data analysis, thick description and reflexivity
data analysis, thick description and reflexivityApproaches to qualitative data analysis |
CHAPTER 28 |
This chapter discusses several forms of qualitative data analysis. Subsequent chapters focus more specifically on content analysis and grounded theory. We deal here with different approaches to qualitative data analysis, including:
data analysis, thick description and reflexivity
ethics in qualitative data analysis
computer assisted qualitative data analysis (CAQDAS)
This chapter sets the scene for more in-depth considerations of different ways of analysing data in Chapters 29 to 33.
Qualitative data analysis involves organizing, accounting for and explaining the data; in short, making sense of data in terms of the participants’ definitions of the situation, noting patterns, themes, categories and regularities.
There is no one single or correct way to analyse and present qualitative data; how one does it should abide by the issue of fitness for purpose. Further, qualitative data analysis, as we shall see here, is often heavy on interpretation, and one has to note that there are firequently multiple interpretations to be made of qualitative data – that is their glory and their headache! Qualitative data analysis is distinguished by its merging of analysis and interpretation and often by the merging of data collection with data analysis (Gibbs, 2007: 3) in an iterative, back-and-forth process (Teddlie and Tashakkori, 2009: 251); indeed the results of the analysis also constitute data for further analysis. As researchers write down notes, memos, thoughts, reflections, in the field or during an interview or observation, these, too, become data.
Qualitative data derive from many sources, for example:
interviews (transcribed or not transcribed);
observation (participant to non-participant);
field notes;
documents and reports;
memos;
emails and online conversations;
diaries;
audio, and video and film materials;
website data;
advertisements, and print materials;
pictures and photographs;
artefacts.
Researchers will need to consider whether to transcribe interview data for analysis. On the one hand transcriptions can provide important detail and an accurate verbatim record of the interview. On the other hand they omit non-verbal aspects, and, indeed, what may take place before or after the interview, and the contextual features of the interview. Further, on a practical level, they are very time-consuming to prepare (e.g. one hour of interview may take up to five or six hours to transcribe, even with a transcription machine (a machine that can be paused (e.g. by a foot pedal) whilst the transcriber writes down the words, or software that will enable a researcher to pause to enter data into, for example, a dialogue box)). The researcher will need to consider the costs and benefits of transcription. An alternative to transcription is to write the analysis of the data directly from the video or audio recording, selecting out the important materials directly from the original source rather than from the mediated source of transcription, thereby avoiding becoming so caught up in detail that sight of the bigger picture is lost.
If transcription is used, then the researcher must make clear the transcription conventions being followed (see also Chapter 30), for example:
give each speaker a name or pseudonym (and keep a list separately of which speaker has which pseudonym);
record hesitations, small to long pauses, and silences (e.g. through dots (. . .) in the text);
recording inflections and tone of voice (rising to falling), e.g. writing down the mood of the speaker or the speech at the time: anger, anxiety, sadness, excitement, questioning, hesitance, etc.;
volume of the speaker (quiet to loud, whispering to shouting);
recording the speed of the speech (slow to fast, hurried to calm);
breaks (sudden to considered) in speech;
stresses and phases in the speech;
audible breathing out or breathing in;
non-verbal activity (e.g. standing up, leaning back, etc.);
record uninterpretable noise (e.g. the words in brackets ‘noise’ or ‘unclear noise’);
record several speakers who are all speaking at the same time (e.g. the word ‘together’ after each speaker’s name);
record non-verbal behaviours (if transcribing from video recording);
being consistent in spelling (so that search and retrieval can be facilitated, particularly if software for this is used, discussed later);
ensuring that each line or section/paragraph is numbered (in Word this can be done through the ‘Layout’ or ‘Page Layout’ menu (depending on the version of Word being used));
ensuring that wide margins and double spacing are used for annotating text in hard copy form.
For a fuller description of these see Atkinson and Heritage (1999), Flick (2009: 300–2) and Woods (2010). The transcriber will need to check the accuracy of the transcription, as it is not uncommon for speech to be heard incorrectly or for words to be confused (Gibbs (2007: 19) gives many examples of such confusions).
