“Unix was not designed to stop you from doing stupid things, because that would also stop you from doing clever things.” —Doug Gwyn
Congratulations for making it this far. You’re not a regular expression novice anymore. You have been introduced to the most commonly used regular expression syntax. And it will open a lot of possibilities up to you in your work as a programmer.
Learning regular expressions has saved me a lot of time. Let me give you an example.
I use a lot of XSLT at work, and often I have to analyze the tags that exist in a group of XML files.
I showed you part of this in the last chapter, but here is a long one-liner that takes a list of tag names from lorem.dita and converts it into a simple XSLT stylesheet:
grep -Eo '<[_a-zA-Z][^>]*>' lorem.dita | sort | uniq | sed '1 i\ <xml:stylsheet version="2.0" xmlns:xsl="http://www.w3.org/1999/XSL/Transform">\ ; s/^</\ <xsl:template match="/;s/ id=\".*\"//;s/>$/">\ <xsl:apply-templates\/>\ <\/xsl:template>/;$ a\ \ </xsl:stylesheet>\ '
I know this script may appear a bit acrobatic, but after you work with this stuff for a long time, you start thinking like this. I am not even going to explain what I’ve done here, because I am sure you can figure it out on your own now.
Here is what the output looks like:
<xml:stylsheet version="2.0" xmlns:xsl="http://www.w3.org/1999/XSL/Transform"> <xsl:template match="body"> <xsl:apply-templates/> </xsl:template> <xsl:template match="li"> <xsl:apply-templates/> </xsl:template> <xsl:template match="p"> <xsl:apply-templates/> </xsl:template> <xsl:template match="title"> <xsl:apply-templates/> </xsl:template> <xsl:template match="topic"> <xsl:apply-templates/> </xsl:template> <xsl:template match="ul"> <xsl:apply-templates/> </xsl:template> </xsl:stylesheet>
That’s only a start. Of course, this simple stylesheet will need a lot of editing before it can do anything useful, but this is the kind of thing that can save you a lot of keystrokes.
I’ll admit, it would be easier if I put these sed commands in a file. As a matter of fact, I did. You’ll find xslt.sed in the sample archive. This is the file:
#!/usr/bin/sed 1 i\ <xml:stylsheet version="2.0" xmlns:xsl="http://www.w3.org/1999/XSL/Transform">\ s/^</\ <xsl:template match="/;s/ id=\".*\"//;s/>$/">\ <xsl:apply-templates\/>\ <\/xsl:template>/;$ a\ \ </xsl:stylesheet>\
And here is how to run it:
grep -Eo '<[_a-zA-Z][^>]*>' lorem.dita | sort | uniq | sed -f xslt.sed
Even though you have a good strong grip on regex now, there is still lots to learn. I have a couple of suggestions of where to go next.
I pass these recommendations along out of experience and observation, not from any sense of obligation or to be “salesy.” I won’t get any kickbacks for mentioning them. I talk about them because these resources will actually benefit you.
Jeffrey E. F. Friedl’s Mastering Regular Expressions, Third Edition is the source many programmers look to for a definitive treatment of the regular expression. Both expansive and well-written, if you are going to do any significant work with regex, you need to have this book on your shelf or in your e-reader. Period.
Jan Goyvaerts and Steven Levithan’s Regular Expressions Cookbook is another great piece of work, especially if you are comparing different implementations. I’d get this one, too.
The Regular Expression Pocket Reference: Regular Expressions for Perl, Ruby, PHP, Python, C, Java and .NET by Tony Stubblebine is a 128-page guide which, though it is several years old, still remains popular.
Andrew Watt’s book Beginning Regular Expressions (Wrox, 2005) is highly rated. I have found Bruce Barnett’s online sed tutorial particularly useful (see http://www.grymoire.com/Unix/Sed.html). He demonstrates a number of sed’s less understood features, features I have not explained here.
I’ve mentioned a number of tools, implementations, and libraries in this book. I’ll recap those here and mention several others.
Perl is a popular, general-purpose programming language. A lot of people prefer Perl for text processing with regular expressions over other languages. You likely already have it, but for information on how to install Perl on your system, go to http://www.perl.org/get.html. Read about Perl’s regular expressions at http://perldoc.perl.org/perlre.html. Don’t get me wrong. There are plenty of other languages that do a great job with regex, but it pays to have Perl in your toolbox. To learn more, I’d get a copy of the latest edition of Learning Perl, by Randal Schwartz, brian d foy, and Tom Phoenix, also published by O’Reilly.
Perl Compatible Regular Expressions or PCRE (see http://www.pcre.org) is a regular expression library written in C (both 8-bit and 16-bit). This library mainly consists of functions that may be called within any C framework or from any other language that can use C libraries. It is compatible with Perl 5 regular expressions, as its name suggests, and includes some features from other regex implementations. The Notepad++ editor uses the PCRE library.
pcregrep is an 8-bit, grep-like tool that
enables you to use the features of the PCRE library on the command line.
You used it in Chapter 3. See http://www.pcre.org for download information (from ftp://ftp.csx.cam.ac.uk/pub/software/programming/pcre/).
You can get pcregrep for the Mac through Macports
(http://www.macports.org) by running the command sudo
port install pcre (Xcode is a prerequisite; see https://developer.apple.com/technologies/tools/, where a
login is required). To install it on the Windows platform (binaries), go
to http://gnuwin32.sourceforge.net/packages/pcre.htm.
