13
Model-Based Reinforcement Learning
AFTER THE SUCCESS of TD-Gammon, people tried to apply Sutton’s temporal difference learning (a type of model-free reinforcement learning) to more complex board games like chess. The results were disappointing.
While model-free approaches like temporal difference learning can do well in backgammon and certain video games, they do not perform well in more complex games like chess. The problem is that in complex situations, model-free learning—which contains no planning or playing out of possible futures—is not good at finding the moves that don’t look great right now but set you up well for the future.
In 2017, Google’s DeepMind released an AI system called AlphaZero that achieved superhuman performance in not only the game of chess but also the game of Go, beating the world Go champion Lee Sedol. Go is an ancient Chinese board game that is even more complex than chess; there are a trillion upon trillion times more possible board positions in Go than in chess.
How did AlphaZero achieve superhuman performance at Go and chess? How did AlphaZero succeed where temporal difference learning could not? The key difference was that AlphaZero simulated future possibilities. Like TD-Gammon, AlphaZero was a reinforcement learning system—its strategies were not programmed into it with expert rules but learned through trial and error. But unlike TD-Gammon, AlphaZero was a model-based reinforcement learning algorithm; AlphaZero searched through possible future moves before deciding what to do next.

Picture from https://en.wikipedia.org/wiki/Go_(game)#/media/File:FloorGoban.JPG
After its opponent moved, AlphaZero would pause, select moves to consider, and then play out thousands of simulations of how the entire game might go given those selected moves. After running a set of simulations, AlphaZero might see that it won thirty-five out of the forty imagined games when it made move A, thirty-nine of the forty imagined games when it made move B, and so on for many other possible next moves. AlphaZero could then pick the move where it had won the highest ratio of imagined games.
Doing this, of course, comes with the search problem; even armed with Google’s supercomputers, it would take well over a million years to simulate every possible future move from an arbitrary board position in Go. And yet AlphaZero ran these simulations within half a second. How? It didn’t simulate the trillions of possible futures; it simulated only a thousand futures. In other words, it prioritized.
There are many algorithms for deciding how to prioritize which branches to search through in a large tree of possibilities. Google Maps uses such an algorithm when it searches for the optimal route from point A to point B. But the search strategy used by AlphaZero was different and offered unique insight into how real brains might work.
We already discussed how in temporal difference learning an actor learns to predict the best next move based on a hunch about the board position, doing so without any planning. AlphaZero simply expanded on this architecture. Instead of picking the single move its actor believed was the best next move, it picked multiple top moves that its actor believed were the best. Instead of just assuming its actor was correct (which it would not always be), AlphaZero used search to verify the actor’s hunches. AlphaZero was effectively saying to the actor, “Okay, if you think move A is the best move, let’s see how the game would play out if we did move A.” And AlphaZero then also explored other hunches of the actor, considering the second and third best moves the actor was suggesting (saying to the actor, “Okay, but if you didn’t take move A, what would your next best hunch be? Maybe move B will turn out even better than you think”).
What is elegant about this is that AlphaZero was, in some sense, just a clever elaboration on Sutton’s temporal difference learning, not a reinvention of it. It used search not to logically consider all future possibilities (something that is impossible in most situations) but to simply verify and expand on the hunches that an actor-critic system was already producing. We will see that this approach, in principle, may have parallels to how mammals navigate the search problem.
While Go is one of the most complex board games, it is still far simpler than the task of simulating futures when moving around in the real world. First, the actions in Go are discrete (from a given board position, there are only about two hundred possible subsequent next moves), whereas in the real world actions are continuous (there are an infinite number of possible body and navigational paths). Second, the information about the world in Go is deterministic and complete, whereas in the real world it is noisy and incomplete. And third, the rewards in Go are simple (you either win or lose the game), but in the real world, animals have competing needs that change over time. And so, while AlphaZero was a huge leap forward, AI systems are still far from performing planning in environments with a continuous space of actions, incomplete information about the world, and complex rewards.
However, the most critical advantage of planning in mammalian brains over modern AI systems like AlphaZero is not their ability to plan with continuous action spaces, incomplete information, or complex rewards, but instead simply the mammalian brain’s ability to flexibly change its approach to planning depending on the situation. AlphaZero—which applied only to board games—employed the same search strategy with every move. In the real world, however, different situations call for different strategies. The brilliance of simulation in mammal brains is unlikely to be some special yet-to-be-discovered search algorithm; it is more likely to be the flexibility with which mammal brains employ different strategies. Sometimes we pause to simulate our options, but sometimes we don’t simulate things at all and just act instinctually (somehow brains intelligently decide when to do each). Sometimes we pause to consider possible futures, but other times we pause to simulate some past event or alternative past choices (somehow brains select when to do each). Sometimes we imagine rich details in our plans, playing out each individual detailed subtask, and sometimes we render just the general idea of the plan (somehow brains intelligently select the right granularity of our simulation). How do our brains do this?
