Techniques that ensure network integrity and availability are often overlooked in a discussion of network security, yet both are important parts of a system-wide plan. They are often given less promotion because they involve careful, time-consuming, meticulous work—it means continuously following procedures, line by line, one after another, day in and day out. It’s typically thankless work and is often delegated to new and junior IT personnel. I’m speaking here of backups, change control, and the patching and provisioning of redundant systems.
NOTE Implementing sound antivirus policies and practices also contributes to the integrity and availability of systems. Be sure to include an effective program that blocks known and suspicious code at the gateway, scans e-mail and desktops, and blocks the execution of mobile code. (Chapter 29 discusses this in more detail).
Despite the tedium of many of the tasks, some of the finest architectural work being done today is in the area of integrity and availability. Automated, intelligent processes are hot on the heels of solving the bone-wearying process of keeping systems patched. Online data vaulting and disk-to-disk backup are beginning to make it possible to keep pace with data—to provide resources for recovery when catastrophic disaster strikes. Shadow copy backups are making it possible for users to recover accidentally deleted files without the help of the IT department. It’s possible to provide redundancy of systems such that it is common to speak not of 99 percent uptime but of 99.999 percent uptime.
No, its not exactly sexy to be in this side of the information security biz, but it’s close. This chapter will look at what gives an information system integrity and availability. The solutions discussed here will provide
• Version control and change control
• Patching
• System and network redundancy
Just when you think you have security nailed—all systems are hardened, all software has been vetted, all users indoctrinated—then it’s necessary to implement a change. Change can range from minor hardware maintenance, the application of patches, or software upgrades to complete migrations to new hardware and software. The problem that change represents is that the security status of the system or network will be reduced. It’s possible that new hardware and new software will not meet requirements that previously enabled a security configuration or that incompatibilities with required service packs, lack of comparable settings, changes in software operation, and even failure by administration to reset security can mean weakened controls.
Improper or missing change control processes can also mean problems in other areas. When changes are not properly documented and recovery is necessary, recovery will not be correct and may fail, or it may produce systems that require reworking to properly fulfill their role. It may also mean that improperly secured systems are put back into production.
The solution is threefold. First, before changes are made, the impact on security must be considered. Second, changes should be documented and require authority. Finally, the impact of change should be monitored, and adjustments should be made as soon as possible and necessary. Change control is the process used to manage this solution, and it should be applied to production environments, test environments, and development environments.
The first step in improving change control is to thoroughly evaluate current practices. Questions to be asked include the following:
• What computers and networked devices are present? Where are they located?
• Who is responsible for operating system installations? Server application installations? Desktop application installations?
• Who installs updates to these systems?
• Who installs and is responsible for updates to in-house or other custom applications?
• Who maintains hardware? Replaces parts? Replaces cables?
• Who configures systems and network devices?
• Is there scheduled maintenance?
• How is physical access to the data center or other locations of servers and network devices controlled?
• Are systems separated into environments, such as production, development, testing, staging?
• Who has physical access to each environment?
• Who has logical access to each environment?
• Are there connections between the environments, and how is access across those borders controlled?
• What current procedures and policies exist to manage change control? Are there checklists, forms, or journals that must be filled out? Are they used? Where are they kept?
• Who restores or recovers systems when that is needed?
• Is an antivirus strategy in place? How is it maintained? Where is it implemented? What happens when a virus is discovered?
• What about backups? Where is backup media kept? Where is it secured? What are the plans for disaster recovery?
• Who has access to e-mail and from where? How is it protected? What types of attachments are allowed? Who has access to other people’s e-mail?
• Is Internet use monitored? Is e-mail use monitored?
Once this data has been collected and analyzed, recommendations for improvements can be made, discussed, modified, approved, and incorporated into the organization’s change control policy.
While no one correct change control policy exists, there are well-known subjects and procedures that commonly are incorporated in such a policy. A change control policy should identify the people involved, the policy’s scope, maintenance schedules, and various procedures.
Key people should be involved in designing and maintaining the change control policy. These people include mangers from each functional area, such as network management, operations, help desk, development, maintenance, and so forth. All areas that must follow the policy should be included in its development to ensure that everyone takes ownership of the result. Upper management must, of course, approve the policy and support its enforcement and therefore should be represented.
The scope of the policy should be based on the management structure of IT operations. In many companies, for example, a separate change control policy exists for in-house development and the maintenance of version control over these products. This is just common sense where some operations and development are managed separately, and because the actual procedures implemented vary.
However scope is addressed, each area requires maintenance schedules, a policy on how changes are approved, and provision for routine or emergency maintenance. For example, the replacement of a crashed hard drive should not require exhaustive review before the drive is replaced—it needs to be replaced immediately (though it still needs to be documented). The introduction of a new desktop operating system, on the other hand, requires substantial review in order to consider the implications for security, as well as other operational concerns, such as budget and additional resources. There is a need for management to ensure that the change is completed following standardized procedures, and perhaps a quality control checklist should be used to ensure the approved change meets its operational and security maintenance goals.
