Kapitel 3. Kernsprache
Vergleichen wir C++ mit einer modernen Interpreter-Sprache wie Python oder einer Compiler-Sprache wie Java, sind die Hürden, um die Sprache zu meistern, die es in C++ zu überwinden gilt, viel höher. Klar, der Vergleich ist ungerecht, muss sich doch Python nicht mit statischer Typisierung auseinandersetzen und verfolgt Java doch relativ streng die objektorientierte Programmiertechnik. Aber die Hürden sind mit C++11 deutlich niedriger geworden als mit C++. Die Usability steht bei C++11 im Fokus.
Usability
Die Range-basierte For-Schleife
Ein kleines, aber feines Feature ist die Range-basierte For-Schleife, die das Iterieren über Container deutlich einfacher von der Hand gehen lässt. Sie ist dem einen oder anderen sicher aus Python oder Java schon bekannt.
Wird diese Schleife mit dem Schlüsselwort auto kombiniert, lässt sich sehr kompakt über die Elemente eines C-Arrays, der Standard Library Container oder auch einer Initialisiererliste iterieren (Listing 3.1). Auch wenn die automatische Typableitung mit auto und die praktische Initialisierung eines Containers mit Initialisiererlisten noch nicht dargestellt wurden, sollte sich ihre Anwendung intuitiv erschließen.
rangeBasedForLoop.cpp
01 #include <iostream>
02 #include <map>
03 #include <vector>
04
05
06 int main(){
07
08 std::cout << "\n";
09
10 // iterating over a C-Array
11 int myArray[5] = {1, 2, 3, 4, 5};
12 for (int &x : myArray) x *= 2;
13 for (int x: myArray) std::cout << x << " ";
14 std::cout << std::endl;
15
16 // iterating over a std::vector
17 std::vector<int> vecInt({1, 2, 3, 4, 5});
18 for (int &x: vecInt) x *= 2;
19 for (int x: vecInt) std::cout << x << " ";
20 std::cout << std::endl;
21
22 // iterating over a initializer list
23 for (const auto x : {1,2,3,5,8,13,21,34}) std::cout << x << " ";
24 std::cout << std::endl;
25
26 // iterating over a initialiser list
27 std::initializer_list<std::string>initList{"Only","For",
"Testing","Purpose"};
28 for ( const auto x: initList) std::cout << x << " ";
29 std::cout << std::endl;
30
31 //iterating over a std::map
32 std::map<std::string,std::string> phonebook{
{"Bjarne Stroustrup","+1 (212) 555-1212"},
{"Gabriel Dos Reis", "+1 (858) 555-9734"},
{"Daveed Vandevoorde","+44 99 74855424"}};
33 for ( auto mapIt: phonebook) std::cout << mapIt.first << ": " <<
mapIt.second << std::endl;
34
35 std::cout << "\n";
36
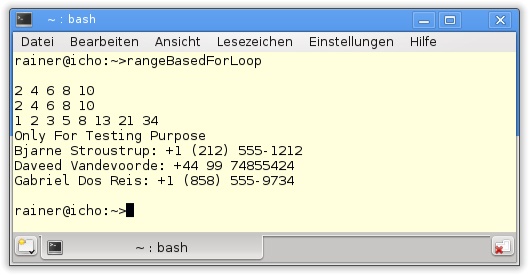
37 }Werden die Elemente des C-Arrays oder STL-Containers als Referenzen angenommen, können die Elemente direkt modifiziert werden (Listing 3.1, Zeilen 12 und 18). Selbst das Iterieren über ein std::map geht schnell von der Hand. Sehr beeindruckend ist es, die neue C++11-Syntax (Zeile 33)
for ( auto mapIt: phonebook) std::cout << mapIt.first << ": " << mapIt.second << std::endl;
der klassischen C++-Syntax gegenüberzustellen:
std::map <std::string,std::string>::iterator mapIt;
for (mapIt= phonebook.begin();mapIt!= phonebook.end();++mapIt){
std::cout << mapIt->first << ": " <<
mapIt->second << std::endl;
}Nun fehlt noch die Ausgabe des Programms.
Wie versprochen, wird das erste Geheimnis zum neuen Schlüsselwort auto in C++11 aufgelöst.
Das automatische Ableiten von Typen
Das automatische Ableiten von Typen, bisher vor allem aus funktionalen Sprachen wie Haskell oder Scala bekannt, verbindet die dynamische Typisierung einer Interpreter- mit der statischen Typisierung einer Compiler-Sprache. Dafür führt C++11 zwei neue Schlüsselwörter ein, auto und decltype.
auto und decltype
Der feine Unterschied ist, dass auto den Typ automatisch aus einem Initialisierer ableitet, während decltype einen Ausdruck benötigt, um den Typ zur Übersetzungszeit zu ermitteln. Dabei ist diese automatische Typableitung (type inference) deutlich mehr als syntactic sugar – können doch Rückgabewerte von Templates so komplex sein, dass es nicht trivial ist, den richtigen Typ zu spezifizieren.
auto und decltype
Mit auto oder auch decltype kann schnell eine neue Variable, Referenz oder auch ein Iterator auf einen Container der Standard Template Library definiert werden.
In Listing 3.2 habe ich als Erstes die aktuell gültige C++98-Syntax verwendet. Es folgt die zukünftige C++11-Syntax, zuerst mit decltype in Listing 3.3 und anschließend mit auto in Listing 3.4.
int a= 5; int b; int& bRef= b; const std::vector<int> v; std::vector<int>::const_iterator itV= v.begin();
decltype(5) a= 5; int b; decltype(b)& bRef = b; const std::vector<int> v; decltype(v.begin()) itV= v.begin();
auto a= 5; int b; auto& bRef= b; const std::vector<int> v; auto itV= v.begin();
Es wird noch mächtiger. Um eine anonyme Funktion oder auch eine Lambda-Funktion in einer Variablen zu speichern, muss in klassischem C++ ein Funktionszeiger definiert werden. In C++11 reduziert sich die ganze Schreibarbeit auf das Schlüsselwort auto.
myAdd.cpp
01 #include <iostream>
02
03 int main(){
04
05 // define the function pointer
06 int (*myAdd1)(int,int)= [](int a, int b){return a + b;};
07
08 // use type inference of the C++11 compiler
09 auto myAdd2= [](int a, int b){return a + b;};
10
11 std::cout << "\n";
12
13 // use the function pointer
14 std::cout << "myAdd1(1,2)= " << myAdd1(1,2) << std::endl;
15
16 // use the auto variable
17 std::cout << "myAdd2(1,2)= " << myAdd2(1,2) << std::endl;
18
19 std::cout << "\n";
20
21 }Neben auto enthält das Listing noch ein weiteres neues Feature von C++11. Die Lambda-Funktion [](int a, int b){return a + b;} nimmt zwei natürliche Zahlen a und b an, addiert sie und gibt das Ergebnis zurück (Abbildung 3.2).

