LEARNING OBJECTIVES
▪ Theory and background of social area indicators and geodemographic classifications
▪ Building area indexes of deprivation
▪ Indexes of poverty and wealth
▪ Indexes of quality of life
▪ Building geodemographic classifications
How much of the consumer behaviours, preferences and socio-economic characteristics of individuals are revealed by where they live? Can we really know something about who you are if we know where you live?
(Harris et al., 2005: xiii)
The relationship between people and places is a key theme in GIS analysis and there has been a rapidly increasing number of relevant GIS studies that bring together multiple pieces of socio-economic and demographic data in order to create composite indicators and classifications that summarise the characteristics of residential areas. This type of research is very relevant to the GIS functionality introduced in the previous chapters. In particular, it has almost become synonymous with GIS, especially in the geodemographics industry discussed later on in this chapter. In particular, mapping and visualisation are the main GIS functions employed, and the data are likely to be contained in the GIS where they can be manipulated relatively easily (in terms of adding/subtracting, calculating rates, etc.). As so many applications of deprivation, wealth and geodemographics are contained within a GIS platform we feel it is essential to include this within the collection of GIS applications. This chapter provides an overview of two key distinctive (but also in some ways conceptually similar) approaches to the socio-economic and demographic classification of areas and people: the social (composite) indicators approach and the geodemographic classification approach.
It can be argued that the first systematic study of social conditions of population is Friedrich Engel’s Conditions of the Working Class (Engels, 1845). However, the first systematic attempt to classify and map socio-economic areas in this way dates back to the seminal work of Charles Booth, a British industrialist, researcher and social reformer who lived in Victorian England (between 1840 and 1916). Booth put together a team of data collectors and conducted a survey of life in the city of London. The output of this survey formed the basis for a study entitled ‘The Life and Labour of the People of London’ first published in 1889. This study was conducted in response to public debates at the time regarding the extent of poverty in London and reports that a quarter of the population lived below the poverty line (Vickers, 2006; Hyndman, 1911; Orford et al., 2002; Simey and Simey, 1960). Charles Booth considered such reports to be exaggerated and he conducted a survey of living conditions in London aimed at proving such claims to be wrong (Vickers, 2006; Norman-Butler, 1972), but eventually concluded that the extent of poverty was actually even higher, with 30.7% of the population living below the poverty line (Simey and Simey 1960; Pfautz, 1967; Vickers, 2006).
Booth classified London’s then population of four million inhabitants into seven social classes on the basis of income and produced maps of every street in London, labelling each house according to the class to which it belonged. He collected information on the living conditions of each household and each street which was then combined with information from school board visitors to establish the general socio-economic conditions in which the residents lived. This information was then used to decide to which group each street should be assigned. A colour scheme was then applied to a base map of London to graphically illustrate the general socio-economic status of the people living in each street. Although not reproduced here, examples of Booth’s classification can be found in the Charles Booth Online Archive of the London School of Economics (LSE, 2015).
This work is considered to be the first attempt worldwide to classify areas and people in a systematic way and Charles Booth is widely considered as the father of area classification (Vickers, 2006; Rothman, 1989). This work was also the source of inspiration for a similar study at the end of the 19th century by Seebohm Rowntree, another British industrialist and social reformer. Rowntree carried out a detailed survey of the living standards of households in York and developed and implemented innovative methods for the measurement of poverty. He reached conclusions similar to those of Booth for London, suggesting that over one-third of the York population lived in poverty. Rowntree monitored the trends of poverty in York throughout the first half of the 20th century by undertaking surveys of the city again in 1936 (Rowntree, 1941) and in 1950 (Rowntree and Lavers, 1951).
The work of Charles Booth and Seebohm Rowntree played a significant role in the advancement of the social sciences and of area classification and poverty studies in particular. Since then there have been numerous area classification studies of poverty and of income inequalities, which have employed a wide range of new methods and alternative definitions of poverty. At the same time, there has been an increasing availability of a wide range of new socio-economic data sources in both the public and private sectors, and increased power and portability of personal computers, which have created an enabling environment for the testing and implementation of new social scientific methods and, more recently, the use of GIS. These methods are now part of a tradition in social geography and, more recently, geoinformatics and GIS, of analysing and combining different variables reflecting the circumstances and quality of life of people in order to provide suitable characterisations or profiles of neighbourhoods. These classifications of areas are routinely used in order to support decision making in the public and private sectors, ranging from allocating public resources to different neighbourhoods to customer-profiling and location-related decisions by retailers.
The remainder of this chapter provides an overview of some key studies and methods in area classification, ranging from indexes of deprivation to indexes of poverty and wealth, human development and geodemographic classifications. The accompanying practical exercise demonstrates how some of these methods can be applied using ArcMap.
Indexes of deprivation
As noted above, the work of Charles Booth and Seebohm Rowntree was extremely innovative and revolutionary for their time and it has been hugely influential in the formulation of new social science research methods and the development of poverty measures and of area classification techniques. In particular, it provided the basis for the development and mapping of poverty measures and composite indicators of deprivation and quality of life. The first efforts were based on measuring absolute poverty and the extent to which the earnings of a household were sufficient in order to maintain a very basic, subsistence standard of living. This was the basis for the setting of social policy and social security benefits worldwide, especially after the end of the Second World War.
However, it has increasingly been argued that the concept of poverty constantly evolves and that the subsistence approach to the definition of poverty is inadequate. There is a need for the development of new indicators that take into account the social role of human beings (and not just the need for physical subsistence) and the extent to which they are able to meet their obligations as workers, parents, neighbours, friends and citizens; obligations that they are expected to meet and which they themselves want to meet (Gordon and Pantazis, 1997). It has been increasingly recognised that poverty is a relative concept and that it should be defined on the basis of contemporary living standards and social norms. Among the key proponents of this approach was Peter Townsend, whose work has been extremely influential in changing the policy debates and focus from absolute to relative poverty. His seminal book entitled Poverty in the United Kingdom (1979) provides an extensive discussion of relevant theoretical work and concepts of relative poverty and relative deprivation and argues that the poverty line should be set at a level of income below which people are excluded from participating in the norms of society in which they live. Townsend argued that people are in poverty if they additionally lack the resources to escape deprivation (Townsend, 1987; Noble et al., 2006). Townsend also distinguished between social and material deprivation and proposed ways to measure them. A key consideration in the development of such a measure is that ‘double counting’ should be avoided to ensure that the distribution and severity of deprivation is not misperceived and resources misallocated as a result (Townsend, 1987).
Adding a geographical dimension to this work, Townsend proposed an area-based measure of material deprivation, based on geographical areas rather than individual circumstances. This index, known as the Townsend index, is based on the following census variables (Townsend et al., 1988):
1 percentage of households without access to a car or van;
2 percentage of households with more than one person per room (overcrowding);
3 percentage of households not owner-occupied (tenure);
4 percentage of economically active residents who are unemployed.
The calculation of the index involves a standardisation of the above percentages using z-scores (which can be calculated by subtracting the mean value and dividing by the standard deviation) to prevent results being excessively influenced by a high or low value for any one variable and to put each variable on the same scale, centred around zero. The four z-scores are then summed for each area to obtain a single value which is known as the Townsend deprivation index. Positive values suggest that an area has high material deprivation, whereas low values suggest that the area is relatively affluent. The Townsend index has long served as a general measure of area deprivation in academic studies in a wide range of fields including health care analysis, educational attainment and the geography of crime, but it has also been used to inform decision making in relation to resource allocation, to target areas of greatest social need.
Townsend’s approach has also been the basis for the development of alternative measures of area classification. For instance, the Carstairs index of deprivation (Carstairs and Morris, 1991; Carstairs, 1995) is derived by combining the following variables:
▪ Unemployment: unemployed male residents over 16 as a proportion of all economically active male residents aged over 16.
▪ Overcrowding: persons in households with one or more persons per room as a proportion of all residents in households.
▪ Non-car ownership: residents in households with no car as a proportion of all residents in households.
▪ Social class: residents in households with an economically active head of household in social class IV or V as a proportion of all residents in households.
As is the case with the Townsend index, the first step in calculating the Carstairs measure is to obtain percentages for the above variables and convert them to z-scores, which are then added up to give a single score for each area. Positive scores are associated with higher deprivation and negative scores with lower deprivation. The practical exercise accompanying this chapter demonstrates how the Carstairs index can be calculated and mapped using ArcMap.
An important note to be made about all area measures of deprivation is that they are based on aggregate attributes (e.g. unemployment rates) of geographic areas, rather than individual circumstances and characteristics. Not everybody in an area ranked as deprived is her/himself deprived and not all people that can be defined as disadvantaged or deprived live in deprived areas (the so-called ‘ecological fallacy’: see Chapter 2 and later discussion). It is also important to consider the compositional, collective and contextual dimensions to deprivation which are as follows:
▪ An area is deprived if it contains a large number or proportion of ‘deprived’ people (compositional meaning).
▪ Area effects: there is an ‘area effect’ which is above and beyond that which is attributable to the concentration of deprived people in the area (collective meaning). For example, there is evidence suggesting that where a person lives might influence their health, even accounting for individual risk factors (Stafford and Marmot, 2003).
▪ Environmental: lack of facilities in the area, or some other area feature (contextual meaning).
There is a wide range of deprivation and other composite indicators applied at the small-area or neighbourhood level. Their suitability depends on the purpose for which they were built. Overall, the key steps for constructing an index can be summarised as follows:
▪ Decide the aim of the composite index (depends on the response variable; e.g. health-related applications, crime, etc.).
▪ Select the variables you wish to include in the index (depends on the aim).
▪ Decide on the form of component measure you need (e.g. percentage, z-score, ratio to mean, ranks).
▪ Decide whether normalisation is needed (conversion of the distribution into a normal one).
▪ Decide on the weighting of the components and any rescaling.
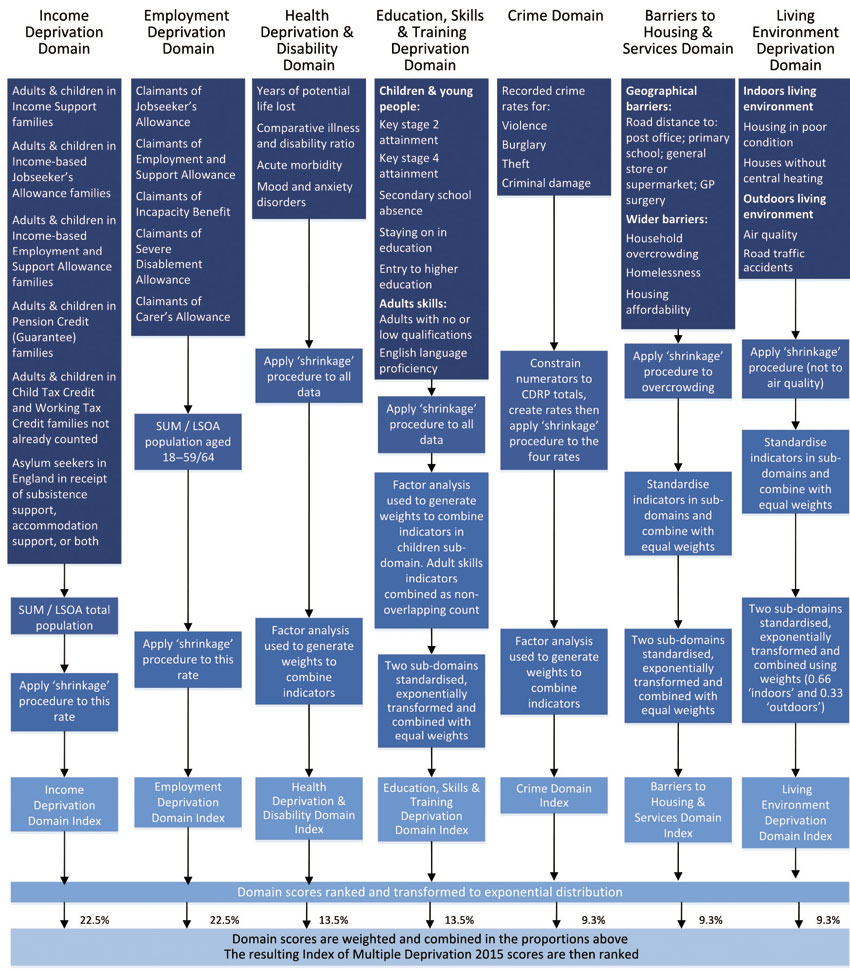
In many cases it is also useful and appropriate to assign different weights to different variables or groups of variables used to build a composite index. A good example is the official Indices of Multiple Deprivation (IMD) produced by the UK Department for Communities and Local Government. These are based on over 40 separate variables across administrative, survey and census data placed between the following ‘domains’ of deprivation: employment, income, health, crime, education, living environment and barriers to services (see Figure 5.1). The IMDs are produced at the UK LSOA geography (on average 1,500 residents) which are scored, ranked and mapped. The IMD was first developed and published in 2000 and was based on a combination of six separate indexes based on different domains of deprivation:1
▪ Income (25% weighting);
▪ Employment (25% weighting);
▪ Health Deprivation and Disability (15% weighting);
▪ Education, Skills and Training (15% weighting);
▪ Housing (10% weighting);
▪ Geographical Access to Services (10% weighting).
