Kapitel 5. Die Standardbibliothek
Die meisten Erweiterungen der Standardbibliothek haben sich schon lange im Einsatz bewährt, sind sie doch aus dem Boost-Projekt (boost, 2011) hervorgegangen und dem Technical Report 1 (C++ Technical Report 1, 2011) 2005 als Ergänzung zum aktuellen C++-Standard hinzugefügt worden. Aber auch neue Komponenten kamen hinzu, und die Funktionalität der C++98-Bibliothek wurde an die mächtigere Kernfunktionalität von C++11 angepasst (Abbildung 5.1).
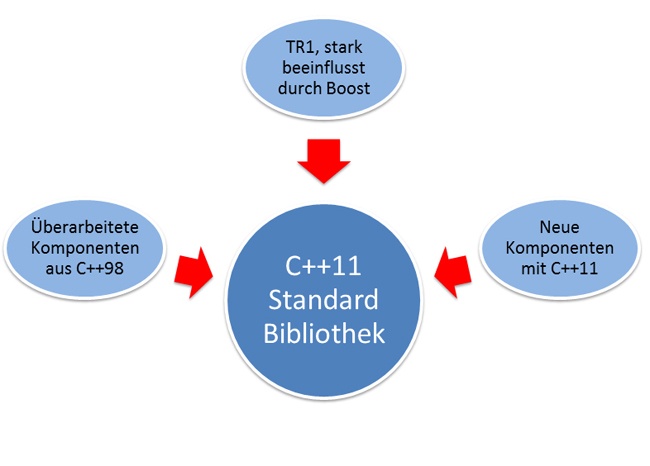
Die großen Highlights im Überblick:
TR1:
Array
Hashtabellen
Reguläre Ausdrücke
Smart Pointer (
shared_ptr,weak_ptr)Tupel
Type-Traits
Zufallszahlen
Neue Komponenten in C++11:
Algorithmen
Multithreading
Smart Pointer (
unique_ptr)
Nach diesem kurzen historischen Abriss über die C++11-Standardbibliothek folgt die neue Funktionalität in kompakter Form. Zuerst stelle ich die neuen Bibliotheken dar und anschließend die Bibliotheken, die bestehende Konzepte von C++98 aufgreifen, erweitern und abrunden.
Neue Bibliotheken
Reguläre Ausdrücke
Die Motivation für eine Bibliothek für reguläre Ausdrücke ähnelt in gewisser Weise der der Multithreading-Bibliothek. Viele Plattformen haben proprietäre Erweiterungen, um mit regulären Ausdrücken zu arbeiten. In C++11 gibt es eine standardisierte Bibliothek. Die neue regex-Bibliothek bietet eine einheitliche Schnittstelle an, um reguläre Ausdrücke anzuwenden, sodass die resultierenden C++11-Programme per se portabel sind.
Drei Schritte
Der Umgang mit regulären Ausdrücken in C++11 erfolgt typischerweise in drei Schritten.
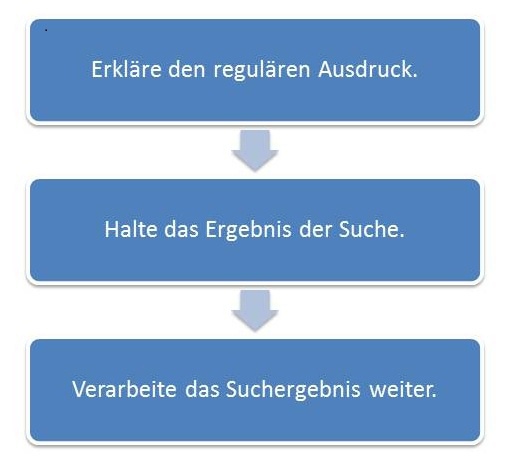
In Listing 5.1 sind diese drei Schritte exemplarisch dargestellt. rgx ist der reguläre Ausdruck, der mit dem Raw-String initialisiert wird. Dabei repräsentiert \d+ eine Zahl, die aus mindestens einer Ziffer besteht. smatch soll das Ergebnis der Suche halten. Dieses Ergebnis wird durch die letzte Zeile angefordert. smatch.prefix() gibt als Ergebnis das Präfix »abc« zurück.
01 std::regex rgx(std::string(R"(\d+)");
02 std::smatch smatch;
03 if (std::regex_search(std::string("abc1234"), smatch, rgx))
std::cout << smatch.prefix();Neben regex_search sind regex_match und regex_replace klassische Anwendungsfälle für reguläre Ausdrücke:
std::regex_match:Prüft, ob der String dem regulären Ausdruck entspricht.std::regex_search:Sucht nach regulärem Ausdruck im Text.std::regex_replace:Ersetzt jedes Vorkommen des regulären Ausdrucks im Text.
