Kapitel 8. Rvalue-Referenzen
Rvalue-Referenzen, in Kapitel 3 im Abschnitt „Rvalue-Referenzen“ eingeführt, sind die Grundlage für zwei mächtige Features: Move Semantik und Perfect Forwarding. Während die Move-Semantik es dem C++11-Autor erlaubt, an der Performanceschraube seiner Anwendung massiv zu drehen, löst Perfect Forwarding das bekannte Problem in C++, Argumente generisch an eine Funktion durchzureichen, ohne ihre Lvalue- und Rvalue-Eigenschaften zu verändern.
Lvalue- versus Rvalue-Referenzen
Lvalue- und Rvalue-Referenzen sind Referenzen auf Lvalues bzw. Rvalues. Eine Lvalue-Referenz wird dadurch erzeugt, dass ein & hinter dem Datentyp platziert wird. Zwei && hingegen definieren eine Rvalue-Referenz (Listing 8.1).
MyData myData; MyData& myDataLvalue= myData; MyData&& myDataRvalue(MyData());
Praxistipp
Rvalue-Referenzen sind spezielle Referenzen.
Rvalue-Referenzen verhalten sich wie die bekannten Lvalue-Referenzen. Sie müssen initialisiert werden und können nicht nachträglich auf ein anderes Objekt verweisen.
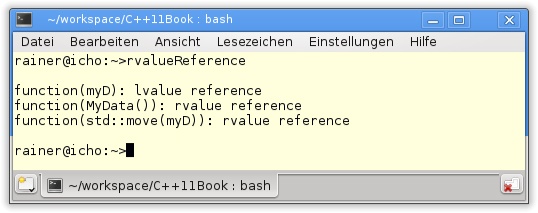
Wird eine Funktion definiert, die ihre Argumente per Lvalue- und Rvalue-Referenz annimmt, entscheidet der Compiler, welche Funktion verwendet wird. Das Entscheidungskriterium für den Compiler ist, ob das Argument ein Lvalue oder ein Rvalue ist (Listing 8.2). Da das Argument in Zeile 21 ein Lvalue ist und das in den Zeilen 22 und 23 jeweils ein Rvalue, wird die entsprechende Funktion function in Listing 8.2 aufgerufen, die das Argument als Lvalue- oder Rvalue-Referenz bindet.
rvalueReference.cpp
01 #include <utility>
02 #include <iostream>
03 #include <string>
04
05 struct MyData{};
06
07 std::string function( MyData & ) {
08 return "lvalue reference";
09 }
10
11 std::string function( MyData && ) {
12 return "rvalue reference";
13 }
14
15 int main(){
16
17 std::cout << std::endl;
18
19 MyData myD;
20
21 std::cout << "function(myD): "
<< function(myD) << std::endl;
22 std::cout << "function(MyData()): "
<< function(MyData()) << std::endl;
23 std::cout << "function(std::move(myD)): "
<< function(std::move(myD)) << std::endl;
24
25 std::cout << std::endl;
26
27 }Der Aufruf function(std::move(myD)) in Zeile 23 ist der interessanteste, denn durch das neue C++11-Funktions-Template std::move wird aus dem Lvalue ein Rvalue. Dies zeigt die Ausgabe.
std::move ist eine wichtige Funktion, wenn es darum geht, die Move-Semantik in C++11 umzusetzen. Dazu bald mehr.
Bindungsregeln Lvalue- und Rvalue-Referenzen
Um bei der Überladung von Funktionen nicht überrascht zu werden, müssen die klassischen Regeln beachtet werden:
Lvalues können an Lvalue-Referenzen gebunden werden.
Rvalues können an konstante Lvalue-Referenzen gebunden werden.
Dazu bringt C++11 neue Regeln mit:
Lvalues können nicht an Rvalue-Referenzen gebunden werden.
Rvalues können an Rvalue-Referenzen gebunden werden.
Die Feinheiten zum Bindungsverhalten von Lvalues und Rvalues soll Listing 8.3 klären.
