The NFV Infrastructure Management
Abstract
In this chapter we revisit the high-level architecture framework we described in Chapter 3, ETSI NFV ISG. We begin with a discussion of the NFV-I functional area as it relates to management and control of the virtualized compute, storage, and network components that together realize all virtualized functions on a given hardware platform—the VIM. We do this within the context of various open source projects such as OpenStack, and OpenDaylight. We introduce the concept of PaaS versus IaaS approaches to NFV and begin to ask questions about the ETSI architecture.
Keywords
OpenStack; controllers; NFVI; VIM; network architecture; OpenDaylight
Introduction
In this and the succeeding chapters, we will look a little bit more closely at the major building blocks of the ETSI-prescribed NFV architecture.
If we revisit our high-level architecture framework in Fig. 5.1 our focus in this chapter is indicated by the highlighted block.
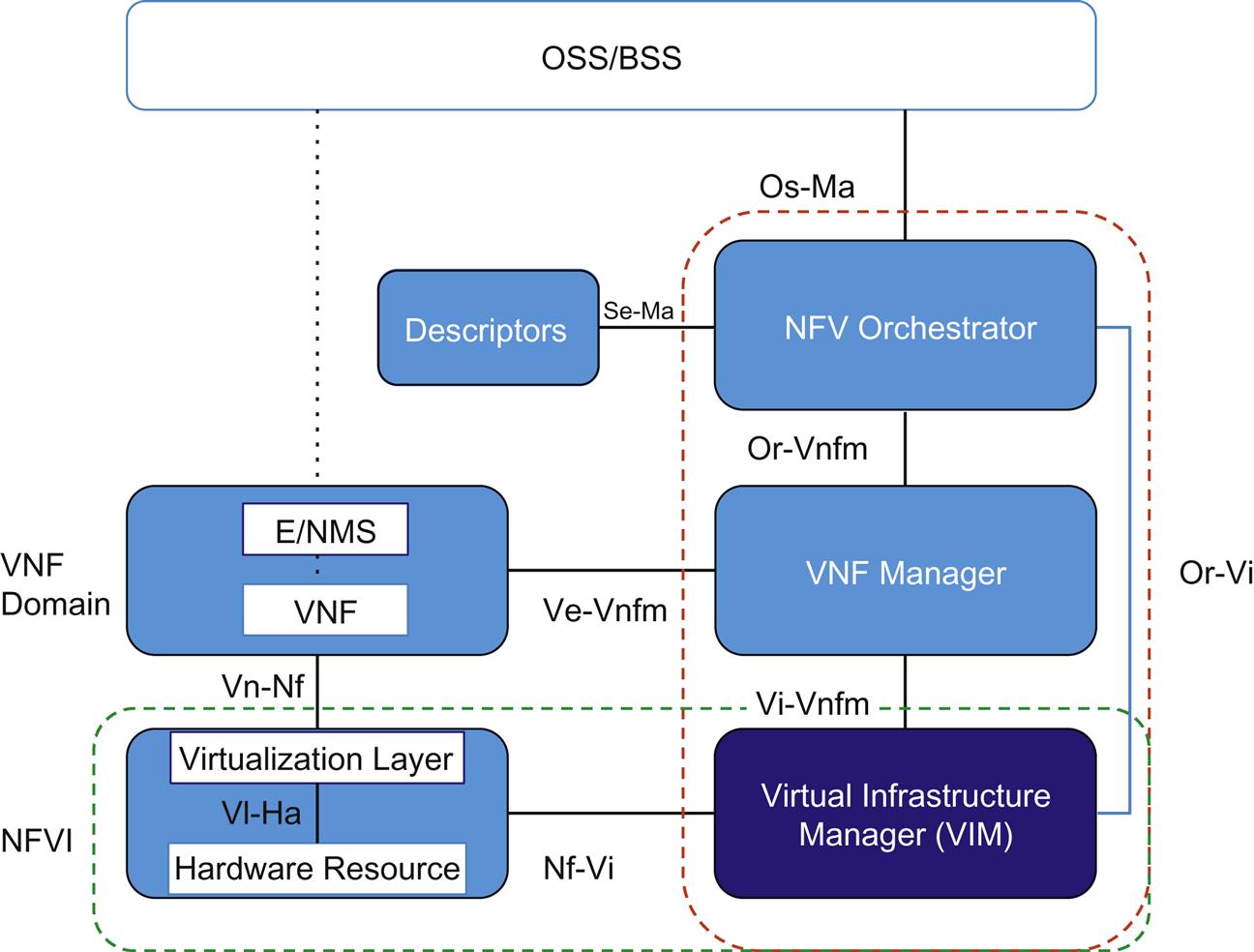
The Network Functions Virtualization Infrastructure (NFVI) functional area represents the hardware (ie, storage, compute, and network) that physically supports the virtualized functions, and the software systems that adapt those virtualized functions to the hardware, and maintain the resources needed for that adaptation to function seamlessly. The latter includes the management and control of the virtualized compute, storage, and network components that together realize all virtualized functions on a given hardware platform.
Because Chapter 7, The Virtualization Layer—Performance, Packaging, and NFV, deals with the virtualization layer and Chapter 8, NFV Infrastructure—Hardware Evolution and Testing, deals with the advances in hardware to accelerate NFV as a separate topic, this chapter will focus specifically on the Virtual Infrastructure Manager (VIM).
The next chapter deals with the MANO block (Management and Orchestration). ETSI associates the VIM with that block in their model; however, we deal with the VIM separately because:
• The VIM is the axis between the physical infrastructure and service orchestration—providing a subset of the overall orchestration as it relates to compute, storage, and network. The VIM is, in our view, more closely coupled to a discussion of infrastructure management.
• Later in the book, when we talk about current organizational purchasing focus, infrastructure-centric purchasing is one of the patterns—centered around the VIM. So, some organizations are treating the VIM separately from higher-level orchestration.
• The NFVI, particularly the VIM, is the first area of focus for OPNFV.
• The VIM is a major tie backwards to the SDN movement and forwards into the open source push of ETSI NFV.
As an aside, here “network” often is used in reference to the network between hosts in a data center and not the greater network encompassing service provider access, edge and core (the “transport” network they provide). The greater “network” resource is often out-of-scope in the discussion of NFV, but becomes important in the context of “end-to-end” services and resource placement. Here, the latency and bandwidth available on different network paths can be important criteria in where and how to host a function.
Finally, we will also use this chapter to touch on the relationship between the VIM and the future potential of NFV.
NFV Virtual Infrastructure Management (VIM)
When we look at the VIM, we will be using the open source projects OpenStack and OpenDaylight (ODL) as exemplars of functionality applicable to this space. This is not in denial of vendor-specific products, but an acknowledgment of an open source driver in the ETSI work. These are also readily available public examples that the reader can quickly gain access to in conjunction with reading this book.
Where appropriate, we will mention proprietary efforts but will not dedicate any indepth sections to those, nor are their inclusion necessarily any sort of endorsement over any of the other options available. The reader should keep in mind that these vendor products may address functionality gaps in the open source, and may have different sets of functionality between them. Further, open source may continue to morph—adding new projects relevant to VIM.
We also do not want to give the impression that “cloud” requires any of these tools. To a certain scale, there has been notable success with DevOps tools like Ansible, Vagrant, Chef, Puppet, and a bit of ingenuity. While overlay networking in multi-tenant DC is a dominant part of the “cloud” conversation, operators have been networking without controllers for a quite a while.1 However, these types of infrastructure management implementations are not normally associated with the ETSI NFV architecture.
OpenStack
OpenStack is a set of software tools for building and managing cloud computing systems. The project is supported by some of the biggest companies in software development and hosting, as well as a community of literally thousands of software engineers. OpenStack is managed by The OpenStack Foundation, a nonprofit organization responsible for the governance and management of the organization.
OpenStack is not limited to the VIM, but as a VIM solution, OpenStack provides controls for the NFV infrastructure; compute, storage, and networking services deployed between the virtual machines (VMs) and other physical hardware such as switches or routers. The OpenStack platform allows users to deploy, manage, reconfigure, and destroy VMs onto the resources in the platform environment.
OpenStack infrastructure can be extensive as illustrated in Fig. 5.2 and is composed of a number of server and client processes on different nodes in the infrastructure.
