Kapitel 10. Erweiterte Datenkonzepte und Literale
Datenkonzepte werden in C++11 deutlich erweitert. Zum einen führt C++11 neue Ideen wie konstante Ausdrücke, Raw-String-Literale und benutzerdefinierte Literale ein, zum anderen rundet es bestehende Konzepte ab. Dies betrifft die erweiterten PODs, unbeschränkte Unions, streng typisierte Aufzählungstypen, die bessere Unicode-Unterstützung und das neue Nullzeigerliteral nullptr.
Konstante Ausdrücke
Konstante Ausdrücke sind Ausdrücke, die zur Übersetzungszeit evaluiert werden können. Das Konzept der konstanten Ausdrücke wurde in C++11 erweitert. Es umfasst in C++11 Funktionen und benutzerdefinierte Typen.
Praxistipp
Beachten Sie das Optimierungspotenzial durch konstante Ausdrücke.
Konstante Ausdrücke stellen eine Möglichkeit zur Optimierung für den Compiler dar. Einerseits liegen die Ergebnisse der Berechnung schon zur Übersetzungszeit vor und stehen zur Laufzeit als Konstanten zur Verfügung, andererseits erhält der Compiler einen tieferen Einblick in den evaluierten Code und besitzt daher ein weiter reichendes Optimierungspotenzial.
Statische und dynamische Initialisierung
Den Unterschied zwischen statischer und dynamischer Initialisierung soll Listing 10.1 aufzeigen. Dabei bezeichnet die statische Initialisierung die Initialisierung zur Übersetzungszeit und die dynamische die zur Laufzeit.
01 #include <iostream>
02
03 constexpr int square(int x) { return x * x; }
04 constexpr int squareToSquare(int x)
{ return square(square(x));}
05
06 int main() {
07
08 std::cout << std::endl;
09
10 static_assert(square(10) == 100,
"you calculated it wrong");
11 static_assert(squareToSquare(10) == 10000,
"you calculated it wrong");
12
13 std::cout<< "square(10)= " << square(10) << std::endl;
14 std::cout<< "squareToSquare(10)= "
<< squareToSquare(10) << std::endl;
15 constexpr int constExpr= square(10);
16
17 int arrayClassic[100];
18 int arrayNewWithConstExpression[constExpr];
19 int arrayNewWithConstExpressioFunction[square(10)];
20
21 std::cout << std::endl;
22
23 }Sowohl die Funktion square (Zeile 3) als auch die Funktion squareToSquare (Zeile 4) in Listing 10.1 sind konstante Ausdrücke. Der Beweis wird durch static_assert in den Zeilen 10 und 11 erbracht. Aufrufe werden zur Übersetzungszeit evaluiert, sodass das Ergebnis als Konstante vorliegt. Damit ist es möglich, das Array arrayNew WithConstExpressioFunction in Zeile 19 direkt zu initialisieren. Dies ist mit C++98 nicht möglich, da ein Funktionsaufruf immer ein Aufruf zur Laufzeit ist. Das Array arrayNewWithConstExpression in Zeile 18 wird indirekt über den Funktionsaufruf initialisiert. Dazu ist es notwendig, dass constExpr in Zeile 15 als konstanter Ausdruck definiert wird.
Der Programmlauf ergibt das erwartete Ergebnis aus Abbildung 10.1.
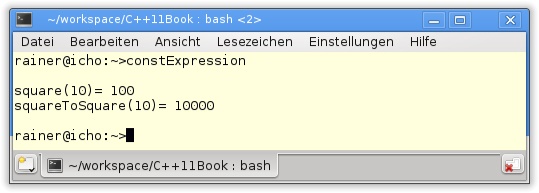
Variablen, Funktionen und benutzerdefinierte Typen
C++11 unterstützt drei Typen von konstanten Ausdrücken: Variablen, Funktionen und benutzerdefinierte Typen. Letztere werden auch benutzerdefinierte Literale genannt. An jeden dieser Typen sind bestimmte strenge Bedingungen geknüpft, damit sie zur Übersetzungszeit evaluiert werden können.
Variable (
constexpr type name= value;)nameist implizitconst.namekann das Ergebnis eines konstanten Ausdrucks oder den Aufruf eines sogenannten konstanten Ausdruckkonstruktors speichern.
Funktion (
constexpr type func(){return expr;})funcmuss einen Wert zurückgeben (keinvoid).An den Funktionskörper
exprsind Bedingungen geknüpft:Der Funktionskörper expr darf nur aus einer Rückgabeanweisung bestehen.exprmuss ein konstanter Ausdruck nach der Variablenersetzung sein.In
exprdürfen nur Funktionen oder Variablen verwendet werden, die konstante Ausdrücke sind.funcdarf erst nach seiner Definition aufgerufen werden.
Benutzerdefinierte Typen (
struct MyLit{ . . . };)MyLiteralbenötigt einen Konstruktor, der als konstanter Ausdruck definiert ist (constant expression constructor) (constexpr MyLit(type v):v_(v) {}).Der Funktionskörper des Konstruktors muss leer sein.
In der Elementinitialisierungsliste (
v_(v)) können nur konstante Ausdrücke verwendet werden.MyLiteralkann Methoden besitzen, die konstante Ausdrücke sind.