Prefrontal Cortex and Controlling the Inner Simulation
In the 1980s, a neuroscientist named Antonio Damasio visited one of his patients—referred to as “L”—who had suffered a stroke. L lay in bed with her eyes open and a blank expression on her face. She was motionless and speechless, but she wasn’t paralyzed. She would, at times, lift up the blanket to cover herself with perfectly fine motor dexterity; she would look over at a moving object, and she could clearly recognize when someone spoke her name. But she did and said nothing. When looking into her eyes, people said it seemed that “she was there but not there.”
Stroke victims with damage to the visual, somatosensory, or auditory neocortex suffer from impairments to perception (such as blindness or deafness). But L showed none of these symptoms; her stroke occurred in a specific region of her prefrontal neocortex. L had developed akinetic mutism—a tragic and bizarre condition caused by damage to certain regions of the prefrontal cortex in which people are able to move and understand things just fine but they don’t move, speak, or care about anything at all.
After six months, as with many stroke patients, L began to recover as other areas of her neocortex remapped themselves to compensate for the damaged area. As L slowly began to speak again, Damasio asked her about her experience over the prior six months. Although L had little memory of it, she did recall the few days before beginning to speak. She described the experience as not talking because she had nothing to say. She claimed her mind was entirely “empty” and that nothing “mattered.” She claimed that she was fully able to follow the conversations around her, but she “felt no ‘will’ to reply.” It seems that L had lost all intention.
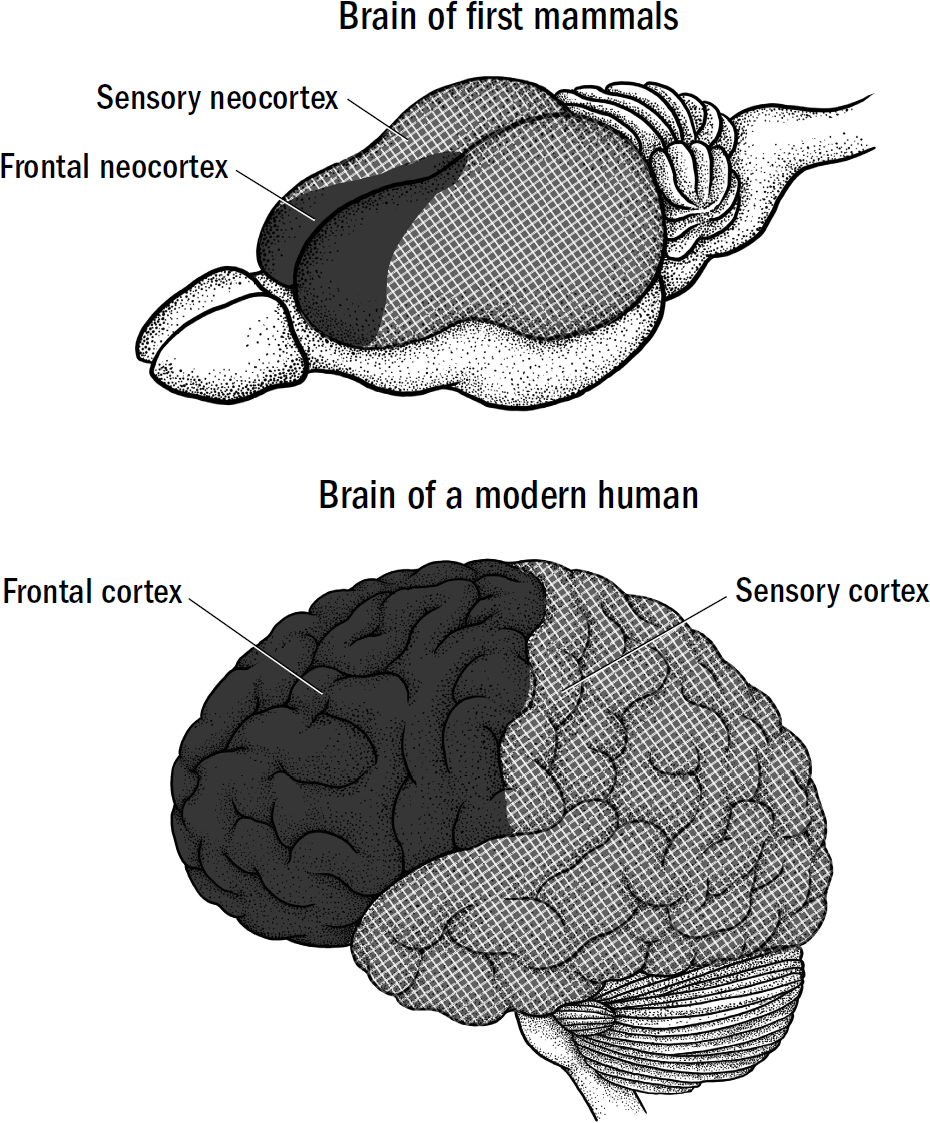
Figure 13.2
Original art by Mesa Schumacher
The neocortex of all mammals can be separated into two halves. The back half is the sensory neocortex, containing visual, auditory, and somatosensory areas. Everything about the neocortex we reviewed in chapter 11 was about sensory neocortex—it is where a simulation of the external world is rendered, either matching its simulation to incoming sensory data (perception by inference) or by simulating alternative realities (imagination). But the sensory neocortex was only half the puzzle of how the neocortex works. The neocortex of the first mammals, just like that of modern rats and humans, had another component, found in the front half: the frontal neocortex.