LvalueRvalueOverload.cpp
01 #include <iostream>
02 #include <string>
03
04 struct MyData{};
05
06 std::string referenceTo(MyData& ) {
07 return "lvalue reference";
08 }
09
10 std::string referenceTo(const MyData& ) {
11 return "const lvalue reference";
12 }
13
14 std::string rValueToFunction(const MyData& ) {
15 return "const lvalue reference";
16 }
17
18 std::string rValueToFunction(MyData&& ) {
19 return "rvalue reference";
20 }
21
22 std::string onlyRvalue(MyData&& ){
23 return "rvalue reference";
24 }
25
26
27 int main(){
28
29 std::cout << std::endl;
30
31 // C++98 rules:
32 // lvalue to lvalue reference
33 // rvalue to const lvalue reference
34 MyData myData;
35 std::cout << "referenceTo(myData): "
<< referenceTo(myData) << std::endl;
36 std::cout << "referenceTo(MyData()): "
<< referenceTo(MyData()) << std::endl;
37
38 std::cout << std::endl;
39
40 // rvalue reference binds stronger than const lvalue reference
41 std::cout << "rValueToFunction(MyData()): "
<< rValueToFunction(MyData()) << std::endl;
42
43 std::cout << std::endl;
44
45 // only for rvalues
46 std::cout << "onlyRvalue(MyData()): "
<< onlyRvalue(MyData()) << std::endl;
47
48 // try it with lvalue and const lvalue
49 /*
50 const MyData myConstData= static_cast<MyData>(myData);
51 onlyRvalue(myData);
52 onlyRvalue(myConstData);
53 */
54
55 std::cout << std::endl;
56
57 }In Listing 8.3 sind drei Funktionen mit verschiedenen Signaturen definiert:
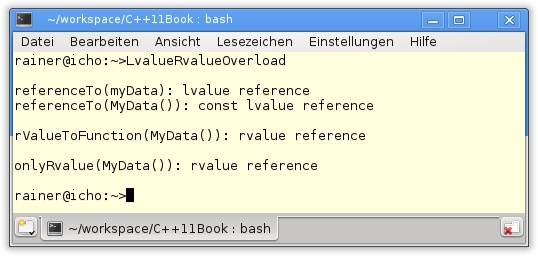
referenceTo(Zeilen 6 und 10): Nimmt eine Lvalue-Referenz und eine konstante Lvalue-Referenz an.rvalueToFunction(Zeilen 14 und 18): Nimmt eine konstante Lvalue-Referenz und eine Rvalue-Referenz an.onlyRValue(Zeile 22): Nimmt eine Rvalue-Referenz an.
referenceTo, in den Zeilen 35 und 36 angewandt, zeigt die klassischen C++-Regeln. Lvalues binden an Lvalue-Referenzen, und Rvalues binden an Rvalue-Referenzen. Hingegen ist rvalueToFunction schon spannender. Da ein Rvalue sowohl nach der klassischen C++98-Regel an eine konstante Lvalue-Referenz als auch nach der neuen C++11-Regel an eine Rvalue-Referenz binden kann, ist die entscheidende Frage, welche Regel vom Compiler angewandt wird. Der Aufruf in Zeile 41 zeigt, dass die Rvalue-Referenz stärker bindet (Abbildung 8.2). Zuletzt folgt die Funktion onlyRValue, die nur eine Rvalue-Referenz als Parameter anbietet.
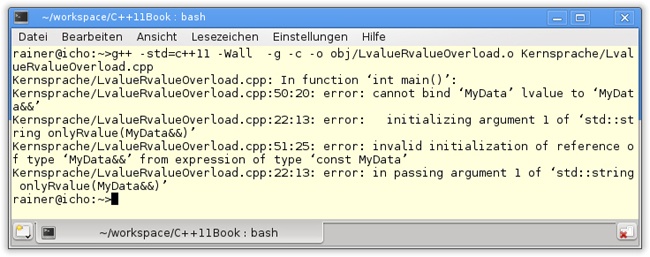
Diese kann konsequenterweise nur durch ein Rvalue-Argument verwendet werden. Werden die Zeilen 50 bis 52 jedoch verwendet, um onlyRValue durch einen Lvalue in Zeile 51 und einen konstanten Lvalue aufzurufen, quittiert der GCC-Compiler das mit zwei Fehlermeldungen.
lValueRValueSolution.cpp
Aufgabe 8-1
Unterscheiden Sie Lvalues von Rvalues.
Die Unterscheidung von Lvalues und Rvalues geht auf die Vorlesungsskripte »Fundamental Concepts in Programming Languages« (Fundamental Concepts in Programming Languages, 2011) von Christopher Strachey (Christopher Strachey, 2011) aus dem Jahr 1967 zurück. Mit Lvalue- und Rvalue-Referenzen werden diese Konzepte hochaktuell für das tiefere Verständnis von C++11.
Entscheiden Sie in Listing 8.4 für jeden Datentyp in der main-Funktion, ob es ein Lvalue oder ein Rvalue ist. Wenden Sie dafür die einfache Regel aus Kapitel 3, Abschnitt „Rvalue-Referenzen“ an: Besitzt ein Objekt einen Namen, ist es ein Lvalue, ansonsten ein Rvalue.
