CHAPTER 12
The perfect diet written in your genes
I was on a family hiking holiday in the north of England in the summer of 2016. We were in Yorkshire (of pudding fame) and staying in the little coastal town of Staithes. The weather, unusually for a summer in Yorkshire, was ‘Goldilocks’ good, so not too hot and not too cold, just enough sun and just enough cloud; perfect outdoor walking conditions. Then in the evenings, after a meal (sometimes even including Yorkshire pudding) and a pint of beer in the pub, we would sit down to watch coverage of the Rio Olympics, which was going on at the time. All in all, it was a fabulous holiday.
I am an avid cyclist, so one of my favourite events to watch was the cycling. Not the road cycling, as I prefer the strategy and masochism of the longer multi-stage races such as the Tour de France; but the crazy explosiveness of track cycling. If you’ve never watched a bunch of adults going round a polished wooden track on two wheels at ridiculous speeds, I can highly recommend it. The competitors, all of whom have thighs with larger circumferences than the waists of most models, go only one way round a track with crazy banking, on bikes that only have one single enormous gear, with no freewheel and no brakes! It is a sport that the UK particularly excels at. We even have our own ‘golden couple’ of track cycling, Jason Kenny and Laura Trott, who were at the time engaged to be married (and are now actually married). Between the two of them, they managed to pick up five gold medals in Rio (three for Jason and two for Laura; they have nine gold medals in total, if you included the 2012 London Olympics)! On this particular evening of competition, Laura had already completed all of her events and she was cheering Jason on to winning his third and final gold medal. As the crowd, and we in our small Yorkshire hotel room, roared Jason across the finish-line, Laura tweeted: Arghhhh!!!!!! I love him to bits. Our kids have to get some of these genes right?’
For my sins, I occasionally write for a major UK tabloid newspaper. I thought long and hard about it before working with them, particularly as I disagree with their political leanings and the vast majority of their headlines. However, because what I write appears in their Health pages, and I have control over the final ‘copy’ that appears in print and online, I am comfortable using the platform to put out sensible science messages in an attempt to educate. As a consequence, the health journalist of this particular tabloid paper had me on ‘speed dial’. Not 30 minutes after Jason won and gave Laura a big hug and a kiss, my phone buzzed. My wife looked at me: Who is calling you at this time of the evening?
I swiped right to answer.
‘Giles? This is Doris from the health desk [I have changed her name to protect the innocent]. Were you watching the cycling? Do you think you could put together a few hundred words discussing the likelihood of Jason’s and Laura’s kids turning out to be Olympians?’
‘Excuse me?! Ummm, I’m on holiday at the moment ...’
‘We’ll provide you with a ghostwriter. This will be a great piece!’
Doris wasn’t kidding and she was insistent.
But then I cogitated about it a bit more, and it did seem like a great opportunity to discuss complex genetics in some depth (relatively speaking). Unlike the colour of Mendel’s peas, there clearly wasn’t going to be a single gene that determined whether or not someone became an ‘Olympic track cyclist’. Rather, it would be down to an optimum mixture of a number of relevant traits, such as aerobic capacity, muscle fibre type, pain threshold, ability to focus, responsiveness to training, to name a few, each of which would be influenced by their own repertoire of many genes. There would also be the important role of the environment. For instance, surely being brought up in a household with two multiple-gold-medal-winning cyclists would also have a powerful influence on their children? Surely the quality of their diets and level of physical activity would be far above the norm? Anyway, the opportunity did seem too good to pass up, so I agreed.
I put the article together, with the help of the ghostwriter, in 48 hours, and it, surprisingly, generated an enormous amount of media interest. In fact, we were still in the middle of our holiday when the piece was published, and I ended up being interviewed live for the main UK satellite news channel, by FaceTime on my phone, from the top of a hill where I had miraculously found some transient 4G coverage. I’m sure it made for gripping television ... my wife found it amusing at any rate. Much of the interest stemmed from the fascination of being able to predict the future, in particular predicting our own futures based on our genes.
