Subtract.java Calc.java Multiply.java SubtractubtractResponse.java CalcService.java MultiplyResponse.java package-info.java $
Koniecznie trzeba przejrzeć wygenerowany kod interfejsu Calc oraz klasy CalcService (jeśli Czytelnik nie buduje ich, czytając tę recepturę, to ich kody można znaleźć w przykładach dołączonych do książki oraz w repozytorium javasrcee w katalogu jaxwsclient). W przypadku usług korzystających z argumentów będących obiektami trzeba będzie przeanalizować inne wygenerowane artefakty, gdyż to właśnie one będą określać faktyczne typy, które klient będzie musiał przekazywać w wywołaniach metod namiastki usługi. Analiza klasy CalcService pozwoli określić nazwę metody, którą należy wykonać w celu nawiązania połączenia z usługą. W naszym przypadku jest to:
/jaxwsclient/TinyClientMain.java — pierwszy wiersz kodu metody main()
Calc client = new CalcService().getCalcPort();
Analiza kodu interfejsu Calc pozwoli nam określić argumenty, jakie należy przekazywać w wywołaniach jego metod. Od tego momentu mamy udawać, że nigdy nie widzieliśmy serwerowej wersji usługi, i musimy bardzo uważać, by nie zaimportować żadnych klas należących do „serwerowego pakietu”! Teraz możemy już napisać drugi wiersz kodu naszego klienta:
/jaxwsclient/TinyClientMain.java — drugi wiersz kodu metody main()
System.out.println(client.add(2, 2));
Możesz być bardzo zawiedziony, jeśli zostanie wyświetlony wynik inny niż 4. Ale, jak widać, to prawda — faktycznie można napisać kompletnego klienta usługi SOAP w dwóch wierszach kodu, oczywiście zakładając, że argumenty są typów prostych, i nie wspominając o wszystkich plikach wygenerowanych przez program wsimport oraz dodatkowej pracy wykonanej przez pakiet JAX-WS. A oto pełny kod źródłowy klienta:
/jaxwsclient/TinyClientMain.java
// Nie ma żadnych instrukcji import! /** Pełny, kompletny kod klienta usługi Calc, który * mieści się w dwóch wierszach. */ public class TinyClientMain { public static void main(String[] args) { Calc client = new CalcService().getCalcPort(); System.out.println(client.add(2, 2)); } }
$ java -cp target/classes jaxwsclient.TinyClientMain 4 $
Faktyczny klient umieszczony w pakiecie jaxwsclient udostępnia interaktywny kalkulator, który pozwala na wprowadzanie wierszy kodu, takich jak 2 + 2, i wyświetlenie wyników.
$ java -cp target/classes jaxwsclient.ClientMain Interaktywny kalkulator. Oddzielaj operatory znakami odstępu. >> 2 + 2 2 + 2 = 4 >> 22 / 7 22 / 7 = 3 >> ^D $
Genialne, prawda? Tak się składa, że w pakiecie klienta usługi dostępne są także test jednostkowy oraz test integracyjny (który używa statycznej metody Endpoint.publish() do uruchamiania i zatrzymywania usługi).
Poniżej przedstawiłem podsumowanie efektów naszej pracy:
Stworzyliśmy usługę (ale tę zazwyczaj otrzymamy gotową).
Pobraliśmy plik WSDL usługi, wykorzystując sztuczkę z dodaniem do adresu usługi końcówki
?wsdl.Przetworzyliśmy plik WSDL przy użyciu programu
wsimportw celu wygenerowania artefaktów klienta.Przeanalizowaliśmy pliki
CalciCalcService(ich nazwy będą w każdej usłudze tworzone według tego samego wzorca) — nazwa usługi będzie nazwą interfejsu, natomiast nazwą klasy wytwórczej będzie nazwą usługi z dodanym słowemService.Wywołaliśmy metodę
getCalcService()klasy wytwórczej, aby pobrać obiekt namiastki usługiCalc.Wywoływaliśmy metody obiektu namiastki.
