Regular expressions are all about matching and finding patterns in text, from simple patterns to the very complex. This chapter takes you on a tour of some of the simpler ways to match patterns using:
String literals
Digits
Letters
Characters of any kind
In the first chapter, we used Steven Levithan’s RegexPal to demonstrate regular expressions. In this chapter, we’ll use Grant Skinner’s RegExr site, found at http://gskinner.com/regexr (see Figure 2-1).
Note
Each page of this book will take you deeper into the regular expression jungle. Feel free, however, to stop and smell the syntax. What I mean is, start trying out new things as soon as you discover them. Try. Fail fast. Get a grip. Move on. Nothing makes learning sink in like doing something with it.

Before we go any further, I want to point out the helps that RegExr provides. Over on the right side of RegExr, you’ll see three tabs. Take note of the Samples and Community tabs. The Samples tab provides helps for a lot of regular expression syntax, and the Community tab shows you a large number of contributed regular expressions that have been rated. You’ll find a lot of good information in these tabs that may be useful to you. In addition, pop-ups appear when you hover over the regular expression or target text in RegExr, giving you helpful information. These resources are one of the reasons why RegExr is among my favorite online regex checkers.
This chapter introduces you to our main text, “The Rime of the Ancient Mariner,” by Samuel Taylor Coleridge, first published in Lyrical Ballads (London, J. & A. Arch, 1798). We’ll work with this poem in chapters that follow, starting with a plain-text version of the original and winding up with a version marked up in HTML5. The text for the whole poem is stored in a file called rime.txt; this chapter uses the file rime-intro.txt that contains only the first few lines.
The following lines are from rime-intro.txt:
THE RIME OF THE ANCYENT MARINERE, IN SEVEN PARTS. ARGUMENT. How a Ship having passed the Line was driven by Storms to the cold Country towards the South Pole; and how from thence she made her course to the tropical Latitude of the Great Pacific Ocean; and of the strange things that befell; and in what manner the Ancyent Marinere came back to his own Country. I. 1 It is an ancyent Marinere, 2 And he stoppeth one of three: 3 "By thy long grey beard and thy glittering eye 4 "Now wherefore stoppest me?
Copy and paste the lines shown here into the lower text box in RegExr. You’ll find the file rime-intro.txt at Github at https://github.com/michaeljamesfitzgerald/Introducing-Regular-Expressions. You’ll also find the same file in the download archive found at http://examples.oreilly.com/9781449392680/examples.zip. You can also find the text online at Project Gutenberg, but without the numbered lines (see http://www.gutenberg.org/ebooks/9622).
The most outright, obvious feature of regular expressions is matching strings with one or more literal characters, called string literals or just literals.
The way to match literal strings is with normal, literal characters. Sounds familiar, doesn’t it? This is similar to the way you might do a search in a word processing program or when submitting a keyword to a search engine. When you search for a string of text, character for character, you are searching with a string literal.
If you want to match the word Ship, for example, which is a word (string of characters) you’ll find early in the poem, just type the word Ship in the box at the top of Regexpal, and then the word will be highlighted in the lower text box. (Be sure to capitalize the word.)
Did light blue highlighting show up below? You should be able to see the highlighting in the lower box. If you can’t see it, check what you typed again.
Note
By default, string matching is case-sensitive in Regexpal. If you want to match both lower- and uppercase, click the checkbox next to the words Case insensitive at the top left of Regexpal. If you click this box, both Ship and ship would match if either was present in the target text.