In Listing 5.2 sind der regex_seach-Codeschnipsel aus Listing 5.1, aber auch regex_match und regex_replace im Einsatz.
regexNumber.cpp
01 #include <regex>
02
03 #include <iostream>
04 #include <string>
05
06 int main(){
07
08 std::cout << std::endl;
09
10 std::string text="abc1234def567";
11
12 std::string regExprStr(R"(\d+)");
13
14 // regular expression holder
15 std::regex rgx(regExprStr);
16
17 // looking for a total match
18 if (std::regex_match(std::string("1234"),rgx))
19 std::cout << regExprStr << " match 1234" << '\n';
20
21 // search result holder
22 std::smatch smatch;
23 // looking for a partial match
24 if (std::regex_search(text,smatch,rgx))
25 std::cout << "The first match of " << regExprStr
<< " after " << smatch.prefix() << " in "
<< text << '\n';
26
27 // replace the match
28 std::string result;
29 std::string replString{"ABC"};
30 std::regex_replace(back_inserter(result),
text.begin(),text.end(),rgx,replString);
31 std::cout << "replace " << regExprStr << " in "
<< text << " with " << replString << ": "
<< result << std::endl;
32
33 std::cout << std::endl;
34
35 }std::regex_match (Zeile 18) kommt in diesem Anwendungsfall genauso wie std::regex_replace (Zeile 30) ohne ein Objekt aus, das das Ergebnis der Suche hält. Gerade der regex_replace-Ausdruck ist relativ anspruchsvoll zu lesen. Paraphrasiert lautet er: Ersetze im String von text.begin() bis text.end() alle Vorkommen des regulären Ausdrucks rgx mit replString, indem du das Ergebnis an den String result hinten anhängst: back_inserter(result). In diesem konkreten Fall werden auch die nicht modifizierten Teilstrings von text mit hinten angehängt. Genau das zeigt die Ausgabe des Programms in Abbildung 5.3.

Mächtigkeit von regulären Ausdrücken
Die regulären Ausdrücke in C++11 können noch viel mehr. Dies sind ein paar Punkte, die in Kapitel 19 im Abschnitt „Reguläre Ausdrücke“ unser Thema sein werden:
Regular-Expression-Syntax
Umgang mit anderen Zeichentypen als
charArbeiten mit Erfassungsgruppen
Charakter- und Token-Ströme über Match-Objekten
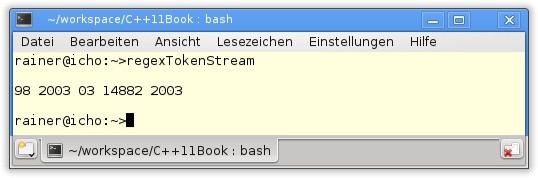
Ein kleines Beispiel soll aber noch zum Abschluss folgen. Iteriere über die Zahlen (Tokens) eines Strings.
regexTokenStream.cpp
01 #include <regex>
02
03 #include <iostream>
04 #include <string>
05
06 int main(){
07
08 std::cout << std::endl;
09
10 // regular expression
11 std::regex rgx(R"(\d+)");
12
13 std::string str="C++98 ist der bis heute gültig C++
Standard, sieht man von seiner kleinen technischen
Korrektur 2003 (C++03), formal ISO/IEC 14882:2003, ab.";
14
15 // define the iterator range
16 std::sregex_token_iterator
it(str.begin(),str.end(),rgx);
17 std::sregex_token_iterator end;
18
19 // iterate over the tokens
20 while (it != end) std::cout << *it++ << " ";
21
22 std::cout << "\n\n";
23
24 }Der Sourcecode ist ungewöhnlich kompakt für C++. Das einzig Neue ist der Token-Iterator (Zeile 16), über den, mittels des regulären Ausdrucks parametrisiert, in der while-Schleife (Zeile 20) iteriert wird. Der Programmlauf gibt die natürlichen Zahlen aus.
Ist die Bibliothek für reguläre Ausdrücke sowohl für den Einsteiger als auch für den Profi von großem Nutzen, so war Template-Metaprogrammierung bisher dem C++-Profi vorbehalten. Das ändert sich aber mit der neuen Type-Traits-Bibliothek.
Type-Traits
Wie funktioniert Template-Metaprogrammierung?
Bei der Template-Metaprogrammierung instanziiert der Compiler die Templates und erzeugt durch diesen Prozess den temporären C++-Sourcecode, der zusammen mit dem restlichen Sourcecode übersetzt wird.
Klassiker der Template-Metaprogrammierung
Ein Klassiker in der C++-Template-Metaprogrammierung sind Klassen-Templates, die zur Übersetzungszeit Charakteristiken eines Typs evaluieren. Das Programm typeTraits.cpp in Listing 5.4 evaluiert zur Übersetzungszeit, ob der abgefragte Typ eine Klasse darstellt, sodass das Ergebnis zur Laufzeit zur Verfügung steht.
typeTraits.cpp
01 #include <string>
02 #include <iostream>
03 #include <type_traits>
04
05 template<typename T>
06 class IsClass{
07 private:
08
09 typedef char One;
10 typedef struct { char a[2]; } Two;
11
12 template<typename C> static One test(int C::*);
13 template<typename C> static Two test(...);
14
15 public:
16 static const bool Yes=
sizeof(IsClass<T>::test<T>(0))==1;
17 static const bool No= (!Yes);
18 };
19
20 int main(){
21
22 std::cout << std::boolalpha << std::endl;
23
24 // use IsClass
25 std::cout << "IsClass<std::string>::Yes: "
<< IsClass<std::string>::Yes << std::endl;
26 std::cout << "IsClass<std::string>::No: "
<< IsClass<std::string>::No << std::endl;
27 std::cout << "IsClass<int>::Yes: " << IsClass<int>::Yes
<< std::endl;
28 std::cout << "IsClass<int>::No: " << IsClass<int>::No
<< std::endl;
29
30 std::cout << std::endl;
31
32 // the C++11 functionality
33 std::cout << "std::is_class<std::string>::value: "
<< std::is_class<std::string>::value
<< std::endl;
34 std::cout << "!(std::is_class<std::string>::value): "
<< !(std::is_class<std::string>::value)
<< std::endl;
35 std::cout << "std::is_class<int>::value: "
<< std::is_class<int>::value
<< std::endl;
36 std::cout << "!(std::is_class<int>::value): "
<< (!std::is_class<int>::value)
<< std::endl;
37
38 std::cout << std::endl;
39
40 }Das Programm in Listing 5.4 ermittelt für die Datentypen std::string und int, dass std::string eine Klasse darstellt, der Built-in-Datentyp int aber nicht. Sowohl das Klassen-Template IsClass (Zeilen 25 bis 28) als auch die neue C++11-Funktionalität std::is_class (Zeilen 33 bis 36) bringen das erwartete Ergebnis.

