Chapter 7. Data Gravity
The COVID-19 pandemic has affected each of us in many different ways. But in the scope of business and IT, what specifically made 2020 (and most of 2021) so particularly challenging? A question that we routinely ask our clients is, “Who is leading your digital transformation?” Oftentimes, the answer has been “our CIO,” “our CFO,” and so on. But in 2020, more often than not the answer was “it’s COVID-19.” There have been massive impacts across employees, partners embedded within companies, and end-user digital experiences as a whole. Increasingly, everything needed to be available and accessible online. Companies accelerated their drive toward cloud, and their customers were pushing urgently for all-digital availability of services.
Our experience during this time as IBMers was an interesting one, to say the least. The nature of our work and the diversity of our client interactions meant that we had the broadest aperture possible to the range of ways businesses have been impacted by and have responded to the pandemic. We have observed businesses that have struggled, but likewise there have been clients that have flourished in the “new normal” (recall the thrivers, divers, and new arrivers we talked about in Chapter 1).
From the perspective of containerized storage (and IBM Storage in general), we’ve recognized three major trends:
- Management and control
In the past, administrators would have procured more storage (in support of applications and users), as needed, from the datacenter—we’re talking about a time well before the advent of cloud. Often the datacenter would in effect be spread across two or more sites: one serving as the primary hub and the other being a smaller satellite for disaster recovery and business continuity services. In these early configurations, storage allocation would be managed by system administrators entirely through the primary site (from which they would also remotely control the satellite locations). With COVID-19, we’ve seen a flip toward working from home—and as such, all of these system administrators are now scrambling to find ways to manage all of their datacenters (the central hub and the satellites) entirely from their remote (at-home) workstations.
- Availability and reliability
Many businesses wish to become a 365x24x7 company, but COVID-19 pushed them into making that level of availability more than a sound byte in an earnings call—it became a necessity, not merely a luxury. Digital transformations were already well underway across the industry at the start of 2020, which naturally applied stress to the digitized services running off-premises. In turn, this put additional stress on the high availability (HA) and disaster recovery (DR) components of those containerized and cloud-centric services. COVID-19 further accentuated that stress because of the push toward contactless, socially distanced, always-online experiences.
- Cyber-resiliency
Cyberattacks continue to rise and escalate in severity with each passing year—and once again, the push toward digital experiences owing to COVID-19 has created an ample supply of untested vendors and businesses (in other words: ripe pickings for an attack) for these malicious entities to target. 2021 is proving this to be true each day: it’s not simply about keeping the “bad guys” out or tracking the attackers down. Sometimes—speaking anecdotally based on what we’ve heard or seen firsthand with clients—your business may not even be aware an attack has occurred until weeks or months after the intrusion has taken place (you’ll recall we touched in this in Chapter 6—almost every report we’ve seen suggests that it takes almost six months before you’re likely to discover malware inside your company). If your enterprise doesn’t have cyber-resilient and well-secured storage in place before your containerization and digital transformation strategy begins, the damage may already be done before you’re even in a position to recognize and react to it. This is one big reason why air-gapping and Safe Guard copying your backups—think of it like an offline-only copy of your data that can only be accessed in case of emergency—is a prudent part of any modern data protection strategy.
Another trend around securing containerized and cloud native applications is the increased sensitivity, among businesses and consumers alike, toward data residency: where does your data reside today, and where (if anywhere) can it move to once generated?
How do concerns and legislation regarding data residency impact those businesses that are looking to adopt the hybrid multicloud approach that we’ve been evangelizing thus far? For example, if a Canadian business is contemplating using three or four different cloud vendors, and one of those vendors does not have a datacenter within a province (or state) covered by that country’s data sovereignty laws, then that vendor cannot be selected (for data storage purposes) by that business. There are multiple countries around the world with similar legislation in place as well. As you evaluate different cloud-first vendors, you need to be cognizant of the fact that no single cloud vendor has a datacenter within the borders of every country on the planet. Therefore, when plotting out your digital transformation and application modernization strategy, you absolutely must take into consideration an on-premises component for data retention, as well as cloud.
This really hits on the theme of our book: you need cloud capabilities at all destinations. It’s precisely why we believe that an on-premises/off-premises (hybrid) blend of several vendors (multicloud) is essential for every business—all of whom will need to be increasingly sensitive to application and customer data residency moving forward. Even though the new (ab)normal is fraught with challenges, there are tremendous opportunities for those that give weight to the data gravity conundrum, which is the residency of data and the challenges of moving it to the cloud, and opportunities for those that strategize toward a blend of on-premises and off-premises, multivendor solutions to those challenges.
Thinking of cloud as a set of capabilities, where any business can harness the powers of multiple vendors and technologies, broadens your organization’s ability to innovate with speed and reach new audiences. That level of agility, resiliency, and adaptability is precisely what the “new normal” of a post-COVID-19 marketplace demands. But it is equally incumbent on organizations to not fall into the trap of thinking of the public cloud as the destination for all of their data. As noted earlier, we can’t change the laws of physics—moving petabytes of data to the cloud will always be a challenge that few can stomach. Likewise, while we aren’t fortune tellers, we’re certain there will be even more demanding and unique challenges relating to data residency and privacy that 2021 and beyond will usher in. One thing we can promise you: establishing a hybrid multicloud strategy premised around secure containerized data, multivendor support, and vendor-agnostic technologies will put your business in the best position for success in the new (ab)normal’s marketplace.
Data Gravity: More Formally Defined
A key consideration for workloads in hybrid multicloud environments is latency. For applications with data dependencies that businesses are looking to modernize, planning and consideration must be given to the ways that distance and distribution over containers (and cloud platforms) may impact these services.
The inconvenient truth is that much of an enterprise’s crown jewels (data) today resides in storage which is not easily adaptable to—or might even be seen as antithetical to—the unique storage requirements of modernized and containerized applications. These challenges are further exacerbated by the fact that containers were not originally developed with persistence and long-term storage in mind. These technologies were conceived with a “build it and bin it” mentality in mind (for rapid development and testing), an “ephemeral” approach to application design. As such, the technology (and vendors that support it) have had to gradually evolve adaptations to these requirements over time.