The policy should specify the areas covered. For example, it might specify updating of systems with service packs; patching, replacing, or upgrading hardware; implementing configuration changes; changing technical controls; and so forth. The policy should specify the following:
• Authority The policy should clearly identify who has the authority to approve change, as well as who has the authority to make changes. The policy should do so by not specifying a name, but by a position.
• Appropriate change checklists The policy should specify that a checklist be used. Just as preflight checklists ensure that even very experienced pilots do not forget any system checks, quality control and maintenance checklists ensure and document the proper completion of changes.
• Appropriate change forms The policy should indicate that a change form must be used. The form documents what change should be made, why, when and by whom. It also provides a place to record when the change was made, where and by whom as well as a place to record any problems during the process, and how the change made was validated. When troubleshooting results in understanding and knowledge that must be applied to future installations or to all similar systems for maintenance purposes, the change control form can be routed appropriately and the changes incorporated in system configuration lists. Documenting troubleshooting steps can also provide a way to back out of unsuccessful changes and record steps that must not be taken if results are poor, useless, or disastrous.
• Reviews of changes A way to judge the change control process and modify it should be built into the policy. When a process isn’t working well, there should be a way to change it. Review of change control documents and logs will reveal what was done, what worked and what did not.
• Policy enforcement How the policy is enforced should be part of every policy. What will happen if employees go around the policy? What if they use procedures that are not approved? What if they fail to document system changes?
A change control policy specifies the absolute requirements for the organization’s change control process. A change control procedure lists the steps for carrying out that policy. The change control policy may specify that a checklist or form be used to document the process; a change control procedure provides the step by step process for using the forms and checklist. The goals of both is not to prevent change but to ensure that change means improvement, or correction of error, or maintenance of existing systems and that it is done with approval and well documented. As such, procedures for managing periodic updates, such as replacing a network card or patching a system, will differ widely from a procedure for replacing a password policy, or a procedure for changes to a system migration plan can occur. This means separate change control procedures will be developed for each type of change by the people that understand the work that needs to be done and by people who understand the implications of change. It also means that separate procedures exist for ordinary maintenance work and for changes that radically change the way ordinary business processes work or that modify the security picture of the organization. An approval process is always part of a change control procedure, but approval authority for ordinary maintenance work is usually delegated to those who manage the systems.
A typical change control procedure will include information on the following topics:
• Proposal process How do you ask for a change, and how does the proposal become a change?
• Approval mechanisms Who has authority to approve the change, and who has authority to carry it out? Who reviews the completed change and validates it?
• Notification process How are those who may be affected by the change notified? Do they have any recourse? Can they prevent the change or move it to a more convenient time?
• Backup and change reversal How can the change be reversed should the change not be acceptable once completed?
• Revision tools What tools are required for the change? Software development and change control usually requires the use of a revision control product, and all major projects benefit from document control.
• Documentation Who is responsible for documentation, where is it kept, and who reviews it?
• Management Who manages peripheral changes, and who propagates necessary, related changes?
• Quality control checklist What steps are taken to ensure a system’s correctness before it is put into production?
• Assessment Once a change is put into place, who assesses the result, and how do they do so?
This is the era of the patched system. In the past, it was often acceptable to leave systems unpatched—the collective wisdom of experienced system administrators indicated that patches often caused more problems than they corrected. “If it ain’t broke, don’t fix it,” they’d quip. And they were most often right. Patching was difficult, too, requiring long phone conversations, ordering of materials, and long sessions in the data center. Who’d want to go to all that trouble, then wait breathlessly to see if the system would successfully reboot?
NOTE This is the era of the patched system, but that does not mean that all systems are patched, just that more of them are, and that much more time is spent trying to develop a comprehensive patching strategy.
The explosive increase in the number of computer systems and the eventual networking of all systems did little to improve patching’s image. There were just more systems to be patched, and bad patches could affect more systems.
Three things have changed the trend of “don’t patch” to “must patch:”
• In 95 percent of compromised systems where a reason for the compromise can be found, that reason is misconfiguration or unpatched systems.
• Several Internet worms—SQL Slammer, Code Red, and Nimda, for example—successfully attacked Windows systems that had not had patches applied.
• Automated patching software audits systems for missing patches and can automatically apply missing patches.
Saying that this is the era of patched systems does not mean that all systems are patched, or that those that are patched are correctly patched, or that patches do not cause problems. It simply means that we are a lot farther down the path to eliminating successful compromises due to unpatched systems. Some day, all systems will be kept up to date. To get there, each organization will need to implement a patching policy and procedures for implementing patches on all systems.
