A decade ago, building a functioning, scalable, and fast neural network was time consuming and required quite a lot of code. In the past few years, however, this process has become far less painful, as more and more high-level interfaces to neural network design have been developed. The Python package Keras is one of these interfaces.
In this chapter, I walk you through how to build a sample neural network using the Keras package. First, I explain how to define a model’s architecture in Keras. Second, we train this model to differentiate between benign and malicious HTML files, and you learn how to save and load such models. Third, using the Python package sklearn, you learn how to evaluate the model’s accuracy on validation data. Finally, we use what you’ve learned to integrate validation accuracy reporting into the model training process.
I encourage you to read this chapter while reading and editing the associated code in the data accompanying this book. You can find all the code discussed in this chapter there (organized into parameterized functions to make things easier to run and adjust), as well as a few extra examples. By the end of this chapter, you’ll feel ready to start building some networks of your own!
To run code listings in this chapter, you not only need to install the packages listed in this chapter’s ch11/requirements.txt file (pip install –r requirements.txt), but also follow the directions to install one of Keras’s backend engines on your system (TensorFlow, Theano, or CNTK). Install TensorFlow by following the directions here: https://www.tensorflow.org/install/.
To build a neural network, you need to define its architecture: which neurons go where, how they connect to subsequent neurons, and how data flows through the whole thing. Luckily, Keras provides a simple, flexible interface to define all this. Keras actually supports two similar syntaxes for model definition, but we’re going to use the Functional API syntax, as it’s more flexible and powerful that the other (“sequential”) syntax.
When designing a model, you need three things: input, stuff in the middle that processes the input, and output. Sometimes your models will have multiple inputs, multiple outputs, and very complex stuff in the middle, but the basic idea is that when defining a model’s architecture, you’re just defining how the input—your data, such as features relating to an HTML file—flows through various neurons (stuff in the middle), until finally the last neurons end up yielding some output.
To define this architecture, Keras uses layers. A layer is a group of neurons that all use the same type of activation function, all receive data from a previous layer, and all send their outputs to a subsequent layer of neurons. In a neural network, input data is generally fed to an initial layer of neurons, which sends its outputs to a subsequent layer, which sends its outputs to another layer, and so on and so forth, until the last layer of neurons generates the network’s final output.
Listing 11-1 is an example of a simple model defined using Keras’s functional API syntax. I encourage you to open a new Python file to write and run the code yourself as we walk through the code, line by line. Alternatively, you can try running the associated code in the data accompanying this book, either by copying and pasting parts of the ch11/model_architecture.py file into an ipython session or by running python ch11/model_architecture.py in a terminal window.
➊ from keras import layers
➋ from keras.models import Model
input = layers.Input(➌shape=(1024,), ➍dtype='float32')
➎ middle = layers.Dense(units=512, activation='relu')(input)
➏ output = layers.Dense(units=1, activation='sigmoid')(middle)
➐ model = Model(inputs=input, outputs=output)
model.compile(➑optimizer='adam',
➒loss='binary_crossentropy',
➓metrics=['accuracy'])
Listing 11-1: Defining a simple model using functional API syntax
First, we import the Keras package’s layers submodule ➊ as well as the Model class from Keras’s models submodule ➋.
Next, we specify what kind of data this model will accept for one observation by passing a shape value (a tuple of integers) ➌ and a data type (string) ➍ to the layers.Input() function. Here, we declared that the input data to our model will be an array of 1,024 floats. If our input was, for example, a matrix of integers instead, the first line would look more like input = Input(shape=(100, 100,) dtype='int32').
NOTE
If the model takes in variable-sized inputs on one dimension, you can use None instead of a number—for example, (100, None,).
Next, we specify the layer of neurons that this input data will be sent to. To do this, we again use the layers submodule we imported, specifically the Dense function ➎, to specify that this layer will be a densely connected (also called fully connected) layer, which means that every output from the previous layer is sent to every neuron in this layer. Dense is the most common type of layer you’ll likely use when developing Keras models. Others allow you to do things like change the shape of the data (Reshape) and implement your own custom layer (Lambda).
We pass the Dense function two arguments: units=512, to specify that we want 512 neurons in this layer, and activation='relu', to specify that we want these neurons to be rectified linear unit (ReLU) neurons. (Recall from Chapter 10 that ReLU neurons use a simple type of activation function that outputs whichever is larger: either 0, or the weighted sum of the neuron’s inputs.) We use layers.Dense(units=512, activation='relu') to define the layer, and then the last part of the line—(input)—declares the input to this layer (namely, our input object). It’s important to understand that this passing of input to our layer is how data flow is defined in the model, as opposed to the ordering of the lines of the code.
