11
Generative Models and the Neocortical Mystery
WHEN YOU LOOK at a human brain, almost everything you see is neocortex. The neocortex is a sheet about two to four millimeters thick. As the neocortex got bigger, the surface area of this sheet expanded. To fit in the skull, it became folded, the way you would bunch up a towel to fit it in a suitcase. If you unfolded a human neocortical sheet, it would be almost three square feet in surface area—about the size of a small desk.
Early experimentation led to the conclusion that the neocortex didn’t serve any one function and instead subserved a multitude of different functions. For example, the back of the neocortex processes visual input and hence is called the visual cortex.* If you removed your visual cortex, you would become blind. If you record the activity of neurons in the visual cortex, they respond to specific visual features at specific locations, such as certain colors or line orientations. If you stimulate neurons within the visual cortex, people will report seeing flashes of lights.
In a nearby region called the auditory cortex, the same thing occurs with auditory perception. Damage to one’s auditory cortex impairs one’s ability to perceive and understand sounds. If you record the activity of neurons in the auditory cortex, you’ll find they are responsive to specific frequencies of sound. If you stimulate certain neurons within the auditory cortex, people will report hearing noises.
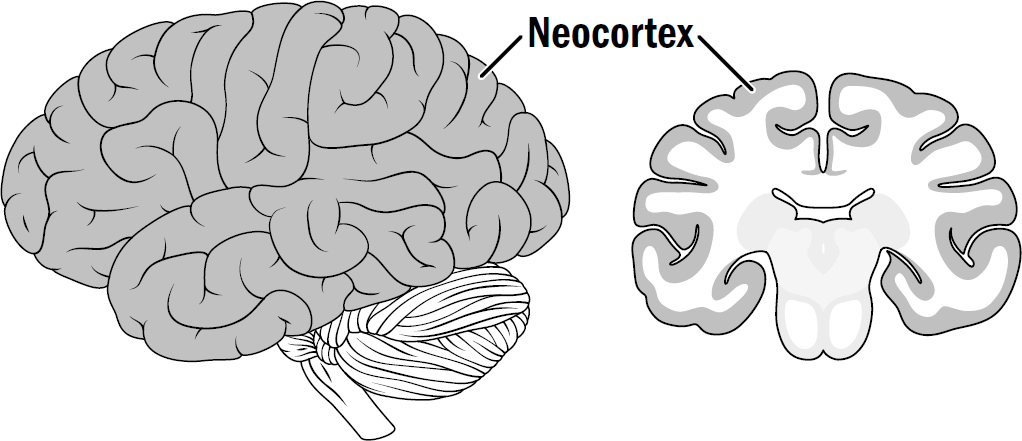
Figure 11.1: The human neocortex
Original art by Rebecca Gelernter
There are other neocortical regions for touch, pain, and taste. And there are other areas of the neocortex that seem to serve even more disparate functions—there are areas for movement, language, and music.
At first glance, this makes no sense. How can one structure do so many different things?
Mountcastle’s Crazy Idea
In the mid-twentieth century, the neuroscientist Vernon Mountcastle was pioneering what was, at the time, a new research paradigm: recording the activity of individual neurons in the neocortex of awake-behaving animals. This new approach offered a novel view of the inner workings of brains as animals went about their life. He used electrodes to record the neurons in the somatosensory cortices (the neocortical area that processes touch input) of monkeys to see what types of touch stimuli elicited what responses.
One of the first observations Mountcastle made was that neurons within a vertical column (about five hundred microns in diameter) of the neocortical sheet seemed to all respond similarly to sensory stimuli, while neurons horizontally farther away did not. For example, an individual column within the visual cortex might contain neurons that all similarly responded to bars of light at specific orientations at a specific location in the visual field. However, neurons within nearby columns responded only to bars of light at different orientations or locations. This same finding has been confirmed within multiple modalities. In rats, there are columns of neocortex that respond only to the touch of a specific single whisker, with each nearby column responding to a completely different whisker. In the auditory neocortex, there are individual columns that are selective for specific frequencies of sound.
