Żyjemy w świecie, w którym jednocześnie wykonywanych jest wiele różnych czynności. Możemy rozmawiać przez telefon i jednocześnie wpisywać lub czytać notatkę. Wielofunkcyjne urządzenia biurowe są w stanie skanować jeden dokument, odbierać drugi i jednocześnie wysyłać trzeci do wydrukowania na wybranym komputerze. Oczekujemy, że programy z graficznym interfejsem użytkownika będą w stanie aktualizować wyświetlane informacje i jednocześnie reagować na wybieranie przez nas z menu opcji. Jednak zwyczajne programy komputerowe mogą wykonywać tylko jedną operację w danej chwili. Standardowy model programistyczny — zakładający, że poszczególne instrukcje są zapisywane jedna po drugiej, a procesem ich wykonywania można sterować przy użyciu pętli oraz warunków binarnych — z założenia jest modelem sekwencyjnym.
Przetwarzanie sekwencyjne jest bardzo proste, choć nie tak efektywne, jak mogłoby być. Aby poprawić efektywność działania, język Java udostępnia wątki — możliwość jednoczesnego wykonywania wielu „ścieżek sterowania”, realizowanych w ramach jednego procesu lub aplikacji. Java daje możliwość obsługi wątków i w rzeczywistości wymaga ich stosowania — środowisko wykonawcze Javy zostało stworzone w sposób wielowątkowy. Na przykład mechanizm obsługi zdarzeń systemu Windows lub automatyczne oczyszczanie pamięci — to cudowne rozwiązanie, dzięki któremu nie musimy własnoręcznie zwalniać wszystkich wykorzystywanych w programie bloków pamięci (co niestety trzeba robić w przypadku korzystania z języków takich jak C) — są realizowane w osobnych wątkach.
A zatem co dokładnie mamy na myśli, mówiąc o zagadnieniach wielowątkowości w języku Java? Wątki można definiować na kilka różnych sposobów, jednak najprostsza ich definicja ma następującą postać: wątki to różne ścieżki sterowania wykonywane w ramach jednego programu lub procesu. Wielozadaniowość pozwala symulować możliwość jednoczesnego wykonywania wielu programów na komputerze wyposażonym w jeden procesor; w podobny sposób wielowątkowość może sprawiać wrażenie, że jeden program lub proces wykonuje jednocześnie kilka różnych czynności. Dzięki wykorzystaniu wielowątkowości aplikacje mogą jednocześnie realizować kilka operacji; daje to możliwość tworzenia bardziej interaktywnej grafiki, lepiej reagujących aplikacji z graficznym interfejsem użytkownika (na przykład program jest w stanie rysować i jednocześnie obsługiwać opcje wybierane z menu, przy czym obie te czynności mogą być wykonywane zupełnie niezależnie), bardziej niezawodnych serwerów sieciowych (jeśli jeden z klientów wykona nieodpowiednie czynności, to serwer wciąż będzie w stanie porozumiewać się z innymi klientami) i tak dalej.
Warto zwrócić uwagę, że w poprzednim akapicie nie użyłem terminu „wieloprocesowość” (ang. multiprocessing). Termin ten jest czasami błędnie zastępowany określeniem „wielozadaniowość”, a odnosi się on do rzadziej spotykanych przypadków, gdy jeden system operacyjny nadzoruje pracę dwóch lub większej liczby procesorów. W rzeczywistości wieloprocesowość nie jest niczym nowym: komputery typu mainframe firmy IBM pracowały w ten sposób już w latach 70., stacje robocze SPARCstation firmy Sun w latach 80., a komputery PC wyposażone w procesory firmy Intel — w latach 90. Obecnie, w drugim dziesięcioleciu XXI wieku, coraz trudniej kupić jednoprocesorowy komputer w czymkolwiek większym od zegarka. Prawdziwa wieloprocesowość[81] oznacza możliwość jednoczesnego wykonywania co najmniej dwóch procesów na kilku (przynajmniej dwóch) procesorach. Mechanizmy wielowątkowe języka Java w niektórych okolicznościach umożliwiają wykorzystanie tak pojmowanej wieloprocesowości. Warunkiem koniecznym jest, by zarówno system operacyjny, jak i wirtualna maszyna Javy dysponowały niezbędnymi mechanizmami. Szczegółowych informacji na ten temat należy poszukać w dokumentacji systemu operacyjnego.
Choć większość nowoczesnych systemów operacyjnych udostępnia wątki, to jednak Java była pierwszym z najpopularniejszych języków programowania, który dysponował wbudowanym wsparciem dla wykorzystania wątków. Semantyka klasy java.lang.Object, po której dziedziczą wszystkie klasy w Javie, zakłada możliwość „kontrolnego blokowania” obiektów, oraz metody (notify(), notifyAll() i wait()), które nabierają znaczenia wyłącznie w kontekście aplikacji wielowątkowych. Java udostępnia także specjalne słowa kluczowe, takie jak synchronized, przeznaczone do kontroli zachowania aplikacji składających się z wielu wątków.
Teraz, kiedy programiści dysponują już wieloletnimi doświadczeniami związanymi z wykorzystywaniem wątków w języku Java, eksperci zaczęli opracowywać lepsze sposoby pisania aplikacji wielowątkowych. Pakiet Concurrency Utilities, opisany w specyfikacji JSR 166[82] i dołączany do każdej nowoczesnej wersji JDK, w dużej mierze bazuje na pakiecie util.concurrent stworzonym przez profesora Douga Lea z Wydziału Informatyki Uniwersytetu Stanu Nowy Jork w Oswego. Ten pakiet został stworzony, by ułatwiać rozwiązywanie problemów, jakich nastręcza tworzenie oprogramowania wielowątkowego, podobnie jak klasy kolekcji (opisane w Rozdział 7.) starają się ułatwić określanie struktury danych. Nie było to wcale proste przedsięwzięcie, jednak udało się uzyskać zamierzone cele.
Pakiet util.java.concurrent zawiera kilka głównych sekcji:
Interfejsy
ExecutoriFutureoraz pule wątków.Kolejki (klasy o nazwach kończących się na
Queue) oraz kolejki blokujące (nazwy tych klas kończą się naBlockingQueue).Blokady i warunki wraz ze wsparciem ze strony JVM pozwalającym na szybsze wykonywanie operacji blokowania i odblokowywania.
Mechanizmy synchronizacji, takie jak klasa
SemaphoreorazCyclicBarrier.Zmienne atomowe.
Jak się można domyślić, implementacja interfejsu Excecutor jest klasą, która może wykonywać dla nas jakiś kod. Kodem tym może być implementacja doskonale znanego interfejsu Runnable bądź też nowego interfejsu Callable. Jednym z często stosowanych obiektów tego typu jest „pula wątków”. Z kolei interfejs Future reprezentuje przyszły stan operacji, której realizacja już została rozpoczęta; dysponuje on metodami do oczekiwania na uzyskanie wyników.
Te proste definicje są niewątpliwie nadmiernym uproszczeniem. Przedstawienie wszystkich zagadnień związanych z wielowątkowością wykracza poza ramy tematyczne tej książki, niemniej zamieściłem w niej kilka receptur prezentujących wybrane zagadnienia.
Należy napisać klasę implementującą interfejs Runnable, stworzyć obiekt tej klasy i uruchomić wątek.
Istnieje kilka sposobów implementacji wątków, a wszystkie z nich wymagają implementacji interfejsu Runnable. Interfejs ten posiada tylko jedną metodę o następującej sygnaturze:
public void run();
Programista, chcąc korzystać z wątków, musi stworzyć implementację tej metody. Gdy realizacja metody run() zostanie zakończona, wątek jest uznawany za „zużyty” i nigdy nie będzie go już można ponownie uruchomić. Należy zauważyć, że w skompilowanym pliku klasowym metoda ta absolutnie niczym się nie wyróżnia — jest to zwyczajna metoda, którą można samemu wywołać. Jednak co się stanie w momencie jej wywołania? Otóż nie zostanie użyta żadna specjalna magia, która spowoduje uruchomienie metody jako niezależnej ścieżki sterowania; a zatem metoda nie zostanie wykonana współbieżnie, równocześnie z programem głównym lub inną ścieżką sterowania. Aby taka współbieżna realizacja metody była możliwa, konieczne będzie wykorzystanie magicznego sposobu tworzenia wątków.
Jednym z możliwych rozwiązań jest stworzenie klasy potomnej klasy java.lang.Thread (która także implementuje interfejs Runnable, dzięki czemu nie trzeba go już implementować samemu). Przykład tego rozwiązania przedstawiłem na Przykład 22-1. Działanie klasy ThreadsDemo1 sprowadza się do wyświetlenia serii pozdrowień z wątku X oraz Y; przy czym nie można z góry ustalać kolejności, w jakiej znaki te będą wyświetlane; ani Java, ani sam program nie dają możliwości określenia tej kolejności.
Przykład 22-1. /threads/ThreadsDemo1.java
public class ThreadsDemo1 extends Thread {
private String mesg;
private int count;
/** Metoda run() wykonuje całą robotę: wyświetla komunikat
* tyle razy, ile wynosi wartość zmiennej count
*/
public void run() {
while (count-- > 0) {
System.out.println(mesg);
try {
Thread.sleep(100); // 100 ms
} catch (InterruptedException e) {
return;
}
}
System.out.println(mesg + " wszystko gotowe.");
}
/**
* Tworzymy obiekt ThreadsDemo1.
* @param m Komunikat do wyświetlenia.
* @param n Ile razy należy go wyświetlić.
*/
public ThreadsDemo1(final String mesg, int n) {
this.mesg = mesg;
count = n;
setName(mesg + "Wątek roboczy nr " + n);
}
/**
* Program główny testujący działanie klasy ThreadsDemo1.
*/
public static void main(String[] argv) {
// Alternatywnie można by napisać
// new ThreadsDemo1("Pozdrowienia z wątku X", 10).run();
// new ThreadsDemo1("Pozdrowienia z wątku Y", 15).run();
// Lecz w takim przypadku nie byłby to program wielowątkowy.
new ThreadsDemo1("Pozdrowienia z wątku X", 10).start();
new ThreadsDemo1("Pozdrowienia z wątku Y", 15).start();
}
}Ale co zrobić w sytuacji, gdy nie można stworzyć klasy potomnej klasy java.lang.Thread, gdyż musi ona rozszerzać inną klasę? W takim przypadku można zastosować dwa rozwiązania: zaimplementować w tworzonej klasie interfejs Runnable lub stworzyć klasę wewnętrzną implementującą ten interfejs. Sposób polegający na implementacji interfejsu Runnable został przedstawiony na Przykład 22-2.
Przykład 22-2. /threads/ThreadsDemo2.java
public class ThreadsDemo2 implements Runnable {
private String mesg;
private Thread t;
private int count;
/**
* Program główny testujący działanie klasy ThreadsDemo2.
*/
public static void main(String[] argv) {
new ThreadsDemo2("Witamy z wątku X", 10);
new ThreadsDemo2("Witamy z wątku Y", 15);
}
/**
* Tworzymy obiekt DemoThread2.
* @param m Wyświetlany komunikat.
* @param n Ile razy komunikat należy wyświetlić.
*/
public ThreadsDemo2(String m, int n) {
count = n;
mesg = m;
t = new Thread(this);
t.setName("Wątek roboczy nr " + m);
t.start();
}
/** Metoda run() wykonuje całą robotę. Przesłaniamy metodę run()
* interfejsu Runnable.
*/
public void run() {
while (count-- > 0) {
System.out.println(mesg);
try {
Thread.sleep(100); // 100 ms
} catch (InterruptedException e) {
return;
}
}
System.out.println(mesg + " wszystko gotowe.");
}
}Aby zakończyć prezentację różnych sposobów tworzenia wątków, Przykład 22-3 przedstawia rozwiązanie, w którym metoda run() jest wykonywana przy użyciu klasy wewnętrznej.
Przykład 22-3. /threads/ThreadsDemo3.java
public class ThreadsDemo3 {
private Thread t;
private int count;
/**
* Program główny testujący klasę ThreadsDemo3.
*/
public static void main(String[] argv) {
new ThreadsDemo3("Witamy z wątku X", 10);
new ThreadsDemo3("Witamy z wątku Y", 15);
}
/**
* Tworzymy obiekt ThreadsDemo3.
* @param m Wyświetlany komunikat.
* @param n Ile razy komunikat należy wyświetlić.
*/
public ThreadsDemo3(final String mesg, int n) {
count = n;
t = new Thread(new Runnable() {
public void run() {
while (count-- > 0) {
System.out.println(mesg);
try {
Thread.sleep(100); // 100 ms
} catch (InterruptedException e) {
return;
}
}
System.out.println(mesg + " wszystko gotowe.");
}
});
t.setName("Wątek roboczy nr " + mesg);
t.start();
}
}W powyższym kodzie metoda run() stanowi część anonimowej klasy wewnętrznej zadeklarowanej w instrukcji rozpoczynającej się od t = new Thread(...). To doskonały sposób wykorzystania klasy wewnętrznej, gdyż nasz wątek nie jest w żaden sposób związany z innymi klasami.
W końcu, w wersji Java 8 języka, jak pokazałem w „9.0. Wprowadzenie ⑧”, można — przynajmniej w większości przypadków — uprościć ten kod, używając zamiast klasy wewnętrznej wyrażenia lambda. Przykład takiego rozwiązania przedstawiłem na Przykład 22-4.