In the next line, we define our model’s output layer, which again uses the Dense function. But this time, we designate only a single neuron to the layer and use a 'sigmoid' activation function ➏, which is great for combining a lot of data into a single score between 0 and 1. The output layer takes the (middle) object as input, declaring that the outputs from our 512 neurons in our middle layer should all be sent to this neuron.
Now that we’ve defined our layers, we use the Model class from the models submodule to wrap up all these layers together as a model ➐. Note that you only have to specify your input layer(s) and output layer(s). Because each layer after the first is given the preceding layer as input, the final output layer contains all the information the model needs about the previous layers. We could have 10 more middle layers declared between our input and output layers, but the line of code at ➐ would remain the same.
Finally, we need to compile our model. We’ve defined the model’s architecture and flow of data, but we haven’t yet specified how we want the model to perform its training. To do this, we use our model’s own compile method and pass it three parameters:
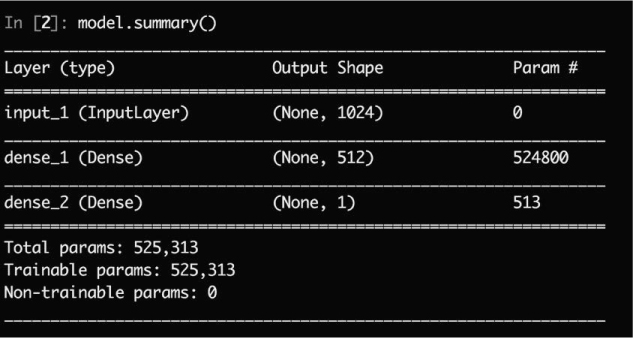
After running the code in Listing 11-1, run model.summary() to see the model structure printed to your screen. Your output should look something like Figure 11-1.
Figure 11-1: Output of model.summary()
Figure 11-1 shows the output of model.summary(). Each layer’s description is printed to the screen, along with the number of parameters associated with that layer. For example, the dense_1 layer has 524,800 parameters because each of its 512 neurons gets a copy of each of the 1,024 input values from the input layer, meaning that there are 1,024 × 512 weights. Add 512 bias parameters, and you get 1,024 × 512 + 512 = 524,800.
Although we haven’t yet trained our model or tested it on validation data, this is a compiled Keras model that is ready to train!
NOTE
Check out the sample code in ch11/model_architecture.py for an example of a slightly more complex model!
To train our model, we need training data. The virtual machine that comes with this book includes a set of about half a million benign and malicious HTML files. This consists of two folders of benign (ch11/data/html/benign_files/) and malicious (ch11/data/html/malicious_files/) HTML files. (Remember not to open these files in a browser!) In this section, we use these to train our neural network to predict whether an HTML file is benign (0) or malicious (1).
To do this, we first need to decide how to represent our data. In other words, what features do we want to extract from each HTML file to use as input to our model? For example, we could simply pass the first 1,000 characters in each HTML file to the model, we could pass in the frequency counts of all letters in the alphabet, or we could use an HTML parser to develop some more complex features. To make things easier, we’ll transform each variable-length, potentially very large HTML file into a uniformly sized, compressed representation that allows our model to quickly process and learn important patterns.
In this example, we transform each HTML file into a 1,024-length vector of category counts, where each category count represents the number of tokens in the HTML file whose hash resolved to the given category. Listing 11-2 shows the feature extraction code.
import numpy as np
import murmur
import re
import os
def read_file(sha, dir):
with open(os.path.join(dir, sha), 'r') as fp:
file = fp.read()
return file
def extract_features(sha, path_to_files_dir,
hash_dim=1024, ➊split_regex=r"\s+"):
➋ file = read_file(sha=sha, dir=path_to_files_dir)
➌ tokens = re.split(pattern=split_regex, string=file)
# now take the modulo(hash of each token) so that each token is replaced
# by bucket (category) from 1:hash_dim.
token_hash_buckets = [
➍ (murmur.string_hash(w) % (hash_dim - 1) + 1) for w in tokens
]
# Finally, we'll count how many hits each bucket got, so that our features
# always have length hash_dim, regardless of the size of the HTML file:
token_bucket_counts = np.zeros(hash_dim)
# this returns the frequency counts for each unique value in
# token_hash_buckets:
buckets, counts = np.unique(token_hash_buckets, return_counts=True)
# and now we insert these counts into our token_bucket_counts object:
for bucket, count in zip(buckets, counts):
➎ token_bucket_counts[bucket] = count
return np.array(token_bucket_counts)
Listing 11-2: Feature extraction code
You don’t have to understand all the details of this code to understand how Keras works, but I encourage you to read through the comments in the code to better understand what’s going on.
