Kapitel 19. Neue Bibliotheken
Mit der Bibliothek für reguläre Ausdrücke erhält C++11 ein lang vermisstes Feature, sind doch reguläre Ausdrücke das Standardwerkzeug für anspruchsvolle String-Manipulationen. Aber auch die Type-Traits-Bibliothek mit ihrer Introspektionsfähigkeit zur Übersetzungszeit, die neuen Bibliotheken zu Zufallszahlen und zur Zeit oder die praktischen Referenz-Wrapper werden bald Standardwerkzeuge des professionellen C++-Programmierers sein.
Reguläre Ausdrücke
<regex>
Bevor wir uns die Syntax der regulären Ausdrücke in C++11 genauer anschauen, zunächst ein kleines Beispiel. In Listing 19.1 wird aus einem String die E-Mail-Adresse extrahiert und analysiert.
regexEmail.cpp
01 #include <regex>
02
03 #include <iostream>
04 #include <string>
05
06 int main(){
07
08 std::cout << std::endl;
09
10 std::string emailDescription="Email addresses,
such as rainer@grimm-jaud.de, have two parts.";
11
12 // regular expression for the email address
13 std::string regExprStr(
R"(([\w.%+-]+)@([\w.-]+\.[a-zA-Z]{2,4}))");
14
15 // regular expression holder
16 std::regex rgx(regExprStr);
17
18 // search result holder
19 std::smatch smatch;
20
21 // looking for a partial match
22 if (std::regex_search(emailDescription,smatch,rgx)){
23
24 std::cout << "Text: " << emailDescription << std::endl;
25
26 std::cout << std::endl;
27
28 std::cout << "Email address: " << smatch[0]
<< std::endl;
29 std::cout << "Local part: " << smatch[1] << std::endl;
30 std::cout << "Domain name: " << smatch[2] << std::endl;
31
32 std::cout << std::endl;
33
34 std::cout << "Text before the email address: "
<< smatch.prefix() << std::endl;
35 std::cout << "Text after the email address: "
<< smatch.suffix() << std::endl;
36
37 }
38
39 std::cout << std::endl;
40
41 }Listing 19.1 verfolgt die klassischen drei Schritte beim Umgang mit regulären Ausdrücken in C++11:
Erklären Sie den regulären Ausdruck (Zeile 16,
regExprStr).Halten Sie das Ergebnis der Suche (Zeile 19,
rgx).Verarbeiten Sie das Suchergebnis weiter (Zeilen 22 bis 37).
Abbildung 19.1 zeigt die Ausgabe von Listing 19.1.
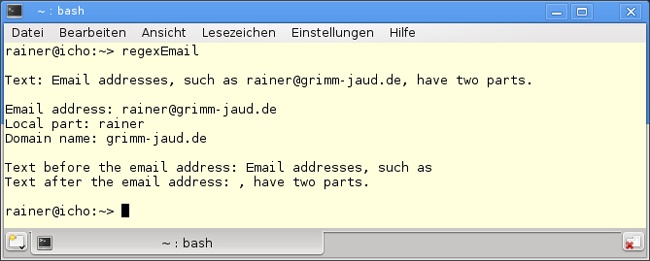
Aus dem Text emailDescription in Zeile 10 wird mithilfe des regulären Ausdrucks regExprStr die E-Mail-Adresse herausgefiltert und für die Auswertung zur Verfügung gestellt. In den Zeilen 22 bis 37 folgt die Auswertung. smatch[0] (Zeile 28) stellt die ganze E-Mail-Adresse, smatch[1] die erste Erfassungsgruppe (capture group) und smatch[2] (Zeile 30) die zweite Erfassungsgruppe zur Verfügung. Die erste Erfassungsgruppe ist der lokale Anteil, die zweite Erfassungsgruppe ist der Domänenanteil der E-Mail-Adresse. Mit smatch.prefix() bzw. smatch.suffix() (Zeilen 34 und 35) kann der Text vor bzw. nach der E-Mail referenziert und ausgegeben werden.
Raw-String-Literale
Für wen reguläre Ausdrücke nicht zum täglichen Brot gehören (den Autor eingeschlossen), für den ist der Ausdruck R"(([\w.%+-]+)@([\w.-]+\.[a-zA-Z]{2,4}))" in Zeile 13 nur schwer verdaulich. Bevor wir uns die Syntax genauer anschauen, noch eine kleine Bemerkung. Durch R"(...)" wird ein Raw-String-Literal in C++11 erklärt. Damit ist es nicht mehr nötig, die Backslash-Zeichen »\« im regulären Ausdruck durch einen vorangestellten zweiten Backslash »\« zu maskieren. Das äquivalente String-Literal "([\\w.%+-]+)@([\\w.-]+\\.[a-zA-Z] {2,4})" ist da schon schwieriger zu lesen.
Syntax der regulären Ausdrücke
Reguläre Ausdrücke lassen sich in C++11 in sechs verschiedenen Grammatiken spezifizieren.
Per Default wird die ECMAScript-Grammatik in C++11 verwendet, die die mächtigste der sechs vorgestellten Grammatiken darstellt. Daher wird sich meine weitere Ausführung über reguläre Ausdrücke auf die ECMAScript-Syntax beschränken. Die folgende Einführung in die Syntax der regulären Ausdrücke erhebt nicht ansatzweise den Anspruch, vollständig zu sein. Sie soll nur einen pragmatischen Einstieg in reguläre Ausdrücke in der ECMAScript-Grammatik anbieten.
Praxistipp
Verwenden Sie die ECMAScript-Grammatik.
Verwenden Sie bei den regulären Ausdrücken die ECMAScript-Grammatik. Zum einen ist sie die voreingestellte Grammatik in den regulären Ausdrücken von C++11, und zum anderen ist sie von den sechs angebotenen Grammatiken die mächtigste.
Zeichen
Die meisten Zeichen in regulären Ausdrücken repräsentieren sich selbst. Die Ausnahme sind die Metazeichen.
Metazeichen
Metazeichen besitzen eine besondere Bedeutung in regulären Ausdrücken. ECMAScript kennt verschiedene Metazeichen:
[ ] ( ) { } | ? + - * ^ $ \ .
Ihr Verständnis ist elementar für das Verständnis von regulären Ausdrücken. In Tabelle 19.1 sind die Metazeichen aufgelistet.
Metazeichen | Bedeutung | Beispiel |
\ | Schützt Metazeichen. Leitet Rückwärtsreferenzen ein. Leitet Zeichenklassen ein. | \\ \1 \d |
.(Punkt) | Beliebiges Zeichen außer dem Zeilenendezeichen. | . |
^ | Anfang eines Strings. Negiert die Zeichen in einer Auswahl. | ^string [^abc] |
$ | Ende eines Strings. | string$ |
| | Alternativauswahl. | a|b |
( ) | Definiert Teilausdrücke. | (ab(c)d) |
[ ] - | Auswahl von Zeichen. Definiert einen Zeichenbereich. | [abcde] [a-e] |
? | Wiederholungsangabe: null- oder einmal. | a? |
* | Wiederholungsangabe: null- oder mindestens einmal. | a* |
+ | Wiederholungsangabe: mindestens einmal. | a+ |
{ } | Wiederholungsangabe: genau n-mal. Zwischen n- und m-mal. Mindestens n-mal. | a{3} a{3,5} a{3,} |
Nach der trockenen Theorie der Metazeichen wird es nun deutlich konkreter.
Zeichenauswahl
Die Zeichenauswahl wird durch die eckigen Klammern definiert. Sie beschreibt eine Menge von Zeichen. Dabei können die einzelnen Zeichen aufgezählt [abcde] oder durch den Bindestrich als Bereich [a-e] angegeben werden. Zahlenbereiche können mehrfach in eckigen Klammern definiert [A-Za-z] werden und Ziffern [1-5] enthalten. Der Zirkumflex ^ besitzt eine besondere Bedeutung in einer Zeichenauswahl, da er die Auswahl negiert.
In Tabelle 19.2 sind ein paar Musterdefinitionen dargestellt.
Zeichenklassen
Zeichenklassen sind besondere Zeichenauswahlen. In ECMAScript sind die folgenden Zeichenklassen definiert:
Zeichenklasse | Beschreibung | Beschreibung |
[:alnum:] | Kleinbuchstaben, Großbuchstaben und die Ziffern 0 bis 9 | [:alpha:] oder [:digit:] |
[:alpha:] | Kleinbuchstaben und Großbuchstaben | a bis z oder A bis Z |
[:blank:] | Leerzeichen oder Tabulator | \t |
[:cntrl:] | Steuerzeichen | \r, \n, \t |
[:digit:] | die Ziffern 0 bis 9 | 0 bis 9 |
[:graph:] | Kleinbuchstaben, Großbuchstaben, die Ziffern 0 bis 9 und Satzzeichen | [:alnum:] oder [:punct:] |
[:lower:] | Kleinbuchstaben | a bis z |
[:print:] | druckbare Buchstaben | [:alnum:] oder [:punct:] oder Leerzeichen |
[:punct:] | Satzzeichen | ! “ # $ % & ‘ ( ) * +, - . / : ; < = > ? @ [ \ ] ^ _ ` { | } ~ |
[:space:] | Tabulator, Zeilenvorschub, Seitenvorschub, Wagenrücklauf und Leerzeichen | |
[:upper:] | Großbuchstaben | A bis Z |
[:xdigit:] | hexadezimale Ziffern | 0 bis 9, A bis F oder a bis f |
Für häufig benötigte Zeichenklassen gibt es in ECMAScript vordefinierte Kurzschreibweisen, die durch einen Backslash eingeleitet werden.
Zeichenklasse | Alternative Schreibweise | Beschreibung |
\d | [[:digit:]] | Ziffern von 0 bis 9 |
\D | [^[:digit]] | Zeichen, die keine Ziffern sind; [^\d] |
\s | [[:space:]] | Tabulator, Zeilenvorschub, Seitenvorschub, Wagenrücklauf und Leerzeichen |
\S | [^[:space:]] | Zeichen, die nicht in [[:space:]] sind; [^\s] |
\w | [a-zA-Z0-9_] | Buchstaben, Ziffern und der Unterstrich |
\W | [^a-zA-Z0-9_] | Zeichen, die nicht in [a-zA-Z0-9_]; [^\w] enthalten sind |
Wiederholungen
Wiederholungen erlauben es, genau zu spezifizieren, wie oft ein Ausdruck vorkommen darf. Dies lässt sich sehr kompakt in der ECMAScript-Grammatik angeben. Am leichtesten fällt der Überblick wieder mit einer Tabelle. Der Wiederholungsfaktor in Tabelle 19.5 bezieht sich immer auf den Ausdruck unmittelbar vor dem Wiederholungsfaktor.
Beschreibung | |
? | Der Ausdruck ist optional. |
+ | Der Ausdruck muss mindestens einmal vorkommen. |
* | Der Ausdruck kann beliebig oft vorkommen. |
{n} | Der Ausdruck muss genau n-mal vorkommen. |
{min,} | Der Ausdruck muss mindestens min-mal vorkommen. |
{min,max} | Der Ausdruck muss zwischen min-mal und max-mal vorkommen. |
{0,max} | Der Ausdruck darf höchstens max-mal vorkommen. |
Ein paar Beispiele machen die Theorie anschaulicher. Dabei bezeichnet “” die leere Zeichenkette in Tabelle 19.6.
Muster | Enthält | Enthält nicht |
“a?” | “a”, “” | “aa” |
“a+” | “a”, “aaaaaa” | “” |
“a*” | “”, “a”, “aaaaaaa”, | |
“a{5}” | “aaaaa” | “aaa” |
“a{5,}” | “aaaaa”, “aaaaaaaaaaaaaaaaaaa” | “aaa” |
“a{5,10}” | “aaaaaaaaaa” | “aaa” |
“a{0,5}” | “”,“a”, “aaa”, “aaaaa” | “aaaaaaaaaaaaaaaa” |
Bevor wir die Basismuster verlassen, sollte die Alternativauswahl nicht unerwähnt bleiben.
Alternative
Die Alternative wird durch den senkrechten Strich (pipe) definiert. So wird der reguläre Ausdruck "ab|12" entweder von der Zeichenkette "ab" oder von "12" erfüllt, hingegen nicht von "a1".
Gruppierungen
Werden die bisher dargestellten Bausteine aneinandergereiht, können die Muster deutlich komplexer werden. Die ECMAScript-Grammatik erlaubt es, Teilmuster durch die runden Klammern »( )« in dem Gesamtmuster zu definieren. Die Grundfrage bleibt aber bestehen. Ist ein vorgegebener String in der Menge der Wörter enthalten, die ein Muster beschreibt?
Erfassungsgruppen
Diese Teilmuster werden Erfassungsgruppen (capture groups) genannt und bieten mächtige Features an. Zuallererst können die Erfassungsgruppen im Suchergebnis abgefragt werden. Ist smatch (Zeile 19) wie in Listing 19.1 das Ergebnis der Suchabfrage, kann mit smatch[0] das gesamte Ergebnis oder auch die nullte Erfassungsgruppe, mit smatch[1] die erste Erfassungsgruppe, mit smatch[2] die zweite Erfassungsgruppe und mit steigendem Index jede weitere Erfassungsgruppe angesprochen werden, die natürlich leer sein kann. Die Nummerierung der Erfassungsgruppen findet in dem Muster von außen nach innen und von links nach rechts statt.
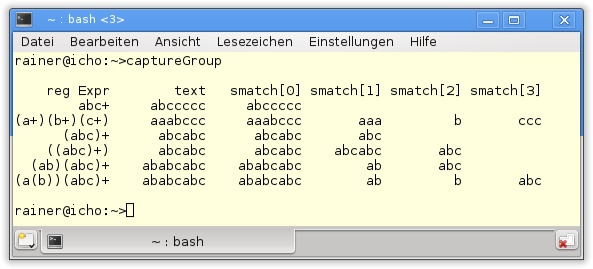
In Listing 19.2 sind Erfassungsgruppen im Einsatz zu sehen.
captureGroup.cpp
01 #include <regex>
02
03 #include <iomanip>
04 #include <iostream>
05 #include <string>
06
07 void showCaptureGroups(const std::string& regEx,
const std::string& text){
08
09 // regular expression holder
10 std::regex rgx(regEx);
11
12 // result holder
13 std::smatch smatch;
14
15 // result evaluation
16 if (std::regex_search(text,smatch,rgx)){
17 std::cout << std::setw(12) << regEx
<< std::setw(12) << text
<< std::setw(12) << smatch[0]
<< std::setw(10) << smatch[1]
<< std::setw(10) << smatch[2]
<< std::setw(10) << smatch[3] << std::endl;
18 }
19
20 }
21
22 int main(){
23
24 std::cout << std::endl;
25
26 std::cout << std::setw(12) << "reg Expr"
<< std::setw(12) << "text"
<< std::setw(12) << "smatch[0]"
<< std::setw(10) << "smatch[1]"
<< std::setw(10) << "smatch[2]"
<< std::setw(10) << "smatch[3]" << std::endl;
27
28 showCaptureGroups("abc+","abccccc");
29
30 showCaptureGroups("(a+)(b+)(c+)","aaabccc");
31
32 showCaptureGroups("(abc)+","abcabc");
33
34 showCaptureGroups("((abc)+)","abcabc");
35
36 showCaptureGroups("(ab)(abc)+","ababcabc");
37
38 showCaptureGroups("(a(b))(abc)+","ababcabc");
39
40 std::cout << std::endl;
41
42 }Da die regulären Ausdrücke in Listing 19.2 keine zu schützenden Sonderzeichen enthalten, sind Raw-String-Literale nicht notwendig. Kompiliert und ausgeführt, lässt sich schön die Anwendung der Erfassungsgruppen studieren.