Magie der Template-Metaprogrammierung
Relativ schwierig zu verstehen ist das Klassen-Template IsClass, das über einen Typ parametrisiert wird. Die Magie der Template-Instanziierung ist aber schnell aufgedeckt. Dazu betrachten wir IsClass<T>::Yes für diese zwei Fälle:
Das Template-Argument
Tist eine Klasse.IsClass<T>::test<T>(0)wird durch Template-Deduktion auftest(int C::*)abgebildet, denn (int C::*)ist ein Zeiger auf eine Methode, dieintzurückgibt; diese Eigenschaft kann nur von Klassen erfüllt werden.Der Rückgabewert der
test-Methode iststatic One.sizeof(static One) == 1ergibttrue, sodassYesauftruegesetzt wird.
Das Template-Argument
Tist keine Klasse.IsClass<T>::test<T>(0)wird auftest (...)abgebildet, denn dieser fängt alle Datentypen auf, die nicht vom Typ (int C::*) sind.Der Rückgabewert der
test-Methode iststatic Two.sizeof(static Two) == 1ergibtfalse, sodassYesauffalsegesetzt wird.
Neben Typabfragen sind mit der Type-Traits-Bibliothek Vergleiche und sogar Transformationen von Datentypen möglich. Dies sind für den fortgeschrittenen C++-Programmierer die Werkzeuge, um Algorithmen zu schreiben, die auf seinen Datentyp optimal angepasst sind.
Neu ist auch die Zufallszahlenbibliothek in C++11.
Zufallszahlen
Zufallszahlen werden in vielen Bereichen in der Softwareentwicklung benötigt, sei es für das Testen von Software oder das Erzeugen von kryptografischen Schlüsseln.
Zufallszahlengenerator
Der Zufallszahlengenerator in C+11 besteht aus zwei Teilen: einem Generator, der einen Strom von Zufallszahlen erzeugt, und einer Verteilung, die die Werte in einem vorgegebenen Bereich verteilt. Die Verteilung wird über den Generator parametrisiert. Damit der Generator nicht jedes Mal mit der gleichen Zufallszahl startet und somit die gleiche Folge von Zufallszahlen erzeugt, wird der sogenannte seed benötigt.
Das Spiel kann beginnen:

Das Programm dazu in Listing 5.5 ist kurz und bündig:
randomNumbers.cpp
01 #include <iostream>
02 #include <random>
03
04 int main(){
05
06 std::cout << std::endl;
07
08 std::random_device seed;
09
10 // generator
11 std::mt19937 engine(seed());
12
13 // distribution
14 std::uniform_int_distribution<int> six(1,6);
15
16 for ( int i=1; i<= 3; ++i){
17 std::cout << "dice["<< i << "]: " << six(engine)
<< std::endl;
18 }
19
20 std::cout << std::endl;
21
22 }Mit dem seed-Aufruf (Zeile 11) wird in Listing 5.5 der Generator initialisiert. Dieser Generator wird an die Verteilung übergeben (Zeile 14), sodass der resultierende Zufallsgenerator (Zeile 17) auf Anfrage die Zufallszahlen produziert.
Tiefere Einsichten in die Erzeugung von Zufallszahlen gibt es in Kapitel 19 im Abschnitt „Zufallszahlen“. Dies umfasst vor allem die vielen verschiedenen Generatoren und Verteilungen, die C++11 von Hause aus mitbringt.
Ähnlich nützlich wie die Zufallszahlenbibliothek ist die neue Zeitbibliothek.
Zeitbibliothek
Die C++11-Zeitbibliothek besteht aus drei Komponenten: einer Komponente für Zeitpunkte und einer für die Dauer zwischen Zeitpunkten sowie letztendlich dem Takt, in dem der Zeitpunkt gemessen wird.
Komponente | Klasse |
Zeitpunkt |
|
Dauer |
|
Takt |
|
Die Hauptmotivation für die Zeitbibliothek war die neue Multithreading-Funktionalität, in der Time-outs für Locks oder asynchrone Aufrufe in der Schlafperiode für Threads in eine relative oder absolute Zeit gesetzt werden können.
Für die einfache Performancemessung des Programms sind die Zeittools in Kombination mit auto sehr praktisch.
auto begin = std::chrono::system_clock::now();
X yCopy(x);
auto end = std::chrono::system_clock::now() - begin;
std::cout << "copying takes "
<< std::chrono::duration<double>(end).count()
<< " seconds time\n";In Listing 5.6 lässt sich die verstrichene Zeit für X yCopy(x) in Sekunden mit std::chrono::duration<double>(end).count() praktisch abfragen.
Praktisch ist eine gute Überleitung. Denn genau das ist ein Referenz-Wrapper.