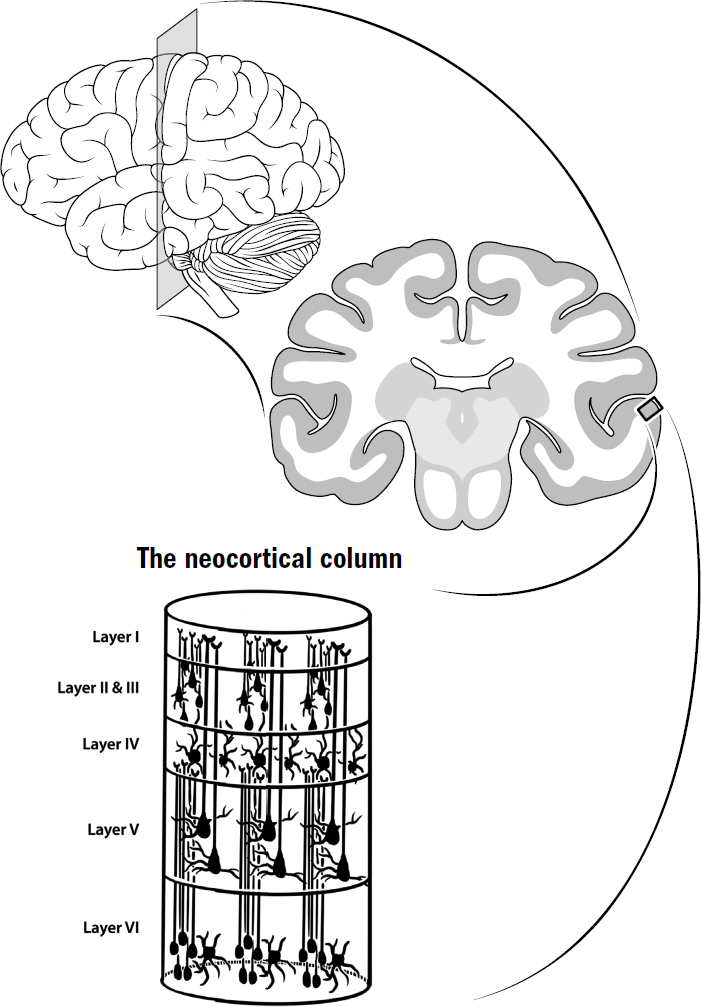
Figure 11.2: The neocortical column
Original art by Rebecca Gelernter
The second observation that Mountcastle made was that there were many connections vertically within a column and comparatively fewer connections between columns.
The third and final observation Mountcastle made was that under a microscope, the neocortex looked largely identical everywhere. The auditory neocortex, somatosensory neocortex, and visual neocortex all contain the same types of neurons organized in the same way. And this is true across species of mammals—the neocortex of a rat, a monkey, and a human all look relatively the same under a microscope.
These three facts—vertically aligned activity, vertically aligned connectivity, and observed similarity between all areas of neocortex—led Mountcastle to a remarkable conclusion: the neocortex was made up of a repeating and duplicated microcircuit, what he called the neocortical column. The cortical sheet was just a bunch of neocortical columns packed densely together.
This provided a surprising answer to the question of how one structure can do so many different things. According to Mountcastle, the neocortex does not do different things; each neocortical column does exactly the same thing. The only difference between regions of neocortex is the input they receive and where they send their output; the actual computations of the neocortex itself are identical. The only difference between, for example, the visual cortex and the auditory cortex is that the visual cortex gets input from the retina, and the auditory cortex gets input from the ear.
In the year 2000, decades after Mountcastle first published his theory, three neuroscientists at MIT performed a brilliant test of Mountcastle’s hypothesis. If the neocortex is the same everywhere, if there is nothing uniquely visual about the visual cortex or auditory about the auditory cortex, then you would expect these areas to be interchangeable. Experimenting on young ferrets, the scientists cut off input from the ears and rewired input from the retina to the auditory cortex instead of the visual cortex. If Mountcastle was wrong, the ferrets would end up blind or visually impaired—input from the eye in the auditory cortex would not be processed correctly. If the neocortex was indeed the same everywhere, then the auditory cortex receiving visual input should work the same way as the visual cortex.
Remarkably, the ferrets could see just fine. And when researchers recorded the area of the neocortex that was typically auditory but was now receiving input from the eyes, they found the area responded to visual stimuli just as the visual cortex would. The auditory and visual cortices are interchangeable.
This was further reinforced by studies of congenitally blind patients whose retinas had never sent any signals to their brains. In these patients, the visual cortex never received input from the eyes. However, if you record the activity of neurons in the visual cortex of congenitally blind humans, you find that the visual cortex has not been rendered a functionally useless region. Instead, it becomes responsive to a multitude of other sensory input, such as sounds and touch. This puts meat on the bone of the idea that people who are blind do, in fact, have superior hearing—the visual cortex becomes repurposed to aid in audition. Again, areas of neocortex seem interchangeable.