Benutzerdefinierte Literale werden zu konstanten Ausdrücken, wenn sie mit konstanten Ausdrücken aufgerufen werden. Erhalten diese aber ein dynamisches Argument, verhalten sie sich wie gewöhnliche benutzerdefinierte Datentypen und werden zur Laufzeit evaluiert (Listing 10.2).
myDouble.cpp
01 #include <iostream>
02
03 class MyDouble{
04 private:
05 double myVal1;
06 double myVal2;
07 public:
08 constexpr MyDouble(double v1,
double v2):myVal1(v1),myVal2(v2){}
09 constexpr double getSum(){ return myVal1+myVal2;}
10 };
11
12
13 int main(){
14
15 std::cout << std::endl;
16
17 // use a constant expression
18 constexpr double myStatVal= 2.0;
19 constexpr MyDouble myStatic(10.5,myStatVal);
20 constexpr double sumStat= myStatic.getSum();
21
22 static_assert(myStatic.getSum() == 12.5,
"you calculated it wrong");
23 static_assert(sumStat == 12.5,
"you calculated it wrong");
24 std::cout << "myStatic.getSum()= "
<< myStatic.getSum() << std::endl;
25
26 // use the constant expression at runtime
27 double myDynVal= 2.0;
28 MyDouble myDyn(10.5,myDynVal);
29 double sumDyn= myDyn.getSum();
30 std::cout << "myDyn.getSum()= "
<< myDyn.getSum() << std::endl;
31
32 std::cout << std::endl;
33
34 }In Listing 10.2 wird das Literal MyDouble definiert. Dies besitzt zwei konstante Ausdrücke, einen Konstruktor und die Methode getSum() in den Zeilen 8 und 9. Verwenden lässt sich der Datentyp sowohl statisch (Zeile 19) als auch dynamisch (Zeile 28). Der entscheidende Punkt ist, ob die Argumente konstante Ausdrücke sind. Auch der Rvalue 10.5 im Konstruktoraufruf ist zulässig. Da myDynVal in Zeile 27 ein dynamischer Wert ist, kann myDyn nicht als constexpr definiert werden. Die ganze Funktionalität der Klasse MyDouble steht aber zur Verfügung, um ein Objekt zur Laufzeit zu instanziieren. Die Ausgabe ist unabhängig davon, ob der Code zur Übersetzungs- oder zur Laufzeit ausgeführt wird.
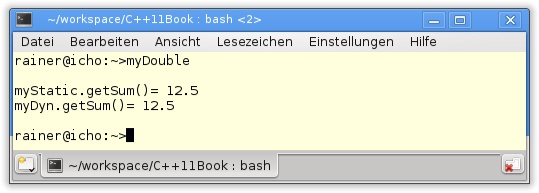
Aufgabe 10-1
Wie alles begann:
Erwin Unruh (Erwin Unruh, 2002) schrieb 1994 auf dem C++-Standardisierungs-Meeting in San Diego sein berühmtes Primzahlenprogramm, das die Primzahlen zur Übersetzungszeit berechnet. Damit war der Beweis erbracht, dass Berechnungen zur Übersetzungszeit durch Template-Instanziierung ausgeführt werden können. In seinem Buch ist eine leicht modifizierte Form zu sehen, die aktuelle Compiler ausführen können.
// Prime number computation by Erwin Unruh
template <int i> struct D { D(void*); operator int(); };
template <int p, int i> struct is_prime {
enum { prim = (p==2) || (p%i) && is_prime<(i>2?p:0),
i-1> :: prim };
};
template <int i> struct Prime_print {
Prime_print<i-1> a;
enum { prim = is_prime<i, i-1>::prim };
void f() { D<i> d = prim ? 1 : 0; a.f();}
};
template<> struct is_prime<0,0> { enum {prim=1}; };
template<> struct is_prime<0,1> { enum {prim=1}; };
template<> struct Prime_print<1> {
enum {prim=0};
void f() { D<1> d = prim ? 1 : 0; };
};
#ifndef LAST
#define LAST 10
#endif
main() {
Prime_print<LAST> a;
a.f();
}Das Ergebnis des Algorithmus ist in den Compiler-Warnungen versteckt. Die wesentlichen Zeilen wurden aus den Compiler-Warnungen herausgefiltert und bringen die ersten Primzahlen bis zur 15 hervor.
unruh.cpp: In Elementfunktion »void Prime_print<i>::f() [mit int i = 13]«: unruh.cpp: In Elementfunktion »void Prime_print<i>::f() [mit int i = 11]«: unruh.cpp: In Elementfunktion »void Prime_print<i>::f() [mit int i = 7]«: unruh.cpp: In Elementfunktion »void Prime_print<i>::f() [mit int i = 5]«: unruh.cpp: In Elementfunktion »void Prime_print<i>::f() [mit int i = 3]«: unruh.cpp: In Elementfunktion »void Prime_print<i>::f() [mit int i = 2]«:
Vergleichen Sie die Berechnung der Primzahlen durch konstante Ausdrücke von Daniel Krügler mit der durch Template-Metaprogramming von Erwin Unruh. Welche Technik ist einfacher zu verstehen?
primeNumbers.cpp
Aufgabe 10-2
Entscheiden Sie zur Übersetzungszeit, ob eine gegebene Zahl eine Primzahl ist.
Erwin Unruhs Programm lässt sich mit Template-Metaprogramming deutlich lesbarer schreiben. Versuchen Sie Ihr Glück.
Plain Old Data (POD)
Plain Old Data folgen dem C-Standardlayout. Damit können sie direkt mit den C-Funktionen memcpy und memmove kopiert und verschoben oder auch mit memset initialisiert werden. Ihre Definition ist aber zu restriktiv für C++, daher wurden die Regeln für PODs in C++11 erweitert.
Eine Klasse ist ein POD, wenn sie trivial ist, ein Standardlayout besitzt und alle ihre nicht statischen Datenelemente PODs sind.
trivial
Eine Klasse oder Struktur ist trivial, wenn sie
einen trivialen Konstruktor besitzt.
einen trivialen Kopierkonstruktor besitzt.
einen trivialen Zuweisungsoperator besitzt.
einen trivialen, nicht virtuellen Destruktor besitzt.