The extract_features function starts by reading in an HTML file as a big string ➋ and then splits up this string into a set of tokens based on a regular expression ➌. Next, the numeric hash of each token is taken, and these hashes are divided into categories by taking the modulo of each hash ➍. The final set of features is the number of hashes in each category ➎, like a histogram bin count. If you want, you can try altering the regular expression split_regex ➊ that splits up the HTML file into chunks to see how it affects the resulting tokens and features.
If you skipped or didn’t understand all that, that’s okay: just know that our extract_features function takes the path to an HTML file as input and then transforms it into a feature array of length 1,024, or whatever hash_dim is.
Now we need to make our Keras model actually train on these features. When working with small amounts of data already loaded into memory, you can use a simple line of code like Listing 11-3 to train your model in Keras.
# first you would load in my_data and my_labels via some means, and then:
model.fit(my_data, my_labels, epochs=10, batch_size=32)
Listing 11-3: Training your model when data is already loaded into memory
However, this isn’t really useful when you start working with large amounts of data, because you can’t fit all your training data into your computer’s memory at once. To get around this, we use the slightly more complex but more scalable model.fit_generator function. Instead of passing in all the training data at once to this function, you pass a generator that yields training data in batches so that your computer’s RAM won’t choke.
Python generators work just like Python functions, except they have a yield statement. Instead of returning a single result, generators return an object that can be called again and again to yield many, or infinite, sets of results. Listing 11-4 shows how we can create our own data generator using our feature extraction function.
def my_generator(benign_files, malicious_files,
path_to_benign_files, path_to_malicious_files,
batch_size, features_length=1024):
n_samples_per_class = batch_size / 2
➊ assert len(benign_files) >= n_samples_per_class
assert len(malicious_files) >= n_samples_per_class
➋ while True:
ben_features = [
extract_features(sha, path_to_files_dir=path_to_benign_files,
hash_dim=features_length)
for sha in np.random.choice(benign_files, n_samples_per_class,
replace=False)
]
mal_features = [
➌ extract_features(sha, path_to_files_dir=path_to_malicious_files,
hash_dim=features_length)
➍ for sha in np.random.choice(malicious_files, n_samples_per_class,
replace=False)
]
➎ all_features = ben_features + mal_features
labels = [0 for i in range(n_samples_per_class)] + [1 for i in range(
n_samples_per_class)]
idx = np.random.choice(range(batch_size), batch_size)
➏ all_features = np.array([np.array(all_features[i]) for i in idx])
labels = np.array([labels[i] for i in idx])
➐ yield all_features, labels
Listing 11-4: Writing a data generator
First, the code makes two assert statements to check that enough data is there ➊. Then inside a while ➋ loop (so it’ll just iterate forever), both benign and malicious features are grabbed by choosing a random sample ➍ of file keys and then extracting features for those files using our extract_features function ➌. Next, the benign and malicious features and associated labels (0 and 1) are concatenated ➎ and shuffled ➏. Finally, these features and labels are returned ➐.
Once instantiated, this generator should yield batch_size features and labels for the model to train on (50 percent malicious, 50 percent benign) each time the generator’s next() method is called.
Listing 11-5 shows how to create a training data generator using the data that comes with this book, and how to train our model by passing the generator to our model’s fit_generator method.
import os
batch_size = 128
features_length = 1024
path_to_training_benign_files = 'data/html/benign_files/training/'
path_to_training_malicious_files = 'data/html/malicious_files/training/'
steps_per_epoch = 1000 # artificially small for example-code speed!