Consider stroke patients. When patients have damage to a specific area of neocortex, they immediately lose the function in that area. If the motor cortex is damaged, patients can become paralyzed. If the visual cortex is damaged, patients become partially blind. But over time, function can return. This is usually not the consequence of the damaged area of neocortex recovering; typically, that area of neocortex remains dead forever. Instead, nearby areas of neocortex become repurposed to fulfill the functions of the now-damaged area of neocortex. This too suggests that areas of neocortex are interchangeable.
To those in the AI community, Mountcastle’s hypothesis is a scientific gift like no other. The human neocortex is made up of over ten billion neurons and trillions of connections; it is a hopeless endeavor to try and decode the algorithms and computations performed by such an astronomically massive hairball of neurons. So hopeless that many neuroscientists believe that attempting to decode how the neocortex works is a fruitless endeavor, doomed to fail. But Mountcastle’s theory offers a more hopeful research agenda—instead of trying to understand the entire human neocortex, perhaps we only have to understand the function of the microcircuit that is repeated a million or so times. Instead of understanding the trillions of connections in the entire neocortex, perhaps we only have to understand the million or so connections within the neocortical column. Further, if Mountcastle’s theory is correct, it suggests that the neocortical column implements some algorithm that is so general and universal that it can be applied to extremely diverse functions such as movement, language, and perception across every sensory modality.
The basics of this microcircuit can be seen under a microscope. The neocortex contains six layers of neurons (unlike the three-layered cortex seen in earlier vertebrates). These six layers of neurons are connected in a complicated but beautifully consistent way. There is a specific type of neuron in layer five that always projects to the basal ganglia, the thalamus, and the motor areas. In layer four, there are neurons that always get input directly from the thalamus. In layer six, there are neurons that always project to the thalamus. It is not just a soup of randomly connected neurons; the microcircuit is prewired in a specific way to perform some specific computation.
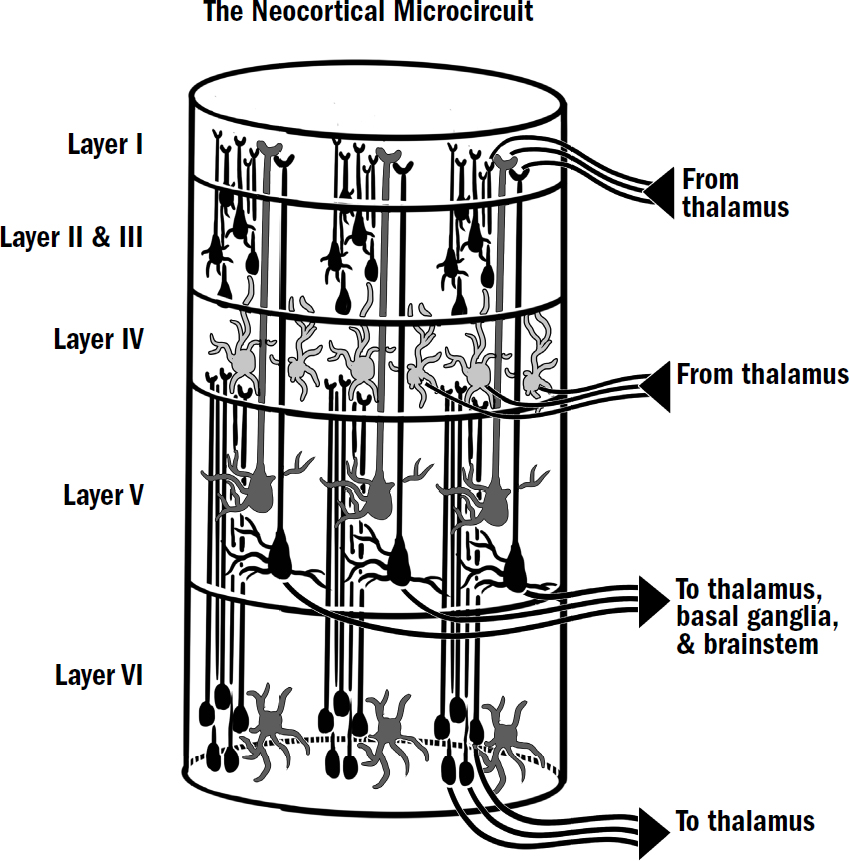
Figure 11.3: The microcircuitry of the neocortical column
Original art by Mesa Schumacher
The question is, of course: What is the computation?
Peculiar Properties of Perception
In the nineteenth century, the scientific study of human perception began in full force. Scientists around the world started probing the mind. How does vision work? How does audition work?