You can’t change the laws of physics. Data that needs to move between distributed systems is inevitably going to suffer from latency or performance drags. The alternative is to constantly move data back and forth across premises to replicate that data into distributed cloud systems. But how then do you maintain, secure, and preserve the integrity of data during such a migration? What happens to the mission-critical business processes on-premises that generated that data in the first place? If synchronization between the endpoints were to break down, how would that impact the applications running across the disconnected sites?
We refer to complex workloads such as these, with deep data dependencies and high volume, as being subject to data gravity. Data’s “weight” on-premises can make it difficult to burst to the cloud, and the further you move that data away from the on-premises IT core of your business, the more tenuous that connection (the gravity) between your data and mission-critical systems becomes. This relates to the connectivity, resiliency, and security challenges of ground-to-cloud operations. Before your business can break free of data’s gravity and boldly set out in search of new ventures, you need the correct storage strategy to accelerate your modernization journey and overcome the “stickiness” of the legacy data dependencies that are dragging you down.
Container-Ready and Container-Native Storage
Chapter 3 introduced you to IT container technology and the curious ways in which the containerized application revolution echoes the shipping container revolution of centuries past. Very often when talking about containers in the IT world, there is an adjacent picture of a container in the physical world (like a shipping container you might see stacked alongside a port). For example, containers in both worlds (logistics and IT) exhibit characteristics of efficiency, organization, standardization, and security. But is there any real value in this metaphor of containerized goods and container-based shipping? Or is it merely a play on words?
Solving Challenges of Business Continuity in a Containerized World
Global container shipping and local road delivery to the doorstep is now well-known across the world thanks to the ubiquity of companies like Amazon and UPS. Their widespread success couldn’t have happened without three essential shipping container innovations or rules:
Containers are orchestrated (translated into normal English: organized) and marshaled according to their intended destination and priority.
Handling facilities are standardized—they simply would not work without standardization.
Freight handlers don’t need access to the contents of containers in order to ship them (they are secured from the point of origin to the place in which a customer unloads them).
Orchestration describes the process by which containers get to where they need to be. Just as a physical shipping container can be moved by different forms of transport (rail, ship, and so on), IT containers can be deployed on different types of cloud destinations (on-premises, public cloud) using the same cloud capabilities. In the same way that a manufacturer or distributor loads a physical container with the goods they are sending, DevOps teams can describe and build container images prior to their deployment because there are standardized ways for distributing, receiving, and running containerized workloads in the environment where they are finally deployed.
Traditionally, IT servers were sized for their peak workloads. This required enormous amounts of upfront work to understand the app being supported; it’s akin to predicting the future, and don’t forget the countless hours finding consensus across the mutual business and IT stakeholders that the architecture was meant to serve. We all know how things go when planning turns to practice: peak capacity demand might only be reached a few times a year; maxing out your capacity in those days was generally thought of as “the exception,” rather than “the rule” of today. Keeping level of service up and running meant that storage was typically directly attached (or locally networked) to those servers, along with specialized data protection, high availability (HA), and disaster recovery (DR) solutions. Satisfying business continuity could be challenging because you needed different solutions for HA and DR to satisfy those needs—particularly if the secondary operating site was a significant distance away from the primary site.
Procurement and management of these bespoke systems required operations staff with specific sets of skills. Within these businesses were glaring inefficiencies such as spare computing capacity and unused networking and storage resources, which very often were underutilized or sitting idle (but nevertheless paid for) much of the time. You’re probably starting to get the picture of how this worked, and to be honest, many of you are quite familiar with it. Traditional architectures require lots of work, plenty of skill, resources you’re willing to sacrifice (at times for potentially no gain), and reams of preventative measures to mitigate risk.
Returning to the example of shipping and logistics: end users are typically happy if their goods are delivered to them in a single, secure package, where the contents of those shipments are just as they were when they left their point of origin. However, in the domain of goods transport, infrastructure operators recognized that further efficiencies were possible if multiple containers could be loaded onto a single transportation platform. Rapidly, long trains and large ships requiring fewer labor resources entered the mainstream and became the de facto method for global container shipping with economies of scale. Today many parts of this process are automated with analytics and AI, making it even more efficient.
In a very similar way, IT containers are engineered to integrate with the deployment infrastructure (what we’ll call “hosts”) in such a way that requires fewer resources than a traditional virtual machine (VM). Multiple guest operating systems and the hypervisor that controls them (the approach used by VMs) are replaced with a single container engine, which also relies on specialized isolation capabilities to ensure that the containers it supports are lightweight and secure. Even the simplest operating system of a VM might require 2 GB of operational space per instance. Every one of those instances needs operational management for security patches, upgrades, and so on. By contrast, a containerized application could strip away the bloat of unnecessary OS libraries and dependencies, only packaging the absolute minimum needed to run the service.
VMs are frequently allocated to individual application users and may also require asset management business processes; containers, on the other hand, are typically not allocated to individual users. Containers are created dynamically in order to provision a service that users need, and then subsequently disappear after the container’s lifecycle has ended. Containers don’t need asset management, only a descriptor so that they can be assigned to a workload when required. Finally, developers love containers because they can be confident that their applications will be deployed with the right libraries, in the correct configuration, every time, on any architecture. Just like a physical container, in the IT world a container image can be made secure so it cannot be deployed or used until it is accessed by a permitted system that has the right key to unlock its capabilities (and contents).
Why Storage? Why Now? The Curious Evolution of Persistence for Containers
Recall that one of the early application development and architecture challenges was dealing with business continuity. The portability of containers addresses two significant operational challenges:
The standardized specification of containers means they can be easily moved, running in a business continuity site as soon as they are needed.
When the server hardware on which a container is running needs maintenance or replacement, another copy of that container can be quickly deployed on different hardware while the upgrade is done—without any service interruption.
Figure 7-1 breaks down the foremost pain points that organizations experience when needing to find storage solutions for containerized applications. As you can see, many (if not all) of these pain points have their roots in the “weightiness” of data—be that the latency and time-to-delivery impacts from moving data across the wire, strict regulatory and data sovereignty laws, or the friction generated when agile innovation rubs against disaster recovery and availability requirements.