Voice recognition software is becoming available that will both recognize and transcribe speech, and this can save time, though the reliability of the transcription is influenced by the accuracy of the speech recognition.
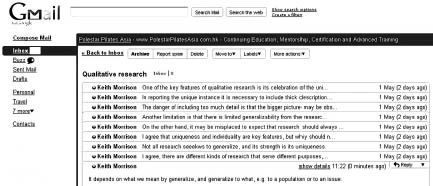
Researchers can analyse ‘threaded’ electronic conversations or communications, in which topics are linked together or the ongoing communications between the same parties are entered onto email inboxes. For example Figure 28.1 provides an edited screen shot of a deliberately prepared sequence of emails sent through Gmail by one of our authors to himself, for the purpose of illustrating how emails can indicate a threaded conversation. Here one can see eight emails in a single thread, and Gmail records the opening words of each of the previous emails in the thread (above the email currently opened), with times (i.e. a chronology) at which the earlier emails were sent.
In abiding by the principle of fitness for purpose, the researcher must be clear what s/he wants the data analysis to do as this will determine the kind of analysis that is undertaken. The researcher can set out, for example:
to describe;
to portray;
to summarize;
to interpret;
to discover patterns;
to generate themes;
to understand individuals and idiographic features;
to understand groups and nomothetic features (e.g. firequencies, norms, patterns, ‘laws’);
to raise issues;
to explain and seek causality;
to explore;
to test;
to discover commonalities, differences and similarities;
to examine the application and operation of the same issues in different contexts.
The significance of deciding the purpose is that it will determine the kind of analysis performed on the data. This, in turn, will influence the way in which the analysis is written up. The data analysis will also be influenced by the kind of qualitative study that is being undertaken. For example, a biography and a case study may be most suitably written as descriptive narrative, often chronologically, with issues raised throughout. An ethnography may be written as narrative or stories, with issues raised, but not necessarily conforming to a chronology of events, and including description, analysis, interpretation and explanation of the key features of a group or culture. A grounded theory and content ana lysis will proceed through a systematic series of analyses, including coding and categorization, until theory emerges that explains the phenomena being studied or which can be used for predictive purposes.
The analysis will also be influenced by the number of data sets and people from whom data have been collected. Qualitative data often focus on smaller numbers of people than quantitative data, yet the data tend to be detailed and rich. Researchers will need to decide, for example, whether to present data individual by individual, and then, if desired, to amalgamate key issues emerging across the individuals, or whether to proceed by working within a largely predetermined analytical frame of issues that crosses the individuals concerned. Some qualitative studies (e.g. Ball, 1990, 1994a; Bowe et al., 1992) deliberately focus on individuals and the responses of significant players in a particular scenario, often quoting verbatim responses in the final account; others are content to summarize issues without necessarily identifying exactly from whom the specific data were derived. Later on here we discuss methods to be used with respect to people and issues.
Some studies include a lot of verbatim conversations; others use fewer verbatim data. Some researchers feel that it is important to keep the flavour of the original data, so they report direct phrases and sentences, not only because they are often more illuminative and direct than the researchers’ own words, but also because they feel that it is important to be faithful to the exact words used. Indeed, as reported in the example later, direct conversations can be immensely rich in data and detail. Ball (1990) and Bowe et al. (1992) use a lot of verbatim data, not least because those whom they interviewed were powerful people and justice needed to be done to the exact words that they used. By contrast Walford (2001: 92), commenting on the ‘fetish of transcription’, admits that he ‘rarely fully transcribed more than a few interviews for any of [his] research studies’, not least because of the time that it took for transcription (Walford suggests a ratio of 5 to 1 – five hours to transcribe one hour of interviews, though it can take much longer than this).
At a theoretical level, a major feature of qualitative research is that analysis often begins early on in the data collection process so that theory generation can be undertaken (LeCompte and Preissle, 1993: 238). LeCompte and Preissle (1993: 237–53) advise that researchers should set out the main outlines of the phenomena that are under investigation. They should then assemble blocks or groups of data, putting them together to make a coherent whole (e.g. through writing summaries of what has been found). Then they should painstakingly take apart their field notes, matching, contrasting, aggregating, comparing and ordering notes made. The intention is to move from description to explanation and theory generation.