Figure 5.1 Summary of the domains, indicators and statistical methods used to create the Indices of Multiple Deprivation, 2015
Source: Smith et al. (2015: 19)
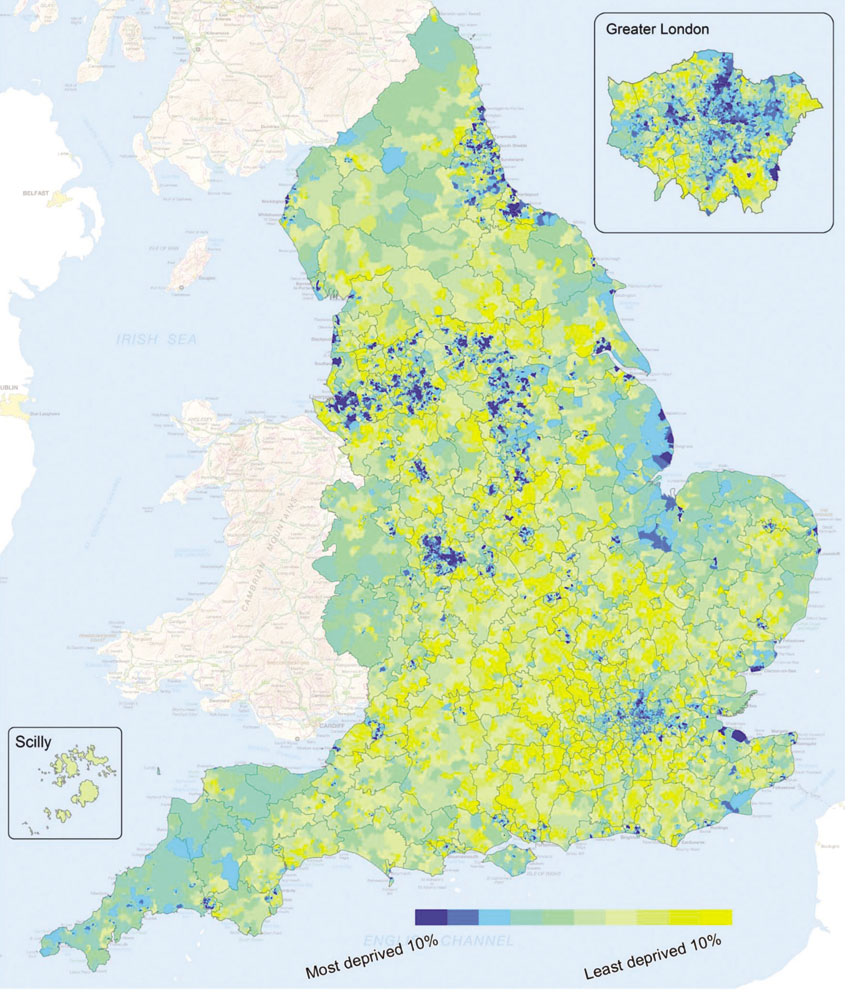
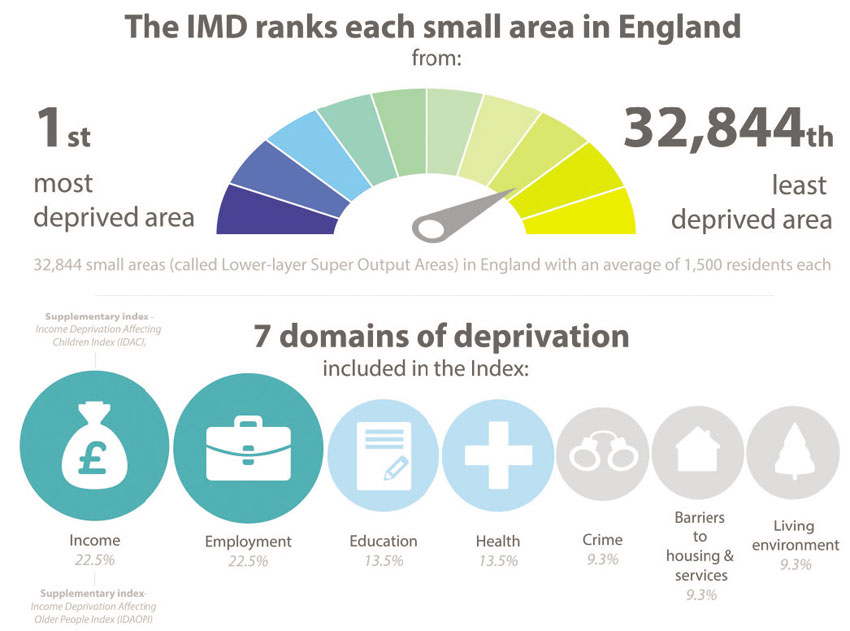
Figure 5.2 English Index of Multiple Deprivation, 2015
Source: Smith et al. (2015: 32). Contains Ordnance Survey data © Crown copyright 2015
The constituent variables included in the IMD have been periodically revised with new variables added and changes to weightings.2 This means that caution is needed when comparing IMDs through time. The most recent index was released in September 2015, covering 32,844 small areas across England (see Figure 5.2) and offering a very useful insight into poverty, deprivation and social geography patterns at the local level.
Figure 5.1 summarises the data sources and method used to attach weights to different domains in the 2015 IMD. Unlike the Carstairs and Townsend index methods, the approach adopted in the IMD does not simply involve adding up the values of different variables. But how can one decide which aspects of deprivation (or ‘domains’) might be more important than others? Noble et al. (2006) ask these questions and suggest that there are at least five possible approaches to the weighting of different variables or groups of variables:
1 weighting driven by considerations emerging from the literature on multiple deprivation and social exclusion;
2 empirically driven;
3 determined by policy relevance;
4 determined by consensus; or
5 entirely arbitrary.
Figure 5.1 also provides more details on the IMD weightings.
It is also interesting to note that there are many examples of area deprivation indexes that are similar to the ones developed in Britain. For instance, Elbner and Sturm (2006) present census-tract level indices of deprivation in the US and they also examine potential links to physical and mental health outcomes. Another example is the work of Singh (2003) who developed an Area Deprivation Index and linked it to county-level mortality data in the US. Singh’s index was also the basis for the development of an area deprivation index data set at the University of Wisconsin-Madison School of Medicine & Public Health (HIPxChange, 2016). Following Singh’s approach they generated an index using US census block data and also developed a freely available toolkit (subject to free registration) which is described in Table 5.1.
INDEXES OF POVERTY, WEALTH AND SOCIAL EXCLUSION Other relevant approaches to area classification involve the analysis of poverty as well as wealth and the extent to which societies are geographically and socio-economically polarised and segregated. To that end a project funded by the Joseph Rowntree Foundation (Dorling et al., 2007) aimed at building indicators of poverty and wealth in Britain by combining suitable national survey data with small-area geographical information from the census and other sources. A key feature of this approach was the use of the so-called Breadline Britain method (Pantazis et al., 2006) that measures relative poverty based on the lack of what the general public (according to social surveys) considers to be a necessity of life. The Breadline Britain surveys showed that:
Between 1983 and 1990, the number of households who lacked three or more socially perceived necessities increased by almost 50 per cent. In 1983, 14 per cent of households were living in poverty, and by 1990 this figure was 21 per cent. Poverty continued to increase during the 1990s and, by 1999, the number of households living in poverty on this definition had again increased to over 24 per cent, approximately 1 in 4 households.
(Gordon et al., 2000: 52)
The approach adopted in this project measured directly what people cannot afford that most other people think are necessities in contemporary times (e.g. being able to afford a television, a personal computer, a DVD player and, more recently, a tablet or a smartphone). In addition to producing measures of social exclusion based on relative poverty, Dorling et al. (2007) argued that there should also be measures of wealth, suggesting that while there has been a considerable body of work on poverty, including a wide range of approaches that attempt to measure poverty, this is not matched by the amount of literature that addresses wealth. Among the few attempts to build wealth indicators is the work of Rentoul (1987) who used Townsend’s approach to suggest that the ‘wealth line’ can be positioned based on the amount of money needed to eliminate poverty. Thus we need to estimate the point ‘in the distribution of resources above which this could be made avail-able’. A similar method has been employed in a study conducted as part of the United Nations Development Programme (Medeiros, 2006). Dorling et al. (2007) introduced the concepts of wealth-rich and income-rich; someone can be very wealthy, but have a very low income (e.g. someone living in a stately home with much in the way of accumulated resources, but little cash income), and equally someone could have a high income and little wealth (e.g. contractors with high levels of income but insufficient stability to buy their own homes or accumulate assets).
Table 5.1 The HIPxChange Area Deprivation Index and toolkit
Variables |
An Area Deprivation Index representing a geographic area-based measure of the socio-economic deprivation experienced by a neighbourhood, using the original index developed by Gopal Singh, PhD, MS, MSc which involved 17 different markers of socio-economic status from the 1990 census data. HIP has generated an updated index using 2000 census block group-level data and the original Singh coefficients from the 1990 data. The index includes the following variables: ▪ Percentage of the population aged 25 and older with less than 9 years of education ▪ Percentage of the population aged 25 and older with at least a high school diploma ▪ Percentage employed persons aged 16 and older in white-collar occupations ▪ Median family income in US dollars ▪ Income disparity ▪ Median home value in US dollars ▪ Median gross rent in US dollars ▪ Median monthly mortgage in US dollars ▪ Percentage of owner-occupied housing units ▪ Percentage of civilian labour force population aged 16 years and older who are unemployed ▪ Percentage of families below federal poverty level ▪ Percentage of the population below 150% of the federal poverty threshold ▪ Percentage of single-parent households with children less than 18 years of age ▪ Percentage of households without a motor vehicle ▪ Percentage of households without a telephone ▪ Percentage of occupied housing units without complete plumbing ▪ Percentage of households with more than one person per room |
What does the Area Deprivation Index toolkit contain? ▪ A file that explains how to use the dataset ▪ Data sets with Area Deprivation Index scores for a variety of US Census data levels: ▪ 9-digit zip codes (available in one large data set or smaller state-specific data sets) ▪ Zip code tabulation areas (ZCTAs) ▪ US Census block group codes ▪ US County For more information see: www.hipxchange.org/ADI |
Source: www.hipxchange.org/ADI
Building on these previous relevant efforts, Dorling et al. assessed the changing geographies of poverty and wealth in Britain over the last three decades of the 20th century and constructed a coherent set of poverty and wealth measures for unchanging geographical areas for time periods around 1970, 1980, 1990 and 2000. The analysis involved the division and mapping of the population of each area at each time period into five groups:
1 The ‘core poor’: defined theoretically according to the Taxonomy of Need (Bradshaw, 1972a, 1972b, 1994) as people suffering from a combination of normative, felt and comparative poverty, i.e. people who are simultaneously income poor, necessities/deprivation poor and subjectively poor (see Bradshaw and Finch, 2003).
2 The ‘breadline poor’: under the Relative Poverty Line – defined theoretically by Townsend (1979) as the resource level that is so low that people are excluded from participating in the norms of society, and measured by the Breadline Britain Index (see Gordon and Pantazis (1997) for a detailed discussion of how the index is derived). This is the same theoretical definition of poverty used by the European Union to measure poverty and social exclusion.
3 The ‘asset wealthy’: those living above an asset wealth line. Here, housing wealth data were used (developed by Thomas and Dorling, 2004) to estimate the number of wealthy households as those living above an asset wealth threshold, for time periods comparable to those used for the poverty measures. While housing wealth is a particular facet of wealth, it is most likely correlated with more general wealth.
4 The ‘exclusive wealthy’: those living above a (higher) wealth line, defined as being over ‘a point in the distribution of resources at which the possibility of enjoying special benefits and advantages of a private sort escalates disproportionately to any increase in resources’ (Scott, 1994: 152); a resource level that is so high that people are able to exclude themselves from participating in the norms of society (if they so wish). This represented the first approach to operationalising a wealth line such as this. This was done by using the UK Family Expenditure Survey (FES) data in combination with the Households Below Average Income (HBAI) adjustments to the incomes of the very ‘rich’. The HBAI adjustments account for household size and type when considering household income and are the same as those used in the Breadline Britain methodology. The adjusted FES data can then be used to discover the average band/level of income at which children go to independent schools, people use private health care, have second homes, boats, pay private club membership fees, etc.
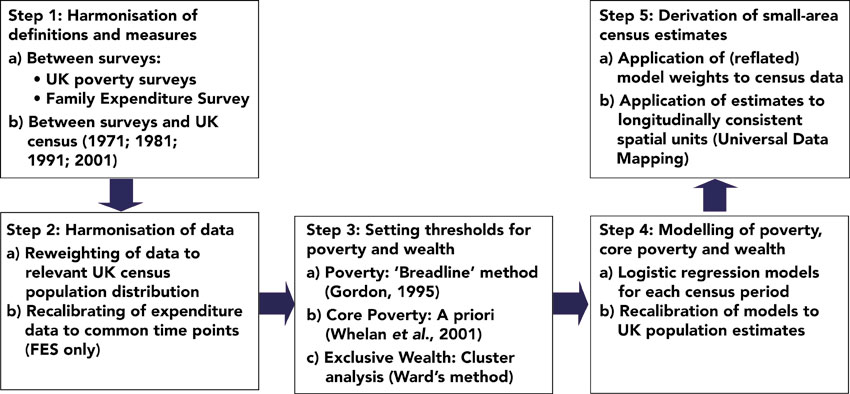
It is assumed that the core poor are a subset of the breadline poor, and similarly that the exclusive wealthy are a subset of the asset wealthy. By defining these four groups of households, a fifth ‘middle’ group is also defined by default – those which are neither poor nor wealthy, counted as the remainder of households in a geographic area after accounting for groups 2 and 3 (which are presumed to contain groups 1 and 4, respectively). As described above, the availability of the data determines the exact time periods under consideration, and in the case of housing wealth data, we do not have data for 1970 or any time around then, limiting the time series with respect to this wealth measure. Table 5.2 and Figure 5.3 describe and summarise the data and methods used in this project.