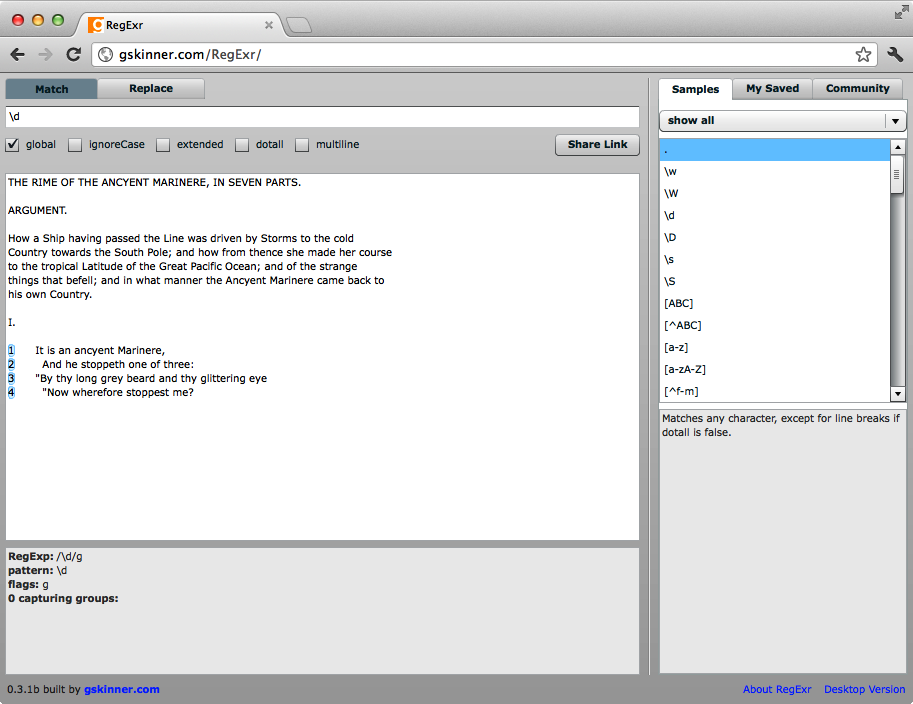
In the top-left text box in RegExr, enter this character shorthand to match the digits:
\d
This matches all the Arabic digits in the text area below because
the global checkbox is selected. Uncheck that
checkbox, and \d will match only the
first occurrence of a digit. (See Figure 2-2.)
Now in place of \d use a
character class that matches the same thing. Enter the following range of
digits in the top text box of RegExr:
[0-9]
As you can see in Figure 2-3, though the syntax is
different, using \d does the same thing
as [0-9].
![Matching all digits in RegExr with [0-9]](httpatomoreillycomsourceoreillyimages1252430.png)
Note
You’ll learn more about character classes in Chapter 5.
The character class [0-9] is a
range, meaning that it will match the range of digits
0 through 9. You could also match digits 0 through 9 by listing all the
digits:
[0123456789]
If you want to match only the binary digits 0 and 1, you would use this character class:
[01]
Try [12] in RegExr and look at
the result. With a character class, you can pick the exact digits you want
to match. The character shorthand for digits (\d) is shorter and simpler, but it doesn’t have
the power or flexibility of the character class. I use character classes
when I can’t use \d (it’s not always
supported) and when I need to get very specific about what digits I need
to match; otherwise, I use \d because
it’s a simpler, more convenient syntax.
As is often the case with shorthands, you can flip-flop—that is, you can go the other way. For example, if you want to match characters that are not digits, use this shorthand with an uppercase D:
\D
Try this shorthand in RegExr now. An uppercase D, rather than a lowercase, matches non-digit characters (check Figure 2-4). This shorthand is the same as the following character class, a negated class (a negated class says in essence, “don’t match these” or “match all but these”):
[^0-9]
which is the same as:
[^\d]

In RegExr, now swap \D
with:
\w
This shorthand will match all word characters (if the
global option is still checked). The difference
between \D and \w is that \D
matches whitespace, punctuation, quotation marks, hyphens, forward
slashes, square brackets, and other similar characters, while \w does not—it matches letters and
numbers.
In English, \w matches
essentially the same thing as the character class:
[a-zA-Z0-9]
Note
You’ll learn how to match characters beyond the set of English letters in Chapter 6.