Standardlayout
Eine Klasse oder Struktur besitzt ein Standardlayout, wenn sie
keine virtuelle Funktion besitzt.
keine virtuelle Basisklasse besitzt.
keine Referenzen besitzt.
keine verschiedenen Zugriffsspezifizierer besitzt.
Um herauszufinden, ob ein Datentyp ein POD ist, hilft Template-Metaprogramming mit der neuen Type-Traits-Bibliothek (Listing 10.5).
isPod.cpp
01 #include <iostream>
02 #include <type_traits>
03
04
05 struct Pod {
06 int a;
07 };
08
09 struct NotPod {
10 int a;
11 NotPod() : a(0) {}
12 virtual int getA(){ return a;}
13 };
14
15
16
17 int main(){
18
19 std::cout << std::endl;
20
21 // Pod remains POD in C++11
22 Pod pod;
23 pod.a=10;
24
25 // still not Pod
26 NotPod notPod();
27
28 const bool isPodPod= std::is_pod<Pod>::value == true;
29 const bool isPodNotPod=
std::is_pod<NotPod>::value == true;
30
31 std::cout << std::boolalpha;
32 std::cout << "Pod is Pod: " << isPodPod << std::endl;
33 std::cout << "NotPod is Pod: " << isPodNotPod
<< std::endl;
34
35 std::cout << std::endl;
36
37 }Die Funktion std::is_pod (Zeilen 29 und 30) der Type-Traits-Bibliothek wird zur Übersetzungszeit ausgewertet und gibt zurück, ob das Template-Argument ein POD ist. Die Ausgabe gibt Aufschluss.
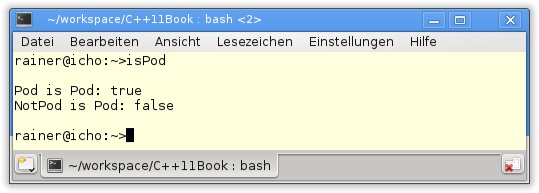
Aufgabe 10-3
Performance zählt.
Es mag verwunderlich erscheinen, warum in einem Buch über das neue C++ die C-Funktionen memcpy, memmove und memset erwähnt werden, werden doch memcyp und memmove durch std::copy und std::move in der STL und memset über Initialisiererlisten-Konstruktoren angeboten. Um an der Performanceschraube zu drehen, greifen die C++-Algorithmen gern auf die C-Algorithmen zurück. Eine typische Anwendung von memcpy im Copy-Algorithmus ist in Kapitel 19 im Abschnitt „Type-Traits“ dargestellt.
Lange Rede, kurzer Sinn: Machen Sie sich mit dem Einsatzgebiet der C-Funktionen memcpy, memmove und memset vertraut.
Unbeschränkte Unions
Unions beherbergen Datentypen, die sich denselben Speicherbereich teilen. Dabei wird die Größe der Union durch die Größe ihres größten Datentyps vorgegeben. Sie spielen eine wichtige Rolle bei der Implementierung von Bibliotheken und Frameworks. Für die Anwendung von Unions gibt es zwei typische Bereiche:
Automatische Typkonvertierung.
Erzwingen von strenger Speicherausrichtung (Alignment) der Datentypen.
Einschränkungen von C++98 Unions
An die klassischen C++98-Unions sind einige Einschränkungen gebunden, so dürfen sie
keine virtuellen Funktionen enthalten,
keine Referenzen enthalten,
keine Basisklasse besitzen,
keinen Datentyp mit speziellen Elementfunktionen besitzen.
Die letzte Einschränkung gilt nicht mehr in C++11. In C++11 ist eine Union erlaubt, die zum Beispiel einen std::string beinhaltet. Dies führt aber dazu, dass die speziellen Elementfunktionen der Union gelöscht werden. Für deren Implementierung hat nun der Programmierer zu sorgen. Werden aus der Union UnionWithString in Listing 10.6, Zeile 14, der Konstruktor und der Destruktor entfernt, zeigt der GCC unmissverständlich einen Fehler an (Abbildung 10.4).
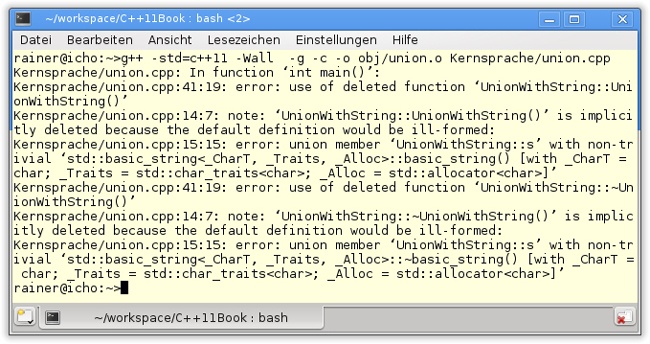
union.cpp
01 #include <iostream>
02 #include <string>
03
04 union MemorySizeChar{
05 char a;
06 char b;
07 };
08
09 union MemorySizeDouble{
10 char a;
11 double d;
12 };
13
14 union UnionWithString{
15 std::string s;
16 int i;
17 UnionWithString():s("hello"){}
18 ~UnionWithString(){}
19 };
20
21 using std::string;
22
23 int main(){
24
25 std::cout << std::endl;
26
27 MemorySizeChar mSC{'a'};
28 std::cout << "mSC.a= " << mSC.a << std::endl;
29 mSC.b='b';
30 std::cout << "mSC.b= " << mSC.b << std::endl;
31
32 std::cout << std::endl;
33
34 std::cout << "sizeof(mSC)= " << sizeof(mSC) << std::endl;
35
36 MemorySizeDouble mSD;
37 std::cout << "sizeof(mSC)= " << sizeof(mSD) << std::endl;
38
39 std::cout << std::endl;
40
41 UnionWithString uWithString;
42
43 std::cout << uWithString.s << std::endl;
44 // invoke the destructor explicitly
45 uWithString.s.~string();
46
47 uWithString.i=10;
48 std::cout << uWithString.i << std::endl;
49
50 // use placement new
51 new (&uWithString.s) std::string("hello again");
52 std::cout << uWithString.s << std::endl;
53 // invoke the destructor explicitly
54 uWithString.s.~string();
55
56 std::cout << std::endl;
57
58 }Werden der Standardkonstruktor und der Destruktor für die Union definiert, lässt sich die Union UnionWithString verwenden (Abbildung 10.5).
