tabulating data
tabulating dataOrganizing and presenting qualitative data |
CHAPTER 29 |
There are several ways in which qualitative data can be organized and presented. In this chapter we introduce some important, useful and widely used ways. These address several issues, including:
tabulating data
seven ways of organizing and presenting data analysis
narrative and biographical approaches to data analysis
systematic approaches to data analysis
methodological tools for analysing qualitative data
We provide several worked examples here, for clarification. It is also important for the researcher to index and provide a record of the provenance of the data, i.e. to record the dates, context, time, participants, researcher, location and so on, so that the setting for the data, and indeed their chronology, can be determined – the latter being useful in charting how situations emerge, evolve, change, lead to other situations, how networks emerge and how causality might be established.
We outline several examples of data analysis and presentation in this chapter and the next. The first of these illustrates simple summary and clear, tabulated data presentation and commentary. It derives from a doctorate thesis.
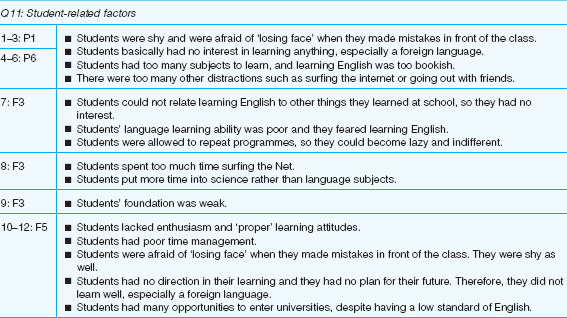
The interview data are presented question by question. In what follows, where the data for respondents in each age phase are similar they are grouped into a single set of responses by row; where there are dissimilar responses they are kept separate. The left-hand column in each table below indicates the number of the respondent (1–12) and the level which the respondent taught (e.g. P1, F3, etc.), so, for example, ‘1–3: P1’ means the responses of respondents 1–3, who taught P1 classes; the right-hand column indicates the responses. In many cases it can be seen that respondents all gave similar responses in terms of the actual items mentioned and the coverage of items specified. A brief summary comment is provided after each table.
The data here derive from a doctorate thesis concerning the problems that school children experience in learning English in China. The data set reproduced is incomplete and has been selected for illustrative purposes only. Note that the data are not verbatim, but have already been summarized by the researcher, i.e. what is presented here is not the first stage of the data analysis, as the first stage would be transcription.
The coding is as follows:
P1–P6 = Primary forms (1–6), P1 = year one, P2 = year two, etc.
F = Secondary forms (1–5), F1 = Form 1 (first year of secondary school), F2 = Form 2 (second year of secondary school, etc.)
The numbers preceding each letter in the left-hand column refers to the number ascribed to the teacher (Table 29.1). There were 12 teachers in all, six from primary and six from secondary schools.
English teaching and learning at school have not really achieved their intended purposes. Students: (a) are poor at understanding written or spoken English, speaking, reading, listening and writing; (b) this limits their abilities, regardless of the number of years of learning English; (c) low-level memorization model leads to superficial learning; (d) teaching and learning are poor; (e) students can enter university, even though their standard is poor, as there are many universities to take students; (f ) students do not require English to gain employment.
Comment: The primary English teachers had a wider range of views than the secondary teachers; there was greater unanimity between the primary teachers in comparison to the secondary teachers; all the Form 3 secondary teachers were unanimous in their comments, and all the Form 5 secondary teachers had different views.
Table 29.2 indicates that the strengths of English teaching were that: (a) students start to learn English very young; (b) schools had autonomy over the design of syllabuses. The weaknesses in English teaching were that: (a) insufficient emphasis was placed on understanding; (b) students were too young to learn English; (c) syllabuses were unrealistic in their demands, being too rich, leading teachers to a ‘spoon-feeding’ mentality in their teaching; (d) undue pressure was put on teachers and students because of the demands of the syllabus; (e) English had to compete with other languages for curriculum space. Hence students did not learn well, despite years of learning English.
Comment: Apart from one primary teacher, the other 11 teachers, drawn from both primary and secondary schools, were unanimous in the comments they gave.
It was clear that high class size (between 30 and 50 students, rising to 60) and tight syllabuses exerted a significant impact on teaching methods and restrictions of class activities, because of control issues (Table 29.3). The nature of this influence is to adopt largely didactic and grammar-translation methods, with little extended recourse to using or ‘thinking in’ English. Teaching utilized some group activity, but this was very limited. Teachers used Chinese to explain English.