At a practical level, qualitative research rapidly amasses huge amounts of data, and early analysis can reduce the problem of data overload by selecting out significant features for future focus. Indeed Miles and Huberman (1984) advise researchers to start writing and analysing early and firequently (i.e. as soon as the first data have been collected, even in a longitudinal study), rather than to leave all the writing and analysis until the data collection is over, as this enables ‘progressive focusing’, and selection of key issues for further investigation to be conducted. As Gibbs (2007: 25) remarks, ‘writing is thinking’. Such analysis should, itself, be given a date and time, and could be included in a diary of field notes which record, for example, what the researcher was doing, where the researcher was, what was happening at the time, who was present, what the data were, particular or notable features of the event, context or situation, reflections and observation (Miles and Huberman, 1994: 50–4).
‘Progressive focussing’, according to Parlett and Hamilton (1976), starts with the researcher taking a wide-angle lens to gather data, and then, by sifting, sorting, reviewing and reflecting on them, the salient features of the situation emerge. These are then used as the agenda for subsequent focusing. The process is akin to funnelling from the wide to the narrow. Miles and Huberman (1984) suggest that careful data display is an important element of data reduction and selection. On the other hand Gibbs (2007: 4) argues that qualitative data analysis, far from reducing data, actually increases its ‘bulk, density and complexity’ as it creates more texts such as notes, reflections, memos (discussed later), summaries, reflexive insights and further notes, in short, in its attempt to generate ‘thick descriptions’ (Geertz, 1973): data that not only describe events in context, but participants’ intentions, strategies and agency.
Geertz (1973) argues that thick descriptions include reflections on meanings attributed to situations and phenomena. As he writes: ‘The ethnographer “inscribes” social discourse; he writes it down. In so doing, he turns it from a passing event, which exists only in its own moment of occurrence, into an account, which exists in its inscriptions and can be reconsulted’ (p. 19). Doing ethnography, he writes, ‘is like trying to read (in the sense of “construct a reading of”) a manuscript – foreign, faded, full of ellipses, incoherencies, suspicious emendations, and tendentious commentaries, but written not in conventionalized graphs of sound but in transient examples of shaped behavior’ (p. 10).
The qualitative data, yielded by research instruments such as interviews, observations and accounts, present several challenges. First, data are so rich that analysis involves much selecting and ordering on the part of the researcher. This, as a result, might involve some personal bias to which the researcher needs to be alert. Second, since the data obtained are all couched in ‘social events’, reporting involves a double hermeneutic process (Giddens, 1976) by which the researcher interprets the data from participants who have already interpreted their world, and then relates them to the audience in his/her own words. Hence the reporting and analysis should strive to catch the different definitions of the situation from the different participants, and to combine etic and emic analysis. This naturally may subject the data to criticisms of lack of objectivity, which is attenuated by reflexivity on the part of the researcher. Given this, qualitative data analysis is often written in the first person, and with colloquial language rather than the conventional third-person, passive voice and past tense of many pieces of reported research.
In selecting, organizing, analysing, reporting and interpreting data the researcher is faced with several decisions and issues. For example, there is a risk that, since data and interpretation are unavoidably combined (the double hermeneutic), the subjective views of the researcher might lead to him or her being over-selective, unrepresentative and unfair to the situation in hand in the choice of data and the interpretation placed on them. Fact and interpretation are inseparable, and the selection of which events and data to include are, to some extent, under the control of the researcher. Indeed, as participants (including the researcher), act on interpretations, interpretations may, themselves, become facts in the situation, i.e. an interpretation can constitute a fact or data. As Geertz (1973: 14) writes: ‘in short, anthropological writings are themselves interpretations, and second and third order ones to boot. . . . They are, thus, fictions; fiction in the sense that they are “something made”.’
The issue concerns validity and reliability in qualitative data analysis, as there may be limited external points of appeal other than respondent validation. The researcher’s choice of which data and events to include inevitably involves a personal choice, but this choice has to be fair to the phenomena under investigation. As Geertz (1973: 13) writes: ‘finding our feet, an unnerving business which never more than distantly succeeds, is what ethnographic research consists of as a personal experience’.