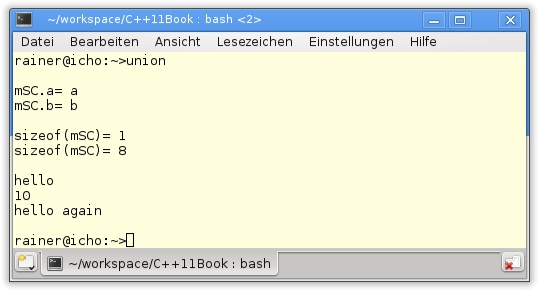
Die Ausgabe zeigt schön, dass die Länge der Union MemorySizeChar (Zeile 4) bzw. MemorySizeDouble (Zeile 9) in Listing 10.6 von der Größe ihres größten Datentyps abhängt. Während char 1 Byte beansprucht, benötigt double 8 Byte. Ab Zeile 41 wird der Typ UnionWithString verwendet. Zuerst wird der Wert der Variablen uWithString.s ausgegeben, die in der Initialisiererliste des Konstruktors gesetzt wird, danach wird die Variable uWithString.i gesetzt und deren Wert ausgegeben. Beim Wechsel von uWithString.s nach uWithString.i muss explizit der Destruktor in Zeile 45 aufgerufen werden. Genau das Gegenteil ist in Zeile 51 notwendig, wenn uWithString.s mit dem Operator placement-new wieder auf einen Wert gesetzt wird.
Die weiteren Details rund um Unions lassen sich schön im C++ Reference Guide (Kalev, 2004 ) von Danny Kalev nachlesen.
Aufgabe 10-4
Alignment-Unterstützung in C++11.
Die Alleinstellungsmerkmale von Unions beginnen zu bröckeln. Mit C++11 werden zwei neue Schlüsselwörter alignas und alignof eingeführt. Damit lässt sich die Speicherausrichtung für Datentypen setzen (alignas) und ermitteln (alignof). Die Anwendung ist sehr explizit (Stroustrup, 2011) und daher der impliziten Speicherausrichtung mit unbeschränkten Unions vorzuziehen.
alignas(double) unsigned char c[1024]; // array of characters, suitably aligned for doubles alignas(16) char[100]; // align on 16 byte boundary constexpr int n = alignof(int); // ints are aligned on n byte boundaries
Den besten Überblick über das neue Feature geben die zwei Vorschläge von Attila Farkas »Adding Alignment Support to the C++ Programming Language« (Feher, 2002) und von Lawrence Crowl »C and C++ Alignment Compatibility« (Crowl, 2010). Machen Sie sich mit der Alignment-Unterstützung in C++11 vertraut.
Streng typisierte Aufzählungstypen
Die neuen scoped und streng typisierten Aufzählungstypen (scoped and strongly typed enums) räumen mit drei Problemen der klassischen Aufzählungstypen auf.
Typsicher, scoped und mit definiertem zugrunde liegendem Typ
Sie sind typsicher, da sie nicht implizit zu
intkonvertieren.Sie verschmutzen (namespace pollution) nicht den umgebenen Bereich (scope), da sie keine Namenskollisionen verursachen.
Ihr zugrunde liegender Typ ist definiert, sodass Aufzählungstypen vorwärts deklariert werden können.
Der neue streng typisierte Aufzählungstyp enum class Color1 ist einfach erklärt.
Optional kann statt class struct und der zugrunde liegende Typ angegeben und der Enumerator über einen konstanten Ausdruck initialisiert werden.
enum struct Color2: char{
red= 100,
blue, // 101
green // 102
};Das Schlüsselwort class bzw. struct unterscheidet insbesondere die klassischen Aufzählungstypen von den C++11-Aufzählungstypen und drückt es explizit aus, dass die C++11-Aufzählungstypen nur über ihren Bereich adressiert werden können. Wird der zugrunde liegende integrale Typ nicht angegeben, ist int der Default-Typ. Listing 10.10 zeigt Color1 und Color2 im Einsatz.
enum.cpp
01 #include <iostream>
02
03 enum class Color1{
04 red,
05 blue,
06 green
07 };
08
09 enum struct Color2: char{
10 red= 100,
11 blue, // 101
12 green // 102
13 };
14
15 void useMe(Color2 color2){
16
17 switch(color2){
18 case Color2::red:
19 std::cout << "Color2::red " << std::endl;
20 break;
21 case Color2::blue:
22 std::cout << "Color2::blue" << std::endl;
23 break;
24 case Color2::green:
25 std::cout << "Color2::green" << std::endl;
26 break;
27 }
28
29 }
30
31
32 int main(){
33
34 std::cout << std::endl;
35
36 std::cout << "sizeof(Color1)= " << sizeof(Color1)
<< std::endl;
37 std::cout << "sizeof(Color2)= " << sizeof(Color2)
<< std::endl;
38
39 std::cout << std::endl;
40
41 Color2 color2Red{Color2::red};
42 useMe(color2Red);
43
44 std::cout << std::endl;
45
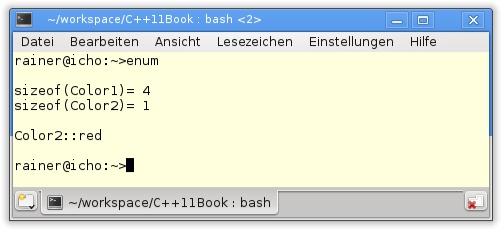
46 }Die Ausgabe des Programms in Listing 10.10 in Abbildung 10.6 zeigt, dass Color2 mit 1 Byte deutlich kompakter als Color1 ist, der 4 Bytes beansprucht. Der Grund liegt in der Definition des Aufzählungstyps. Während Color1 (Zeile 3) den Standarddatentyp int verwendet, wird für Color2 (Zeile 9) explizit char spezifiziert. useMe in Zeile 15 verwendet als Typ des Parameters Color2. Schön ist im Funktionskörper der Funktion und der Definition des Enumerators color2Red in Zeile 41 zu sehen, dass nur ein qualifizierter Zugriff auf den Enumerator zulässig ist.