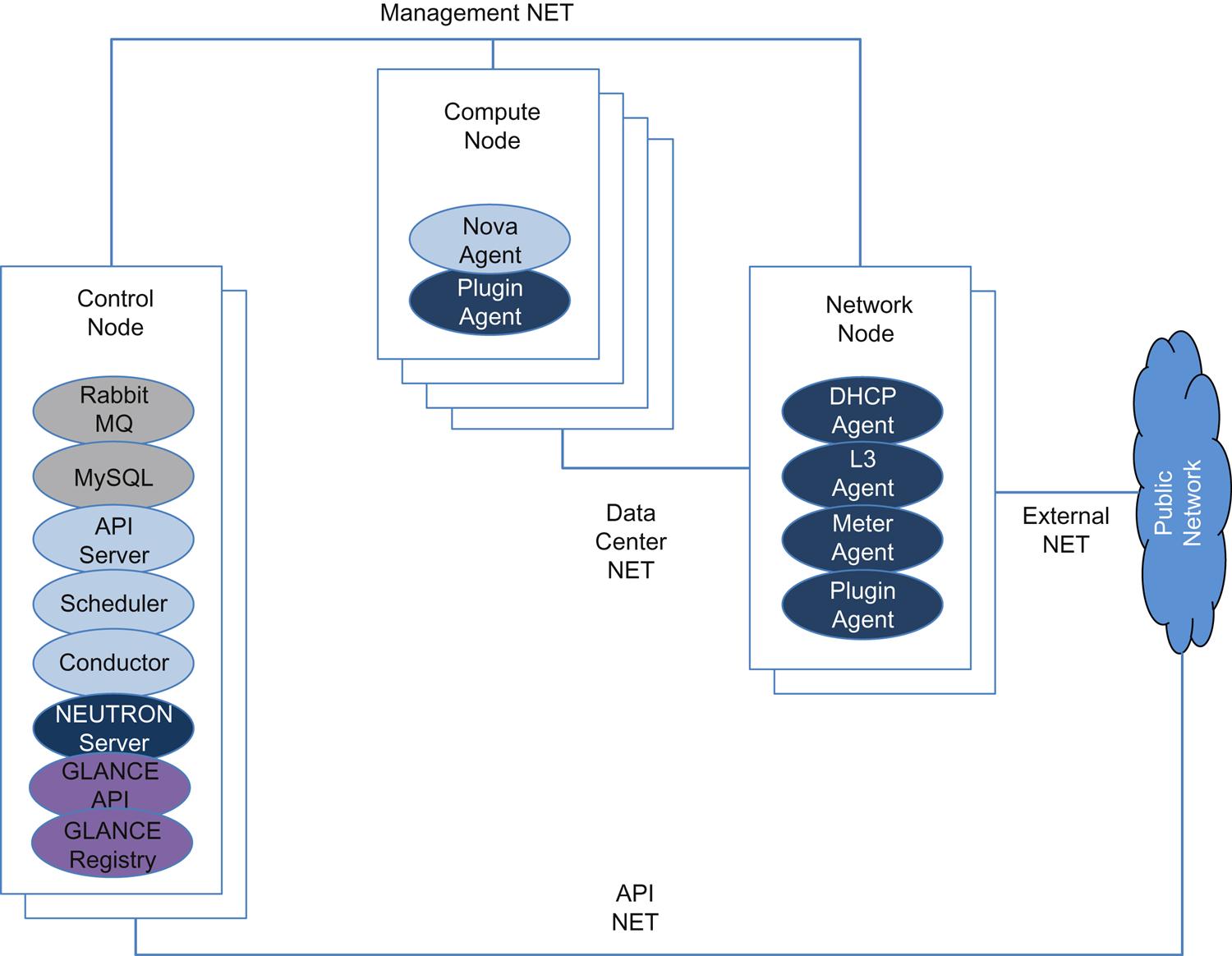
A collection of networks connects the redundant controllers with network elements (network, disk, and compute devices) and the outside world (Fig. 5.2). The Management Network is internal and should not be externally reachable. The Data Center Network is for inter-VM data communication. Infrastructure nodes run one or more agents (here we show the Compute Node with both a NOVA and a NEUTRON agent while the Network Node has any number of NEUTRON agents depending on the service required). IP addressing depends on the plugin. The External Network provides VMs with Internet access in NFV scenarios. Access from the Public Network to the Data Center network is dependent on policies in the Network Node. Finally, the API Network offers the OpenStack APIs between tenants and operator. This interface assumes a policy-based public access. Configurations that use a common external network access for the API network and Data Center network is quite common.
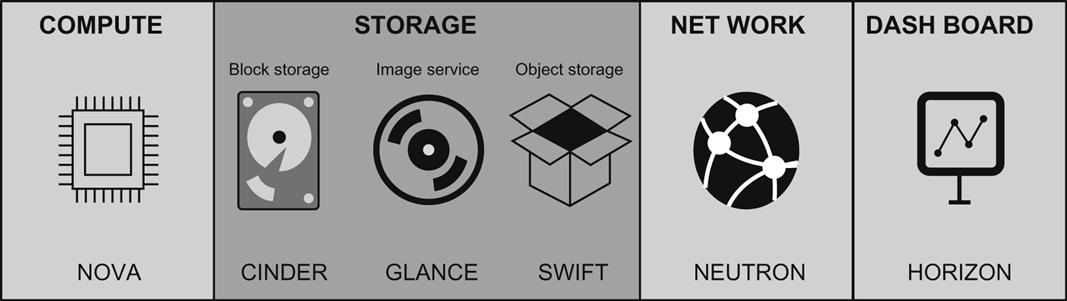
OpenStack currently consists of many software projects that together form the platform: OpenStack Compute (code name Nova), OpenStack Block Storage (code names Swift and Cinder), OpenStack Networking (code name Neutron), OpenStack Image Service (code name Glance), OpenStack Identity (code name Keystone), and OpenStack Dashboard (code name Horizon) which provides a graphical dashboard through which users can use to quickly and easily control and interact with the system.
These projects deliver a pluggable and extendable framework that forms an open source operating system for public and private clouds. They are the OpenStack Infrastructure-as-a-Service (IaaS) building blocks (Fig. 5.3).
The OpenStack system has grown in popularity due to its tight integration with the most popular hypervisors in the industry. For example, support includes ESX, Hyper-V, KVM, LXC, QEMU, UML, Xen, and XenServer.
Nova is open source software designed to provision and manage large networks of VMs, creating a redundant and scalable cloud-computing platform. This project represents what most people envision when they imagine what OpenStack does. The software provides control panels and APIs required to orchestrate a cloud. This includes running VM instances, managing networks, and access control for both users and groups (ie, projects). OpenStack Compute is hardware- and hypervisor-agnostic in theory, although actual builds and support is limited largely to the most popular server platforms.
One of the main components of Nova is its scheduler, which determines where a requested VM instance should run. The scheduler has a series of filters and weights (cost functions) that it uses in selecting a target.
Swift and Cinder are the software components for creating redundant, scalable data storage using clusters of standard servers to store multiple blocks of accessible data. It is not a file system or real-time data system, but rather a long-term storage system for large amounts of static data that can be retrieved or updated. Object Storage uses a distributed architecture in order to not have a central point of failure. This also affords the user greater flexibility of deployment options, as well as the obvious scalability, redundancy, and performance.
Glance provides discovery, registration, and delivery services for virtual disk images. The Image Service API server provides a well-defined RESTful web services interface for querying information about virtual disk images. These disk images may be stored in a variety of backend stores, including OpenStack Object Storage, as well as others. Clients can register new virtual disk images with the Image Service, query for information on publicly-available disk images, and use the Image Service’s client library for streaming virtual disk images. Imagines can then be referenced later much in the way a menu of dishes can be made available to a diner in a restaurant.
Nova has some primordial network capabilities. It will not configure physical network interfaces, but will automatically create all virtual network bridges (eg, br100) and VM virtual interfaces (through the nova-network subset of functions). Nova assigns a private IP address to each VM instance it deploys. This address is then attached to the Linux Bridge via the nova-network API and then (potentially) to a NAT function that allows the virtual interfaces to connect to the outside network through the physical interface. The network controller with nova-network provides virtual networks to enable compute servers to interact with each other and with the public network.
Currently, Nova (nova-network) supports three kinds of networks, implemented in three Network Manager types: Flat Network Manager, Flat DHCP Network Manager, and the VLAN Network Manager. The three kinds of networks can coexist in a cloud system.
Nova will automatically create all network bridges (ie, br100) and VM virtual interfaces. All physical machines must have a public and internal network interface.
Neutron provides the API that builds required network connectivity between OpenStack physical nodes (ie, between the vNICs managed by OpenStack Nova—providing them network as a service functionality). This makes the Neutron API most pertinent to the discussion of NFV. Though it should be noted that because of its focus on the delivery of primitives required by a single application (orchestration), the Neutron API is a subset of the capabilities that could be exposed through the northbound API of most SDN controllers/frameworks/systems.
Neutron was originally targeted at the creation of advanced virtual topologies and services like the commonly used layer 2-in-layer 3 overlays that are used in larger deployments to skirt the limits of traditional VLAN-based deployments. That is, Neutron seeks to decouple service specification APIs (what) from service implementation (how), exploiting a capabilities-rich underlying topology consisting of virtual and physical systems.
In the Havana OpenStack release, the Modular Layer 2 core plugin was introduced in Neutron. Until then, the plugin drivers were monolithic (eg, Open vSwitch (OVS) and Linux bridge) with a lot of redundant code. The ML2 plugin allowed the installation to support a variety of Layer 2 networking scenarios for more complex networks (eg, multi-segment networks, tunnel networks without flooding, L3 service plugins) and separated the management of the network types from the mechanism to access them (Fig. 5.4).