Lambda-Funktionen
Lambda-Funktionen sind eine Anleihe aus der funktionalen Programmierung. Da sie Funktionen ohne Namen sind, werden sie auch gern anonyme Funktionen genannt.
Die Struktur einer Lambda-Funktion ist schnell erklärt.
[]()optional → optional {}
Komponente | Bereich der Lambda-Funktion | |
[ ] | Bindung an die Variablen des lokalen Bereichs | |
[] | keine Bindung | |
[=] | die Werte werden kopiert | |
[&] | die Werte werden referenziert | |
( ) | Argumente des Funktionskörpers (optional) | |
-> | Rückgabewert (optional) | |
{ } | Funktionskörper | |
Info
Die Details zu Lambda-Funktionen folgen in Teil II.
Streng genommen sind Lambda-Funktionen lediglich syntactic sugar in C++11, kann mit ihnen doch nichts ausgedrückt werden, was mit klassischem C++ nicht schon möglich wäre. Richtig eingesetzt, erhöhen sie aber deutlich die Lesbarkeit des Codes, da durch sie die Funktionalität genau auf den Punkt gebracht wird. Beispiel gefällig?
In Listing 3.6 wird ein Vektor von Strings sortiert, wobei das Sortierkriterium die Länge der Strings ist. Das erste Sortierkriterium ist die Funktion lessLength, die an die Sortierfunktion in Zeile 26, std::sort(myStrVec.begin(),myStrVec.end(),lessLength), übergeben wird. Das Funktionsobjekt GreaterLength in Zeile 11 kommt in der nächsten Sortierroutine in Zeile 31 zum Einsatz. Die Lambda-Funktion in Zeile 36 bringt es ohne Definition einer Funktion oder eines Funktionsobjekts direkt auf den Punkt.
Die Details rund um Funktionsobjekte sind im Anhang B, genauer erklärt.
mySort.cpp
01 #include <algorithm
02 #include <iostream>
03 #include <iterator>
04 #include <string>
05 #include <vector>
06
07 bool lessLength(const std::string& f, const std::string& s){
08 return f.length() < s.length();
09 }
10
11 class GreaterLength{
12 public:
13 bool operator()(const std::string& f,
const std::string& s) const{
14 return f.length() > s.length();
15 }
16 };
17
18 int main(){
19
20 // initializing with a initializer lists
21 std::vector<std::string> myStrVec=
{"12345","123456","1234","1","12","123","12345"};
22
23 std::cout << "\n";
24
25 // sorting with the function
26 std::sort(myStrVec.begin(),myStrVec.end(),lessLength);
27 std::copy(myStrVec.begin(),myStrVec.end(),
std::ostream_iterator<std::string>(std::cout, " "));
28 std::cout << "\n";
29
30 // sorting with the function object
31 std::sort(myStrVec.begin(),myStrVec.end(),
GreaterLength());
32 std::copy(myStrVec.begin(),myStrVec.end(),
std::ostream_iterator<std::string>(std::cout, " "));
33 std::cout << "\n";
34
35 // sorting with the lambda function
36 std::sort(myStrVec.begin(),myStrVec.end(),
[](const std::string& f,const std::string& s)
{return f.length() < s.length();});
37 std::copy(myStrVec.begin(),myStrVec.end(),
std::ostream_iterator<std::string>(std::cout, " "));
38 std::cout << "\n";
39
40 // using the lambda function for output
41 std::for_each(myStrVec.begin(), myStrVec.end(),
[](const std::string& s {std::cout << s << ",";});
42
43 std::cout << "\n\n";
44
45 }Noch ein paar Worte zur Ausgabe des Programms auf der Konsole. Durch std::copy ist es möglich, die Ausgabe direkt nach std::cout zu kopieren (Zeile 32). Das geht mit Lambda-Funktionen einfacher. In Zeile 41 benutze ich std::for_each, um die Strings direkt nach std::cout zu schreiben.
Die Ausgabe des Programms zeigt die sortierten Strings.
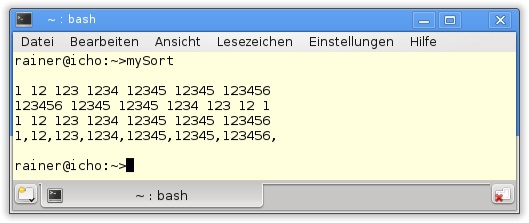
Dem aufmerksamen Leser wird die sehr kompakte Definition eines Vektors myStrVec={"12345","123456",..., "12345"} in Listing 3.6 nicht entgangen sein. Durch Initialisiererlisten wird das Initialisieren von Datentypen nicht nur für den C++-Novizen deutlich einfacher in C++11. Das moderne C++ hat einiges rund um die vereinheitlichte Initialisierung zu bieten.
Vereinheitlichte Initialisierung
Strukturen, Arrays und Container
Die Initialisierung von Objekten in klassischem C++ setzt einiges an Wissen voraus, gibt es doch viele verschiedene Arten, diese zu initialisieren. So lassen sich die C-Strukturen struct sowie Arrays über Initialisiererlisten initialisieren (Listing 3.7, Zeilen 7 und 10), C++-Container der Standard Template Library aber nicht. Als Alternative bietet es sich an, jedes Element beim std::vector einzeln (Listing 3.7, Zeilen 14 bis 18) oder die Elemente indirekt über ein Array (Listing 3.7, Zeile 21) zu initialisieren.
01 struct MyStruct{
02 int a;
03 double b;
04 };
05
06 // direct initialization with initializer list
07 MyStruct myStruct = {4,5.5};
08
09 // direct in initialization with initializer list
10 int intArray[]= {1,2,3,4,5};
11
12 // elementwise initialization
13 std::vector <int> myIntVec;
14 myIntVec.push_back(1);
15 myIntVec.push_back(2);
16 myIntVec.push_back(3);
17 myIntVec.push_back(4);
18 myIntVec.push_back(5);
19
20 // using intArray for initialization
21 std::vector<int> myIntVec2(intArray,intArray+4);Konstante Element- und Heap-Arrays
Es wird noch komplizierter. C++ kann kein Array myData als Datenelement und kein konstantes Heap-Array pData initialisieren (Listing 3.8), da dafür keine Syntax existiert.