Referenz-Wrapper
Ein Referenz-Wrapper ist ein kopierkonstruierbarer und zuweisbarer Wrapper um ein Objekt vom Typ T&. Damit lösen Sie das bekannte Problem in C++, dass Referenzen nicht die notwendigen Eigenschaften für Standardcontainer mitbringen. Ein Ausdruck der Form std::vector<int&> quittiert der GCC-Compiler mit einer langen Fehlermeldung. Durch die Verwendung von std::reference_wrapper<int> in Listing 5.7 ist er aber möglich.
referenceWrapper.cpp
01 #include <functional>
02 #include <iostream>
03 #include <vector>
04
05 int main(){
06
07 std::cout << std::endl;
08
09 // will not compile
10 //std::vector<int&> myIntRefVector;
11
12 int a= 0;
13 int b= 0;
14 int c= 0;
15
16 std::vector< std::reference_wrapper<int>> myIntRefVector=
{std::ref(a),std::ref(b),std::ref(c)};
17
18 for (auto b: myIntRefVector ) std::cout << b << " ";
19
20 std::cout << std::endl;
21
22 // modify b and also myIntRefVec[1] !!!!
23 b=2011;
24
25 for (auto b: myIntRefVector ) std::cout << b << " ";
26
27 std::cout << "\n\n";
28
29 }Mit der Initialisiererliste (Listing 5.7, Zeile 16) wird der Vektor mit dem Referenz-Wrapper über die drei natürlichen Zahlen initialisiert. std::ref und std::cref sind zwei Hilfsfunktionen, die einfach eine Referenz oder einen konstanten Referenz-Wrapper erzeugen. Der entscheidende Punkt befindet sich in Zeile 23, denn darin wird die Referenz von b auch im Container myIntRefVector modifiziert, sodass dessen Wert auf 2011 verändert wird.

Damit verlassen wir das Gebiet der neuen Bibliotheken in C++11 und widmen uns den überarbeiteten C++11-Bibliotheken. Diese bieten bewährte C++-Funktionalität in generischer Form an. Sowohl der Novize als auch der Profi profitieren von diesen Erweiterungen – der Novize, da sich die Bibliotheken einfacher ansprechen lassen und daher deren Benutzung weniger fehleranfällig ist, der Profi, da das Laufzeitverhalten seines Programms insbesondere von den neuen Containern profitiert.
Verbesserte Bibliotheken
Viele bewährte C++-Bibliotheken wurden in C++11 runderneuert. Dies betrifft die Smart Pointer, die neben dem C++-Smart-Pointer std::auto_ptr die neuen Smart Pointer std::shared_ptr, std::weak_ptr und std::unique_ptr enthalten. Dies betrifft die neuen Container, indem dem std::pair ein std::tuple, dem std::vector ein std::array und dem std::map ein std::unordered_map in C++11 gegenübergestellt wurden. Dies betrifft den C++11-Funktionsadapter std::bind, der die klassischen Funktionsadapter std::bind1st und std::bind2nd in C++ deutlich erweitert und dessen resultierende Objekte an std::function gebunden werden können.
Smart Pointer
shared_ptr, weak_ptr und unique_ptr
Die neuen Smart Pointer std::shared_ptr und std::weak_ptr, die schon lange in der Boost-Bibliothek (boost, 2011) im Einsatz sind, und der neue Smart Pointer std::unique_ptr gelten als eine, wenn nicht gar die wichtigste Erweiterung im neuen C++11-Standard. Diese drei erweitern deutlich die Funktionalität des klassischen std::auto_ptr und räumen mit seinen konzeptionellen Schwächen auf. Das ist der Grund dafür, dass dieser in C++11 als deprecated erklärt wird und stattdessen ein std::unique_ptr verwendet werden sollte. In der Tabelle 5.2 sind die wichtigsten Charakteristiken der Smart Pointer von C++11 zusammengefasst.
Name | Im C++- Standard | Beschreibung |
| C++98 | Besitzt eine Ressource exklusiv. Wendet implizite (heimliche) Move-Semantik an. |
| C++11 | Referenzzähler auf eine gemeinsam genutzte Ressource. |
| C++11 | Hilft, zyklische Referenzen zu brechen. |
| C++11 | Besitzt eine Ressource exklusiv. Unterstützt keine implizite (heimliche) Move-Semantik. |
Aus welchem Grund wurde der std::auto_ptr als deprecated erklärt?
auto_ptr
Der std::auto_ptr besitzt zwei Eigenschaften, die leicht zu undefiniertem Verhalten des Programms führen:
Beim Kopieren eines
std::auto_ptrwird dessen Inhalt verschoben. Das Kopieren verändert somit die Quellressource.std::auto_ptrist weder kopierkonstruierbar noch zuweisbar. Er kann also nicht in den Containern der STL verwendet werden.
Während der Compiler in der Regel bemerkt, wann ein std::auto_ptr in einem STL-Container verwendet wird, ist das implizite Verschieben der Ressource beim Kopieren eine häufige Fehlerquelle.
autoPtrCopy.cpp
#include <memory>
int main(){
std::auto_ptr<int> auto1(new int(5));
// implicit transfer of ownership
std::auto_ptr<int> auto2(auto1);
// undefined behaviour
int a= *auto1;
}Listing 5.8 bringt es auf den Punkt. In dem Ausdruck auto2(auto1) wird der Inhalt von auto1 nach auto2 verschoben (Abbildung 5.8).

Interessant sind sowohl das Kompilieren als auch das Ausführen des Programms.
Der Compiler moniert die Verwendung von std::auto_ptr mit einer deprecated-Warnung.