Now to match a non-word character, use an uppercase W:
\W
This shorthand matches whitespace, punctuation, and other kinds of characters that aren’t used in words in this example. It is the same as using the following character class:
[^a-zA-Z0-9]
Character classes, granted, allow you more control over what you match, but sometimes you don’t want or need to type out all those characters. This is known as the “fewest keystrokes win” principle. But sometimes you must type all that stuff out to get precisely what you want. It is your choice.
Just for fun, in RegExr try both:
[^\w]
and
[^\W]
Do you see the differences in what they match?
Table 2-1 provides an extended list of character shorthands. Not all of these work in every regex processor.
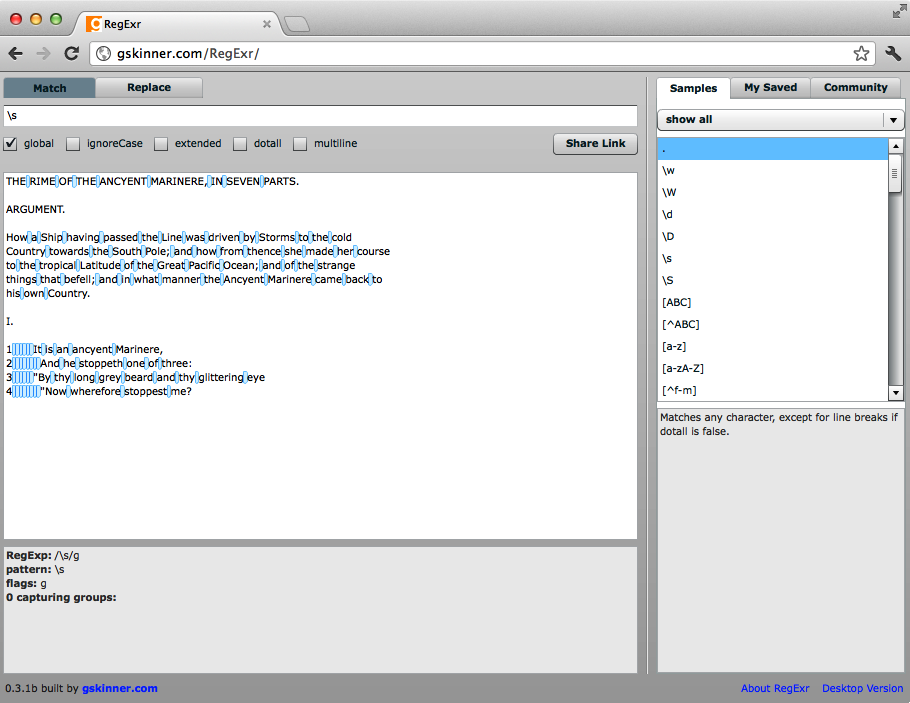
To match whitespace, you can use this shorthand:
\s
Try this in RegExr and see what lights up (see Figure 2-5). The following character class matches the same
thing as \s:
[ \t\n\r]
In other words, it matches:
Spaces
Tabs (
\t)Line feeds (
\n)Carriage returns (
\r)
Note
Spaces and tabs are highlighted in RegExr, but not line feeds or carriage returns.
As you can imagine, \s has its
compañero. To match a non-whitespace character,
use:
\S
This matches everything except whitespace. It matches the character class:
[^ \t\n\r]
Or:
[^\s]
Test these out in RegExr to see what happens.
In addition to those characters matched by \s, there are other, less common whitespace
characters. Table 2-2 lists character shorthands for
common whitespace characters and a few that are more rare.
Note
If you try \h, \H, or \V
in RegExr, you will see results, but not with \v. Not all whitespace shorthands work with
all regex processors.