THE GENETIC CRYSTAL BALL
Would you pay £249 to find out whether you are genetically predisposed to gaining weight? Or if you’re likely to develop high blood pressure if you eat too much salt? Or to become a supertaster? Or if you are better suited to a high-protein diet? That’s certainly the hope behind the ‘personalised’ gene tests now available from companies such as 23andMe, Nutrigenomix and DNAFit. They not only claim their tests can identify genes related to diseases including dementia and obesity, but also predict how you might respond to specific diets, such as low salt, low caffeine or high fat. By using this information, you can then exercise more effectively, lose weight and stay healthy; that is their pitch.1
The idea of peering into a genetic crystal ball to predict your future self, or how you might respond to specific treatments and diets should, in principle, be possible. After all, your genes shape who you are and how you respond to the environment. A couple of weeks after the Jason and Laura piece had come out, Doris contacted me again and asked if I was willing to review one of the genetic test products offered by DNAfit? They would pay for me to get the super-duper premium plan, which did indeed cost £249, and then wanted my opinion of the results and their interpretation. From the perspective of intellectual curiosity, it seemed like yet another opportunity too good to miss, so I agreed.
INFORMATION TO HELP ME ACHIEVE MY GENETIC POTENTIAL?
A few days later, a package arrived in my pigeonhole at work. When I brought it back to my office and opened it up, I found a DNAfit-branded cardboard box about the size of an airport paperback novel. The DNAfit strapline, which was found on its logo, was Achieve your genetic potential’. On one end of the box was a little ‘pull me’ tab attached to a drawer. As I tugged at it to see what was in the box, another drawer on the other end of the box, through some unseen mechanism, unexpectedly slid open smoothly and simultaneously. It was all very slick and very swish. I mean, the engineering and design that went into just the box itself was a sight to behold.. In one of the drawers was everything I needed to collect my DNA sample and in the other was the bar-coded paperwork where I had to initial here, here and here, and then sign my life away. I followed the instructions to take a cheek swab, and then put it into the provided container with what I assumed to be some type of preservation solution. I placed everything into the pre-paid, self-addressed and barcoded packaging, and as easy as 1-2-3, my DNA sample was winging its way to DNAfit. Then in a little under two weeks, I received an email containing a clickable link to access and download my results.
The ‘premium’ option from DNAfit, which is what I plumped for, meant that both my diet and my fitness ‘genetic profiles’ had been assessed, so I received three different files; a poster summarising the results, one with my detailed fitness results and one with my diet results. Each of the very glossy detailed reports began with a simple genetics primer, some Ts & Cs stating that the information provided was not intended to be a diagnosis, followed by, while not in name, something which certainly looked and smelt like a diagnosis.
Let’s start with my fitness results. In total, DNAfit tested 21 different genetic variations, and from there made conclusions about four different ‘fitness traits’; my power versus endurance profile, my aerobic potential, my recovery speed and my risk of injury. For instance, illustrated to me using a crazy shape in two different shades of green, my ‘power response’ was 51.2 per cent as compared to my endurance response which was 48.8 per cent. These appeared to be very specific numbers indeed. They then elaborated:
‘Your assessment has determined that your genetic profile is almost equally balanced between power and endurance activities, based on variations in your genes. In your training mix power and endurance activities to benefit from your intermediate profile’.
My aerobic potential, speed of recovery and risk of injury were all confidently predicted to be ‘medium’. My reading of these results? I appear to be boringly ‘average’.
OK, and how about my personalised diet profile based on my genes? Surely this is why all of you have stuck with this book to Chapter 12, with undoubtedly bated breath? Well, DNAfit tested 25 different genetic variations, 9 of which overlapped with the ‘fitness test’, and made conclusions about my carbohydrate sensitivity, saturated fat sensitivity, detoxification ability of the liver, antioxidant need, omega-3 need, vitamin B and D requirements, salt, alcohol and caffeine sensitivity, lactose intolerance and predisposition to coeliac disease. Some highlights included, based on my liver’s ‘detoxification ability’, advising me to limit my consumption of grilled or smoked meat to 1–2 servings per week; that I had a raised requirement for B vitamins, in particular B6 and B12; and that I had raised salt sensitivity. Taking all of this information into account, DNAfit assures me that my optimal diet should be a Mediterranean diet, as opposed to a low-carb or low-fat diet.
Keeping in mind that the only personal information that I provided to DNAfit was my age and sex, with no additional anthropometric measurements or even my ethnicity, these were, from both a fitness and diet perspective, pretty extraordinary conclusions to be made. In fact, I’d go so far as to say that the vast majority of predictions provided for me would have been impossible to reach based simply on these 37 different genetic variations across both my fitness and diet profiles.