The frontal neocortex of a human brain contains three main subregions: motor cortex, granular prefrontal cortex (gPFC), and agranular prefrontal cortex (aPFC). The words granular and agranular differentiate parts of the prefrontal cortex based on the presence of granule cells, which are found in layer four of the neocortex. In the granular prefrontal cortex, the neocortex contains the normal six layers of neurons. However, in the agranular prefrontal cortex, the fourth layer of neocortex (where granule cells are found) is weirdly missing.* Thus, the parts of the prefrontal cortex that are missing layer four are called the agranular prefrontal cortex (aPFC), and the parts of the prefrontal cortex that contain a layer four are called the granular prefrontal cortex (gPFC). It is still unknown why, exactly, some areas of frontal cortex are missing an entire layer of neocortex, but we will explore some possibilities in the coming chapters.
The granular prefrontal cortex evolved much later in early primates, and we will learn all about it in breakthrough #4. The motor cortex evolved after the first mammals but before the first primates (we will learn about the motor cortex in the next chapter). But the agranular prefrontal cortex (aPFC) is the most ancient of frontal regions and evolved in the first mammals. It was the aPFC that was damaged in Damasio’s patient L. The aPFC is so ancient and fundamental to the proper functioning of the neocortex that when damaged, L was deprived of something central to what it means to be human—or, more specifically, what it means to be a mammal.
In the first mammals, the entire frontal cortex was just agranular prefrontal cortex. All modern mammals contain an agranular prefrontal cortex inherited from the first mammals. To understand L’s akinetic mutism and how mammals decide when and what to simulate, we must first roll back the evolutionary clock to explore the function of the aPFC in the brains of the first mammals.
It seems that in early mammals, the sensory neocortex was where simulations were rendered, and the frontal neocortex was where simulations were controlled—it is the frontal neocortex that decided when and what to imagine. A rat with a damaged frontal neocortex loses the ability to trigger simulations; it no longer engages in vicarious trial and error, episodic-memory recall, or counterfactual learning. This impairs rats in many ways. They become worse at solving spatial-navigation challenges that require preplanning, such as when they are placed in completely new starting locations in a maze. Rats make lazier choices, often taking the easier paths even if they offer substantially fewer rewards, as if the rats are unable to stop and play out each option and realize that the effort is worth it. And without episodic memory, they fail to internally recall old memories of dangerous cues and are thereby more likely to repeat past mistakes.
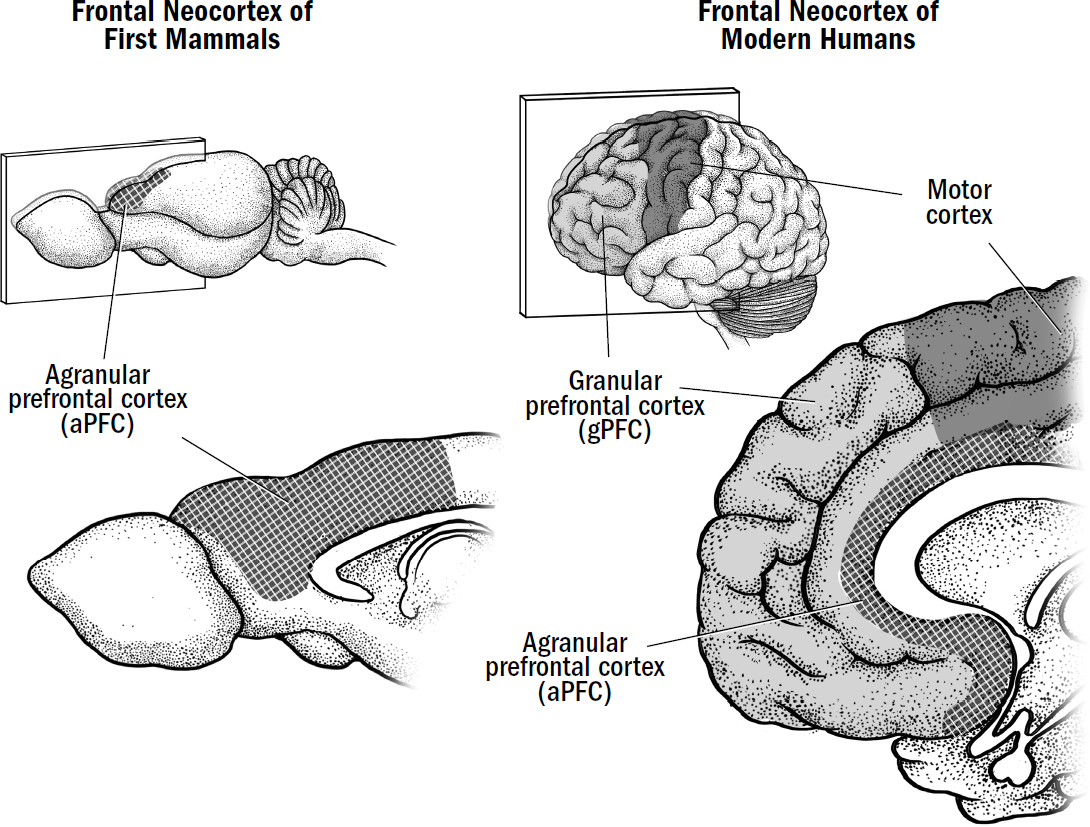
Figure 13.3: The frontal regions of the first mammals and of modern humans
Original art by Mesa Schumacher
Even those rats with only partial frontal damage who retain some ability to trigger these simulations still struggle to monitor these simulated “plans” as they unfold. Rats with aPFC damage struggle to remember where they are in an ongoing plan, do actions out of sequence, and unnecessarily repeat already completed actions. Rats with aPFC damage also become impulsive; they will prematurely respond in tasks that require them to wait and be patient to get food.