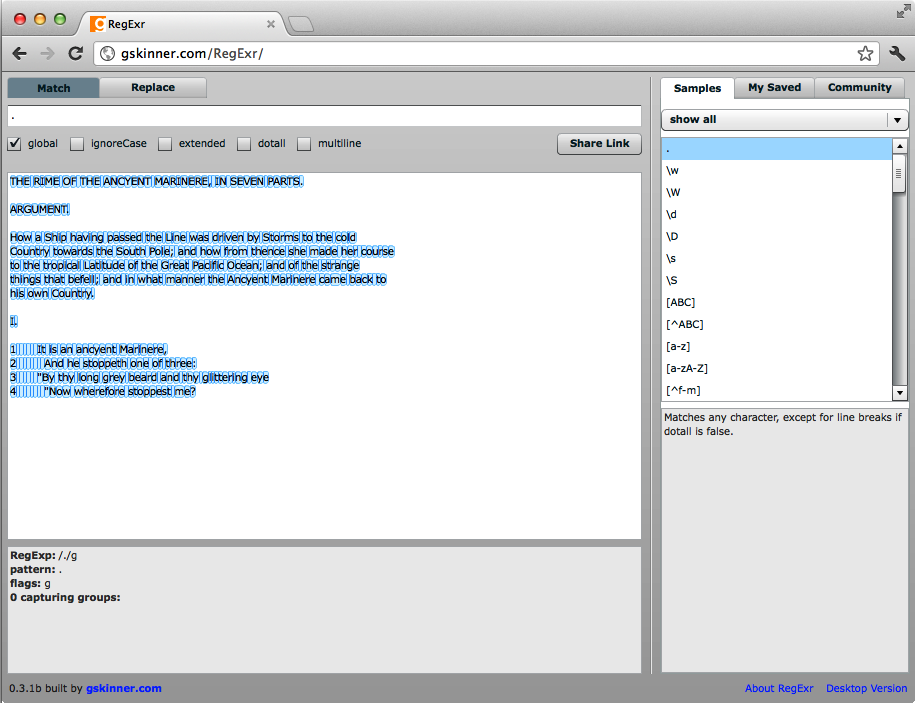
There is a way to match any character with regular expressions and that is with the dot, also known as a period or a full stop (U+002E). The dot matches all characters but line ending characters, except under certain circumstances.
In RegExr, turn off the global setting by clicking the checkbox next to it. Now any regular expression will match on the first match it finds in the target.
Now to match a single character, any character, just enter a single dot in the top text box of RegExr.
In Figure 2-6, you see that the dot matches the first character in the target, namely, the letter T.
If you wanted to match the entire phrase THE RIME, you could use eight dots:
........
But this isn’t very practical, so I don’t recommend using a series of dots like this often, if ever. Instead of eight dots, use a quantifier:
.{8}and it would match the first two words and the space in between, but crudely so. To see what I mean by crudely, click the checkbox next to global and see how useless this really is. It matches sequences of eight characters, end on end, all but the last few characters of the target.
Let’s try a different tack with word boundaries and starting and ending letters. Type the following in the upper text box of RegExr to see a slight difference:
\bA.{5}T\bThis expression has a bit more specificity. (Try saying specificity three times, out loud.) It matches the word ANCYENT, an archaic spelling of ancient. How?
The shorthand
\bmatches a word boundary, without consuming any characters.The characters A and T also bound the sequence of characters.
.{5}matches any five characters.Match another word boundary with
\b.
This regular expression would actually match both ANCYENT or ANCIENT.
Now try it with a shorthand:
\b\w{7}\bFinally, I’ll talk about matching zero or more characters:
.*
which is the same as:
[^\n]
or
[^\n\r]
Similar to this is the dot used with the one or more quantifier (+):
.+
Try these in RegExr and they will, either of them, match the first
line (uncheck global). The reason why is that,
normally, the dot does not match newline characters, such as a line feed
(U+000A) or a carriage return (U+000D). Click the checkbox next to
dotall in RegExr, and then .* or .+ will match all the text
in the lower box. (dotall means a dot will match all
characters, including newlines.)
The reason why it does this is because these quantifiers are greedy; in other words, they match all the characters they can. But don’t worry about that quite yet. Chapter 7 explains quantifiers and greediness in more detail.
“The Rime of the Ancient Mariner” is just plain text. What if you wanted to display it on the Web? What if you wanted to mark it up as HTML5 using regular expressions, rather than by hand? How would you do that?