Table 5.2 Poverty, wealth and place data sources and methods
Poverty and core poverty |
Asset wealth |
▪ 1968/9 Household Resources & Standard of Living Survey (Townsend, 1979) |
▪ Tract-level data on housing asset ownership (Thomas and Dorling, 2004) |
▪ 1983 Poor Britain Survey (Mack and Lansley, 1985) ▪ 1990 Breadline Britain Survey (Gordon and Pantazis, 1997) ▪ 1999 Poverty & Social Exclusion Survey (Gordon et al., 2000) |
Exclusive wealth ▪ Family Expenditure Survey data for the years: – 1970–72 – 1980–81 – 1990–92 – 2000–02 |
Source: Dorling et al. (2007)
Figure 5.3 Poverty, wealth and place overview of methodology
Figure 5.4 Poverty, wealth and place in Britain
Source: Dorling et al. (2007)
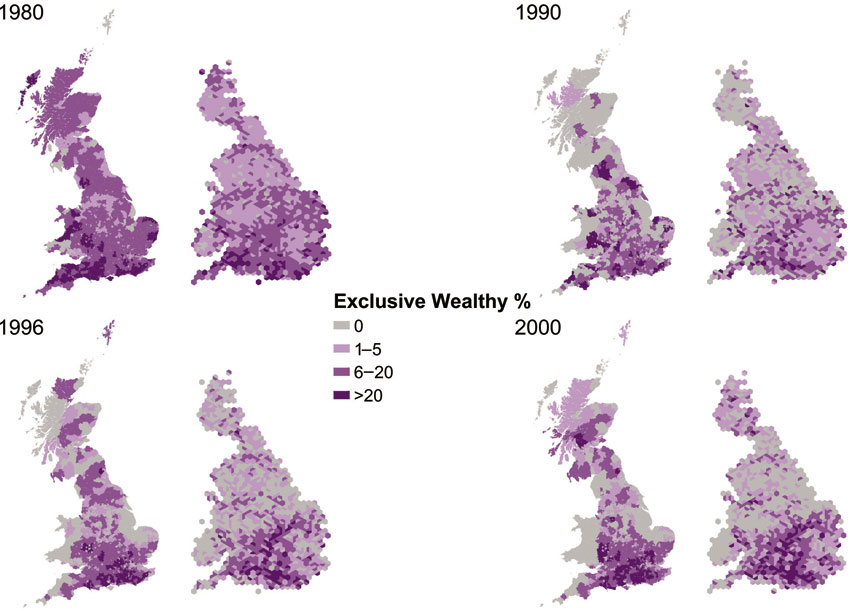
Figure 5.4 gives a flavour of the GIS mapping that was used to depict the distribution of these areas across Britain using conventional thematic mapping as well as the human cartographic approach discussed in Chapter 3. In general, mapping of these poverty and wealth data sets indicates that wealth and poverty each demonstrate similar geographical patterns at every time period. The highest wealth and lowest poverty rates tend to be clustered in the south-east of England (with the exception of most of inner London); conversely the lowest wealth and highest poverty rates are concentrated in large cities and industrialised/ de-industrialising areas of Britain. However, this project revealed some interesting and substantial changes to this generalisation over time. Analyses of the degree of polarisation and spatial concentration suggest that Britain’s population became less polarised with regard to area breadline poverty rates during the 1970s. However, polarisation increased through the 1980s and the 1990s. Asset wealth also became more polarised during the 1980s, but this trend reversed in the first half of the 1990s, before polarisation could be seen to be increasing again at the end of that decade.
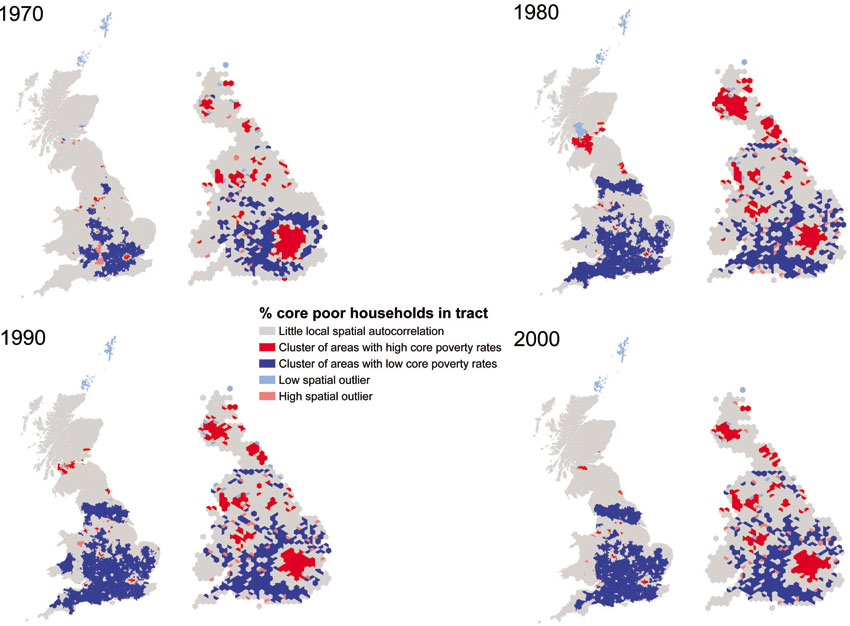
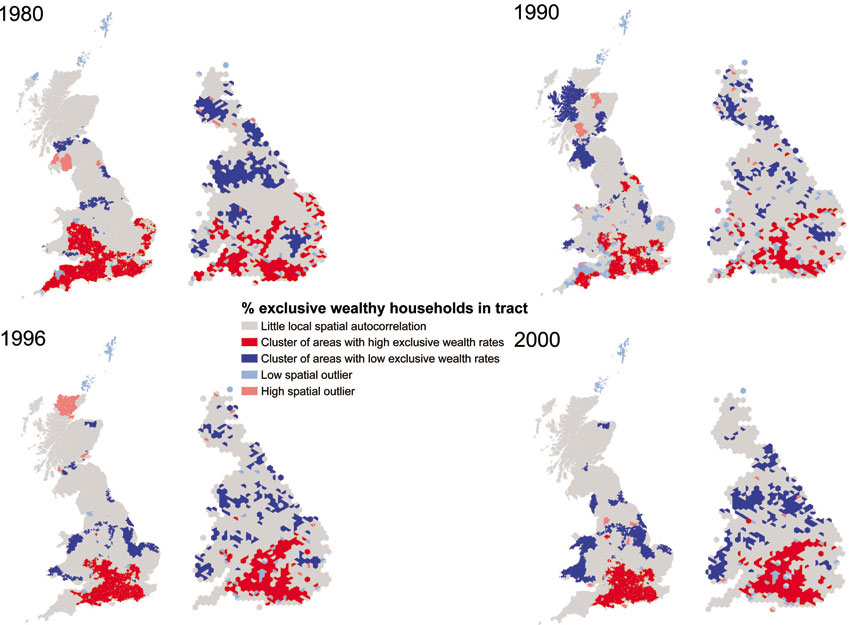
Dorling et al. (2007) also conducted GIS-based spatial analysis and, in particular, spatial autocorrelation analysis, to identify clusters of poverty and wealth, or in other words to indicate the extent to which areas with high levels of poverty tend to be found near to other areas with high levels of poverty and, similarly, areas of high wealth are found near other areas of high wealth. Spatial autocorrelation involves the calculation of measures of spatial association and they are increasingly embedded in GIS packages. For example, they are a standard feature of the Spatial Statistics toolbox of ArcGIS3 (which is part of the ‘Modelling spatial relationships’ tools4) that enables the analysis of spatial patterns of a variable and the statistical evaluation of whether any observed patterns can be considered to be clustered, dispersed or random. Dorling et al. (2007) carried out spatial autocorrelation analysis to effectively measure how similar or dissimilar each area is to its neighbours, giving an indication of the degree of spatial concentration of poverty and wealth. In particular, they calculated a spatial association measure on a local/regional basis, resulting in a map of ‘spatial clusters’ of similar areas, building on a relevant study by Orford (2004) that employed ‘Local Indicators of Spatial Association’ (LISA; Anselin, 1995) techniques to investigate the spatial concentration of poverty in 1896 and 1991 using a social class measure. Figures 5.5 and 5.6 show the results of this analysis, highlighting clusters of poverty and wealth rates, respectively (for a comprehensive discussion of these outputs and of the data and methods used see Dorling et al., 2007).
Figure 5.5 Local Indicators of Spatial Association (LISA) for the percentage of households classified as core poor at each time period
Source: Dorling et al. (2007)
Figure 5.6 Local Indicators of Spatial Association (LISA) for the percentage of households classified as exclusive wealthy at each time period
Source: Dorling et al. (2007)
INDEXES OF ANOMIE In addition to measures of poverty and wealth there are possibilities of composite indicators that attempt to quantify concepts that relate to living conditions, quality of life and social norms and social well-being. One example is the so-called ‘anomie’ measure which can be seen as an index of ‘local well-being’ (anomie is the sociological term to describe, according to some interpretations, the feeling of ‘not belonging’). Such measures can also be described as ‘loneliness indices’. Ballas and Dorling (2013) and Dorling et al. (2008) present such an index to explore the geography of loneliness or anomie in Britain in a study commissioned by the BBC which aimed at comparing variations across BBC radio and TV regions. The index used was based on a scale and weightings which have now been widely employed in many pieces of research (Congdon, 1996). In particular, the index is calculated based on weighted sums of non-married adults, one-person households, people who have moved to the area within the last year and people renting privately. The index is equal to the sum of the following multiples in each area:
▪ number of non-married adults multiplied by a weight of 0.18;
▪ number of one-person households multiplied by a weight of 0.50;
▪ number of people who have moved to their current address within the last year multiplied by a weight of 0.38;
▪ number of people renting privately multiplied by a weight of 0.80.
The data used to calculate the index are readily available in Britain for small areas from the census of population and it can be argued that they represent a number of variables that are associated with happiness and well-being (we revisit this subject in the next chapter with more sophisticated geographical approaches to small-area estimation including happiness). For instance, it has long been argued that single people appear to be on average less happy than married couples (Ballas and Dorling, 2013; Frey and Stutzer, 2002; Inglehart, 1990; Helliwell, 2003) and in general there is evidence that stable and secure intimate relationships are beneficial for happiness. In contrast, the dissolution of such relationships is damaging (Dolan et al., 2007). In this context the census variables ‘number of one-person households’ and ‘number of non-married adults’ could be considered suitable to measure at the local level. Also, as noted above, length of time at current address and social networks have an impact on well-being. The census variables ‘number of people who have moved to their current address within the last year’ and ‘number of people renting privately’ capture, to some extent, the degree to which people are integrated in the local community and might feel that they ‘belong’. This variable also implicitly incorporates in the analysis the spatial process of migration (as it provides the number of in-migrants in the area within the year before the census date).