Na temat usług SOAP można napisać znacznie więcej. Problemy, jakich przysparza tworzenie większych, bardziej złożonych usług internetowych tego typu, są dokładnie takie same jak te, z którymi muszą się borykać twórcy wszystkich usług sieciowych; można do nich zaliczyć niezawodność, czas dostępności serwera i tak dalej. Połączenie z usługą może zostać zerwane w dowolnym momencie bądź to z powodu awarii serwera, bądź też problemów z połączeniem sieciowym. Dostępne są protokoły wyższego poziomu, które pozwalają zapewnić niezawodność, bezpieczeństwo, szyfrowanie połączenia i tak dalej. Jednak nawet w przypadku korzystania z nich może wystąpić awaria sieci, dlatego też klient musi być przygotowany na to, że usługa SOAP nie odpowie na żądanie. Dosyć popularne jest stosowanie rozwiązania, w którym wartość zwracana przez usługę internetową jest sekwencją składającą się z liczby całkowitej (oznaczającej poprawność wykonania operacji lub jakiś kod błędu), łańcucha znaków z komunikatem o błędzie (na wypadek gdyby stary klient korzystał z nowej usługi i nie rozumiał niektórych zwracanych przez nią kodów błędów) oraz faktycznych danych zwróconych przez usługę — w naszym przykładzie był to wynik obliczenia. Więcej informacji na ten temat można znaleźć w książce Java Web Services: Up and Running (http://oreil.ly/Java_web_services) wydanej przez wydawnictwo O’Reilly.
Program przedstawiony w tej recepturze jest prostym klientem usługi Telnet. Jak wiadomo, Telnet jest najstarszym i wciąż używanym programem do zdalnego logowania się do komputerów przez internet. Usługa ta była początkowo stosowana w sieciach ARPANET, a później została przeniesiona i przystosowana do użycia w internecie. Wciąż stosowany jest uniksowy klient tej usługi obsługiwany z poziomu wiersza poleceń, a dodatkowo jest także dostępnych kilka programów przeznaczonych do użycia w systemach operacyjnych z graficznym interfejsem użytkownika. Ze względów bezpieczeństwa wykorzystanie usługi Telnet w celu logowania się do zdalnych komputerów zostało w znacznym stopniu zastąpione przez protokół SSH (http://www.openssh.com/), niemniej wciąż nie można się obyć bez klientów usługi Telnet — są one wykorzystywane na przykład podczas logowania się do lokalnych komputerów lub testowania serwerów, z którymi nawiązuje się połączenia za pomocą gniazd i które stosują protokoły tekstowe, oraz do dokładnego poznawania takich „tekstowych” protokołów. Na przykład często spotykanym rozwiązaniem jest stosowanie klienta usługi Telnet do nawiązywania połączenia z serwerem SMTP (poczty elektronicznej). Serwer SMTP można z dobrymi wynikami obsługiwać na wyczucie, nawet jeśli nie cała sesja obsługi poczty jest wykonywana interaktywnie.
Gdy mniej więcej w tym samym czasie dane mają być kopiowane w dwóch kierunkach — z klawiatury do zdalnego programu oraz ze zdalnego programu na ekran — to problem ten można rozwiązać na dwa sposoby. Niektóre biblioteki obsługujące operacje wejścia-wyjścia w języku C udostępniają funkcje poll() lub select(), które pozwalają sprawdzić grupę plików, aby przekonać się, który z nich jest gotowy do odczytu lub zapisu. Język Java nie obsługuje takiego sposobu postępowania. Drugie rozwiązanie, wykorzystywane w większości systemów i języków programowania, w tym także w Javie, polega na użyciu dwóch niezależnych wątków[51], z których każdy obsługuje transmisję danych w jednym kierunku. Takie właśnie rozwiązanie wykorzystamy w niniejszej recepturze. Klasa Pipe reprezentuje wątek i dysponuje dodatkowo kodem umożliwiającym kopiowanie danych w jednym kierunku. Nasz program wykorzystuje dwa obiekty tej klasy, z których każdy obsługuje transfer danych w jednym kierunku i działa niezależnie od drugiego.
