To thoroughly understand a malicious program, we often need to go beyond basic static analysis of its sections, strings, imports, and images. This involves reverse engineering a program’s assembly code. Indeed, disassembly and reverse engineering lie at the heart of deep static analysis of malware samples.
Because reverse engineering is an art, technical craft, and science, a thorough exploration is beyond the scope of this chapter. My goal here is to introduce you to reverse engineering so that you can apply it to malware data science. Understanding this methodology is essential for successfully applying machine learning and data analysis to malware.
In this chapter I start with the concepts you’ll need to understand x86 disassembly. Later in the chapter I show how malware authors attempt to bypass disassembly and discuss ways to mitigate these anti-analysis and anti-detection maneuvers. But first, let’s review some common disassembly methods as well as the basics of x86 assembly language.
Disassembly is the process by which we translate malware’s binary code into valid x86 assembly language. Malware authors generally write malware programs in a high-level language like C or C++ and then use a compiler to compile the source code into x86 binary code. Assembly language is the human-readable representation of this binary code. Therefore, disassembling a malware program into assembly language is necessary to understand how it behaves at its core.
Unfortunately, disassembly is no easy feat because malware authors regularly employ tricks to thwart would-be reverse engineers. In fact, perfect disassembly in the face of deliberate obfuscation is an unsolved problem in computer science. Currently, only approximate, error-prone methods exist for disassembling such programs.
For example, consider the case of self-modifying code, or binary code that modifies itself as it executes. The only way to disassemble this code properly is to understand the program logic by which the code modifies itself, but that can be exceedingly complex.
Because perfect disassembly is currently impossible, we must use imperfect methods to accomplish this task. The method we’ll use is linear disassembly, which involves identifying the contiguous sequence of bytes in the Portable Executable (PE) file that corresponds to its x86 program code and then decoding these bytes. The key limitation of this approach is that it ignores subtleties about how instructions are decoded by the CPU in the course of program execution. Also, it doesn’t account for the various obfuscations malware authors sometimes use to make their programs harder to analyze.
The other methods of reverse engineering, which we won’t cover here, are the more complex disassembly methods used by industrial-grade disassemblers such as IDA Pro. These more advanced methods actually simulate or reason about program execution to discover which assembly instructions a program might reach as a result of a series of conditional branches.
Although this type of disassembly can be more accurate than linear disassembly, it’s far more CPU intensive than linear disassembly methods, making it less suitable for data science purposes where the focus is on disassembling thousands or even millions of programs.
Before you can begin analysis using linear disassembly, however, you’ll need to review the basic components of assembly language.
Assembly language is the lowest-level human-readable programming language for a given architecture, and it maps closely to the binary instruction format of a particular CPU architecture. A line of assembly language is almost always equivalent to a single CPU instruction. Because assembly is so low level, you can often retrieve it easily from a malware binary by using the right tools.
Gaining basic proficiency in reading disassembled malware x86 code is easier than you might think. This is because most malware assembly code spends most of its time calling into the operating system by way of the Windows operating system’s dynamic-link libraries (DLLs), which are loaded into program memory at runtime. Malware programs use DLLs to do most of the real work, such as modifying the system registry, moving and copying files, making network connections and communicating via network protocols, and so on. Therefore, following malware assembly code often involves understanding the ways in which function calls are made from assembly and understanding what various DLL calls do. Of course, things can get much more complicated, but knowing this much can reveal a lot about the malware.
In the following sections I introduce some important assembly language concepts. I also explain some abstract concepts like control flow and control flow graphs. Finally, we disassemble the ircbot.exe program and explore how its assembly and control flow can give us insight into its purpose.
There are two major dialects of x86 assembly: Intel and AT&T. In this book I use Intel syntax, which can be obtained from all major disassemblers and is the syntax used in the official Intel documentation of the x86 CPU.
Let’s start by taking a look at CPU registers.
Registers are small data storage units on which x86 CPUs perform computations. Because registers are located on the CPU itself, register access is orders of magnitude faster than memory access. This is why core computational operations, such as arithmetic and condition testing instructions, all target registers. It’s also why the CPU uses registers to store information about the status of running programs. Although many registers are available to experienced x86 assembly programmers, we’ll just focus on a few important ones here.
General-purpose registers are like scratch space for assembly programmers. On a 32-bit system, each of these registers contains 32, 16, or 8 bits of space against which we can perform arithmetic operations, bitwise operations, byte order–swapping operations, and more.