Geertz’s view is echoed in the later edition of Whyte’s (1993) Appendix A to his celebrated study of Street Corner Society, where he writes that:
it seemed as if the academic world had imposed a conspiracy of silence regarding the personal experiences of field workers. . . . It was impossible to find realistic accounts that revealed the errors and confusions and the personal involvements that a field worker must experience. I decided to do my bit to fill this gap. In undertaking this task it seemed to me important to be as honest about myself as I could possibly be.
(Whyte, 1993: 358–9)
Indeed he writes that ‘participatory action research (PAR) provides one important means of bridging the gap between professional researchers and members of the organization we study’ (Whyte, 1993: 364).
Further, he reports commentaries that the researcher:
abandons any hope of establishing scientific conclusions, and speaks rather of ‘rendering your account credible through rendering your person so’. . . . Ethnography takes . . . more and more openly today, a rather introspective turn. To be a customary ‘I-witness’ one must, so it seems, first become a convincing ‘I’. Ethnological writing thus comes to depend on persuasion of the reader. . . . I have come to recognize that the objective-subjective distinction is not as clear as I once thought. . . . We seek to observe behavior that is significant to our research purposes. Selection therefore depends upon some implicit or explicit theory – a process which is in large part subjective. But the choice is not random. If we specify our theoretical assumptions and the research methods we use, others can utilize the same assumptions and methods to either verify or challenge our conclusions.
(Whyte, 1993: 366–7)
Further, in the same volume Whyte (1993: 362) even questions the practicality of, or necessity for, respondent validation, particularly if the researcher discovers something that might contradict or upset the values and practices of the group. There is ‘the right of the researcher to publish conclusions and interpretations as he or she sees them’ (p. 362).
Respondent validation may be problematic as, for example, respondents:
may change their minds as to what they wished to say, or meant, or meant to say but did not say, or wished to have included or made public;
may have faulty memories and may have recalled events over-selectively, or incorrectly, or not at all;
may disagree with the interpretations made by the researcher;
may wish to withdraw comments made in light of subsequent events in their lives;
may have said what they said in the heat of the moment or because of peer pressure or authority pressure;
may feel embarrassed by, or nervous about, what they said.
If respondents are asked to validate the data and the data analysis and interpretation, then, as Gibbs (2007: 95) remarks, their responses may then become data. For example, if respondents wish to withdraw their comments (and they may be entitled to do this if informed consent was given for all stages of the research, but they may not be entitled to do this if the informed consent was given to participate in the research but not to alter the reporting, i.e. the researcher owns the data, once given), or change them, or prevent their public disclosure, then the researcher may wish to explore the reasons for this, and this, too, may become part of the research.
Further, whilst many qualitative data derive from field notes, some of these, given the exigencies of the moment (the ‘personal convenience’ of the researcher (Hammersley and Atkinson, 1983: 173)) and the press for time, also may use the researcher’s own memory, and this might be fallible, selective and over-interpreting a situation (Hammersley and Atkinson, 1983: 172). The same authors also indicate that ‘there is no single correct way of retrieving the data for analysis’ (p. 173). Indeed, to repeat Geertz (1973: 19), ‘the ethnographer “inscribes” social discourse; he writes it down’. He adds:
So, there are three characteristics of ethnographic description: it is interpretive; what it is interpretive of is the flow of social discourse; and the interpreting involved consists in trying to rescue the “said” of such discourse from its perishing occasions and fix it in perusable terms. . . . But there is, in addition, a fourth characteristic of such description . . .: it is microscopic.
(Geertz, 1973: 20–1)
Hence it is important not only to examine a situation and events through the eyes of the researcher, but also to use a range of data and to ensure that these data include the views of other participants in a situation, in order to give some ‘externality’ to the situation and to focus on actual things that happened and which can be corroborated by other participants. The process is inductive and reflexive, yet true to the indicators and constructs of the interpretation made.