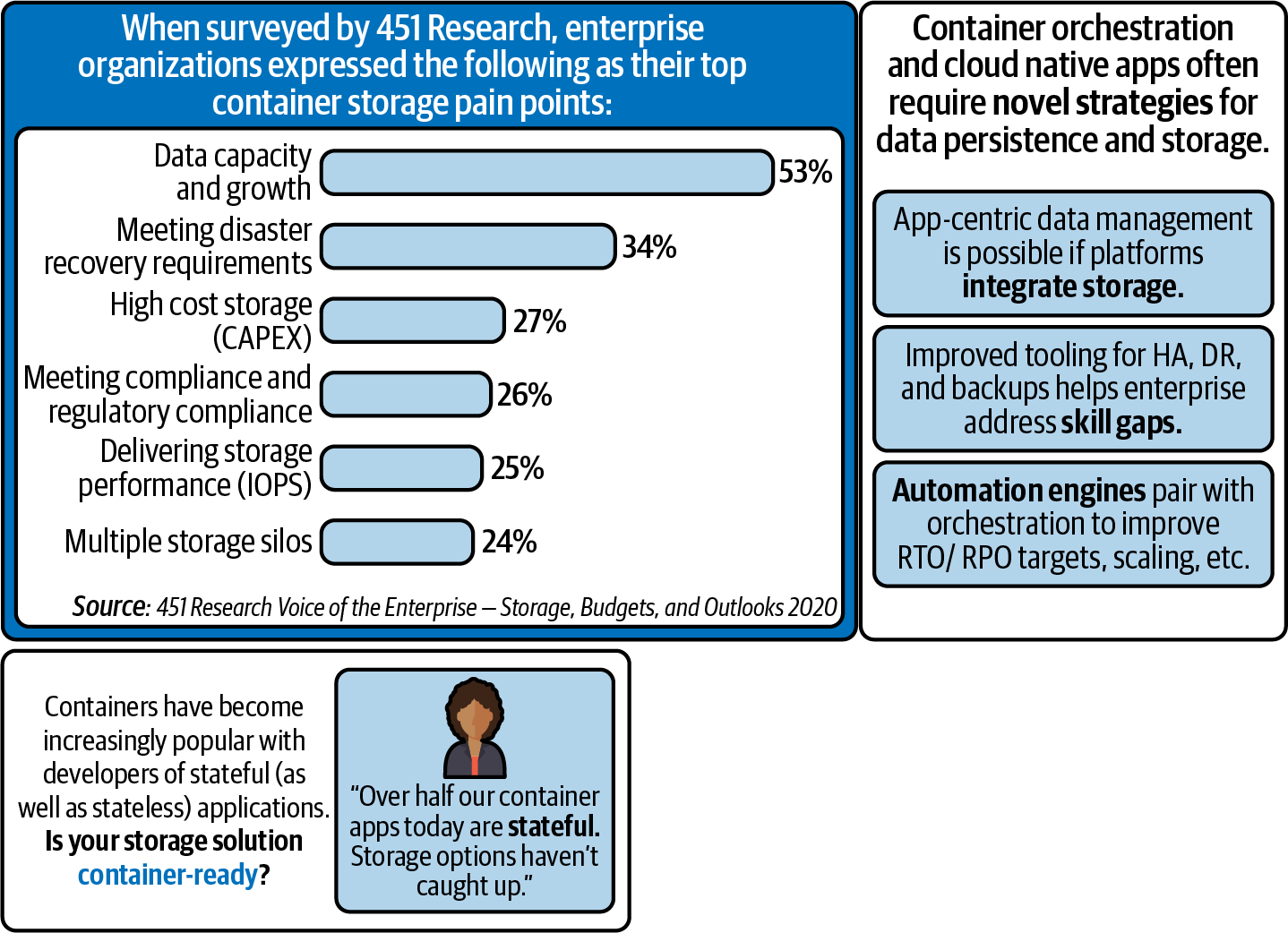
Figure 7-1. Typical pain points enterprises run into when needing to find storage solutions for their containerized applications
Performance is a key requirement for any business application, even those running via (relatively lightweight) containerized microservices. As memory and CPU resources become cheaper and more ubiquitous, legacy hard drives that read one block at a time are becoming a performance bottleneck for data-intensive applications (see Figure 7-1). Built with multiple channels and flash devices, solid state drives (SSDs), and storage class memory (SCM), today’s storage is inherently parallel and able to provide orders of magnitude higher internal bandwidth compared to traditional hard drives. In addition, for clients looking to use file storage, leveraging parallel filesystems (like Spectrum Scale based on the General Parallel File System, or Lustre) can provide a huge boost to performance as well. One thing to never forget when you design your cloud architectures: all servers wait at the same speed for the data!
From an availability perspective, when your team moves containers, you need to be on the lookout for industry-leading storage capabilities that include automated, policy-driven data movement, synchronous and asynchronous copy services, high availability configurations, and intelligent storage tiering. You want six 9s (99.9999%) uptime for data assurance and resiliency, as well as 100% data availability guarantee with multisite options.
Manageability is another big challenge for your running containers. Ensure your team looks for easy-to-use tools to manage your containerized applications. These tools should provide capabilities to easily deploy, manage, monitor, and scale applications. They need to be integrated with environments that provide a private image repository, a management console, and monitoring frameworks to seamlessly hook containerized apps and services into your broader application ecosystem.
To round out this list of concerns we want you to be aware of, think about data protection for containerized applications. There are many aspects of a containerized environment that need robust backup and disaster recovery routines, as well as contingency planning in place for protecting the state of the cluster, container image registries, and runtime (state) information.
Containers for one reason or another will inevitably need to be reconstituted (brought back into their operational state) after a hardware failure, crash, or software maintenance to their image layer. Although containers are resilient against such failure conditions, it does require architects and designers to consider how a containerized application will retain any data between reconstituted container environments.
Figure 7-2 illustrates the challenges associated with application data storage (stateless or stateful) for containers (ephemeral or persistent, respectively).