Przykład 22-4. /threads/ThreadsDemo4.java
public class ThreadsDemo4 {
private String mesg;
private Thread t;
private int count;
/**
* Program główny testujący klasę ThreadsDemo4.
*/
public static void main(String[] argv) {
new ThreadsDemo4("Witamy z wątku X", 10);
new ThreadsDemo4("Witamy z wątku Y", 15);
}
/**
* Tworzymy obiekt ThreadsDemo4.
* @param m Wyświetlany komunikat.
* @param n Ile razy należy wyświetlić komunikat.
*/
public ThreadsDemo4(final String mesg, int n) {
count = n;
t = new Thread(() -> {
while (count-- > 0) {
System.out.println(mesg);
try {
Thread.sleep(100); // 100 ms
} catch (InterruptedException e) {
return;
}
}
System.out.println(mesg + " wszystko gotowe.");
});
t.setName("Wątek roboczy nr " + mesg);
t.start();
}
}Podsumowując, istnieją cztery sposoby tworzenia wątków:
Stworzenie klasy potomnej klasy
Thread(patrz przykładThreadDemo1). Metoda ta najlepiej nadaje się do wykorzystania w niezależnych aplikacjach, które nie muszą być klasami potomnymi.Zaimplementowanie interfejsu
Runnable. Metodę tę można stosować przy tworzeniu klas rozszerzających inne klasy, które ze względu na model jednokrotnego dziedziczenia używany w Javie nie mogą rozszerzać klasyThread.Stworzenie obiektu
Threadpoprzez przekazanie w wywołaniu jego konstruktora obiektu będącego interfejsemRunnable. Tę metodę można stosować w sytuacjach, gdy metodarun()wątku jest bardzo prosta, a wymiana informacji z pozostałymi częściami aplikacji ma ograniczony wymiar.W wersji Java 8 języka można także utworzyć obiekt
Thread, przekazując wyrażenie lambda zgodne z interfejsemRunnable, który jest interfejsem funkcyjnym.
Istnieją także inne metody, które należy pokrótce opisać. Przede wszystkim istotne są konstruktory klasy Thread: Thread(), Thread("Nazwa wątku") oraz Thread(Runnable). Konstruktor bezargumentowy oraz konstruktor, w którego wywołaniu podawana jest nazwa, są wykorzystywane wyłącznie w przypadku wyprowadzania klas potomnych. Jednak czym jest ta nazwa? Cóż, domyślnie nazwa wątku składa się z nazwy klasy oraz kolejnego numeru bądź z kodu mieszającego obiektu; w standardowej wersji JDK numery te są kolejnymi cyframi, na przykład Thread-0, Thread-1, Thread-2 i tak dalej. Ten sposób nazewnictwa wątków nie jest szczególnie interesujący, jeśli musimy analizować wątki, na przykład wykorzystując program uruchomieniowy. Natomiast przypisanie wątkom nazw opisowych, takich jak „Wątek czasomierza” lub „Wątek zapisu w tle”, może nam znacznie ułatwić życie, kiedy (i jeśli) zostaniemy zmuszeni do przetestowania naszej wielowątkowej aplikacji. Z tych samych powodów klasa Thread udostępnia także metody getName() oraz setName(String), które odpowiednio pobierają i określają nazwę wątku.
Jak już pokazałem, metoda start() rozpoczyna proces przydzielania wątkowi czasu procesora, co powoduje zaś wywołanie jego metody run(). Z kolei odpowiadająca im metoda stop() została odrzucona; więcej informacji na jej temat można znaleźć w „22.3. Zatrzymywanie działania wątku”, w której opisuję także metodę interrupt() pozwalającą na przerwanie każdej czynności aktualnie realizowanej przez wątek. Metoda boolean isAlive() zwraca wartość true, jeśli wykonywanie wątku nie zostało zakończone oraz jeśli nie zostało przerwane na skutek wywołania metody stop(). Kolejnymi odrzuconymi metodami dostępnymi w klasie Thread są suspend() oraz resume(). Pierwsza z nich powoduje wstrzymanie realizacji wątku, natomiast druga z nich sprawia, że wykonywanie wątku jest kontynuowane. Metody te zwiększają prawdopodobieństwo wystąpienia błędów i wzajemnego blokowania realizacji wątków i dlatego nie należy ich stosować. Jeśli aplikacja wykorzystuje wiele wątków, to przy użyciu metody join() można zaczekać, aż określony wątek się zakończy (więcej informacji na ten temat można znaleźć w „22.4. Spotkania i ograniczenia czasowe”).
Kolejne metody — int getPriority() oraz void setPriority(int) — pozwalają odpowiednio na pobranie i określenie priorytetu wątku; wątki o wyższym priorytecie będą obsługiwane przez procesor w pierwszej kolejności. Ostatnia grupa metod — wait(), notify() oraz notifyAll() — pozwala na implementację klasycznych rozwiązań związanych z wykorzystaniem semaforów, na przykład powiązania dwóch wątków relacją typu producent-konsument. Klasa Thread udostępnia także kilka innych metod, informacje na ich temat można znaleźć w dokumentacji JDK.
Każda z tych technik pozwoli nam rozpocząć tworzenie aplikacji wielowątkowych, jednak raczej nie zapewniają one zbyt dużych możliwości skalowania. W przypadku gdy ilość pracy, którą należy wykonać, jest naprawdę duża, niemal bezwarunkowo zalecane jest skorzystanie z puli wątków. Pule wątków można utworzyć przy użyciu klasy Executors.
Musimy aktualizować graficzny interfejs programu, podczas gdy jego fragmenty realizują inne czynności.
Jednym z najpopularniejszych zastosowań wątków jest tworzenie animatorów — czyli klas wyświetlających poruszające się obrazy. W taki właśnie sposób działa program przedstawiony w tej recepturze. Wyświetla on obrazki (patrz „12.8. Wyświetlanie obrazu”) w różnych miejscach okna; współrzędne tych miejsc są następnie aktualizowane, a obrazki wyświetlane ponownie, każdy w odrębnym wątku (obiekcie Thread). Przedstawiony program jest apletem, a zatem na Rysunek 22-1 został on uruchomiony w programie Applet Viewer.
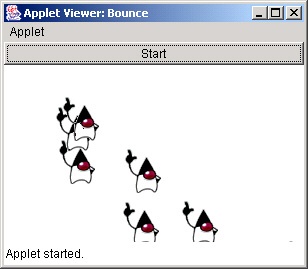
Kod przedstawionego tu rozwiązania składa się z dwóch klas: Sprite (przedstawionej na Przykład 22-5) oraz Bounce[83] (przedstawionej na Przykład 22-6). Klasa Sprite reprezentuje jeden obrazek poruszający się w oknie programu, natomiast Bounce jest głównym programem.
Przykład 22-5. /threads/Sprite.java (część programu animatora)
/** Sprite jest obrazkiem (obiektem Image) samodzielnie poruszającym się * po ekranie. */ public class Sprite extends Component implements Runnable { protected static int spriteNumber = 0; protected Thread t; protected int x, y; protected Component parent; protected Image img; protected volatile boolean done = false; /** Czas w milisekundach pomiędzy kolejnymi przesunięciami. */ protected volatile int sleepTime = 250; /** Kierunek ruchu danego obrazka. */ protected int direction; /** Kierunek poruszania się - w poziomie */ public static final int HORIZONTAL = 1; /** Kierunek poruszania się - w pionie */ public static final int VERTICAL = 2; /** Kierunek poruszania się - po skosie */ public static final int DIAGONAL = 3; /** Tworzy obiekt Sprite, dysponując komponentem nadrzędnym, obrazkiem * oraz kierunkiem ruchu. * Tworzy i uruchamia wątek (obiekt Thread) obsługujący danego "duszka". */ public Sprite(Component parent, Image img, int dir) { this.parent = parent; this.img = img; switch(dir) { case VERTICAL: case HORIZONTAL: case DIAGONAL: direction = dir; break; default: throw new IllegalArgumentException( "Kierunek " + dir + " jest nieprawidłowy"); } setSize(img.getWidth(this), img.getHeight(this)); } /** Tworzy obiekt Sprite, wykorzystując domyślny kierunek ruchu */ public Sprite(Component parent, Image img) { this(parent, img, DIAGONAL); } /** Uruchamia wątek sterujący poruszaniem obiektu Sprite. */ public void start() { t = new Thread(this); t.setName("Sprite nr " + ++spriteNumber); t.start(); } /** Zatrzymuje wątek obiektu Sprite. */ public void stop() { if (t == null) return; System.out.println("Zatrzymujemy " + t.getName()); done = true; } /** Zamiana szybkości ruchu */ protected void setSleepTime(int n) { sleepTime = n; } /** * Przesuwamy "duszka" po ekranie. * Ta wersja programu umożliwia jedynie ruch w poziomie, pionie * oraz po skosie (pod kątem 45 stopni). */ public void run() { int width = parent.getSize().width; int height = parent.getSize().height; // Określamy położenie początkowe x = (int)(Math.random() * width); y = (int)(Math.random() * height); // Zmieniamy kierunki ruchu w pionie/poziomie int xincr = Math.random()>0.5?1:-1; int yincr = Math.random()>0.5?1:-1; while (!done) { width = parent.getSize().width; height = parent.getSize().height; if ((x+=xincr) >= width) x=0; if ((y+=yincr) >= height) y=0; if (x<0) x = width; if (y<0) y = height; switch(direction) { case VERTICAL: x = 0; break; case HORIZONTAL: y = 0; break; case DIAGONAL: break; } //System.out.println("Z " + getLocation() + "->" + x + "," + y); setLocation(x, y); repaint(); try { Thread.sleep(sleepTime); } catch (InterruptedException e) { return; } } } /** paint -- wyświetlamy obrazek w wyznaczonym, bieżącym położeniu */ public void paint(Graphics g) { g.drawImage(img, 0, 0, this); } }
Przykład 22-6. /threads/Bounce.java (część programu animatora)
public class Bounce extends Applet implements ActionListener {
private static final long serialVersionUID = -5359162621719520213L;
/** Panel główny. */
protected Panel p;
/** Obrazek wykorzystywany wspólnie przez wszystkie obiekty Sprite */
protected Image img;
/** Vector zawierająca obiekty Sprite. */
protected List<Sprite> v;
public void init() {
Button b = new Button("Start");
b.addActionListener(this);
setLayout(new BorderLayout());
add(b, BorderLayout.NORTH);
add(p = new Panel(), BorderLayout.CENTER);
p.setLayout(null);
String imgName = getParameter("imagefile");
if (imgName == null) imgName = "duke.gif";
img = getImage(getCodeBase(), imgName);
MediaTracker mt = new MediaTracker(this);
mt.addImage(img, 0);
try {
mt.waitForID(0);
} catch(InterruptedException e) {
throw new IllegalArgumentException(
"InterruptedException podczas pobierania obrazu " + imgName);
}
if (mt.isErrorID(0)) {
throw new IllegalArgumentException(
"Nie można pobrać obrazu " + imgName);
}
v = new Vector<Sprite>(); // Działa wielowątkowo,
// używamy klasy Vector.
}
public void actionPerformed(ActionEvent e) {
System.out.println("Tworzymy następny!");
Sprite s = new Sprite(this, img);
s.start();
p.add(s);
v.add(s);
}
public void stop() {
for (int i=0; i<v.size(); i++) {
v.get(i).stop();
}
v.clear();
}
}Nie należy używać metody Thread.stop(); zamiast niej powinno się zastosować zmienną logiczną, której wartość będzie sprawdzana wewnątrz głównej pętli wykonywanej w metodzie run().
Choć można posługiwać się metodą stop() wątku, firma Sun zaleca, aby tego nie robić. Wynika to z faktu, iż działanie tej metody jest tak niepewne, że w programach, w których istnieje wiele aktywnych wątków, nigdy nie będzie można zagwarantować jej poprawnego działania. Właśnie z tego powodu próba jej wykorzystania spowoduje wygenerowanie przez kompilator ostrzeżenia o użyciu odrzuconej metody. Zalecanym rozwiązaniem jest skorzystanie ze zmiennej logicznej, której wartość będzie sprawdzana w głównej pętli wykonywanej w metodzie run(). Program przedstawiony na Przykład 22-7 w nieskończoność wyświetla ten sam komunikat — aż do momentu wywołania metody shutDown(), która przypisuje zmiennej done wartość false, co z kolei przerywa działanie pętli i powoduje zakończenie metody run() oraz wątku. Program ThreadStoppers (dostępny w kodach dołączonych do książki w katalogu threads) tworzy obiekt tej klasy, uruchamia go, a następnie wywołuje jego metodę shutDown().
Przykład 22-7. /threads/StopBoolean.java
public class StopBoolean extends Thread {
// MUSI być volatile... W przeciwnym przypadku "agresywne" kompilatory
// optymalizujące mogą skompilować kod w taki sposób,
// że nie będzie działać poprawnie!!
protected volatile boolean done = false;
public void run() {
while (!done) {
System.out.println("Wątek StopBoolean uruchomiony.");
try {
sleep(720);
} catch (InterruptedException ex) {
// Nie mamy nic do zrobienia.
}
}
System.out.println("Wątek StopBoolean zakończony.");
}
public void shutDown() {
done = true;
}
public static void main(String[] args)
throws InterruptedException {
StopBoolean t1 = new StopBoolean();
t1.start();
Thread.sleep(1000*5);
t1.shutDown();
}
}Uruchomienie tego programu spowoduje wygenerowanie następujących wyników:
Wątek StopBoolean uruchomiony. Wątek StopBoolean uruchomiony. Wątek StopBoolean uruchomiony. Wątek StopBoolean uruchomiony. Wątek StopBoolean uruchomiony. Wątek StopBoolean uruchomiony. Wątek StopBoolean uruchomiony. Wątek StopBoolean zakończony.