Further, Hammersley and Atkinson (1983: 173) indicate the importance of reflexivity in addressing validity and reliability in the analysis qualitative data. They write that:
When it comes to writing up, the principle of reflexivity implies a number of things. The construction of the researcher’s account is, in principle, no different from other varieties of account: just as there is no neutral language of description, so there is no neutral mode of report. The reflexive researcher, then, must remain self-conscious as an author, and the chosen modes of writing should not be taken for granted. There can be no question, then, of viewing writing as a purely technical matter . . . [as a qualitative analysis or account; it] is more informal and impressionistic and thus written in the first person.
(Hammersley and Atkinson, 1983: 207–8)
Hammersley and Atkinson (1983) suggest that a qualitative data analysis itself becomes a text, i.e. as constructed interpretations, and that their organization, ordering, chronology chosen, selection of themes and narrative style have to be subject to reflexivity (pp. 212–17). Hence, the validity of the selection, analysis and interpretation of events and the data that are included in analysis, whilst being inductively and reflexively chosen, and whilst being unavoidably personal and partly impressionistic, are not only that – they are subject to the validity checks of having other participants’ views included and a faithful record made of actual events which involve more than the single researcher.
Qualitative data can be analysed for their nomothetic properties (patterns, themes (both emergent and pre-ordinate/a priori), trends, commonalities, generalizations, similarities, laws of behaviour) and their idiographic properties (individual, unique events, people, behaviours, contexts, actions, intentions). Nomothetic approaches to data analysis are well represented in the work of Miles and Huberman (1994), whilst idiographic approaches are well represented in life histories, case studies, individual biographies and narratives.
Given that qualitative data analysis firequently concerns individual cases and unique instances, and may involve personal and sensitive matters, it raises the question of identifiability, confidentiality and privacy of individuals. Whilst numerical data can be aggregated so that individuals are not traceable, this may not be the case in qualitative data analysis, even if individuals are not named or are given pseudonyms. The researcher has an ethical obligation to reflect on the principles of non-maleficence, loyalties (and to whom) and beneficence set out in Chapter 5, and to ensure that the principle of primum non nocere is addressed – do no harm to participants. This may call not only for respondent validation but respondent clearance for what is included, which, in turn, places the researcher in a dilemma of whether to include material that has not been cleared or which participants indicate they do not wish to have included or with which they disagree (e.g. in the case of an interpretation).
Given that some qualitative data may be sensitive or personal, the researcher will not only need to consider who will perform any transcription, but the ethical conditions (e.g. of confidentiality) to which the transcriber must be subject.
LeCompte and Preissle (1993) provide a summary of ways in which information technology can be utilized in supporting qualitative research (see also Tesch, 1990 and Gibbs, 2007: chapter 8) in Computer Assisted Qualitative Data Analysis Software (CAQDAS). As can be seen from the list below, its uses are diverse. Data have to be processed, and as word data are laborious to process, and as several powerful packages for data analysis and processing exist, researchers will find it useful to make full use of computing facilities. These can be used as follows (LeCompte and Preissle, 1993: 280–1; Flick, 2009: 360–1):
To make notes.
To transcribe field notes and audio data.
To manage and store data in an ordered and organized way (e.g. by ascribing data to specific addresses).
For search and retrieval of text.
To edit, extend or revise field notes.
To code data (i.e. words or very short phrases which describe the textual data in question, for later ordering, combining or retrieval) and to arrange codes into hierarchies (trees) and nodes (key codes).
To conduct content analysis (e.g. in terms of firequencies, meanings, sequences, locations, people, etc.).
To store and check (e.g. proofread) data.
To collate and segment data and to make numerous copies of data.
To enable memoing to take place, together with details of the circumstances in which the memos were written.
To conduct a search for words or phrases in the data and to retrieve text.
To attach identification labels to units of text, (e.g. questionnaire responses), so that subsequent sorting can be undertaken.
To annotate and append text.
To partition data into units which have been determined either by the researcher or in response to the natural language itself.
To enable preliminary coding of data to be undertaken.
To sort, re-sort, collate, classify and reclassify pieces of data to facilitate constant comparison and to refine schemas of classification.
To code memos and bring them into the same schema of classification.
