When did information become so important? When did it start to matter so much that we needed to keep it secret? How did it happen that information about which illnesses we’ve had, which bills we paid or didn’t pay, became a matter to pass national laws about? Why does it matter whether there are 25 apples in the barrel or 24? Who cares so passionately that any time of the day or night they must be able to purchase books, groceries, concert tickets, and underwear, and have it delivered right to their door? Have we really solved the problem of deniability?
The amount and variety of data that we require to be secret today is immense, but the problems of data security were recognized centuries ago. We have records that show that early Romans encrypted messages carried by couriers to distant battlefields. Kings and queens kept secret the details of family madness and peccadilloes. Nobles sent tokens (a ring, a seal) with their messages to prove their source. Ancient religious stories complain of tax collectors and recount arguments over the validity of their records.
Like our ancestors, we design data security with the tools that we have, and like them we still require data security to follow several basic principles:
• Confidentiality Information must be kept secret
• Privacy Personal information must not be made generally available
• Integrity Data must not be changed unless the change is authorized
• Availability The information must be there when it is needed
• Non-repudiation The sender must not be able to deny sending the information, and the receiver must not be able to deny it was received
The difference today is the sophisticated manner in which we enable data security, the array of approaches we use, and the multitude of places where security is applied.
This chapter is divided into two sections: the first covers the principles of data security architecture, in which these five principles will be defined, and the second covers applications of data security architecture and will outline interesting products that have incorporated one or more of these elements.
Securing data in a digital world starts with the question “How do I obtain confidentiality, privacy, integrity, availability and non-repudiation?” In short, the same concerns that we have with any data, that we can keep our secrets, prevent personal information under our control, ensure that it doesn’t change unless we want it to and that it’s always there when we need it.
In every organization, there is information that needs little protection. This information is considered public knowledge, and it may even be desirable to share it: product features, store locations, a web site address. Other information needs to be held close: formulas, new products under development, quarterly earnings before they are released to the general public, customer lists, employee phone numbers, and other private information. Each bit of data must, of course, be accurate and ready when needed. It is also good to know for sure that communications, such as the e-mail from your boss, are really from the person they say they’re from.
These data requirements can be addressed using data security tools, but to select the correct tools, you must first understand the goals.
Keeping secrets by disguising them, hiding them, or making them indecipherable to others, is an ancient practice. It evolved into the modern practice of cryptography—the science of secret writing, or the study of obscuring data using algorithms and secret keys.
Once upon a time, keeping data secret was not so hard. Hundreds of years ago, when few people were literate, the use of written language often sufficed to keep information from becoming general knowledge. To keep secrets then, you had to know who around you could read and keep ordinary people from learning how to read. This may sound simplistic, but it is difficult to decipher the meaning of a document if it is written in a language you do not know.
History tells us that important secrets were kept by writing them down and hiding them from literate people. Persian border guards in the fourth century B.C. let blank wax writing tablets pass, but the tablets hid a message warning Greece of an impending attack—the message was simply covered by a thin layer of fresh wax. Scribes also tattooed messages on the shaved heads of messengers. When their hair grew back in, the messengers could travel incognito through enemy lands. When they arrived at their destination, their heads were shaved and the knowledge was revealed. But the fate of nations could not rely for very long on such obfuscation. It did not take very long for ancient military leaders to create and use more sophisticated techniques.
When hiding meanings in ordinary written language, and hiding the message itself became passé, the idea of hiding the meaning became the rule. From what we know of early civilizations, they loved a good puzzle. What greater puzzle than to obscure a message using a series of steps? Unless you knew the steps taken—the algorithm used to produce the cipher (the name for the disguised message)—you couldn’t untangle or decipher it without a great deal of difficulty. Ah, but everyone knows the challenge of an unsolvable puzzle is bound to draw the best minds to solving it. Eventually each code was broken, each secret revealed. Soon every side had its makers of codes and its code breakers. The game was afoot!
Early code attempts used transposition. They simply rearranged the order of the letters in a message. Of course, this rearrangement had to follow some order, or the recipient would not be able to put things back to rights. The use of the scytale by the Spartans in the fifth century B.C. is our earliest record of a pattern being used for a transposition code. The scytale was a rod around which a strip of paper was wrapped. The message was written down the side of the rod, and when it was unwound, the message was unreadable. If the messenger was caught, the message was safe. If he arrived safely, the message was wound around an identical rod and read.
Other early attempts at cryptography (the science of data protection via encryption) used substitution. A substitution algorithm simply replaces each character in a message with another. Caesar’s cipher is an example of this, and you may have used a similar code in grade school thinking that the teacher would never know what you were writing. To create these messages, list the alphabet across a page and agree with the recipient on the starting letter—suppose you started with the fourth letter of the alphabet, D. Starting with this letter, write down a new alphabet under the old, so it looks like this:
To write a coded message, simply substitute the letter in the second row every time its corresponding letter in the first row would be used in the message. The message “The administrator password is password” becomes “Wkh dgplqlvwudwru sdvvzrug lv sdvvzrug.” To decipher the message, of course, you simply match the letters in the coded message to the second row and substitute the letters from the first.