Co się jednak stanie w sytuacji, gdy wątek będzie zablokowany ze względu na odczytywanie danych z połączenia sieciowego? W takim przypadku nie można przecież sprawdzić wartości zmiennej logicznej, gdyż wątek odczytujący informacje jest „uśpiony”. To właśnie z myślą o takich sytuacjach została stworzona metoda stop(), która — jak się jednak okazuje — została teraz odrzucona. A zatem rozwiązaniem, jakie należy zastosować, jest zamknięcie połączenia sieciowego (gniazda). Program przedstawiony na Przykład 22-8 celowo próbuje doprowadzić do zablokowania wątku, odczytując w tym celu informacje z gniazda, w którym niby mamy coś zapisywać. Celem tego przykładu jest pokazanie, że zamknięcie gniazda faktycznie powoduje zakończenie pętli.
Przykład 22-8. /threads/StopClose.java
public class StopClose extends Thread {
protected Socket io;
public void run() {
try {
io = new Socket("java.sun.com", 80); // HTTP
BufferedReader is = new BufferedReader(
new InputStreamReader(io.getInputStream()));
System.out.println("Wątek StopClose czyta dane...");
// Wykonanie kolejnej instrukcji spowoduje (celowo) zablokowanie
// wątku, gdyż protokół HTTP wymaga, aby przed odebraniem
// odpowiedzi klient przesłał żądanie (na przykład:
// "GET / HTTP/1.0") oraz pusty wiersz.
String line = is.readLine(); // BLOKADA
// Wykonywanie metody readLine może zostać przerwane wyłącznie
// w przypadku zgłoszenia wyjątku lub zamknięcia gniazda.
// A zatem poniższa instrukcja nigdy nie powinna zostać wykonana.
System.out.printf("Wątek StopClose ZAKOŃCZONY po odczytaniu " +
"wierszy tekstu %s!?", line);
} catch (IOException ex) {
System.out.println("Kończymy działanie wątku StopClose: " + ex);
}
}
public void shutDown() throws IOException {
if (io != null) {
// To powinno przerwać oczekiwanie na odczytanie danych z gniazda.
synchronized(io) {
io.close();
}
}
System.out.println("Zakończono wywołanie StopClose.shutDown()");
}
public static void main(String[] args)
throws InterruptedException, IOException {
StopClose t = new StopClose();
t.start();
Thread.sleep(1000*5);
t.shutDown();
}
}Po uruchomieniu program wyświetla komunikat informujący o zamknięciu wątku:
Wątek StopClose czyta dane... Kończymy działanie wątku StopClose: java.net.SocketException: socket closed
Być może Czytelnik zapyta: „Ale zaraz, co zrobić, jeśli chcemy przerwać oczekiwanie bez jednoczesnego zamykania gniazda?”. Cóż, to dobre pytanie. Niestety nie ma na nie dobrej odpowiedzi. Można co prawda przerwać wątek próbujący odczytać dane — operacja odczytu jest przerywana w wyniku zgłoszenia wyjątku java.io.InterruptedIOException, jednak wciąż istnieje możliwość ponowienia próby odczytu. Program zapisany w pliku Intr.java przedstawia takie rozwiązanie.
Musimy wiedzieć, czy jakaś operacja została zakończona lub czy została zakończona w określonym czasie.
Należy uruchomić to „coś” w niezależnym wątku i wywołać metodę join(), podając lub pomijając argument określający limit czasu wykonania.
Wywołanie metody join() wątku docelowego pozwala na wstrzymanie realizacji bieżącego wątku aż do momentu zakończenia realizacji wątku docelowego (zakończenia jego metody run()). Metoda join() jest przeciążona; wywołanie jej bezargumentowej wersji sprawia, że wątek będzie oczekiwać w nieskończoność na zakończenie wątku docelowego, z kolei druga wersja metody — wymagająca podania argumentu — sprawi, że wątek będzie oczekiwać tylko podany czas. W ramach bardzo prostego przykładu napisałem program, który tworzy (i uruchamia!) prosty wątek odczytujący znaki z terminala, podczas gdy wątek główny oczekuje na jego zakończenie. Poniżej przedstawiłem przykład działania tego programu:
darwinsys.com$ java Join
Uruchamiamy.
Łączymy.
Odczytujemy.
witamy w standardowym strumieniu wejściowym #program czeka dowolnie długo
na wpisanie tego wiersza
Wątek zakończony.
Program główny zakończony.
darwinsys.com$Kod źródłowy programu Join przedstawiłem na Przykład 22-9.
Przykład 22-9. /threads/Join.java
public class Join {
public static void main(String[] args) {
Thread t = new Thread() {
public void run() {
System.out.println("Odczytujemy.");
try {
System.in.read();
} catch (java.io.IOException ex) {
System.err.println(ex);
}
System.out.println("Wątek zakończony.");
}
};
System.out.println("Uruchamiamy.");
t.start();
System.out.println("Łączymy.");
try {
t.join();
} catch (InterruptedException ex) {
// To nie powinno się zdarzyć.
System.out.println("Kto ośmiela się przerywać mój sen?");
}
System.out.println("Program główny zakończony.");
}
}Jak widać, w celu utworzenia wątku program wykorzystuje wewnętrzną klasę Thread (patrz „22.1. Uruchamianie kodu w innym wątku”).
Musimy zabezpieczyć pewne fragmenty kodu, aby jednocześnie nie mogło ich wykonywać wiele wątków.
Metodę lub fragment kodu, który chcemy zabezpieczyć, należy poprzedzić słowem kluczowym synchronized.
Słowo kluczowe synchronized oraz jego znaczenie omówiłem pokrótce w „16.4. Obsługa wielu klientów”. Oznacza ono, że wskazaną metodę (lub jakąkolwiek inną synchronizowaną metodę tej samej klasy) konkretnego obiektu może w danej chwili wykonywać tylko jeden wątek. (W przypadku metod statycznych metoda może być wykonywana w danej chwili przez tylko jeden wątek). Za pomocą słowa kluczowego synchronized można synchronizować zarówno metody, jak i mniejsze bloki kodu. Łatwiejszym rozwiązaniem jest synchronizowanie całych metod, jednak może ono być kosztowne ze względu na potencjalną możliwość blokowania wątków, które w innych przypadkach mogłyby działać. Aby synchronizować metodę, wystarczy ją poprzedzić słowem kluczowym synchronized. Na przykład klasa Vector (przedstawiona w „7.4. Klasa podobna do tablicy, lecz bardziej dynamiczna”) posiada wiele synchronizowanych metod. Dzięki temu obiekty tej klasy będą zawierać i zwracać poprawne wyniki, nawet jeśli będą jednocześnie używane przez większą liczbę wątków.
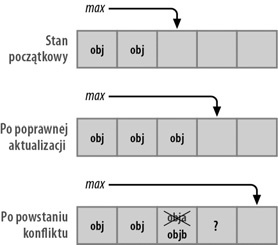
Należy pamiętać, że niemal w każdej chwili można przerwać realizację jednego wątku i przekazać sterowanie do innego. Wyobraźmy sobie dwa wątki, które jednocześnie dodają elementy do jakiejś struktury danych. Załóżmy, że posługujemy się takimi samymi metodami, jakie udostępnia klasa Vector, lecz operujemy na zwyczajnej tablicy. Metoda add() dodaje nowy element do tablicy, posługując się wartością określającą liczbę elementów tablicy jako indeksem, a następnie inkrementuje tę wartość:
public void add(Object obj) {
data[max] = obj; // ➊
max = max + 1; // ➋
}Dysponujemy dwoma wątkami — A i B — które jednocześnie chcą wywołać metodę add(). Załóżmy teraz, że realizacja wątku A zostanie przerwana po wykonaniu wiersza ➊, lecz przed rozpoczęciem wykonywania wiersza ➋. Następnie uruchamiany jest wątek B.
➊ Wątek ten wykonuje wiersz ➊, zapisując nową wartość komórki
data[max]— w tym momencie tracone jest odwołanie do obiektu zapisanego w wątku A!➋ Następnie wątek B inkrementuje wartość zmiennej
maxw wierszu ➋ i kończy działanie. Program ponownie rozpoczyna realizację wątku A — w wierszu ➋ inkrementowana jest zmiennamaxi w tym momencie zaczyna ona wskazywać komórkę, która nie zawiera żadnego poprawnego obiektu. A zatem sposób realizacji obu wątków nie tylko doprowadził do utraty jednego obiektu, lecz także spowodował powstanie jednej niezainicjalizowanej komórki tablicy. Przebieg opisanych powyżej zdarzeń zilustrowałem na Rysunek 22-2.
Czytelnik może pomyśleć: „Nie ma problemu, połączymy zatem te dwa wiersze kodu”:
data[max++] = obj;
Cóż, jak czasami mawiają prezenterzy prowadzący telewizyjne programy typu talk-show: „Temu panu już podziękujemy!”. Powyższa zmiana skróciła może nieco kod programu, jednak nie ma ona najmniejszego wpływu na niezawodność jego działania. Przerwania nie zachodzą w bezpieczny dla nas sposób pomiędzy instrukcjami języka Java; mogą one zachodzić pomiędzy dowolnymi maszynowymi instrukcjami JVM reprezentującymi skompilowany program. A zatem wciąż istnieje możliwość przerwania naszego programu tuż po wykonaniu inkrementacji. Jedynym dobrym rozwiązaniem tego problemu jest wykorzystanie synchronizacji.
Synchronizacja metody — czyli umieszczenie słowa kluczowego synchronized w jej definicji — sprawi, że jeśli metoda taka jest aktualnie wykonywana, to wszystkie kolejne jednoczesne próby jej realizacji zostaną wstrzymane aż do czasu zakończenia pierwszego wywołania:
public synchronized void add(Object obj) {
....
}Może się także zdarzyć, że będziemy chcieli synchronizować jakiś fragment kodu, lecz nie całą metodę. W takim przypadku można poprzedzić słowem kluczowym synchronized dowolny nienazwany blok kodu wewnątrz metody, na przykład:
public void add(Object obj) {
synchronized (someObject) {
// Ten kod będzie wykonywany w danej chwili tylko przez jeden wątek.
}
}W nawiasach podanych za słowem kluczowym synchronized można umieścić dowolny obiekt. Czasami sensowne jest synchronizowanie obiektu zawierającego wykonywany kod; takie właśnie rozwiązanie przedstawiłem na Przykład 22-10. Natomiast w przypadku synchronizacji dostępu do obiektu ArrayList należałoby umieścić w nawiasach odpowiedni obiekt ArrayList, jak na poniższym listingu:
synchronized(myArrayList) {
if (myArrayList.indexOf(someObject) != -1) {
// Wykonujemy jakieś operacje na obiekcie.
} else {
// W przeciwnym razie tworzymy obiekt i dodajemy go do listy...
}
}Program przedstawiony na Przykład 22-10 jest serwletem, który napisałem na zajęcia lekcyjne, kierując się sugestią nadesłaną przez Scotta Weingusta (scott@sysoft.ca)[84]. Serwlet ten pozwala na prowadzenie gry przypominającej teleturniej, podczas której pierwsza osoba, która naciśnie przycisk dzwonka (prześle odpowiedni sygnał), będzie miała szansę podać poprawną odpowiedź na zadane pytanie. Aby wykluczyć sytuację, w której dwie osoby jednocześnie „zadzwonią”, stworzony przeze mnie program synchronizuje blok kodu zmieniający wartość zmiennej logicznej iWon. Dla zapewnienia jak największej niezawodności działania serwletu synchronizowany jest także kod umożliwiający odczytanie wartości tej zmiennej.
Przykład 22-10. /threads/buzzin/BuzzInServlet.java
public class BuzzInServlet extends HttpServlet {
/** Wykorzystywana w serwlecie nazwa atrybutu. */
protected final static String WINNER = "buzzin.winner";
/** Metoda doGet jest wywoływana przez strony WWW poszczególnych graczy.
* Wykorzystuje ona synchronizowany blok kodu, aby zapewnić, że tylko
* jeden z graczy będzie w stanie zmienić stan zmiennej "buzzed".
*/
public void doGet(HttpServletRequest request, HttpServletResponse response)
throws ServletException, IOException
{
ServletContext application = getServletContext();
boolean iWon = false;
String user = request.getRemoteHost() + '@' + request.getRemoteAddr();
// W pierwszej kolejności synchronizujemy dostęp do zmiennej
// i wykonujemy inne związane z tym operacje.
synchronized(application) {
if (application.getAttribute(WINNER) == null) {
application.setAttribute(WINNER, user);
application.log("BuzzInServlet: Zwycięzcą jest " + user);
iWon = true;
}
}
response.setContentType("text/html");
PrintWriter out = response.getWriter();
out.println("<html><head><title>Dziękujemy za wzięcie " +
"udziału w zabawie</title></head>");
out.println("<body bgcolor=\"white\">");
if (iWon) {
out.println("<b>Udało ci się</b>");
// Do zrobienia - zmienić generowany kod HTML, tak by po
// wyświetleniu strony odtwarzany był plik dźwiękowy:-)
} else {
out.println("Dziękujemy za wzięcie udziału w rozgrywce, " +
request.getRemoteAddr());
out.println(", jednak pierwszy był " +
application.getAttribute(WINNER) + ".");
}
out.println("</body></html>");
}
/** Metoda Post jest wykorzystywana przez stronę administracyjną (która
* powinna być zainstalowana w katalogu lokalnej witryny administratora).