To assemble, reassemble and recall data into categories.
To display data in different ways.
To undertake frequency counts (e.g. of words, phrases, codes).
To cross-check data to see if they can be coded into more than one category, enabling linkages between categories and data to be discovered.
To establish the incidence of data that are contained in more than one category.
To retrieve coded and noded data segments from subsets (e.g. by sex) in order to compare and contrast data.
To search for pieces of data which appear in a certain (e.g. chronological) sequence.
To filter, assemble and relate data according to preferred criteria (e.g. words, codes, themes, nodes).
To establish linkages between coding categories.
To display relationships of categories (e.g. hierarchical, temporal, relational, subsumptive, superordinate).
To draw conclusions and to verify conclusions and hypotheses.
To quote data in the final report.
To generate and test theory.
To communicate with other researchers or participants.
Flick (2009: 362) suggests that CAQDAS software can be grouped into several types:
those that act as word processors (e.g. entering, editing and searching text);
those that retrieve text (searching, summarizing, listing sequences of words);
those that manage text (e.g. searching, sorting and organizing passages of text);
those that code and retrieve text (i.e. which enable text to be split into smaller units and segments by relevant code and which list and organize and order codes and nodes);
those that enable theory building (e.g. through coding and the categorization and classification of codes and taxonomies to enable relations and superordinate and subordinate categories to be constructed);
those that enable conceptual networks to be plotted and visualized.
Which software one uses, he avers (pp. 364–5), depends on what questions one wishes to ask of the data, what kinds of data one has, what one wishes to do with the data, what processes of analysis one wishes to conduct, the technical requirements of the software, the competence level of the researcher/user of the software, the costs and the level of detail required in the analysis.
Kelle (1995) suggests that computers are particularly effective at coping with the often-encountered problem of data overload and retrieval in qualitative research. Computers, it is argued, enable the researcher to use codes, memos, hypertext systems, selective retrieval, co-occurring codes, and to perform quantitative counts of qualitative data types (see also Seidel and Kelle, 1995). In turn, these authors suggest, this enables linkages of elements to be undertaken, the building of networks and, ultimately, theory generation to be undertaken. Indeed Lonkila (1995) indicates how computers can assist in the generation of grounded theory through coding, constant comparison, linkages, memoing, annotations and appending, use of diagrams, verification and, ultimately, theory building. For a full discussion of coding we refer the reader to Chapter 30.
Kelle and Laurie (1995: 27) suggest that computeraided methods can enhance: (a) validity (by the management of samples); and (b) reliability (by retrieving all the data on a given topic, thereby ensuring trustworthiness of the data), without losing contextual factors (Gibbs, 2007: 106). An important feature here is the speed of organized and systematic data collation and retrieval; though data entry is time-consuming, a great advantage of software is its ability subsequently to process data rapidly.
Coding the data is part of a six-step sequence of using software (Kelle, 2000: 295):
Step 1: |
Entering and formatting the text data. |
Step 2: |
Coding the data. |
Step 3: |
Memoing (with reference to specific segments of data). |
Step 4: |
Comparison of textual segments which have the same codes, to check for consistency |
Step 5: |
Integrating the codes that have been generated, and memoing the codes. |
Step 6: |
Developing the core category – a feature of grounded theory (see Chapter 33 here). |
There are several computer packages for qualitative data (see Kelle, 1995), for example: AQUAD, HyperQuad2, HyperRESEARCH, Hypersoft, Kwaliton, Martin, MAXqda, QSR.NUD*IST, NVivo, QUALPRO, Text-base Alpha, Ethnograph, ATLAS.ti, Code-A-Text, Decision Explorer, Diction. Some of these are reviewed by Prein et al. (1995: 190–209), Gibbs (2007: 105–42), Lewins and Silver (2004, 2009) and García-Horta and Guerra-Ramos (2009); these authors indicate how to choose software and which to choose. These do not actually perform the analysis (in contrast to packages for quantitative data analysis) but facilitate and assist it. As Kelle (2004: 277) remarks, they do not analyse text so much as organize and structure text for subsequent analysis. Though there are many software packages available, Gibbs (2007) focuses on three: NVivo, MAXqda and ATLAS.ti; these share common features such as: (a) the ability to import, work with and display rich texts; (b) the ability to code text into key codes (nodes) and to arrange codes and nodes into hierarchies, clusters and (c) the ability to sort, combine and retrieve text using different combinations and search strings/terms; (d) the ability to work with original documents using codes or to combine selected extracts from documents using codes; (e) the ability to annotate, add memos, comments or additional documents to existing data files and documents; (f ) the ability to sort material using codes. Some software allows researchers to combine different kinds of data (e.g. NVivo and ATLAS.ti allow the researcher to combine word data with images, video material and sound recordings) and to code these different kinds of data (cf. Gibbs, 2007: 114).