While the frontal and sensory cortices seem to serve different functions (the frontal neocortex triggers simulations, the sensory neocortex renders simulations), they are both different areas of the neocortex and thus should execute the same fundamental computation. This presents a conundrum: How does the frontal neocortex, simply another area of neocortex, do something so seemingly different from the sensory neocortex? Why does a modern human with a damaged aPFC become devoid of intention? How does the aPFC trigger simulations in the sensory neocortex? How does it decide when to simulate something? How does it decide what to simulate?
Predicting Oneself
In a column of the sensory cortex, the primary input comes from external sensors, such as the eyes, ears, and skin. The primary input to the agranular prefrontal cortex, however, comes from the hippocampus, hypothalamus, and amygdala. This suggests that the aPFC treats sequences of places, valence activations, and internal affective states the way the sensory neocortex treats sequences of sensory information. Perhaps, then, the aPFC tries to explain and predict an animal’s own behavior the same way that the sensory neocortex tries to explain and predict the flow of external sensory information?
Perhaps the aPFC is always observing a rat’s basal-ganglia-driven choices and asking, “Why did the basal ganglia choose this?” The aPFC of a given rat might thereby learn, for example, that when the rat wakes up and has these specific hypothalamic activations, it always runs down to the river and consumes water. The aPFC might then learn that the why of such behavior is “to get water.” Then in similar circumstances, the aPFC can predict what the animal will do before the basal ganglia triggers any behavior—it can predict that when thirsty, the animal will run toward nearby water. In other words, the aPFC learns to model the animal itself, inferring the intent of behavior it observes, and uses this intent to predict what the animal will do next.
As philosophically fuzzy as intent might sound, it is conceptually no different from how the sensory cortex constructs explanations of sensory information. When you see a visual illusion that suggests a triangle (even when there is no triangle), your sensory neocortex constructs an explanation of it, which is what you perceive—a triangle. This explanation—the triangle—is not real; it is constructed. It is a computational trick that the sensory neocortex uses to make predictions. The explanation of the triangle enables your sensory cortex to predict what would happen if you reached out to grab it or turned the light on or tried to look at it from another angle.
Frontal vs Sensory Neocortex in the First Mammals
FRONTAL NEOCORTEX
|
SENSORY NEOCORTEX
|
A self model |
A world model |
Gets input from hippocampus, amygala, and hypothalamus
|
Gets input from sensory organs
|
“I did this because I want to get to water” |
“I see this because there is a triangle right there” |
Tries to predict what the animal will do next |
Tries to predict what external objects will do next |
Recording studies corroborate the idea that the aPFC creates a model of an animal’s goals. If you look at a recording of the aPFC of a rat, you can see patterns of activity that encode the task a rat is performing—with specific populations of neurons selectively firing only at specific locations within a complex task sequence, reliably tracking progress toward an imagined goal.
What is the evolutionary usefulness of this model of self in the frontal cortex? Why try to “explain” one’s own behavior by constructing “intent”? It turns out, this might be how mammals choose when to simulate things and how to select what to simulate. Explaining one’s own behavior might solve the search problem. Let’s see how.
How Mammals Make Choices
Let’s take the example of a rat navigating a maze and making a choice as to which direction to go when it reaches a fork. Going to the left leads to water, going to the right leads to food. It is these situations when vicarious trial and error occurs, and it occurs in three steps.