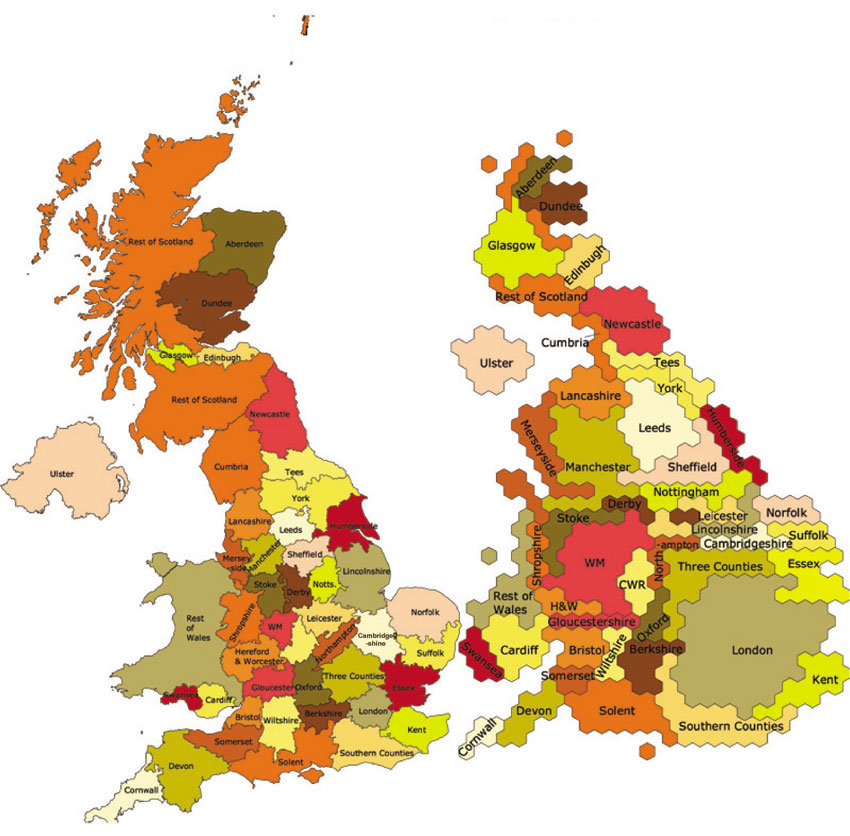
Figure 5.7 The BBC radio regions map and human cartogram
Source: After Dorling et al. (2008)
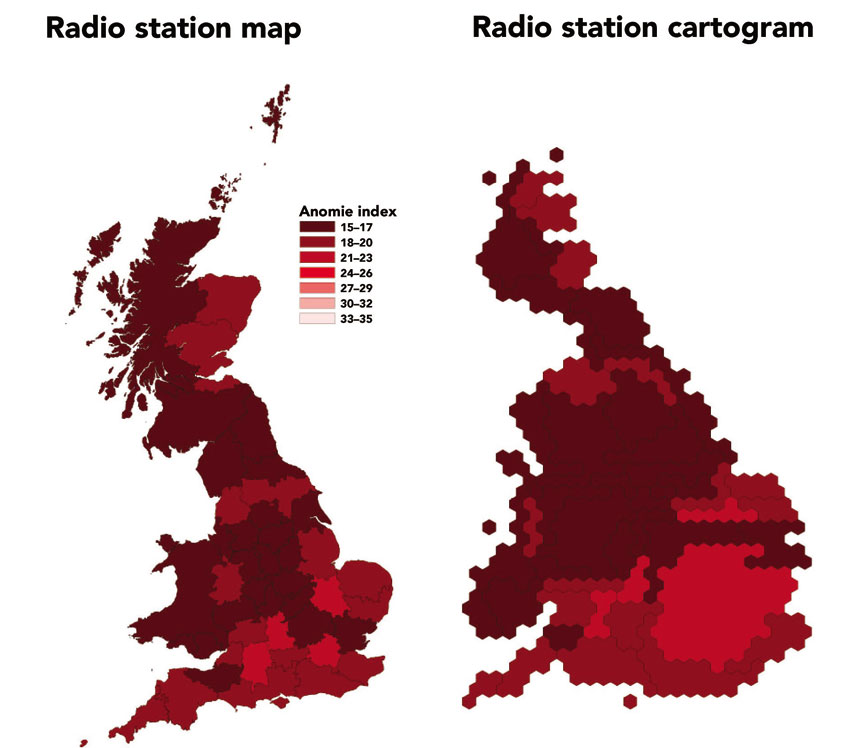
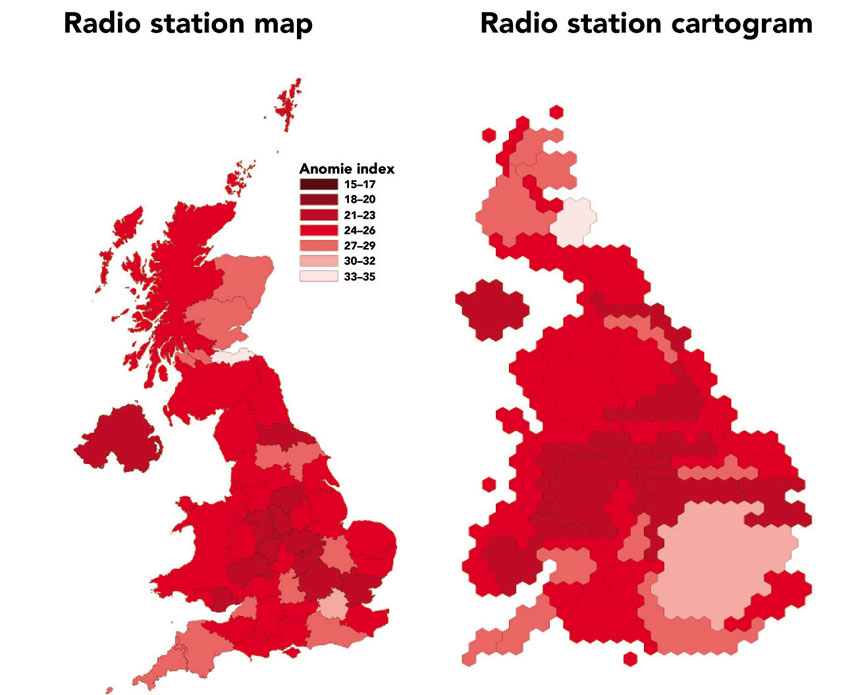
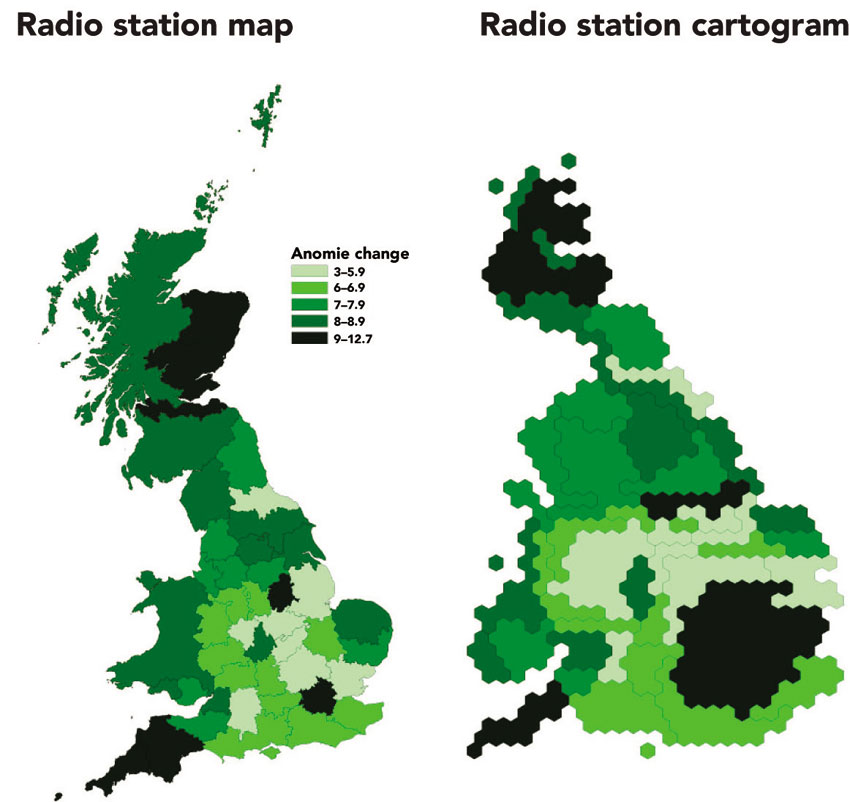
Dorling et al. (2008) collected these data from the British censuses for the years 1971, 1981, 1991 and 2001 to compare the anomie index levels between different regions (using the BBC radio regions as a the geographical unit of analysis). They mapped this proxy of social fragmentation or local well-being index across Britain using both conventional maps as well as human cartograms that show areas in proportion to their populations (see Figure 5.7). Figure 5.8 shows the spatial distribution of anomie index in 1971, and Figure 5.9 depicts the same variable in 2001. The gap between the index extreme values has grown over time (other than during the 1970s). Figure 5.10 shows the spatial distribution of anomie index change between 1971 and 2001.
Figure 5.8 Spatial distribution of anomie index, 1971
Source: After Dorling et al. (2008)
Figure 5.9 Spatial distribution of anomie index, 2001
Source: After Dorling et al. (2008)
Figure 5.10 Spatial distribution of anomie index difference between 1971 and 2001
Source: After Dorling et al. (2008)
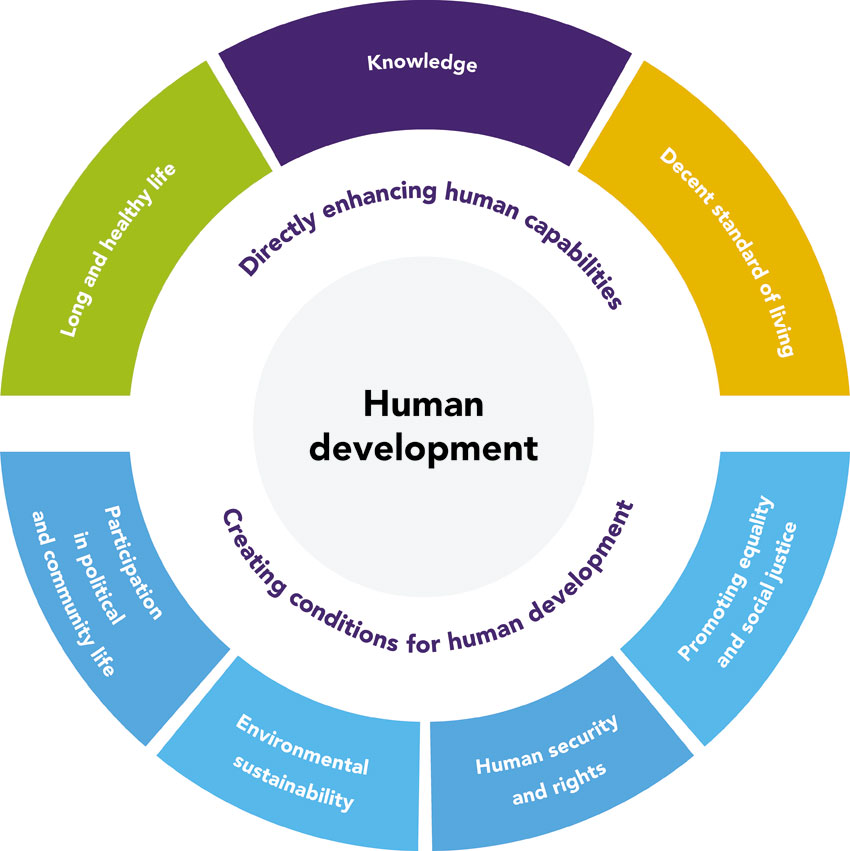
AREA INDEXES OF QUALITY OF LIFE, HUMAN DEVELOPMENT AND DIVERSITY Other possibilities of geographical composite indexes involve the combination of variables that relate to human development, quality of life and policy goals. A good example is the United Nations Human Development Index which measures average achievement in a series of domains (see Figure 5.11) based on the human capability approach proposed by Nobel Laureate Amartya Sen and other award-winning economists and social scientists such as Martha Nussbaum and John Rawls.
This index, which is calculated every year by the United Nations for all countries around the world, has been the basis for the development of regional and local area indexes. For instance, the European Union calculates the EU Human Development Index at the regional level (see Figure 5.12).5 The index is based on life expectancy in good health, net adjusted household income per head and on levels of educational attainment of the population aged 25–64. The higher the index the better off the people of the area are said to be. Figure 5.12 is a human cartogram (Hennig projection, as discussed in Chapter 3) showing the geographical distribution of this index across the European region. The British capital city region Inner London has the highest value of 100, followed by the Surrey, East and West Sussex (93.64). The Swedish capital city region of Stockholm is third with an index of 93.25, followed by Berkshire, Buckinghamshire and Oxfordshire (92.43) in the United Kingdom and Utrecht (92.43) in the Netherlands. At the other end of the range, the bottom five regions are all in Romania: Sud-Est with a value of zero and also Sud-Muntenia (0.15), Nord-Est (0.5), Nord-Vest (2.36) and Sud-Vest Oltenia (2.71).
Figure 5.11 Dimensions of human development
Source: http://hdr.undp.org/sites/default/files/2015_human_development_report_1.pdf
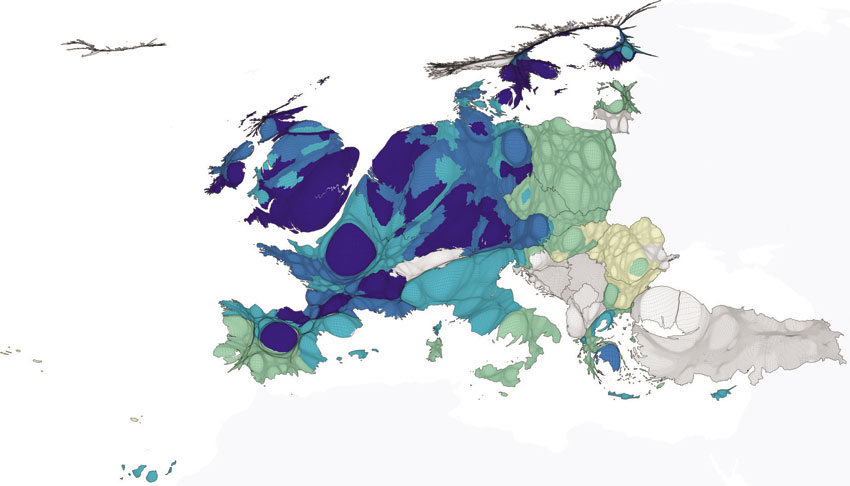
Figure 5.12 The EU Human Development Index, 2007 (0 = low level of human development 100 = high level of human development)
Source: European Commission, 2010; based on data from Eurostat, DG REGIO (after Ballas et al., 2014)
Figure 5.13 shows a gridded population cartogram coloured by the geographical distribution of the so-called Lisbon Index, showing how close an EU region is to the following targets: 85% for employment rate for men aged 15–54; 64% for employment rate for women aged 15–54; 50% employment rate for people aged 55–64; 10% employment secured by early school leavers aged 18–24; 85% of people aged 20–24 attaining secondary level education as a minimum; 12.5% of lifelong learning participation among people aged 25–64; 2% for business expenditure in R&D as a proportion of GDP; 1% for government, higher education and non-profit expenditure in R&D as a proportion of GDP (European Commission, 2010). The index can take values ranging from 0 (for the region which is furthest away from the targets) to a maximum of 100 (meaning that all targets have been reached).