These codes are interesting, but they are actually quite easy to break. Perhaps your code was never broken, but the one used by Mary, Queen of Scots in the 16th century was. Mary plotted to overthrow Queen Elizabeth of England, but her plans were found and decoded, and she was beheaded.
The use of such codes, in which knowledge of the algorithm is all that keeps the message safe, has long been known to be poor practice. Sooner or later, someone will deduce the algorithm, and all is lost. Monoalphabetic algorithms (those using a single alphabet), like the previous code, are easily broken by using the mathematics of frequency analysis. This science relies on the fact that some letters occur more often in written language than others. If you have a large enough sample of the secret code, you can apply the knowledge of these frequencies to eventually break the code. Frequency analysis is an example of cryptanalysis (the analysis of cryptographic algorithms).
Eventually, of course, variations of substitution algorithms appeared. These algorithms used multiple alphabets and could not be cracked by simple frequency analysis. One of these, the Vigenère Square, used 26 copies of the alphabet and a key word to determine which unique substitution was to be used on each letter of the message. This complex, polyalphabetic algorithm, developed by the 16th century French diplomat, Blaise de Vigenère, was not broken for 300 years. One of the reasons for its success was the infinite variety of keys—the keyspace that could be used. The key itself, a word or even a random combination of letters, could be of varied length, and any possible combination of characters could be used. In general, the larger the keyspace, the harder a code is to crack.
The use of a modern one-time pad algorithm for authentication was described in Chapter 6. The first one-time pads were actual collections of paper—pads that had a unique key written on each page. Each correspondent possessed a duplicate of the pad, and each message used a new key from the next sheet in the pad. After its one-time use, the key was thrown away. This technique was successfully used during World War I. The key was often used in combination with a Vigenère Square. Since the key changed for each message, the impact of a deduced key only resulted in the current message being lost.
The modern stream and block ciphers used today are sophisticated encryption algorithms that run on high speed computers, but their origins were in simple physical devices used during colonial times. An example of such an early device is the cipher disk. The cipher disk was actually composed of two disks, each with the alphabet inscribed around its edge. Since the diameter of the disks varied, the manner in which the alphabets lined up differed from set to set. To further complicate the matter, an offset, or starting point, was chosen. Only the possessor of a duplicate cipher disk set with knowledge of the offset could produce the same “stream” of characters.
In 1918, the German Enigma machine used the same principle but included 15,000 possible initial settings. Even the possession of the machine was no guarantee of success in breaking the code, as you had to know the setting used at the start. Imagine, if you will, a series of rotators and shifters that change their location as they are used. Input the letter D, and after a bit, the letter F is output. Put in another D and you may get a G or a U. While this encoding may seem arbitrary, it can be reproduced if you have an identical machine and if you configure it exactly the same way. This machine was used extensively during World War II, but its code was broken with the use of mathematics, statistics, and computational ability. Early versions of the machine were actually produced for commercial purposes, and long before Hitler came to power, the code was broken by the brilliant Polish mathematician Marian Rejewski. Another version of the machine was used during World War II. Alan Turing and the British cryptographic staff at Bletchley Park used an Enigma machine provided by the Poles and again broke the codes.
Other encryption devices were produced and used during this same time period. The U.S. government’s “Big Machine” looks like an early typewriter on steroids. This machine, officially known as the Sigaba, is the only known encryption machine whose code was not broken during World War II. Other machines are the Typex, designed for secure communications between the British and the Americans, the American Tunney and Sturgeon machines, which were capable of both encrypting and transmitting, and the Japanese Purple and Jade machines.
These machines, or parts of them, can be seen at the National Security Association Museum and viewed online at www.nsa.gov/museum/big.html.
XOR (exclusive or) is represented by a table that indicates the result of XORing any combination of 1 and 0:
![]()
![]()
![]()
If you have a binary number, such as 1011, and another, such as 1001, you can successfully XOR them by lining them up and calculating the result of XORing each successive 1 or 0 with its match in the row below. So 1011 XOR 1001 is the result of 1 XOR 1, 0 XOR 0, 1 XOR 0, and 0 XOR 1, which produces the result 0010. If you XOR this result with either one of the other numbers, you’ll get the other.
Every encryption technology from the past is still used today. Modern steganography hides messages in web graphics files and in the static that accompanies radio messages. School children and journal writers compose messages using simple substitution algorithms, and sophisticated one-time pads are reproduced in software and hardware tokens.
Likewise, stream ciphers are often produced in code today, a modern example being RC4. Programmatic stream ciphers use a key to produce a key table, and then a byte of the key table and a byte of plaintext (text that is not encrypted) are XORed. The key table is remixed and a new byte of the table is XORed with the next byte of the plaintext message. When the entire message has been thus encrypted to produce ciphertext, it is delivered. XOR, or exclusive OR, is a logic statement by which ones and zeros can be added. Since XOR is reversible, if the original key and the algorithm for producing the table is known, the ciphertext can be decrypted.