Rückwärtsreferenzen
Erfassungsgruppen können nicht nur in dem Suchergebnis, sondern direkt im Muster referenziert werden. Dieses mächtige Feature nennt sich Rückwärtsreferenz. So lässt sich mit \1 die erste, mit \2 die zweite und mit \i die i-te Erfassungsgruppe referenzieren. Dabei ist das Muster nur gültig, wenn für die i-te Rückwärtsreferenz eine i-te Erfassungsgruppe definiert wurde.
In Tabelle 19.7 sind ein paar Beispiele für Rückwärtsreferenzen dargestellt.
Muster | Gültige Zeichenketten | Beschreibung |
“(\w+)\s+\1” | “12 12” “a a” | Beliebig langes Wort, das sich, durch space getrennt, wiederholt. |
“(\w{3})\w*\1” | “abc___abc” “12_12_” | Drei Zeichen langes Wort, das sich, durch beliebig viele Zeichen getrennt, wiederholt. |
“(\d+)(\w+)\2\1” | “1aa1” “123TestTest123” | Ziffern gefolgt von Zeichen wiederholen sich. Dabei ist ihre Reihenfolge vertauscht. |
“(.)(.).*\2\1” | “otto”, “rentner” “otABCto” | Zeichenkette endet mit den ersten zwei Buchstaben in umgekehrter Reihenfolge. |
Mit der Syntax für reguläre Ausdrücke gewappnet, lässt sich nun auch der reguläre Ausdruck ([\w.%+-]+)@([\w.-]+\.[a-zA-Z] {2,4})für die E-Mail-Adresse aus Listing 19.1 in Prosa übersetzen, der eine E-Mail-Adresse in ihren lokalen und den Domänenanteil zerlegt. Für die erste Analyse des E-Mail-Ausdrucks werden die Erfassungsgruppen ignoriert. Damit lässt sich der reguläre Ausdruck auf [\w.%+-]+@[\w.-]+\.[a-zA-Z]{2,4} vereinfachen.
Der lokale Anteil [\w.%+-]+ besteht aus:
mindestens einem Zeichen (
[...]+) aus der Menge der Wortzeichen (\w), einem Punkt (.), einem Plus- (+) oder einem Minuszeichen (-).
Der Domänenanteil [\w.-]+\.[a-zA-Z]{2,4} folgt auf das at-Zeichen @ und besteht aus:
mindestens einem Zeichen (
[...]+) aus der Menge der Wortzeichen (\w), einem Punkt (.) oder einem Minuszeichen (-),einem Punkt (
\.),zwei bis vier (
{2,4}) Buchstaben[a-zA-Z].
Die Zeichenkette [...]+ enthält mindestens ein Zeichen aus der Zeichenmenge [...] im Gegensatz zur Zeichenkette [...]*, die auch leer sein kann. Werden zu dem einfachen regulären Ausdruck wieder die Erfassungsgruppen hinzugefügt, lassen sich der lokale und der Domänenanteil aus diesem extrahieren.
Diese Einführung in die ECMAScript-Grammatik sollte ausreichen, um die weitere Funktionalität zu regulären Ausdrücken in C++11 im Detail zu betrachten.
Mehr Informationen zu regulären Ausdrücken.
Um tiefer in die Syntax der regulären Ausdrücke einzutauchen, sei auf (Friedl, 2002) verwiesen. Auch Onlinetools wie der REGEXP-EVALUATOR von Jens Henneberg (Henneberg, 2010) leisten wertvolle Dienste, wenn es darum geht, schnell einen regulären Ausdruck auszuwerten.
Diese Muster, die reguläre Ausdrücke beschreiben, werden in C++11-Objekten gekapselt.
Objekte vom Typ regulärer Ausdruck
basic_regex
Objekte vom Typ regulärer Ausdruck sind Instanzen des Klassen-Templates std::basic_regex, die über ihren Charaktertyp und die Traits-Klasse parametrisiert werden. Dabei legt die Traits-Klasse fest, wie das Objekt Eigenschaften der regulären Grammatik interpretiert. Das hört sich komplizierter an, als es ist, denn in Anlehnung an std::string und std::wstring gibt es zwei Typsynonyme für std::basic_regex, die diese Komplexität verbergen:
typedef basic_regex<char> regex; typedef baisc_regex<wchar_t> wregex;
Anpassung von regex und wregex
Hier hört aber die Parametrisierung nicht auf. Für Instanzen vom Typ std::regex bzw. std::wregex lässt sich die verwendete Grammatik, Optimierungseigenschaften und Modifikationen der Syntax des resultierenden Objekts an die eigenen Bedürfnisse anpassen. Als mögliche Grammatiken stehen neben der Standardgrammatik ECMAScript auch basic, extended, awk, grep und egrep zur Verfügung. Während die Optimierung der Instanzen vom Typ regulärer Ausdruck den Spezialisten adressiert, bietet std::regex_constants::icase die Möglichkeit, den regulären Ausdruck unabhängig von Groß- und Kleinschreibung (case insensitive) zu behandeln. Werden die Optimierungsflags oder auch Modifikatoren der Grammatik verwendet, muss die Syntax der Grammatik verbindlich angegeben werden. Alle drei Parameter werden an den Konstruktor von std::regex bzw. std::wregex über eine Bitmaske übergeben.
Nach der Theorie nun das einfache Listing 19.4, das die case sensitive und case insensitive Suche in einem String anwendet.
case.cpp
01 #include <regex>
02
03 #include <iostream>
04 #include <string>
05
06 int main(){
07
08 std::cout << std::endl;
09
10 std::string theQuestion="C++ or c++, that's the question.";
11
12 // regular expression for c++
13 std::string regExprStr(R"(c\+\+)");
14 // std::string regExprStr("c\\+\\+");
15
16 // regular expression object
17 std::regex rgx(regExprStr);
18
19 // search result holder
20 std::smatch smatch;
21
22 std::cout << theQuestion << std::endl;
23
24 // looking for a partial match (case sensitive)
25 if (std::regex_search(theQuestion,smatch,rgx)){
26
27 std::cout << std::endl;
28 std::cout << "The answer is case sensitive: "
<< smatch[0] << std::endl;
29
30 }
31
32 // regular expression object (case insensitive)
33 std::regex rgxIn(regExprStr,
std::regex_constants::ECMAScript|std::regex_constants::icase);
34
35 // looking for a partial match (case insensitive)
36 if (std::regex_search(theQuestion,smatch,rgxIn)){
37
38 std::cout << std::endl;
39 std::cout << "The answer is case insensitive: "
<< smatch[0] << std::endl;
40
41 }
42
43 std::cout << std::endl;
44
45 }In Zeile 13 in Listing 19.4 wird der reguläre Ausdruck definiert, der für die Suche in std::string theQuestion (Zeile 10) verwendet werden soll. In Zeile 14 ist der äquivalente reguläre Ausdruck ohne den Einsatz eines Raw-String-Literals dargestellt. Das erste Objekt vom Typ regulärer Ausdruck wird case sensitive instanziiert und in Zeile 25 angewandt. Im Gegensatz dazu wird das zweite Objekt über die Bitmaske std::regex_constants::ECMAScript|std::regex_constants::icase in Zeile 33 parametrisiert, sodass die Suche case insensitive ausgeführt wird. Abbildung 19.3 zeigt die Ausführung des Programms.

Weitere Elementfunktionen
Objekte vom Typ std::regex und std::wregex bieten noch weitere Funktionen an. Das Tauschen (swap) des Inhalts zweier Objekte wird in C++11 unterstützt. Seine Lokalisierungseigenschaften lassen sich ändern (imbue) und ausgeben (getloc). Dies ist auch für die Flags (flags) möglich. Weiter ist es möglich, die Anzahl der Erfassungsgruppen des regulären Ausdrucks, den das Objekt hält, durch die Elementfunktion (mark_count) abzufragen.
Aufgabe 19-2
Der Blick in die Tiefe.
In dem Buch »The C++ Standard Library Extensions« (Becker, The C++ Standard Library Extension, 2006) lässt Pete Becker in Kapitel 16 keine Frage zu den weiteren Details, insbesondere auch zur Ausnahmebehandlung der Objekte vom Typ reguläre Ausdrücke, offen.
Analyse des Suchergebnisses mit match_results
Praxistipp
Bleiben Sie Ihrem Zeichentyp treu.
Der Zeichentyp des regulären Ausdrucks, der zu untersuchenden Zeichenkette und des Suchergebnisses müssen übereinstimmen. char und wchar_t sind die Zeichentypen, die eine Bibliothek zu regulären Ausdrücken in C++11 unterstützen muss.
std::match_results stellt das Ergebnis eines std::regex_match- oder std::regex_search-Aufrufs zur Verfügung. Dabei ist std::match_results ein sequenzieller Container, der seine einzelnen Erfassungsgruppen als std::sub_match-Objekte zurückgibt. std::sub_match ist eine Sequenz von Zeichen.
Damit lässt sich komfortabel in Listing 19.5 über die Erfassungsgruppen und die Zeichenketten der Erfassungsgruppen iterieren.
iterate.cpp
01 #include <regex>
02
03 #include <algorithm>
04 #include <iomanip>
05 #include <iostream>
06 #include <string>
07
08 int main(){
09
10 std::cout << std::endl;
11
12 std::string privateAddress="192.168.178.21";
13
14 // regular expression for IP4 adresses
15 std::string
ip4RegEx(R"((\d{1,3})\.(\d{1,3})\.(\d{1,3})\.(\d{1,3}))");
16
17 // regular expression holder
18 std::regex rgx(ip4RegEx);
19
20 // search result holder
21 std::smatch smatch;
22
23 // looking for the exact match
24 if (std::regex_match(privateAddress,smatch,rgx)){
25
26 for ( auto cap: smatch ){
27
28 std::cout << "capture group: " << cap << std::endl;
29 if (cap.matched){
30
31 // print each character in hexadecimal notation,
including the base
32 std::cout << "hex: ";
33 std::for_each(cap.first,cap.second,
[](int v){std::cout << std::showbase
<< std::hex << v << " ";});
34 std::cout << "\n\n";
35
36 }
37
38 }
39
40 }
41
42 }Listing 19.5 beginnt vertraut. In Zeile 15 wird ein regulärer Ausdruck für IP4-Adressen erklärt, der in Zeile 18 an das Objekt vom Typ regulärer Ausdruck übergeben wird. Spannender wird es in dem if-Block (Zeilen 24 bis 40). std::regex_match prüft, ob der Eingabestring privateAddress eine gültige IP4-Adresse ist. Ist das der Fall, wird der if-Block ausgeführt und in der for-Schleife (Zeilen 26 bis 38) jeder Erfassungsgruppe ausgegeben. Dies ist aber nur die Iteration über alle Erfassungsgruppen. In Zeile 33 wird über die Zeichen jeder Erfassungsgruppe iteriert. Um den Unterschied optisch zu verdeutlichen, stellt die Lambda-Funktion jedes Zeichen hexadezimal dar.
In Abbildung 19.4 ist die Ausgabe des Programms zu sehen.

Noch eine Feinheit: Während das Suchergebnis smatch vom Typ std::match_results ist, ist die Erfassungsgruppe cap vom Typ std::sub_match. Dies erklärt, warum die Objekte smatch und cap verschiedene Interfaces anbieten. Um den Überblick zu behalten, sind in den zwei folgenden Tabellen die wichtigsten Funktionen des Datentyps std::match_results (Tabelle 19.8) sowie des Datentyps std::sub_match (Tabelle 19.9) dargestellt.
match_result-Funktionen
Funktion | Beschreibung |
| Tausche |
| Gibt die i-te Erfassungsgruppe vom Typ |
| Gibt den Offset vom Anfang des Suchstrings bis zum Beginn der i-ten Erfassungsgruppe zurück. Default-Wert i= 0. |
| Gibt die Länge der i-ten Erfassungsgruppe zurück. Default-Wert i= 0. |
| Gib die Zeichenkette der i-ten Erfassungsgruppe als String zurück. Default-Wert i= 0. |
| Ermöglicht die Formatierung der Eingabestrings mithilfe des Suchergebnisses (Genaueres hierzu folgt in Kapitel 19 im Abschnitt „Formatieren mit regex_replace und match_results.format“.) |
| Gibt ein |
| Gibt ein |
| Gibt einen Iterator auf die erste Erfassungsgruppe zurück. |
| Gibt die Zeichenkette nach dem Suchergebnis ( |
| Gibt die Anzahl der Erfassungsgruppen zurück. |
| Gibt die Länge der längsten Erfassungsgruppe zurück. |
| Gibt |
| Gibt eine Kopie des Allokators für |
| Vergleicht die Suchergebnisse |
sub_match-Funktionen
Funktion | Beschreibung |
| Rückgabewert |
| Iterator auf den Beginn der Zeichenkette. |
| Iterator auf die Position nach dem letzten gültigen Zeichen der Zeichenkette. |
| Gibt die Länge der Zeichenkette zurück. |
| Gibt eine Zeichenkette als String zurück. |
| Vergleicht |
Für die Zeichentypen char und wchar_t gibt es sowohl für std::match_results als auch für std::sub_match Typsynonyme, die das Leben eines Programmierers einfacher machen.
typedef match_results<const char*> cmatch; typedef match_results<const wchar_t*> wcmatch; typedef match_results<string::const_iterator> smatch; typedef match_results<wstring::const_iterator> wsmatch;
typedef sub_match<const char*> csub_match; typedef sub_match<const wchar_t*> wcsub_match; typedef sub_match<string::const_iterator> ssub_match; typedef sub_match<wstring::const_iterator> wssub_match;
iterateSolution.cpp
Aufgabe 19-3
Implementieren Sie Listing 19.5 für den Charaktertyp const char*.
Das Programm iterate.cpp aus Listing 19.5 ist für den Zeichentyp std::string implementiert. Ein paar Modifikationen, und es kann auf const char* angewandt werden.
Exakte Treffer mit regex_match
std::regex_match soll helfen, die Frage zu beantworten: Entspricht meine Zeichenkette dem regulären Ausdruck? Da sich diese einfache Frage mit Ja oder Nein beantworten lässt, kann std::regex_match ohne ein Suchergebnis std::match_results (Listing 19.5) verwendet werden.