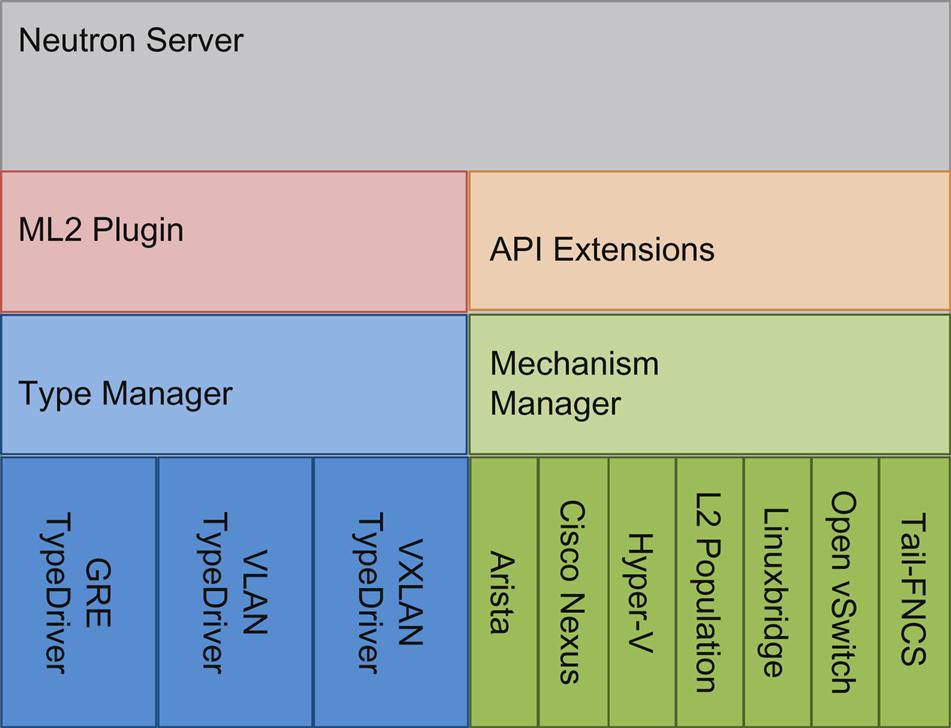
Plugins may be distributed as part of the public Neutron release or privately. The plug-in architecture allows vendors to support the standard API in the configuration of a network service while hiding their own backend implementation specifics.
When a VM is invoked, it is typically attached to a virtual layer 2 switch, most often an OVS. However, some physical devices can be managed as well when they need to be spliced into one of the virtual network overlays (assuming the vendor provides a plugin). For example, this can be accomplished using the OVS-DB interface to program their network overlay end points (known as VTEPs when using VXLAN as an overlay). Neutron is capable of creating primarily layer 2 overlays and is most often used with this type of overlay, although one can program an OVS to do other things including creating OpenFlow paths.
In Fig. 5.5, we see Nova and Neutron interact during VM creation. Briefly, (1) the OpenStack Nova control prompts the Nova agent on a selected compute node to create a VM. In Step (2), the agent then signals Neutron server to create a port for that VM an adds that port in (3) by signaling the br-int structure that in our example, is hanging off OVS in the compute node. In (4) the OVS Neutron agent detects the port add, requests its security group association from Neutron server in (5) and binds that in the ip-tables structure in the node in (6). In (7), the OVS agent fetches port details from the Neutron server, applies these as OpenFlow rules associated with the port on the br-int structure and other associated ports in OVS (eg, the VLAN mapping on Eth0) in (8) and (if all goes well) sets the port state to active and returns this status to the Neutron server in (9). Neutron server can then signal a matching VLAN entry to the Neutron plugin element on the Network Node (a vendor switch).
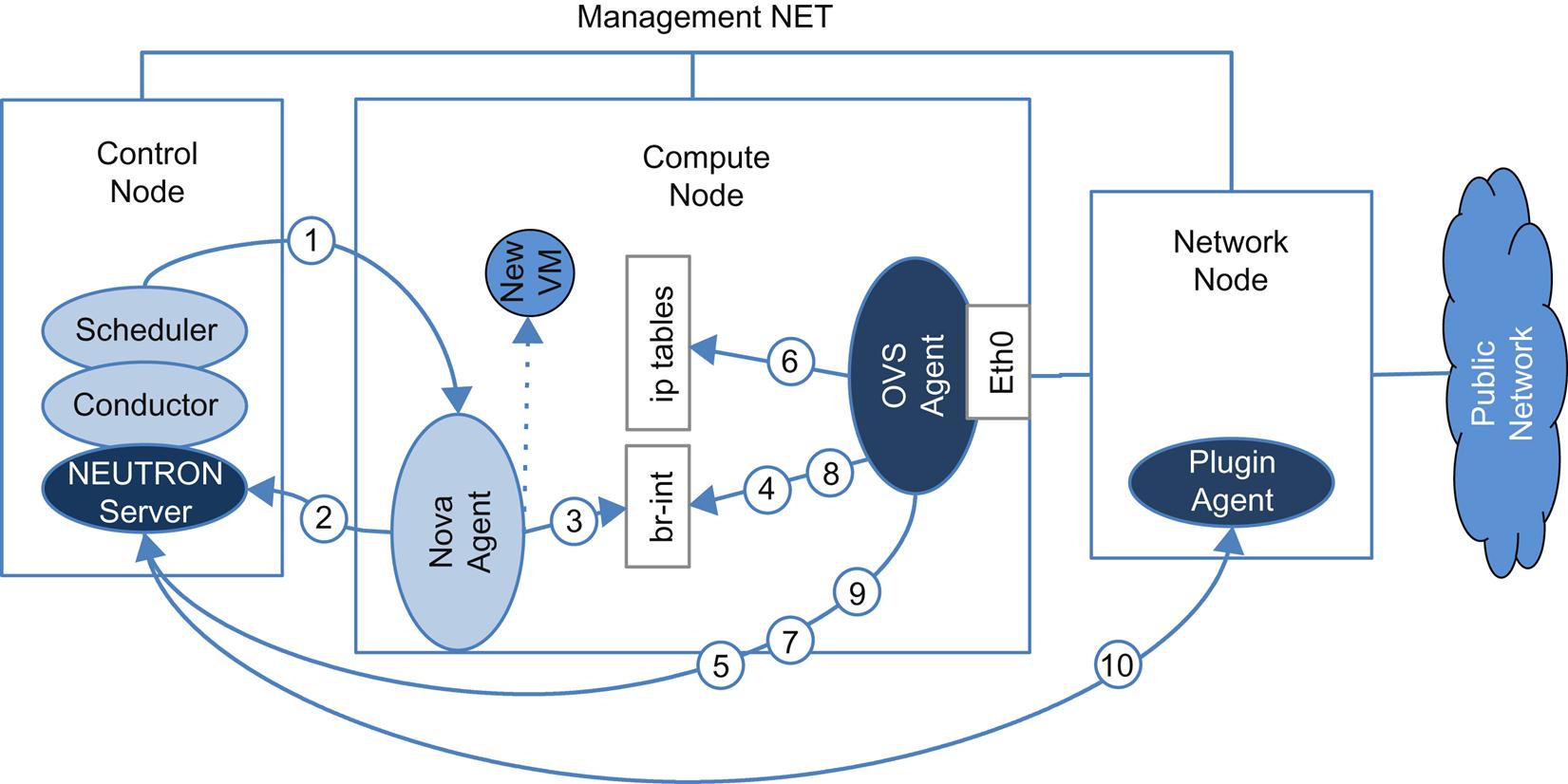
The plugin architecture is how a number of vendor networking equipment and controllers are linked to OpenStack (eg, Cisco, Brocade, Nicira, Nuage Networks, Juniper’s OpenContrail, HP, Big Switch).
While OpenStack is an extremely popular framework, Neutron in particular has been a bit problematic. Many of the advanced networking features supporting the networking aspect of NFV infrastructure often offloaded to a Network Controller entity, which is normally integrated with OpenStack through a Neutron plugin (often through the Modular Layer 2 framework).
In 2015, the process of adding Neutron functionality was generally perceived as complex and slow. At the same time, the poor general performance of early OpenStack implementations was also a bit underwhelming (large VM adds were not very “agile”). As a result, there was a loss of momentum and interest in adding complex network features to OpenStack. Policy was an example of one such area. Both the concept of Group Based Policy (GBP) and early work in SFC were introduced as a combination of OpenStack and the ODL (controller) projects.
Neutron had become so fraught with projects and plugins that they have started what can be described as a master project (Neutron Stadium2) to help demystify the process of adding functionality and setting the rules for inclusion of a project in Neutron. Alternative proposals (e.g. Gluon—an arbiter) attempt to work around making Neutron the only provider of “ports” (networking) to Nova, but to-date have enjoyed limited traction.
The Neutron project has been moving some NFV-centric features forward. For example, as of the Liberty release, Neutron will support the SFC specification, including an OVS reference implementation.
Stretching OpenStack
OpenStack Foundation has their own view of how they are progressing in the support of NFV,3 noting that they are a reference implementation of the ETSI NFV specification in OPNFV (Arno) and are actively working on a number of blueprints submitted on behalf of both ETSI and OPNFV. They also boast impressive adoption, listing support from both service provider and enterprise network operators including AT&T, Verizon, NTT Group, Deutsche Telekom, SK Telecom, China Mobile, Telus, Telecom Italia, Telefonica, and Wells Fargo.
The same document notes that a subsequent release of OPNFV (Brahmaputra) will include a focus on multisite data centers, stretching beyond the 1:1 site:VIM correlation (Fig. 5.6).