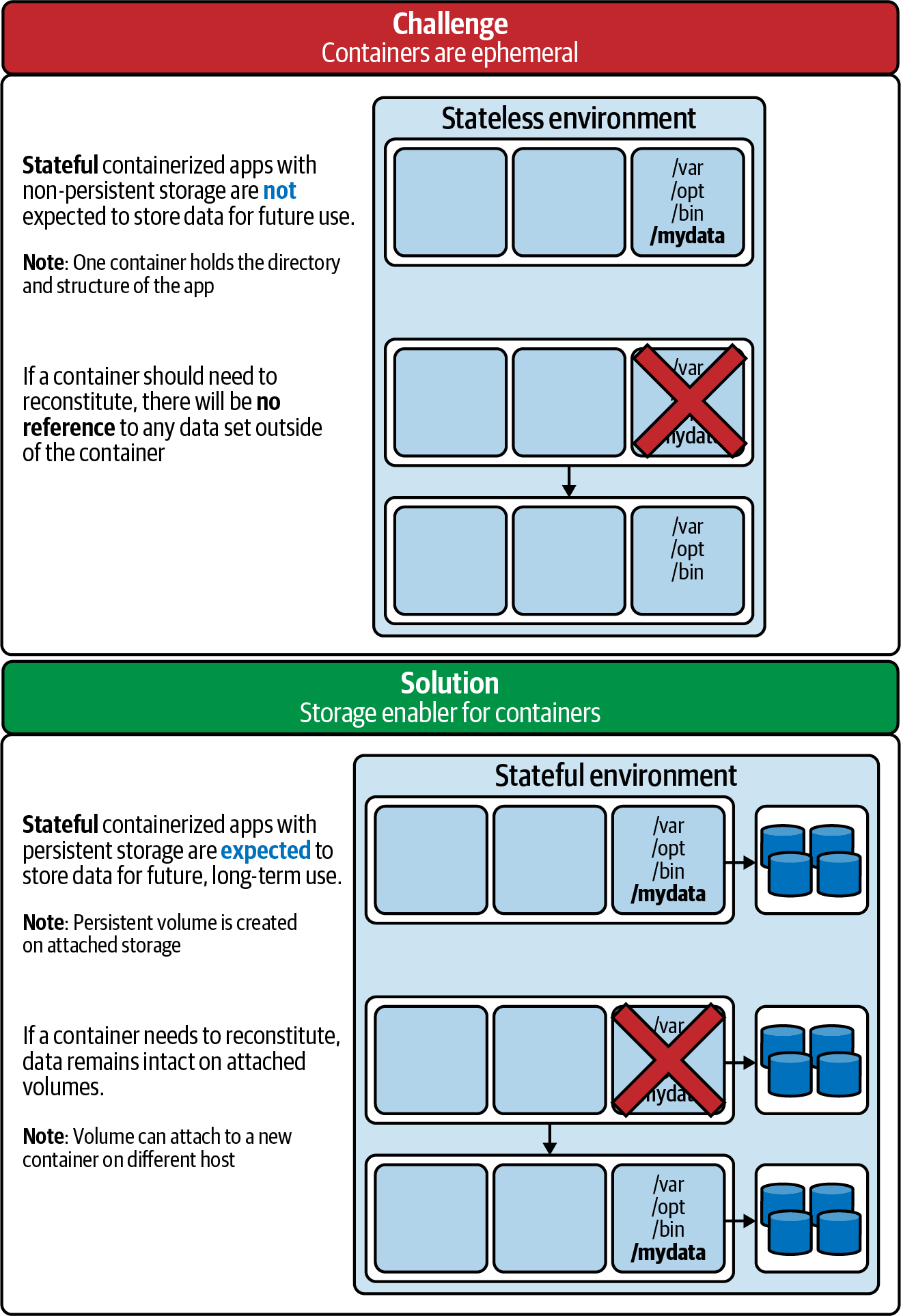
Figure 7-2. It’s not a question of if an outage will occur, but when: these are the challenges associated with application data storage for different kinds of containers
Container: May Ye Live Long and Prosper
By default, containers are inherently ephemeral environments. Any information about their state that is created over the course of a container’s lifecycle will be deleted (lost) when that container’s lifecycle is complete—think of it as amnesia. This includes each time a container is restarted, such as for an update, migration into a new environment, or because of a stoppage. We refer to this default container behavior as stateless.
Persistent storage is the means by which data that is created by application usage is retained throughout the lifecycle of a business process, allowing the entities it manages to change state. A stateful containerized environment is one that persists and retains data across sessions in a permanent fashion—in other words, by using persistent storage. Using external storage devices, a containerized application can persist its data throughout and beyond the lifecycle of the container, meeting the needs of long-term business processes (not merely short-lived or technical processes).
Persistent storage for “stateful” containerized applications has proven particularly difficult for the industry. Unlike monolithic applications—which reserve storage resources once—containers and microservices bounce in and out of existence, migrating between machines at breakneck speeds. The repeating cycle of coding and testing, followed by agile production deployment, further exacerbates the data storage challenges for containerized applications. Data services fashioned for traditional application architectures must now serve a new, very transient data paradigm.
The unit of storage capacity that a container can make use of is called a volume. There are mechanisms built into container orchestration environments that allow these volumes to be named and attached as required. Kubernetes allows containerized applications to request storage, locating the best match from available resources, and delivers a volume (a place to store your data).
Red Hat OpenShift elevates the management claim to provide a catalog of storage providers from which the most suitable can be easily chosen by a cluster administrator. Microservices are no longer tied to a single implementation of business logic and storage access libraries. They can be deployed in a loosely coupled fashion with the most appropriate technology for their needs, while DevOps tools allow storage to be presented using a consistent approach through the whole of the release lifecycle. As a result, only those storage solutions capable of providing shared storage to both existing (virtualized and bare-metal application infrastructures) and container-native applications with a consistent set of data services are likely to survive.
Container-Ready and Container-Native: Reinventing Storage for Containerized Applications
Persistent storage for containers is generally defined in two categories: container-ready storage and container-native storage.
What benefits does container-native storage confer over container-ready storage types? First, it simplifies management: a single control plane within your K8s containerized environment is able to manage the integrated (native) storage. Second, both internal drives and external storage can be leveraged, giving further flexibility in terms of where application data and state are persisted. Third, this architecture paradigm is consistent with the “hyper-converged” approach for containerized applications, in which storage and compute are able to scale independently of one another.