#include <string>
#include <vector>
int three= 3;
int& getThree(){return three;}
int main(){
int n;
std::vector<char> myVec(10);
n= 5;
myVec[0] = 'a';
int a=1, b=2, c=3;
a= b + c;
std::string z= std::string("z");
int* p= new int;
getThree()= 10;
int si= myVec.size();
}Aufgabe 8-2
Ein kleines Rätsel rund um Pre- und Post-Inkrement.
Das Programm in Listing 8.5 verhält sich anständig.
01 int main(){
02
03 int i= 0;
04 //int&& rValue= ++i;
05 int&& rvalue=i++;
06
07 }Wird jedoch die Pre-Inkrement-Operation in Zeile 4 verwendet, quittiert das der GCC mit einer Fehlermeldung.
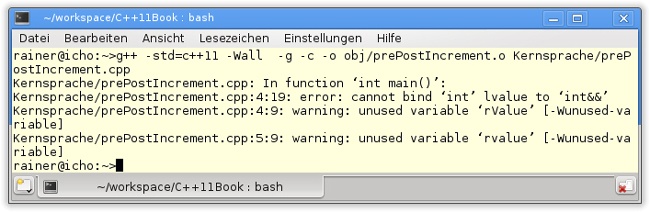
Die Lösung des Rätsels liegt in den Lvalue- bzw. Rvalue-Eigenschaften der Inkrement-Operatoren verborgen.
Aufgabe 8-3
Welche Version der Rvalue-Referenzen implementiert Ihr Compiler?
Diese Frage lässt sich recht einfach beantworten. Übersetzen Sie Listing 8.5. Verwenden Sie dabei Zeile 4. Das Übersetzen des Programms sollte zu einer ähnlichen Fehlermeldung wie der in Abbildung 8.4 führen.
Im Exkurs zu Rvalue-Referenzen in Exkurs: Version 1 und 2 von Rvalue-Referenzen gehe ich auf die Unterschiede zwischen Version 1 und Version 2 der Rvalue-Referenzen ein.
withReferenceMemberFunction.cpp
Aufgabe 8-4
Elementfunktionen, die als Lvalue- und Rvalue-Referenzen ausgezeichnet sind.
Die Klasse WithReferenceMemberFunction besitzt eine eigenwillige Syntax.
class WithReferenceMemberFunction{
public:
void reference() & {
std::cout << "LValue Reference" << std::endl;
}
void reference() && {
std::cout << "RValue Reference" << std::endl;
}
};Erzeugen Sie Lvalue- und Rvalue-Instanzen vom Typ WithReference MemberFunction und rufen Sie die Elementfunktion reference auf.
Entspricht die Ausgabe Ihren Erwartungen? Natürlich müssen Sie auf die Antwort so lange warten, bis Ihr Compiler dieses Feature unterstützt.
Move-Semantik
Praxistipp
Unterscheiden Sie zwischen Copy- und Move-Semantik.
Bei der Copy-Semantik wird durch einen Aufruf der Form a=b der Inhalt von b nach a kopiert, während bei der Move-Semantik der Inhalt von b nach a verschoben wird. Bildlich ist dies in Abbildung 3.9 dargestellt.
Der Compiler sorgt dafür, dass ein Lvalue an eine Lvalue-Referenz und ein Rvalue an eine Rvalue-Referenz gebunden wird. Diese Fähigkeit des Compilers ist die Grundvoraussetzung für die Move-Semantik. Der zweite Teil fehlt noch. Der Programmierer hat dafür zu sorgen, dass die automatisch aufgerufenen Funktionen die gewünschte Funktionalität anbieten. Im Fall der STL-Container ist dies bereits geschehen. Beim Entwurf eigener Datentypen muss die Funktionalität beim Klassenentwurf berücksichtigt werden.
Optimiertes Kopieren
Dass die Move-Semantik als optimiertes Kopieren verstanden werden kann, lässt sich schön durch den klassischen swap-Algorithmus zeigen (Listing 8.6).