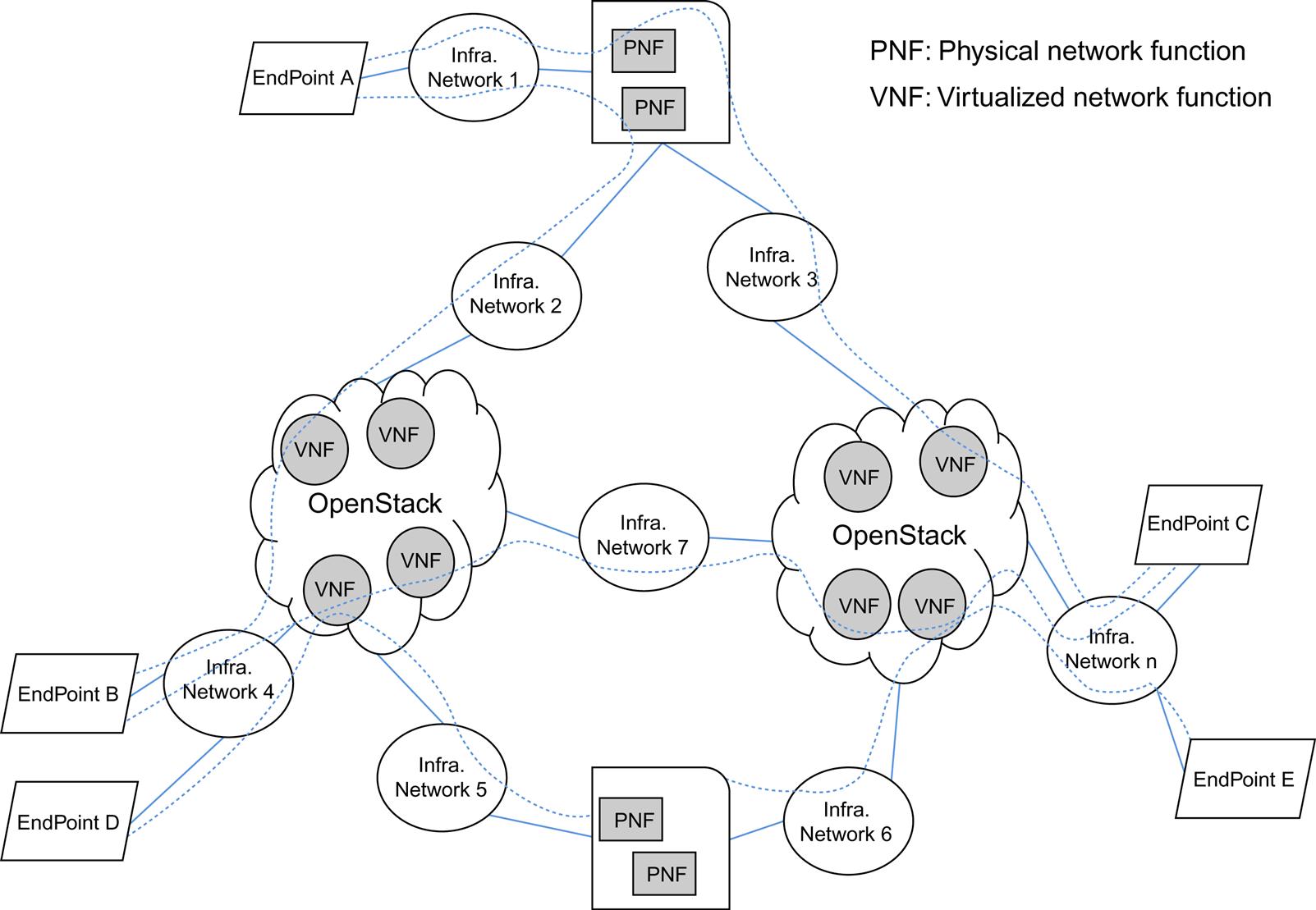
Because most operators envision supporting a distributed datacenter model that could include a granularity that places racks of infrastructure in more than one metro access hub or multiple small sites possibly needing a VIM instance per site, the cost and complexity of running a separate and necessarily highly available OpenStack instance per site could present a difficult hurdle to deployment.
Needless to say, service solutions that require the placement and management of infrastructure at a remote customer location will probably look to a leaner and more focused solution leveraging common DevOps tools we alluded to at the beginning of this section.
Although the original conversation around NFV infrastructure is very focused on virtualization, OpenStack has added the Ironic project (to support bare metal deployments), which could be considered a stretch of the VIM.
OpenStack is also stretching beyond the VIM. OpenStack members started Heat (an orchestration project) in 2013 and more recently added Tacker (a VNFM and orchestration project) as well as Ceilometer (Metering—which has applications in Service Assurance) which are all “interesting” to NFV. We will look at Tacker in more detail in our next chapter. The OpenStack NFV white paper also lists Astara (described as “network service orchestration” project to collapse multiple Neutron L3 related agent functions), Blazer (resource reservation), Congress (policy), Mistral (workflow), and Senlin (clustering) as NFV related projects. How well the OpenStack community delivers on these projects remains to be seen.
At the end of the chapter, we will look at another “stretch” of OpenStack that may be one of the keys to NFV in the future.
To fork or not fork open source distributions
In a broader sense, a question arose with OpenStack that is applicable to many open source projects—the question of whether a particular go-to-market packaging of OpenStack was a “fork” of the open source distribution. The drive to provide feature functionality beyond the current OpenStack distribution led some vendors to offer “advanced functionality” by forking the OpenStack distribution for their own private development. This is sometimes done because of a resistance to add functionality into the “upstream” or mainline release, or even a desire to withhold functionality as to “add value” or uniqueness to their distribution.
Generally, direct forking approaches have proven to be difficult propositions for the company maintaining the fork, and ultimately for the end users consuming and deploying them. The reason for this is simple: over time, the growing divergence from the main line code base results in more and more development and maintenance effort required on the part of the distribution vendor. Not only will they have to maintain bug fixes, but possibly larger functional patches. Given the rapid pace of change of the upstream code base of many projects including OpenStack, this may only take a few cycles to emerge as an issue in keeping up with the change. Another issue that can exacerbate this is when a vendor supports many previous releases. Having to support those past releases and their bug fixes can become a difficult burden to carry over time.
It is useful to note that there are varying shades of distribution code base purity with regard to how much they package and distribute from the upstream code base. Some vendors do not directly fork the main distribution but provide an “installer” that not only eases the installation burden of OpenStack. This, on its own, represents a true value-added service if you have tried installing any of the recent releases yourself! Other improvements that can be found in commercial distributions are patches that are “back ported” to previous releases from the most recent distribution, to bring forward particular functionality that was planned to be integrated into one or more main releases of the project in the future. Other distributions might include subsets of upstream functionality. In projects such as ODL, this is done by some of the commercial distributions due to the varying levels of stability of the upstream projects. In these cases, they may wish to only ship “stable” project components and so do not ship those marked as “unstable.” This is also commonly done with Linux distributions.
The danger with a fork of the main distribution of the project is that the customer could be dependent on a single vendor due to their customizations—the vendor becomes nonsubstitutable, which is definitely counter to one of the promises of open source. A number of nonforked distributions are available commercially and include those from Canonical and RedHat.
Network Controllers
Through the network controller, the worlds of SDN and NFV intersect. As previously mentioned, the OpenStack IaaS functions in networking are often augmented with a scalable and (hopefully) flexible SDN network controller. At a really high level, both components are just a layer of middleware used in ultimately achieving the goals of service orchestration.
In this section we will look at examples of open source network controllers. As with service layer orchestration (see the next chapter), there are notable proprietary offers on the market for network control. There are also controller projects that are “open in name,” that is to say that project governance is such that a vendor or body controls all submissions and (in effect) are the only realistic avenue for support.
Controller Architecture
To begin the discussion, let us start off where our previous book ended this discussion. That was roughly three years ago at the time of the writing of this book, and so it is worth updating some of the concepts discussed therein. For starters, let us begin with updating the Idealized Controller Framework as a grounded reference point for discussing other network controllers and how they have evolved in this space.
Behind every well-designed controller lies a well-thought-out framework on which it is not only based, but will continue to be built on in the future. The controller framework should act like an architectural blueprint for where the controller is and wants to be in a couple of iterations. This of course lends itself well to a quote from someone who was very important in the early days of SDN, OpenFlow, and ODL: David Meyer. He is quoted as saying, “The most important thing you can do is focus on your approach, and not on the specific artifacts that are an immediate result of the most recent iteration of that approach because those artifacts are ephemeral, and might not be useful in a short time.” To this end, let us explore the important components of a sound controller framework at this point in time.
Controllers are expected to scale to very significant levels. Therefore, the usual rules of layering to achieve high scale distributed systems apply. To this end, the general design of controllers has evolved into a three-layer model: northbound interfaces, compute/data store, and southbound interfaces. At the root of this layered design is code modularity, with clear boundaries between subsystems with the ability to dynamically load or unload modules.
Also note that we indicated the northbound and southbound layers in the plural sense. This is because (as we discovered in our first survey of this space), the SDN controller should not be a mono-protocol culture. Limiting the southbound narrows the addressable market space and applicability of the controller. As a goal, this is called “protocol agnosticism.”
