The world of computing in 2003 is very different from the world of computing as it was up to 1993. Little more than a decade ago, the Internet was a playground for universities, government labs, and high-tech companies, with little participation from regular businesses or domestic users. For the latter, in particular, software was something that came from a store in a cardboard box, containing a stack of diskettes (or a CD-ROM if you were lucky) and maybe even some genuine “dead tree” documentation.
Today, things are very, very different. Massive interconnectivity is the norm, and the Internet has evolved into a medium essential to our daily lives. We are in the midst of a transition to ubiquitous computing, where a wide range of everyday devices possess computational capabilities, as well as a transition to spontaneous networking, where those devices have the capacity to interact in a highly fluid and autonomous manner. Software has become much more dynamic, with the emergence of mobile code that can be moved between machines on demand, without human intervention. The importance of the desktop as an application platform has diminished, with the Internet itself being increasingly seen as the platform on which an application executes.
In this brave new world, the risks we face from malicious software or unscrupulous hackers are greater than ever before, as is our need for protection. Users of networked computers need some way of managing execution such that trusted code can run but malicious code is blocked. Developers need programming languages that don’t introduce dangerous back doors into applications via buffer overruns and the like. Developers also need ways of preventing malicious code from luring their own code into breaking security.
Microsoft’s .NET Framework is equipped with many sophisticated features to support the development of secure applications running on the desktop, intranets, and the Internet. This chapter explores the most important of those features; the interested reader is referred to the excellent Addison-Wesley book .NET Framework Security by Brian LaMacchia and colleagues, or to the equally worthy O’Reilly book Programming .NET Security by Adam Freeman and Allan Jones, for more detailed coverage of this important topic.
The first part of this chapter discusses the security features integral to .NET’s Common Language Runtime: managed code, role-based security, code access security, application domains, and isolated storage. The second part considers application-level security within the .NET Framework. It discusses .NET’s cryptographic capabilities and how they are used to secure communication between .NET applications running across a network. It also considers briefly some of the issues involved in securing web services and web applications running within ASP.NET.
.NET provides a number of fundamental features designed to ensure safer execution of code on your machine. Foremost amongst these is the use of managed code, rather than the native machine code of the platform on which an application runs. Also of great importance are the two complementary approaches used to determine the privileges granted to a piece of managed code: role-based security (RBS), where decisions are based on the identity of the user running the code; and code access security (CAS), where decisions are based on the identity of the code itself. Finally, the .NET Framework provides application domains and isolated storage, features that allow .NET components to be isolated from each other and from the file system on your computer’s hard disk.
When it first appeared, Sun Microsystems’ Java broke new ground as a development platform for network-centric computing. Central to Sun’s vision was the notion of code portability, summed up in the pithy (if somewhat inaccurate) phrase “Write once, run anywhere.” This degree of portability is achieved by compiling source code to an intermediate representation called bytecode. Bytecode consists of instructions for a virtual machine (VM), rather than a real CPU. Hence, it follows that an instance of this VM must be active on any machine onto which bytecode is downloaded for execution. The VM interprets the bytecode for a given method call, translating it on the fly into the native machine instructions of the underlying hardware and caching them for use the next time the method is called—a process known as just-in-time (JIT) compilation.
Although there is arguably less emphasis placed on code portability in .NET, it nevertheless adopts a similar approach. .NET applications are compiled to instructions in Common Intermediate Language (CIL), also known as Microsoft Intermediate Language (MSIL). These CIL instructions are subsequently JIT-compiled for execution within the Common Language Runtime (CLR), .NET’s version of the Java VM. Such code is described as managed code.
Use of bytecode or managed code confers some important security benefits. Because both are designed to execute on a relatively simple, abstract, stack-based VM, it becomes easier (though not trivial) to check the type safety of the code before running it. The term “type safety” suggests relatively simple checking—that an integer isn’t being used where a floating-point value is expected, for example—but there is actually a lot more to it than that. Enforcing type safety ensures that code cannot perform an operation on an object unless the operation is permitted for that object, and that it consequently cannot access memory that does not belong to it. An example of type-unsafe code that attempts to do this is presented in the upcoming section titled “Verification.”
Another benefit of managed code compared with native code is that array bounds checking is performed automatically whenever an array is accessed. Hence, an application written entirely as managed code should not be susceptible to buffer overruns, which are the source of many security bugs in unmanaged code.
A third security benefit of managed code is that it comes complete with metadata describing the types defined by the code, their fields and methods, and their dependence on other types. Metadata can provide information useful in the resolution of code access security policy for a particular piece of managed code.
Checking of .NET managed code is, in fact, divided into two distinct phases. First is the validation phase. Type safety checks are the basis of the second phase, verification. Code deemed to be invalid will never run; code that cannot be verified will not run unless it is fully trusted by .NET.
In .NET, managed code is organized into units called assemblies, the contents of which must be validated before execution. An assembly may consist of more than one file, but usually it is a single file, in Microsoft’s standard Portable Executable/Common Object File Format (PE/COFF). All executable code for Windows is stored in this format, which is extensible. This fact has allowed Microsoft to use the format for managed code, as well as unmanaged code.
An assembly contains CIL instructions, the metadata describing those instructions, and, optionally, a resource block (possibly holding strings used for localization, bitmaps used for icons, and so on). Validation is the process of checking that
• The assembly is a conforming PE/COFF file
• All necessary items of metadata exist and are uncorrupted
• The CIL instructions are legal, meaning that
• Where a CIL instruction is expected, the byte at that position in the file corresponds to a recognized CIL instruction
• The operands required by certain instructions are present on the stack and are of the correct type
• An instruction will not push a value onto the stack if the number of values already on the stack equals that specified by the method’s maxstack directive
As an example of invalid code, consider the following piece of CIL, intended to add two user-supplied integers and display the result:
Even if you have never seen CIL before, it is fairly easy to see what’s going on here, and what’s wrong; clearly, the programmer has forgotten to write CIL instructions to prompt for the second number, read it, and store it on the stack. As a result, the add instruction is not valid. Despite this error, the code compiles to an assembly using the ilasm command-line tool supplied with the .NET Framework SDK (see sidebar). However, on running Add.exe, we see the following error reported by the CLR:
![]()
Note that we can validate an assembly offline using peverify, the command-line tool for assembly validation and verification supplied with the .NET Framework SDK. Running this tool on Add.exe yields output like the following:

Whereas validation checks for internal consistency, verification of an assembly is concerned with checking that its CIL instructions are safe. To illustrate the purpose of verification more clearly, let us consider a simple example of type safety violation and its detection. In this example, we have a C# class named Secret, containing a private, randomly initialized integer field:

Let us suppose that a hacker writes a similar class, Hack, with a public integer field, and then attempts a “type confusion” attack by making a Hack reference point to a Secret object, in the hope that this will give access to the private field of the latter:

A bona fide C# compiler will recognize that this is highly dangerous and refuse to compile the code. But what if the hacker writes in CIL rather than C#?
The Main method from a version of the Hack class written directly in CIL is shown here, the comment indicating where the type confusion occurs:

This code assembles successfully with ilasm and, what is more, executes, displaying the random integer supposedly hidden inside the Secret object!
So, what’s going on? Is the CLR somehow unable to detect this type safety violation? Executing peverify on Hack.exe demonstrates that this cannot be the case:

Although Hack.exe fails verification, the CLR goes ahead and runs it anyway because the assembly originates from the local machine and, in the default code access security (CAS) policy, code from the local machine is trusted fully. If Hack.exe had been downloaded from a remote site, it would not have been executed. CAS and security policy are discussed in detail in the section entitled “Code Access Security” later in this chapter.
The decision about whether valid, verified code is allowed to execute can, if you wish, be based on the identity of the user running the code. This approach is known as role-based security (RBS).
RBS is, of course, very familiar to computer users, since it forms the basis of OS security. When you log in to a Windows machine, you provide credentials—typically a user ID and password—that must match a user account known to Windows. In this way, Windows authenticates you as a legitimate user of the system. The account provides you with an identity on the system, and the groups to which that account belongs represent the various roles you may play as a user of the system. Each of those roles can have different privileges associated with it.
It is important for you to recognize that .NET’s RBS system is completely independent of, and does not replace, the underlying RBS of Windows. The former is for application-level decisions about who may run particular pieces of code, whereas the latter is for protection of the operating system as a whole. Nevertheless, .NET RBS can integrate easily enough with Windows RBS if, for example, you wish user identities in your .NET application to be based on Windows user accounts. It is also important to realize that .NET RBS is completely independent of, and incompatible with, COM+ security. It you write a class in .NET that uses COM+ services—known as a “serviced component”—then you should use the RBS facilities offered by COM+ rather than those of .NET.
When you use RBS in .NET, security decisions are based on a principal—an object encapsulating the single identity and (possibly) multiple roles associated with a user. In the .NET Framework, identities and principals are represented by objects that implement the IIdentity and IPrincipal interfaces from the System.Security.Principal namespace. The contents of this namespace are shown in the UML diagram in Figure 25-1. Most notable here are the WindowsIdentity and WindowsPrincipal classes, representing identities and principals derived from Windows user accounts. The following program shows how instances of these classes can be created and queried for information on the user running the program:
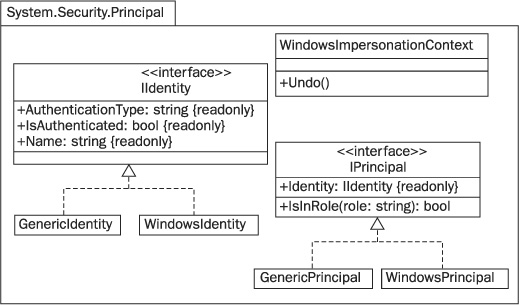
FIGURE 25-1 Classes and interfaces supporting role-based security in .NET

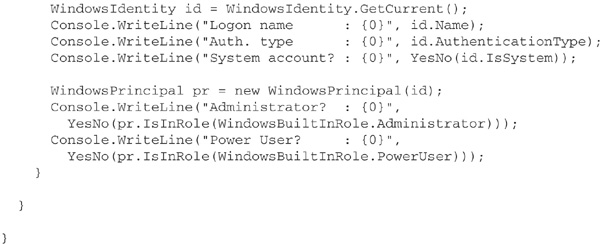
To activate RBS, you must assign the principal you have created to the CurrentPrincipal property of the active thread, or invoke the SetPrincipalPolicy method of System.AppDomain. For example, to make the current principal represent the Windows user calling your code, you can do this:
![]()
If you want any thread created in the current application domain to have the Windows principal assigned to it automatically by the CLR, it is easier to do this, instead:
![]()
Once you have activated RBS, other parts of your application are free to make security demands concerning the current principal. The concept of a security demand is discussed properly in the upcoming section “Code Access Security,” but here is a quick example of a role-based demand to whet your appetite:
![]()
If this statement is placed in front of a method definition, then that method can be invoked only by a principal with the identity “Joe”.
.NET RBS also supports impersonation, a common requirement in server applications. Consider, for example, a multitier system in which there is interaction with a database server on behalf of different users. The identity under which code in the middle tier executes is not the identity we wish to present to the database server; instead, we need somehow to flow the identity of the original caller downstream to the database server. This is achieved by having the application server impersonate the caller.
Impersonation is implemented in .NET code by obtaining the Windows access token of the user to be impersonated and then creating a WindowsIdentity object representing that user. The process of obtaining the access token is not described here; the interested reader should consult other texts such as Freeman and Jones’ Programming .NET Security for full details. Assuming that the token is available as an object named token, the following C# code will impersonate the token’s owner:
Note the call to the Undo method, which is necessary to turn off impersonation and revert to the code’s true identity.
More interesting than RBS is the idea of basing security decisions on the identity of the code to be executed, rather than the identity of the user wanting to execute it. This is known as code access security (CAS). Fundamental to CAS is the notion of evidence— information gathered by the CLR about code. Evidence is compared with the various membership conditions found within a hierarchy of code groups; whenever a match is found, the assembly is granted the set of permissions associated with the matching code group. This is entirely analogous to the process in Windows RBS of a user accumulating privileges based on the user groups to which they belong. The code groups, their membership conditions, and their permission sets constitute CAS policy and are represented in an XML document that can be modified to configure security policy.
There are, in fact, multiple policy documents representing different policy levels. The processes of evidence evaluation and permission assignment are conducted independently at each level, and the intersection of the various policy level “grant sets” yields the maximal set of permissions that may be granted to the assembly. The final step is to modify this grant set based on permission requests specified in the assembly’s metadata. The assembly may declare
• The minimum set of permissions needed to function properly
• The set of permissions that are desirable, but not necessary for minimal operation
• The set of permissions that will never be required
These declarations are used to reduce the initial grant set if necessary, but will never result in an increase in the permissions granted to an assembly. The entire process of CAS policy resolution is summarized in Figure 25-2.
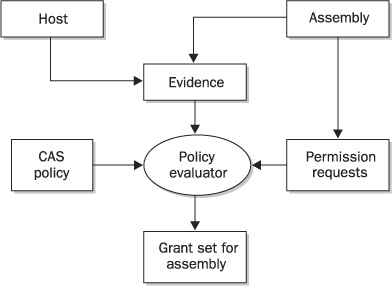
FIGURE 25-2 How the CLR’s Policy Manager resolves CAS policy for an assembly
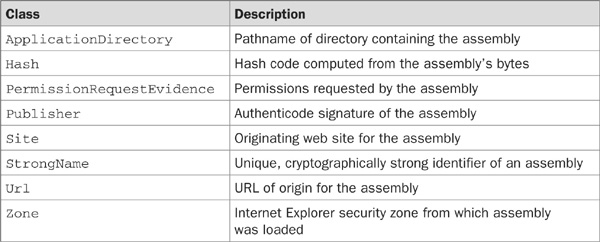
.NET defines a standard set of evidence classes to represent various kinds of evidence associated with an assembly, and you can create your own classes to represent new kinds of evidence. The standard classes are described in Table 25-1. When an assembly is loaded, instances of the appropriate classes are created and associated with the assembly.
TABLE 25-1 Standard Evidence Classes for Code Access Security
As suggested in Figure 25-2, .NET distinguishes between evidence that the hosting application provides about an assembly and evidence that an assembly provides about itself. The latter is regarded as untrusted, for obvious reasons, and it does not feature in .NET’s default security policy. The evidence classes of Table 25-1 all represent host-provided evidence; they cannot be used to represent assembly provided evidence, so you must define your own classes for this purpose.
Using .NET’s reflection capabilities, it is relatively easy to write a program that will display the host-provided evidence for an assembly:


The enumerateEvidence method should really be a simple while loop that prints out each piece of evidence as a string, but the standard string representation of hash evidence is, for some unfathomable reason, the bytes from which the hash is computed, encoded in XML, rather than a much more compact hash code! Hence, we test for hash evidence and, if detected, obtain the SHA-1 hash from it.
If you run the program on an assembly, you will see output like this:

In this example, the CLR has provided Zone, Url, and Hash evidence for the assembly. We don’t see any other types of evidence because the assembly was loaded locally and because it has neither a strong name nor an Authenticode signature. If Add.exe is moved to a web server, then Zone and Url evidence change to Internet and the URL of the assembly, respectively, and Site evidence appears, containing the domain name of the web server.
.NET defines a standard set of classes to represent various code group membership conditions. Broadly speaking, these correspond to the various evidence types. For example, there is a HashMembershipCondition class that stores a hash value and compares it with hash evidence from an assembly. You may supplement these standard classes with your own membership condition classes, perhaps corresponding to custom evidence classes that you have created. If you do so, these matched pairs of classes should be placed in the same assembly, and this assembly will need to be added to the “policy assembly list.” This is a section of a CAS policy document specifying assemblies that are trusted fully by the CLR while CAS policy is being loaded, in order to prevent cyclic policy resolution problems.
The permissions that .NET grants based on membership conditions are, likewise, represented as classes. Again, there is a standard set of classes, to which you may add your own. Three examples of standard classes are SocketPermission, which dictates whether network socket connections may be opened or accepted; FileIOPermission, which controls access to the file system; and RegistryPermission, which guards the Windows registry. Permissions may be grouped into permission sets, and the class PermissionSet from the System.Security namespace is provided for this purpose. .NET provides a small number of standard, named permission sets, represented by the NamedPermissionSet class. Figure 25-3 is a UML diagram showing the relationships between the classes mentioned here and some of the other classes and interfaces used to model CAS permissions.
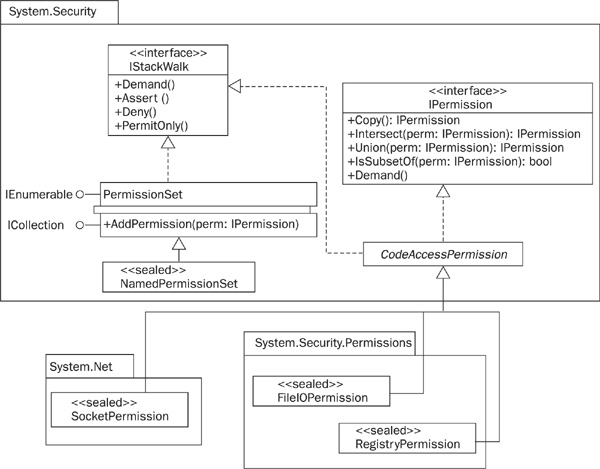
FIGURE 25-3 Some of the classes and interfaces used to model CAS permissions
Code groups essentially specify the binding between membership conditions and permission sets. From a policy perspective, they are statements of the degree of trust that you are willing to grant code. As with membership conditions and permissions, the standard collection of code groups can be extended with new groups that you have defined yourself. The standard groups include