Genau diese Anwendung zeigt Listing 19.8.
regexMatch.cpp
01 #include <regex>
02
03 #include <iostream>
04 #include <string>
05 #include <vector>
06
07 int main(){
08
09 std::cout << std::endl;
10
11 // regular expression for a number,
not including an exponent
12 std::string numberRegEx(
R"([-+]?([0-9]*\.[0-9]+|[0-9]+))");
13
14 // regular expression holder
15 std::regex rgx(numberRegEx);
16
17 // using const char*
18 const char* numChar{"2011"};
19 if (std::regex_match(numChar,rgx)){
20 std::cout << numChar << " is a number." << std::endl;
21 }
22
23 // using std::string
24 const std::string numStr{"3.14159265359"};
25 if (std::regex_match(numStr,rgx)){
26 std::cout << numStr << " is a number." << std::endl;
27 }
28
29 // using bidirectional iterators
30 const std::vector<char> numVec{
{'-','2','.','7','1','8','2','8','1','8','2','8'}};
31 if (std::regex_match(numVec.begin(),numVec.end(),
rgx)){
32 for (auto c: numVec){ std::cout << c ;};
33 std::cout << " is a number." << std::endl;
34 }
35
36 std::cout << std::endl;
37
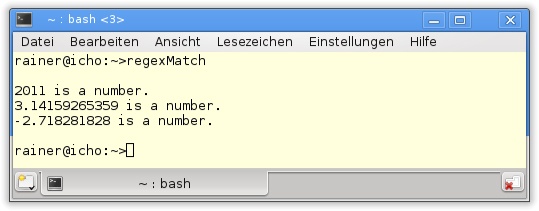
38 }In Listing 19.8 wird std::regex_match in Zeile 19 mit einem Zeiger auf const char, in Zeile 25 mit einem std::string und in Zeile 31 mit zwei Iteratoren aufgerufen. Alle drei Aufrufe ergeben das erwartete Ergebnis (Abbildung 19.5).
Neben diesen drei überladenen Versionen des Funktions-Templates std::regex_match existieren noch drei weitere Varianten, die ein Suchergebnis vom Typ std::match_results erwarten. Diese sind bereits in Listing 19.5 angewandt worden.
Weitere Flags in regex_constants
regexMatchSolution.cpp
Aufgabe 19-4
Erweitern Sie die Zahlenerkennung in Listing 19.8 um die Exponentialschreibweise.
Listing 19.8 ist nur die halbe Lösung des Problems. Literale der Form »-3.44E+4« sind für das Programm keine Zahlen. Erweitern Sie daher den regulären Ausdruck so, dass er Zahlen in der wissenschaftlichen Notation auch erkennt.
Testen Sie Ihren Algorithmus mit den Zahlen 2011, 3.14159, -3.44E+4 und -1.02E-4.
Suchen mit regex_search
regex_search
Die Anwendung von std::regex_search ist der von std::regex_match sehr ähnlich. Zu jeder der sechs Varianten von std::regex_match existiert eine Variante von std::regex_search, die die gleiche Signatur besitzt. Während std::regex_match entscheidet, ob eine Zeichenkette einem gegebenen regulären Ausdruck entspricht, sucht std::regex_search eine dem regulären Ausdruck entsprechende Zeichenkette in dem Eingabetext.
In Listing 19.2 und Listing 19.3 haben wir schon std::regex_search zusammen mit einem Suchergebnis im Einsatz gesehen. Was aber noch fehlt, ist der Einsatz von verschiedenen Zeichentypen. In Listing 19.9 wird ein regulärer Ausdruck verwendet, um die Zeit aus der Zeichenkette zu extrahieren. Die Datentypen const char*, std::string, cont wchar_t* und std::wstring werden verwendet.
regexSearch.cpp
01 #include <regex>
02
03 #include <iostream>
04 #include <string>
05
06 int main(){
07
08 std::cout << std::endl;
09
10 // regular expression holder for time
11 std::regex crgx("([01]?[0-9]|2[0-3]):[0-5][0-9]");
12
13 // const char*
14 std::cout << "const char*" << std::endl;
15 std::cmatch cmatch;
16
17 const char* ctime{"Now it is 23:10."};
18
19 if (std::regex_search(ctime,cmatch,crgx)){
20
21 std::cout << ctime << std::endl;
22 std::cout << "Time: " << cmatch[0] << std::endl;
23
24 }
25
26 std::cout << std::endl;
27
28 // std::string
29 std::cout << "std::string" << std::endl;
30 std::smatch smatch;
31
32 std::string stime{"Now it is 23:25."};
33 if (std::regex_search(stime,smatch,crgx)){
34
35 std::cout << stime << std::endl;
36 std::cout << "Time: " << smatch[0] << std::endl;
37
38 }
39
40 std::cout << std::endl;
41
42 // regular expression holder for time
43 std::wregex wrgx(L"([01]?[0-9]|2[0-3]):[0-5][0-9]");
44
45 // const wchar_t*
46 std::cout << "const wchar_t* " << std::endl;
47 std::wcmatch wcmatch;
48
49 const wchar_t* wctime{L"Now it is 23:47."};
50
51 if (std::regex_search(wctime,wcmatch,wrgx)){
52
53 std::wcout << wctime << std::endl;
54 std::wcout << "Time: " << wcmatch[0] << std::endl;
55
56 }
57
58 std::cout << std::endl;
59
60 // std::wstring
61 std::cout << "std::wstring" << std::endl;
62 std::wsmatch wsmatch;
63
64 std::wstring wstime{L"Now it is 00:03."};
65
66 if (std::regex_search(wstime,wsmatch,wrgx)){
67
68 std::wcout << wstime << std::endl;
69 std::wcout << "Time: " << wsmatch[0] << std::endl;
70
71 }
72
73 std::cout << std::endl;
74
75 }Listing 19.9 zeigt den Umgang mit den verschiedenen Datentypen const char* (Zeilen 13 bis 24), std::string (Zeilen 28 bis 38), const wchar_t* (Zeilen 45 bis 56) und std::wstring (Zeilen 60 bis 71). Werden alle Parameter von std::regex_search mit dem gleichen Zeichentyp verwendet, klappt es auch mit der Ausgabe (Abbildung 19.6).

Zum Abschluss will ich den Umgang mit std::wstring in Listing 19.9 explizit auf den Punkt bringen. Für das richtige Verarbeiten von std::regex_search ist es erforderlich, dass der reguläre Ausdruck wrgx (Zeile 43), das Suchergebnis wsmatch (Zeile 62), die zu untersuchende Zeichenkette wstime (Zeile 64) und der Ausgabekanal std::wcout (Zeile 68) vom gleichen Datentyp sind.
repetitiveSearch
Aufgabe 19-5
Verwenden Sie std::regex_search für das wiederholte Suchen einer Zeichenkette in einem Eingabestring.
Suchen Sie alle Ganzzahlen in einem Eingabestring und geben Sie diese aus. Bjarne Stroustrup über C++11 als möglichen Eingabestring: »This is close to the final draft international standard formally accepted by a 21-0 national vote in August 2011. Unless the ISO bureaucracy is unusually slow, the standard will be officially issued this year so that it will be referred to as C++11 or C++2011.« (Stroustrup, 2011).
Ersetzen mit regex_replace
Während die Algorithmen std::regex_match und std::regex_search mächtige Helfer sind, um einen String in einem Eingabestring mithilfe eines regulären Ausdrucks zu identifizieren, erlaubt es std::regex_replace, diesen identifizierten String durch einen neuen String zu ersetzen.
In Listing 19.10 wird jeweils std::string in zwei Schritten modifiziert zurückgegeben.
regexReplace.cpp
01 #include <regex>
02
03 #include <iomanip>
04 #include <iostream>
05 #include <string>
06
07 int main(){
08
09 std::cout << std::endl;
10
11 std::string future{"Future"};
12 int len= sizeof(future);
13
14 std::string unofficialStandardName
{"The unofficial name of the new C++ standard is C++0x."};
15 std::cout << std::setw(len) << std::left << "Now: "
<< unofficialStandardName << std::endl;
16
17 // replace C++0x with C++11
18 std::regex rgxCpp(R"(C\+\+0x)");
19 std::string newCppName{"C++11"};
20
21 std::string newStandardName{std::regex_replace(
unofficialStandardName,rgxCpp,newCppName)};
22 std::cout << std::setw(len) << std::left << "Now: "
<< newStandardName << std::endl;
23
24 // replace unofficial with official
25 std::regex rgxOff{"unofficial"};
26 std::string makeOfficial{"official"};
27
28 std::string officialName{std::regex_replace(
newStandardName,rgxOff,makeOfficial)};
29 std::cout << std::setw(len) << std::left << "Future: "
<< officialName << std::endl;
30
31 std::cout << std::endl;
32
33 }Das Programm in Listing 19.10 versucht, mit der für einen Autor undankbaren Situation umzugehen, dem neuen Kind einen Namen geben zu müssen. Durch std::regex_replace wird in den Zeilen 21 und 28 der bestehende String durch einen neuen ersetzt. So bewirkt der Aufruf von std::regex_replace(unofficialStandardName,rgxCpp,newCppName), dass jeder Teilstring in unofficialStandardName, der dem Muster rgxCpp entspricht, durch den String newCppName ersetzt wird.
In der Hoffnung, dass die Ausgabe in Abbildung 19.7 korrekt ist:

Verallgemeinertes regex_replace
Neben dem dargestellten Funktions-Template std::regex_replace, das das Ergebnis der Ersetzung als Rückgabewert zurückgibt, bietet C++11 noch eine allgemeinere Form des Funktions-Templates an. Dieses Funktions-Template arbeitet in bekannter STL-Manier auf Iteratoren.
Listing 19.11 stellt den std::regex_replace-Einsatz von Listing 19.10 dem verallgemeinernden Iteratorenansatz gegenüber. Der Einfachheit halber sind die Variablennamen deutlich verkürzt.
01 std::string unoff{"The unofficial name of the new C++ standard is C++0x."};
02
03 std::regex rgx(R"(C\+\+0x)");
04 std::string cpp{"C++11"};
05
06 // string version
07 std::string newName{std::regex_replace(unoff,rgx,cpp)};
08
09 // iterator version
10 std::string newName2;
11 std::regex_replace(std::back_inserter(newName2),
unoff.begin(),unoff.end(),rgx,cpp);In der Iterator-Version in Listing 19.11 wird in Zeile 10 eine Variable newName2 angelegt, in der das Ergebnis gespeichert werden soll. Der Ausdruck in Zeile 11, in Prosa übersetzt, lautet: Gehe durch den Bereich unoff.begin() bis unoff.end(), indem du alle Treffer von rgx durch cpp ersetzt und an newName2 hinten anhängst (std::back_inserter(newName2)).
Zwei Flags: format_no_copy, format_first_only
std::regex_replace kann über zwei Flags noch weiter parametrisiert werden. So bewirkt std::regex_constants::format_no_copy, dass lediglich die Teilstrings in den Ergebnisstring kopiert werden, die den regulären Ausdruck erfüllen. Soll nur der erste Teilstring kopiert werden, lässt sich dieses Verhalten über das Flag std::regex_constants::format_first_only steuern.
replaceText.cpp
Aufgabe 19-6
Schieben Sie alle Treffer auf einen neuen Vektor.
Verwenden Sie std::regex_replace und das Flag std::regex_constants::format_not_copy, um die Zahlen in dem String auf einen anderen Vektor zu schieben. Geben Sie den neuen Vektor aus.
Ein möglicher Eingabestring: »This is close to the final draft international standard formally accepted by a 21-0 national vote in August 2011. Unless the ISO bureaucracy is unusually slow, the standard will be officially issued this year so that it will be referred to as C++11 or C++2011.« (Stroustrup, 2011).
Nutzen Sie dabei aus, dass in dem Eingabestring nur Ganzzahlen vorkommen. Dabei bezeichnet »$&« den gesamten Treffer im Ersetzungstext (Tabelle 19.10).
replaceTextFirst.cpp
Aufgabe 19-7
Ersetzen Sie den ersten Treffer durch einen neuen Text.
Die E-Mail ist leider nicht mehr aktuell. Ersetzen Sie die erste Zahl durch 2012.
»We happily announce to you the draw of the Euro – Afro Asian Sweepstake Lottery International programs held on the first of May 2004 in Dakar Senegal.Your e-mail address attached to ticket number: 564-75600545-188 with Serial number 5388/02 drew the lucky numbers: 31-6-26-13-35-7, which subsequently won you the lottery in the 2nd category.\n\n CONGRATULATIONS!!!«
Formatieren mit regex_replace und match_results.format
Um in Listing 19.10 den endgültigen String zu erhalten, waren zwei Iterationen notwendig. Das ist umständlich, verlangt doch jede Ersetzung eine Iteration. Erfassungsgruppen in Kombination mit der Elementfunktion std::match_results.format erlauben dies in einem Schritt. Dabei wird das Problem umformuliert. Statt in einen bestehenden String einen Teilstring über mehrere Iterationen hinweg zu verändern, wird ein Formatstring mit Platzhaltern vorgegeben, in den die neuen Werte eingesetzt werden. Dieser einfache Anwendungsfall lässt sich auch noch mit dem alten Bekannten std::regex_replace umsetzen.
regexFormat.cpp
01 #include <regex>
02
03 #include <iomanip>
04 #include <iostream>
05 #include <string>
06
07 int main(){
08
09 std::cout << std::endl;
10
11 std::string future{"Future"};
12 int len= sizeof(future);
13
14 const std::string unofficial{"unofficial,C++0x"};
15 const std::string official{"official,C++11"};
16
17 std::regex regValues{"(.*),(.*)"};
18
19 std::string standardText{
"The $1 name of the new C++ standard is $2."};
20
21 // using std::regex_replace
22 std::string textNow= std::regex_replace(
unofficial,regValues,standardText );
23
24 std::cout << std::setw(len) << std::left << "Now: "
<< textNow << std::endl;
25
26 // using std::match_results
27 // typedef match_results<string::const_iterator> smatch;
28 std::smatch smatch;
29 if ( std::regex_match(official,smatch,regValues)){
30
31 std::string textFuture= smatch.format(standardText);
32 std::cout << std::setw(len) << std::left << "Future: "
<< textFuture << std::endl;
33
34 }
35
36 std::cout << std::endl;
37
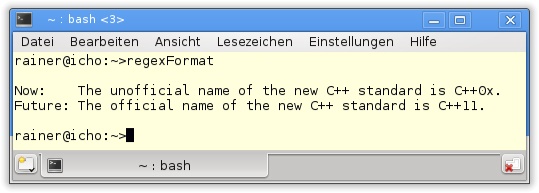
38 }In Listing 19.12 wird die erste Ausgabe mit std::regex_replace (Zeile 22), die zweite Ausgabe mit std::match_results.format (Zeile 31) formatiert. Durch »$i« kann in dem Formatstring standardText (Zeile 19) die i-te Erfassungsgruppe referenziert werden. Dabei beschreibt regValues{"(.*),(.*)"} in Zeile 17 die erste und zweite Erfassungsgruppe der Strings unofficial (Zeile 14) und official (Zeile 15).