In general, a preference for ReSTful interfaces has evolved, especially on the northbound side. As the rapid evolution of application programming has taken hold, these sorts of APIs are critical to interface with those applications. This is less so on the southbound side where protocols such as NETCONF or even the old-school SNMP, remain due to the widespread deployment of both old and new devices in most nonresearch networks of the day.
A controller needs to support “brownfield” networks, and not just “greenfield” networks. For those unfamiliar with the terminology, the former is a network that has evolved over time—or at least grown in place via the addition of new equipment, and the often-slow replacement of older pieces. In the case of greenfield networks, these are defined as being brand new or “clean slate” deployments. Even in the case of many greenfield deployments, these are simply built as facsimiles, at least architecturally, of existing networks. An example is, say, a new “pod” for a new data center. While it is technically a brand new installation in perhaps a brand new building, its equipment and design are identical (or similar enough) to existing ones. In general, true greenfield networks have been limited to academic research or the rare startup network operator. While NFV focuses a lot on the networking between the virtual service instances, they will still need to be stitched into traditional networks.
Over time the controller system has evolved to serve more like a service bus that interconnects various internal services to the northbound and southbound interfaces—effectively becoming a message routing system. This approach has proven to be very effective in facilitating horizontal scale through various clustering approaches.
A model-driven approach has also proven itself to be critical in driving rapid development and evolution of some controllers. Particularly, the use of the Yang data modeling language as the model and the literally hundreds of models available as well as tools to compile, edit, and manipulate those models.
Further, attaching the controller to an enterprise message bus is critical in both bridging the gap between existing enterprise applications—of which there is a huge mass—and the controller’s functions. This also lends itself to another important element which is a large scale or “big data” collection and management interface (which recently has been evolving more toward a Kafka interface). This is critical to provide data to postfacto analytics or even machine learning backend systems that can comb over the data, and then push back changes to alter the network’s behavior based on decisions made often automatically.
In an idealized framework, this can exist as part of either the northbound or southbound interfaces, or even as a bespoke plugin into the inner portion of the controller for perhaps more direct access to the data store and functions therein.
One often-overlooked element of a controller is some form of policy management and an interface that provides a clean and easy model to manage and program those rules. Much research, discussion, and coding have gone into various approaches in this area. It is too early to conclude any a particular winner, but there seem to be a momentum gaining around intent-based policy management. That is, policy rules are specified in terms of intended result or outcomes, and then programmed. Once programmed, they are enforced later by the system. In this way, the resulting state can be better modeled by the network operator. However, the real trick with intent-based API is whether it can flexibly render the intent into more than one southbound expression—which ties back to the modularity and dynamic nature of a controller mentioned earlier.
Finally, a high-scale, clustered data store is needed within the middle layer of the controller. This can augment or extend the just-described data collection and management framework components of the controller, but must be present to provide the controller with simple, often overlooked things such as configuration storage and migration capabilities, or data collection snapshot/caching services.
We have illustrated all of the aforementioned concepts in the three-layered illustration in Fig. 5.7.
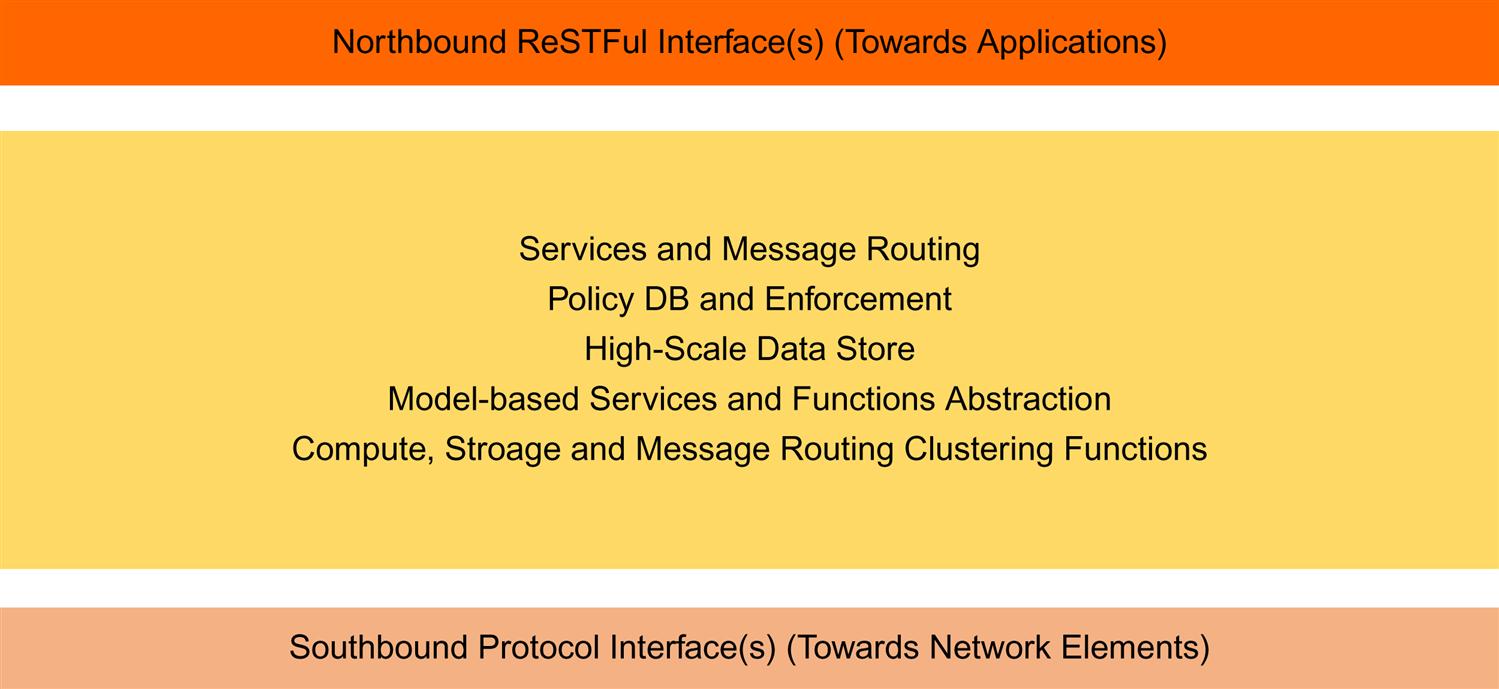
In this picture, based on the earlier functional descriptions, the infrastructure (the layer in the middle) needs to function as the enabler of a microservice architecture—providing the data structures and message handling to flexibly connect producers and consumers—otherwise, the controller ends up being a collection of unrelated-able, protocol-specific pipelines.
OpenDaylight
In March of 2013, the OpenDaylight (ODL) Project consortium5 was formed as a Linux Foundation project.6 The ODL project sits squarely tasked with the creation and evolution of the SDN Controller, although many other projects exist within the organization. Prior to the formation of ODL, a number of companies, including Nicera, Cisco, Big Switch, and IBM had all either investigated, or created their own proprietary, controllers. However, in 2013 it was obvious that the creation of yet another proprietary controller was going to overload the industry. The logical decision at the time was to form an open source SDN controller project whose goals would be to create a common controller infrastructure as a vehicle to overcome the market duplication the plethora of proprietary controllers had brought to the marketplace.
While the project began with the support of a modest set of prominent equipment and controller vendors, as well as a number of popular open source software vendors in the industry, its membership has grown dramatically since then. A few original members have dropped out, but by in large, the trajectory has been very positive. In 2015 AT&T and Comcast both joined ODL, the organization’s first service provider members. ODL’s success can be squarely attributed to its robust and relatively diverse community of some 150+ software developers, and dozens of supporting corporations.
A number of others including Ericsson, Nokia, and Ciena forked initial distributions of the controller to combine that code within some internal products (see prior comments about the forking of OpenStack). It is unclear if those projects have continued (in fact Ciena announced a switch to the ON.Labs ONOS controller in 2016). It is also worth noting that in 2015, commercial distributions of the ODL were made available from Brocade,7 Inocybe,8 and Cisco.9 AT&T also publically announced its use and deployment of ODL in its Domain 2.0 network initiative,10 proving ODL’s commercial viability. It is reported that ODL is in dozens of commercial trials as of the time of this writing in early 2016.
Since the ultimate goal of this organization would be that of application portability and robustness of features, the organization was thus chartered to create a common SDN controller “core” infrastructure that possessed a well-defined (but not Standards-based) northbound API based on the IETF’s RESTCONF protocol, as well as support for a variety of southbound protocols including the now prominent NETCONF protocol.
ODL continues to be at the pinnacle of OpenFlow performance numbers, and as such has grown into a very viable controller used not only in commercial applications, but also in academic and research environments.
The result of the ODL Project is a true open source controller/framework that ultimately a wide variety of SDN applications can be built upon.
For the longer term, contributions may arise that standardize the east–west interface for the exchange of network operational state between ODL and other controller solutions, as well as to enhance the interoperability of controller federation both within a single operational domain, but also across administrative domains.
The ODL framework is very modular, Java-based (ie, a pure JVM), and supports bidirectional REST and OSGi framework programming. To simplify OSGi package management, Karaf has been incorporated. This will support applications that run in the same address space as the controller application.11
One of the main components of ODL that differentiates it from many other offerings, but which we feel is a critical part of the ideal controller framework is its Model-Driven Service Abstraction Layer (MD-SAL).
