Kapitel 13. Atomare Datentypen
C++11 bringt im Header <atomic> atomare Datentypen mit. Operationen auf diesen Datentypen sind atomar.
Neben dem Klassen-Template std::atomic für das Erzeugen eines atomaren Typs bietet C++11 die entsprechenden Built-in-Datentypen in atomarer Ausprägung an (Tabelle 13.1).
Atomarer Typ | Built-in-Typ |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Das kleine Beispiel in Abbildung 12.3 lässt sich nun mit den neuen atomaren Datentypen als lauffähiges Programm formulieren.
atomic.cpp
01 #include <atomic>
02 #include <chrono>
03 #include <iostream>
04 #include <thread>
05
06 std::atomic_int x;
07 std::atomic_int y;
08 int r1;
09 int r2;
10
11 void writeX(){
12 x.store(1);
13 //std::this_thread::sleep_for(
std::chrono::milliseconds(10));
14 r1= y.load();
15 }
16
17 void writeY(){
18 y.store(1);
19 //std::this_thread::sleep_for(
std::chrono::milliseconds(10));
20 r2=x.load();
21 }
22
23 int main(){
24
25 std::cout << std::endl;
26
27 x= 0;
28 y= 0;
29 std::thread a(writeX);
30 std::thread b(writeY);
31 a.join();
32 b.join();
33 std::cout << "(r1,r2)= "
<< "(" << r1 << "," << r2 << ")" << std::endl;
34
35 std::cout << std::endl;
36
37 }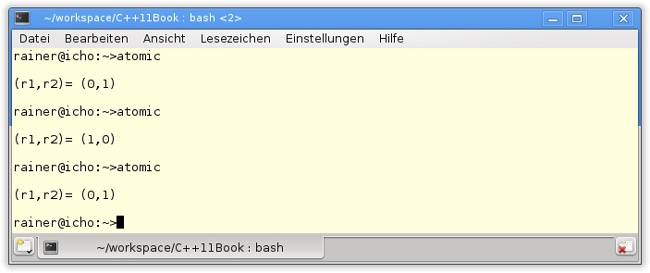
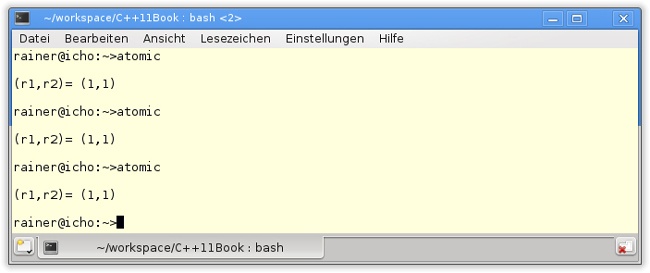
Wird das Programm in Listing 13.1 ausgeführt, sind fast alle Kombinationen für r1 und r2 möglich. Da die Schreib- und Leseoperationen auf x und y atomar sind, ist einzig das Ergebnis (0,0) für (r1,r2) nicht möglich. Um das Ergebnis (1,1) für (r1,r2) zu erzwingen, müssen die Threads schlafen gelegt werden, denn die Funktionskörper für writeX (Zeile 11) und writeY (Zeile 17) sind zu schnell abgearbeitet. Daher wird die Ausführung der beiden Threads in Zeile 13 und Zeile 19 für 10 Millisekunden ausgesetzt. Abbildung 13.1 zeigt die Ausführung des Programms mit auskommentiertem sleep_for-, Abbildung 13.2 ohne auskommentierten sleep_for-Aufruf.
Mit dem std::atomic-Klassen-Template kann der Anwender seinen eigenen atomaren Typ definieren. Ein Typ MyType hat aber strenge Kriterien einzuhalten, damit er zum atomaren Typ std::atomic <MyType> erklärt wird.
Einschränkungen von MyType sind:
Er darf keine virtuellen Funktionen besitzen.
Er darf keine virtuelle Basisklasse besitzen.
Er und alle seine Basisklassen dürfen nur den automatisch erzeugten Copy-Zuweisungsoperator besitzen.
Er muss bitweise auf Gleichheit vergleichbar sein.
Diese Eigenschaften sichern zu, dass std::atomic<MyType> von den C-Funktionen memcpy und memcmp verwendet werden kann.
Praxistipp
Schützen Sie Ihre Daten.
Erfüllt MyType nicht die Anforderungen, um durch ihn einen atomaren Typ std::atomic<MyType> zu erklären, sollte der Zugriff auf MyType über einen Mutex std::mutex oder noch besser ein Lock std::lock_guard geschützt werden.
Operationen auf Atomen
Operationen auf atomaren Datentypen sind atomar. Ohne Anspruch auf Vollständigkeit folgen ein paar Operationen, die abhängig vom atomaren Datentyp angewandt werden können. Dabei soll a der atomare Datentyp, res das Ergebnis und arg das Argument der Operation sein.
Das Speichermodell in C++11 ist per Default sequenziell konsistent. Dieses intuitive Modell lässt sich mit C++11 aufbrechen, um so die Lese- und Schreibordnung von Operationen genauer zu spezifizieren. Die extrem haarigen Details rund um das Aufbrechen der Speicherordnung und um Fences (Speicherbarrieren) mit dem Ziel die Reihenfolge von Operationen auf atomaren Datentypen zu gewährleisten, sollten aber besser in dem Buch »C++ Concurrency in Action« von Anthony Williams nachgelesen werden. In seinem Werk gibt der Betreuer der Boost Thread Library sehr tiefe Einsichten in die neuen Multithreading-Fähigkeiten von C++11 (Williams, 2011).
Praxistipp
Unterscheiden Sie Java volatile von C++ volatile.
Eine Warnung noch zum Abschluss: In Java werden atomare Datentypen durch das Schlüsselwort volatile deklariert. Das C++-Schlüsselwort volatile hat aber nichts gemein mit Multithreading. Atomare Variablen werden in C++11 durch die vorgestellten atomaren Datentypen definiert.
Aufgabe 13-1
Watch more videos: Lock-freie Datenstrukturen.
Listing 13.1 zeigt das Lock-freie Programmieren. Ein Lock-freies Programm ist ein Programm, das den Thread-sicheren Zugriff auf die gemeinsam genutzten Variablen ohne Locks sicherstellt. Einen ersten Einblick in Lock-freie Datenstrukturen in C++ gibt Tony Van Eerd in seiner Vorstellung »Lockfree Programming Part 2: Data Structures« (Van Eerd, 2011), die er auf der Boost Library Conference (boostcon) 2011 hielt. Van Eerd stellte unter anderem eine Lock-freie Stack- und Queue-Implementierung vor.