swap.cpp
01 #include <utility>
02 #include <iostream>
03 #include <vector>
04
05 template <typename T>
06 void swapCopy(T& a, T& b){
07 T tmp(a);
08 a = b;
09 b = tmp;
10 }
11
12 template <typename T>
13 void swapMove(T& a, T& b){
14 T tmp(std::move(a));
15 a = std::move(b);
16 b = std::move(tmp);
17 }
18
19 struct MyData{
20 std::vector<int> myData;
21
22 MyData():myData({1,2,3,4,5}){}
23
24 // copy semantic
25 MyData(const MyData& m):myData(m.myData){
26 std::cout << "copy constructor" << std::endl;
27 }
28
29 MyData& operator=(const MyData& m){
30 myData= m.myData;
31 std::cout << "copy assignment operator" << std::endl;
32 return *this;
33 }
34
35 // move semantic
36 MyData(MyData&& m): myData(std::move(m.myData)){
37 std::cout << "move constructor" << std::endl;
38 }
39
40 MyData& operator=(MyData&& m){
41 myData= std::move(m.myData);
42 std::cout << "move assignment operator" << std::endl;
43 return *this;
44 }
45
46 };
47
48 int main(){
49
50 std::cout << std::endl;
51
52 MyData a,b;
53 std::cout << "-- swapCopy ------------" <<std::endl;
54 swapCopy(a,b);
55 std::cout << "---swapMove ------------" << std::endl;
56 swapMove(a,b);
57
58 std::cout << std::endl;
59
60 };Das Programm in Listing 8.6 ist recht einfach gehalten. Es besteht aus zwei Versionen des swap-Algorithmus in den Zeilen 5 und 12, dem einfachen Datentyp MyData, der sowohl Copy- als auch Move-Semantik anbietet, und einem kleinen Hauptprogramm, das Objekte vom Typ MyData vertauscht. Der Unterschied von swapCopy und swapMove ist, dass Ersterer beim Dreieckstausch seine Elemente kopiert, während swapMove seine Elemente verschiebt. Daher benötigt swapCopy sechs Kopien des Typs T, swapMove hingegen nur drei. Der Grund dafür ist, dass durch das Kopieren die Copy-Semantik von MyData angesprochen wird. Sowohl im Kopierkonstruktor als auch im Kopierzuweisungsoperator wird eine Kopie des Eingabetyps erzeugt. Diese Kopie ist beim Move-Konstruktor (Zeile 36) und Move-Zuweisungsoperator nicht notwendig, denn darin wird die Ressource std::vector<int> durch std::move verschoben.
Für den Aufruf »Methoden für die Copy- bzw. Move-Semantik« sorgt der Compiler.
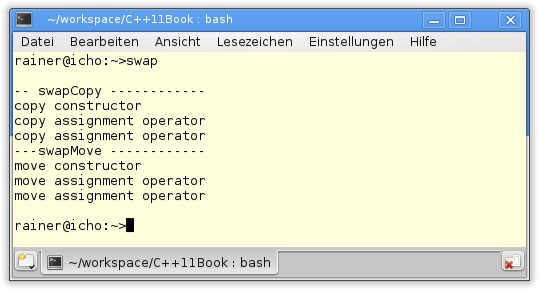
Werden die Zeilen 36 bis inklusive 44 in Listing 8.6 auskommentiert, sodass MyData keine Move-Semantik mehr anbietet, führt die Anwendung von swapMove in Zeile 12 dazu, dass die Copy-Semantik von MyData in die Bresche springt (Abbildung 8.6). Dies ist aber nicht verwunderlich, kann doch ein Rvalue auch an eine konstante Lvalue-Referenz gebunden werden. Genau von diesem Typ sind die Variablen des Kopierkonstruktors und des Kopierzuweisungsoperators. Dieses Verhalten besitzt eine sehr praktische Konsequenz.
Praxistipp
Betrachten Sie die Copy-Semantik als Fallback.
Implementieren Sie Ihre Algorithmen für die Move-Semantik. Bietet der Datentyp keine Move-Semantik an, wird als Fallback die Copy-Semantik verwendet.
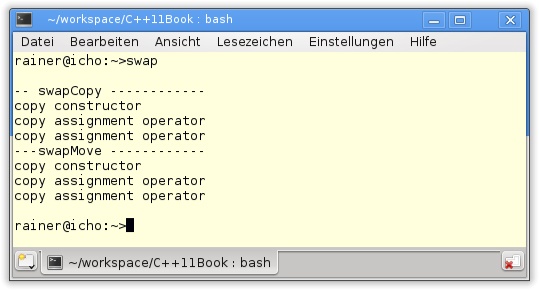
Algorithmen für Datentypen, die nur die Move-Semantik unterstützen
Das Implementieren von Algorithmen, die für die Move-Semantik ausgelegt sind, hat weitreichende Konsequenzen. Datentypen, die nur die Move-Semantik anbieten, können diese Algorithmen verwenden. Dies trifft auf viele Implementierungen der STL-Algorithmen zu. Verwendet der Algorithmus unter der Decke jedoch eine Kopieroperation, wird das durch den Compiler moniert. Typische Vertreter dieser nur verschiebbaren Datentypen sind Dateiobjekte, Threads, Smart Pointer oder auch Locks. In Listing 8.7 wird der neue C++11-Smart-Pointer std::unique_ptr in einem std::vector verwendet.