Comment: All the teachers here were unanimous in their comments which fell mainly into two sets of points.
Students contributed significantly to their own success or failure in learning English (Table 29.4), they: (a) were shy, afraid of making mistakes and of losing face, (b) had little interest in learning at all, let alone English; (c) were overloaded with other subjects, a situation exacerbated by their poor time management; (d) held negative attitudes to the bookish nature of learning English and its unrelatedness to other curriculum subjects; (e) had too many other distractions; (f ) had limited abilities in English; (g) had little incentive to learn fast as they could repeat courses; (h) gave little priority to English; (i) had poor foundations for learning English; (j) had limited motivation or positive attitudes to learning English; (k) were given limited direction in their learning; (l) had limited incentive to learn English well, as universities required only a low standard of English.
Comment: There was a great variety of comments here. There were degrees of agreement: the teachers of the younger primary children agreed with each other; the teachers of the older primary children agreed with each other; and the teachers of the older secondary children agreed with each other. The teachers of the younger secondary children raised different points from each other. However, the four groups of teachers (younger primary, older primary, younger secondary and older secondary) raised different points from each other.
For an example of the layout of tabulated word-based data and supporting analysis see the accompanying website.
The issues that emerge from the interview data are striking in several ways. What characterizes the data is the widespread agreement of the respondents on the issues. For example:
1 There was absolute unanimity in the responses to questions 9, 12.
2 There was very considerable, though not absolute, unanimity on question 11.
3 In addition to the unanimity observed in point (1), there was additional unanimity amongst the primary teachers in respect of question 11.
4 In addition to the considerable, though not absolute, unanimity observed in point (2), there was much unanimity amongst the primary teachers concerning question 6.
Such a degree of unanimity gives considerable power to the results, even though, because of the sampling used, they cannot be said to be representative of the wider population. However, the sample of experienced teachers was deliberately selected to provide an informed overview of the key issues to be faced. It must be remembered that, though the unanimity is useful, the main purpose of the interview data was to identify key issues, regardless of unanimity, convergence or frequency of mention. That the respondents articulated similar issues, however, signals that these may be important elements.
Further, the issues themselves are seen to lie in a huge diversity of fields, such that there is no single or simplistic set of problems or solutions. Hence, to complement the considerable unanimity of voice is a similar consensus in identifying the scope of the problem, yet the range of the problems is vast. Both singly and together, the issues of English language teaching, learning and achievement in Macau are complex. The messages are clear in respect of F5 students and their English teaching and learning:
i English performance is weak in all its aspects – reading, writing, speaking and listening – but it is particularly weak in speaking and writing.
ii Local cultural factors exert an influence on learning English:
students do not wish to lose face in public (and the Chinese emphasis on gaining and maintaining face is powerful);
students are shy and afraid of making mistakes;
the pressure of examination success is universal and severe;
the local culture is not English; it is Chinese and, if anything else, is Portuguese rather than English, though this latter is very limited; there is little need for people to speak or use English at present.
iii In some quarters knowledge of English culture is seen to be an important element in learning English; this was refuted by the teachers in this sample.
iv English is seen instrumentally, but this message has to be qualified, as many students gain employment and university entrance even though their English is weak. The fact of English being an international language has limited effect on student motivation or achievement.
v Poor teaching and learning are significant contributors to poor performance, in several areas:
the emphasis on drill, rote learning and memorization;
the predominance of passive rather than active learning, with teaching as the delivery of facts rather than the promotion of learning and understanding;
the use of traditional didactic methods;
the reliance on a very limited range of teaching and learning styles;
the limited subject and pedagogical knowledge of English teachers, compounded by the lack of adequate initial and post-initial teacher education;
frequently the careful laying of foundations of English teaching and learning are absent;
students use so much Chinese during English lessons that they have little chance to think in English – they translate rather than think in English.
From the interview data it can be seen that the size of the problems and issues to be faced in English language teaching and learning is vast. In this example, tables are carefully laid out to draw together similar sets of responses. The tables enable the reader to see, at a glance, where similarities and differences lie between the two groups of respondents. Note also that after each table there is a summary of the main points to which the researcher wishes to draw the reader’s attention, and that these comprise both substantive and overall comments (e.g. on the topic in hand and on the similarities and differences between the groups of respondents respectively). Finally, note that an overall summary of ‘key messages’ has been provided at the end of all the tables and their commentaries. This is a very abridged and selective example, and justice has not been done to the whole of the data that the original researcher used. Nevertheless the point is clearly illustrated here that summarizing and presenting data in tabular form can address the twin issues of qualitative research: data reduction through careful data display and commentary.