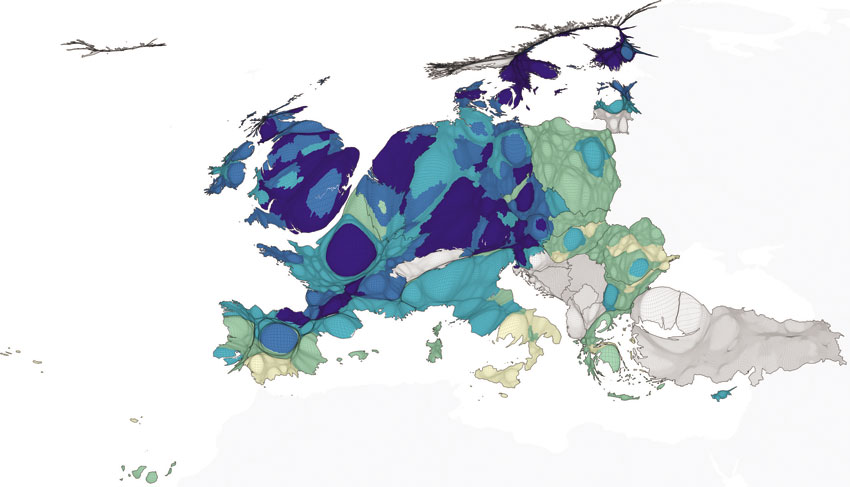
Figure 5.13 The Lisbon Index, 2008 (average score between 0 and 100)
Source: European Commission (2010); Eurostat, DG REGIO (after Ballas et al., 2014)
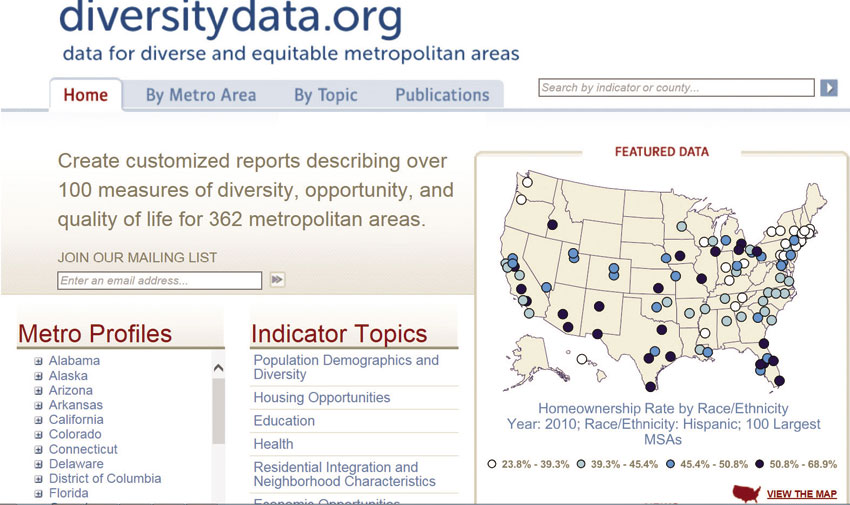
Another relevant example is the diversitydata.org project in the US. This project has produced a wide range of area indicators of diversity, opportunity, quality of life and health which are available via an interactive website (see Figure 5.14) which is aimed at allowing researchers, policy makers and community advocates to describe, profile and rank US metropolitan areas in terms of quality of life. Similarly, the diversitydatakids.org project (see Figure 5.15) focuses on child well-being and includes maps based on a ‘Child Opportunity Index’ (Acevedo-Garcia et al., 2014).
Geodemographic classifications
Demography is the study of population types and their dynamics therefore geodemographics may be labelled as the study of population types and their dynamics as they vary by geographical area.
(Birkin and Clarke, 1998: 88)
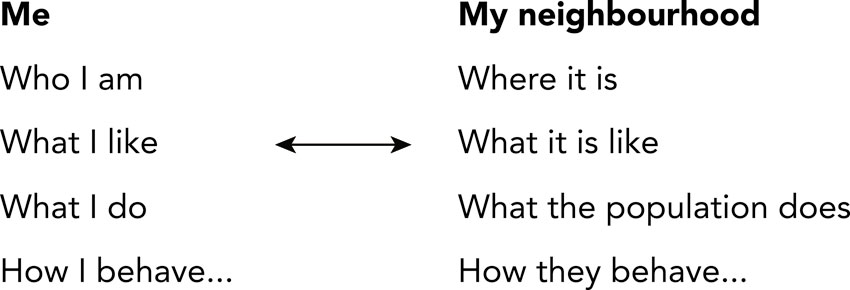
The methods discussed so far in this chapter aim at classifying areas by a composite index in relation to different themes ranging from deprivation to poverty and wealth and human development. In this section we present a conceptually related but methodologically different approach to the development and application of area typologies and classifications of neighbourhoods, widely known as ‘geodemographics’. As noted above, geodemographics and GIS have become almost synonymous. As is the case with composite indicators, geodemographics involves an analysis of poverty and wealth within cities and regions and the quantitative characterisation of areas (typically neighbourhoods). However, geodemographics aims to provide a more detailed and sophisticated labelling and description of places. It can be defined as the ‘analysis of people by where they live’ (Sleight, 1997: 16) and as the suggestion that where you live says something about who you are (Harris et al., 2005) illustrated in Figure 5.16.
Figure 5.14 The diversitydata.org project
Source: Screenshot from www.diversitydata.org
Figure 5.15 The diversitydatakids.org project
Source: Screenshot from www.diversitydatakids.org
A key concept that underpins geodemographic classifications is that people who live close to each other tend to have similar characteristics (Harris et al., 2005) which also relates to what is known as Tobler’s First Law of Geography according to which, ‘Everything is related to everything else, but near things are more related than those far apart’ (Tobler, 1970: 236). As Vickers (2006: 16) points out, ‘Geodemographics takes Tobler’s law and gives it a twist, using his principle that two houses next to each other are likely to be fairly similar and contain people with comparable characteristics.’ Geodemographics involves the grouping of neighbourhoods in the same locality but also similar neighbourhoods that are not geographically connected, and redefining Tobler’s law as follows: ‘People who live in the same neighbourhood are more similar than those who live in a different neighbourhood, but they may be just as similar to people in another neighbourhood in a different place’ (Vickers, 2006: 16).
Figure 5.16 Geodemographics is about ‘linking people to places’
Source: After Harris et al. (2005: 2)
The origins of geodemographic classification systems date back to the work of Charles Booth (which was briefly discussed in the introduction to this chapter) and by later work in social area analysis and factorial ecology by human ecologists in the US in the 1920s and 1930s (for detailed reviews of the background and history see Burrows and Gane, 2006; Harris et al., 2005; Singleton and Spielman, 2014; Vickers, 2006; Birkin and Clarke, 2009). However, the first attempt to build modern computer-based geodemographic classifications can be traced back to the 1960s in Britain with the first release of the census small-area statistics in machine-readable form. This generated a lot of interest by the public sector and, in particular, local authorities that explored the possibility of using census data to classify areas by socio-economic characteristics in order to identify localities in need of investment (Vickers, 2006). One of the first analyses of these data to that end was conducted by Liverpool City Council in 1969 in their ‘Social Malaise’ study that was used to support decision making regarding the allocation of social services. This was followed by the work of Webber and Craig (1976) on National Classifications of areas in Britain commissioned by the UK Office of Population Censuses and Surveys (OPCS) in the 1970s and providing the foundation for the modern geodemographic industry. The OPCS classification attracted the attention of the British Market Research Bureau (BMRB) which saw the potential to use these typologies to examine variations in consumer patterns and eventually restructured and renamed Webber’s classification work A Classification of Residential Neighbourhoods (ACORN) developed by a company called CACI6 and launched it at the Market Research Society’s 1979 conference, as a marketer’s dream (Vickers, 2006). Another key development in Britain was the creation of GB Profiles by Stan Openshaw using data from the 1991 census of population and creating typologies of small (with an average size of 200 households) census tracts (Blake and Openshaw, 1995; Rees et al., 2002). Similar computer-based geodemographic systems were also developed in the US, such as the work of Jonathan Robbin (Robbin, 1980).
The development of ACORN was followed by Mosaic (also led by Richard Webber) a geodemographic system developed by Experian7 with classifications available for most of Western Europe, the US, Japan and Australia. Tables 5.3 and 5.4 provide examples and summaries of geodemographic classification systems in the US and Britain (drawing on a recent review by Singleton and Spielman, 2014), including information on the number of variables analysed, number of segment groups (level 1) and sub-groups (level 2 and micro-level) generated as well as the smallest geographical unit (taxonomic unit) at which the classification is available.
Figure 5.17 gives an example of ‘pen portraits’, describing geodemographic classification groups for Experian’s Mosaic classification in Britain. These ‘pen portraits’ are created by using statistical methods, known as data reduction techniques. There are also similar geodemographic systems in the US (two examples can be seen in Figures 5.18 and 5.19).
As is the case with the composite indicator approaches, the development of geodemographics involves a classification of areas according to a set of characteristics. But unlike the composite indicator approach, which involves building a single index by combining different variables, geodemographic classification is based on a statistical method known as cluster analysis (Everitt, 1993; Everitt et al., 2001). This is a classificatory technique particularly valuable and suitable for constructing typologies with data sets comprising many variables and ‘cases’ (which in a GIS context are geographical districts or neighbourhoods). The technique is capable of analysing large multidimensional data sets to find clusters of areas that have similar aggregate socio-demographic characteristics (e.g. young service workers with medium/average incomes or middle-aged high-income professionals). The creation of the classification involves running a cluster algorithm on a data set of areas (e.g. neighbourhoods) containing a wide range of variables (e.g. unemployment rates, rates of population by five-year age groups, percentage of different social classes as the total population in each area, etc.). The original set is then split into a smaller number of data sets (clusters or super-groups) that maximise within-cluster homogeneity and between-cluster differences. Each of these data sets (clusters) is then split into separate data sets to create a sub-group and each sub-group can then be split into further sub-groups. Overall, the steps of creating a geodemographic classification can be summarised as follows (after Everitt et al., 2001; Vickers, 2006; Vickers and Rees, 2007; Milligan, 1996):
Table 5.3 US general purpose area-based geodemographic classifications available in 2012
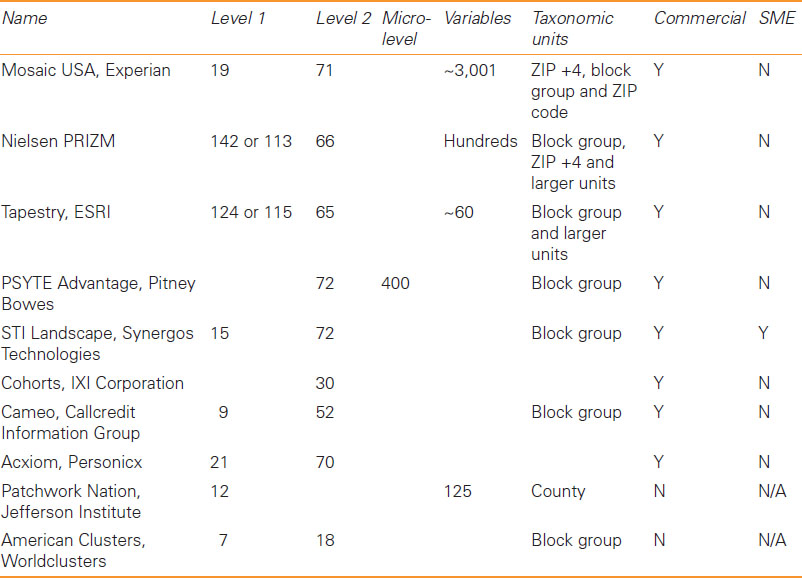
Note: SME = small to medium-sized enterprise.
Source: After Singleton and Spielman (2014)
Table 5.4 UK general purpose area-based geodemographic classifications in 2012
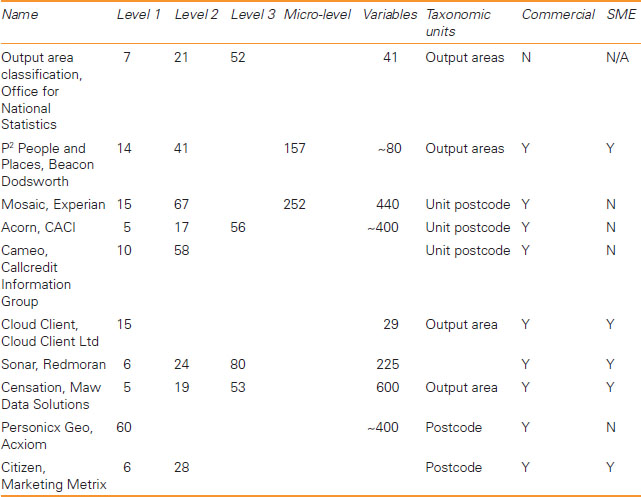
Note: SME = small to medium-sized enterprise.
Source: After Singleton and Spielman (2014)
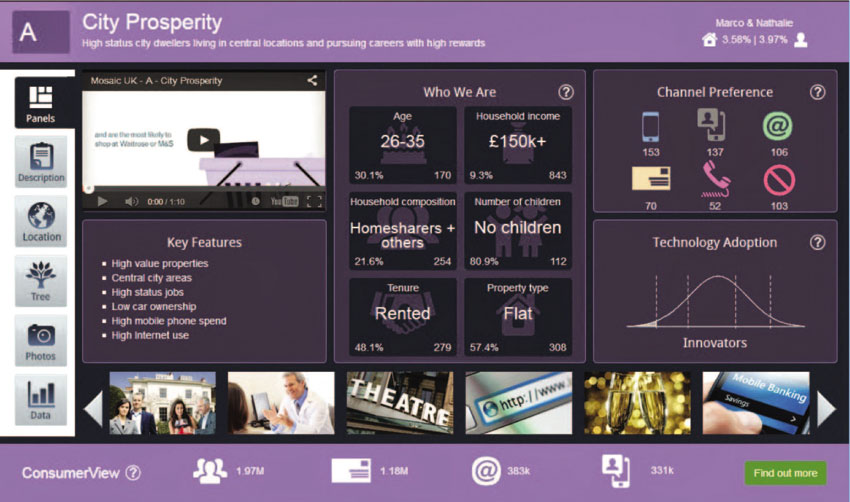
Figure 5.17 Mosaic UK: City Prosperity ‘pen portrait’
Source: www.experian.co.uk/assets/marketing-services/brochures/mosaic_uk_brochure.pdf
1 clustering elements (objects to cluster, also known as ‘operational taxonomic units’; these would be geographical areas in a GIS context);
2 clustering variables (attributes of objects to be used, e.g. area unemployment rate, average household income, population by age);
3 variable standardisation;
4 measure of association (proximity measure);
5 clustering method;
6 number of clusters;
7 interpretation, testing and replication.