moveOnly.cpp
01 #include <iostream>
02 #include <memory>
03 #include <vector>
04 #include <utility>
05
06 template <typename T>
07 void swapCopy(T& a, T& b){
08 T tmp(a);
09 a = b;
10 b = tmp;
11 }
12
13 template <typename T>
14 void swapMove(T& a, T& b){
15 T tmp(std::move(a));
16 a = std::move(b);
17 b = std::move(tmp);
18 }
19
20 int main(){
21
22 std::unique_ptr<int> unique1(new int(1));
23 std::unique_ptr<int> unique2(new int(5));
24
25 std::vector<std::unique_ptr<int> > myInt1;
26 myInt1.push_back(std::move(unique1));
27 myInt1.push_back(std::move(unique2));
28
29 std::vector<std::unique_ptr<int> > myInt2;
30 myInt2.push_back(std::move(unique1));
31
32 swapMove(myInt1,myInt2);
33
34 swapCopy(myInt1,myInt2);
35
36 }Während der Aufruf swapMove in Zeile 32 gültig ist, führt der Aufruf swapCopy in Zeile 34 zum Übersetzungsfehler. In der sehr wortreichen Fehlermeldung findet sich die Ursache des Fehlers am Ende des Screenshots wieder (Abbildung 8.7):
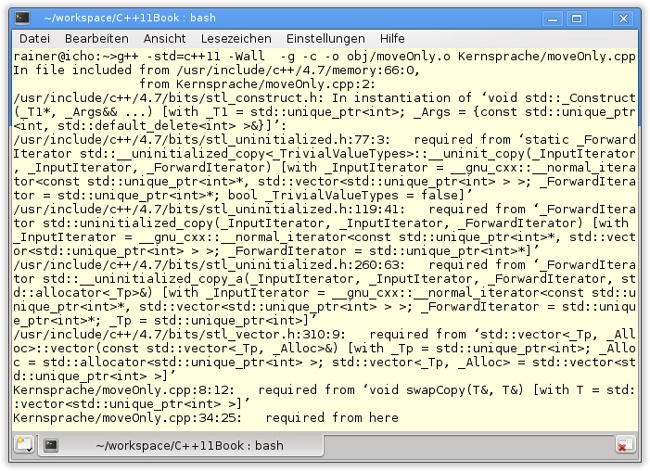
Neben den Smart Pointern std::unique_ptr, die exklusiv eine Ressource besitzen, hat C++11 noch die std::shared_ptr im Angebot. std::shared_ptr teilt sich eine Ressource und verwaltet den Lebenszyklus dieser Ressource mit einem Referenzzähler. Zwar unterstützt std::shared_ptr neben der Move-Semantik auch die Copy-Semantik, jedoch profitiert std::shared_ptr auch von der Move-Semantik eines Algorithmus, denn durch die Copy-Semantik wird der Referenzzähler implizit in- und dekrementiert.
std::move-Implementierung
Um aus einem Lvalue in einen Rvalue zu konvertieren, wurde in vielen Beispielen das neue Funktions-Template std::move verwendet.
Lvalue als Rvalue-Referenz deklariert
Parameter, die als Rvalue-Referenzen deklariert werden, können Lvalues sein. Verwirrend? Listing 8.9 bringt das Problem, das auf den ersten Blick nicht intuitiv erscheint, auf den Punkt.
rvalueReferenceToLvalue.cpp
01 #include <utility>
02 #include <iostream>
03
04
05 struct MyData{
06
07 MyData()= default;
08
09 // copy constructor
10 MyData(const MyData& m){
11 std::cout << "copy constructor MyData" << std::endl;
12 }
13
14 // move constructor
15 MyData(MyData&& m){
16 std::cout << "move constructor MyData" << std::endl;
17 }
18
19 };
20
21 struct CopyMyData{
22
23 CopyMyData()= default;
24
25 MyData myData;
26
27 // move constructor
28 CopyMyData(CopyMyData&& m): myData(m.myData){
29 std::cout << "move constructor CopyMyData" << std::endl;
30 }
31
32 };
33
34 struct MoveMyData{
35
36 MoveMyData()= default;
37
38 MyData myData;
39
40 // move constructor
41 MoveMyData(MoveMyData&& m): myData(std::move(m.myData)){
42 std::cout << "move constructor MoveMyData" << std::endl;
43 }
44
45 };
46
47 void rvalueReferenceToLvalue(MyData&& myData){
48 std::cout << "rvalueReferenceToLvalue(MyData&& myData): ";
49 MyData myData1(myData);
50 }
51
52 void rvalueReferenceToRvalue(MyData&& myData){
53 std::cout << "rvalueReferenceToRvalue(MyData&& myData): ";
54 MyData myData1(std::move(myData));
55 }
56
57 int main(){
58
59 std::cout << std::endl;
60
61 rvalueReferenceToLvalue(MyData());
62 rvalueReferenceToRvalue(MyData());
63
64 std::cout << std::endl;
65
66 CopyMyData copyMyData;
67 CopyMyData c(std::move(copyMyData));
68
69 std::cout << std::endl;
70
71 MoveMyData moveMyData;
72 MoveMyData m(std::move(moveMyData));
73
74 std::cout << std::endl;
75
76 }Die Ausgabe von Listing 8.9 sollte vorhersehbar sein. Sowohl die Funktionen rvalueReferenceToLvalue und rvalueReferenceToRvalue in den Zeilen 61 und 62 als auch die Objekte c und m vom Typ CopyMyData und MoveMyData erhalten ihre Argumente als Rvalues und nehmen sie als Rvalue-Referenz an. Damit ist klar: Beim Initialisieren von MyData in den Funktionskörpern und den Move-Konstruktoren wird der Move-Konstruktor von MyData verwendet. Die Ausgabe des Programms entspricht nicht dieser naiven Annahme.