Die formatierte Ausgabe ist in Abbildung 19.8 zu sehen.
Die weiteren Format-Escape-Sequenzen der ECMAScript-Grammatik sind in Tabelle 19.10 zusammengefasst.
Format-Escape-Sequenz | Ersetzungstext |
“$&” | Gibt den Gesamttreffer aus. Dies ist die 0-te Erfassungsgruppe. (smatch[0]) |
“$$” | Gibt »$« aus. |
“$’” (Dollarzeichen gefolgt vom Backquote) | Gibt den Text vor dem Gesamttreffer aus. (smatch[0].prefix()) |
“$’” (Dollarzeichen gefolgt vom Vorwärtsquote) | Gibt den Text nach dem Gesamttreffer aus. (smatch[0].suffix()) |
“$i” (eine Ziffer) | Gibt die i-te Erfassungsgruppe aus. (smatch[i]) |
“$ii” (zwei Ziffern) | Gibt die ii-te Erfassungsgruppe aus. |
Mächtigkeit von match_results
Auch wenn der Einsatz des Suchergebnisses std::match_results aufwendiger ist als der von std::regex_replace, so bietet er doch zwei Vorteile.
Ein bereits erzeugtes Suchergebnis lässt sich weiterverwenden.
Abhängig von den Eigenschaften des Suchergebnisses kann die Ausgabe angepasst werden.
Praxistipp
Ziehen Sie regex_replace match_results::format vor.
Für die meisten Anwendungsfälle ist die direkte Anwendung std::regex_replace für die formatierte Ausgabe ausreichend. Der Einsatz von std::match_results.format sollte dann in Erwägung gezogen werden, wenn die Erzeugung des Suchergebnisses von dessen Anwendung in einem Formatstring getrennt werden muss.
In Analogie zu std::regex_replace (Listing 19.11) gibt es die Funktion std::match_results.format in zwei Varianten. Die einfache Variante, die in Listing 19.12 angewandt wurde, gibt einen String zurück. Die allgemeinere Form setzt Iteratoren voraus.
regexFormatStandard.cpp
Aufgabe 19-8
Gewappnet für die Zukunft.
Im mittlerweile bekannten Text von Bjarne Stroustrup (Stroustrup, 2011) sind die Jahreszahlen als Variablen vorgehalten.
»This is close to the final draft international standard formally accepted by a 21-0 national vote in August $1. Unless the ISO bureaucracy is unusually slow, the standard will be officially issued this year so that it will be referred to as C++$2 or C++$1.«
Ein einfaches std::regex_replace löst das Problem. In erster Annäherung soll $1 den Wert 2011 und $2 den Wert 11 besitzen.
Wiederholtes Suchen mit regex_iterator und regex_token_iterator
Mit std::regex_iterator und std::regex_token_iterator bietet die C++11-Bibliothek zwei mächtige Werkzeuge an, um über Vorkommen eines Teilstrings in einem String zu iterieren. Dabei erlaubt std::regex_iterator die Iteration über die Suchergebnisse std::match_results jedes Teilstrings, der einem regulären Ausdruck entspricht. Im Gegensatz hierzu geht die Iteration bei std::regex_token_iterator noch weiter ins Detail. Nicht nur über das Such-ergebnis, sondern auch über die einzelnen Erfassungsgruppen wird iteriert. Die Art der Iteration lässt sich bei ihm durch Indizes genauer steuern.
regex_iterator
Wie oft kommt ein Wort in einem Text vor? Dieser Klassiker aller Programmieraufgaben lässt sich in C++11 annähernd mit der Leichtigkeit einer Interpretersprache wie Python programmieren (Listing 19.12).
regexIterator.cpp
01 #include <regex>
02
03 #include <iostream>
04 #include <string>
05 #include <unordered_map>
06
07 int main(){
08
09 std::cout << std::endl;
10
11 // Bjarne Stroustrup about C++0x on
http://www2.research.att.com/~bs/C++0xFAQ.html
12 std::string text{"That's a (to me) amazingly frequent
question. It may be the most frequently asked question.
Surprisingly, C++0x feels like a new language: The
pieces just fit together better than they used to and I
find a higher-level style of programming more natural
than before and as efficient as ever."};
13
14 // regular expression for a word
15 std::regex wordReg(R"(\w+)");
16
17 // get all words from text
18 std::sregex_iterator wordItBegin(
text.begin(),text.end(),wordReg);
19 const std::sregex_iterator wordItEnd;
20
21 // use unordered_map to count the words
22 std::unordered_map<std::string, std::size_t> allWords;
23
24 // count the words
25 for (; wordItBegin != wordItEnd;++wordItBegin){
26 ++allWords[wordItBegin->str()];
27 }
28
29 for ( auto wordIt: allWords) std::cout
<< "(" << wordIt.first << ":" << wordIt.second << ")" ;
30
31 std::cout << "\n\n" ;
32
33 }Das Programm in Listing 19.12 sollte zum größten Teil vertraut sein. In Zeile 18 wird ein Iterator definiert. In diesem konkreten Fall iteriert er über alle Wörter von text.begin() bis text.end(), die dem regulären Ausdruck wordReg (Zeile 15) entsprechen. Diese Wörter werden in den Zeilen 25 und 26 in die neue C++11-Hashtabelle eingefügt, und der Zähler wird erhöht. Dabei beendet wordItEnd die Iteration. wordItBegin ist vom bekannten Typ std::match_results, sodass die String-Repräsentation der ersten Erfassungsgruppe mittels wordItBegin->str() zur Verfügung steht. Sind alle Wörter durchlaufen, kann das Ergebnis in Zeile 29 kompakt ausgegeben werden.
Abbildung 19.9 zeigt das Ergebnis.

Eines sei nochmals explizit erwähnt. Jeder Teilstring, der dem regulären Ausdruck entspricht, wird über den Typ std::match_results zur Verfügung gestellt. Damit lässt sich jedes einzelne Suchergebnis mit der Mächtigkeit der Funktionen aus Tabelle 19.8 weiterverarbeiten.
Diese Mächtigkeit zeigt das folgende Beispiel. Darin wird auf jede Erfassungsgruppe direkt Bezug genommen.
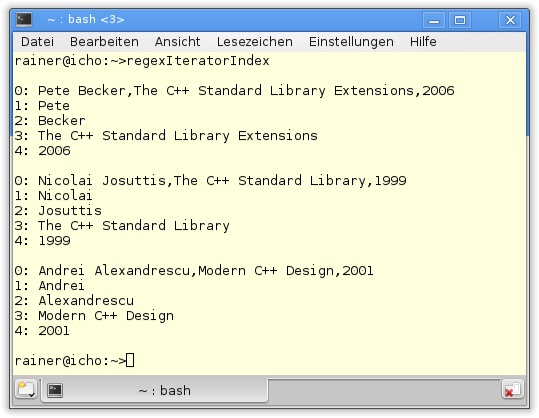
regexIteratorIndex.cpp
01 #include <regex>
02
03 #include <iostream>
04 #include <string>
05 #include <vector>
06
07 int main(){
08
09 std::cout << std::endl;
10
11 // a few books
12 std::string text{"
Pete Becker,The C++ Standard Library Extensions,2006:
Nicolai Josuttis,The C++ Standard Library,1999:
Andrei Alexandrescu,Modern C++ Design,2001"};
13
14 // regular expression for a book description
15 std::regex regBook(
R"((\w+)\s(\w+),([\w\s\+]*),(\d{4}))");
16
17 // get all books from text
18 std::sregex_iterator bookItBegin(
text.begin(),text.end(),regBook);
19 const std::sregex_iterator bookItEnd;
20
21 // iterate over each match_results
22 while ( bookItBegin != bookItEnd){
23 auto match= *bookItBegin++;
24 // iterate over each capture group
25 for ( size_t i= 0; i < match.size(); ++i){
26 std::cout << i << ": " << match[i] << std::endl;
27 }
28 std::cout << std::endl;
29 }
30
31 }Der reguläre Ausdruck in Listing 19.14 in Zeile 15 ist relativ schwierig zu lesen. Ein Suchergebnis besteht aus dem Vornamen (\w+) und dem Nachnamen des Autors (\w+), dem Titel ([\w\s\+]*) und dem Erscheinungsdatum (\d{4}) des Werks. Diese Einträge, die zugleich die Erfassungsgruppen sind, sind durch Kommata (,) getrennt. Der std::sregex_token_iterator in Zeile 18 wendet diesen regulären Ausdruck an. In den Zeilen 21 bis 29 wird das Ergebnis optisch aufbereitet, indem jede Erfassungsgruppe mit ihrem Index und ihrem Wert ausgegeben wird (Listing 19.14).
Praxistipp
Verwenden Sie regex_iterator und regex_token_iterator.
Natürlich bietet std::regex_search die ganze Funktionalität an, um einen String von Hand auf Teilstrings zu durchsuchen. Von diesem Unterfangen ist energisch abzuraten, da std::regex_iterator und std::regex_token_iterator ein mächtiges Interface anbieten. Welche Gefahren im Detail bei der Anwendung von std::regex_search lauern, beispielsweise das Verlieren der Wortgrenzen oder leere Treffer, kann wiederum in dem Buch »The C++ Standard Library Extensions« von Pete Becker (Becker, The C++ Standard Library Extension, 2006) nachgelesen werden.
In bekannter C++-Tradition gibt es für die Standardzeichentypen in C++11 die bekannten Synonyme, um Schreibarbeit zu sparen.
typedef regex_iterator<const char*> cregex_iterator; typedef regex_iterator<std::string::const_iterator> sregex_iterator; typedef regex_iterator<const wchar_t*> wcregex_iterator; typedef regex_iterator<std::wstring::const_iterator> wsregex_iterator;
regexIteratorSolution.cpp
Aufgabe 19-9
Bestimmen Sie, wie oft ein Wort in einem Text vorkommt.
Listing 19.13 ist der erste Schritt zur Antwort auf die Frage: Welches Wort kommt am häufigsten im Text vor? Bestimmen Sie die Häufigkeit der Wörter in einem Text und geben Sie diese nach ihrer Häufigkeit sortiert aus.
countAlphabet.cpp
Aufgabe 19-10
Bestimmen Sie, wie oft ein Buchstabe in einem Text vorkommt.
In der kleinen Variation von Aufgabe 19-9 soll die Häufigkeit der Buchstaben des Alphabets ermittelt werden – und dies ohne Berücksichtigung der Klein- oder Großschreibung. Geben Sie die Buchstaben nach ihrer Häufigkeit sortiert aus.
regex_token_iterator
std::regex_token_iterator iteriert über die Suchergebnisse und deren Erfassungsgruppen. Darüber hinaus ist insbesondere konfigurierbar, welche Komponenten einer Erfassungsgruppe angesprochen werden sollen. Dazu besitzt std::regex_token_iterator Konstruktoren, die im Gegensatz zu std::regex_iterator mit Indizes verwendet werden können. Diese Indizes bewirken, dass nur über die entsprechenden Erfassungsgruppen iteriert wird. Ein Index kann die Form einer einfachen Zahl oder auch eines Vektors besitzen. Die Zahl -1 hat eine besondere Bedeutung, da der Teilstring zwischen den Suchergebnissen ausgegeben wird.
Dieser besondere Anwendungsfall soll Variationen von Listing 19.14 mit Indizes in Listing 19.16 verdeutlichen.
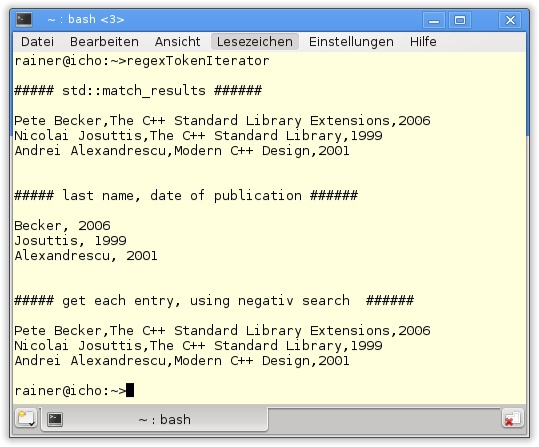
regexTokenIterator.cpp
01 #include <regex>
02
03 #include <iostream>
04 #include <string>
05 #include <vector>
06
07 int main(){
08
09 std::cout << std::endl;
10
11 // a few books
12 std::string text{
"Pete Becker,The C++ Standard Library Extensions,2006:
Nicolai Josuttis,The C++ Standard Library,1999:
Andrei Alexandrescu,Modern C++ Design,2001"};
13
14 // regular expression for a book
15 std::regex regBook(
R"((\w+)\s(\w+),([\w\s\+]*),(\d{4}))");
16
17 // get all books from text
18 std::sregex_token_iterator bookItBegin(
text.begin(),text.end(),regBook);
19 const std::sregex_token_iterator bookItEnd;
20
21 std::cout << "##### std::match_results ######"
<< "\n\n";
22 while ( bookItBegin != bookItEnd){
23 std::cout << *bookItBegin++ << std::endl;
24 }
25
26 std::cout << "\n\n"
<< "##### last name, date of publication ######"
<< "\n\n";
27
28 // get all last name and date of publication for the entries
29 std::sregex_token_iterator bookItNameIssueBegin(
text.begin(),text.end(),regBook,{{2,4}});
30 const std::sregex_token_iterator bookItNameIssueEnd;
31 while ( bookItNameIssueBegin != bookItNameIssueEnd){
32 std::cout << *bookItNameIssueBegin++ << ", ";
33 std::cout << *bookItNameIssueBegin++ << std::endl;
34 }
35
36 // regular expression for a book, using negativ search
37 std::regex regBookNeg(":");
38
39 std::cout << "\n\n"
<< "##### get each entry, using negative search ######"
<< "\n\n";
40
41 // get all entries, only using ":" as regular expression
42 std::sregex_token_iterator bookItNegBegin(
text.begin(),text.end(),regBookNeg,-1);
43 const std::sregex_token_iterator bookItNegEnd;
44 while ( bookItNegBegin != bookItNegEnd){
45 std::cout << *bookItNegBegin++ << std::endl;
46 }
47
48 std::cout << std::endl;
49
50 }Für das Verständnis von Listing 19.16 ist die Ausgabe des Programmlaufs sehr hilfreich (Abbildung 19.11), die in drei Drittel geteilt ist.