While the policy and procedures will reflect the types of systems each organization has, their comfort with vendor patches, and their own use of products and homegrown processes, there are common elements that each patching policy should address, and for which procedures should be developed. These include:
• What should be patched
• Where notification of patches, service packs, and configuration recommendations can be found
• The decision-making process for patching
• Procedures for discovering unpatched systems, obtaining patches, applying patches, and validating them
All systems need patching, and a patching policy will outline the regularity and frequency of patching for each system. First, however, a list of what will need to be patched should be compiled, and it should consider each of the following:
• Operating systems, such as Microsoft, AIX, HP, Solaris, Linux, and so forth
• Utilities that are not considered to be part of the OS, such as Microsoft resource kit tools, free downloads, AIX third-party tools, and backup software
• Server applications, such as web servers like Apache and IIS; databases, such as Microsoft SQL Server and DB2; mail servers and groupware, such as sendmail, Microsoft Exchange, and Lotus Notes
• End-user applications, such as Microsoft Office and Start Office
• Drivers for network cards, mice, smart card readers, SCSI drives, and so on
• Network devices such as Cisco routers and appliance firewalls
• Network management systems
A location must be specified where valid and authorized notification of changes can be found. In many cases, vendors provide e-mail lists and announcement pages. The wise administrator will also subscribe to lists such as Security Focus’s BugTraq (www.securityfocus.com/popups/forums/bugtraq/intro.shtml) and ntbugtraq (www.ntbugtraq.com). These lists provide information on all systems. Care should be taken to filter list communications, since they may or may not be filtered, and opinions are often allowed even so. Another good source of lists and sites that contain information on multiple systems is CERT (www.cert.org). Vendors also provide list services, and while not every vendor does so, it is important to check and register for lists provided by vendors of major products used in your network.
Wherever notification is obtained, the existence of the patch should be verified via a visit to the vendor’s web site or another location where the vendor will verify the information.
NOTE Several attempts have been made to spoof Microsoft patch announcements. These announcements have been accompanied by a “patch,” and the receiver has been admonished to apply the patch immediately. These announcements are invalid and are most likely attempts to trick users and administrators into loading Trojan software. There is no known vendor that e-mails out patches with notices. Policies and procedures should dictate the proper way of obtaining patches and obtaining authority to apply them—using an e-mailed, unsolicited patch is not a sound action.
The decision about whether to patch or not has gotten more complex, not less. Patches are available more quickly, there are more of them (according to Symantec, 80 percent more patches in 2002 than in 2001), and there is an urgency like never before. Once a vulnerability has been announced, it may be only days or months before attack code is written, or it may never be written at all. However, chances are that new worms written to take advantage of vulnerabilities will be swift. Hence, there is pressure to immediately apply a patch, and there is still the fear that a patch will have unexpected and damaging results. There have, after all, been patches that caused problems.
NOTE Examples of updating problems abound. When Service Pack 4 for Windows 2000 was first introduced, many reported problems. Even though the results of installing on thousands of machines showed no problems, some others did. The first indications were that certain hardware and software combinations caused major problems, including slow downs, blue screens, and excess memory usage. Where did the problem lie? Was it with vendors whose products aren’t compliant with Microsoft Windows 2000 or with Windows 2000 itself? We sometimes hear that an upgrade manages to use some feature that a vendor’s older driver software cannot handle—the older software worked fine, but since it did not meet some specification, it eventually succumbs. On the other hand, many believe that Windows should remain perfectly backward compatible with all existing hardware and software. In reality, the latter is nearly impossible, and vendor compliance with standards may be the way things are resolved.
The first step in making a patching decision, of course, is to determine the patch-level status on systems. This can be done with the use of several scanning tools. Next, from the list of currently recommended patches (as identified from vendor sites, bulletins, and the like) a list should be compiled about which patches need to be applied to which systems. Then comes the difficult part: deciding which patches should be applied and which ignored. How much should you test a patch to determine whether it will be safe? Often, it’s a process of risk judgment. What is the risk to the system and to the network if it remains unpatched? What if it is patched?
Many administrators do tests before rolling out patches, and others wait, hoping someone else will discover any flaws before they take the plunge. The problem with this approach, of course, is that the system is vulnerable until it is patched. If you wait too long, the system may already be compromised.
While more systems are being patched these days, no one really knows anything close to actual statistics. Companies can track how many patches are downloaded, but there is no way to know if they are applied or how many systems each downloaded patch is applied to. Because automated patch-application programs exist, a single download could result in the patching of thousands of systems.
Any patching process should include the following steps:
1. Evaluate the need for the patch.
2. Install the patch on a test system.
3. Back up production systems before applying any patches.
4. Apply the patch on a single production system.
5. Apply the patch across all systems.
6. Audit the system to determine if the patch really was applied.
7. Document the results.
8. If the patch failed to install, determine why and reapply.
It is the last three steps that are often left out of any patching procedure. It is critical that systems are audited to check and see if the patch actually was applied. Many things can happen during installation. Files might be open and so not overwritten, network problems might interfere and so on. A system which is supposed to be patched but is not, is worse than one that isn’t patched since we have a false sense of security about the system.
No standard for patch application exists. Most companies tout the need for patching, and most have some effort in place, but there will always be a hesitancy to patch because of fear of damage, complacency, or overwork. Some options for applying patches are outlined in the following sections.
Microsoft has a number of options for patching systems, and it provides online, automated, and manual approaches.
Windows Update is an online service that can be used by all current versions of the operating system. The site is accessed and permitted to scan the host, and it then reports on recommended patches that can be downloaded and applied.
Automatic Update is a service for Windows XP, Windows 2000 (once Service Pack 3 has been installed), and Windows Server 2003. If Automatic Update is configured, each individual computer contacts the Microsoft update site to obtain patching information. The system can notify the user that patches need to be downloaded, it can download the patches and notify the user that they need to be installed, or it can automatically download and apply the patches.