Table 5.5 lists the data sets that were analysed to derive the Mosaic geodemographic ‘pen portraits’ described in Figure 5.17.
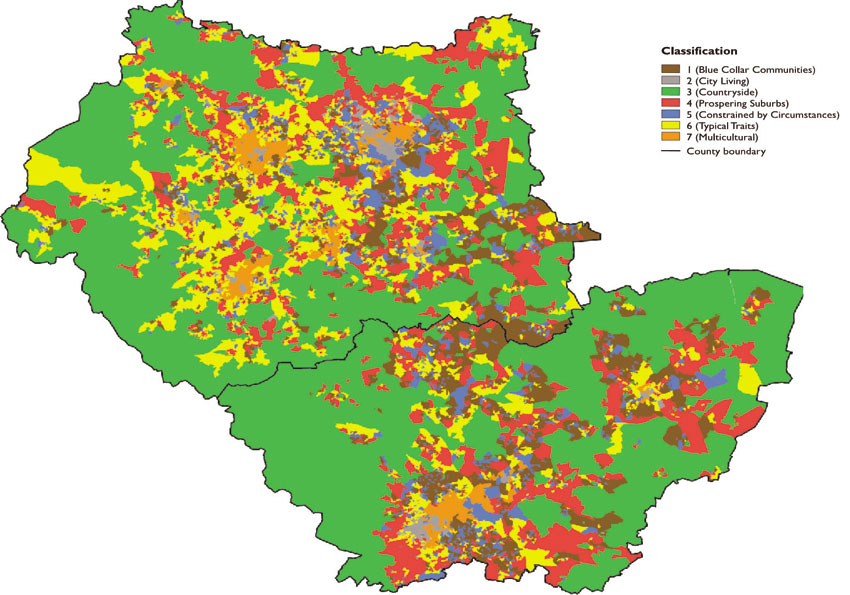
The information provided in Table 5.5 gives an indication of the overall themes used to create the classification. Nevertheless, there is very limited publicly available information on the data and variables used (e.g. how many age groups there are in the age variable described in Table 5.5) and methods (e.g. regarding any data transformation and the particular cluster analysis technique) used in commercial geo-demographic systems such as Mosaic. This is due to commercial competition and confidentiality reasons. However, there has been an increasing number of so-called ‘open geodemographic’ classification systems which do not have such limitations. A good example of such a system is the official UK Office for National Statistics geodemographic classification developed by Dan Vickers at the Universities of Leeds and Sheffield (Vickers, 2006, 2010; Vickers and Rees, 2007, 2011) using data from the 2001 census of population. Appendix 5.1 provides more details on how this system was developed, and Figure 5.20 presents maps of these outputs for South and West Yorkshire.
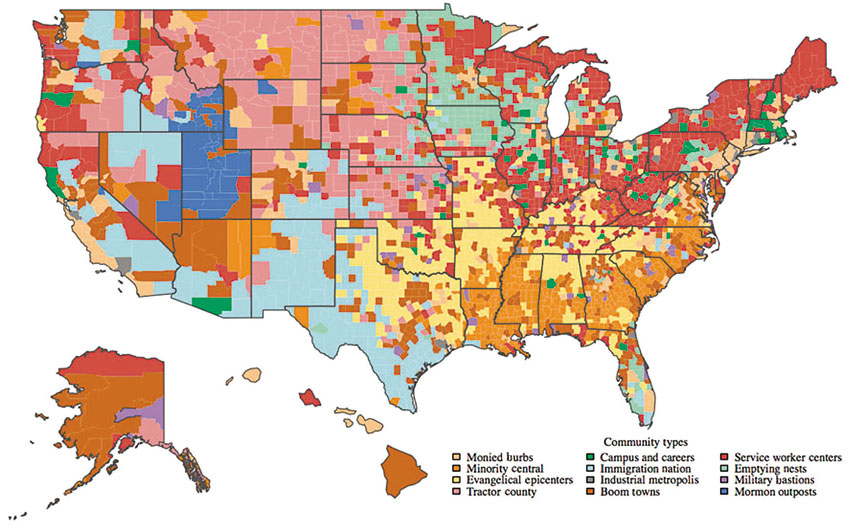
Figure 5.18 A map showing ‘Patchwork Nation’, which is an example of a geodemographic classification for the United States
Source: After Singleton and Spielman (2014: 559)
Figure 5.19 The Nielsen PRIZM geodemographic classification: segment details
Table 5.5 Indicative data sets (by theme) used in the construction of Mosaic
Individual ▪ Gender ▪ Age ▪ Marital status ▪ Surname origin ▪ Length of residency ▪ Head of household |
Financial ▪ Personal and household income and assets ▪ Shareholding value ▪ Outstanding mortgage ▪ Directorships ▪ Employment status |
Property ▪ Age ▪ Type ▪ Size ▪ Tenure ▪ Council tax band ▪ Value |
Family ▪ Presence of children ▪ Household composition ▪ Lifestage |
Source: Compiled by the authors based on Experian Mosaic marketing materials
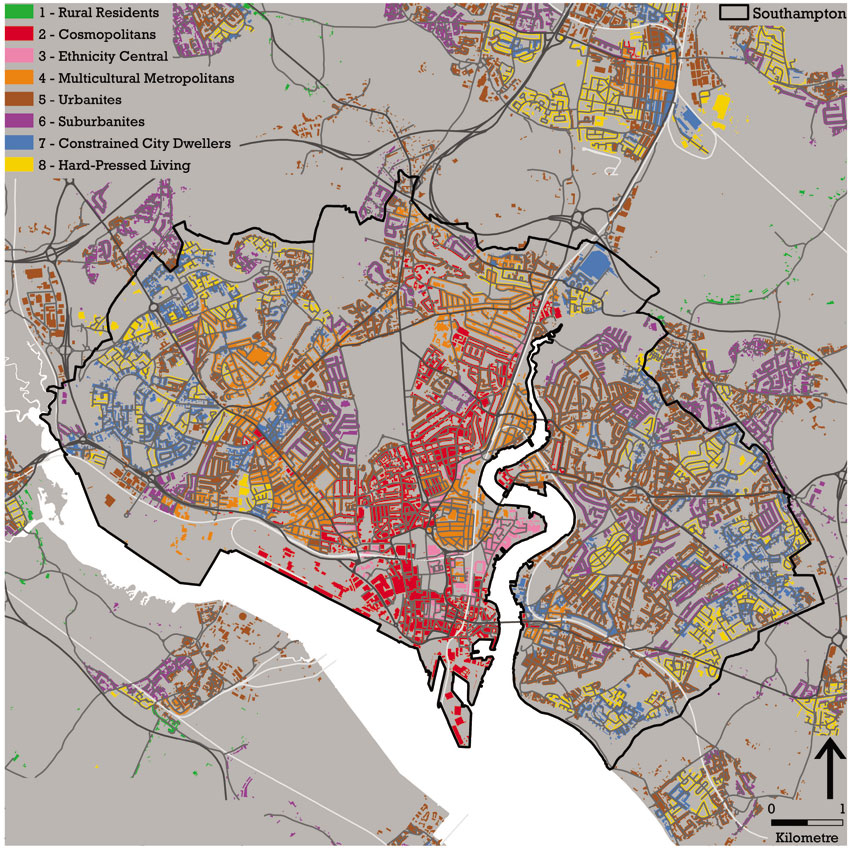
Building on this work Chris Gale and colleagues (2014) at University College London developed an open geodemographic classification using data from the 2011 census of population (see Figure 5.21). Such open geodemographic classification systems are free to download8 and use for any application and the data and methods used to develop them are publicly available.
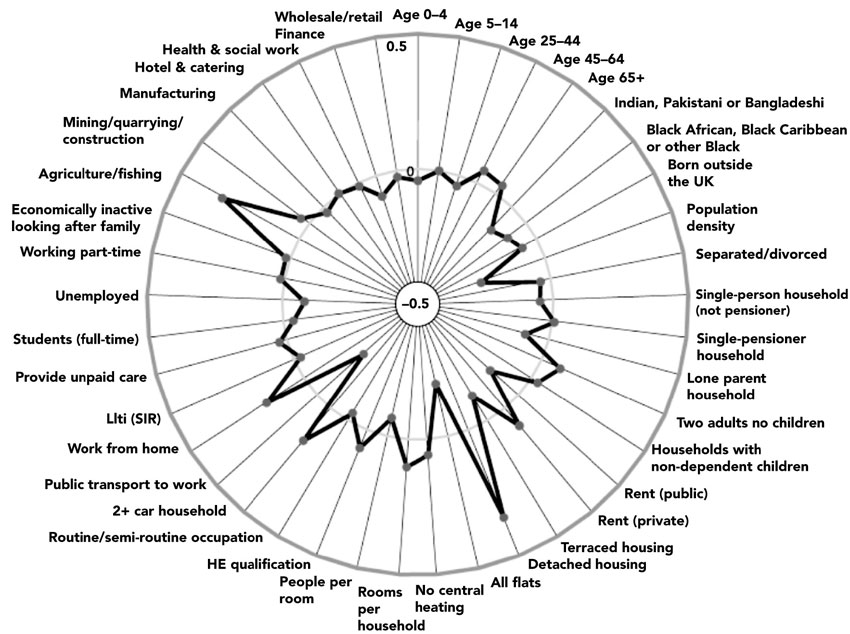
The names of the clusters described (in Figure 5.21 and Appendix 5.2) are the output of the final step in building a classification that involves a meticulous analysis in order to produce a short description by combining text and visual information such as graphs summarising statistical information, photographs of typical homes and lifestyle-related consumer products. In order to generate a suitable description the average values for each of the variables used in the cluster analysis are calculated across all areas in each cluster in turn. These average values are then compared to the average values for the full data set to establish the characteristics of each cluster group. Clusters that have extreme values for one or more variables are generally easier to describe than clusters that have average values for all variables (Vickers and Rees, 2006). The process of identifying common characteristics and attributes that can be used to name clusters can be greatly enhanced with the use of radial plots for each cluster, as demonstrated by Vickers (2006) and Vickers and Rees (2007) in the development of the UK Office for National Statistics Census Output Area Classification discussed above. Figure 5.22 shows a radial plot cluster summary for the supergroup ‘Countryside’ within this classification. The radial plots represent the standardised values for each variable and the numbers on the scale show the difference from the mean value for that variable (i.e. the mean for all variables is 0). The value of each variable for each cluster group can be seen by the distance each point is above or below the middle (0) ring, with the outer ring representing a value of 0.5 and the inner ring a value of –0.5 (Vickers and Rees, 2007: 399).
Figure 5.20 Mapping the first UK output area classification, South and West Yorkshire, UK, 2001
Source: Vickers and Rees (2006)
Figure 5.21 The UK Office for National Statistics output area classification for the city of Southampton, UK, 2011
Source: Gale et al. (2016). Contains National Statistics data © Crown copyright and database right 2016; contains Ordnance Survey data © Crown copyright and database right 2016
Vickers and Rees (2007) adopted two general principles when naming their clusters: the names must not offend residents (and it is interesting to compare these cluster names with those of Booth presented in Figure 5.1) and they must not contradict other official classifications or use already established names. For instance, in their classification the terms ‘rural’ and ‘urban’ were not used to avoid confusion with official urban-rural classification of the Office for National Statistics, whereas words such as ‘affluent’ were avoided due to giving potential stigma of wealth (or non-wealth) to areas. As they put it: ‘Coming up with descriptive inoffensive names for some areas is easier than for others. For a pleasant area it is not such an arduous task as for areas where few would choose to live’ (Vickers and Rees, 2007: 399).