In common computational workflows, programs move data into registers from memory or from external hardware devices, perform some operations on this data, and then move the data back out to memory for storage. For example, to sort a long list, a program typically pulls list items in from an array in memory, compares them in the registers, and then writes the comparison results back out to memory.
To understand some of the nuances of the general-purpose register model in the Intel 32-bit architecture, take a look at Figure 2-1.
Figure 2-1: Registers in the x86 architecture
The vertical axis shows the layout of the general-purpose registers, and the horizontal axis shows how EAX, EBX, ECX, and EDX are subdivided. EAX, EBX, ECX, and EDX are 32-bit registers that have smaller, 16-bit registers inside them: AX, BX, CX, and DX. As you can see in the figure, these 16-bit registers can be subdivided into upper and lower 8-bit registers: AH, AL, BH, BL, CH, CL, DH, and DL. Although it’s sometimes useful to address the subdivisions in EAX, EBX, ECX, and EDX, you’ll mostly see direct references to EAX, EBX, ECX, and EDX.
The stack management registers store critical information about the program stack, which is responsible for storing local variables for functions, arguments passed into functions, and control information relating to the program control flow. Let’s go over some of these registers.
In simple terms, the ESP register points to the top of the stack for the currently executing function, whereas the EBP register points to the bottom of the stack for the currently executing function. This is crucial information for modern programs, because it means that by referencing data relative to the stack rather than using its absolute address, procedural and object-oriented code can access local variables more gracefully and efficiently.
Although you won’t see direct references to the EIP register in x86 assembly code, it’s important in security analysis, particularly in the context of vulnerability research and buffer-overflow exploit development. This is because EIP contains the memory address of the currently executing instruction. Attackers can use buffer-overflow exploits to corrupt the value of the EIP register indirectly and take control of program execution.
In addition to its role in exploitation, EIP is also important in the analysis of malicious code deployed by malware. Using a debugger we can inspect EIP’s value at any moment, which helps us understand what code malware is executing at any particular time.
EFLAGS is a status register that contains CPU flags, which are bits that store status information about the state of the currently executing program. The EFLAGS register is central to the process of making conditional branches, or changes in execution flow resulting from the outcome of if/then-style program logic, within x86 programs. Specifically, whenever an x86 assembly program checks whether some value is greater or less than zero and then jumps to a function based on the outcome of this test, the EFLAGS register plays an enabling role, as described in more detail in “Basic Blocks and Control Flow Graphs” on page 19.
Instructions operate on general-purpose registers. You can perform simple computations with the general-purpose registers using arithmetic instructions. For example, add, sub, inc, dec, and mul are examples of arithmetic instructions you’ll encounter frequently in malware reverse engineering. Table 2-1 lists some examples of basic instructions and their syntax.
Table 2-1: Arithmetic Instructions
Instructions |
Description |
add ebx, 100 |
Adds 100 to the value in EBX and then stores the result in EBX |
sub ebx, 100 |
Subtracts 100 from the value in EBX and then stores the result in EBX |
inc ah |
Increments the value in AH by 1 |
dec al |
Decrements the value in AL by 1 |
The add instruction adds two integers and stores the result in the first operand specified, whether this is a memory location or a register according to the following syntax. Keep in mind only one argument can be a memory location. The sub instruction is similar to add, except it subtracts integers. The inc instruction increments a register or memory location’s integer value, whereas dec decrements a register or memory location’s integer value.
The x86 processor provides a robust set of instructions for moving data between registers and memory. These instructions provide the underlying mechanisms that allow us to manipulate data. The staple memory movement instruction is the mov instruction. Table 2-2 shows how you can use the mov instruction to move data around.
Table 2-2: Data Movement Instructions
Instructions |
Description |
mov ebx,eax |
Moves the value in register EAX into register EBX |
mov eax, [0x12345678] |
Moves the data at memory address 0x12345678 into the EAX register |
mov edx, 1 |
Moves the value 1 into the register EDX |
mov [0x12345678], eax |
Moves the value in EAX into the memory location 0x12345678 |
Related to the mov instruction, the lea instruction loads the absolute memory address specified into the register used for getting a pointer to a memory location. For example, lea edx, [esp-4] subtracts 4 from the value in ESP and loads the resulting value into EDX.