enumAdd.cpp
Aufgabe 10-5
Vergleichen Sie die klassischen mit den neuen Aufzählungstypen.
In Listing 10.11 geschieht ein bisschen Arithmetik mit den Aufzählungstypen. Vergleichen Sie die Anwendung von OldEnum und NewEnum.
01 #include <iostream>
02
03 enum OldEnum{
04 one= 1,
05 ten= 10,
06 hundred= 100,
07 thousand= 1000
08 };
09
10 enum struct NewEnum: int {
11 one= 1,
12 ten= 10,
13 hundred= 100,
14 thousand= 1000
15 };
16
17 int main(){
18
19 std::cout << "C++11= "
<< 2*thousand + 0*hundred + 1*ten + 1*one
<< std::endl;
20 std::cout << "C++11= "
<< 2*static_cast<int>(NewEnum::thousand) +
0*static_cast<int>(NewEnum::hundred) +
1*static_cast<int>(NewEnum::ten) +
1*static_cast<int>(NewEnum::one)
<< std::endl;
21
22 }Die Anwendung des klassischen Aufzählungstyps OldEnum ist recht einfach. In Zeile 19 kann direkt auf die Elemente des Aufzählungstyps zugegriffen werden, da sie im globalen Namensraum verfügbar sind. Diese Elemente des OldEnum konvertieren implizit nach int, sodass die einzelnen Elemente addiert werden können. Das ist mit NewEnum in Zeile 20 nicht möglich. Hier müssen die Elemente mit NewEnum:: qualifiziert aufgerufen und explizit nach int konvertiert werden.
Aufgabe 10-6
Werden Sie mit den Anwendungsfällen der streng typisierten Aufzählungstypen vertraut.
In der neuen C++11-Standardbibliothek werden die streng typisierten Aufzählungstypen gern für Fehlercodes benutzt. Schauen Sie ihre Anwendung im Sourcecode der STL an.
Raw-String-Literale
Die Besonderheit eines Raw-String-Literals ist, dass die in ihm enthaltenen Zeichen nicht interpretiert werden. Damit erlauben es Raw-String-Literale bei regulären Ausdrücken oder auch Pfadangaben, den Backslash »\« direkt zu verwenden, da er keine Fluchtsequenz mehr darstellt.
Ein Raw-String wird in C++11 durch R"(raw string)" definiert. Optional ist auch die Syntax R"Trenner(raw string)Trenner" möglich. An den String-Trenner sind Bedingungen geknüpft. So darf er maximal 16 Zeichen lang sein und weder Leerzeichen noch öffnende »)« oder schließende »)« Klammern oder den Backslash »\« enthalten.
rawString.cpp
01 #include <iostream>
02 #include <string>
03
04 int main(){
05
06 std::cout << std::endl;
07
08 std::string nat="a \t native string \n a native string";
09 std::cout << nat << std::endl;
10
11 // including \t \n
12 std::string raw1=
std::string(R"(a \t raw string \n a raw string)");
13 std::cout << "\n" << raw1 << std::endl;
14
15 // including \t \n and using delimiter
16 std::string raw2= std::string(
R"MyDel(a \t raw string \n a raw string)MyDel");
17 std::cout << "\n" << raw2 << std::endl;
18
19 // raw string including
20 std::string raw3=
std::string(R"(a raw string including ")");
21 std::cout << "\n" << raw3 << std::endl;
22
23 std::cout << std::endl;
24
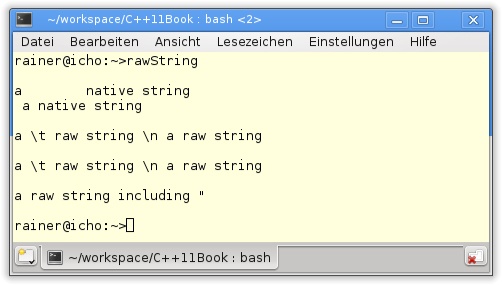
25 }Das Programm rawString in Listing 10.12 ergibt ausgeführt das erwartete Ergebnis. Im normalen String (Zeile 8) werden der Tabulator und der Zeilenumbruch bei der Ausgabe korrekt interpretiert. Die zwei Raw-Strings (Zeilen 12 und 16) geben den String unverändert aus. In einem Raw-String kann auch ein Anführungszeichen (") eingebettet und ausgegeben werden.
Aufgabe 10-7
Welche Anwendungsfälle von Raw-String-Literalen fallen Ihnen ein?
Reguläre Ausdrücke oder auch Pfadangaben unter Windows sind typische Anwendungsfälle für Raw-String-Literale. Dies sind aber natürlich nicht alle. Welche weiteren Anwendungsfälle gibt es für Raw-String-Literale?