Note
The early days of public cloud-backed data lakes and data warehouses taught vendors some tough lessons about certain Hadoop as a Service (HaaS) offerings that soon became HaaS-been (get it?) offerings. Imagine needing to buy more storage capacity and being forced to bundle that with purchasing additional CPU and memory, every time (on a system where you’ve already got plenty of excess processing power)! Today, many data warehousing SaaS offerings have adapted in response to these lessons learned to allow for independent scaling of compute and storage.
What do we mean by container-ready? As customers are moving to container-based environments, they are able to use storage as a persistent storage layer for both block and file architectures. For example, storage is container-ready today, while many vendors are still in the early stages of delivery for container readiness (alpha or beta versions of their storage plug-ins as of the time this book was written). It unifies traditional and container storage, and provides cloud native agility with the reliability, availability, and security to manage enterprise containers in production.
Container-ready storage includes devices such as Storage Area Network (SAN), Software Defined Storage (SDS), and Network Attached Storage (NAS). These devices support capabilities such as backup/snapshots, clones, and data replication. Another benefit to choosing amongst these options is that they often allow clients to leverage existing investments that they’ve already made in infrastructure (either in networking or storage), processes, management, and monitoring solutions. IBM Spectrum Virtualize, IBM Spectrum Scale, Heketi with GlusterFS, and IBM Cloud Object Storage are products that clients may have invested in previously, which can be immediately made available as “container-ready” storage options.
Container-native storage is deployed directly with containers. It is immediately available in the cluster catalog and appears to the administrator in a very similar way to how storage would be in an appliance. Red Hat OpenShift Data Foundation (ODF) is an example of container-native storage. It is capable of provisioning block, file, and object storage—which a variety of applications might require. It operates using the same management control plane as the Red Hat OpenShift platform on which it runs. With ODF, both internal and external drives can be configured. Data persistence is available right in the heart of the container environment itself, where applications need it most readily. Yet both the compute and storage solutions can still scale independently in order to meet changing demand or workload requirements. Container-native storage won’t let you down when it comes to data protection or resiliency. It is usually deployed in a mirrored or replicated architecture, and it supports the same snapshot capabilities as container-ready storage.
Adding Storage for Containers…The Right Way
OpenShift has many prebuilt containers that can be used to assemble applications, but it’s important that you fully understand the differences between ephemeral and persistent storage. What does it look like to provision a containerized service with available storage?
If you’re working from the command line, you’re working with Podman commands. Red Hat originally used Docker infrastructure, and due to some design limitations in the way that Docker works—in particular, the single process background daemon that is a bottleneck, and more—Red Hat switched over and designed a new daemonless container engine for handling the starting and management of containers: Podman. (Don’t get confused. As we said earlier, K8s runs Docker containers—all containers that adhere to the standard OCI, really—we’re specifically talking about the past reliance on the Docker command interface.) This is Red Hat OpenShift’s container engine and also the command line for communicating with containers. If you are familiar with Docker syntax, Podman is essentially the same. Podman works with all Open Container Initiative (OCI)–compliant containers on Linux systems. Containers with Podman can be run either as root or in rootless modes—running containers created by Podman seems indistinguishable, to us, from those created by any other common container engine that we’ve played around with.
To start, stop, and work with containers, you’ll likewise use Podman. It contains all of the subcommands needed to create and manage containers. There are different commands related to different types of objects or states. Essentially, you are searching against external registries: first you must pull containerized images from the external registries into the local storage (disk space—not the internal registry), and afterwards those images are then made available on the local machines for deployment. Conversely, when you go to do a run, it pulls it from the local storage; it doesn’t have to go out to an external registry to first retrieve it (as it already exists in local storage.) Commands such as images, inspect, and history are all executed against the node local storage in this manner.
When you have a running container and you stop it, it goes to a “stop” state (of course) but it still remains in memory. If you are accustomed to working with processes, you expect that when you stop/kill a process that it will disappear from the system memory. Containers are different. When you run containers, they take up memory and they perform tasks; when you stop a container, it stops but it continues to reside in memory.
There’s an important reason for this logic: containers are designed to be stood up, perform a task, and then be thrown away. This is unlike enterprise services or VMs, which store their information on some persistent storage device. Without creating persistent storage, the container will be completely ephemeral and stateless. So when it goes away, you’ve lost everything it’s done and any knowledge it ever had about anything, including itself.
One of the reasons why containers stay resident in memory after they have been “stopped” is so that you retain the ability to query them afterwards. For example, if a container were to fail or disappear, you’d lose the container logs (which are also in-memory); so how would you be able to dissect what went wrong afterwards? By keeping stopped containers in-memory, administrators and developers can still query those stopped containers (using Podman logs, as an example), debug containers, and troubleshoot them.
Stopped containers are not like VMs. They don’t pick up where they left off. In fact, stopped containers are like imposters when you think about it. For example, if you restart a container it actually cheats or misleads you, so to speak, by throwing away the old container and instantiating (creating) a new one with the old process ID that it had been using beforehand—while it does make a new container, it’s disguised as the old container using the same process ID (this is typically done for a restart Podman task).
Red Hat conforms to the Container Networking Interface (CNI) open source project to define standards for consistency for software-defined networking for containers across many platforms and clouds. Based on this, Podman attaches each container to a virtual bridge that Red Hat can manipulate and add richer capabilities to (including security), and then uses that to assign to each container a private IP address and makes it accessible (not necessarily externally, but this is internally how networking and connectivity work). You have to make a container available to the outside world by mapping a port. What we want to do is declare a container port that maps to a host port, so that we can connect to the host and get to the container.
Seven Best Practices for Securing Containerized Data and Applications
We cover security throughout this book because we think it is important. Many of the concepts suggested in this section provide the foundation for what we discussed in Chapter 6. This isn’t an either/or suggestion—you need both. Containerized applications make it easy to ensure consistency of development, consistency of testing, and consistency of deployment—across physical servers, virtual machines (VMs), and public and private clouds. But does this level of consistency also extend equally to concerns like security? Organizations are keen to know the answer to such questions (and rightly so). However, the answer is not always immediately obvious; likewise, your results may vary depending on your choice of containerization platform and the vendor supplying it.