The MD-SAL maps both internal and external service requests to the appropriate southbound plugin and provides basic service abstractions that higher-level services are built upon depending on the capabilities of the plugin(s). This is an example of enabling a microservice architecture. It specifies this to a large degree, using models that are defined using the Yang modeling language. These models are used by the core functions of the project, including the yangtools parser and compiler, to generate a large portion of the internal code of the controller. Not only are the internals of the controller generated from models, but the portions of the northbound and southbound plugins are (dynamically, at run time) as well. These are what create the actual north and southbound APIs shown in Fig. 5.8.
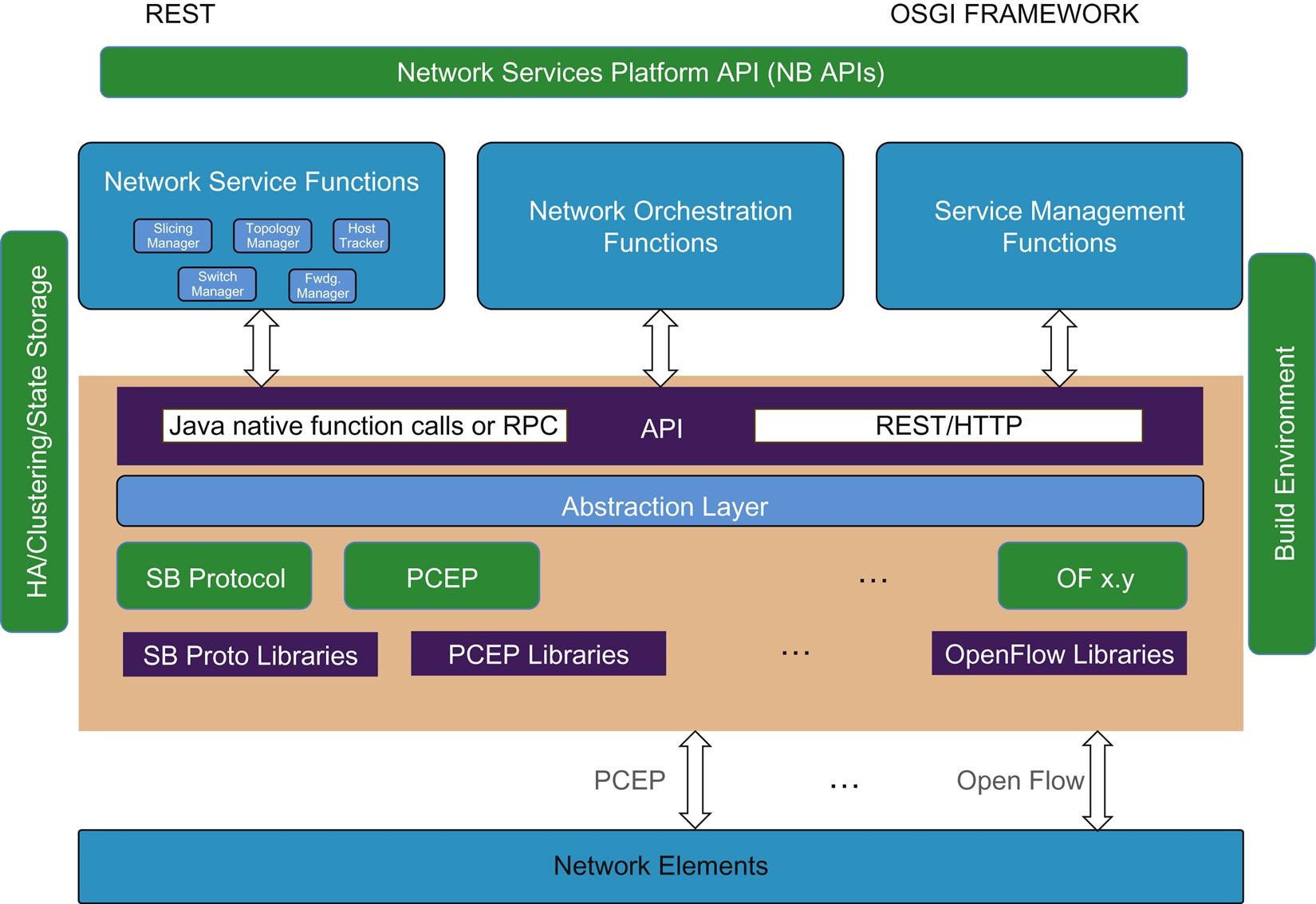
The project had advanced its functionality to also include an AKKA-based clustering and data store framework. This provides the system user with high availability functions, as well as an avenue to horizontally scale the system. ODL is also adding a Kafka plugin, which will make ODL capable of publishing its data to analytics engines. In addition to these key features, the project also has many subprojects that are poised at adding auxiliary functionality or integration with such things as OVS-DB, Neutron/OpenStack, Tacker, SFC, or Policy functions (ie, the NIC12 and GBP projects).
Although still in early days, we mentioned previously that there are now commercial deployments of ODL with dozens of commercial trials underway. The future is bright for ODL as long as network operators continue to see value in its community-based development model and the quality of the project itself. Future points of integration for NFVI are also important.
ODL and OpenStack Collaboration
ODL has proven to be a great base for exhibiting NFV-related behavior that has been harder to complete in the OpenStack project. Using the ODL Neutron plugin for OpenStack, collaborators have extended the functionality of both projects to implement SFC the IETF Standard-in-progress, and GBP.
The latter, GBP,13 shares some concepts with Promise Theory and is essentially an intent based policy system. GBP is built on the concepts of endpoints (hosts, VMs, containers, ports), endpoint grouping (a group of related things), and contracts (their relationship). The contract is a mixture of subjects, rules, classifiers, and actions—the relationships of which are used to express “intent.” Using a render framework in ODL, mappings between Neutron primitives, other policy “surfaces” like existing state, and operational constraints and the expressed intent are resolved into primitives or rules for a number of southbound protocols. This essentially moves from a “core” model to a forwarding model (a network context). The first instantiation could render to OVS and OpenFlow overlays, but NETCONF or other renderings are possible.
Both the functionality of GBP and SFC renderer were considered (at the time) to be too complex to execute in OpenStack.
In Fig. 5.9, an NFV Orchestrator provisions SFCs and GBPs in ODL. Using metadata, it triggers OpenStack to place workloads. The metadata includes endpoint groups to place the workload in and a VNF-type. The metadata passes from OpenStack to ODL via the Neutron v2.0 plugin for ODL. ODL maps the workload to a policy and that policy to a service chain, rendering and implementing the protocol appropriate ruleset/forwarding entries to instantiate both.
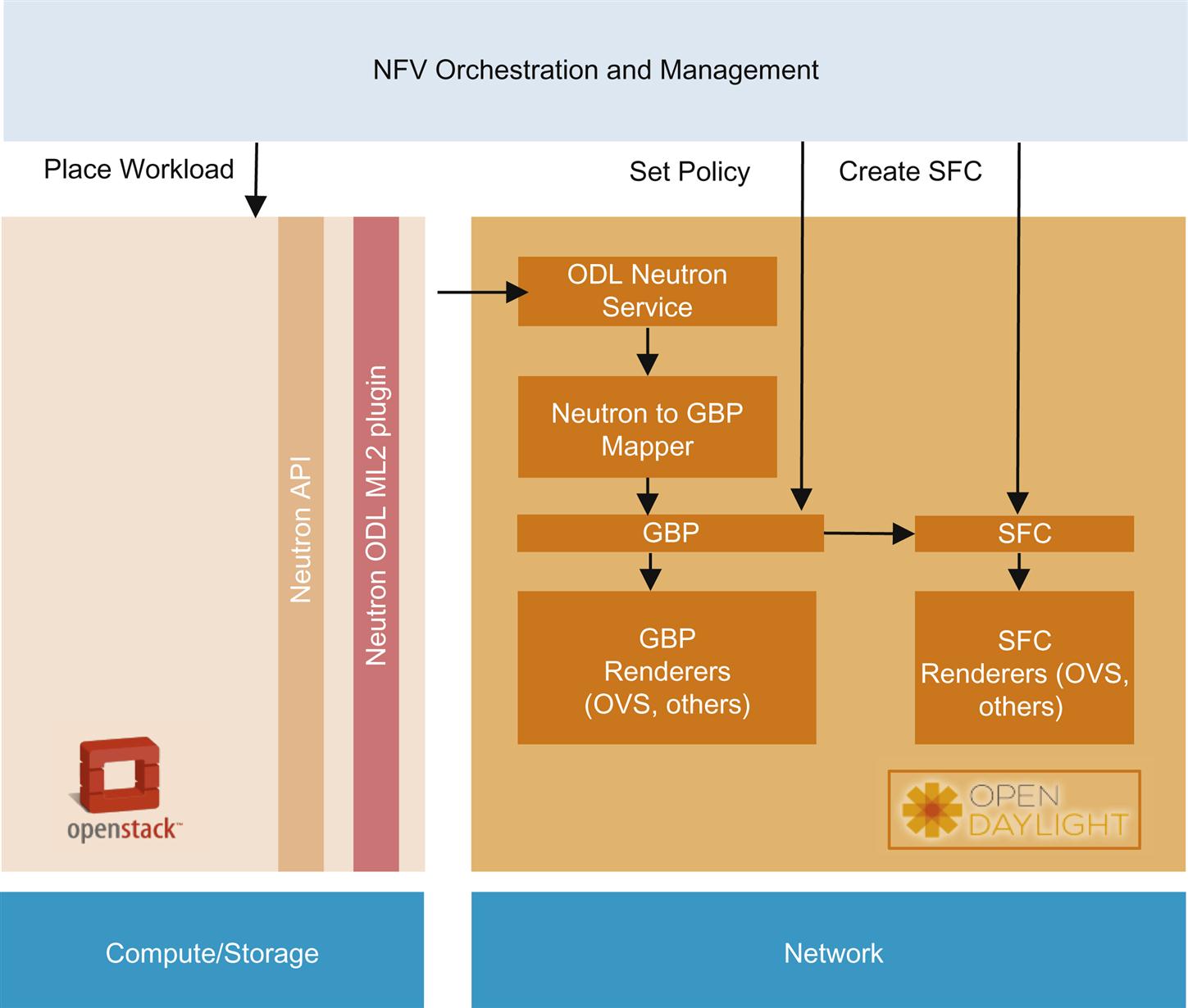
Like most ODL capabilities, the rendering infrastructure makes GBP/SFC available across heterogeneous network types, regardless of the northbound, domain-specific language the devices might speak (if the proper rendering module in the rendering framework is available).