The inquiry into perception began with the use of illusions; by manipulating people’s visual perceptions, scientists uncovered three peculiar properties of perception. And because much of perception, in humans at least, occurs in the neocortex, these properties of perception teach us about how the neocortex works.
Property #1: Filling In
The first thing that became clear to these nineteenth-century scientists was that the human mind automatically and unconsciously fills in missing things. Consider the images in figure 11.4. You immediately perceive the word editor. But this is not what your eye is actually seeing—most of the lines of the letters are missing. In the other images too, your mind perceives something that is not there: a triangle, a sphere, and a bar with something wrapped around it.
This filling in is not a property unique to vision; it is seen across most of our sensory modalities. This is how you can still understand what someone is saying through a garbled phone connection and how you can identify an object through touch even with your eyes closed.

Figure 11.4: Filling-in property of perception
“Editor” from Jastrow, 1899. Others from Lehar, 2003.
Property #2: One at a Time
If your mind fills in what it thinks is there based on sensory evidence, what happens if there are multiple ways to fill in what you see? All three of the images in figure 11.5 are examples of visual illusions devised in the 1800s to probe this question. Each of these images can be interpreted in two different ways. On the left side of figure 11.5, you can see it as a staircase, but you can also see it as a protrusion from under a staircase.* In the middle of figure 11.5, the cube could be one where the bottom right square is the front or where the top left square is the front. On the right of figure 11.5, the picture could be a rabbit or a duck.
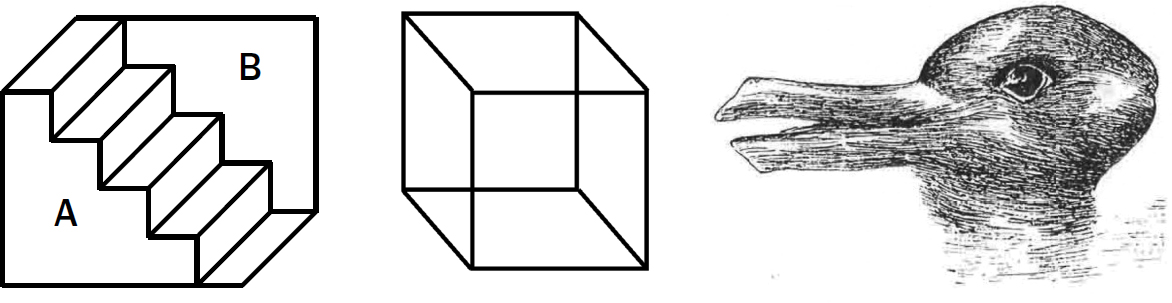
Figure 11.5: One-at-a-time property of perception
Staircase from Schroeder, 1858. “Necker cube” from Necker, 1832. Duck or rabbit from from Jastrow, 1899.
What is interesting about all these ambiguous pictures is that your brain can see only one interpretation at a time. You cannot see a duck and a rabbit simultaneously, even though the sensory evidence is equally suggestive of both. The mechanisms of perception in the brain, for some reason, require it to pick only one.
This also applies to audition. Consider the “cocktail-party effect.” If you are at a noisy cocktail party, you can tune in to the conversation of the person you are speaking to or the conversation of a nearby group. But you cannot listen to both conversations at the same time. No matter which conversation you tune in to, the auditory input into your ear is identical; the only difference is what your brain infers from that input. You can perceive only a single conversation at a time.
Property #3: Can’t Unsee
What happens when sensory evidence is vague—when it isn’t clear that it can be interpreted as anything meaningful at all? Consider the image in 11.6. If you haven’t seen these before, they will look like nothing—just blobs. If I give you a reasonable interpretation of these blobs, all of a sudden, your perception of them will change.
Figure 11.6 can be interpreted as a frog (see here if you don’t see this). Once your mind perceives this interpretation, you will never be able to unsee it. This is what might be called the can’t-unsee property of perception. Your mind likes to have an interpretation that explains sensory input. Once I give you a good explanation, your mind sticks to it. You now perceive a frog.

Figure 11.6: The can’t-unsee property of perception
Image from Fahle et al., 2002. Used with permission by The MIT Press.
In the nineteenth century, a German physicist and physician named Hermann von Helmholtz proposed a novel theory to explain these properties of perception. He suggested that a person doesn’t perceive what is experienced; instead, he or she perceives what the brain thinks is there—a process Helmholtz called inference. Put another way: you don’t perceive what you actually see, you perceive a simulated reality that you have inferred from what you see.