* Metoda Post jest używana do celów administracyjnych:
* 1) aby wyświetlić zwycięzcę;
* 2) aby przygotować aplikację do zadania następnego pytania.
*/
public void doPost(HttpServletRequest request, HttpServletResponse response)
throws ServletException, IOException
{
ServletContext application = getServletContext();
response.setContentType("text/html");
HttpSession session = request.getSession();
PrintWriter out = response.getWriter();
if (request.isUserInRole("host")) {
out.println("<html><head><title>Witam ponownie, " +
request.getUserPrincipal().getName() + "</title><head>");
out.println("<body bgcolor=\"white\">");
String command = request.getParameter("command");
if (command.equals("reset")) {
// Synchronizujemy dokładnie to, co trzeba, nic ponad to.
synchronized(application) {
application.setAttribute(WINNER, null);
}
session.setAttribute("buzzin.message", "RESET");
} else if (command.equals("show")) {
String winner = null;
synchronized(application) {
winner = (String)application.getAttribute(WINNER);
}
if (winner == null) {
session.setAttribute("buzzin.message",
"<b>Jeszcze nie ma zwycięzcy!</b>");
} else {
session.setAttribute("buzzin.message",
"<b>Zwycięzcą jest: </b>" + winner);
}
}
else {
session.setAttribute("buzzin.message",
"BŁĄD: polecenie " + command + " nie jest prawidłowe.");
}
RequestDispatcher rd = application.getRequestDispatcher(
"/hosts/index.jsp");
rd.forward(request, response);
} else {
out.println(
"<html><head><title>Cóż, spróbowałeś, ale... </title><head>");
out.println("<body bgcolor=\"white\">");
out.println(
"Przykro mi, Dave, ale wiesz, że nie mogę ci na to pozwolić.");
out.println("Nawet jeśli jesteś " + request.getUserPrincipal());
}
out.println("</body></html>");
}
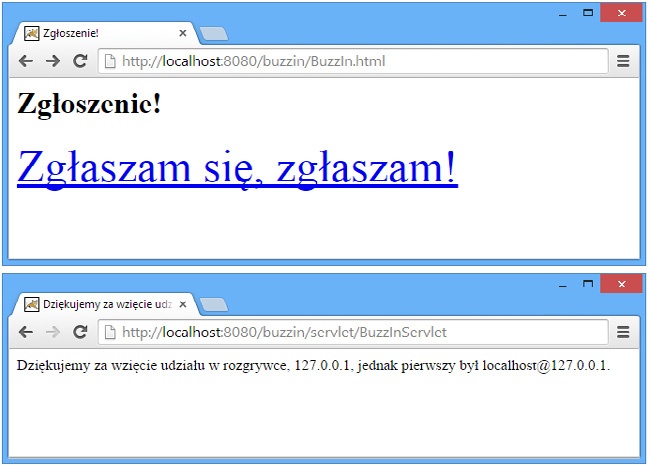
}Dostęp do naszego przykładowego serwletu zapewniają dwie strony WWW. Strona z zawartością zawiera jedynie duże połączenie (<a href="/servlet/BuzzInServlet">). Kliknięcie takiego połączenia sprawia, że przeglądarka wygeneruje żądanie GET, a zatem zostanie wywołana metoda doGet() serwletu.
<html><head><title>Zgłoszenie!</title></head> <body> <h1>Zgłoszenie!</h1> <p> <font size=+6> <a href="servlet/BuzzInServlet"> Zgłaszam się, zgłaszam! </a> </font>
Kod HTML tej strony jest bardzo prosty, lecz pomimo to doskonale spełnia ona swoje zadanie. Jej wygląd przedstawiłem w górnej części Rysunek 22-3.
Osoba prowadząca grę ma dostęp do formularza HTML przesyłającego żądania metodą POST. Odebranie takiego żądania powoduje wywołanie metody doPost() serwletu. Metoda doPost() wyświetla zwycięzcę gry oraz przywraca początkową wartość zmiennej określającej, czy zwycięzca już został wyłoniony. Obsługa tej strony wymaga podania hasła; na tym listingu zostało ono na stałe umieszczone w kodzie HTML, jednak w normalnej aplikacji powinno być odczytywane z pliku właściwości (patrz „7.12. Zapisywanie łańcuchów znaków w obiektach Properties i Preferences”) lub parametru inicjalizacyjnego serwletu (patrz książka Java Servlet Programming).
<html><head><title>Administracja zgłoszeniami</title></head>
<body>
<h1>Okno wyników</h1>
<p>
<b>Zwycięzcą jest:
<form method="post" action="servlet/BuzzInServlet">
<input type="hidden" name="command" value="show">
<input type="hidden" name="password" value="syzzy">
<input type="submit" name="Show" value="Pokaż zwycięzcę">
</form>
<h1>Przywróć początkowy stan aplikacji</h1>
<p>
<b>Pamiętaj, aby przywracać początkowy stan aplikacji przed
zadaniem każdego pytania!</b>
<form method="post" action="servlet/BuzzInServlet">
<input type="hidden" name="command" value="reset">
<input type="hidden" name="password" value="syzzy">
<input type="submit" name="Reset" value="Przywróć stan początkowy!">
</form>Wygląd strony administracyjnej przedstawiłem na Rysunek 22-4.
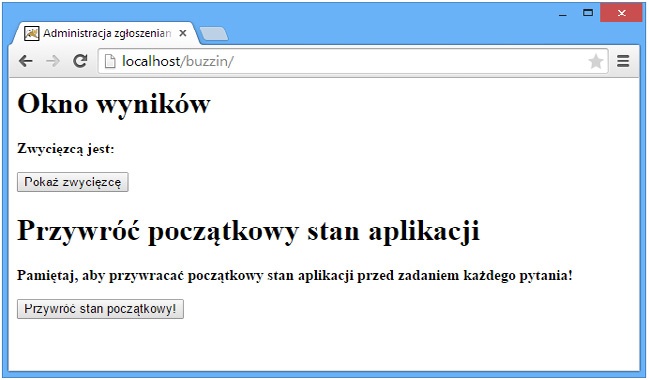
Rysunek 22-4. Możliwości, jakimi dysponuje administrator gry prowadzonej przy użyciu serwletu BuzzInServlet
Każdy bardziej zaawansowany i kompletny serwlet obsługujący grę tego typu, dysponowałby obiektem Stack (patrz „7.18. Stos”) przechowującym informacje o graczach, zapisane w kolejności, w jakiej się zgłaszali. Byłoby to konieczne do prowadzenia dalszej gry, gdyby osoba, która zgłosiła się jako pierwsza, nie podała poprawnej odpowiedzi na zadane pytanie. Oczywiście dostęp i wszelkie operacje na tym obiekcie także należałoby synchronizować.
Należy skorzystać z mechanizmu blokad zaimplementowanych w pakiecie java.util.concurrent.locks.
Rozwiązaniem tego problemu jest zastosowanie pakietu java.util.concurrent.locks, którego jednym z najważniejszych elementów jest interfejs Lock. Interfejs ten definiuje kilka metod służących do blokowania oraz jedną do odblokowywania. Poniżej został przedstawiony ogólny wzorzec wykorzystania tego interfejsu:
Lock theLock = ...
try {
theLock.lock();
// Wykonujemy prace chronione blokadą.
} finally {
theLock.unlock();
}Jak można się domyślić, wywołanie metody unlock() zostało umieszczone w bloku finally, aby nie zostało pominięte w razie zgłoszenia jakiegoś wyjątku (kod może także zawierać jedną lub kilka klauzul catch, zależnie od wymagań wykonywanych operacji).
Korzyści, jakie daje to rozwiązanie w porównaniu z tradycyjnymi sposobami synchronizacji metod i bloków kodu, polega na tym, że wykorzystanie obiektów Lock w końcu wygląda tak, jak można by sobie wyobrażać operacje blokowania! A zgodnie z informacjami podanymi wcześniej dostępnych jest kilka metod służących do blokowania; zostały one przedstawione w Tabela 22-1.
Tabela 22-1. Metody klasy Lock służące do blokowania
Typ wyniku | Metoda | Opis |
|---|---|---|
|
| Pobiera blokadę, nawet jeśli miałoby to oznaczać oczekiwanie na zwolnienie jej przez inny wątek. |
|
| Pobiera blokadę, jednak wyłącznie wtedy, gdy jest ona dostępna w danej chwili. |
|
| Próbuje pobrać blokadę, jednak oczekuje na nią wyłącznie przez określony czas. |
|
| Pobiera blokadę, oczekując na nią aż do momentu przerwania. |
|
| Zwalnia blokadę. |
Klasa TimeUnit pozwala podać jednostki, w jakich zostanie określona długość czasu, jaki upłynął; dostępne są między innymi następujące wartości: TimeUnit.SECONDS, TimeUnit.MILLISECONDS, TimeUnit.MICROSECONDS oraz TimeUnit.NANOSECONDS.
We wszystkich przypadkach, zanim będzie można ponownie użyć blokady, trzeba ją będzie zwolnić, wywołując w tym celu metodę unlock().
Standardowa klasa Lock doskonale nadaje się do wykorzystania w wielu aplikacjach, jednak w zależności od wymagań konkretnej aplikacji lepszym rozwiązaniem może być użycie jednego z innych typów blokad. W przypadku aplikacji o symetrycznym wzorcu obciążenia korzystne może być zastosowanie popularnego wzorca określanego jako „blokada czytelnika-pisarza” — osobiście wolę go jednak określać jako „blokadę czytelników-pisarza”, aby podkreślić, że czytelników może być dowolnie wiele, lecz pisarz tylko jeden. Wzorzec ten tworzy para wzajemnie ze sobą powiązanych blokad, blokadę do odczytu może posiadać dowolnie wiele czytelników, z których każdy może odczytywać dane, o ile tylko nie są one w danej chwili zapisywane (odpowiada to współdzielonemu dostępowi do odczytu). Wątek próbujący uzyskać blokadę do zapisu musi czekać na zakończenie wszystkich operacji odczytu, a kiedy ją uzyska, blokuje wszystkich czytelników aż do momentu zakończenia wykonywanych operacji (odpowiada to wyłącznemu dostępowi do zapisu). Aby zapewnić wsparcie dla tego wzorca blokowania, udostępniony został interfejs ReadWriteLock oraz klasa ReentrantReadWriteLock stanowiąca jego implementację. Interfejs ten posiada tylko dwie metody: readLock() oraz writeLock(), które zwracają odwołanie do odpowiedniej implementacji interfejsu Lock. Metody te same z siebie nie realizują żadnych operacji blokowania lub odblokowywania — zapewniają jedynie dostęp do obiektów, których można w tym celu użyć; dlatego też często można zobaczyć poniższe wywołania:
rwlock.readLock().lock(); rwlock.readLock().unlock();
Aby zademonstrować praktyczne zastosowanie interfejsu ReadWriteLock, napisałem klasę stanowiącą logikę biznesową internetowej aplikacji do głosowania. Z powodzeniem mogłaby ona znaleźć zastosowanie w głosowaniach na kandydatów bądź w znacznie bardziej popularnych ankietach internetowych. Jeśli przyjmiemy, że wyniki takiego głosowania będą prezentowane na stronie głównej, a zmiany wprowadzane wyłącznie po kliknięciu przycisku przesyłającego ankietę, to okaże się, że taka aplikacja odpowiada kryteriom działania interfejsu ReadWriteLock — czyli sytuacji, w której jest więcej czytelników niż pisarzy. Klasa główna rozwiązania, ReadersWriterDemo, została przedstawiona na Przykład 22-11. Kod źródłowy klasy pomocniczej BallotBox, można natomiast znaleźć w przykładach dołączonych do książki. Jest to bardzo prosta klasa, która przechowuje informacje o oddanych głosach i jeśli zostanie poproszona, to zwraca obiekt Iterator pozwalający na odczytanie wyników. Należy zwrócić uwagę, że w metodzie run() wątku odczytującego można pobrać ten iterator, jeśli dysponuje się blokadą, lecz zwolnić ją jeszcze przed wyświetleniem wyników. Rozwiązanie to poprawia możliwości współbieżnego działania aplikacji oraz jej wydajność, choć z drugiej strony (zależnie od konkretnej aplikacji) może wymuszać dodatkowe blokowanie podczas realizacji współbieżnych operacji aktualizacji.
Przykład 22-11. /threads/ReadersWriterDemo.java
public class ReadersWriterDemo {
private static final int NUM_READER_THREADS = 3;
public static void main(String[] args) {
new ReadersWriterDemo().demo();
}
/** Tej fladze należy przypisać wartość true, aby
* zakończyć działanie programu. */
private volatile boolean done = false;
/** Chronione dane. */
private BallotBox theData;
/** Połączenie blokad odczytu i zapisu. */
private ReadWriteLock lock = new ReentrantReadWriteLock();
/**
* Konstruktor: generujemy pseudolosowe dane początkowe.
*/
public ReadersWriterDemo() {
List<String> questionsList = new ArrayList<>();
questionsList.add("Za");
questionsList.add("Przeciw");
questionsList.add("Nie mam zdania");
theData = new BallotBox(questionsList);
}
/**
* Metoda uruchamia przykład, tworząc więcej wątków odczytujących
* niż zapisujących.