Aufgabe 10-8
Wie lässt sich ein Raw-String-Literal definieren, das ein (")) enthält?
Angenommen, Ihr regulärer Ausdruck, den Sie als Raw-String-Literal definieren wollen, soll die Zeichenkette (")) enthalten. Dies ist die Zeichenkombination, mit der ein Raw-String-Literal beendet wird. Wie können Sie das Problem lösen?
Definieren Sie ein Raw-String-Literal, das die Zeichenkombination (")) enthält, und geben Sie es aus.
Unicode-Unterstützung
Der zweite neue Typ von String-Literalen sind die Unicode-String-Literale. Zwar besitzt C++98 die sogenannten Wide-Strings, die durch ein L"wide String" eingeleitet werden. Diese haben aber einen entscheidenden Nachteil, sodass sie nicht plattformunabhängig verwendet werden können. Ihre Länge ist nicht exakt spezifiziert.
UTF-8, UTF-16 und UTF-32
C++11 unterstützt die drei Unicode-Kodierungen UTF-8, UTF-16 und UTF-32. Für UTF-16 und UTF-32 wurde C++11 um zwei neue Zeichentypen char16_t und char32_t erweitert.
Unicode-Kodierung | Zeichentypen | String-Literale |
UTF-8 | char | u8“UTF-8 String” |
UTF-16 | char16_t | u“UTF-16 String” |
UTF-32 | char32_t | U“UTF-32 String” |
Durch die Zeichenkombination \u oder \U eingeleitet, können in Unicode-Strings Unicode-Codepunkte eingebettet werden (Zeilen 6, 10 und 14 in Listing 10.13). Dabei muss nach dem \u eine 16-Bit-, hingegen nach dem \U eine 32-Bit-Hexadezimalzahl stehen. Die Unicode-Präfixe u8, u und U oder auch die Wide-String-Präfixe L können mit dem Raw-String-Präfix R kombiniert werden (Zeilen 22, 23 und 24), wobei das Raw-String-Präfix an letzter Stelle folgen muss.
unicodeString.cpp
01 #include <string>
02
03 int main(){
04
05 // initialize std::string with the UTF-8 literal
06 const char* u8=
u8"I'm a UTF-8 literal including a codepoint \u2620";
07 std::string s1{u8};
08
09 // initialize std::wstring with the wide literal
10 const wchar_t* w=
L"I'm a wide literal including a codepoint \u2620";
11 std::wstring s2{w};
12
13 // initialize std::u16string with the UTF-16 literal
14 const char16_t* u16=
u"I'm a UTF-16 literal including a codepoint \u2620";
15 std::u16string u16string{u16};
16
17 // initialize std::u32string with the UTF-32 literal
18 const char32_t* u32=
U"I'm a UTF-32 literal including a codepoint\u2620";
19 std::u32string u32string{u32};
20
21 // combine unicode and raw String literale
22 const char* u8R= u8R"XXX(I'm a "raw UTF-8" literal.)XXX";
23 const char16_t* uR16=
uR"*(This is a "raw UTF-16" literal.)*";
24 const char32_t* uR32=
UR"(This is a "raw UTF-32" literal.)";
25
26 }Konvertierung zwischen den Kodierungen
Für die Konvertierung zwischen den verschiedenen Kodierungen steht das Klassen-Template codecvt, eine sogenannte Fassette (facet), bereit. Das Klassen-Template codecvt verlangt drei Typparameter:
template <class internT, class externT, class stateT> class codecvt;
Dabei beschreiben die Typparameter die Konvertierung:
internT: Zeichentyp für den internen ZeichensatzexternT: Zeichentyp für den externen ZeichensatzstateT: Status der Konvertierung
Über die Methoden codecvt::in und codecvt:out wird die Richtung der Konvertierung vorgegeben. Für das Klassen-Template codecvt stehen Spezialisierungen bereit, die die tatsächlich implementierten Konvertierungen spezifizieren. In Tabelle 10.3 und Tabelle 10.4 werden die verschiedenen Konvertierungen dargestellt.
Zuerst die Konvertierungen, die im klassischen C++ möglich sind.
Zeichentyp | Zeichentyp | Name |
|
|
|
|
|
|
Mit dem neuen Zeichentyp bringt C++11 einige neue Template-Spezialisierungen mit.
Zeichentyp | Zeichentyp | Name |
UTF-16 | UTF-8 |
|
UTF-32 | UTF-8 |
|
UTF-8 | UCS-2 UCS-4 |
|
UTF-16 | UCS-2 UCS-4 |
|
UTF-8 | UTF-16 |
|
wstring_convert wbuffer_convert
Die neuen Klassen-Templates std::wstring_convert und std::wbuffer_convert vollziehen ihre Konvertierung direkt ohne einen Stream oder eine Locale. Beide werden über eine codecvt-Fassette parametrisiert. Dabei wirkt std::wstring_convert auf einem String und std::wbuffer_convert auf einem Byte-Stream-Puffer.
Die nicht so ganz einfachen Details zu IOStreams, Fassetten und Locales lassen sich in dem Standardwerk »C++ IOStreams and Locales« von Angelika Langer und Klaus Kreft nachlesen (Langer & Kreft, 2000).
Aufgabe 10-9
Was jeder Softwareentwickler mindestens und unbedingt über Unicode und Zeichensätze wissen muss (kein Pardon!).
Verbindlicher lässt sich die Übungsaufgabe nicht beschreiben als der Titel des Dokuments »The Absolute Minimum Every Software Developer Absolutely, Positively Must Know About Unicode and Character Sets (No Excuses!)« von Joel on Software (Spolsky, 2003). Die deutsche Übersetzung von Hans-Werner Heinzen ist auch verfügbar (Heinzen, 2009).