Software Update Services (SUS) is a free server application that can be downloaded from Microsoft. Once installed, patches can be downloaded to the SUS server, reviewed by system administrators, and approved or disapproved and automatically downloaded and applied to Windows XP systems (and above). In essence, the Windows Update service is pointed to the SUS server in this scenario, instead of to Microsoft. Microsoft also provides a free update for its Systems Management Server product, which provides it with patch-management capabilities.
In addition, Microsoft provides the Microsoft Baseline Security Analyzer, a vulnerability and patch assessment tool that can be used to scan Windows NT systems (and above) and report on major weaknesses, as well as report the systems’ patching status.
The problem with all these solutions is that some of them provide contradictory information and some are unpalatable to some administrators. First, while automated updating direct from Microsoft seems like a good idea, there is no way to pick and choose among the patches, or to test patches before installing them. If there is a patch problem, or if you would choose not to apply some patch, you cannot do so. In addition, each system must individually connect to Microsoft, be evaluated, and download patches. If a thousand Windows systems are set to automatic update, then a thousand systems will be connecting to Microsoft and downloading patches. SUS solves much of the updating process, since there is choice in whether a patch should be applied or not, and individual systems do not connect to Microsoft but get their patches locally from the SUS server.
Internet Security Systems (ISS) is integrating its vulnerability scanner (Internet Scanner 7.0) and host-based intrusion-detection system (IDS) to stop new worms as they come to the attention of the security community. The idea is to block newly found attacks until the system can be patched. As new attack information is discovered, the scanner will be updated and will examine operating systems, routers, switches, mail servers, and other systems to see if a weakness exists.
The concept works like this: A scan can be performed when a new threat (a newly discovered vulnerability) is discovered to determine which machines might be vulnerable. If the network manager allows, ISS’s RealSecure SiteProtector management application can direct network or host sensors to block access or take other steps.
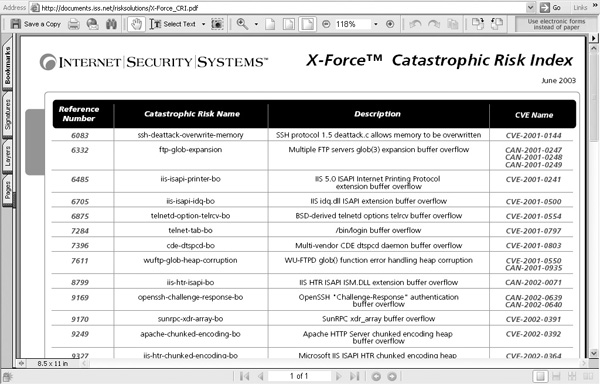
Note that ISS also provides the X-Force Catastrophic Risk Index, a listing and rating of the most serious vulnerabilities and attacks (http://xforce.iss.net/xforce/riskindex/), shown in Figure 15-1.
FIGURE 15-1 ISS’s X-Force Catastrophic Risk Index
One option for organizations where control is distributed is to host a web-based procedure for patch application that includes the location of patches. Such a web site should be on the company intranet and not available for public Internet access, as it exposes information that might be useful to an attacker.
NOTE Vulnerability scanning can vary in complexity. A tool might detect whether a system is vulnerable to Code Red and report back, or it could be like NMAP, which is used to discover information about systems on a network. Comparing the result, NMAP returns information to known vulnerabilities and provides the user with a list of places where security can be tightened. If NMAP finds a server listening on common Trojan ports, for example, you know that that server is potentially compromised. If it finds a system listening on NetBIOS ports then you know that server has a vulnerability.
Routine patching and security configuration can answer the questions posed by these scans. Emergency patching in response to the discovery of high-risk vulnerabilities can be centrally coordinated. The recommended process is for system administrators to pay daily attention to the patch status of their systems and apply patches as necessary.
A number of free and commercial utilities are available to assist in the process of scanning for patch status, as well as for implementing patching programs. Free utilities often provide enough capability for smaller organizations or for assessing a companion commercial product. Sources and availability of products will change over time.
• Configuresoft’s Security Update Manager
www.configuresoft.com/product_sum_overview.htm
• Sunbelt Software’s UpdateEXPERT
www.sunbelt-software.com/product.cfm?id=357
• Ecora PatchLite (a free utility for use with Microsoft and Sun Solaris) and Ecora Patch Manager
www.ecora.com/ecora/products/free_utilities.asp
• Opsware System (automated patch management subsystem)
www.loudcloud.com/software/functions/patch-mgmt.htm
• Windows Hotfix Checker (WHC)
www.codeproject.com/tools/whotfixcheck2.asp
• Rippletech patchworks for Windows systems
www.rippletech.com/pdf/patchworksdatasheet.pdf
• Shavlik’s HFNetChkPro and HFNetChkLT
www.shavlik.com
Restoring from a backup is usually perceived as the last resort. When systems fail, the first goal is to try to fix them. When that’s not possible, we use a backup. Backups may be used for complete system restore, and backups can also allow you to recover the contents of a mailbox, or an “accidentally” deleted document. Backups can be extended to saving more than just digital data. Backup processes can include the backup of specifications and configurations, policies and procedures, equipment, and data centers.