Note the resemblance to Internet Explorer security zones! You can see how these groups are defined and how they link membership conditions with permission sets if you browse CAS policy using either of the tools that the .NET Framework provides for this purpose. If you prefer a graphical user interface, then use the .NET Framework configuration tool, a Microsoft Management Console snap-in named mscorcfg.msc; alternatively, you can use the command-line CAS policy tool, caspol.exe. This has the advantage that it can be invoked from batch files, allowing system administrators to automate policy manipulation easily.
The .NET Framework defines four different CAS policy levels: enterprise, machine, user, and application domain. The last of these is optional and often not used; it is described briefly in the section entitled “AppDomains and Isolated Storage” later in this chapter. The other three are all defined statically using XML documents. Enterprise and machine policy are specified in files named enterprisesec.config and security.config, respectively, located in the config subdirectory of the .NET Framework root directory. For version 1.1 of the Framework, this root directory is C:\WINDOWS\Microsoft.NET\Framework\v1.1.4322. User policy is specified by a security.config file located in a subdirectory of each user’s profile. Note that there will be one version of each of these files for each version of the .NET Framework that is installed on your machine.
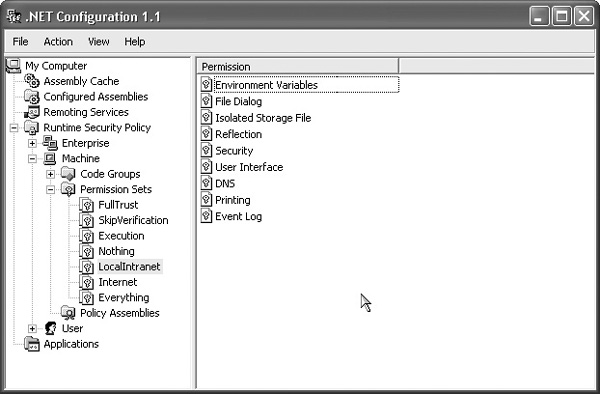
Being written in XML, a policy document can be readily browsed using Notepad or some other text editor, although you will probably find it easier to use the tools mentioned earlier. Figure 25-4 shows the .NET Framework configuration tool, mscorcfg.msc, being used to browse the permissions of the named permission set LocalIntranet in the machine-level CAS policy document. You may find that the command-line tool, caspol, is quicker to use once you’ve learned its command-line options.
FIGURE 25-4 Using mscorcfg.msc to browse CAS policy
The policy administration tools can be used to test how policy affects a given assembly. The .NET Framework Configuration tool provides the Evaluate Assembly Wizard for this purpose, whereas caspol has two relevant command-line options. For example, to identify the code groups to which an assembly named Foo.exe belongs, you simply enter the command
![]()
If you then wish to enumerate the permissions granted to Foo.exe, simply enter
![]()
But why is policy so complex? Why are there multiple policy levels? The reason lies in the possibly conflicting security needs of the various parties involved in managing and using .NET applications. Imagine a scenario in which network administrators have implemented their organization’s security policy in the enterprisesec.config document deployed on all machines. However, there may be certain machines—those used by visitors and hotdesking employees, for instance—where a more restrictive policy is desired. The administrators may specify this in the security.config documents of those machines. Now imagine an individual user of one of these machines who is particularly concerned about security and wishes to lock down the machine still further whenever she is running .NET applications on it. She may do this in her own security.config document.
To make CAS principles more concrete, let’s consider a simple example of policy resolution. Imagine running an application that uses two assemblies, Foo.dll and Bar.dll. Foo.dll is installed in the application’s directory on the local disk, whereas Bar.dll is a plug-in of some kind, originating from the web site www.acme.com. Neither of the assemblies makes any special permission requests.
We will assume that the enterprise and user-level policy documents have their default contents, in which there is a single code group, All_Code, with no membership conditions and the permission set FullTrust. Both assemblies will therefore be assigned to the All_Code group and gain full trust as a result of policy resolution at each of these levels. Although this sounds dangerous, it isn’t a problem in practice because policy is also evaluated at the machine level, and machine policy assigns trust in a more careful manner. (Remember that permissions from the different levels are intersected to determine an assembly’s maximal grant.)
Let’s suppose that the machine policy document defines a code group tree with All_Code as the root; the standard groups My_Computer_Zone, LocalIntranet_Zone, and Internet_Zone as children of All_Code; and the group Acme_Site as the sole child of Internet_Zone. Acme_Site is a custom group with the membership condition that Site equals www.acme.com and the custom named permission set AcmePermissions.
When machine policy is resolved for Foo.dll, the CLR traverses the code group tree from the root downwards, ignoring a group’s subtree if the membership conditions of that group aren’t met. Because All_Code has no membership conditions, a match is inevitable. However, no real permissions are accumulated because the permission set for All_Code at the machine level is Nothing. Next, the CLR looks at the children of All_Code. The membership conditions for the children are based on Zone evidence. Because Foo.dll is loaded locally, it offers Zone = MyComputer as evidence, which matches the conditions for the My_Computer_Zone group only. Hence, Foo.dll is granted the FullTrust permission set associated with this group and, because the My_Computer_Zone group has no children, policy resolution stops there. The result is full trust for Foo.dll. This outcome is depicted in Figure 25-5. The boxes in this diagram represent code groups. Shading is used to indicate which groups have their membership conditions checked, and a heavy outline indicates the groups to which Foo.dll belongs.
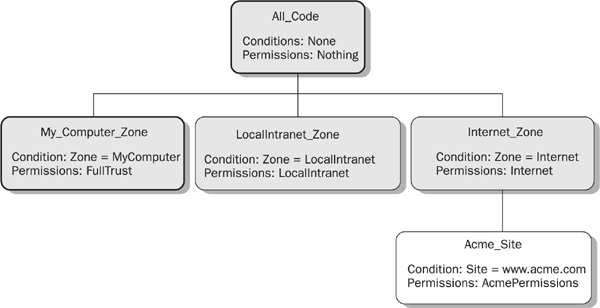
FIGURE 25-5 Example of policy resolution for an assembly loaded locally
Now, what about Bar.dll? The same process occurs for this assembly, only with a different outcome, depicted in Figure 25-6. Once again, there is the inevitable match with All_Code, leading to further examination of the code group tree. This time, however, Zone evidence results in a match with the membership conditions of the Internet_Zone group only. So, Bar.dll is granted the Internet permission set of this group, and the CLR proceeds to examine its subtree. Bar.dll offers Site = www.acme.com as evidence, which matches the membership condition for Acme_Site, so the assembly is a member of this group and receives the permissions set AcmePermissions. The final set of permissions granted to Bar.dll at the machine level is the union of the three permission sets granted to it—Nothing, Internet, and AcmePermissions.
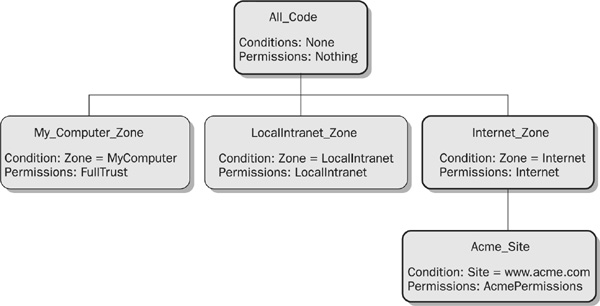
FIGURE 25-6 Example of policy resolution for an assembly loaded from the web site www.acme.com
A union of permission sets is the default for CAS, which makes granting of code access permissions mimic the familiar RBS behaviour of accumulating privileges for an operating system user based on the user groups to which they belong. It is possible, however, to configure CAS for alternative behavior; for example, if Acme_Site was given the special code group attribute Exclusive, then code belonging to this group would be granted only the permissions in AcmePermissions.
To arrive at final permissions for our assemblies, the intersection (rather than union) of the permission sets at all three policy levels must be computed. This ensures that policy defined at the enterprise level cannot be overridden with a less-restrictive policy by an individual user, or vice versa. We’ve already stated that enterprise and user policy is to grant full trust, so intersecting the grant sets computed for the three policy levels results in no further restrictions of permission. We’ve also stated that the assemblies don’t make any special permission requests; hence, the final permissions determined by CAS policy for Foo.dll and Bar.dll are FullTrust (that is, all permissions) and Internet + AcmePermissions, respectively.
After assembly loading and CAS policy resolution, there are various situations in which policy may cause the CLR to prevent execution of code. For example, when an assembly has declared a minimum set of permissions that is not a subset of its maximal grant, a PolicyException is thrown immediately. The same thing occurs when an assembly containing code has not been granted the right to execute that code, as indicated by a flag within a SecurityPermission object.
Thereafter, CAS policy is enforced during execution by means of security demands. This process is best illustrated with an example using the .NET Framework’s class library. Let’s imagine an assembly that attempts a connection to a remote machine by invoking the Connect method of a standard Socket object. The first thing the Connect method does is create a SocketPermission object and call its Demand method. This forces the CLR to check that our imaginary assembly has been granted SocketPermission, but checking cannot stop there; the CLR must also ensure that code calling the method in our assembly also has SocketPermission. In fact, the CLR walks up the call stack, to the very top if necessary, making sure that all callers in the chain have the necessary permission. If any caller does not, the operation does not proceed and a SecurityException is thrown (see Figure 25-7). This process is necessary to prevent luring attacks, in which malicious code co-opts trusted code to break security.
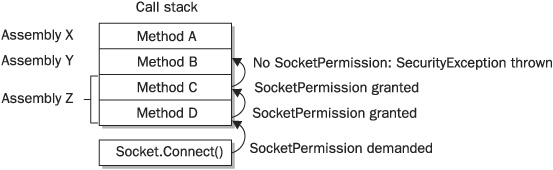
FIGURE 25-7 Prevention of a luring attack via a stack walk
When writing code, you may wish to mimic the class library and make security demands of your own. This is particularly relevant when you’ve created custom permissions, but can be useful with the standard permissions, as well. The .NET Framework allows you to achieve this in an imperative or declarative manner. Imperative security is programmed by creating objects and calling their methods, whereas declarative security involves placement of attributes in the source code for an assembly. The two approaches complement one another: imperative security allows security decisions to be based on information available only at run time, but knowledge of those decisions becomes available only by executing the code; declarative security fixes your decisions at compile time, but generates metadata that tools can access via reflection, without the need to run code.
Let’s look at an example of a security demand made using these two approaches. The demand will be for read access to the file C:\Windows\app.ini and write access to the file C:\tmp\app.log. The demand can be written imperatively in C# as follows:

The corresponding declarative version is

Let us suppose that this declarative demand has been applied to a method named LoadConfig in a class MyApp. Information regarding the demand can be extracted from the assembly containing the class using the permview command-line tool. The command
![]()
will yield output like the following:

.NET allows you to override normal stack walking behavior in an imperative or declarative fashion, using other security actions such as Assert or Deny. Asserting a permission or permission set terminates a stack walk that is looking for that permission or permission set, without triggering a SecurityException. If you assert permissions for a particular method in your code, you are, in effect, vouching for callers of that method. Obviously, this can be dangerous; you had better be very sure that untrusted code cannot cause any damage by calling your method! If you are sure of this, however, assertion has its uses. Suppose, for example, that you have created an assembly that logs its activity by writing to a file. Every call to its LogAction method results in a FileIOPermission demand that assemblies calling into your assembly may not be able to meet. However, if you know that there is no way for those assemblies to subvert logging because they cannot influence what is written to the logfile in any way, then it may be reasonable to assert the appropriate FileIOPermission, like this:

It is worth emphasizing once again that security assertions must be used with extreme caution. They are one of the first things you should look at when analyzing a .NET application for security holes.
Denial may also lead to early termination of a stack walk, but is the opposite of assertion, guaranteeing failure of an operation if a stack walk looking for any of the denied permissions reaches the method making the denial. Note that an assertion or denial can be cancelled by calling the static RevertAssert or RevertDeny methods of the CodeAccessPermission class.
A fundamental principle in security is compartmentalization: the isolation of system components from each other so as to minimize the risk of damage should one component be compromised. .NET supports this by providing mechanisms to
• Isolate assemblies from one another in memory while they execute
• Isolate user preferences and other persistent elements of application state from those of other applications and from other parts of the local file system
A .NET application may consist of multiple assemblies. By default, the process hosting that .NET application will contain all of these assemblies within a single application domain, or appdomain. However, it is possible to create more than one appdomain and have assemblies loaded into different appdomains. The relationship between operating system processes, appdomains, and assemblies is summarized in Figure 25-8.
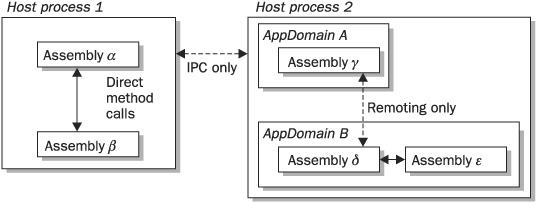
FIGURE 25-8 Use of appdomains for assembly isolation
From a security perspective, there are two advantages to isolating assemblies within appdomains. The first is that assemblies in different appdomains cannot interfere with one another; in fact, the only way they can communicate is via .NET’s remoting mechanism. This mirrors, but on a finer-grained level, the use of processes by the operating system to isolate one running program from another.
The second advantage of creating different appdomains is that security policy can be defined at the appdomain level, in addition to the enterprise, machine, and user levels discussed earlier. This allows a host to, for example, create a more restricted execution environment for managed code with a particular, and untrusted, origin. Unlike policy at the enterprise, machine, and user levels, which is managed statically using the tools provided for that purpose in the .NET Framework, appdomain policy must be defined programmatically. It can therefore be more dynamic than the other policy levels, which may be useful in certain situations.
When a managed host creates a new appdomain, it needs some way of controlling the loading of assemblies in that appdomain. This is commonly achieved by writing a small “controller class” with the capability to load assemblies. For example, you could compile the following class into an assembly called ControlAssembly.dll:

After creating the new appdomain, you must instantiate a Controller object in that appdomain. Assemblies are subsequently loaded by invoking the controller’s LoadAssembly method:

To lock down a new appdomain, you must create objects representing the required named permission sets, membership conditions, and code group tree. These objects must then be registered with a PolicyLevel object, created via the following call:
![]()
The final step is to assign the new policy to your new appdomain:
![]()
Any standard library assemblies requiring a high degree of trust should be loaded into the new appdomain before you lock it down using the new policy. These assemblies will have their permissions computed in the normal way, as specified in the static CAS policy documents, whereas those loaded after the call to SetAppDomainPolicy will be subject to myPolicy as well as enterprise-, machine-, and user-level policy. This will quite likely result in a smaller grant set for those assemblies and for any assemblies that they cause to be loaded transitively.
It is clearly risky to allow downloaded code access to your computer’s hard disk. And yet it is clearly useful for an application to write user preferences, configuration data, and other elements of application state to some kind of persistent store that can be accessed next time the application runs. Windows applications have historically used specialized .ini files or the Windows registry for this purpose—an approach that isolates data from different users with reasonable success, but cannot, for example, stop applications run by the same user from interfering with each other’s data. Granting unrestricted access to particular areas of the file system is generally a bad idea, because it then becomes all too easy for malicious code to trash important files or execute a denial of service (DoS) attack by filling your hard disk with random bytes.
.NET’s solution to these problems is isolated storage. This provides applications with private compartments called stores, to which data may be written and from which data may be read. A given assembly run by a particular user will have a unique store associated with it, one that cannot be accessed by other assemblies run by that user or by other users executing that assembly. In some instances, this level of isolation isn’t sufficient—when an assembly is used in multiple applications run by the same user, for example—so .NET also allows stores to be isolated by user, assembly, and application domain.
Within its own store, an assembly can create a virtual file system consisting of directories and files, but it cannot manipulate pathnames to access data in other stores, nor can it specify a path to any part of the file system outside of isolated storage. Furthermore, limits can be placed on the maximum size of a store, preventing DoS attacks that target your machine’s hard disk. The Internet permission set, for example, specifies a default quota of 10KB for a store.
Now, let’s look at some C# code that will create a store and write data to it:

In this example, a directory named Test is created in the store for the assembly containing the code, and the string “Hello!” is written to the file message.txt in this directory. We can use the command-line tool for administering isolated storage, storeadm, to see the effect of executing this code. Before execution, running storeadm with the /list option yields no output (unless you’ve already run .NET applications that create stores, of course); after execution, rerunning storeadm yields output like the following:
You can dispose of this store, and all others that you own, using the /remove option of storeadm.
Although core features of .NET, such as use of managed code and CAS, are extremely important security measures, they are not the whole story. The .NET Framework also provides support for application-level security. Fundamental to this is the ability to guarantee the confidentiality of communication between components of a .NET application, as well as the integrity of the data that are exchanged. The .NET Framework’s class library provides a powerful set of cryptography classes to help you achieve these goals. This part of the chapter examines .NET’s cryptographic capabilities and how they can be used, along with other techniques, to secure .NET remoting applications. It also discusses application-level security for web services and web applications deployed using ASP.NET.
.NET’s cryptographic capabilities are encapsulated within a set of classes from the System .Security.Cryptography namespace. These classes are, in part, an abstraction layer on top of a fundamental component of the Windows operating system—the Crypto API; some of the .NET classes rely on unmanaged code in the CryptoServiceProvider classes from this API, whereas others are implemented purely as managed code. The .NET classes support several different algorithms for computing hash codes, several algorithms for symmetric cryptography and one algorithm for public key cryptography.
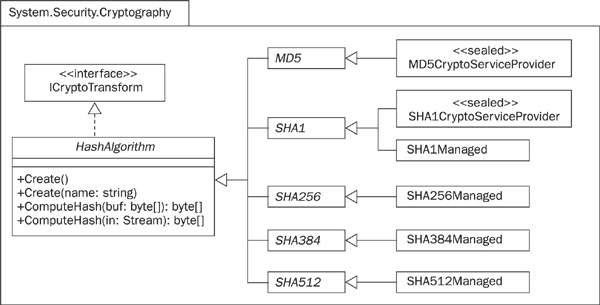
Hashing algorithms are discussed in Chapter 7. .NET supports a number of the standard algorithms via the class hierarchy shown in the UML diagram in Figure 25-9. You can see that the well-established MD5 and SHA1 algorithms are supported, as are newer, larger hashes such as SHA256. There are implementations of MD5 and SHA1 based on the Crypto API, and managed code implementations of all the SHA algorithms. The diagram does not show keyed hashing algorithms, which use a secret key to prevent an eavesdropper from replacing a message and its hash code. The .NET Framework supports two such algorithms: HMAC-SHA1 and MAC-TripleDES.
FIGURE 25-9 The hierarchy of .NET hash algorithm classes
Now, let’s look at some example code. The following C# class, FileHash, provides a method to compute the hash code of bytes in a file, using an algorithm specified by name when the FileHash object is created. This approach relies on the static method Create of the abstract HashAlgorithm class, but you can, if you wish, instantiate a specific implementation of a hashing algorithm, such as SHA1Managed. Whichever approach you use, it is good object-oriented programming practice to work through the abstract HashAlgorithm class wherever possible, as this will minimize the number of changes you’ll need to make to your code if you decide to use a different algorithm at a later date.

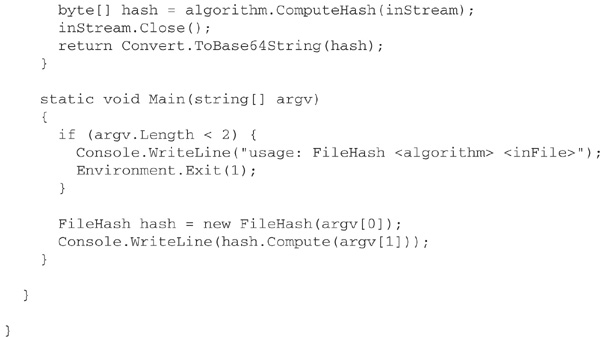
Here’s a session at the command line showing FileHash being used to compute three different hash codes for an assembly:
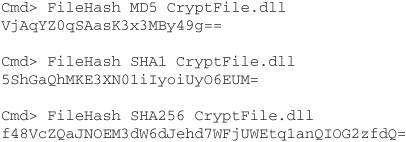
Note the differences in hash code length. Longer hash codes are less susceptible to attack, but take longer to compute (as you will observe if you try running this program on a very large file).
The .NET Framework supports the RC2, DES, Triple-DES, and Rijndael (AES) symmetric encryption algorithms via the class hierarchy shown in Figure 25-10. Use of DES is inadvisable except where needed for backward compatibility; its short key length means that DES encryption can be broken relatively easily by modern hardware. As Figure 25-10 indicates, .NET uses a managed code implementation of Rijndael together with Crypto API implementations of the other algorithms. As with hashing, it is a good idea to work with the abstract top-level class—SymmetricAlgorithm, in this case—wherever possible, since this makes it easier to switch to a different algorithm should the need arise.
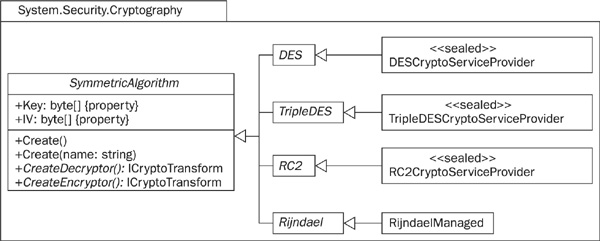
FIGURE 25-10 The hierarchy of .NET classes for symmetric encryption
The tasks of encrypting and decrypting a block of data are modeled abstractly in .NET by the ICryptoTransform interface. SymmetricAlgorithm defines methods, CreateEncryptor and CreateDecryptor, that return objects implementing this interface. The TransformBlock and TransformFinalBlock methods can be called on those objects to perform the desired operation; alternatively, you can introduce a further layer of abstraction by using CryptoStream. A CryptoStream object is created from an existing stream object and an implementation of ICryptoTransform that either encrypts or decrypts data. It behaves just like any other stream object, except that a Read or Write on the stream may result in calls to TransformBlock or TransformFinalBlock behind the scenes.
The following C# class, CryptFile, demonstrates these ideas. Like FileHash, discussed earlier, it uses the approach of specifying the desired algorithm by name and calling a static Create method to manufacture an appropriate object. The methods Encrypt and Decrypt perform encryption and decryption, respectively, from one named file to another. WriteKey stores the key in another file. This file should be exchanged securely with the recipient of the ciphertext, who must use ReadKey to load it. Each invocation of Encrypt must be followed by a call to WriteIV, to store the just-used initialization vector in a file. Each invocation of Decrypt on a file of ciphertext must be preceded by a call to ReadIV, to read the initialization vector associated with that file of ciphertext.