// impossible to initialize myData
class Array{
public:
Array(): myData( ... ) {}
private:
int myData[5];
};
// impossible to initialize pData
int* const pData = new const int[5];{}-Initialisiererlisten
Hier räumt C++11 auf. C++11 erlaubt {}-Initialisiererlisten für alle Initialisierungen. Damit ist die Initialisierung von Strukturen, Arrays und Containern vereinheitlicht, und Element- sowie konstante Heap-Arrays lassen sich in C++11 einfach initialisieren.
uniformInitialisation.cpp
01 #include <vector>
02
03 struct MyStruct{
04 int a;
05 double b;
06 };
07
08 class Array{
09 public:
10 Array(): myData{1,2,3,4,5} {}
11 private:
12 int myData[5];
13 };
14
15 int main(){
16
17 // valid for C++
18 MyStruct myStruct = {4,5.5};
19
20 // valid for C++
21 int invArray[]= {1,2,3,4,5};
22
23 // valid for C++11
24 std::vector <int> myIntVec{1,2,3,4,5};
25
26 // valid for C++11
27 Array myArray;
28
29 // valid for C++11
30 const float* pData = new const float[5]{1,2,3,4,5};
31 }Hier stellt sich natürlich jetzt die Frage, was ein Datentyp bieten muss, damit er mit Initialisiererlisten initialisiert werden kann. Diese Frage führt uns direkt zum nächsten Kapitel.
Entwurf von Klassen
Der Entwurf von Klassen wird in C++11 viel mächtiger und expliziter. Einerseits gibt es neue Features rund um die Definition von Konstruktoren, andererseits können Methoden mit Bezeichnern annotiert werden, sodass der Compiler dies prüft.
Mächtigere Initialisierung
Neben der Initialisiererliste für Konstruktoren, die wir im letzten Kapitel in Aktion gesehen haben, unterstützt C++11 jetzt auch deren Delegation und Vererbung. Aber nicht nur der Umgang mit Konstruktoren ist mächtiger, einfacher und mit weniger Schreibaufwand verbunden, auch das direkte Initialisieren von Klassenelementen ist jetzt möglich.
Initialisiererliste-Konstruktor
Initialisiererliste-Konstruktoren sind der Widerpart zu den Initialisiererlisten in Listing 3.9. Das Schöne ist, dass die Container der Standard Template Library diese speziellen Konstruktoren schon definiert haben, sodass ein Vektor über eine Initialisiererliste direkt initialisiert werden kann. Aber auch eigene Datentypen lassen sich mit diesen Konstruktoren einfach ausstatten (Listing 3.10).
initializerListConstructor.cp
01 #include <iostream>
02 #include <map>
03 #include <string>
04
05 // class template, parametrized with T
06 template <typename T>
07 class MyContainer{
08 public:
09 MyContainer(std::initializer_list<T> values){
10
11 for (auto v : values) std::cout << v << " ";
12
13 }
14 };
15
16 int main(){
17
18 // using a initialiser list for a string
19 std::string cppInventor={"Bjarne Stroustrup"};
20
21 std::cout << "\n";
22 std::cout << "Name of the cpp Inventor: "
<< cppInventor << std::endl;
23
24 // using a initializer list for a map
25 std::cout << "\nA few import cpp developer: "
<< std::endl;
26 std::map<std::string,std::string> phonebook{
{cppInventor,"+1 (212) 555-1212"},
{"Gabriel Dos Reis", "+1 (858) 555-9734"},
{"Daveed Vandevoorde","+44 99 74855424"}};
27
28 for (auto mapIt= phonebook.begin();
mapIt!= phonebook.end();++mapIt){
29 std::cout << mapIt->first << ": "
<< mapIt->second << std::endl;
30 }
31
32 std::cout << "\n";
33
34 // using MyContainer with int
35 MyContainer<int> myIntCont{1,2,3,4,5,6,7,8,9,10};
36 std::cout << "\n";
37
38 // using MyContainer with string
39 MyContainer<std::string>
myStringCont{"Range","based","for","loop."};
40
41 std::cout << "\n\n";
42
43 }Sowohl ein String (Zeile 19) als auch der Standardcontainer std::map (Zeile 26) in Listing 3.10 lassen sich über eine Initialisiererliste initialisieren. Das Klassen-Template MyContainer in Zeile 6 nimmt als Argument eine Initialisiererliste von Ganzzahlen und Strings (Zeilen 35 und 39) an. Im Initialisiererliste-Konstruktor von MyContainer (Zeile 9) wird die Initialisiererliste direkt ausgegeben. Hier sehen Sie eine generische Range-basierte For-Schleife im Einsatz. In Kombination mit auto lässt sich so äußerst kompakt über STL-Container iterieren.
Nun fehlt nur noch die Ausgabe des Programms.

Delegation von Konstruktoren
Java oder auch D kennen die Delegation von Konstruktoren. C++ führt sie mit C++11 ein.
Besitzt in klassischem C++ eine Klasse mehrere Konstruktoren, die ähnliche Initialisierungsschritte ausführen müssen, gibt es zwei Lösungen. Die naheliegende Lösung ist, den Initialisierungscode in jedem Konstruktor zu duplizieren. Dies ist fehleranfällig und mit viel Schreibaufwand verbunden. Da ist es schon deutlich besser, eine private Methode init zu definieren, in diese den gemeinsamen Code auszulagern und die Initialisierungsmethode in jedem Konstruktor aufzurufen.
Im neuen C++11 kann der Initialisierungscode in einem Konstruktor definiert werden, der dann von allen anderen Konstruktoren verwendet wird.
delegatingConstructor.cpp
01 #include <cmath>
02 #include <iostream>
03
04 class MyHour{
05 int myHour_;
06 public:
07
08 // constructor validating the data
09 MyHour(int hour){
10 if (0 <=hour and (hour<=23)) myHour_= hour;
11 else myHour_=0;
12 std::cout << "hour= " << hour << std::endl;
13 }
14
15 // default constructor for setting hour to 0
16 MyHour(): MyHour(0){};
17
18 // accept also doubles
19 MyHour(double hour)
:MyHour( static_cast<int>(ceil(hour))) {};
20
21 };
22
23 int main(){
24
25 std::cout << std::endl;
26
27 // use the validating constructor
28 MyHour(10);
29
30 // use the validating constructor
31 MyHour(100);
32
33 // use the default constructor
34 MyHour();
35
36 // use the constructor accepting doubles
37 MyHour(22.45);
38
39 std::cout << std::endl;
40
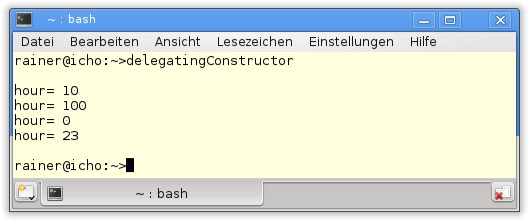
41 }Der Konstruktor MyHour(int hour) (Listing 3.11, Zeile 9) validiert seinen Eingabewert. Daher können die zwei folgenden Konstruktoren in Zeile 16 und 19 ihre Validierung der Daten direkt an diesen durch MyHour():MyHour(0) bzw. MyHour(double hour):MyHour(...)delegieren.