However, if the backup is not good, or is too old, or the backup media is damaged then it will not fix the problem. Just having a backup procedure in place does not always offer adequate protection.
In addition, traditional, routine and regular backup processes can also be obsolete. When it is unacceptable to do an offline backup, when an online backup would unacceptably degrade system performance, and when restoring from a backup would take so much time that a business would not be recoverable, alternatives to backing up, such as redundant systems, may be used.
Backup systems and processes, therefore, reflect the availability needs of an organization as well as its recovery needs. This section will address traditional data backup methodologies and provide information on newer technologies.
NOTE One year after the World Trade Center bombing in 1993, 34 percent of businesses damaged in the blast, that were without offsite backups failed.
In the traditional backup process, data is copied to backup media, primarily tape, in a predictable and orderly fashion for secure storage both onsite and offsite. Backup media can thus be made available to restore data to new or repaired systems after failure. In addition to data, modern operating systems and application configurations are also backed up. This provides faster restore capabilities and occasionally may be the only way to restore systems where applications that support data are intimately integrated with a specific system.
An example of a system backup is the system-state backup function provided with Microsoft Windows 2000 and later versions. This function automatically includes the backup of boot files, the registry, the COM+ registration database, and other files, depending on the role of the computer.
There are several standard types of backups:
• Full Backs up all data selected, whether or not it has changed since the last backup. Pay attention to definitions for this kind of backup. In some cases a full backup includes a system backup, and in other cases it simply backs up data.
• Copy Data is copied from one disk to another.
• Incremental When data is backed up, the archive bit on a file is turned off. When changes are made to the file, the archive bit is set again. An incremental backup uses this information to only back up files that have changed since the last backup. An incremental backup turns the archive bit off again, and the next incremental backup backs up only the files that have changed since the last incremental backup. This sort of backup saves time, but it means that the restore process will involve restoring the last full backup and every incremental backup made after it. Figure 15-2 illustrates an incremental backup plan. The circle encloses all of the backups that must be restored.
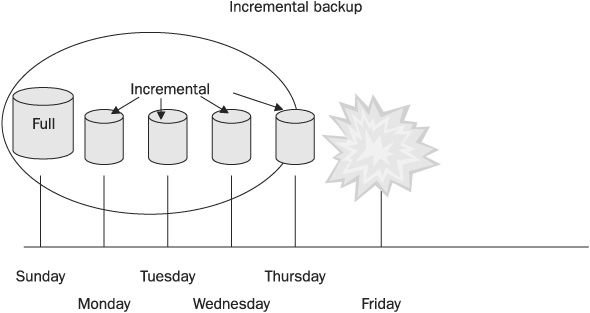
FIGURE 15-2 To restore from an incremental backup requires that all backups be applied.
• Differential Like an incremental backup, a differential backup only backs up files with the archive bit set—files that have changed since the last backup. Unlike the incremental backup, however, the differential backup does not reset the archive bit. Each differential backup backs up all files that have changed since the last backup that reset the bits. Using this strategy, a full backup is followed by differential backups. A restore consists of restoring the full backup and then only the last differential backup made. This saves time during the restore, but depending on your system, it will take some time longer to create differential backups than incremental backups. Figure 15-3 illustrates an incremental backup plan. The circle encloses all of the backups that must be restored. (Compare this to Figure 15-2.)
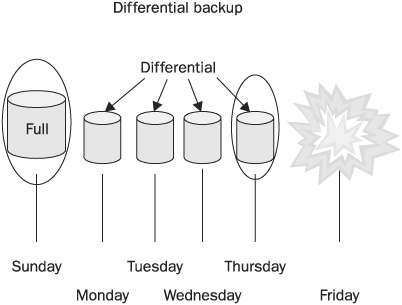
FIGURE 15-3 To restore from a differential backup you need only apply the full backup and the last differential backup.
In the traditional backup process, old backups are usually not immediately replaced by the new backup. Instead, multiple previous copies of backups are kept. This ensures recovery should one backup tape set be damaged or otherwise be found not to be good. Two traditional backup rotation strategies are grandfather, father, son (GFS) and Tower of Hanoi.
In the GFS rotation strategy, a backup is made to separate media each day. Each Sunday a full backup is made, and each day of the week an incremental backup is made. Full weekly backups are kept for the current month, and the current week’s incremental backups are also kept (each week, a new set of incremental backups are made at the end of the month and you have 4 or 5 weekly backups and one set of daily backups, the last set). On the first Sunday of the month, a new tape or disk is used to make a full backup. The previous full backup becomes the last full backup of the prior month and is labeled as a monthly backup. Weekly and daily tapes are rotated as needed, with the oldest being used for the current backup. Thus, on any one day of the month, that week’s backup is available, as well as the previous four or five weeks’ backups, and the incremental backups taken each day of the preceding week. If the backup scheme has been in use for a while, prior month backups are also available.