Przedstawiony program pozwala na nawiązanie połączenia z dowolną usługą sieciową wykorzystującą protokół tekstowy. Na przykład za jego pośrednictwem można prowadzić „konwersację” z lokalnym serwerem SMTP (prosty protokół przesyłania poczty elektronicznej) bądź z serwerem Daytime (na porcie 13) wykorzystywanym w kilku przykładach przedstawionych we wcześniejszej części tego rozdziału.
$ java network.Telnet darian 13
Komputer darian; port 13
Połączenie nawiązano.
Sat Apr 28 14:07:41 2001
^C
$Kod źródłowy programu zaprezentowałem na Przykład 13-11.
Przykład 13-11. /network/Telnet.java
public class Telnet {
String host;
int portNum;
public static void main(String[] argv) {
new Telnet().talkTo(argv);
}
private void talkTo(String av[]) {
if (av.length >= 1)
host = av[0];
else
host = "localhost";
if (av.length >= 2)
portNum = Integer.parseInt(av[1]);
else portNum = 23;
System.out.println("Komputer " + host + "; port " + portNum);
try {
Socket s = new Socket(host, portNum);
// Kojarzymy wyniki zdalnego programu ze strumieniem stdout
new Pipe(s.getInputStream(), System.out).start();
// Kojarzymy stdin z wejściem zdalnego programu
new Pipe(System.in, s.getOutputStream()).start();
} catch(IOException e) {
System.out.println(e);
return;
}
System.out.println("Połączenie nawiązano.");
}
/* Ta klasa obsługuje jeden kierunek transmisji dupleksowej
* (dwukierunkowej). Pracuje w trybie obsługi wierszy.
* Wykorzystywane są strumienie, a nie pisarze.
*/
class Pipe extends Thread {
BufferedReader is;
PrintStream os;
/** Tworzymy obiekt Pipe odczytujący ze strumienia os
* i zapisujący w strumieniu os. */
Pipe(InputStream is, OutputStream os) {
this.is = new BufferedReader(new InputStreamReader(is));
this.os = new PrintStream(os);
}
/** Metoda obsługująca transmisję. */
public void run() {
String line;
try {
while ((line = is.readLine()) != null) {
os.print(line);
os.print("\r\n");
os.flush();
}
} catch(IOException e) {
throw new RuntimeException(e.getMessage());
}
}
}
}Oczywiście powyższemu programowi wiele brakuje do „prawdziwego” klienta Telnet, jednak do jakichkolwiek faktycznych działań w internecie zamiast programu Telnet należałoby używać SSH — patrz http://openssh.com.
W tej recepturze przedstawiłem przykład prostego klienta służącego do prowadzenia pogawędek internetowych. Za jego pomocą nie można prowadzić pogawędek z osobami korzystającymi z takich programów jak ICQ lub AIM, gdyż każdy z nich używa własnych protokołów[52]. Przedstawiony tu program zapisuje i odczytuje dane z serwera, który jest odnajdywany przy użyciu stosowanej w apletach metody getCodeBase(). Serwer, z którym komunikuje się ten program, zostanie przedstawiony w Rozdział 16. A jak nasz przykładowy program wygląda po uruchomieniu? Na Rysunek 13-2 przedstawiłem przykład pogawędki, którą pewnego dnia odbyłem sam ze sobą.
Kod programu jest na tyle prosty, że nie wymaga żadnych dodatkowych komentarzy. Dane wejściowe odczytujemy z serwera, tak wykorzystując niezależny wątek, że odczyt i wysyłanie danych nie kolidują ze sobą; rozwiązanie to zostało przedstawione w Rozdział 22. Zagadnienia związane z odczytywaniem i wysyłaniem danych przez sieć zostały omówione w niniejszym rozdziale. Kod źródłowy tego programu przedstawiłem na Przykład 13-12.