We present seven ways of organizing and presenting analysis as follows: the first two methods are by people, and the next two methods are by issue or theme, the fifth method is by instrument, the sixth is by case studies and the final method is by narrative account.
One can observe in the example of teaching English in Macau that the data have been organized and presented by respondents, in response to particular issues. Indeed, where the respondents said the same, they have been organized by groups of respondents in relation to a given issue. The groups of respondents were also organized by their membership of different strata in a stratified sample: teachers of younger primary children, older primary children, younger secondary children and older secondary children. This is only one way of organizing a qualitative data analysis – by groups. The advantage of this method is that it automatically groups the data and enables themes, patterns and similarities to be seen at a glance. Whilst this is a useful method for summarizing similar responses, the collective responses of an individual participant are dispersed across many categories and groups of people, and the integrity and coherence of the individual respondent risks being lost to a collective summary. Further, this method is often used in relation to a single-instrument approach, otherwise it becomes unwieldy (for example, trying to put together the data derived from qualitative questionnaires, interviews and observations could be very cumbersome in this approach). So, researchers may find it helpful to use this approach instrument by instrument.
A second way of organizing the data analysis is by individuals. Here the total responses of a single participant are presented, and then the analysis moves on to the next individual. This preserves the coherence and integrity of the individual’s response and enables a whole picture of that person to be presented, which may be important for the researcher. On the other hand, this integrity exacts its price, in that, unless the researcher is only interested in individual responses, it often requires him/her then to put together the issues arising across the individuals (a second level of analysis) in order to look for themes, shared responses, patterns of response, agreement and disagreement, to compare individuals and issues that each of them has raised, i.e. to summarize the data.
Whilst approaches that are concerned with people strive to be faithful to those involved in terms of the completeness of the picture of them qua people, unless case study approaches are deemed to be driving the research, they are usually accompanied by a second round of analysis, which is of the issues that arise from the people, and it is to the matter of issues that we turn now.
A third way of organizing data is to present all the data that are relevant to a particular issue or theme. This is the method that was used in the example of Chinese students learning English. Whilst it is economical in making comparisons across respondents (the issue of data reduction through careful data display, mentioned earlier), again the wholeness, coherence and integrity of each individual respondent risks being lost.
The derivation of the issue/theme for which data are gathered needs to be clarified. For example, it could be that the issue has been decided pre-ordinately, in advance of the data collection. Then all the relevant data for that issue are simply collected together into that single basket – the issue in question. Whilst this is an economical approach to handling, summarizing and presenting data, it raises three main concerns:
a the integrity and wholeness of each individual can be lost, such that comparisons across the whole picture from each individual is almost impossible;
b the data can become decontextualized. This may occur in two ways; first in terms of their place in the emerging sequence and content of the interview or the questionnaire (e.g. some data may require an understanding of what preceded a particular comment or set of comments), and second in terms of the overall picture of the relatedness of the issues, as this approach can fragment the data into relatively discrete chunks, thereby losing their interconnectedness;
c having had its framework and areas of interest already decided pre-ordinately, the analysis may be unresponsive to additional relevant factors that could emerge responsively in the data. It is akin to lowering a magnet onto data – the magnet picks up relevant data for the issue in question but it also leaves behind data not deemed relevant and these risk being lost. The researcher, therefore, has to trawl through the residual data to see if there are other important issues that have emerged that have not been caught in the pre-ordinate selection of categories and issues for attention.
The researcher, therefore, has to be mindful of the strengths and weaknesses not only of pre-ordinate categorization (and, by implication, include responsive categorization), but she must also decide whether it is or is not important to consider the whole set of responses of an individual, i.e. to decide whether the data analysis is driven by people/respondents or by issues.
A fourth method of organizing the analysis is by research question. This is a very useful way of organizing data, as it draws together all the relevant data for the exact issue of concern to the researcher, and preserves the coherence of the material. It returns the reader to the driving concerns of the research, thereby ‘closing the loop’ on the research questions that typically were raised in the early part of an enquiry. In this approach all the relevant data from various data streams (interviews, observations, questionnaires, etc.) are collated to provide a collective answer to a research question. There is usually a degree of systematization here, in that, for example, the numerical data for a particular research question will be presented, followed by the qualitative data, or vice versa. This enables patterns, relationships, comparisons and qualifications across data types to be explored conveniently and clearly.