Diese Delegation von Konstruktoren ist schön in Abbildung 3.5 in Anwendung zu sehen.
Vererbung von Konstruktoren
Das Vererben von Konstruktoren erspart einige Schreibarbeit. Ein einfaches using Base::Base in der Definition der Klasse Derived (Listing 3.12) reicht aus, und alle Konstruktoren der Basisklasse stehen in der abgeleiteten Klasse zur Verfügung.
inheritingConstructor.cpp
01 #include <iostream>
02 #include <string>
03
04 class Base{
05 public:
06
07 Base()= default;
08
09 Base(int i){
10 std::cout << "Base::Base("<< i << ")" << std::endl;
11 }
12
13 Base(std::string s){
14 std::cout << "Base::Base("<< s << ")" << std::endl;
15 }
16 };
17
18 class Derived: public Base{
19 public:
20
21 using Base::Base;
22
23 Derived(double d){
24 std::cout << "Derived::Derived("<< d << ")"
<< std::endl;
25 }
26
27 };
28
29 int main(){
30
31 // inheriting Base
32 Derived(2011); // Base::Base(2011)
33
34 // inheriting Base // Base::Base(C++0x)
35 Derived("C++0x");
36
37 // using Derived
38 Derived(0.33); // Derived::Derived(0.33)
39
40 }Anmerkung
Da der aktuelle GCC 4.7 (C++0x Support in GCC) die Vererbung von Konstruktoren noch nicht unterstützt, ist die Ausgabe des Programms in den entsprechenden Kommentaren der main-Funktion enthalten.
Direktes Initialisieren der Klassenelemente
Aber nicht nur das Initialisieren mithilfe des Konstruktors, auch das direkte Initialisieren der Klassenelemente wird in modernem C++ unterstützt. Konnten in C++98 nur statische, konstante Elemente integralen Typs initialisiert werden, so gilt die Einschränkung in C++11 nicht mehr. Diese Einschränkung stellte sicher, dass die Initialisierung zur Übersetzungszeit möglich war. Wird ein Klassenelement sowohl direkt als auch über den Konstruktor initialisiert, wird nur Letzteres angewandt.
Ein paar Beispiele zeigen die neue Funktionalität. Der Einfachheit halber verwende ich den Datentyp struct, da hier alle Klassenelemente öffentlich sind.
classMemberInitializer.cpp
01 #include <iostream>
02 #include <string>
03 #include <vector>
04
05 struct ClassMemberInitializer{
06
07 ClassMemberInitializer()= default;
08
09 ClassMemberInitializer(int override):x(override){};
10
11 // valid with C++98
12 const static int oldX=5;
13
14 // valid with C++11
15 int x=5; //class member initializer
16
17 // valid with C++11
18 std::string s="Hello C++0x";
19
20 // valid with C++11
21 std::vector<int> myVec{1,2,3,4,5};
22
23 };
24
25 int main(){
26
27 std::cout << "\n";
28
29 // class member initialization
30 ClassMemberInitializer cMI;
31 std::cout << "cMI.oldX " << cMI.oldX << "\n";
32 std::cout << "cMI.x " << cMI.x << "\n";
33 std::cout << "cMI.s " << cMI.s << "\n";
34 for (auto vec: cMI.myVec) std::cout << vec << " ";
35
36 std::cout << "\n\n";
37
38 // class member initialization
39 // x will be overridden by the constructor value
40 ClassMemberInitializer cMI2(10);
41 std::cout << "cMI2.oldX " << cMI2.oldX << "\n";
42 std::cout << "cMI2.x " << cMI2.x << "\n";
43 std::cout << "cMI2.s " << cMI2.s << "\n";
44 for (auto vec: cMI2.myVec) std::cout << vec << " ";
45
46 std::cout << "\n\n";
47
48 }Die Ausgabe des Programms zeigt die erwarteten Werte.
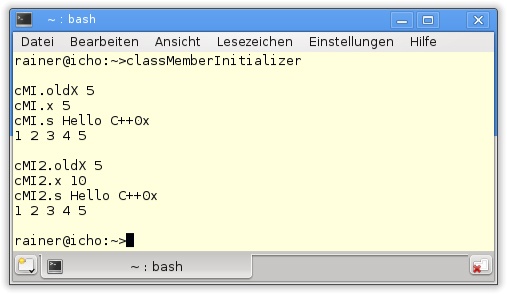
Rund um die Initialisierung von Objekten und Klassenelementen gibt es viele neue Features; so können Methoden in C++11 mit Bezeichnern annotiert werden, die das Verhalten der Methode explizit beschreiben.
Explizite Klassendefinitionen
Wieso sollte Pythons Designprinzip »Explicit is better then implicit.« von Tim Peters (Peters, 2004) nicht auch für C++11 gelten?
Methoden können in modernem C++ mit den Bezeichnern default, delete, override, final oder auch explicit ausgezeichnet werden. Der Compiler sorgt dafür, dass der Vertrag eingehalten wird.
default und delete
Für eine Klasse werden viele spezielle Methoden vom Compiler erzeugt, um den Lebenszyklus seiner Instanzen zu gewährleisten. Dies betrifft den Standard- und den Kopierkonstruktor, den Zuweisungsoperator und den Destruktor. Aber auch spezielle Methoden wie operator new werden vom Compiler bei Bedarf erzeugt.
Für C++-Entwickler gibt es viele Idiome in klassischem C++, um den Lebenszyklus eines Objekts direkt zu kontrollieren. Diese Idiome setzen viel Wissen und noch mehr Disziplin voraus. Mit den Bezeichnern default und delete hat sich der C++-Standard dieser Problematik angenommen.
Soll eine Klasse zum Beispiel nicht kopierbar sein, werden der Kopierkonstruktor und der Zuweisungsoperator lediglich privat deklariert, aber nicht definiert. Hier setzt der delete-Bezeichner an. Steht delete hinter dem Methodennamen, wird die Methode vom Compiler nicht mehr erzeugt.