This idea explains all three of these peculiar properties of perception. Your brain fills in missing parts of objects because it is trying to decipher the truth that your vision is suggesting (“Is there actually a sphere there?”). You can see only one thing at a time because your brain must pick a single reality to simulate—in reality, the animal can’t be both a rabbit and a duck. And once you see that an image is best explained as a frog, your brain maintains this reality when observing it.
While many psychologists came to agree, in principle, with Helmholtz’s theory, it would take another century before anyone proposed how Helmholtz’s perception by inference might actually work.
Generative Models: Recognizing by Simulating
In the 1990s, Geoffrey Hinton and some of his students (including the same Peter Dayan that had helped discover that dopamine responses are temporal difference learning signals) set their sights on building an AI system that learned in the way that Helmholtz suggested.

We reviewed in chapter 7 how most modern neural networks are trained with supervision: a picture is given to a network (e.g., a picture of a dog) along with the correct answer (e.g., “This is a dog”), and the connections in the network are nudged in the right direction to get it to give the right answer. It is unlikely the brain recognizes objects and patterns using supervision in this way. Brains must somehow recognize aspects of the world without being told the right answer; they must engage in unsupervised learning.
One class of unsupervised-learning methods are auto-associative networks, like those we speculated emerged in the cortex of early vertebrates. Based on correlations in input patterns, these networks cluster common patterns of input into ensembles of neurons, offering a way in which overlapping patterns can be recognized as distinct, and noisy and obstructed patterns can be completed.
But Helmholtz suggested that human perception was doing something more than this. He suggested that instead of simply clustering incoming input patterns based on their correlations, human perception might optimize for the accuracy with which the inner simulated reality predicts the current external sensory input.
In 1995, Hinton and Dayan came up with a proof of concept for Helmholtz’s idea of perception by inference; they named it the Helmholtz machine. The Helmholtz machine was, in principle, similar to other neural networks; it received inputs that flowed from one end to the other. But unlike other neural networks, it also had backward connections that flowed the opposite way—from the end to the beginning.
Hinton tested this network with images of handwritten numbers between 0 and 9. A picture of a handwritten number can be given at the bottom of the network (one neuron for each pixel) and will flow upward and activate a random set of neurons at the top. These activated neurons at the top can then flow back down and activate a set of neurons at the bottom to produce a picture of its own. Learning was designed to get the network to stabilize to a state where input that flows up the network is accurately re-created when it flows back down.
At first, there will be big discrepancies between the values in neurons from the image flowing in and the result flowing out. Hinton designed this network to learn with two separate modes: recognition mode and generative mode. When in recognition mode, information flows up the network (starting from an input picture of a 7 to some neurons at the top), and the backward weights are nudged to make the neurons activated at the top of the network better reproduce the input sensory data (make a good simulated 7). In contrast, when in generative mode, information flows down the network (starting from the goal to produce an imagined picture of a 7), and the forward weights are nudged so that the neurons activated at the bottom of the network are correctly recognized at the top (“I recognize what I just made as a 7”).
Nowhere was this network told the right answer; it was never told what properties make up a 2 or even which pictures were 2s or 7s or any other number. The only data the network had to learn from was pictures of numbers. The question was, of course, would this work? Would this toggling back and forth between recognition and generation enable the network to both recognize handwritten numbers and generate its own unique pictures of handwritten numbers without ever having been told the right answer?
Amazingly, it did; it learned on its own. When these two processes toggle back and forth, the network magically stabilizes. When you give it a picture of the number 7, it will be able to, for the most part, create a similar image of a 7 on the way down. If instead you give it an image of an 8, it will be able to regenerate an input image of an 8.