A fifth method of organizing the data is by instrument. Typically this approach is often used in conjunction with another approach, e.g. by issue or by people. Here the results of each instrument are presented, e.g. all the interview data are presented and organized, and then all the data from questionnaires are presented, followed by all the documentary data and field notes and so on. Whilst this approach retains fidelity to the coherence of the instrument and enables the reader to see clearly which data derive from which instrument, one has to observe that the instrument is often only a means to an end, and that further analysis will be required to analyse the content of the responses – by issue and by people. Hence if it is important to know from which instrument the data are derived then this is a useful method; however, if that is not important then this could be adding an unnecessary level of analysis to the data. Further, connections between data could be lost if the data are presented instrument by instrument rather than across instruments.
In analysing qualitative data, a major tension may arise from using contrasting holistic and fragmentary/atomistic modes of analysis. The example of teaching English in Macau is clearly atomistic, breaking down the analysis into smaller sections and units. It could be argued that this violates the wholeness of the respondents’ evidence, and there is some truth to this, though one has to ask whether this is a problem or not. Sectionalizing and fragmenting the analysis can make for easy reading. On the other hand, holistic approaches to qualitative data presentation will want to catch the wholeness of individuals and groups, and this may lead to a more narrative, almost case study or story style of reporting with issues emerging as they arise during the narrative! Neither approach is better than the other; researchers need to decide how to present data with respect to their aims and intended readership.
A sixth way of organizing and writing up a qualitative data is by one or more (e.g. a series) of case studies, or by combining case studies into an overall study that sets out common and singular features and properties of the cases (see also Miles and Huberman (1994) on within site and cross-site analysis). Or a series of individual case studies can be followed by an analysis that draws together common findings from the different case studies and also indicates the exclusive features of each. The researcher can also identify common themes in and across the case studies, or, if a theme has been decided in advance (pre-ordinately) or indeed responsively when reading through all the case studies (see content analysis and coding, discussed in later chapters), then materials from case studies can be used selectively to illustrate specific themes (whilst adhering to the principle of fidelity to the case in question).
A seventh way of organizing the analysis is by constructing a narrative that may be in the form of a chronology, a logical analysis, a thematic analysis, a series of ‘stories’ about the research findings. This is an important approach, and we address it in further detail below.
Clearly these seven ways are not all mutually exclusive, and they may be used in combination, so as to better answer the research questions.
Bruner (1986) remarks that humans make meaning and think in terms of ‘storied text’ which catch the human condition, human intentionality, the vividness of human experience very fully (pp. 14 and 19) and the multiple perspectives and lived realities (‘subjective landscapes’) of participants (p. 29). They model the world (p. 7), starting as metaphors and metamorphosing into empirical statements by verifiable data. They make the familiar strange, ‘rescue it from obviousness’ (p. 24) and require the reader to fill in the gaps, i.e. they are an interactive medium (p. 24).
Stories personalize generalizations (Gibbs, 2007: 57) and are evidence-based. Further, they catch the chronology of events as they unfold over time, and this can enable the researcher to infer causality, coupled with the dramatic and dramaturgical power of carefully chosen words. Narrative not only conveys information but brings information to life. As the poet Pasternak remarks, events ‘catch fire’ on their way, through the reporting of personal experiences, dramatic events and even the simple unfolding of a sequence of activities, behaviours or people over time. Gibbs (2007: 60) comments that narratives not only pass on information but they meet people’s psychological needs in coping with life, or help a group to crystallize or define an issue, view, stance or perspective, or they can persuade or create a positive image, they can help researchers and readers to understand the experiences of participants and cultures, and contribute to the structuring of identity (as, indeed, is the case with life histories and biographies). Narratives are a foil to the supremacy of coding and coding-derived analysis.
Biographies, too, tend to follow a chronology, to report critical or key events and moments, to report key decisions and people, and to establish causality. Indeed, for their authors, they may even be restorative of broken identities or shattered futures (Gibbs, 2007: 67).
Both narratives and biographies may have a chronology (but this is not a requirement, as some narratives are structured by logical relations or psychological coherence rather than chronology). They may have a beginning, a middle and an end, they may include critical moments and decisions, complicating factors, evaluation and outcomes (cf. Labov’s (1972) characteristics of a narrative as having an abstract, orientation (context), complicating actions (sequences of events that decide the course of the narrative), evaluation (indicating the significance of the narrative and its main points), resolution (outcomes), and a coda (a rounding off of the narrative)).