Aufgabe 10-10
Machen Sie sich nach der Theorie mit der Praxis vertraut.
Es wird anspruchsvoller. C++ besitzt eine Lokalisierungsbibliothek local (locale). Machen Sie sich damit vertraut, wenn Sie Ihr C++-Programm lokalisieren wollen.
Benutzerdefinierte Literale
C++ kennt viele Literale:
true: Wahrheitswerte'c': Zeichen2,0x2: ganze Zahlen0.123,6.7L: Fließkommazahlen"Text",L"Text",u"Text",rU"text": Strings
Neu hingegen ist in C++11, dass der Anwender Literale selbst definieren kann. Häufig gewünschte Literale, die sich mit der neuen Syntax umsetzen lassen, sind:
1101010101010101_b: binäre Literale63_s: Sekundenangabe123.45_km: Abstandsangabe33_cent: Währungsangabe"Hallo"_i18n: Text zur Lokalisierung
Details
Ein benutzerdefiniertes Literal besteht aus einem C++98-Built-in-Literal ohne Suffix, das mit einem Unterstrich und einem Bezeichner verbunden ist. Es ist nur zulässig, den Bezeichner als Suffix anzuhängen. Literale besitzen keine Längeneinschränkung. Bestehende C++-Literale dürfen nicht neu definiert werden. Diese Literale werden dann von der C++11-Laufzeit auf den Literal-Operator abgebildet, der den Wert aus dem Literal extrahiert und, wie in Listing 10.14 exemplarisch dargestellt, als Distanzobjekt zur Verfügung stellt.
MyDistance operator "" _km(long double d){
return MyDistance(d);
}inline und constexpr
Dabei können die Literal-Operatoren inline oder als konstanter Ausdruck mit constexpr deklariert werden, damit sie zur Übersetzungszeit evaluiert werden.
Aufgabe des Anwenders
Die Aufgabe des Anwenders ist es, die speziellen Konvertierungsoperatoren, Literal-Operatoren genannt, zu implementieren. Dabei kann der Wert in raw- oder in cooked-Form von den Literal-Operatoren angenommen werden. In der raw-Form nimmt das Literal sein Argument als const char* entgegen, in der cooked-Form als Zahl. Ein paar Beispiele sollen die Begrifflichkeiten entflechten.
Benutzerdefiniertes Literal | raw-Form | cooked-Form |
101010101_b | “101010101” | 101010101 |
63_s | “63” | 63 |
2.17_km | “2.17” | 2.17 |
raw- und cooked-Form
Im Gegensatz zu Listing 10.14, in dem das Literal 123.45km in cooked-Form angenommen wird, nimmt der Literal-Operator in Listing 10.15 die Distanzangabe in raw-Form entgegen. Damit steht das Literal im Funktionskörper als const char* zur Verfügung.
MyDistance operator"" _km(const char* c){
return MyDistance(c);
}C++11 unterstützt Literale für natürliche Zahlen, Fließkommazahlen, Strings und Zeichen. Während die natürlichen Zahlen und Fließkommazahlen in raw- und cooked-Form angenommen werden können, ist das für Strings und Zeichen nur in raw-Form möglich. In der folgenden Tabelle sind die Typen der Argumente abhängig vom Datentyp dargestellt. Dies bildet die Grundlage für den Compiler, die Literal-Operatoren implizit aufzurufen.
Datentyp | raw-Form | cooked-Form |
Ganze Zahlen |
|
|
Fließkommazahlen |
|
|
Strings |
| |
Zeichen |
|
Wird sowohl die raw- als auch die cooked-Form für ein Literal definiert, besitzt die raw-Form die höhere Präzedenz. Die raw-Form wird in der Literatur auch als uncooked-Form bezeichnet.
Eine Besonderheit stellen die String-Literale dar. In Listing 10.16 wird die Funktion func (Zeile 1) mit dem String-Literal "myString"_str (Zeile 7) aufgerufen. Dies führt dazu, dass der Literal-Operator (Zeile 3) verwendet wird. Da die Länge des String-Literals 8 ist, wird len implizit auf 8 gesetzt und kann im Konstruktor von std::string (Zeile 4) angewandt werden. Das Ergebnis der Konvertierung ist, dass die Funktion mit einem String-Objekt aufgerufen wird.
01 void func(std::string s);
02
03 std::string operator "" _str(const char* s, size_t len){
04 return std::string(s,len);
05 }
06
07 func("myString"_str);Praxistipp
Verwenden Sie Namensräume für Literale.
Um Namenskollisionen von eigenen Literalen zu vermeiden, da sie in der Regel recht kurze Identifier besitzen, ist es eine gute Idee, die Literale in Namenräumen zu definieren und sie für ihre Anwendung in den globalen Namensraum zu importieren.
Das zugegeben etwas konstruierte Beispiel für die Berechnung von Abständen in Listing 10.18 soll die Vorteile der benutzerdefinierten Literale auf den Punkt bringen. Werden die Literal-Operatoren mit Operatorüberladung geschickt kombiniert, entsteht eine Domain-Specific-Embedded-Language, kurz DSEL.