Wird std::regex_token_iterator ohne einen Index verwendet (Zeile 18), zeigt er ähnlich wie std::regex_iterator jeden Eintrag an. Die erste und die dritte Teilausgabe sind identisch. Bemerkenswert ist, dass dies durch verschiedene reguläre Ausdrücke erreicht wurde. Während die erste Teilausgabe durch den bekannten regulären Ausdruck "(\w+)\s(\w+),([\w\s\+]*),(\d{4})" erzeugt wurde, resultiert die letzte aus dem regulären Ausdruck ":". Der Trick besteht darin, alle Teilstrings zu suchen, die nicht diesem regulären Ausdruck entsprechen. Das sind genau die gesuchten Einträge. Für diese negative Suche benötigt der Konstruktor von std::regex_token_iterator den Index -1 (Zeile 42). Die Ausgabe in der Mitte von Abbildung 19.11 besteht nur aus den Nachnamen und dem Veröffentlichungsdatum des Werks. Dazu wird der Konstruktor mit der Initialisiererliste {2,4} gefüttert (Zeile 29). Um den Zeilenumbruch für die dargestellten Erfassungsgruppen zu unterdrücken, werden zwei Einträge in einem Schleifendurchlauf ausgegeben (Zeilen 32 und 33).
Für den einfachen Umgang mit dem Standardzeichentyp hält C++11 wieder die bekannten Typsynonyme vor.
typedef regex_token_iterator<const char*> cregex_token_iterator; typedef regex_token_iterator<std::string::const_iterator> sregex_token_iterator; typedef regex_token_iterator<const wchar_t*> wcregex_token_iterator; typedef regex_token_iterator<<std::wstring::const_iterator> wsregex_token_iterator;
split.cpp
Aufgabe 19-11
Schreiben Sie die split-Funktion in C++11.
Die Python-Funktion str.split(sep), auf einen String str angewandt, gibt eine Liste von Strings zurück, die mittels sep getrennt werden.
Das geht auch in C++11. Schreiben Sie eine Funktion split, die einen std::string und ein Trennzeichen als Argument annimmt und als Ergebnis einen std::vector<std::string> zurückgibt. Wenden Sie die Funktion an.
Type-Traits
Die neue Type-Traits-Bibliothek in C++11 ist ein mächtiges Werkzeug für den Bibliotheksautor, erlaubt sie es doch, Typabfragen und Typvergleiche, ja sogar Typtransformationen zur Übersetzungszeit auszuführen. Kosten für die Laufzeit des C++-Programms sind nicht vorhanden, da der resultierende Code bereits zur Laufzeit vorliegt. Mit dieser Bibliothek verliert Template-Metaprogramming viel von seiner Magie und setzt keinen Expertenstatus in C++ voraus. Konsequenterweise werden die Funktionen, die zur Übersetzungszeit den C++-Sourcecode erzeugen, als Metafunktionen bezeichnet. Der Name Metafunktion trifft natürlich nicht nur auf die Funktionen der Type-Traits-Bibliothek, die unter der Decke Klassen-Templates sind, zu. Dieser Name trifft auf alle Klassen-Templates zu, die zur Übersetzungszeit wie Funktionen angewandt werden können, um den resultierenden C++-Sourcecode zu erzeugen.
Verfolgtes Ziel
Welche Ziele werden mit der Type-Traits-Bibliothek verfolgt? Die Antwort ist schnell parat:
Optimierung
Korrektheit
Optimierung, da aufgrund von Typeigenschaften die schnellere Implementierung, Korrektheit, da aufgrund von Typeigenschaften die richtige Implementierung eines Algorithmus ausgewählt werden kann.
Anwendungen
Wer Anwendungen zur neuen Type-Traits-Bibliothek sucht, der wird in der Boost-Bibliothek fündig. Diese Beispiele lassen sich direkt auf C++11 übertragen, da die Boost-Implementierung Grundlage für die C++11-Type-Traits-Bibliothek ist. So finden sich Beispiele für:
eine optimierte Version von
std::copy,eine optimierte Version von
std::fill,ein Array, das auf den Destruktoraufruf verzichtet,
eine verbesserte Version von
std::iter_swap.
Ermöglicht werden diese Optimierungen und Modifikationen durch die Type-Traits-Bibliothek. Deren Funktionen fragen die Typen zur Übersetzungszeit ab, ob diese hinreichende Bedingungen für die Optimierung anbieten. So setzen std::copy und std::fill unter anderem voraus, dass die Typen trivial zuweisbar (std::is_trivially_copy_assignable in C++11) sein sollen. Sind die Typen hinreichend einfach, können C-Funktionen für die Algorithmen angewandt werden, die die Operationen bitweise und nicht elementweise durchführen. Auf den Destruktoraufruf kann nur verzichtet werden, wenn dieser trivial ist (std::is_trivially_destructible in C++11). Die Bedingungen an std::iter_swap sind schon strenger. Die zu tauschenden Elemente müssen vom gleichen Typ und Referenzen (std::is_reference in C++11) sein. Dadurch lässt sich die std::iter_swap-Version anwenden.
Am einfachsten lässt sich der Einsatz der Type-Traits-Bibliothek an einem Beispiel erläutern. Der Klassiker hierzu ist eine optimierte std::copy-Implementierung, die die Struktur in Listing 19.18 besitzen kann.
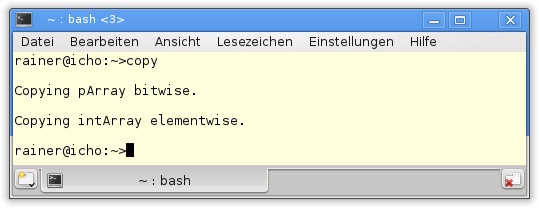
copy.cpp
01 // because of memcpy
02 #include <string.h>
03
04 #include <iostream>
05 #include <type_traits>
06
07
08 namespace my{
09
10 template<typename I1, typename I2, bool b>
11 I2 copy_imp(I1 first, I1 last, I2 out,
const std::integral_constant<bool, b>&){
12
13 while(first != last){
14 *out = *first;
15 ++out;
16 ++first;
17 }
18
19 std::cout << "elementwise." << std::endl;
20 return out;
21
22 }
23
24 template<typename T>
25 T* copy_imp(const T* first, const T* last, T* out,
const std::true_type&){
26
27 memcpy(out, first, (last-first)*sizeof(T));
28 std::cout << "bitwise." << std::endl;
29 return out+(last-first);
30
31 }
32
33 template<typename I1, typename I2>
34 I2 copy(I1 first, I1 last, I2 out){
35
36 typedef typename std::iterator_traits<I1>::value_type
value_type;
37 // standard name commented out
38 //return copy_imp(first, last, out,
std::is_trivially_copy_assignable<value_type>());
39 return copy_imp(first, last, out,
std::has_trivial_copy_assign<value_type>());
40
41 }
42 }
43
44 const int arraySize = 1000;
45
46 // intialize all elements to 0
47 int intArray[arraySize] = {0,};
48 int intArray2[arraySize]={0,};
49
50 int* pArray = intArray;
51 const int* pArray2 = intArray2;
52
53 int main(){
54
55 std::cout << std::endl;
56
57 std::cout << "Copying pArray ";
58
59 my::copy(pArray2, pArray2 + arraySize, pArray);
60
61 std::cout << "\n" << "Copying intArray ";
62
63 my::copy(intArray2, intArray2 + arraySize, intArray);
64
65 std::cout << std::endl;
66
67 }Tatsächlich wird in der Implementierung des std::copy-Algorithmus des GCC 4.7 eine Kopierfunktion verwendet, die gegebenenfalls auf die C-Funktion memmove zurückgreift. Diese kann überlappende Speicherbereiche im Gegensatz zu memcpy (Listing 19.18, Zeile 27) verwenden. Das verrät die Dokumentation der Funktion std::copy im Sourcecode des STL-Algorithmus: This inline function will boil down to a call to @c memmove whenever possible.
In Abbildung 19.13 ist zu sehen, dass pArray2 in Zeile 50 bitweise, intArray2 in Zeile 54 elementweise kopiert wird.
Wie funktioniert dieser Polymorphismus zur Übersetzungszeit? Um die performantere Implementierung von copy_imp in Zeile 24 zu verwenden, müssen die Argumente drei Bedingungen erfüllen. Diese Bedingungen, die sich alle in der Signatur der Funktion wiederfinden, sind insbesondere die, die memcpy fordert, um angewendet werden zu können.
Die Iteratoren müssen Zeiger sein:
const T* first, const T* last, T* out(Zeile 25)Die Iteratoren müssen auf die gleichen Typen verweisen:
template <typename T>enthält nur einen Typ (Zeile 24)Die Elemente des Containers müssen einen trivialen Zuweisungsoperator besitzen:
const std::true_type&(Zeile 25)
Den eigentlichen Dispatch vollzieht das Funktions-Template copy in Zeile 33. In Zeile 36 wird durch typedef typename std::iterator_traits<I1>::value_type value_type der Typ der Containerelemente bestimmt, um ihn anschließend im Rückgabewert der Funktion in dem Klassen-Template std::is_trivially_copy_assignable<value_type>() zu nutzen. Ist dieses Klassen-Template von std::true_type abgeleitet worden, findet der Dispatch auf die spezielle Implementierung in Zeile 33, sonst auf die generische Implementierung in Zeile 24 statt.
Zugegeben, das war schwer verdauliche Kost. Zumeist sind die Funktionen der Type-Traits-Bibliothek einfach anzuwenden.
Typeigenschaften abfragen
Primäre Typkategorien
Die primären Typkategorien sind vollständig und schließen sich gegenseitig aus. Jeder Datentyp kann genau nur einer Kategorie angehören. Dabei ist das Ergebnis der Abfrage unabhängig davon, ob der Typ als const oder volatile deklariert ist. C++11 kennt 13 verschiedene primäre Typkategorien, die sich über ein Prädikat abfragen lassen.
template <class T> struct is_void; template <class T> struct is_integral; template <class T> struct is_floating_point; template <class T> struct is_array; template <class T> struct is_pointer; template <class T> struct is_reference; template <class T> struct is_member_object_pointer; template <class T> struct is_member_function_pointer; template <class T> struct is_enum; template <class T> struct is_union; template <class T> struct is_class; template <class T> struct is_function;
Zusammengesetzte Typkategorien
Die zusammengesetzten Typkategorien bauen auf den primären Typkategorien auf. Abfragen an sie ignorieren in Analogie zur primären Typkategorie, ob diese als const oder volatile deklariert wurde. Ausgehend von den 13 primären Typkategorien, bietet die Type-Traits-Bibliothek sechs verschieden zusammengesetzte Typkategorien an, die im Listing 19.21 dargestellt sind.
template <class T> struct is_arithmetic; template <class T> struct is_fundamental; template <class T> struct is_object; template <class T> struct is_scalar; template <class T> struct is_compound; template <class T> struct is_member_pointer;
Die Komposition der zusammengesetzten aus den primären Typkategorien ist in Tabelle 19.11 dargestellt.
Zusammengesetzte Typkategorie | Primäre Typkategorie |
| is_floating_point<T>::value == true oder is_integral<T>::value == true |
| is_arithmetic<T>::value == true oder is_void<T>::value == true |
| is_reference<T>::value == false und is_function<T>::value == false und is_void<T>::value == false |
| is_arithmetic<T>::value == true oder is_enum<T>::value == true oder is_pointer<T>::value == true oder is_member_pointer<T>::value == true |
| is_compound<T>::value != is_fundamental<T>::value |
| is_member_object_pointer<T>::value == true oder is_member_function_pointer<T>::value == true |
Dabei ist die Tabelle 19.11 so zu lesen, dass
std :: is _ arithmetic <T>:: value == true genau dann zutrifft, wenn
std :: is _ floating _ point <T>== true oder
std :: is _ integral <T>:: value == true gilt.
Einzig std::is_compound::value<T>::value wird über das Komplement von std::is_fundamental<T>::value definiert.
Listing 19.22 zeigt die Introspektionsfähigkeit der primären und zusammengesetzten Typkategorien.
typeCategories.cpp
01 #include <iostream>
02 #include <string>
03 #include <type_traits>
04
05
06 // using Euclid's Algorithm
07 template<typename T>
08 T gcd(T a, T b){
09
10 static_assert(std::is_integral<T>::value,
"T should be an integral type!");
11
12 if( b == 0 ){
13 return a;
14 }
15 else{
16 return gcd(b, a % b);
17 }
18 }
19
20 int main(){
21
22 std::cout << std::endl;
23 std::cout << std::boolalpha << std::endl;
24
25 std::cout << "primary type categories" << std::endl;
26
27 std::cout << "std::is_void<void>::value: "
<< std::is_void<void>::value << std::endl;
28 std::cout << "std::is_integral<short>::value: "
<< std::is_integral<short>::value << std::endl;
29 std::cout << "std::is_floating_point<double>::value: "
<< std::is_floating_point<double>::value
<< std::endl;
30 std::cout << "std::is_array<int []>::value: "
<< std::is_array<int [] >::value << std::endl;
31 std::cout << "std::is_pointer<int*>::value: "
<< std::is_pointer<int*>::value << std::endl;
32 std::cout << "std::is_reference<int&>::value: "
<< std::is_reference<int&>::value << std::endl;
33 struct A{
34 int a;
35 int f(double){return 2011;}
36 };
37 std::cout << "std::is_member_object_pointer<int A::*>::value: "
<< std::is_member_object_pointer<int A::*>::value
<< std::endl;
38 std::cout << "std::is_member_function_pointer<int(A::*)
(double)>::value: "
<< std::is_member_function_pointer<int (A::*)
(double)>::value << std::endl;
39 enum E{
40 e= 1,
41 };
42 std::cout << "std::is_enum<E>::value: "
<< std::is_enum<E>::value << std::endl;
43 union U{
44 int u;
45 };
46 std::cout << "std::is_union<U>::value: "
<< std::is_union<U>::value << std::endl;
47 std::cout << "std::is_class<std::string>::value: "
<< std::is_class<std::string>::value
<< std::endl;
48 std::cout << "std::is_function<int * (double)>::value: "
<< std::is_function<int * (double)>::value
<< std::endl;
49
50 std::cout << std::endl;
51
52 std::cout << "compound type categories" << std::endl;
53
54 std::cout << "gcd(100,10)= " << gcd(100,10)
<< std::endl;
55 std::cout << "gcd(100,33)= " << gcd(100,33) << std::endl;
56 std::cout << "gcd(100,0)= " << gcd(100,0) << std::endl;
57
58 /*
59 std::cout << gcd(3.5,4.0) << std::endl;
60 std::cout << gcd("100","10") << std::endl;
61 */
62
63 std::cout << std::endl;
64
65 }Abbildung 19.14 zeigt die wortreichere Ausgabe des Programms in Listing 19.22. Während der Einsatz aller primären Typkategorien in der Ausgabe überflogen werden kann, verlangt der Einsatz der zusammengesetzten Typkategorie mehr Aufmerksamkeit. In den Zeilen 7 bis 18 wird der größte gemeinsame Teiler nach dem euklidischen Algorithmus (Euklidscher Algorithmus, 2011) berechnet. Der Algorithmus ist generisch formuliert. Mit der statischen Zusicherung static_assert(std::is_integral<T>::value, ...) wird sichergestellt, dass nur Ganzzahlen verwendet werden. Dies ist jedoch nur die halbe Wahrheit, denn ein Aufruf gcd(true,true) führt zum Abbruch der Übersetzung. In Zeile 16 wird in diesem Fall der gcd-Algorithmus mit den Datentypen gcd(bool&,int) instanziiert. Die gcd-Implementierung setzt aber voraus, dass beide Argumente den gleichen Typ besitzen. Sieht man von diesem Grenzfall ab, führt die Übersetzung der auskommentierten Zeilen 59 und 60 zur erwarteten Fehlermeldung in Abbildung 19.15.