Das Ausführen des Programms führt zu einem Laufzeitfehler.

unique_ptr
Als der std::auto_ptr deprecated erklärt wurde, musste ein Ersatz geschaffen werden: der neue C++11-Smart-Pointer std:unique_ptr. Dieser ist nahezu aufrufkompatibel zum std::auto_ptr und besitzt auch seine Ressource exklusiv. Wenn der std::unique_ptr seine Gültigkeit verliert (out of scope), wird sein Destruktor aufgerufen und gleichzeitig die Ressource des std::unique_ptr zerstört. Im Gegensatz zum std::auto_ptr unterstützt der std::unique_ptr kein Kopieren, sondern nur das explizite Verschieben seiner Ressource durch die neue Funktion std::move. Das explizite Verschieben einer Ressource mit std::unique_ptr analog zum impliziten Kopieren einer Ressource mit std::auto_ptr (Listing 5.8) ist schnell implementiert.
uniquePtrMove.cpp
#include <memory>
int main(){
std::unique_ptr<int> unique1(new int(5));
// explicit transfer of ownership
std::unique_ptr<int> unique2(std::move(unique1));
}In Abbildung 5.11 ist das explizite Transferieren der Ressource grafisch dargestellt.
shared_ptr
Während der std::unique_ptr eine 1:1-Beziehung zu seiner Ressource besitzt, ist der typische Einsatzbereich des std:shared_ptr, eine gemeinsame Ressource zu nutzen. Jeder std::shared_ptr besitzt einen Zeiger auf seine Ressource und den Referenzzähler. Wird nun ein std::shared_ptr kopiert, referenziert dieser sowohl die gemeinsame Ressource als auch den Referenzzähler. Beim Erzeugen eines std::shared_ptr wird dessen Referenzzähler auf 1 gesetzt. Beim Kopieren wird er um 1 inkrementiert, beim Löschen um 1 dekrementiert. Erreicht der Referenzzähler den Wert 0, führt dies zum automatischen Löschen der Ressource. Damit ist er kopierkonstruierbar und zuweisbar und kann in den Containern als STL-Bibliothek verwendet werden.
Abbildung 5.12 zeigt exemplarisch das Kopieren eines std::shared_ptr.
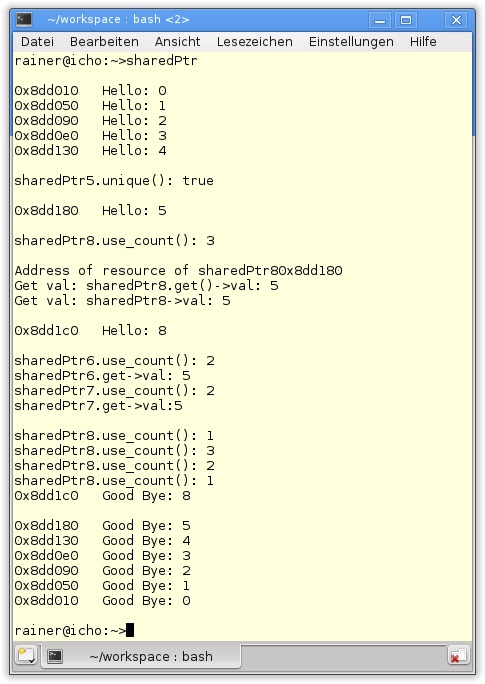
Abgerundet wird die Funktionalität des std::shared_ptr durch den std::weak_ptr, denn dieser hilft, zyklische Referenzen von std::shared_ptr aufzubrechen. Der std::weak_ptr verändert nicht den Zähler auf die gemeinsam genutzte Ressource. Genau genommen ist der std::weak_ptr kein Smart Pointer, denn er bietet keinen transparenten Zugriff auf die Ressource an. Er verfügt nur über ein einfaches Interface auf eine Ressource, die von einem std::shared_ptr verwaltet wird. Um die Ressource eines std::weak_ptr zu adressieren, muss dieser zuerst gelockt werden, sodass anschließend über einen initialisierten std:shared_ptr auf dessen Ressource zugegriffen werden kann.
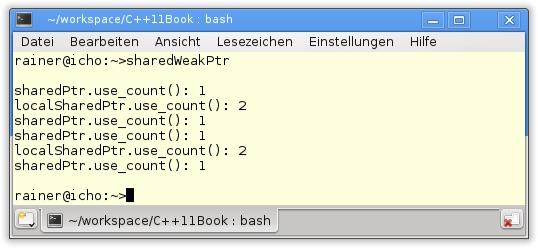
Listing 5.10 zeigt den einfachen Umgang mit std:shared_ptr und std:weak_ptr.