Narratives and biographies cannot record all the events; rather a selective focus should be adopted, based on the criteria that the researcher wishes to use. These may include, for example: key decision points in the story or narrative, or key, critical (or meaningful to the participants) events, themes, behaviours, actions, decisions, people, points in the chronology, or meaningful events to the participants, reconstruction of the case history (Flick, 2009: 347), key places, key experiences. Once the researcher has identified the textual units in the biography or narrative, based on the criteria that are fit for the researcher’s purpose, the researcher can then analyse and interpret the text for the meanings contained in it, develop working hypotheses to explain what is taking place, check these hypotheses against the data and the remainder of the text, see the text as a whole rather than as discrete units, and ensure that different interpretations of the text have been considered and the one(s) chosen are the most secure in terms of fidelity to the text.
Following these stages of text selection, analysis, interpretation and checking, the process of construction of the final narrative takes place. This can be undertaken in several ways, for example:
by temporal sequence (a chronology);
by a sequence of causal relations;
by key participants;
by key behaviours or actions;
by emergent or key themes;
by key issues and clusters of issues;
by biographies of the participants;
by critical or key events;
by turning points in a life history or biography;
by different perspectives;
by key decision points;
by key behaviours;
by individual case studies or a collective analysis of the unfolding of events for many cases/participants over time.
In constructing a narrative analysis (as, indeed, in other forms of qualitative data analysis), the researcher can introduce verbatim quotations from participants where relevant and illuminative; these can add life to the narrative and often convey the point very expressively – without it being mediated or softened by the academic language of the researcher. It is important to keep them short enough to convey the main point without distortion or exclusion of relevant details and context, but not so long that the reader does not know what is the point of the quotation (i.e. having to perform an analysis of the data for herself/himself (Gibbs, 2007: 97)). When using verbatim quotations from participants, it is often useful to accompany them with the researcher’s interpretive commentary. Quotations are often chosen for their ability to crystallize or exemplify an issue or example really well, or typically, or extremely, and the researcher will need to decide whether to identify the person who said it (see the discussion of ethics in Chapter 28).
Narrative analysis, together with biographical data, can give the added dimension of realism, authenticity, humanity, personality, emotions, views and values in a situation, and the researcher must ensure that these are featured in the narratives that have been constructed. By ‘telling a story’ a narrative account, case study or biography breaks with the strictures of coding and the risk of disembodied text that can too easily result from coding and retrieval exercise; it keeps text and content together, it retains the integrity of people rather than fragmenting bits of them into common themes or codes, it enables evolving situations, causes and consequences to be charted. It enables events to ‘catch fire’ as they unfold. Narratives are powerful, human and integrated; truly qualitative.
Data analysis can be very systematic. Becker and Geer (1960) indicate how this might proceed:
1 comparing different groups simultaneously and over time;
2 matching the responses given in interviews to observed behaviour;
3 analysing deviant and negative cases;
4 calculating frequencies of occurrences and responses;
5 assembling and providing sufficient data that keeps separate raw data from analysis.
In qualitative data the analysis here is almost inevitably interpretive, hence the data analysis is less a completely accurate representation (as in the numerical, positivist tradition) but more of a reflexive, reactive interaction between the researcher and the decontextualized data that are already interpretations of a social encounter. Indeed reflexivity is an important feature of qualitative data analysis, and we discuss this separately (Chapter 11). The issue here is that the researcher brings to the data her own preconceptions, interests, biases, preferences, biography, background and agenda. As Walford (2001: 98) writes: ‘all research is researching yourself’. In practical terms it means that the researcher may be selective in her focus, or that the research may be influenced by the subjective features of the researcher. Robson (1993: 374–5) and Lincoln and Guba (1985: 354–5) suggest that these can include:
data overload (humans may be unable to handle large amounts of data);
first impressions (early data analysis may affect later data collection and analysis);
availability of people (e.g. how representative these are and how to know if missing people and data might be important);
information availability (easily accessible information may receive greater attention than hard-to-obtain data);
positive instances (researchers may overemphasize confirming data and under-emphasize disconfirming data);
internal consistency (the unusual, unexpected or novel may be under-treated);
uneven reliability (the researcher may overlook the fact that some sources are more reliable/unreliable than others);
missing data (that issue for which there are incomplete data may be overlooked or neglected);
revision of hypotheses (researchers may overreact or under-react to new data);
confidence in judgement (researchers may have greater confidence in their final judgements than is tenable);
co-occurrence may be mistaken for association;
inconsistency (subsequent analyses of the same data may yield different results); a notable example of this is Bennett (1976) and Aitken et al. (1981).