While a stream cipher works on one character at a time, block ciphers work on a block of many bits at a time. A non-linear Boolean function is used. Unlike stream ciphers, early block ciphers did not vary the key, which made the results easier to break because encrypting the same combinations of letters resulted in the same ciphertext. Frequency analysis could effectively be used to break the code. Later block ciphers incorporated additional functions against the ciphertext to obscure any repetitive data. DES, once the encryption standard of the United States government, is a block cipher that uses 16 rounds of activity against a 64-bit block of data, with each round adding a layer of complexity. This algorithm is well known, but without the secret key (which is 40 or 56 bits in length) it is difficult to decrypt. In fact, DES was once considered so secure that it was forecast that it would take a million years before it could be broken. Scientists, using less than $10,000 in computational equipment have broken DES in just a few hours.
Triple DES is an enhancement to DES, and it concatenates DES ciphertext with itself and uses up to three keys. The Advanced Encryption Standard (AES) replaces DES as the new U.S. Federal Standard. AES (which is actually the Rijndael algorithm) is a cipher block algorithm that uses a 128-bit, 192-bit, or 256-bit block size and a key size of 128 bits. Other examples of block ciphers are RSA Data Security’s RC2 and RC5, Entrust’s CAST, and Counterpane Systems’ Blowfish. Unlike DES, they can use variable-sized, large keys.
The previously described cryptographic algorithms have at their heart the use of a single, secret key. This key is used to encrypt the data, and the same key, or a copy of it, is used to decrypt the data. This key may be used to produce other keys, but the principle is the same. These single-key, symmetric algorithms work fine as long as the key can somehow be shared between the parties that wish to use it. In the past, this has often been done by the out-of-bounds means, such as using a courier or a personal visit, or some other method that did not involve the as yet to be established communication. Over time, the needs of cryptography spread, and with this came an increasing need to frequently change keys to prevent discovery or to lessen the impact of a compromised key. It was not always possible for people to meet, or to scale the out-of-bounds method. The problem gets increasingly large when you want to apply the use of cryptography to thousands of machine-generated communications.
A way to solve this problem was first proposed by Whitfield Diffie and Martin Hellman. The Diffie-Hellman key agreement protocol uses two sets of mathematically related keys and a complex mathematical equation that takes advantage of this relationship. If each of two computers calculates its own set of related keys (neither set being related to the other) and shares one of the keys with the other computer, they each can independently calculate a third secret key that will be the same on each computer. (You can learn more about the mathematics of encryption at www.rsasecurity.com/rsalabs/faq/A.html, and specifically about the calculations used by the Diffie-Hellman algorithm at www.math.rutgers.edu/~sasar/Crypto/.) This secret key can be used independently to generate a number of symmetric encryption keys that the two computers can use to encrypt data traveling from one to the other.
Another method for exchanging a session key is to use public key cryptography. This algorithm is asymmetric—it uses a set of related keys. If one key is used to encrypt the message, the other is used to decrypt it, and vice versa. This means that if each party holds one of the keys, a session key can be securely exchanged. In the typical arrangement, each party has their own set of these asymmetric keys. One of the key pairs is known as the private key and the other as the public key. Public keys are exchanged and private keys are kept secret. Even if a public key becomes, well, public, it does not compromise the system.
In addition to its use for key exchange, public key cryptography is used to create digital signatures. These algorithms traditionally use very large keys, and while you could use public key cryptography to encrypt whole messages or blocks of data on a disk, the process is remarkably slow compared to symmetric key cryptography.
Bigger is better, but maybe not forever. Much security, both on the Internet and off, relies on the security behind public key algorithms, such as RSA Security’s algorithms. Public key cryptography relies in part, on the inability of large numbers to be factored.
Since 1991, RSA has presented factoring challenges, mathematical contests that test participants’ ability to factor large numbers (see www.rsasecurity.com/rsalabs/challenges/index.html). In 1999, over a period of seven months, a team headed by Arjen K. Lenstra using 300 computers was able to factor RSA-155, a number with 155 digits. The factorization of this 512-bit number is significant, since 512 bits is the default key size for most public keys e-commerce uses. RSA says it believes this means that a dedicated team with a source of distributed computing power could break a 512-bit key in just a few hours.
NOTE RSA believes the cost of using a distributed network to crack encryption keys is still somewhat prohibitive, but I wonder if public peer-to-peer networks already in place, or attacks which take over computers without a user’s permission might not be used to crack code. There are several distributed networking schemes in place today, such as those that provide music over the Internet in exchange for permission to use your computer’s idle time for the provider’s own purposes. If you are interested in participating in such a scheme, investigate it first. A malicious individual or group, could start such a program, and use the idle time on your computer to crack code. There is evidence that large numbers of computers have been compromised and harnessed to launch distributed denial of service (DDoS) attacks. The power of distributed networking could equally be harnessed to provide computational power for unethical cryptographic efforts. This is not to say that organizations behind distributed networking efforts are using the computing power for evil ends—many of the causes are very good. But it is worth checking into before you get your computer involved.