sharedWeakPtr.cpp
01 #include <iostream>
02 #include <memory>
03
04 int main(){
05
06 std::cout << std::endl;
07
08 std::shared_ptr<int> sharedPtr(new int(5));
09
10 std::cout << "sharedPtr.use_count(): "
<< sharedPtr.use_count() << std::endl;
11
12 // block scope
13 {
14 std::shared_ptr<int> localSharedPtr(sharedPtr);
15
16 std::cout << "localSharedPtr.use_count(): "
<< localSharedPtr.use_count() << std::endl;
17
18 }
19 std::cout << "sharedPtr.use_count(): "
<< sharedPtr.use_count() << std::endl;
20
21 std::weak_ptr<int> weakPtr(sharedPtr);
22 std::cout << "sharedPtr.use_count(): "
<< sharedPtr.use_count() << std::endl;
23
24 // if block scope
25 if(std::shared_ptr<int> localSharedPtr = weakPtr.lock()){
26
27 std::cout << "localSharedPtr.use_count(): "
<< localSharedPtr.use_count() << std::endl;
28 }
29
30 std::cout << "sharedPtr.use_count(): "
<< sharedPtr.use_count() << std::endl;
31
32 std::cout << std::endl;
33
34 }Die Methode use_count des std:shared_ptr in Listing 5.10 gibt den Wert des Referenzzählers aus. In Zeile 8 wird der sharedPtr erzeugt. Der Referenzzähler besitzt den Wert 1. localSharedPtr (Zeile 14) erhöht den Referenzzähler um 1. Am Ende des lokalen Blocks verliert dieser seinen Gültigkeitsbereich, sodass er um 1 dekrementiert wird (Zeile 19). Der weakPtr, der über den sharedPtr initialisiert wird, erhöht nicht den Referenzzähler (Zeile 22). Wird die Ressource des weakPtr verwendet, um damit den localSharedPtr zu initialisieren, wird dessen Ressourcenzähler inkrementiert (Zeile 27).
Genau dieses Verhalten zeigt das Programm:
Neben dem Smart Pointer erweitern die neuen Container in C++11 die bestehenden C++-Container deutlich. Dies betrifft bei std::tuple dessen Mächtigkeit, da es im Gegensatz zu std::pair beliebig viele Argumente annehmen kann, dies betrifft bei std::array und den Hashtabellen deren Performance gegenüber den klassischen sequenziellen Containern oder assoziativen Arrays.
Neue Container
Tupel
tuple
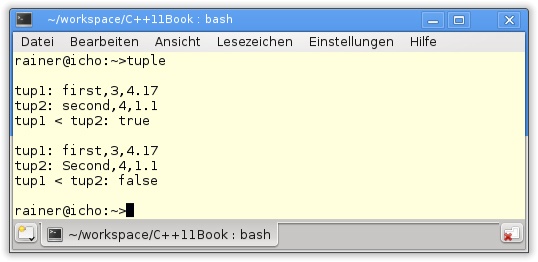
std::tuple ist ein heterogener Container fester Länge. Er kann beliebig viele Argumente annehmen. Dies ist möglich, da std::tuple ein Variadic Template ist (siehe Kapitel 9, Abschnitt „Variadic Templates“). Ein Tupel lässt sich über einen Konstruktoraufruf oder die Hilfsfunktion std::make_tuple einfach erzeugen. Die instanziierten Tupel können verglichen, gelesen und modifiziert werden (Listing 5.11).
tuple.cpp
01 #include <iostream>
02 #include <string>
03 #include <tuple>
04
05 int main(){
06
07 std::cout << std::boolalpha << std::endl;
08
09 // create two tuples
10 std::tuple<std::string,int,float> tup1("first",3,4.17);
11 std::tuple<std::string,int,double> tup2=
std::make_tuple("second",4,1.1);
12
13 // read the values
14 std::cout << "tup1: "
<< std::get<0>(tup1) << ","
<< std::get<1>(tup1) << ","
<< std::get<2>(tup1) << std::endl;
15 std::cout << "tup2: "
<< std::get<0>(tup2) << ","
<< std::get<1>(tup2) << ","
<< std::get<2>(tup2) << std::endl;
16
17 // compare them
18 std::cout << "tup1 < tup2: " << (tup1 < tup2)
<< std::endl;
19
20 std::cout << std::endl;
21
22 // modify a tuple value
23 std::get<0>(tup2)= "Second";
24
25 // read the values
26 std::cout << "tup1: "
<< std::get<0>(tup1) << ","
<< std::get<1>(tup1) << ","
<< std::get<2>(tup1) << std::endl;
27 std::cout << "tup2: "
<< std::get<0>(tup2) << ","
<< std::get<1>(tup2) << ","
<< std::get<2>(tup2) << std::endl;
28
29 // compare them
30 std::cout << "tup1 < tup2: " << (tup1 < tup2)
<< std::endl;
31
32 std::cout << std::endl;
33
34 }Der umständliche Zugriff auf die Elemente des Tupels std::get<0> (tup1) (Zeile 14) ist der Tatsache geschuldet, dass get ein Template und der Index eine Compile-Zeitkonstante ist.
Abbildung 5.14 zeigt die Ausgabe des Programms.
Dank auto geht das Definieren eines Tupels deutlich einfacher von der Hand.
auto tup= std::make_tuple("second",4,1.1,true,'a');Array
array
Der neue sequenzielle Container Array hat mit dem Tupel gemein, dass er eine feste Länge besitzt. std::array bietet das Laufzeitverhalten des C-Arrays mit der Schnittstelle des C++-Vektors an. Damit ist er STL-konform und kann deren Algorithmen verwenden (Listing 5.12).
array.cpp
01 #include <algorithm>
02 #include <array>
03 #include <iostream>
04
05
06 int main(){
07
08 std::cout << std::endl;
09
10 // output the array
11 std::array <int,8> array{{1,2,3,4,5,6,7,8}};
12 std::for_each( array1.begin(),array1.end(),
[](int v){std::cout << v << " ";});
13
14 std::cout << std::endl;
15
16 // calculate the sum of the array by using a global variable
17 int sum = 0;
18 std::for_each(array1.begin(), array1.end(),
[&sum](int v) { sum += v; });
19 std::cout << "sum of array{1,2,3,4,5,6,7,8}: "
<< sum << std::endl;
20
21 // change each array element to the second power
22 std::for_each(array1.begin(), array1.end(),
[](int& v) { v=v*v; });
23 std::for_each( array1.begin(),array1.end(),
[](int v){std::cout << v << " ";});
24 std::cout << std::endl;
25
26 std::cout << std::endl;
27
28 }Zu der einfachen Arithmetik in Listing 5.12 noch ein paar Bemerkungen. Die Lambda-Funktion [&sum](int v) { sum += v; } (Zeile 19) bindet sich per Referenz an die globale Variable sum, die die Zahlen aufsummiert. Durch die Lambda-Funktion [](int& v) { v=v*v; } (Zeile 22) lassen sich die Elemente des Arrays direkt quadrieren, da die Argumente per Referenz adressiert werden. Nun fehlt nur noch die Ausgabe.