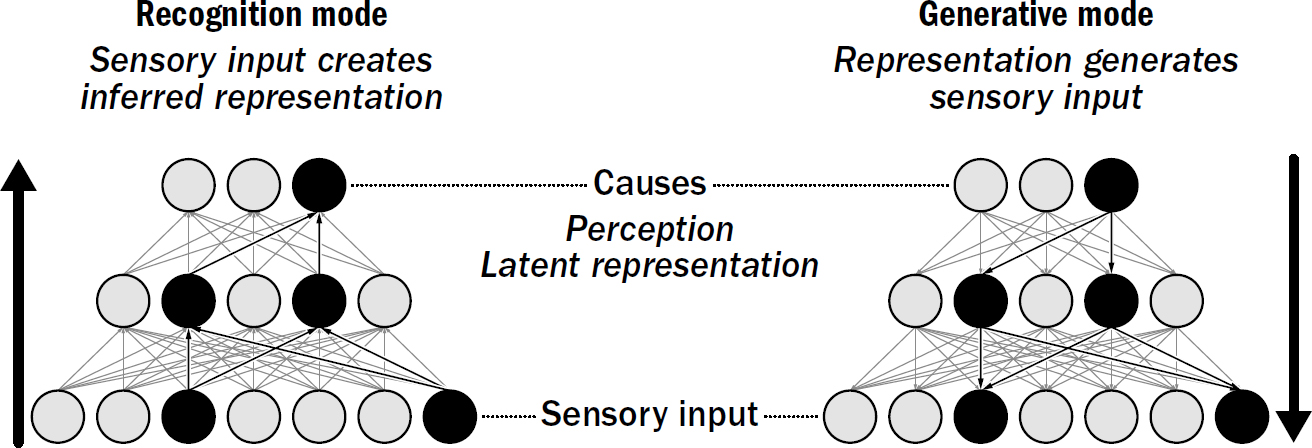
Figure 11.7: The Helmholtz Machine
Original art by Rebecca Gelernter
This might not seem particularly impressive. You gave a network a picture of a number, and it spit out a picture of that same number—what’s the big deal? There are three attributes of this network that are groundbreaking. First, the top of this network now reliably “recognizes” imperfectly handwritten letters without any supervision. Second, it generalizes impressively well; it can tell that two differently handwritten pictures of 7s are both a 7—they will activate a similar set of neurons at the top of the network. And third, and most important, this network can now generate novel pictures of handwritten numbers. By manipulating neurons at the top of this network, you can create lots of handwritten 7s or handwritten 4s or any number it has learned. This network has learned to recognize by generating its own data.

The Helmholtz machine was an early proof of concept of a much broader class of models called generative models. Most modern generative models are more complicated than the Helmholtz machine, but they share the essential property that they learn to recognize things in the world by generating their own data and comparing the generated data to the actual data.
If you aren’t impressed with the generation of small pixelated handwritten numbers, consider how far these generative models have come since 1995. As this book is going to print, there is an active website called thispersondoesnotexist.com. Every time you refresh the page, you will see a picture of a different person. The reality is more shocking: every time you reload the page, a generative model creates a completely new, never before seen, made-up face. The faces you see do not exist.
What is so amazing about these generative models is that they learn to capture the essential features of the input they are given without any supervision. The ability to generate realistic novel faces requires the model to understand the essence of what constitutes a face and the many ways it can vary. Just as activating various neurons at the top of the Helmholtz machine can generate images of different handwritten numbers, if you activate various neurons at the top of this generative model of faces, you can control what types of faces it generates. If you change the value of one set of neurons, the network will spit out the same face but rotated. If you change the value of a different set of neurons, it will add a beard or change the age or alter the color of the hair (see figure 11.10).

Figure 11.9: StyleGAN2 from thispersondoesnotexist.com
Pictures from thispersondoesnotexist.com
While most AI advancements that occurred in the early 2000s involved applications of supervised-learning models, many of the recent advancements have been applications of generative models. Deepfakes, AI-generated art, and language models like GPT-3 are all examples of generative models at work.
Helmholtz suggested that much of human perception is a process of inference—a process of using a generative model to match an inner simulation of the world to the sensory evidence presented. The success of modern generative models gives weight to his idea; these models reveal that something like this can work, at least in principle. It turns out that there is, in fact, an abundance of evidence that the neocortical microcircuit is implementing such a generative model.

Figure 11.10: Changing images by changing latent representations in generative models
Figure from He et al., 2019. Used with permission.
Evidence for this is seen in filling-in, one-at-a-time, can’t-unsee visual illusions; evidence is seen in the wiring of the neocortex itself, which has been shown to have many properties consistent with a generative model; and evidence is seen in the surprising symmetry—the ironclad inseparability—between perception and imagination that is found in both generative models and the neocortex. Indeed, the neocortex as a generative model explains more than just visual illusions—it also explains why humans succumb to hallucinations, why we dream and sleep, and even the inner workings of imagination itself.
Hallucinating, Dreaming, and Imagining: The Neocortex as a Generative Model
People whose eyes stop sending signals to their neocortex, whether due to optic-nerve damage or retinal damage, often get something called Charles Bonnet syndrome. You would think that when someone’s eyes are disconnected from their brain, they would no longer see. But the opposite happens—for several months after going blind, people start seeing a lot. They begin to hallucinate. This phenomenon is consistent with a generative model: cutting off sensory input to the neocortex makes it unstable. It gets stuck in a drifting generative process in which visual scenes are simulated without being constrained to actual sensory input—thus you hallucinate.