There were two key exceptions, both of which I touched on briefly in Chapter 6. Two of the genes tested were Alcohol Dehydrogenase 1C (ADH1C)2 and Lactase (LCT).3 I have one copy of a genetic variant of ADH1C, which meant that while I could metabolise alcohol, I couldn’t drink as much as many of my white Caucasian friends (correctly predicted based upon real world data); and because I lacked the lactase persistence genetic variation at LCT, I was lactose intolerant (also correct). Both of these traits, however, are like the colour of Mendel’s peas or the severely obese kids lacking leptin,4 in that they are determined by single genes; these are referred to in genetics as Mendelian traits. As a result, these were accurately predicted by DNAfit. Using the other 35 genetic variations, however, to try and ‘predict’ some very complex traits is, just simply, fundamentally flawed.
OK, before I get accused of libelling any company or anyone, let me just be crystal clear about what I am saying. First, my criticisms are not levelled only at DNAfit; it just happened to be their product that I was testing out. Rather, all of the companies that attempt to make predictions about complex traits purely based on genetic information are equally flawed. Second, the actual genetic information provided by all of these companies is very likely going to be correct. That is because the technology to determine your precise genetic code is (relatively) cheap and it is robust. Your genetic code is also an empirical measurement, which means that if any vendor gets it wrong, either premeditated or by mistake, they would get in serious trouble for false advertising. In fact, the gene ‘diagnostic’ sector is very heavily regulated; with specific protocols needing to be followed and ensuring the application of good laboratory practice. For example, even though my lab at the University of Cambridge is perfectly capable of performing genetic tests for research purposes, we are not actually licensed to provide any genetic diagnoses. Interpreting the results, however, is another thing entirely. Finally, the science quoted and used by DNAfit and other personal genetic testing companies to support their claims and make their ‘predictions’ is, by and large, respectable and sound. The information would have come from epidemiological studies of varying size and robustness, but all would have been peer-reviewed and published in scientific journals.
These companies are not lying. Rather, they are trying to get the data to do what it was not designed to do; they are misinterpreting the genetic results.
INCONVENIENT TRUTHS
Let’s look in more detail at why these types of tests aren’t able to make accurate predictions. At the end of Chapter 2, I discussed the fact that there are over a hundred genes that are associated with bodyweight and how one could actually create a ‘risk score’ for our likelihood of becoming obese.5 To calculate such a score, consider each genetic variant having a possible score of 2 (homozygous for the risk allele), 1 (heterozygous) or o (homozygous for the protective allele). With 100 genes, that is a notional maximum risk score of 200 (100 x 2) and a minimum of o. When plotted against a large enough population, what we observe is the higher your obesity risk score, the higher your BMI is likely to be (see figure 10). Similar types of risk scores can be produced for most complex diseases and traits. This is, essentially, what these companies are doing; looking at our genes and then comparing it with data that already exists about the rest of the population. The question is, can you take people with an empirically high genetic risk of developing disease – obesity, say – and make a pre-emptive intervention before they become obese? This is, after all, the holy grail of so-called ‘precision medicine’, where bespoke treatments are designed to fit each individual. The personal genetic testing companies certainly think so.

FIGURE 10
There are, however, a couple of inconvenient truths that get in the way. Most complex traits (such as height, weight, aerobic capacity or age of puberty) or diseases (such as type 2 diabetes, high blood pressure, rheumatoid arthritis or heart disease) will have a large genetic component that is modulated by the environment. We now know that there are hundreds of genetic variations that influence each of these traits. For instance, if we consider weight as an exemplar, more than a hundred genes had to be studied in hundreds of thousands of individuals in order to show the relationship with BMI.6 There are rare types of severe obesity, such as those seen in the children with no leptin,7 that are the result of catastrophic mutations in single genes. This is not the situation for the vast majority of us with ‘common’ obesity, where there is no one ‘obese’ gene. Instead, each of us will have our own personal mix of the more than 100 obesity risk vs protective variants. None of the genetic companies, however, test more than a small handful of genes per given trait, including for bodyweight. DNAfit, for example, only test between one to seven genes for each characteristic they are claiming to predict. By examining only a few of the hundreds of known variants, they are already massively reducing the predictive power of the risk score. Inconvenient truth Number 1.