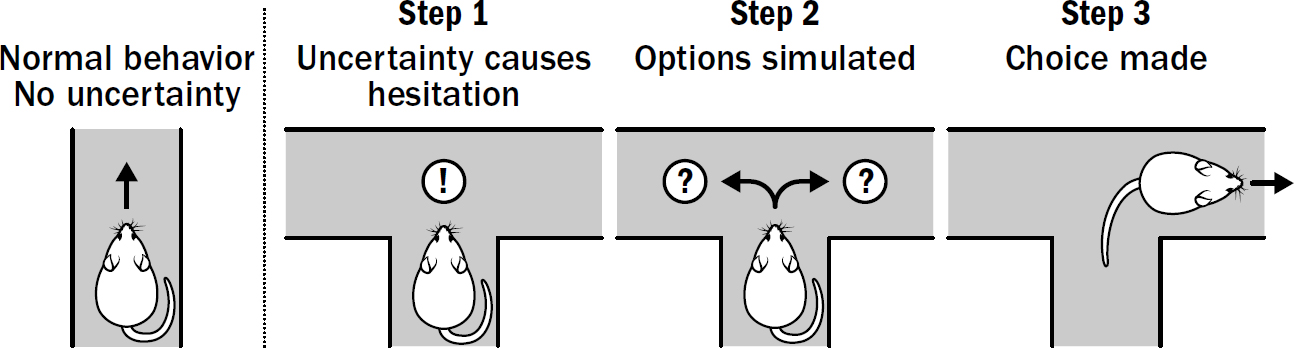
Figure 13.4: Speculations on how mammals make deliberative choices
Original art by Rebecca Gelernter
Step #1: Triggering Simulation
The columns in the aPFC might always be in one of three states: (1) silent; the behavior it observes is not recognizing any specific intent (like a column in the visual cortex not recognizing anything meaningful in an image); (2) many or all columns in the frontal cortex recognize an intent and predict the same next behavior (“Oh! We are obviously about to go to the left here”); or (3) many columns in the frontal cortex recognize an intent but predict different and inconsistent behaviors (some columns predict “I’m going to go down to the left to get water!” and other columns predict “I’m going to go to the right to get food!”). It might be in this last state, in which aPFC columns don’t agree in their predictions, where the aPFC might be most useful. Indeed, the aPFC of mammals gets most excited when something goes wrong or something unexpected happens in an ongoing task.
The degree of disagreement of predictions is a measure of uncertainty. This is, in principle, how many state-of-the-art machine learning models measure uncertainty: An ensemble of different models makes predictions, and the more divergent such predictions, the more uncertainty there is reported to be.
It might be this uncertainty that triggers simulations. The aPFC can trigger a global pause signal through connecting directly to specific parts of the basal ganglia, and aPFC activation has been shown to correlate with levels of uncertainty. And as we saw in the last chapter, it is exactly when things change or are hard (i.e., are uncertain) that animals pause to engage in vicarious trial and error. It is also possible that uncertainty could be measured in the basal ganglia; perhaps there are parallel actor-critic systems, each making independent predictions about the next best action, and the divergence in their predictions is what triggers pausing.
Either way, this provides a speculation for how mammal brains tackle the challenge of deciding when to go through the effort of simulating things. If events are unfolding as one would expect, there is no reason to waste time and energy simulating options, and it is easier just to let the basal ganglia drive decisions (model-free learning), but when uncertainty emerges (something new appears, some contingency is broken, or costs are close to the benefits), then simulation is triggered.
Step #2: Simulating Options
Okay, so the rat paused and decided to use simulation to resolve its uncertainty—now what? This brings us back to the search problem. A rat in a maze could do any one of a billion things, so how does it decide what to simulate?
We saw how AlphaZero solved this problem: It played out the top moves it was already predicting were the best. This idea aligns quite nicely with what is known about neocortical columns and the basal ganglia. The aPFC doesn’t sit there combing through every possible action, instead it specifically explores the paths that it is already predicting an animal will take. In other words, the aPFC searches through the specific options that different columns of the aPFC are already predicting. One set of columns predicted going left all the way to water, and another predicted going right, so there are only two different simulations to run.
After an animal pauses, different columns in the aPFC take turns playing out their predictions of what they think the animal will do. One group of columns plays out going left and following that path all the way to water. Another group of columns plays out going right and following that path all the way to get food.
The connectivity between the aPFC and the sensory neocortex is revealing; the aPFC projects extensively to diffuse regions of the sensory cortex and has been shown to dramatically modulate the activity of the sensory neocortex. And specifically when rats engage in this vicarious trial and error behavior, the activity in the aPFC and the sensory cortex become uniquely synchronized. One speculation is that the aPFC is triggering the sensory neocortex to render a specific simulation of the world. The aPFC first asks, “What happens if we go to the left?” The sensory neocortex then renders a simulation of turning left, which then passes back to the aPFC. The aPFC then says, “Okay, and then what happens if we keep going forward?” which the sensory neocortex renders again, and so on and so forth all the way to the imagined goal modeled in the aPFC.
Alternatively, it could be the basal ganglia that determines the actions taken during these simulations. This would be even closer to how AlphaZero worked—it selected simulated actions based on the actions its model-free actor predicted were best. In this case, it would be the aPFC that selects which of the divergent action predictions of the basal ganglia to simulate, but the basal ganglia would continue to decide which actions it wants to take in the imagined world rendered by the sensory neocortex.