How you go about securing a container, and the approach you take to achieve this, depends on the background of the person you ask. For example, if your background is in managing infrastructure, you may perceive a “container” as a lightweight alternative to VMs, such as a sandboxed application process, that shares a Linux operating system (OS) kernel with other containers. Alternatively, if your background is as a developer, you might conceptualize a “container” as a packaged bundle of an application (like you would a JAR file in Java) and all of its dependencies, provisionable in seconds within any environment of your choosing, and readily enabled for continuous integration and continuous delivery (CI/CD).
Regardless of whether you subscribe to the application-builder or infrastructure-manager perspective on containers, there are seven key elements essential to securing any containerized environment, which are summarized in Figure 7-3 and explored in more detail in the following sections.
Containers (and container-ready storage) make the portability of data easier than it’s arguably ever been before—and that’s something to be wary of, particularly for those of us operating in environments with strict data sovereignty and regulatory compliance laws that must be met. Under these conditions and within these countries, the pull of data gravity is ironclad. Likewise, the controls and safeguards built into your hybrid multicloud environment must be equally solid in order to ensure your business doesn’t run afoul of these laws.
From our time spent working with clients operating under these strict data guidelines, we’ve compiled a list of seven elements that encompass each layer of the container’s solution stack (like you would do for any running process)—from before you deploy and run your container, to the lifecycle of the containerized application once it has been placed into production. We’ll dig into each element and provide you some lessons learned on how to prepare your hybrid multicloud for the realities of containerized data and applications.
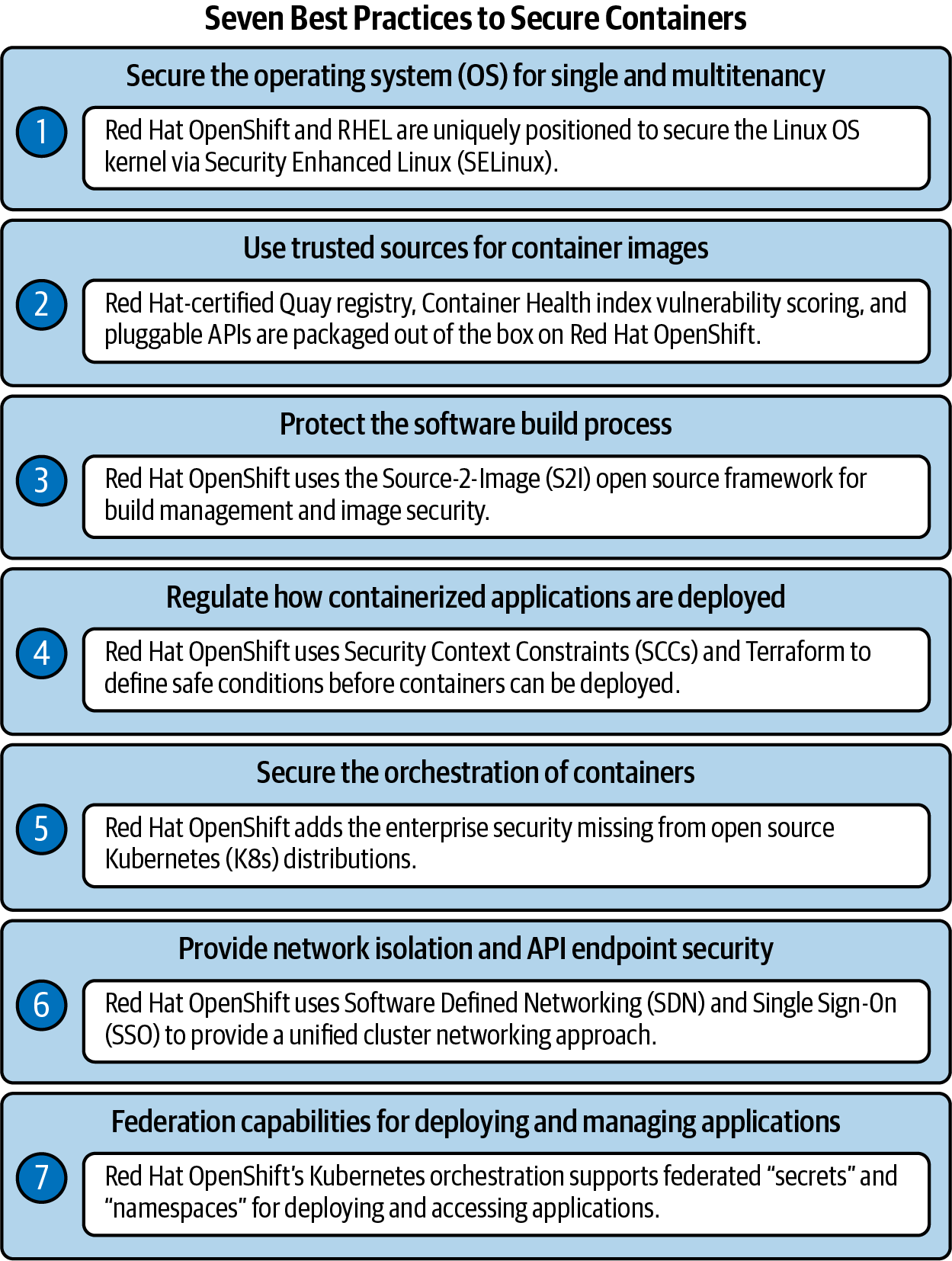
Figure 7-3. The seven best practices any organization can apply toward securing their containerized applications and services
1. Multitenancy and the Unusual World of Container Host Operating Systems
We mentioned before how containers simplify work for developers by allowing containerized applications to be conceptualized as a single bundle of your code and all of its dependencies (a single “unit,” if you will). This has a knock-on effect—multiple containerized applications are able to run on a shared host, as all containers can be deployed in a multitenant fashion on the same machine without cluttering or polluting the underlying operating system with conflicting binaries or other dependencies. With containers you also eliminate the need for traditional VM hypervisors or guest OSs, further decreasing the complexity and size footprint that would otherwise be placed on hardware with virtualized machines.