Figure 5.22 Cluster radial plot for ‘Countryside’ supergroup
Source: After Vickers (2006)
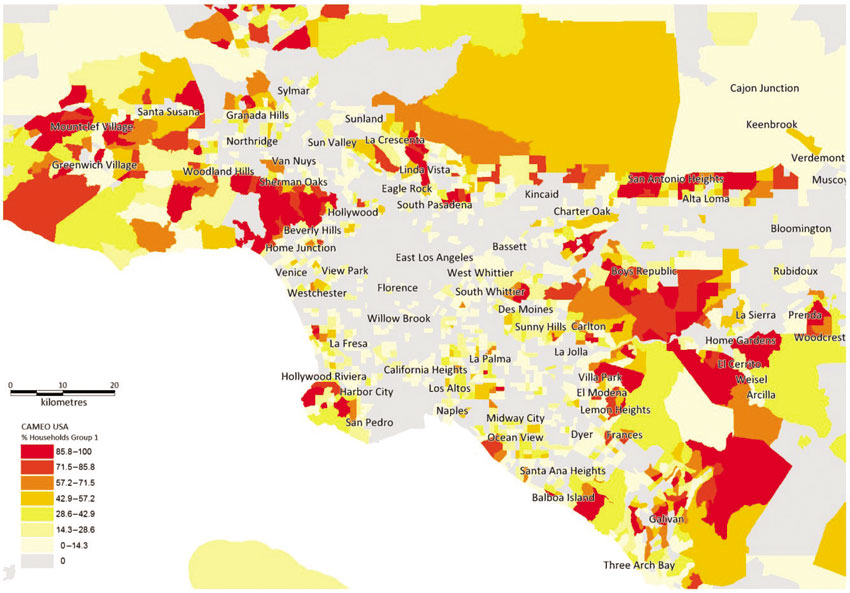
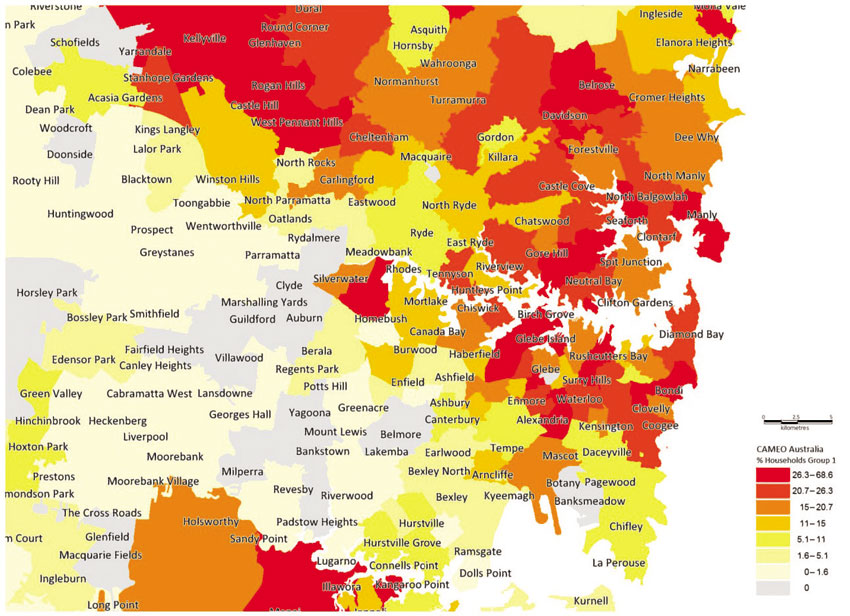
Finally we note that many geodemographic suppliers are now producing pan-international classifications, in addition to classifications for different individual countries. Figures 5.23 and 5.24 for example, shows CAMEO’s international classification scheme mapped for Los Angeles and Sydney, respectively. These maps pick out the highest income areas in both cities using the same worldwide classification scheme.
In this chapter we have provided an overview of key methods for the classification and mapping of areas and people. We discussed the first attempts to create such classifications and the rationale for classifying areas using secondary data in the social sciences, briefly drawing on the social indicators literature and then giving examples of how indexes of deprivation and quality of life can be built on the basis of existing secondary data. We also introduced geodemographic classification methods, providing examples highlighting the key steps needed to develop geodemographic typologies of places and the issues that need to be considered. There is a growing number of new systems and further developments in this field (for a recent review see Singleton and Spielman, 2014) and ongoing research on the strengths and limitations of these approaches.
Figure 5.23 Distribution of high-income earners in Los Angeles, California, US, using geodemographics
Source: Callcredit’s CAMEO International 2014
Figure 5.24 Distribution of high-income earners in Sydney, Australia, using geodemographics
Source: Callcredit’s CAMEO International 2014
Nevertheless, it is also important to note that the methods discussed in this chapter have long been at the centre of lively debates and concerns pertaining to privacy, confidentiality, the production/labelling of space, ethical issues, consumer identity and stereo-typing and electronic surveillance. Among the first and most influential and comprehensive overviews of these issues is a book entitled Ground Truth: The Social Implications of Geographic Information Systems (Pickles, 1994) as well as an article published in the journal Economic Geography and entitled ‘“We know who you are and we know where you live”: the instrumental rationality of geodemographic systems’ (Goss, 1995). Also of relevance are debates about the social implications of the ‘geospatial web’ (Ellwood, 2010). There have been ongoing efforts to further consider and address such concerns in a wide range of contexts (e.g. see Flowerdew, 1998; Uprichard and Burrows, 2009; Beer and Burrows, 2013) and to also more generally acknowledge and highlight the societal and ethical implications of using GIS in the social sciences.
An important methodological limitation of the methods and studies discussed in this chapter is that area-level index value or geodemographic labels (as is the case with all group averages) can lead to what is known as the ecological fallacy, which was introduced and discussed in Chapter 2. This can happen when statistical information relating to an aggregated areal unit (e.g. the neighbourhood) is assumed to apply to all smaller units or individual within this areal unit (Tranmer and Steel, 1998). This issue is particularly important for areas of high levels of socio-economic and demographic diversity. For instance, it is possible to find pockets of deprivation (or single individuals or households that are considered to be deprived) in areas that are overall affluent and, similarly, pockets of affluence in areas that otherwise appear to be poor. This issue can be potentially addressed with the use of more sophisticated small-area estimation methods such as spatial microsimulation which are presented in the next chapter.
|
This chapter is accompanied by a linked practical (Practical 1: Area classification – creating a small-area deprivation index). We walk you through the process of downloading, preparing and importing data from the 2011 census in England. You use these data to construct an area-based deprivation index known as the Carstairs index (see above). We use the Carstairs index due to its relative simplicity, allowing you to gain experience of all the steps needed to download and process the data in order to construct and visualise the index in your GIS.
Notes
1 See http://webarchive.nationalarchives.gov.uk/20100410180038; http://www.communities.gov.uk/archived/general-content/communities/indicesofdeprivation/indicesofdeprivation/.
2 See www.gov.uk/government/collections/english-indices-of-deprivation.
3 http://pro.arcgis.com/en/pro-app/tool-reference/spatial-statistics/spatial-autocorrelation.htm.
4 http://pro.arcgis.com/en/pro-app/tool-reference/spatial-statistics/modeling-spatial-relationships.htm.
5 Also see Chapter 3 for a discussion of the cartographic method used to create this map and www.europemapper.org for more details on the geography of Europe.
8 E.g. see www.opengeodemographics.com.
Dorling, D., Rigby, J., Wheeler, B., Ballas, D., Thomas, B., Fahmy, E., et al. (2007) Poverty, Wealth and Place in Britain, 1968 to 2005, Policy Press, Bristol.
Harris, R., Sleight, P., & Webber, R. (2005) Geodemographics, GIS and Neighbourhood Targeting, Wiley, Chichester.
Singleton, A. D., & Spielman, S. E. (2014) The past, present, and future of geodemographic research in the United States and United Kingdom. The Professional Geographer, 66(4), 558–567.
Vickers, D., & Rees, P. (2007) Creating the UK national statistics 2001 output area classification. Journal of the Royal Statistical Society: Series A. Statistics in society, 170(2), 379–403.
Online resources (including data sources)
Consumer Data Research Centre: www.cdrc.ac.uk
Open Geodemographics: www.opengeodemographics.com
The 2001 UK Census Area Classification, Office for National Statistics Open Geodemographic Classification system: www.sasi.group.shef.ac.uk/area_classification
The 2011 UK Census Area Classification, Office for National Statistics Open Geodemographic Classification system: http://geogale.github.io/2011OAC
UK Output Area Classification User Group: www.areaclassification.org.uk
Data: 41 census variables
Demographic
1 Age 0–4: Percentage of resident population aged 0–4
2 Age 5–14: Percentage of resident population aged 5–14
3 Age 25–44: Percentage of resident population aged 25–44
4 Age 45–64: Percentage of resident population aged 45–64
5 Age 65+: Percentage of resident population aged 65+
6 Indian, Pakistani or Bangladeshi: Percentage of people identifying as Indian, Pakistani or Bangladeshi
7 Black African, Black Caribbean or other Black: Percentage of people identifying as Black African, Black Caribbean or other Black
8 Born outside the UK: Percentage of people not born in the UK
9 Population density: Population density (number of people per hectare)
Household composition
10 Separated/divorced: Percentage of residents 16+ who are not living in a couple and are separated/divorced
11 Single-person household (not pensioner): Percentage of households with one person, who is not a pensioner
12 Single-pensioner household: Percentage of households which are single-pensioner households
13 Lone parent household: Percentage of households which are lone parent households with dependent children
14 Two adults no children: Percentage of households which are cohabiting or married couple households with no children
15 Households with non-dependent children: Percentage of households comprising one family and no others with non-dependent children living with their parents
Housing
16 Rent (public): Percentage of households that are resident in public sector rented accommodation
17 Rent (private): Percentage of households that are resident in private/other rented accommodation
18 Terraced housing: Percentage of all household spaces which are terraced
19 Detached housing: Percentage of all household spaces which are detached
20 All flats: Percentage of household spaces which are flats
21 No central heating: Percentage of occupied household spaces without central heating
22 Average house size: Average house size (rooms per household)
23 People per room: The average number of people per room
Socio-economic
24 HE qualification: Percentage of people aged 16–74 with a higher education qualification
25 Routine/semi-routine occupation: Percentage of people aged 16–74 in employment working in routine or semi-routine occupations
26 2+ car household: Percentage of households with two or more cars
27 Public transport to work: Percentage of people aged 16–74 in employment who usually travel to work by public transport
28 Work from home: Percentage of people aged 16–74 in employment who work mainly from home
29 LLTI (SIR): Percentage of people who reported suffering from a Limiting Long Term Illness (Standardised Illness Ratio, standardised by age)
30 Provide unpaid care: Percentage of people who provide unpaid care
Employment
31 Students (full-time): Percentage of people aged 16–74 who are students
32 Unemployed: Percentage of economically active people aged 16–74 who are unemployed
33 Working part-time: Percentage of economically active people aged 16–74 who work part-time
33 Economically inactive looking after family: Percentage of economically inactive people aged 16–74 who are looking after the home
34 Agriculture/fishing employment: Percentage of all people aged 16–74 in employment working in agriculture and fishing
35 Mining/quarrying/construction employment: Percentage of all people aged 16–74 in employment working in mining, quarrying and construction
37 Manufacturing employment: Percentage of all people aged 16–74 in employment working in manufacturing
38 Hotel and catering employment: Percentage of all people aged 16–74 in employment working in hotel and catering
39 Health and social work employment: Percentage of all people aged 16–74 in employment working in health and social work
40 Financial intermediation employment: Percentage of all people aged 16–74 in employment working in financial intermediation
41 Wholesale/retail trade employment: Percentage of all people aged 16–74 in employment working in wholesale/retail trade
How many data inputs are involved?
223,060 OAs, 41 Variables = 9,145,460 data points
Data transformation: Log transformation
▪ Reduce the effect of extreme values
▪ Range standardisation (0–1)
▪ Problems will occur if there are differing scales or magnitudes among the variables. In general, variables with larger values and greater variation will have more impact on the final similarity measure. It is necessary, therefore, to make each variable equally represented in the distance measure by standardising the data.
Clustering method: K-means clustering
K-means is an iterative relocation algorithm based on an error sum of squares measure. The basic operation of the algorithm is to move the seeded cluster centres to see if the move would improve the sum of squared deviations within each cluster (Aldenderfer and Blashfield, 1984). The case is then assigned/ re-allocated to the cluster to which it brings the greatest improvement. The next iteration occurs when all the cases have been processed. A stable classification is therefore reached when no moves occur during a complete iteration of the data. After clustering is complete, it is then possible to examine the means of each cluster for each dimension (variable) in order to assess the distinctiveness of the clusters (Everitt et al., 2001).
When choosing the number of clusters to have in the classification there were three main issues which need to be considered:
▪ Issue 1: Analysis of average distance from cluster centres for each cluster number option. The ideal solution would be the number of clusters that gives the smallest average distance from the cluster centre across all clusters.
▪ Issue 2: Analysis of cluster size homogeneity for each cluster number option. It would be useful, where possible, to have clusters of as similar size as possible in terms of the number of members within each.
▪ Issue 3: The number of clusters produced should be as close to the perceived ideal as possible. This means that the number of clusters needs to be of a size that is useful for further analysis.