POPULATION RISK VERSUS INDIVIDUAL PREDICTION
It is, however, the second inconvenient truth that presents the real problem. Even if all of the known variations for each trait or characteristic were taken into account, it would make very little measurable difference in the ability of the genetic testing companies to make the predictions they are claiming. Why? Because they are fundamentally misunderstanding the difference between population-level risk and individual diagnosis or prediction. What exactly do I mean by this?
In addition to running a research group at the University of Cambridge, I also do some undergraduate teaching. In particular, I teach a few lectures in biochemistry ‘101’ (mysteriously called ‘Molecules In Medical Science’ or MIMS) to the first-year pre-clinical medical and veterinary students; I am, in fact, the first lecturer that these students see as they begin their journey as Cambridge students (I know, I know, what did they do to deserve that?) Those of you (myself included) who had the fortune of sitting through first-year biochemistry will recall the rote memorisation of dozens of different biochemical pathways, such as glycolysis or the Krebs cycle, only to have them evaporate from the mind almost immediately after disgorging them on to an exam paper. In an effort to combat this dreadful waste of glucose by the brain, the department has structured the course around disease themes, with the first term focusing on diabetes and obesity, and the second term on cancer. These then formed an architecture on which to place basic biochemical principles into a clinical perspective. In the last lecture of term, though, I leave the curriculum and give the students a talk on the genetics of obesity, not unlike what I’ve covered in the first few chapters of this book. When I get to the point about risk versus prediction, this is the analogy I use to try and illustrate the point.
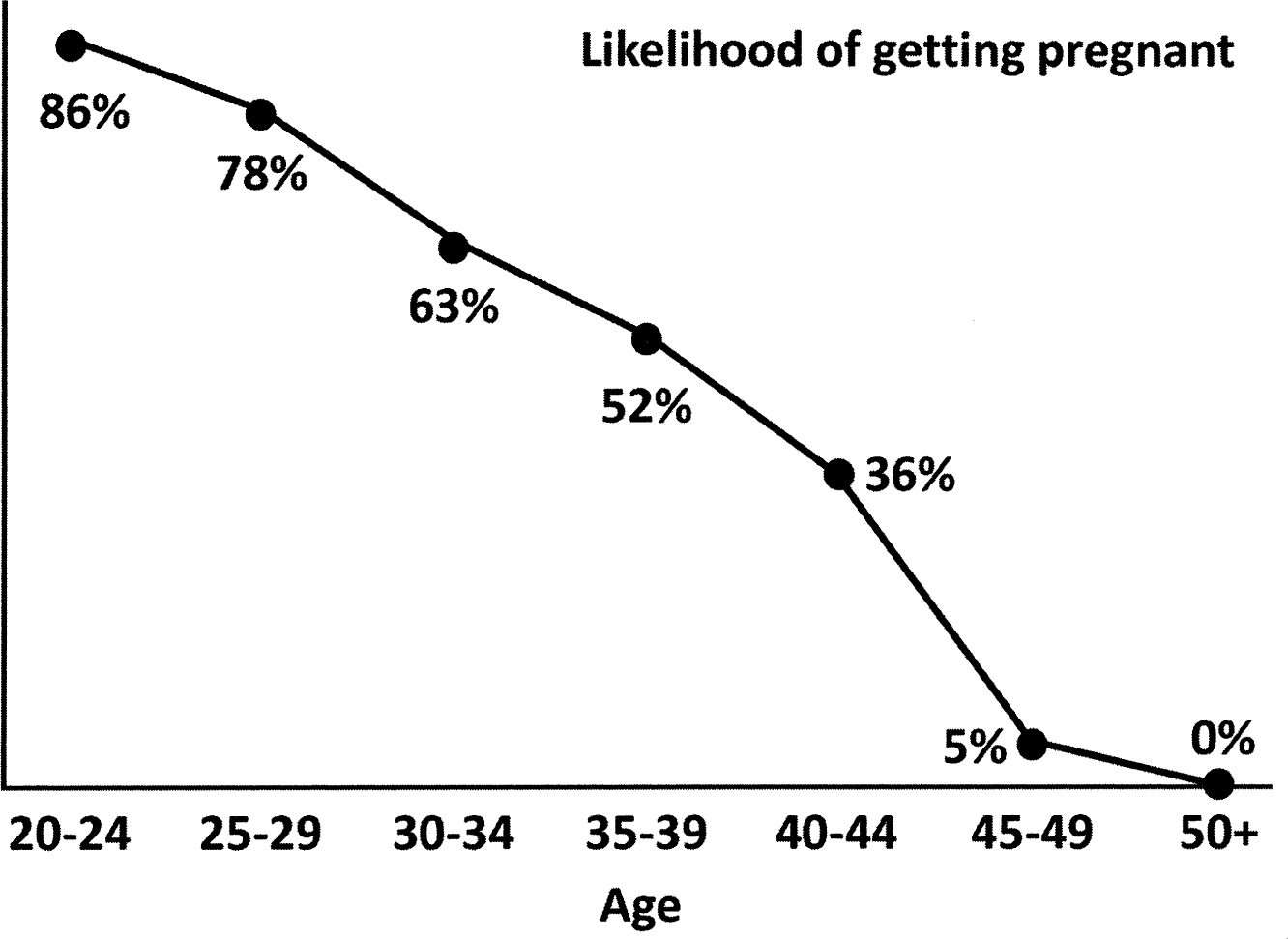
FIGURE 11
Let us consider the likelihood of getting pregnant. To the mostly eighteen-year-old first-year undergraduate students to whom I am trying to make the point, it is clearly more of a ‘risk’, but you get my drift. It is very well known that younger women are more fertile and are therefore more likely to get pregnant than someone older. The graph above illustrates this point, with twenty-to twenty-four-year-old women having an 86 per cent chance, when trying to get pregnant, of actually getting pregnant.8 This decreases as women get older, till the menopause hits post-fifty, and the likelihood drops to o per cent. Given the number of women who have ever been pregnant (a whole lot), plus everything we know about the biology of reproduction, you would imagine the graph to be extremely robust. However, while the likelihood of a woman between the ages of thirty and thirty-four years getting pregnant is 63 per cent, could you take a random thirty-four-year-old woman off the street and predict, simply based on this graph, whether or not she would become