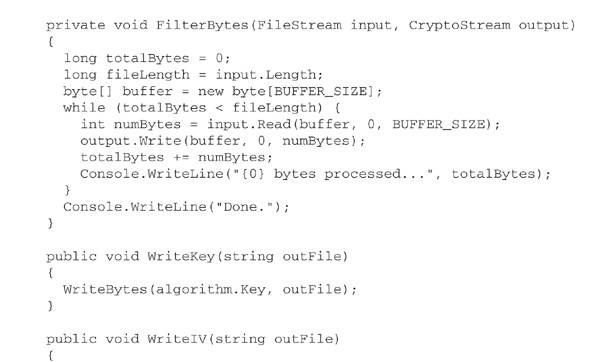
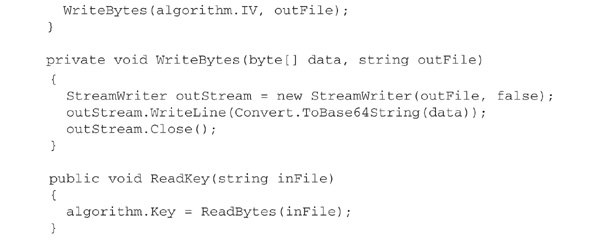

Use of CryptFile is fairly straightforward, as illustrated by the following small encryption program:

When this program is run with the command line
![]()
it writes the encryption key and initialization vector as Base64-encoded strings to the files TripleDES.key and TripleDES.iv, respectively. It then transfers bytes from test.doc to a new file, encrypted.doc, encrypting them en route using the Triple-DES algorithm.
Currently, the .NET Framework supports only one public key algorithm: the well-known RSA algorithm. Also, there is only one implementation of this algorithm available: that provided by the Crypto API, via the RSACryptoServiceProvider class. This class provides the methods Encrypt and Decrypt, both of which operate on, and return, arrays of bytes. ICryptoTransform and CryptoStream functionality is not supported for the simple reason that public key cryptography is 2–3 orders of magnitude slower than symmetric cryptography, making it unsuitable for the processing of large quantities of data. Instead, you will want to use RSA for
• Secure exchange of small pieces of data, such as the keys used by symmetric algorithms
• Creation or verification of digital signatures, via the SignHash, SignData, VerifyHash, and VerifyData methods
Key exchange is supported by the methods ExportParameters and ImportParameters, which may be used to pass key information from one instance of an algorithm to another as an object of type RSAParameters. Key information can also be exported in XML, using the ToXMLString method, and imported likewise, with the FromXMLString method. A public key exported in XML looks something like this:

(The <Modulus> element is not shown in its entirety, as it is rather large.)
Here is some C# code to illustrate public-key cryptography using the RSA algorithm. The class PkCrypt encapsulates RSACryptoServiceProvider, adding methods for encryption and decryption of text strings and exchange of keys as XML documents. The program in Main simulates encrypted communication between individuals Alice and Bob using two instances of PkCrypt. Bob’s public key is exported to a file rsapub.xml, which Alice then imports. This enables Alice to encrypt a message for Bob’s eyes only. Bob decrypts the message, and the result is displayed on the console, beneath Alice’s original message.

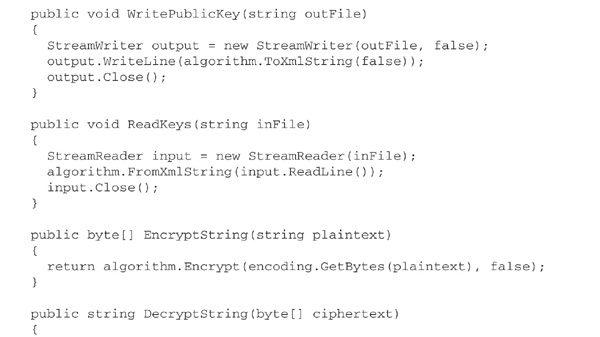
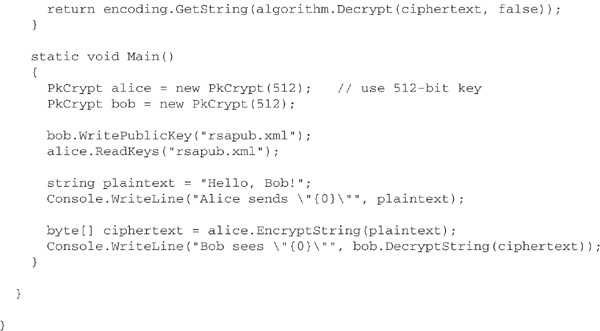
The DPAPI is a part of the Crypto API consisting of just two functions: CryptProtectData and CryptUnprotectData. DPAPI is particularly useful for simple operations such as encrypting the credentials required to connect to a database or log on to a web application of some kind. DPAPI is attractive because it places the burden of key management on the operating system rather than the developer; the encryption key is, in fact, derived from the password of the DPAPI’s caller.
Unfortunately, DPAPI is not mirrored in the .NET Framework class library. However, a simple C# class encapsulating the DPAPI functions is easy to write; an example appears in the book Building Secure Microsoft ASP.NET Applications from Microsoft Press.
Remoting allows method calls in .NET to cross appdomain, and even machine, boundaries. The degree to which these remote method calls are secure depends on the way in which remoting is configured and on the environment that is hosting the remote object. If you’ve worked with remoting before, you’ll be well aware of its flexibility; a remoting application can use TCP or HTTP as the protocol underlying a remote call, and can format the call as binary data or as a SOAP message. If you opt for HTTP, then you can host the remote object using ASP.NET and IIS, which allows you to
• Use the authentication and authorization features of ASP.NET and IIS (although direct Forms-based or Passport authentication is not possible)
• Encrypt the call with SSL/TLS, assuming that IIS has been configured for this and that the remote object is given an https:// URL
If you choose TCP, then you get no built-in support for authentication and authorization, and no built-in means of ensuring confidentiality. If you require the latter, then one option is to introduce cryptography into the lowest layer of the protocol stack, via IPSec. This is entirely transparent from the developer’s perspective and has the additional advantage of securing all IP traffic, not just remote method invocation; however, it isn’t programmable and requires OS support on all participating machines—something that may be feasible only for tightly controlled intranets. Another option is to introduce cryptography into the application layer. Fortunately, .NET’s remoting architecture makes it possible to do this in a very elegant way.
In .NET remoting, a method call passes through a chain of channel sink objects, responsible for formatting the call as a message and sending that message according to a given transport protocol. The .NET Framework allows you to introduce your own channel sinks into the chain, to perform operations such as logging or, in this case, encryption and decryption of the datastream. In fact, you needn’t go to the trouble of implementing this yourself, as there are several implementations of secure channels available for download (see sidebar). Because remoting can be configured for both client and server entirely by means of XML configuration files, it is possible to plug in one of these secure channels without making any changes to client and server code.
Web services and web applications are typically hosted by ASP.NET and IIS. Securing a web service or web application is more a matter of configuring these environments than of programming. For example, ensuring confidentiality through encryption is best achieved using SSL/TLS. Activating this for your application simply involves configuring IIS appropriately and then using the https prefix for URLs.
Configuration of ASP.NET security mainly involves editing a hierarchical collection of XML documents. At the top of the tree is machine.config, where global settings for all ASP.NET applications running on the machine are made. Underneath the global configuration file are the web.config files containing settings for each individual ASP.NET application. The remainder of this chapter discusses the entries needed in these files to configure CAS, authentication, impersonation, and authorization.
Although CAS is primarily seen as a way of protecting the client side of a system from malicious mobile code, it has some relevance to the deployment of web services and web applications on the server side. A single server might, for example, host ASP.NET applications authored by more than one individual, group, or organization; in this context, CAS helps reduce the risk of an application owned by one entity interfering with an application owned by another, or with the server machine’s OS.
You should note, however, that CAS policy grants ASP.NET applications a full set of permissions by default, because they run from the local machine. Clearly, you should do something to rectify this when configuring your application. The .NET Framework defines a number of different trust levels that you may use to determine the privileges granted to ASP.NET applications: Full, High, Medium, Low, and Minimal. Policy for all but the first of these is specified in the configuration files web_hightrust.config, web_mediumtrust.config, and so on, located in the config subdirectory of the .NET Framework’s root directory. To grant a particular ASP.NET application a medium level of trust, you must give its web.config file the following structure:

The “worker processes” that handle individual ASP.NET requests run in the context of the Windows account ASPNET. This special account has a limited set of Windows privileges, in order to contain the damage should an ASP.NET application be compromised. It is possible, however, for worker processes to be executed under the same account as IIS, the SYSTEM account. If you wish for this to happen, you must edit machine.config like so:

It will be necessary to restart IIS Admin Service and the WWW Publishing Service in order for this change to take effect.
One reason for doing this might be to allow your ASP.NET code to call LogonUser from the Win32 API, in order to obtain a Windows user access token for impersonation purposes. However, this violates the fundamental security principle of least privilege and increases significantly the damage that a successful attack can cause. You should think very carefully before doing it.
ASP.NET provides four types of authentication: None, Windows, Forms, and Passport. Each of these is configured in the root web.config file of an application. For example, to disable ASP.NET authentication entirely, which would be appropriate for public web sites requiring no user login, you need a configuration like this:

You should bear in mind the interaction between IIS authentication and ASP.NET authentication; both will need to be configured properly to achieve the desired effect. Typically, you will use Windows authentication mode in both IIS and ASP.NET, or else use Anonymous mode in IIS and either None, Forms, or Passport in ASP.NET.
Use of Windows authentication in both IIS and ASP.NET has the advantage that passwords are not sent across the network; instead, the client application provides information concerning the identity of the currently logged-on user to IIS, which forwards this information on to your ASP.NET application. The disadvantage of this approach is its dependency on Windows on both the client side and the server side. Forms authentication will be a more appropriate approach for Internet-based systems, but it is essential in this case also to use SSL/TLS, to ensure that credentials supplied by the user are encrypted.
ASP.NET authentication does not dictate the user context under which an ASP.NET application executes, regardless of whether Windows authentication has been selected or not. If you wish your application to run in the context of any account other than ASPNET, you must enable impersonation. Assuming that the user making the request has been authenticated as a valid Windows user by IIS, this is achieved with the following content in web.config:
This will result in the ASP.NET application impersonating the user making the request. If, however, IIS is set up for Anonymous authentication, the ASP.NET application will impersonate whichever user account has been configured for anonymous access in IIS.
If you want your ASP.NET application to impersonate a specific user, this is straightforward:

The obvious danger here is the presence of plaintext user credentials in web.config. It is possible to avoid this by storing encrypted credentials in the registry and referencing them from the <identity> element of web.config:

The utility Aspnet_setreg.exe must be used to encrypt the user’s credentials and store them in the registry. Further details of this tool can be found on MSDN.
When you use Windows authentication in ASP.NET, the authenticated user must have the necessary NTFS permissions in order to access a given resource. This is known as file authorization. ASP.NET supports another, more flexible type of authorization, known as URL authorization. Unlike file authorization, this is configurable via the application’s web.config files. It is based on the principal assigned to the application by ASP.NET authentication, rather than on the permissions of an authenticated Windows account. A simple example of URL authorization configuration is this:

This example allows users Fred and Joe to submit HTTP GET requests to the application for any resources in the web site managed by this web.config file, but denies them the ability to access these resources via HTTP POST requests. Anyone in the Developers role (other than Fred or Joe) is permitted unrestricted access to the site, but all other users are denied any access whatsoever. The order of these elements is important, as the first match is what ASP.NET will use. The final explicit <deny users=“*”/> is normally required to lock down a site because, by default, the machine.config file includes this configuration:

This chapter has explored various aspects of .NET security. The security benefits of using managed code have been discussed, and you have seen how it is validated and verified prior to execution. You have also seen how .NET’s Common Language Runtime can control whether code gets the chance to execute, basing its decision on evidence concerning that code—site and URL of origin, hash code, presence of a verifiable digital signature, and so on—and a multilevel code access security (CAS) policy specified in three different XML documents. You have seen how CAS policy is enforced through a process of checking for demanded permissions via a stack walk, thereby preventing luring attacks, and you have seen how run-time security is further strengthened through the provision of features to isolate executing code from other code and from your machine’s hard disk.
This chapter has also examined application-level security, beginning with the .NET Framework’s cryptography API. This provides the .NET programmer with access to all of the most common hashing and encryption algorithms, implemented either as managed code or as unmanaged code in the underlying Windows Crypto API. As an application of .NET cryptography, you have seen how it can be plugged into .NET’s remoting architecture to secure method calls between assemblies running in different application domains, or even on different machines.
Finally, brief consideration has been given to ASP.NET security; here, you have seen how authentication, impersonation, and authorization are configured through the editing of various XML documents.