The issue here is that great caution and self-awareness must be exercised by the researcher in conducting qualitative data analysis, for the analysis and the findings may say more about the researcher than about the data. For example, it is the researcher who sets the codes and categories for analysis, be they pre-ordinate or responsive (decided in advance of or in response to the data analysis respectively). It is the researcher’s agenda that drives the research and she who chooses the methodology.
As the researcher analyses data, she will have ideas, insights, comments, reflections to make on data. These can be noted down in memos, and, indeed, these can become data themselves in the process of reflexivity (though they should be kept separate from the primary data themselves). Glaser (1978) and Robson (1993: 387) argue that memos are not data in themselves but help the process of data analysis; this is debatable, for if reflexivity is part of the data analysis process then memos may become legitimate secondary data in the process or journey of data analysis. Many computer packages for qualitative data analysis (discussed later) have a facility not only for the researcher to write a memo, but also to attach it to a particular piece of datum. There is no single nature or format of a memo; it can include subjective thoughts about the data, with ideas, theories, reflections, comments, opinions, personal responses, suggestions for future and new lines of research, reminders, observations, evaluations, critiques, judgements, conclusions, explanations, considerations, implications, speculations, predictions, hunches, theories, connections, relationships between codes and categories, insights and so on. Memos can be reflections on the past, present and the future, thereby beginning to examine the issue of causality. There is no required minimum or maximum length, though memos should be dated not only for ease of reference but also for a marking of the development of the researcher as well as of the research.
Memos are an important part of the self-conscious reflection on the data and have considerable potential to inform the data collection, analysis and theorizing processes. They should be written whenever they strike the researcher as important – during and after analysis. They can be written at any time, indeed some researchers deliberately carry a pen and paper with them wherever they go, so that ideas that occur can be written down before they are forgotten. They enable the researcher to comment and theorize on events, situations, behaviours and so on as they are being analysed, and can focus on observations, methodological and theoretical matters, or personal matters (cf. Gibbs, 2007: 30–1).
The great tension in data analysis is between maintaining a sense of the holism of the data – the text – and the tendency for analysis to atomize and fragment the data – to separate them into constituent elements, thereby losing the synergy of the whole, and often the whole is greater than the sum of the parts. There are several stages in analysis, e.g.
generating natural units of meaning;
classifying, categorizing and ordering these units of meaning;
structuring narratives to describe the contents;
interpreting the data.
These are comparatively generalized stages. Miles and Huberman (1994) suggest 12 tactics for generating meaning from transcribed data:
counting frequencies of occurrence (of ideas, themes, pieces of data, words);
noting patterns and themes (Gestalts), which may stem from repeated themes and causes or explanations or constructs;
seeing plausibility – trying to make good sense of data, using informed intuition to reach a conclusion;
clustering – setting items into categories, types, behaviours and classifications;
making metaphors – using figurative and connotative language rather than literal and denotative language, bringing data to life, thereby reducing data, making patterns, decentring the data and connecting data with theory;
splitting variables to elaborate, differentiate and ‘unpack’ ideas, i.e. to move away from the drive towards integration and the blurring of data;
subsuming particulars into the general (akin to Glaser’s (1978) notion of ‘constant comparison’ – see Chapter 33 in this book) – a move towards clarifying key concepts;
factoring – bringing a large number of variables under a smaller number of (frequently) unobserved hypothetical variables;
identifying and noting relations between variables;
finding intervening variables – looking for other variables that appear to be ‘getting in the way’ of accounting for what one would expect to be strong relationships between variables;
building a logical chain of evidence – noting causality and making inferences;
making conceptual/theoretical coherence – moving from metaphors to constructs, to theories to explain the phenomena.
This progression, though perhaps positivist in its tone, is a useful way of moving from the specific to the general in data analysis. Running through the suggestions from Miles and Huberman (1994) is the importance that they attach to coding of data, partially as a way of reducing what is typically data overload from qualitative data. Huberman and Miles suggest that analysis through coding can be performed both within-site and cross-site, enabling causal chains, networks and matrices to be established, all of these addressing what they see as the major issue of reducing data overload through careful data display.