pregnant? Clearly not. It could be a 100 per cent chance because she was ovulating at the time, or she could be infertile for a myriad different reasons and the chances would then be o per cent. Without additional biological or hormonal information, you simply cannot take population-level data on the likelihood of pregnancy, no matter how robust and how many millions of women were used to generate the graph, and use it to predict the outcome for an individual.
The same analogy holds true for population-level risk scores. So while the graph showing the relationship between the obesity risk score and BMI has, by definition, been generated using genetic information from hundreds of thousands of people, its predictive value for an individual is little better than flipping a coin.
The question of course is why? Given that our genes determine our biology, why am I arguing that we can’t use it to predict our health or behaviour? The answer has to do with how much of our genetic code we are actually even looking at and our ability, or more accurately our inability, to effectively ‘measure’ the environment.
WHAT MAKES US DIFFERENT?
Greater that 99 per cent of the genome is the same in all humans, it is what defines us as human. However, what makes us all different lies in the 0.01 per cent of our DNA, around 30 million base-pairs, that varies between us all. So there we have our first problem; the risk scores are generated from only a minuscule proportion of the DNA that make us different, and an even smaller proportion of our total amount of genetic material. The obesity risk score that I’ve discussed, for instance, is generated from around just 100 different genetic variations. That is 100 out of 3 billion or 0.00000003 per cent of the genome.
The genetic variations that are associated with disease are also, by and large, the most common ones. These common variants are placed on chips so that up to 3 million can be screened in any given individual at the same time, making it easy to scale up and study millions of variations at a population level. It has proven to be a very powerful technology indeed, allowing scientists to reveal the genetic architecture of complex traits and diseases. However, in addition to these ‘known knowns’, there are also likely to be ‘unknown unknowns’, or genetic variations that are rare or ‘private’ to individual families, that would also play a significant role in disease. Because they are rare or unknown, they can’t be easily screened. The only way to do that would be to perform whole genome sequencing on a large number of people. That is beginning to happen now, but is going to take time, a lot of money and the ability to analyse and interpret such an enormous amount of data. The bottom line is, while those 100 variations used to generate the obesity risk score do indeed subtly influence BMI, we just don’t know enough, yet, about how these individual variations interact with themselves, let alone with all the rest of the genes and regulatory elements.