Aber es lauern auch Gefahren rund um den Lebenszyklus eines Objekts. Wird in einer Klasse ein Konstruktor definiert, erzeugt der Compiler keinen Standardkonstruktor mehr. Genau dies kann der Klassendesigner dem Compiler jedoch durch den Bezeichner default vorschreiben. default sorgt dafür, dass der Compiler seine Default-Version der Methode erzeugt.
Der Lebenszyklus eines Objekts lässt sich in C++11 rein deklarativ beschreiben.
defaultedDeletedMethods.cpp
01 #include <iostream>
02
03 class NonCopyableClass{
04 public:
05
06 // state the compiler generated default constructor
07 NonCopyableClass()= default;
08
09 // disallow copying
10 NonCopyableClass& operator=
11 (const NonCopyableClass&)= delete;
12 NonCopyableClass(const NonCopyableClass&)= delete;
13 };
14
15 class SomeType{
16 public:
17
18 // state the compiler generated default constructor
19 SomeType()= default;
20
21 // constructor for int
22 SomeType(int value){};
23
24 };
25
26 class TypeOnStack {
27 public:
28
29 void* operator new(std::size_t)= delete;
30 };
31
32 int main(){
33
34 NonCopyableClass nonCopyableClass;
35 SomeType someType;
36 TypeOnStack typeOnStack;
37
38 // force the compiler error
39 NonCopyableClass nonCopyableClass2(nonCopyableClass);
40
41 // force the compiler error
42 TypeOnStack* typeOnHeap= new TypeOnStack;
43
44 }Vor der Übersetzung des Programms aus Listing 3.14 noch ein paar Worte zum Sourcecode:
In der Klasse NonCopyableClass (Zeile 3) werden sowohl der Kopierzuweisungsoperator als auch der Kopierkonstruktor als delete erklärt, und der Standardkonstruktor des Compilers wird verwendet. Der Standardkonstruktor wird in der Klasse NonCopyableClass nicht automatisch vom Compiler erzeugt, da der Kopierzuweisungsoperator und der Kopierkonstruktor als delete deklariert wurden. Damit lassen sich Objekte der Klasse nur direkt instanziieren. Auch die Klasse SomeType (Zeile 15) nutzt den vom Compiler erzeugten Standardkonstruktor, den der Compiler in diesem Fall nicht erzeugt, da ein spezieller Konstruktor für int vorhanden ist. Interessant ist auch die Klasse TypeOnStack (Zeile 26), denn das Setzen des new-Operators auf delete bewirkt, dass deren Instanzen nicht mehr mit new erzeugt werden können. Der interessanteste Teil des Programms ist aber die main-Funktion, denn in ihr wird sowohl ein nicht kopierbares Objekt kopiert als auch ein Objekt auf dem Heap angelegt, obwohl dessen new-Operator auf delete gesetzt ist.
Wie geht der GCC-Compiler mit dem Vertragsbruch um?
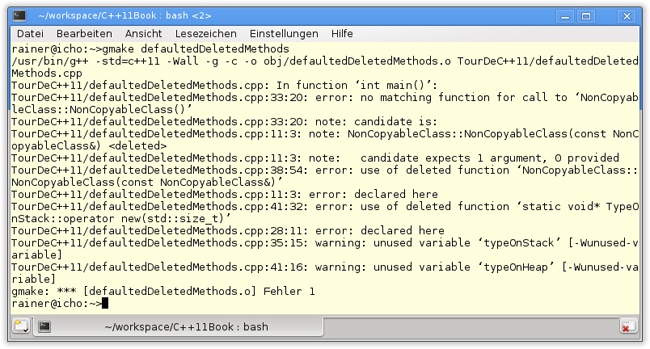
Der GCC schreibt eine aussagekräftige Fehlermeldung. Was will man mehr?
Explizite Virtualität
Es bleibt deklarativ. Eine beliebte Fehlerquelle beim Überschreiben von virtuellen Funktionen ist, dass die Signatur der neuen Methode nicht der der zu überschreibenden Methode entspricht. Das Ergebnis zeigt sich erst sehr viel später zur Laufzeit, wenn sich das Programm unerwartet verhält. Diese Fehlerquelle lässt sich mit C++11 elegant beseitigen. Wird die neue Funktion mit dem Schlüsselwort override versehen, stellt der Compiler sicher, dass diese auch tatsächlich eine Methode der Basisklasse überschreibt. Der Compiler stellt ebenfalls sicher, dass Methoden, die als final deklariert sind, nicht überschrieben werden können.
Vom Novizen zum Profi
Bisher hatte C++11 viel für den C++-Novizen zu bieten: das automatische Ableiten von Typen, die vereinheitlichte Initialisierung von Datentypen, die mächtigere Initialisierung von Objekten, die deklarativen Klassendefinitionen. Selbst Lambda-Funktionen sind, ist das erste Fremdeln einmal überwunden, leicht zu schreiben und zu lesen. Nun ist der Profi an der Reihe. In den beiden folgenden Abschnitten „Rvalue-Referenzen“ und „Generische Programmierung“ findet dieser die Werkzeuge, die er braucht, um seine Datentypen und Bibliotheken genau auf seine Bedürfnisse abzustimmen.
Rvalue-Referenzen
Zwei spezielle Methoden sind im Abschnitt „Mächtigere Initialisierung“ nicht genannt worden: der neue Move-Konstruktor und der Move-Zuweisungsoperator, den die STL-Container und auch der Datentyp String besitzen.
Betrachten wir die vereinfachte Implementierung des std::vector-Containers in Listing 3.15, fällt auf, dass neben dem klassischen Kopierkonstruktor (Zeile 6) und dem Zuweisungsoperator (Zeile 7) zwei sehr ähnliche neue Methodendeklarationen in Zeile 10 und 11 existieren. Der auffälligste Unterschied ist, dass die traditionellen Methoden ihre Argumente als eine konstante Lvalue-Referenz mit einem & annehmen, während die neuen Methoden ihre Argumente als Rvalue-Referenz mit && annehmen.
01 template<typename T>
02 class vector {
03 public:
04
05 // copy semantic
06 vector(const vector& v);
07 vector& operator=(const vector& v);
08
09 // move semantic
10 vector(vector&& v);
11 vector& operator=(vector&& v);
12
13 // ...
}Beides sind Referenzen im klassischen C++-Sinn. Der C++-Compiler entscheidet aber, welche Implementierung bei der Konstruktion oder auch Zuweisungsoperation verwendet wird, denn mit Lvalue-Referenzen wird die klassische und bekannte Copy-Semantik implementiert, mit Rvalue-Referenzen die neue Move-Semantik.