Content analysis involves reading and judgement; Brenner et al. (1985) set out several steps in undertaking a content analysis of open-ended data:
1 briefing (understanding the problem and its context in detail);
2 sampling (of people, including the types of sample sought, see Chapter 4);
3 associating (with other work that has been done);
4 hypothesis development;
5 hypothesis testing;
6 immersion (in the data collected, to pick up all the clues);
7 categorizing (in which the categories and their labels must: (a) reflect the purpose of the research; (b) be exhaustive; (c) be mutually exclusive);
8 incubation (e.g. reflecting on data and developing interpretations and meanings);
9 synthesis (involving a review of the rationale for coding and an identification of the emerging patterns and themes);
10 culling (condensing, excising and even reinterpreting the data so that they can be written up intelligibly);
11 interpretation (making meaning of the data);
12 writing (including (pp. 140–3): giving clear guidance on the incidence of occurrence; proving an indication of direction and intentionality of feelings; being aware of what is not said as well as what is said – silences; indicating salience (to the readers and respondents));
13 rethinking.
Content analysis is addressed more fully in the next chapter. This process, Brenner et al. (1985: 144), requires researchers to address several factors:
1 Understand the research brief thoroughly.
2 Evaluate the relevance of the sample for the research project.
3 Associate their own experiences with the problem, looking for clues from the past.
4 Develop testable hypotheses as the basis for the content analysis (the authors name this the ‘Concept Book’).
5 Test the hypotheses throughout the interviewing and analysis process.
6 Stay immersed in the data throughout the study.
7 Categorize the data in the Concept Book, creating labels and codes.
8 Incubate the data before writing up.
9 Synthesize the data in the Concept Book, looking for key concepts.
10 Cull the data; being selective is important because it is impossible to report everything that happened.
11 Interpret the data, identifying its meaning and implication.
12 Write up the report.
13 Rethink and rewrite: have the research objectives been met?
Hycner (1985) sets out procedures that can be followed when phenomenologically analysing interview data. We saw in Chapter 1 that the phenomenologist advocates the study of direct experience taken at face value and sees behaviour as determined by the phenomena of experience rather than by external, objective and physically described reality. Hycner points out that there is a reluctance on the part of phenomenologists to focus too much on specific steps in research methods for fear that they will become reified. The steps suggested by Hycner, however, offer a possible way of analysing data which allays such fears. As he himself explains, his guidelines ‘have arisen out of a number of years of teaching phenomenological research classes to graduate psychology students and trying to be true to the phenomenon of interview data while also providing concrete guidelines’ (Hycner, 1985). In summary, the guidelines are as follows:
Transcription: having the interview tape transcribed, noting not only the literal statements but also nonverbal and paralinguistic communication.
Bracketing and phenomenological reduction: for Hycner (1985) this means, ‘suspending (bracketing) as much as possible the researcher’s meaning and interpretations and entering into the world of the unique individual who was interviewed’. The researcher thus sets out to understand what the interviewee is saying rather than what she expects that person to say.
Listening to the interview for a sense of the whole: this involves listening to the entire tape several times and reading the transcription a number of times in order to provide a context for the emergence of specific units of meaning and themes later on.
Delineating units of general meaning: this entails a thorough scrutiny of both verbal and non-verbal gestures to elicit the participant’s meaning. Hycner (1985) says, ‘It is a crystallization and condensation of what the participant has said, still using as much as possible the literal words of the participant.’
Delineating units of meaning relevant to the research question: once the units of general meaning have been noted, they are then reduced to units of meaning relevant to the research question.
Training independent judges to verify the units of relevant meaning: findings can be verified by using other researchers to carry out the above procedures. Hycner’s own experience in working with graduate students well trained in this type of research is that there are rarely significant differences in the findings.
Eliminating redundancies: at this stage, the researcher checks the lists of relevant meaning and eliminates those clearly redundant to others previously listed.
Clustering units of relevant meaning: the researcher now tries to determine if any of the units of relevant meaning naturally cluster together; whether there seems to be some common theme or essence that unites several discrete units of relevant meaning.
Determining themes from clusters of meaning: the researcher examines all the clusters of meaning to determine if there is one (or more) central theme(s) which expresses the essence of these clusters.
Writing a summary of each individual interview: it is useful at this point, the author suggests, to go back to the interview transcription and write up a summary of the interview incorporating the themes that have been elicited from the data.
Return to the participant with the summary and themes, conducting a second interview: this is a check to see whether the essence of the first interview has been accurately and fully captured.
Modifying themes and summary: with the new data from the second interview, the researcher looks at all the data as a whole and modifies them or adds themes as necessary.
Identifying general and unique themes for all the interviews: the researcher now looks for the themes common to most or all of the interviews as well as the individual variations. The first step is to note if there are themes common to all or most of the interviews. The second step is to note when there are themes that are unique to a single interview or a minority of the interviews.
Contextualization of themes: at this point it is helpful to place these themes back within the overall contexts or horizons from which they emerged.