The stack in x86 assembly is a data structure that allows you to push and pop values onto and off of it. This is similar to how you would add and remove plates on and off the top of a stack of plates.
Because control flow is often expressed through C-style function calls in x86 assembly and because these function calls use the stack to pass arguments, allocate local variables, and remember what part of the program to return to after a function finishes executing, the stack and control flow need to be understood together.
The push instruction pushes values onto the program stack when the programmer wants to save a register value onto the stack, and the pop instruction deletes values from the stack and places them into a designated register.
The push instruction uses the following syntax to perform its operations:
push 1
In this example, the program points the stack pointer (the register ESP) to a new memory address, thereby making room for the value (1), which is now stored at the top location on the stack. Then it copies the value from the argument to the memory location the CPU has just made room for on the top of the stack.
Let’s contrast this with pop:
pop eax
The program uses pop to pop the top value off the stack and move it into a specified register. In this example, pop eax pops the top value off the stack and moves it into eax.
An unintuitive but important detail to understand about the x86 program stack is that it grows downward in memory, so that the highest value on the stack is actually stored at the lowest address in stack memory. This becomes very important to remember when you analyze assembly code that references data stored on the stack, as it can quickly get confusing unless you know the stack’s memory layout.
Because the x86 stack grows downward in memory, when the push instruction allocates space on the program stack for a new value, it decrements the value of ESP so that it points to a lower location in memory and then copies a value from the target register into that memory location, starting at the top address of the stack and growing up. Conversely, the pop instruction actually copies the top value off of the stack and then increments the value of ESP so it points to a higher memory location.
An x86 program’s control flow defines the network of possible instruction execution sequences a program may execute, depending on the data, device interactions, and other inputs the program might receive. Control flow instructions define a program’s control flow. They are more complicated than stack instructions but still quite intuitive. Because control flow is often expressed through C-style function calls in x86 assembly, the stack and control flow are closely related. They’re also related because these function calls use the stack to pass arguments, allocate local variables, and remember what part of the program to return to after a function finishes executing.
The call and ret control flow instructions are the most important in terms of how programs call functions in x86 assembly and how programs return from functions after these functions are done executing.
The call instruction calls a function. Think of this as a function you might write in a higher-level language like C to allow the program to return to the instruction after the call instruction is invoked and the function has finished executing. You can invoke the call instruction using the following syntax, where address denotes the memory location where the function’s code begins:
call address
The call instruction does two things. First, it pushes the address of the instruction that will execute after the function call returns onto the top of the stack so that the program knows what address to return to after the called function finishes executing. Second, call replaces the current value of EIP with the value specified by the address operand. Then, the CPU begins execution at the new memory location pointed to by EIP.
Just as call initiates a function call, the ret instruction completes it. You can use the ret instruction on its own and without any parameter, as shown here:
ret
When invoked, ret pops the top value off the stack, which we expect to be the saved program counter value (EIP) that the call instruction pushed onto the stack when the call instruction was invoked. Then it places the popped program counter value back into EIP and resumes execution.
The jmp instruction is another important control flow construction, which operates more simply than call. Instead of worrying about saving EIP, jmp simply tells the CPU to move to the memory address specified as its parameter and begin execution there. For example, jmp 0x12345678 tells the CPU to start executing the program code stored at memory location 0x12345678 on the next instruction.
You may be wondering how you can make jmp and call instructions execute in a conditional way, such as “if the program has received a network packet, execute the following function.” The answer is that x86 assembly doesn’t have high-level constructs like if, then, else, else if, and so on. Instead, branching to an address within a program’s code typically requires two instructions: a cmp instruction, which checks the value in some register against some test value and stores the result of that test in the EFLAGS register, and a conditional branch instruction.
Most conditional branch instructions start with a j, which allows the program to jump to a memory address, and are post-fixed with letters that stand for the condition being tested. For example, jge tells the program to jump if greater than or equal to. This means that the value in the register being tested must be greater than or equal to the test value.
The cmp instruction uses the following syntax:
cmp register, memory location, or literal, register, memory location, or
literal
As stated earlier, cmp compares the value in the specified general-purpose register with value and then stores the result of that comparison in the EFLAGS register.