Der Grund für dieses Verhalten ist schnell exemplarisch an der Funktion rvalueReferenceToLvalue(MyData&& myData)in Zeile 47 erklärt. Die Rvalue-Referenz besitzt den Namen myData, der im Konstruktoraufruf MyData myData1(myData) (Zeile 49) verwendet wird. Die einfache Regel zum Unterscheiden eines Lvalue von einem Rvalue aus Kapitel 3, „Rvalue-Referenzen“ lautet:
Praxistipp
Rvalues besitzen keinen Namen.
Besitzt ein Objekt einen Namen, ist es ein Lvalue, ansonsten ein Rvalue.
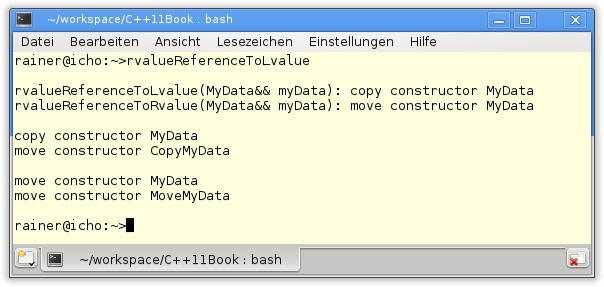
Dieses Verhalten trifft natürlich auch auf den Move-Konstruktor von CopyMyData in Zeile 28 zu. Nur durch das explizite Verwenden des Funktions-Templates std::move in den Zeilen 41 und 54 wird der Move-Konstruktor von MyData angestoßen.
Praxistipp
Verwenden Sie move, wenn möglich.
Da std::move einerseits die Intention des Codes explizit ausdrückt und andererseits das Laufzeitverhalten des Programms durch den Gebrauch des Funktions-Templates nicht negativ beeinflusst wird, spricht nichts dagegen, std::move im Zweifelsfall zu oft zu verwenden. std::move wird als Funktions-Template zur Übersetzungszeit evaluiert, sodass der neue Typ zur Laufzeit fertig vorliegt.
Return-Value-Optimierung
Return-Value-Optimierung (RVO) ist eine Technik, die zeitgemäße C++-Compiler anwenden. Funktionen der Form
MyData function(){
MyData myData;
...
return myData;
}kann ein Compiler so optimieren, dass der Wert myData direkt in den Rückgabewert von function kopiert wird. Somit wird das teure zweimalige Kopieren von myData vermieden. Dank RVO ist es nicht sinnvoll, die Funktion so umzuschreiben, dass sie einen Rvalue zurückgibt.
Move-Semantik automatisch erzeugt
Sind alle Datenelemente einer Klasse und deren Basisklasse verschiebbar (moveable), erzeugt der Compiler automatisch den Move-Konstruktor und den Move-Zuweisungsoperator neben dem Copy-Konstruktor und dem Copy-Zuweisungsoperator.
Unterbinden der Move- bzw. Copy-Semantik
Das Implementieren des Move-Konstruktors verhindert das automatische Erzeugen des Copy-Konstruktors, und durch das Implementieren des Move-Zuweisungsoperators wird das automatische Erzeugen des Copy-Zuweisungsoperators unterbunden. Durch die Definition eines Copy-Konstruktors wird die Erzeugung des Move-Konstruktors und des Copy-Zuweisungsoperators verhindert.
swapMe.cpp
Aufgabe 8-5
Lassen Sie den Compiler entscheiden.
In Listing 8.6 wird ein generisches swapCopy und swapMove angeboten. Der Anwender muss selbst entscheiden, ob er kopieren oder verschieben will. Das ist nicht schön. Diese Entscheidungen sollten automatisch durch den C++-Compiler getroffen werden. Genau das tut er automatisch. Vereinfachen Sie Listing 8.6 so, dass nur die Funktion swapMe verwendet wird. Diese soll die Implementierung der swapMove-Funktion verwenden. Erzeugen Sie zusätzlich zwei Datentypen, die jeweils nur die Copy- bzw. Move-Semantik unterstützen, und wenden Sie die neue Funktion swapMe an. Beeindruckt?
myIntCopy.cpp
Aufgabe 8-6
Wenden Sie Rvalue-Referenzen beim +-Operator an.