Open Network Operating System (ONOS)
ONOS is also an open source SDN controller comprised of multiple modules in a tiered architecture. While this architecture should now be familiar, it has a few twists. ONOS has generated interest through its CORD (Central Office Re-architected as Datacenter) project—with a first use case to implement PON access networking.14
ONOS, as a project, is currently managed by ON.Lab and is part of the Linux Foundation.
At the time of this writing, the project’s governance structure still remains relatively closed as compared to those of other Linux Foundation projects. Specifically, code contribution and architectural decisions are made by a small set of ON.Lab staff developers. Recent agreement to re-home ONOS under the Linux Foundation umbrella will hopefully change and improve these processes.
Source code, builds and other resources are made available to outside observers via an Apache 2 license, and so in this way the project is open and transparent. However, this model makes it difficult to create an independent, commercial release of the controller (unless you fork).
A single commercial distribution of the controller exists and is offered by Ciena in order to implement a relatively simple use case wherein the controller interfaces to their optical switches using an unratified version of the OpenFlow protocol (ie, version 1.4). Control and management applications are offered as well as integration with their existing EMSs.
The overall ONOS project is structured as a set of subprojects. Each subproject is maintained as its own compartmentalized entity not only for development purposes, but also in the reality of loading it into a running configuration.
Like ODL before it, ONOS is written to leverage Apache Karaf as its OSGi framework. In doing so, it also enjoys similar advantages to ODL in terms of startup dependency resolution at startup, dynamic module loading (and unloading) at runtime, as well as strict semantic versioning of code bundles making it safer, more secure and straightforward to invoke and execute as a system.
ONOS itself is designed with a few goals in mind:
• Code Modularity: It should be possible to introduce new functionalities as self-contained units.
• Configurability: It should be possible to load and unload various features without disrupting the system, although some may require the system to be restarted in reality.
• Separation of Concern: The system will maintain clear boundaries between subsystems to facilitate modularity of the systems and their interfaces.
Fig. 5.10 shows the ONOS multilevel architecture.

ONOS labels the top layer, consumer interface, the Application Intent Framework layer. This layer is also where a variety of controller services such as topology management reside.
The northbound API provides applications with abstractions that describe network components and properties, so that they may define their desired actions in terms of intended policy. The intent framework provides a system by which intended policy gets translated into OpenFlow rules that can then be programmed on the network devices (ie, switches) using the southbound plugin. Unlike GBP’s rendering framework in ODL, this intent framework appears to be a static mapping.
The edge of the intent framework provides ReSTful interfaces to network applications built around the controller framework. These applications can reside within the controller, or exist externally.15 This is the growing canonical model of applications build around a controller framework.
The distributed core layer is responsible for tracking, routing, and serving information about network state, and applications that consume and act upon the information provided by the core upwards into the northbound interface of the controller (the consumer interface).
In many ways, the ONOS architecture is like ODL when it only had the AD-SAL, a manually supported API. It lacks the plug-in, model-driven, run-time loaded API expansion that ODL demonstrates.
At the lowest layer, the provider interface to the system is OpenFlow. Although the ONOS architecture claims to strive for protocol agnosticism the northbound API is bound to the southbound instantiation—OpenFlow, and it appears to be difficult to add any other functionality to the existing infrastructure. There have been many statements made about future support for items such as NETCONF. However, the realization of any NETCONF model currently will likely be limited to functionality that fits expression in a Layer-2/Ethernet model (eg, access control lists).
In its core, ONOS has a single producer and a single consumer model. In combination with the governance (core code control by a single entity), this inhibits the ability to add functionality to the controller. A developer who wants to exploit new capability has to wait for the core team to provide an API. That capability normally has to be representable as an Ethernet/Layer 2 function.
While all the right words are in the description of the ONOS architecture design principles, it is hard to work around the fact that it is a static, single-protocol design. As long as a solution required can be hammered into this model, it is realizable with ONOS. The question is whether all solutions can be made to conform to that model—either through the native support of OpenFlow or some abstraction by an entity agent—and if that abstraction is “lossless” when it comes to functionality and data transparency.
There have been other single-protocol design controllers (proprietary) that have expanded their claims over time to include “other southbound protocols” (some of those claims ironically included the addition of OpenFlow support!). These too theoretically had policy “compilers” that could accommodate these new protocols. Over time they have failed to deliver this functionality because the proper framework is not in the core.16
Without the proper framework, such designs CAN implement vertical stacks within the controller that are hidden on the surface by a broad API. Such a design is compromised because the stacks have great difficulty sharing state/data. This functions like multiple logical controllers, where the task of resolving the state/data sharing and orchestration coordination is pushed to “a higher level.”
PaaS, NFV, and OpenStack
Both in Chapter 3, ETSI NFV ISG and later in Chapter 7, The Virtualization Layer—Performance, Packaging, and NFV, the concept of microservices is raised. We have even seen them here in the context of SDN controller internals.
In Chapter 3, ETSI NFV ISG, the ETSI early work focused on functional decomposition of complex VNFs into multiple components (VNFC), but did not go much further. Later work by the Phase 2 group had moved from the VM basis of virtualization to containers—and the rise of container networking is documented in Chapter 7, The Virtualization Layer—Performance, Packaging, and NFV.
In the interim (roughly from 2012 to the present), the ideas behind cloud native computing,17 the work of CloudFoundry18 and others involving the creation of new development-and-deployment environments labeled “Platform as a Service” (PaaS) were advancing in developer-oriented communities and gaining significant interest. These ideas were an evolution from earlier projects like Heroku, OpenShift, to CloudFoundry, CliQr, and Kubernetes/Marathon, with a great acceleration in 2014/2015.
The frameworks that support these concepts made the rapid shift to applications based on cooperative small functions using container runtimes in a continuous delivery environment.19 These cooperative small functions were called “microservices.”
The idea of “microservices” has trickled down to NFV, but it generally terminates with a smaller vision—“does your function run in a container?” Yet there is no reason to limit the vision.
The real issue here might be (again) cultural, because the target of the cloud native environment is the developer—NOT the IT professional or the traditional network operator. Of course, these are the dominant sources of input into the ETSI architecture.
Many of these frameworks are open source projects.
For example, a CloudFoundry “foundry” itself provides a number of enabling services. You will note that many of them have parallels in what we currently conceive of as service chaining: traffic routing, authentication, lifecycle management, state and elasticity management and reconciliation, a code repository (blob store), execution agents, logging and statistics services, and perhaps the most interesting—service brokers and a message bus. More specifically, the PaaS approach takes care of the Middleware and runtime so that we can focus on the application and data.
True to the open source business model, others build value-add features around the framework—enterprise features, documentation, support, certification, and other services.
Each of the frameworks listed would be a separate picture, all slightly different, and longer descriptions would take a separate book. Our purpose is to point you in this direction so you can explore the idea yourself.
The point is, a PaaS framework will efficiently deliver a microservices development and deployment environment. Thinking IaaS alone for NFV is not going to make it hard to deliver the benefits of microservice architectures as efficiently and transparently.
Although some frameworks have their own deployment and optimization services (eg, cloud controller), they can work in combination with IaaS tools like OpenStack, Kubernetes, etc.20
OpenStack Cue21
Fortunately, the OpenStack community has already anticipated this potential synergy. Cue provides a service for OpenStack to provision, manage, and administer message brokers.
The use case they describe is integration with the CloudFoundry service broker.
The great benefit here is that OpenStack is extended to understand and manage the messaging service infrastructure the PaaS framework requires. Authentication is also passed through so that the worker in the PaaS environment does not need to know OpenStack.
The Impact of PaaS on NFV
The impact of PaaS on how network operators deploy NFV can be difficult to estimate—but when deployed using this approach it could be potentially revolutionary because:
• It can allow for an environment where there is not so much duplication between the functions, thereby optimizing the resource footprint of the service. By their very definition, microservices are relatively atomic, so there is no need to have multiple similar “microservices” unless of course its done to scale-out/scale-up growth of total resource power for that service. This is a clear step forward in efficiency.