*/
private void demo() {
// Uruchamiamy dwa wątki czytelników.
for (int i = 0; i < NUM_READER_THREADS; i++) {
new Thread() {
public void run() {
while (!done) {
lock.readLock().lock();
try {
theData.forEach(p ->
System.out.printf("%s: oddano %d głosów%n",
p.getName(),
p.getVotes()));
} finally {
// Odblokowujemy w klauzuli "finally", aby
// mieć pewność, że blokada zostanie zwolniona.
lock.readLock().unlock();
}
try {
Thread.sleep(((long)(Math.random()* 1000)));
} catch (InterruptedException ex) {
// Nie ma nic do zrobienia.
}
}
}
}.start();
}
// Uruchamiamy jeden wątek pisarza, symulując w ten sposób
// sporadyczne operacje przesłania ankiety.
new Thread() {
public void run() {
while (!done) {
lock.writeLock().lock();
try {
theData.voteFor(
// Głosujemy na losową odpowiedź.
// Poprawa wydajności: należałoby zastosować
// po jednym generatorze liczb pseudolosowych
// dla każdego wątku.
(((int)(Math.random()*
theData.getCandidateCount()))));
} finally {
lock.writeLock().unlock();
}
try {
Thread.sleep(((long)(Math.random()*1000)));
} catch (InterruptedException ex) {
// Nie ma nic do zrobienia.
}
}
}
}.start();
// W wątku głównym czekamy przez chwilę, a następnie kończymy
// działanie programu.
try {
Thread.sleep(10 * 1000);
} catch (InterruptedException ex) {
// Nie ma nic do zrobienia.
} finally {
done = true;
}
}
}Ponieważ powyższa aplikacja jest symulacją, a głosowanie odbywa się w sposób losowy, zatem nie zawsze uzyskamy taką samą liczbę głosów oddanych na każdą z dostępnych opcji. Poniżej przedstawiłem ostateczne wyniki uzyskane podczas dwóch symulacji głosowania:
# symulacja 1. Za: oddano 8 głosów Przeciw: oddano 8 głosów Nie mam zdania: oddano 5 głosów # symulacja 2. Za: oddano 7 głosów Przeciw: oddano 6 głosów Nie mam zdania: oddano 8 głosów
Słowo kluczowe synchronized pozwala na blokowanie realizacji wielu wątków, lecz nie daje możliwości komunikacji między nimi.
Klasa java.lang.Object udostępnia trzy metody, dzięki którym każdy obiekt może się stać elementem synchronizującym działanie wątków. Metodami tymi są wait(), notify() oraz notifyAll().
wait()Wywołanie tej metody sprawia, że bieżący wątek zostanie zablokowany na danym obiekcie, a jego realizacja zostanie wstrzymana aż do momentu „obudzenia”, czyli wywołania metody
notify()lubnotifyAll().notify()Powoduje wznowienie realizacji losowo wybranego wątku oczekującego „na” danym obiekcie. Wątek ten musi następnie podjąć próbę kontrolnego zablokowania innych wątków.
notifyAll()Powoduje wznowienie realizacji wszystkich wątków oczekujących „na” danym obiekcie. Każdy z nich podejmie następnie próbę kontrolnego zablokowania innych wątków. Miejmy nadzieję, że jednemu z nich się uda.
Większość programistów używa metody notifyAll() zamiast notify(), ponieważ wznawiając działanie wszystkich wątków, ten, który powinien być realizowany jako następny, w końcu zostanie uruchomiony.
Wszystko to wygląda na dosyć skomplikowane, jednak większość operacji jest realizowana wewnątrz samego mechanizmu obsługi wątków.
Należy także zwrócić uwagę, że zarówno metoda wait(), jak i pozostałe dwie omawiane tu metody mogą być stosowane wyłącznie w przypadku, gdy dany obiekt jest już synchronizowany, a zatem muszą być wywoływane wewnątrz synchronizowanej metody lub bloku kodu synchronizowanego względem obiektu, którego chcemy użyć do wywołania metod wait() lub notify().
Aby w prosty sposób przedstawić zasady wykorzystania metod wait() oraz notify(), zaprezentuję aplikację działającą według modelu producent-konsument. Wzorzec ten można wykorzystać do symulowania wielu sytuacji zachodzących w prawdziwym świecie, w których to jeden obiekt tworzy lub przydziela inne obiekty (czyli produkuje je) w losowych (zazwyczaj) odstępach czasu, natomiast drugi obiekt pobiera je i wykorzystuje do wykonania jakichś czynności (czyli „konsumuje” je). Jednowątkowy program działający według modelu producent-konsument został przedstawiony na Przykład 22-12. Jak widać, w programie tym nie są tworzone żadne wątki, a zatem wszystkie jego operacje — metody read(), produce() oraz consume() wywoływane w metodzie main() — są wykonywane w tym samym wątku. W tym przypadku proces tworzenia oraz wykorzystywania obiektów jest sterowany ręcznie poprzez podanie wiersza tekstu zawierającego odpowiednie litery. Każda litera „p” powoduje stworzenie jednego elementu, natomiast każda litera „c” — wykorzystanie jednego elementu. A zatem jeśli po uruchomieniu programu zostanie wpisany ciąg znaków pcpcpcpc, to program będzie cyklicznie tworzyć i zużywać elementy. Z kolei w przypadku podania łańcucha pppccc program najpierw utworzy trzy elementy, a następnie je zużyje.
Przykład 22-12. /threads/ProdCons1.java
public class ProdCons1 {
protected LinkedList<Object> list = new LinkedList<>();
protected void produce() {
int len = 0;
synchronized(list) {
Object justProduced = new Object();
list.addFirst(justProduced);
len = list.size();
list.notifyAll();
}
System.out.println("Bieżąca długość listy " + len);
}
protected void consume() {
Object obj = null;
int len = 0;
synchronized(list) {
while (list.size() == 0) {
try {
list.wait();
} catch (InterruptedException ex) {
return;
}
}
obj = list.removeLast();
len = list.size();
}
System.out.println("'Konsumujemy' obiekt " + obj);
System.out.println("Bieżąca długość listy " + len);
}
public static void main(String[] args) throws IOException {
ProdCons1 pc = new ProdCons1();
System.out.println("Program gotowy (wpisz 'p', aby wyprodukować,
oraz 'c', by skonsumować obiekt):");
int i;
while ((i = System.in.read()) != -1) {
char ch = (char)i;
switch(ch) {
case 'p': pc.produce(); break;
case 'c': pc.consume(); break;
}
}
}
}Rozwiązanie przyjęte w powyższym programie — polegające na synchronizacji jego działania względem zmiennej list, a nie głównej klasy programu — może się wydawać nieco dziwne. Każdy obiekt posiada własną kolejkę oczekujących wątków, a zatem to, którego obiektu użyjemy do synchronizacji, nie ma znaczenia. Teoretycznie rzecz biorąc, można wykorzystać dowolny obiekt, pod warunkiem że obiekt, względem którego przeprowadzamy synchronizację, jest jednocześnie obiektem, w którym są wywoływane metody wait() oraz notify(). Oczywiście dobrym rozwiązaniem jest odwoływanie się do obiektu, który chcemy ochronić przed współbieżnymi aktualizacjami, i właśnie dlatego w powyższym listingu użyłem w tym celu obiektu list.
Mam nadzieję, że zastanawiasz się teraz, co to ma wspólnego z synchronizacją wątków. Istnieje tylko jeden wątek, lecz wydaje się, że program działa poprawnie:
> javac +E -d . threads.ProdCons1.java > java threads.ProdCons1 Program gotowy (wpisz 'p', aby wyprodukować, oraz 'c', by skonsumować obiekt): pppccc Bieżąca długość listy 1 Bieżąca długość listy 2 Bieżąca długość listy 3 'Konsumujemy' obiekt java.lang.Object@d9e6a356 Bieżąca długość listy 2 'Konsumujemy' obiekt java.lang.Object@d9bea356 Bieżąca długość listy 1 'Konsumujemy' obiekt java.lang.Object@d882a356 Bieżąca długość listy 0
Jednak przedstawiony program nie jest całkowicie poprawny. Rozważmy, co się stanie, jeśli określając wykonywane czynności, wpiszemy więcej liter „c” niż „p”? Metoda consume() wywoła metodę wait(), jednak metoda read() pobierająca znaki wpisane przez użytkownika nie jest już w stanie niczego odczytać. W takiej sytuacji mówimy, że wystąpiła blokada (ang. deadlock) — program czeka na coś, co się nigdy nie wydarzy. Na szczęście ten prosty przypadek blokady jest wykrywany przez środowisko wykonawcze Javy:
pppcccc Bieżąca długość listy 1 Bieżąca długość listy 2 Bieżąca długość listy 3 'Konsumujemy' obiekt java.lang.Object@c78e57 Bieżąca długość listy 2 'Konsumujemy' obiekt java.lang.Object@5224ee Bieżąca długość listy 1 'Konsumujemy' obiekt java.lang.Object@f6a746 Bieżąca długość listy 0 Dumping live threads: 'gc' tid 0x1a0010, status SUSPENDED flags DONTSTOP blocked@0x19c510 (0x1a0010->|) 'finaliser' tid 0x1ab010, status SUSPENDED flags DONTSTOP blocked@0x10e480 (0x1ab010->|) 'main' tid 0xe4050, status SUSPENDED flags NOSTACKALLOC blocked@0x13ba20 (0x34050->|) Deadlock: all threads blocked on internal events Abort (core dump)
W rzeczywistości metoda read() nie zostanie ponownie wykonana, dlatego też nie ma szansy na wywołanie metody produce(), a co za tym idzie — także metody notify(). Aby rozwiązać ten problem, należy wykonywać metodę produkującą obiekty oraz metodę konsumującą je w osobnych wątkach. Zadanie to można przeprowadzić na kilka sposobów. Zdecydowałem się na przekształcenie metody producer() oraz consumer() na klasy wewnętrzne Producer oraz Consumer. Obie są klasami potomnymi klasy Thread, a czynności realizowane wcześniej przez odpowiednie metody teraz wykonują metody run() tych klas. Jednocześnie usunąłem z listingu kod odczytujący znaki z konsoli i zastąpiłem go rozwiązaniem, które pozwoli, by oba wątki działały przez pewną określoną liczbę sekund. W ten sposób nasz listing stanie się raczej symulacją działania rozproszonego mechanizmu producent-konsument. Kod źródłowy drugiej, zmodyfikowanej wersji przykładu — ProdCons2 — pokazałem na Przykład 22-13.
Przykład 22-13. /threads/ProdCons2.java
public class ProdCons2 {
/** W tej wersji programu obiektem używanym do synchronizacji
* działania wątków jest this, a zatem także on będzie
* wykorzystywany do wywoływania metod wait() oraz notifyAll().
*/
protected LinkedList<Object> list = new LinkedList<>();
protected int MAX = 10;
protected boolean done = false; // Także chroniony przez blokadę listy.
/** Klasa wewnętrzna reprezentująca wątek producenta. */
class Producer extends Thread {
public void run() {
while (true) {
Object justProduced = getRequestFromNetwork();
// Pobieramy żądanie z sieci - poza synchronizowanym
// fragmentem kodu. W naszym programie metoda ta symuluje
// odczyt danych przesyłanych przez klienta, a to może
// trwać wiele godzin (jeśli klient właśnie wyszedł na kawę).
synchronized(list) {
while (list.size() == MAX) { // Kolejka jest "pełna".
try {
System.out.println("Producent CZEKA");
list.wait(); // Ograniczamy wielkość.
} catch (InterruptedException ex) {
System.out.println(
"DZIAŁANIE PRODUCENTA ZOSTAŁO PRZERWANE");
}
}
list.addFirst(justProduced);
list.notifyAll(); // Musimy mieć blokadę.
System.out.println(
"Wyprodukowano 1 obiekt; aktualna wielkość listy " +
list.size());
if (done)
break;
// yield(); // Przydatna w przypadku wątków i programów
// demonstracyjnych.
}
}
}
Object getRequestFromNetwork() { // Symulacja odczytu danych
// z klienta.
// try {
// Thread.sleep(10); // Symulujemy czas, jaki zabiera
// odczyt danych.
// } catch (InterruptedException ex) {
// System.out.println(
// "Odczyt danych od producenta został PRZERWANY");
// }
return(new Object());
}
}
/** Klasa wewnętrzna reprezentująca wątek konsumenta. */
class Consumer extends Thread {
public void run() {
while (true) {
Object obj = null;
synchronized(list) {
while (list.size() == 0) {
try {
System.out.println("KONSUMENT CZEKA");
list.wait(); // Musimy mieć blokadę.
} catch (InterruptedException ex) {
System.out.println(
"DZIAŁANIE KONSUMENTA ZOSTAŁO PRZERWANE");
}
}
obj = list.removeLast();
list.notifyAll();
int len = list.size();
System.out.println("Aktualna wielkość listy " + len);
if (done)
break;
}
process(obj); // Poza synchronizowanym blokiem kodu (może
// trwać długo).
//yield();
}
}
void process(Object obj) {
// Thread.sleep(1234) // Symulujemy upływający czas.
System.out.println("Wykorzystujemy obiekt " + obj);
}
}
ProdCons2(int nP, int nC) {
for (int i=0; i<nP; i++)
new Producer().start();
for (int i=0; i<nC; i++)
new Consumer().start();
}
public static void main(String[] args)
throws IOException, InterruptedException {
// Uruchamiamy wątki producentów i konsumentów.
int numProducers = 4;
int numConsumers = 3;
ProdCons2 pc = new ProdCons2(numProducers, numConsumers);
// Niech wątki działają przez, powiedzmy, 10 sekund.