Der Datentyp MyInt ist eine einfache Hülle um den Datentyp int.
struct MyInt{
int val;
MyInt(int i):val(i){
std::cout << i << std::endl;
}
};Variation 1:
Implementieren Sie den
+-Operator fürMyIntzuerst in der klassischen Weise mit konstanten Lvalue-Referenzen. Berechnen Sie diesen Ausdruck:MyInt erg= MyInt(1)+MyInt(2)+MyInt(3)+MyInt(4);Wie viele temporäre
MyInt-Objekte wurden durch den arithmetischen Ausdruck erzeugt?Implementieren Sie zusätzlich den
+-Operator für Rvalue-Referenzen und führen Sie die Arithmetik nochmals aus. Vergleichen Sie die Ergebnisse von Variation 1 und 2.
Perfect Forwarding
Die Idee des Perfect Forwarding ist recht einfach. Eine Funktion nimmt ihre Daten als Lvalue- oder Rvalue-Referenz an und verwendet diese, um eine weitere Funktion oder auch einen Konstruktor mit diesen Datentypen aufzurufen. Der entscheidende Punkt beim Perfect Forwarding ist, dass dabei die Lvalue- bzw. Rvalue-Eigenschaften des Datentyps erhalten bleiben.
Howard E. Hinnant, Bjarne Stroustrup und Bronek Kozicki stellen dazu lapidar in »A Brief Introduction to Rvalue References« fest: »... a herefore unsolved problem in C++.« (Hinnant, Stroustrup, & Kozicki, 2006)
Problem Perfect Forwarding
Für das bessere Verständnis des Problems und insbesondere für dessen generische Lösung mithilfe von Perfect Forwarding dient Listing 8.11. Die Grundidee des Programms ist, dass alle Datentypen ein oder zwei große interne Daten besitzen, die über den Konstruktoraufruf initialisiert werden sollen.
perfectForwarding.cpp
01 #include <utility>
02 #include <string>
03 #include <vector>
04
05 class BigData1{
06 public:
07 BigData1(std::vector<int> data):data(data){}
08 private:
09 std::vector<int> data;
10 };
11
12
13 class BigData2{
14 public:
15 BigData2(std::vector<int>& data):data(data){}
16 BigData2(std::vector<int>&& data)
:data(std::move(data)){}
17 private:
18 std::vector<int> data;
19 };
20
21 class BigData3{
22 public:
23 BigData3(std::vector<int>& data,std::string& str)
:data(data),str(str){}
24 BigData3(std::vector<int>& data,std::string&& str)
:data(data),str(std::move(str)){}
25 BigData3(std::vector<int>&& data,std::string& str)
:data(std::move(data)),str(str){}
26 BigData3(std::vector<int>&& data,std::string&& str)
:data(std::move(data)),str(std::move(str)){}
27 private:
28 std::vector<int> data;
29 std::string str;
30 };
31
32
33 class BigDataNew{
34 public:
35 template<typename T1, typename T2>
36 BigDataNew(T1&& vec,T2&& s)
:data(std::forward<T1>(vec)),str(std::forward<T2>(s)){}
37 private:
38 std::vector<int> data;
39 std::string str;
40 };
41
42 int main(){
43
44 std::vector<int> myVec{1,2,3,4,5,6,7,8,9};
45
46 // copy
47 BigData1 bigData11(myVec);
48
49 // copy
50 BigData2 bigData21(myVec);
51 // move
52 BigData2 bigData22({1,2,3,4,5,6,7,8,9});
53
54 std::string s{"Only for testing purpose."};
55
56 // copy, copy
57 BigData3 bigData31(myVec,s);
58 // copy, move
59 BigData3 bigData32(myVec,{"Only for testing purpose."});
60 // move, copy
61 BigData3 bigData33({1,2,3,4,5,6,7,8,9},s);
62 // move, move
63 BigData3 bigData34({1,2,3,4,5,6,7,8,9},
{"Only for testing purpose."});
64
65
66 std::string tempStr{"testing first"};
67 std::vector<int>vec{10,20};
68 // copy, copy
69 BigDataNew bigData41(myVec,s);
70 // copy, move
71 BigDataNew bigData42(myVec,std::move(tempStr));
72 // move, copy
73 BigDataNew bigData43(std::move(myVec),s);
74 // move, move
75 BigDataNew bigData44(std::move(vec),std::move(s));
76