• It can be used to create “complete offers” from vendors that overlay the IaaS below it and work beside the MANO pieces to create a new view of how a service is constructed. When based on an open framework, this environment has the potential to be extensible to include an operator’s custom microservices or those of additional partners. Examples of how this works might be found in commercial PaaS offers today such as Amazon Web Services’ media services offer. This service includes their own tools as well as integrated set of tools from Elemental. An OTT service such as Netflix can then build their customizations on top of those services by extending them or adding to them—adding value to the environment.
• Once we are working at the microservice level, we now have the license and freedom to change our view of service creation and how to build new services that are not built around traditional functional boundaries. We illustrate this in an example below.
• It may change the way we think about “chaining” in service creation in that not every microservice needs to see the original packet in order to render the overall service!22
The latter points are demonstrated in Fig. 5.11. In the figure, several microservices each denoted by a series of similarly colored boxes, each a container.
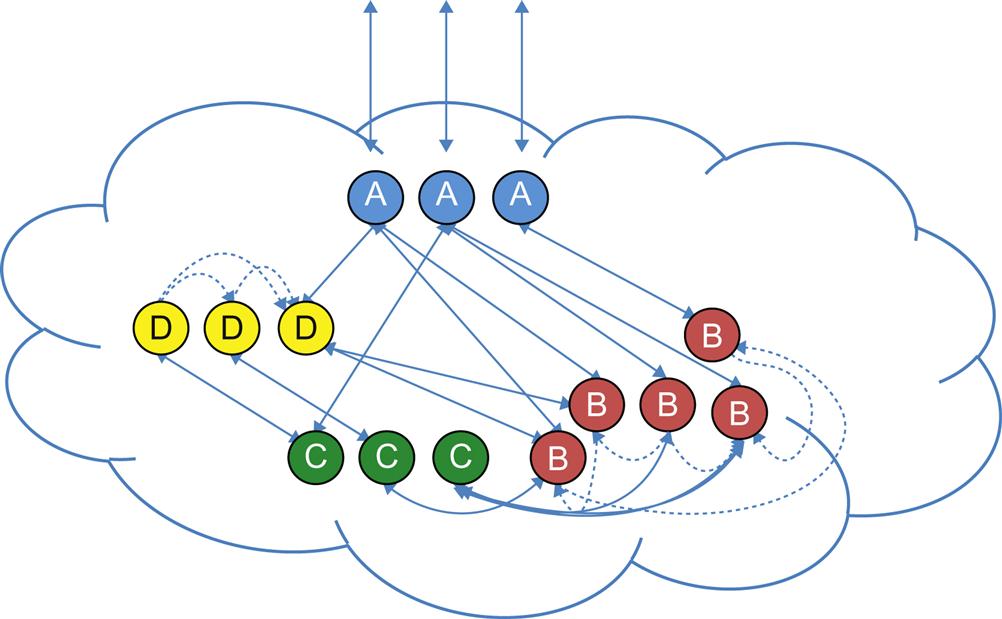
The container clusters for each microservice do not all have to be in the packet path. What they do have to be is the most optimized containers possible. That is, in order to maximize the underlying resources, the containers should only contain the minimum functions and processes needed to achieve their goal. This also promotes maximum reuse down the road, as well as scale of the entire system.
Service A can scale via external load balancing or internal routing to handle the incoming/outgoing packet events—dissembling the packet into multiple data fields (and reassembly on egress).
A majority of the work could be done in A, with exceptions in that code set spawning further work that is handled by the other services, which can all scale to handle demand and all have their own interrelationships. A-B, A-C, A-D, A-B-C, A-B-D, etc. are all potential interactions of microservices that make a complete service (or subsets of total service functionality).
Each of the services may have their own interconnectivity to provide cooperative state management as well as associated data repositories. Microservices B and D exhibit this behavior.
In the underlay network, their containers may be on separate hosts (this is a question of the algorithms involved in resource placement, lifecycle management, and other interactions between PaaS framework elements) so that there is a potential network transaction to service the request.
The big difference as it applies to our present understanding of NFV is that those microservices are actually linked at the application layer via a message bus. They are often working on a “unit of work”—a transaction, and not necessarily the original packet.23 Their relationships are managed by the service broker and connected by a message bus.
We do not need to worry about the internal, underlying network transitions from a service chaining perspective as much as we did in the IaaS focused approach to “service.”
Both IaaS and PaaS paradigms for NFV rely on a resource optimization or packing algorithm that can maintain certain SLAs while at the same time maximize resource “bin packing.” For example, in order to maximize the CPU/memory resources of a particular physical server, this resource optimizer might place as many containers on the same host as possible without overdriving its resources so as to not violate the overall service SLA.
With the PaaS approach an NFV service can appear to the consumer as a single somewhat amorphous network element—much like a web service.
Ironically, the explanation of the network versus application level differences in approach completely ignores the strengths of the environment as a continuous develop/deploy platform—which is part of the cultural shift we have to make. This includes the reusability of the microservices as components of multiple services.
Perhaps a simple way to think of a PaaS approach might be to look at how a cloud-driven business might look at one of the services network operators offer today.
For example, think about how a new competitor might approach a security service. Would they chain together a series of physical or virtual devices labeled “firewall,” “intrusion detection,” “web security” in some virtual pipeline that mimics taking the physical equivalents of these services and physically wiring them together, or instead to completely reinvent the concept of security with a collaborative set of functions that used a message bus to communicate instead of a fixed pipeline and were used deployed in a manner that was more “situation aware” than “topologically bound.” Of course, underlying their approach, they would have the same elasticity and resource efficiency goals as the current goals of NFV prescribe.
When it comes to NFV, a PaaS orientation is complimentary to the IaaS focus we exist in today. The additional layer of abstraction, if embraced, could remove some of the expertise burden around IaaS noted earlier in our major section on OpenStack—for the subset of the network operator that will be service function developer. These frameworks provide a layer of abstraction that handles the resource management and placement problems for them.
Conclusions
This chapter focused on presenting the reader with the first big architectural block in the NFV conceptualization of the ETSI NFV work: VIM. The discussion honors two recurring themes in NFV—open source (though proprietary solutions for the VIM functionality exist and may have some value-added capability) and programmability.
OpenStack projects enjoy a great degree of interest and adoption for resource orchestration in the VIM. OpenStack is the open source framework for the VIM. However, shortcomings in Neutron and the potential complexity of evolving network requirements have led to the use of network controllers in the VIM.
The fact that OpenStack has flaws is not a surprise and certainly not unique to an open source framework. At a high level, OpenStack is working on eliminating some of its shortcoming (eg, user awareness of project interdependencies that had unexpected consequences during upgrades) including the networking aspects. Of the things that may bedevil the VIM related projects, user competency in OpenStack is a difficult hill to climb and probably the biggest obstacle in its use for NFV.
The ability to move complexity from the orchestrator into the network controller has proven to be a boon for rapid prototyping around concepts like SFC and policy.
We updated our concept of an idealized controller framework (from our previous book on SDN) to reflect what have been successful framework designs available today.
For example, model-driven approaches, not only for API definition but also the frequent use of automated code generation based on these models is an important advance in the state of the art. This lends itself to rapid development and iteration of various components inside of software systems. This is important because one of the most important features of SDN and NFV is rapid programmability. The ability to quickly iterate on and evolve a software platform, whether it be derived from open source projects or proprietary, is now emerging as a key feature of successful software systems in this space.
We looked at two open source network controllers in this regard—one apparently bit more open and flexible than the other. Setting aside the governance issues, the question remains whether NFV solutions will be single protocol in their network (OpenFlow) or a polyglot. Whatever the answer, we have to move beyond “controller wars” if we are to make progress. In the end, controllers are middleware in the NFV process—not the focal point.
Beyond the VIM, OpenStack has a growing sprawl of projects that have spun up to expand the functionality of OpenStack. Whether these distract from core competencies and/or add value that rivals proprietary products in these new areas remains to be seen. We venture into some of these areas in the next chapter—service management and orchestration (MANO).
A PaaS approach to NFV brings a different perspective to the development and deployment of services, providing a framework required for cloud native computing using container runtimes to realize application (network services) built on microservices. The relationships between these microservices can have a profound impact on how we perceive NFV and SFC.
One of the OpenStack projects, Cue, allows for the integration of a PaaS foundry with an OpenStack IaaS-focused resource manager.
PaaS for NFV may be a hard concept to deal with while we are grappling with the existing architecture already prescribed for NFV.
The IaaS approach is much easier to understand because it is still focused on “how we wire things together,” which is very consumption- and deployment-oriented and not very creation-oriented. The PaaS approach seeks to minimize the deployment problem and enable creation.
If it is any comfort, in many ways, thinking about NFV as a PaaS problem instead of an IaaS problem is compatible with the basic thinking behind NFV—it just takes it to a slightly different place.
At this point we can ask ourselves a few questions too. First, “how are we going to realize microservices for NFV?” and second, “can we achieve the goals set out by the ETSI working group, albeit using methods and architecture that likely differ from those that might have been specified?” While these are questions that may occur to you when we get to Chapter 7, The Virtualization Layer—Performance, Packaging, and NFV, at this point we offer that PaaS is a viable answer to both questions.