Praxistipp
Unterscheiden Sie die Copy- von der Move-Semantik.
Beim Erzeugen von neuen Objekten aus bestehenden werden die Inhalte der Objekte bei der Move-Semantik verschoben, bei der Copy-Semantik hingegen kopiert. Damit wird bei der Move-Semantik kein neues Objekt erzeugt.
Verwirrt? Verständlich! Das kleine Listing 3.15 soll für Aufklärung sorgen.
01 #include <iostream>
02 #include <string>
03 #include <utility>
04
05 int main(){
06
07 std::string str1{"ABCEF"};
08 std::string str2;
09
10 std::cout << "\n";
11
12 // initial value
13 std::cout << "str1= " << str1 << std::endl;
14 std::cout << "str2= " << str2 << std::endl;
15
16 // copy semantik
17 str2= str1;
18 std::cout << "str2= str1;\n";
19 std::cout << "str1= " << str1 << std::endl;
20 std::cout << "str2= " << str2 << std::endl;
21
22 std::cout << "\n";
23
24 std::string str3;
25
26 // initial value
27 std::cout << "str1= " << str1 << std::endl;
28 std::cout << "str3= " << str3 << std::endl;
29
30 // move semantik
31 str3= std::move(str1);
32 std::cout << "str3= std::move(str1);\n";
33 std::cout << "str1= " << str1 << std::endl;
34 std::cout << "str3= " << str3 << std::endl;
35
36 std::cout << "\n";
37
38 }Die neue C++11-Funktion std::move in Zeile 31 hat zur Folge, dass der String str1 als Rvalue vom C++-Compiler interpretiert wird. Damit wird der Inhalt von str1 nach str3 verschoben.
Die nächsten zwei Abbildungen stellen den Unterschied zwischen der Copy- und der Move-Semantik dar. Während nach dem Kopieren sowohl die Quelle str1 als auch das Ziel str2 den gleichen Inhalt besitzen, ist die Quelle str1 nach dem Verschieben des Inhalts leer.


Die Ausgabe des Programmlaufs in Abbildung 3.10 zeigt die Ergebnisse auf der Konsole.
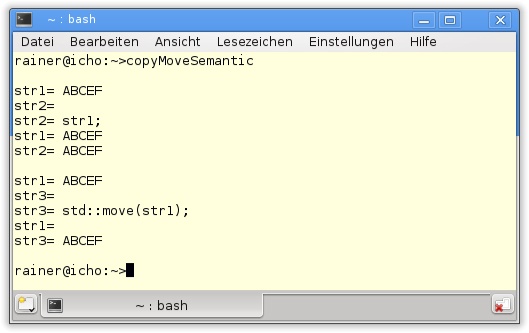
Die Grundlage für diese Optimierungen sind die Rvalues. Anhand dieser kann der C++-Compiler entscheiden, welche Implementierung der Methode verwendet werden soll.
Praxistipp
Rvalues besitzen keinen Namen.
Besitzt ein Objekt einen Namen, ist es ein Lvalue, ansonsten ein Rvalue.
Wie der C++-Entwickler eigene Datentypen entwirft, die mit Move-Semantik ausgestattet sind, wird in Teil II erläutert. Dies gilt auch für das Perfect Forwarding, bei dem Argumente an eine andere Funktion weitergegeben werden, ohne ihre Lvalue- oder Rvalue-Eigenschaft zu verändern. Ein bisher ungelöstes Problem in C++.
Weiter geht es mit neuen Features für den C++-Profi. Das Programmieren mit Templates wird deutlich mächtiger in C++11.
Generische Programmierung
Das generische Programmieren, auf dem die Standard Template Library basiert, ist in C++ ein wichtiges Paradigma. Daher verwundert es nicht, dass C++11 hier einiges Neues zu bieten hat:
Templates, die beliebig viele Parameter annehmen,
Zusicherungen, die zur Compile-Zeit ausgewertet werden,
Konstanten, die zur Compile-Zeit evaluiert werden,
Aliase Templates, um einfache Namen für teilweise gebundene Templates zu definieren.
Variadic Templates
Variadic Templates
Variadic Templates in C++11 erlauben es, Templates zu schreiben, die beliebig viele Argumente annehmen können. Ein prominentes Beispiel für den Einsatz von Variadic Templates ist der neue heterogene sequenzielle Datentyp std::tuple, der eine beliebige Länge besitzen kann.
Da die neue Syntax der Variadic Templates doch recht ungewohnt wirkt, zuerst ein einfaches Beispiel. Das Funktions-Template countMe in Listing 3.17 zählt die Anzahl seiner Argumente.
countMe.cpp
01 #include <iostream>
02 #include <list>
03
04 template <typename ... Args>
05 int countMe(Args ... args){
06 return (sizeof ... args);
07 }
08
09 int main(){
10
11 std::cout << "\n";
12
13 std::list<int> myList{1,2,3,4,5,6,7,8,9};
14
15 std::cout << "countMe() has " << countMe()
<< " arguments" << std::endl;
16 std::cout << "countMe(\"one\", 3.14 , myList ) has "
<< countMe("one", 3.14 , myList )
<< " arguments" << std::endl;
17 std::cout << "countMe(myList) has " << countMe(myList)
<< " argument" << std::endl;
18
19 std::cout << "\n";
20
21 }Ungewohnt an dem Funktions-Template countMe sind zuallererst die drei Punkte ... Dabei gilt es, aufmerksam darauf zu achten, ob diese links (<typename ... Args>, Zeile 4) oder rechts ((Args ... args), Zeile 5) von Args stehen. Links packt der Ellipsenoperator ... das sogenannte Parameter Pack, rechts entpackt er es wieder. Neu ist auch der Operator sizeof ... (Zeile 6), der direkt mit Parameter Packs umgehen kann.
Jetzt fehlt nur noch die Ausgabe des Programms.
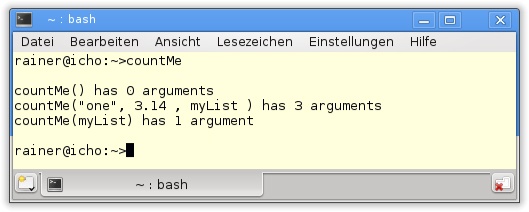
Das Programm countMe in Listing 3.17 ist aber nicht der klassische Anwendungsfall für Variadic Templates. Deutlich typischer ist das folgende Muster aus der funktionalen Programmierung, wenn es um die Verarbeitung beliebig langer Listen geht.