Composite summary: the author considers it useful to write up a composite summary of all the interviews which would accurately capture the essence of the phenomenon being investigated. Hycner (1985) concludes, ‘Such a composite summary describes the “world” in general, as experienced by the participants. At the end of such a summary the researcher might want to note significant individual differences.’
There are several procedural tools for analysing qualitative data. LeCompte and Preissle (1993: 253) see analytic induction, constant comparison, typological analysis and enumeration as valuable techniques for the qualitative researcher to use in analysing data and generating theory.
Analytic induction is a term and process that was introduced by Znaniecki (1934) in deliberate opposition to statistical methods of data analysis. LeCompte and Preissle (1993: 254) suggest that the process is akin to the several steps set out above, in that: (a) data are scanned to generate categories of phenomena; (b) relationships between these categories are sought; (c) working typologies and summaries are written on the basis of the data examined; (d) these are then refined by subsequent cases and analysis; (e) negative and discrepant cases are deliberately sought to modify, enlarge or restrict the original explanation/theory. Denzin (1970: 192) uses the term ‘analytical induction’ to describe the broad strategy of participant observation that is set out below:
1 A rough definition of the phenomenon to be explained is formulated.
2 A hypothetical explanation of that phenomenon is formulated.
3 One case is studied in the light of the hypothesis, with the object of determining whether or not the hypothesis fits the facts in that case.
4 If the hypothesis does not fit the facts, either the hypothesis is reformulated or the phenomenon to be explained is redefined, so that the case is excluded.
5 Practical certainty may be attained after a small number of cases has been examined, but the discovery of negative cases disproves the explanation and requires a reformulation.
6 This procedure of examining cases, redefining the phenomenon and reformulating the hypothesis is continued until a universal relationship is established, each negative case calling for a redefinition of a reformulation.
A more deliberate seeking of disconfirming (negative) cases is advocated by Bogdan and Biklen (1992: 72). Here the researcher searches for cases which do not fit the other data, or cases, or that do not fit expected patterns of findings. They can be used to extend, expand or modify the existing or emerging hypothesis. Bogdan and Biklen (1992) also enumerate five main stages in analytic induction:
1 In the early stages of the research a rough definition and explanation of the particular phenomenon is developed.
2 This definition and explanation is examined in the light of the data that are being collected during the research.
3 If the definition and/or explanation that have been generated need modification in the light of new data (e.g. if the data do not fit the explanation or definition) then this is undertaken.
4 A deliberate attempt is made to find cases that may not fit into the explanation or definition.
5 The process of redefinition and reformulation is repeated until the explanation is reached that embraces all the data, and until a generalized relationship has been established, which will also embrace the negative cases.
In constant comparison the researcher compares newly acquired data with existing data and categories and theories that have been devised and which are emerging, in order to achieve a perfect fit between these and the data. Hence negative cases or data which challenge these existing categories or theories lead to their modification until they can fully accommodate all the data. We discuss this technique more fully in the next chapter, as it is a major feature of qualitative techniques for data analysis.
Typological analysis is essentially a classificatory process (LeCompte and Preissle, 1993: 257) wherein data are put into groups, subsets or categories on the basis of some clear criterion (e.g. acts, behaviour, meanings, nature of participation, relationships, settings, activities). It is the process of secondary coding (Miles and Huberman, 1984) where descriptive codes are then drawn together and put into subsets. Typologies are a set of phenomena that represent subtypes of a more general set or category (Lofland, 1970). Lazarsfeld and Barton (1951) suggest that a typology can be developed in terms of an underlying dimension or key characteristic. In creating typologies Lofland insists that the researcher must: (a) deliberately assemble all the data on how a participant addresses a particular issue – what strategies are being employed; (b) disaggregate and separate out the variations between the ranges of instances of strategies; (c) classify these into sets and subsets; and (d) present them in an ordered, named and numbered way for the reader.
The process of enumeration is one in which categories and the frequencies of codes, units of analysis, terms, words or ideas are counted. This enables incidence to be recorded, and, indeed, statistical analysis of the frequencies to be undertaken (e.g. Monge and Contractor, 2003). This is a method used in conventional forms of content analysis, and we address this topic in the next chapter.
This chapter has suggested several approaches to analysing and presenting qualitative data. It should be read in conjunction with the next chapter, as they complement each other.
 Companion Website
Companion Website The companion website to the book includes PowerPoint slides for this chapter, which list the structure of the chapter and then provide a summary of the key points in each of its sections. This resource can be found online at www.routledge.com/textbooks/cohen7e.