Przykład 13-12. /chat/ChatClient.java
public class ChatClient extends JFrame {
private static final long serialVersionUID = -3686334002367908392L;
private static final String userName =
System.getProperty("user.name", "Bezimienny użytkownik");
/** Czy użytkownik jest zalogowany? */
protected boolean loggedIn;
/** Główna ramka aplikacji. */
protected JFrame cp;
/** Domyślny numer portu. */
protected static final int PORTNUM = ChatProtocol.PORTNUM;
/** Używany numer portu. */
protected int port;
/** Gniazdo */
protected Socket sock;
/** Obiekt BufferedReader służący do odczytu danych z gniazda */
protected BufferedReader is;
/** Obiekt PrintWriter służący do wysyłania wierszy tekstu */
protected PrintWriter pw;
/** TextField - pole wejściowe */
protected TextField tf;
/** TextArea - pole do wyświetlania pogawędki */
protected TextArea ta;
/** Przycisk Login */
protected Button loginButton;
/** Przycisk Logout */
protected Button logoutButton;
/** Tytuł wyświetlany na pasku nagłówka */
final static String TITLE = "ChatClient: Prosty klient pogawędek Iana Darwina";
/** Przygotowanie graficznego interfejsu użytkownika. */
public ChatClient() {
cp = this;
cp.setTitle(TITLE);
cp.setLayout(new BorderLayout());
port = PORTNUM;
// Interfejs użytkownika
ta = new TextArea(14, 80);
ta.setEditable(false); // tylko do odczytu
ta.setFont(new Font("Monospaced", Font.PLAIN, 11));
cp.add(BorderLayout.NORTH, ta);
Panel p = new Panel();
// Przycisk do logowania.
p.add(loginButton = new Button("Logowanie"));
loginButton.setEnabled(true);
loginButton.requestFocus();
loginButton.addActionListener(new ActionListener() {
public void actionPerformed(ActionEvent e) {
login();
loginButton.setEnabled(false);
logoutButton.setEnabled(true);
tf.requestFocus(); // Określenie miejsca wprowadzania!
}
});
// Przycisk do wylogowania
p.add(logoutButton = new Button("Wyloguj się"));
logoutButton.setEnabled(false);
logoutButton.addActionListener(new ActionListener() {
public void actionPerformed(ActionEvent e) {
logout();
loginButton.setEnabled(true);
logoutButton.setEnabled(false);
loginButton.requestFocus();
}
});
p.add(new Label("Treść wiadomości:"));
tf = new TextField(40);
tf.addActionListener(new ActionListener() {
public void actionPerformed(ActionEvent e) {
if (loggedIn) {
pw.println(ChatProtocol.CMD_BCAST+tf.getText());
tf.setText("");
}
}
});
p.add(tf);
cp.add(BorderLayout.SOUTH, p);
cp.setDefaultCloseOperation(JFrame.EXIT_ON_CLOSE);
cp.pack();
}
protected String serverHost = "localhost";
/** Podłączamy się do pogawędki */
public void login() {
showStatus("Logujemy się!");
if (loggedIn)
return;
try {
sock = new Socket(serverHost, port);
is = new BufferedReader(new InputStreamReader(sock.getInputStream()));
pw = new PrintWriter(sock.getOutputStream(), true);
showStatus("Mamy połączenie");
// Udajemy logowanie - na razie nie potrzeba hasła.
pw.println(ChatProtocol.CMD_LOGIN + userName);
loggedIn = true;
} catch(IOException e) {
showStatus("Nie można nawiązać połączenia z " +
serverHost + "/" + port + ": " + e);
cp.add(new Label("Nie można uzyskać gniazda: " + e));
return;
}
// Tworzymy i uruchamiamy czytelnika: z serwera do wielowierszowego
// pola tekstowego. Aby uniknąć blokowania, używamy wątku.
new Thread(new Runnable() {
public void run() {
String line;
try {
while (loggedIn && ((line = is.readLine()) != null))
ta.append(line + "\n");
} catch(IOException e) {
showStatus("POŁĄCZENIE ZOSTAŁO UTRACONE!!");
return;
}
}
}).start();
}
/** Wychodzimy stąd, Scotty, nie ma tu żadnych inteligentnych form
* życia! */
public void logout() {
if (!loggedIn)
return;
loggedIn = false;
try {
if (sock != null)
sock.close();
} catch (IOException ign) {
// No i co z tego?