In some of the following chapters, I'll show you ways to do this. I'll start out small in this chapter and then add more and more markup as you go along.
In RegExr, click the Replace tab, check multiline, and then, in the first text box, enter:
(^T.*$)
Beginning at the top of the file, this will match the first line of the poem and then capture that text in a group using parentheses. In the next box, enter:
<h1>$1</h1>
The replacement regex surrounds the captured group, represented by
$1, in an h1
element. You can see the result in the lowest text area. The $1 is a backreference, in Perl style. In most
implementations, including Perl, you use this style: \1; but RegExr supports only $1, $2,
$3 and so forth. You’ll learn more
about groups and backreferences in Chapter 4.
On a command line, you could also do this with sed. sed is a Unix streaming editor that accepts regular expressions and allows you to transform text. It was first developed in the early 1970s by Lee McMahon at Bell Labs. If you are on the Mac or have a Linux box, you already have it.
Test out sed at a shell prompt (such as in a Terminal window on a Mac) with this line:
echo Hello | sed s/Hello/Goodbye/
This is what should have happened:
The echo command prints the word Hello to standard output (which is usually just your screen), but the vertical bar (|) pipes it to the sed command that follows.
This pipe directs the output of echo to the input of sed.
The s (substitute) command of sed then changes the word Hello to Goodbye, and Goodbye is displayed on your screen.
If you don’t have sed on your platform already, at the end of this chapter you’ll find some technical notes with some pointers to installation information. You’ll find discussed there two versions of sed: BSD and GNU.
Now try this: At a command or shell prompt, enter:
sed -n 's/^/<h1>/;s/$/<\/h1>/p;q' rime.txt
And the output will be:
<h1>THE RIME OF THE ANCYENT MARINERE, IN SEVEN PARTS.</h1>
Here is what the regex did, broken down into parts:
The line starts by invoking the sed program.
The
-noption suppresses sed’s default behavior of echoing each line of input to the output. This is because you want to see only the line effected by the regex, that is, line 1.s/^/<h1>/places an h1 start-tag at the beginning (^) of the line.s/$/<\/h1>/places an h1 end-tag at the end ($) of the line.The p command prints the affected line (line 1). This is in contrast to
-n, which echoes every line, regardless.Lastly, the q command quits the program so that sed processes only the first line.
All these operations are performed against the file rime.txt.
Another way of writing this line is with the -e option. The -e option appends the editing commands, one
after another. I prefer the method with semicolons, of course, because
it’s shorter.
sed -ne 's/^/<h1>/' -e 's/$/<\/h1>/p' -e 'q' rime.txt
You could also collect these commands in a file, as with h1.sed shown here (this file is in the code repository mentioned earlier):
#!/usr/bin/sed s/^/<h1>/ s/$/<\/h1>/ q
To run it, type:
sed -f h1.sed rime.txt
Finally, I’ll show you how to do a similar process with Perl. Perl is a general purpose programming language created by Larry Wall back in 1987. It’s known for its strong support of regular expressions and its text processing capabilities.
Find out if Perl is already on your system by typing this at a command prompt, followed by Return or Enter:
perl -v
This should return the version of Perl on your system or an error (see Technical Notes).
To accomplish the same output as shown in the sed example, enter this line at a prompt:
perl -ne 'if ($. == 1) { s/^/<h1>/; s/$/<\/h1>/m; print; }' rime.txtand, as with the sed example, you will get this result:
<h1>THE RIME OF THE ANCYENT MARINERE, IN SEVEN PARTS.</h1>
Here is what happened in the Perl command, broken down again into pieces:
perl invokes the Perl program.
The
-noption loops through the input (the file rime.txt).The
-eoption allows you to submit program code on the command line, rather than from a file (like sed).The if statement checks to see if you are on line 1.
$.is a special variable in Perl that matches the current line.The first substitute command s finds the beginning of the first line (
^) and inserts an h1 start-tag there.The second substitute command searches for the end of the line (
$), and then inserts an h1 end-tag.The m or multiline modifier or flag at the end of the substitute command indicates that you are treating this line distinctly and separately; consequently, the
$matches the end of line 1, not the end of the file.At last, it prints the result to standard output (the screen).