These programs have the attraction of coping with large quantities of text-based material rapidly and without any risk of human error in computation and retrieval, and releasing researchers from some mechanical tasks. With respect to words, phrases, codes, nodes and categories they can:
a search for and return text, codes, nodes and categories;
b search for specific terms and codes, singly or in combination;
c filter text;
d return counts;
e present the grouped data according to the selection criterion desired, both within and across texts;
f perform the qualitative equivalent of statistical analyses, such as:
Boolean searches (intersections of text which have been coded by more than one code or node, using ‘and’, ‘not’ and ‘or’; looking for overlaps and co-occurrences);
proximity searches (looking at clustering of data and related contextual data either side of, or near to, or preceding, or following, a node or code);
restrictions, trees, crosstabs (including and excluding documents for searching, looking for codes subsumed by a particular node, and looking for nodes which subsume others).
g construct dendrograms (tree structures) of related nodes and codes;
h present data in sequences and locate the text in surrounding material in order to provide the necessary context;
i locate and return similar passages of text;
j look for negative cases (Gibbs, 2007: 126);
k look for terms in context (lexical searching) (Gibbs, 2007: 126);
l select text on combined criteria (e.g. joint occurrences, collocations);
m enable analyses of similarities, differences and relationships between texts and passages of text;
n annotate text and enable memos to be written about text.
Additionally, dictionaries and concordances of terms can be employed to facilitate coding, searching, retrieval and presentation.
Since the rules for coding and categories are public and rule-governed, computer analysis can be particularly useful for searching, retrieving and grouping text, both in terms of specific words and in terms of words with similar meanings. Single words and word counts can overlook the importance of context. Hence computer software packages have been developed that look at Key-Words-In-Context. Most software packages have advanced functions for memoing, i.e. writing commentaries to accompany text that are not part of the original text but which may or may not be marked as incorporated material into the textual analysis. Additionally many software packages include an annotation function, which lets the researcher annotate and append text, and the annotation is kept in the text but marked as an annotation.
Computers do not do away with ‘the human touch’, as humans are still needed to decide and generate the codes and categories, to verify and interpret the data. Similarly ‘there are strict limits to algorithmic interpretations of texts’ (Kelle, 2004: 277), as texts contain more than that which can be examined mechanically. Further, Kelle (2004: 283) suggests that there may be problems where assumptions behind the software may not accord with those of the researchers or correspond to the researcher’s purposes, and that the software does not enable the range and richness of analytic techniques that are associated with qualitative research. He argues that software may be more closely aligned to the technique of grounded theory than to other techniques (e.g. hermeneutics, discourse analysis) (Coffey et al., 1996), that it may drive the analysis rather than vice versa (Fielding and Lee, 1998) and that it has a preoccupation with coding categories (Seidel and Kelle, 1995). One could also argue that the software for qualitative data analysis does not give the same added value that one finds in quantitative data analysis software that automatically yields statistics, and the textual input is a highly laborious process; qualitative data analysis software does not perform the analysis but only supports the researcher doing the analysis by organizing data and recording codes and nodes, etc. It is more like a word processor and collator than an analytical software tool (Flick, 2009: 359).