➊ train_benign_files = os.listdir(path_to_training_benign_files)
➋ train_malicious_files = os.listdir(path_to_training_malicious_files)
# make our training data generator!
➌ training_generator = my_generator(
benign_files=train_benign_files,
malicious_files=train_malicious_files,
path_to_benign_files=path_to_training_benign_files,
path_to_malicious_files=path_to_training_malicious_files,
batch_size=batch_size,
features_length=features_length
)
➍ model.fit_generator(
➎ generator=training_generator,
➏ steps_per_epoch=steps_per_epoch,
➐ epochs=10
)
Listing 11-5: Creating the training generator and using it to train the model
Try reading through this code to understand what’s happening. After importing a necessary package and creating some parameter variables, we read the filenames for our benign ➊ and malicious training data ➋ into memory (but not the files themselves). We pass these values to our new my_generator function ➌ to get our training data generator. Finally, using our model from Listing 11-1, we use the model’s built-in fit_generator method ➍ to start training.
The fit_generator method takes three parameters. The generator parameter ➎ specifies the data generator that produces training data for each batch. During training, parameters are updated once per batch by averaging all the training observations’ signals for that batch. The steps_per_epoch parameter ➏ sets the number of batches we want the model to process each epoch. As a result, the total number of observations the model sees per epoch is batch_size*steps_per_epoch. By convention, the number of observations a model sees per epoch should be equal to the dataset size, but in this chapter and in the virtual machine sample code, I reduce steps_per_epoch to make our code run faster. The epochs parameter ➐ sets the number of epochs we want to run.
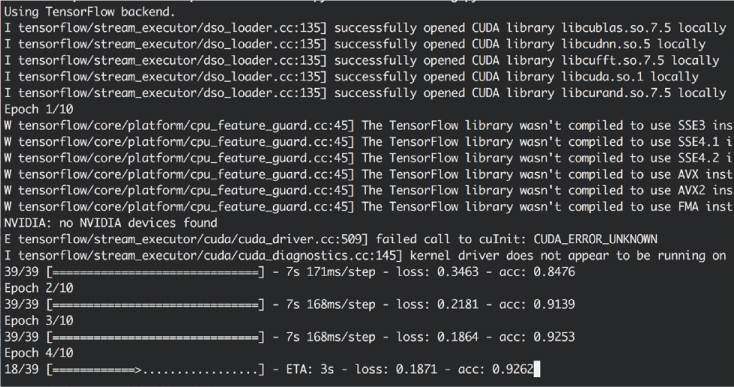
Try running this code in the ch11/ directory that accompanies this book. Depending on the power of your computer, each training epoch will take a certain amount of time to run. If you’re using an interactive session, feel free to cancel the process (CTRL-C) after a few epochs if it’s taking a while. This will stop the training without losing progress. After you cancel the process (or the code completes), you’ll have a trained model! The readout on your virtual machine screen should look something like Figure 11-2.
Figure 11-2: Console output from training a Keras model
The top few lines note that TensorFlow, which is the default backend to Keras, has been loaded. You’ll also see some warnings like in Figure 11-2; these just mean that the training will be done on CPUs instead of GPUs (GPUs are often around 2–20 times faster for training neural networks, but for the purposes of this book, CPU-based training is fine). Finally, you’ll see a progress bar for each epoch indicating how much longer the given epoch will take, as well as the epoch’s loss and accuracy metrics.
In the previous section, you learned how to train a Keras model on HTML files using the scalable fit_generator method. As you saw, the model prints statements during training, indicating each epoch’s current loss and accuracy statistics. However, what you really care about is how your trained model does on validation data, or data that it has never seen before. This better represents the kind of data your model will face in a real-life production environment.
When trying to design better models and figure out how long to train your model for, you should try to maximize validation accuracy rather than training accuracy, the latter of which was shown in Figure 11-2. Even better would be using validation files originating from dates after the training data to better simulate a production environment.
Listing 11-6 shows how to load our validation features into memory using our my_generator function from Listing 11-4.
import os
path_to_validation_benign_files = 'data/html/benign_files/validation/'
path_to_validation_malicious_files = 'data/html/malicious_files/validation/'
# get the validation keys:
val_benign_file_keys = os.listdir(path_to_validation_benign_files)
val_malicious_file_keys = os.listdir(path_to_validation_malicious_files)
# grab the validation data and extract the features:
➊ validation_data = my_generator(
benign_files=val_benign_files,
malicious_files=val_malicious_files,
path_to_benign_files=path_to_validation_benign_files,
path_to_malicious_files=path_to_validation_malicious_files,
➋ batch_size=10000,
features_length=features_length
➌ ).next()
Listing 11-6: Reading validation features and labels into memory by using the my_generator function
This code is very similar to how we created our training data generator, except that the file paths have changed and now we want to load all the validation data into memory. So instead of just creating the generator, we create a validation data generator ➊ with a large batch_size ➋ equal to the number of files we want to validate on, and we immediately call its .next() ➌ method just once.