All these operations are performed again the file rime.txt.
You could also hold all these commands in a program file, such as this file, h1.pl, found in the example archive.
#!/usr/bin/perl -n
if ($. == 1) {
s/^/<h1>/;
s/$/<\/h1>/m;
print;
}And then, in the same directory as rime.txt, run the program like this:
perl h1.pl rime.txt
There are a lot of ways you can do things in Perl. I am not saying this is the most efficient way to add these tags. It is simply one way. Chances are, by the time this book is in print, I’ll think of other, more efficient ways to do things with Perl (and other tools). I hope you will, too.
In the next chapter, we’ll talk about boundaries and what are known as zero-width assertions.
How to match string literals
How to match digits and non-digits
What the global mode is
How character shorthands compare with character classes
How to match word and non-word characters
How to match whitespace
How to match any character with the dot
What the dotall mode is
How to insert HTML markup to a line of text using RegExr, sed, and Perl
RegExr is found at http://www.gskinner.com/RegExr and also has a desktop version (http://www.gskinner.com/RegExr/desktop/). RegExr was built in Flex 3 (http://www.adobe.com/products/flex.html) and relies on the ActionScript regular expression engine (http://www.adobe.com/devnet/actionscript.html). Its regular expressions are similar to those used by JavaScript (see https://developer.mozilla.org/en/JavaScript/Reference/Global_Objects/RegExp).
Git is a fast version control system (http://git-scm.com). GitHub is a web-based repository for projects using Git (http://github.com). I suggest using the GitHub repository for samples in this book only if you feel comfortable with Git or with other modern version control systems, like Subversion or Mercurial.
HTML5 (http://www.w3.org/TR/html5/) is the fifth major revision of the W3C’s HTML, the markup language for publishing on the World Wide Web. It has been in draft for several years and changes regularly, but it is widely accepted as the heir apparent of HTML 4.01 and XHTML.
sed is readily available on Unix/Linux systems, including the Mac (Darwin or BSD version). It is also available on Windows through distributions like Cygwin (http://www.cygwin.com) or individually at http://gnuwin32.sourceforge.net/packages/sed.htm (currently at version 4.2.1, see http://www.gnu.org/software/sed/manual/sed.html).
To use the Perl examples in this chapter, you may have to install Perl on your system. It comes by default with Mac OS X Lion and often is on Linux systems. If you are on Windows, you can get Perl by installing the appropriate Cygwin packages (see http://www.cygwin.com) or by downloading the latest package from the ActiveState website (go to http://www.activestate.com/activeperl/downloads). For detailed information on installing Perl, visit http://learn.perl.org/installing/ or http://www.perl.org/get.html.
To find out if you already have Perl, enter the command below at a shell prompt. To do this, open a command or shell window on your system, such as a Terminal window (under Applications/Utilities) on the Mac or a Windows command line window (open Start, and then enter cmd in the text box at the bottom of the menu). At the prompt, type:
perl -v
If Perl is alive and well on your system, then this command will return version information for Perl. On my Mac running Lion, I’ve installed the latest version of Perl (5.16.0 at the time of this writing) from source and compiled it (see http://www.cpan.org/src/5.0/perl-5.16.0.tar.gz). I get the following information back when I enter the command above:
This is perl 5, version 16, subversion 0 (v5.16.0) built for darwin-2level Copyright 1987-2012, Larry Wall Perl may be copied only under the terms of either the Artistic License or the GNU General Public License, which may be found in the Perl 5 source kit. Complete documentation for Perl, including FAQ lists, should be found on this system using "man perl" or "perldoc perl". If you have access to the Internet, point your browser at http://www.perl.org/, the Perl Home Page.
Both
perlandperldocare installed at/usr/local/binwhen compiled and built from source, which you can add to your path. For information on setting your path variable, see http://java.com/en/download/help/path.xml.