Step #3: Choosing an Option
The neocortex simulates sequences of actions, but what makes the final decision as to what direction the rat will actually go? How does a rat choose? Here’s one speculation. The basal ganglia already has a system for making choices. Even the ancient vertebrates had to make choices when presented with competing stimuli. The basal ganglia accumulates votes for competing choices, with different populations of neurons representing each competing action ramping up in excitement until it passes a choice threshold, at which point an action is selected.
And so, as the process of vicarious trial and error unfolds, the results of these vicarious replays of behavior accumulate votes for each choice in the basal ganglia—the same way it would if the trial and error were not vicarious but real. If the basal ganglia keeps getting more excited by imagining drinking water than by imagining eating food (as measured by the amount of dopamine released), then these votes for water will quickly pass the choice threshold. The basal ganglia will take over behavior, and the rat will go get water.
The emergent effect of all this is that the aPFC vicariously trained the basal ganglia that left was the better option. The basal ganglia doesn’t know whether the sensory neocortex is simulating the current world or an imagined world. All the basal ganglia knows is that when it turned left, it got reinforced. Hence, when the sensory neocortex goes back to simulating the current world at the beginning of the maze, the basal ganglia immediately tries to repeat the behavior that was just vicariously reinforced. Voilà—the animal runs to the left to get water.
Goals and Habits (or the Inner Duality of Mammals)
In the early 1980s, a Cambridge psychologist by the name of Tony Dickinson was engaging in the popular psychology experiments of the time: training animals to push levers to get rewards. Dickinson was asking a seemingly mundane question: What happens if you devalue the reward of a behavior after the behavior is learned? Suppose you teach a rat that pushing a lever releases a food pellet from a nearby contraption. The rat will rapidly go back and forth between pushing the lever and gobbling up the food. Now suppose one day, completely out of the context of the box with the lever, you give the rat the same pellet and secretly lace it with a chemical that makes the rat feel sick. How does this change their behavior?
The first result is expected: Rats, even after they have long recovered from their short bout of nausea, no longer find the pellets as appetizing as they did before. When given a mound of such pellets, rats eat substantially fewer. But the more interesting question was this: What would happen the next time the rats were shown the lever? If animals are simply governed by Thorndike’s law of effect, then they would run up to the lever and push it as rapidly as before—the lever had been reinforced many times, and nothing had yet unreinforced the act of pushing the lever. On the other hand, if animals are indeed able to simulate the consequences of pushing the lever and realize that the result is a pellet that they no longer like, they won’t want to push the lever as much. What Dickinson found was that after this procedure, rats who had the pellet paired with illness pushed the lever almost 50 percent less than those that had not.
This is consistent with the idea that the neocortex enables even simple mammals such as rats to vicariously simulate future choices and change their behaviors based on the imagined consequences. But as Dickinson continued these experiments, he noticed something weird: Some rats continued to push the lever with as much, if not more, vigor after the pellet was paired with illness. Some rats became what he called “insensitive to devaluation.” The difference, he found, was merely a consequence of how many times the rats had pushed the lever to get a reward. Rats that had done the task one hundred times did the smart thing—they no longer wanted to push the lever once the food was devalued. But rats that had done the task five hundred times ran up to the lever and just started pushing it like crazy, even if the food was devalued. And in all these tests, the food pellets never were given; the group that had become insensitive to devaluation just kept pushing the lever without ever getting a reward.
Dickinson had discovered habits. By engaging in the behavior five hundred times, rats had developed an automated motor response that was triggered by a sensory cue and completely detached from the higher-level goal of the behavior. The basal ganglia took over behavior without the aPFC pausing to consider what future these actions would produce. The behavior had been repeated so many times that the aPFC and basal ganglia did not detect any uncertainty and therefore the animal did not pause to consider the consequences.
Perhaps this is a familiar experience. People wake up and look at their phones without asking themselves why they are choosing to look at their phones. They keep scrolling through Instagram even though if someone had asked them if they wanted to keep scrolling, they’d say “no.” Of course, not all habits are bad: You don’t think about walking, and yet you walk perfectly; you don’t think about typing, and yet the thoughts flow effortlessly from your mind to your fingertips; you don’t think about speaking, and yet thoughts magically convert themselves into a repertoire of tongue, mouth, and throat movements.
Habits are automated actions triggered by stimuli directly (they are model-free). They are behaviors controlled directly by the basal ganglia. They are the way mammalian brains save time and energy, avoiding unnecessarily engaging in simulation and planning. When such automation occurs at the right times, it enables us to complete complex behaviors easily; when it occurs at the wrong times, we make bad choices.