Some neuroscientists refer to perception, even when it is functioning properly, as a “constrained hallucination.” Without sensory input, this hallucination becomes unconstrained. In our example of the Helmholtz machine, this is like randomly activating neurons at the top of the network and producing hallucinated images of numbers without ever grounding these hallucinations in real sensory input.
This idea of perception as a constrained hallucination is, of course, exactly what Helmholtz meant by inference and exactly what a generative model is doing. We match our inner hallucination of reality to the sensory data we are seeing. When the visual data suggests there is a triangle in a picture (even if there is not actually a triangle there), we hallucinate a triangle, hence the filling-in effect.
Generative models may also explain why we dream and why we need sleep. Most animals sleep, and it has numerous benefits, such as saving energy; but only mammals and birds show unequivocal evidence of dreaming as measured by the presence of REM sleep. And it is only mammals and birds who exhibit hallucinations and disordered perception if deprived of sleep. Indeed, birds seem to have independently evolved their own neocortex-like structure.
The neocortex (and presumably the bird equivalent) is always in an unstable balance between recognition and generation, and during our waking life, humans spend an unbalanced amount of time recognizing and comparatively less time generating. Perhaps dreams are a counterbalance to this, a way to stabilize the generative model through a process of forced generation. If we are deprived of sleep, this imbalance of too much recognition and not enough generation eventually becomes so severe that the generative model in the neocortex becomes unstable. Hence, mammals start hallucinating, recognition becomes distorted, and the difference between generation and recognition gets blurred. Fittingly, Hinton even called the learning algorithm to train his Helmholtz machine a “wake-sleep algorithm.” Recognition step was when the model was “awake”; the generation step was when the model was “asleep.”
Many features of imagination in mammals are consistent with what we would expect from a generative model. It is easy, even natural, for humans to imagine things that they are not currently experiencing. You can imagine the dinner you ate last night or imagine what you will be doing later today. What are you doing when you are imagining something? This is just your neocortex in generation mode. You are invoking a simulated reality in your neocortex.
The most obvious feature of imagination is that you cannot imagine things and recognize things simultaneously. You cannot read a book and imagine yourself having breakfast at the same time—the process of imagining is inherently at odds with the process of experiencing actual sensory data. In fact, you can tell when someone is imagining something by looking at that person’s pupils—when people are imagining things, their pupils dilate as their brains stop processing actual visual data. People become pseudo-blind. As in a generative model, generation and recognition cannot be performed simultaneously.
Further, if you record neocortical neurons that become active during recognition (say, neurons that respond to faces or houses), those exact same neurons become active when you simply imagine the same thing. When you imagine moving certain body parts, the same area activates as if you were actually moving the body parts. When you imagine certain shapes, the same areas of visual cortex become activated as when you see those shapes. In fact, this is so consistent that neuroscientists can decode what people are imagining simply by recording their neocortical activity (and as evidence that dreaming and imagination are the same general process, scientists can also accurately decode people’s dreams by recording their brains). People with neocortical damage that impairs certain sensor data (such as being unable to recognize objects on the left side of the visual field) become equally impaired at simply imagining features of that same sensory data (they struggle even to imagine things in the left visual field).
None of this is an obvious result. Imagination could have been performed by a system separate from recognition. But in the neocortex, this is not the case—they are performed in the exact same area. This is exactly what we would expect from a generative model: perception and imagination are not separate systems but two sides of the same coin.
Predicting Everything
One way to think about the generative model in the neocortex is that it renders a simulation of your environment so that it can predict things before they happen. The neocortex is continuously comparing the actual sensory data with the data predicted by its simulation. This is how you can immediately identify anything surprising that occurs in your surroundings.
As you walk down the street, you are not paying attention to the feelings of your feet. But with every movement you make, your neocortex is passively predicting what sensory outcome it expects. If you placed your left foot down and didn’t feel the ground, you would immediately look to see if you were about to fall down a pothole. Your neocortex is running a simulation of you walking, and if the simulation is consistent with sensor data, you don’t notice it, but if its predictions are wrong, you do.
Brains have been making predictions since early bilaterians, but over evolutionary time, these predictions became more sophisticated. Early bilaterians could learn that the activation of one neuron tended to precede the activation of another neuron and could thereby use the first neuron to predict the second. This was the simplest form of prediction. Early vertebrates could use patterns in the world to predict future rewards. This was a more sophisticated form of prediction. Early mammals, with the neocortex, learned to predict more than just the activation of reflexes or future rewards; they learned to predict everything.