Key Exchange Public/private key pairs can be used to exchange session keys. To do so, each party that needs to exchange keys generates a key pair. The public keys are either exchanged among the parties or are kept in a database. The private keys are kept secret. When it is necessary to exchange a key, one party can encrypt it using the public key of the other. The encrypted key is then transmitted to the other party. Since only the intended recipient holds the private key that is related to the public key used to encrypt the session key, only that party can decrypt the session key. The confidentiality of the session key is assured, and it can then be used to encrypt communications between the two parties.
The steps are outlined here and are illustrated in Figure 7-1. The operations 1 and 2 can take place at the same time, as can the operations 3 and 4. Included is a key, for clarity.
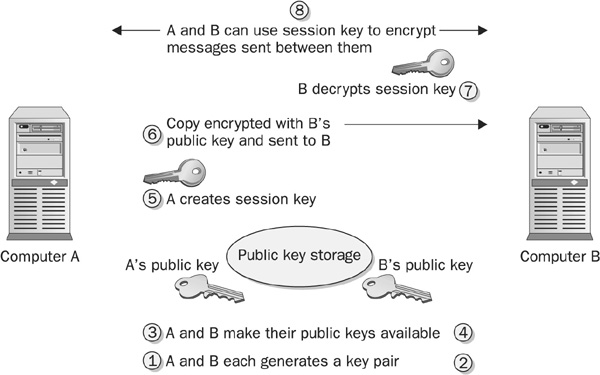
FIGURE 7-1 Using public key cryptography for key exchange
This key explains the operations (see corresponding number in art) that may take place simultaneously and are not intended to be ordered steps.
1 A generates a key pair.
2 B generates a key pair.
3 A makes its public key available, the private key is kept secret.
4 B makes its public key available, the private key is kept secret.
5 A generates a session key.
6 The key is encrypted using B’s public key and sent to B.
7 B uses its private key to decrypt the session key.
8 A and B can use the session key to encrypt communications between themselves.
Keeping data confidential by using encryption is only one part of securing data. Encryption keeps data from being read by those unauthorized to do so, but you must also consider what is done with data by those who are authorized to see it. You cannot assume that those who have access to data will understand their obligation to protect it.
A data privacy policy should be part of your security policy, and it should take into consideration the laws that govern personal information, such as patient records, but also the impact of information exposure. Loose controls on data and on the approval of applications for credit and identification mean that in today’s interconnected world, very little information or time is necessary in order to steal identities. Someone can become you with little effort. Identity theft occurs when someone takes another’s name and personal information with the intent to commit fraud, such as opening a credit card or bank account and using them while not paying the bills. Authorities estimate that nearly a million cases of identity theft occur in the United States each year. Having a privacy policy and good data security practices will help ensure that the stolen private and personal data doesn’t come from your data stores of customers and employees.
Some of the best practices that will discourage identity theft are accountability and education:
• Accountability Ensure that each employee has a unique logon ID, that auditing systems record access to sensitive information, and those records are reviewed.
• Education of employees Let employees know that you consider them to be trustworthy, that they have access to information that should not be communicated elsewhere. Train employees in what can be done with information and what can’t. Inform them about how individuals might try to obtain that information from them.
You deposit money in a checking account, you write checks and receive a monthly statement, and when you check the statement, you expect that your records will agree with the bank’s records. You expect that the change in your account balance will be the result of your deposits, checks, and perhaps bank fees. The account can be reconciled. Money doesn’t just disappear. We expect this, and we are not disappointed.
Integrity is the quality that guarantees that data is not arbitrarily changed. It ensures that data is only modified by those who have the authority to do so. But how is the integrity of the data in the bank’s information system, or in any information system, guaranteed? A number of processes contribute to that guarantee:
• Using quality software Calculations are properly programmed and processes follow appropriate procedures
• Using appropriate hardware Appropriate hardware ensures that a hardware failure is less likely to damage data, and it will alert administrators to potential damage
• Following proper administrative procedures Proper backups and access controls are used
• Guarding against malicious manipulation of data Use proper security controls on computer access, and data access, and validate data against additional records.
In early computer communications, the major challenge was to guarantee that potential errors in the communication process didn’t change the data. The data that was sent from one computer to another, from one city to another, was just a series of electrical impulses, and a change could be introduced by interference or errors on the line. To detect such errors, a checksum was calculated and added to the end of the data. A checksum is a numerical value that is based on the number of set bits in the message. Upon receipt of the message, another checksum is calculated based on the received message, and if the two checksums match, the integrity of the data is assured. While the equipment is better today, data can still be adversely affected by heat, magnetism, electrical surges, and even dust.
One the first hard drives was the IBM RAMAC (Random Access Method of Accounting Control). Introduced in 1955, this drive, which was as large as two refrigerators and weighed over 1,000 pounds, eventually signaled the end of storage on punched cards and paper or tape. Like all computer equipment of the time, it was meant to be housed in a carefully constructed, climate-controlled data center. Today’s hard drives store a lot more data, transfer that data at lightning speed (spindle speeds of 15,000 revolutions per minute are not unusual), and they are often subjected to varying environmental conditions. While they can handle larger variations of temperature, they can still be affected by some of the same environmental issues that the RAMAC was. Heat, humidity, dust, and electrical surges are still the enemies of data.