The various conditional jmp instructions are then invoked as follows:
j* address
As you can see, we can prefix j to any number of conditional test instructions. For example, to jump only if the value tested is greater than or equal to the value in the register, use the following instruction:
jge address
Note that unlike the case of the call and ret instructions, the jmp family of instructions never touches the program stack. In fact, in the case of the jmp family of instructions, the x86 program is responsible for tracking its own execution flow and potentially saving or deleting information about what addresses it has visited and where it should return to after a particular sequence of instructions has executed.
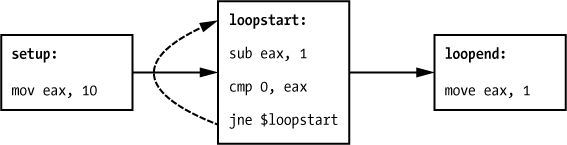
Although x86 programs look sequential when we scroll through their code in a text editor, they actually have loops, conditional branches, and unconditional branches (control flow). All of these give each x86 program a network structure. Let’s use the simple toy assembly program in Listing 2-1 to see how this works.
setup: # symbol standing in for address of instruction on the next line
➊ mov eax, 10
loopstart: # symbol standing in for address of the instruction on the next
line
➋ sub eax, 1
➌ cmp 0, eax
jne $loopstart
loopend: # symbol standing in for address of the instruction on the next
line
mov eax, 1
# more code would go here
Listing 2-1: Assembly program for understanding control flow graph
As you can see, this program initializes a counter to the value 10, stored in register EAX ➊. Next, it does a loop in which the value in EAX is decremented by 1 ➋ on each iteration. Finally, once EAX has reached a value of 0 ➌, the program breaks out of the loop.
In the language of control flow graph analysis, we can think of these instructions as comprising three basic blocks. A basic block is a sequence of instructions that we know will always execute contiguously. In other words, a basic block always ends with either a branching instruction or an instruction that is the target of a branch, and it always begins with either the first instruction of the program, called the program’s entry point, or a branch target.
In Listing 2-1, you can see where the basic blocks of our simple program begin and end. The first basic block is composed of the instruction mov eax, 10 under setup:. The second basic block is composed of lines beginning with sub eax, 1 through jne $loopstart under loopstart:, and the third starts at mov eax, 1 under loopend:. We can visualize the relationships between the basic blocks using the graph in Figure 2-2. (We use the term graph synonymously with the term network; in computer science, these terms are interchangeable.)
Figure 2-2: A visualization of the control flow graph of our simple assembly program
If one basic block can ever flow into another basic block, we connect it, as shown in Figure 2-2. The figure shows that the setup basic block leads to the loopstart basic block, which repeats 10 times before it transitions to the loopend basic block. Real-world programs have control flow graphs such as these, but they’re much more complicated, with thousands of basic blocks and thousands of interconnections.
Now that you have a good understanding of the basics of assembly language, let’s disassemble the first 100 bytes of ircbot.exe’s assembly code using linear disassembly. To do this, we’ll use the open source Python libraries pefile (introduced in Chapter 1) and capstone, which is an open source disassembly library that can disassemble 32-bit x86 binary code. You can install both of these libraries with pip using the following commands:
pip install pefile
pip install capstone
Once these two libraries are installed, we can leverage them to disassemble ircbot.exe using the code in Listing 2-2.
#!/usr/bin/python
import pefile
from capstone import *
# load the target PE file
pe = pefile.PE("ircbot.exe")
# get the address of the program entry point from the program header
entrypoint = pe.OPTIONAL_HEADER.AddressOfEntryPoint
# compute memory address where the entry code will be loaded into memory
entrypoint_address = entrypoint+pe.OPTIONAL_HEADER.ImageBase
# get the binary code from the PE file object
binary_code = pe.get_memory_mapped_image()[entrypoint:entrypoint+100]
# initialize disassembler to disassemble 32 bit x86 binary code
disassembler = Cs(CS_ARCH_X86, CS_MODE_32)
# disassemble the code
for instruction in disassembler.disasm(binary_code, entrypoint_address):
print "%s\t%s" %(instruction.mnemonic, instruction.op_str)
Listing 2-2: Disassembling ircbot.exe
This should produce the following output:
➊ push ebp
mov ebp, esp
push -1
push 0x437588
push 0x41982c
➋ mov eax, dword ptr fs:[0]
push eax
mov dword ptr fs:[0], esp
➌ add esp, -0x5c
push ebx
push esi
push edi
mov dword ptr [ebp - 0x18], esp
➍ call dword ptr [0x496308]
--snip--
Don’t worry about understanding all of the instructions in the disassembly output: that would involve an understanding of assembly that goes beyond the scope of this book. However, you should feel comfortable with many of the instructions in the output and have some sense of what they do. For example, the malware pushes the value in register EBP onto the stack ➊, saving its value. Then it proceeds to move the value in ESP into EBP and pushes some numerical values onto the stack. The program moves some data in memory into the EAX register ➋, and it adds the value -0x5c to the value in the ESP register ➌. Finally, the program uses the call instruction to call a function stored at the memory address 0x496308 ➍.