Now that we have some validation data loaded into memory, Keras allows us to simply pass fit_generator() our validation data during training, as shown in Listing 11-7.
model.fit_generator(
➊ validation_data=validation_data,
generator=training_generator,
steps_per_epoch=steps_per_epoch,
epochs=10
)
Listing 11-7: Using validation data for automatic monitoring during training
Listing 11-7 is almost identical to the end of Listing 11-5, except that validation_data is now passed to fit_generator ➊. This helps enhance model monitoring by ensuring that validation loss and accuracy are calculated alongside training loss and accuracy.
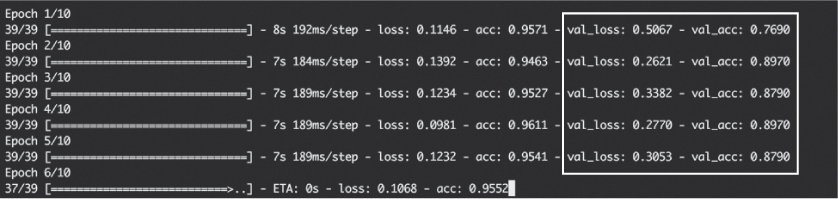
Now, training statements should look something like Figure 11-3.
Figure 11-3: Console output from training a Keras model with validation data
Figure 11-3 is similar to Figure 11-2, except that instead of just showing training loss and acc metrics for each epoch, now Keras also calculates and shows val_loss (validation loss) and val_acc (validation accuracy) for each epoch. In general, if validation accuracy is going down instead of up, that’s an indication your model is overfitting to your training data, and it would be best to halt training. If validation accuracy is going up, as is the case here, it means your model is still getting better and you should continue training.
Now that you know how to build and train a neural network, let’s go over how to save it so you can share it with others.
Listing 11-8 shows how to save our trained model to an .h5 file ➊ and reload ➋ it (at a potentially later date).
from keras.models import load_model
# save the model
➊ model.save('my_model.h5')
# load the model back into memory from the file:
➋ same_model = load_model('my_model.h5')
Listing 11-8: Saving and loading Keras models
In the model training section, we observed some default model evaluation metrics like training loss and accuracy as well as validation loss and accuracy. Let’s now review some more complex metrics to better evaluate our models.
One useful metric for evaluating the accuracy of a binary predictor is called area under the curve (AUC). The curve refers to a Receiver Operating Characteristic (ROC) curve (see Chapter 8), which plots false-positive rates (x-axis) against true-positive rates (y-axis) for all possible score thresholds.
For example, our model tries to predict whether a file is malicious by using a score between 0 (benign) and 1 (malicious). If we choose a relatively high score threshold to classify a file as malicious we’ll get fewer false-positives (good) but also fewer true-positives (bad). On the other hand, if we choose a low score threshold, we’ll likely have a high false-positive rate (bad) but a very high detection rate (good).
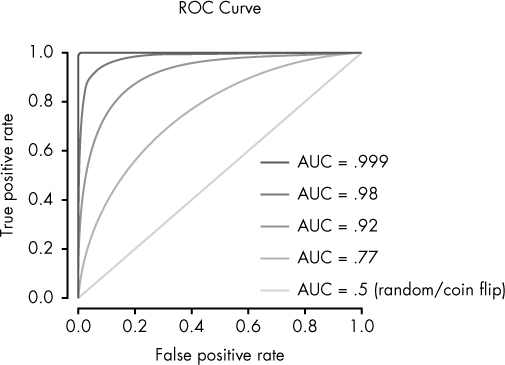
These two sample possibilities would be represented as two points on our model’s ROC curve, where the first would be located toward the left side of the curve and the second near the right side. AUC represents all these possibilities by simply taking the area under this ROC curve, as shown in Figure 11-4.
In simple terms, an AUC of 0.5 represents the predictive capability of a coin flip, while an AUC of 1 is perfect.
Figure 11-4: Various sample ROC curves. Each ROC curve (line) corresponds to a different AUC value.