Today’s drive manufacturers indicate the environmental limits for their products. Soundly built systems are also designed to prevent problems that can result in data errors. They use steel cases that can dissipate heat, and they provide adequate fans. Are your computer systems optimally built and protected? Here are a number of specific things you can check on:
• Check the construction of the enclosure. Will the material quickly dissipate heat? Is there adequate space for air flow? Are the cooling fans sufficient?
• Look for maintenance support and redundancy. Is failure-reporting built into the system? Are the hot swappable drives and power supplies standard?
• Check your power supply. UPS systems are not meant to compensate for faulty internal power supplies or circuitry. Sound internal systems will supply appropriate levels of power to drives and other components at all times.
• Check whether the circuit board design is maximized to prevent crosstalk or other types of interference or signal degradation.
Determine whether environmental controls are capable of keeping things within the manufacturer’s optimal ranges. What backup systems are in place for times of high heat or air-conditioning failure? In addition to the physical issues that may reduce the integrity of stored or transported data, you must also consider accidental or unauthorized manipulation of data. Key to this type of protection are access controls, quality software, and encryption.
Access controls, in the form of authentication and authorization, were discussed in Chapter 6. They can be used to ensure that no unauthorized individual has the ability to modify data.
Software that works as expected is important. Proper software construction ensures the integrity of the data that it manipulates. This topic is discussed in Part V of this book.
The use of encryption to ensure data integrity is important, because it can be used even when there is no need to keep the information confidential. You may just want to make sure that it does not change. If bank records are kept encrypted while on disk, and remain encrypted when they must be transmitted, integrity can be an additional benefit. Because the data is encrypted on disk, not only does someone have to have the authority to change the data, but they must also possess the appropriate encryption key—this makes it less likely that some unauthorized person will change the data.
When the data is transmitted, its integrity is assured if it is encrypted. But what if it’s intercepted, and different encrypted data is substituted? How would this be detected? There are specialized cryptographic algorithms to guard against this sort of attack. These integrity algorithms are based on one-way cryptographic hash algorithms—one-way algorithms cannot be decrypted, and given a unique piece of data, they will always produce a unique result. Put another way, it is statistically unlikely that the integrity algorithm hashing two different pieces of data will produce the same result, or digest. These two characteristics—that the algorithms are one-way and they produce unique results—are used to guarantee the integrity of data in transport.
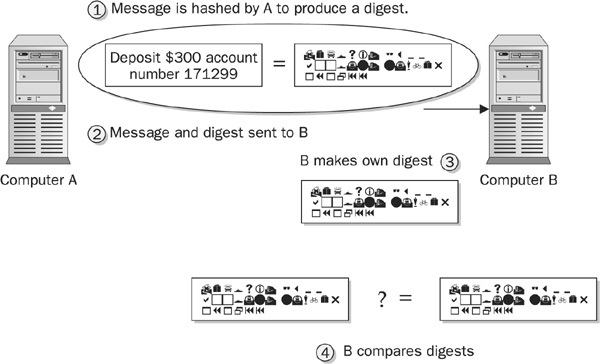
The following steps outline the use of a hash algorithm for integrity while sending a message between two computers, A and B. Figure 7-2 illustrates the process. Note that the message, itself, is not encrypted. If the message should also be kept secret, it can be encrypted using another algorithm.
FIGURE 7-2 Cryptographic hash algorithms are used to ensure integrity.
This key explains the steps of operations (see corresponding number in art).
1 The data is hashed before it leaves A to produce a digest—a small piece of data that represents the message.
2 The plaintext (unencrypted) message and the digest are sent to B.
3 B receives the data and uses the same algorithm to make its own digest of the message.
4 B compares the digest it made to the one it received from A. If the digests match, then the data has not changed. If they do not match, than the data has changed.
What would prevent an attacker from capturing the message, modifying it, and providing its own digest? Nothing. To guarantee that the message sent by A is the message received by B, an additional step should be taken. After A has prepared the digest, A encrypts the message and the digest with a session key known to B. When B receives the message, B decrypts it to obtain the plaintext message and A’s digest. Then B can make its own digest and compare it with the one sent by A. If an attacker wishes to introduce a false message, they must first break the encryption. SHA1 and MD5 are examples of integrity algorithms.
The confidentiality, privacy, and integrity of data as it resides on disks or traverses the network is important. However, if the data is unavailable when it is needed, it cannot be used. Business obligations cannot be met, products may not ship, the details of employee benefits, wages, and work schedules will be in doubt, and so on.
The root purpose of information security is to make sure that good data is available when it is needed to those who are authorized to use it. Confidentiality, privacy, and integrity all play a part, but information security is not the only element that ensures the availability of data. Managing the system properly and keeping it maintained also play a role.
Security can hinder availability. If its controls are not set properly, the right people cannot get the information they need. If encryption keys are not properly maintained, even those authorized to see the data may not be able to decipher it. If passwords are too long, people cannot remember them, and much time and money is spent having them reset.