C-Array, C++-Vektor und C++11-Array
Tabelle 5.3 stellte die Charakteristiken der drei sequenziellen Datentypen C-Array, C++-Vektor und C++11-Array gegenüber.
Einfach verkettete Liste
Der neue Container std::forward_list ist eine einfach verkettete Liste und kann nur vorwärts durchlaufen werden.
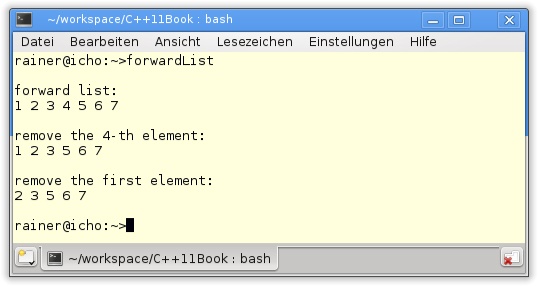
std:forward_list ist optimiert für schnelles Einfügen und Entfernen von Elementen, bietet aber keinen wahlfreien Zugriff auf seine Elemente an. Bedingt durch seine Struktur, besitzt sie ein eingeschränktes und eigenwilliges Interface und bricht mit bekannten Konventionen aus der Standard Template Library. So sucht man bei ihr beispielsweise vergeblich eine size- oder push_back-Methode.
Den einfachen Umgang mit der std::forward_list zeigt Listing 5.13.
forwardList.cpp
01 #include <forward_list>
02 #include <iostream>
03
04 int main(){
05
06 std::cout << std::endl;
07
08 //std::forward_list<int> myForList{1,2,3,4,5,6,7};
09 std::forward_list<int> myForList;
10 myForList.push_front(7);
11 myForList.push_front(6);
12 myForList.push_front(5);
13 myForList.push_front(4);
14 myForList.push_front(3);
15 myForList.push_front(2);
16 myForList.push_front(1);
17
18 std::cout << "forward list: " << std::endl;
19 //for (auto f: myForList) std::cout << f << " ";
20 for (auto It= myForList.cbegin();
It != myForList.cend();++It) std::cout << *It << " ";
21 std::cout << "\n\n";
22
23 std::cout << "remove the 4-th element: " << std::endl;
24 auto begin= myForList.begin();
25 begin++;
26 begin++;
27 myForList.erase_after(begin);
28
29 //for (auto f: myForList) std::cout << f << " ";
30 for (auto It= myForList.cbegin();
It != myForList.cend();++It) std::cout << *It << " ";
31 std::cout << "\n\n";
32
33 std::cout << "remove the first element: " << std::endl;
34 myForList.erase_after(myForList.before_begin());
35
36 //for (auto f: myForList) std::cout << f << " ";
37 for (auto It= myForList.cbegin();
It != myForList.cend();++It) std::cout << *It << " ";
38 std::cout << "\n";
39
40 std::cout << std::endl;
41
42 }Das umständliche Initialisieren der std::forward_list in Listing 5.13 (Zeilen 10 bis 16) ist der Tatsache geschuldet, dass das Programm mit dem VC10-Compiler von Microsoft übersetzt wurde. VC10 unterstützt keine Initialisiererlisten (Zeile 8) und auch keine Range-basierte For-Schleife in den Zeilen 19, 29 und 36. Da die std::forward_list keinen wahlfreien Zugriff erlaubt, setzt das Entfernen eines Elements einen Iterator auf einem Element (Zeilen 27 und 34) voraus. myForList.before_begin() gibt einen Iterator vor dem ersten Element zurück. Abbildung 5.16 zeigt die Ausführung des Programms.
Hashtabellen
Eines der im C++98-Standard am häufigsten vermissten Features sind Hashtabellen, auch unter dem Namen Dictionary oder assoziatives Array bekannt.
Praxistipp
Betrachten Sie ein assoziatives Array als eine Verallgemeinerung eines Arrays.
Der einfachste Zugang zu einem assoziativen Array ist es meines Erachtens, dieses als ein verallgemeinertes Array zu betrachten. Die Verallgemeinerung besteht darin, dass nicht nur natürliche Zahlen als Indizes erlaubt sind. Ungewohnt ist dann einzig nur noch, dass die Indizes beim assoziativen Array Schlüssel genannt werden.
C++ versus C++11 assoziative Arrays
Es wog aber nicht so schwer, dass es keine Hashtabellen in C++98 gab. Mit std::map und std::set bzw. std::multimap und std::multiset gibt es Datenstrukturen in C++98, die sich nahezu wie Hashtabellen verhalten, denn sie erlauben den schlüsselbasierten Zugriff auf ihre Elemente. Doch in zwei Punkten unterscheiden sie sich davon. Die klassischen Maps und Sets
besitzen eine Ordnung auf dem Schlüssel,
ermöglichen eine Zugriffszeit, die logarithmisch von der Anzahl der Schlüssel abhängt, während Hashtabellen konstante Zugriffszeit anbieten.