Let’s use our validation data to calculate validation AUC using the code in Listing 11-9.
from sklearn import metrics
➊ validation_labels = validation_data[1]
➋ validation_scores = [el[0] for el in model.predict(validation_data[0])]
➌ fpr, tpr, thres = metrics.roc_curve(y_true=validation_labels,
y_score=validation_scores)
➍ auc = metrics.auc(fpr, tpr)
print('Validation AUC = {}'.format(auc))
Listing 11-9: Calculating validation AUC using sklearn’s metric submodule
Here, we split our validation_data tuple into two objects: the validation labels represented by validation_labels ➊, and flattened validation model predictions represented by validation_scores ➋. Then, we use the metrics.roc_curve function from sklearn to calculate false-positive rates, true-positive rates, and associated threshold values for the model predictions ➌. Using these, we calculate our AUC metric, again using an sklearn function ➍.
Although I won’t go over the function code here, you can also use the roc_plot() function included in the ch11/model_evaluation.py file in the data accompanying this book to plot the actual ROC curve, as shown in Listing 11-10.
from ch11.model_evaluation import roc_plot
roc_plot(fpr=fpr, tpr=tpr, path_to_file='roc_curve.png')
Listing 11-10: Creating a ROC curve plot using the roc_plot function from this book’s accompanying data, in ch11/model_evaluation.py
Running the code in Listing 11-10 should generate a plot (saved to roc_curve.png) that looks like Figure 11-5.
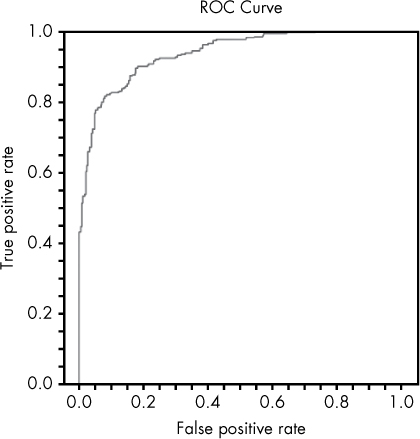
Figure 11-5: A ROC curve!
Each point in the ROC curve in Figure 11-5 represents a specific false-positive rate (x-axis) and true-positive rate (y-axis) associated with various model prediction thresholds ranging from 0 to 1. As false-positive rates increase, true-positive rates increase, and vice versa. In production environments, you generally have to pick a single threshold (a single point on this curve, assuming validation data mimics production data) with which to make your decision, based on your willingness to tolerate false positives, versus your willingness to risk allowing a malicious file to slip through the cracks.
So far, you’ve learned how to design, train, save, load, and evaluate Keras models. Although this is really all you need to get a fairly good start, I also want to introduce Keras callbacks, which can make our model training process even better.
A Keras callback represents a set of functions that Keras applies during certain stages of the training process. For example, you can use a Keras callback to make sure that an .h5 file is saved at the end of each epoch, or that validation AUC is printed to the screen at the end of each epoch. This can help record and inform you more precisely of how your model is doing during the training process.
We begin by using a built-in callback, and then we try writing our own custom callback.
To use a built-in callback, simply pass your model’s fit_generator() method a callback instance during training. We’ll use the callbacks.ModelCheckpoint callback, which evaluates validation loss after each training epoch, and saves the current model to a file if the validation loss is smaller than any previous epoch’s validation losses. To do this, the callback needs access to our validation data, so we’ll pass that in to the fit_generator() method, as shown in Listing 11-11.
from keras import callbacks
model.fit_generator(
generator=training_generator,
# lowering steps_per_epoch so the example code runs fast:
steps_per_epoch=50,
epochs=5,
validation_data=validation_data,
callbacks=[
callbacks.ModelCheckpoint(save_best_only=True,➊
➋ filepath='results/best_model.h5',
➌ monitor='val_loss')
],
)
Listing 11-11: Adding a ModelCheckpoint callback to the training process
This code ensures that the model is overwritten ➊ to a single file, 'results/best_model.h5' ➋, whenever 'val_loss' ➌ (validation loss) reaches a new low. This ensures that the current saved model ('results/best_model.h5') always represents the best model across all completed epochs with regard to validation loss.