What prevents someone from sending information and claiming to be someone they are not? What if your boss sends you an e-mail telling you to take the rest of the day off? How do you know it is from your boss? Even if you don’t care whether the contents of a message are kept secret, you may want to be able to identify for sure who a message came from. Take this a little further, and wouldn’t it be nice to know that the software you downloaded was really produced by the company listed as its manufacturer, and that another company’s software wasn’t substituted, or that someone wasn’t presenting malicious code as something from a company that you trust? Non-repudiation is the guarantee that something came from the source it claims. Non-repudiation also means the sender cannot claim to have not sent the message. Digital signatures can be used to establish non-repudiation.
Digital signatures can be produced using public key cryptography. In this scenario, the private key of the sender is used to encrypt the message, and the sender’s public key can be used to decrypt it. Since only the sender of the message can have the private key, if the message is decrypted with the corresponding public key, it must have come from that person.
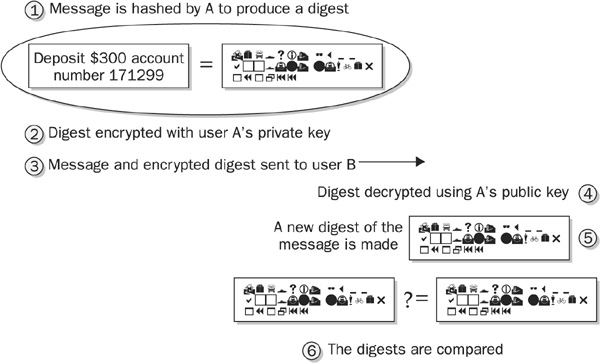
The following steps outline the process for A to send a digitally signed message to B. The process is illustrated in Figure 7-3.
FIGURE 7-3 Non-repudiation can be established with a digital signature.
This key explains the steps of operations (see corresponding number in art).
1 A creates a message digest of the message.
2 A uses its private key to encrypt the message digest.
3 A sends the message and the encrypted digest to B.
4 B uses A’s public key to decrypt the digest. If A’s public key can decrypt the digest, then A’s private key was used to encrypt it. (If one key of a key pair is used to encrypt, only the other key of the pair can decrypt.) Since A’s private key can only be accessed by A, the encrypted digest came from A.
5 B uses the same algorithm as A to make a new digest of the message.
6 B compares the two message digests. If they are the same, the message hasn’t changed (proving integrity). If they are the same, the message must have come from A and only A since, in step 4, it was established that the digest came from A (guaranteeing non-repudiation).
A digital signature can be used for more than just validating who sent a message. It can also be used to digitally sign software, therefore identifying that the software was written by a company you trust. Some examples of this use are the signing of Microsoft ActiveX scripts, Office macros, and approved hardware device drivers. If the private keys are properly linked to the software authors and are kept secret, and the software authors are identified by you as being trustworthy, then you can automate the acceptance of this software while preventing unknown code from running on a system.
This doesn’t mean that the code itself is without vulnerabilities, nor that it can never harbor malicious code. A virus or Trojan program could be signed by the possessor of a signing key just as easily as could anything else. It only means that you know who wrote the code. It is up to you to specify what signatures you will accept, based on your trust in the individuals or organizations that write the code.
FIGURE 7-4 Part of a certificate’s contents
Data security is maintained by the use of encryption, access controls, authentication, and physical protection. In an enterprise and on the desktop of the home computer, many applications can be used to structure a data security architecture. You must decide what data must be protected and where it must be protected. The technologies described in this chapter can be used to provide the protection.
Examining, as we have done in previous sections, the risks to data on a disk drive is one thing, but when data moves between two computers, it is exposed to a different kind of risk. An attacker does not have to penetrate the access controls set on machines and files, they only need to connect to the network and use commonly available tools to capture the information. Other types of attack also exist, such as spoofing, where the attacker masquerades as the expected endpoint of the communication, or man-in-the-middle attacks, where the attacker captures and perhaps modifies data before sending it on to the expected endpoint.
There are several ways of protecting against these attacks. Which one you should use often depends on where the data must travel.
When data moves from one network to another across a third, perhaps untrusted, network, virtual private networks (VPNs) are used. The strength of a VPN lies in its use of encryption and authentication. Two major protocols exist: Point-to-Point Tunneling Protocol (PPTP) and IP Security (IPSec). IPSec is also used in conjunction with Layer Two Tunneling Protocol (L2TP). VPNs are discussed in depth in Chapter 12.
IPSec is also used to secure communications between two computers on the same network. IPSec is a complex protocol that combines two subprotocols and a variety of encryption algorithms to provide authentication, confidentiality, and integrity. IPSec sessions can be established between IPSec-aware devices on a network. Computers, routers, and firewalls are examples of devices that may have the ability to establish an IPSec session.
A device may be configured to start an IPSec session when specific types of communication are attempted, such as the use of specific ports or protocols, or when the source of the communication is specified in a filter. This information, along with the acceptable authentication, encryption, and integrity algorithms, is configured and stored in a policy. Figure 7-5 shows an IPSec policy definition on a Windows 2000 computer.