The use of CAQDAS is not without its concerns. For example Gibbs (2007) reports that researchers may feel distanced from their data (p. 106), that software is too strongly linked to grounded theory rather than other forms of qualitative data analysis (p. 107) (though this is also questioned by newer software packages that are more methodologically eclectic (p. 107)). Indeed Flick (2009: 370) suggests that qualitative data analysis software is best suited to data which require coding and categorization for developing grounded theory. However, Kelle (1997: para. 3.2) has suggested that the software Ethnograph is rooted in ethnographic and phenomenological research, that MAXqda has its roots in Weberian ‘ideal types’ and AQUAD has its roots in Popperian methodology. Richards (2002) remarks on the tendency of many software packages to focus on ‘code and retrieve’ techniques (p. 266), with the risk that software encourages researchers to opt for coding and patterning to the neglect of more complex interrogation of texts (p. 269), and, indeed, that many researchers do not wish to use coding techniques with their qualitative data but are more concerned to review their texts iteratively (p. 270).
Gibbs (2007) also worries that too great an emphasis is placed on coding and its applications (p. 107), and that some important context may be stripped out of the data when they are assembled by codes alone (p. 122), a view shared by Crowley et al. (2002), who argue that the software drives the analysis rather than vice versa. Gibbs (2007: 140) reminds researchers that the use of much of the software is only as good as the codes that have been used and the careful coding of the data, i.e. if poor codes or poor coding has been undertaken (e.g. inconsistent coding, or coding that overlooks some text, or miscoding, or using a different code for the same kind or meaning of data) then poor results are likely to ensue (i.e. a problem of reliability). This applies similarly to the searching codes, terms or combinations that have been undertaken. Flick (2009: 370) worries that the practicalities of data entry, coding and retrieval with software might detract researchers from the ‘real’ task of hermeneutically understanding, thinking about and explaining the meanings of the research and the texts.
Further, as mentioned earlier, the ‘added value’ of software packages may not be as great as their statistical counterparts, for they require a significant amount of time and effort in entering transcribed and other word data, and then the software only searches, organizes, retrieves and collates the data, leaving the researcher still to analyse the data. Whilst statistical packages (e.g. SPSS) only process data, and whilst the researcher still has to analyse these data, the return on effort is much greater, as the software gives test results that do not have their simple equivalent in qualitative data analysis software. As García-Horta and Guerra-Ramos (2009: 152) argue, qualitative software is no substitute for the requirement and capability of the researcher to ‘assign meaning, identify similarities and differences, establish relations’ between data. Indeed they suggest that, whilst software for qualitative data analysis might be useful for working with structure, to date there have been no software packages that can handle the making of meaning, the interpretations of data, the working out of categories, the making of decisions on coding and the interpretation of the outcomes of the analysis and processing (p. 153).
There are many websites that contain useful materials on qualitative data analysis, e.g.
http://qualitative-research.net/fqs
www.esds.ac.uk/qualidata/support/teaching.asp
www.nova.edu/ssss/QR/text.html
www.qualitative-research.net/fqs/fqs-e/rubriken-e.htm
www.qualitativeresearch.uga.edu/QualPage/
www.ringsurf.com/netring?ring=QualitativeResearch;action=list
http://caqdas.soc.surrey.ac.uk/
http://onlineqda.hud.ac.uk/resources.php
www.edu.plymouth.ac.uk/resined/
www.esds.ac.uk/qualidata/about/introduction.asp
Many of these provide links to a host of other websites providing guidance and resources for qualitative data analysis.
For working with audio and visual data (e.g. annotating and incorporating) the following are websites for software:
www.eval.org/resources/qda.htm
www.ideaworks.com/qualrus/index.html
www.kwalitan.nl/engels/index.html
We advise readers to go to the papers by Lewins and Silver (2004, 2009) for a fuller guide as to which software to select.
The accompanying website contains an introductory manual for using QSR NUD*IST (the principles of testing (these have also been saved into Word which apply to NVivo). The website also contains a full set of word-based data files specifically prepared for QSR, concerning a single project of assessment and testing (these have also been saved into word documents).
 Companion Website
Companion Website The companion website to the book includes PowerPoint slides for this chapter, which list the structure of the chapter and then provide a summary of the key points in each of its sections. In addition there is further information on presenting qualitative data in tabular form. These resources can be found online at www.routledge.com/textbooks/cohen7e.