}
}
public void showStatus(String message) {
System.out.println(message);
}
/** Metoda główna umożliwiająca uruchomienie programu jako
* normalnej aplikacji.
*/
public static void main(String[] args) {
ChatClient room101 = new ChatClient();
room101.pack();
room101.setVisible(true);
}
}Istnieje wiele innych sposobów tworzenia klientów pogawędek charakteryzujących się lepszą strukturą. Można do nich zaliczyć takie rozwiązania jak gniazda sieciowe (WebSocket), RMI (wywoływanie zdalnych metod) oraz Java Messaging Services (usługi rozsyłania komunikatów). RMI jest interfejsem RPC (ang. Remote Procedure Call — wywoływanie zdalnych procedur) w języku Java, który wchodzi w skład zarówno standardowej, jak i korporacyjnej wersji języka Java. Nie opisywałem go w tym wydaniu książki, choć poprzednie wydanie zawierało rozdział na jego temat. Pozostałe technologie wchodzą w skład Java EE — korporacyjnej wersji języka Java — a więcej informacji na ich temat można znaleźć w książce Java EE 7 Essentials napisanej przez Aruna Guptę i wydanej przez wydawnictwo O’Reilly.
Jeśli konieczne jest szyfrowanie informacji przesyłanych za pośrednictwem gniazd, można wykorzystać bibliotekę JSSE firmy Sun (ang. Java Secure Socket Extension — rozszerzenie do obsługi bezpiecznych gniazd języka Java). (Jeśli Czytelnik skorzystał z wcześniejszej rady i użył standardowego protokołu HTTP, to teraz może zaszyfrować pogawędki, zmieniając adresy URL tak, by korzystały z protokołu HTTPS).
Doskonałe omówienie zagadnień programowania sieciowego z wykorzystaniem języka C można znaleźć w książce Unix Network Programming W. Richarda Stevensa. Wbrew temu, co sugeruje tytuł książki, omawia ona zagadnienia związane z wykorzystaniem gniazd oraz obsługą protokołów TCP/IP/UDP i w sposób zadziwiająco szczegółowy prezentuje wszystkie fragmenty interfejsu programistycznego służącego do obsługi sieci (w wersji dostępnej w systemach Unix) oraz protokoły (na przykład takie jak TFTP).
Sprawdzanie poprawności odnośników jest ciągłym problemem dla wszystkich właścicieli witryn WWW, jak również dla osób piszących dokumentacje techniczne zawierające odwołania do materiałów zewnętrznych (takich jak autor tej książki). Programy do sprawdzania odnośników (ang. link checkers) są narzędziami, których takie osoby nieustannie używają do sprawdzania poprawności odnośników umieszczanych na swoich stronach, i to niezależnie od tego, czy są to strony witryn WWW, czy książek. Implementacja narzędzia tego typu sprowadza się do: a) pobrania odnośników oraz b) próby ich otworzenia. Dokładnie tak samo działa program przedstawiony w tej recepturze. Nadałem mu nazwę KwikLinkChecker, gdyż można uznać, że jest to rozwiązanie „szybkie i dalekie od ideału” — nie sprawdza on zawartości odnośnika, by upewnić się, że wciąż zawiera on to, co zawierał niegdyś; a zatem jeśli na przykład zapomnę odnowić rejestrację domeny i zostanie ona przejęta przez jakąś witrynę pornograficzną, to mój program się o tym nie dowie. Pomimo tej niedoskonałości program wykonuje to, co do niego należy, i to całkiem dobrze i całkiem szybko:
/com/darwinsys/tools/KwikLinkChecker.java