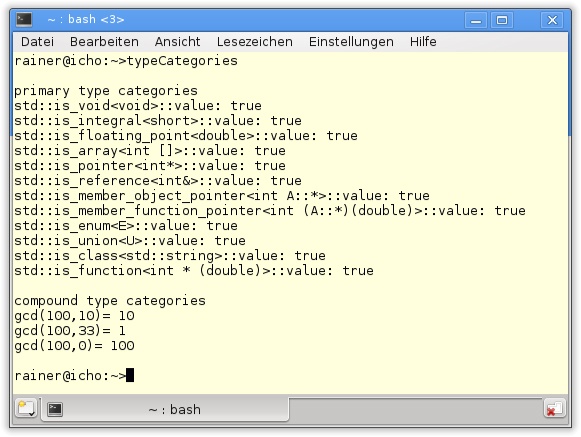
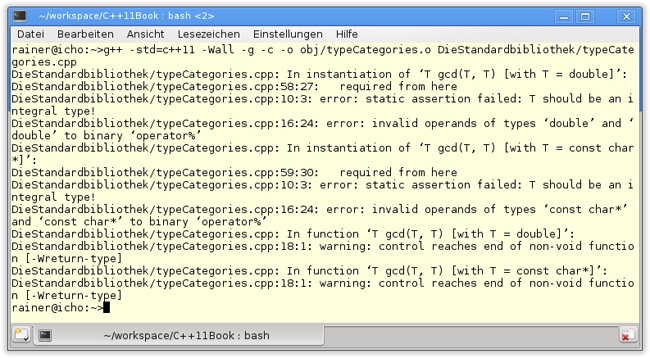
Typeigenschaften
Typeigenschaften bieten Zugang zu den wichtigeren Eigenschaften von Typen. Diese müssen von einer aktuellen Implementierung nicht implementiert werden, sodass eine Abfrage automatisch zu false evaluiert. In Listing 19.18 wurde die Typeigenschaft std::is_trivially_copy_assignable angewandt, um gegebenenfalls eine optimierte Version des std::copy-Algorithmus zu verwenden. In Listing 19.23 sind die vielen Prädikate zu den Datentypen aufgelistet.
template <class T> struct is_const; template <class T> struct is_volatile; template <class T> struct is_trivial; template <class T> struct is_trivially_copyable; template <class T> struct is_standard_layout; template <class T> struct is_pod; template <class T> struct is_literal_type; template <class T> struct is_empty; template <class T> struct is_polymorphic; template <class T> struct is_abstract; template <class T> struct is_signed; template <class T> struct is_unsigned; template <class T, class... Args> struct is_constructible; template <class T> struct is_default_constructible; template <class T> struct is_copy_constructible; template <class T> struct is_move_constructible; template <class T, class U> struct is_assignable; template <class T> struct is_copy_assignable; template <class T> struct is_move_assignable; template <class T> struct is_destructible; template <class T, class... Args> struct is_trivially_constructible; template <class T> struct is_trivially_default_constructible; template <class T> struct is_trivially_copy_constructible; template <class T> struct is_trivially_move_constructible; template <class T, class U> struct is_trivially_assignable; template <class T> struct is_trivially_copy_assignable; template <class T> struct is_trivially_move_assignable; template <class T> struct is_trivially_destructible; template <class T, class... Args> struct is_nothrow_constructible; template <class T> struct is_nothrow_default_constructible; template <class T> struct is_nothrow_copy_constructible; template <class T> struct is_nothrow_move_constructible; template <class T, class U> struct is_nothrow_assignable; template <class T> struct is_nothrow_copy_assignable; template <class T> struct is_nothrow_move_assignable; template <class T> struct is_nothrow_destructible; template <class T> struct has_virtual_destructor;
Einzig die Eigenschaft nothrow im Namen eines Klassen-Templates scheint ein bisschen ungewohnt. Die Klassen unterscheiden sich von ihrem Namensvetter ohne die nothrow-Eigenschaft (siehe Exkurs: noexcept) nur darin, dass sie keine Ausnahme werfen. Im Gegensatz zu den Prädikaten aus Listing 19.23 geben die weiteren speziellen Typabfragen integrale Konstanten zurück. Das ist bei alignment_of die Speicherausrichtung eines Datentyps, bei rank die Anzahl der Dimensionen eines Arrays.
Typen vergleichen
Zur Übersetzungszeit Typen zu vergleichen, ist mit der Type-Traits-Bibliothek möglich. Die Type-Traits-Bibliothek kennt die vier Vergleiche in Tabelle 19.12.
Anwendung | |
|
|
|
|
|
|
|
|
In Listing 19.24 wird der Funktionsaufruf std::is_same<T,U>::value verwendet.
Typen transformieren
Mit der Type-Traits-Bibliothek lässt sich ein Typ auf dessen Eigenschaften abfragen, es lassen sich Typen vergleichen, und darüber hinaus kann ein Typ zur Übersetzungszeit modifiziert werden. Bevor die einzelnen Funktionen dargestellt werden, soll das Programm in Listing 19.24 seine Mächtigkeit demonstrieren.
typeTransformation.cpp
01 #include <iostream>
02 #include <type_traits>
03
04 using namespace std;
05
06 int main(){
07
08 cout << endl;
09
10 cout << boolalpha;
11
12 // basic invocations
13 cout << "is_const<int>::value: "
<< is_const<int>::value << endl;
14 cout << "is_const<const int>::value: "
<< is_const<const int>::value << endl;
15
16 cout << endl;
17
18 // add const to int
19 cout << "is_const<add_const<int>::type>::value: "
<< is_const<add_const<int>::type>::value << endl;
20
21 cout << endl;
22
23 // declare new types
24 typedef add_const<int>::type myConstInt;
25 cout << "is_const<myConstInt>::value: "
<< is_const<myConstInt>::value << endl;
26 typedef const int myConstInt2;
27 cout << "is_same<myConstInt,myConstInt2>::value: "
<< is_same<myConstInt,myConstInt2>::value << endl;
28
29 cout << endl;
30
31 // recursive invocation
32 cout << "is_same<int,remove_const<
add_const<int>::type>::type>::value: "
<< is_same<int,remove_const<
add_const<int>::type>::type>::value << endl;
33 cout << "is_same<const int,
add_const<add_const<int>::type>::type>::value: "
<< is_same<constint,add_const<
add_const<int>::type>::type>::value << endl;
34
35 cout << endl;
36
37 }Die Spielereien aus Listing 19.24 rund um const int sind am einfachsten in der Ausgabe des Programms in Abbildung 19.16 zu verfolgen.

Ein paar Worte noch zu Listing 19.24. Die Aufrufe in den Zeilen 13 und 14 stellen den Standardfall dar. Für einen Typ wird mit der Funktion std::is_const evaluiert, ob er konstant ist. std::add_const in Zeile 19 bewirkt, dass ein int zur Übersetzungszeit in einen const int transformiert wird. Damit lassen sich neue Typen deklarieren, wie in den Zeilen 24 und 26 dargestellt. Dies kann man auf die Spitze treiben, indem die Aufrufe rekursiv in den Zeilen 32 und 33 verschachtelt werden. Bei der Abfrage, ob zwei Typen gleich sind, hilft auch wieder die Type-Traits-Bibliothek mit der Metafunktion std::is_same.
Praxistipp
Prägen Sie sich die Konvention von Template-Metaprogramming ein.
Es ist Konvention – und das nicht nur in der Type-Traits-Bibliothek –, dass ein Wert durch ::value, hingegen der Typ einer Metafunktion durch ::type zur Verfügung steht. Beides ist in Listing 19.24 schön zu sehen.
Um ein Gefühl für das umfassende Interface zum Transformieren der Datentypen mit der Type-Traits-Bibliothek zu bekommen, will ich die wichtigsten Funktionen schnell überfliegen.
const-volatile
Neben den bereits bekannten Funktionen std::remove_const und std::add_const ist auch die Eigenschaft volatile eines Datentyps (Listing 19.25) zur Übersetzungszeit veränderbar.
template <class T> struct remove_volatile; template <class T> struct remove_cv; template <class T> struct add_const; template <class T> struct add_volatile; template <class T> struct add_cv;
Referenzen
Diese Transformation trifft auf Referenzen und vorzeichenbehaftete Typen zu.
template <class T> struct remove_reference; template <class T> struct add_lvalue_reference; template <class T> struct add_rvalue_reference;
Vorzeichen
template <class T> struct make_signed; template <class T> struct make_unsigned;
Die Modifikationen des Vorzeichens in Listing 19.27 benötigen keine std::remove_signed-Funktion, da diese Funktionalität durch std::make_unsigned angeboten wird. Komplizierter ist da schon die Transformation von Rvalues und Lvalues in Listing 19.26, da die Funktionen std::add_lvalue_reference und std::add_rvalue_reference die Referenz-Collapsing-Regeln (siehe Kernsprache: Rvalue-Referenzen) respektieren.
Zeiger
Hingegen ist die Modifikation der Zeigereigenschaft eines Datentyps deutlich direkter.
template <class T> struct remove_pointer; template <class T> struct add_pointer;
Array
Selbst die Anzahl der Dimensionen eines Arrays lässt sich zur Übersetzungszeit durch std::remove_extent um 1, durch std::remove_all_extents auf 0 reduzieren.
template <class T> struct remove_extent; template <class T> struct remove_all_extents;
Aufgabe 19-12
Schmökern Sie in der Standard Template Library.
Die Metafunktionen der Type-Traits-Bibliothek werden in der Implementierung der Standard Template Library häufig verwendet. Schauen Sie zum Beispiel die Implementierung der Algorithmen std::copy, std::fill oder auch std::iter_swap an und versuchen Sie, das Muster hinter ihrer Verwendung zu verstehen.
removeConst.cpp
Aufgabe 19-13
Implementieren Sie RemoveConst.
Schreiben Sie eine Metafunktion, die von einem Datentyp die const-Eigenschaft entfernt. Stellen Sie den modifizierten Typ über ::type zur Verfügung. Stellen Sie die Funktionalität durch die Type-Traits-Metafunktion std::is_const sicher.
Zufallszahlen
<random>
Die C++11-Zufallszahlenfunktionalität besteht aus zwei Teilen:
einem Zufallszahlererzeuger:
Erzeugt einen Zufallszahlenstrom zwischen Minimum- und Maximumwert.
einer Zufallszahlenverteilung:
Bildet die Zufallszahlen mithilfe des Zufallszahlenerzeugers auf die entsprechende Verteilung ab.
Sowohl für den Erzeuger als auch für den Verteiler der Zufallszahlen bietet C++11 verschiedene Implementierungen an. In bewährter Tradition folgt zuerst ein einführendes Beispiel (Listing 19.30).
distribution.cpp
01 #include <cstdlib>
02 #include <fstream>
03 #include <iostream>
04 #include <map>
05 #include <random>
06
07 static const int NUM=1000000;
08
09 void writeToFile(const char* fileName ,const std::map<int,int>& data ){
10
11 std::ofstream file(fileName);
12
13 if ( !file ){
14 std::cerr << "Could not open the file "
<< fileName << ".";
15 exit(EXIT_FAILURE);
16 }
17
18 // print the datapoints to the file
19 for ( auto mapIt: data) file << mapIt.first << " "
<< mapIt.second << std::endl;
20
21 }
22
23 int main(){
24
25 std::random_device seed;
26
27 // default generator
28 std::mt19937 engine(seed());
29
30 // distributions
31
32 // min= 0; max= 20
33 std::uniform_int_distribution<> uniformDist(0,20);
34 // mean= 50; sigma= 8
35 std::normal_distribution<> normDist(50,8);
36 // mean= 6;
37 std::poisson_distribution<> poiDist(6);
38 // alpha= 1;
39 std::gamma_distribution<> gammaDist;
40
41 std::map<int,int> uniformFrequency;
42 std::map<int,int> normFrequency;
43 std::map<int,int> poiFrequency;
44 std::map<int,int> gammaFrequency;
45
46 for ( int i=1; i<= NUM; ++i){
47 ++uniformFrequency[uniformDist(engine)];
48 ++normFrequency[round(normDist(engine))];
49 ++poiFrequency[poiDist(engine)];
50 ++gammaFrequency[round(gammaDist(engine))];
51 }
52
53 writeToFile("uniform_int_distribution.txt",uniformFrequency);
54 writeToFile("normal_distribution.txt",normFrequency);
55 writeToFile("poisson_distribution.txt",poiFrequency);
56 writeToFile("gamma_distribution.txt",gammaFrequency);
57
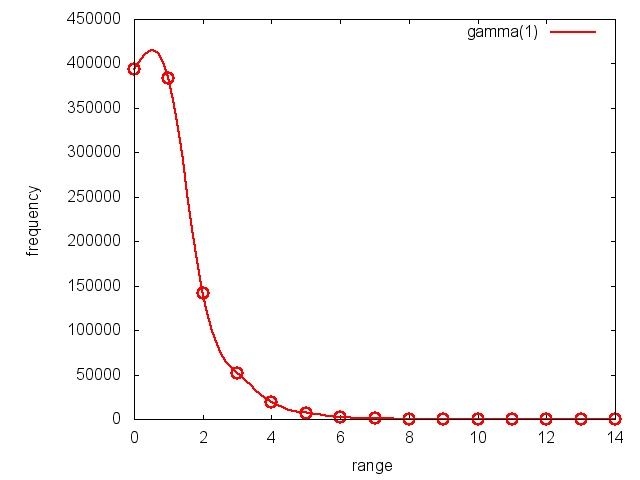
58 }In Listing 19.30 werden mithilfe des Mersenne-Twister (Mersenne Twister, 2011) 1.000.000 Zufallszahlen erzeugt. Um mit einem zufälligen Startwert zu beginnen, muss der Zufallszahlenerzeuger mit der sogenannten seed in Zeile 28 initialisiert werden. Dieser Zufallszahlenstrom wird anschließend gleich-, normal-, Poisson- und gammaverteilt (Wahrscheinlichkeitsverteilung, 2011). Genauer gesagt, die 1.000.000 Zufallszahlen in Zeile 33 werden auf die natürlichen Zahlen 0 bis 20 gleichmäßig verteilt. In Zeile 35 wird die Normalverteilung oder auch Gaußverteilung mit dem Mittelwert 50 und der Standardabweichung 8 angewandt. In Zeile 37 kommt die Poisson-Verteilung mit dem Mittelwert 6 zum Einsatz, in Zeile 39 die Gammaverteilung. Die Ergebnisse der Normal- sowie der Gammaverteilung werden auf eine Ganzzahl gerundet. Für jede vorkommende natürliche Zahl wird ihre Häufigkeit gezählt (Zeilen 46 bis 51) und in eine Datei geschrieben (Zeilen 9 bis 21).