NOTE No backup strategy is complete without plans to test backup media and backups by doing a restore. If a backup is unusable, it’s worse than having no backup at all, because it has lured users into a sense of security. Be sure to add the testing of backups to your backup strategy, and do this on a test system.
The Tower of Hanoi strategy is based on a game played with three poles and a number of rings. The object is to move the rings from their starting point on one pole to the other pole. However, since the rings are of different sizes, you are not allowed to have a ring on top of one that is smaller than itself. In order to accomplish the task, a certain order must be followed.
To use the same strategy with backup tapes requires the use of multiple tapes in this same complicated order. Each backup is a full backup, and multiple backups are made to each tape. Since each tape’s backups are not sequential, the chance that the loss of one tape or damage to one tape will destroy backups for the current period is nil. A fairly current backup is always available on another tape. A more complete description of the backup strategy can be found in the article at www.lanscape.com.au/Support/backup.htm A mathematical discussion of the algorithm used to play the game can be found at www.lhs.berkeley.edu/Java/Tower/towerhistory.html.
Many new and exciting backup strategies are available for use today. Here are a few of them:
• Hierarchical Storage Management (HSM) HSM is not a new technology and is not considered by some to be a backup. It is, indeed, more of an archiving system. Long available for mainframe systems, it is now also available on Windows 2000 and Windows Server 2003. HSM is an automated process that moves the least-used files to progressively more remote data storage. In other words, frequently used and changed data is stored online on high speed, local disks. As data ages (as it is not accessed and is not changed) it is moved to more remote storage locations, such as disk appliances or even tape systems. However, the data is still cataloged and appears readily available to the user. If accessed, it can be automatically made available—it can be moved to local disks, or returned via network access, or in the case of offline storage, operators can be prompted to load the data.
• Windows shadow copy This Windows Server 2003 and Windows XP service takes a snapshot of a working volume, and then a normal data backup can be made that includes open files. The shadow copy service doesn’t make a copy, it just fixes a point in time and then places subsequent changes in a hidden volume. When a backup is made, closed files, and disk copies of open files are stored along with the changes. When files are stored on Windows Server 2003, the service runs in the background, constantly recording file changes. If a special client is loaded (the client is available for Windows XP), previous versions of a file can be accessed and restored by any user who has authorization to read the file. Imagine that Joe deletes a file on Monday, or Ann makes a mistake in a complex spreadsheet design on Friday. On the following Tuesday, each can obtain their old versions of the files on their own, without a call to the help desk, and without IT getting involved.
• Online backup or data-vaulting An individual or business can contract with an online service that automatically and regularly connects to a host or hosts and copies identified data to an online server. Typical arrangements can be made to back up everything, data only, or specific datasets. Payment plans are based both on volume of data backed up and on the number of hosts, ranging up to complete data backups of entire data centers.
NOTE Online (Internet) backup is available for prices ranging from $19.95 for 3GB of storage. Boomarang (www.boomarangdbs.com) is one such service that backs up data over the Internet and provides a mirror site for redundancy. Retention of the previous ten versions of files may be provided, with older versions and “deleted” files being erased after 90 days. Data is secured in storage by 3DES encryption. The Data Vault Corporation (www.datavaultcorp.com) is another such vendor, and it provides encryption for data as it traverses the Internet and while it is stored on Data Vault’s disks, and for the encryption of the user’s password on their client system.
• Dedicated backup networks An Ethernet LAN can become a backup bottleneck if disk and tape systems are provided in parallel and exceed the LAN’s throughput capacity. Backups also consume bandwidth and thus degrade performance for other network operations. Dedicated backup networks are often implemented using a Fibre Channel Storage Area Network (SAN) or Gigabit Ethernet network and Internet Small Computer Systems Interface (iSCSI). iSCSI and Gigabit Ethernet can provide wirespeed data transfer. A Fibre Channel SAN can provide 80 to 90 MBps data transfer rates. Backup is to servers or disk appliances on the SAN. Two providers of such systems are Okapi (now owned by Overlandstorage; see www.overlandstorage.com/jump_page_okapi.html) and XIOtech (www.xiotech.com/).
• Disk-to-disk (D2D) technology A slow tape backup system may be a bottleneck, as servers may be able to provide data faster than the tape system can record it. D2D servers don’t wait for a tape drive, and disks can be provided over high-speed dedicated backup networks, so both backups and restores can be faster. D2D uses a disk array or appliance disk to store data on. Traditional Network Attached Storage (NAS) systems supported by Ethernet connectivity, and the Network File System (NFS on Unix) or Common Internet File System (CIFS, on Windows) protocols can be used, or dedicated backup networks can be provided.
When backing up is a regular part of IT operations, many benefits can be obtained:
• Cost savings It takes many people-hours to reproduce digitally stored data. The cost of backup software and hardware is available at a fraction of this cost.
• Productivity Users cannot work without data. When data can be restored quickly, productivity is maintained.
• Increased security When backups are available, the impact of an attack that destroys or corrupts data is lessened. Data can be replaced or compared to ensure its integrity.
• Simplicity When centralized backups are used, no user need make a decision about what to back up.