Thread.sleep(10*1000);
// Koniec symulacji - kończymy ją w "delikatny" sposób.
synchronized(pc.list) {
pc.done = true;
pc.list.notifyAll();
}
}
}Jestem dumny, mogąc zakomunikować, że powyższy program jest dobry. Może on poprawnie działać przez długi czas bez niepożądanych awarii czy przypadków pojawiania się blokad. Poniżej przedstawiłem fragment wyników wygenerowanych przez program po dłuższym okresie działania:
Wyprodukowano 1 obiekt; aktualna wielkość listy 118 Wykorzystujemy obiekt java.lang.Object@2119d0 Aktualna wielkość listy 117 Wykorzystujemy obiekt java.lang.Object@2119e0 Aktualna wielkość listy 116
Modyfikując liczbę producentów i konsumentów tworzonych w konstruktorze, można uzyskiwać różne długości kolejek; niemniej jednak niezależnie od liczby wykorzystywanych wątków program zawsze będzie działać poprawnie.
Należy dodatkowo pamiętać, że w rzeczywistych zastosowaniach zazwyczaj nie będziemy chcieli wykonywać operacji wejścia-wyjścia w czasie posiadania blokady, gdyż ma to bardzo zły wpływ na wydajność działania aplikacji.
Jako przykład ułatwień, jakie udostępnia pakiet java.util.concurrent, rozważmy jeszcze raz program producent-konsument przedstawiony na Przykład 22-7. Klasa ProdCons15, przedstawiona na Przykład 22-14, korzysta z interfejsu java.util.concurrent.BlockingQueue (który rozszerza interfejs java.util.Queue), aby zaimplementować program ProdCons2 z Przykład 22-13 przy użyciu około dwóch trzecich kodu poprzedniego rozwiązania. Dzięki zastosowaniu tych nowych możliwości aplikacja nie musi się już przejmować wywoływaniem metody wait() ani kaprysami metody notify() czy też zastępowaniem jej metodą notifyAll().
Aplikacja po prostu umieszcza obiekty w kolejce, a następnie je z niej pobiera. W tym przykładzie (podobnie jak wcześniej) tworzonych jest czterech producentów i tylko trzech konsumentów, przez co w końcu producenci muszą czekać. Kiedy uruchomiłem ten program na jednym z moich starych notebooków, w ciągu około 10 sekund działania przewaga producentów nad konsumentami wyniosła około 350 produktów.
Przykład 22-14. /threads/ProdCons15.java
public class ProdCons15 {
protected volatile boolean done = false;
/** Klasa wewnętrzna reprezentująca producenta. */
class Producer implements Runnable {
protected BlockingQueue<Object> queue;
Producer(BlockingQueue<Object> theQueue) { this.queue = theQueue; }
public void run() {
try {
while (true) {
Object justProduced = getRequestFromNetwork();
queue.put(justProduced);
System.out.println(
"Wyprodukowano 1 obiekt; obecnie lista zawiera " +
queue.size() + " elementów.");
if (done) {
return;
}
}
} catch (InterruptedException ex) {
System.out.println(
"DZIAŁANIE PRODUCENTA ZOSTAŁO PRZERWANE");
}
}
Object getRequestFromNetwork() { // Symulujemy odczyt.
try {
Thread.sleep(10); // Symulujemy upływ czasu podczas
// operacji odczytu.
} catch (InterruptedException ex) {
System.out.println(
"Odczyt przez producenta został PRZERWANY");
}
return new Object();
}
}
/** Klasa wewnętrzna reprezentująca konsumenta. */
class Consumer implements Runnable {
protected BlockingQueue<Object> queue;
Consumer(BlockingQueue<Object> theQueue) { this.queue = theQueue; }
public void run() {
try {
while (true) {
Object obj = queue.take();
int len = queue.size();
System.out.println("Lista zawiera obecnie " + len +
" elementów." );
process(obj);
if (done) {
return;
}
}
} catch (InterruptedException ex) {
System.out.println(
"DZIAŁANIE KONSUMENTA ZOSTAŁO PRZERWANE");
}
}
void process(Object obj) {
// Thread.sleep(123) // Symulujemy upływ czasu.
System.out.println("Wykorzystujemy obiekt " + obj);
}
}
ProdCons15(int nP, int nC) {
BlockingQueue<Object> myQueue = new LinkedBlockingQueue<>();
for (int i=0; i<nP; i++)
new Thread(new Producer(myQueue)).start();
for (int i=0; i<nC; i++)
new Thread(new Consumer(myQueue)).start();
}
public static void main(String[] args)
throws IOException, InterruptedException {
// Uruchamiamy wątki producentów i konsumentów.
int numProducers = 4;
int numConsumers = 3;
ProdCons15 pc = new ProdCons15(numProducers, numConsumers);
// Niech wątki działają przez, powiedzmy, 10 sekund.
Thread.sleep(10*1000);
// Koniec symulacji - kończymy ją w "delikatny" sposób.
pc.done = true;
}
}Klasa ProdCons15 jest pod niemal wszystkimi względami lepsza od implementacji przedstawionych w poprzedniej recepturze. Jednak prezentowane przez program wielkości kolejki nie zawsze będą dokładnie odpowiadały jej wielkości po dodaniu lub usunięciu obiektu. Ponieważ program nie używa już blokowania do wymuszenia operacji atomowych, pomiędzy wstawieniem lub usunięciem obiektu z kolejki przez wątek A oraz odczytaniem przez niego wielkości kolejki dowolnie wiele wątków może wykonać na niej jakieś inne operacje wstawienia lub usunięcia.
Fork/Join jest implementacją interfejsu ExecutorService, przeznaczoną przede wszystkim do realizacji stosunkowo dużych zadań, które w naturalny sposób można rekurencyjnie podzielić na mniejsze i które nie wymagają przydzielania poszczególnym podzadaniom równych czasów realizacji. Szkielet ten korzysta z techniki „podkradania pracy” w celu zapewnienia, że poszczególne wątki będą miały co robić.
Podstawowym sposobem korzystania ze szkieletu Fork/Join jest rozszerzanie klas RecursiveTask lub RecursiveAction i przesłanianie w nich metody compute() w sposób, który można opisać przy użyciu poniższego fragmentu pseudokodu:
if (przypisane mi zadanie jest „dostatecznie małe") {
wykonuję zadanie samodzielnie;
} else {
dzielę zadanie na dwa podzadania,
wywołuję te podzadania i czekam na wyniki;
}Szkielet Fork/Join udostępnia dwie klasy: RecursiveTask oraz RecursiveAction. Podstawowa różnica pomiędzy nimi polega na tym, że w przypadku klasy RecursiveTask każdy krok wykonywanych operacji zwraca jakąś wartość, natomiast w przypadku klasy RecursiveAction tak się nie dzieje. Innymi słowy, typem wartości wynikowej metody compute() klasy RecursiveAction jest void, w przypadku klasy RecursiveTask jest to typ T, gdzie T jest parametrem typu. Klasy RecursiveTask można używać w przypadkach, gdy każde wywołanie compute() zwraca wartość reprezentującą wynik obliczeń danego fragmentu problemu, innymi słowy, kiedy chcemy na przykład podzielić problem taki jak sumowanie danych, a każde zadanie sumowałoby fragment pełnego zbioru danych. Z kolei klasy RecursiveAction można by użyć do wykonania jakichś operacji na wielkiej strukturze danych, przy czym operacja ta polegałaby na przekształceniu danych bezpośrednio w miejscu, w którym są one przechowywane.
Poniżej zostały przedstawione dwa przykłady wykorzystania szkieletu Fork/Join. Ich nazwy odpowiadają dwóm klasom potomnym klasy ForkJoinTask:
Program
RecursiveTaskDemojawnie używa metodfork()ijoin().Program
RecursiveActionDemoużywa metodyinvokeAll(), by wywołać dwa podzadania. Metodainvoke()stanowi odpowiednik wywołania metodfork()orazjoin(); natomiast metodainvokeAll()robi to samo tak długo, aż zadanie zostanie wykonane. Wystarczy porównać metodycompute()przedstawione na listingach 22.15 oraz 22.16, a wszystko nabierze sensu.
Przykład 22-15. /threads/RecursiveActionDemo.java
/** Prosty przykład wykorzystania szkieletu "Fork/Join": * podnosimy do kwadratu grupę liczb, używając do tego celu * obiektu RecursiveAction. * W tym przykładzie została zastosowana klasa RecursiveAction, * gdyż nie jest konieczne, by każde wywołanie metody compute() * zwracało wynik. Wyniki cząstkowe są zbierane w tablicy "dest". * @author Ian Darwin */ public class RecursiveActionDemo extends RecursiveAction { private static final long serialVersionUID = 3742774374013520116L; static int[] raw = { 19, 3, 0, -1, 57, 24, 65, Integer.MAX_VALUE, 42, 0, 3, 5 }; static int[] sorted = null; int[] source; int[] dest; int length; int start; final static int THRESHOLD = 4; public static void main(String[] args) { sorted = new int[raw.length]; RecursiveActionDemo fb = new RecursiveActionDemo(raw, 0, raw.length, sorted); ForkJoinPool pool = new ForkJoinPool(); pool.invoke(fb); System.out.print('['); for (int i : sorted) { System.out.print(i + ","); } System.out.println(']'); } public RecursiveActionDemo(int[] src, int start, int length, int[] dest) { this.source = src; this.start = start; this.length = length; this.dest = dest; } @Override protected void compute() { System.out.println("ForkJoinDemo.compute()"); if (length <= THRESHOLD) { // Obliczamy bezpośrednio. for (int i = start; i < start + length; i++) { dest[i] = source[i] * source[i]; } } else { // Dziel i rządź. int split = length / 2; invokeAll( new RecursiveActionDemo(source, start, split, dest), new RecursiveActionDemo(source, start + split, length - split, dest)); } } }
Przykład 22-16. /threads/RecursiveTaskDemo.java
/** * Program przedstawia zastosowanie szkieletu "Fork/Join" do * wyliczenia średniej dużej tablicy liczb. * Wykonanie tego programu na komputerze z wielordzeniowym * procesorem przy użyciu poniższego wywołania: * $ time java threads.RecursiveTaskDemo * pokazuje, że czas zużyty przez procesor zawsze jest większy * od czasu działania programu, co stanowi dowód na wykorzystywanie * kilku rdzeni procesora. Trzeba jednak pamiętać o tym, że jest * to dosyć sztuczny przykład. * * Jak pokazuje ten przykład, typu RecursiveTask<T> można używać, gdy * każde wywołanie zwraca wartość reprezentującą wynik obliczeń * dokonanych na pewnym fragmencie całego zadania. * @author Ian Darwin */ public class RecursiveTaskDemo extends RecursiveTask<Long> { private static final long serialVersionUID = 3742774374013520116L; static final int N = 10000000; final static int THRESHOLD = 500; int[] data; int start, length; public static void main(String[] args) { int[] source = new int[N]; loadData(source); RecursiveTaskDemo fb = new RecursiveTaskDemo(source, 0, source.length); ForkJoinPool pool = new ForkJoinPool(); long before = System.currentTimeMillis(); pool.invoke(fb); long after = System.currentTimeMillis(); long total = fb.getRawResult(); long avg = total / N; System.out.println("Średnia: " + avg); System.out.println("Czas :" + (after - before) + " ms"); } static void loadData(int[] data) { Random r = new Random(); for (int i = 0; i < data.length; i++) { data[i] = r.nextInt(); } } public RecursiveTaskDemo(int[] data, int start, int length) { this.data = data; this.start = start; this.length = length; } @Override protected Long compute() { if (length <= THRESHOLD) { // Obliczamy bezpośrednio. long total = 0; for (int i = start; i < start + length; i++) { total += data[i]; } return total; } else { // Dziel i rządź. int split = length / 2; RecursiveTaskDemo t1 = new RecursiveTaskDemo(data, start, split); t1.fork(); RecursiveTaskDemo t2 = new RecursiveTaskDemo(data, start + split, length - split); return t2.compute() + t1.join(); } } }
Najpoważniejszym niezdefiniowanym problemem jest określenie, co oznacza termin „dostatecznie małe” — a wyznaczenie konkretnej wartości może wymagać przeprowadzenia pewnych eksperymentów. Jeszcze lepszym rozwiązaniem, wymagającym co prawda napisania nieco większego kodu, byłoby stworzenie systemu kontrolnego mierzącego przepustowość systemu podczas dynamicznego modyfikowania wartości parametrów i potrafiącego samodzielnie określić optymalne wartości parametrów dla konkretnego systemu komputerowego i używanego środowiska wykonawczego. Implementację takiego rozwiązania pozostawiam jednak Czytelnikowi jako ćwiczenie do samodzielnego wykonania.
Przedstawiony poniżej fragment kodu tworzy nowy wątek obsługujący zapis danych w tle. Podobne rozwiązanie jest wykorzystywane niemal we wszystkich edytorach tekstu.
/threads/AutoSave.java
public class AutoSave extends Thread {
/** Interfejs FileSaver jest implementowany przez klasę główną. */
protected FileSaver model;
/** Okres oczekiwania pomiędzy próbami. */
public static final int MINUTES = 5;
private static final int SECONDS = MINUTES * 60;
public AutoSave(FileSaver m) {
super("AutoSave Thread");
setDaemon(true); // A zatem główna aplikacja nie musi działać.
model = m;
}
public void run() {
while (true) { // Cała metoda działa bez końca.
try {
sleep(SECONDS*1000);
} catch (InterruptedException e) {
// Nic nie robimy.