01 namespace Distance{
02 class MyDistance{
03 private:
04 int meter;
05 public:
06 /* ... */
07 };
08 MyDistance operator +(const MyDistance& a,
09 const MyDistance& b){
10 return MyDistance(a.meter + b.meter);
11 }
12 MyDistance operator -(const MyDistance& a,
13 const MyDistance& b){
14 return MyDistance(a.meter - b.meter);
15 }
16 namespace Unit{
17 operator "" _km(long double d){
18 return MyDistance(1000*d);
19 }
20 operator "" _m(long double m){
21 return MyDistance(m);
22 }
23 operator "" _dm(long double d){
24 return MyDistance(d/10);
25 }
26 operator "" _cm(long double c){
27 return MyDistance(c/100);
28 }
29 }
30 }
31
32 using namespace Distance::Unit;
33
34 Distance::MyDistance myDistance= 10345.5_dm + 123.45_km – 1200_m +
150000_cm;Im Namensraum Distance in Listing 10.18 wird eine Subsprache in C++ definiert, auf der die Addition und Subtraktion von verschiedenen Längenangaben implementiert sind. Erreicht wird dies durch das Überladen des +- und des –-Operators in den Zeilen 8 und 12 und die Literal-Operatoren in den Zeilen 17, 20, 23 und 26, die den numerischen Wert aus dem Literal extrahieren und damit ein Distance-Objekt normiert instanziieren.
Domain-Specific-Embedded-Language
userDefinedLiterale.cpp
Aufgabe 10-11
Implementieren Sie Listing 10.18.
In Listing 10.18 wird die Idee einer Domain-Specific-Language für die Berechnung von Abständen skizziert. Ein Punkt fehlt noch: Die Klasse MyDistance benötigt einen Konstruktor und einen Ausgabeoperator.
nullptr
0 und NULL
Das neue Nullzeiger-Literal nullptr räumt mit der Mehrdeutigkeit der Zahl 0 und dem Makro NULL in C++ auf. Das Problem mit dem Literal 0 ist, dass es abhängig vom Kontext den Nullzeiger ((void*)0) oder die natürliche Zahl 0 bezeichnet. Das Problem an dem C-Makro NULL ist, dass NULL sich in der Regel nach int konvertieren lässt. Dieses Verhalten hängt von der Definition des Makros NULL ab.
Das C++11-Schlüsselwort nullptr besitzt ein eindeutiges Verhalten. Es lässt sich als Zeiger, als Zeiger auf ein Klassenmitglied oder als bool-Wert verwenden. Es kann aber nicht nach int konvertiert werden.
nullptr.cpp
01 #include <iostream>
02 #include <string>
03
04 std::string overloadTest(char*){
05 return "char*";
06 }
07
08 std::string overloadTest(int){
09 return "int";
10 }
11
12 int main(){
13
14 std::cout << std::endl;
15
16 int* pi = nullptr; // OK
17 // int i= nullptr; // ERROR
18 bool b = nullptr; // OK. b is false.
19
20 std::cout << std::boolalpha << "b: " << b << std::endl;
21
22 // calls int
23 std::cout << "overloadTest(0)= " <<
overloadTest(0) << std::endl;
24
25 // calls char*
26 std::cout << "overloadTest(static_cast<char*>(0))= "
<< overloadTest(static_cast<char*>(0))
<< std::endl;
27
28 // calls char*
29 std::cout << "overloadTest(nullptr)= "
<< overloadTest(nullptr)
<< std::endl;
30
31 // ambiguous error
32 // std::cout << "overloadTest(NULL)= "
<< overloadTest(NULL)
<< std::endl;
33
34 std::cout << std::endl;
35
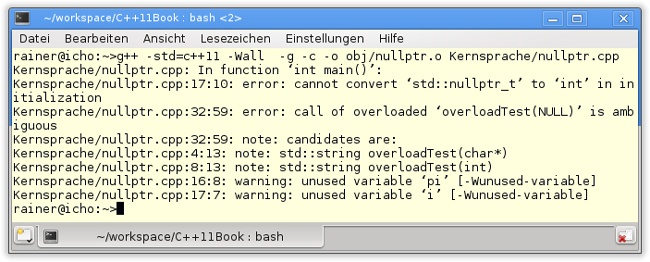
36 }In Listing 10.19 (Zeilen 16 und 18) wird der nullptr nach int* und bool konvertiert. Der in Zeile 20 ausgegebene Wert der booleschen Variablen b ergibt false. Interessanter sind die Ausgaben der Funktion overloadTest (Zeilen 23, 26 und 29). (char*)0 und nullptr werden als char* interpretiert, hingegen 0 als Integer.
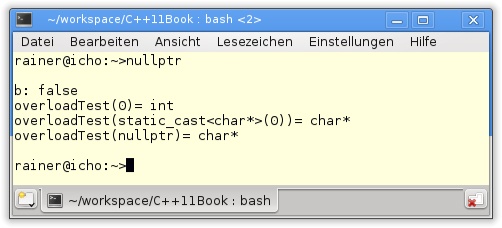
Werden die Zeilen 17 und 32 in Listing 10.19 auskommentiert, bricht die Übersetzung des Programms mit dem aktuellen GCC ab, denn einerseits lässt sich der nullptr nicht nach int konvertieren, und andererseits lässt sich NULL sowohl nach char* als auch nach int konvertieren.
nullptrPerfectForwarding.cpp
Aufgabe 10-12
Überprüfen Sie Ihren Sourcecode auf Nullzeiger.
Durchsuchen Sie Ihren Sourcecode auf die Verwendung der Zahl 0 als Nullzeiger und das Makro NULL.
Entscheiden Sie, welche Konsequenzen der Einsatz des neuen nullptr gegenüber dem Einsatz der Zahl 0 oder des Makros NULL als Nullzeiger mit sich bringt.
Aufgabe 10-13
Lassen Sie nullptr mit Perfect Forwarding zusammenarbeiten.
Rufen Sie die die zwei Funktionen overloadTest(char*) und overloadTest(int) aus Listing 4.19 indirekt über Perfect Forwarding auf. Dies ist am einfachsten, wenn Sie createT aus Listing 2.12 als Grundlage nehmen. Prüfen Sie zum Abschluss, ob der direkte Aufruf der overloadTest-Funktionen zum gleichen Ergebnis (Abbildung 10.8 und Abbildung 10.9) führt wie der indirekte Aufruf.