Because this is not a book on reverse engineering, I won’t go into any more depth here about what the code means. What I’ve presented is a start to understanding how assembly language works. For more information on assembly language, I recommend the Intel programmer’s manual at http://www.intel.com/content/www/us/en/processors/architectures-software-developer-manuals.html.
In this chapter and Chapter 1, you learned about a variety of ways in which static analysis techniques can be used to elucidate the purpose and methods of a newly discovered malicious binary. Unfortunately, static analysis has limitations that render it less useful in some circumstances. For example, malware authors can employ certain offensive tactics that are far easier to implement than to defend against. Let’s take a look at some of these offensive tactics and see how to defend against them.
Malware packing is the process by which malware authors compress, encrypt, or otherwise mangle the bulk of their malicious program so that it appears inscrutable to malware analysts. When the malware is run, it unpacks itself and then begins execution. The obvious way around malware packing is to actually run the malware in a safe environment, a dynamic analysis technique I’ll cover in Chapter 3.
NOTE
Software packing is also used by benign software installers for legitimate reasons. Benign software authors use packing to deliver their code because it allows them to compress program resources to reduce software installer download sizes. It also helps them thwart reverse engineering attempts by business competitors, and it provides a convenient way to bundle many program resources within a single installer file.
Another anti-detection, anti-analysis technique malware authors use is resource obfuscation. They obfuscate the way program resources, such as strings and graphical images, are stored on disk, and then deobfuscate them at runtime so they can be used by the malicious program. For example, a simple obfuscation would be to add a value of 1 to all bytes in images and strings stored in the PE resources section and then subtract 1 from all of this data at runtime. Of course, any number of obfuscations are possible here, all of which make life difficult for malware analysts attempting to make sense of a malware binary using static analysis.
As with packing, one way around resource obfuscation is to just run the malware in a safe environment. When this is not an option, the only mitigation for resource obfuscation is to actually figure out the ways in which malware has obfuscated its resources and to manually deobfuscate them, which is what professional malware analysts often do.
A third group of anti-detection, anti-analysis techniques used by malware authors are anti-disassembly techniques. These techniques are designed to exploit the inherent limitations of state-of-the-art disassembly techniques to hide code from malware analysts or make malware analysts think that a block of code stored on disk contains different instructions than it actually does.
An example of an anti-disassembly technique involves branching to a memory location that the malware author’s disassemblers will interpret as a different instruction, essentially hiding the malware’s true instructions from reverse engineers. Anti-disassembly techniques have huge potential and there’s no perfect way to defend against them. In practice, the two main defenses against these techniques are to run malware samples in a dynamic environment and to manually figure out where anti-disassembly strategies manifest within a malware sample and how to bypass them.
A final class of anti-analysis techniques malware authors use involves externally sourcing data and code. For example, a malware sample may load code dynamically from an external server at malware startup time. If this is the case, static analysis will be useless against such code. Similarly, malware may source decryption keys from external servers at startup time and then use these keys to decrypt data or code that will be used in the malware’s execution.
Obviously, if the malware is using an industrial-strength encryption algorithm, static analysis will not be sufficient to recover the encrypted data and code. Such anti-analysis and anti-detection techniques are quite powerful, and the only way around them is to acquire the code, data, or private keys on the external servers by some means and then use them in one’s analysis of the malware in question.
This chapter introduced x86 assembly code analysis and demonstrated how we can perform disassembly-based static analysis on ircbot.exe using open source Python tools. Although this is not meant to be a complete primer on x86 assembly, you should now feel comfortable enough that you have a starting place for figuring out what’s going on in a given malware assembly dump. Finally, you learned ways in which malware authors can defend against disassembly and other static analysis techniques, and how you can mitigate these anti-analysis and anti-detection strategies. In Chapter 3, you’ll learn to conduct dynamic malware analysis that makes up for many of the weaknesses of static malware analysis.