}
if (model.wantAutoSave() && model.hasUnsavedChanges())
model.saveFile(null);
}
}
// Czego nie pokazano:
// 1) Metoda saveFile() nie może być synchronizowana.
// 2) Metoda zamykająca program główny musi być synchronizowana
// na *tym samym* obiekcie.
}
/** Lokalna kopia interfejsu FileSaver, niezbędna do kompilacji
* programu AutoSave. */
interface FileSaver {
/** Wczytujemy model z pliku o nazwie fn; jeśli jest równy null,
* to prosimy o podanie nowej nazwy. */
public void loadFile(String fn);
/** Pytamy model, czy mają być wykonywane automatyczne zapisy. */
public boolean wantAutoSave();
/** Pytamy model, czy są jakieś niezapisane zmiany, jeśli nie ma,
* to operacja zapisu nie zostanie wykonana. */
public boolean hasUnsavedChanges();
/** Zapisujemy bieżącą zawartość modelu w pliku o nazwie fn.
* Jeśli fn jest równe null, używamy bieżącej nazwy pliku lub
* prosimy o podanie nowej.
*/
public void saveFile(String fn);
}Krótka analiza kodu metody run() pokazuje, że powyższy program czeka przez 5 minut (300 sekund), po czym sprawdza, czy należy coś zrobić. Jeśli użytkownik wyłączył opcję automatycznego zapisu lub jeśli nie wprowadził żadnych zmian od czasu ostatniego zapisu, program uznaje, że nie ma nic do zrobienia. W przeciwnym przypadku w programie głównym wywoływana jest metoda saveFile(), która zapisuje dane do aktualnie wybranego pliku. Lepszym rozwiązaniem byłoby jednak zapisywanie danych do pliku kopii tymczasowej, jak to robią niektóre dobre edytory tekstu.
Powyższy listing nie pokazuje jednak, w jaki sposób należy synchronizować metodę saveFile(). Łatwo domyślić się, dlaczego także te metody muszą być synchronizowane, jeśli zastanowimy się, w jaki sposób musi się zachować metoda, gdy użytkownik kliknął przycisk Zapisz w tym samym czasie, gdy został uruchomiony proces automatycznego zapisu danych, lub jeśli użytkownik kliknął przycisk Zamknij, gdy plik danych właśnie został otwarty do zapisu. Rozwiązanie polegające na cyklicznym zapisywaniu zmian w pracy w pliku kopii tymczasowej rozwiązuje niektóre z tych problemów, jednak także w tym przypadku należy zachować bardzo daleko idącą ostrożność.
Postawiony problem można rozwiązać na dwa sposoby: tworzyć nowy wątek w momencie nawiązania każdego nowego połączenia bądź na samym początku działania serwera stworzyć pulę wątków, z których każdy będzie oczekiwać na żądania (wywołując metodę accept()).
Język Java standardowo udostępnia dwa niezwykle potężne interfejsy programistyczne — pierwszy z nich służy do obsługi połączeń sieciowych (zagadnienia sieciowe zostały opisane w Rozdział 13. i Rozdział 16.), a drugi do obsługi wątków. Nawet jeśli są one wykorzystywane niezależnie, to i tak każdy z nich jest w stanie powiększyć możliwości tworzonych programów. Jednak bardzo często wykorzystywanym rozwiązaniem jest tworzenie wielowątkowych serwerów sieciowych, które bądź to wstępnie tworzą określoną liczbę wykorzystywanych później wątków, bądź też tworzą nowe wątki za każdym razem, gdy zostanie odebrane żądanie. Wielką zaletą takiego rozwiązania jest możliwość zablokowania jednego wątku (na przykład w wyniku odczytywania danych) bez jakichkolwiek negatywnych konsekwencji lub opóźnień w realizacji wątków obsługujących inne żądania.
Przykład wielowątkowego serwera wykorzystującego gniazda został już przedstawiony w „16.4. Obsługa wielu klientów”. W tej recepturze przedstawię kolejny przykład takiego programu. Można dojść do wniosku, że tworzenie wielowątkowego serwera WWW napisanego wyłącznie w języku Java stało się pewnym rytuałem (niekoniecznie dobrym), który musi przejść każdy programista używający tego języka. Serwer przedstawiony w niniejszej recepturze jest stosunkowo mały i prosty. Jeśli chciałbyś znaleźć przykłady w pełni funkcjonalnych wielowątkowych serwerów WWW, to polecam produkty stworzone w ramach Fundacji Apache — Apache (napisany w C) oraz Tomcat (napisany w Javie; choć w tym przypadku mogę być trochę nieobiektywny, gdyż jestem współautorem książki Tomcat: The Definitive Guide, wydanej przez wydawnictwo O’Reilly i polecanej wszystkim, którzy chcą się zajmować zarządzaniem serwem Tomcat). W moim serwerze główny program tworzy obiekt klasy Httpd. Ten z kolei tworzy gniazdo i oczekuje na żądania, wywołując metodę accept(). Każde zakończenie realizacji metody accept() oznacza odebranie żądania od klienta. W takim przypadku tworzony jest nowy wątek służący do obsługi danego żądania. Wszystkie te czynności są wykonywane w metodach main() oraz runserver() umieszczonych na początku kodu pokazanego na Przykład 22-17.
Przykład 22-17. /webserver/Httpd.java
/** * Bardzo prosty serwer WWW. * <p> * BEZ ZABEZPIECZEŃ. NIEWYMAGAJĄCY PRAWIE ŻADNEJ KONFIGURACJI. * BEZ OBSŁUGI cgi. BEZ OBSŁUGI SERWLETÓW. *<p> * Wersja wielowątkowa. Wszelkie operacje wejścia-wyjścia są wykonywane * w klasie Handler. */ public class Httpd { /** Domyślny numer portu */ public static final int HTTP = 80; /** Gniazdo serwera używane do odbierania żądań od klientów */ protected ServerSocket sock; /** Obiekt Properties służący do pobierania informacji konfiguracyjnych */ private Properties wsp; /** Obiekt Properties służący do pobierania informacji o typach MIME */ private Properties mimeTypes; /** Katalog główny serwera */ private String rootDir; public static void main(String argv[]) throws Exception { System.out.println("DarwinSys JavaWeb Server 0.1 \nUruchamiamy serwer..."); Httpd w = new Httpd(); if (argv.length == 2 && argv[0].equals("-p")) { w.startServer(Integer.parseInt(argv[1])); } else { w.startServer(HTTP); } w.runServer(); // Nigdy tu nie docieramy } /** Metoda realizuje główną pętlę serwera. Za każdym razem, gdy klient * nawiąże połączenie, metoda ServerSocket accept() zwróci nowy obiekt * Socket, który będziemy wykorzystywać do obsługi operacji * wejścia-wyjścia. Obiekt Socket przekazujemy do konstruktora klasy * Handler, który utworzy i uruchomi nowy wątek (Thread). */ void runServer() throws Exception { while (true) { final Socket clntSock = sock.accept(); Thread t = new Thread(){ public void run() { new Handler(Httpd.this).process(clntSock); } }; t.start(); } } /** Tworzymy nowy obiekt serwera działający na domyślnym porcie */ Httpd() throws Exception { wsp=new FileProperties("httpd.properties"); rootDir = wsp.getProperty("rootDir", "."); mimeTypes = new FileProperties( wsp.getProperty("mimeProperties", "mime.properties")); } public void startServer(int portNum) throws Exception { String portNumString = null; if (portNum == HTTP) { portNumString = wsp.getProperty("portNum"); if (portNumString != null) { portNum = Integer.parseInt(portNumString); } } sock = new ServerSocket(portNum); System.out.println("Nasłuchuję na porcie " + portNum); } public String getMimeType(String type) { return mimeTypes.getProperty(type); } public String getMimeType(String type, String dflt) { return mimeTypes.getProperty(type, dflt); } public String getServerProperty(String name) { return wsp.getProperty(name); } public String getRootDir() { return rootDir; } }
Klasa Handler — przedstawiona na Przykład 22-18 — jest tą częścią programu, która „rozumie” protokół HTTP, a przynajmniej jego fragment. Można zauważyć (mniej więcej w połowie długości kodu), że odczytane nagłówki HTTP zostają przetworzone i zapisane w obiekcie HashMap, jednak klasa do niczego więcej ich nie wykorzystuje. Poniżej przedstawiłem rejestr nagłówków odebranych podczas obsługi jednego żądania:
Odebrano połączenie z localhost/127.0.0.1
Żądanie: Polecenie GET, plik /, wersja HTTP/1.0
hdr(Connection,Keep-Alive)
hdr(User-Agent,Mozilla/4.6 [en] (X11; U; OpenBSD 2.8 i386; Nav))
hdr(Pragma,no-cache)
hdr(Host,127.0.0.1)
hdr(Accept,image/gif, image/jpeg, image/pjpeg, image/png, */*)
hdr(Accept-Encoding,gzip)
hdr(Accept-Language,en)
hdr(Accept-Charset,iso-8859-1,*,utf-8)
Pobieramy plik //index.html
KONIEC OBSŁUGI ŻĄDANIAW aktualnym stadium serwer jest już gotowy, by tworzyć obiekty HttpServletRequest, jednak jeszcze nie jest odpowiednio zaawansowany, aby faktycznie móc je utworzyć. Przedstawiony poniżej listing prezentuje jedynie pewien etap wciąż kontynuowanych prac nad serwerem. Znacznie bardziej interesujący jest obiekt Hashtable służący jako swoista pamięć podręczna, dzięki któremu jesteśmy w stanie uniknąć narzutów czasowych związanych z wykonywaniem na plikach operacji wejścia-wyjścia. Wykorzystanie takiego rozwiązania wiąże się jednak z koniecznością ponownego uruchamiania serwera w przypadku zmiany któregokolwiek z plików. Bardziej zaawansowane rozwiązania, takie jak porównywanie znaczników czasu (patrz „11.1. Pobieranie informacji o pliku”) oraz pobieranie zmodyfikowanych plików, można potraktować jako zadanie do samodzielnego wykonania.
Przykład 22-18. /webserver/Handler.java
public class Handler {
/** Gniazdo (Socket), z którego odczytujemy i w którym zapisujemy dane. */
protected Socket clntSock;
/** Strumień wejściowy z przeglądarki */
protected BufferedReader is;
/** Strumień wyjściowy do przeglądarki */
protected PrintStream os;
/** Program główny */
protected Httpd parent;
/** Nazwa domyślna w danym katalogu. */
protected final static String DEF_NAME = "/index.html";
/** Obiekt Hashtable służący do przechowywania adresów URL i stron
* w swoistej pamięci podręcznej. Statyczny, współużytkowany przez
* wszystkie obiekty klasy Handler (jeden taki obiekt służy do obsługi
* jednego żądania; prawdopodobnie rozwiązanie to jest nieefektywne,
* lecz za to proste. Należałoby wykorzystać pulę wątków - ThreadPool).
* Warto pamiętać, że metody klasy Hashtable *są* synchronizowane.
*/
private static Hashtable h = new Hashtable();
/** Kolejne numery używane do identyfikacji wątków */
private static int n = 0;
/** Tworzymy obiekt Handler */
Handler(Httpd prnt) {
parent = prnt;
// Pierwszy raz dodajemy pusty Handler.
if (h.size() == 0) {
h.put("", "<HTML><BODY><B>Nieznany błąd serwera".getBytes());
}
}
protected static final int RQ_INVALID = 0, RQ_GET = 1, RQ_HEAD = 2,
RQ_POST = 3;
public void process(Socket sock) {
clntSock = sock;
String request; // To co przesłała przeglądarka.
int methodType = RQ_INVALID;
try {
System.out.println("Odebrano połączenie z " +
clntSock.getInetAddress());
is = new BufferedReader(new InputStreamReader(
clntSock.getInputStream()));
// Musimy to zrobić, zanim będzie można wywołać errorResponse!
os = new PrintStream(clntSock.getOutputStream());
request = is.readLine();
if (request == null || request.length() == 0) {
// Dalsze działanie nie ma sensu: gniazdo nieaktywne,
// nawet jeśli będziemy co sił krzyczeć w cyberprzestrzeń,
// i tak nikt nas nie usłyszy... Można by to zapisywać
// w dzienniku.
return;
}
// Wykorzystujemy obiekt StringTokenizer, aby podzielić
// żądania na trzy części: metodę HTTP, nazwę zasobu oraz
// wersję protokołu HTTP
StringTokenizer st = new StringTokenizer(request);
if (st.countTokens() != 3) {
errorResponse(444,
"Dane wejściowe nie nadają się do przetworzenia " +
request);
return;
}
String rqCode = st.nextToken();
String rqName = st.nextToken();
String rqHttpVer = st.nextToken();
System.out.println("Żądanie: Polecenie " + rqCode +
", plik " + rqName + ", wersja " + rqHttpVer);
// Teraz obsługujemy nagłówki, włącznie z pustym wierszem
// poprzedzającym treść żądania; dzięki temu treść będzie
// można odczytać bezpośrednio (jeśli obsługujemy żądanie POST).