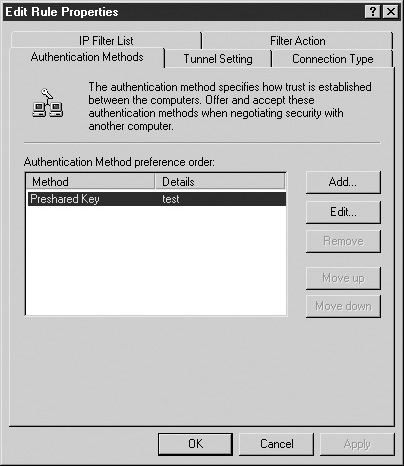
FIGURE 7-5 An IPSec policy specifies the algorithms to be used, as well as defining when the session is triggered
IPSec uses the steps listed in the key shown in Figure 7-6 to protect data in transit from computer A to B.

FIGURE 7-6 IPSec protects data in transit.
This key explains the steps of operations (see corresponding numbers in art).
1 Each machine must first prove its identity to the other. Different implementations of IPSec may offer choices for authentication. Certificates and shared keys are commonly used. Microsoft Windows can also use Kerberos.
2 Once authenticated, Phase I uses Internet Key Exchange (IKE) to produce a master key. IKE is a standard that uses Diffie-Hellman to produce a master key on each device without passing the key across the network.
3 Phase I also establishes a Security Association (SA). An SA is a secure session between the devices over which the rest of the session can be negotiated. During Phase I, the encryption algorithms for this session are negotiated.
4 In Phase II, a session key is calculated from the master key.
5 Phase II also includes the negotiation of the encryption, authentication, and integrity algorithms that are to be used, and the frequency of key change.
6 During Phase II, two SAs are created, and incoming and outgoing pair for each specific protocol or different policy rule.
NOTE The use of IPSec to secure communications is becoming increasingly prevalent. Encryption is processor intensive and so network interface cards (NICs) have been developed that are capable of performing the encryption in provided processors.
E-commerce transactions and other communications between browsers and web sites can be secured using Secure Sockets Layer (SSL). Another, similar protocol, Transport Layer Security, may also be used. SSL was described in Chapter 6 and is mentioned here again for completeness. In addition to the authentication process, SSL uses encryption to secure information as it travels between the client and web server.
When SSL is used to secure browser-based e-mail, encryption adds protection for password-based authentication. First, the SSL session is established, and then the user must authenticate to the mail system. Since all data traveling between the web server and the client is encrypted, the user’s credentials are also encrypted, even if the authentication algorithm does not call for it.
When data is stored, it is often protected by access controls, and the server may also be physically protected. Sensitive data can be further protected by encrypting files. How sensitive is sensitive? That is a decision you will have to make for yourself. In most cases, the security policy will establish what data needs to be protected, and appropriate encryption will be established on the drives and servers that store this information. However, if data is stored on the desktop, or if it travels with users on laptops or on PDAs and smart phones, data encryption should be available and should be promoted as necessary to secure sensitive information.
File encryption products are available for all desktop operating systems. Some well known products are Pretty Good Privacy (PGP) and the Microsoft encrypting file system (EFS). PGP is the most ubiquitous e-mail security program, and most versions of it also enable file encryption. EFS is built into and is only available for Microsoft Windows XP Professional, Windows 2000, and Windows Server 2003.
Both file-encryption systems use symmetric keys to encrypt the files, and public key technology to protect the encryption key. File encryption, once configured, is transparent to the user. If the user who encrypted the file, or the recovery agent, opens a file using the appropriate program, they will be able to read the file. If any other user attempts to open the file, access is denied. Ordinary file ACLs can and should be used to protect the files. Note, though, that an encrypted file can still be deleted by anyone who has the file permission to do so.
EFS, as implemented on Windows 2000, is described next. A recovery agent is assigned per computer in workgroups, and per domain in domains. The recovery agent, by default the Administrator, can also decrypt, or recover the file.
The following steps outline the EFS encryption process on Windows 2000.
1. A random symmetric key, the File Encryption Key (FEK), is generated and is used to encrypt the file.
2. The FEK is encrypted with the user’s public key.
3. The FEK is encrypted with the recovery agent’s public key.
4. The FEK is stored with the file.
5. The user’s private key is used to decrypt the FEK.
6. The FEK is used to decrypt the file.
The following steps outline the EFS file-recovery process on Windows 2000.
1. The recovery agent’s private key is used to decrypt the FEK.
2. The FEK is used to decrypt the file.
PDAs, smart phones, and other devices now contain significant data—contact lists, databases of critical information, documents, and so on. They are also portals back to the corporate network. VPN clients are available for them, and remote administration products, as well. Access to these devices should be protected with passwords at a minimum, and with the use of biometric or token devices when possible, due to the threat they pose to sensitive data both on the device and within the networks they can reach.