The way to ensure that backups are made and protected is to have an enforceable and enforced backup policy. The policy should identify the goals of the process, such as frequency, the necessity of onsite and offsite storage, and requirements for formal processes, authority, and documentation. Procedures can then be developed, approved, and used, which interpret policy in light of current applications, data sets, equipment, and the availability of technologies. The following topics should be specifically detailed:
• Administrative authority Designate who has the authority to physically start the backup, transport and check out backup media, perform restores, sign off on activity, and approve changes in procedures. This should also include guidelines for how individuals are chosen. Recommendations should include separating duties between backing up and restoring, between approval and activity, and even between systems. (For example, those authorized to back up directory services and password databases should be different from those given authority to back up databases.) This allows for role-separation, a critical security requirement, and the delegation of many routine duties to junior IT employees.
• What to back up Someone needs to decide what information should be backed up. Should system data or just application data be backed up? What about configuration information, patch levels, and version levels? How will applications and operating systems be replaced? Are original and backup copies of their installation disks provided for? These details should be specified.
• Scheduling Identify how often backups should be performed.
• Monitoring Specify how backup completion and retention is to be ensured.
• Storage for backup media There are many ways to store backup media, and the appropriate methods should be specified. Is media stored both onsite and offsite? What are the requirements for each type of storage. For example, are fireproof vaults or cabinets available? Are they kept closed? Where are they? Onsite backup media needs to be available, but storing backups near the original systems may be counterproductive. A disaster that damages the original system might take out the backup media as well.
• Type of media and process used The details of how backups are made needs to be spelled out. How many backups are made, and of what type? How often are they made, and how long are they kept? How often is backup media replaced?
Not too long ago, most businesses closed at 5 P.M. Many were not open on the weekends, holidays were observed by closings or shortened hours, and few of us worried when we couldn’t read the latest news at midnight or shop for bath towels at 3 A.M. That’s not true anymore. Even ordinary businesses maintain computer systems around the clock, and their customers expect instant gratification at any hour. Somehow, since computers and networks are devices and not people, we expect them to just keep working without breaks, or sleep.
Of course, they do break. Procedures, processes, software, and hardware that enable system and network redundancy is a necessary part of operations. But it serves another purpose as well. Redundancy ensures the integrity and availability of information.
What effect does system redundancy have? Calculations including the mean time to repair (how long it takes to replace a failed component) and uptime (the percentage of time a system is operational) can show the results of having versus not having redundancy built into a computer system or a network. However, the importance of these figures depends on the needs and requirements of the system. Most desktop systems, for example, do not require built-in redundancy; if one fails and our work is critical, we simply obtain another desktop. The need for redundancy is met by another system. In most cases, however, we do something else while the system is fixed. Other systems, however, are critical to the survival of a business or perhaps even of a life. These systems need either built-in hardware redundancy, support alternatives that can keep their functions intact, or both.
NOTE Critical systems are those systems a business must have, and without which it would be critically damaged, or whose failure might be life-threatening. Which systems are critical to a business must be determined by the business. For some it will be their e-commerce site, for others the billing system, and for still others their customer information databases. Everyone, however, can recognize the critical nature of air traffic control systems, and those systems used in hospitals to support medical analysis.
Evaluating where redundancy is needed, and how much, can be decided by two methods. The first one, weighing the cost of providing redundancy against the cost of downtime without redundancy, is the more traditional method. These factors can be calculated. The second is harder to calculate but is increasingly easy to justify. That decision is based on the fear that customers of web site hosting, or of other online services, will gravitate to the company that can provide the best availability of service. This, in turn, is based on the increasing demands that online services, unlike traditional services, be available 24×7.
There are automated methods for providing system redundancy, such as hardware fault tolerance, clustering, and network routing, and there are operational methods, such as component hot-swapping and standby systems.
It has become commonplace to expect significant hardware redundancy and fault tolerance in server systems. A wide range of components are either duplicated within the systems or are effectively duplicated by linking systems into a cluster. Here are some typical components and techniques that are used:
• Clustering Entire computers or systems are duplicated. If a system fails, operation simply automatically transfers to the other systems. Clusters may be set up as active-standby, in which case one system is live and the other is idle, or active-active, where multiple systems are kept perfectly in synch, and even dynamic load-sharing is possible. This situation is ideal, as no system stands idle and the total capacity of all systems can always be utilized. If there is a system failure, there are just fewer systems to carry the load. When the failed system is replaced, load-balancing readjusts. Clustering does have its downside, though. When active-standby is the rule, duplication of systems is expensive. These active-standby systems may also take seconds for the failover to occur, which is a long time when systems are under heavy loads. Active/active systems, however, may require specialized hardware, and additional, specialized administrative knowledge and maintenance.
• Fault tolerance Components may have backup systems or parts of systems, which allow them to either recover from errors or to survive in spite of them. For example, fault-tolerant CPUs use multiple CPUs running in lockstep, each using the same processing logic. In the typical case, three CPUs will be used, and the results from all CPUs are compared. If one CPU produces results that don’t match the other two, it is considered to have failed, and it is no longer consulted until it is replaced. Another example is the fault tolerance built into Microsoft’s NTFS file system. If the system detects a bad spot on a disk during a write, it automatically marks it as bad and writes the data elsewhere. The logic to both these strategies is to isolate failure and continue on. Meanwhile, alerts can be raised, and error messages recorded in order to prompt maintenance.