/** * Metoda sprawdza jeden odnośnik HTTP. Nie działa rekurencyjnie. * Zwraca obiekt LinkStatus z logicznym polem określającym status * wykonanego sprawdzenia i nazwą pliku lub komentarzem o błędzie * w polu message. Końcówka tej metody jest jednym z niewielu * miejsc, w których konieczna jest cała sekwencja różnych * klauzul catch, niezbędnych do prawidłowego działania programu. */ public LinkStatus check(String urlString) { URL url; HttpURLConnection conn = null; HttpURLConnection.setFollowRedirects(false); try { url = new URL(urlString); conn = (HttpURLConnection) url.openConnection(); switch (conn.getResponseCode()) { case 200: return new LinkStatus(true, urlString); case 403: return new LinkStatus(false,"403: " + urlString ); case 404: return new LinkStatus(false,"404: " + urlString ); } conn.getInputStream(); return new LinkStatus(true, urlString); } catch (IllegalArgumentException | MalformedURLException e) { // JDK firmy Oracle zgłasza wyjątek IllegalArgumentException, // jeśli na podstawie adresu URL nie uda się określić // komputera docelowego return new LinkStatus(false, "Nieprawidłowy adres URL: " + urlString); } catch (UnknownHostException e) { return new LinkStatus(false, "Nieprawidłowy lub nieaktywny komputer: " + urlString); } catch (FileNotFoundException e) { return new LinkStatus(false, "NIE ODNALEZIONO (404) " + urlString); } catch (ConnectException e) { return new LinkStatus(false, "Serwer nie działa: " + urlString); } catch (SocketException e) { return new LinkStatus(false, e + ": " + urlString); } catch (IOException e) { return new LinkStatus(false, e.toString()); // Dołączamy URL. } catch (Exception e) { return new LinkStatus(false, "Nieoczekiwany wyjątek! " + e); } finally { if (conn != null) { conn.disconnect(); } } }
Oczywiście dostępne są bardziej wymyślne narzędzia do sprawdzania odnośników, jednak jak na moje potrzeby ten sprawdza się bardzo dobrze.
[46] Informacje o usługach są przechowywane w różnych miejscach. W systemach Unix może to być plik /etc/services, a w systemach MS Windows plik services zapisywany w katalogach \windows lub \winnt; informacje te mogą być także przechowywane w scentralizowanych rejestrach, takich jak Network Information Services firmy Sun (w skrócie NIS, wcześniej określana jako YP), lub innych miejscach zależnych od używanego systemu operacyjnego bądź sieci.
[47] A przynajmniej była uniwersalna w czasach, gdy większość komputerów podłączonych do sieci była administrowana przez wykwalifikowane osoby zatrudnione na cały etat lub wynajmowane w celu zarządzania komputerami. Obecnie na bardzo wielu komputerach podłączonych do internetu „localhost” nie jest prawidłowo skonfigurowany.
[48] W niektórych sieciach pakiety UDP będą musiały zostać podzielone na mniejsze fragmenty, jednak na poziomie UDP nie ma to większego znaczenia, gdyż na drugim końcu połączenia pakiet zostanie ponownie scalony.
[49] Jeśli aplikacja nie zwraca uwagi na numer używanego portu, to jest on zazwyczaj wyznaczany przez system operacyjny. Na przykład jeśli dzwonisz do firmy, to zazwyczaj nie interesuje jej numer telefonu stacjonarnego lub komórkowego, z którego dzwonisz, a jeśli informacja ta ma dla firmy znaczenie, to istnieją sposoby, aby ją zdobyć. Generowane numery portów zwykle należą do zakresu od 1024 (pierwszy numer portu, który nie jest uprzywilejowany; patrz Rozdział 16.) do 65 535 (największa wartość, jaką można zapisać w 16 bitach).
[50] Jednocześnie należy mieć świadomość potencjalnych zagrożeń bezpieczeństwa — nie powinno się uruchamiać serwera TFTP bez wcześniejszego przeczytania dobrej książki na temat zabezpieczania komputerów, takiej jak Building Internet Firewalls wydanej przez wydawnictwo O’Reilly.
[51] Wątek to (prawdopodobnie) jeden z wielu możliwych przepływów sterowania w obrębie danego procesu; patrz „24.1. Uruchamianie zewnętrznego programu”.
[52] Programem o dostępnym kodzie źródłowym, który pozwala na komunikowanie się z programami ICQ oraz AIM, jest Jabber (http://www.jabber.org/).