The following are some of the encryption products available for these devices:
• FileCrypto www.f-secure.com/products/filecrypto/
• Sentry 2020 www.softwinter.com/sentry_ce.html
• PDA Defense www.pdadefense.com/professional.asp
• PDA Safe www.astawireless.com/products/pdasafe/
Storage area networks (SANs) and network-attached storage (NAS) present new challenges to data security. Large amounts of data reside in dedicated storage devices, and in whole networks. When SAN systems were first introduced as network storage, they primarily relied on physical security. These systems were closed, and few were distributed or remotely accessible. That is not the case now, and it is necessary to secure the data while it resides on these systems, and when it is transported between devices.
Since many of these systems still rely on the data communications protocol Fibre Channel, and not IP, for transport, adaptations of encryption algorithms exist. Encapsulating Security Payload (ESP), the subprotocol of IPSec that provides confidentiality, is one such standard. ESP over Fibre Channel is further supported by using the Diffie-Hellman Key Encryption Protocol-Challenge Handshake Authentication Protocol (DH-CHAP) for authentication. This protocol does not require certificates but uses 128-bit keys and no text characters.
Once you’ve ensured confidentiality during transport, how can stationary data be kept secure? Encrypting large amounts of data is a challenge, because encryption takes time. Making sure that data is encrypted and yet is quickly available may be contradictory. Products exist, however, that claim to match these requirements. One such is Neoscale Systems’ CryptoStor (www.neoscale.com/English/Products/CryptoStor.html), an appliance that intercepts data bound to or from SAN storage and encrypts or decrypts as necessary.
Digital Rights Management (DRM) is available to protect proprietary information. Though it’s most well known as the harbinger of protection for audio and video recordings, it is beginning to be used in organizations to protect sensitive and proprietary data. DRM offers a solution that is granular and that can be used to not only control who can read specific data, but when and how many times. It also solves the problem of anyone who can read a file being able to copy it.
In the typical data-file system, permission to read data also allows those people to copy the data. DRM can be used to prevent copying, or to restrict it to a limited number of copies that themselves cannot be copied. DRM technologies are available in version 9 of the Microsoft Windows Media Player, Macrospace’s ProvisionX (www.macrospace.com/products.shtml), Macrovision’s SafeCast (www.macrovision.com/solutions/software/drm/), Real Networks’ Helix DRM (www.realnetworks.com/products/drm/), and many others.
NOTE Opponents to DRM believe it threatens privacy, free speech, and fair use principals. It’s easy to discount these claims. After all, who wouldn’t want to allow the developers of proprietary information the right to protect it? But then, imagine a world where music is sold by the play. Currently you can purchase a CD that you can listen to over and over again and copy to your computer so that you can listen to it while working; you can alternate songs from one artist and another, jukebox style. In the “sold by the play” model you would pay each time you listened to the song. Software, likewise, could be sold based on the number of times you ran it, or on the number of documents you produced. To read more on these complaints, visit the Electronic Privacy Information Center (EPIC) at www.epic.org/privacy/drm/.
E-mail is sent without any protection by default. Once captured, it can easily be read. Most e-mail systems do obscure the data by encoding it, but they do not encrypt it. Simple visual inspection of a network capture does not reveal its contents but the encoding is not meant to keep the data secret, and it can easily be decoded.
To ensure protection, e-mail security products are used to encrypt and sign e-mail. One of the most ubiquitous is PGP, developed by Philip Zimmerman. Offered for many years as a free download, the product was managed for a while as a commercial enterprise by Network Associates, but it is now owned by PGP Corporation (www.pgp.com). You can download a version of PGP for personal use at no charge from http://web.mit.edu/network/pgp.html.
PGP uses public key technology to secure e-mail messages. The software generates a key pair and stores them securely on the computer. A copy of the public key can be made and shared with those you wish to share communications with. It is common to store one’s public key in a public key database, such as the one run by MIT at http://pgpkeys.mit.edu:11371/.
This way, anyone who runs PGP can obtain a copy of your public key and securely communicate with you, and you can obtain the public keys of others. The steps involved in a PGP-protected e-mail session between Alice and Bob are as follows:
1. Alice composes a message for Bob and clicks the send button.
2. A one-way hash function is used to hash the message.
3. The message is signed with Alice’s private key.
4. A random encryption key, the session key, is generated.
5. The session key is used to encrypt the message.
6. Bob’s public key is used to encrypt the session key.
7. The encrypted session key and signed message is sent to Bob.
8. Bob decrypts the encrypted session key using his private key.
9. Bob decrypts the message using the decrypted session key.
10. Bob’s PGP program makes its own hash of the message.
11. Alice’s public key is used to decrypt her signature.
12. The two results are compared. If they match, the message came from Alice.
Protecting data from harm is a complex process. Data can be protected by restricting access, providing physical security for computers, and by using confidentiality, integrity, and non-repudiation processes. Deciding the processes which are correct in a given situation requires knowledge of how these processes work, and the ability to match them with conditions where they can be used. Finally, no security process can be considered to be foolproof. Multiple protection processes should be used and they should be changed in order to keep up to date with changes in technology.