Aus diesem Grund stellten viele Compiler-Hersteller eigene Bibliotheken zur Verfügung. Damit waren die intuitiven Namen für die neuen C++11-Hashtabellen vergeben, und die C++11-Hashtabellen erhielten recht sperrige Namen:
std::unordered_mapstd::unordered_setstd::unordered_multimapstd::unordered_multiset
Zwei Tabellen helfen, den Überblick über die acht Container zu behalten, die doch sehr ähnlich sind. Zuerst eine Gegenüberstellung der Container, die ein ähnliches Interface anbieten:
C++98 | C++11 |
|
|
|
|
|
|
|
|
Die zweite Charakteristik der assoziativen Container lässt sich am besten als Frage formulieren:
Ist dem Schlüssel ein Wert zugeordnet, und
darf ein Schlüssel öfter als einmal vorkommen?
Exemplarisch wird dies anhand der neuen C++11-Container in Tabelle 5.5 dargestellt.
Assoziative Container | Ist dem Schlüssel ein Wert zugeordnet? | Darf ein Schlüssel öfter als einmal vorkommen? |
| ja | nein |
| nein | nein |
| ja | ja |
| nein | ja |
Der Einsatz der neuen assoziativen Container ist immer dann überlegenswert, wenn die Datenstruktur relativ groß ist und keine Ordnung auf den Schlüsseln benötigt wird. Der Umstieg von den alten auf die neuen assoziativen Container wird dadurch erleichtert, dass beide ein sehr ähnliches Interface anbieten (Listing 5.14).
unorderedMap.cpp
01 #include <iostream>
02 #include <map>
03 #include <unordered_map>
04
05 int main(){
06
07 std::cout << std::endl;
08
09 // using the C++ map
10 std::map<std::string,int> m {{"Dijkstra",1972},
{"Scott",1976},{"Wilkes",1967},{"Hamming",1968}};
11 m["Ritchie"] = 1983;
12 for(auto p : m) std::cout << '{' << p.first << ','
<< p.second << '}';
13
14 std::cout << std::endl;
15
16 // using the C++11 unordered_map
17 std::unordered_map<std::string,int> um {{"Dijkstra",1972},
{"Scott",1976},{"Wilkes",1967},{"Hamming",1968} };
18 um["Ritchie"] = 1983;
19 for(auto p : um) std::cout << '{' << p.first << ','
<< p.second << '}';
20
21 std::cout << std::endl;
22 std::cout << std::endl;
23
24 }Listing 5.14 zeigt, dass das Initialisieren, das Schreiben und das Lesen der Elemente von std::map und std::unordered_map der gleichen Syntax folgen. Lediglich bei der Ausgabe variiert es, denn die Schlüssel/Wert-Paare sind bei std::map nach den Schlüsseln aufsteigend sortiert.
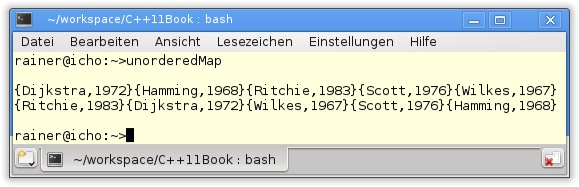
Neue Algorithmen
Zu den vielen bekannten bringt C++11 noch knapp 20 neue Algorithmen mit. Diese Algorithmen helfen, einfache logische Zusicherungen auf Bereichen zu verifizieren, Bereiche zu kopieren oder schnell neue Werte in einem Bereich zu erzeugen. Aber auch neue Algorithmen rund um Partitionen, rund ums Sortieren und rund um die Datenstruktur Heap stehen zur Verfügung.
std::all_of, std::any_of und std::none_of für die logische Zusicherung auf Bereichen, std::copy_if und std::copy_n als weitere Kopieralgorithmen, std::iota für das schnelle Erzeugen von Werten sind nur ein paar der neuen Algorithmen.
bind und function
std::bind und std::function ergänzen sich ideal. Während std::bind neue Funktionsobjekte aus bestehenden Funktionsobjekten oder Funktionen erzeugt, indem es Argumente bindet und Platzhalter erklärt, kann std::function diesem Funktionsobjekt auf einfache Art und Weise einen Namen zuweisen, sodass ein aufrufbares Objekt entsteht.
std::bind erweitert die beiden C++98-Templates std::bind1st und std::bind2nd, die nur ein Argument binden können und dann auch nur das erste oder das zweite.
Das kann std::bind viel besser, denn es erlaubt:
die Argumente an beliebiger Position zu binden,
die Reihenfolge der Argumente umzustellen,
Platzhalter für Argumente einzuführen,
Funktionen nur teilweise zu evaluieren,
das resultierende Funktionsobjekt direkt aufzurufen, in den Algorithmen der STL zu verwenden oder in
std::functionzu speichern.
function
std::function nimmt die Funktionsobjekte von std::bind an und bindet sie unter einem neuen Namen. Damit können die resultierenden Funktionsobjekte wie gewöhnliche Werte kopiert oder auch als Callback verwendet werden.
Die Tour de C++11 ist beendet. Die nächsten drei Kapitel widmen sich den Details zum neuen C++11-Standard. Auf die Suche in die Breite folgt die in die Tiefe. Der Anspruch wird steigen.