MEASURING THE ENVIRONMENT
The two essential ingredients to obtaining meaningful genetic associations on a population level are power (the number of individuals studied, preferably in the tens to hundreds of thousands; here, bigger is undoubtedly better) and an unambiguous and empirical measure or characteristic. When I say empirical, I mean a measure that does not rely on anyone’s memory or opinion. So BMI, waist-to-hip ratio or height, for example, are all very easy to obtain, requiring only a set of bathroom scales and a measuring tape, and yet informative. They can all change over time of course, but at any given moment, they do not lie and they are what they are. Then there are slightly more complicated measures such as blood pressure, blood glucose and insulin levels, cholesterol levels and body-fat percentage. These are all unambiguous and empirical measures, but obtaining them requires specialised equipment and/or medically qualified personnel. That being said, they are still relatively easy to collect on a population level.
But then we get to behaviours and characteristics, which on the surface seem very straightforward, but are actually incredibly difficult to measure accurately, particularly in large numbers of people. Measurement of feeding behaviour and energy expenditure – so both sides of the energy-balance equation – most certainly falls into this category.
WHAT AND HOW MUCH WE EAT
Feeding behaviour, broadly speaking, encompasses what and how much you eat. Aspects of feeding behaviour are measurable in small numbers of people within a laboratory setting, but suffers from the perennial conundrum that by studying a behaviour you invariably change the behaviour. So imagine you sign up for a study, and when you arrive on the day and step into the lab, someone produces some food and tells you to ‘eat naturally’. Except for young children, this is nearly impossible to do. Adults get self-conscious, they begin to imagine what is being measured ... is it the amount of food I am eating? I don’t want to look like a glutton ... What is possible to measure in this controlled setting is food ‘choice’, such as the chicken korma and Eton mess study looking into fat and sugar preference that I described in Chapter 2.9 These types of studies, however, are very difficult to scale up even to hundreds of people, let alone the tens of thousands of people required for population-level studies.
What and how much people eat can be measured at the population level, but it is notoriously difficult to do so accurately. The current ‘state of the art’ still involves food diaries and questionnaires, which of course aren’t state of any art at all. If I asked you what you ate for breakfast just a couple of days ago, chances are you’d remember it was a slice of toast with peanut butter, some steel-cut oats in milk with honey and a mug of white coffee. But the moment you are asked how much you ate of everything, it becomes very tricky. How much butter and peanut butter did you actually spread on the toast? How much porridge, milk and honey actually went into the bowl? How much milk went into your coffee? Now imagine doing that for a meal you had two weeks ago, and you begin to see how such data is entirely at the mercy of opinion and memory.
HOW MUCH WE HAVE BURNT
Energy expenditure, broadly speaking, encompasses three components; basal metabolic rate, diet-induced thermogenesis and physical activity. Your metabolic rate is the energy used to keep your entire body functioning while you are at rest and accounts for about 60 per cent of total energy burnt; diet-induced thermogenesis, which accounts for 10 per cent of expenditure is the heat given off when you eat and digest food; and physical activity is self-explanatory and accounts for around 30 per cent of energy expended. The first two components, which account for 70 per cent of energy expenditure, we cannot actually influence; it is largely determined by our body size, with a healthy dose of genetic influence thrown in. Many people might imagine that smaller, more wiry individuals would burn a lot more energy than a slower and larger person. The reality is actually the opposite; the larger the person, the higher the metabolic rate. The analogy I would use here is to compare a Mini Cooper with a Range Rover (other compact cars and large SUVs are available). While a Mini might seem to be very agile compared to the larger vehicle, it clearly has a far lower fuel consumption than a Range Rover. The larger engine and bigger mass to move about demands more fuel. The same is true for humans (and, in fact, all living creatures).
These first two components can be measured very accurately by placing a person in a ‘chamber calorimeter’, a completely sealed room in which the exact amount of oxygen and carbon dioxide going in and coming out of the room is recorded. This is pretty much the ‘gold-standard’. Keeping with the vehicle analogy, we breathe in oxygen as fuel and breathe out carbon dioxide as exhaust, so measuring the ins and outs of this process allows us to indirectly calculate energy expenditure. You have to live in the chamber calorimeter for a few days, during which your metabolic rate can be measured when you are resting, when you are eating and, if there is a stationary bike in the room, when you are exercising. But as you might imagine, such rooms are technologically very complex, and as such there are only a handful in the UK for instance. So this method, although invaluable in a clinical or research setting, cannot be realistically scaled up to a population level. Instead, when measuring energy expenditure beyond a handful of individuals, portable hoods that can be placed over one’s head are used instead. This follows the same principle of measuring oxygen used and carbon dioxide produced, but is less accurate because the hood is not airtight and measurements are taken over a far shorter period of time; typically around 30 minutes. Even so, this technique remains time-consuming and labour-intensive and scaling up beyond a few thousand people is very challenging.