77 }Die erste, naive Lösung bietet BigData1 in Listing 8.11, Zeile 5, an. Diese Lösung ist nicht optimal, da sowohl beim Aufruf des Konstruktors in Zeile 44 als auch beim Initialisieren des std::vector<int> in Zeile 7 unnötig kopiert wird. Das geht besser. BigData2 vermeidet das erste Kopieren, da es myVec in Zeile 50 per Referenz adressiert. Werden darüber hinaus die Initialisierungsdaten {1,2,3,4,5,6,7,8,9} (Zeile 52) als Rvalue übergeben, nimmt der zweite Konstruktor von BigData2 diese (Zeile 16) per Rvalue-Referenz an. Somit kann in der Initialisiererliste des Konstruktors std::move verwendet werden, und jegliches Kopieren wird vermieden. Das Überladen des Konstruktors mit einer Lvalue- und Rvalue-Referenz hat aber einen entscheidenden Nachteil. Ist die Anzahl der zu initialisierenden Elemente n, werden 2^n verschiedene Versionen des Konstruktors benötigt. Diese kombinatorische Explosion ist nicht zu meistern, denn selbst BigData3 benötigt schon vier verschiedene Konstruktoren. Die Lösung des Problems ist das C++11-Funktions-Template std::forward in Zeile 36, das in dem generischen Konstruktor (Zeile 36) die Argumente von BigDataNew an die zu initialisierenden Daten weiterdelegiert. Die Arbeit von 2^n überladenen Konstruktoren wird durch ein Konstruktor-Template erledigt. Das Zusammenspiel des Funktions-Templates mit den Rvalue-Referenzen bewirkt in diesem speziellen Konstruktor, dass er sowohl Lvalues als auch Rvalues annimmt. Hier wirken die gleichen Gesetzmäßigkeiten zur Template-Instanziierung und die Referenz-Collapsing-Regeln wie bei std::move (Tabelle 8.1). Die eigentliche Arbeit wird an das Funktions-Template std::forward delegiert.
forward
std::forward besitzt nur eine einzige Aufgabe. Das Funktions-Template soll die Argumente exakt weiterreichen. Seine Implementierung erinnert an die von std::move.
template<typename T>
struct identity {
typedef T type;
};
template<typename T>
T&& forward(typename identity<T>::type&& param){
return static_cast<identity<T>::type&&>(param);
}Für den Rückgabewert wird ein static_cast auf identity<T>::type&& durchgeführt. Dieser Trick, das Hilfs-Template identity anzuwenden, bewirkt, dass das Template-Argument explizit angegeben werden muss und nicht automatisch abgeleitet werden kann. Das automatische Ableiten des Template-Arguments hat den unerwünschten Nebeneffekt, dass param einen Namen besitzt und daher ein Lvalue ist.
Praxistipp
Übergeben Sie explizit das Template-Argument bei forward.
Im Gegensatz zu std::move verlangt std::forward, dass das Template-Argument explizit angegeben wird.
data(std::move(vec)) data(std::forward<T1>(vec))
Variadic Templates
Variadic Templates sind Templates, die beliebig viele Argumente annehmen können. Wird dieses C++11-Feature zusammen mit Perfect Forwarding verwendet, können generische Fabrikfunktionen implementiert werden, die beliebig viele Argumente annehmen und dabei deren Lvalue- bzw. Rvalue-Eigenschaften respektieren.
template <typename T, typename ... Args>
T createT(Args&&...args){
return T(std::forward<Args>(args)...);
}createT ist solch eine Fabrikfunktion, die eine Klasse T instanziiert und zurückgibt.
createT.cpp
Aufgabe 8-7
Wenden Sie die generische Fabrikfunktion createT in Listing 8.12 an.
Ein paar Ideen: Instanziieren Sie:
int()int(1)std::string("Only for testing purpose")MyData()MyData(1,3.14,'a')std::vector<int>{1,2,3,4,5}
baseDerived.cpp
Aufgabe 8-8
Verwenden Sie Perfect Forwarding, um die Argumente der abgeleiteten Klasse an ihre Basisklasse unverändert durchzureichen.
Python kennt schon lange Perfect Forwarding, um die Argumente der abgeleiteten Klasse Derived generisch an ihre Basisklasse Base durchzureichen.
class Derived(Base):
def __init__(self, *args, **kwargs):
Base.__init__(self,*args, **kwargs)Dieses Python-Idiom lässt sich jetzt auch in C++11 implementieren. Die Lösung führt über eine Variation von Listing 8.12. Prüfen Sie Ihre Lösung, indem Sie in Base zwei Konstruktoren implementieren. Der erste soll sein Argument als konstante Lvalue-Referenz annehmen, der zweite als Rvalue-Referenz.