HashMap map = new HashMap();
String hdrLine;
while ((hdrLine = is.readLine()) != null &&
hdrLine.length() != 0) {
int ix;
if ((ix=hdrLine.indexOf(':')) != -1) {
String hdrName = hdrLine.substring(0, ix);
String hdrValue = hdrLine.substring(ix+1).trim();
System.out.println("hdr("+hdrName+","+hdrValue+")");
map.put(hdrName, hdrValue);
} else {
System.err.println("NIEWŁAŚCIWY NAGŁÓWEK: " +
hdrLine);
}
}
// Sprawdzamy, czy rqCode to GET, HEAD, czy też...
if ("get".equalsIgnoreCase(rqCode))
methodType = RQ_GET;
else if ("head".equalsIgnoreCase(rqCode))
methodType = RQ_HEAD;
else if ("post".equalsIgnoreCase(rqCode))
methodType = RQ_POST;
else {
errorResponse(400, "niewłaściwa metoda: " + rqCode);
return;
}
// Czasami paranoiczne rozwiązanie nie jest złe...
if (rqName.indexOf("..") != -1) {
errorResponse(404, "nie można odnaleźć: " + rqName);
return;
}
// Kiedyś, w przyszłości:
// new MyRequest(clntSock, rqName, methodType);
// new MyResponse(clntSock, os);
// if (isServlet(rqName)) [
// doServlet(rqName, methodType, map);
// else
doFile(rqName, methodType == RQ_HEAD, os /*, map */);
os.flush();
clntSock.close();
} catch (IOException e) {
System.out.println("IOException " + e);
}
System.out.println("KONIEC OBSŁUGI ŻĄDANIA");
}
/** Obsługa jednego żądania dotyczącego pliku */
void doFile(String rqName, boolean headerOnly, PrintStream os)
throws IOException {
File f;
byte[] content = null;
Object o = h.get(rqName);
if (o != null && o instanceof byte[]) {
content = (byte[])o;
System.out.println("Pobieramy plik z pamięci podręcznej " +
rqName);
sendFile(rqName, headerOnly, content, os);
} else if ((f = new File(parent.getRootDir() +rqName)).isDirectory()){
// Katalog zawierający plik index.html? Przetwarzamy go.
File index = new File(f, DEF_NAME);
if (index.isFile()) {
doFile(rqName + DEF_NAME, index, headerOnly, os);
return;
}
else {
// Katalog? Nie zapisujemy w pamięci podręcznej;
// zawsze tworzymy listę zawartości.
System.out.println("ODNALEZIONO KATALOG");
doDirList(rqName, f, headerOnly, os);
sendEnd();
}
} else if (f.canRead()) {
// ZWYCZAJNY PLIK
doFile(rqName, f, headerOnly, os);
}
else {
errorResponse(404, "Nie odnaleziono pliku");
}
}
void doDirList(String rqName, File dir, boolean justAHead,PrintStream os){
os.println("HTTP/1.0 200 Nie odnaleziono katalogu");
os.println("Content-type: text/html");
os.println("Date: " + new Date().toString());
os.println("");
if (justAHead)
return;
os.println("<HTML>");
os.println("<TITLE>Zawartość katalogu " + rqName + "</TITLE>");
os.println("<H1>Zawartość katalogu " + rqName + "</H1>");
String fl[] = dir.list();
Arrays.sort(fl);
for (int i=0; i<fl.length; i++)
os.println("<BR><A HREF=\"" + fl[i] + "\">" +
"<IMG ALIGN=absbottom BORDER=0 SRC=\"internal-gopher-unknown\">" +
' ' + fl[i] + "</A>");
}
/** Wysyła jeden plik przekazany jako obiekt File. */
void doFile(String rqName, File f, boolean headerOnly, PrintStream os)
throws IOException {
System.out.println("Odczytuje plik " + rqName);
InputStream in = new FileInputStream(f);
byte c_content[] = new byte[(int)f.length()];
// Jeden odczyt całego pliku powinien być szybszy.
int n = in.read(c_content);
h.put(rqName, c_content);
sendFile(rqName, headerOnly, c_content, os);
in.close();
}
/** Wysyła jeden plik, dysponując jego nazwą i zawartością.
* @param justHead - jeśli true - metoda wysyła nagłówki i
* kończy działanie.
*/
void sendFile(String fname, boolean justHead,
byte[] content, PrintStream os) throws IOException {
os.println("HTTP/1.0 200 Oto plik");
os.println("Content-type: " + guessMime(fname));
os.println("Content-length: " + content.length);
os.println();
if (justHead)
return;
os.write(content);
}
/** Typ nieodgadnionych plików */
final static String UNKNOWN = "unknown/unknown";
String guessMime(String fn) {
String lcname = fn.toLowerCase();
int extenStartsAt = lcname.lastIndexOf('.');
if (extenStartsAt<0) {
if (fn.equalsIgnoreCase("makefile"))
return "text/plain";
return UNKNOWN;
}
String exten = lcname.substring(extenStartsAt);
String guess = parent.getMimeType(exten, UNKNOWN);
// System.out.println("guessMime: input " + fn +
// ", rozszerzenie " + exten + ", result " + guess);
return guess;
}
/** Zwraca informacje o błędzie według numeru, może z uwzględnieniem
* lokalizacji. */
protected void errorResponse(int errNum, String errMsg) {
// Sprawdzamy zlokalizowaną odpowiedź
ResourceBundle messages = ResourceBundle.getBundle("errors");
String response;
try { response = messages.getString(Integer.toString(errNum)); }
catch (MissingResourceException e) { response=errMsg; }
// Generujemy i wysyłamy odpowiedź
os.println("HTTP/1.0 " + errNum + " " + response);
os.println("Content-type: text/html");
os.println();
os.println("<html>");
os.println("<head><title>Błąd " + errNum + "--" + response +
"</title></head>");
os.println("<H1>" + errNum + " " + response + "</H1>");
sendEnd();
}
/** Dodaje końcówkę do każdej generowanej strony. */
protected void sendEnd() {
os.println("<hr>");
os.println("<address>Java Web Server,");
String myAddr = "http://www.darwinsys.com/freeware/";
os.println("<a href=\"" + myAddr + "\">" +
myAddr + "</a>");
os.println("</address>");
os.println("</html>");
os.println();
}
}Z punktu widzenia efektywności działania lepszym rozwiązaniem może być stworzenie puli wątków i realizacja obsługi odbieranych żądań w tych wątkach. Właśnie w taki sposób mechanizmy obsługi serwletów uzyskują bardzo wysoką efektywność działania — unikają kosztów czasowych związanych z tworzeniem nowych wątków (obiektów Thread) na potrzeby obsługi kolejnych odbieranych żądań. A można to zrobić w bardzo prosty sposób, korzystając z klas dostępnych w pakiecie java.util.concurrent.
Pakiet java.util.concurrent udostępnia interfejs Executor, a implementujące go klasy — zgodnie z tym, co sugeruje nazwa interfejsu — mogą być używane do wykonywania kodu. Ten wykonywany kod może być implementacją doskonale już nam znanego interfejsu Runnable bądź też nowego interfejsu o nazwie Callable. Jedną z często stosowanych implementacji interfejsu Executor jest tak zwana „pula wątków”. Przykład 22-19 przedstawia klasę rozszerzającą prosty, wielowątkowy serwer WWW przedstawiony w „22.11. Wielowątkowy serwer sieciowy”. Klasa ta korzysta z puli obiektów Thread, aby współbieżnie obsługiwać wiele żądań.
Przykład 22-19. /webserver/HttpdConcurrent.java
/** * HttpConcurrent - klasa rozszerzająca klasę Httpd i korzystająca * z narzędzi dostępnych w pakiecie java.lang.concurrent. */ public class HttpdConcurrent extends Httpd { private final Executor myThreadPool; public HttpdConcurrent() throws Exception { super(); myThreadPool = Executors.newFixedThreadPool(5); } public static void main(String[] argv) throws Exception { System.out.println( "DarwinSys JavaWeb Server 0.1 \nUruchamiamy serwer..."); HttpdConcurrent w = new HttpdConcurrent(); if (argv.length == 2 && argv[0].equals("-p")) { w.startServer(Integer.parseInt(argv[1])); } else { w.startServer(HTTP); } w.runServer(); } public void runServer() throws Exception { while (true) { final Socket clientSocket = sock.accept(); myThreadPool.execute(new Runnable() { public void run() { new Handler(HttpdConcurrent.this).process(clientSocket); } }); } } }
Rysunek 22-5 przedstawia tę nową wersję serwera w działaniu.
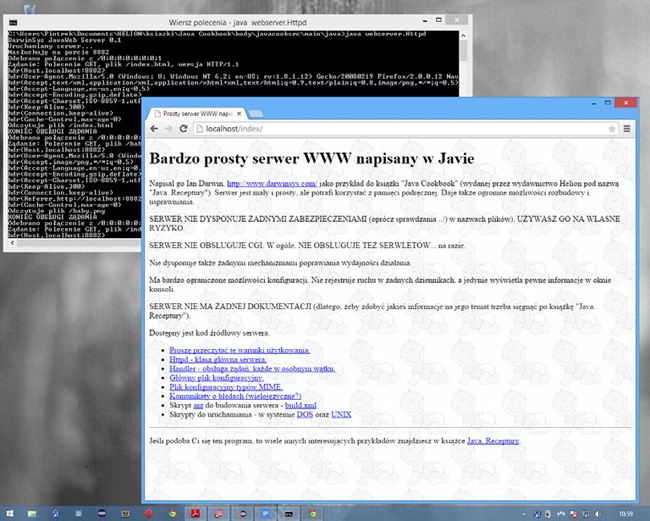
Szczegółowe informacje na temat pakietu java.util.concurrent można znaleźć w dokumentacji JDK. Natomiast zarys informacji na temat JSR 166 można znaleźć na stronie Douga Lea (http://gee.cs.oswego.edu/) oraz na stronie JSR 166 (http://gee.cs.oswego.edu/dl/concurrency-interest/index.html). Organizacja o nazwie Parallel Universe[85] (co, swoją drogą, stanowi w tym kontekście ciekawą grę słów) zaproponowała (jak również zaimplementowała oraz udostępniła) rozwiązanie stanowiące alternatywę dla wątków Javy. Chodzi o bibliotekę Quasar, która została opisana przez twórców w następujący sposób:
„Quasar jest biblioteką, która dodaje do JVM naprawdę »lekkie« wątki. Te lekkie wątki, określane także jako fibres[86], przypominają zwyczajne wątki, lecz zużywają znacznie mniej zasobów i można je przełączać znacznie szybciej niż klasyczne wątki Javy (systemu operacyjnego). Jedna wirtualna maszyna Javy bez trudu może jednocześnie wykonywać setki tysięcy, a nawet miliony takich lekkich wątków.
A do czego można je zastosować? Pozwalają one cieszyć się wydajnością działania oraz skalowalnością (wykorzystującą wiele rdzeni procesora) asynchronicznego kodu bazującego na wywołaniach zwrotnych, zapewniając jednocześnie możliwość korzystania z naturalnego, prostego oraz intuicyjnego modelu blokowania, charakterystycznego dla kodu wielowątkowego. Quasar udostępnia wiele konstrukcji służących do komunikacji pomiędzy lekkimi wątkami, w tym kanały umożliwiające programowanie w stylu zbliżonym do języka CSP (bardzo podobne do tych stosowanych w języku Go). Oprócz tego biblioteka Quasar udostępnia pełny system obsługi aktorów, przypominający ten z języka Erlang, wraz z obsługą zachowań, nadzorców, selektywnego odbierania oraz dystrybucją w obrębie klastra.
Biblioteka jest także wyposażona w API Clojure o nazwie Pulsar, które bardzo dokładnie odwzorowuje możliwości funkcjonalne języka Erlang”.
—blog organizacji Parallel Universe, http://blog.paralleluniverse.co/2014/01/22/introducing-comsat/
[81] Pod tym pojęciem rozumiem „wieloprocesowość symetryczną” (ang. symmetric multiprocessing, SMP), która pozwala, by system operacyjny lub aplikacja działały na dowolnym z dostępnych procesorów. W niektórych momentach system operacyjny może działać na trzech spośród czterech dostępnych procesorów, natomiast w innych wszystkie cztery procesory mogą być używane do realizacji procesu użytkownika. W niektórych systemach operacyjnych, na przykład w systemie Solaris 2.x, istnieje nawet możliwość, aby jeden (wielowątkowy) proces był współbieżnie wykonywany na kilku procesorach. Możliwości te zapewniają niezwykle wysoką efektywność działania serwerów; efektywność ta była jednym z czynników, które przyczyniły się do odniesienia przez firmę Sun komercyjnego sukcesu na rynku serwerów internetowych.
[82] JSR to skrót angielskich słów „Java Specification Request” (co można przetłumaczyć jako: prośba o specyfikację rozwiązania w języku Java). Standardy tworzone w ramach Java Community Process (procesu konsultacji rozwijanych technologii związanych z językiem Java), i to zarówno te już przyjęte, jak i dopiero opracowywane, są określane właśnie jako „JSR”.
[83] Ta nazwa nawiązuje do niespełnionych celów, by obrazki były animowane wzdłuż krzywych odbijających się od krawędzi okna, przypominających działanie niektórych animacji pisanych w technologii Flash.
[84] Serwlet jest interfejsem programowania niskiego poziomu, przeznaczonym do komunikacji ze zdalnymi klientami; obecnie zamiast serwletów byłaby zapewne zastosowana technologia JavaServer Faces.
[85] Wszechświat równoległy — przyp. tłum.
[86] Czyli „włókna” — przyp. tłum.