The neocortex seems to be in a continuous state of predicting all its sensory data. If reflex circuits are reflex-prediction machines, and the critic in the basal ganglia is a reward-prediction machine, then the neocortex is a world-prediction machine—designed to reconstruct the entire three-dimensional world around an animal to predict exactly what will happen next as animals and things in their surrounding world move.
Somehow the neocortical microcircuit implements such a general system that it can render a simulation of many types of input. Give it visual input and it will learn to render a simulation of the visual aspects of the world; give it auditory input and it will learn to render a simulation of auditory aspects of the world. This is why the neocortex looks the same everywhere. Different subregions of neocortex simulate different aspects of the external world based on the input they receive. Put all these neocortical columns together, and they make a symphony of simulations that render a rich three-dimensional world filled with objects that can be seen, touched, and heard.
How the neocortex does this is still a mystery. At least one possibility is that it is prewired to make a set of clever assumptions. Modern AI models are often viewed as narrow—that is, they’re able to work in a narrow set of situations they are specifically trained for. The human brain is considered general—it is able to work in a broad set of situations. The research agenda has therefore been to try and make AI more general. However, we might have it backward. One of the reasons why the neocortex is so good at what it does may be that, in some ways, it is far less general than our current artificial neural networks. The neocortex may make explicit narrow assumptions about the world, and it may be exactly these assumptions that enable it to be so general.
The Evolution of Prediction
PREDICTION IN EARLY BILATERIANS |
PREDICTION IN EARLY VERTEBRATES |
PREDICTION IN EARLY MAMMALS |
Predict reflex activation |
Predict future rewards |
Predict all sensory data |
Reflex circuits |
Cortex and basal ganglia |
Neocortex |
For example, the neocortex may be prewired to assume that incoming sensor data, whether visual, auditory, or somatosensory, represent three-dimensional objects that exist separately from ourselves and can move on their own. Therefore, it does not have to learn about space, time, and the difference between the self and others. Instead, it tries to explain all incoming sensory information it receives by assuming it must have been derived from a 3D world that unfolds over time.
This provides some intution about what Helmholtz meant by inference—the generative model in the neocortex tries to infer the causes of its sensory input. Causes are just the inner simulated 3D world that the neocortex believes best matches the sensory input it is being given. This is also why generative models are said to try to explain their input—your neocortex attempts to render a state of the world that could produce the picture that you are seeing (e.g., if a frog was there, it would “explain” why those shadows look the way they do).
But why do this? What is the point of rendering an inner simulation of the external world? What value did the neocortex offer these ancient mammals?
There are many ongoing debates about what is missing in modern AI systems and what it will take to get AI systems to exhibit human-level intelligence. Some believe the key missing pieces are language and logic. But others, like Yann LeCun, head of AI at Meta, believe they are something else, something more primitive, something that evolved much earlier. In LeCun’s words:
We humans give way too much importance to language and symbols as the substrate of intelligence. Primates, dogs, cats, crows, parrots, octopi, and many other animals don’t have human-like languages, yet exhibit intelligent behavior beyond that of our best AI systems. What they do have is an ability to learn powerful “world models” that allow them to predict the consequences of their actions and to search for and plan actions to achieve a goal. The ability to learn such world models is what’s missing from AI systems today.
The simulation rendered in the neocortices of mammals (and perhaps in similar structures of birds or even octopuses) is exactly this missing “world model.” The reason the neocortex is so powerful is not only that it can match its inner simulation to sensory evidence (Helmholtz’s perception by inference) but, more important, that its simulation can be independently explored. If you have a rich enough inner model of the external world, you can explore that world in your mind and predict the consequences of actions you have never taken. Yes, your neocortex enables you to open your eyes and recognize the chair in front of you, but it also enables you to close your eyes and still see that chair in your mind’s eye. You can rotate and modify the chair in your mind, change its colors, change its materials. It is when the simulation in your neocortex becomes decoupled from the real external world around you—when it imagines things that are not there—that its power becomes most evident.
This was the gift the neocortex gave to early mammals. It was imagination—the ability to render future possibilities and relive past events—that was the third breakthrough in the evolution of human intelligence. From it emerged many familiar features of intelligence, some of which we have re-created and surpassed in AI systems, others of which are still beyond our grasp. But all of them evolved in the minuscule brains of the first mammals.
In the coming chapters, we will learn how the neocortex enabled early mammals to perform feats like planning, episodic memory, and causal reasoning. We will learn how these tricks were repurposed to enable fine motor skills. We will learn about how the neocortex implements attention, working memory, and self-control. We will see that it is in the neocortex of early mammals where we will find many of the secrets to human-like intelligence, those that are missing from even our smartest AI systems.