Die Ergebnisse sind in den nächsten vier Abbildungen dargestellt. Für die Optik sind die Datenpunkte mit einem Spline (Spline, 2011) interpoliert. Lediglich die Ergebnisse der Gleichverteilung (Abbildung 19.17) sind mit einer Geraden verbunden.

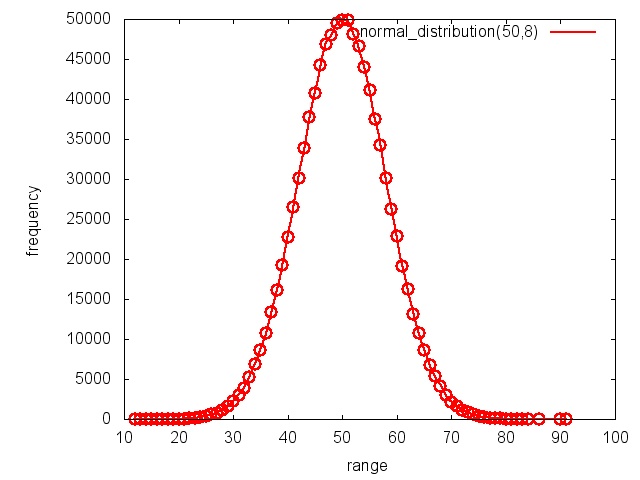
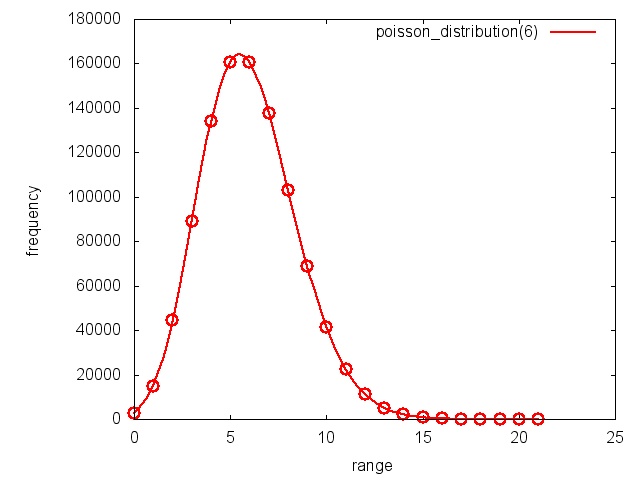
Zufallszahlenerzeuger
Jeder Zufallszahlenerzeuger gen vom Typ Generator muss vier Anfragetypen unterstützen:
Generator::result_type: Datentyp der folgenden drei Ergebnisse vongen(),gen.min()undgen.max()gen():Rückgabe eines Zufallswertsgen.min(): minimaler Wert, der vongen()zurückgegeben wirdgen.max(): maximaler Wert, der vongen()zurückgegeben wird
Zufallszahlenerzeuger gibt es in C++11 in verschiedenen Ausprägungen. Sechs Templates und zehn Synonyme für die am häufigsten verwendeten Zufallszahlenerzeuger stehen zur Verfügung.
Die sechs Templates sind:
template<class UIntType, UIntType a, UIntType c, UIntType m>
class linear_congruential_engine;
template<class UIntType, size_t w, size_t n, size_t m,
size_t r,UIntType a, size_t u, UintType d, size_t s,
UIntType b, size_t t,UIntType c, size_t l, UintType f>
class mersenne_twister_engine;
template<class UIntType, size_t w, size_t s, size_t r>
class subtract_with_carry_engine;
template<class Engine, size_t p, size_t r>
class discard_block_engine;
template<class Engine, size_t w, class UIntType>
class independent_bits_engine;
template<class Engine, size_t k>
class shuffle_order_engine;Aufbauend auf den Templates in Listing 19.31 hier die zehn Synonyme, die das Leben eines Programmierers leichter machen:
typedef linear_congruential_engine<uint_fast32_t, 16807, 0, 2147483647>
minstd_rand0;
typedef linear_congruential_engine<uint_fast32_t, 48271, 0, 2147483647>
minstd_rand;
typedef mersenne_twister_engine<uint_fast32_t,
32,624,397,31,0x9908b0df,11,0xffffffff,7,0x9d2c5680,15,0xefc60000,18,1812433253>
mt19937;
typedef mersenne_twister_engine<uint_fast64_t,
64,312,156,31,0xb5026f5aa96619e9,29,
0x5555555555555555,17,
0x71d67fffeda60000,37,
0xfff7eee000000000,43,
6364136223846793005>
mt19937_64;
typedef subtract_with_carry_engine<uint_fast32_t, 24, 10, 24>
ranlux24_base;
typedef subtract_with_carry_engine<uint_fast64_t, 48, 5, 12>
ranlux48_base;
typedef discard_block_engine<ranlux24_base, 223, 23>
ranlux24;
typedef discard_block_engine<ranlux48_base, 389, 11>
ranlux48;
typedef shuffle_order_engine<minstd_rand0,256>
knuth_b;
typedef implementation-defined
default_random_engine;Eine kurze Bemerkung noch zu der default_random_engine in Listing 19.32. Es hängt von der Implementierung ab, welcher konkrete Zufallserzeuger verwendet wird. Die Entscheidungskriterien für die Implementierung sollen Performance, Größe und Qualität des Zufallszahlenerzeugers sein.
random_device
random_device ist ein nicht deterministischer Zufallszahlenerzeuger. Auf Systemen, auf denen dieser Zufallszahlenerzeuger nicht verfügbar ist, wird einer der vorhandenen Zufallszahlenerzeuger aus Listing 19.32 verwendet. Unter Linux wird random_device auf die spezielle Datei /dev/urandom abgebildet.
Zufallszahlenverteilung
Die Zufallszahlenverteiler in C++11 lassen sich in zwei Klassen aufteilen. Die diskreten Verteiler erzeugen Ganzzahlen, kontinuierliche Verteiler erzeugen Fließkommazahlen in C++11.
Sowohl bei der diskreten als auch bei der kontinuierlichen Verteilung kann der Anwender auf viele bekannte Verteilungen zurückgreifen.
template<class IntType = int> class uniform_int_distribution; template<class RealType = double> class uniform_real_distribution; class bernoulli_distribution; template<class IntType = int> class binomial_distribution; template<class IntType = int> class geometric_distribution; template<class IntType = int> class negative_binomial_distribution; template<class IntType = int> class poisson_distribution; template<class RealType = double> class exponential_distribution; template<class RealType = double> class gamma_distribution; template<class RealType = double> class weibull_distribution; template<class RealType = double> class extreme_value_distribution; template<class RealType = double> class normal_distribution; template<class RealType = double> class lognormal_distribution; template<class RealType = double> class chi_squared_distribution; template<class RealType = double> class cauchy_distribution; template<class RealType = double> class fisher_f_distribution; template<class RealType = double> class student_t_distribution; template<class IntType = int> class discrete_distribution; template<class RealType = double> class piecewise_constant_distribution; template<class RealType = double> class piecewise_linear_distribution;
Die Unterscheidung, ob eine Verteilung diskret oder kontinuierlich ist, lässt sich aus Listing 19.33 direkt ablesen. Lautet der Template-Parameter IntType, ist die Verteilung diskret. Im Fall von RealType ist die Verteilung kontinuierlich. Lediglich die Bernoulli-Verteilung bernoulli_distribution stellt eine Ausnahme von der Regel dar, da sie Wahrheitswerte zurückgibt.
Interface einer Verteilung
Eine Verteilung dist bietet nicht viel mehr an, als den nächsten Wert durch den Aufruf dist(gen) des Zufallszahlengenerators gen zu erhalten, den Zustand der Verteilung auf einen Ausgabestream out << dist zu schreiben und den Zustand einer Verteilung von einem Eingabestrom in >> dist zu lesen. Durch dist.reset() lässt sich der Zustand einer Verteilung zurücksetzen.
zeroOneSequence.cpp
Aufgabe 19-14: Zufallszahlen
Erzeugen Sie eine zufällige Folge von 0/1-Werten.
Zeitbibliothek
<chrono>
Die C++11-Zeitbibliothek besteht aus drei Komponenten: der Zeitdauer (duration), dem Zeitpunkt (time_point) und den Zeitgebern (system_clock, steady_clock und high_resolution_clock). Um die Begriffe, die sehr voneinander abhängen, besser unterscheiden zu können, finden Sie in dem folgenden Kasten die Definitionen.
In Listing 19.34 werden einige Features der neuen Zeitbibliothek angewandt.
timeBibliothek.cpp
01 #include <chrono>
02 #include <iostream>
03 #include <ratio>
04 #include <thread>
05
06 int main(){
07
08 std::cout << std::endl;
09
10 // get the actual time
11 std::chrono::system_clock::time_point
start = std::chrono::system_clock::now();
12
13 // sleep 1000 * 1 Millisecond
14 for ( int i = 0; i <= 1000;++i){
15 std::this_thread::sleep_for(
std::chrono::milliseconds(1));
16 }
17
18 std::chrono::duration<double> dur =
std::chrono::system_clock::now() - start;
19
20 std::cout << "sleeping 1000 times 1 Milliseconds take: "
<< dur.count() << std::endl;
21
22 auto begin= std::chrono::system_clock::now();
23
24 auto end = std::chrono::system_clock::now() +
std::chrono::duration<double, std::ratio<1>>(0.5);
25
26 while (std::chrono::system_clock::now() < end);
27
28 std::chrono::duration<double> dur1 =
std::chrono::system_clock::now() - begin;
29
30 std::cout << "busy waiting for half a second :"
<< dur1.count() << std::endl;
31
32 // typedef for minutes, seconds and milliseconds
33 typedef std::chrono::duration<long long,
std::ratio<60>> minutes;
34 typedef std::chrono::duration<long long,
std::ratio<1>> seconds;
35 typedef std::chrono::duration<long long,
std::ratio<1,1000>> milliseconds;
36
37 seconds sec(5);
38 minutes min(2);
39 milliseconds mil(10);
40
41 milliseconds milRes= min + sec + mil;
42
43 std::cout << "2 Minutes + 5 Seconds + 10 Milliseconds="
<< milRes.count() << " Milliseconds"
<< std::endl;
44
45 // typedef for hours
46 typedef std::chrono::duration<double,
std::ratio<3600>> hours;
47 hours hourRes= milRes;
48
49 std::cout << "2 Minutes + 5 Seconds + 10 Milliseconds= "
<< hourRes.count() << " Hours" << std::endl;
50
51 std::cout << std::endl;
52
53 }In Listing 19.34 wird in Zeile 11 der Startpunkt start mit der neuen Systemzeit in Zeile 18 verrechnet. Die eigentliche Arbeit findet in der for-Schleife in Zeile 14 statt, in der der aktuelle Thread 1.000 Mal für eine Millisekunde schlafen gelegt wird. In Abbildung 19.21 ist schön zu erkennen, dass durch das häufige Schlafenlegen und wieder Aufwachen ca. 13 % mehr Zeit beansprucht wird. Dieser Overhead ist beim busy waiting nicht vorhanden, denn die while-Schleife in Zeile 26 wird genau für eine halbe Sekunde ausgeführt (Abbildung 19.21). Sehr interessant ist das Rechnen mit verschiedenen Zeitdauern. Dazu wird in den Zeilen 33 bis 35 und 46 ein Synonym für Millisekunden, Sekunden, Minuten und Stunden definiert. Dabei bezeichnet das erste Argument des Templates den Datentyp, der die Zeitdauer hält, und das zweite Argument die Einheit. Während std::ratio<1> eine Sekunde definiert, steht std::ratio<60> für 60 Sekunden bzw. eine Minute. Erhält std::ratio wie im Fall von std::ratio<1,1000>zwei Argumente, steht dieser Ausdruck für 1/1000 Sekunde bzw. eine Millisekunde. Nach diesen Synonymen kann sehr elegant mit den Zeitdauern gerechnet werden. Wird der Zeitdauertyp als natürliche Zahl definiert und mit dem Datentyp Millisekunde (Zeile 41) angenommen, steht das Ergebnis normiert auf Millisekunden zur Verfügung. Aber auch im Stundenformat lässt sich das Ergebnis darstellen. Dazu ist es notwendig, als Repräsentation des Datentyps eine Fließkommazahl zu wählen und das Ergebnis in dem entsprechenden Typsynonym hours (Zeile 47) zu speichern. Diese verschiedenen Repräsentationen der gleichen Zeitdauer sind in Abbildung 19.21 schön zu sehen.
Zeitdauer
Die Zeitdauer ist die Differenz zwischen zwei Zeitpunkten. Sie besteht aus einem arithmetischen Typ und dem Zeittakt (tick period).
template <class Rep, class Period = ratio<1>> class duration;
Ist der arithmetische Typ eine Fließkommazahl, unterstützt die Zeitdauer Bruchteile ihres Zeittakts. Der Zeittakt ist eine rationale Zahl vom neuen Typ std::ratio. Per Default ist 1 Sekunde die Grundeinheit des Zeittakts.
Vordefinierte Zeitdauern
Die wichtigsten Zeitdauern sind bereits in der Bibliothek als Synonyme definiert.
typedef duration<signed integer type of at least 64 bits , nano> nanoseconds; typedef duration<signed integer type of at least 55 bits , micro> microseconds; typedef duration<signed integer type of at least 45 bits , milli> milliseconds; typedef duration<signed integer type of at least 35 bits > seconds; typedef duration<signed integer type of at least 29 bits , ratio< 60> > minutes; typedef duration<signed integer type of at least 23 bits , ratio<3600> > hours;
Hierzu ein paar Anmerkungen. Eine Zeitdauer muss mindestens +/–292 Jahre umfassen. Daraus resultieren die verschiedenen Anforderungen an die Größe der Datentypen in Listing 19.36. nano, micro und milli sind wiederum Aliase des Datentyps std::ratio.