The 30 per cent of energy expended that is encompassed by physical activity is the only component we can actively influence. It is easier to measure because of the proliferation of wearable fitness monitors that have flooded the market. These range from technically advanced accelerometers, with inbuilt heart-rate monitors and gyroscopes that can tell if you are standing, sitting or lying down, to simple pedometers that count the number of steps you might accumulate in a day, and everything in between. What is interesting is that while in the short term owning one of these monitors does seem to have a beneficial effect in terms of activity and weight loss, sadly these effects disappear in the long term, presumably when we begin to ignore or tire of what used to be the exciting new toy on our wrists.10
Currently, most of the genes linked to BMI produce proteins that function in the brain, many of which, including components of the melanocortin pathway such as POMC and MC4R, regulate food intake.11 To date, however, there are no genes that have been convincingly linked to metabolism and energy expenditure. Does that mean that differences in metabolic rate don’t influence BMI? Absolutely not. Food-intake data is simply easier to collect from large numbers of people. So even though food diaries and questionnaires are far from perfect, you can mitigate against the imperfect data to a degree with a large enough dataset. The most likely explanation for the lack of energy expenditure genes associated with BMI is the difficulty of measuring it accurately in a large enough population.
So there we have our second problem. Until we find better and more accurate ways of measuring the environment, such as what people eat and the amount of energy they burn, the predictions based on just a genetic risk score being claimed by the various personal gene testing companies are simply not (yet) possible. In fact, I have spoken to quite a few people who have taken these tests. Almost universally, the predictions, with small variations, are that everyone needs to eat more healthily, maybe Mediterranean-style, and everyone needs to move a little bit more, with a balance of aerobic and resistance training. These tests say that they are giving personalised advice, but end up giving common-sense ‘healthy-living’ advice, which I could have given to you for free.
THE DAWN OF NUTRIGENOMICS?
Are there going to be genetic influences on our preference for protein, fat (me), carbs or sugar? Yes. Will our genes play a role in whether we will respond to a high-protein, versus a low-carb high-fat, versus a low-GI, versus a Mediterranean diet? Undoubtedly. Are there genes involved in whether or not we eat when we are stressed, and whether or not we live to eat (me) or eat to live (not me)? One hundred per cent. Are there genes that make it more difficult for someone to lose weight and keep it off than someone else; genes that make some of us feel hungrier than others; genes that simply make some of us more efficient with calories than others? Yes, yes and yes.
As I have mentioned, every single one of our traits, behaviours, characteristics and tendencies will have a genetic component. The trick is to find out what genes are involved, how they are involved and how large a role they play. For instance, the 100 BMI genes probably cover the full ambit above. So just simply knowing that someone has a higher than average genetic risk for being obese, such as the ‘Constant Cravers’ in Chapter 11, doesn’t mean you can predict if they will become obese, or pinpoint the exact reasons why they have become obese. Although the genetic risk score is an empirical number, each individual’s mix of genetic variations that lead to the score will be different. In other words, we will all have our own unique reasons that lead us to eat more or less or an average amount.
Do I think that at some point in the future we will be able to actually do what the personal genetic testing companies are currently (mistakenly) claiming they can do? Do I believe there is a future for this field of ‘nutrigenomics’? Do I believe that ‘the perfect diet’ for each of us is somewhere to be found in our genes? Yes, I do. But until we are able to be more sophisticated in our analysis of genetic information and couple it to a far better capability of measuring our environment, that time is not now.
CAN WE CHANGE OUR GENES?
As a geneticist working in obesity, I am often asked if we can change our genes to fix our obesity. Given the advances over the past few years in the field of ‘gene editing’, the question is not as far-fetched as you might imagine. While we have possessed the ability to modify DNA for a few decades now, it was always limited by the organisms we could actually genetically engineer (mostly mice and a few plants) and the areas in the genome that were accessible. The development of CRISPR-Cas9, which is short for Clustered Regularly Interspaced Short Palindromic Repeats and CRISPR-associated protein 9, however, has now given scientists the ability to change the DNA of any organism or cell, and at pretty much any location in the genome.12 Developed from a naturally occurring bacterial defence mechanism, CRISPR-Cas9 acts simultaneously as both molecular scalpel and tweezers, allowing very precise editing of the genome to occur. It is most certainly ‘now technology’ in that it is in wide use in laboratories throughout the world; although most scientists, myself included, use it to edit the DNA of cells and of animal models, purely for the purposes of research.