The linchpin therefore becomes the OS that these containerized applications share and run upon. The host OS kernel must be able to secure the host kernel from container escapes and it must be able to secure containers from one another.
Decreasing risk to the shared OS begins with how you design your containerized application. For example, you should drop privileges from the application where you can (or assign only what you need at minimum) to create containers with the least number of OS-level permissions possible. (Security aficionados tend to group this concept into something they call the principle of least privilege—a cornerstone of any security playbook.) Run and execute applications as “user” rather than as “root,” wherever possible. The second task is ensuring that your Linux operating system is surrounded by multiple levels of security.
Red Hat CoreOS and Red Hat OpenShift are positioned to secure the Linux operating system through a combination of SELinux, available as a part of CoreOS and RHEL, for isolation of namespaces, control groups (cgroups), secure computing mode (seccomp), and more. Namespaces provide a level of abstraction inside a container to make an application appear as though it is running its own OS inside of the container—with its own dedicated allocation of resources from the global pool. SELinux isolates containers from the host kernel, as well as containers from each other. Administrators can enforce mandatory access controls (MAC) for every user, application, process, or file. This serves as a net of protections if the namespace abstraction of a container is ever breached or exploited by an attacker.
Compromised containers running on the same host OS is a common vector of attack for those looking to exploit unsecured networking between containers not running on SELinux. Utilizing cgroups can place limitations on the resources that a container (or collection of containers) is able to consume from the host system, mitigating their ability to “stomp over” other (healthy) containers. Seccomp profiles can be defined and associated with a container, restricting the system calls available to it.
2. Trusting Your Sources
You must be mindful of any packages or external code that you bring into your environment. Can you guarantee that the container you’re downloading from a third-party repository won’t compromise your infrastructure or contaminate other containers running in the same environment? Does the application layer of the container have vulnerabilities that could be exploited? What is the frequency with which the container is updated? And who authors those updates? (Think of all the reasons why you shouldn’t go hunting for movies from a BitTorrent site—aside from the fact it’s illegal—you just don’t know what’s in the file you’re downloading.) Our pro tip? Hardware can help here with the cross-container memory contamination protocols we are starting to see (for example, on IBM Power 10).
Containerized software from public repositories, even highly reputable ones such as Docker Hub or GitHub, carries the same potential risks. The unavoidable fact is that if your organization is working with containers published in these repositories, you are ultimately inheriting code and work performed by others, almost certainly from people you’ve never met. This is not to suggest that code from public repositories is riddled with malicious code—far from it! But there is always the risk that the containerized code may inadvertently come with vulnerabilities that the original developer(s) failed to recognize.
Modern software projects are enormous undertakings and might contain upwards of thousands of different dependencies and libraries. If you’re working with someone else’s code (or another person’s container), some of those dependencies won’t be fully under your control. Data gravity once again rears its ugly head with the “pull” these containerized apps and repositories have on us: the reliance we (as developers) have on extending the open source projects of others; and the need to include dependencies within our projects over which we have limited (or no) control.
One way to mitigate the risks is to work with trusted and established vendors when sourcing containerized application code. For example, Red Hat has been packaging and delivering trusted Linux content for years in RHEL, and likewise they now do the same via Red Hat–certified containers that run anywhere RHEL runs, including OpenShift. Red Hat’s Quay container and application registry can also provide additional levels of secure storage, distribution, and deployment of containers on any infrastructure, for those who might need that.
If you want to use your own container scanning tools to check for vulnerabilities, you can also leverage RHEL’s and OpenShift’s pluggable API. This makes it simple to integrate scanners such as OpenSCAP, Black Duck Hub, JFrog Xray, and Twistlock with your CI/CD pipeline.
3. Protecting the Software Build Process
For containers, the Build phase of an application’s lifecycle occurs when application code is integrated with runtime libraries and other dependencies. One of the key hallmarks of containers is the repeatable, consistent manner in which they deploy across any infrastructure. Consider the frictionless portability of these containers and the multitude of environments that one container might be deployed over the lifecycle of its code (and the utility it provides). The gravity of the legal and privacy situation in the European Union (and increasingly across the globe) demands that businesses and individuals maintain tight control over data ingress (data in) and egress (data out) over national boundaries. Defining what and how a container is deployed (the Build process) is critical to securing a container that may be deployed dozens or hundreds of times over its history.
The Source-2-Image (S2I) open source framework provides build management and image security for containerized applications and code. As developer code is built and committed to a repository (such as Git—a version-control system for tracking changes) via S2I, a platform such as OpenShift can trigger CI/CD processes to automatically assemble a new container image using the freshly committed code, deploy that image for testing, and promote the tested image to full production status.
We strongly recommend that your organization adopts integrating automated security testing and scanning into your CI/CD pipelines as a best practice. Making use of RESTful APIs allows your business to readily integrate Static Application Security Testing (SAST) or Dynamic Application Security Testing (DAST) tools like IBM AppScan or HCL AppScan, among others. Ultimately, this approach of securing the software build process allows operations teams to manage base images, architects to manage middleware and software needed by your application layer, and developers to focus on writing better code.
4. Wrangling Deployments on Clusters
Tools for automated, policy-based deployments can further secure your containers, beyond the software Build process and into the production Deployment phase. Consider this in the context of the regulatory compliance and data sovereignty issues we discussed earlier. If the country or market in which your business operates demands that data-generating applications or PII records stay within a particular boundary (some countries and regions have stronger gravitational pull than others, it turns out), then it is absolutely critical that you have reliable control over how apps and services are deployed. It becomes doubly important if those deployments depend on semi or fully automated orchestration engines, or if those applications are easily portable (such as with containers).
An important concept to Kubernetes orchestration is Security Context Constraints (SCCs), which define a set of conditions that must be met before a collection of containers (sometimes referred to as a “pod” or, in essence, an application) can be deployed. SCCs were contributed back to the K8s open source project by Red Hat, to form the basis of K8s “Pod Security Policy,” and are now packaged as part of the OpenShift Container Platform. By employing SCCs, an administrator can control a variety of sensitive functions, including running of privileged containers; capabilities that a running container may request; allowing or denying access to volumes (like host directories); container user ID; and the SELinux context of the container.