• Redundant System Slot (RSS) Entire hot swappable computer units are provided in a single unit. Each system has its own operating system and bus, but all systems are connected and share other components. Like clustered systems, RSS systems can be either active-standby or active-active. RSS systems exist as a unit, and systems cannot be removed from their unit and continue to operate.
• Cluster in a box Two or more systems are combined in a single unit. The difference between these systems and RSS systems is that each unit has its own CPU, bus, peripherals, operating system, and applications. Components can be hot-swapped, and therein lies its advantage over a traditional cluster.
• High availability design Two or more complete components are placed on the network, and one may serve as either a standby system (with traffic being routed to the standby system if the primary fails) or load-balancing is used (with multiple systems sharing the load, and if one fails, only the other functional systems are used). Figure 15-4 represents such a configuration. In the figure, note that multiple ISP backbones are available, and duplicate firewalls, load balancing systems, application servers, and database servers support a single web site.
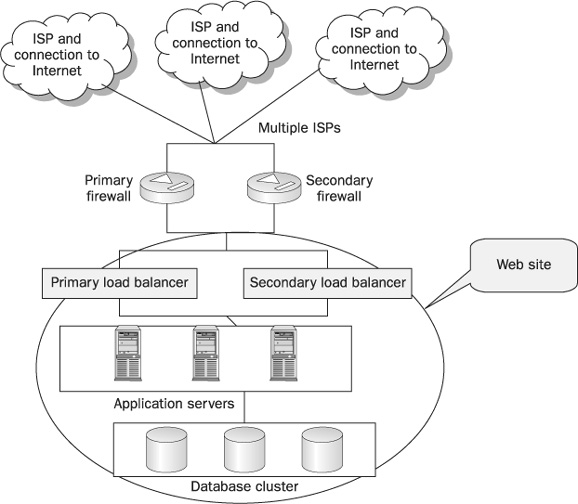
FIGURE 15-4 A high availability network design supporting a web site
• Internet network routing In an attempt to achieve redundancy for Internet-based systems similar to that of the Public Switched Telephone Network (PSTN), new architectures for Internet routing are adding or proposing a variety of techniques, such as these:
• System and geographic diversity
• Size limits
• Dynamic restoration switching
• Self-healing protection switching (typically accomplished with the use of two sources, such as with SONET’s Automatic Switching Protection dual-ring scheme)
• Fast rerouting (which reverses traffic at the point of failure so that it can be directed to an alternative route)
• RSVP-based backup tunnels (where a node adjacent to a failed link signals failure to upstream nodes, and traffic is thus rerouted around the failure)
• Two-path protection (in which sophisticated engineering algorithms develop alternative paths between every node)
An example of such architectures are Multiprotocol Label Switching (MPLS), which integrates IP and data-link layer technologies in order to introduce sophisticated routing control, and SONET’s Automatic Switching Protection (ASP), which provides the fast restoration times (50 ms or so, compared with the possible seconds required in some architectures) that modern technologies, such as voice and streaming media, require.
In addition to redundancy, there are many processes that will keep systems running, or help you to quickly get up and running if there is a problem. Here are a few of them.
• Standby systems Complete or partial systems are kept ready. Should a system, or one of its subsystems, fail, the standby system can be put into service. There are many variations on this technique. Some clusters are deployed in active-standby state, so the clustered system is ready to go but idle. To quickly recover from a CPU or other major system failure, a hard drive might simply be moved to another duplicate, online system. To quickly recover from the failure of a database system, a duplicate system complete with database software may be kept ready. The database is periodically updated by replication, or by export and import functions. If the main system fails, the standby system can be placed online, though it may be lacking some recent transactions.
• Hot-swapping Many hardware components can now be replaced without shutting down systems. Hard drives, network cards, and memory are examples of current hardware components that can be added. Modern operating systems detect the addition of these devices on the fly, and operations continue with minor, if any, service outages. In a RAID array, for example, drive failure may be compensated for by the built-in redundancy of the array. If the failed drive can be replaced without shutting down the system, the array will return to its prefailure state. Interruptions in service will be nil, though performance may suffer depending on the current load.
NOTE Maine Hosting Solutions (www.mainehost.com) feels it has solved the redundancy and reliability problem by utilizing three different ISPs: FGC, Qwest, and AT&T. To further enhance reliability, Maine Hosting Solutions’ facilities are in the same building as these three providers, enabling direct connections between them. In addition, it maintains peering connections with other major T1 providers, so traffic could be switched to alternate backbones if necessary.
Providing availability and integrity for networks is a huge responsibility. In addition to protecting the infrastructure by providing and following proper change control procedures, a network must be protected against loss due to complete or partial system failure by adequate backup. Many systems are considered so critical that data restoration is not a valid operation. For these systems it is critical that adequate redundancy be provided by using duplicate systems, providing clustering or other operations. Finally, systems are not perfect. As problems are found, a methodology to ensure that proper patches or fixes are applied is necessary.