But the great excitement and interest is to use it in the prevention and treatment of human diseases. It is already being used, for example, in the treatment of certain types of cancer. This is done by taking immune cells out of a patient with cancer, modifying them using gene editing to give them the ability to recognise a specific protein on cancer cells, after which they are infused back into the patient. This process, in effect, ‘weaponises’ the immune cells and programmes them to attack the cancer cells. This approach, however, does not result in any heritable changes. Once the immune cells have done their job, the body gets rid of them. Ethical concerns arise when we begin to discuss altering the human genome in a way that can be passed on to the next generation, which means editing egg or sperm cells or embryos themselves. While it is technically possible to do it now, there is the big question of safety. How sure can we be that by changing one bit of the genome, we don’t change something else, for instance? Also, while removing a debilitating genetic condition so that it doesn’t blight a family ever again would seem a no-brainer, what happens when people want to begin to change their eye colour, their hair colour or, heaven forbid, their weight? I am not proffering an opinion either way, but this is a discussion that society needs to have, and soon. In the meantime, based on concerns about ethics and safety, editing of egg and sperm cells and embryos is currently illegal in most countries.
The other thing about gene-editing technologies, ethical and safety questions notwithstanding, is that they are currently only able to make single changes to the genome. So it would in theory, for example, be possible to fix the mutation causing leptin deficiency in those kids I told you about back in Chapter 2. However, if you had a high genetic risk for obesity, you would not be able to change fifty or sixty genetic variants, in an attempt to lower your obesity risk score.
HAND OF POKER
Another question I am asked as a geneticist studying obesity is whether I feel I am simply providing obese people with an excuse? With a genetic crutch? It is an interesting question, but one that seems to only be asked about the genetics of a ‘behaviour’. So if instead I was studying the genetics of heart disease, or osteoporosis, or arthritis or Alzheimer’s or Parkinson’s, would people ask me the same question? Would I be giving people suffering from those diseases an excuse as well? What I, and everyone else in the field of obesity genetics, is trying to understand is the biology underlying the problem, because if we don’t understand the problem, then we can’t fix it.
I always consider our genes to be like a hand of poker. You could get a good hand or you could get a bad hand, and the only people you can blame are your folks. But you can win with a bad hand of poker – it’s more difficult, but you can do it – and you can certainly lose with a good hand of poker. So it depends how you play the cards. Using another analogy, I will never ever be able to run as fast as Usain Bolt. A large part of that (it’s my excuse and I’m sticking to it) is going to be down to my genes. However, that doesn’t mean that if I trained, I wouldn’t be able to run faster. Yes, your genes do set limits on what is possible, but for the most part they are not ‘deterministic’; rather, your genes give a range of possible outcomes, depending on how they interact with the environment. It’s all about trying to reach your genetic potential for any given trait; be it a student at university working hard and trying to reach their genetic potential for intelligence, or an Olympic athlete trying to maximise their genetic potential for physicality or athleticism by eating well and training hard. An obese person, because of the genes they carry, some of which may have been a holdover from the ‘feast-famine’ environment all those tens of thousands of years on the Serengeti, needs to work harder than others to lose weight and to keep it off. I recall a conversation I had with one of the ‘Constant Cravers’ I worked with on the Right Diet programme. I had told him that he had a high obesity risk score, and that likely played a role in why he found it difficult to lose weight. But I also told him that there was no magic bullet, no magic pill, and he still needed to eat less to lose the weight. What he told me will stick with me to my grave:
‘I have been large all my life. I was made fun of as a kid at school. I’ve been called some very awful things as an adult that I won’t repeat. I know there is no magic pill. But now I know that when I am finding it really difficult to say no to food, when the weight just won’t go off, that I am NOT a bad person. It is difficult because I am fighting my genes. That makes a huge difference in motivation for me. Thank you so much for helping me’.
Obese people are not lazy, or weak, or morally bereft; they are most certainly not bad. They are fighting their genes, they are struggling against their biology. Until we in society understand that, until we are able to remove the stigma from being obese, we are never, ever, going to be able to fix the problem.