In terms of where containerized applications deploy and how those images are deployed, OpenShift and IBM Cloud Paks use open source Terraform (recall from Chapter 3 that Terraform is an infrastructure as code software toolchain) for deployment to any public or private cloud infrastructure, as well as open source Helm Charts (a collection of files that describe a related set of K8s resources) for consistency of operations.
5. Orchestrating Securely
Modern microservices-based applications are made possible in large part because of orchestration services like K8s, which handles the complexities of deploying multiple containerized applications across distributed hosts or nodes. However, as is the case with any large open source project that we’ve ever been involved in across our aggregated century of IT experience, rolling your own version of Kubernetes is hard to implement from scratch and rife with challenges. Why do it yourself when you can adopt a platform with enterprise-hardened Kubernetes orchestration already engineered at the core of the solution?
One of the key tenets of any successful orchestration platform should be access to collaborative multitenancy between all members of a client’s workforce, while still ensuring that the self-service access to the environment remains secure. To once again use OpenShift as an example, the platform was fully architected around K8s in order to deliver container orchestration, scheduling automation, and containerized application management at the scale and with the rigidity needed by enterprise. That last point about enterprise is important. Naturally, enterprise organizations are subject to stringent regulatory and compliance requirements that go above and beyond what smaller shops may need to adhere to. However, we believe that it is in the interest of every business (from enterprise, to “ma and pa” brick and mortar) that OpenShift secures K8s in a multitude of ways over the RYO stock (100% free) edition. For example, OpenShift enterprise hardens K8s in many ways including: all access to master nodes is handled over Transport Layer Security (TLS); API server access is based on tokens or X.509; etcd (an open source key-value store database) is no longer exposed directly to the cluster; and the platform runs on Red Hat–exclusive SELinux to provide the kernel-level security that we discussed earlier.
When you think about it, selecting a container orchestration platform (on top of which will run your data, services, applications, and users) is akin to determining the center of critical mass for your modern IT estate. It is a center of gravity for your hybrid multicloud architecture, if you will. This platform will serve as the nexus of the future investments of your business, the hub for both your workforce and customer base, and naturally will be where data from both of those sources accumulates and resides. Selection of an orchestration platform with enterprise-certified container security already built into the Kubernetes layer puts your organization in the best position moving forward.
6. Lockdown: Network Isolation and API Endpoint Security
When working with containerized applications that are deployed across multiple distributed hosts or nodes, it becomes critical to secure your network topology. Network namespaces usually assign a port range and IP address to a collection of containers, which helps to distinguish and isolate containerized applications (pods) from one another. By default, pods of different namespaces cannot send or receive data packets—unless exceptions are otherwise made by the system administrator. This is helpful for isolating things like dev, test, and pod environments within the same infrastructure.
A container orchestration platform that uses software-defined networking (SDN) to provide a unified cluster networking approach to assigning namespaces (for pods) can simplify this architecture immensely. A platform that is able to control egress traffic (outbound data moving outside of the cluster) using a router or firewall method will also allow you to conduct IP whitelisting (explicitly stating which IP addresses are allowed and denying access to all others), for further network access control.
Red Hat OpenShift supplies all of these tools that are well known in any best security practices playbook, as well as numerous other network security measures, in abundance. Chief amongst the API authentication and authorization services it provides are Red Hat Single Sign-On (RH-SSO), which provides SAML 2.0 (Security Assertion Markup Language) and OpenID Connect–based authentication. Furthermore, Web Single Sign-On and federation services are also available via open source Keycloak. RH-SSO 7.1 also features client adapters for Red Hat JBoss, a Node.js client adapter, and integration with LDAP-based directory services. API management tools such as Red Hat 3scale API Management can also be readily added to OpenShift to provide API authentication and organization.
7. United Federation of Containerized Applications
Federation is invaluable when deploying and accessing applications that are running across multiple distributed datacenters or clouds. Kubernetes orchestration supports and facilitates this in two different ways: federated secrets and federated namespaces:
Federated secrets automatically create and manage all authentication and authorization “secrets” (sensitive information like API keys that serve as license files, passwords that get buried in configuration files, and so on) across all clusters belonging to the federation. The result is a globally consistent and up-to-date record of authentication secrets across the whole of the cluster.
Federated namespaces create namespaces in the federation control plane, ensuring that K8s pods have consistent IP addresses and port ranges assigned to them, across all federated environments in the cluster.
Readying Data for the New Normal
Back in 2010, Dave McCrory (an engineer at GE Digital) coined the term data gravity in an attempt to describe the natural attraction between data and applications. (In “millennial speak,” apps swipe right on data every time.) We think that McCrory’s turn of phrase couldn’t be more apt, coming at the start of a decade where more data was generated and collected than all previous years of recorded human history combined.
This trend shows absolutely no signs of wavering in 2021 and beyond. In fact, we believe that the COVID-19 pandemic only further accelerated the explosion of data capture—as more and more work moves to remote, digitally-delivered experiences and processes. Whatever the future holds—from edge computing, to AI, to cloud-born startups offering you fantastic new ways to post something about anything—it all means huge growth in enterprise and personal data.
Following the techniques and strategies outlined in this chapter will enable your organization to overcome many of the challenges associated with data gravity, as we all grapple with how to adapt to the hybrid multicloud paradigm shift. We’ll say it again: there’s no changing the laws of physics (not outside of Hollywood, at any rate). There will inevitably be friction against such changes: the substantial gravity of legacy and on-premises data will drag performance and time-to-delivery for systems spanning public and hybrid clouds; regulatory and security concerns for newly containerized data and applications will require proactive care to mitigate risks; and even the culture within your enterprise or business may be slow to adapt to the new ways of operating in a hybrid multicloud marketplace.
Yet it is our firm conviction that the momentum toward cloud is far greater than the drag from legacy application services that have yet to be modernized for blended off- and on-premises ways of doing business. The techniques covered here (and throughout the book) can give your organization the boost needed to overcome such friction. Data gravity will keep us grounded, but it won’t hold us back.