Dazu wird die Liste in die zwei Teile first und rest getrennt, wobei
firstdas erste Element der Liste undrestden Rest der Liste
bezeichnet.
Für beide Bereiche der Liste werden zwei Aktionen registriert.
Aktion (
first): Verarbeitefirst.Aktion (
rest): Verarbeitefirstund führe Aktion (rest) auf der verbleibenden Liste aus.
Der Trick ist, dass rest bei jeder Rekursion um das erste Element first gekürzt wird.
Genau diesem Muster folgt das Programm in Listing 3.18. Als Aktion auf dem Kopf der Liste first werden dessen Typinformation und Größe herausgegeben.
printValueInfo.cpp
01 #include <iomanip>
02 #include <iostream>
03 #include <typeinfo>
04
05 template <typename T>
06 void printInfoFor(T value){
07
08 std::cout << std::boolalpha;
09 std::cout << std::setw(5) << value << ": " << "(type: "
<< std::setw(3) << typeid(value).name()
<< ",size: " << sizeof(value) << ")\n";
10
11 }
12
13 template<typename T>
14 void printValueInfo(T value){
15
16 // print the information of the value
17 printInfoFor(value);
18
19 }
20
21 template<typename First,typename ... Rest>
22 void printValueInfo(First first,Rest ... rest){
23
24 // print the information of the value
25 printInfoFor(first);
26
27 // invoke value Information for the rest,
excluding first
28 printValueInfo(rest...);
29
30 }
31
32 int main(){
33
34 std::cout << std::endl;
35
36 printValueInfo(); // => compile error
37
38 printValueInfo(true,42,2.3,'c',"C++11");
39
40 std::cout << std::endl;
41
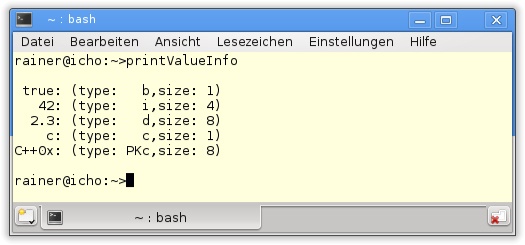
42 }In Zeile 38 wird die Aktion printValueInfo auf der ganzen Liste angestoßen. Die Liste besitzt mehr als ein Element, sodass das Funktions-Template printValueInfo(First first, Rest ... rest ) in Zeile 22 aufgerufen wird. Dabei wird true an first gebunden, und die verbleibenden Argumente werden an rest gebunden. true wird über die Hilfsfunktion printInfoFor (Zeile 5) ausgegeben, und rest wird rekursiv wieder aufgerufen (Zeile 28). Die Rekursion terminiert, sobald rest nur noch ein Element besitzt, denn in diesem Fall wird in Zeile 13 das Funktions-Template für ein Argument printValueInfo(T value) verwendet.
Anmerkung
In der funktionalen Programmierung hat sich für das Paar (first,rest) einer Liste das Namenspaar (head,tail) oder auch (car,cdr) etabliert.
Die Ausgabe zeigt die Typ- und Größeninformationen der Werte.
Anmerkung
Leider ist das vorgestellte Programm nicht sehr robust. Zum einen setzt es voraus, dass printValueInfo mindestens ein Argument erhält, und zum anderen, dass die Argumente direkt auf std::cout ausgegeben werden können.
Wird das Programm mit den falschen oder keinen Argumenten aufgerufen, moniert dies der Compiler sofort mit einer Fehlermeldung.

Es gilt als Codierungsstandard in C++, beschrieben von Herb Sutter und Andrei Alexandrescu in ihrem Buch »C++ Coding Standards« (Sutter & Alexandrescu, 2005), Fehler zur Übersetzungszeit denen zur Laufzeit vorzuziehen. C++11 führt für die Zusicherung zur Übersetzungszeit das neue Schlüsselwort static_assert ein.
Zusicherungen zur Compile-Zeit
static_assert
Es gibt bereits Werkzeuge in C++, um Zusicherungen an den Programmcode zu formulieren. So wirkt die Präprozessordirektive #error während der Ausführung des Präprozessors, das Makro assert hingegen während der Laufzeit des Programms. Die Lücke zwischen Präprozessorlauf und Ausführung des Programms schließt das neue C++11-Schlüsselwort static_assert, denn es wird zur Übersetzungszeit ausgeführt. Daher ist es sehr nützlich, wenn es darum geht, Bedingungen an den Template-Code zu verifizieren. Dies trifft umso mehr zu, da Concepts, ein Typsystem für Templates, aus dem aktuellen Standard entfernt wurden.
Aliase Templates
Aliase Templates
Dient static_assert dazu, den Template-Code robuster zu machen, so betreffen Aliase Templates vor allem die Lesbarkeit des Codes. Aliase Templates erlauben es, mittels des Schlüsselworts using Synonyme auf Templates zu erzeugen, die ihre Template-Parameter teilweise gebunden haben.
01 template< typename T, int V> 02 class MyType; 03 04 template< typename T> 05 using MyType10 = MyType<T,10>; 06 07 template<typename T> 08 using VecMyAlloc = std::vector<T,MyAllocator<T>>;
In MyType10 wird der zweite Template-Parameter von MyType mit 10 gebunden (Zeile 5). VecMyAlloc geht aus std::vector hervor, indem als zweites Element der Speicheranforderer (Zeile 8) gebunden wird.
Die Template-Instanziierung ist ein Prozess, der zur Übersetzungszeit stattfindet. Genauso verhält es sich mit den folgenden konstanten Ausdrücken.
Erweiterte Datenkonzepte und Literale
Viele Datenkonzepte aus dem klassischen C++ wurden in C++11 aufgegriffen und erweitert. Diese Erweiterungen betreffen die konstanten Ausdrücke, die sogenannten Plain Old Data (POD), aber auch Enums. Neben den neuen String-Literalen R"raw string" und U"unicode string" kann der C++-Entwickler eigene Literale definieren.
Konstante Ausdrücke
In C++11 wird das Konzept der konstanten Ausdrücke (constexpr) erweitert. Variablen, Funktionen oder auch Objekte können, sofern sie strenge Bedingungen einhalten, als constexpr deklariert werden. Damit lassen sich Funktionen als konstante Ausdrücke verwenden und Objekte zur Übersetzungszeit evaluieren. In C++11 ist es erlaubt, Arrays über Funktionen zu initialisieren, die als constexpr deklariert wurden.
constexpr int getSize() {return 10;}
int someValue[getSize() + 7];Anmerkung
Der große Vorteil der konstanten Ausdrücke ist, dass sie der Compiler optimieren kann, denn sie werden schon zur Übersetzungszeit evaluiert.