The duality between model-based and model-free decision-making methods shows up in different forms across different fields. In AI, the terms model-based and model-free are used. In animal psychology, this same duality is described as goal-driven behavior and habitual behavior. And in behavioral economics, as in Daniel Kahneman’s famous book Thinking, Fast and Slow, this same duality is described as “system 2” (thinking slow) versus “system 1” (thinking fast). In all these cases, the duality is the same: Humans and, indeed, all mammals (and some other animals that independently evolved simulation) sometimes pause to simulate their options (model-based, goal-driven, system 2) and sometimes act automatically (model-free, habitual, system 1). Neither is better; each has its benefits and costs. Brains attempt to intelligently select when to do each, but brains do not always make this decision correctly, and this is the origin of many of our irrational behaviors.
The language used in animal psychology is revealing—one type of behavior is goal-driven and the other is not. Indeed, goals themselves may not have evolved until early mammals.
The Evolution of the First Goal
Just as the explanations of sensory information are not real (i.e., you don’t perceive what you see), so intent is not real; rather, it is a computational trick for making predictions about what an animal will do next.
This is important: The basal ganglia has no intent or goals. A model-free reinforcement learning system like the basal ganglia is intent-free; it is a system that simply learns to repeat behaviors that have previously been reinforced. This is not to say that such model-free systems are dumb or devoid of motivation; they can be incredibly intelligent and clever, and they can rapidly learn to produce behavior that maximizes the amount of reward. But these model-free systems do not have “goals” in the sense that they do not set out to pursue a specific outcome. This is one reason why model-free reinforcement learning systems are painfully hard to interpret—when we ask, “Why did the AI system do that?,” we are asking a question to which there is really no answer. Or at least, the answer will always be the same: because it thought that was the choice with the most predicted reward.
In contrast, the aPFC does have explicit goals—it wants to go to the fridge to eat strawberries or go to the water fountain to drink water. By simulating a future that terminates at some end result, the aPFC has an end state (a goal) that it seeks to achieve. This is why it is possible, at least in circumstances where people make aPFC-driven (goal-oriented, model-based, system 2) choices, to ask why a person did something.
It is somewhat magical that the very same neocortical microcircuit that constructs a model of external objects in the sensory cortex can be repurposed to construct goals and modify behavior to pursue these goals in the frontal cortex. Karl Friston of University College London—one of the pioneers of the idea that the neocortex implements a generative model—calls this “active inference.” The sensory cortex engages in passive inference—merely explaining and predicting sensory input. The aPFC engages in active inference—explaining one’s own behavior and then using its predictions to actively change that behavior. By pausing to play out what the aPFC predicts will happen and thereby vicariously training the basal ganglia, the aPFC is repurposing the neocortical generative model for prediction to create volition.
When you pause and simulate different dinner options, choose to get pasta, then begin the long action sequence to get to the restaurant, this is a “volitional” choice—you can answer why you are getting in the car; you know the end state you are pursuing. In contrast, when you act only from habit, you have no answer as to why you did what you did.
Karl Friston also offers an explanation for the perplexing fact that some parts of the frontal cortex are missing the fourth layer of the neocortical column. What does layer four do? In the sensory cortex, layer four is where raw sensory input flows into a neocortical column. Layer four is speculated to have the role of pushing the rest of the neocortical column to render a simulation that best matches its incoming sensory data (perception by inference). There is evidence that when a neocortical column is engaged in simulating, layer-four activity declines as active incoming sensory input is suppressed—this is how the neocortex can render a simulation of something not currently experienced (e.g., imagining a car when looking at the sky). This is a clue. Active inference suggests that the aPFC constructs intent and then tries to predict behavior consistent with that intent; in other words, it tries to make its intent come true. If the animal does something inconsistent with the aPFC’s constructed intent, the aPFC doesn’t want to adjust its model of intent to match the behavior, it wants to adjust the behavior: if you are thirsty and your basal ganglia makes a decision to go in the direction that has no water, the aPFC doesn’t want to adjust its model of your intent to assume you are not thirsty, instead it wants to pause the basal ganglia’s mistake, and convince it to turn around and go toward the water. Thus, the aPFC spends very little, if any, time trying to match its inferred intent to the behavior it sees, and so it has no need for a large, or even any, layer four.
Of course, the aPFC isn’t evolutionarily programmed to understand the goals of the animal, instead it learns these goals by first modeling behavior originally controlled by the basal ganglia. The aPFC constructs goals by observing behavior that is originally entirely devoid of them. And only once these goals are learned does the aPFC begin to exert control over behavior: the basal ganglia begins as the teacher of the aPFC, but as a mammal develops, these roles flip, and the aPFC becomes the teacher of the basal ganglia. And indeed, during brain development, agranular parts of the frontal cortex begin with a layer four that then slowly atrophies and disappears during development, leaving layer four largely empty. Perhaps this is part of a developmental program for constructing a model of self, starting by matching one’s internal model to its observations (hence beginning with a layer 4), and then transitioning to pushing behavior to match one’s internal model (hence no need for a layer 4 anymore). Again we see a beautiful bootstrapping in evolution.
This also offers some insight into the experience of Damasio’s patient L. It makes some sense why her head was “empty”: She was unable to render an inner simulation. She had no thoughts. She had no will to respond to anything because her inner model of intent was gone, and without that, her mind could not set even the simplest of goals. And without goals, tragically, nothing mattered.