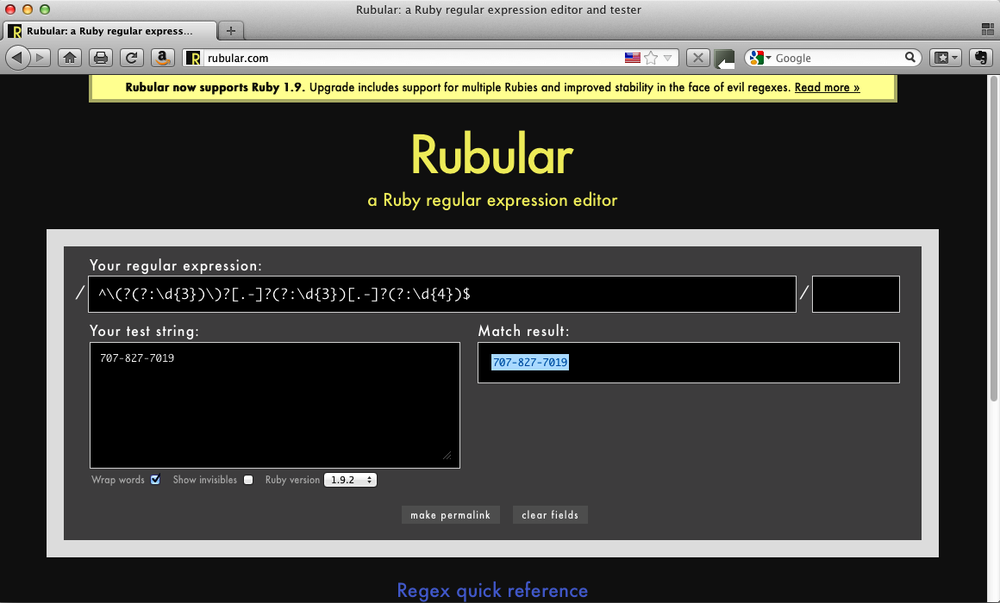
Oniguruma is a regular expression library that is standard with Ruby 1.9; see http://oniguruma.rubyforge.org/. It is written in C and was written specifically to support Ruby. You can try out Ruby’s regular expression using Rubular, an online app that supports both 1.8.7 and 1.9.2 (see http://www.rubular.com and Figure 10-1). TextMate, by the way, uses the Oniguruma library.
Python is a general-purpose programming language that supports regular expressions (see http://www.python.org). It was first created by Guido van Rossum in 1991. You can read about Python 3’s regular expression syntax here: http://docs.python.org/py3k/library/re.html?highlight=regular%20expressions.
RE2 is a non-backtracking C++ regular expression library (see http://code.google.com/p/re2). While RE2 is quite fast, it does not do backtracking or backreferences. It is available as a CPAN package for Perl and can fall back on Perl’s native library if backreferences are needed. For instructions on making API calls, see http://code.google.com/p/re2/wiki/CplusplusAPI. For an interesting discussion on RE2, see “Regular Expression Matching in the Wild” at http://swtch.com/~rsc/regexp/regexp3.html.
You remember the North American phone number example from the first chapter? You’ve come a long way since then.
Here is a more robust regular expression for matching phone numbers than the one we used there. It is adapted from Goyvaerts and Levithan’s example on page 235 of their Regular Expressions Cookbook (first edition).
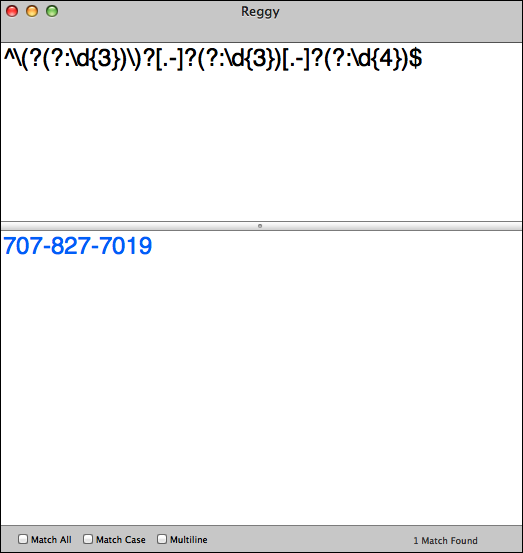
^\(?(?:\d{3})\)?[-.]?(?:\d{3})[-.]?(?:\d{4})$Play with it with the tool of your choice (see it in Reggy in Figure 10-2). By now, you should be able to pick this regex apart with hardly any hand-holding. I’m proud of you for that. But I’ll go over it for good measure.
^is the zero-width assertion for the beginning of a line or subject.\(?is a literal left parenthesis, but it is optional (?).(?:\d{3})is a non-capturing group matching three consecutive digits.\)?is an optional right parenthesis.[-.]?allows for an optional hyphen or period (dot).(?:\d{3})is another non-capturing group matching three more consecutive digits.[-.]?allows for an optional hyphen or dot again.(?:\d{4})is yet another non-capturing group matching exactly four consecutive digits.$matches the end of a line or subject.
This expression could be even more refined, but I leave that to you because you can now do it on your own.
Lastly, I’ll throw one more regular expression at you, an email address:
^([\w-.!#$%&'*+-/=?^_`{|}~]+)@((?:\w+\.)+)(?:[a-zA-Z]{2,4})$This is an adaptation of one provided by Grant Skinner with RegExr. I’d like to challenge you to do your best to explain what each character means in the context of a regular expression, and to see if you can improve on it. I am sure you can.
Thank you for your time. I’ve enjoyed spending it with you. You should now have a good grasp of the fundamental concepts of regular expressions. You are no longer a member of the beginners’ club. I hope you’ve made friends with regular expressions and learned something worthwhile along the way.
How to extract a list of XML elements from a document and convert the list into an XSLT stylesheet.
Where to find additional resources for learning about regular expressions.
What are some notable regex tools, implementations, and libraries.
A slightly, more robust pattern for matching a North American phone number.