Alternatively, we can use the code in Listing 11-12 to save the model after every epoch to a separate file regardless of validation loss.
callbacks.ModelCheckpoint(save_best_only=False,➍
➎ filepath='results/model_epoch_{epoch}.h5',
monitor='val_loss')
Listing 11-12: Adding a ModelCheckpoint callback to the training process that saves the model to a different file after each epoch
To do this, we use the same code in Listing 11-11 and the same function ModelCheckpoint, but with save_best_only=False ➍ and a filepath that asks Keras to fill in the epoch number ➎. Instead of only saving the single “best” version of our model, Listing 11-12’s callback saves each epoch’s version of our model, in results/model_epoch_0.h5, results/model_epoch_1.h5, results/model_epoch_2.h5, and so on.
Although Keras doesn’t support AUC, we can design our own custom callback to, for example, allow us to print AUC to the screen after each epoch.
To create a custom Keras callback, we need to create a class that inherits from keras.callbacks.Callback, the abstract base class used to build new callbacks. We can add one or more of a selection of methods, which will be run automatically during training, at times that their names specify: on_epoch_begin, on_epoch_end, on_batch_begin, on_batch_end, on_train_begin, and on_train_end.
Listing 11-13 shows how to create a callback that calculates and prints validation AUC to the screen at the end of each epoch.
import numpy as np
from keras import callbacks
from sklearn import metrics
➊ class MyCallback(callbacks.Callback):
➋ def on_epoch_end(self, epoch, logs={}):
➌ validation_labels = self.validation_data[1]
validation_scores = self.model.predict(self.validation_data[0])
# flatten the scores:
validation_scores = [el[0] for el in validation_scores]
fpr, tpr, thres = metrics.roc_curve(y_true=validation_labels,
y_score=validation_scores)
➍ auc = metrics.auc(fpr, tpr)
print('\n\tEpoch {}, Validation AUC = {}'.format(epoch,
np.round(auc, 6)))
model.fit_generator(
generator=training_generator,
# lowering steps_per_epoch so the example code runs fast:
steps_per_epoch=50,
epochs=5,
➎ validation_data=validation_data,
➏ callbacks=[
callbacks.ModelCheckpoint('results/model_epoch_{epoch}.h5',
monitor='val_loss',
save_best_only=False,
save_weights_only=False)
]
)
Listing 11-13: Creating and using a custom callback to print AUC to the screen after each training epoch
In this example, we first create our MyCallback class ➊, which inherits from callbacks.Callbacks. Keeping things simple, we overwrite a single method, on_epoch_end ➋, and give it two arguments expected by Keras: epoch and logs (a dictionary of log information), both of which Keras will supply when it calls the function during training.
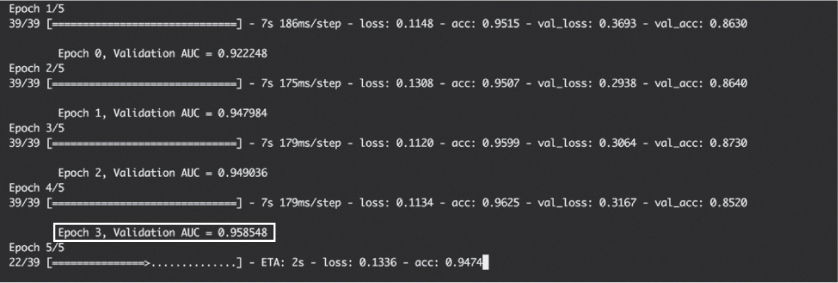
Then, we grab the validation_data ➌, which is already stored in the self object thanks to callbacks.Callback inheritance, and we calculate and print out AUC ➍ like we did in “Evaluating the Model” on page 209. Note that for this code to work, the validation data needs to be passed to fit_generator() so that the callback has access to self.validation_data during training ➎. Finally, we tell the model to train and specify our new callback ➏. The result should look something like Figure 11-6.
Figure 11-6: Console output from training a Keras model with a custom AUC callback
If what you really care about is minimizing validation AUC, this callback makes it easy to see how your model is doing during training, thus helping you assess whether you should stop the training process (for example, if validation accuracy is going consistently down over time).
In this chapter, you learned how to build your own neural network using Keras. You also learned to train, evaluate, save, and load it. You then learned how to enhance the model training process by adding built-in and custom callbacks. I encourage you to play around with the code accompanying this book to see what changes model architecture and feature extraction can have on model accuracy.
This chapter is meant to get your feet wet, but is not meant as a reference guide. Visit https://keras.io for the most up-to-date official documentation. I strongly encourage you to spend time researching aspects of Keras that interest you. Hopefully, this chapter has served as a good jumping-off point for all your security deep learning adventures!