How Mammals Control Themselves: Attention, Working Memory, and Self-Control
In a typical neuroscience textbook, the four functions ascribed to the frontal neocortex are attention, working memory, executive control, and, as we have already seen, planning. The connecting theme of these functions has always been confusing; it seems odd that one structure would subserve all these distinct roles. But through the lens of evolution, it makes sense that these functions are all intimately related—they are all different applications of controlling the neocortical simulation.
Remember the ambiguous picture of a duck or a rabbit? As you oscillate between perceiving a duck or a rabbit, it is your aPFC that is nudging your visual cortex back and forth between each interpretation. Your aPFC can trigger an internal simulation of ducks when you close your eyes, and your aPFC can use the same mechanism to trigger an internal simulation of ducks with your eyes open and you are looking at a picture that could be either a duck or a rabbit. In both cases, the aPFC is trying to invoke a simulation; the only difference is that with your eyes closed, the simulation is unconstrained, and with your eyes open it is constrained to be consistent with what you are seeing. The aPFC’s triggering of simulation is called imagination when it is unconstrained by current sensory input and attention when it is constrained by current sensory input. But in both cases, the aPFC is, in principle, doing the same thing.
What is the point of attention? When a mouse selects an action sequence after its imagined simulation, it must stick to its plan as it runs down its path. This is harder than it sounds. The imagined simulation will not have been perfect; the mouse will not have predicted each sight, smell, and contour of the environment that it will actually experience. This means that the vicarious learning that the basal ganglia experienced will differ from the actual experience as the plan unfolds, and therefore, the basal ganglia may not correctly fulfill the intended behavior.
One way the aPFC can solve this problem is using attention. Suppose a rat’s basal ganglia learned, through trial and error, to run away from ducks and run toward rabbits. In this case, the basal ganglia will have opposite reactions to seeing the duck/rabbit depending on what pattern gets sent to it from the neocortex. If the aPFC had previously imagined seeing a rabbit and running toward it, then it can control the basal ganglia’s choices by using attention to ensure that when the rat sees this ambiguous picture, it sees a rabbit, not a duck.
Controlling ongoing behavior often also requires working memory—the maintenance of representations in the absence of any sensory cues. Many imagined paths and tasks involve waiting. For example, when a rodent forages among trees for nuts, it must remember which trees it has already foraged. This is a task shown to require the aPFC. If you inhibit a rodent’s aPFC during these delay periods, rodents lose their ability to perform such tasks from memory. And during such tasks, the aPFC exhibits “delay activity,” remaining activated even in the absence of any external cues. These tasks require the aPFC because working memory functions in the same way as attention and planning—it is the invoking of an inner simulation. Working memory—holding something in your head—is just your aPFC trying to keep re-invoking an inner simulation until you no longer need it.
In addition to planning, attention, and working memory, the aPFC can also control ongoing behavior more directly: It can inhibit the amygdala. There is a projection from the aPFC to inhibitory neurons surrounding the amygdala. During the fulfillment of an imagined plan, the aPFC can attempt to prevent the amygdala from triggering its own approach and avoidance responses. This was the evolutionary beginning of what psychologists call behavioral inhibition, willpower, and self-control: the persistent tension between our moment-to-moment cravings (as controlled by the amygdala and basal ganglia) and what we know to be a better choice (as controlled by the aPFC). In moments of willpower, you can inhibit your amygdala-driven cravings. In moments of weakness, the amygdala wins. This is why people become more impulsive when tired or stressed—the aPFC is energetically expensive to run, so if you are tired or stressed, the aPFC will be much less effective at inhibiting the amygdala.
To summarize: Planning, attention, and working memory are all controlled by the aPFC because all three are, in principle, the same thing. They are all different manifestations of brains trying to select what simulation to render. How does the aPFC “control” behavior? The idea presented here is that it doesn’t control behavior per se; it tries to convince the basal ganglia of the right choice by vicariously showing it that one choice is better and by filtering what information makes it to the basal ganglia. The aPFC controls behavior not by telling but by showing.
The benefit of this can be seen when comparing the performance of mammals to other vertebrates like lizards on tasks that require inhibiting reflexive responses in favor of “smarter” choices. If you put a lizard in a maze and try to train it to go toward a red light to get appealing food and avoid a green light which offers unappealing food, it takes lizards hundreds of trials to learn this simple task. The hardwired preference of lizards toward green light takes a long time to be untrained. Without a neocortex to pause and vicariously consider options, the only way lizards learn this task is through endless real trial and error. In contrast, rats learn to inhibit their hardwired responses much more rapidly, an advantage that disappears if you damage a rat’s aPFC.
Early mammals had the ability to vicariously explore their inner model of the world, make choices based on imagined outcomes, and stick to the imagined plan once chosen. They could flexibly determine when to simulate futures and when to use habits; and they intelligently selected what to simulate, overcoming the search problem. They were our first ancestors to have goals.