Appendix 5.2 TheThe 2001 ONS Census Output Area Classification groups
1: Blue Collar Communities |
1a: Terraced Blue Collar |
1a1: Terraced Blue Collar (1) |
1a2: Terraced Blue Collar (2) |
||
1a3: Terraced Blue Collar (3) |
||
1b: Younger Blue Collar |
1b1: Younger Blue Collar (1) |
|
1b2: Younger Blue Collar (2) |
||
1c: Older Blue Collar |
1c1: Older Blue Collar (1) |
|
1c2: Older Blue Collar (2) |
||
1c3: Older Blue Collar (3) |
||
2: City Living |
2a: Transient Communities |
2a1: Transient Communities (1) |
2a2: Transient Communities (2) |
||
2b: Settled in the City |
2b1: Settled in the City (1) |
|
2b2: Settled in the City (2) |
||
3: Countryside |
3a: Village Life |
3a1: Village Life (1) |
3a2: Village Life (2) |
||
3b: Agricultural |
3b1: Agricultural (1) |
|
3b2: Agricultural (2) |
||
3c: Accessible Countryside |
3c1: Accessible Countryside (1) |
|
3c2: Accessible Countryside (2) |
||
4: Prospering Suburbs |
4a: Prospering Younger Families |
4a1: Prospering Younger Families (1) |
4a2: Prospering Younger Families (2) |
||
4b: Prospering Older Families |
4b1: Prospering Older Families (1) |
|
4b2: Prospering Older Families (2) |
||
4b3: Prospering Older Families (3) |
||
4b4: Prospering Older Families (4) |
||
4c: Prospering Semis |
4c1: Prospering Semis (1) |
|
4c2: Prospering Semis (2) |
||
4c3: Prospering Semis (3) |
||
4d: Thriving Suburbs |
4d1: Thriving Suburbs (1) |
|
4d2: Thriving Suburbs (2) |
||
5: Constrained by Circumstances |
5a: Senior Communities |
5a1: Senior Communities (1) |
5b: Older Workers |
||
5b3: Older Workers (3) |
||
5b4: Older Workers (4) |
||
5c: Public Housing |
5c1: Public Housing (1) |
|
5c2: Public Housing (2) |
||
5c3: Public Housing (3) |
||
6: Typical Traits |
6a: Settled Households |
6a1: Settled Households (1) |
6a2: Settled Households (2) |
||
6b: Least Divergent |
6b1: Least Divergent (1) |
|
6b2: Least Divergent (2) |
||
6b3: Least Divergent (3) |
||
6c: Young Families in Terraced Homes |
6c1: Young Families in Terraced Homes (1) |
|
6c2: Young Families in Terraced Homes (2) |
||
6d: Aspiring Households |
6d1: Aspiring Households (1) |
|
6d2: Aspiring Households (2) |
||
7: Multicultural |
7a: Asian Communities |
7a1: Asian Communities (1) |
7a2: Asian Communities (2) |
||
7a3: Asian Communities (3) |
||
7b: Afro-Caribbean Communities |
7b1: Afro-Caribbean Communities (1) |
|
7b2: Afro-Caribbean Communities (2) |
All website URLs accessed 30 May 2017.
Acevedo-Garcia, D., McArdle, N., Hardy, E. F., Crisan, U. I., Romano, B., Norris, D., et al. (2014) The Child Opportunity Index: improving collaboration between community development and public health. Health Affairs, 33(11), 1948–1957.
Aldenderfer, M. S., & Blashfield, R. K. (1984) Cluster Analysis, Sage, London.
Anselin, L. (1995) Local Indicators of Spatial Association – LISA. Geographical Analysis, 27, 93–115.
Ballas, D., & Dorling, D. (2013) The geography of happiness, in S. David, I. Boniwell, & A. Conley Ayers (eds) The Oxford Handbook of Happiness, Oxford University Press, Oxford, 465–481.
Ballas, D., Dorling, D., & Hennig, B. (2014) The Social Atlas of Europe, Policy Press, Bristol.
Beer, D., & Burrows, R. (2013) Popular culture, digital archives and the new social life of data. Theory, Culture and Society, 30, 47–71.
Birkin, M., & Clarke, G. P. (1998) GIS, geodemographics, and spatial modelling in the UK financial service industry. Journal of Housing Research, 9, 87–111.
Birkin, M., & Clarke, G. P. (2009) Geodemographics, in R. Kitchin & N. Thrift (eds) International Encyclopaedia of Human Geography, Vol. 4, Elsevier, Amsterdam, 382–389.
Blake, M., & Openshaw, S. (1995) Selecting variables for small area classifications of 1991 UK census data, Working Paper 95/2, School of Geography, University of Leeds. Available from: www.geog.leeds.ac.uk/papers/95-2.
Bradshaw, J. R. (1972a) The concept of social need. New Society, 496, 640–643.
Bradshaw, J. R. (1972b) The taxonomy of social need, in G. McLachlan (ed.) Problems and Progress in Medical Care, Oxford University Press, Oxford, 69–82.
Bradshaw, J. R. (1994) The conceptualisation and measurement of need: a social policy perspective, in J. Popay, & G. Williams (eds) Researching the People’s Health, Routledge, London, 45–57.
Bradshaw, J., & Finch, N. (2003) Overlaps in dimensions of poverty. Journal of Social Policy, 32, 513–525.
Burrows, R., & Gane, N. (2006) Geodemographics, software and class. Sociology, 40(5), 793–812.
Carstairs, V. (1995) Deprivation indices: their interpretation and use in relation to health. Journal of Epidemiology and Community Health, 49, 3–8.
Carstairs, V., & Morris, R. (1991) Deprivation and Health in Scotland, Aberdeen University Press, Aberdeen.
Congdon, P. (1996) Suicide and parasuicide in London: a small-area study. Urban Studies, 33(1), 137–158.
Dolan, P., Peasgood, T., & White, M. (2007) Do we really know what makes us happy? A review of the literature on the factors associated with subjective well-being. Journal of Economic Psychology. DOI: https://doi.org/10.1016/j.joep.2007.09.001.
Dorling, D., Rigby, J., Wheeler, B., Ballas, D., Thomas, B., Fahmy, E., et al. (2007) Poverty, Wealth and Place in Britain, 1968 to 2005, Policy Press, Bristol.
Dorling, D., Vickers, D., Thomas, B., Pritchard, J., & Ballas, D. (2008) Changing UK: The Way We Live Now, report commissioned for the BBC. Available from: http://news.bbc.co.uk/1/shared/bsp/hi/pdfs/01_12_08_changinguk.pdf.
Elbner, C., & Sturm, R. (2006) US-based indices of area-level deprivation: results from HealthCare for Communities. Social Science and Medicine, 62(2), 348–359.
Ellwood, S. (2010) Geographic information science: emerging research on the societal implications of the geospatial web. Progress in Human Geography, 34(3), 349–357.
Engels, F. (1845) Conditions of the Working Class in England. Marx/Engels Internet Archive. Available from: www.marxists.org/archive/marx/works/1845/condition-working-class/index.htm.
European Commission (2010) Investing in Europe’s future: fifth report on economic, social and territorial cohesion. Available from: http://ec.europa.eu/regional_policy/sources/docoffic/official/reports/cohesion5/index_en.cfm.
Everitt, B. S. (1993) Cluster Analysis, Edward Arnold, London.
Everitt, B. S., Landau, S., & Leese, M. (2001) Cluster Analysis (4th edition), Edward Arnold, London.
Flowerdew, R. (1998) Reacting to ground truth. Environment and Planning A, 30, 289–301.
Frey, B., & Stutzer, A. (2002) Happiness and Economics, Princeton University Press, Princeton, NJ.
Gale, C., Singleton, A., Bates, A. G., & Longley, P. (2014) Creating the 2011 Area Classification for Output Areas (2011 OAC), JOSIS discussion forum. Available from: http://josis.net/index.php/josis/article/view/232/150.
Gale, C. G., Singleton, A. D., Bates, A. G., & Longley, P. A. (2016) Creating the 2011 area classification for output areas (2011 OAC). Journal of Spatial Information Science, 12, 1–27.
Gordon, D. (1995) Census based deprivation indices: their weighting and validation. Journal of Epidemiology and Community Health, 49(Suppl.2), S39–S44.
Gordon, D., & Pantazis, C. (eds) (1997) Breadline Britain in the 1990s, Ashgate, Aldershot.
Gordon, D., Adelman, A., Ashworth, K., Bradshaw, J., Levitas, R., Middleton, S., et al. (2000) Poverty and Social Exclusion in Britain, Joseph Rowntree Foundation, York.
Goss, J. (1995) ‘We know who you are and we know where you live’: the instrumental rationality of geodemographic systems. Economic Geography, 71(2), 171–198.
Harris, R. J., Sleight, P., & Webber, R. J. (2005) Geodemographics, GIS and Neighbourhood Targeting, Wiley, London.
Helliwell, J. F. (2003) How’s life? Combining individual and national variables to explain subjective well-being. Economic Modelling, 20, 331–360.
HIPxChange (2016) Area Deprivation Index. Available from: www.hipxchange.org/ADI.
Hyndman, H. (1911) The Record of an Adventurous Life, Macmillan, New York.
Inglehart, R. (1990) Culture Shift, Princeton University Press, Princeton, NJ.
London School of Economics (LSE) (2015) Charles Booth Online Archive. Available from: http://booth.lse.ac.uk/static/a/2.html.
Mack, J., & Lansley, S. (1985) Poor Britain, George Allen & Unwin, London.
Medeiros, M. (2006) Poverty, Inequality and Redistribution: A Methodology to Define the Rich. International Poverty Centre, United Nations Development Programme, Working Paper 18, May. Available from: www.ipc-undp.org/pub/IPCWorkingPaper18.pdf.
Milligan, G. W. (1996) Clustering validation: results and implications for applied analyses, in P. Arabie, L. J. Hubert & G. De Soete (eds) Clustering and Classification, World Scientific, Singapore, 345–379.
Noble, M., Wright, G., & Smith, G. (2006) Measuring multiple deprivation at the small-area level. Environment and Planning A, 38, 169–185.
Norman-Butler, B. (1972) Victorian Aspirations: The Life and Labour of Charles and Mary Booth, George Allen & Unwin, London.
Orford, S. (2004) Identifying and comparing changes in the spatial concentrations of urban poverty and affluence: a case study of inner London. Computers Environment and Urban Systems, 28, 701–717.
Orford, S., Dorling, D., Mitchell, R., Shaw, M., & Smith, G. D. (2002) Life and death of the people of London: a historical GIS of Charles Booth’s inquiry. Health & Place, 8(1), 25–35.
Pantazis, C., Gordon, D., & Levitas, R. (eds) (2006) Poverty and Social Exclusion in Britain, Policy Press, Bristol.
Pfautz, H. W. (1967) Charles Booth on the City Physical Pattern and Social Structure, University of Chicago Press, Chicago, IL.
Pickles, J. (1994) Ground Truth: The Social Implications of Geographic Information Systems, Guilford Press, New York.
Rees, P., Denham, C., Charlton, J., Openshaw, S., Blake, M., & See, L. (2002) ONS classifications and GB profiles: census typologies for researchers, in P. Rees, D. Martin, & P. Williamson (eds) The Census Data System, Wiley, Chichester, 149–170.
Rentoul, J. (1987) The Rich Get Richer: The Growth of Inequality in Britain in the 1980s, HarperCollins, London.
Robbin, J. E. (1980) Geodemographics: the new magic. Campaigns and Elections, 1(1), 106–125.
117Rothman, J. (1989) Editorial. Journal of the Market Research Society, 31(1), 1–5.
Rowntree, B. S. (1941) Poverty and Progress: A Second Social Survey of York, Longman, London.
Rowntree, B. S., & Lavers, G. R. (1951) Poverty and the Welfare State, Longman, London.
Scott, J. (1994) Poverty and Wealth: Citizenship, Deprivation and Privilege, Longman, London.
Simey, T., & Simey, M. (1960) Charles Booth, Social Scientist, Oxford University Press, London.
Singh, G. (2003) Area deprivation and widening inequalities in US mortality, 1969–1998. American Journal of Public Health, 93, 1137–1143.
Singleton, A. D., & Spielman, S. E. (2014) The past, present, and future of geodemographic research in the United States and United Kingdom. The Professional Geographer, 66(4), 558–567.
Sleight, P. (1997) Targeting Customers: How to Use Geodemographic and Lifestyle Data in Your Business, NTC Publications, Henley-on-Thames.
Smith, T., Noble, M., Noble, S., Wright, G., McLennan, D., & Plunkett, E. (2015) The English Indices of Deprivation 2015: Research Report, Department for Communities and Local Government. Available from: www.gov.uk/government/publications/english-indices-of-deprivation-2015-research-report.
Stafford, M. & Marmott, M. (2003) Neighbourhood deprivation and health: does it affect us all equally? International Journal of Epidemiology, 32, 357–366.
Thomas, B., & Dorling, D. (2004) Investigation Report: Know Your Place, Shelter, London. Available from: http://scotland.shelter.org.uk/__data/assets/pdf_file/0008/48329/Knowyourplace.pdf/_nocache.
Tobler, W. (1970) A computer movie simulating urban growth in the Detroit region. Economic Geography, 46, 234–240.
Townsend, P. (1979) Poverty in the United Kingdom: A Survey of Household Resources and Standards of Living, Penguin Books and Allen Lane, London.
Townsend, P. (1987) Deprivation. Journal of Social Policy, 16, 125–146.
Townsend, P., Phillimore, P., & Beattie, A. (1988) Health and Deprivation: Inequality and the North, Croom Helm, London.
Tranmer, M., & Steel, D. G. (1998) Using census data to investigate the causes of the ecological fallacy. Environment and Planning A, 30, 817–831.
Uprichard, E., & Burrows, R. (2009) Geodemographic code and the production of space. Environment and Planning A, 41, 2823–2835.
Vickers, D. W. (2006) Multi-Level Integrated Classifications Based on the 2001 Census. PhD thesis, University of Leeds.
Vickers, D. W. (2010) England’s changing social geology, in J. Stillwell & P. Norman (eds) Spatial and Social Inequality, Springer, Berlin, 37–51.
Vickers, D., & Rees, P. (2006) Introducing the area classification of output areas. Population Trends, 125, 15–29.
Vickers, D., & Rees, P. H. (2007) Creating the UK national statistics 2001 output area classification. Journal of the Royal Statistical Society: Series A. Statistics in Society, 170(2), 379–403.
Vickers, D., & Rees, P. H. (2011) Ground-truthing geodemographics. Applied Spatial Analysis and Policy, 4(1), 3–21.
Webber, R. J., & Craig, J. (1976) Which local authorities are alike? Population Trends, 5, 13–19.
Whelan, C. T., Layte, R., Maitre, B., & Nolan, B. (2001) Income, deprivation and economic strain: an analysis of the European Community Household Panel. European Sociological Review, 17(4), 357–372.