Um die Optimierung geht es auch bei den Erweiterungen der Plain Old Data (POD).
Plain Old Data (POD)
Plain Old Data sind Datenstrukturen, die ein C-Standardlayout besitzen. Damit können sie direkt mit den effizienten C-Funktionen memcpy und memmove kopiert oder auch mit memset initialisiert werden. C++11 erweitert die Regeln, da nun Klassen und Strukturen als POD gelten, wenn sie drei Bedingungen erfüllen. Sie müssen trivial sein, ein Standardlayout besitzen, und ihre nicht statischen Datenelemente müssen auch PODs sein. Genauer lässt sich das im Kapitel 10 im Abschnitt „Plain Old Data (POD)“ nachlesen.
Analog zu POD erfahren auch Unions mit C++11 einige Erweiterungen.
Unbeschränkte Unions
Unions können in C++11 Elemente von Datentypen wie std::string mit nicht trivialen speziellen Elementfunktionen besitzen. Spezielle Elementfunktionen sind Funktionen, die der Compiler automatisch erzeugt.
Wird die Anwendung durch Unions erweitert, so wird sie durch Enums typsicherer.
Streng typisierte Aufzählungstypen
Die klassischen Aufzählungstypen enum haben drei Probleme.
Sie konvertieren implizit zu
int.Sie führen ihre Bezeichner in dem umgebenden Bereich ein.
Der zugrunde liegende Typ kann nicht angegeben werden.
Diesen Problemen begegnen die neuen, streng typisierten Aufzählungstypen, auf die nur über den Namen des Aufzählungstyps zugegriffen werden kann. Sie vereinen die Funktionalität der klassischen enum-Datenstruktur mit Aspekten von Klassen. Eine streng typisierte enum-Color vom zugrunde liegenden Datentyp unsigned int ist kompakt definiert.
enum class Color: unsigned int {red, green, blue};Optional kann statt class struct verwendet werden, und der Datentyp unsigned int kann weggelassen werden, sodass red, green und blue vom Typ int sind.
Neben streng typisierten Aufzählungstypen gibt es auch neue String-Literale in C++11: die Raw-String-Literale und die Unicode-String-Literale.
Neue String-Literale
Raw-String-Literale
Raw-String-Literale haben sich in Python als äußerst praktisch erwiesen, wenn es darum geht, den Inhalt eines Strings nicht zu interpretieren. Typische Anwendungsfälle für Raw-Strings sind reguläre Ausdrücke oder auch Dateipfade unter Windows. Ein Raw-String wird in C++11 durch R"(raw string)" definiert.
Unicode-String-Literale
Der zweite neue Typ von String-Literalen sind die Unicode-String-Literale. C++11 unterstützt die drei Unicode-Kodierungen UTF-8, UTF-16 und UTF-32. Für UTF-16 und UTF-32 wurde C++11 um zwei neue Zeichentypen char16_6 und char32_t erweitert.
Benutzerdefinierte Literale
Darüber hinaus bietet C++11 benutzerdefinierte Suffix-Literale für ganze Zahlen, Fließkommazahlen, Strings und Zeichen an. Damit lassen sich Literale wie 130.3_km oder auch “978-3-16-148410-0”_ISBN definieren. Interpretiert werden diese Literale durch die Literal-Operatoren, die die Anwendungslogik implementieren.
Von der C++11-Laufzeit wird das Literal 130.3_km auf den Literal-Operator abgebildet.
Kilometer operator "" _km(long double d){
return Kilometer(d);
}nullptr
Das neue Schlüsselwort nullptr definiert eine Nullzeigerkonstante in C++11. Damit räumt es mit der Mehrdeutigkeit der Zahl 0 in C++ und dem C-Makro NULL auf. Denn abhängig vom Kontext bezeichnet 0 den Nullzeiger ((void*)0) oder die natürliche Zahl 0. NULL hingegen lässt sich in der Regel nach int konvertieren. Der nullptr kann aber nur als Zeiger oder in einem booleschen Ausdruck verwendet werden.
Neben dem C++11-Literal nullptr gibt es noch weitere Verbesserungen in C++11, die die Sprache klarer machen. Auch der aktuelle C-Standard C99 ist größtenteils in C++11 integriert.
Weitere Aufräumarbeiten und Integration von C99
Aufräumarbeiten
Parser-Probleme mit >>
C++98 hat Probleme, einen Ausdruck der Form std::vector<std::vector<int>> richtig auszuwerten, denn >> wird vom Parser irrtümlich als Token und damit als Rechts-Shift-Operator interpretiert. Daher war es erforderlich, zwischen den zwei abschließenden >> ein Leerzeichen zu setzen. Dies ist mit C++11 nicht mehr notwendig.
Integration von C99
Da der alte C++-Standard C++98 vor dem aktuell gültigen C99-Standard verabschiedet wurde, werden dessen Features in den neuen C++-Standard C++11 aufgenommen.
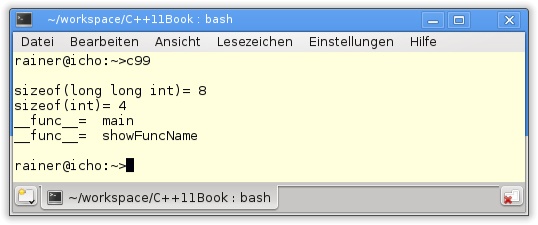
long long int
C++11 erbt den Datentyp long long int von C99, der mindestens 64 Bit (Listing 3.20, Zeile 14) groß ist.
__func__
Der Präprozessor kann den Namen __func__ (Zeilen 4 und 17) evaluieren.
c99.cpp
01 #include <iostream>
02
03 void showFuncName(){
04 std::cout << "__func__= " << __func__ << std::endl;
05 }
06
07 int main(){
08
09 std::cout << std::endl;
10
11 long long int ll=10;
12 int i= 10;
13
14 std::cout << "sizeof(long long int)= " << sizeof(ll)
<< std::endl;
15 std::cout << "sizeof(int))= " << sizeof(i) << std::endl;
16
17 std::cout << "__func__= " << __func__ << std::endl;
18 showFuncName();
19
20 std::cout << std::endl;
21
22 }Abbildung 3.14 zeigt die Ausgabe des Programms.
Damit verlassen wir den Bereich der Kernsprache von C++11. Es folgt die neue Multithreading-Funktionalität von C++11, die ihre Erweiterungen insbesondere in den neuen Bibliotheken anbietet.