Neben der Arithmetik mit Zeitdauern (Listing 19.34) ist die Definition eigener Zeittakte sicher ein interessanter Anwendungsbereich der Klasse duration. In Listing 19.38 werden die vordefinierten Zeitdauern ausgegeben. Darüber hinaus werden eine Schulstunde (45 Minuten) und eine Sekunde definiert.
duration.cpp
01 #include <chrono>
02 #include <iostream>
03 #include <ratio>
04
05 int main(){
06
07 std::cout << std::endl;
08
09 typedef std::chrono::duration<long long, std::ratio<1>>
MySecondTick;
10
11 MySecondTick aSecond(1);
12
13 std::chrono::nanoseconds nano(aSecond);
14 std::cout << nano.count() << " nanoseconds" << std::endl;
15
16 std::chrono::microseconds micro(aSecond);
17 std::cout << micro.count() << " microseconds"
<< std::endl;
18
19 std::chrono::milliseconds milli(aSecond);
20 std::cout << milli.count() << " milliseconds"
<< std::endl;
21
22 std::chrono::seconds seconds(aSecond);
23 std::cout << seconds.count() << " seconds" << std::endl;
24
25 // std::chrono::minutes minutes(aSecond);
26 std::chrono::minutes minutes(
std::chrono::duration_cast<
std::chrono::minutes>(aSecond));
27 std::cout << minutes.count()
<< " minutes(truncated value)" << std::endl;
28
29 //std::chrono::hours hours(aSecond);
30 std::chrono::hours hours(
std::chrono::duration_cast<
std::chrono::hours>(aSecond));
31 std::cout << hours.count() << " hours( truncated value)"
<< std::endl;
32
33 std::cout << std::endl;
34
35 typedef std::chrono::duration<double, std::ratio<60>>
MyMinuteTick;
36 MyMinuteTick myMinute(aSecond);
37 std::cout << myMinute.count() << " minutes" << std::endl;
38
39 typedef std::chrono::duration<double, std::ratio<3600>>
MyHourTick;
40 MyHourTick myHour(aSecond);
41 std::cout << myHour.count() << " hours" << std::endl;
42
43 typedef std::chrono::duration<double, std::ratio<2700>>
MyLessonTick;
44 MyLessonTick myLesson(aSecond);
45 std::cout << myLesson.count() << " lessons" << std::endl;
46
47 typedef std::chrono::duration<long long, std::ratio<1,2>>
MyHalfASecondTick;
48 MyHalfASecondTick myHalfASecond(aSecond);
49 std::cout << myHalfASecond.count() << " HalfASeconds"
<< std::endl;
50
51 std::cout << std::endl;
52
53 }In Listing 19.38 ist das Programm duration.cpp in Aktion zu sehen. aSecond(1) vom Typ MySecondTick in Zeile 11 ist die Zeitdauer, die es auszugeben gilt. Es ist in Abbildung 19.22 schön zu sehen, dass die Werte für die Minute und die Stunde abgeschnitten werden. Das wird durch die explizite Konvertierung std::chrono::duration_cast in den Zeilen 25 und 30 erreicht. Ein naiver Aufruf von std::chrono::minutes minutes(aSecond) führt zum Kompilierungsfehler, da sich eine Sekunde nicht als natürliche Zahl mit der Einheit Minute darstellen lässt. Für die exakte Darstellung der Sekunde in einer Minute und einer Stunde werden in den Zeilen 35 und 49 eigene Datentypen MyMinuteTick und MyHourTick definiert. Aber auch die eigenen Datentypen MyLessonTick oder MyHalfASecondTick sind schnell definiert, um eigene Zeiteinheiten zu verwenden.
Praxistipp
Repräsentierung des arithmetischen Typs.
Während die vordefinierten Zeitdauern alle einen integralen Datentyp als Zeitzähler verwenden, stehen beim Definieren eigener Zeitdauern Fließkommazahlen neben den integralen Datentypen zur Verfügung. Während die Repräsentierung mit integralen Datentypen exakt ist, lassen sich bei der Repräsentierung mit Fließkommazahlen auch integrale Werte darstellen, ohne diese abzuschneiden.
Zeitgeber
Die Zeitgeber in C++11 umfassen eine Zeitdauer mit einem Zeitpunkt, sodass der aktuelle Zeitpunkt durch now() zurückgegeben werden kann. Im neuen C++11-Standard werden drei verschiedene Zeitgeber angeboten.
std::chrono::system_clock: Systemzeit, die mit der externen Uhr synchronisiert werden kann.std::chrono::steady_clock: Uhrzeit, die nicht explizit verändert werden kann.std::chrono::high_resolution_clock: Systemzeit mit der höchsten Auflösung.
Jeder dieser Zeitgeber zeichnet sich durch ein einheitliches Interface aus.
class Clock {
public:
typedef an arithmetic-like type rep;
typedef an instantiation of ratio period;
typedef bchrono::duration<rep, period> duration;
typedef bchrono::time_point<Clock> time_point;
static constexpr bool is_steady = true or false;
static time_point now();
};Lediglich für den Zeitgeber std::chrono::steady_clock gilt, dass is_steady == true ist, denn dessen Werte können nie kleiner werden. Durch dieses einheitliche Interface lässt sich gegebenenfalls schnell das Programm von std::chrono::high_resolution_order auf std::chrono::system_clock modifizieren, da insbesondere std::chrono::high_resolution_order deutlich teurer in der Anwendung ist.
Mithilfe der Typsynonyme aus Listing 19.39 und dem neuen Schlüsselwort auto lässt es sich einfach bestimmen, wie viele Nanosekunden seit der Epoche (1.1.1970) vergangen sind. Nanosekunden sind die Genauigkeit der Systemzeit auf meiner Plattform.
clock.cpp
01 #include <chrono>
02 #include <iostream>
03
04 int main(){
05
06 std::cout << std::boolalpha<< std::endl;
07
08 auto timeNow= std::chrono::system_clock::now();
09 auto duration= timeNow.time_since_epoch();
10
11 std::cout << "nanoseconds since 1.1.1970 :"
<< duration.count() << std::endl;
12
13 std::cout << "is steady: "
<< std::chrono::system_clock::is_steady << std::endl;
14
15 std::cout << std::endl;
16
17 }In Listing 19.40 ist schön zu sehen, wie die statische Funktion system_clock()::now() in Zeile 8 verwendet wird, um den aktuellen Zeitpunkt zu erhalten. Dieser ist der Schlüssel für die Zeitdauer duration seit der Epoche in Zeile 9. Eine weitere statische Funktion von std::chrono::system_clock wird in Zeile 13 angewandt, um die Frage zu beantworten, ob diese stetig ist. Das bisschen Ausgabe ist in Abbildung 19.23 zu sehen.
Als einziger Zeitgeber besitzt std::chrono::system_clock zwei Methoden, um mit der C-API zu interagieren.
static time_t to_time_t (const time_point& t); static time_point from_time_t(time_t t);
Auf POSIX-Systemen wird std::chrono::system_clock auf times, auf Windows-Systemen auf GetProcessTimes abgebildet.
Zeitpunkt
Ein Zeitpunkt wird durch einen Startpunkt, die sogenannte Epoche und die darauf bezogene Zeitdauer festgelegt.
template <class Clock, class Duration = typename Clock::duration> class time_point;
Epoche
Dabei enthält ein Zeitpunkt einen Zeitgeber und eine Zeitdauer. Über die Funktion time_since_epoch erhält der Aufrufer die Zeitdauer seit der Epoche zurück. Dabei ist der Beginn der Zeitrechnung für std::chrono::system_clock der 1.1.1970 und für die beiden anderen Zeitgeber std::chrono::steady_clock und std::chrono::high_resolution_clock der Bootzeitpunkt des Rechners.
timeSinceEpoch.cpp
Aufgabe 19-15
Bestimmen Sie die Zeitdauer seit dem 1.1.1970.
Gut 40 Jahre alt ist das Computerzeitalter. Bestimmen Sie die Zeit seit der Epoche in Sekunden, Minuten, Stunden, Tagen, Wochen, Monaten und Jahren. Der Einfachheit halber soll ein Monat 30 Tage lang sein.
Referenz-Wrapper
Ein std::reference_wrapper<T> ist ein kopierkonstruierbarer und zuweisbarer Wrapper um ein Objekt vom Typ T&. Damit entsteht ein Objekt, das sich zwar wie eine Referenz verhält, aber, und das ist der entscheidende Punkt, auch kopiert werden kann.
Diese Eigenschaften ermöglichen zwei neue Anwendungsfälle von std::reference_wrapper<T> gegenüber Referenzen.
Sie können in Containern der Standard Template Library verwendet werden.
Klassen, die
std::reference_wrapper<T>-Objekte enthalten, lassen sich kopieren.
Während die Verwendung von Referenz-Wrappern in Containern aus dem Kapitel 5, Abschnitt „Referenz-Wrapper“ der Teil I bekannt ist, fehlt noch der zweite Anwendungsfall.
referenceWrapperClass.cpp
01 #include <functional>
02 #include <iostream>
03 #include <string>
04
05 class Bad{
06 public:
07 Bad(std::string& s):message(s){}
08 private:
09 std::string& message;
10 };
11
12 class Good{
13 public:
14 Good(std::string& s):message(s){}
15 std::string getMessage(){
16 return message.get();
17 }
18 void changeMessage(std::string s){
19 message.get()= s;
20 }
21 private:
22 std::reference_wrapper<std::string> message;
23 };
24
25 int main(){
26
27 std::cout << std::endl;
28
29 std::string bad1{"bad1"};
30 std::string bad2{"bad2"};
31
32 Bad b1(bad1);
33 Bad b2(bad2);
34 // will not compile, because of reference
35 //b1= b2;
36
37 std::string good1{"good1"};
38 std::string good2{"good2"};
39
40 Good g1(good1);
41 Good g2(good2);
42 std::cout << "g1.getMessage(): " << g1.getMessage()
<< std::endl;
43 std::cout << "g2.getMessage(): " << g2.getMessage()
<< std::endl;
44
45 std::cout << std::endl;
46
47 std::cout << "g2= g1" << std::endl;
48 g2= g1;
49 std::cout << "g1.getMessage(): " << g1.getMessage()
<< std::endl;
50 std::cout << "g2.getMessage(): " << g2.getMessage()
<< std::endl;
51
52 std::cout << std::endl;
53
54 g1.changeMessage("veryGood");
55 std::cout << "g1.changeMessage(\"veryGood\")"
<< std::endl;
56 std::cout << "g1.getMessage(): " << g1.getMessage()
<< std::endl;
57 std::cout << "g2.getMessage(): " << g2.getMessage()
<< std::endl;
58
59 std::cout << std::endl;
60
61 }Werden Instanzen der Klasse Bad (Zeile 32) in Listing 19.43 zugewiesen, moniert dies der GCC-Compiler unmissverständlich mit der eindeutigen Fehlermeldung aus Abbildung 19.24.

Dank Referenz-Wrapper wird dieser Anwendungsfall mit der Klasse Good unterstützt. Die Zuweisung in Zeile 48 führt zur Modifikation von g2 (Abbildung 19.25).

Der wesentliche Unterschied der Klasse Good (Zeile 12) gegenüber Bad (Zeile 5) ist, dass Good den std::string in einem Referenz-Wrapper hält (Zeile 19). Interessant ist auch die Elementfunktion changeMessage in Zeile 18. Durch die get-Methode des Referenz-Wrappers steht eine Referenz auf das interne Datenobjekt zur Verfügung, sodass dieses (Zeile 19) auf einen neuen Wert gesetzt werden kann. Somit werden g1 und g2 in Abbildung 19.25 modifiziert.
Interface
Das Interface der Referenz-Wrapper ist schnell erklärt. Neben der bereits verwendeten get-Methode, die eine Referenz auf das interne Objekt anbietet, ist der Klammeroperator für Referenz-Wrapper überladen. Damit lässt sich eine aufrufbare Einheit in einem Referenz-Wrapper kapseln und anwenden.
void foo(){
std::cout << "it works" << std::endl;
}
...
01 typedef void callable();
02 std::reference_wrapper<callable> refWrap1(foo);
03 refWrap1();Für die Funktion foo aus Listing 19.44 wird in Zeile 1 ein Funktionstyp deklariert. Dieser wird in Zeile 2 verwendet, um einen Referenz-Wrapper zu definieren. Zuletzt wird der Referenz-Wrapper refWrap1() angewandt und die Funktion foo ausgeführt.
Die Hilfsfunktionen ref und cref
Für das einfache Definieren einer Referenz oder einer Referenz auf ein konstantes Objekt bietet C++11 die zwei Funktionen std::ref und std::cref an. Beide Funktionen nehmen ein Argument an und verpacken es. In Listing 19.45 werden die beiden Hilfsfunktionen angewandt.
refCref.cpp
01 #include <functional>
02 #include <iostream>
03 #include <string>
04
05 void invokeMe(std::string& s){
06 std::cout << s << ": not const " << std::endl;
07 }
08
09 void invokeMe(const std::string& s){
10 std::cout << s << ": const " << std::endl;
11 }
12
13
14 template <typename T>
15 void doubleMe(T t){
16 t *=2;
17 }
18
19 int main(){
20
21 std::cout << std::endl;
22
23 std::string s{"string"};
24
25 invokeMe(std::ref(s));
26 invokeMe(std::cref(s));
27
28 std::cout << std::endl;
29
30 int i=1;
31 std::cout << "i: " << i << std::endl;
32
33 doubleMe(i);
34 std::cout << "doubleMe(i): " << i << std::endl;
35
36 doubleMe(std::ref(i));
37 std::cout << "doubleMe(std::ref(i)): " << i << std::endl;
38
39 double a=5;
40 std::cout << "a= " << a << std::endl;
41 doubleMe(std::ref(a));
42 std::cout << "doubleMe(std::ref(a)): " << a << std::endl;
43
44 std::cout << std::endl;
45
46 }Die Funktion invokeMe steht in zwei Varianten in Listing 19.45 zur Verfügung. In Zeile 5 nimmt sie eine Referenz auf einen std::string, in Zeile 9 eine Referenz auf einen konstanten std::string an. Durch den Aufruf invokeMe(std::ref(s)) wird die nicht konstante, durch den Aufruf invokeMe(std::cref(s)) die konstante Version verwendet. Das Funktions-Template in Zeile 14 verdoppelt ihr Argument. Dazu ist es aber notwendig, dass der Funktionskörper auf einer Referenz agiert. Genau dies wird mit den Funktionsaufrufen in Zeile 36 doubleMe(std::ref(i)) und Zeile 41 doubleMe(std::ref(a)) erreicht. In der Ausgabe in Abbildung 19.26 ist schön zu sehen, dass der Funktionsaufruf doubleMe(i) in Zeile 33 i nicht verdoppelt.
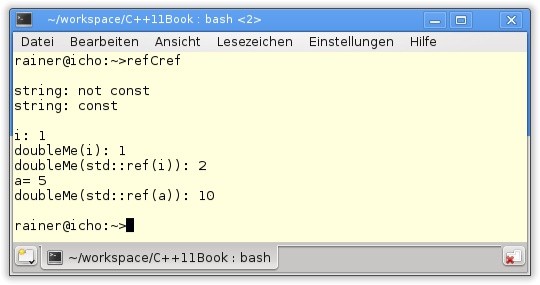
Aufgabe 19-16
Führen Sie ein paar Funktionen in einem separaten Thread aus.
Die fünf Funktionen geben jeweils einen einfachen String auf der Konsole aus.
void func1(){std::cout << "Only ";}
void func2(){std::cout << "for ";}
void func3(){std::cout << "testing ";}
void func4(){std::cout << "purpose";}
void func5(){std::cout << ".\n";}Verpacken Sie diese Funktion in einen Referenz-Wrapper, schieben Sie sie auf einen Vektor und führen Sie die Funktionen in dem Vektor in einem separaten Thread aus. Diese Aufgabe lässt sich auch mit dem neuen C++11-Feature std::function lösen, indem die Funktionen in Funktionsobjekte verpackt werden.